Encyclopédie de l'informatique. Grande encyclopédie soviétique - informatique. Approche alphabétique dans le cursus d'informatique à la fondation de l'école
Dans les pays anglophones, le terme informatique est utilisé - informatique.
La base théorique de l'informatique est un ensemble de sciences fondamentales telles que : la théorie de l'information, la théorie des algorithmes, la logique mathématique, la théorie langages formels et grammaire, analyse combinatoire, etc. En plus d'eux, l'informatique comprend des sections telles que l'architecture informatique, les systèmes d'exploitation, la théorie des bases de données, la technologie de programmation et bien d'autres. Il est important pour définir l'informatique en tant que science que, d'une part, elle traite de l'étude des dispositifs et des principes de fonctionnement de la technologie informatique et, d'autre part, de la systématisation des techniques et des méthodes de travail avec des programmes qui contrôler cette technologie.
La technologie de l'information est un ensemble d'outils matériels et logiciels spécifiques qui sont utilisés pour effectuer une variété d'opérations de traitement de l'information dans toutes les sphères de notre vie et de nos activités. La technologie de l'information est parfois appelée technologie informatique ou informatique appliquée.
Informations analogiques et numériques.
Le terme "informations" vient du latin informatio, – explication, exposition, prise de conscience.
Les informations peuvent être classifiées différentes façons, et différentes sciences le font de différentes manières. Par exemple, en philosophie, faites la distinction entre les informations objectives et subjectives. L'information objective reflète les phénomènes de la nature et de la société humaine. Les informations subjectives sont créées par des personnes et reflètent leur point de vue sur des phénomènes objectifs.
En informatique, les informations analogiques et les informations numériques sont considérées séparément. Ceci est important, car une personne, grâce à ses sens, est habituée à traiter des informations analogiques, alors que la technologie informatique, au contraire, travaille principalement avec des informations numériques.
Une personne perçoit les informations par les sens. La lumière, le son, la chaleur sont des signaux énergétiques, et le goût et l'odorat sont le résultat de l'exposition à des composés chimiques, eux aussi basés sur la nature énergétique. Une personne subit continuellement des impacts énergétiques et peut ne jamais rencontrer deux fois la même combinaison. Il n'y a pas deux feuilles vertes identiques sur un arbre et deux sons absolument identiques - il s'agit d'informations analogiques. Si vous attribuez des nombres à différentes couleurs et des notes à différents sons, les informations analogiques peuvent être transformées en informations numériques.
La musique, lorsqu'elle est écoutée, transporte des informations analogiques, mais lorsqu'elle est notée, elle devient numérique.
La différence entre l'information analogique et l'information numérique est, tout d'abord, que l'information analogique est continue, tandis que l'information numérique est discrète.
Les appareils numériques comprennent les ordinateurs personnels - ils fonctionnent avec des informations présentées dans forme numérique, les lecteurs de CD laser sont également numériques.
Encodage des informations.
Le codage de l'information est le processus de formation d'une certaine représentation de l'information. .
Dans un sens plus étroit, le terme « codage » est souvent compris comme le passage d'une forme de présentation de l'information à une autre, plus commode pour le stockage, la transmission ou le traitement.
Un ordinateur ne peut traiter que des informations présentées sous forme numérique. Toutes les autres informations (sons, images, relevés d'instruments, etc.) doivent être converties sous forme numérique pour être traitées sur ordinateur. Par exemple, pour quantifier un son musical, on peut mesurer l'intensité du son à de courts intervalles sur certaines fréquences, représentant les résultats de chaque mesure sous forme numérique. À l'aide de programmes informatiques, il est possible de transformer les informations reçues, par exemple en «superposant» des sons de différentes sources les uns sur les autres.
De même, les informations textuelles peuvent être traitées sur un ordinateur. Lorsqu'elle est entrée dans un ordinateur, chaque lettre est codée avec un certain nombre, et lors de la sortie vers des périphériques externes (écran ou impression), pour la perception humaine, des images de lettres sont construites à l'aide de ces chiffres. La correspondance entre un ensemble de lettres et de chiffres s'appelle un codage de caractères.
En règle générale, tous les nombres dans l'ordinateur sont représentés par des zéros et des uns (et non par dix chiffres, comme c'est la coutume pour les gens). En d'autres termes, les ordinateurs fonctionnent généralement en binaire système de numérotation, car dans ce cas, les dispositifs pour leur traitement sont beaucoup plus simples.
Unités de mesure de l'information. Bit. Octet.
Un bit est la plus petite unité de représentation de l'information. Octet - la plus petite unité de traitement et de transmission de l'information .
Résolvant divers problèmes, une personne utilise des informations sur le monde qui nous entoure. On entend souvent dire qu'un message véhicule peu d'informations ou au contraire contient des informations exhaustives, alors que différentes personnes recevant le même message (par exemple, après avoir lu un article dans un journal) estiment différemment la quantité d'informations qu'il contient. Cela signifie que la connaissance que les gens avaient de ces événements (phénomènes) avant de recevoir le message était différente. La quantité d'informations dans un message dépend donc de la nouveauté du message pour le destinataire. Si, à la suite de la réception d'un message, une clarté complète sur un problème donné est atteinte (c'est-à-dire que l'incertitude disparaît), ils disent que des informations exhaustives ont été reçues. Cela signifie qu'il n'y a pas besoin de Informations Complémentaires sur ce thème. Au contraire, si après réception du message l'incertitude restait la même (l'information rapportée était déjà connue ou non pertinente), alors aucune information n'a été reçue (zéro information).
Lancer une pièce et la regarder tomber fournit certaines informations. Les deux côtés de la médaille sont "égaux", donc les deux côtés sont également susceptibles de se présenter. Dans de tels cas, on dit que l'événement porte des informations sur 1 bit. Si nous mettons deux balles de couleurs différentes dans un sac, puis en tirant aveuglément une balle, nous obtiendrons également des informations sur la couleur de la balle en 1 bit.
L'unité de mesure de l'information s'appelle un bit (bit) - une abréviation des mots anglais chiffre binaire, que signifie un chiffre binaire.
En informatique, un bit correspond à l'état physique du support d'information : aimanté - non aimanté, il y a un trou - il n'y a pas de trou. Dans ce cas, un état est généralement désigné par le chiffre 0 et l'autre par le chiffre 1. Le choix de l'une des deux options possibles vous permet également de faire la distinction entre la vérité logique et le mensonge. Une séquence de bits peut encoder du texte, une image, un son ou toute autre information. Cette méthode de présentation des informations est appelée codage binaire. (encodage binaire) .
En informatique, une quantité appelée octet est souvent utilisée et est égale à 8 bits. Et si le bit vous permet de choisir une option sur deux possibles, alors l'octet, respectivement, est 1 sur 256 (2 8). Outre les octets, des unités plus grandes sont utilisées pour mesurer la quantité d'informations :
1 Ko (un kilo-octet) = 2\up1210 octets = 1024 octets ;
1 Mo (un mégaoctet) = 2\up1210 Ko = 1024 Ko ;
1 Go (un gigaoctet) = 2\up1210 Mo = 1024 Mo.
Par exemple, un livre contient 100 pages ; 35 lignes par page, 50 caractères par ligne. Le volume d'informations contenues dans le livre est calculé comme suit:
La page contient 35 × 50 = 1750 octets d'informations. Le volume de toutes les informations dans le livre (dans différentes unités):
1750 × 100 = 175 000 octets.
175 000 / 1024 = 170,8984 Ko.
170,8984 / 1024 = 0,166893 Mo.
Déposer. Formats de fichiers.
Un fichier est la plus petite unité de stockage d'informations contenant une séquence d'octets et portant un nom unique.
Le but principal des fichiers est de stocker des informations. Ils sont également conçus pour transférer des données d'un programme à l'autre et d'un système à l'autre. En d'autres termes, un fichier est un référentiel de données stables et mobiles. Mais un fichier est plus qu'un simple magasin de données. Le fichier contient généralement nom, attributs, heure de modification et heure de création.
Une structure de fichiers est un système de stockage de fichiers sur un périphérique de stockage, tel qu'un disque. Les fichiers sont organisés en répertoires (parfois appelés répertoires ou dossiers). Tout répertoire peut contenir un nombre arbitraire de sous-répertoires, chacun pouvant stocker des fichiers et d'autres répertoires.
La façon dont les données sont organisées en octets s'appelle le format de fichier. .
Pour lire un fichier, comme une feuille de calcul, vous devez savoir comment les octets représentent les nombres (formules, texte) dans chaque cellule ; lire le fichier éditeur de texte, vous devez savoir quels octets représentent des caractères et quelles polices ou champs, ainsi que d'autres informations.
Les programmes peuvent stocker des données dans un fichier d'une manière choisie par le programmeur. Cependant, on s'attend souvent à ce que les fichiers soient utilisés par différents programmes, de sorte que de nombreux programmes d'application prennent en charge certains des formats les plus courants afin que d'autres programmes puissent comprendre les données du fichier. Les éditeurs de logiciels (qui souhaitent que leurs logiciels deviennent des « standards ») publient souvent des informations sur les formats qu'ils créent afin qu'ils puissent être utilisés dans d'autres applications.
Tous les fichiers peuvent être conditionnellement divisés en deux parties - texte et binaire.
Les fichiers texte sont le type de données le plus courant dans le monde informatique. Un octet est le plus souvent alloué pour stocker chaque caractère, et les fichiers texte sont encodés à l'aide de tables spéciales dans lesquelles chaque caractère correspond à un certain nombre n'excédant pas 255. Un fichier qui n'utilise que 127 premiers nombres pour encoder est appelé ASCII- fichier (abréviation de American Standard Code for Information Intercange - code standard américain pour l'échange d'informations), mais un tel fichier ne peut pas contenir de lettres autres que latines (y compris le russe). La plupart des alphabets nationaux peuvent être codés à l'aide d'une table à huit bits. Pour la langue russe, trois encodages sont actuellement les plus populaires : Koi8-R, Windows-1251 et l'encodage dit alternatif (alt).
Des langues telles que le chinois contiennent beaucoup plus de 256 caractères, donc plusieurs octets sont utilisés pour encoder chaque caractère. Pour économiser de l'espace, l'astuce suivante est souvent utilisée : certains caractères sont codés sur un octet, tandis que d'autres utilisent deux octets ou plus. Une tentative de généralisation de cette approche est la norme Unicode, qui utilise une gamme de nombres de zéro à 65 536 pour coder les caractères. Une telle gamme permet de représenter numériquement les caractères d'une langue de n'importe quel coin de la planète.
Mais propre fichiers texte deviennent de moins en moins courants. Les documents contiennent souvent des images et des diagrammes, et diverses polices sont utilisées. En conséquence, des formats apparaissent qui sont diverses combinaisons de formes de données textuelles, graphiques et autres.
Les fichiers binaires, contrairement aux fichiers texte, ne sont pas aussi faciles à visualiser et ils ne contiennent généralement pas de mots familiers - seulement beaucoup de caractères obscurs. Ces fichiers ne sont pas destinés à être directement lisibles par des humains. Des exemples de fichiers binaires sont des programmes exécutables et des fichiers graphiques.
Exemples de codage binaire d'informations.
Parmi la variété d'informations traitées sur un ordinateur, une part importante est constituée d'informations numériques, textuelles, graphiques et audio. Familiarisons-nous avec certaines façons de coder ces types d'informations dans un ordinateur.
Encodage des nombres.
Il existe deux formats principaux pour représenter les nombres dans la mémoire de l'ordinateur. L'un d'eux est utilisé pour encoder des nombres entiers, le second (la représentation dite à virgule flottante d'un nombre) est utilisé pour spécifier un certain sous-ensemble de nombres réels.
L'ensemble des nombres entiers pouvant être représentés dans la mémoire de l'ordinateur est limité. La plage de valeurs dépend de la taille de la zone mémoire utilisée pour stocker les nombres. DANS k-la cellule bit peut stocker 2 k différentes valeurs d'entiers .
Pour obtenir la représentation interne d'un entier positif N stocké dans k-bit machine word, il vous faut :
1) traduire le nombre N dans le système de numération binaire ;
2) le résultat obtenu est complété à gauche par des zéros non significatifs jusqu'à k digits.
Par exemple, pour obtenir la représentation interne de l'entier 1607 dans une cellule de 2 octets, le nombre est converti en binaire : 1607 10 = 11001000111 2 . La représentation interne de ce numéro dans la cellule est : 0000 0110 0100 0111.
Pour écrire une représentation interne d'un entier nombre négatif(–N) il vous faut :
1) obtenir la représentation interne d'un nombre positif N;
2) récupérer le code retour de ce numéro en remplaçant 0 par 1 et 1 par 0 ;
3) ajouter 1 au numéro reçu.
La représentation interne d'un entier négatif est -1607. En utilisant le résultat de l'exemple précédent, la représentation interne du nombre positif 1607 s'écrit : 0000 0110 0100 0111. Le code inverse est obtenu en inversant : 1111 1001 1011 1000. On en ajoute un : 1111 1001 1011 1001 - c'est le code interne représentation binaire du nombre -1607.
Le format à virgule flottante utilise une représentation numérique réelle R comme produit de la mantisse m basé sur le système de numération n dans une certaine mesure p, qui s'appelle l'ordre : R=m * np.
La représentation d'un nombre sous forme de virgule flottante est ambiguë. Par exemple, les égalités suivantes sont vraies :
12,345 \u003d 0,0012345 × 10 4 \u003d 1234,5 × 10 -2 \u003d 0,12345 × 10 2
Le plus souvent, les ordinateurs utilisent une représentation normalisée d'un nombre sous forme de virgule flottante. La mantisse dans cette représentation doit satisfaire la condition :
0,1 pJ m p. En d'autres termes, la mantisse est inférieure à 1 et le premier chiffre significatif n'est pas zéro ( p est la base du système numérique).
Dans la mémoire de l'ordinateur, la mantisse est représentée sous la forme d'un entier contenant uniquement des chiffres significatifs (les entiers 0 et une virgule ne sont pas stockés), donc pour le nombre 12,345, le nombre 12,345 sera stocké dans la cellule mémoire allouée pour stocker la mantisse. restaurer uniquement le numéro d'origine, il ne reste plus qu'à le sauvegarder afin, dans cet exemple est 2.
Encodage de texte.
L'ensemble de caractères utilisé pour écrire un texte s'appelle un alphabet. Le nombre de caractères d'un alphabet s'appelle sa cardinalité.
Pour représenter des informations textuelles dans un ordinateur, on utilise le plus souvent un alphabet d'une capacité de 256 caractères. Un caractère d'un tel alphabet porte 8 bits d'information, puisque 2 8 \u003d 256. Mais 8 bits constituent un octet, par conséquent, le code binaire de chaque caractère occupe 1 octet de mémoire informatique.
Tous les caractères d'un tel alphabet sont numérotés de 0 à 255, et chaque numéro correspond à un code binaire de 8 bits de 00000000 à 11111111. Ce code est le nombre ordinal du caractère dans le système de numération binaire.
Pour différents types d'ordinateurs et de systèmes d'exploitation, différentes tables de codage sont utilisées, qui diffèrent dans l'ordre dans lequel les caractères alphabétiques sont placés dans la table de codage. La table de codage ASCII déjà mentionnée est la norme internationale sur les ordinateurs personnels.
Le principe du codage alphabétique séquentiel est que dans la table des codes ASCII, les lettres latines (majuscules et minuscules) sont classées par ordre alphabétique. La disposition des nombres est également ordonnée par ordre croissant de valeurs.
Seuls les 128 premiers caractères sont standard dans ce tableau, c'est-à-dire les caractères avec des nombres de zéro (code binaire 00000000) à 127 (01111111). Cela inclut les lettres de l'alphabet latin, les chiffres, les signes de ponctuation, les parenthèses et certains autres symboles. Les 128 codes restants, commençant par 128 (code binaire 10000000) et se terminant par 255 (11111111), sont utilisés pour coder les lettres des alphabets nationaux, les pseudographies et les symboles scientifiques.
Codage des informations graphiques.
La mémoire vidéo contient informations binaires sur l'image affichée à l'écran. Presque toutes les images créées, traitées ou visualisées à l'aide d'un ordinateur peuvent être divisées en deux grandes parties - les graphiques raster et vectoriels.
Les images raster sont une grille à une seule couche de points appelés pixels (pixel, de l'élément d'image anglais). Le code du pixel contient des informations sur sa couleur.
Pour une image en noir et blanc (sans demi-teintes), un pixel ne peut prendre que deux valeurs : blanc et noir (s'allume - ne s'allume pas), et un bit de mémoire suffit à l'encoder : 1 - blanc, 0 - noir.
Un pixel sur un écran couleur peut avoir différentes couleurs, donc un bit par pixel ne suffit pas. Deux bits par pixel sont nécessaires pour coder une image en 4 couleurs car deux bits peuvent prendre 4 états différents. Par exemple, cette option de codage couleur peut être utilisée : 00 - noir, 10 - vert, 01 - rouge, 11 - marron.
Sur les moniteurs RVB, toute la variété des couleurs est obtenue en combinant les couleurs de base - rouge (Rouge), vert (Vert), bleu (Bleu), à partir desquelles vous pouvez obtenir 8 combinaisons de base :
Bien sûr, si vous avez la possibilité de contrôler l'intensité (luminosité) de la lueur des couleurs de base, le nombre d'options différentes pour leurs combinaisons, générant diverses nuances, augmente. Nombre de couleurs différentes - POUR et le nombre de bits pour les coder - N sont interconnectés par une formule simple : 2 N = POUR.
Contrairement aux graphiques raster image vectorielle en couches. Chaque élément d'une image vectorielle - une ligne, un rectangle, un cercle ou un fragment de texte - est situé dans son propre calque, dont les pixels sont définis indépendamment des autres calques. Chaque élément d'une image vectorielle est un objet qui est décrit à l'aide d'un langage spécial (équations mathématiques de lignes, d'arcs, de cercles, etc.) Objets complexes(lignes brisées, formes géométriques diverses) se présentent comme un ensemble d'objets graphiques élémentaires.
Les objets d'image vectorielle, contrairement aux graphiques raster, peuvent changer de taille sans perte de qualité (le grain augmente lorsqu'une image raster est agrandie).
Codage sonore.
Nous savons par la physique que le son sont les vibrations de l'air. Si vous convertissez l'audio en signal électrique(par exemple, à l'aide d'un microphone), vous pouvez voir la tension évoluer en douceur avec le temps. Pour le traitement informatique, un tel signal analogique doit en quelque sorte être converti en une séquence de nombres binaires.
Cela se fait, par exemple, comme ceci - la tension est mesurée à intervalles réguliers et les valeurs résultantes sont enregistrées dans la mémoire de l'ordinateur. Ce processus est appelé échantillonnage (ou numérisation) et le dispositif qui l'exécute est appelé convertisseur analogique-numérique (ADC).
Pour reproduire le son ainsi encodé, il faut faire la conversion inverse (pour cela on utilise un convertisseur numérique-analogique). - DAC), puis lisser le signal de pas résultant.
Plus le taux d'échantillonnage est élevé et plus il y a de bits alloués pour chaque échantillon, plus le son sera représenté avec précision, mais la taille du fichier son augmentera également. Par conséquent, en fonction de la nature du son, des exigences de sa qualité et de la quantité de mémoire occupée, certaines valeurs de compromis sont choisies.
La méthode décrite d'encodage des informations sonores est assez universelle, elle vous permet de représenter n'importe quel son et de le transformer de différentes manières. Mais il y a des moments où il est plus avantageux d'agir différemment.
Une manière assez compacte de représenter la musique a longtemps été utilisée - la notation musicale. Il indique avec des symboles spéciaux quelle est la hauteur du son, sur quel instrument et comment jouer. En fait, cela peut être considéré comme un algorithme pour un musicien, écrit dans un langage formel spécial. En 1983, les principaux fabricants d'ordinateurs et de synthétiseurs musicaux ont développé une norme définissant un tel système de codes. C'est ce qu'on appelle le MIDI.
Bien sûr, un tel système de codage ne vous permet pas d'enregistrer tous les sons, il ne convient qu'à la musique instrumentale. Mais il a aussi des avantages indéniables : un enregistrement extrêmement compact, naturel pour un musicien (presque n'importe quel éditeur MIDI permet de travailler avec de la musique sous forme de notes ordinaires), facilité de changement d'instruments, changement de tempo et de tonalité de la mélodie.
Il existe d'autres formats d'enregistrement de musique purement informatiques. Parmi eux se trouve le format MP3, qui permet d'encoder de la musique avec une qualité et un taux de compression très élevés, tandis qu'au lieu de 18 à 20 compositions musicales, environ 200 sont placées sur un disque compact standard (CDROM).Une chanson occupe environ 3,5 Mo, ce qui permet aux internautes d'échanger facilement des compositions musicales.
L'ordinateur est une machine universelle d'information.
L'un des principaux objectifs d'un ordinateur est le traitement et le stockage d'informations. Avec l'avènement des ordinateurs, il est devenu possible de travailler avec des volumes d'informations auparavant impensables. Les bibliothèques contenant de la littérature scientifique et de fiction sont converties sous forme électronique. Les anciennes archives de photos et de films gagnent nouvelle vie sous forme numérique.
Anna Chugainova
M. : FIZMATLIT, 2006. - 768 p.
Le dictionnaire de référence encyclopédique contient plus de 18 000 termes russes et anglais, thématiquement systématisés dans les principales sections suivantes : I. Principes fondamentaux des technologies de l'information ; II. Automatisation des processus d'information et des systèmes automatisés (AC); III. Appui technique de l'UA ; IV. logiciel AS ; V. Multimédia, hypermédia, réalité virtuelle, vision artificielle ; VI. Technologies de réseau pour le traitement et la transmission de données; VII. Argot informatique et réseau ; VIII. Pictogrammes utilisés dans les e-mails ; IX. Abréviations de mots et d'expressions utilisés sur Internet.
Les entrées du dictionnaire sont de nature étendue et comprennent des données de référence sur les objets de description, ainsi que des liens vers des sources documentaires primaires pour une connaissance plus complète de celles-ci pour les utilisateurs intéressés.
La structure et le contenu du dictionnaire permettent de l'utiliser pour une étude systématique des matériaux sur les sections et sous-sections thématiques d'intérêt pour le lecteur, pour faire une étude préliminaire des décisions liées à la conception de systèmes automatisés d'information et de télécommunication hétérogènes, et aussi de préparer sur sa base une documentation pédagogique et méthodologique, de révision, de référence, etc.
Le dictionnaire s'adresse à un large éventail d'utilisateurs dont les activités professionnelles ou les intérêts sont liés aux technologies modernes de l'information.
Format: djvu
Taille: 7,1 Mo
Télécharger: yandex.disk
CONTENU
Préface à l'édition encyclopédique du dictionnaire ....................................... 7
Préface à la troisième édition du dictionnaire, sur le dictionnaire de référence et son auteur... 9
De l'auteur ....................................................... ... .... onze
À propos de l'utilisation du dictionnaire .................................................. 13
I. Fondamentaux des technologies de l'information ...................... 15
1.1. Données, informations, connaissances, logique............................................ 15
1.2. Ressources informationnelles, théorie de l'information, informatique 19
1.3. Supports de données, documents, documentation, publications.............. 22
1.4. Principes de représentation structurée des documents et des données....... 27
1.4.1. Éléments d'information et leurs types .............. 27
1.4.2. Enregistrement, Fichier, Tableau, Clé .................................. 30
1.4.3. Structures, modèles de données et termes associés 34
1.4.4. Format, champ de données et termes associés .................................. 45
1.5. Technologies de l'information.................................. 49
1.5.1. Concepts et termes généraux .................................. 49
1.5.2. Manipulation et traitement des documents et des données .................................. 52
1.5.3. Saisie de documents et de données dans un ordinateur ....................... 58
1.5.4. Recherche d'informations ^ concepts et termes généraux ...... 63
1.5.5. Indexation, recherche image de documents et requêtes 66
1.6. Sécurité des technologies de l'information .................................. 74
1.6.1. Concepts et termes généraux .................................. 74
1.6.2. Encodage et décodage de documents et de données.............. 83
1.6.3. Cryptologie et concepts associés ....................... 87
II. Automatisation des processus d'information et systèmes d'information automatisés 93
2.1. Concepts et termes généraux ....................................................... 93
2.2. Automatisation des processus d'information et de bibliothèque............ 95
2.2.1. Termes liés à l'automatisation.............................. 95
2.3. Systèmes automatisés.................................. 98
2.3.1. Concepts et termes généraux .................................. 98
2.3.2. Systèmes automatisés orientés vers la fonctionnalité..... 106
2.4. Support linguistique et informationnel des systèmes automatisés 117
2.4.1. Support linguistique ^ concepts et termes généraux ......... 117
2.4.2. Langages de recherche d'informations et dictionnaires AIS....... 119
2.4.3. Métadonnées et formats AIS 128
2.4.4. Prise en charge des informations de l'AIS ....................... 147
2.5. Personnel et utilisateurs des systèmes automatisés ....................... 153
2.5.1. Développeurs et personnel AIS .................................. 153
2.5.2. Utilisateurs AIS ....................................... 157
2.5.3. Certification des spécialistes en AIS .................................. 159
2.6. Processus de création et d'exploitation des systèmes automatisés ......... 162
2.6.1. Conception de systèmes automatisés................................. 162
2.6.2. Cycle de vie AIS et intégration du système.................................. 165
III. Support technique des systèmes automatisés ......... 169
3.1. Ordinateurs, leurs types et classification générale 169
3.2. Architecture, configuration, plate-forme informatique............ 175
3.3. Ordinateurs personnels (PC) .................................. 178
3.4. PC portables et appareils numériques autonomes à usages divers... 185
3.4.1. Types d'ordinateurs portables .................................................. 185
3.4.2. Appareils de lecture et d'enregistrement numériques 188
3.5. Unité système et éléments de sa conception ....................... 191
3.5.1. Processeurs, leurs types et termes associés.............. 192
3.5.2. Mémoire d'ordinateur ^ concepts et termes ....................... 202
3.5.3. Périphériques fonctionnels de la mémoire de l'ordinateur .................. 208
3.5.4. Adaptateurs, interfaces et termes associés.............. 216
3.5.5. Cartes, Ports, Bus, Slots................................................ 224
3.6. Périphériques informatiques (externes) .................................. 233
3.6.1. Mémoire d'ordinateur externe, lecteurs et termes associés ...... 233
3.6.2. CD et termes associés .................................. 251
3.6.3. Périphériques d'entrée de données, manipulateurs ................ 260
3.6.4. Périphériques de sortie.............................................. 271
3.6.5. Modems, encodeurs, alimentations.................. 286
3.7. Cartes PC ....................................................... ............... .. 289
3.8. Base informatique microélectronique .................................. 294
3.9. Dispositifs optoélectroniques.................................. 299
IV. Logiciels pour systèmes automatisés ......... 303
4.1. Algorithmes, programmes, programmation.................................. 303
4.1.1. Concepts et termes généraux 303
4.1.2. Langages de programmation.................................. 307
4.1.3. Termes liés à la programmation.............................. 319
4.2. Logiciel général.................................. 327
4.2.1. Systèmes d'exploitation................................. 328
4.2.2. Outils de service logiciel généraux 338
4.3. Logiciels d'application pour les systèmes automatisés ...... 339
4.3.1. Concepts et termes généraux .................................. 339
4.3.2. Programmes d'application.................................. 342
4.3.3. Virus informatiques et antivirus ....................... 346
4.4. Termes liés au fonctionnement des outils logiciels 350
4.4.1. Quelques concepts et termes généraux ....................... 350
4.4.2. Archivage, compression-restauration des fiches de données............. 352
4.4.3. Accès, adresse et termes associés.................................. 364
V. Multimédia, hypermédia, réalité virtuelle, vision artificielle. 372
5.1. Systèmes multimédias et termes associés. .................. 372
5.2. Moyens de fournir un accompagnement musical et vocal ...... 375
5.2.1. Concepts et termes généraux .................................. 375
5.2.2. Fichiers son, leurs normes et formats .................................. 380
5.3. Graphiques machine (ordinateur) .................. 389
5.3.1. Concepts et termes généraux .................................. 389
5.3.2. Fichiers graphiques et leurs formats.............................. 392
5.3.3. Technologie de l'infographie .................................. 400
5.4. Vidéo informatique, télévision numérique et animation .................. 408
5.4.1. Concepts et termes généraux .................................. 408
5.4.2. Technologie vidéo .................................................. 412
5.4.3. Technologie d'animation.............................. 416
5.4.4. Télévision numérique 420
5.5. Réalité virtuelle, mondes parallèles. ....................... 424
5.6. Vision par ordinateur.................................................. 427
VI. Technologies de réseau. Moyens de traitement et de transmission des informations 430
6.1. Concepts et termes généraux ....................................... 430
6.2. Réseaux locaux .................................................. 433
6.3. Réseaux informatiques distribués.................................. 441
6.3.1. Concepts et termes généraux .................................. 441
6.3.2. Intranet....................................... 450
6.3.3. ETHERNET ............................... 455
6.4. Réseaux informatiques mondiaux, Internet ....................... 471
6.4.1. Concepts et termes généraux .................................. 471
6.4.2. Technologie Web.................................................. 482
6.4.3. Technologies de transmission de données sur les canaux Internet............ 489
6.4.4. Services et outils de service sur Internet.............................. 499
6.4.5. Services de réseau numérique intégrés - RNIS .................................. 518
6.4.6. Communication cellulaire et téléphonie informatique .................... 520
6.4.7. Equipements de télécommunication des bâtiments .................................. 526
6.4.8. Développement de moyens et complexes techniques basés sur l'utilisation des technologies de télécommunication 532
6.4.9. Objets des relations juridiques sur Internet .................................. 533
6.5. Moyens et technologies de protection des réseaux informatiques .................................. 536
6.6. Normes de base pour les réseaux de données. ....................... 541
6.6.1. Normes ISO ....................................................... . 541
6.6.2. Normes IEEE .................................. 543
6.6.3. Normes UIT-T .................................................. 554
6.6.4. Autres normes et protocoles.............................. 560
VII. Argot informatique et réseau ............................... 565
VIII. Icônes et symboles smiley pour E-mail........... 592
IX. Abréviations de mots et d'expressions utilisés sur Internet ...... 594
Références ............................................... 597
Index alphabétique anglais.............................................................. 644
Index alphabétique russe.............................................................. ... 708
INFORMATION (informatique en anglais), science consistant à extraire des informations à partir de messages, à créer des ressources d'information, à programmer le comportement de machines et d'autres entités liées à la construction et à l'utilisation d'un environnement homme-machine pour résoudre des problèmes de modélisation, de conception, d'interaction, d'apprentissage, etc. Elle étudie les propriétés de l'information, les méthodes pour l'extraire des messages et la présenter sous une forme donnée ; propriétés, méthodes et moyens d'interaction de l'information ; propriétés des ressources d'information, méthodes et moyens de leur création, présentation, stockage, accumulation, recherche, transfert et protection ; propriétés, méthodes et moyens de construction et d'utilisation des machines programmables et de l'environnement homme-machine pour la résolution de problèmes.
Production scientifique de l'informatique
La production scientifique de l'informatique sert de base méthodologique à la construction d'un environnement homme-machine pour résoudre des problèmes (Fig. 1) liés à divers domaines d'activité.
Les résultats des études d'entités (généralement appelées objets en science) sont représentés par leurs modèles symboliques et/ou physiques. Les modèles symboliques sont des descriptions des connaissances acquises [voir. Modélisation symbolique(s-modélisation)], et physiques sont des prototypes des objets étudiés, reflétant leurs propriétés, leur comportement, etc. Le résultat scientifique est un modèle d'un système de connaissances (ou un composant d'un modèle préalablement défini et publié) qui décrit un ensemble d'objets, y compris l'objet à l'étude, et les relations entre eux . La description du modèle est présentée sous la forme d'un message destiné à être reconnu et interprété par la communauté scientifique. La valeur du résultat dépend du pouvoir prédictif, de la reproductibilité et de l'applicabilité du modèle, ainsi que des propriétés du message contenant sa description.
Des exemples de résultats qui ont joué un rôle remarquable dans le support méthodologique de la construction d'un environnement homme-machine pour la résolution de problèmes peuvent être : le modèle d'une machine électronique numérique inventée par J. von Neumann avec des instructions de programme et des données stockées dans une mémoire partagée [ connu sous le nom de modèle de von Neumann] et l'architecture de von Neumann] ; inventé par le créateur du Web (cf. Le World Wide Web) T Berner Lee Protocole HTTP (eng. Hypertext transfer protocol - hypertext transfer protocol), qui est un protocole au niveau de l'application qui définit les règles de transfert de messages dans les systèmes hypermédias (voir Multimédia), et un identifiant de ressource uniforme URI (eng. Uniform Resource Identifier), qui est devenu la norme pour enregistrer une adresse de ressource publiée sur Internet. Il est difficile de trouver aujourd'hui (2017) un domaine d'activité où les produits scientifiques de l'informatique ne soient pas appliqués. Sur cette base, le courrier électronique, le Web, les moteurs de recherche, la téléphonie IP, l'Internet des objets et d'autres services Internet ont été créés (voir Internet); enregistrement audio, photo et vidéo numérique; systèmes de conception assistée par ordinateur (CAO); simulateurs informatiques et robots (voir. Modélisation informatique), systèmes de communication numériques, systèmes de navigation, imprimantes 3D, etc.
Concepts de base
La formation continue de l'informatique s'accompagne du développement de son appareil conceptuel et de l'affinement de l'objet de recherche. En 2006, un nouveau domaine de recherche a été créé à l'Institut des problèmes informatiques de l'Académie russe des sciences (IPI RAS) - modélisation symbolique d'objets arbitraires dans un environnement homme-machine (en abrégé- Avec simulation symbolique ou s-simulation). L'un des premiers projets scientifiques dans ce domaine a été consacré à la méthodologie de construction d'un modèle symbolique du système de connaissance informatique dans un environnement homme-machine. . Dans la théorie de la modélisation symbolique (s-modélisation) créée en 2009, la prochaine version du modèle symbolique du noyau du système de concepts informatiques a été proposée, qui comprend les concepts suivants.
Message(message anglais) est considéré comme un ensemble ordonné fini de symboles (visuels, audio, etc.; voir Symbole en informatique) ou son code (voir Code en informatique) qui satisfait le protocole d'interaction entre la source et le destinataire. L'existence d'un message présuppose l'existence d'une source de message, d'un destinataire, d'un transporteur, d'un support de transmission, d'un moyen de livraison et d'un protocole d'interaction entre la source et le destinataire. Dans l'environnement homme-machine pour la résolution de problèmes (environnement s), les personnes à l'aide de machines programmables (machines s) forment des messages, les présentent dans des langages de requête, de programmation, etc. ; effectuer diverses conversions (par exemple, de l'analogique au numérique et vice versa; du non compressé au compressé et vice versa; d'une forme de représentation de document à une autre); reconnaître, utiliser des messages pour construire de nouveaux messages (programmes, documents, etc.) ; interpréter sur des modèles de systèmes conceptuels (qui sont stockés dans la mémoire de l'interprète également sous forme de messages); échanger des messages à l'aide de systèmes de règles implémentés par logiciel et matériel (protocoles réseau, voir ci-dessous). Réseau informatique); enregistrer et accumuler des messages (en créant des bibliothèques électroniques, des encyclopédies et d'autres ressources d'information), résoudre les problèmes de recherche et de protection des messages.
Interprète de messages est étudié en tant que constructeur du message de sortie en fonction de l'entrée conformément au système donné de règles d'interprétation. Une condition nécessaire à la construction d'un interpréteur de messages est l'existence de modèles des langages d'entrée et de sortie, ainsi que de modèles de systèmes de concepts sur lesquels les messages écrits dans les langages d'entrée et de sortie doivent être interprétés.
Données(Données anglaises) - un message nécessaire pour résoudre un certain problème ou ensemble de problèmes, présenté sous une forme conçue pour la reconnaissance, la transformation et l'interprétation par le résolveur (programme ou personne). Une personne perçoit des données (textes, images, etc.) sous forme symbolique, tandis qu'un programme informatique ou un appareil informatique (smartphone, appareil photo numérique, etc.) les perçoit sous forme de code.
Information(informations en anglais) est étudié à la suite de l'interprétation du message sur le modèle du système de concepts [voir. Modélisation symbolique(s-simulation)]. Pour extraire des informations d'un message, il est nécessaire que le message reçu soit présenté sous une forme conçue pour être reconnue et interprétée par le destinataire du message ; des modèles de systèmes conceptuels stockés dans la mémoire de l'interprète, parmi lesquels celui nécessaire à l'interprétation du message reçu ; mécanismes pour rechercher le modèle nécessaire, interpréter le message, présenter le résultat de l'interprétation sous une forme conçue pour le destinataire (Fig. 2).
Par exemple, le résultat de l'interprétation du message ma, présenté en langue a, reçu par le traducteur (humain ou robot) sous la forme d'un message mb en langue b, est l'information extraite du message ma.
Tâche programmable(s-problème) est considéré comme un ensemble (Formul , Rulsys , Alg , Prog ), où Formul est l'énoncé du problème ; Rulsys - un ensemble de systèmes de règles obligatoires et d'orientation pour résoudre un problème, alignés sur Formula; Alg est l'union d'ensembles d'algorithmes dont chacun correspond à un élément de Rulsys ; Prog est l'union d'ensembles de programmes, dont chacun est affecté à l'un des éléments de Alg . Chaque élément de Rulsys , Alg et Prog doit faire l'objet d'une description d'application. Les descriptions de l'utilisation des éléments Rulsys incluent la spécification du type de résolveur de problèmes (s-machine autonome, coopération réseau de s-machines, coopération homme-s-machine, etc.), les exigences de sécurité de l'information, etc. les modes de fonctionnement du résolveur de problèmes ( automatique local, automatique distribué, interactif local, etc.), les exigences relatives au résultat obtenu, etc. Les descriptions de l'application des programmes incluent des données sur les langages de mise en œuvre, les systèmes d'exploitation, etc.
Algorithme– une description formalisée d'un ensemble fini d'étapes de résolution du problème, correspondant à l'un des éléments de Rulsys et permettant une correspondance univoque entre un ensemble donné de données d'entrée et l'ensemble résultant de données de sortie.
Programme- un algorithme implémenté dans un langage de programmation haut niveau, un langage orienté machine et/ou un système d'instructions machine. Présenté sous la forme d'un message qui définit le comportement d'un solveur de problème s-machine avec des propriétés données. Existe en incarnations symboliques, de code et de signal, reliées par des relations de traduction (voir Compilateur en informatique).
Symbole(symbole anglais) - substitut d'un objet naturel ou inventé, désignant cet objet et étant un élément d'un certain système de construction de messages symboliques (textes, notations musicales, etc.), destiné à être perçu par une personne ou un robot. Par exemple, l'alphabet russe est un système de symboles textuels ; la lettre A dans ce système est un symbole qui remplace le son correspondant du système de symboles audio de la parole de la langue russe; La lettre A correspond à un symbole textural tactile (perçu par le toucher avec les doigts) dans un système de messagerie texte pour aveugles connu sous le nom de Braille (voir Fig. Braille). L'ensemble des symboles visuels, sonores et autres choisis pour construire des messages d'un certain type est considéré comme un ensemble d'objets constructifs élémentaires, dont chacun est doté d'un ensemble d'attributs et d'un ensemble d'opérations autorisées. La création de structures à partir des éléments de cet ensemble est déterminée par le système de règles de construction des modèles symboliques [pour plus de détails, voir l'article Symbole en informatique (s-symbole)].
Code(code anglais) - substitut d'un symbole ou d'un message symbolique utilisé pour les représenter dans les ordinateurs, les smartphones et autres machines programmables et conçu pour construire, enregistrer, transmettre et interpréter des messages symboliques [pour plus de détails, voir l'article Code en informatique ( code s)].
Signal(signal anglais) est un impact optique, sonore ou autre perçu par les sens humains ou les capteurs de la machine, ou la représentation du code sous la forme d'une fréquence de rayonnement électromagnétique, de compositions de valeurs de tension électrique, ou autre, conçu pour être perçu par le matériel de la machine (par exemple, unité centrale de traitement ordinateur, microprocesseur navigateur automobile). Symboles, codes et signaux sont interconnectés par des relations de transformation. Chaque symbole et construction symbolique, conçu pour être perçu par un humain ou un robot, peut être associé à une correspondance biunivoque avec des codes conçus pour les manipuler à l'aide de logiciels et de dispositifs informatiques.
Modèle de système conceptuel. Le modèle S Cons d'un système de concepts est considéré comme un couple (ConsSet , ConsRel ), où ConsSet est un ensemble de concepts ; ConsRel est une famille de relations définies sur ConsSet . Définition d'un système de concepts - une description de son modèle, accompagnée d'une indication de la portée. La description est présentée sous la forme d'un message destiné à être interprété par le destinataire, présenté, stocké, distribué, accumulé et recherché dans l'environnement homme-machine de l'activité intellectuelle. Un système de concepts considéré comme défini ne devrait pas inclure des concepts qui n'ont pas de définitions (et en même temps ne sont pas liés à des concepts-axiomes). Détermination de la portée du modèle - une description des types de correspondants (à qui la définition s'adresse), l'objectif en cours de réalisation auquel la définition a du sens (classes de tâches dans l'étude desquelles la définition peut être utile) , l'étape à laquelle il convient d'utiliser la définition (concept, méthodologie de résolution, etc.) d.).
Modèle de système de connaissances. Le concept de "savoir" dans la modélisation s [voir. Modélisation symbolique(s-simulation)] est défini comme l'état du récepteur du message lorsque le message de sortie résultant de l'interprétation du message d'entrée est reconnu comme déjà connu et ne nécessite pas de modifications des modèles de systèmes conceptuels stockés dans la mémoire du message destinataire. Le concept de "connaissance" est défini comme une capacité complexe à extraire des informations de messages contenant les conditions de tâches d'une certaine classe (il peut s'agir de tâches de reconnaissance de formes, de traduction d'une langue à une autre, ou d'autres classes de tâches). Le S-modèle du système de connaissances est considéré comme une triade (Cons , Lang , Interp ), où Cons est le s-modèle du système de concepts ; Lang est le s-modèle de l'ensemble des langages de messages interprétés sur Cons ; Interp est le s-model de la collection d'interprètes sur Cons de messages composés dans des langues de Lang.
L'interprétation du message sur le modèle Cons comprend :
1) construire un message de sortie (extraction d'informations) en fonction d'un message d'entrée donné (les messages sont présentés dans des langues de l'ensemble Lang) ;
2) analyse du message de sortie (si des changements sont nécessaires dans le modèle Cons);
3) si nécessaire, modifiez le modèle Cons ; sinon, fin.
Par exemple, le centre cérébral d'un système moderne de conception assistée par ordinateur (CAO) est le système de connaissances. La productivité de la conception dépend de la qualité de sa construction.
Machine programmable(s-machine) est une structure logicielle et matérielle permettant de résoudre des problèmes. Les superordinateurs, les ordinateurs centraux, les ordinateurs personnels, les ordinateurs portables, les smartphones, les navigateurs, les appareils photo numériques et les caméras vidéo sont tous des s-cars. Les claviers, souris, trackballs, pavés tactiles et autres périphériques d'entrée sont des composants des s-machines qui convertissent les caractères en codes acceptés par les pilotes (voir Pilote en informatique) des périphériques correspondants. Les moniteurs d'ordinateurs personnels, les écrans d'ordinateurs portables, les navigateurs, etc. convertissent les codes générés par les contrôleurs vidéo en compositions symboliques conçues pour le canal visuel humain.
(environnement s) - une association de réseaux informatiques et de machines programmables individuelles utilisées pour résoudre divers problèmes. Moyens d'informatisation de divers types d'activité. L'environnement S doit permettre la représentation de codes numériques de modèles symboliques et la manipulation de ces codes à l'aide de machines s. Au cœur des technologies modernes de communication numérique, conception assistée par ordinateur, etc., il y a une idée remarquable par les conséquences de sa mise en œuvre : réduire toute diversité symbolique à des codes numériques [et chacun d'eux à un seul code (ils ont toujours un code binaire)] et instruisent le travail avec des codes sur des machines programmables, combinées dans un environnement homme-machine pour résoudre des problèmes.
Interaction de l'information dans le milieu s(Fig. 3) est étudié comme un ensemble d'interfaces telles que "homme - homme", "homme - programme", "homme - matériel d'une machine programmable", "programme - programme", "programme - matériel" (voir Interface Port en informatique). Une personne perçoit des signaux analogiques d'entrée (lumière, son, etc.) à l'aide de dispositifs d'entrée visuels, auditifs et autres de la biointelligence (un système biologique qui assure le fonctionnement de l'intellect). Il convertit les signaux qui l'intéressent en constructions symboliques visuelles, sonores et autres utilisées dans les processus de la pensée. Les signaux de sortie de la biointelligence sont réalisés par des gestes (par exemple, utilisés lors de la saisie à partir du clavier et de la souris), de la parole, etc. . L'entrée et la sortie des programmes sont les données d'entrée et les codes de résultat (voir Fig. Code en informatique), et l'entrée et la sortie du matériel sont des signaux. Les signaux analogiques d'entrée sont convertis en signaux numériques à l'aide convertisseurs analogique-numérique(ADC), et la sortie numérique vers analogique en utilisant convertisseurs numérique-analogique(DAC).
Dans l'environnement s moderne (2017), les moyens naturels de perception, de traitement et de stockage des signaux humains sont complétés par des moyens inventés : caméras numériques photo et vidéo, smartphones, etc. Une partie bien connue des technologies d'interaction de l'information est représentée par le développement rapide Services Internet. Utilisé pour interagir avec les gens E-mail(e-mail en anglais), différents types de connexion Internet [ Téléphonie Internet(téléphonie IP); par exemple, mis en œuvre dans le service Internet Skype ; messagers (messager anglais - connecté); par exemple, le service Internet Telegram), les réseaux sociaux (réseaux sociaux anglais), etc. Internet des objets » sont utilisés (voir. Internet ).
Classes de tâches de base
Basé sur l'étude des propriétés et des modèles modélisation symbolique(s-simulation) les classes suivantes de problèmes informatiques de base sont définies.
Représentation de modèles d'objets arbitraires, conçu pour la perception humaine et les machines programmables, est associé à l'invention de langages de messages répondant à certaines exigences. Cette classe étudie les systèmes de symboles et de codes utilisés respectivement dans les langages orientés vers l'homme et vers la machine. Le premier comprend les langages de spécification, de programmation, de requêtes, le second - les systèmes d'instructions machine. Cette classe comprend également des tâches de présentation de données. Il comprend les tâches de représentation des modèles de systèmes de concepts sur lesquels les messages sont interprétés. Au niveau supérieur de la hiérarchie des tâches de cette classe se trouve la représentation des modèles de systèmes de connaissances.
Conversion des types et des formes de représentation des modèles symboliques permet d'établir une correspondance entre les modèles. Les tâches de conversion de types (par exemple, parole en texte et vice versa) et de formulaires (par exemple, analogique en numérique et vice versa ; non compressé en compressé et vice versa ; *.doc en *.pdf) sont un complément nécessaire à la tâches de représentation de modèles.
Reconnaissance des messages implique la nécessité de le présenter dans un format connu du destinataire. Lorsque cette condition est remplie, pour reconnaître le message, les tâches de mise en correspondance avec des modèles modèles, ou de mise en correspondance des propriétés du modèle reconnu avec les propriétés des modèles modèles, sont résolues. Par exemple, dans la tâche d'identification biométrique d'une personne, ses données biométriques (message d'entrée) sont comparées à un échantillon biométrique de la base de données du système biométrique.
Modélisme systèmes de concepts, systèmes de connaissances, interprètes de messages sur des modèles de systèmes de concepts ; modèles de tâches, technologies de programmation, interaction dans l'environnement s ; modèles d'architecture de s-machines, réseaux informatiques, architectures orientées services ; modèles de messages et moyens de leur construction, documents et flux de travail. Au niveau supérieur de la hiérarchie de cette classe se trouvent les tâches de construction de modèles d'environnement s et de technologies de modélisation symbolique.
Interprétation des messages(extraction d'information) présuppose l'existence du message reçu, le modèle du système de concepts sur lequel il doit être interprété et le mécanisme d'interprétation. La résolution de problèmes dans l'environnement homme-machine est l'interprétation des données initiales (message d'entrée) sur le modèle du système de concepts présenté dans l'algorithme. Le résultat de la solution est le message de sortie (information extraite du message d'entrée). Si l'interpréteur est un programme exécutable, alors les données initiales, le programme et le résultat de la résolution du problème sont représentés par les codes correspondants (voir Code en informatique). Pour le microprocesseur de la machine programmable, les messages à interpréter et les résultats de l'interprétation sont représentés par des signaux correspondant à des instructions machine et des codes de données. Par exemple, lors d'une prise de vue avec un appareil photo numérique, un message (sous la forme d'un signal lumineux) agit sur une matrice photosensible, est reconnu par celle-ci, puis converti en un code d'image numérique, qui est interprété par un programme qui améliore l'image qualité. Le résultat obtenu est converti et enregistré (sur le stockage intégré de l'appareil photo ou sur la carte mémoire) sous forme de fichier graphique.
Echange de messages : les tâches de construction d'interfaces de type "homme - homme", "homme - programme", "homme - matériel d'une machine programmable", "programme - programme", "programme - matériel" (voir Interface en informatique), " hardware - hardware » (voir Port en informatique) ; tâches de messagerie dans un environnement homme-machine pour résoudre des problèmes (avec typage des expéditeurs et des destinataires ; moyens d'envoyer, de transmettre et de recevoir des messages ; environnements de messagerie). Des systèmes de règles d'échange de messages (protocoles de réseau) sont inventés ; architectures réseau ; systèmes de gestion de documents. Par exemple, les messages sont échangés entre les processus systèmes d'exploitation(OS), programmes s-machine dans un réseau informatique, utilisateurs de messagerie, etc.
Enregistrement, accumulation et recherche de messages : les dispositifs de mémoire et de stockage, leurs mécanismes de contrôle sont étudiés et typifiés ; formes de conservation et d'accumulation ; médias, méthodes de conservation, d'accumulation et de recherche ; bases de données et bibliothèques de logiciels. Des modèles de sujet de recherche (par modèle, par caractéristiques, par description de biens) et des méthodes de recherche sont étudiés.
Protection des informations : les problématiques de prévention et de détection de vulnérabilités, de contrôle d'accès, de protection contre les intrusions, les malwares, l'interception de messages et les utilisations non autorisées sont étudiées.
Domaines de recherche
Les idées scientifiques les plus importantes qui influencent le développement de l'informatique sont incarnées dans le support méthodologique pour la construction d'outils pour soutenir les processus de cognition, d'interaction d'informations et de résolution automatisée de divers problèmes. Au stade actuel (2017) du développement de l'informatique, les complexes interconnectés suivants de domaines de recherche sont pertinents.
Automatisation des calculs(calcul à l'aide de machines programmables) : modèles, architectures et systèmes de commande de machines programmables sont étudiés ; algorithmisation de tâches programmables [algorithmes et structures de données, algorithmes distribués (Distributed Algorithms), algorithmes randomisés (Randomized Algorithms), etc.] ; informatique distribuée (Distributed Computing), informatique en nuage (Cloud Computing); la complexité et l'intensité des ressources des calculs.
La programmation: les systèmes de symboles textuels et de codes sont étudiés ; langages de programmation et spécifications de tâches ; traducteurs; bibliothèques de programmes ; Programmation du système ; système d'exploitation ; systèmes de programmation instrumentale; Systèmes de gestion de bases de données; technologies de programmation; services en ligne pour résoudre des problèmes, etc.
Environnement homme-machine pour la résolution de problèmes(s-environnement) : modèles, méthodes et outils de construction d'un s-environnement, réseaux informatiques, réseaux de communication numériques, Internet sont étudiés.
Perception et présentation des messages, interaction dans l'environnement s : des modèles, des méthodes et des moyens de perception et de présentation de messages visuels, sonores, tactiles et autres sont étudiés ; vision par ordinateur, audition et autres capteurs artificiels ; formation de messages audio, visuels, tactiles et autres (y compris combinés) conçus pour une personne et un robot partenaire ; reconnaissance de messages audio, visuels et autres (paroles, gestes, etc.); traitement d'images, infographie, visualisation, etc.; échange de messages (modèles de messages, méthodes et moyens de leur réception et transmission); interfaces de l'utilisateur, programmes, matériel, programmes avec matériel; les services d'interaction en ligne (messagers, réseaux sociaux, etc.).
Ressources et systèmes d'information pour résoudre les problèmes dans l'environnement s : les modèles, les méthodes et les moyens de construire, de représenter, de sauvegarder, d'accumuler, de rechercher, de transférer et de protéger les ressources informationnelles sont étudiés ; gestion électronique de documents; bibliothèques électroniques et autres systèmes d'information; internet (voir Le World Wide Web).
Sécurité des informations et cryptographie : les méthodes de prévention et de détection des vulnérabilités sont étudiées ; contrôle d'accès; protection des systèmes d'information contre les intrusions, les logiciels malveillants, l'interception de messages ; l'utilisation non autorisée des ressources d'information, des logiciels et du matériel.
Intelligence artificielle: des modèles, méthodes et outils de construction de robots intelligents utilisés comme partenaires humains (résolution de problèmes de sécurité, contrôle de situation, etc.) sont étudiés ; méthodes de décision expertes.
Modélisation symbolique : des systèmes de symboles visuels, sonores, tactiles et autres sont étudiés, considérés comme des objets constructifs pour la construction de modèles d'entités arbitraires conçues pour une personne (systèmes de concepts et systèmes de connaissances, objets environnement et des objets inventés par des personnes) ; des systèmes de codes, mis en conformité avec des systèmes de symboles, qui sont destinés à la construction d'équivalents en code de modèles symboliques destinés à être manipulés à l'aide de programmes ; les langages pour décrire des modèles symboliques ; typage des modèles symboliques et de leurs équivalents en code ; méthodes de construction de modèles symboliques de systèmes de concepts et de systèmes de connaissances (y compris les systèmes de connaissances sur les tâches programmables) [pour plus de détails, voir l'article Modélisation symbolique(s-simulation)].
La formation de l'informatique
Modélisation symbolique des objets étudiés a longtemps été le principal outil de présentation des connaissances acquises. L'invention de symboles (gestuels, graphiques, etc.) et les modèles de messages symboliques construits à partir d'eux, la représentation et l'accumulation de tels modèles dans l'environnement extérieur sont devenus des moyens clés pour la formation et le développement des capacités intellectuelles. Le rôle dominant des modèles symboliques dans l'activité intellectuelle est déterminé non seulement par leur compacité et leur expressivité, mais aussi par le fait qu'il n'y a pas de restrictions sur les types de supports utilisés pour les stocker. Le support peut être une mémoire humaine, une feuille de papier, une matrice d'appareil photo numérique, une mémoire d'enregistreur vocal numérique ou autre chose. Les coûts de construction, de copie, de transfert, de sauvegarde et d'accumulation de modèles symboliques sont incomparablement inférieurs aux coûts similaires associés à des modèles non symboliques (par exemple, des modèles de navires, de bâtiments, etc.). Sans outils de modélisation symbolique, il est difficile d'imaginer le développement de la science, de l'ingénierie et d'autres activités.
Aux premiers stades du développement de la modélisation, la variété des objets modélisés se limitait à ce qu'on appelle communément les objets environnementaux, et les modèles de ces objets étaient physiques. Le développement du son, du geste et d'autres moyens de modélisation symbolique des significations, provoqué par la nécessité de signaler un danger, le placement d'objets de chasse et d'autres objets d'observation, a contribué à l'amélioration des mécanismes de cognition, de compréhension mutuelle et d'apprentissage. Des langages de message ont commencé à se former, y compris des symboles sonores et gestuels. Le désir de modéliser le comportement (y compris le sien) a posé de nouveaux défis. On peut supposer qu'au départ, ce désir était associé à l'enseignement d'un comportement rationnel à la chasse, dans la vie quotidienne, lors de catastrophes naturelles. À un certain stade, ils ont pensé à créer de tels outils de modélisation qui permettraient de construire des modèles permettant leur stockage, leur copie et leur transfert.
La volonté d'accroître l'efficacité des explications accompagnant le spectacle a conduit à l'amélioration de l'appareil conceptuel et des moyens de son incarnation verbale. Le développement de modèles symboliques sous forme de schémas graphiques et l'amélioration de la parole ont conduit à un modèle graphique de la parole. L'écriture s'est créée. Il est devenu non seulement une étape importante dans le développement de la modélisation symbolique, mais aussi un outil puissant dans le développement de l'activité intellectuelle. Désormais, les descriptions des objets de modélisation et les relations entre eux pourraient être représentées par des compositions de textes, de diagrammes et de dessins. Une boîte à outils a été créée pour afficher les observations, les raisonnements et les plans sous forme de modèles symboliques pouvant être stockés et transmis. Les tâches d'invention de supports, d'outils pour écrire et créer des images, de colorants, etc.
Une étape importante de la modélisation graphique est associée aux modèles d'images schématiques (les ancêtres des dessins) - la base de la conception. La représentation d'un objet tridimensionnel en cours de conception dans trois projections bidimensionnelles, qui montrent les dimensions et les noms des pièces, a joué un rôle décisif dans le développement de l'ingénierie. Sur le chemin des textes manuscrits, des dessins et des schémas à la typographie et aux modèles graphiques dans le design, de l'enregistrement sonore, de la photographie et de la radio au cinéma et à la télévision, des ordinateurs et des réseaux locaux au réseau mondial, aux laboratoires virtuels et à l'enseignement à distance, le rôle de la symbolique modèles qu'une personne crée avec des machines.
La productivité des résolveurs de problèmes est un problème clé de la productivité de l'activité intellectuelle, qui est constamment au centre de l'attention des inventeurs. Le besoin d'évaluations quantitatives des objets matériels a longtemps stimulé l'invention de systèmes de symboles sonores, gestuels, puis graphiques. Pendant un temps, ils se sont débrouillés avec la règle : chaque valeur a son propre symbole. Le comptage à l'aide de cailloux, de bâtons et d'autres objets (comptage objectif) a précédé l'invention du comptage symbolique (basé sur une représentation graphique des quantités). Au fur et à mesure que le nombre d'objets à utiliser augmentait, la tâche de représentation symbolique des quantités devenait plus urgente. La formation du concept de "nombres" et l'idée de sauvegarder des symboles lors de la modélisation des nombres ont conduit à l'invention des systèmes de nombres. L'idée des systèmes de nombres positionnels mérite une mention spéciale, dont l'un (binaire) au XXe siècle. était destiné à jouer un rôle clé dans l'invention des machines programmables numériques et le codage numérique des modèles de caractères. Changer la signification d'un symbole avec un changement de sa position dans la séquence de symboles est une idée très productive qui a fait progresser l'invention des dispositifs informatiques (de l'abaque à l'ordinateur).
Outils pour augmenter la productivité des résolveurs de problèmes. En 1622-1633, le scientifique anglais William Otred proposa une variante règle à calcul, qui est devenu le prototype des règles à calcul que les ingénieurs et les chercheurs du monde entier utilisent depuis plus de 300 ans (avant que les ordinateurs personnels ne soient disponibles). En 1642, B. Pascal, essayant d'aider son père dans les calculs lors de la perception des impôts, crée un dispositif d'addition à cinq chiffres ("Pascaline" ), construit sur la base de roues dentées. Au cours des années suivantes, il a créé des appareils à six et huit chiffres conçus pour additionner et soustraire des nombres décimaux. En 1672, le scientifique allemand G.W. Leibniz crée une calculatrice mécanique numérique pour les opérations arithmétiques sur les nombres décimaux à douze chiffres. C'était la première calculatrice à effectuer toutes les opérations arithmétiques. Le mécanisme, appelé "roue de Leibniz", jusque dans les années 1970. reproduit dans diverses calculatrices de poche. En 1821, la production industrielle de machines à additionner débute. En 1836–48 C. Babbage a terminé le projet d'un ordinateur décimal mécanique (appelé par lui un moteur analytique), qui peut être considéré comme un prototype mécanique des futurs ordinateurs. Le programme de calcul, les données et le résultat ont été enregistrés sur des cartes perforées. L'exécution automatique du programme était assurée par le dispositif de contrôle. La voiture n'a pas été construite. En 1934 - 38 K. Zuse créé un ordinateur binaire mécanique (longueur de mot– 22 chiffres binaires ; mémoire– 64 mots; opérations en virgule flottante). Initialement, le programme et les données étaient entrés manuellement. Environ un an plus tard (après le début de la conception), un dispositif de saisie d'un programme et de données à partir d'un film perforé a été fabriqué, et une unité de calcul mécanique (AU) a été remplacée par une AU construite sur des relais téléphoniques. En 1941, Zuse, avec la participation de l'ingénieur autrichien H. Schreier, a créé le premier ordinateur binaire fonctionnant entièrement à relais au monde avec contrôle de programme (Z3). En 1942, Zuse a également créé le premier ordinateur numérique de contrôle au monde (S2), qui a été utilisé pour contrôler les avions à projectiles. En raison du secret des travaux effectués par Zuse, leurs résultats ne sont devenus connus qu'après la fin de la 2e guerre mondiale. Le premier langage de programmation de haut niveau au monde Plankalkül (Allemand Plankalkül - plan de calcul) a été créé par Zuse en 1943-45, publié en 1948. Les premiers ordinateurs électroniques numériques, à commencer par l'ordinateur américain ENIAC [(ENIAC - Electronic Numerical Integrator and Computer - intégrateur numérique électronique et calculateur); début du développement - 1943, présenté au public en 1946], ont été créés comme un moyen d'automatiser les calculs mathématiques.
Créer la science de l'informatique avec des machines programmables. Tout R 20ième siècle la production d'ordinateurs numériques a commencé, qui aux États-Unis et en Grande-Bretagne étaient appelés ordinateurs (ordinateurs) et en URSS - ordinateurs électroniques (ordinateurs). Depuis les années 1950 au Royaume-Uni et à partir des années 1960 aux États-Unis, la science de l'informatique à l'aide de machines programmables a commencé à se développer, appelée Computer Science (informatique). En 1953 Université de Cambridge un programme a été formé dans la spécialité informatique; aux États-Unis programme similaire introduit en 1962 à l'Université Purdue.
En Allemagne, l'informatique s'appelait Informatik (informatique). En URSS, le domaine de la recherche et de l'ingénierie consacré à la construction et à l'application des machines programmables s'appelait "informatique". En décembre 1948, I. S. Bruk et B. I. Rameev ont reçu le premier certificat de droit d'auteur en URSS pour l'invention d'une machine numérique automatique. Dans les années 1950 la première génération d'ordinateurs domestiques a été créée (élément de base - lampes électroniques): 1950 - MESM (le premier ordinateur électronique soviétique, développé sous la direction de S. A. Lebedev ); 1952 - M-1, BESM (jusqu'en 1953 l'ordinateur le plus rapide d'Europe); 1953 - "Flèche" (le premier ordinateur produit en série en URSS); 1955 - Oural-1 de la famille Ural d'ordinateurs numériques à usage général (concepteur en chef B. I. Rameev).
Améliorer les méthodes et les moyens d'automatisation. Avec la disponibilité croissante des ordinateurs pour les utilisateurs de divers domaines d'activité, qui a commencé dans les années 1970, on observe une diminution de la part des problèmes mathématiques résolus à l'aide d'ordinateurs (créés à l'origine comme un moyen d'automatiser les calculs mathématiques), et une augmentation de la part de problèmes non mathématiques (communication, recherche, etc.). Quand dans la seconde moitié des années 1960. des terminaux informatiques avec écrans ont commencé à être produits, le développement de programmes d'édition d'écran pour saisir, enregistrer et corriger du texte avec l'afficher sur plein écran[l'un des premiers éditeurs d'écran était le O26, créé en 1967 pour les opérateurs de console des ordinateurs de la série CDC 6000 ; en 1970, vi a été développé, l'éditeur d'écran standard pour les systèmes d'exploitation Unix et Linux]. L'utilisation d'éditeurs d'écran a non seulement augmenté la productivité des programmeurs, mais a également créé les conditions préalables à des changements importants dans les outils de construction automatisée de modèles symboliques d'objets arbitraires. Par exemple, utiliser des éditeurs d'écran pour générer des textes à des fins diverses(articles et livres scientifiques, manuels, etc.) déjà dans les années 1970. a permis d'augmenter considérablement la productivité de la création de ressources d'informations textuelles. En juin 1975, le chercheur américain Alan Kay [le créateur du langage de programmation orienté objet Smalltalk (Smalltalk) et l'un des auteurs de l'idée d'un ordinateur personnel] dans l'article "Personal Computing" (« Informatique personnelle» ) a écrit : "Imaginez-vous en tant que propriétaire d'une machine à connaissances autonome dans mallette portative, qui a la taille et la forme d'un bloc-notes ordinaire. Comment l'utiliseriez-vous si ses capteurs étaient supérieurs à votre vue et à votre ouïe, et si sa mémoire vous permettait de stocker et de récupérer, si nécessaire, des milliers de pages de documents de référence, des poèmes, des lettres, des recettes, ainsi que des dessins, des animations, des oeuvres, graphismes, modèles dynamiques et quelque chose d'autre que vous aimeriez créer, mémoriser et changer ? . Cette déclaration reflétait le tournant qui s'était opéré à cette époque dans l'approche de la construction et de l'application des machines programmables : des outils d'automatisation, principalement des calculs mathématiques, aux outils de résolution de problèmes de divers domaines d'activité. En 1984 Kurzweil Music Systems (KMS), créé par l'inventeur américain Raymond Kurzweil, a produit le premier synthétiseur de musique numérique au monde, le Kurzweil 250. C'était le premier ordinateur dédié au monde qui convertissait les caractères gestuels tapés sur le clavier en sons musicaux.
Amélioration des méthodes et des moyens d'interaction de l'information. En 1962, les chercheurs américains J. Licklider et W. Clark ont publié un rapport sur l'interaction homme-machine en ligne. Le rapport contenait une justification de l'opportunité de construire un réseau mondial en tant que plate-forme d'infrastructure qui donne accès à ressources d'information hébergés sur des ordinateurs connectés à ce réseau. Justification théorique de la commutation de paquets lors de la transmission de messages dans réseaux informatiques a été donnée dans un article publié en 1961 par le scientifique américain L. Kleinrock.En 1971, R. Tomlinson (USA) a inventé le courrier électronique, en 1972 ce service a été mis en place. L'événement clé de l'histoire de la création d'Internet a été l'invention en 1973 par les ingénieurs américains V. Cerf et R. Kahn du protocole de contrôle de transmission - TCP. En 1976, ils ont démontré la transmission d'un paquet réseau sur le protocole TCP. En 1983, la famille de protocoles TCP/IP a été normalisée. En 1984, le système de noms de domaine (DNS) a été créé (voir. Domaine en informatique). En 1988, le protocole de chat [Internet Real Time Text Messaging Service (IRC - Internet Relay Chat)] a été développé. En 1989, le projet Web a été mis en œuvre (voir. Le World Wide Web) développé par T. Berner Lee. 6.6.2012 - un jour important dans l'histoire d'Internet : grands fournisseurs d'accès Internet, fabricants d'équipements pour réseaux informatiques et les sociétés Web ont commencé à utiliser le protocole IPv6 (avec le protocole IPv4), résolvant pratiquement le problème de la rareté des adresses IP (voir Internet). Le taux de développement élevé d'Internet est facilité par le fait que depuis sa création, les professionnels impliqués dans les tâches scientifiques et techniques de construction d'Internet échangent sans tarder des idées et des solutions en utilisant ses capacités. Internet est devenu une plate-forme infrastructurelle pour un environnement homme-machine permettant de résoudre des problèmes. Il sert d'infrastructure de communication E-mail, Web, moteurs de recherche, Téléphonie Internet(téléphonie IP) et autres services Internet utilisés dans l'informatisation de l'éducation, de la science, de l'économie, de l'administration publique et d'autres activités. Les services électroniques créés sur la base d'Internet ont permis le bon fonctionnement de diverses entités Internet commerciales et non commerciales : boutiques en ligne, réseaux sociaux[Facebook (Facebook), VKontakte, Twitter (Twitter), etc.], moteurs de recherche [Google (Google), Yandex (Yandex), etc.], ressources Web encyclopédiques [Wikipedia (Wikipedia), Webopedia, etc.], électroniques bibliothèques [World Digital Library (World Digital Library), Scientific Electronic Library eLibrary, etc.], portails d'information d'entreprises et gouvernementaux, etc.
Depuis les années 2000, le nombre de solutions Internet n'a cessé de croître - "maison intelligente" (Smart House), "système d'alimentation intelligent" (Smart Grid), etc. Les solutions M2M (M2M - Machine-to-Machine) basées sur les technologies de l'information de l'interaction machine-machine et conçues pour surveiller les capteurs de température, les compteurs d'électricité, les compteurs d'eau, etc. se développent avec succès ; suivi de l'emplacement des objets en mouvement sur la base des systèmes GLONASS et GPS (voir. Système de positionnement par satellite); contrôle d'accès aux objets protégés, etc.
Enregistrement officiel de l'informatique en URSS. L'informatique a été officiellement officialisée en URSS en 1983, lorsque le Département d'informatique, de génie informatique et d'automatisation a été créé dans le cadre de l'Académie des sciences de l'URSS. Il comprenait l'Institut des problèmes informatiques de l'Académie des sciences de l'URSS, créé la même année, ainsi que l'Institut de mathématiques appliquées de l'Académie des sciences de l'URSS, le Centre de calcul de l'Académie des sciences de l'URSS, l'Institut de transmission de l'information Problèmes de l'Académie des sciences de l'URSS et de plusieurs autres instituts. Au premier stade, la recherche dans le domaine du matériel et des logiciels pour l'informatique de masse et les systèmes basés sur ceux-ci était considérée comme la principale. Les résultats obtenus devaient devenir la base de la création d'une famille d'ordinateurs personnels (PC) domestiques et de leur application pour l'informatisation des activités scientifiques, éducatives et autres activités pertinentes.
Problèmes et perspectives
Appui méthodologique pour la construction d'un s-environnement personnel. Dans les années à venir, l'un des axes d'actualité de l'accompagnement méthodologique pour l'amélioration de l'environnement s sera associé à la création de systèmes personnalisés de résolution de problèmes, dont le matériel est placé dans l'équipement de l'utilisateur. Vitesses de la technologie avancée Communication sans fil déjà suffisant pour résoudre de nombreux problèmes basés sur les services Internet. On s'attend à ce que d'ici 2025, le taux et la prévalence technologies sans fil les communications atteindront des niveaux tels qu'une partie des interfaces filaires de nos jours seront remplacées par des interfaces sans fil. La baisse des prix des services Internet contribuera également à la promotion des technologies de personnalisation de l'environnement s de l'utilisateur. Les problèmes réels associés à la personnalisation de l'environnement s sont : la création de systèmes symboliques et de codage plus avancés ; conversion logicielle et matérielle de messages audio et tactiles envoyés par une personne en messages graphiques, représentés par une composition de texte, d'hypertexte, caractères spéciaux et photos ; amélioration technologique et unification des interfaces sans fil [principalement des interfaces vidéo (sortie au choix de l'utilisateur : sur des lunettes spéciales, des écrans de moniteur, un téléviseur ou un autre périphérique de sortie vidéo)].
Le support méthodologique pour la construction d'un environnement s personnel devrait être basé sur les résultats de la recherche dans le domaine de l'intelligence artificielle visant à construire non pas un simulateur de machine de l'intelligence humaine, mais un partenaire intelligent contrôlé par une personne. Le développement de technologies pour la construction d'un environnement personnel s implique l'amélioration des méthodologies d'apprentissage à distance, d'interaction, etc.
Le nom général "documentation", qui sert parfois de synonyme au terme "je.". En 1931, l'Institut international de bibliographie a été fondé par P. Otlet et un avocat et personnalité publique belge. Lafontaine en 1895, a été rebaptisé l'Institut international de documentation, et en 1938 - la Fédération internationale de documentation, qui continue d'être la principale organisation internationale qui rassemble des spécialistes en . et activités scientifiques et d'information (voir Fédération internationale de documentation). En 1945, le scientifique et ingénieur américain W. Bush publie The Possible Mechanism of Our Thinking, dans lequel, pour la première fois, la question de la nécessité de mécaniser la recherche d'informations est largement posée. Des conférences internationales sur l'information scientifique (Londres, 1948 ; Washington, 1958) ont marqué les premières étapes du développement de I. L'étude des schémas de diffusion des publications scientifiques réalisée a été d'une grande importance. Bradford (Royaume-Uni, 1948). Jusqu'au milieu des années 60. 20ième siècle principalement des principes et des méthodes de recherche d'informations et des moyens techniques de leur mise en œuvre ont été développés. W. Batten (Grande-Bretagne), . Muers et. Taube (États-Unis) a jeté les bases de l'indexation des coordonnées ; . Vickery, . Fosket (Grande-Bretagne), J. Perry, A. Kent , J. Costello, . P. Lun, . Bernier (États-Unis), . C. Garden (France) a développé les bases de la théorie et de la méthodologie de la recherche d'informations ; S. Cleverdon (Grande-Bretagne) a étudié des méthodes permettant de comparer l'efficacité technique des systèmes de recherche documentaire de divers types ; R. Shaw (États-Unis) et J. Samin (France) ont créé les premiers dispositifs de recherche d'informations sur microfilms et diamicrocartes, qui ont servi de prototypes à de nombreuses machines d'information spéciales ; K. Muller et C. Carlson (USA) ont proposé de nouvelles méthodes de reproduction de documents, qui ont constitué la base des techniques modernes de reprographie. L'étape actuelle du développement de l'information (les années 1970) est caractérisée par une compréhension plus profonde de la signification scientifique générale de l'activité d'information scientifique et par l'utilisation toujours plus large des ordinateurs électroniques dans celle-ci. D. Price (USA), développant les idées de J. Bernal (Grande-Bretagne), a souligné la possibilité de mesurer les processus de développement de la science en utilisant des indicateurs et des moyens de I.; . Garfield (États-Unis) a développé et introduit de nouvelles méthodes de service d'information scientifique ; G. Menzel et W. Garvey (USA) ont étudié les besoins d'information des scientifiques et des spécialistes, l'importance des différents processus de communication scientifique. La théorie générale de I. à l'étranger est formée dans les travaux de A. Avramescu (Roumanie), A. Vysotsky et M. Dembovskaya (Pologne), I. Koblitz (RDA), A. Merta (Tchécoslovaquie), I. Polzovich (Hongrie), . Peach (Allemagne), A. Rees, R. Taylor, J. Shira (États-Unis), R. Fairthorn (Grande-Bretagne) et d'autres En URSS, le développement des activités scientifiques et d'information est allé parallèlement au développement de la science soviétique et l'économie nationale. Dans les années 30. 20ième siècle la Commission pour la publication des index (index) de la littérature scientifique a travaillé, des revues abstraites de l'Académie des sciences de l'URSS dans les sciences physiques et mathématiques, la chimie, etc. ont commencé à apparaître (voir Bibliographie). Cette activité a commencé à se développer de manière particulièrement intensive à partir des années 50. La formation d'I. en tant que discipline scientifique indépendante remonte à la fin des années 40 et au début des années 50. En URSS, l'information a été institutionnalisée en 1952, lorsque l'Institut d'information scientifique de l'Académie des sciences de l'URSS, aujourd'hui l'Institut d'information scientifique et technique de toute l'Union (VINITI), a été créé. Depuis 1959, le Conseil des ministres de l'URSS a adopté un certain nombre de résolutions visant à améliorer et à développer un système national unifié d'information scientifique et technique. Trois conférences de toute l'Union sur le traitement automatisé de l'information scientifique (en 1961, 1963 et 1966) ont été des étapes importantes dans le développement de l'informatique en URSS. Le symposium international des pays membres du Conseil d'assistance économique mutuelle et de la Yougoslavie sur les problèmes théoriques de l'informatique (Moscou, 1970) et pour l'amélioration des moyens techniques de I a été d'une grande importance pour le développement de la théorie de I. - les expositions internationales "Inforga-65" et "Interorgtekhnika-66", qui ont démontré les moyens techniques de mécanisation complexe et d'automatisation des processus de traitement, de stockage, de recherche et de diffusion de l'information scientifique. De nombreuses études sur le russe I. ont constitué la base de son développement ultérieur: dans le domaine de la théorie générale de I. - les travaux de V. A. Uspensky, Yu. A. Shreider; construction de systèmes de recherche d'informations - G. E. Vladutsa, D. G. Lakhuti, E. . Skorokhodko, V. P. Cherenina ; problèmes scientifiques de I. - G. M. Dobrova, V. V. Nalimova; documentaires - G. G. Vorobyova, K. R. Simona,. I. Shamurina ; création de dispositifs de recherche d'informations et autres moyens techniques - . I. Gutenmakher, V. A. Kalmanson, B. M. Rakov et autres I. est divisé en les sections suivantes: théorie de I. (sujet et méthodes, contenu, structure et propriétés de l'information scientifique), communication scientifique (processus informels et formels, activité d'information scientifique), recherche d'information, diffusion et utilisation de l'information scientifique, organisation et historique de l'activité d'information scientifique. Principal tâches théoriques I. consistent à révéler les schémas généraux de la création de l'information scientifique, de sa transformation, de son transfert et de son utilisation dans diverses sphères de l'activité humaine. I. n'étudie pas et ne développe pas de critères d'évaluation de la véracité, de la nouveauté et de l'utilité de l'information scientifique, ainsi que des méthodes pour son traitement logique afin d'obtenir de nouvelles informations. Les tâches appliquées de I. sont de développer des méthodes et des moyens plus efficaces de mise en œuvre des processus d'information, de déterminer la communication scientifique optimale à la fois au sein de la science et entre la science et l'industrie. Pour étudier des problèmes particuliers et résoudre des problèmes appliqués, I. sont utilisés méthodes individuelles: la cybernétique (lors de la formalisation des processus des activités scientifiques et informationnelles en vue de leur automatisation, lors de la construction de machines information-logiques, etc.) ; théorie mathématique de l'information (lors de l'étude des propriétés générales de l'information, pour assurer son codage optimal, stockage à long terme , télétransmission); la logique mathématique (pour formaliser les processus d'inférence logique, développer des méthodes de programmation d'algorithmes d'information, etc.) ; la sémiotique (lors de la construction de systèmes de recherche d'informations, de l'élaboration de règles de traduction des langues naturelles vers les langues artificielles et inversement, de l'élaboration de principes d'indexation, de l'étude des transformations de la structure du texte qui ne changent pas son sens, etc.) ; la linguistique (dans le développement des principes de la traduction automatique et des langages de recherche d'information, l'indexation et le résumé, les méthodes de transcription et de translittération, dans la compilation de thésaurus, la rationalisation de la terminologie) ; psychologie (lors de l'étude des processus de pensée liés à la création et à l'utilisation d'informations scientifiques, de la nature des besoins d'information et de leur formulation en requêtes, lors du développement de méthodes de lecture efficaces, de systèmes de services d'information machine, de la conception de dispositifs d'information); science du livre, bibliothéconomie, bibliographie, archivistique (lors de l'élaboration de formes optimales d'un document scientifique, de l'amélioration des processus formels de communication scientifique, du système de publications secondaires); science de la science (lors de l'étude des processus informels de communication scientifique, de l'élaboration des principes d'organisation d'un système de service d'information, de la prévision du développement de la science, de l'évaluation de son niveau et de son rythme, de l'étude de diverses catégories de consommateurs d'informations scientifiques); sciences techniques (pour fournir des moyens techniques pour les processus des activités scientifiques et d'information, leur mécanisation et leur automatisation). Certaines méthodes I., à leur tour, trouvent une application dans la bibliothéconomie et la bibliographie (dans la compilation de catalogues, d'index, etc.). L'information scientifique reflète les lois objectives de la nature, de la société et de la pensée de manière adéquate à l'état actuel de la science et est utilisée dans la pratique socio-historique. Étant donné que la base du processus de cognition est la pratique sociale, la source d'information scientifique n'est pas seulement la recherche scientifique, mais aussi tous les types d'activités vigoureuses des personnes pour transformer la nature et la société. L'information scientifique est divisée en types selon les domaines de sa réception et de son utilisation (biologique, politique, technique, chimique, économique, etc.), par finalité (de masse et spéciale, etc.). Les hypothèses et les théories, qui s'avèrent plus tard erronées, sont des informations scientifiques pendant tout le temps où leurs dispositions sont systématiquement étudiées et testées dans la pratique. Le critère d'usage dans la pratique socio-historique permet de distinguer l'information scientifique des vérités connues ou dépassées, des idées de science-fiction, etc. e) L'ensemble des processus de présentation, de transmission et de réception de l'information scientifique constitue la communication scientifique. Sans exception, les scientifiques ou spécialistes sont toujours impliqués dans tous les processus de communication scientifique. Le degré de leur participation peut être différent et dépend des spécificités du processus. Distinguez les processus « informels » et « formels ». « Informel » désigne les processus qui sont principalement effectués par des scientifiques ou des spécialistes eux-mêmes : un dialogue direct entre eux sur la recherche ou le développement en cours, la visite du laboratoire de leurs collègues et des expositions scientifiques et techniques, la prise de parole devant un public, l'échange de lettres et de réimpressions de publications, préparer des résultats de recherche ou des développements pour publication. Le « formel » comprend : les processus de rédaction, d'édition et d'impression ; distribution de publications scientifiques, y compris libraire, bibliothèque et activités bibliographiques; processus d'échange de littérature scientifique; archivage; réellement une activité scientifique et d'information. Tous les processus « formels », à l'exception du dernier, ne sont pas spécifiques à la communication scientifique et s'inscrivent dans la sphère de la communication de masse, dont les principaux moyens sont la presse écrite, la radio, la télévision, etc. La complexité accrue du travail scientifique et la la nécessité d'accroître son efficacité conduit à sa division supplémentaire, qui se déroule sur différents plans: sur la recherche théorique et expérimentale, sur la recherche scientifique, l'information scientifique et les activités scientifiques et organisationnelles. Les services d'information sont chargés d'effectuer des tâches de plus en plus complexes de sélection et de traitement de l'information scientifique, qui ne peuvent être résolues qu'avec l'utilisation simultanée des réalisations de l'information et des théories et méthodes de branches spécifiques de la science. L'activité d'information scientifique consiste en la collecte, le traitement, le stockage et la recherche d'informations scientifiques fixées dans des documents, ainsi que leur mise à disposition de scientifiques et de spécialistes afin d'accroître l'efficacité de la recherche et du développement. Cette activité est de plus en plus réalisée par des systèmes d'information intégrés basés sur le principe d'un traitement unique et exhaustif de chaque document scientifique par des spécialistes hautement qualifiés, saisissant les résultats de ce traitement dans un complexe de machines composé d'un ordinateur et d'une machine de photocomposition, et réutilisant ces résultats pour résoudre divers problèmes d'information: édition de revues de résumés, bulletins d'informations sur les signaux, revues analytiques, recueils de traductions, pour effectuer une diffusion sélective de l'information (voir. langage d'information), travail de référence et d'information, copie de documents et autres types de services d'information. Depuis le milieu des années 40. 20ième siècle les premières grandes revues sur I. paraissent dans différents pays : le Journal of Documentation (L., depuis 1945) ; « Tidskrift pour la documentation » (Stockh., depuis 1945) ; "American Documentation" (Washington, depuis 1950, depuis 1970 - "Journal of the American Society for Information Science"); "Nachrichten fur Documentation" (Fr./M., depuis 1950); "Documentation" (Lpz., depuis 1953, depuis 1969 - "Informatik"). Depuis octobre 1961, l'URSS publie la collection mensuelle "Scientific Informations techniques», publié depuis 1967 en deux séries : « Organisation et méthodes du travail d'information » et « Processus et systèmes d'information ». Depuis 1963, VINITI a commencé à publier d'abord tous les 2 mois, et depuis 1966 - revue mensuelle abstraite "Information scientifique et technique", qui depuis 1970 est publiée sous le nom "Informatique". Depuis 1967, ce magazine est également publié en anglais. Les revues de résumés suivantes sur I. sont publiées à l'étranger: en Grande-Bretagne - "Library and Information Science Abstracts" (L., depuis 1969; en 1950-68, elle s'appelait "Library Science Abstracts"), aux États-Unis - "Information Science Abstracts" (Phil. , depuis 1969; en 1966-68 il s'appelait "Documentation Abstracts"), en France - "Bulletin signalétique. Information scientifique et technique » (P., depuis 1970). Depuis 1964, l'information expresse Theory and Practice of Scientific Information est publiée, et depuis 1965 - des collections de traductions de publications étrangères sur les sciences de l'information.Depuis 1969, la collection périodique Science of Science and Informatics est publiée à Kiev. La formation des travailleurs scientifiques en I. s'effectue depuis 1959 à travers l'école doctorale de VINITI, la formation du personnel aux activités scientifiques et d'information - depuis 1963 lors des cours de perfectionnement pour les ingénieurs de premier plan et les travailleurs techniques et scientifiques (depuis 1972 - l'Institut de formation avancée des travailleurs de l'information), la formation de jeunes scientifiques - futurs consommateurs d'information - depuis 1964 au Département d'information scientifique de l'Université d'État de Moscou. M. V. Lomonosov, ingénieurs pour la mécanisation et l'automatisation des processus d'information - dans plusieurs instituts polytechniques et de construction de machines. A l'étranger, les disciplines de l'information sont enseignées dans les universités et les écoles techniques supérieures. Il y a une tendance à unir dans une spécialisation éducative un complexe de problèmes d'I. et de technologie informatique. Lit.: Mikhailov A. I., Cherny A. I., Gilyarevsky R. S., Fundamentals of Informatics, 2e éd., M., 1968; eux, Problèmes d'informations en science moderne, M., 1972; Problèmes théoriques de l'informatique. Assis. Art., M., 1968; Forum international sur l'informatique. Assis. Art., volumes 1-2, M., 1969 ; Bush V., Comme on peut le penser, Atlantic Monthly, 1945, juillet, p. 101-108 ; Revue annuelle des sciences et technologies de l'information, v. 1-7, N. Y. - a. o., 1966-72 ; Dembowska M., Documentation et informations scientifiques, Varsovie, 1968. A. I. Mikhailov, A. I. Cherny, R. S. Gilyarevsky.
Liste des articles
1. Mesure de l'information - approche alphabétique
2. Mesurer l'information - une approche significative
3. Processus d'information
4. Informations
5. Cybernétique
6. Informations d'encodage
7. Traitement des informations
8. Transfert d'informations
9. Représentation des nombres
10. Systèmes de numération
11. Stockage des informations
Les principaux objets d'étude de la science de l'informatique sont information Et processus d'information. L'informatique en tant que science indépendante est apparue au milieu du XXe siècle, mais l'intérêt scientifique pour l'information et la recherche dans ce domaine est apparu plus tôt.
Au début du XXe siècle, les moyens techniques de communication (téléphone, télégraphe, radio) se développent activement.
À cet égard, la direction scientifique "Théorie de la communication" apparaît. Son développement a donné naissance à la théorie du codage et à la théorie de l'information, dont le fondateur était le scientifique américain C. Shannon. La théorie de l'information a résolu le problème des mesures
information transmis sur les canaux de communication. Il existe deux approches pour mesurer les informations : significatif Et alphabétique.
La tâche la plus importante posée par la théorie de la communication est la lutte contre la perte d'informations dans les canaux de transmission de données. Au cours de la résolution de ce problème, une théorie a été formée codage , dans le cadre duquel ont été inventés des procédés de présentation d'informations permettant de transmettre le contenu du message au destinataire sans distorsion, même en présence de pertes dans le code transmis. Ces résultats scientifiques sont d'une grande importance même aujourd'hui, alors que le volume des flux d'informations dans les canaux de communication techniques a augmenté de plusieurs ordres de grandeur.
Le précurseur de l'informatique moderne était la science de la "Cybernétique", fondée par les travaux de N. Wiener à la fin des années 1940 - début des années 50. En cybernétique il y a eu un approfondissement du concept d'information, la place de l'information dans les systèmes de contrôle des organismes vivants, dans les systèmes sociaux et techniques a été déterminée. La cybernétique a exploré les principes du contrôle des programmes. Née simultanément avec l'avènement des premiers ordinateurs, la cybernétique a jeté les bases scientifiques tant de leur développement constructif que de nombreuses applications.
EVM (ordinateur) - dispositif automatique conçu pour résoudre des problèmes d'information en mettant en œuvre des processus d'information: stockage, traitement Et transmission d'informations. La description des principes de base et des modèles de processus d'information fait également référence aux fondements théoriques de l'informatique.
L'ordinateur ne travaille pas avec le contenu d'informations que seule une personne peut percevoir, mais avec des données représentatives de l'information. Par conséquent, la tâche la plus importante pour la technologie informatique est présentation des informations sous la forme de données adaptées à leur traitement. Les données et les programmes sont codés sous forme binaire. Le traitement de tout type de données dans un ordinateur se réduit à des calculs avec des nombres binaires. C'est pourquoi la technologie informatique est aussi appelée numérique. Le concept de systèmes de numération, à propos de représentation des nombres dans l'ordinateur appartiennent aux concepts de base de l'informatique.
Le concept de "langue" vient de la linguistique. Langue - Ce système de représentation symbolique de l'information utilisé pour son stockage et sa transmission. Le concept de langage est l'un des concepts de base de l'informatique, car les données et les programmes d'un ordinateur sont représentés sous forme de structures symboliques. Le langage de communication entre un ordinateur et une personne se rapproche de plus en plus des formes du langage naturel.
La théorie des algorithmes fait partie des fondements fondamentaux de l'informatique. concept algorithme introduit dans l'article « Traitement de l'information ». Ce sujet est traité en détail dans la cinquième section de l'encyclopédie.
1. Mesure de l'information. Approche alphabétique
L'approche alphabétique est utilisée pour mesurer quantité d'informations dans un texte représenté comme une séquence de caractères d'un certain alphabet. Cette approche n'est pas liée au contenu du texte. La quantité d'informations dans ce cas est appelée volume d'information du texte, qui est proportionnel à la taille du texte - le nombre de caractères qui composent le texte. Parfois, cette approche de mesure de l'information est appelée l'approche volumétrique.
Chaque caractère du texte contient une certaine quantité d'informations. Il est appelé symbole information poids. Par conséquent, le volume d'informations du texte est égal à la somme des poids d'informations de tous les caractères qui composent le texte.
![]()
Ici, on suppose que le texte est une chaîne consécutive de caractères numérotés. Dans la formule (1) je 1 désigne le poids informationnel du premier caractère du texte, je 2 - le poids informationnel du second caractère du texte, etc. ; K- taille du texte, c'est-à-dire le nombre total de caractères dans le texte.
L'ensemble des différents caractères utilisés pour écrire des textes s'appelle alphabétiquement. La taille de l'alphabet est un entier appelé le pouvoir de l'alphabet. Il faut garder à l'esprit que l'alphabet comprend non seulement les lettres d'une certaine langue, mais tous les autres caractères pouvant être utilisés dans le texte : chiffres, signes de ponctuation, parenthèses diverses, espaces, etc.
La détermination des poids d'information des symboles peut se faire selon deux approximations :
1) sous l'hypothèse d'une probabilité égale (même fréquence d'occurrence) de tout caractère dans le texte ;
2) en tenant compte de la probabilité différente (fréquence d'occurrence différente) des différents caractères dans le texte.
Approximation de l'égalité de probabilité des caractères dans un texte
Si nous supposons que tous les caractères de l'alphabet dans n'importe quel texte apparaissent avec la même fréquence, alors le poids de l'information de tous les caractères sera le même. Laisser N- pouvoir de l'alphabet. Alors la proportion de n'importe quel caractère dans le texte est 1/ Nème partie du texte. Selon la définition de la probabilité (cf. « Mesure de l'information. Approche de contenu ») cette valeur est égale à la probabilité d'occurrence d'un caractère à chaque position du texte :
Selon la formule de K. Shannon (voir. « Mesure de l'information. Approche de contenu »), la quantité d'informations qu'un symbole contient est calculée comme suit :
je = log2(1/ p) = log2 N(bit) (2)
Par conséquent, le poids informationnel du symbole ( je) et la cardinalité de l'alphabet ( N) sont interconnectés par la formule de Hartley (voir " Mesure des informations. Approche de contenu » )
2 je = N
Connaître le poids informationnel d'un caractère ( je) et la taille du texte, exprimée en nombre de caractères ( K), vous pouvez calculer le volume d'informations du texte à l'aide de la formule :
je= K · je (3)
Cette formule est une version particulière de la formule (1), dans le cas où tous les symboles ont le même poids d'information.

De la formule (2) il résulte qu'à N= 2 (alphabet binaire) le poids d'information d'un caractère est de 1 bit.
Du point de vue de l'approche alphabétique de la mesure de l'information 1 bit -est le poids informationnel d'un caractère de l'alphabet binaire.
Une plus grande unité d'information est octet.
1 octet -est le poids d'information d'un caractère d'un alphabet avec une puissance de 256.
Depuis 256 \u003d 2 8, la connexion entre un bit et un octet découle de la formule de Hartley :
2 je = 256 = 2 8
D'ici: je= 8 bits = 1 octet
Pour représenter des textes stockés et traités dans un ordinateur, on utilise le plus souvent un alphabet d'une capacité de 256 caractères. Ainsi,
1 caractère d'un tel texte "pese" 1 octet.
En plus du bit et de l'octet, des unités plus grandes sont également utilisées pour mesurer les informations :
1 Ko (kilooctet) = 2 10 octets = 1024 octets,
1 Mo (mégaoctet) = 2 10 Ko = 1024 Ko,
1 Go (gigaoctet) = 2 10 Mo = 1024 Mo.
Approximation des différentes probabilités d'occurrence des caractères dans le texte
Cette approximation tient compte du fait que dans un texte réel, différents caractères apparaissent avec des fréquences différentes. Il s'ensuit que les probabilités d'apparition de différents caractères dans une certaine position du texte sont différentes et, par conséquent, leurs poids d'information sont différents.
L'analyse statistique des textes russes montre que la fréquence de la lettre « o » est de 0,09. Cela signifie que pour 100 caractères, la lettre « o » apparaît en moyenne 9 fois. Le même nombre indique la probabilité que la lettre « o » apparaisse à une certaine position du texte : p o = 0,09. Il s'ensuit que le poids d'information de la lettre "o" dans le texte russe est égal à :
La lettre la plus rare dans les textes est la lettre "f". Sa fréquence est de 0,002. D'ici:
Une conclusion qualitative en découle : le poids informationnel des lettres rares est supérieur au poids des lettres fréquentes.
Comment calculer le volume d'information du texte en tenant compte des différents poids d'information des symboles de l'alphabet ? Cela se fait selon la formule suivante :

Ici N- taille (puissance) de l'alphabet ; New Jersey- nombre de répétitions du numéro de caractère j dans le texte; je j- poids de l'information du numéro de symbole j.
Approche alphabétique dans le cursus d'informatique à la fondation de l'école
Dans le cours d'informatique à l'école primaire, la familiarisation des élèves avec l'approche alphabétique de la mesure de l'information se produit le plus souvent dans le contexte de la représentation informatique de l'information. La déclaration principale va comme ceci:
La quantité d'informations est mesurée par la taille du code binaire avec lequel ces informations sont représentées.
Étant donné que tout type d'information est représenté dans la mémoire de l'ordinateur sous la forme d'un code binaire, cette définition est universelle. Elle est valable pour les informations symboliques, numériques, graphiques et sonores.

Un caractère ( décharge)le code binaire porte 1peu d'informations.
Lors de l'explication de la méthode de mesure du volume d'information d'un texte dans le cours d'informatique de base, cette problématique se révèle à travers la séquence de concepts suivante : alphabet-taille du code binaire des caractères-volume d'information du texte.
La logique du raisonnement va des exemples particuliers à l'obtention d'une règle générale. Qu'il n'y ait que 4 caractères dans l'alphabet d'une langue. Notons-les : , , , . Ces caractères peuvent être codés à l'aide de quatre codes binaires à deux chiffres : - 00, - 01, - 10, - 11. Ici, toutes les options de placement de deux caractères par deux, dont le nombre est 2 2 = 4, sont utilisées. L'alphabet à 4 caractères est égal à deux bits.
Le cas particulier suivant est un alphabet à 8 caractères, dont chaque caractère peut être codé avec un code binaire à 3 bits, puisque le nombre de placements de deux caractères par groupes de 3 est de 2 3 = 8. Par conséquent, le poids de l'information de un caractère d'un alphabet à 8 caractères est de 3 bits. Etc.
En généralisant des exemples particuliers, on obtient une règle générale : en utilisant b- bit code binaire, vous pouvez coder un alphabet composé de N = 2 b- symboles.
Exemple 1. Pour écrire le texte, seules les lettres minuscules de l'alphabet russe sont utilisées et un "espace" est utilisé pour séparer les mots. Quel est le volume d'information d'un texte composé de 2000 caractères (une page imprimée) ?
Solution. Il y a 33 lettres dans l'alphabet russe. En le réduisant de deux lettres (par exemple, "ё" et "й") et en entrant un espace, nous obtenons un nombre très pratique de caractères - 32. En utilisant l'approximation de l'égalité de probabilité des caractères, nous écrivons la formule de Hartley :
2je= 32 = 2 5
D'ici: je= 5 bits - poids informationnel de chaque caractère de l'alphabet russe. Alors le volume d'information de tout le texte est égal à :
je = 2000 5 = 10 000 bit
Exemple 2. Calculer le volume d'informations d'un texte d'une taille de 2000 caractères, dans l'enregistrement duquel l'alphabet de représentation informatique des textes d'une capacité de 256 est utilisé.
Solution. Dans cet alphabet, le poids d'information de chaque caractère est de 1 octet (8 bits). Par conséquent, le volume d'informations du texte est de 2000 octets.
Dans les tâches pratiques sur ce sujet, il est important de développer les compétences des élèves pour convertir la quantité d'informations en différentes unités : bits - octets - kilooctets - mégaoctets - gigaoctets. Si on recalcule le volume d'information du texte de l'exemple 2 en kilo-octets, on obtient :
2000 octets = 2000/1024 1,9531 Ko
Exemple 3. Le volume d'un message contenant 2048 caractères était de 1/512 de mégaoctet. Quelle est la taille de l'alphabet avec lequel le message est écrit ?
Solution. Traduisons le volume d'informations du message de mégaoctets en bits. Pour ce faire, on multiplie cette valeur deux fois par 1024 (on obtient des octets) et une fois par 8 :
Je = 1/512 1024 1024 8 = 16384 bits.
Étant donné que cette quantité d'informations est portée par 1024 caractères ( POUR), alors un caractère représente :
je = je/K= 16 384/1024 = 16 bits.
Il s'ensuit que la taille (puissance) de l'alphabet utilisé est de 2 16 = 65 536 caractères.
Approche volumétrique dans le cours d'informatique au lycée
En étudiant l'informatique en 10e et 11e année au niveau de l'enseignement général de base, les élèves peuvent laisser leurs connaissances de l'approche volumétrique pour mesurer l'information au même niveau que celui décrit ci-dessus, c'est-à-dire dans le contexte de la quantité de code informatique binaire.
Lors de l'étude de l'informatique au niveau du profil, l'approche volumétrique doit être considérée à partir de positions mathématiques plus générales, en utilisant des idées sur la fréquence des caractères dans un texte, sur les probabilités et la relation des probabilités avec les poids d'information des symboles.
La connaissance de ces questions est importante pour une meilleure compréhension de la différence dans l'utilisation du codage binaire uniforme et non uniforme (voir. "Encodage des informations"), pour comprendre certaines techniques de compression de données (voir. "Compression des données") et algorithmes cryptographiques (voir "Cryptographie" ).
Exemple 4. Dans l'alphabet de la tribu MUMU, il n'y a que 4 lettres (A, U, M, K), un signe de ponctuation (point) et un espace est utilisé pour séparer les mots. Il a été calculé que le roman populaire "Mumuka" ne contient que 10 000 caractères, dont: lettres A - 4000, lettres U - 1000, lettres M - 2000, lettres K - 1500, points - 500, espaces - 1000. Combien d'informations contient livre?
Solution. Le volume du livre étant assez important, on peut supposer que la fréquence d'apparition dans le texte de chacun des symboles de l'alphabet calculé à partir de celui-ci est typique de tout texte en langue MUMU. Calculons la fréquence d'occurrence de chaque caractère dans tout le texte du livre (c'est-à-dire la probabilité) et les poids d'information des caractères


La quantité totale d'informations dans le livre est calculée comme la somme des produits du poids de l'information de chaque symbole et du nombre de répétitions de ce symbole dans le livre :

2. Mesure de l'information. Approche de contenu
1) une personne reçoit un message concernant un événement ; alors qu'il est connu d'avance incertitude de la connaissance personne au sujet de l'événement attendu. L'incertitude de la connaissance peut s'exprimer soit par le nombre de variantes possibles de l'événement, soit par la probabilité des variantes attendues de l'événement ;
2) à la suite de la réception du message, l'incertitude de la connaissance est levée : parmi un certain nombre d'options possibles, une a été choisie ;
3) la formule calcule la quantité d'informations dans le message reçu, exprimée en bits.
La formule utilisée pour calculer la quantité d'informations dépend des situations, qui peuvent être au nombre de deux :
1. Toutes les variantes possibles de l'événement sont également probables. Leur nombre est fini et égal N.
2. Probabilités ( p) les variantes possibles de l'événement sont différentes et elles sont connues à l'avance :
(p je ), je = 1.. N. Voici encore N- le nombre de variantes possibles de l'événement.
Des événements incroyables. Si désigné par je la quantité d'informations dans le message que l'un des Névénements équiprobables, alors les quantités je Et N sont interconnectés par la formule de Hartley :
2je=N (1)
Valeur je mesuré en bits. De là découle la conclusion :
1 bit est la quantité d'informations dans le message concernant l'un des deux événements également probables.
La formule de Hartley est une équation exponentielle. Si je est une quantité inconnue, alors la solution de l'équation (1) sera :
je = log 2 N (2)
Les formules (1) et (2) sont identiques l'une à l'autre. Parfois, dans la littérature, la formule de Hartley est appelée (2).
Exemple 1. Quelle quantité d'informations contient le message indiquant que la dame de pique a été tirée d'un jeu de cartes ?
Il y a 32 cartes dans un jeu. Dans un jeu mélangé, la perte de n'importe quelle carte est un événement équiprobable. Si je- la quantité d'informations dans le message indiquant qu'une carte particulière est tombée (par exemple, la dame de pique), puis de l'équation de Hartley :
2 je = 32 = 2 5
D'ici: je= 5 bits.

Exemple 2. Combien d'informations le message contient-il sur le jet d'un visage avec le chiffre 3 sur un dé à six faces ?
Considérant la perte de n'importe quel visage comme un événement également probable, nous écrivons la formule de Hartley : 2 je= 6. D'où : je= log 2 6 = 2,58496 bit.

Événements peu probables (approche probabiliste)
Si la probabilité d'un événement est p, UN je(bit) est la quantité d'informations dans le message indiquant que cet événement s'est produit, alors ces valeurs sont liées par la formule :
2 je = 1/p (3)
Résoudre l'équation exponentielle (3) par rapport à je, on a:
i = log 2 (1/ p) (4)
La formule (4) a été proposée par K. Shannon, c'est pourquoi on l'appelle la formule de Shannon.
Une discussion sur la relation entre la quantité d'informations dans un message et son contenu peut avoir lieu sur différents niveaux profondeurs.
Approche qualitative
Approche qualitative, qui peut être utilisé au niveau de la propédeutique du cours d'informatique de base (grades 5-7) ou dans le cours de base (grades 8-9).
À ce niveau d'étude, la chaîne de concepts suivante est discutée : information - message - caractère informatif du message.
emballage d'origine : information- c'est la connaissance des personnes reçues par eux à partir de divers messages. La question suivante est : qu'est-ce qu'un message ? Message- il s'agit d'un flux d'informations (flux de données) qui, lors de la transmission d'informations, parvient au sujet qui les reçoit. Le message est à la fois le discours que nous écoutons (un message radio, l'explication d'un enseignant), et les images visuelles que nous percevons (un film à la télé, un feu de circulation), et le texte du livre que nous lisons, etc.
question sur message informatif Je devrais discuter des exemples donnés par l'enseignant et les élèves. Règle: informatifappelonsmessage, qui reconstitue la connaissance humaine, c'est-à-dire porte des informations pour lui. Pour différentes personnes, le même message en termes de son caractère informatif peut être différent. Si l'information est "ancienne", c'est-à-dire une personne le sait déjà, ou le contenu du message n'est pas clair pour une personne, alors ce message n'est pas informatif pour elle. Informatif est le message qui contient nouveau et compréhensible intelligence.
Exemples de messages non informatifs pour un élève de 8e :
1) "La capitale de la France - Paris" (pas nouveau) ;
2) "La chimie des colloïdes étudie les états de dispersion des systèmes à haut degré de fragmentation" (pas clair).
Un exemple de message informatif (pour ceux qui ne le savaient pas) : « La Tour Eiffel a une hauteur de 300 mètres et un poids de 9000 tonnes.
L'introduction du concept de « contenu informatif d'un message » est la première approche pour étudier la question de la mesure de l'information au sein du concept de contenu. Si le message n'est pas informatif pour une personne, la quantité d'informations qu'il contient, du point de vue de cette personne, est égale à zéro. La quantité d'informations dans le message informatif est supérieure à zéro.
Approche quantitative dans l'approximation d'équiprobabilité
Cette approche peut être étudiée soit dans la version avancée du cours de base à l'école de base, soit lors de l'étude de l'informatique en 10e et 11e année au niveau de base.
La chaîne de concepts suivante est considérée : événements équiprobables - incertitude des connaissances - bit comme unité d'information - La formule de Hartley - solution de l'équation exponentielle pour N égal à des puissances entières de deux.
Révéler le concept équiprobabilité, il faut s'appuyer sur la représentation intuitive des enfants, en l'étayant d'exemples. Les événements sont tout aussi probablessi aucun d'eux n'a d'avantage sur les autres.
Après avoir introduit la définition particulière d'un bit qui a été donnée ci-dessus, il convient alors de généraliser :
Un message qui réduit l'incertitude des connaissances d'un facteur 2 porte 1 bitinformation.
Cette définition est étayée par des exemples de messages concernant un événement sur quatre (2 bits), sur huit (3 bits), etc.
À ce niveau, vous ne pouvez pas discuter des options pour les valeurs N, non égal à des puissances entières de deux, afin de ne pas se heurter au problème du calcul des logarithmes, qui n'a pas encore été étudié dans le cours des mathématiques. Si les enfants ont des questions, par exemple : " Combien d'informations le message contient-il sur le résultat du lancer d'un dé à six faces ?", l'explication peut être construite comme suit. De l'équation de Hartley : 2 je= 6. Depuis 2 2< 6 < 2 3 , следовательно, 2 < je < 3. Затем сообщить более точное значение (с точностью до пяти знаков после запятой), что je= 2,58496 bits. Notez qu'avec cette approche, la quantité d'informations peut être exprimée sous forme de valeur fractionnaire.
Approche probabiliste pour mesurer l'information
Il peut être étudié en 10e et 11e année dans le cadre d'un cours de formation générale de niveau spécialisé ou d'un cours au choix sur les fondements mathématiques de l'informatique. Une définition mathématiquement correcte de la probabilité doit être introduite ici. De plus, les élèves doivent connaître la fonction logarithme et ses propriétés, être capables de résoudre des équations exponentielles.
En introduisant le concept de probabilité, il convient de signaler que la probabilité d'un événement est une valeur qui peut prendre des valeurs de zéro à un. La probabilité d'un événement impossible est nulle(par exemple : "demain le soleil ne se lèvera pas au-dessus de l'horizon"), la probabilité d'un certain événement est égale à un(par exemple : "Demain le soleil se lèvera à l'horizon").
Disposition suivante : la probabilité d'un événement est déterminée par de multiples observations (mesures, tests). De telles mesures sont dites statistiques. Et plus il y a de mesures, plus la probabilité d'un événement est déterminée avec précision.
La définition mathématique de la probabilité est : probabilitéest égal au rapport du nombre de résultats qui favorisent cet événement au nombre total de résultats également possibles.
Exemple 3. Deux lignes de bus s'arrêtent à un arrêt de bus : n° 5 et n° 7. L'élève est chargé de : déterminer la quantité d'informations contenues dans le message indiquant que le bus n° 5 s'est approché de l'arrêt, et combien l'information est dans le message que le bus n°5 s'est approché du 7.
L'étudiant a fait la recherche. Pendant toute la journée de travail, il a calculé que les bus se sont approchés de l'arrêt de bus 100 fois. Parmi ceux-ci, le bus numéro 5 s'est approché 25 fois et le bus numéro 7 s'est approché 75 fois. En supposant que les bus circulent avec la même fréquence les autres jours, l'élève a calculé la probabilité que le bus numéro 5 s'arrête : p 5 = 25/100 = 1/4, et la probabilité d'apparition du bus n°7 est : p 7 = 75/100 = 3/4.
Par conséquent, la quantité d'informations dans le message sur le bus numéro 5 est : je 5 = journal 2 4 = 2 bits. La quantité d'informations dans le message sur le bus numéro 7 est :
je 7 \u003d log 2 (4/3) \u003d log 2 4 - log 2 3 \u003d 2 - 1,58496 \u003d 0,41504 bit.

Remarquez le résultat qualitatif suivant : plus la probabilité d'un événement est faible, plus de quantité informations dans le message. La quantité d'informations sur un certain événement est nulle. Par exemple, le message "Demain matin viendra" est fiable et sa probabilité est égale à un. De la formule (3) il s'ensuit : 2 je= 1/1 = 1. Par conséquent, je= 0 bit.
La formule de Hartley (1) est un cas particulier de la formule (3). Si disponible Névénements également probables (résultat d'un lancer de pièce de monnaie, de dé, etc.), alors la probabilité de chaque variante possible est égale à p = 1/N. En substituant dans (3), on obtient à nouveau la formule de Hartley : 2 je = N Si dans l'exemple 3 bus #5 et #7 s'arrêtaient 100 fois chacun 50 fois, alors la probabilité que chacun d'eux apparaisse serait égale à 1/2. Par conséquent, la quantité d'informations dans le message sur l'arrivée de chaque bus est je= journal 2 2 = 1 bit. Nous sommes arrivés à la variante bien connue du contenu informatif du message sur l'un des deux événements également probables.
Exemple 4. Considérons une autre version du problème du bus. Arrêt à l'arrêt des bus n° 5 et 7. Le message indiquant que le bus n° 5 s'est approché de l'arrêt porte 4 bits d'information. La probabilité que le bus numéro 7 apparaisse à l'arrêt est deux fois moindre que la probabilité d'apparition du bus numéro 5. Combien de bits d'information contient le message concernant le bus numéro 7 qui apparaît à l'arrêt ?
Nous écrivons la condition du problème sous la forme suivante :
je 5 = 4 bits, p 5 = 2 p 7
Rappelons la relation entre la probabilité et la quantité d'informations : 2 je = 1/p
D'ici: p = 2 –je
En substituant en égalité à partir de la condition du problème, on obtient :
La conclusion découle du résultat obtenu: une diminution de la probabilité d'un événement de 2 fois augmente le contenu informatif du message à ce sujet de 1 bit. La règle inverse est également évidente: une augmentation de la probabilité d'un événement de 2 fois réduit le contenu informatif du message à ce sujet de 1 bit. Connaissant ces règles, le problème précédent pourrait être résolu « dans la tête ».
3. Processus d'information
Le sujet d'étude de la science de l'informatique est information Et processus d'information. Comme il n'y a pas de définition unique généralement acceptée de l'information (cf. "Information"), il n'y a pas non plus d'unité dans l'interprétation de la notion de « processus d'information ».
Abordons la compréhension de ce concept d'un point de vue terminologique. Mot processus représente un événement survenant dans le temps: contentieux, processus de production, processus éducatif, processus de croissance d'organismes vivants, processus de raffinage du pétrole, processus de combustion de carburant, processus de vol d'engins spatiaux, etc. Chaque processus est associé à certains Actions accomplie par l'homme, les forces de la nature, dispositifs techniques, ainsi qu'en raison de leur interaction.
Chaque processus a objet d'influence Mots-clés : accusé, étudiants, pétrole, carburant, vaisseau spatial. Si le processus est associé à l'activité intentionnelle d'une personne, alors une telle personne peut être appelée exécuteur de processus: juge, professeur, astronaute. Si le processus est effectué à l'aide d'un appareil automatique, c'est alors l'exécuteur du processus: un réacteur chimique, une station spatiale automatique.
Évidemment, dans les processus d'information l'objet d'influence est l'information. Dans le manuel S.A. Bechenkova, E.A. Rakitina en donne la définition suivante : « Dans sa forme la plus générale, le processus d'information est défini comme un ensemble d'actions séquentielles (opérations) effectuées sur des informations (sous forme de données, d'informations, de faits, d'idées, d'hypothèses, de théories, etc.) pour obtenir n'importe quel résultat (objectifs de réalisation)".
Une analyse plus approfondie du concept de « processus d'information » dépend de l'approche du concept d'information, de la réponse à la question : « Qu'est-ce que l'information ? ». Si accepter attributif point de vue sur l'information (cf. "Information"), alors il faut reconnaître que les processus d'information se produisent à la fois dans la nature vivante et inanimée. Par exemple, à la suite d'une interaction physique entre la Terre et le Soleil, entre les électrons et le noyau d'un atome, entre l'océan et l'atmosphère. De la position fonctionnel les processus d'information conceptuelle se produisent dans les organismes vivants (plantes, animaux) et dans leur interaction.
AVEC anthropocentrique point de vue, l'exécuteur des processus d'information est une personne. Les processus d'information sont une fonction de la conscience humaine (pensée, intellect). Une personne peut les réaliser de manière indépendante, ainsi qu'à l'aide d'outils d'activité d'information créés par elle.
Toute activité d'information arbitrairement complexe d'une personne est réduite à trois principaux types d'actions avec des informations: enregistrement, réception / transmission, traitement. Habituellement, au lieu de "réception-transmission", on dit simplement "transmission", en comprenant ce processus comme bidirectionnel : transmission de la source au récepteur (synonyme de "transport").
Le stockage, la transmission et le traitement de l'information sont les principaux types de processus d'information.
La mise en œuvre de ces actions avec l'information est associée à sa présentation sous forme de données. Toutes sortes d'outils de l'activité humaine d'information (par exemple : papier et stylo, canaux de communication techniques, appareils informatiques, etc.) sont utilisés pour le stockage, le traitement et la transmission. données.
Si l'on analyse les activités de toute organisation (le service du personnel d'une entreprise, la comptabilité, un laboratoire scientifique) qui travaille avec des informations "à l'ancienne", sans utiliser d'ordinateurs, alors trois types de moyens sont nécessaires pour assurer son activités:
Papier et instruments d'écriture (stylos, machines à écrire, instruments de dessin) pour fixer des informations à des fins de stockage;
Moyens de communication (courriers, téléphones, courrier) pour recevoir et transmettre des informations ;
Outils informatiques (comptes, calculatrices) pour le traitement de l'information.
De nos jours, tous ces types d'activités d'information sont effectués à l'aide de la technologie informatique : les données sont stockées sur des supports numériques, la transmission s'effectue par courrier électronique et d'autres services de réseau informatique, les calculs et autres types de traitement sont effectués sur un ordinateur.
La composition des principaux dispositifs d'un ordinateur est déterminée précisément par le fait que l'ordinateur est conçu pour effectuer stockage, traitement Et transmission de données. Pour ce faire, il comprend la mémoire, le processeur, les canaux internes et les périphériques d'entrée/sortie externes (voir. "Ordinateur").
Afin de séparer terminologiquement les processus de travail avec des informations qui se produisent dans l'esprit humain, et les processus de travail avec des données qui se produisent dans des systèmes informatiques, A.Ya. Friedland suggère de les appeler différemment: le premier - processus d'information, le second - processus d'information.
Une autre approche de l'interprétation des processus d'information est offerte par la cybernétique. Les processus d'information se produisent dans divers systèmes de contrôle qui ont lieu dans la faune, dans le corps humain, dans les systèmes sociaux, dans les systèmes techniques (y compris un ordinateur). Par exemple, l'approche cybernétique est appliquée en neurophysiologie (cf. "Information"), où la gestion des processus physiologiques dans le corps d'un animal et d'une personne, se produisant à un niveau inconscient, est considérée comme un processus d'information. Dans les neurones (cellules du cerveau) stocké Et traité l'information est transportée le long des fibres nerveuses diffuser informations sous forme de signaux de nature électrochimique. La génétique a établi que l'information héréditaire stocké dans les molécules d'ADN qui composent les noyaux des cellules vivantes. Il détermine le programme de développement de l'organisme (c'est-à-dire contrôle ce processus), qui se réalise à un niveau inconscient.
Ainsi, dans l'interprétation cybernétique, les processus d'information se réduisent au stockage, à la transmission et au traitement d'informations présentées sous forme de signaux, de codes de nature diverse.
À n'importe quelle étape de l'étude de l'informatique à l'école, les idées sur les processus d'information ont une fonction méthodologique systématisante. En étudiant le dispositif d'un ordinateur, les élèves devraient avoir une compréhension claire des dispositifs utilisés pour stocker, traiter et transférer des données. Lors de l'étude de la programmation, les étudiants doivent faire attention au fait que le programme fonctionne avec des données stockées dans la mémoire de l'ordinateur (comme le programme lui-même), que les commandes du programme déterminent les actions du processeur pour le traitement des données et l'action des périphériques d'entrée-sortie pour recevoir et transmettre des données. Maîtrisant les technologies de l'information, il convient d'être attentif au fait que ces technologies sont également axées sur le stockage, le traitement et la transmission de l'information.
Voir les articles " Stockage de données”, “Traitement de l'information”, “Transfert d'informations” 2.
4. Informations
Origine du terme « informations »
Le mot "information" vient du latin information, qui se traduit par clarification, présentation. Dans le dictionnaire explicatif de V.I. Dahl n'a pas le mot "information". Le terme "information" est entré en usage dans le discours russe à partir du milieu du XXe siècle.
Dans une large mesure, le concept d'information doit sa diffusion à deux domaines scientifiques : théorie de la communication Et cybernétique. Le résultat du développement de la théorie de la communication a été théorie de l'information fondée par Claude Shannon. Cependant, K. Shannon n'a pas donné de définition de l'information, tout en définissant quantité d'informations. La théorie de l'information est consacrée à résoudre le problème de la mesure de l'information.
Dans la science cybernétique fondée par Norbert Wiener, la notion d'information est centrale (cf. "Cybernétique" 2). Il est généralement admis que c'est N. Wiener qui a introduit le concept d'information dans l'usage scientifique. Pourtant, dans son premier livre sur la cybernétique, N. Wiener ne définit pas l'information. " L'information est de l'information, pas de la matière ou de l'énergie», a écrit Wiener. Ainsi, le concept d'information, d'une part, s'oppose aux concepts de matière et d'énergie, d'autre part, il est assimilé à ces concepts par leur degré de généralité et de fondamentalité. Par conséquent, il est au moins clair que l'information est quelque chose qui ne peut être attribué ni à la matière ni à l'énergie.
Informations en philosophie
La science de la philosophie traite de la compréhension de l'information en tant que concept fondamental. Selon l'un des concepts philosophiques, l'information est la propriété de tout, tous les objets matériels du monde. Ce concept d'information s'appelle attributif (l'information est un attribut de tous les objets matériels). L'information dans le monde est apparue avec l'univers. Dans ce sens l'information est une mesure de l'ordre, de la structure de tout système matériel. Les processus de développement du monde depuis le chaos initial qui a suivi le "Big Bang" jusqu'à la formation de systèmes inorganiques, puis de systèmes organiques (vivants) sont associés à une augmentation du contenu informationnel. Ce contenu est objectif, indépendant de la conscience humaine. Un morceau de charbon contient des informations sur des événements qui ont eu lieu dans les temps anciens. Cependant, seul un esprit curieux peut extraire ces informations.
Un autre concept philosophique de l'information s'appelle fonctionnel. Selon l'approche fonctionnelle, l'information est apparue avec l'émergence de la vie, car elle est associée au fonctionnement de systèmes auto-organisés complexes, qui incluent les organismes vivants et la société humaine. Vous pouvez également dire ceci: l'information est un attribut inhérent uniquement à la nature vivante. C'est l'une des caractéristiques essentielles qui séparent le vivant du non-vivant dans la nature.
Le troisième concept philosophique de l'information est anthropocentrique, selon lequel l'information n'existe que dans la conscience humaine, dans la perception humaine. L'activité d'information n'est inhérente qu'à l'homme, se produit dans les systèmes sociaux. En créant des technologies de l'information, une personne crée des outils pour son activité d'information.
On peut dire que l'utilisation du concept d'"information" dans Vie courante se déroule dans un contexte anthropocentrique. Il est naturel pour chacun d'entre nous de percevoir les informations comme des messages échangés entre les personnes. Par exemple, les médias de masse - les médias de masse sont conçus pour diffuser des messages, des nouvelles parmi la population.
Informations en biologie
Au XXe siècle, le concept d'information imprègne partout la science. Les processus d'information dans la nature vivante sont étudiés par la biologie. La neurophysiologie (section de biologie) étudie les mécanismes de l'activité nerveuse de l'animal et de l'homme. Cette science construit un modèle des processus d'information se produisant dans le corps. Les informations provenant de l'extérieur sont converties en signaux de nature électrochimique, qui sont transmis des organes sensoriels le long des fibres nerveuses aux neurones (cellules nerveuses) du cerveau. Le cerveau transmet des informations de contrôle sous forme de signaux de même nature aux tissus musculaires, contrôlant ainsi les organes du mouvement. Le mécanisme décrit est en bon accord avec le modèle cybernétique de N. Wiener (cf. "Cybernétique" 2).
Dans une autre science biologique - la génétique, le concept d'information héréditaire intégrée dans la structure des molécules d'ADN présentes dans les noyaux des cellules d'organismes vivants (plantes, animaux) est utilisé. La génétique a prouvé que cette structure est une sorte de code qui détermine le fonctionnement de tout l'organisme : sa croissance, son développement, ses pathologies, etc. Grâce aux molécules d'ADN, l'information héréditaire se transmet de génération en génération.
En étudiant l'informatique à l'école de base (cours de base), il ne faut pas plonger dans la complexité du problème de la détermination de l'information. Le concept d'information est donné dans un contexte signifiant :
Information - c'est le sens, le contenu des messages reçus par une personne du monde extérieur à travers ses sens.
Le concept d'information se révèle à travers la chaîne :
message - sens - information - connaissance
Une personne perçoit les messages à l'aide de ses sens (principalement par la vue et l'ouïe). Si une personne comprend signification enfermé dans un message, alors on peut dire que ce message porte une personne information. Par exemple, un message dans une langue inconnue ne contient pas d'information pour une personne donnée, mais un message dans une langue maternelle est compréhensible, donc informatif. Les informations perçues et stockées dans la mémoire se reconstituent connaissance personne. Notre connaissance- il s'agit d'une information systématisée (liée) dans notre mémoire.
Lorsque l'on révèle le concept d'information du point de vue d'une approche significative, il faut partir des idées intuitives sur l'information dont disposent les enfants. Il est conseillé de mener une conversation sous forme de dialogue, en posant aux élèves des questions auxquelles ils sont capables de répondre. Les questions, par exemple, peuvent être posées dans l'ordre suivant.
Dites-nous d'où vous tenez vos informations ?
Vous entendrez probablement :
Des livres, des émissions de radio et de télévision .
Le matin j'ai entendu la météo à la radio .
Saisissant cette réponse, l'enseignant conduit les élèves à la conclusion finale :
Donc, au début, vous ne saviez pas quel temps il ferait, mais après avoir écouté la radio, vous avez commencé à savoir. Par conséquent, après avoir reçu des informations, vous avez reçu de nouvelles connaissances !
Ainsi, l'enseignant, avec les élèves, en vient à la définition : informationpour une personne, il s'agit d'informations qui complètent ses connaissances, qu'elle reçoit de diverses sources. De plus, sur de nombreux exemples familiers aux enfants, cette définition devrait être fixée.
Après avoir établi un lien entre l'information et les connaissances des gens, on en vient inévitablement à la conclusion que l'information est le contenu de notre mémoire, car la mémoire humaine est le moyen de stocker les connaissances. Il est raisonnable d'appeler de telles informations internes, des informations opérationnelles qu'une personne possède. Cependant, les personnes stockent des informations non seulement dans leur propre mémoire, mais également dans des enregistrements sur papier, sur des supports magnétiques, etc. Ces informations peuvent être qualifiées d'externes (par rapport à une personne). Pour qu'une personne puisse l'utiliser (par exemple, pour préparer un plat selon une recette), il doit d'abord le lire, c'est-à-dire transformez-le en formulaire interne, puis effectuez certaines actions.
La question de la classification des connaissances (et donc des informations) est très complexe. En science, il existe différentes approches. Les spécialistes du domaine de l'intelligence artificielle sont particulièrement engagés dans cette problématique. Dans le cadre du cours de base, il suffit de se borner à décomposer les connaissances en déclaratif Et de procédure. La description des connaissances déclaratives peut commencer par les mots : « Je sais que… ». Description des connaissances procédurales - avec les mots: "Je sais comment ...". Il est facile de donner des exemples pour les deux types de connaissances et d'inviter les enfants à proposer leurs propres exemples.
L'enseignant doit être bien conscient de l'importance propédeutique de discuter de ces questions pour la familiarisation future des élèves avec le dispositif et le fonctionnement de l'ordinateur. Un ordinateur, comme une personne, possède une mémoire interne - opérationnelle - et une mémoire externe - à long terme. La division des connaissances en déclaratives et procédurales à l'avenir peut être liée à la division de l'information informatique en données - informations déclaratives et programmes - informations procédurales. L'utilisation de la méthode didactique d'analogie entre la fonction d'information d'une personne et d'un ordinateur permettra aux étudiants de mieux comprendre l'essence de l'appareil et le fonctionnement d'un ordinateur.
Sur la base de la position «la connaissance humaine est une information stockée», l'enseignant informe les élèves que les odeurs, les goûts et les sensations tactiles (tactiles) transmettent également des informations à une personne. La raison en est très simple : puisque nous nous souvenons des odeurs et des goûts familiers, nous reconnaissons les objets familiers au toucher, puis ces sensations sont stockées dans notre mémoire et, par conséquent, ce sont des informations. D'où la conclusion: avec l'aide de tous ses sens, une personne reçoit des informations du monde extérieur.
Tant d'un point de vue substantiel que méthodologique, il est très important de distinguer le sens des concepts « information" Et " données”. À la représentation de l'information dans tout système de signalisation(y compris ceux utilisés dans les ordinateurs) terme doit être utilisé “données". UN information- Ce la signification contenue dans les données, incorporée dans celles-ci par une personne et compréhensible uniquement par une personne.
Un ordinateur travaille avec des données : il reçoit des données d'entrée, les traite et transmet des données de sortie à une personne - des résultats. L'interprétation sémantique des données est effectuée par une personne. Néanmoins, dans le discours familier, dans la littérature, on dit et on écrit souvent qu'un ordinateur stocke, traite, transmet et reçoit des informations. Cela est vrai si l'ordinateur n'est pas séparé de la personne, le considérant comme un outil avec lequel une personne effectue des processus d'information.
5. Cybernétique
Le mot « cybernétique » est d'origine grecque, signifiant littéralement l'art de contrôler.
Au IVe siècle av. dans les écrits de Platon, ce terme était utilisé pour désigner la gestion au sens général. Au XIXe siècle, A. Ampère propose d'appeler cybernétique la science de la gestion de la société humaine.
Dans une interprétation moderne cybernétique- une science qui étudie les lois générales du contrôle et des relations dans les systèmes organisés (machines, organismes vivants, dans la société).
L'émergence de la cybernétique en tant que science indépendante est associée à la publication des livres du scientifique américain Norbert Wiener "Cybernetics, or Control and Communication in Animal and Machine" en 1948 et "Cybernetics and Society" en 1954.
La principale découverte scientifique de la cybernétique a été la justification Unité des lois de contrôle dans les systèmes naturels et artificiels. N. Wiener est arrivé à cette conclusion en construisant modèle d'information processus de gestion.

Norbert Wiener (1894–1964), États-Unis
Un schéma similaire était connu dans la théorie du contrôle automatique. Wiener l'a généralisé à tous les types de systèmes, faisant abstraction des mécanismes de communication spécifiques, considérant cette connexion comme informationnelle.

Schéma de contrôle de rétroaction
Le canal de communication directe transmet des informations de contrôle - commandes de contrôle. Le canal de rétroaction transmet des informations sur l'état de l'objet contrôlé, sur sa réponse à l'action de contrôle, ainsi que sur l'état de l'environnement extérieur, qui est souvent un facteur important dans la gestion.
La cybernétique développe le concept d'information en tant que contenu de signaux transmis par des canaux de communication. La cybernétique développe le concept d'algorithme en tant qu'information de contrôle qu'un objet de contrôle doit posséder pour effectuer son travail.
L'émergence de la cybernétique se produit simultanément avec la création d'ordinateurs électroniques. Le lien entre ordinateurs et cybernétique est si étroit que ces concepts ont souvent été identifiés dans les années 1950. Les ordinateurs étaient appelés machines cybernétiques.
Le lien entre les ordinateurs et la cybernétique existe sous deux aspects. Premièrement, un ordinateur est un automate autonome dans lequel le dispositif de contrôle, qui fait partie du processeur, joue le rôle d'un gestionnaire, et tous les autres dispositifs sont des objets de contrôle. La communication directe et en retour s'effectue via des canaux d'information, et l'algorithme se présente sous la forme d'un programme en langage machine (un langage « compréhensible » par le processeur) stocké dans la mémoire de l'ordinateur.
Deuxièmement, avec l'invention de l'ordinateur, la perspective d'utiliser la machine comme objet de contrôle dans une variété de systèmes s'est ouverte. Il devient possible de créer des systèmes complexes avec contrôle de programme, de transférer de nombreux types d'activités humaines vers des dispositifs automatiques.
Le développement de la filière « cybernétique - informatique » conduit dans les années 1960 à l'émergence de la science informatique avec un système plus développé de concepts liés à l'étude de l'information et des processus d'information.
A l'heure actuelle, les dispositions générales de la cybernétique théorique acquièrent dans une plus large mesure une signification philosophique. Parallèlement, les domaines appliqués de la cybernétique se développent activement, liés à l'étude et à la réalisation de systèmes de contrôle dans diverses disciplines : cybernétique technique, cybernétique biomédicale, cybernétique économique. Avec le développement des systèmes d'apprentissage par ordinateur, on peut parler de l'émergence d'une cybernétique pédagogique.
Il existe différentes manières d'intégrer les questions de cybernétique dans le cours de formation générale. L'une d'entre elles passe par la ligne d'algorithmique. Algorithme considéré comme informations de contrôle dans le modèle cybernétique du système de contrôle. Dans ce contexte, le thème de la cybernétique se dévoile.
Une autre façon est d'inclure le sujet de la cybernétique dans la ligne significative de la modélisation. En révisant processus de gestion comme un processus d'information complexe donne une idée de Schéma de N. Wiener Comment modèles d'un tel processus. Dans la version du référentiel pédagogique pour l'école fondamentale (2004), ce thème est présent dans le cadre de la modélisation : « modèle cybernétique des processus de gestion ».
Dans les travaux d'A.A. Kuznetsova, S.A. Beshenkova et al., « Cours d'informatique continue », ont nommé trois domaines principaux du cours d'informatique scolaire : modélisation de l'information, processus d'information Et bases d'informations gestion. Les lignes de contenu sont le détail des directions principales. Ainsi, le thème cybernétique - le thème de la gestion, prend encore plus d'importance que la ligne de contenu. Il s'agit d'un sujet à multiples facettes qui vous permet d'aborder les questions suivantes :
Éléments de cybernétique théorique : modèle cybernétique de contrôle par rétroaction ;
Éléments de cybernétique appliquée : structure des systèmes informatiques de contrôle automatique (systèmes à contrôle de programme) ; nomination de systèmes de contrôle automatisés ;
Fondamentaux de la théorie des algorithmes.
Eléments de cybernétique théorique
Parlant du modèle de contrôle cybernétique, l'enseignant doit l'illustrer avec des exemples familiers et compréhensibles pour les élèves. Dans ce cas, les principaux éléments du système de contrôle cybernétique doivent être mis en évidence : objet de contrôle, objet géré, canaux directs et de rétroaction.
Commençons par des exemples évidents. Par exemple, un chauffeur et une voiture. Le conducteur est le gestionnaire, la voiture est l'objet contrôlé. Canal de communication direct - système de contrôle de la voiture : pédales, volant, leviers, clés, etc. Canaux de rétroaction : instruments sur le panneau de commande, vue depuis les fenêtres, audition du conducteur. Toute action sur les commandes peut être considérée comme une information transmise : « augmenter la vitesse », « ralentir », « tourner à droite », etc. Les informations transmises par les canaux de rétroaction sont également nécessaires pour une gestion réussie. Proposez aux élèves une tâche : que se passe-t-il si l'un des canaux directs ou de rétroaction est désactivé ? La discussion de telles situations est généralement très animée.
Le contrôle par rétroaction est appelé contrôle adaptatif. Les actions du gestionnaire sont adaptées (c'est-à-dire ajustées) à l'état de l'objet de contrôle, l'environnement.
L'exemple le plus proche pour les étudiants de la gestion dans un système social : un enseignant qui gère le processus d'apprentissage dans la classe. Discutez des diverses formes de contrôle de l'enseignant sur les élèves : parole, gestes, expressions faciales, notes au tableau. Demandez aux élèves d'énumérer différentes formes de rétroaction; expliquer comment l'enseignant adapte le déroulement de la leçon en fonction des résultats de la rétroaction, donner des exemples d'une telle adaptation. Par exemple, les élèves n'ont pas fait face à la tâche proposée - l'enseignant est obligé de répéter l'explication.
Lorsqu'on étudie ce sujet au lycée, on peut s'interroger sur les modes de gestion dans les grands systèmes sociaux : gestion d'une entreprise par l'administration, gestion du pays par les organes de l'État, etc. Ici, il est utile d'utiliser le matériel du cours d'études sociales. Lors de l'analyse des mécanismes d'anticipation et de rétroaction dans de tels systèmes, attirez l'attention des élèves sur le fait que, dans la plupart des cas, il existe de nombreux canaux d'anticipation et de rétroaction. Ils sont dupliqués afin d'augmenter la fiabilité du système de contrôle.
Algorithmes et contrôle
Cette rubrique permet de dévoiler le concept d'algorithme d'un point de vue cybernétique. La logique d'extension est la suivante. La gestion est un processus délibéré. Il doit fournir un certain comportement de l'objet de contrôle, la réalisation d'un certain objectif. Et pour cela, il faut un plan de gestion. Ce plan est mis en œuvre par une séquence de commandes de contrôle transmises sur une liaison directe. Une telle séquence de commandes s'appelle un algorithme de contrôle.
Algorithme de contrôle est un élément d'information du système de gestion. Par exemple, un enseignant enseigne une leçon selon un plan prédéterminé. Le conducteur conduit la voiture le long d'un itinéraire prédéterminé.
Dans les systèmes de contrôle, où le rôle du gestionnaire est joué par une personne, l'algorithme de contrôle peut changer, être affiné au cours du travail. Le conducteur ne peut pas planifier à l'avance chacune de ses actions pendant la conduite ; L'enseignant ajuste le plan de cours au fur et à mesure. Si le processus est contrôlé par un dispositif automatique, un algorithme de contrôle détaillé doit y être intégré à l'avance sous une forme formalisée. Dans ce cas, il s'appelle programme de gestion. Pour mémoriser le programme, le dispositif de contrôle automatique doit avoir mémoire programme.
Ce sujet devrait explorer le concept système autogéré. Il s'agit d'un objet unique, un organisme, dans lequel tous les composants des systèmes de contrôle mentionnés ci-dessus sont présents: contrôle et parties contrôlées (organes), communication d'informations directes et de rétroaction, informations de contrôle - algorithmes, programmes et mémoire pour les stocker. De tels systèmes sont des organismes vivants. Le plus parfait d'entre eux est l'homme. L'homme se contrôle. Le principal organe de contrôle est le cerveau humain, contrôlé - toutes les parties du corps. Manger gestion consciente(je fais ce que je veux) et mange subconscient(gestion des processus physiologiques). Des processus similaires se produisent chez les animaux. Cependant, la proportion de contrôle conscient chez les animaux est moindre que chez les humains en raison d'un niveau de développement intellectuel humain plus élevé.
La création de systèmes artificiels autonomes est l'une des tâches les plus difficiles de la science et de la technologie. La robotique est un exemple d'une telle direction scientifique et technique. Elle associe de nombreux domaines scientifiques : cybernétique, intelligence artificielle, médecine, modélisation mathématique, etc.
Éléments de cybernétique appliquée
Ce sujet peut être divulgué soit dans une version approfondie de l'étude du cours de base d'informatique, soit au niveau du profil au lycée.
Aux tâches cybernétique technique comprend le développement et la création de systèmes de contrôle technique dans les entreprises manufacturières, dans les laboratoires de recherche, dans les transports, etc. Ces systèmes sont appelés systèmes avec contrôle automatique - SCA . Des ordinateurs ou des contrôleurs spécialisés sont utilisés comme dispositif de contrôle dans l'ACS.
Le modèle de contrôle cybernétique par rapport à l'ACS est illustré sur la figure.

Schéma du système de contrôle automatique
Il s'agit d'un système technique fermé qui fonctionne sans intervention humaine. La personne (programmeur) a préparé programme de gestion, l'a mis dans la mémoire de l'ordinateur. Ensuite, le système fonctionne automatiquement.
Compte tenu de ce problème, les étudiants doivent faire attention au fait qu'ils ont déjà rencontré la conversion d'informations de l'analogique au numérique et vice versa (conversion DAC - ADC) dans d'autres sujets ou qu'ils se rencontreront à nouveau. Le modem fonctionne sur le même principe dans les réseaux informatiques, carte son lors de l'entrée/sortie du son (voir " Présentation sonore » 2).Dans ce système, un signal électrique analogique passant par le canal de retour des capteurs de l'appareil contrôlé en utilisant Convertisseur analogique-numérique(ADC), se transforme en données numériques discrètes, entrer dans l'ordinateur. Fonctionne en ligne directe DAC - convertisseur numérique-analogique, qui effectue inverse métamorphose - données numériques, provenant de l'ordinateur en un signal électrique analogique fourni aux noeuds d'entrée du dispositif commandé.
Une autre direction de la cybernétique appliquée : systèmes de contrôle automatisés (ACS). ACS est un système homme-machine. En règle générale, les systèmes de contrôle automatisés sont axés sur la gestion des activités des équipes de production et des entreprises. Il s'agit de systèmes informatiques de collecte, de stockage, de traitement de diverses informations nécessaires au fonctionnement de l'entreprise. Par exemple, des données sur les flux financiers, la disponibilité des matières premières, les volumes de produits finis, les informations sur le personnel, etc. et ainsi de suite. L'objectif principal de ces systèmes est de fournir rapidement et avec précision aux chefs d'entreprise information nécessaire pour prendre des décisions de gestion.
Les tâches résolues au moyen de systèmes de contrôle automatisés appartiennent au domaine cybernétique économique. En règle générale, la base technique de ces systèmes sont les réseaux informatiques locaux. ACS utilise diverses technologies de l'information : bases de données, infographie, modélisation informatique, systèmes experts, etc.
6. Informations d'encodage
Code -un système de signes conventionnels (symboles) pour la transmission, le traitement et le stockage d'informations (messages).
Codage - le processus de présentation des informations (messages) sous forme de code.
L'ensemble des caractères utilisés pour l'encodage est appelé alphabet de codage. Par exemple, dans la mémoire d'un ordinateur, toute information est codée à l'aide d'un alphabet binaire contenant seulement deux caractères : 0 et 1.
Les fondements scientifiques du codage ont été décrits par K. Shannon, qui a étudié les processus de transmission de l'information sur les canaux de communication techniques ( théorie de la communication, théorie du codage). Avec cette approche codage compris dans un sens plus étroit : transition de la représentation de l'information dans un système de symboles à sa représentation dans un autre système de symboles. Par exemple, convertir un texte russe écrit en code Morse pour transmission par télégraphe ou radio. Un tel codage est lié à la nécessité d'adapter le code aux moyens techniques de traitement des informations utilisées (voir " Transfert d'informations" 2).
Décodage - le processus de reconversion du code sous la forme du système de caractères d'origine, c'est à dire. obtenir le message d'origine. Par exemple : traduction du code Morse en un texte écrit en russe.
Plus largement, le décodage est le processus de récupération du contenu d'un message codé. Avec cette approche, le processus d'écriture d'un texte en utilisant l'alphabet russe peut être considéré comme un encodage, et sa lecture est un décodage.
Objectifs du codage et méthodes de codage
L'encodage d'un même message peut être différent. Par exemple, nous sommes habitués à écrire du texte russe en utilisant l'alphabet russe. Mais la même chose peut être faite en utilisant l'alphabet anglais. Parfois, vous devez le faire en envoyant un SMS sur un téléphone mobile qui ne contient pas de lettres russes, ou en envoyant un e-mail en russe depuis l'étranger s'il n'y a pas de logiciel russifié sur l'ordinateur. Par exemple, la phrase : "Bonjour, chère Sasha !" Je dois écrire comme ceci: "Zdravstvui, chère Sasha!".
Il existe d'autres façons d'encoder la parole. Par exemple, sténographie - moyen rapide d'enregistrer la langue parlée. Il n'appartient qu'à quelques personnes spécialement formées - des sténographes. Le sténographe parvient à écrire le texte de manière synchrone avec le discours de la personne qui parle. Dans la transcription, une icône désignait un mot ou une phrase entière. Seul un sténographe peut déchiffrer (décoder) une transcription.
Les exemples donnés illustrent la règle importante suivante : différentes manières peuvent être utilisées pour coder la même information ; leur choix dépend de plusieurs facteurs : but du codage, conditions, fonds disponibles. Si vous avez besoin d'écrire le texte au rythme de la parole, nous utilisons la sténographie ; s'il est nécessaire de transférer le texte à l'étranger - nous utilisons l'alphabet anglais; s'il est nécessaire de présenter le texte sous une forme compréhensible pour un russe lettré, nous l'écrivons selon les règles de la grammaire de la langue russe.
Autre circonstance importante : le choix de la manière dont les informations sont codées peut être lié à la manière prévue de les traiter. Montrons-le sur un exemple de représentation des nombres - l'information quantitative. En utilisant l'alphabet russe, vous pouvez écrire le nombre "trente-cinq". En utilisant l'alphabet du système de numération décimale arabe, nous écrivons : « 35 ». La deuxième méthode est non seulement plus courte que la première, mais également plus pratique pour effectuer des calculs. Quelle entrée est la plus pratique pour effectuer des calculs : « trente-cinq fois cent vingt-sept » ou « 35 x 127 » ? Évidemment le deuxième.
Cependant, s'il est important de conserver le numéro sans distorsion, il est préférable de l'écrire sous forme de texte. Par exemple, dans les documents monétaires, le montant est souvent écrit sous forme de texte : "trois cent soixante-quinze roubles". au lieu de "375 roubles". Dans le second cas, la distorsion d'un chiffre changera la valeur entière. Lors de l'utilisation de la forme textuelle, même les erreurs grammaticales peuvent ne pas modifier le sens. Par exemple, une personne illettrée a écrit : "Trois cent soixante-quinze roubles". Cependant, le sens a été préservé.
Dans certains cas, il est nécessaire de classer le texte d'un message ou d'un document afin qu'il ne puisse pas être lu par ceux qui ne sont pas censés le faire. On l'appelle protection contre les accès non autorisés. Dans ce cas, le texte secret est crypté. Dans les temps anciens, le cryptage était appelé cryptographie. Chiffrement est le processus de conversion du texte en clair en texte chiffré, et décryptage- le processus de transformation inverse, dans lequel le texte original est restauré. Le cryptage est également un codage, mais avec une méthode secrète connue uniquement de la source et du destinataire. Les méthodes de cryptage sont traitées par une science appelée cryptographie(cm . "Cryptographie" 2).
Histoire des moyens techniques d'encodage de l'information
Avec l'avènement des moyens techniques de stockage et de transmission de l'information, de nouvelles idées et techniques de codage sont apparues. Le premier moyen technique de transmission d'informations à distance fut le télégraphe, inventé en 1837 par l'Américain Samuel Morse. Un message télégraphique est une séquence de signaux électriques transmis d'un appareil télégraphique par des fils à un autre appareil télégraphique. Ces circonstances techniques ont conduit S. Morse à l'idée de n'utiliser que deux types de signaux - courts et longs - pour coder un message transmis sur les lignes télégraphiques.

Samuel Finley Breeze Morse (1791–1872), États-Unis
Cette méthode de codage est appelée code Morse. Dans celui-ci, chaque lettre de l'alphabet est codée par une séquence de signaux courts (points) et de signaux longs (tirets). Les lettres sont séparées les unes des autres par des pauses - l'absence de signaux.
Le message télégraphique le plus célèbre est le signal de détresse SOS ( S ave O tu S les âmes- Sauvez nos âmes). Voici à quoi cela ressemble dans le code Morse appliqué à l'alphabet anglais :
–––
Trois points (lettre S), trois tirets (lettre O), trois points (lettre S). Deux pauses séparent les lettres les unes des autres.
La figure montre le code Morse par rapport à l'alphabet russe. Il n'y avait pas de signes de ponctuation spéciaux. Ils ont été écrits avec les mots: "point" - un point, "spt" - une virgule, etc.
Un trait caractéristique du code Morse est code de longueur variable de différentes lettres, donc le code Morse s'appelle code inégal. Les lettres qui apparaissent plus souvent dans le texte ont plus petit code que des lettres rares. Par exemple, le code de la lettre "E" est un point et le code d'un caractère plein se compose de six caractères. Ceci est fait afin de raccourcir la longueur du message entier. Mais à cause de la longueur variable du code des lettres, il y a un problème de séparation des lettres les unes des autres dans le texte. Par conséquent, il est nécessaire d'utiliser une pause (saut) pour la séparation. Par conséquent, l'alphabet télégraphique Morse est ternaire, puisque il utilise trois caractères : point, tiret, espace.

Le code télégraphique uniforme a été inventé par le Français Jean Maurice Baudot à la fin du XIXe siècle. Il n'utilisait que deux types de signaux différents. Peu importe comment vous les appelez : point et tiret, plus et moins, zéro et un. Ce sont deux signaux électriques différents. La longueur du code de tous les caractères est la même et est égal à cinq. Dans ce cas, le problème de la séparation des lettres les unes des autres ne se pose pas : chacun des cinq signaux est un signe textuel. Par conséquent, un laissez-passer n'est pas nécessaire.

Jean Maurice Émile Baudot (1845-1903), France
Le code Baudot est la première méthode de l'histoire de la technologie pour encoder des informations en binaire.. Grâce à cette idée, il a été possible de créer un appareil télégraphique à impression directe qui ressemble à une machine à écrire. Appuyer sur une touche avec une certaine lettre génère le signal correspondant à cinq impulsions, qui est transmis sur la ligne de communication. La machine réceptrice, sous l'influence de ce signal, imprime la même lettre sur une bande de papier.
Les ordinateurs modernes utilisent également un code binaire uniforme pour coder les textes (voir " Systèmes de codage de texte » 2).
Le sujet du codage de l'information peut être présenté dans le programme à toutes les étapes de l'étude de l'informatique à l'école.
Dans un cours de propédeutique, on propose souvent aux étudiants des tâches qui ne sont pas liées au codage de données informatiques et qui sont, en quelque sorte, une forme de jeu. Par exemple, à partir de la table de code Morse, il est possible de proposer à la fois des tâches d'encodage (encoder du texte russe en code Morse) et des tâches de décodage (déchiffrer du texte encodé en code Morse).
L'exécution de telles tâches peut être interprétée comme le travail d'un cryptographe, proposant diverses clés de chiffrement simples. Par exemple, alphanumérique, en remplaçant chaque lettre par son numéro ordinal dans l'alphabet. De plus, des signes de ponctuation et d'autres symboles doivent être ajoutés à l'alphabet afin d'encoder complètement le texte. Demandez aux élèves de trouver une façon de faire la distinction entre les lettres minuscules et majuscules.
Lors de l'exécution de telles tâches, les élèves doivent faire attention au fait qu'un caractère de séparation est requis - un espace, car le code s'avère être inégal: certaines lettres sont cryptées avec un chiffre, d'autres avec deux.
Invitez les élèves à réfléchir à la façon dont ils peuvent s'en sortir sans séparer les lettres dans le code. Ces réflexions doivent conduire à l'idée d'un code uniforme, dans lequel chaque caractère est codé par deux chiffres décimaux : A - 01, B - 02, etc.
Des collections de tâches d'encodage et de cryptage d'informations sont disponibles dans un certain nombre de manuels scolaires.
Dans le cours d'informatique de base de l'école principale, le thème du codage est davantage associé au thème de la représentation dans un ordinateur. divers types données : chiffres, textes, images, son (voir « Informatique” 2).
Dans les classes supérieures, le contenu d'un cours de formation générale ou à option peut traiter plus en détail des questions liées à la théorie du codage développée par K. Shannon dans le cadre de la théorie de l'information. Il existe un certain nombre de tâches intéressantes ici, dont la compréhension nécessite un niveau accru de formation en mathématiques et en programmation des étudiants. Ce sont les problèmes de codage économique, d'algorithme de codage universel, de codage correcteur d'erreurs. Beaucoup de ces questions sont discutées en détail dans le manuel "Mathematical Foundations of Informatics".
7. Traitement des informations
Traitement de l'information - le processus de changement systématique du contenu ou de la forme de présentation de l'information.
Le traitement de l'information est effectué conformément à certaines règles par un sujet ou un objet (par exemple, une personne ou un dispositif automatique). Nous l'appellerons exécuteur du traitement de l'information.
L'exécutant du traitement, en interaction avec l'environnement extérieur, reçoit de celui-ci informations d'entrée qui est en cours de traitement. Le résultat du traitement est imprimer transmis au milieu extérieur. Ainsi, l'environnement externe agit comme une source d'informations d'entrée et un consommateur d'informations de sortie.
Le traitement de l'information s'effectue selon certaines règles connues de l'exécutant. Les règles de traitement, qui sont une description de la séquence d'étapes de traitement individuelles, sont appelées l'algorithme de traitement de l'information.
L'exécuteur de traitement doit comprendre une unité de traitement, que nous appellerons processeur, et un bloc mémoire dans lequel sont stockées à la fois les informations traitées et les règles de traitement (algorithme). Tout ce qui précède est représenté schématiquement sur la figure.

Schéma de traitement de l'information
Exemple. L'élève, résolvant le problème de la leçon, effectue le traitement de l'information. L'environnement extérieur pour lui est l'atmosphère de la leçon. L'information d'entrée est la condition de la tâche, qui est rapportée par l'enseignant qui dirige la leçon. L'élève mémorise l'état du problème. Pour faciliter la mémorisation, il peut utiliser des notes dans un cahier - une mémoire externe. De l'explication de l'enseignant, il a appris (se souvenait) la façon de résoudre le problème. Le processeur est l'appareil mental de l'étudiant, à l'aide duquel pour résoudre le problème, il reçoit une réponse - des informations de sortie.
Le schéma représenté sur la figure est un schéma général de traitement de l'information qui ne dépend pas de qui (ou de quoi) est l'exécuteur du traitement : un organisme vivant ou un système technique. C'est ce schéma qui est mis en oeuvre par des moyens techniques dans un ordinateur. Par conséquent, nous pouvons dire que l'ordinateur est modèle technique système de traitement de l'information "en direct". Il comprend tous les composants principaux du système de traitement : processeur, mémoire, périphériques d'entrée, périphériques de sortie (voir " Périphérique informatique" 2).
Les informations d'entrée présentées sous forme symbolique (caractères, lettres, chiffres, signaux) sont appelées des données d'entrée. À la suite du traitement par l'interprète, sortir. Les données d'entrée et de sortie peuvent être un ensemble de valeurs - des éléments de données individuels. Si le traitement consiste en des calculs mathématiques, alors les données d'entrée et de sortie sont des ensembles de nombres. La figure suivante X: {X 1, X 2, …, xn) désigne l'ensemble des données d'entrée, et Oui: {y 1, y 2, …, ym) - ensemble de données de sortie :

Schéma de traitement des données
Le traitement consiste à transformer l'ensemble X dans la multitude Oui:
P( X) Oui
Ici R désigne les règles de traitement utilisées par l'exécutant. Si l'exécuteur du traitement de l'information est une personne, les règles de traitement selon lesquelles il agit ne sont pas toujours formelles et univoques. Une personne agit souvent de manière créative, pas formelle. Même les mêmes problèmes mathématiques peuvent être résolus de différentes manières. Le travail d'un journaliste, d'un scientifique, d'un traducteur et d'autres spécialistes est un travail créatif avec des informations qu'ils ne suivent pas de règles formelles.
Pour désigner des règles formalisées qui déterminent l'enchaînement des étapes de traitement de l'information, l'informatique utilise le concept d'algorithme (voir " Algorithme" 2). Le concept d'algorithme en mathématiques est associé à une méthode bien connue de calcul du plus grand diviseur commun (PGCD) de deux nombres naturels, appelée algorithme d'Euclide. Sous forme verbale, il peut être décrit comme suit :
1. Si deux nombres sont égaux, prenez leur valeur commune comme PGCD, sinon passez à l'étape 2.
2. Si les nombres sont différents, remplacez le plus grand d'entre eux par la différence entre le plus grand et le plus petit des nombres. Revenez à l'étape 1.
Ici, l'entrée est deux nombres naturels - X 1 et X 2. Résultat Oui est leur plus grand diviseur commun. Règle ( R) est l'algorithme d'Euclide :
Algorithme d'Euclide ( X 1, X 2) Oui
Un tel algorithme formalisé est facile à programmer pour un ordinateur moderne. L'ordinateur est l'exécuteur universel du traitement des données. L'algorithme de traitement formalisé se présente sous la forme d'un programme placé dans la mémoire de l'ordinateur. Pour un ordinateur, les règles de traitement ( R) - Ce programme.
Des lignes directricesEn expliquant le sujet "Traitement de l'information", il convient de donner des exemples de traitement, à la fois liés à l'obtention de nouvelles informations et liés à la modification de la forme de présentation de l'information.
Le premier type de traitement : les traitements associés à l'obtention de nouvelles informations, de nouveaux contenus de connaissances. Ce type de traitement inclut la résolution de problèmes mathématiques. Le même type de traitement de l'information comprend la résolution de divers problèmes en appliquant un raisonnement logique. Par exemple, l'enquêteur sur un certain ensemble de preuves trouve un criminel ; une personne, analysant les circonstances, prend une décision sur ses actions futures; un scientifique résout le mystère des manuscrits anciens, etc.
Deuxième type de traitement : traitement associé à la modification de la forme, mais pas à la modification du contenu. Ce type de traitement de l'information comprend, par exemple, la traduction d'un texte d'une langue à une autre : la forme change, mais le contenu doit être préservé. Un type de traitement important pour l'informatique est le codage. Codage- Ce transformation de l'information en une forme symbolique propice à son stockage, sa transmission, son traitement(cm. " Codage” 2).
La structuration des données peut également être classée comme un second type de traitement. La structuration est associée à l'introduction d'un certain ordre, d'une certaine organisation dans le stockage de l'information. Le classement des données par ordre alphabétique, le regroupement selon certains critères de classement, l'utilisation d'une représentation tabulaire ou graphique sont autant d'exemples de structuration.
Un type particulier de traitement de l'information est recherche. La tâche de recherche est généralement formulée comme suit : il y a un certain stockage d'informations - tableau d'informations(annuaire téléphonique, dictionnaire, horaires des trains, etc.), vous devez y trouver les informations nécessaires qui répondent à certaines termes de recherche(numéro de téléphone de cette organisation, traduction de ce mot en langue anglaise, l'heure de départ de ce train). L'algorithme de recherche dépend de la manière dont les informations sont organisées. Si l'information est structurée, alors la recherche est plus rapide, elle peut être optimisée (voir " Recherche de données » 2).
Dans un cours d'informatique propédeutique, les problèmes de « boîte noire » sont populaires. L'exécutant du traitement est considéré comme une "boîte noire", c'est-à-dire système, dont nous ignorons l'organisation et le mécanisme internes. La tâche consiste à deviner la règle de traitement des données (P) que l'interprète implémente.

L'exécuteur de traitement calcule la valeur moyenne des valeurs d'entrée : Oui = (X 1 + X 2)/2
A l'entrée - un mot en russe, à la sortie - le nombre de voyelles.
La maîtrise la plus profonde des problèmes de traitement de l'information se produit lors de l'étude des algorithmes pour travailler avec les quantités et la programmation (au primaire et au secondaire). L'exécuteur du traitement de l'information dans ce cas est un ordinateur, et toutes les capacités de traitement sont intégrées dans le langage de programmation. La programmation Il y a description des règles de traitement des données d'entrée afin d'obtenir des données de sortie.
Les élèves doivent se voir confier deux types de tâches :
Tâche directe : créer un algorithme (programme) pour résoudre le problème ;
Problème inverse : étant donné un algorithme, il est nécessaire de déterminer le résultat de son exécution en traçant l'algorithme.
Lors de la résolution d'un problème inverse, l'étudiant se met dans la position d'un exécutant de traitement, exécutant pas à pas l'algorithme. Les résultats de l'exécution à chaque étape doivent être reflétés dans la table de trace.
8. Transfert d'informationsComposantes du processus de transfert d'informations
Le transfert d'informations se produit de la source au destinataire (récepteur) des informations. source l'information peut être n'importe quoi : tout objet ou phénomène de nature vivante ou inanimée. Le processus de transfert d'informations se déroule dans un environnement matériel qui sépare la source et le destinataire de l'information, appelé canaliser transfert d'informations. Les informations sont transmises via un canal sous la forme d'une certaine séquence de signaux, symboles, signes, appelés message. Destinataire l'information est un objet qui reçoit un message, à la suite duquel certains changements dans son état se produisent. Tout ce qui précède est représenté schématiquement sur la figure.

Transfert d'informations
Une personne reçoit des informations de tout ce qui l'entoure, par les sens : ouïe, vue, odorat, toucher, goût. Une personne reçoit la plus grande quantité d'informations par l'ouïe et la vue. Les messages sonores sont perçus par l'oreille - des signaux acoustiques dans un milieu continu (le plus souvent dans l'air). La vision perçoit des signaux lumineux porteurs de l'image des objets.
Tous les messages ne sont pas informatifs pour une personne. Par exemple, un message dans une langue incompréhensible, bien que transmis à une personne, ne contient pas d'informations pour elle et ne peut pas provoquer de changements adéquats dans son état (voir " Information").
Un canal d'information peut soit être de nature naturelle (air atmosphérique à travers lequel les ondes sonores sont transmises, lumière solaire réfléchie par les objets observés), soit être créé artificiellement. Dans ce dernier cas, on parle de moyens techniques de communication.
Systèmes de transmission d'informations techniquesLe premier moyen technique de transmission d'informations à distance fut le télégraphe, inventé en 1837 par l'Américain Samuel Morse. En 1876, l'Américain A. Bell invente le téléphone. Basé sur la découverte des ondes électromagnétiques par le physicien allemand Heinrich Hertz (1886), A.S. Popov en Russie en 1895 et presque simultanément avec lui en 1896 G. Marconi en Italie, la radio est inventée. La télévision et Internet sont apparus au XXe siècle.
Toutes les méthodes techniques énumérées de communication d'informations sont basées sur la transmission d'un signal physique (électrique ou électromagnétique) à distance et sont soumises à certaines lois générales. L'étude de ces lois est théorie de la communication qui a émergé dans les années 1920. Appareil mathématique de la théorie de la communication - théorie mathématique de la communication, développé par le scientifique américain Claude Shannon.

Claude Elwood Shannon (1916–2001), États-Unis
Claude Shannon a proposé un modèle du processus de transmission d'informations par des canaux de communication techniques, représenté par un schéma.

Système de transmission d'informations techniques
Par codage, on entend ici toute transformation d'une information provenant d'une source sous une forme adaptée à sa transmission sur un canal de communication. Décodage - transformation inverse de la séquence signal.
Le fonctionnement d'un tel système peut s'expliquer par le processus familier de parler au téléphone. La source d'information est la personne qui parle. Un encodeur est un microphone combiné qui convertit les ondes sonores (parole) en signaux électriques. Le canal de communication est le réseau téléphonique (fils, commutateurs des nœuds téléphoniques par lesquels passe le signal). Le dispositif de décodage est combiné(écouteur) d'une personne qui écoute - un récepteur d'informations. Ici, le signal électrique entrant est converti en son.
Moderne systèmes informatiques transmission d'informations - les réseaux informatiques fonctionnent sur le même principe. Il existe un processus d'encodage qui convertit le code informatique binaire en signal physique du type qui est transmis sur le canal de communication. Le décodage est la transformation inverse du signal transmis en code informatique. Par exemple, lors de l'utilisation de lignes téléphoniques dans des réseaux informatiques, les fonctions de codage et de décodage sont assurées par un dispositif appelé modem.
Capacité du canal et taux de transfert d'informationsLes développeurs de systèmes de transmission d'informations techniques doivent résoudre deux tâches interdépendantes : comment assurer la plus grande vitesse de transfert d'informations et comment réduire la perte d'informations pendant la transmission. Claude Shannon a été le premier scientifique à s'attaquer à la solution de ces problèmes et à créer une nouvelle science pour cette époque - théorie de l'information.
K.Shannon a déterminé la méthode de mesure de la quantité d'informations transmises sur les canaux de communication. Ils ont introduit le concept Bande passante du canal,comme le taux de transfert d'informations maximal possible. Cette vitesse est mesurée en bits par seconde (ainsi qu'en kilobits par seconde, mégabits par seconde).
Le débit d'un canal de communication dépend de sa mise en œuvre technique. Par exemple, les réseaux informatiques utilisent les moyens de communication suivants :
lignes téléphoniques,
Connexion de câble électrique,
câblage de fibre optique,
Communication radio.
Débit des lignes téléphoniques - dizaines, centaines de Kbps ; le débit des lignes à fibres optiques et des lignes de communication radio se mesure en dizaines et en centaines de Mbps.
Bruit, protection contre le bruit
Le terme "bruit" fait référence à divers types d'interférences qui déforment le signal transmis et entraînent une perte d'informations. De telles interférences se produisent principalement pour des raisons techniques : mauvaise qualité des lignes de communication, insécurité les uns des autres des différents flux d'informations transmis sur les mêmes canaux. Parfois, en parlant au téléphone, nous entendons des bruits, des crépitements, qui rendent difficile la compréhension de l'interlocuteur, ou la conversation de personnes complètement différentes se superpose à notre conversation.
La présence de bruit entraîne la perte des informations transmises. Dans de tels cas, une protection contre le bruit est nécessaire.
Tout d'abord, des méthodes techniques sont utilisées pour protéger les canaux de communication des effets du bruit. Par exemple, utiliser un câble blindé au lieu d'un fil nu ; l'utilisation de différents types de filtres qui séparent le signal utile du bruit, etc.
Claude Shannon a développé théorie du codage, qui donne des méthodes pour traiter le bruit. L'une des idées importantes de cette théorie est que le code transmis sur la ligne de communication doit être redondant. De ce fait, la perte d'une partie des informations pendant la transmission peut être compensée. Par exemple, si vous êtes difficile à entendre lorsque vous parlez au téléphone, alors en répétant chaque mot deux fois, vous avez plus de chances que l'interlocuteur vous comprenne correctement.
Cependant, vous ne pouvez pas rendre la redondance trop importante. Cela entraînera des retards et des coûts de communication plus élevés. La théorie du codage permet d'obtenir un code qui sera optimal. Dans ce cas, la redondance des informations transmises sera la plus faible possible, et la fiabilité des informations reçues sera la plus élevée.
Dans les systèmes de communication numériques modernes, la technique suivante est souvent utilisée pour lutter contre la perte d'informations lors de la transmission. L'ensemble du message est divisé en parties - paquets. Pour chaque forfait est calculé somme de contrôle(somme de chiffres binaires) qui est transmis avec ce paquet. Au site de réception, la somme de contrôle du paquet reçu est recalculée et, si elle ne correspond pas à la somme d'origine, la transmission ce paquet répète. Cela continuera jusqu'à ce que les sommes de contrôle initiales et finales correspondent.
Des lignes directricesCompte tenu du transfert d'informations dans les cours de propédeutique et d'informatique de base, ce sujet doit tout d'abord être abordé du point de vue d'une personne en tant que destinataire d'informations. La capacité de recevoir des informations du monde environnant est la condition la plus importante pour l'existence humaine. Les organes sensoriels humains sont les canaux d'information du corps humain, réalisant la connexion d'une personne avec l'environnement extérieur. Sur cette base, les informations sont divisées en visuelles, auditives, olfactives, tactiles et gustatives. La justification du fait que le goût, l'odorat et le toucher transmettent des informations à une personne est la suivante : nous nous souvenons des odeurs d'objets familiers, du goût d'aliments familiers, nous reconnaissons des objets familiers au toucher. Et le contenu de notre mémoire est constitué d'informations stockées.
Il faut dire aux élèves que dans le monde animal, le rôle informationnel des sens est différent de celui des humains. important fonction d'information effectue le sens de l'odorat pour les animaux. L'odorat accru des chiens d'assistance est utilisé par les forces de l'ordre pour rechercher des criminels, détecter des drogues, etc. La perception visuelle et sonore des animaux diffère de celle des humains. Par exemple, les chauves-souris sont connues pour entendre les ultrasons et les chats sont connus pour voir dans l'obscurité (d'un point de vue humain).
Dans le cadre de ce thème, les étudiants doivent être capables de diriger exemples concrets le processus de transfert d'informations, pour déterminer pour ces exemples la source, le récepteur d'informations, les canaux de transmission d'informations utilisés.
Lors des études d'informatique au lycée, les élèves doivent être initiés aux dispositions de base de la théorie technique de la communication : les notions de codage, de décodage, de taux de transfert d'informations, débit canal, bruit, protection contre le bruit. Ces questions peuvent être abordées dans le cadre du thème « Moyens techniques des réseaux informatiques ».
9. Représentation des nombresLes nombres en mathématiques
Le nombre est le concept le plus important des mathématiques, qui a évolué et évolué au cours d'une longue période de l'histoire humaine. Les gens travaillent avec les nombres depuis l'Antiquité. Initialement, une personne n'opérait qu'avec des nombres entiers positifs, appelés nombres naturels: 1, 2, 3, 4, ... Pendant longtemps, il y avait une opinion selon laquelle il y avait le plus grand nombre, "l'esprit humain ne peut pas comprendre plus que ceci » (comme ils l'écrivaient dans les traités mathématiques de l'ancien slavon) .
Le développement de la science mathématique a conduit à la conclusion qu'il n'y a pas de plus grand nombre. D'un point de vue mathématique, la suite des nombres naturels est infinie, c'est-à-dire n'est pas limité. Avec l'avènement du concept de nombre négatif en mathématiques (R. Descartes, XVIIe siècle en Europe; en Inde beaucoup plus tôt), il s'est avéré que l'ensemble des nombres entiers est illimité à la fois «à gauche» et «à droite». L'ensemble mathématique des nombres entiers est discret et illimité (infini).
Le concept de nombre réel (ou réel) a été introduit en mathématiques par Isaac Newton au 18ème siècle. D'un point de vue mathématique l'ensemble des nombres réels est infini et continu. Il comprend de nombreux entiers et un nombre infini de non-entiers. Entre deux points quelconques sur l'axe des nombres se trouve un ensemble infini de nombres réels. La notion de nombre réel est associée à l'idée d'un axe numérique continu dont tout point correspond à un nombre réel.
Représentation entièreDans la mémoire de l'ordinateur les nombres sont stockés dans un système de nombre binaire(cm. " Systèmes de numération” 2). Il existe deux formes de représentation des nombres entiers dans un ordinateur : les nombres entiers non signés et les nombres entiers signés.
Entiers sans signe - Ce l'ensemble des nombres positifs dans la plage, Où k- il s'agit de la profondeur de bits de la cellule mémoire allouée au numéro. Par exemple, si une cellule mémoire de 16 bits (2 octets) est allouée pour un entier, alors le plus grand nombre sera :
En décimal, cela correspond à : 2 16 - 1 \u003d 65 535
Si tous les chiffres de la cellule sont des zéros, alors ce sera zéro. Ainsi, 2 16 = 65 536 entiers sont placés dans une cellule de 16 bits.
Entiers signés est l'ensemble des nombres positifs et négatifs dans la plage[–2 k–1 , 2 k-onze]. Par exemple, lorsque k= 16 gamme de représentation entière : [–32768, 32767]. L'ordre supérieur de la cellule mémoire stocke le signe du nombre : 0 - nombre positif, 1 - nombre négatif. Le plus grand nombre positif 32 767 a la représentation suivante :
Par exemple, le nombre décimal 255, après avoir été converti en binaire et inséré dans une cellule mémoire 16 bits, aura la représentation interne suivante :
Les entiers négatifs sont représentés en complément à deux. Code supplémentaire nombre positif N- Ce est sa représentation binaire, qui, lorsqu'elle est ajoutée au code numérique N donne de la valeur 2 k. Ici k- le nombre de bits dans la cellule mémoire. Par exemple, le code supplémentaire pour le nombre 255 serait :
C'est la représentation du nombre négatif -255. Ajoutons les codes des nombres 255 et -255 :

Celui de l'ordre le plus élevé a «abandonné» de la cellule, de sorte que la somme s'est avérée être nulle. Mais c'est comme ça que ça devrait être : N + (–N) = 0. Le processeur de l'ordinateur effectue l'opération de soustraction sous la forme d'une addition avec le code supplémentaire du nombre soustrait. Dans ce cas, le débordement de la cellule (dépassement des valeurs limites) ne provoque pas l'interruption de l'exécution du programme. Cette circonstance que le programmeur doit connaître et prendre en compte !
Le format de représentation des nombres réels dans un ordinateur s'appelle format virgule flottante. nombre réel R représenté comme un produit de la mantisse m basé sur le système de numération n dans une certaine mesure p, qui s'appelle l'ordre : R= m ? np.
La représentation d'un nombre sous forme de virgule flottante est ambiguë. Par exemple, pour le nombre décimal 25,324, les égalités suivantes sont vraies :
25,324 = 2,5324 ? 10 1 = 0,0025324 ? 10 4 \u003d 2532,4? 10 -2, etc...
Pour éviter toute ambiguïté, nous avons convenu d'utiliser l'ordinateur une représentation normalisée d'un nombre sous forme de virgule flottante. Mantisse dans la représentation normalisée doit satisfaire la condition : 0,1 nm < 1 n. En d'autres termes, la mantisse est inférieure à un et le premier chiffre significatif n'est pas zéro. Dans certains cas, la condition de normalisation est prise comme suit : 1 n m < 10 n .
DANS mémoire d'ordinateur mantisse représenté sous la forme d'un nombre entier ne contenant que des chiffres significatifs(0 entiers et virgules ne sont pas stockés). Ainsi, la représentation interne d'un nombre réel se réduit à la représentation d'un couple d'entiers : mantisse et exposant.
Différents types d'ordinateurs utilisent différentes manières de représenter les nombres sous forme de virgule flottante. Considérons l'une des variantes de la représentation interne d'un nombre réel dans une cellule mémoire de quatre octets.
La cellule doit contenir les informations suivantes sur le nombre : le signe du nombre, l'exposant et les chiffres significatifs de la mantisse.

Le signe du nombre est stocké dans le bit le plus significatif du 1er octet : 0 signifie plus, 1 signifie moins. Les 7 bits restants du premier octet contiennent commande de machines. Les trois octets suivants stockent les chiffres significatifs de la mantisse (24 bits).
Les nombres binaires compris entre 0000000 et 1111111 sont placés sur sept chiffres binaires, ce qui signifie que l'ordre de la machine varie entre 0 et 127 (en système décimal). Il y a 128 valeurs au total. L'ordre, évidemment, peut être positif ou négatif. Il est raisonnable de répartir ces 128 valeurs de manière égale entre les valeurs d'ordre positives et négatives : de -64 à 63.
Commande de machines biaisé par rapport au mathématique et n'a que des valeurs positives. Le décalage est choisi de sorte que le minimum valeur mathématique l'ordre correspondait à zéro.
La relation entre l'ordre machine (Mp) et l'ordre mathématique (p) dans le cas considéré s'exprime par la formule : Mp = p + 64.
La formule résultante est écrite dans le système décimal. En binaire, la formule ressemble à : Mp 2 = p 2 + 100 0000 2 .
Pour écrire la représentation interne d'un nombre réel, il faut :
1) traduire le module d'un nombre donné en un système binaire à 24 chiffres significatifs,
2) normaliser un nombre binaire,
3) trouver l'ordre de la machine dans le système binaire,
4) en tenant compte du signe du nombre, écrivez sa représentation dans un mot machine de quatre octets.
Exemple. Écrivez la représentation interne du nombre 250,1875 sous forme de virgule flottante.
1. Traduisons-le en un système de numération binaire à 24 chiffres significatifs :
250,1875 10 = 11111010,0011000000000000 2 .
2. Écrivons sous la forme d'un nombre à virgule flottante binaire normalisé :
0.111110100011000000000000 H 10 2 1000 .
Voici la mantisse, la base du système numérique
(2 10 \u003d 10 2) et l'ordre (8 10 \u003d 1000 2) sont écrits en binaire.
3. Calculez l'ordre de la machine dans le système binaire :
MP2 = 1000 + 100 0000 = 100 1000.
4. Écrivons la représentation du nombre dans une cellule de mémoire de quatre octets, en tenant compte du signe du nombre
Forme hexadécimale : 48FA3000.
La gamme des nombres réels est beaucoup plus large que la gamme des nombres entiers. Les nombres positifs et négatifs sont disposés symétriquement autour de zéro. Par conséquent, les nombres maximum et minimum sont égaux en valeur absolue.
Le plus petit nombre absolu est zéro. Le plus grand nombre à virgule flottante en valeur absolue est le nombre avec la plus grande mantisse et le plus grand exposant.
Pour un mot machine de quatre octets, ce nombre serait :
0.111111111111111111111 10 2 1111111 .
Après conversion au système décimal, nous obtenons :
MAX = (1 - 2 -24) 2 63 10 19 .
Si, lors du calcul avec des nombres réels, le résultat est en dehors de la plage autorisée, l'exécution du programme est interrompue. Cela se produit, par exemple, lors de la division par zéro ou par un très petit nombre proche de zéro.
Les nombres réels dont la longueur en bits de la mantisse dépasse le nombre de bits alloués à la mantisse dans une cellule mémoire sont représentés dans le calculateur approximativement (avec une mantisse "tronquée"). Par exemple, le nombre décimal rationnel 0,1 dans un ordinateur sera représenté approximativement (arrondi) car dans le système binaire sa mantisse a un nombre infini de chiffres. La conséquence de cette approximation est l'erreur des calculs de la machine avec des nombres réels.
L'ordinateur effectue des calculs avec des nombres réels approximativement. L'erreur de ces calculs est appelée erreur d'arrondi machine.
L'ensemble des nombres réels qui peuvent être exactement représentés dans la mémoire de l'ordinateur sous forme de virgule flottante est limité et discret. La discrétion est une conséquence du nombre limité de chiffres de la mantisse, comme discuté ci-dessus.
Le nombre de nombres réels qui peuvent être exactement représentés dans la mémoire de l'ordinateur peut être calculé à l'aide de la formule : N = 2 t · ( tu
– L+ 1) + 1. Ici t- le nombre de chiffres binaires de la mantisse ; tu- la valeur maximale de l'ordre mathématique ; L- valeur minimale de commande. Pour l'option de représentation considérée ci-dessus ( t = 24, tu = 63,
L= -64) il s'avère : N = 2 146 683 548.
Le thème de la représentation des informations numériques dans un ordinateur est présent à la fois dans la norme pour le primaire et pour le secondaire.
A l'école de base (cours de base), il suffit de considérer la représentation des nombres entiers dans un ordinateur. L'étude de cette question n'est possible qu'après s'être familiarisée avec le sujet «Systèmes de nombres». De plus, à partir des principes de l'architecture informatique, les étudiants doivent être conscients qu'un ordinateur fonctionne avec un système de numération binaire.
Compte tenu de la représentation des entiers, l'attention principale doit être portée sur la plage limitée d'entiers, sur la connexion de cette plage avec la capacité de la cellule mémoire allouée - k. Pour les nombres positifs (non signés) : , pour les nombres positifs et négatifs (signé) : [–2 k–1 , 2 k–1 – 1].
L'obtention de la représentation interne des nombres doit être analysée à l'aide d'exemples. Après cela, par analogie, les élèves doivent résoudre ces problèmes de manière indépendante.
Exemple 1 Obtenir la représentation interne signée de l'entier 1607 dans un emplacement mémoire à deux octets.
1) Convertissez le nombre au système binaire : 1607 10 = 11001000111 2 .
2) En ajoutant des zéros aux 16 chiffres de gauche, on obtient la représentation interne de ce nombre dans la cellule :
Il est souhaitable de montrer comment la forme hexadécimale est utilisée pour la forme compressée de ce code, qui s'obtient en remplaçant chacun des quatre chiffres binaires par un chiffre hexadécimal : 0647 (voir " Systèmes de numération” 2).
Plus difficile est le problème d'obtention de la représentation interne d'un entier négatif (– N) - code supplémentaire. Vous devez montrer aux élèves l'algorithme de cette procédure :
1) obtenir la représentation interne d'un nombre positif N;
2) obtenir le code retour de ce numéro en remplaçant 0 par 1 et 1 par 0 ;
3) ajouter 1 au nombre obtenu.
Exemple 2. Obtenir la représentation interne d'un entier négatif -1607 dans un emplacement mémoire à deux octets.

Il est utile de montrer aux élèves à quoi ressemble la représentation interne du plus petit nombre négatif. Dans une cellule à deux octets, c'est -32 768.
1) il est facile de convertir le nombre 32 768 en système binaire, puisque 32 768 = 2 15. Donc en binaire c'est :
1000000000000000
2) écrivez le code inverse :
0111111111111111
3) ajouter un à ce nombre binaire, on obtient
Celui dans le premier bit signifie le signe moins. Pas besoin de penser que le code reçu est moins zéro. C'est -32 768 sous forme de complément à deux. Ce sont les règles de la représentation machine des nombres entiers.
Après avoir montré cet exemple, demandez aux élèves de prouver par eux-mêmes que l'addition des codes numériques 32767 + (-32768) donne le code numérique -1.
Selon la norme, la représentation des nombres réels devrait être étudiée au lycée. Lors de l'étude de l'informatique en 10e et 11e année au niveau de base, il suffit d'informer les élèves des principales caractéristiques d'un ordinateur avec des nombres réels : à propos de la plage limitée et de l'interruption du programme lorsqu'il la dépasse ; sur l'erreur des calculs de la machine avec des nombres réels, que l'ordinateur effectue des calculs avec des nombres réels plus lentement qu'avec des nombres entiers.
Étudier au niveau du profil nécessite analyse détaillée façons de représenter des nombres réels au format à virgule flottante, analyse des caractéristiques d'exécution de calculs sur un ordinateur avec des nombres réels. Un problème très important ici est l'estimation de l'erreur de calcul, l'avertissement contre la perte de valeur, contre l'interruption du programme. Des informations détaillées sur ces questions sont disponibles dans le manuel de formation.
10. Système de numérotation
Système de numération - c'est une façon de représenter les nombres et les règles correspondantes pour opérer sur les nombres. Les différents systèmes de numération qui existaient auparavant et qui sont utilisés aujourd'hui peuvent être divisés en non positionnel Et positionnel. Signes utilisés lors de l'écriture des nombres, sont appelés Nombres.
DANS systèmes de nombres non positionnels la valeur d'un chiffre ne dépend pas de sa position dans le nombre.
Un exemple de système de numération non positionnel est le système romain (chiffres romains). Dans le système romain, les lettres latines sont utilisées comme nombres :
Exemple 1. Le nombre CCXXXII est composé de deux cents, trois dizaines et deux unités et est égal à deux cent trente-deux.
Les chiffres romains s'écrivent de gauche à droite dans l'ordre décroissant. Dans ce cas, leurs valeurs sont ajoutées. Si un plus petit nombre est écrit à gauche et un grand nombre à droite, leurs valeurs sont soustraites.
VI = 5 + 1 = 6 ; IV \u003d 5 - 1 \u003d 4.
MCMXCVIII = 1000 + (-100 + 1000) +
+ (–10 + 100) + 5 + 1 + 1 + 1 = 1998.
DANS systèmes de numérotation positionnelle la valeur indiquée par un chiffre dans une entrée numérique dépend de sa position. Le nombre de chiffres utilisés est appelé la base du système de numération positionnel.
Le système de numération utilisé en mathématiques modernes est système décimal positionnel. Sa base est dix, car Tous les nombres sont écrits à l'aide de dix chiffres :
0, 1, 2, 3, 4, 5, 6, 7, 8, 9.
La nature positionnelle de ce système est facile à comprendre par l'exemple de n'importe quel nombre à plusieurs chiffres. Par exemple, dans le nombre 333, les trois premiers signifient trois cents, le deuxième - trois dizaines, le troisième - trois unités.
Écrire des nombres dans un système positionnel avec une base n Doit avoir alphabet depuis n chiffres. Généralement pour cela n < 10 используют n premiers chiffres arabes, et n> 10 lettres sont ajoutées à dix chiffres arabes. Voici des exemples d'alphabets de plusieurs systèmes :

S'il est nécessaire d'indiquer la base du système auquel appartient le numéro, un indice est alors attribué à ce numéro. Par exemple:
1011012, 36718, 3B8F16.
Dans le système de numération de base q (q-ary number system) les unités de chiffres sont des puissances successives d'un nombre q. q les unités de n'importe quelle catégorie forment l'unité de la catégorie suivante. Pour écrire un nombre à q-système de numération aire requis q divers caractères (chiffres) représentant les chiffres 0, 1, ..., q– 1. Écrire un nombre q V q-le système numérique a la forme 10.
Forme développée d'écriture d'un nombre
Laisser Aq- numéro dans le système de base q, ai - chiffres d'un système numérique donné présents dans la notation d'un nombre UN, n+ 1 - le nombre de chiffres de la partie entière du nombre, m- le nombre de chiffres de la partie fractionnaire du nombre :
Forme développée d'un nombre UN est appelé un enregistrement sous la forme :
Par exemple, pour un nombre décimal :
Les exemples suivants montrent la forme développée des nombres hexadécimaux et binaires :
Dans tout système numérique, sa base s'écrit 10.
Si tous les termes sous la forme développée d'un nombre non décimal sont présentés dans le système décimal et que l'expression résultante est calculée selon les règles de l'arithmétique décimale, alors un nombre dans le système décimal égal à celui donné sera obtenu. Selon ce principe, une conversion d'un système non décimal vers un système décimal est effectuée. Par exemple, la conversion au système décimal des nombres écrits ci-dessus se fait comme ceci :

Traduction d'entiers
nombre entier décimal X doit être transféré vers un système avec une base q: X = (un n un n-1
…un 1 un 0) q .
Trouver les chiffres significatifs d'un nombre : ![]() .
Représentons le nombre sous forme développée et effectuons la transformation identique :
.
Représentons le nombre sous forme développée et effectuons la transformation identique :
De là, il est clair que un 0 est le reste après division du nombre X par numéro q. L'expression entre parenthèses est le quotient entier de cette division. Désignons-le comme X 1. En effectuant des transformations similaires, on obtient :
Ainsi, un 1 est le reste de la division X 1 sur q. En continuant la division avec un reste, nous obtiendrons une séquence de chiffres du nombre souhaité. Nombre un dans cette chaîne de divisions sera le dernier privé, plus petit q.
Formulons la règle résultante : pour ça pour convertir un nombre décimal entier en un système numérique avec une base différente, vous avez besoin:
1) exprimer la base du nouveau système de nombres dans le système de nombres décimaux et effectuer toutes les actions ultérieures selon les règles de l'arithmétique décimale ;
2) diviser séquentiellement le nombre donné et les quotients partiels résultants par la base du nouveau système de nombres jusqu'à ce que nous obtenions un quotient incomplet inférieur au diviseur ;
3) les restes reçus, qui sont les chiffres d'un nombre dans le nouveau système de numérotation, les alignent sur l'alphabet du nouveau système de numérotation ;
4) composer un numéro dans le nouveau système de numérotation, en l'écrivant à partir du dernier numéro privé.
Exemple 1. Convertissez le nombre 37 10 au système binaire.
Pour désigner les nombres dans la notation d'un nombre, nous utilisons le symbolisme : un 5 un 4 un 3 un 2 un 1 un 0

D'où : 37 10 = l00l0l 2
Exemple 2. Convertissez le nombre décimal 315 en systèmes octal et hexadécimal :

Il s'ensuit d'ici : 315 10 = 473 8 = 13B 16. Rappelons que 11 10 = B 16 .
Décimal X < 1 требуется перевести в систему с основанием q: X = (0, un –1 un –2 … un–m+1 un–m) q . Trouver les chiffres significatifs d'un nombre : un –1 ,un –2 , …, un-m. Nous représentons le nombre sous forme développée et le multiplions par q:
De là, il est clair que un–1 X par numéro q. Dénoter par X 1 partie fractionnaire du produit et multipliez-la par q:
Ainsi, un –2 il y a toute une partie du travail X 1 par numéro q. En continuant la multiplication, nous obtiendrons une séquence de chiffres. Formulons maintenant la règle : pour convertir une fraction décimale en un système numérique avec une base différente, vous avez besoin:
1) multiplier successivement le nombre donné et les parties fractionnaires résultantes des produits par la base du nouveau système jusqu'à ce que la partie fractionnaire du produit devienne égale à zéro ou que la précision requise pour représenter le nombre dans le nouveau système numérique soit atteinte ;
2) les parties entières résultantes des produits, qui sont les chiffres d'un nombre dans le nouveau système de numération, les alignent sur l'alphabet du nouveau système de numération ;
3) composent la partie fractionnaire du nombre dans le nouveau système de numération, en commençant par la partie entière du premier produit.
Exemple 3. Convertissez le nombre décimal 0,1875 en binaire, octal et hexadécimal.

Ici, la partie entière des nombres est dans la colonne de gauche et la partie fractionnaire est dans la colonne de droite.
D'où : 0,1875 10 = 0,0011 2 = 0,14 8 = 0,3 16
La traduction des nombres mixtes contenant des parties entières et fractionnaires s'effectue en deux étapes. Les parties entières et fractionnaires du nombre d'origine sont traduites séparément selon les algorithmes correspondants. Dans l'enregistrement final d'un nombre dans le nouveau système de numération, la partie entière est séparée de la virgule fractionnaire (point).
Des lignes directricesLe sujet « Systèmes de nombres » est directement lié à la théorie mathématique des nombres. Cependant, dans le cours scolaire de mathématiques, en règle générale, il n'est pas étudié. La nécessité d'étudier ce sujet dans un cours d'informatique est liée au fait que les nombres dans la mémoire de l'ordinateur sont représentés dans le système de numération binaire et que les systèmes hexadécimaux ou octaux sont utilisés pour représenter de manière externe le contenu de la mémoire, les adresses mémoire. C'est l'un des sujets traditionnels d'un cours d'informatique ou de programmation. Étant lié aux mathématiques, ce sujet contribue également à l'éducation mathématique fondamentale des écoliers.
Pour un cours d'informatique, l'intérêt principal est la familiarité avec le système de numération binaire. L'utilisation du système de numération binaire dans un ordinateur peut être envisagée sous deux aspects : 1) la numérotation binaire, 2) l'arithmétique binaire, c'est-à-dire effectuer des calculs arithmétiques sur des nombres binaires.
Numérotation binaire
Avec la numérotation binaire, les élèves se retrouvent dans le sujet « Représenter du texte dans la mémoire de l'ordinateur ». Lorsqu'il parle de la table d'encodage, l'enseignant doit informer les élèves que le code binaire interne d'un caractère est son numéro de série dans le système de numération binaire. Par exemple, le numéro de la lettre S dans la table ASCII est 83. Le code binaire à huit chiffres de la lettre S est égal à la valeur de ce nombre dans le système binaire : 01010011.
Informatique binaire
Selon le principe de John von Neumann, l'ordinateur effectue des calculs dans le système binaire. Dans le cadre du cours de base, il suffit de se borner à considérer des calculs avec des entiers binaires. Pour effectuer des calculs avec des nombres à plusieurs chiffres, vous devez connaître les règles d'addition et les règles de multiplication des nombres à un chiffre. Voici les règles :

Le principe de permutation de l'addition et de la multiplication fonctionne dans tous les systèmes de numération. Les techniques pour effectuer des calculs avec des nombres à plusieurs chiffres dans le système binaire sont similaires à la décimale. En d'autres termes, les procédures d'addition, de soustraction et de multiplication par une "colonne" et de division par un "coin" dans le système binaire sont effectuées de la même manière que dans le système décimal.
Considérez les règles de soustraction et de division des nombres binaires. L'opération de soustraction est l'inverse de l'addition. À partir du tableau d'addition ci-dessus, les règles de soustraction suivent :
0 - 0 = 0; 1 - 0 = 1; 10 - 1 = 1.
Voici un exemple de soustraction à plusieurs chiffres :
Le résultat obtenu peut être vérifié en additionnant la différence avec le sous-traitant. Ce devrait être un nombre décroissant.
La division est l'opération inverse de la multiplication.
Dans n'importe quel système numérique, vous ne pouvez pas diviser par 0. Le résultat de la division par 1 est égal au dividende. La division d'un nombre binaire par 102 déplace la virgule décimale d'une position vers la gauche, tout comme la division décimale par dix. Par exemple:

Diviser par 100 décale la virgule de 2 positions vers la gauche, et ainsi de suite. Dans le cours de base, vous ne pouvez pas considérer des exemples complexes de division de nombres binaires à valeurs multiples. Bien que les étudiants capables puissent y faire face, ayant compris les principes généraux.
La représentation des informations stockées dans la mémoire de l'ordinateur sous sa vraie forme binaire est très lourde en raison du grand nombre de chiffres. Il s'agit de l'enregistrement de ces informations sur papier ou de leur affichage à l'écran. A ces fins, il est d'usage d'utiliser des systèmes mixtes binaire-octal ou binaire-hexadécimal.
Existe connexion simplifiée entre la représentation binaire et hexadécimale d'un nombre. Lors de la traduction d'un nombre d'un système à un autre, un chiffre hexadécimal correspond à un code binaire à quatre bits. Cette correspondance est reflétée dans le tableau binaire-hexadécimal :
Table hexadécimale binaire

Une telle relation est basée sur le fait que 16 = 2 4 et que le nombre de combinaisons différentes à quatre chiffres des chiffres 0 et 1 est 16 : de 0000 à 1111. Par conséquent la conversion des nombres de l'hexadécimal au binaire et vice versa se fait par conversion formelle par tableau binaire-hexadécimal.
Voici un exemple de traduction d'un code binaire 32 bits dans un système hexadécimal :
1011 1100 0001 0110 1011 1111 0010 1010 BC16BF2A
Si une représentation hexadécimale de l'information interne est donnée, il est facile de la traduire en code binaire. L'avantage de la représentation hexadécimale est qu'elle est 4 fois plus courte que la représentation binaire. Il est souhaitable que les élèves mémorisent le tableau binaire-hexadécimal. Alors effectivement pour eux la représentation hexadécimale deviendra équivalente au binaire.
En octal binaire, chaque chiffre octal correspond à une triade de chiffres binaires. Ce système permet de réduire de 3 fois le code binaire.
11. Stockage des informationsUne personne stocke des informations dans sa propre mémoire, ainsi que sous forme d'enregistrements sur divers supports externes (par rapport à une personne): sur pierre, papyrus, papier, supports magnétiques et optiques, etc. Grâce à ces enregistrements, les informations sont transmis non seulement dans l'espace (de personne à homme), mais aussi dans le temps - de génération en génération.
Variété de supports de stockageLes informations peuvent être stockées sous différentes formes : sous forme de textes, sous forme de figures, schémas, dessins ; sous forme de photographies, sous forme d'enregistrements sonores, sous forme de films ou d'enregistrements vidéo. Dans chaque cas, leurs transporteurs sont utilisés. Transporteur - Ce le support matériel utilisé pour enregistrer et stocker des informations.
Les principales caractéristiques des supports d'informations comprennent : le volume d'informations ou la densité de stockage d'informations, la fiabilité (durabilité) du stockage.
Support papier
Le transporteur le plus utilisé est toujours papier. Inventé au 2ème siècle après JC. en Chine, le papier est au service des gens depuis 19 siècles.

Pour comparer les volumes d'informations sur différents supports, nous utiliserons une unité universelle - octet, en supposant qu'un caractère du texte « pèse » 1 octet. Un livre contenant 300 pages, avec une taille de texte d'environ 2 000 caractères par page, a un volume d'informations de 600 000 octets, soit 586 Ko. Le volume d'information de la bibliothèque de l'école secondaire, dont le fonds est de 5000 volumes, est approximativement égal à 2861 Mo = 2,8 Go.
Quant à la durabilité du stockage des documents, livres et autres produits en papier, elle dépend beaucoup de la qualité du papier, des colorants utilisés pour écrire le texte et des conditions de stockage. Fait intéressant, jusqu'au milieu du XIXe siècle (depuis lors, le bois a commencé à être utilisé comme matière première pour le papier), le papier était fabriqué à partir de coton et de déchets textiles - des chiffons. Les encres étaient des colorants naturels. La qualité des documents manuscrits de cette époque était assez élevée et ils pouvaient être stockés pendant des milliers d'années. Avec le passage à une base en bois, avec la diffusion des outils de dactylographie et de copie, avec l'utilisation de colorants synthétiques, la durée de conservation des documents imprimés a diminué à 200-300 ans.

Support magnétique
L'enregistrement magnétique a été inventé au 19e siècle. Initialement, l'enregistrement magnétique n'était utilisé que pour préserver le son. Le tout premier support d'enregistrement magnétique était un fil d'acier d'un diamètre allant jusqu'à 1 mm. Au début du XXe siècle, le ruban d'acier laminé était également utilisé à ces fins. Les caractéristiques de qualité de tous ces supports étaient très faibles. La production d'un enregistrement magnétique de 14 heures des présentations orales au Congrès international de Copenhague en 1908 a nécessité 2 500 km, soit environ 100 kg de fil.
Dans les années 1920, il est apparu Bande magnetique d'abord sur papier, puis sur une base synthétique (lavsan), à la surface de laquelle une fine couche de poudre ferromagnétique est appliquée. Dans la seconde moitié du XXe siècle, ils ont appris à enregistrer une image sur bande magnétique, des caméras vidéo et des magnétoscopes sont apparus.
Sur les ordinateurs des première et deuxième générations, la bande magnétique était utilisée comme seul type de support amovible pour les périphériques de mémoire externes. Environ 500 Ko d'informations ont été placées sur une bobine de bande magnétique, qui a été utilisée dans les lecteurs de bande des premiers ordinateurs.
Depuis le début des années 1960, l'informatique disques magnétiques: un disque en aluminium ou en plastique recouvert d'une fine couche de poudre magnétique de quelques microns d'épaisseur. Les informations sur un disque sont disposées le long de pistes concentriques circulaires. Les disques magnétiques sont durs et flexibles, amovibles et intégrés dans un lecteur d'ordinateur. Ces derniers sont traditionnellement appelés disques durs et les disquettes amovibles sont appelées disquettes.
Le disque dur d'un ordinateur est un paquet de disques magnétiques mis sur un axe commun. La capacité d'information des disques durs modernes se mesure en gigaoctets - des dizaines et des centaines de Go. Le type de disquette le plus courant avec un diamètre de 3,5 pouces contient 2 Mo de données. Les disquettes dans Dernièrement sont hors d'usage.
Les cartes plastiques se sont généralisées dans le système bancaire. Ils utilisent également principe magnétique enregistrements d'informations utilisées par les distributeurs automatiques de billets, caisses enregistreuses associées au système bancaire d'informations.
L'utilisation de la méthode optique, ou laser, d'enregistrement des informations commence dans les années 1980. Son apparition est associée à l'invention d'un générateur quantique - un laser, source d'un faisceau très fin (épaisseur de l'ordre du micron) de haute énergie. Le faisceau est capable de graver un code binaire de données à très haute densité à la surface d'un matériau fusible. La lecture s'effectue par réflexion sur une telle surface "perforée" d'un faisceau laser de moindre énergie (faisceau "froid"). En raison de la densité d'enregistrement élevée, les disques optiques ont un volume d'informations beaucoup plus important que les supports magnétiques à disque unique. La capacité d'information d'un disque optique est de 190 à 700 Mo. Les disques optiques sont appelés CD.
Dans la seconde moitié des années 1990, les disques vidéo numériques polyvalents (DVD) sont apparus. D numérique V polyvalent D isque) avec une grande capacité, mesurée en gigaoctets (jusqu'à 17 Go). L'augmentation de leur capacité par rapport aux CD est due à l'utilisation d'un faisceau laser de plus petit diamètre, ainsi qu'à l'enregistrement sur deux couches et recto verso. Repensez à l'exemple de la bibliothèque scolaire. L'ensemble de son fonds de livres peut être placé sur un seul DVD.
Actuellement, les disques optiques (CD - DVD) sont les supports matériels les plus fiables d'informations enregistrées numériquement. Ces types de supports sont soit à écriture unique - lecture seule, soit réinscriptibles - lecture-écriture.
Mémoire flash
Récemment, de nombreux appareils numériques mobiles sont apparus : appareils photo numériques et caméras vidéo, lecteurs MP3, PDA, Téléphones portables, lecteurs de livres électroniques, navigateurs GPS et plus encore. Tous ces appareils nécessitent des supports de stockage portables. Mais comme tous les appareils mobiles sont assez miniatures, ils ont également des exigences particulières en matière de supports de stockage. Ils doivent être compacts, avoir une faible consommation d'énergie pendant le fonctionnement et être non volatiles pendant le stockage, avoir une grande capacité, des vitesses d'écriture et de lecture élevées et une longue durée de vie. Toutes ces exigences sont remplies cartes flash mémoire. Le volume d'informations d'une carte flash peut atteindre plusieurs gigaoctets.
En tant que support externe pour un ordinateur large utilisation reçu des porte-clés flash ("lecteurs flash" - on les appelle familièrement), dont la sortie a commencé en 2001. Une grande quantité d'informations, une compacité, une vitesse de lecture-écriture élevée, une facilité d'utilisation sont les principaux avantages de ces appareils. Le porte-clés flash se connecte au port USB d'un ordinateur et vous permet de télécharger des données à une vitesse d'environ 10 Mo par seconde.
"Nano-porteurs"
Ces dernières années, des travaux ont été activement menés pour créer des supports d'information encore plus compacts en utilisant les dites «nanotechnologies», travaillant au niveau des atomes et des molécules de la matière. En conséquence, un seul CD fabriqué à l'aide de la nanotechnologie peut remplacer des milliers de disques laser. Selon les experts, dans une vingtaine d'années, la densité de stockage de l'information augmentera à tel point que chaque seconde d'une vie humaine pourra être enregistrée sur un support d'un volume d'environ un centimètre cube.
Organisation des stockages d'informationsLes informations sont stockées sur des supports afin qu'elles puissent être consultées, rechercher les informations nécessaires, les documents nécessaires, reconstituer et modifier, supprimer les données qui ont perdu leur pertinence. En d'autres termes, les informations stockées sont nécessaires à une personne pour travailler avec elles. La commodité de travailler avec de tels référentiels d'informations dépend fortement de la manière dont les informations sont organisées.
Deux situations sont possibles : soit les données ne sont organisées d'aucune façon (cette situation est parfois appelée un tas), soit les données structuré. Avec l'augmentation de la quantité d'informations, l'option « tas » devient de plus en plus inacceptable en raison de la complexité de son utilisation pratique (recherche, mise à jour, etc.).
Les mots « les données sont structurées » signifient la présence d'un certain ordre de données dans leur stockage : dans un dictionnaire, un calendrier, une archive, une base de données informatique. Les ouvrages de référence, les dictionnaires, les encyclopédies utilisent généralement le principe alphabétique linéaire d'organisation (structuration) des données.
Les bibliothèques sont le plus grand dépôt d'informations. Les mentions des premières bibliothèques remontent au VIIe siècle av. Avec l'invention de l'imprimerie au XVe siècle, les bibliothèques ont commencé à se répandre dans le monde entier. La bibliothéconomie a des siècles d'expérience dans l'organisation de l'information.
Pour organiser et rechercher des livres dans les bibliothèques, des catalogues sont créés : listes du fonds du livre. Le premier catalogue de bibliothèque a été créé dans la célèbre bibliothèque d'Alexandrie au 3ème siècle avant JC. A l'aide du catalogue, le lecteur détermine la disponibilité du livre dont il a besoin dans la bibliothèque, et le bibliothécaire le trouve dans le dépôt de livres. Lors de l'utilisation de la technologie papier, un catalogue est un ensemble organisé de cartes en carton contenant des informations sur les livres.
Il existe des catalogues alphabétiques et systématiques. DANS alphabétique catalogues, les fiches sont classées par ordre alphabétique des noms des auteurs et sous forme linéaire(un niveau)Structure de données. DANS systématique les fiches catalogue sont systématisées selon le contenu des livres et la forme structure de données hiérarchique. Par exemple, tous les livres sont divisés en art, éducatif, scientifique. La littérature éducative est divisée en école et université. Les livres pour l'école sont divisés en classes, etc.
Dans les bibliothèques modernes, les catalogues papier sont remplacés par des catalogues électroniques. Dans ce cas, la recherche de livres s'effectue automatiquement. Système d'Information bibliothèques.
Les données stockées sur des supports informatiques (disques) ont une organisation en fichiers. Un dossier est comme un livre dans une bibliothèque. Comme un répertoire de bibliothèque, le système d'exploitation crée un répertoire sur disque, qui est stocké sur des pistes dédiées. L'utilisateur recherche le fichier souhaité en parcourant le répertoire, après quoi le système d'exploitation trouve ce fichier sur le disque et le fournit à l'utilisateur. Les premiers supports de disque de petite capacité utilisaient une structure de stockage de fichiers à un seul niveau. Avec l'avènement des disques durs de grande capacité, une structure d'organisation hiérarchique des fichiers a commencé à être utilisée. Parallèlement à la notion de « fichier », la notion de dossier est apparue (voir « Fichiers et système de fichiers” 2).
Un système plus flexible pour organiser le stockage et la récupération des données sont les bases de données informatiques (voir . “Base de données” 2).
Fiabilité du stockage des informationsLe problème de la fiabilité du stockage des informations est associé à deux types de menaces sur les informations stockées : la destruction (perte) d'informations et le vol ou la fuite d'informations confidentielles. Les archives papier et les bibliothèques ont toujours été menacées d'extinction physique. La destruction de la Bibliothèque d'Alexandrie mentionnée ci-dessus au 1er siècle avant JC a causé de grands dommages à la civilisation, car la plupart des livres qui s'y trouvaient existaient en un seul exemplaire.
Le principal moyen de protéger les informations contenues dans les documents papier contre la perte est leur duplication. L'utilisation des médias électroniques rend la duplication plus facile et moins chère. Cependant, la transition vers les nouvelles technologies de l'information (numériques) a créé de nouveaux problèmes de sécurité de l'information. Voir l'article " Protection des données” 2.
Au cours de l'étude du cours d'informatique, les étudiants acquièrent certaines connaissances et compétences liées au stockage de l'information.
Les élèves apprennent à travailler avec des sources d'information traditionnelles (papier). La norme pour l'école primaire note que les élèves doivent apprendre à travailler avec des sources d'information non informatiques : ouvrages de référence, dictionnaires, catalogues de bibliothèques. Pour ce faire, ils doivent être familiarisés avec les principes d'organisation de ces sources et avec les méthodes de recherche optimale dans celles-ci. Étant donné que ces connaissances et compétences revêtent une grande importance dans l'enseignement général, il est souhaitable de les transmettre le plus tôt possible aux étudiants. Dans certains programmes du cours d'informatique propédeutique, une grande attention est accordée à ce sujet.
Les étudiants doivent maîtriser les techniques de travail avec des supports de stockage informatiques amovibles. De plus en plus rares ces dernières années, les disquettes magnétiques ont été utilisées, qui ont été remplacées par des supports flash volumineux et rapides. Les étudiants doivent être en mesure de déterminer la capacité d'information du support, la quantité d'espace libre et de comparer le volume de fichiers enregistrés avec celui-ci. Les élèves doivent comprendre que les disques optiques sont le support le plus approprié pour le stockage à long terme de grandes quantités de données. Si vous avez un graveur de CD, apprenez-leur à écrire des fichiers.
Un point important de la formation est d'expliquer les dangers auxquels les informations informatiques de programmes malveillants - virus informatiques. Les enfants doivent apprendre les règles de base de "l'hygiène informatique": effectuer un contrôle antivirus de tous les fichiers nouvellement arrivés; mettre à jour régulièrement les bases de données antivirus.
12. Langues
Définition et classification des langues
Langue - Ce un certain système de représentation symbolique de l'information. Dans le dictionnaire scolaire d'informatique compilé par A.P. Ershov, la définition suivante est donnée : « Langue- un ensemble de symboles et un ensemble de règles qui déterminent comment composer des messages significatifs à partir de ces symboles". Puisqu'un message significatif est compris comme une information, alors cette définition sensiblement le même que le premier.
Les langues sont divisées en deux groupes : naturelles et formelles. langues naturelles- Ce langues de langue nationale historiquement formées. La plupart des langues modernes se caractérisent par la présence de formes de discours orales et écrites. L'analyse des langues naturelles relève principalement des sciences philologiques, en particulier de la linguistique. En informatique, l'analyse des langues naturelles est réalisée par des spécialistes du domaine de l'intelligence artificielle. L'un des objectifs du développement du projet informatique de cinquième génération est d'apprendre à l'ordinateur à comprendre les langues naturelles.
Les langages formels sont langues créées artificiellement pour un usage professionnel. Ils sont généralement de nature internationale et ont une forme écrite. Des exemples de ces langages sont le langage des mathématiques, le langage des formules chimiques, la notation musicale - le langage de la musique, etc.
Les concepts suivants sont associés à n'importe quel langage : alphabet - de nombreux symboles utilisés; syntaxe- règles d'écriture des constructions de langage(texte en langue); sémantique - aspect sémantique des constructions linguistiques; pragmatique - conséquences pratiques de l'utilisation d'un texte dans une langue donnée.
Pour langages formels caractérisée par l'appartenance à un nombre limité Domaine(mathématiques, chimie, musique, etc.). But du langage formel - une description adéquate du système de concepts et de relations inhérents à un domaine donné. Par conséquent, toutes les composantes susmentionnées de la langue (alphabet, syntaxe, etc.) sont axées sur les spécificités du domaine. Une langue peut se développer, changer et être complétée avec le développement de son domaine.
Les langues naturelles ne sont pas limitées dans leur application, en ce sens elles peuvent être qualifiées d'universelles. Cependant, il n'est pas toujours pratique d'utiliser uniquement le langage naturel dans des domaines hautement spécialisés. Dans de tels cas, les gens ont recours à l'aide de langages formels.
Il existe des exemples connus de langues qui sont dans un état intermédiaire entre naturel et formel. Langue espéranto a été créé artificiellement pour la communication entre personnes de nationalités différentes. UN Latin, qui dans l'Antiquité était parlée par les habitants de l'Empire romain, est devenue la langue officielle de la médecine et de la pharmacologie à notre époque, ayant perdu la fonction de langue parlée.
Langages informatiquesLes informations circulant dans un ordinateur sont divisées en deux types : les informations traitées (données) et les informations qui contrôlent le fonctionnement de l'ordinateur (commandes, programmes, opérateurs).
Les informations présentées sous une forme adaptée au stockage, à la transmission et au traitement par un ordinateur sont appelées données. Exemples de données : nombres lors de la résolution d'un problème mathématique ; séquences de caractères dans le traitement de texte ; une image saisie dans un ordinateur par numérisation, pour être traitée. La façon dont les données sont représentées dans un ordinateur s'appelle langage de présentation des données.
Chaque type de données a une représentation de données externe et interne différente. Représentation externe orienté vers l'humain, détermine le type de données sur les périphériques de sortie: sur l'écran, sur l'impression. Représentation interne- Ce représentation sur un support de stockage dans un ordinateur, c'est à dire. en mémoire, dans les lignes de transmission de l'information. L'ordinateur opère directement sur les informations de la représentation interne, et la représentation externe est utilisée pour communiquer avec la personne.
Dans le sens le plus général, on peut dire que le langage de représentation des données informatiques est langage de code binaire. Cependant, du point de vue des propriétés ci-dessus que tout langage devrait avoir : alphabet, syntaxe, sémantique, pragmatique, on ne peut pas parler d'un langage commun de codes binaires. La seule chose qu'il a en commun est l'alphabet binaire : 0 et 1. Mais pour différents types de données, les règles de syntaxe et de sémantique du langage de représentation interne diffèrent. La même séquence de chiffres binaires pour différents types de données a une signification complètement différente. Par exemple, le code binaire "0100000100101011" dans le langage de représentation des nombres entiers désigne le nombre décimal 16683, et dans le langage de représentation des données de caractères, il désigne deux caractères - "A+". Ainsi, différents types de données utilisent différents langages de représentation internes. Tous ont un alphabet binaire, mais diffèrent dans l'interprétation des séquences de caractères.
Les langages de représentation de données externes sont généralement proches de la forme familière aux humains: les nombres sont représentés dans le système décimal, lors de l'écriture de textes, d'alphabets en langage naturel, de symboles mathématiques traditionnels, etc.. Dans la présentation des structures de données, une pratique forme tabulaire est utilisée (bases de données relationnelles). Mais même dans ce cas, il existe toujours certaines règles de syntaxe et de sémantique du langage, un ensemble limité de symboles valides est utilisé.
Le langage interne de représentation des actions sur les données (langage de gestion du fonctionnement de l'ordinateur) est langage de commande du processeur de l'ordinateur. Les langages externes pour représenter les actions sur les données incluent langages de programmation de haut niveau, langues d'entrée des packages d'application, langages de commande du système d'exploitation, langages de manipulation de données dans les SGBD etc.
Tout langage de programmation de haut niveau comprend à la fois des moyens de représentation des données - la section données, et des moyens de représentation des actions sur les données - la section opérateur (voir " Langages de programmation” 2). Il en va de même pour les autres types de langages informatiques listés ci-dessus.
Parmi les langages formels de la science, le plus proche de l'informatique est le langage des mathématiques.
À leur tour, parmi les nombreuses disciplines mathématiques, la théorie des nombres et la logique mathématique ont la plus grande application en informatique.
À cet égard, on peut dire que les thèmes des systèmes numériques (le langage de représentation des nombres) et les fondements de la logique mathématique (le langage de la logique) sont liés aux fondements fondamentaux de l'informatique (voir " Systèmes de numération" Et " Expressions booléennes” 2).
Dans les cours de propédeutique et d'informatique de base, une conversation sur les langues en relation avec une personne revêt une grande importance pédagogique. Le terme « langue » familier aux élèves prend un nouveau sens dans leur esprit. Tout un système de concepts scientifiques se construit autour de ce terme. Le concept de langage est l'un des concepts de base les plus importants du cours d'informatique.
Lors de l'étude de chaque nouvel outil TIC, l'étudiant doit être attiré par le fait que pour travailler avec, l'utilisateur doit maîtriser un certain langage formalisé, que son utilisation nécessite le strict respect des règles du langage : connaissance de l'alphabet, de la syntaxe , sémantique et pragmatique. Cette rigueur est due au fait que les langages formalisés, en règle générale, n'ont pas de redondance. Par conséquent, toute violation des règles (utilisation d'un caractère qui n'est pas inclus dans l'alphabet, utilisation incorrecte de caractères séparateurs, par exemple une virgule au lieu d'un point, etc.) entraîne une erreur.
Les élèves doivent prêter attention aux points communs de certaines constructions linguistiques utilisées dans diverses technologies. Par exemple, les règles d'écriture des formules dans les feuilles de calcul et des expressions arithmétiques dans les langages de programmation sont presque les mêmes. Il existe également des différences auxquelles vous devez également prêter attention. Par exemple, dans les langages de programmation, les connecteurs logiques (NOT, AND, OR) sont des signes d'opérations, et dans les feuilles de calcul, ce sont des noms de fonctions.
Pour simplifier le travail de l'utilisateur dans les logiciels modernes, différents types de shells sont souvent utilisés pour fournir une interface utilisateur pratique. Il convient d'expliquer aux étudiants que derrière ces coques, en règle générale, se cache un certain langage formalisé. Par exemple, derrière la coque graphique de l'opérateur Systèmes Windows masque le langage de commande du système d'exploitation. Autre exemple : le SGBD MS Access offre à l'utilisateur la possibilité d'utiliser le concepteur de tables pour créer une base de données et le concepteur de requêtes pour créer des requêtes. Cependant, derrière ces outils de haut niveau, SQL est "caché" - un langage universel pour décrire des données et manipuler des données. En passant au mode approprié, vous pouvez montrer à quoi ressemblent les commandes SQL générées à la suite de l'utilisation du constructeur.
Bibliographie de la rubrique « Informations théoriques »1. Andreeva E.DANS.,Bosova L.L.,Falina I.H. Fondements mathématiques de l'informatique. Cours au choix. M. : BINOM. Laboratoire de connaissances, 2005.
2. Bechenkov S.UN.,Rakitina E.UN. L'informatique. Cours systématique. Manuel pour la 10e année. Moscou : Laboratoire des connaissances fondamentales, 2001, 57 p.
3.Wiener N.. La cybernétique ou le contrôle et la communication chez l'animal et la machine. Moscou : radio soviétique, 1968, 201 p.
4. Informatique. Cahier-atelier en 2 volumes / Ed. I. G. Semakina, E.K. Henner. T. 1. M. : BINOM. Laboratoire de connaissances, 2005.
5. Kuznetsov A.A., Beshenkov S.A., Rakitina E.A., Matveeva N.V., Milokhina L.V. Cours continu d'informatique (concept, système de modules, programme modèle). Informatique et éducation, n° 1, 2005.
6. Dictionnaire encyclopédique mathématique. Rubrique : "Dictionnaire de l'informatique scolaire". M. : Encyclopédie soviétique, 1988.
7.FriedlandA.je. Informatique : processus, systèmes, ressources. M. : BINOM. Laboratoire de connaissances, 2003.
 Charger des fichiers dans le partage de fichiers
Charger des fichiers dans le partage de fichiers Comment utiliser la barre d'adresse du navigateur
Comment utiliser la barre d'adresse du navigateur Nous faisons une signature dans le courrier Yandex Comment insérer une image dans le corps d'une lettre Yandex
Nous faisons une signature dans le courrier Yandex Comment insérer une image dans le corps d'une lettre Yandex Qu'est-ce que FaceTime et comment l'utiliser Où est Face Time sur iPhone
Qu'est-ce que FaceTime et comment l'utiliser Où est Face Time sur iPhone Comment changer la date sur iPhone ?
Comment changer la date sur iPhone ?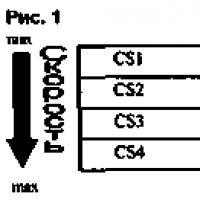 Que signifie internet gprs
Que signifie internet gprs Comment définir une animation GIF comme fond d'écran en direct sur iPhone Fond d'écran en direct pour iPhone 6s
Comment définir une animation GIF comme fond d'écran en direct sur iPhone Fond d'écran en direct pour iPhone 6s