Développement d'une leçon et une présentation sur le "codage des informations texte". Leçon ouverte sur la science informatique et les TIC sur la rubrique "Codage des informations textuelles" Leçon abstraite Codage binaire des informations textuelles
Cours abstrait en informatique et classe TIC 8
Topic de leçon: codage d'informations sur le texte
Type de leçon : Étudier de nouveaux matériaux et consolidation primaire.
Objectifs leçon:
Introduisez les élèves des moyens d'encoder des informations dans l'ordinateur;
Envisager des exemples de problèmes de résolution;
Promouvoir le développement des intérêts éducatifs des étudiants.
Éduquer l'exposition et la patience dans le travail, le sens du partenariat et la compréhension mutuelle.
TÂCHES LEÇON:
Former des connaissances des étudiants sur le sujet "codage des informations texte (symboliques)";
Faciliter la formation des écoliers de la pensée figurative;
Développer une analyse et une auto-analyse des compétences;
Formant la capacité de planifier vos activités.
Équipement:
jobs étudiant (ordinateur personnel),
le lieu de travail de l'enseignant,
board interactif,
projecteur multimédia,
présentation multimédia
Leçon de structure
Bibliographie:
1. Informatique et TIC. Cours de base. Tutoriel pour la 8e année. / N. Ugrinovich. - M. Binin. Laboratoire de connaissances, 20010.
2. Atelier sur la science informatique et la technologie de l'information. Tutoriel pour les établissements d'enseignement général / nd. Ugrinovich, L.L. Bosova, N.I. Mikhailova. - 3ème éd. - M. Binin. Laboratoire de connaissances, 2010.
3. Dictionnaire des proverbes et des dictons russes. - M.: Terra, 1997
4. Les méthodes les plus simples de cryptage de texte / D.M. Zlatopolsky. - M.: Étangs propres, 2007
5. Textes des tests de démonstration sur l'informatique et selon les matériaux de EGE 2009-2011.
Pendant les classes
Temps d'organisation.
Sur un tableau blanc interactif, la première diapositive de la présentation multimédia avec la leçon.
Prof: Bonjour gars. S'asseoir. En service, rapport manquant. (Rapport sur le devoir). Merci.
II. Travailler sur la leçon.
1. Explication du nouveau matériel.
L'explication du nouveau matériau se présente sous la forme d'une conversation heuristique avec un affichage simultané de la présentation multimédia sur une carte interactive (annexe 1).
Prof : Lors de l'étude de la rubrique "Processus d'information et d'information", nous avons dit que dans les processus de perception, de transmission et de stockage d'informations par des organismes vivants, des humains et des dispositifs techniques, il est codé selon un système de signalisation. Rappelez-vous quel est le résultat de l'information de codage?
Répondre: Le résultat de codage est la séquence de symboles de ce système de caractères.
Prof: Donnez des exemples de codes.
Répondre: La séquence de lettres dans le texte, des nombres entre le code génétique, le code informatique binaire, etc.
Prof: Aujourd'hui, nous ferons connaître la classe avec les méthodes de codage d'informations de texte dans l'ordinateur. Enregistrez le sujet «Codage des informations de texte» (diapositive 1). À la leçon, considérez les questions suivantes (diapositive 2):
Excursion historique;
Codage binaire des informations textuelles;
Calcul du nombre d'informations textuelles.
Excursion historique
L'humanité utilise le cryptage (encodage) du texte à partir du moment même où les premières informations secrètes sont apparues. Avant de vous trouver plusieurs techniques pour le codage de texte, qui ont été inventées à différentes étapes du développement de la pensée humaine (diapositive 3):
La cryptographie est une gradient, un système de changement de lettre afin de rendre le texte incompréhensible à des personnes non présidiées;
L'alphabet Morse ou un code de télégraphe inégal dans lequel chaque lettre ou signe est représentée par sa combinaison de colis électriques élémentaires (points) et de parcelles élémentaires de la durée triplée (Dash);
SLURGOES - Langue de geste utilisé par les personnes ayant une déficience auditive.
Question: Quels exemples d'informations de texte codant peuvent être amenés plus?
Les élèves dirigent des exemples.
Prof: (Diapositive 4). L'une des premières méthodes de cryptage connues est le nom de l'empereur romain Julia Caesar (Ie siècle BC). Cette méthode est basée sur le remplacement de chaque lettre du texte crypté, à un autre, par déplacement dans l'alphabet de la lettre originale au nombre fixe de caractères, et l'alphabet est lu dans un cercle, c'est-à-dire après la lettre I suis considéré comme un. Donc, l'octet de mot lorsqu'il est déplacé deux caractères à droite est codé par le mot GVF. Le processus inverse du déchiffrement de ce mot - il est nécessaire de remplacer chaque lettre cryptée, à la seconde à gauche de celle-ci.
(Diapositive 5) Décrypte la phrase du poète Persian par Jalaleddine Rumi «Knusm Yogkg Fesl Tcfhy Fvsezhd FHGRZH YogkSP», codé avec César Cipher. On sait que chaque lettre du texte source est remplacée par le troisième après. En tant que support, utilisez les lettres de l'alphabet russe situé sur la diapositive.
Question: Qu'est-ce que tu as fait?
Répondre: Fermez vos yeux que vos yeux seront les yeux.
Prof: Bien fait! Correctement adapté avec la tâche.
La réponse est comparée à la réponse correcte qui apparaît sur 5 traîné.
Codage binaire des informations texte
Prof: Dans laquelle des techniques de codage énumérées sont utilisées le principe binaire du codage d'informations?
Répondre: Dans l'alphabet de morse.
Prof: L'ordinateur utilise également le principe du codage binaire d'informations. Seulement au lieu d'un point et d'une pointe d'utilisation 0 et 1 (diapositive 6). Traditionnellement, 1 octet des informations sont utilisés pour encoder un symbole. L'utilisateur appuie sur un clavier avec un panneau sur le clavier et une certaine séquence de huit impulsions électriques arrive à l'ordinateur (signal 0-no, 1-Signal). Il s'agit d'un code de signalisation binaire stocké dans la RAM de l'ordinateur, où il faut une cellule. Pendant la sortie du panneau sur l'écran de l'ordinateur, le transcodage inverse est effectué.
Question: Combien de caractères différents peuvent être codés?
Répondre: N \u003d 2 i \u003d 2 8 \u003d 256.
Prof: Droite. Est-ce suffisant pour la présentation d'informations textuelles, y compris les lettres majuscules et minuscules de l'alphabet, des nombres et d'autres caractères en majuscules et latins?
Les enfants comptent le nombre de caractères différents:
33 Les lettres minuscules de l'alphabet russe + 33 lettres majuscules \u003d 66;
Pour l'alphabet anglais 26 + 26 \u003d 52;
Chiffres de 0 à 9, etc.
Prof: Votre conclusion?
Du côté des étudiants: Il s'avère que 127 caractères ont besoin. Il existe toujours 129 valeurs pouvant être utilisées pour désigner des marques de ponctuation, des signes arithmétiques, des opérations de service (traduction de la chaîne, espace, etc. Par conséquent, un octet suffit à encoder les caractères nécessaires pour encoder des informations sur le texte.
Prof : Sur l'ordinateur, chaque caractère est codé par un code unique.
Un accord international est adopté pour attribuer chaque symbole de son code unique. En tant que norme internationale, la table de code ASCII est adoptée (code standard américain pour l'échange d'informations) (diapositive 7).
Cette table présente des codes de 0 à 127 (lettres de l'alphabet anglais, signes d'opérations mathématiques, de service à partir des semelles, etc.), et les codes de 0 à 32 ne sont pas définis sous forme de symboles, mais les touches de fonction. Enregistrez le nom de cette table de code et la plage de caractères codés.
Les codes de 128 à 255 sont alloués à des normes nationales de chaque pays. Cela suffit pour la plupart des pays développés.
Pour la Russie, plusieurs normes de table de code différents ont été introduites (codes de 128 à 255).
Voici certains d'entre eux (diapositive 8-9). Considérez et écrivez leurs noms:
Koi8-R, CP1251, CP866, MAS, ISO.
Ouvrez l'atelier d'informatique à la page 65-66 et lisez sur ces tables de codage.
Prof: spécifie les questions sur le matériel de lecture:
Quelle standard a été appliquée d'abord pour encoder des lettres russophones?
Quel type de norme de codage est le plus courant maintenant?
Que signifie la combinaison de lettres "wed" dans les codages de CP1251, CP866?
Les élèves sont responsables des questions.
Prof : Dans l'éditeur de texte MS Word, afin d'afficher un symbole sur son code sur son écran, vous devez contenir la touche "ALT" du clavier pour saisir le code de caractères sur le clavier numérique supplémentaire.
Exécutez l'éditeur de texte MS Word. Maintenez la touche "Alt", tapez les codes sur un clavier numérique supplémentaire (diapositive 10):
Quel mot obtenu?
Répondre: bit.
Prof: Fermez le fichier sans sauvegarder.
Le concept d'encodage enicode.
(Diapositive 11) Il y a environ 6 800 langues différentes dans le monde. Si vous lisez le texte imprimé au Japon sur un ordinateur en Russie ou aux États-Unis, il sera impossible de le comprendre. Pour que les lettres de tout pays lisent sur n'importe quel ordinateur, deux octets (16 bits) ont commencé à les utiliser pour leur codage. Ceci est une norme de codage de symboles de texte standard internationale. Unicode..
Question: Combien de caractères peuvent être codés avec deux octets? (Pour les étudiants faiblement parlants, vous pouvez leur offrir d'utiliser la calculatrice d'ingénierie).
Répondre: N \u003d 2 i \u003d 2 16 \u003d 65536 /
Un tel codage s'appelle Unicode et est désigné comme UCS-2. Ce code comprend tous les alphabets existants du monde, ainsi que de nombreux symboles mathématiques, musicaux, chimiques et bien plus encore. Il y a codage et UCS-4, où 4 octets sont utilisés pour le codage, c'est-à-dire que vous pouvez encoder plus de 4 milliards de caractères.
Calcul du nombre d'informations texte
Étant donné que chaque symbole est codé par 1 octet, les informations du texte peuvent être trouvées en multipliant le nombre de caractères dans le texte par octet.
Vérifiez-le dans la pratique. Activez le moniteur, créez un document texte dans l'éditeur de bloc-notes et tapez le proverbe (diapositive 12): "Heures - Ataman et inacceptable - Komar". Combien de caractères dedans?
Répondre: 36
Prof : Enregistrez et fermez le fichier. Déterminer son volume en octets. Qu'est-il?
Répondre: 36 octets.
Prof : Votre conclusion?
Les élèves discutent et tirent des conclusions.
Fizkultminutka:Les gars, font maintenant des exercices pour améliorer la circulation cérébrale: 1) assis, mains sur la ceinture. Une fois - habitant, mettez la main gauche à travers l'épaule droite, tournez à gauche vers la gauche. Deux position initiale. Trois, quatre - la même main droite. Répétez 5 fois. Le rythme est lent.
2) assis sur la chaise. Une fois - la tête à incliner à droite. Deuxième position initiale. Trois-tête inclinaison à gauche. Quatre - position de départ répéter 5 fois. Thèmes moyens.
Et maintenant avec de nouvelles forces qui ont freiné la deuxième partie de notre sujet: analyse et solution de tâches.
2. Résolution et solution de tâches
Transition de la présentation du mode de visualisation sur un mode de la carte interactive.
Prof (Travailler au tableau): Considérons un exemple d'encodage de texte dans différentes tables de codage. Ouvrir la page 66 Technologies de l'informatique et de l'information. En tant que matériau de référence, nous utiliserons le présenté à la Fig. 2.4 et 2.5 Tables de codage KOO8-P et CP1251. (Sur un plateau interactif est placé à l'aide de la galerie de dessins et de la photo de l'image des mêmes tables de codage). Nous codifions le mot "rome" ( Pièce jointe 1)
CP1251: 208 232 236
Koi8-R: 242 201 205
Nous traduisons en utilisant la calculatrice d'ingénierie de la séquence des codes d'un système de nombres décimaux à Hexadecimal. On a:
CP1251: D0 E8 CE
Koi8-P: F2 C9 CD
(Aller à la présentation en mode Afficher).
Travailler en équipe de deux. (La classe est divisée en paires).
Prof: Nettoyez les mêmes tables de codage de mots à vous sur des cartes.
Lisez soigneusement la tâche sur la diapositive (diapositive 13).
La tâche: Tous les concepts sont utilisés en informatique ou y sont liés. Déterminez ces concepts et codez-les à l'aide de tables KOO8-P ou CP1251. Déplacez la séquence des codes du système décimal en hexadécimal à l'aide d'une calculatrice d'ingénierie. Éteéquit le hexadécide résultant aucun espaces dans le champ de saisie approprié. Appuie sur le bouton. Vérifiez et assurez-vous que la solution est correcte. Concepts pour enregistrer des lettres majuscules, sauf les noms géographiques.
Carte 1.. Quels concepts sont conformes aux commentaires ci-dessous?
1. Et dans le journal de l'étudiant et dans la table de base de données.
2. et programme médical et informatique.
Carte 2.. Les noms géographiques énumérés sont utilisés dans les concepts utilisés en informatique ou les associés.
1. L'état, la capitale dont le Caire
2. La ville en Ouzbékistan, avec le titre de laquelle le concept d'algorithme est associé.
Carte 3.. Les termes correspondant aux définitions sont également utilisés dans le contexte de l'appareil et de l'opération de la voiture.
1. Partie du moteur à combustion interne
2. Dispositif dans la voiture pour la purification de carburant
Réponses
2. Procédure
3. Égypte (triangle égyptien), Khorezm (algorithme du nom de la mathématique d'Asie centrale Al-Khorezmi)
4. Cylindre (pistes de totalité avec le même numéro sur les disques magnétiques)
filtre (condition pour laquelle les entrées sont sélectionnées dans la base des salles de bains)
Codes
Fiche CP1251: 231 224 239 239 239 232 241 252 E7 E0 EF E8 F1 FC
Egypte CP1251: 197 227 232 239 229 242 C5 E3 E8 EF E5 F2
Cylindre CP1251: 246 232 232 235 232 237 228240 F 6E 8EB E 8ED E 4F 0
COOI8-R Procédure: 208 210 207 195 197 196 213 210 193
D0 D2 C3 C5 C4 D5 D2 C1
Khorezm koi8-p: 232 207 210 197 218 205 E8 CF D2 C5 DA CD
Filtre Koi8-P: 198 201 204 216 212 210 C6 C9 CC D8 D4 D2
Les étudiants ouvrent des cartes en fonction du numéro appelé l'enseignant pour chaque paire d'étudiants.
Prof: Nommez les termes ou concepts prévus. Qui a eu le bon code? Qui n'a pas travaillé? Quelle est votre erreur, que pensez-vous?
Les élèves répondent aux questions sous forme de discussion.
(Basculez vers le fonctionnement du panneau interactif).
Prof: Nous allons maintenant résoudre des problèmes sur le nombre d'informations textuelles et de valeurs associées à la détermination du nombre d'informations texte.
Notez la condition tâches Numéro 1..(Sur un tableau blanc interactif - la condition du numéro de problème 1.) Considérant que chaque caractère est codé par un octet, appréciez le volume d'informations de la phrase suivante:
"Mon oncle des règles les plus honnêtes, quand je ne suis pas une blague, il s'est forcé et ne pouvait pas mieux l'inventer." ( Annexe 2.)
Décision: Dans cette phrase, 108 caractères, étant donné les marques de ponctuation, les citations et les espaces. Multipliez ce montant par 8 bits. Nous obtenons 108 * 8 \u003d 864 bits. Y a-t-il des questions sur la résolution?
L'enseignant répond aux questions ou un élève répond à la question d'une autre.
Prof: Considérer tâche№ 2 . (La condition est affichée sur un tableau interactif). Enregistrez son état: l'imprimante laser Canon LBP est imprimée en moyenne de 6,3 kbps par seconde. Combien de temps aurez-vous besoin d'imprimer un document de 8 pages, s'il est connu que sur une seule page, il y a une moyenne de 45 lignes, dans une chaîne de 70 caractères (1 symbole - 1 octet).
Décision:
1) Nous trouvons la quantité d'informations contenues sur 1 page:
45 * 70 * 8 bits \u003d 25200 bits
2) Nous trouvons la quantité d'informations sur 8 pages:
25200 * 8 \u003d 201600 bit
3) conduire à une seule unité de mesure. Pour cette mbité, nous traduisons en bits:
6.3 * 1024 \u003d 6451,2 bits / s.
4) Trouver Temps d'impression: 201600: 6451.2? 31 secondes.
(Annexe 3.)
Vos questions.
Les étudiants posent des questions s'ils se posent.
L'enseignant demande d'abord de répondre à la question d'un autre élève, s'il n'y a pas de réponse, il se répond.
Prof: Seul résoudre les tâches électroniques. Pour ce faire, ouvrez le dossier "Tâches 8" dans le dossier "Informatique" - L'ordinateur "codage" évaluera vos réponses et donnez la bonne réponse.
Tache 1.Considérant que chaque caractère est codé par deux octets, évaluez le volume d'informations de la phrase suivante dans l'encodage UNICODE:
Une poudre - environ 16,4 kilogrammes
Entrez la réponse ici: _________
Tâche 2.En 45 secondes, le texte a été imprimé. Calculez le nombre de pages dans le texte, s'il est connu que, en moyenne, sur la page 50 de 75 caractères, la vitesse d'impression de l'imprimante laser est de 8 kbps / s., 1 symbole est 1 octet. La réponse est arrondie à toute la partie.
Entrez la réponse ici: __________
Transition vers la présentation.
III. Généralisation
Questions d'enseignant (diapositive 14):
1. Quel est le principe de codage des informations de texte utilisées dans l'ordinateur?
2. Quel est le nom de la table de codage du symbole international?
3. Énumérez les noms des tables de codage pour les caractères russophones.
4. Dans quel système sont les codes dans les tables de codage répertoriées?
Les gars sont responsables des questions.
Iv. Devoirs
(Diapositive 15) sur le manuel Ugrinovich § 3.1, Tâches d'exécution indépendante 3.1, 3.2. Pour ceux qui veulent: montez avec leur chiffrement et encoder une phrase. Apportez à la prochaine leçon sur des feuilles séparées.
L'enseignant résume la leçon, définit les estimations.
Au revoir, merci pour la leçon.
Pièce jointe 1
Annexe 2.
Annexe 3.
Analyse pédagogique générale de la formation pédagogique en physique de la 8e année
Piyaeva Olga Nikolaevna
Lieu de travail: Institution budgétaire municipale "École secondaire du Taraskovskaya"
Positionner: Informatique
Adresse de l'école: Région de Moscou Kashirsky District Village Taraskovo Street Komsomolskaya D.22
Classe: 8.
LEÇON THEME:Codage des informations de texte. (Première leçon sur le sujet "codage d'informations")
Type de leçon:etude de nouvelles connaissances
Type de leçon:traditionnelle utilisant la technologie de l'information
Objectifs:
Éducatif:
introduisez les élèves des moyens d'encoder des informations dans l'ordinateur;
envisager des exemples de problèmes de résolution;
Développement:
promouvoir le développement des intérêts éducatifs des étudiants.
Éducatif:
Éduquer l'exposition et la patience dans le travail, le sens du partenariat et la compréhension mutuelle.
Tâches:
Éducatif:
former une connaissance des étudiants sur le sujet "codage des informations texte";
Développement:
développer une analyse et une auto-analyse des compétences;
faciliter la formation des écoliers de la pensée figurative;
Éducatif:
formant la capacité de planifier vos activités.
Équipement:
jobs étudiant (ordinateur personnel),
le lieu de travail de l'enseignant,
projecteur multimédia,
Logiciel:PC, Programme PowerPoint, Tables, Schemes.
Leçon de carte d'information:
№ p / p.
Cours de scène
Pr-
les mesures
temps
Didactique
but de kaya
Formes et méthodes de travail
Types d'activité des étudiants
Organisationnel
à la naissance
2 minutes
Inclure les étudiants en rythme professionnel, préparer une classe à travailler
Professeur de message oral
Humeur sur la productivité
travail
nosta
Étude
nouveau
matériel
18 min
Former des motifs cognitifs. Assurer l'adoption des objectifs de la leçon. Former des idées spécifiques sur le codage des informations textuelles.
Explication du nouveau matériau utilisant
présentation
Écoute et mémorisation, réponses aux questions de l'enseignant, remplissant la tâche de décodage
informations
Fizkultminutka
2 minutes.
Empêcher la fatigue des enfants
Exercice d'exercice
Exercice d'exercice
Fixation des connaissances acquises
10 minutes.
Organiser des activités pour appliquer de nouvelles connaissances
Travaux pratiques
Mise en œuvre de la pratique
travail
Essais primaires de la compréhension
8 min
Révéler le niveau d'apprentissage primaire nouveau matériau
Enquête frontale
Travail indépendant différencié
Répondez aux questions de l'enseignant
Effectuer un emploi indépendant
Devoirs
2 minutes.
Donnez des informations sur les devoirs et les instructions pour sa mise en œuvre
Tailleur pour effectuer les devoirs
Enregistrement des devoirs dans les journaux
Résumant la leçon (réflexion)
3 min.
Auto-analyse des étudiants comprenant le sujet
Réception d'une phrase inachevée
Discussion sur ce que vous avez appris et comment fonctionne
Pendant les classes.
Temps d'organisation.
Les gars, je suis heureux de vous voir pleinement, de bonne humeur et d'espoir d'une leçon fructueuse.
S'asseoir.
Maintenant, nous allons passer un raid prêt à la leçon:
journalier
montrer les poignées
afficher les manuels
montrer des cahiers
Tout est prêt pour la leçon, nous pouvons commencer.
Étudier un nouveau matériau
Aujourd'hui, nous procédons à l'étude du grand thème "codage et traitement de l'information textuelle", et notre première leçon est appelée "codage des informations textuelles"
Sur l'écran, la première diapositive de la présentation multimédia avec la leçon.
Dans la leçon d'aujourd'hui, nous nous familiariserons avec les méthodes de codage de texte, qui ont été inventées par des personnes à différentes étapes du développement de la pensée humaine, avec un codage binaire d'informations sur l'ordinateur, apprendre à identifier les codes de caractères numériques, entrez des caractères à l'aide de caractères. Codes numériques et transcodent le texte russophone dans un éditeur de texte.
Le problème de la protection de l'information est inquiet pour les personnes de quelques siècles.
Les codes sont apparus dans les temps anciens sous la forme de cryptogrammes (qui ont traduit du grec signifie "Titizoin"). Parfois, des textes juifs sacrés sont cryptés par remplacement. Au lieu de la première lettre de l'alphabet, la dernière lettre a été écrite au lieu de la seconde - l'avant-dernier, etc. Cet ancien chiffre s'appelait ATBASH.
Affichage de la diapositive numéro 2.
Avant de vous faire plusieurs techniques pour le codage de texte, qui ont été inventées à différentes étapes du développement de la pensée humaine.
- cryptographie - il s'agit d'une sécrétion, un système de changement de lettre afin de rendre le texte incompréhensible pour les personnes non inticiées;
- abc morse ou un code de télégraphe inégal dans lequel chaque lettre ou signe est représentée par sa combinaison de colis élémentaires courtes de courant électrique (points) et de colis élémentaires de la durée triplée (DASH);
- justifié - la langue des gestes utilisés par les personnes atteintes d'une déficience auditive.
Question: Quels exemples de codage d'informations texte peuvent être amenés plus?
Les élèves dirigent des exemples . ( vizizer chiffré, chiffre de remplacement)
Montrant la diapositive numéro 3.
L'une des premières méthodes de cryptage connues est le nom de l'empereur romain Julia Caesar (Ie siècle BC). Cette méthode est basée sur le remplacement de chaque lettre du texte de chiffrement, à une autre, par décalage dans l'alphabet de la lettre source au nombre fixe de caractères. Alors mot octet Lorsque vous déplacez trois caractères à droite, est codé par un mot dGMH . Le processus inverse de décrypter ce mot - il est nécessaire de remplacer chaque lettre cryptée, sur la troisième à gauche de celle-ci.
Diaporama numéro 4
Dans la Grèce antique (II Century BC), un chiffre était connu, qui a été créé à l'aide d'une place de Polybia. Pour le cryptage, une table a été utilisée, qui est une carrée avec six colonnes et six rangées, qui sont numérotées de 1 à 6. Dans chaque cellule, une telle table a été enregistrée une lettre. En conséquence, un couple de chiffres correspond à chaque lettre et le cryptage a été réduit à remplacer la lettre avec une paire de chiffres. Le premier chiffre indique le numéro de ligne, le second est le numéro de colonne. Le mot octet est codé dans ce cas: 12 11 25 42
Montrant la diapositive numéro 5.
Déchiffrer avec un carré de polybia la phrase suivante
"33 11 36 24 32 16 36 11 45 43 51 24 32 41 63"
Question: Qu'est-ce que tu as fait?
Répondre aux étudiants: Dans les exemples apprennent
La réponse est comparée à la réponse correcte qui apparaît sur le numéro de la diapositive 5.
Codage binaire des informations de texte dans l'ordinateur
Prof: Les informations exprimées par des langues naturelles et formelles par écrit sont généralement appelées informations de texte.
Afficher le numéro de la diapositive 6.
Pour la présentation des informations textuelles (majuscules, lettres minuscules des alphabets, chiffres, signes et symboles mathématiques russes et latins) suffisent à 256 caractères différents.
Si vous pliez tous les signes:
33 Les lettres minuscules de l'alphabet russe + 33 lettres majuscules \u003d 66;
Pour l'alphabet latin 26 + 26 \u003d 52;
Chiffres de 0 à 9
il s'avère que 127 caractères ont besoin. Il existe également 129 valeurs pouvant être utilisées pour désigner des marques de ponctuation, des signes arithmétiques, des opérations de service (rangée de traduction, d'espace, etc.)
Montrant la diapositive numéro 7
Selon la formule N \u003d 2 Je peux calculer combien d'informations sont nécessaires pour encoder chaque signe:
N. = 2 JE. 256 = 2 JE. 2 8 = 2 JE. JE. \u003d 8 bits
Pour gérer les informations de texte sur l'ordinateur, il est nécessaire de le présenter dans un système emblématique binaire. Nous avons été calculés que 8 bits d'informations sont nécessaires pour coder chaque signe, c'est-à-dire. La durée du code de signalisation binaire est de huit signes binaires. Chaque panneau doit être mis en ligne avec un code binaire unique de l'intervalle de 00000000 à 11111111 (en code décimal de 0 à 255).
En entrant dans le texte des informations de texte, son codage binaire se produit. L'utilisateur appuie une clé sur le clavier et une séquence spécifique de huit impulsions électriques arrive à l'ordinateur (code de signalisation binaire). Pendant la sortie à l'écran de l'ordinateur, le recodage inverse est fait, c'est-à-dire Transformation du code binaire dans son image.
Diaporama n ° 8
L'attribution d'un signe de code binaire spécifique est une question d'un accord fixé dans la table de code. Un accord international est adopté pour attribuer chaque symbole de son code unique. En tant que norme internationale adoptée la table de code ASCII (code standard américain pour l'échange d'informations - Code standard américain pour échange d'informations)
Cette table présente des codes de 0 à 127 (lettres de l'alphabet anglais, signes d'opérations mathématiques, de caractères de service, etc.), et les codes de 0 à 32 sont attribués à des symboles, mais les touches de fonction.
Enregistrez le nom de cette table de code et la plage de caractères codés.
Les codes de 128 à 255 sont alloués à des normes nationales de chaque pays. Cela suffit pour la plupart des pays développés.
Pour la Russie, plusieurs normes de table de code différents ont été introduites (codes de 128 à 255).
Afficher les diapositives Numérapez 9.
Voici certains d'entre eux. Considérez et écrivez leurs noms:
Koi. - 8 , les fenêtres MS-DOS. , Mas, Iso.
Il y a environ 6 800 langues différentes dans le monde. Si vous lisez le texte imprimé au Japon sur un ordinateur en Russie ou aux États-Unis, il sera impossible de le comprendre. Pour que les lettres de tout pays lisent sur n'importe quel ordinateur, deux octets (16 bits) ont commencé à les utiliser pour leur codage.
Nous définissons également le nombre de caractères pouvant être codés selon cette norme:
N \u003d 2 I \u003d 2 16 \u003d 65536
ce nombre de caractères suffit à encoder non seulement des alphabets russes et latins, mais aussi grec, arabe, hébreu et d'autres alphabets.
Fizkultminutka
Et maintenant, je vais passer une pièce jointe physique: j'écris d'abord la pointe du nez en forme du plafond "J'aime l'informatique."
FizkultMinutka pour les yeux:
Peler rapidement, fermez les yeux et asseyez-vous calmement, comptant lentement jusqu'à 5. Répétez 4-5 fois.
Tirez la main droite vers l'avant. Suivez les yeux sans transformer la tête, derrière les mouvements lents de l'index de la main allongée gauche et droite, de haut en bas. Répétez 4-5 fois.
Regardez un index d'une main allongée pour compte 1 à 4, puis transférez le regard sur 1 à 6. Répétez 4-5 fois.
À un rythme moyen, faire 3-4 mouvements circulaires à travers les yeux sur le côté droit, autant sur le côté gauche. Détendez les muscles des yeux, pour examiner la distance jusqu'au compte 1 à 6. Répéter 1-2 fois.
Fixer les connaissances acquises.
Pas en vain, le bassinople romain Fedr a déclaré: "Science - capitaine et pratique - soldats." Par conséquent, nous passons maintenant de la théorie à la pratique.
Ouvrez le tutoriel à la page 152, trouvez un numéro de travail pratique 8, lisez-le.
Notez dans le cahier le thème du travail pratique "Codage des informations textuelles", Objectif: Découvrez comment identifier les codes de caractères numériques, entrez des caractères à l'aide de codes numériques et transcodant le texte russophone dans un éditeur de texte.
Activez les ordinateurs et nous effectuerons ce travail ensemble.
Numéro de tâche 1. Dans le mot éditeur de texte, identifiez les codes numériques de plusieurs caractères:
sous Windows codant;
dans l'encodage Enicode (Unicode)
Exécuter le mot de texte éditeur
entrez la commande (insérer - symbole ...). Un panneau de dialogue apparaît à l'écran. La partie centrale du panneau de dialogue prend la table des caractères.
Pour déterminer le code de symbole numérique décimal dans l'encodage Windows à l'aide de la liste déroulante de: Sélectionnez le type de codage Cyrillic (DES.).
Dans la table de caractères, sélectionnez un symbole. Dans la zone de texte, le code de signalisation: un code de symbole décimal apparaîtra.
Pour déterminer le code numérique hexadécimal dans l'encodage Unicode à l'aide de la liste déroulante de: Sélectionnez le type de codage Unicode (six.).
Dans la table de caractères, sélectionnez un symbole. Dans la zone de texte, le code de signalisation: un code de symbole numérique de seize numériques apparaîtra.
Utilisation d'une calculatrice électronique pour traduire le code numérique hexadécimal en un système de nombres décimaux:
0586 16 \u003d x 10; 1254 16 \u003d x 10; 8569 16 \u003d x 10;
Numéro de tâche 2. Dans l'éditeur de texte, entrez la séquence de caractères dans les codages Windows et MS-DOS à l'aide de codes numériques.
Démarrez la commande Standard Notepad Application (Programme - Standard - Notepad).
Utilisation d'un clavier numérique en option tout en appuyant sur la touche Alt, entrez le numéro 0224, relâchez la touche alt , le symbole "A" apparaît dans le document. Répétez la procédure pour les codes numériques de 0225 à 0233, une séquence de 10 caractères "ABSGDJUSES" apparaît dans le document en codage de Windows.
Utilisation d'un clavier numérique en option tout en appuyant sur la touche Alt, entrez le numéro 224, relâchez la touche alt , le symbole «P» apparaîtra dans le document. Répétez la procédure pour les codes numériques de 225 à 233, une séquence de 10 caractères "Fuffhschch" apparaît dans le codage MS-DOS.
Essais primaires de la compréhension
Questions de l'enseignant
1. Quel est le principe de codage des informations de texte utilisées dans l'ordinateur? (Lorsque vous entrez dans les informations de texte, il prend son codage binaire sur l'ordinateur. L'utilisateur appuie une clé sur le clavier avec un signe et une certaine séquence de huit impulsions électriques (code de signalisation binaire) arrive sur l'ordinateur. Pendant la sortie de l'ordinateur, le transcodage inverse est effectué, c'est-à-dire la transformation du code binaire dans son image.)
2. Quel est le nom de la table de codage du symbole international?( Ascii.CODE AMÉRICAIN NORMALISÉ POUR L'ÉCHANGE D'INFORMATION - américain la norme le code pour échange informations )
3. Énumérez les noms des tables de codage pour les caractères russophones. (Koi - 8., MME. - Dos. , Mas, Iso. , les fenêtres )
L'enseignant distribue des cartes avec des tâches individuelles. (Petya et Kolya écrivent les uns des autres emails dans Koi coding - 8. Une fois que Petya se trompait et envoya une lettre au codage de Windows. Kolya a reçu une lettre et comme toujours la lire à Koi - 8. Il s'est avéré un texte sans signification. répété le mot *** ***. Quel mot était dans le texte source de la lettre?
1 option - voleur (scanner)
2 option - rbnsfsfs (mémoire)
3 Option - RTIFET (imprimante)
4 Option - Dyulefb (disquette)
5 Option - FTelvpm (Trackball)
6 Option - NPOOFPT (moniteur)
7 Option - RTPGECT (processeur)
8 Option - Lambchjbfkhtb (clavier)
9 Option - NBFETYOULBS RMCFB (carte mère)
10 Option - FBLFFCCHBS Subuffbb RTPGuUruptb (fréquence d'horloge de processeur)
Devoirs
Selon le manuel N. Ugrinovich p.3.1. p. 74 - 77
Code dans le code KOI - 8 Votre nom et votre nom de famille. Notez le résultat dans la forme:
code binaire
code décimal
Tâche supplémentaire (sur la carte): Texte de décrire en utilisant KOI -8 coding:
254 212 207 194 205 213 196 210 207 214 201 218 206 216 208 210 207 214 201 212 216, 218 206 193 212 216 206 193 196 207 194 206 207 206 197 205 193 204 207,
228 215 193 215 193 214 206 217 200 208 215 193 215 201 204 193 218 193 208 207 205 206 201 196 204 209 206 193 222 193 204 193:
244 217 204 213 222 219 197 199 207 204 207 196 193 202, 222 197 205 222 212 207 208 207 208 193 204 207 197 211 212 216,
233 204 213 222 219 197 194 213 196 216 207 196 201 206, 222 197 205 215 205 197 211 212 197 21 203 197 205 208 207 208 193 204 207.
(Alors que la vie sage habite, vous devez en savoir mal,
Deux réglementations importantes de mémoriser pour commencer:
Tu es mieux que la faim que ça tombe
Informatique et technologie de l'information. Tutoriel pour la 8e année / ND. Ugrinovich. - M. Binin. Laboratoire de connaissances, 2011. - 205 p.: Il.
Magazine "Informatique et éducation", № 4 2003, №62006
Informatique 7 - 9 CL. /.G. Kushnirenko, G.V. Lebedev, ya.n. Zapaderman, M.: Drop, 2001. - 336 p.: Il.
LEÇON THEME: « Codage des informations de texte. "
Chose: Informatique et TIC.
Classer: 9-10.
Mots clés : informatique, codage de texte, codage d'informations.
Littérature, eor.
1. Manuel Ugrinovich N.D. Informatique et cours de base de TIC 9e année 9;
Équipement : classe d'ordinateur, programmesMicrosoft.Bureau.Power Point., Tâches à la leçon sous forme électronique (voir annexe).
Type de leçon : Étude d'un nouveau sujet.
Formulaires de travail : frontal, collectif, individuel.
Annotation: nombre de cours d'étudiants, sous-groupe.
Le but de la leçon: Donner une idée de codage d'informations de texte.
Tâches:
Formation de la présentation du codage des informations textuelles;
Contribuer à l'éducationsentimentsmais Collectivisme, intelligentje Écouter les camarades réponses;
Développement de l'attention et de la pensée logique;
Développement d'intérêt pour l'apprentissage des programmes informatiques.
Pendant les cours:
Histoire de l'enseignant introductif Avec l'aide de la présentation (sur la CEla plaie est présentée une présentation sur le sujet).
Depuis les années 60, les ordinateurs se sont devenus de plus en plus utilisés pour gérer des informations texte et actuellement la plupart des PC du monde sont occupés par le traitement des informations texte.
Pour la présentation des informations texte, 256 caractères suffisent.
Selon la formuleN \u003d 2.
JE.
, 256=
2
8
Par conséquent, pour coder un caractère, la quantité d'informations est égale à 1 octet. (Une attention particulière devrait être portée à la formule).
La codage est que chaque symbole est mis en ligne avec un code binaire unique de 00000000 à 1111111111 (ou de code décimal de 0 à 255).
Il est important que l'attribution d'un code spécifique soit une question de l'accord fixé par la table de code.
Pour différents types d'ordinateurs, divers codages sont utilisés.
Avec distributionIBM.PC. La norme internationale est devenue une table de codageAscii. ( Américain. Standart. Code. pour Informations Échange. ) - Code standard américain pour échange d'information.
La norme dans ce tableau n'est que la première moitié, c'est-à-dire Symboles avec des nombres de 0 (00000000) à 127 (0111111). Ici comprend la lettre de l'alphabet, des nombres, des marques de ponctuation, des supports et d'autres personnages de ponctuation.
Les 128 codes restants sont utilisés dans différentes versions. Dans les codages russes, les symboles de l'alphabet russe sont placés.
Actuellement, il y a 5 tables de code différentes pour les lettres russes (Koi8,Cp1251 , Cp866,MAC., Iso.).
Actuellement reçu une nouvelle norme internationale généraliséeUnicode. qui allume sur chaque symbole de deux octets. Avec elle, vous pouvez coder 65536 (2 16 \u003d 65536) caractères différents.
Les chiffres sont codés selon la norme ASCII dans deux cas - lors de la saisie de sortie et lorsqu'ils se trouvent dans le texte. Si les chiffres sont impliqués dans les calculs, ils sont transformés en un autre code binaire.
Prendre le numéro57 .
Lorsqu'il est utilisé dans le texte, chaque chiffre sera représenté par son code conformément à la table ASCII. Dans le système binaire, il est 0011010100110111.
Lorsqu'il est utilisé dans des calculs, le code de ce numéro sera obtenu par les règles de transfert dans le système binaire et obtenir - 00111001.
Aujourd'hui, il y a beaucoup de gens à préparer des lettres, des documents, des articles, des livres, etc. en utilisantediteurs de texte d'ordinateur . Les éditeurs informatiques travaillent surtoutavec alphabet taille 256 caractères .
Dans ce cas, il est facile de calculer la quantité d'informations dans le texte. Si un1 Symbole de l'alphabet transporte 1 informations sur les octets , alors vous avez juste besoin de compter le nombre de caractères; Le nombre résultant donnera des informations le texte en octets.
JE.= K.× jE.où
JE.-Information du message
K.- Nombre de caractères dans le texte
jE.- Poids d'information d'un symbole
2 jE. \u003d N.
N.- Puissance de l'alphabet
Résoudre les tâches. La présentation a été construite selon le principe "décidé de l'enseignant - décidé pour eux-mêmes".
Résumant. Points de fixation. Devoirs.
Leçon numéro 13.
LEÇON THEME: "Informations de texte codant."
Type de leçon: formation.
Objectifs leçon:
Introduisez les élèves des moyens d'encoder des informations dans l'ordinateur;
Envisager des exemples de problèmes de résolution;
Promouvoir le développement des intérêts éducatifs des étudiants.
Éduquer l'exposition et la patience dans le travail, le sens du partenariat et la compréhension mutuelle.
TÂCHES LEÇON:
Former des connaissances des étudiants sur le sujet "codage des informations texte (symboliques)";
Faciliter la formation des écoliers de la pensée figurative;
Développer une analyse et une auto-analyse des compétences;
Formant la capacité de planifier vos activités.
Équipement:
jobs étudiant (ordinateur personnel),
le lieu de travail de l'enseignant,
board interactif,
projecteur multimédia,
présentation multimédia
Pendant les classes
I. Moment organisationnel.
Sur un tableau blanc interactif, la première diapositive de la présentation multimédia avec la leçon.
Prof: Bonjour gars. S'asseoir. En service, rapport manquant. (Rapport sur le devoir). Merci.
II. Travailler sur la leçon.
1. Explication du nouveau matériau.
L'explication du nouveau matériau se présente sous la forme d'une conversation heuristique avec une affichage simultanée d'une présentation multimédia sur un tableau interactif.(Pièce jointe 1).
Prof: Quelle information codante que nous avons étudiée dans les activités précédentes?
Répondre : Codation des informations graphiques et multimédia.
Prof : Passons à l'étude d'un nouveau matériau. Enregistrer le sujet "Informations sur le texte codant" (faire glisser une). Questions considérées (faire glisser 2):
Excursion historique;
Codage binaire des informations textuelles;
Calcul du nombre d'informations textuelles.
Excursion historique
L'humanité utilise le cryptage (encodage) du texte à partir du moment même où les premières informations secrètes sont apparues. Avant de trouver plusieurs techniques de codage de texte, qui ont été inventées à différentes étapes du développement de la pensée humaine (faire glisser 3) :
Cryptographie - il s'agit d'une sécrétion, un système de changement de lettre afin de rendre le texte incompréhensible pour les personnes non inticiées;
Abc morse ou un code de télégraphe inégal dans lequel chaque lettre ou signe est représentée par sa combinaison de colis élémentaires courtes de courant électrique (points) et de colis élémentaires de la durée triplée (DASH);
Justifié - la langue des gestes utilisés par les personnes atteintes d'une déficience auditive.
Question : Quels exemples de codage d'informations texte peuvent être amenés plus?
Les étudiants dirigent des exemples (panneaux de signalisation, circuits électriques, code à barres de produit).
Enseignant: (Afficher faire glisser quatre). L'une des premières méthodes de cryptage connues est le nom de l'empereur romain Julia Caesar (Ie siècle BC). Cette méthode est basée sur le remplacement de chaque lettre du texte crypté, à un autre, par déplacement dans l'alphabet de la lettre originale au nombre fixe de caractères, et l'alphabet est lu dans un cercle, c'est-à-dire après la lettre.je Considérantmais . Donc le mot octet Lorsque vous avez déplacé, deux caractères à droite sont codés par le motgvlf . Le processus inverse du déchiffrement de ce mot - il est nécessaire de remplacer chaque lettre cryptée, à la seconde à gauche de celle-ci.
(Diapositive 5) déchiffrer la phrase du poète persan Jalaleddine Rumi "kgnusm yogkg fesl tcfhy fssezhz fhgrzh yogksp", Codé avec César Cipher. On sait que chaque lettre du texte source est remplacée par le troisième après. En tant que support, utilisez les lettres de l'alphabet russe situé sur la diapositive.
Question : Qu'est-ce que tu as fait?
Réponse de l'étudiant:
Fermez vos yeux ses yeux laissé le coeur devenir un œil
La réponse est comparée à la réponse correcte qui apparaît sur la diapositive 5.
Codage binaire des informations texte
Les informations exprimées à l'aide de langues naturelles et formelles par écrit sont appeléesinformations de texte (faire glisser 6).
Quelle quantité d'informations est nécessaire pour coder chaque signe peut être calculée par la formule: n \u003d 2JE.
Question : Laquelle des techniques de codage répertoriées est utilisée le principe binaire du codage d'informations?
La réponse des étudiants: dans l'alphabet de Morse.
Prof : L'ordinateur utilise également le principe du codage des informations binaires. Seulement au lieu d'un point et d'une pointe d'utilisation 0 et 1 (faire glisser 7) .
Traditionnellement, 1 octet des informations sont utilisés pour encoder un symbole.
Question : Combien de caractères différents peuvent être codés? (Rappelez-vous que 1 octet \u003d 8 bits)
Réponse de l'étudiant: n \u003d 2 i \u003d 2 8 \u003d 256.
Prof : Droite. Est-ce suffisant pour la présentation d'informations textuelles, y compris les lettres majuscules et minuscules de l'alphabet, des nombres et d'autres caractères en majuscules et latins?
Les enfants comptent le nombre de caractères différents:
33 Les lettres minuscules de l'alphabet russe + 33 lettres majuscules \u003d 66;
Pour l'alphabet anglais 26 + 26 \u003d 52;
Chiffres de 0 à 9, etc.
Enseignant: votre conclusion?
Conclusion des étudiants : Il s'avère que 127 caractères ont besoin. Il existe toujours 129 valeurs pouvant être utilisées pour désigner des marques de ponctuation, des signes arithmétiques, des opérations de service (traduction de la chaîne, espace, etc. Par conséquent, un octet suffit à encoder les caractères nécessaires pour encoder des informations sur le texte.
Prof : Dans l'ordinateur, chaque caractère est codé par un code unique.
Un accord international est adopté pour attribuer chaque symbole de son code unique. En tant que norme internationale, la table de code ASCII est adoptée (code standard américain pour l'échange d'informations) (faire glisser 8).
Cette table présente des codes de 0 à 127 (lettres de l'alphabet anglais, signes d'opérations mathématiques, de caractères de service, etc.), et les codes de 0 à 32 sont attribués à des symboles, mais les touches de fonction. Enregistrez le nom de cette table de code et la plage de caractères codés.
Les codes de 128 à 255 sont alloués à des normes nationales de chaque pays. Cela suffit pour la plupart des pays développés.
Pour la Russie, plusieurs normes de table de code différents ont été introduites (codes de 128 à 255).
Voici certains d'entre eux (faire glisser 9-10). Considérez et écrivez leurs noms:
Koi8-R, CP1251, CP866, MAS, ISO.
Ouvrez l'atelier d'informatique à la page 65-66 et lisez sur ces tables de codage.
Prof : Dans l'éditeur de texte MS Word, afin d'afficher le symbole de son code à l'écran, vous devez contenir la touche "ALT" pour taper le code de caractères sur le clavier numérique supplémentaire (faire glisser 11):
Concept d'encodage Enicode
Décision : Dans cette phrase, 108 caractères, compte tenu des signes de ponctuation, de citations et d'espaces. Multipliez ce montant par 8 bits. Nous obtenons 108 * 8 \u003d 864 bits.
Prof : Pensez à la tâche n ° 2. (la condition est affichée sur un tableau interactif).<Рисунок 3> Enregistrez son état: l'imprimante laser Canon LBP est imprimée en moyenne de 6,3 kbps par seconde. Combien de temps aurez-vous besoin d'imprimer 8 documents de page s'il est connu que sur une page sur une page en moyenne 45 lignes, dans la chaîne de 70 caractères (1 symbole - 1 octet) (voir fig. 2).
Décision:
1) Nous trouvons la quantité d'informations contenues sur 1 page:
45 * 70 * 8 bits \u003d 25200 bits
2) Nous trouvons la quantité d'informations sur 8 pages:
25200 * 8 \u003d 201600 bit
3) conduire à une seule unité de mesure. Pour cela, Kbit se traduit par des bits:
6.3 * 1024 \u003d 6451,2 bits / s.
4) Nous trouvons le temps d'impression: 201600: 6451.2 \u003d 31,25 secondes.
III. Généralisation
Questions de l'enseignant (faire glisser 14):
1. Quel est le principe de codage des informations de texte utilisées dans l'ordinateur?
2. Quel est le nom de la table de codage du symbole international?
3. Énumérez les noms des tables de codage pour les caractères russophones.
4. Dans quel système sont les codes dans les tables de codage répertoriées?
Nous avons codé les symboles, le son et les graphiques. Puis-je encoder des émotions?
La diapositive est démontrée14.
Iv. Le résultat de la leçon. Devoirs
§ 2.1, Tâche 2.1, enregistrements dans des cahiers.
L'encodage des informations est le processus de conversion d'informations d'une forme, pratique à une utilisation directe, sous une forme, pratique pour la transmission, le stockage ou le traitement automatique.
Codage des informations de texte
Pour écrire des informations de texte (emblématique), il y a toujours une langue (naturelle ou formelle).
Tous les ensembles utilisés dans les symboles de langue sont appelés Alphabet. Nombre complet de caractères alphabet N. appelé ça Pouvoir. Lors de l'écriture de texte, n'importe lequel de la prochaine position peut apparaître N. caractères alphabet, c'est-à-dire peut-être survenir N. événements. Par conséquent, chaque symbole de l'alphabet contient jE.informations sur le bit où jE. Déterminé à partir de l'inégalité (Formula Hartley): 2 jE. ≥ N.. Ensuite, la quantité totale d'informations dans le texte est déterminée par la formule:
V. = k. * jE. ,
où V. - la quantité d'informations dans le texte; k. - le nombre de signes dans le texte (y compris les marques de ponctuation et même les espaces), jE.- le nombre de bits alloués au codage d'un signe.
Étant donné que chaque bit est 0 ou 1, tout texte peut être représenté par une séquence de zéros et d'unités. C'est ainsi que les informations de texte sont stockées dans la mémoire de l'ordinateur. L'attribution d'un symbole d'alphabet de code binaire spécifique est une question d'accord fixé dans la table de code. Les tables actuelles ont reçu une large distribution Ascii. et Unicode..
Ascii.(Code Standart américain pour l'échange d'information - Code de change d'informations standard américain) est utilisé pendant une longue période. Pour stocker un seul code de symbole, 8 bits sont surlignés, par conséquent, la table de code prend en charge 28 = 256 symboles. La première moitié de la table (128 caractères) - Contrôler des caractères, des chiffres et des lettres de l'alphabet latin. La seconde moitié est déchargée sous les symboles des alphabets nationaux. Malheureusement, il existe actuellement cinq options pour les tables de code pour les lettres russes (KOI-8, Windows-1251, ISO, DOS, MAC), de sorte que les textes créés dans un codage sont affichés de manière incorrecte dans une autre. (Probablement, avez-vous rencontré des sites russophones dont les textes ressemblent à un ensemble de signes dénués de sens?).
Unicode. - Distribution reçue ces dernières années. Pour stocker un seul code de symbole, 16 bits sont attribués, par conséquent, la table de code prend en charge 216 = 65536 Symboles. Cet espace suffit pour combiner toutes les écritures officielles «vivantes» (appartenant à l'état) dans une norme. Au fait, la norme ASCII est entrée unicode.
Si un codage - Il s'agit du transfert d'informations d'une langue à une autre (enregistrement dans un autre système de symboles, dans un autre alphabet), puis décodage - Remplacement.
Lors de l'encodage d'un symbole de message source peut être remplacé par un symbole d'un nouveau code ou plusieurs caractères, et vice-versa - plusieurs symboles de source sont remplacés par un seul caractère dans un nouveau code (les caractères chinois indiquent des mots entiers et des concepts), donc le codage peut-il être uniforme et inégal.Avec codage uniforme, tous les caractères sont codés par des codes de longueur égale, avec codage inégal, différents caractères peuvent être codés par des codes de différentes longueurs, ce qui rend difficile la décodage.
décodé depuis le débutSi exécuté condition Fano: aucun mot mot n'est le début d'un autre mot de code. Le message codé peut être sans ambiguïté. décodé de la finSi exécuté fano de condition inverse: aucun mot mot n'est la fin d'un autre mot de code. La condition de Fano est une condition suffisante, mais pas nécessaire pour le décodage sans ambiguïté.
Résoudre les tâches pour coder les informations de texte
1. Le périphérique automatique transcodage du message d'information en russe en longueur en 20 caractères, enregistré à l'origine dans le code Unicode à 2 octets, dans le codage KOI-8 à 8 bits. Combien de bits diminuaient la longueur du message? En réponse, écrivez uniquement le nombre.
Décision:
1) avec codage de 16 bits le volume du message - 16 * 20 bits
2) Lorsqu'il a été recodé dans un code 8 bits, son volume est devenu égal à 8 * 20 bits
3) Ainsi, le message a diminué de 16 * 20 - 8 * 20 \u003d 8 * 20 \u003d 160 bits
Répondre: 160
2. Déterminez les informations du texte dans les bits
Bambarbia! Kerguda!
Décision:
1) Dans ce texte, 19 caractères (veillez à considérer les espaces et les marques de ponctuation)
2) S'il n'y a pas d'informations supplémentaires, nous pensons que le codage 8 bits est utilisé (le plus souvent, il est clairement indiqué que le codage est de 8 ou 16 bits), donc dans le message 19 * 8 \u003d 152 bits d'informations
Répondre: 152
3. Le tableau ci-dessous montre une partie de la table de code ASCII:
symbole | |||||||
Code décimal | |||||||
Code hexagonal |
Quel est le code hexadécimal du symbole "q"?
Décision:
1) Dans la table de code ASCII, tous les lettres latins de titre A-Z sont placées par ordre alphabétique, en commençant par un symbole avec code 65 \u003d 4116
2) toutes les lettres latines minuscules A-Z sont placées par ordre alphabétique, en commençant par un symbole avec code 97 \u003d 6116
3) À partir de là, il s'ensuit que la différence entre les codes des lettres "Q" et "A" est égale à la différence de codes des lettres "Q" et "A", c'est-à-dire 5116 - 4116 \u003d 1016
4) Ensuite, le code hexadécimal "Q" est égal à la lettre "A" Code plus 1016
5) À partir d'ici, nous trouvons 6116 + 1016 \u003d 7116.
Répondre: 71
4. Pour encoder une séquence composée de lettres A, B, B, G et D, un code binaire inégal est utilisé, ce qui vous permet de décoder sans ambiguïté la séquence binaire résultante. Ce code: A-00, B-010, B-011, G-101, D-111. Est-il possible de réduire pour l'une des lettres de la longueur du mot de code afin que le code puisse toujours être décodé sans ambiguïté? Les codes des lettres restantes ne doivent pas changer. Sélectionnez l'option de réponse correcte.
1) pour la lettre B est impossible
3) Pour la lettre dans les lettres R - 01
Décision (1 Méthode - Vérifier les conditions de Fano):
3) Pour le décodage sans ambiguïté, il suffit d'effectuer l'une des conditions de Fano: une condition directe ou inversée de Fano;
4) Vérifiez les options 1, 3 et 4 successivement; Si aucun d'entre eux ne convient, vous devrez choisir l'option 2 («c'est impossible»);
3) Vérification de l'option 1: A-00, B-01, B-011, M-101, D-111.
La condition "directe" du FANO n'est pas satisfaite (le code de la lettre B coïncide avec le début du code de la lettre B);
La condition "inverse" du FANO n'est pas satisfaite (le code de la lettre B coïncide avec la fin du code de la lettre d); Par conséquent, cette option ne convient pas;
4) Vérification de l'option 3: A-00, B-010, B-01, G-101, D-111.
"Direct" condition Fano n'est pas satisfait (le code de la lettre en coïncide avec le début de la lettre B);
La condition Fano "inverse" n'est pas satisfaite (le code de la lettre coïncide avec la fin du code de la lettre d); Par conséquent, cette option ne convient pas;
5) Vérifiez l'option 4: A-00, B-010, B-011, M., D-111.
La condition "directe" du FANO n'est pas satisfaite (le code de la lettre G coïncide avec le début des codes des lettres B et B); mais Conditions "Inverser" Fano (Le code de la lettre G ne coïncide pas avec la fin du code des lettres restantes); Par conséquent, cette option convient;
Répondre: 4
Décision (2 voies, arbre):
1) Nous construirons un arbre binaire dans lequel deux branches sont disputées de chaque nœud, correspondant au choix du code de chiffre suivant - 0 ou 1; Placons sur cet arbre les lettres A, B, B, G et D de sorte que leur code ressemble à une séquence de nombres sur les roams qui composent le chemin de la racine à cette lettre (Red Il est mis en surbrillance dans le code 011 ):
https://pandia.ru/text/78/419/Images/image003_52.gif "largeur \u003d" 391 "hauteur \u003d" 166 "\u003e div_adblock100"\u003e
3) Mais le peu de parité nous assez pas besoinAutre important: cinquième bit dans chaque cinq vous pouvez laisser tomber!
4) Différences de la séquence spécifiée dans les groupes de 5 bits chacun:
01010, 10010, 01111, 00011.
5) lancer le cinquième (dernier) bit de chaque groupe:
0101, 1001, 0111, 0001.
ce sont des codes binaires de nombres transmis:
01012 = 5, 10012 = 9, 01112 = 7, 00012 = 1.
6) Ainsi, les nombres 5, 9, 7, 1 ou le nombre 5971 ont été transmis.
Répondre: 2
Tâches de formation:
1) Le périphérique automatique a été transcodé le message d'information en russe, enregistré à l'origine en code 16 bits Unicode.En codage à 8 bits
Koi-8.. Dans le même temps, le message d'information a diminué de 800 bits. Quelle est la longueur du message dans les caractères?
2) Le tableau ci-dessous montre une partie de la table de code ASCII:
symbole | |||||||
Code décimal | |||||||
Code hexagonal |
Quel est le code hexadécimal du symbole "p"?
3) Un document de texte composé de 3072 caractères a été stocké dans le codage KOI-8 8 bits. Ce document a été transformé en un codage unicode 16 bits. Spécifiez quelle quantité supplémentaire de KB devra stocker le document. En réponse, écrivez uniquement le nombre.
4) Pour encoder des lettres A, B, B, G a décidé d'utiliser des nombres binaires séquentiels à deux chiffres (de 00 à 11, respectivement). Si de cette façon de coder la séquence de symboles de la GBAV et d'enregistrer le résultat dans un système de numéros hexadécimal, il s'avérera:
5) Pour 5 lettres de l'alphabet latin, leurs codes binaires sont définis (pour certaines lettres - de deux bits, pour certains - à partir de trois). Ces codes sont présentés dans le tableau:
Déterminez quel ensemble de lettres est codé chaîne binaire
1) Baade 2) Bade 3) BACDE 4) BACDB
6) Pour encoder les lettres A, B, C, D, des nombres binaires séquentiels à trois chiffres, en commençant par 1 (de 100 à 111, respectivement) sont utilisés. Si de cette façon de coder la séquence de symboles du CDAB et d'écrire le résultat dans le code hexadécimal, il s'avérera:
1) A5SD16 4) DE516
7) Pour 6 lettres de l'alphabet latin, leurs codes binaires sont définis (pour certaines lettres de deux bits, pour une partie de trois). Ces codes sont présentés dans le tableau:
Déterminez quelle séquence de 6 lettres est codée par une chaîne binaire.
8) Pour coder un message composé uniquement de lettres A, B, B et G, est utilisé de manière inégale du code binaire de longueur:
Si de cette manière d'encoder la séquence de caractères Gavbvg et d'enregistrer le résultat dans le code hexadécimal, il s'avérera:
1) 62DD2) 6213316
9) Pour la transmission sur le canal de communication, le message composé uniquement des lettres A, B, B, G, a été décidé d'utiliser le code de code inégal: A \u003d 1, B \u003d 01, B \u003d 001. Comment encoder la lettre R de sorte que la longueur du code est minimale et a été autorisée à scinder sans ambiguïté le message codé dans les lettres?
10) Pour transmettre des nombres par canal avec interférences, le code de contrôle de parité est utilisé. Chaque chiffre est écrit dans une représentation binaire, avec l'ajout de zéros de pointe à la longueur 4, et la somme de ses éléments 2 est ajoutée à la séquence résultante (par exemple, si nous transmettons 23, nous obtenons une séquence). Déterminez quel numéro a été transmis via Canal sous forme de?
11) Pour encoder une séquence composée de lettres A, B, B, G et D, un code binaire inégal est utilisé, ce qui vous permet de décoder sans ambiguïté la séquence binaire résultante. Ce code: A-10, B-11, B-000, M-001, D-011. Est-il possible de réduire pour l'une des lettres de la longueur du mot de code afin que le code puisse toujours être décodé sans ambiguïté? Les codes des lettres restantes ne doivent pas changer. Sélectionnez l'option de réponse correcte.
1) C'est impossible 2) pour la lettre B - 1
3) Pour la lettre G - pour les lettres D - 01
12) Pour encoder une séquence composée de lettres A, B, B, G et D, a décidé d'utiliser un code binaire inégal, qui vous permet de décoder sans ambiguïté la séquence binaire apparaissant sur le côté de la réception du canal de communication. Code d'occasion: A-111, B-110, B-100, M-101. Spécifiez quel type de mot de code peut être codé par la lettre D. Le code doit satisfaire la propriété du décodage sans ambiguïté. Si vous pouvez utiliser plus d'un mot de code, spécifiez les plus courts d'entre eux.
13) Pour la transmission sur le canal de communication, le message composé uniquement des lettres A, B, B, G, a décidé d'utiliser le code de longueur inégale: A \u003d 1, B \u003d 000, B \u003d 001. Comment encoder la lettre R de sorte que la longueur du code est minimale et a été autorisée à scinder sans ambiguïté le message codé dans les lettres?
Codage des informations graphiques
La transformation des informations graphiques de forme analogique à la discrete est faite par discrétisation, c'est-à-dire, partitionnement d'une image graphique continue aux éléments individuels. Pendant le processus d'échantillonnage, le codage est effectué, c'est-à-dire une affectation à chaque élément d'une valeur spécifique sous forme de code.
Échantillonnage – il s'agit d'une conversion d'une image continue en un ensemble de valeurs discrètes sous forme de code.
Dans le processus d'encodage de l'image est faite discrétisation spatiale. L'échantillonnage de l'image spatiale peut être comparé à la construction d'une image d'une mosaïque. L'image est divisée en petits fragments séparés (points), dont chacun est attribué le code de couleur.
À la suite d'un échantillonnage spatial, des informations graphiques sont représentées comme image raster. L'image raster consiste en un certain nombre de lignes, chacune d'entre elles contenant un certain nombre de points (pixels).
La qualité de l'image dépend de la résolution.
La résolution de l'image bitmap est déterminée par le nombre de points horizontaux (x) et le nombre de points verticaux ( Y.) Longueur d'image par unité.
Plus la taille du point, plus la résolution est grande (des lignes plus grandes du raster et des points de la chaîne) et, en conséquence, au-dessus de la qualité de l'image.
La valeur de la résolution est exprimée en (point par pouce - points par pouce), c'est-à-dire dans le nombre de points de la bande d'une image d'une longueur de 1 pouce (1 dyum \u003d 2,54 cm). La numérisation d'images graphiques à partir de papier ou de films est effectuée à l'aide d'un scanner. Le balayage est effectué en déplaçant les éléments photosensibles le long de l'image. Les caractéristiques du scanner sont exprimées par deux chiffres, tels que 1200x2400 DPI. Le premier numéro détermine le nombre d'éléments photosensibles sur un pouce de la bande et est une résolution optique. La seconde est une résolution matérielle et détermine le nombre de micros lors du déplacement d'un pouce le long de l'image.
Pendant le processus d'échantillonnage, différentes palettes de couleurs peuvent être utilisées. Chaque couleur peut être considérée comme un point de point possible. Le nombre de n dans la palette et la quantité d'informations pour coder la couleur de chaque point sont liés à la formule Hartley bien connue: N \u003d 2i,où je suis la profondeur de la couleur et n est le nombre de couleurs (palette).
La quantité d'informations utilisées pour coder l'image couleur de couleur est appelée profondeur couleurs. Les valeurs les plus courantes de la profondeur de couleur sont des valeurs de la table:
Tableau. Profondeur de couleur et nombre de couleurs affichées.
Profondeur de couleur (I) | ||||
Le nombre de couleurs représentées (n) |
La qualité de l'image sur l'écran du moniteur dépend de la taille. autorisation spatiale et des profondeurs de couleur. La résolution spatiale de l'écran du moniteur est définie comme un produit du nombre de chaînes de l'image sur le nombre de points de la ligne. La permission peut être: 800x600, 1024x768, 1152x864 et supérieure. Le nombre de couleurs affichées peut varier de 256 couleurs à plus de 16 millions.
|
|
Figure. Former un bitmap sur l'écran.
Considérez un exemple de formage d'une image raster sur l'écran du moniteur composé de 600 lignes de 800 points de chaque rangée (tous points) et de la profondeur de couleur de 8 bits. Le code de couleur binaire de tous les points est stocké dans la mémoire vidéo informatique, située sur la carte vidéo.
Périodiquement, avec une certaine fréquence, les codes de couleur des points sont lus à partir de la mémoire vidéo et les points sont affichés sur l'écran du moniteur. La fréquence de lecture d'image affecte la stabilité de l'image à l'écran. Dans les moniteurs modernes, la mise à jour de l'image se produit avec une fréquence de 75 fois ou plus par seconde, ce qui garantit le confort de la perception par l'utilisateur.
Informations requises Mémoire vidéo requise peut être calculé par la formule:
V. \u003d I · x · y,
où v est le volume d'informations de la mémoire vidéo dans les bits;
X · y - le nombre de points d'image (résolution d'écran);
I - profondeur de couleur dans les bits par point.
Par exemple, le volume requis de la mémoire vidéo pour le mode graphique avec une résolution de 800x600 points et une profondeur de couleur de 24 bits est la suivante:
V \u003d i · x · y \u003d 24 x 800 x 600 \u003d bit \u003d 1 octet.
L'image couleur sur l'écran du moniteur est formée en mélangeant les couleurs de base: rouge, vert et bleu (palette RVB). Pour obtenir une palette de couleurs riche avec des couleurs de base, diverses intensités peuvent être spécifiées. Par exemple, avec une profondeur de couleur de 24 bits par chacune des couleurs, 8 bits sont libérés, c'est-à-dire pour chacune des couleurs, N \u003d 28 \u003d 256 niveaux d'intensité spécifiée par des codes binaires du minimum au maximum.
Tableau. Formation de certaines couleurs avec une profondeur de couleur de 24 bits.
Nom | Intensité |
||
Souvent, la couleur est écrite sous la forme de - #RRGGBBB, où RR est un code hexadécimal de composants de couleur rouge, GG est un code hexadécimal pour les composants de couleur vert, BB est un code hexadécimal de composants de couleur bleue. Plus la valeur du composant est grande, plus l'intensité de la lueur de la couleur de base correspondante est grande. 00 - Pas de luminescence, FF - Glow maximum (FF16 \u003d 25510), 8016 - La valeur de luminosité moyenne. Si le composant a une intensité de couleur<8016 , то это даст темный оттенок, а если >\u003d 8016, puis la lumière.
Par example,
# FF0000 - rouge (le composant rouge est maximum et le reste est zéro)
# 000000 - Couleur noire (pas de composant rayon)
#Ffffff - couleur blanche (tous les composants sont maximum et identique, la couleur la plus vive)
# 404040 - gris foncé (tous les composants sont les mêmes et les valeurs inférieures à la valeur de luminosité moyenne)
# 8080FF - Bleu clair (luminosité maximale dans le composant bleu et la luminosité des autres composants sont identiques et égales à 8016).
Résoudre les tâches pour encoder des informations graphiques
1. Pour stocker une image raster avec une taille de 32 × 32 pixels, 512 octets de mémoire ont pris. Quel est le nombre maximum possible de couleurs dans la palette d'images?
Décision: Lors de l'encodage avec une palette, le nombre de bits par pixel ( K.) dépend du nombre de couleurs de la palette N.Ils sont associés à la formule: https://pandia.ru/text/78/419/images/image005_31.gif "largeur \u003d" 71 "hauteur \u003d" 21 src \u003d "\u003e (2), où - le nombre de bits sur le pixel et - nombre total de pixels.
1) Trouver un nombre total de pixels https://pandia.ru/text/78/419/images/image009_17.gif "largeur \u003d" 61 "hauteur \u003d" 19 "\u003e bytebitbitbit
3) Déterminez le nombre de bits sur pixel: # xxxxxx, "où des valeurs d'intensité hexadécimale du composant de couleur dans le modèle RVB 24 bits sont définies dans des guillemets.
Quelle couleur sera proche de la couleur de la page définie par balise
?1) blanc 2) gris 3) jaune 4) violet
Décision: L'intensité de couleur la plus élevée (99) dans les composants de couleurs rouges et bleues. Il donne de la couleur violette.
Répondre: 4
3. Quelle est la largeur (en pixels) d'une image raster décompressée rectangulaire de 64 couleurs qui occupe 1,5 Mo sur le disque, si sa hauteur est deux fois plus que la largeur?
Décision: Étant donné que la quantité de mémoire à l'image entière est calculée par la formule (1), où - le nombre de bits par pixel et https://pandia.ru/text/78/419/Images/Image014_12.gif "largeur \u003d "36" Hauteur \u003d "41 src \u003d"\u003e.
64 \u003d 26. D'ici K.= 6.
Nous substituons ces valeurs dans la formule (1), nous obtenons:
* 6 \u003d 1.5 * 220 * 23. Après coupes: x.2 = 222. D'ici: x.= 211=2048.
À PROPOS DEtVETY: 4
Tâches de formation:
1. Pour stocker une image raster de 128 x 128 pixels, 4 kilo-octets de mémoire ont pris. Quel est le nombre maximum possible de couleurs dans la palette d'images?
2. Pour encoder la page de couleur, la page Internet est utilisée Attribut BGColor \u003d "# xxxxxx", où des valeurs d'intensité hexadécimale du composant de couleur dans le modèle RVB 24 bits sont définies dans des guillemets. De quelle couleur sera proche de la couleur de la page donnée par balise
?1) jaune 2) rose 3) vert clair 4) bleu clair
3. Quelle est la largeur (en pixels) d'une image raster décompressée de 16 couleurs rectangulaire qui occupe 1 Mo sur un disque, si sa hauteur est deux fois plus de largeur?
Codage d'informations audio
Le son est une onde sonore avec une amplitude et une fréquence de changement continu. Plus l'amplitude du signal est grande, plus la fréquence la plus forte, plus le ton est élevé. Pour que l'ordinateur traite le son, un bip continu doit être transformé en une séquence d'impulsions électriques (zéros binaires et unités).
Dans le processus d'encodage d'un signal audio continu, sa discrétion temporaire est faite. Dans ce cas, l'onde sonore est divisée en petites zones temporaires, car chacune de la valeur d'amplitude est définie.
Discrétisation temporaire -le processus auquel, pendant le codage d'un signal sonore continu, l'onde sonore est divisée en petites sections temporaires séparées et une certaine amplitude est établie pour chaque site de ce type. Plus l'amplitude du signal, le son plus fort.
Sur le graphique (voir fig.) On dirait que le remplacement d'une courbe lisse à la séquence des "étapes", chacune à laquelle on a attribué la valeur de niveau de volume. Plus la quantité de niveaux de volume sera plus importante sera mise en évidence pendant le processus de codage, plus la qualité sera qualitative.
| |||||||||||

Figure. Échantillonnage de son temporaire
Profondeur sonore (profondeur de codage) - Le nombre de bits sur le codage du son.
Niveaux de volume (niveaux de signal) - Le son peut avoir des niveaux de volume différents. Le nombre de niveaux de volume différents sont calculés par la formule Hartley: N.= 2 JE. OùJE. - la profondeur des niveaux de son et N - volume.
Les cartes audio modernes fournissent une profondeur de codage au son 16 bits. Le nombre de niveaux de signal différents peut être calculé par la formule: n \u003d 216 \u003d 65536. T. À propos., Les cartes son modernes fournissent un codage 65536 niveaux de signal. Chaque valeur d'amplitude est attribuée à un code 16 bits.
Avec codage binaire d'un bip continu, il est remplacé par une séquence de niveaux de signal discrets. La qualité de codage dépend du nombre de mesures du niveau de signal par unité de temps, c'est-à-dire la fréquence d'échantillonnage. Plus la quantité de mesures est réalisée en 1 seconde (plus la fréquence de discrétisation) est importante, plus la procédure de codage binaire est précise.
Fréquence d'échantillonnage– le nombre de mesures du niveau de signal d'entrée par unité de temps (pour 1 s). Plus la fréquence de discrétisation est grande, plus la procédure de codage binaire est grande. La fréquence est mesurée à Hertz (Hz).
1 mesure pour 1 seconde -1 Hz, 1000 mesures pendant 1 seconde 1 kHz.
Dénote la fréquence de la lettre d'échantillonnageF.. Pour encoder, choisissez l'une des trois fréquences:44,1 kHz, 22,05 kHz, 11,025 kHz.
On pense que la gamme de fréquences que la personne entend de 20 Hz à 20 kHz.
La qualité de l'encodage du son binaire est déterminée par la profondeur de codage et la fréquence d'échantillonnage.
La fréquence d'échantillonnage d'un signal de son analogique peut prendre des valeurs de 8 kHz à 48 kHz. À une fréquence de 8 kHz, la qualité du signal sonore sans distincte correspond à la qualité des émissions radio et une fréquence de 48 kHz - la qualité du son audio-CD. Il convient également de garder à l'esprit que les mono -oïsmes et les stéréoisismes sont possibles.
Adaptateur audio (frais sonores) -un dispositif convertit les oscillations électriques de fréquence sonore dans un code binaire numérique lors de la saisie de son et de son dos (du code numérique dans des oscillations électriques) lors de la lecture du son.
Caractéristiques de l'adaptateur audio: Fréquence d'échantillonnage et décharge du registre.
La décharge du registre -le nombre de bits dans le registre de l'adaptateur audio. Plus la décharge est grande, plus l'erreur est la plus petite de chaque transformation de la valeur de courant électrique et de l'arrière. Si la décharge est égale JE., lors de la mesure du signal d'entrée peut être obtenu 2JE. = N. Différentes valeurs.
Taille de monoadylfile numérique (UNE.) Il est mesuré par la formule:
UNE.\u003d F *T.* JE./8 ,
oùF -fréquence de discrétisation (Hz),T. - un temps sain ou un enregistrement sonore,JE. la décharge du registre (permission). Selon cette formule, la taille est mesurée en octets.
Taille de fichier audio stéréo numérique (UNE.) Il est mesuré par la formule:
UNE.=2* F.* T.* JE./8 ,
le signal est enregistré pour deux colonnes, car les canaux sonores gauche et droit sont codés séparément.
Exemple. Essayons d'évaluer le volume d'informations du fichier audio stéréo avec la durée du son de 1 seconde avec son de haute qualité (16 bits, 48 \u200b\u200bkHz). Pour cela, le nombre de bits doit être multiplié par le nombre d'échantillons en 1 seconde et multiplier par 2 (stéréo):
16 bits * 48 000 * 2 \u003d 1 536 000 bits \u003d 192 000 octets \u003d 187,5 kb
Le tableau 1 montre combien de MB occupera une minute codée d'informations sonores avec une fréquence d'échantillonnage différente:
Type de signal | Discrétisation des fréquences, KHz |
||
16 bits, stéréo | |||
16 bits, mono | |||
8 bits, mono |
Exemples de tâches:
1. Déterminez la taille (en octets) du fichier audio numérique, dont l'heure sonore est de 10 secondes à une fréquence de discrétisation de 22,05 kHz et une résolution de 8 bits. La compression de fichier n'est pas soumise.
Décision:
Formule pour calculer la taille (en octets) Fichier audio numérique: UNE.= F.* T.* JE./8.
Pour transférer des octets, la valeur obtenue doit être divisée en 8 bits.
22.05 kHz \u003d 22.05 * 1000 Hz \u003d 22050 Hz
UNE.= F.* T.* JE./8 = 22050 x 10 x 8/8 \u003d 220500 octets.
Répondre: 220500
2. L'utilisateur a une mémoire de 2,6 Mo. Il est nécessaire d'enregistrer un fichier audio numérique avec une durée d'un son de 1 minute. Quelle devrait être la fréquence d'échantillonnage et la décharge?
Décision:
Formule pour calculer la fréquence d'échantillonnage et de bit: F * i \u003d A / T
(Capacité de mémoire en octets): (temps sonore en secondes):
2, 6 Mo \u003d 26 octets
F * I \u003d A / T \u003d 26 octets: 60 \u003d 45438.3 octet
F \u003d 45438.3 octet: i
La décharge de l'adaptateur peut être de 8 ou 16 bits. (1 octet ou 2 octets). Par conséquent, la fréquence de discrétisation peut être soit 45438.3 Hz \u003d 45,4 kHz 44,1 kHz - Fréquence caractéristique standard de discrétisation, ou 22719.15 Hz \u003d 22,7 kHz 22.05 kHz - Taux d'échantillonnage de caractéristiques standard
Répondre:
Fréquence d'échantillonnage | La décharge de l'adaptateur audio |
|
1 option | ||
Option 2 |
3. La quantité de mémoire libre sur le disque est de 5,25 Mo, la décharge de la carte son - 16. Quelle est la durée du fichier audio numérique, enregistrée avec une fréquence de discrétisation de 22,05 kHz?
Décision:
Formule pour calculer la durée du son: t \u003d A / F / I
(Capacité de mémoire en octets): (fréquence d'échantillonnage en Hz): (bit de la planche sonore en octets):
5.25 MB \u003d 5505024 octet
5505024 octet: 22050 Hz: 2 octets \u003d 124,8 secondes
Répondre: 124,8
4. Calculez le nombre d'informations d'octet occupant une seconde enregistrement stéréo sur un CD (fréquence 44032 Hz, 16 bits par valeur). Combien faut-il une minute? Quelle est la capacité de disque maximale (comptant la durée maximale de 80 minutes)?
Décision:
Formule pour calculer la mémoire UNE.=
F.*
T.*
JE.:
(Temps d'enregistrement en secondes) * (fleur de circuit sonore) * (fréquence d'échantillonnage). 16 bits -2 octet.
1) 1C x 2 x 44032 HZ \u003d 88064 octets (1 seconde enregistrement stéréo sur un CD)
2) 60C x 2 x 44032 HZ \u003d 5283840 Octet (1 minute Cartes stéréo sur un CD)
3) 4800C x 2 x 44032 HZ \u003d BYTE \u003d 412800 KB \u003d 403,125 Mo (80 minutes)
Réponse: 88064 octets (1 seconde), 5283840 octet (1 minute), 403,125 Mo (80 minutes)
Tâches de formation:
1) Un seul canal (mono) est produit un enregistrement sonore avec une fréquence de discrétisation de 22 kHz et une profondeur de codage de 16 bits. L'enregistrement dure 2 minutes, ses résultats sont enregistrés dans le fichier, la compression de données n'est pas effectuée. Lequel des nombres suivants sont les plus proches de la taille du fichier reçu exprimé en mégaoctets?
2) Enregistrement sonore à double canal (stéréo) avec une fréquence d'échantillonnage de 48 kHz et une profondeur de 24 bits codant. L'enregistrement dure 1 minute, ses résultats sont enregistrés dans un fichier, la compression de données n'est pas effectuée. Lequel des nombres suivants sont les plus proches de la taille du fichier reçu exprimé en mégaoctets?
3) Un seul canal (mono) a été effectué un enregistrement sonore avec une fréquence de discrétisation de 16 kHz et une résolution 24 bits. En conséquence, un fichier a été obtenu avec une taille de 3 Mo, la compression de données n'a pas été effectuée. Laquelle des valeurs suivantes est la plus proche de la période pendant laquelle l'enregistrement a été enregistré?
1) 30 SexexExek
4) Enregistrement du son mono-canal (mono) avec une fréquence d'échantillonnage de 128 Hz. Lors de l'enregistrement, 64 niveaux d'échantillonnage ont été utilisés. L'enregistrement dure 6 minutes 24 secondes, ses résultats sont écrits dans le fichier et chaque signal est codé par le nombre minimum possible et identique de bits. Lequel des nombres ci-dessous sont les plus proches de la taille du fichier reçu exprimé en kilo-octets?
5) Enregistrement de son à deux canaux (stéréo) avec une fréquence d'échantillonnage de 16 kHz et une profondeur de codage 32 bits. L'enregistrement dure 12 minutes, ses résultats sont écrits dans le fichier, la compression de données n'est pas effectuée. Lequel des nombres suivants sont les plus proches de la taille du fichier reçu exprimé en mégaoctets?
 Comment payer un nom de domaine
Comment payer un nom de domaine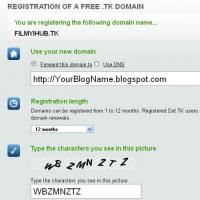 Zone de domaine des îles Tokelau
Zone de domaine des îles Tokelau Quel est le domaine quels problèmes peuvent être
Quel est le domaine quels problèmes peuvent être Yandex WordStat: instructions détaillées pour l'utilisation des opérateurs de service et de regroupement et une demande compliquée
Yandex WordStat: instructions détaillées pour l'utilisation des opérateurs de service et de regroupement et une demande compliquée Modification des fichiers DBF
Modification des fichiers DBF Xenu Link Sleuth - Qu'est-ce que ce programme Comment utiliser le programme Xenu
Xenu Link Sleuth - Qu'est-ce que ce programme Comment utiliser le programme Xenu Méthodes Copiez et insérez du texte du clavier sans utiliser de la souris
Méthodes Copiez et insérez du texte du clavier sans utiliser de la souris