TesseRact training. TesseRact-OCR in Visual Studio - recognize the page of the text. Digitization of images one by one
Tesseract. - a free platform for optical recognition of text, the sources of which Google presented the community in 2006. If you write a software to recognize text, you probably have to access the services of this powerful library. And if she did not cope with your text, then you have one way left - to teach it. This process is quite complicated and replete with no obvious and sometimes directly with magical actions. The original description is. I needed almost a whole day to comprehend all his depths, so I want to save, I hope its more understandable option. So to help yourself and others go through this path the next time faster.
0. What we need
- TesseRact actually.
gedit /etc/apt/sources.list.
dEB http://notesalexp.net/debian/precise/ Precise Main
wget -o - http://notesalexp.net/debian/alexp_Key.Asc
aPT-KEY Add alexp_key.asc
aPT-GET UPDATE
aPT-Get Install Tesseract-OCR
- Image with text for training
1. Create and edit the Box file
For. To mark the characters on the image and set their matches of UTF-8 text symbols are Box files. These are the usual text files in which each character corresponds to a string with a symbol and rectangle coordinates in pixels. Initially, you generate a utility from the TESSERACT package:
tesseRact CCC.Eee.Eee.Exp0 Batch.Nochop MakeBox
Received CCC.Eee.Exp0.Box file in the current directory. Look at it. Symbols at the beginning of the line fully match the characters in the file? If so, then you don't need to train anything, you can sleep well. In our case, most likely the characters will not coincide any of the essentially in number. Those. TesseRact with the default dictionary did not recognize not only the characters but also considered some of them for two or more. Perhaps part of the characters we will "stick", i.e. will fall into a common box and will be recognized as one. It all needs to fix before you go further. Work tedious and painstaking, but fortunately there are a number third-party utilities. For example, I used PytesTrainer-1.03. We open the image to them, the box-file with the same name he himself pulls out.
Half a day passed ... You with a sense of deep satisfaction with the PyteSeractTrainer (you did not forget to save the result, right?) And you have a correct Box file. Now you can go to the next step.
2. Training Tesseract
tesseRact CCC.Eee.Eee.EEE.EEE.EEE.EE.EEE.EVP0 NOBATCH BOX.TRAIN
We get a lot of errors, but we are looking at something like "Found 105 Good Blobs". If the figure is significantly greater than the number of "studied" characters, that is, the chance that the training as a whole has succeeded. Otherwise, we return to the beginning. As a result of this step, you have a CCC.Eee.EEE.Exp0.tr file
3. Remove the symbol set
unicharset_Extractor CCC.Eee.Exp0.Box.
We receive a set of characters as a Unicharset file in the current directory, where each character and its characteristics are located in a separate line. Here our task will check and correct the characteristics of the characters (the second column in the file). For small letters of the alphabet, we put a sign 3 for large 5, for the punctuation of 10 for numbers 8, everything else (type + \u003d -) marked 0. Chinese and Japanese hieroglyphs We note 1. Usually all signs are right, so this stage is a lot of time You will not take.
4. Describe the font style
Create a CCC.Font_Properties file with a single string: Eee 0 0 0 0 0. Here you first write the name of the font, then the number 1 or 0 is labeled the presence of style characters (respectively, ITALIC BOLD Fixed Serif Fraktur). In our case there are no styles, so we leave everything in zeros.
5. Clusters of figures, prototypes and other magic
For further studies, we need to perform three more operations. You can try to understand their meaning from the official description, I was not before :). Just perform:
shapeclustering -f CCC.Font_Properties -u Unicharset CCc.Eee.Exp0.tr
... file shapetable
and then:
mFTRAINING -F CCC.Font_Properties -u Unicharset -o CCC.UNICHARSET CCC.Eee.Exp0.tr
... get files cCC.Unicharset, Inttemp, PFFMTABLE
Finally:
cntraining CCC.Eee.Exp0.tr.
... We get the NORMPROTO file.
6. Dictionaries
The theoretically filling of the dictionaries of frequently used words (and words at all) helps TesseRact-u to deal with your doodles. Understanding dictionaries, but if you suddenly want, make filesfrequent_Words_List and Words_List in which enter (each with new String) Accordingly, frequently used and simply words of the language.
To convert these lists to the correct format, perform:
wordList2Dawg Frequent_Words_List CCC.FREQ-DAWG CCC.UNICHARSET
wordList2Dawg Words_List CCC.WORD-DAWG CCC.UNICHARSET
7. Last mysterious file
His name is UnicharamBigs. In theory, he must pay attention to the TesseRact on similar symbols. it text file In each row with the separators, the tabs are described by pairs of strings that can be confused when recognizing. Fully file format is described in the documentation, it was not needed and I left it empty.
8. Last team
All files must be renamed so that their names begin with the name of the language. Those. Only files will remain in the directory:
cCC.BOX.
cCC.INTTEMP.
cCC.PFFMTABLE
cCC.tif.
cCC.Font_Properties.
cCC.NORMPROTO.
cCC.Shapetable
cCc.tr.
cCC.Unicharset.
And finally, we perform:
cOMBINE_TESSDATA CCC.
(!) The point is obligatory. As a result, we get the CCC.TrainedData file, which will allow us further to recognize our mysterious new language.
9. We check whether it was worth it :)
Now let's try to recognize our sample using the already trained TESSERACT-A:
sudo CP CCC.TrainedData / USR / Share / Tesseract-OCR / TESSDATA /
tesseRact CCC.tif Output -L CCC
Now we look at Output.txt and rejoice (or getting up-minded, depending on the result).
We needed to improve the workflow in our company, first of all, to increase the speed of processing paper documents. To do this, we decided to develop software solution On the basis of one of the OCR (Optical Character Recognition) libraries.
OCR, or optical text recognition, is a mechanical or electronic conversion of printed text images into a machine. OCR is a method of digitizing printed text so that it can be electronically saved, edited, is displayed and applied in such machine processes as cognitive calculations, machine translation and intelligent data analysis.
In addition, OCR is used as a method for entering information from paper documents (including financial entries, business Cards, invoices and much more).
Before implementing the application itself, we conducted a thorough analysis of the three most popular OCR libraries in order to determine the most appropriate option to solve our tasks.
We analyzed the three most popular OCR libraries:
- Google Text Recognition API
Google Text Recognition API
Google Text Recognition API is the process of detecting text in images and video streams and recognition text contained in it. After detection, the recognizer determines the actual text in each block and breaks it to words and lines. He discovers the text of various languages \u200b\u200b(French, German, English, etc.) in real time.
It is worth noting that, in general, this OCR has coped with the task. We got the opportunity to recognize the text both in Real-Time and with already ready-made images of text documents. In the course of the analysis of this library, we revealed both the advantages and disadvantages of its use.
Benefits:
- the ability to recognize text in real time
- the ability to recognize text from images;
- small size library;
- High recognition speed.
Disadvantages:
- Large size files with trained data (~ 30MB).
Tesseract.
TesseRact is an open source OCR library for different operating systems. It is free software, issued under the Apache license, version 2.0, supports various languages.
The development of TesseRACT was funded company Google Since 2006, the time when it was considered one of the most accurate and efficient OCR libraries with open source.
Be that as it may, at that time, the results of the introduction of TesseRact we remained not very satisfied, because The library is incredibly volumetric and does not allow to recognize the text in real time.
Benefits:
- has an open source code;
- Accordingly, it is enough to teach OCR to recognize the desired fonts and improve the quality of recognizable information. After fast settings Libraries and learning The quality of recognition results rapidly increased.
Disadvantages:
- insufficient recognition accuracy, which is eliminated by training and learning the recognition algorithm;
- To recognize text in real time, additional processing of the resulting image is required;
- Small recognition accuracy when using standard files with font data, words and symbols.
Anyline
Anyline provides multi-platform SDK, which allows developers to easily integrate OCR functions in applications. This OCR library attracted us by numerous capabilities setting recognition parameters and provided by models to solve specific applied tasks. It is worth noting that the library is paid and intended for commercial use.
Benefits:
- pretty simple setup recognition of the desired fonts;
- text recognition in real time;
- Easy and convenient setting of recognition parameters;
- the library can recognize barcodes and QR codes;
- Provides finished modules To solve various tasks.
Disadvantages:
- low recognition speed;
- to obtain satisfactory results required initial setup Fonts for recognition.
In the course of the analysis performed to solve our tasks, we were staying on Google Text Recognition API, which combines high speed in itself, light setting and high recognition results.
The solution developed by us allows you to scan paper documents automatically digitize them and save to a single database. The quality of recognizable information is about 97%, which is a very good result.
Due to the introduction of the developed system internal (including document processing, their creation and exchange between departments, etc.) was accelerated by 15%.
It took me to get the values \u200b\u200bof the clogged numbers. Numbers robbed From the screen.
I thought, and not try to try OCR? I tried TesseRact.
Below I will tell you how I tried to adapt TesseRact, why did I train it, and what happened from it. The project on Hithabe lies a CMD script that automates how much time the workout process is possible, and the data on which I conducted training. In a word, there is everything you need to train TesseRact to train something useful.
Preparation
Cloning the repository or download zIP archive (~ 6MB). Install Tesserator 3.01 with from.Syta. If it is no longer there, then from the ZIP archive subdirectory / Distros.
Go to the samples folder, run montage_all.cmd.
This script will create a final image. samples / total.png., you can not start the script, because I already placed it in the root folder of the project.
Why train?
Perhaps and without training the result will be good? Check.
./exp1 - As IS\u003e TesseRact ../total.png Total
Position the corrected result in the file model_total.txtTo compare the results of recognition. An asterisk marks the wrong values.
| model_total.txt | Recognition default |
|---|---|
| 27 33 39 625.05 9 163 1,740.10 15 36 45 72 324 468 93 453 1,200.10 80.10 152.25 158.25 176.07 97.50 170.62 54 102 162 78 136.50 443.62 633.74 24 1,579.73 1,576.73 332.23 957.69 954.69 963.68 1,441.02 1,635.34 50 76 168 21 48 30 42 108 126 144 114 462 378 522 60 240 246 459.69 456.69 198 61 255 |
27 33 39 525 05* 9 153* 1,740 10* 15 35* 45 72 324 455* 93 453 1,200 10* 50 10* 152 25* 155 25* 175 07* 97 50* 170 52* 54 102 152* 75* 135 50* 443 52* 533 74* 24 1,579 73* 1,575 73* 332 23* 957 59* 954 59* 953 55* 1,441 02* 1,535 34* 50 75* 155* 21 45* 30 42 105* 125* 144 114 452* 375* 522 50* 240 245* 459 59* 455 59* 195* 51* 255 |
default recognition errors

It can be seen that there are many errors. If you look closely, you can see that the decimal point is not recognized, the numbers 6 and 8 are recognized as 5. Will the workout help get rid of errors?
Workout
Training TesseRact allows you to ride it on recognizing images of texts in the form in which you will feed it similar images in the recognition process.
You pass TesseRact training images, correct the recognition errors and transmit these directions to the Tesseract-y. And he corrects the coefficients in his algorithms to continue to prevent the errors you found.
To perform workout you want to run. / Exp2 - Trained\u003e Train.cmd
What is the workout process? And in the fact that TesseRACT processes the training image and forms so-called. Boxes of characters - highlights individual characters from the text creating a list of restricting rectangles. At the same time, he makes guessing about what kind of symbol is limited by a rectangle.
The results of this work writes to the Total.Box file, which looks like this:
2 46 946 52 956 0
7 54 946 60 956 0
3 46 930 52 940 0
3 54 930 60 940 0
3 46 914 52 924 0
9 53 914 60 924 0
6 31 898 38 908 0
2 40 898 46 908 0
5 48 898 54 908 0
0 59 898 66 908 0
…
Here in the singel column symbol, and in 2 - 5 columns coordinates of the lower left corner of the rectangle, its height and width.
Of course, it is difficult to edit it manually and uncomfortable, so graphic utilities facilitating this work were created by enthusiasts. I used to be written in Java.
 After startup. / EXP2 - Trained\u003e Java -Jar JTESSBOXEDITOR-0.6JTESSBOXEditor.jar You need to open the file. / Exp2 - trained / total.png, the file will be automatically open. / Exp2 - trained / total.box and rectangle defined in it Will be superimposed on the training image.
After startup. / EXP2 - Trained\u003e Java -Jar JTESSBOXEDITOR-0.6JTESSBOXEditor.jar You need to open the file. / Exp2 - trained / total.png, the file will be automatically open. / Exp2 - trained / total.box and rectangle defined in it Will be superimposed on the training image.
In the left part, the contents of the Total.Box file are given on the right there is a training image. Above the image is the active line of the Total.Box file
Blue depicted boxes, and red - boxing corresponding to the active row.
I corrected all the wrong 5-ki on the right 6-ki and 8th, added rows with definitions of all decimal points in the file and saved Total.Box
After editing is complete, it is necessary that the script continues to work, you need to close the JTESSBOXEDITOR. Further, all actions are performed by a script automatically without user participation. The script writes the results of training under the code TTN
To use the learning outcomes when recognizing, you need to start TESSERACT C key -L TTN
./exp2 - Trained /\u003e Tesseract ../total.png Total-Trained -l TTN
It can be seen that all the numbers began to be recognized correctly, but the decimal point is still not recognized.
| model_total.txt | Recognition default |
Recognition after workout |
|---|---|---|
| 27 33 39 625.05 9 163 1,740.10 15 36 45 72 324 468 93 453 1,200.10 80.10 152.25 158.25 176.07 97.50 170.62 54 102 162 78 136.50 443.62 633.74 24 1,579.73 1,576.73 332.23 957.69 954.69 963.68 1,441.02 1,635.34 50 76 168 21 48 30 42 108 126 144 114 462 378 522 60 240 246 459.69 456.69 198 61 255 |
27 33 39 525 05* 9 153* 1,740 10* 15 35* 45 72 324 455* 93 453 1,200 10* 50 10* 152 25* 155 25* 175 07* 97 50* 170 52* 54 102 152* 75* 135 50* 443 52* 533 74* 24 1,579 73* 1,575 73* 332 23* 957 59* 954 59* 953 55* 1,441 02* 1,535 34* 50 75* 155* 21 45* 30 42 105* 125* 144 114 452* 375* 522 50* 240 245* 459 59* 455 59* 195* 51* 255 |
27 33 39 625 05* 9 163 1,740 10* 15 36 45 72 324 468 93 453 1,200 10* 80 10* 152 25* 158 25* 176 07* 97 50* 170 62* 54 102 162 78 136 50* 443 62* 633 74* 24 1,579 73* 1,576 73* 332 23* 957 69* 954 69* 963 68* 1,441 02* 1,635 34* 50 76 168 21 48 30 42 108 126 144 114 462 378 522 60 240 246 459 69* 456 69* 198 61 255 |
learning Recognition Errors

Enlarge image
You can increase in different ways, I tried two ways: scale and resize
| total-scaled.png (fragment) | total-resized.png (fragment) |
|---|---|
| Convert Total.png Total-Scaled.png -Scale "208x1920" | convert Total.png Total-resized.png -Resize "208x1920" |

|

|
Since the images of the characters increased with the images themselves, the training data under the code TTN is outdated. Therefore, then I recognized without a key -L TTN.
It can be seen that in the image Total-scaled.png Tesseract confuses 7-ku with a 2nd, and it does not confuse Total-resized.png. On both images, the decimal point is correct. Image recognition Total-resized.png is almost perfect. There are only three errors - the gap between the numbers in numbers 21, 114 and 61.
But this error is not critical, because It is easy to fix it by simply removal from the lines of spaces.
total-Scaled.png Recognition Errors

total-Resized.png Recognition Errors

| model_total.txt | Recognition default |
Recognition after workout |
total-scaled.png. | total-resized.png. |
|---|---|---|---|---|
| 27 33 39 625.05 9 163 1,740.10 15 36 45 72 324 468 93 453 1,200.10 80.10 152.25 158.25 176.07 97.50 170.62 54 102 162 78 136.50 443.62 633.74 24 1,579.73 1,576.73 332.23 957.69 954.69 963.68 1,441.02 1,635.34 50 76 168 21 48 30 42 108 126 144 114 462 378 522 60 240 246 459.69 456.69 198 61 255 |
27 33 39 525 05* 9 153* 1,740 10* 15 35* 45 72 324 455* 93 453 1,200 10* 50 10* 152 25* 155 25* 175 07* 97 50* 170 52* 54 102 152* 75* 135 50* 443 52* 533 74* 24 1,579 73* 1,575 73* 332 23* 957 59* 954 59* 953 55* 1,441 02* 1,535 34* 50 75* 155* 21 45* 30 42 105* 125* 144 114 452* 375* 522 50* 240 245* 459 59* 455 59* 195* 51* 255 |
27 33 39 625 05* 9 163 1,740 10* 15 36 45 72 324 468 93 453 1,200 10* 80 10* 152 25* 158 25* 176 07* 97 50* 170 62* 54 102 162 78 136 50* 443 62* 633 74* 24 1,579 73* 1,576 73* 332 23* 957 69* 954 69* 963 68* 1,441 02* 1,635 34* 50 76 168 21 48 30 42 108 126 144 114 462 378 522 60 240 246 459 69* 456 69* 198 61 255 |
22*
33 39 625.05 9 163 1,240.10* 15 36 45 22* 324 468 93 453 1,200.10 80.10 152.25 158.25 126.02* 92.50* 120.62* 54 102 162 28* 136.50 443.62 633.24* 24 1,529.23* 1,526.23* 332.23 952.69* 954.69 963.68 1,441.02 1,635.34 50 26* 168 2 1* 48 30 42 108 126 144 1 14* 462 328* 522 60 240 246 459.69 456.69 198 6 1* 255 |
27 33 39 625.05 9 163 1,740.10 15 36 45 72 324 468 93 453 1,200.10 80.10 152.25 158.25 176.07 97.50 170.62 54 102 162 78 136.50 443.62 633.74 24 1,579.73 1,576.73 332.23 957.69 954.69 963.68 1,441.02 1,635.34 50 76 168 2 1* 48 30 42 108 126 144 1 14* 462 378 522 60 240 246 459.69 456.69 198 6 1* 255 |
Digitization of images one by one
OK, what if you need to digitize images one after another in real linen mode?
I try one by one.
./exp5 - one by one\u003e for / r% i in (* .png) do tesseract "% I" "% i"
Two and three-digit numbers are not determined at all!
| 625.05 | |
| 1740.10 | |
Digitization of small packages
And if you want to digitize images by packets by several images (6 or 10 in the package)? Ten time.
./exp6 - Ten in Line\u003e TesseRact Teninline.png Teninline
Recognized, and even without a gap among 61.
conclusions
In general, I expected the worst results, because Small raster fonts are a boundary case due to their small size, distinct granularity and constancy - different images One symbol completely coincide. And the practice has shown that the arranged artificially inspired figures are better recognized.
Pre-processing image has a greater effect than learning. Increase with smoothing: convert -resize ...
Recognition of separate "short" two and three-digit numbers of unsatisfactory - numbers need to be collected in packages.
But in general, Tesseract almost coped with the task, despite the fact that it is sharpened for other tasks - recognizing inscriptions in the photo and video, scans of documents.
Tesseract. - a free platform for optical recognition of text, the sources of which Google presented the community in 2006. If you write a software to recognize text, you probably have to access the services of this powerful library. And if she did not cope with your text, then you have one way left - to teach it. This process is quite complicated and replete with no obvious and sometimes directly with magical actions. The original description is. I needed almost a whole day to comprehend all his depths, so I want to save, I hope its more understandable option. So to help yourself and others go through this path the next time faster.
0. What we need
- TesseRact actually.
gedit /etc/apt/sources.list.
dEB http://notesalexp.net/debian/precise/ Precise Main
wget -o - http://notesalexp.net/debian/alexp_Key.Asc
aPT-KEY Add alexp_key.asc
aPT-GET UPDATE
aPT-Get Install Tesseract-OCR
- Image with text for training
1. Create and edit the Box file
For. To mark the characters on the image and set their matches of UTF-8 text symbols are Box files. These are the usual text files in which each character corresponds to a string with a symbol and rectangle coordinates in pixels. Initially, you generate a utility from the TESSERACT package:
tesseRact CCC.Eee.Eee.Exp0 Batch.Nochop MakeBox
Received CCC.Eee.Exp0.Box file in the current directory. Look at it. Symbols at the beginning of the line fully match the characters in the file? If so, then you don't need to train anything, you can sleep well. In our case, most likely the characters will not coincide any of the essentially in number. Those. TesseRact with the default dictionary did not recognize not only the characters but also considered some of them for two or more. Perhaps part of the characters we will "stick", i.e. will fall into a common box and will be recognized as one. It all needs to fix before you go further. Work tedious and painstaking, but fortunately there are a number of third-party utilities for this. For example, I used PytesTrainer-1.03. We open the image to them, the box-file with the same name he himself pulls out.
Half a day passed ... You with a sense of deep satisfaction with the PyteSeractTrainer (you did not forget to save the result, right?) And you have a correct Box file. Now you can go to the next step.
2. Training Tesseract
tesseRact CCC.Eee.Eee.EEE.EEE.EEE.EE.EEE.EVP0 NOBATCH BOX.TRAIN
We get a lot of errors, but we are looking at something like "Found 105 Good Blobs". If the figure is significantly greater than the number of "studied" characters, that is, the chance that the training as a whole has succeeded. Otherwise, we return to the beginning. As a result of this step, you have a CCC.Eee.EEE.Exp0.tr file
3. Remove the symbol set
unicharset_Extractor CCC.Eee.Exp0.Box.
We receive a set of characters as a Unicharset file in the current directory, where each character and its characteristics are located in a separate line. Here our task will check and correct the characteristics of the characters (the second column in the file). For small letters of the alphabet, we put a sign 3 for large 5, for the punctuation of 10 for numbers 8, everything else (type + \u003d -) marked 0. Chinese and Japanese hieroglyphs We note 1. Usually all signs are right, so this stage is a lot of time You will not take.
4. Describe the font style
Create a CCC.Font_Properties file with a single string: Eee 0 0 0 0 0. Here you first write the name of the font, then the number 1 or 0 is labeled the presence of style characters (respectively, ITALIC BOLD Fixed Serif Fraktur). In our case there are no styles, so we leave everything in zeros.
5. Clusters of figures, prototypes and other magic
For further studies, we need to perform three more operations. You can try to understand their meaning from the official description, I was not before :). Just perform:
shapeclustering -f CCC.Font_Properties -u Unicharset CCc.Eee.Exp0.tr
... file shapetable
and then:
mFTRAINING -F CCC.Font_Properties -u Unicharset -o CCC.UNICHARSET CCC.Eee.Exp0.tr
... get files cCC.Unicharset, Inttemp, PFFMTABLE
Finally:
cntraining CCC.Eee.Exp0.tr.
... We get the NORMPROTO file.
6. Dictionaries
The theoretically filling of the dictionaries of frequently used words (and words at all) helps TesseRact-u to deal with your doodles. Understanding dictionaries, but if you suddenly want, make filesfrequent_Words_List and Words_List in which you enter (each from a new line), respectively, often used and simply words of the language.
To convert these lists to the correct format, perform:
wordList2Dawg Frequent_Words_List CCC.FREQ-DAWG CCC.UNICHARSET
wordList2Dawg Words_List CCC.WORD-DAWG CCC.UNICHARSET
7. Last mysterious file
His name is UnicharamBigs. In theory, he must pay attention to the TesseRact on similar symbols. This text file in each row with tab separators is described by pairs of strings that can be confused when recognizing. Fully file format is described in the documentation, it was not needed and I left it empty.
8. Last team
All files must be renamed so that their names begin with the name of the language. Those. Only files will remain in the directory:
cCC.BOX.
cCC.INTTEMP.
cCC.PFFMTABLE
cCC.tif.
cCC.Font_Properties.
cCC.NORMPROTO.
cCC.Shapetable
cCc.tr.
cCC.Unicharset.
And finally, we perform:
cOMBINE_TESSDATA CCC.
(!) The point is obligatory. As a result, we get the CCC.TrainedData file, which will allow us further to recognize our mysterious new language.
9. We check whether it was worth it :)
Now let's try to recognize our sample using the already trained TESSERACT-A:
sudo CP CCC.TrainedData / USR / Share / Tesseract-OCR / TESSDATA /
tesseRact CCC.tif Output -L CCC
Now we look at Output.txt and rejoice (or getting up-minded, depending on the result).
TESSERACT-OCR is a free library for text recognition. In order to connect it to you need to download the following components:
Leptonica - http://code.google.com/p/leptonica/downloads/detail?name\u003dleptonica-1.68-win32-lib-include-dirs.zip.
The latest version of TeesRact-OCR (on this moment 3.02) - https://code.google.com/p/tesseract-ocr/downloads/detail?name\u003dtesshant-3.02.02-win32-lib-include-dirs.zip&can\u003d2&q\u003d
Labor learning data - https://tessract-ocr.googlecode.com/files/Tesseract-ocr-3.02.rus.tar.gz
Everything can be collected yourself by downloading source codesBut we will not do this.
By creating a new project, connect paths to LIB and H files. And write a simple code.
#Include.
Connect LIB files:
libteseratorAct302.Lib.
liblept168.lib
Complete - the program is successfully created. As an example, take the following picture:
We run the program so that the information is displayed in the file (since UTF-8 in the Capo console will be):
Test\u003e A.Txt.
File content below:
Tesseract-OCR Version: 3.02
Leptonica Version: Leptonica-1.68 (Mar 14 2011, 10:47:28)
OCR OUTPUT:
, Substituting this expression in (63), we see that
Titled single-band, signal is industrial
and the depth of the modulation is equal to a.
7 envelope ho) primary signal directly
It is impossible to observe the oscilloscope, so
How this signal is narrow-band, and we
'Case "clarity" is absent, but
With single-band modulation, narrow
'Salmon signal with the same envelope, and then she
"And manifests itself explicitly and sometimes (as in op
"Sunny case) makes confusion in the minds of poorly
and researchers ..
6.4. "Costa Formula"
G U.
With the advent of OM in textbooks, coffee `
Estatys and monographs debaught the question of
how winning gives the transition from amplitude
Modulations to single-lane. It was much expressed
Disordered opinions. At the beginning of the 60s of Ame-
Rican scientist J. Kostas wrote that, see
Trebuned journal literature on Ohm, he
discovered in each article its estimate of energy
"Clear winnings about AM-two to
Multitious dozen. As a result, he installed
- Winning, indicated in each article,
It makes approximately (z-k-s!) dB, where M-number co-'g
\u003e Authors of this article.
E, '11 If this joke and inaccurate, it is still correct
'Music reflects that maturity that existed
; In those years. In addition to the fact that different authors
D climbed a comparison in various conditions and once-m
, Nomu determined the energy winnings, they are so- 1
', `The same allowed a lot of different mistakes. four "
, `Here are examples of some reasoning. ",
1. With usual AM, believing the power 'carrier
 Cellular - what it is on the iPad and what's the difference
Cellular - what it is on the iPad and what's the difference Go to digital television: What to do and how to prepare?
Go to digital television: What to do and how to prepare? Social polls work on the Internet
Social polls work on the Internet Savin recorded a video message to the Tyuments
Savin recorded a video message to the Tyuments Menu of Soviet tables What was the name of Thursday in Soviet canteens
Menu of Soviet tables What was the name of Thursday in Soviet canteens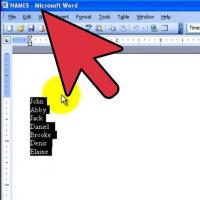 How to make in the "Word" list alphabetically: useful tips
How to make in the "Word" list alphabetically: useful tips How to see classmates who retired from friends?
How to see classmates who retired from friends?