Application du filtre de Kalman pour traiter une séquence de coordonnées GPS. Filtrage de Kalman Évaluation des paramètres de radionavigation à l'aide du filtre de Kalman
Sur Internet, y compris sur Habré, vous pouvez trouver de nombreuses informations sur le filtre de Kalman. Mais il est difficile de trouver une dérivation facilement digestible des formules elles-mêmes. Sans conclusion, toute cette science est perçue comme une sorte de chamanisme, les formules ressemblent à un ensemble de symboles sans visage et, plus important encore, de nombreuses déclarations simples qui se trouvent à la surface d'une théorie s'avèrent incompréhensibles. Le but de cet article sera de parler de ce filtre dans un langage aussi accessible que possible.
Le filtre de Kalman est un puissant outil de filtrage de données. Son principe de base est que lors du filtrage, des informations sur la physique du phénomène lui-même sont utilisées. Par exemple, si vous filtrez les données du compteur de vitesse d'une voiture, alors l'inertie de la voiture vous donne le droit de percevoir les sauts de vitesse trop rapides comme une erreur de mesure. Le filtre de Kalman est intéressant car, en un sens, c'est le meilleur filtre. Nous discuterons plus en détail ci-dessous de ce que signifient exactement les mots « le meilleur ». À la fin de l'article, je montrerai que dans de nombreux cas, les formules peuvent être simplifiées à un point tel qu'il n'en restera presque rien.
Programme éducatif
Avant de me familiariser avec le filtre de Kalman, je propose de rappeler quelques définitions et faits simples de la théorie des probabilités.
Valeur aléatoire
Quand ils disent qu'une variable aléatoire est donnée, ils veulent dire que cette quantité peut prendre des valeurs aléatoires. Il prend différentes valeurs avec différentes probabilités. Lorsque vous lancez, disons, un dé, un ensemble discret de valeurs disparaîtra :. Lorsqu'il s'agit, par exemple, de la vitesse d'une particule errante, alors, évidemment, il faut faire face à un ensemble continu de valeurs. Nous désignerons les valeurs "abandonnées" d'une variable aléatoire par, mais parfois, nous utiliserons la même lettre, que nous utilisons pour désigner une variable aléatoire :.
Dans le cas d'un ensemble continu de valeurs, la variable aléatoire est caractérisée par la densité de probabilité, qui nous dicte que la probabilité que la variable aléatoire « tombe » dans un petit voisinage d'un point de longueur est égale à. Comme nous pouvons le voir sur l'image, cette probabilité est égale à l'aire du rectangle ombré sous le graphique :
Assez souvent dans la vie, les variables aléatoires sont gaussiennes lorsque la densité de probabilité est égale.
On voit que la fonction a la forme d'une cloche centrée en un point et avec une largeur caractéristique de l'ordre.
Puisque nous parlons de la distribution gaussienne, ce serait un péché de ne pas mentionner d'où elle vient. Tout comme les nombres sont fermement établis en mathématiques et apparaissent dans les endroits les plus inattendus, la distribution gaussienne s'est profondément enracinée dans la théorie des probabilités. Une déclaration remarquable qui explique en partie l'omniprésence gaussienne est la suivante :
Soit une variable aléatoire avec une distribution arbitraire (en fait, il y a quelques restrictions sur cet arbitraire, mais elles ne sont pas du tout strictes). Réalisons des expériences et calculons la somme des valeurs "abandonnées" de la variable aléatoire. Faisons beaucoup de ces expériences. Il est clair qu'à chaque fois nous recevrons une valeur différente du montant. En d'autres termes, cette somme est elle-même une variable aléatoire avec sa propre loi de distribution. Il s'avère que pour assez grand la loi de distribution de cette somme tend vers la distribution gaussienne (d'ailleurs, la largeur caractéristique de la "cloche" croît comme). En savoir plus sur Wikipedia : Théorème central limite. Dans la vie, il existe très souvent des quantités constituées d'un grand nombre de variables aléatoires indépendantes également distribuées, et donc distribuées selon la gaussienne.
Moyenne
La valeur moyenne d'une variable aléatoire est ce que nous obtenons dans la limite si nous effectuons beaucoup d'expériences et calculons la moyenne arithmétique des valeurs abandonnées. La moyenne est désignée de différentes manières : les mathématiciens aiment désigner par (attente) et les mathématiciens étrangers par (attente). Les physiciens sont à travers ou. Nous désignerons de manière étrangère :.
Par exemple, pour une distribution gaussienne, la moyenne est.
Dispersion
Dans le cas de la distribution gaussienne, nous voyons clairement que la variable aléatoire préfère tomber dans un certain voisinage de sa valeur moyenne. Comme on peut le voir sur le graphique, la dispersion caractéristique des valeurs d'ordre. Comment peut-on estimer cet étalement de valeurs pour une variable aléatoire arbitraire, si l'on connaît sa distribution. Vous pouvez tracer un graphique de sa densité de probabilité et estimer la largeur caractéristique à l'œil nu. Mais nous préférons suivre le chemin algébrique. Vous pouvez trouver la longueur moyenne de l'écart (module) par rapport à la moyenne :. Cette valeur sera une bonne estimation de la dispersion caractéristique des valeurs. Mais vous et moi savons très bien que l'utilisation de modules dans les formules est un casse-tête, donc cette formule est rarement utilisée pour estimer la propagation caractéristique.
Un moyen plus simple (simple en termes de calculs) est de trouver. Cette valeur est appelée variance et est souvent appelée. La racine de la variance s'appelle l'écart type. L'écart type est une bonne estimation de la propagation d'une variable aléatoire.
Par exemple, pour une distribution gaussienne, on peut calculer que la variance définie ci-dessus est exactement égale, ce qui signifie que l'écart type est égal, ce qui concorde très bien avec notre intuition géométrique.
En fait, il y a une petite fraude cachée ici. Le fait est que dans la définition de la distribution gaussienne, sous l'exposant se trouve l'expression. Ce deux dans le dénominateur est précisément pour que l'écart type soit égal au coefficient. C'est-à-dire que la formule de distribution gaussienne elle-même est écrite sous une forme spécialement affinée pour que nous considérions son écart type.
Variables aléatoires indépendantes
Les variables aléatoires sont dépendantes et non. Imaginez que vous jetez une aiguille sur un avion et notez les coordonnées des deux extrémités. Ces deux coordonnées sont dépendantes, elles sont liées par la condition que la distance qui les sépare soit toujours égale à la longueur de l'aiguille, bien qu'il s'agisse de valeurs aléatoires.
Les variables aléatoires sont indépendantes si le résultat de la première d'entre elles est totalement indépendant du résultat de la seconde d'entre elles. Si les variables aléatoires sont indépendantes, alors la valeur moyenne de leur produit est égale au produit de leurs valeurs moyennes :
Preuve
Par exemple, avoir les yeux bleus et avoir obtenu son diplôme d'études secondaires avec une médaille d'or sont des variables aléatoires indépendantes. Si les médaillés d'or aux yeux bleus, disons, alors les médaillés aux yeux bleus. Cet exemple nous dit que si les variables aléatoires et sont données par leurs densités de probabilité et, alors l'indépendance de ces valeurs est exprimée par le fait que la densité de probabilité (la première valeur abandonnée et la seconde) est trouvée par la formule :
Il en découle immédiatement que :
Comme vous pouvez le voir, la preuve est effectuée pour des variables aléatoires qui ont un spectre continu de valeurs et sont données par leur densité de probabilité. Dans d'autres cas, l'idée de preuve est similaire.
Filtre de Kalman
Formulation du problème
Notons par la valeur que nous allons mesurer, puis filtrer. Cela peut être les coordonnées, la vitesse, l'accélération, l'humidité, la puanteur, la température, la pression, etc.
Commençons par un exemple simple qui nous conduira à formuler un problème général. Imaginez que nous ayons une voiture radiocommandée qui ne peut que faire des allers-retours. Connaissant le poids de la voiture, sa forme, la surface de la route, etc., nous avons calculé comment le joystick de contrôle affecte la vitesse de déplacement.
Ensuite, les coordonnées de la voiture changeront selon la loi :
Dans la vraie vie, nous ne pouvons pas prendre en compte dans nos calculs les petites perturbations agissant sur la voiture (vent, bosses, cailloux sur la route), donc la vitesse réelle de la voiture sera différente de celle calculée. Une variable aléatoire est ajoutée à la droite de l'équation écrite :
Nous avons un capteur GPS installé sur une machine à écrire qui essaie de mesurer la vraie coordonnée de la voiture et, bien sûr, ne peut pas la mesurer exactement, mais la mesure avec une erreur, qui est également une variable aléatoire. En conséquence, nous recevons des données erronées du capteur :
La tâche est que, connaissant les mauvaises lectures du capteur, trouve une bonne approximation pour la vraie coordonnée de la voiture.
Dans la formulation de la tâche générale, tout peut être responsable de la coordonnée (température, humidité...), et le terme responsable du contrôle du système de l'extérieur sera noté (dans l'exemple avec une machine). Les équations pour les lectures des coordonnées et des capteurs ressembleront à ceci :
Discutons en détail de ce que nous savons :
Il est à noter que la tâche de filtrage n'est pas une tâche d'anticrénelage. Nous n'essayons pas de lisser les données du capteur, nous essayons d'obtenir la valeur la plus proche de la coordonnée réelle.
L'algorithme de Kalman
Nous argumenterons par induction. Imaginez qu'à la ième étape, nous ayons déjà trouvé la valeur filtrée du capteur, qui se rapproche bien de la vraie coordonnée du système. N'oublions pas que nous connaissons l'équation qui contrôle le changement de la coordonnée inconnue :
par conséquent, ne recevant pas encore la valeur du capteur, nous pouvons supposer qu'à une étape le système évolue selon cette loi et le capteur montrera quelque chose de proche. Malheureusement, nous ne pouvons rien dire de plus précis pour le moment. Par contre, à une étape, nous aurons une lecture inexacte du capteur sur nos mains.
L'idée de Kalman est la suivante. Pour obtenir la meilleure approximation de la vraie coordonnée, nous devons choisir le juste milieu entre la lecture d'un capteur inexact et notre prédiction de ce que nous en attendions. Nous donnerons du poids à la lecture du capteur et le poids restera sur la valeur prédite :
Le coefficient est appelé coefficient de Kalman. Cela dépend du pas d'itération, il serait donc plus correct de l'écrire, mais pour l'instant, afin de ne pas encombrer les formules de calcul, nous allons omettre son index.
Nous devons choisir le coefficient de Kalman de sorte que la valeur de coordonnée optimale résultante soit la plus proche de la vraie. Par exemple, si nous savons que notre capteur est très précis, alors nous ferons davantage confiance à sa lecture et donnerons plus de poids à la valeur (proche de un). Si le capteur, au contraire, est complètement imprécis, alors nous nous concentrerons davantage sur la valeur théoriquement prédite.
En général, pour trouver la valeur exacte du coefficient de Kalman, il suffit de minimiser l'erreur :
Nous utilisons les équations (1) (celles de la case avec un fond bleu) pour réécrire l'expression de l'erreur :
Preuve
Il est maintenant temps de discuter de ce que signifie l'expression minimiser l'erreur ? Après tout, l'erreur, comme nous pouvons le voir, est elle-même une variable aléatoire et prend à chaque fois des valeurs différentes. En fait, il n'y a pas d'approche unique pour définir ce que cela signifie que l'erreur est minime. Tout comme dans le cas de la variance d'une variable aléatoire, lorsque nous avons essayé d'estimer la largeur caractéristique de sa propagation, nous choisirons donc ici le critère de calcul le plus simple. Nous allons minimiser la moyenne de l'erreur au carré :
Écrivons la dernière expression :
Preuve
Du fait que toutes les variables aléatoires incluses dans l'expression pour sont indépendantes, il s'ensuit que tous les termes "croisés" sont égaux à zéro :
Nous avons utilisé le fait que la formule de la variance semble alors beaucoup plus simple :.
Cette expression prend une valeur minimale lorsque (on assimile la dérivée à zéro) :
Ici, nous écrivons déjà une expression pour le coefficient de Kalman avec l'indice de pas, nous soulignons ainsi qu'il dépend du pas d'itération.
Nous substituons la valeur optimale obtenue dans l'expression que nous avons minimisée. Nous recevons;
Notre tâche est accomplie. Nous avons une formule itérative pour calculer le coefficient de Kalman.
Résumons nos connaissances acquises dans un cadre :
Exemple
Code Matlab
Tout effacer; N = 100 % nombre d'échantillons a = 0,1 % d'accélération sigmaPsi = 1 sigmaEta = 50 ; k = 1 : N x = k x (1) = 0 z (1) = x (1) + normrnd (0, sigmaEta) ; pour t = 1 : (N-1) x (t + 1) = x (t) + a * t + normrnd (0, sigmaPsi) ; z (t + 1) = x (t + 1) + normrnd (0, sigmaEta); finir; % filtre de Kalman xOpt (1) = z (1) ; eOpt (1) = sigmaEta ; pour t = 1 : (N-1) eOpt (t + 1) = sqrt ((sigmaEta ^ 2) * (eOpt (t) ^ 2 + sigmaPsi ^ 2) / (sigmaEta ^ 2 + eOpt (t) ^ 2 + sigmaPsi ^ 2)) K (t + 1) = (eOpt (t + 1)) ^ 2 / sigmaEta ^ 2 xOpt (t + 1) = (xOpt (t) + a * t) * (1-K (t +1)) + K (t + 1) * z (t + 1) fin ; tracé (k, xOpt, k, z, k, x)
Une analyse
Si nous traçons comment le coefficient de Kalman change avec le pas d'itération, on peut montrer qu'il se stabilise toujours à une certaine valeur. Par exemple, lorsque les erreurs efficaces du capteur et du modèle se rapportent l'une à l'autre comme dix à un, alors le tracé du coefficient de Kalman en fonction de l'étape d'itération ressemble à ceci :
Dans l'exemple suivant, nous verrons comment cela peut nous rendre la vie beaucoup plus facile.
Deuxième exemple
En pratique, il arrive souvent que nous ne sachions rien du tout du modèle physique de ce que nous filtrons. Par exemple, vous souhaitez filtrer les lectures de votre accéléromètre préféré. Vous ne savez pas à l'avance par quelle loi vous comptez faire tourner l'accéléromètre. La plupart des informations que vous pouvez obtenir sont la variance de l'erreur du capteur. Dans une situation aussi difficile, toute ignorance du modèle de mouvement peut être ramenée à une variable aléatoire :
Mais, franchement, un tel système ne satisfait plus les conditions que l'on imposait à la variable aléatoire, car maintenant toute la physique du mouvement qui nous est inconnue y est cachée, et donc on ne peut pas dire qu'à des instants différents les erreurs du modèle sont indépendantes de chacune. autre et que leurs valeurs moyennes sont nulles. Dans ce cas, dans l'ensemble, la théorie du filtre de Kalman n'est pas applicable. Mais, nous ne ferons pas attention à ce fait, mais appliquons bêtement tout le colosse de formules, en choisissant les coefficients à l'œil nu, pour que les données filtrées aient l'air mignonnes.
Mais vous pouvez prendre un chemin différent, beaucoup plus simple. Comme nous l'avons vu plus haut, le coefficient de Kalman se stabilise toujours vers une valeur avec augmentation. Par conséquent, au lieu de choisir les coefficients et de rechercher le coefficient de Kalman à l'aide de formules complexes, nous pouvons considérer ce coefficient comme toujours constant, et ne sélectionner que cette constante. Cette hypothèse ne gâche presque rien. Premièrement, nous utilisons déjà illégalement la théorie de Kalman, et deuxièmement, le coefficient de Kalman se stabilise rapidement à une constante. En conséquence, tout sera très simplifié. En général, nous n'avons besoin d'aucune formule de la théorie de Kalman, nous avons juste besoin de trouver une valeur acceptable et de l'insérer dans la formule itérative :
Le graphique suivant montre les données d'un capteur fictif filtrées de deux manières différentes. A condition de ne rien savoir de la physique du phénomène. La première façon est honnête, avec toutes les formules de la théorie de Kalman. Et le second est simplifié, sans formules.
Comme on peut le voir, les méthodes sont presque les mêmes. Une petite différence n'est observée qu'au début, lorsque le coefficient de Kalman ne s'est pas encore stabilisé.
Discussion
Comme nous l'avons vu, l'idée principale du filtre de Kalman est de trouver un coefficient tel que la valeur filtrée
en moyenne, ce serait le moins différent de la valeur réelle de la coordonnée. Nous pouvons voir que la valeur filtrée est une fonction linéaire de la lecture du capteur et de la valeur filtrée précédente. Et la valeur filtrée précédente est, à son tour, une fonction linéaire de la lecture du capteur et de la valeur filtrée précédente. Et ainsi de suite, jusqu'à ce que la chaîne se déploie complètement. C'est-à-dire que la valeur filtrée dépend de de tout lectures précédentes du capteur linéairement :
Par conséquent, le filtre de Kalman est appelé filtre linéaire.
Il peut être prouvé que le filtre de Kalman est le meilleur de tous les filtres linéaires. Meilleur dans le sens où le carré moyen de l'erreur de filtre est minime.
Cas multidimensionnel
Toute la théorie du filtre de Kalman peut être généralisée au cas multidimensionnel. Les formules y ont l'air un peu plus effrayantes, mais l'idée même de leur dérivation est la même que dans le cas unidimensionnel. Vous pouvez les voir dans cet excellent article : http://habrahabr.ru/post/140274/.
Et dans ce merveilleux vidéo un exemple de leur utilisation est analysé.
Les filtres de Wiener sont les mieux adaptés au traitement de processus ou de sections de processus en général (traitement par blocs). Pour un traitement séquentiel, une estimation courante du signal à chaque cycle d'horloge est requise, en tenant compte des informations entrant dans l'entrée du filtre pendant le processus d'observation.
Avec le filtrage de Wiener, chaque nouvel échantillon de signal nécessiterait un recalcul de tous les poids de filtre. Actuellement, les filtres adaptatifs se sont généralisés, dans lesquels les nouvelles informations entrantes sont utilisées pour corriger en permanence l'évaluation du signal précédemment effectuée (suivi de cible dans le radar, systèmes d'automatismes en contrôle, etc.). Les filtres adaptatifs de type récursif connus sous le nom de filtre de Kalman sont particulièrement intéressants.
Ces filtres sont largement utilisés dans les boucles de régulation des systèmes de régulation et de contrôle automatiques. C'est à partir de là qu'ils sont apparus, comme en témoigne une terminologie si spécifique utilisée pour décrire leur travail comme l'espace d'état.
L'une des principales tâches à résoudre dans la pratique de l'informatique neuronale est d'obtenir des algorithmes rapides et fiables pour l'apprentissage des réseaux de neurones. À cet égard, il peut être utile d'utiliser des filtres linéaires dans la boucle de rétroaction. Étant donné que les algorithmes d'apprentissage sont de nature itérative, un tel filtre doit être un estimateur récursif séquentiel.
Problème d'estimation des paramètres
L'un des problèmes de la théorie des décisions statistiques, d'une grande importance pratique, est le problème de l'estimation des vecteurs d'état et des paramètres des systèmes, qui se formule comme suit. Supposons qu'il soit nécessaire d'estimer la valeur du paramètre vectoriel $ X $, qui est inaccessible à la mesure directe. Au lieu de cela, un autre paramètre $ Z $ est mesuré, en fonction de $ X $. Le problème d'estimation est de répondre à la question : que peut-on dire de $ X $, connaissant $ Z $. Dans le cas général, la procédure d'évaluation optimale du vecteur $ X $ dépend du critère accepté de la qualité de l'évaluation.
Par exemple, l'approche bayésienne du problème de l'estimation des paramètres nécessite des informations a priori complètes sur les propriétés probabilistes du paramètre à estimer, ce qui est souvent impossible. Dans ces cas, ils recourent à la méthode des moindres carrés (OLS), qui nécessite beaucoup moins d'informations a priori.
Considérons l'application de l'OLS pour le cas où le vecteur d'observation $ Z $ est lié au vecteur d'estimation du paramètre $ X $ par un modèle linéaire, et l'observation contient du bruit $ V $, non corrélé avec le paramètre estimé :
$ Z = HX + V $, (1)
où $ H $ est une matrice de transformation décrivant la relation entre les quantités observées et les paramètres estimés.
L'estimation $ X $ minimisant l'erreur au carré s'écrit comme suit :
$ X_ (оц) = (H ^ TR_V ^ (- 1) H) ^ (- 1) H ^ TR_V ^ (- 1) Z $, (2)
Que le bruit $ V $ ne soit pas corrélé, dans ce cas la matrice $ R_V $ n'est que la matrice identité, et l'équation pour l'estimation devient plus simple :
$ X_ (ots) = (H ^ TH) ^ (- 1) H ^ TZ $, (3)
L'écriture sous forme matricielle permet d'économiser beaucoup de papier, mais cela peut être inhabituel pour certains. L'exemple suivant, tiré de la monographie de Yu. M. Korshunov, "Mathematical Foundations of Cybernetics", illustre tout cela.
Le circuit électrique suivant est disponible :
Les valeurs observées dans ce cas sont les lectures des appareils $ A_1 = 1 A, A_2 = 2 A, V = 20 B $.
De plus, la résistance $ R = 5 $ Ohm est connue. Il est demandé d'estimer au mieux, du point de vue du critère du carré moyen minimum de l'erreur, les valeurs des courants $ I_1 $ et $ I_2 $. La chose la plus importante ici est qu'il existe une relation entre les valeurs observées (lectures de l'instrument) et les paramètres estimés. Et cette information est apportée de l'extérieur.
Dans ce cas, ce sont les lois de Kirchhoff, dans le cas du filtrage (qui sera discuté plus loin) - un modèle autorégressif d'une série temporelle, qui suppose la dépendance de la valeur actuelle par rapport aux précédentes.
Ainsi, la connaissance des lois de Kirchhoff, qui n'a rien à voir avec la théorie des décisions statistiques, permet d'établir un lien entre les valeurs observées et les paramètres estimés (qui a étudié le génie électrique - ils peuvent vérifier, le reste aura de les croire sur parole):
$$ z_1 = A_1 = I_1 + \ xi_1 = 1 $$
$$ z_2 = A_2 = I_1 + I_2 + \ xi_2 = 2 $$
$$ z_2 = V / R = I_1 + 2 * I_2 + \ xi_3 = 4 $$
C'est sous forme vectorielle :
$$ \ begin (vmatrix) z_1 \\ z_2 \\ z_3 \ end (vmatrix) = \ begin (vmatrix) 1 & 0 \\ 1 & 1 \\ 1 & 2 \ end (vmatrix) \ begin (vmatrix) I_1 \ \ I_2 \ end (vmatrix) + \ begin (vmatrix) \ xi_1 \\ \ xi_2 \\ \ xi_3 \ end (vmatrix) $$
Ou $ Z = HX + V $, où
$$ Z = \ begin (vmatrix) z_1 \\ z_2 \\ z_3 \ end (vmatrix) = \ begin (vmatrix) 1 \\ 2 \\ 4 \ end (vmatrix); H = \ début (vmatrice) 1 & 0 \\ 1 & 1 \\ 1 & 2 \ fin (vmatrice); X = \ begin (vmatrix) I_1 \\ I_2 \ end (vmatrix); V = \ begin (vmatrix) \ xi_1 \\ \ xi_2 \\ \ xi_3 \ end (vmatrix) $$
Compte tenu des valeurs de l'interférence décorrélées entre elles, on retrouve l'estimation de I 1 et I 2 par la méthode des moindres carrés selon la formule 3 :
$ H ^ TH = \ début (vmatrice) 1 & 1 & 1 \\ 0 & 1 & 2 \ fin (vmatrice) \ début (vmatrice) 1 & 0 \\ 1 & 1 \\ 1 & 2 \ fin (vmatrice) = \ begin (vmatrix) 3 & 3 \\ 3 & 5 \ end (vmatrix); (H ^ TH) ^ (- 1) = \ frac (1) (6) \ begin (vmatrix) 5 & -3 \\ -3 & 3 \ end (vmatrix) $;
$ H ^ TZ = \ begin (vmatrix) 1 & 1 & 1 \\ 0 & 1 & 2 \ end (vmatrix) \ begin (vmatrix) 1 \\ 2 \\ 4 \ end (vmatrix) = \ begin (vmatrix) 7 \ \ 10 \ fin (vmatrice); X (ots) = \ frac (1) (6) \ begin (vmatrix) 5 & -3 \\ -3 & 3 \ end (vmatrix) \ begin (vmatrix) 7 \\ 10 \ end (vmatrix) = \ frac (1) (6) \ début (vmatrice) 5 \\ 9 \ fin (vmatrice) $;
Donc $ I_1 = 5/6 = 0,833 A $ ; $ I_2 = 9/6 = 1,5 A $.
Tâche de filtration
Contrairement au problème de l'estimation de paramètres qui ont des valeurs fixes, dans le problème du filtrage, il est nécessaire d'estimer les processus, c'est-à-dire de trouver les estimations actuelles d'un signal variable dans le temps, déformé par des interférences, et, par conséquent, inaccessible à la mesure directe. En général, le type d'algorithmes de filtrage dépend des propriétés statistiques du signal et du bruit.
Nous supposerons que le signal utile est une fonction du temps variant lentement et que l'interférence est un bruit non corrélé. Nous utiliserons la méthode des moindres carrés, encore une fois en raison du manque d'informations a priori sur les caractéristiques probabilistes du signal et des interférences.
Tout d'abord, nous obtenons une estimation de la valeur actuelle de $ x_n $ sur la base des $ k $ disponibles des dernières valeurs de la série temporelle $ z_n, z_ (n-1), z_ (n-2) \ dots z_ (n- (k-1)) $. Le modèle d'observation est le même que dans le problème d'estimation des paramètres :
Il est clair que $ Z $ est un vecteur colonne constitué des valeurs observées de la série temporelle $ z_n, z_ (n-1), z_ (n-2) \ dots z_ (n- (k-1)) $, $ V $ - vecteur-colonne d'interférence $ \ xi _n, \ xi _ (n-1), \ xi_ (n-2) \ dots \ xi_ (n- (k-1)) $, déformant le vrai signal. Que signifient les symboles $ H $ et $ X $ ? De quoi, par exemple, le vecteur colonne $ X $ peut-on parler s'il suffit de donner une estimation de la valeur actuelle de la série temporelle ? Et ce que l'on entend par la matrice de transformation $ H $ n'est pas clair du tout.
Toutes ces questions ne peuvent trouver de réponse que si le concept d'un modèle de génération de signaux est introduit en considération. C'est-à-dire qu'un modèle du signal d'origine est nécessaire. Cela se comprend, en l'absence d'information a priori sur les caractéristiques probabilistes du signal et des interférences, il ne reste plus qu'à faire des hypothèses. Vous pouvez appeler cela une divination sur le marc de café, mais les experts préfèrent une terminologie différente. Sur leur "sèche-cheveux", cela s'appelle un modèle paramétrique.
Dans ce cas, les paramètres de ce modèle particulier sont estimés. Lors du choix d'un modèle de génération de signal approprié, n'oubliez pas que toute fonction analytique peut être développée dans une série de Taylor. Une propriété étonnante de la série de Taylor est que la forme d'une fonction à n'importe quelle distance finie $ t $ d'un certain point $ x = a $ est uniquement déterminée par le comportement de la fonction dans un voisinage infiniment petit du point $ x = a $ (nous parlons de ses dérivés du premier ordre et des ordres supérieurs).
Ainsi, l'existence de séries de Taylor signifie que la fonction analytique a une structure interne avec un couplage très fort. Si, par exemple, nous nous limitons à trois membres de la série de Taylor, le modèle de génération de signal ressemblera à ceci :
$ x_ (n-i) = F _ (- i) x_n $, (4)
$$ X_n = \ begin (vmatrix) x_n \\ x "_n \\ x" "_ n \ end (vmatrix); F _ (-i) = \ begin (vmatrix) 1 & -i & i ^ 2/2 \\ 0 & 1 & -i \\ 0 & 0 & 1 \ end (vmatrice) $$
C'est-à-dire que la formule 4, pour un ordre donné du polynôme (dans l'exemple, c'est 2) établit une connexion entre la $ n $ -ième valeur du signal dans la séquence temporelle et le $ (n-i) $ -ième. Ainsi, le vecteur d'état estimé comprend dans ce cas, en plus de la valeur estimée réelle, les dérivées première et seconde du signal.
Dans la théorie du contrôle automatique, un tel filtre serait appelé filtre d'astatisme du 2ème ordre. La matrice de transformation $ H $ pour ce cas (l'estimation est effectuée sur la base des échantillons courants et $ k-1 $ précédents) ressemble à ceci :
$$ H = \ begin (vmatrice) 1 & -k & k ^ 2/2 \\ - & - & - \\ 1 & -2 & 2 \\ 1 & -1 & 0.5 \\ 1 & 0 & 0 \ fin (vmatrice) $$
Tous ces nombres sont obtenus à partir de la série de Taylor sous l'hypothèse que l'intervalle de temps entre les valeurs observées adjacentes est constant et égal à 1.
Ainsi, la tâche de filtrage sous nos hypothèses a été réduite à la tâche d'estimation des paramètres ; dans ce cas, les paramètres du modèle de génération de signal adopté sont estimés. Et l'estimation des valeurs du vecteur d'état $ X $ est réalisée selon la même formule 3 :
$$ X_ (ots) = (H ^ TH) ^ (- 1) H ^ TZ $$
Essentiellement, nous avons mis en œuvre un processus d'estimation paramétrique basé sur un modèle autorégressif du processus de génération de signal.
La formule 3 peut être facilement implémentée par programmation, pour cela vous devez remplir la matrice $ H $ et la colonne vectorielle des observations $ Z $. Ces filtres sont appelés filtres à mémoire finie, puisqu'ils utilisent les dernières $ k $ observations pour obtenir l'estimation actuelle de $ X_ (nоц) $. À chaque nouveau cycle d'observation, un nouveau est ajouté à l'ensemble actuel d'observations et l'ancien est supprimé. Ce processus d'obtention de notes est appelé fenêtre coulissante.
Filtres de mémoire croissants
Les filtres à mémoire finie ont pour principal inconvénient qu'après chaque nouvelle observation, il est nécessaire d'effectuer un recalcul complet sur toutes les données stockées en mémoire. De plus, le calcul des estimations ne peut être lancé qu'après avoir accumulé les résultats des premières $ k $ observations. C'est-à-dire que ces filtres ont un temps transitoire long.
Pour pallier cet inconvénient, il est nécessaire de passer d'un filtre à mémoire persistante à un filtre à mémoire croissante... Dans un tel filtre, le nombre de valeurs observées pour lesquelles l'estimation est faite doit coïncider avec le nombre n de l'observation courante. Ceci permet d'obtenir des estimations à partir du nombre d'observations égal au nombre de composantes du vecteur estimé $ X $. Et cela est déterminé par l'ordre du modèle adopté, c'est-à-dire le nombre de termes de la série de Taylor utilisés dans le modèle.
En même temps, avec l'augmentation de n, les propriétés de lissage du filtre s'améliorent, c'est-à-dire que la précision des estimations augmente. Cependant, la mise en œuvre directe de cette approche est associée à une augmentation des coûts de calcul. Par conséquent, des filtres de mémoire croissants sont implémentés comme récurrent.
Le fait est qu'au moment n, nous avons déjà une estimation $ X _ ((n-1) оц) $, qui contient des informations sur toutes les observations précédentes $ z_n, z_ (n-1), z_ (n-2) \ points z_ (n- (k-1)) $. L'estimation $ X_ (nоц) $ est obtenue à partir de l'observation suivante $ z_n $ en utilisant les informations stockées dans l'estimation $ X _ ((n-1)) (\ mbox (оц)) $. Cette procédure est appelée filtrage récurrent et comprend les étapes suivantes :
- selon l'estimation $ X _ ((n-1)) (\ mbox (оц)) $ prédire l'estimation de $ X_n $ selon la formule 4 avec $ i = 1 $ : $ X _ (\ mbox (nоtsapriori)) = F_1X _ ((n-1 ) sc) $. Il s'agit d'une estimation a priori ;
- selon les résultats de l'observation courante $ z_n $, cette estimation a priori est convertie en une vraie, c'est-à-dire a posteriori ;
- cette procédure est répétée à chaque étape, à partir de $ r + 1 $, où $ r $ est l'ordre de filtrage.
La formule finale pour le filtrage récurrent ressemble à ceci :
$ X _ ((n-1) оц) = X _ (\ mbox (nоtsapriori)) + (H ^ T_nH_n) ^ (- 1) h ^ T_0 (z_n - h_0 X _ (\ mbox (nоtsapriori))) $ , (6 )
où pour notre filtre de deuxième ordre :
Un filtre à mémoire croissante basé sur la Formule 6 est un cas particulier d'un algorithme de filtrage connu sous le nom de filtre de Kalman.
Dans la mise en œuvre pratique de cette formule, il faut se rappeler que l'estimation a priori qui y est incluse est déterminée par la formule 4, et la valeur $ h_0 X _ (\ mbox (notspriori)) $ est la première composante du vecteur $ X _ (\ mbox (notspriori)) $.
Le filtre de mémoire croissante a une caractéristique importante. Si vous regardez la formule 6, le score final est la somme du vecteur de score prédit et du terme de correction. Cette correction est importante pour les petits $ n $ et diminue avec l'augmentation de $ n $, tendant vers zéro comme $ n \ rightarrow \ infty $. C'est-à-dire qu'avec une augmentation de n, les propriétés de lissage du filtre augmentent et le modèle qui lui est inhérent commence à dominer. Mais le signal réel ne peut correspondre au modèle que dans certaines zones, par conséquent, la précision des prévisions se détériore.
Pour lutter contre cela, à partir de quelque $ n $, une interdiction est imposée de réduire davantage le terme de correction. Cela équivaut à changer la bande passante du filtre, c'est-à-dire que pour un petit n le filtre est plus large (moins d'inertie), pour un grand n il devient plus inertiel.
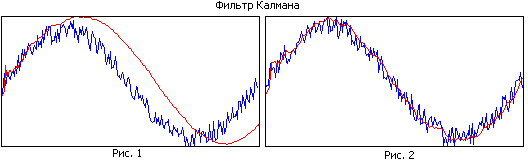
Comparez la figure 1 et la figure 2. Dans la première figure, le filtre a une grande mémoire, alors qu'il lisse bien, mais en raison de la bande étroite, la trajectoire estimée est en retard par rapport à la trajectoire réelle. Dans la deuxième figure, la mémoire du filtre est plus petite, elle lisse moins bien, mais suit mieux la trajectoire réelle.
Littérature
- YM Korshunov "Fondements mathématiques de la cybernétique"
- A.V. Balakrishnan "Théorie de la filtration de Kalman"
- VNFomin "Estimation récurrente et filtrage adaptatif"
- C.F.N. Cowen, P.M. Accorder des "Filtres adaptatifs"
Ce filtre est utilisé dans divers domaines - de l'ingénierie radio à l'économie. Ici, nous allons discuter de l'idée principale, de la signification, de l'essence de ce filtre. Il sera présenté de la manière la plus simple possible.
Supposons que nous ayons besoin de mesurer certaines quantités d'un objet. En ingénierie radio, il s'agit le plus souvent de mesures de tensions à la sortie d'un certain appareil (capteur, antenne, etc.). Dans l'exemple avec un électrocardiographe (voir) nous avons affaire à des mesures de biopotentiels sur le corps humain. En économie, par exemple, la valeur mesurée peut être le taux de change. Chaque jour, le taux de change est différent, c'est-à-dire chaque jour "ses mensurations" nous donnent une valeur différente. Et si pour généraliser, alors nous pouvons dire que la majeure partie de l'activité d'une personne (sinon la totalité) se réduit précisément à des mesures constantes-comparaisons de certaines quantités (voir le livre).
Donc, supposons que nous mesurions constamment quelque chose. Supposons également que nos mesures comportent toujours une erreur - cela est compréhensible, car il n'y a pas d'instruments de mesure idéaux et chacun produit un résultat avec une erreur. Dans le cas le plus simple, ce qui a été décrit peut se réduire à l'expression suivante : z = x + y, où x est la vraie valeur que l'on veut mesurer et qui serait mesurée si on avait un appareil de mesure idéal, y est la erreur de mesure introduite par l'appareil de mesure, et z - la valeur que nous avons mesurée. Ainsi, la tâche du filtre de Kalman est de deviner (déterminer) par le z mesuré, quelle était la vraie valeur de x lorsque nous avons reçu notre z (dans lequel la vraie valeur et l'erreur de mesure "se trouvent"). Il est nécessaire de filtrer (éliminer) la vraie valeur de x de z - supprimer le bruit de distorsion y de z. Autrement dit, n'ayant que le montant en main, nous devons deviner quels termes ont donné ce montant.
A la lumière de ce qui précède, nous allons maintenant tout formuler comme suit. Supposons qu'il n'y ait que deux nombres aléatoires. On ne nous donne que leur somme et nous sommes tenus de déterminer par cette somme quels en sont les termes. Par exemple, on nous a donné le nombre 12 et ils disent : 12 est la somme des nombres x et y, la question est de savoir à quoi x et y sont égaux. Pour répondre à cette question, nous composons l'équation : x + y = 12. Nous avons une équation à deux inconnues, donc, à proprement parler, il n'est pas possible de trouver deux nombres qui donnent cette somme. Mais nous pouvons encore dire quelque chose sur ces chiffres. On peut dire que c'était soit les nombres 1 et 11, soit 2 et 10, soit 3 et 9, soit 4 et 8, etc., aussi c'est soit 13 et -1, soit 14 et -2, soit 15 et - 3, etc C'est-à-dire que par la somme (dans notre exemple, 12), nous pouvons déterminer l'ensemble d'options possibles qui totalisent exactement 12. L'une de ces options est la paire que nous recherchons, qui donne actuellement 12. Il convient également de noter que toutes les variantes de paires de nombres donnant un total de 12 forment une ligne droite illustrée à la figure 1, qui est donnée par l'équation x + y = 12 (y = -x + 12).
Fig. 1
Ainsi, la paire que nous recherchons se situe quelque part sur cette ligne droite. Je le répète, il est impossible de choisir parmi toutes ces options la paire qui était réellement - qui a donné le nombre 12, sans avoir d'indices supplémentaires. Mais, dans la situation pour laquelle le filtre de Kalman a été inventé, il existe de tels indices... On sait à l'avance quelque chose sur les nombres aléatoires. En particulier, l'histogramme dit de distribution pour chaque couple de nombres y est connu. Elle est généralement obtenue après une assez longue observation de l'occurrence de ces nombres très aléatoires. C'est-à-dire, par exemple, on sait par expérience que dans 5% des cas une paire x = 1, y = 8 tombe généralement (nous notons cette paire comme: (1,8)), dans 2% des cas une paire x = 2, y = 3 ( 2,3), dans 1% des cas une paire (3,1), dans 0,024% des cas une paire (11,1), etc. Encore une fois, cet histogramme est défini pour tous les couples nombres, y compris ceux qui forment un total de 12. Ainsi, pour chaque paire, ce qui donne un total de 12, on peut dire que, par exemple, une paire (1, 11) tombe dans 0,8% des cas, une paire ( 2, 10) - dans 1% des cas, une paire (3, 9) - dans 1,5% des cas, etc. Ainsi, nous pouvons utiliser l'histogramme pour déterminer dans quel pourcentage de cas la somme des termes d'une paire est 12. Supposons, par exemple, dans 30% des cas, la somme est 12. Et dans les 70% restants, les paires restantes tombent out - ce sont (1,8), (2, 3), (3,1), etc. - ceux qui totalisent des nombres autres que 12. Et laissent, par exemple, tomber une paire (7,5) dans 27% des cas, tandis que toutes les autres paires qui totalisent 12 tombent dans 0,024% + 0,8% + 1% + 1,5 % +… = 3 % des cas. Ainsi, selon l'histogramme, nous avons découvert que les nombres donnant un total de 12 tombent dans 30% des cas. Dans le même temps, nous savons que si 12 tombait, alors le plus souvent (dans 27% de 30%) la raison en est la paire (7,5). C'est-à-dire si déjà Avec 12 sortis, on peut dire que dans 90 % (27 % sur 30 % - ou, ce qui est la même chose 27 fois sur 30), la raison d'un 12 jetés est une paire (7,5). Sachant que le plus souvent la raison pour laquelle la somme est égale à 12 est la paire (7,5), il est logique de supposer que, très probablement, elle est tombée maintenant. Bien sûr, ce n'est toujours pas un fait qu'en fait maintenant le nombre 12 est formé par cette paire particulière, cependant, les prochaines fois, si nous rencontrons 12, et nous supposons à nouveau la paire (7,5), alors quelque part dans 90% des cas sur 100% nous aurons raison. Mais si nous supposons la paire (2, 10), alors nous n'aurons raison que 1 % sur 30 % du temps, ce qui correspond à 3,33 % de suppositions correctes contre 90 % si nous supposons la paire (7,5). C'est tout - c'est le but de l'algorithme du filtre de Kalman. C'est-à-dire que le filtre de Kalman ne garantit pas qu'il ne fera pas d'erreur dans la détermination de la somme, mais il garantit qu'il fera une erreur le nombre minimum de fois (la probabilité d'erreur sera minime), car il utilise des statistiques - un histogramme des paires de nombres manquantes. Il convient également de souligner que la densité de distribution de probabilité (PDF) est souvent utilisée dans l'algorithme de filtrage de Kalman. Cependant, vous devez comprendre que la signification est la même que celle de l'histogramme. De plus, un histogramme est une fonction construite à partir du PDF et son approximation (voir, par exemple,).
En principe, nous pouvons représenter cet histogramme en fonction de deux variables, c'est-à-dire comme une surface au-dessus du plan xy. Lorsque la surface est plus élevée, il y a une probabilité plus élevée d'une paire correspondante. La figure 2 montre une telle surface.

figure 2
Comme vous pouvez le voir ci-dessus la droite x + y = 12 (qui est une variante de paires donnant un total de 12) les points de la surface sont situés à différentes hauteurs et la hauteur la plus élevée pour la variante avec coordonnées (7.5). Et lorsque l'on rencontre une somme égale à 12, dans 90 % des cas la raison de l'apparition de cette somme est précisément le couple (7,5). Celles. c'est cette paire, donnant un total de 12, qui a la probabilité d'occurrence la plus élevée, à condition que le total soit 12.
Ainsi, l'idée derrière le filtre de Kalman est décrite ici. C'est sur elle que sont construites toutes sortes de ses modifications - récurrentes en une étape, en plusieurs étapes, etc. Pour une étude plus approfondie du filtre de Kalman, je recommande le livre : Van Tries G. Theory of detection, estimation and modulation.
p.s. Pour ceux qui sont intéressés à expliquer les concepts des mathématiques, ce qu'on appelle "sur les doigts", vous pouvez conseiller ce livre et, en particulier, les chapitres de sa section "Mathématiques" (vous pouvez acheter le livre lui-même ou des chapitres individuels de ce).
Random Forest est l'un de mes algorithmes d'exploration de données préférés. Premièrement, il est incroyablement polyvalent ; il peut être utilisé pour résoudre à la fois des problèmes de régression et de classification. Recherchez des anomalies et sélectionnez des prédicteurs. Deuxièmement, il s'agit d'un algorithme qui est vraiment difficile à appliquer de manière incorrecte. Tout simplement parce que, contrairement à d'autres algorithmes, il possède peu de paramètres configurables. Il est également étonnamment simple à la base. Et en même temps, il est remarquable par sa précision.
Quelle est l'idée derrière un algorithme aussi merveilleux ? L'idée est simple : disons que nous avons un algorithme très faible, disons. Si nous créons de nombreux modèles différents en utilisant cet algorithme faible et faisons la moyenne du résultat de leurs prédictions, le résultat final sera bien meilleur. C'est ce qu'on appelle l'entraînement d'ensemble en action. L'algorithme Random Forest est donc appelé la « Random Forest », car les données obtenues créent de nombreux arbres de décision et font ensuite la moyenne du résultat de leurs prédictions. Un point important ici est l'élément d'aléatoire dans la création de chaque arbre. Après tout, il est clair que si nous créons de nombreux arbres identiques, le résultat de leur moyenne aura la précision d'un arbre.
Comment travaille-t-il ? Supposons que nous ayons des données d'entrée. Chaque colonne correspond à un paramètre, chaque ligne correspond à un élément de données.
Nous pouvons sélectionner au hasard un certain nombre de colonnes et de lignes dans l'ensemble de données et construire un arbre de décision basé sur celles-ci.

Jeudi 10 mai 2012
Jeudi 12 janvier 2012

C'est tout. Le vol de 17 heures est terminé, la Russie est laissée à l'étranger. Et à travers la fenêtre d'un confortable appartement de 2 chambres à San Francisco, la célèbre Silicon Valley, en Californie, aux États-Unis, nous regarde. Oui, c'est la raison même pour laquelle je n'ai pratiquement pas écrit ces derniers temps. Nous avons déménagé.
Tout a commencé en avril 2011 lorsque je faisais un entretien téléphonique chez Zynga. Ensuite, tout cela ressemblait à une sorte de jeu qui n'avait rien à voir avec la réalité, et je ne pouvais même pas imaginer à quoi cela aboutirait. En juin 2011, Zynga est venu à Moscou et a mené une série d'entretiens, environ 60 candidats qui ont passé des entretiens téléphoniques ont été considérés, et environ 15 d'entre eux ont été sélectionnés (je ne connais pas le nombre exact, quelqu'un a changé d'avis plus tard, quelqu'un a immédiatement refusé). L'entretien s'est avéré étonnamment simple. Pas de tâches de programmation, pas de questions délicates sur la forme des trappes, la plupart du temps, la capacité de discuter a été testée. Et la connaissance, à mon avis, n'a été évaluée que superficiellement.
Et puis le gadget a commencé. On a d'abord attendu les résultats, puis l'offre, puis l'approbation LCA, puis l'approbation de la demande de visa, puis les documents des USA, puis la file d'attente à l'ambassade, puis un contrôle supplémentaire, puis le visa. Parfois, il m'a semblé que j'étais prêt à tout lâcher et à marquer. Parfois, je doutais que nous ayons besoin de cette Amérique, après tout, ce n'est pas mal en Russie non plus. L'ensemble du processus a pris environ six mois, en conséquence, à la mi-décembre, nous avons reçu des visas et avons commencé à préparer le départ.
Lundi était mon premier jour de travail. Le bureau a toutes les conditions pour non seulement travailler, mais aussi vivre. Petits-déjeuners, déjeuners et dîners de nos propres chefs, une panoplie de plats variés entassés un peu partout, une salle de sport, des massages et même un coiffeur. Tout cela est entièrement gratuit pour les employés. Beaucoup de gens se rendent au travail à vélo et il y a plusieurs salles pour ranger les véhicules. En général, je n'ai jamais rien rencontré de tel en Russie. Tout, cependant, a son propre prix, nous avons été immédiatement prévenus qu'il nous faudrait beaucoup travailler. Ce qui est "beaucoup", selon leurs critères, n'est pas très clair pour moi.
Avec un peu de chance, malgré la quantité de travail, je pourrai reprendre mon blog dans un avenir prévisible et peut-être vous parler de la vie américaine et du travail de programmeur en Amérique. Attend et regarde. En attendant, je félicite tout le monde pour le Nouvel An et Noël à venir et à bientôt !
Pour un exemple d'utilisation, nous imprimerons le rendement du dividende des sociétés russes. Comme cours de base, nous prenons le cours de clôture d'une action le jour de la clôture du registre. Pour une raison quelconque, ces informations ne figurent pas sur le site de la troïka, mais elles sont bien plus intéressantes que les valeurs absolues des dividendes.
Attention! Le code prend beaucoup de temps à s'exécuter, car pour chaque promotion, vous devez faire une demande aux serveurs de finam et obtenir sa valeur.
Résultat<- NULL for(i in (1:length(divs[,1]))){ d <- divs if (d$Divs>0) (essayez ((guillemets<- getSymbols(d$Symbol, src="Finam", from="2010-01-01", auto.assign=FALSE) if (!is.nan(quotes)){ price <- Cl(quotes) if (length(price)>0) (jj<- d$Divs result <- rbind(result, data.frame(d$Symbol, d$Name, d$RegistryDate, as.numeric(dd)/as.numeric(price), stringsAsFactors=FALSE)) } } }, silent=TRUE) } } colnames(result) <- c("Symbol", "Name", "RegistryDate", "Divs") result

De même, vous pouvez créer des statistiques pour les années passées.
D'une manière ou d'une autre, il se trouve que j'aime vraiment toutes sortes d'algorithmes qui ont une justification mathématique claire et logique) Mais souvent, leur description sur Internet est tellement surchargée de formules et de calculs qu'il est tout simplement impossible de comprendre le sens général de l'algorithme. Mais comprendre l'essence et le principe de fonctionnement d'un appareil/mécanisme/algorithme est bien plus important que de mémoriser d'énormes formules. Aussi banal soit-il, mémoriser même des centaines de formules ne servira à rien si vous ne savez pas comment et où les appliquer 😉 En fait, à quoi ça sert tout ça. avec en pratique. Je vais essayer de ne pas surcharger de calculs mathématiques, afin que le matériel soit clair et que la lecture soit facile.
Et aujourd'hui, nous allons parler de Filtre de Kalman, découvrons ce que c'est, pourquoi et comment il est utilisé.
Commençons par un petit exemple. Soyons confrontés à la tâche de déterminer les coordonnées d'un avion en vol. De plus, bien sûr, la coordonnée (désignons-la) doit être déterminée le plus précisément possible. 
Dans l'avion, nous avons pré-installé un capteur, qui nous donne les données de localisation souhaitées, mais, comme tout dans ce monde, notre capteur n'est pas parfait. Par conséquent, au lieu d'une valeur, nous obtenons :
où est l'erreur du capteur, c'est-à-dire une variable aléatoire. Ainsi, à partir des relevés imprécis de l'équipement de mesure, il faut obtenir la valeur de coordonnée () la plus proche possible de la position réelle de l'aéronef.
Le problème est posé, passons à sa résolution.
Faites-nous savoir l'action de contrôle (), grâce à laquelle l'avion vole (le pilote nous a dit quels leviers il tire 😉). Ensuite, connaissant la coordonnée au kième pas, on peut obtenir la valeur au (k+1) pas :
Il semblerait que c'est ce qu'il vous faut ! Et aucun filtre de Kalman n'est nécessaire ici. Mais tout n'est pas si simple.. En réalité, on ne peut pas prendre en compte tous les facteurs externes affectant le vol, la formule prend donc la forme suivante :
où se trouve une erreur causée par des influences externes, une imperfection du moteur, etc.
Alors que se passe-t-il ? A l'étape (k+1), nous avons, d'une part, une lecture inexacte du capteur, et d'autre part, une valeur calculée inexactement obtenue à partir de la valeur de l'étape précédente.
L'idée du filtre de Kalman est d'obtenir une estimation exacte de la coordonnée souhaitée (pour notre cas) à partir de deux valeurs imprécises (en les prenant avec des coefficients de poids différents). En général, la valeur mesurée peut être absolument quelconque (température, vitesse..). Voici ce qui se passe :
Par des calculs mathématiques, on peut obtenir une formule de calcul du coefficient de Kalman à chaque étape, mais, comme convenu au début de l'article, on ne rentrera pas dans les calculs, d'autant plus qu'il a été établi en pratique que le coefficient de Kalman toujours tend vers une certaine valeur lorsque k augmente. On obtient la première simplification de notre formule :
Supposons maintenant qu'il n'y ait pas de communication avec le pilote et que nous ne connaissions pas l'action de contrôle. Il semblerait que dans ce cas nous ne puissions pas utiliser le filtre de Kalman, mais ce n'est pas le cas 😉 Nous « jetons » simplement de la formule ce que nous ne savons pas, puis
Nous obtenons la formule de Kalman la plus simplifiée, qui néanmoins, malgré des simplifications aussi « dures », remplit parfaitement sa tâche. Si vous représentez les résultats graphiquement, vous obtenez quelque chose comme ce qui suit :

Si notre capteur est très précis, alors naturellement le facteur de pondération K devrait être proche de un. Si la situation est inverse, c'est-à-dire que notre capteur n'est pas très bon, alors K devrait être plus proche de zéro.
C'est probablement tout, c'est ainsi que nous venons de comprendre l'algorithme de filtrage de Kalman ! J'espère que l'article a été utile et clair =)
 Les technologies de l'information et de la communication dans l'éducation musicale
Les technologies de l'information et de la communication dans l'éducation musicale Yagma Medical Physics Dispositifs à haute impédance d'onde
Yagma Medical Physics Dispositifs à haute impédance d'onde Caractéristiques de la formation de la compétence informationnelle Formation de la compétence informationnelle des écoliers
Caractéristiques de la formation de la compétence informationnelle Formation de la compétence informationnelle des écoliers Programmateur USB (AVR): description, objectif
Programmateur USB (AVR): description, objectif Analyse syntaxique HP Pavilion dv7. Ressource informatique U SM
Analyse syntaxique HP Pavilion dv7. Ressource informatique U SM Comment installer les fichiers DLL sur Windows ?
Comment installer les fichiers DLL sur Windows ? Désactiver le pare-feu Le pare-feu interfère avec le jeu comment désactiver
Désactiver le pare-feu Le pare-feu interfère avec le jeu comment désactiver