2 способи стиснення інформації в файлах. Стиснення способом кодування серій. Передача по електронній пошті
Доброго вам дня.
Сьогодні я хочу торкнутися теми стиснення даних без втрат. Незважаючи на те, що на Хабре вже були статті, присвячені деяким алгоритмам, мені захотілося розповісти про це трохи детальніше.
Я постараюся давати як математичний опис, Так і опис в звичайному вигляді, для того, щоб кожен міг знайти для себе щось цікаве.
У цій статті я торкнуся фундаментальних моментів стиснення і основних типів алгоритмів.
Стиснення. Чи потрібне воно в наш час?
Зрозуміло, так. Звичайно, всі ми розуміємо, що зараз нам доступні і носії інформації великого обсягу, і високошвидкісні канали передачі даних. Однак, одночасно з цим зростають і обсяги переданої інформації. Якщо кілька років тому ми дивилися 700-мегабайтні фільми, що уміщаються на одну болванку, то сьогодні фільми в HD-якості можуть займати десятки гігабайт.
Звичайно, користі від стиснення всього і вся не так багато. Але все ж існують ситуації, в яких стиснення вкрай корисно, якщо не потрібно.
- Пересилання документів по електронній пошті(Особливо великих обсягів документів з використанням мобільних пристроїв)
- При публікації документів на сайтах, потреба в економії трафіку
- економія дискового просторув тих випадках, коли заміна або додавання коштів зберігання важко. Наприклад, подібне буває в тих випадках, коли вибити бюджет під капітальні витрати непросто, а дискового простору не вистачає
Звичайно, можна придумати ще безліч різних ситуацій, в яких стиснення виявиться корисним, але нам досить і цих кількох прикладів.
Всі методи стиснення можна розділити на дві великі групи: стиснення з втратами і стиснення без втрат. Стиснення без втрат застосовується в тих випадках, коли інформацію потрібно відновити з точністю до біта. Такий підхід є єдино можливим при стисненні, наприклад, текстових даних.
У деяких випадках, однак, не потрібно точного відновлення інформації та допускається використовувати алгоритми, що реалізують стиснення з втратами, яке, на відміну від стиснення без втрат, зазвичай простіше реалізується і забезпечує більш високу ступінь архівації.
Отже, перейдемо до розгляду алгоритмів стиснення без втрат.
Універсальні методи стиснення без втрат
У загальному випадку можна виділити три базові варіанти, на яких будуються алгоритми стиснення.перша групаметодів - перетворення потоку. Це передбачає опис нових надходять незжатих даних через уже оброблені. При цьому не обчислюється ніяких ймовірностей, кодування символів здійснюється тільки на основі тих даних, які вже були оброблені, як наприклад в LZ - методах (названих по імені Абрахама Лемпеля і Якоба Зива). В цьому випадку, друге і подальші входження якоїсь підрядка, вже відомої кодувальнику, замінюються посиланнями на її перше входження.
друга групаметодів - це статистичні методи стиснення. У свою чергу, ці методи поділяються на адаптивні (або потокові), і блокові.
У першому (адаптивному) варіанті, обчислення ймовірностей для нових даних відбувається за даними, вже оброблених при кодуванні. До цих методів належать адаптивні варіанти алгоритмів Хаффмана і Шеннона-Фано.
У другому (блочному) випадку, статистика кожного блоку даних вираховується окремо, і додається до самого стислому блоку. Сюди можна віднести статичні варіанти методів Хаффмана, Шеннона-Фано, і арифметичного кодування.
третя групаметодів - це так звані методи перетворення блоку. Вхідні дані розбиваються на блоки, які потім трансформуються цілком. При цьому деякі методи, особливо засновані на перестановці блоків, можуть не приводити до істотного (або взагалі будь-якого) зменшення обсягу даних. Однак після подібної обробки, структура даних значно поліпшується, і подальше стиснення іншими алгоритмами проходить більш успішно і швидко.
Загальні принципи, на яких грунтується стиснення даних
Всі методи стиснення даних засновані на простому логічному принципі. Якщо уявити, що найбільш часто зустрічаються елементи закодовані більш короткими кодами, а рідше зустрічаються - довшими, то для зберігання всіх даних буде потрібно менше місця, ніж якби всі елементи представлялися кодами однакової довжини.
Точна взаємозв'язок між частотами появи елементів, і оптимальними довжинами кодів описана в так званої теореми Шеннона про джерелі шифрування (Shannon "s source coding theorem), яка визначає межу максимального стиснення без втрат і ентропію Шеннона.
трохи математики
Якщо ймовірність появи елемента s i дорівнює p (s i), то найбільш вигідно буде представити цей елемент - log 2 p (s i) битами. Якщо при кодуванні вдається домогтися того, що довжина всіх елементів буде приведена до log 2 p (s i) бітам, то і довжина всієї кодируемой послідовності буде мінімальною для всіх можливих методів кодування. При цьому, якщо розподіл ймовірностей всіх елементів F = (p (s i)) незмінно, і ймовірності елементів взаємно незалежні, то середня довжина кодів може бути розрахована якЦе значення називають ентропією розподілу ймовірностей F, або ентропією джерела в заданий момент часу.
Однак зазвичай ймовірність появи елемента не може бути незалежною, навпаки, вона знаходиться в залежності від якихось чинників. В цьому випадку, для кожного нового кодованого елемента s i розподіл ймовірностей F прийме деяке значення F k, тобто для кожного елемента F = F k і H = H k.
Іншими словами, можна сказати, що джерело знаходиться в стані k, якому відповідав би якийсь набір ймовірностей p k (s i) для всіх елементів s i.
Тому, з огляду на цю поправку, можна висловити середню довжину кодів як
Де P k - ймовірність знаходження джерела в стані k.
Отже, на даному етапі ми знаємо, що стиснення засноване на заміні часто зустрічаються елементів короткими кодами, і навпаки, а так само знаємо, як визначити середню довжину кодів. Але що ж таке код, кодування, і як воно відбувається?
Кодування без пам'яті
Коди без пам'яті є найпростішими кодами, на основі яких може бути здійснено стиснення даних. У коді без пам'яті кожен символ в кодованому векторі даних замінюється кодовим словом з префіксного безлічі двійкових послідовностей або слів.На мій погляд, не саме зрозуміле визначення. Розглянемо цю тему трохи більш докладно.
Нехай заданий деякий алфавіт ![]() , Що складається з деякого (кінцевого) числа букв. Назвемо кожну кінцеву послідовність символів з цього алфавіту (A = a 1, a 2, ..., a n) словом, А число n - довжиною цього слова.
, Що складається з деякого (кінцевого) числа букв. Назвемо кожну кінцеву послідовність символів з цього алфавіту (A = a 1, a 2, ..., a n) словом, А число n - довжиною цього слова.
Нехай заданий також інший алфавіт ![]() . Аналогічно, позначимо слово в цьому алфавіті як B.
. Аналогічно, позначимо слово в цьому алфавіті як B.
Введемо ще два позначення для безлічі всіх непустих слів в алфавіті. Нехай - кількість непустих слів в першому алфавіті, а - в другому.
Нехай також поставлено відображення F, яке ставить у відповідність кожному слову A з першого алфавіту деякий слово B = F (A) з другого. Тоді слово B буде називатися кодомслова A, а перехід від вихідного слова до його коду буде називатися кодуванням.
Оскільки слово може складатися і з однієї літери, то ми можемо виявити відповідність букв першого алфавіту і відповідних їм слів з другого:
a 1<->B 1
a 2<->B 2
…
a n<->B n
Це відповідність називають схемою, І позначають Σ.
У цьому випадку слова B 1, B 2, ..., B n називають елементарними кодами, А вид кодування з їх допомогою - алфавітним кодуванням. Звичайно, більшість з нас стикалися з таким видом кодування, нехай навіть і не знаючи всього того, що я описав вище.
Отже, ми визначилися з поняттями алфавіт, слово, код,і кодування. Тепер введемо поняття префікс.
Нехай слово B має вигляд B = B "B" ". Тоді B" називають початком, або префіксомслова B, а B "" - його кінцем. Це досить просте визначення, але потрібно відзначити, що для будь-якого слова B, і якесь порожнє слово ʌ ( «пробіл»), і саме слово B, можуть вважатися і началами і кінцями.
Отже, ми підійшли впритул до розуміння визначення кодів без пам'яті. Останнє визначення, яке нам залишилося зрозуміти - це префіксних безліч. Схема Σ має властивість префікса, якщо для будь-яких 1≤i, j≤r, i ≠ j, слово B i не є префіксом слова B j.
Простіше кажучи, префіксних безліч - це таке кінцеве безліч, в якому жоден елемент не є префіксом (або початком) будь-якого іншого елемента. простим прикладомтакого безлічі є, наприклад, звичайний алфавіт.
Отже, ми розібралися з основними визначеннями. Так як же відбувається саме кодування без пам'яті?
Воно відбувається в три етапи.
- Складається алфавіт Ψ символів вихідного повідомлення, причому символи алфавіту упорядковано відповідно до зменшенням їх ймовірності появи в повідомленні.
- Кожному символу a i з алфавіту Ψ ставиться у відповідність деяке слово B i з префіксного безлічі Ω.
- Здійснюється кодування кожного символу, з подальшим об'єднанням кодів в один потік даних, який буде результатами стиснення.
Одним з канонічних алгоритмів, які ілюструють даний метод, є алгоритм Хаффмана.
алгоритм Хаффмана
Алгоритм Хаффмана використовує частоту появи однакових байт у вхідному блоці даних, і ставить у відповідність часто зустрічається блокам ланцюжка біт меншої довжини, і навпаки. Цей код є мінімально - надлишковим кодом. Розглянемо випадок, коли, не залежно від вхідного потоку, Алфавіт вихідного потоку складається з усього 2 символів - нуля і одиниці.В першу чергу при кодуванні алгоритмом Хаффмана, нам потрібно побудувати схему Σ. Робиться це в такий спосіб:
- Всі букви вхідного алфавіту упорядковуються в порядку убування ймовірностей. Всі слова з алфавіту вихідного потоку (тобто те, чим ми будемо кодувати) спочатку вважаються порожніми (нагадаю, що алфавіт вихідного потоку складається тільки з символів (0,1)).
- Два символи a j-1 і a j вхідного потоку, що мають найменші ймовірності появи, об'єднуються в один «псевдосімвол» з ймовірністю pрівній сумі ймовірностей назв символів. Потім ми дописуємо 0 в початок слова B j-1, і 1 в початок слова B j, які будуть згодом бути кодами символів a j-1 і a j відповідно.
- Видаляємо ці символи з алфавіту вихідного повідомлення, але додаємо в цей алфавіт сформований псевдосімвол (природно, він повинен бути вставлений в алфавіт на потрібне місце, з урахуванням його ймовірності).
Для кращої ілюстрації, розглянемо невеликий приклад.
Нехай у нас є алфавіт, що складається з усього чотирьох символів - (a 1, a 2, a 3, a 4). Припустимо також, що ймовірності появи цих символів рівні відповідно p 1 = 0.5; p 2 = 0.24; p 3 = 0.15; p 4 = 0.11 (сума всіх ймовірностей, очевидно, дорівнює одиниці).
Отже, побудуємо схему для даного алфавіту.
- Об'єднуємо два символу з найменшими ймовірностями (0.11 і 0.15) в псевдосімвол p ".
- Об'єднуємо два символу з найменшою вірогідністю (0.24 і 0.26) в псевдосімвол p "".
- Видаляємо об'єднані символи, і вставляємо вийшов псевдосімвол в алфавіт.
- Нарешті, об'єднуємо залишилися два символу, і отримуємо вершину дерева.
Якщо зробити ілюстрацію цього процесу, вийде приблизно наступне:

Як ви бачите, при кожному об'єднанні ми присвоюємо об'єднуються символам коди 0 і 1.
Таким чином, коли дерево побудовано, ми можемо легко отримати код для кожного символу. У нашому випадку коди будуть виглядати так:
A 1 = 0
a 2 = 11
a 3 = 100
a 4 = 101
Оскільки жоден з даних кодів не є префіксом якогось іншого (тобто, ми отримали горезвісне префіксних безліч), ми можемо однозначно визначити кожен код у вихідному потоці.
Отже, ми домоглися того, що найчастіший символ кодується найкоротшим кодом, і навпаки.
Якщо припустити, що спочатку для зберігання кожного символу використовувався один байт, то можна порахувати, наскільки нам вдалося зменшити дані.
Нехай на входу у нас був рядок з 1000 символів, в якій символ a 1 зустрічався 500 раз, a 2 - 240, a 3 - 150, і a 4 - 110 разів.
Від самого початку дана рядокзаймала 8000 біт. Після кодування ми отримаємо рядок довжиною в Σp i l i = 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 = 1760 біт. Отже, нам вдалося стиснути дані в 4,54 рази, витративши в середньому 1,76 біта на кодування кожного символу потоку.
Нагадаю, що згідно з Шеннону, середня довжина кодів становить. Підставивши в це рівняння наші значення ймовірностей, ми отримаємо середню довжину кодів рівну 1.75496602732291, що вельми і вельми близько до отриманого нами результату.
Проте, слід враховувати, що крім самих даних нам необхідно зберігати таблицю кодування, що злегка збільшить підсумковий розмір закодованих даних. Очевидно, що в різних випадках можуть з використовуватися різні варіації алгоритму - наприклад, іноді ефективніше використовувати заздалегідь задану таблицюймовірностей, а іноді - необхідно скласти її динамічно, шляхом проходу по стисливим даними.
висновок
Отже, в цій статті я постарався розповісти про загальні принципи, за якими відбувається стиснення без втрат, а також розглянув один з канонічних алгоритмів - кодування по Хаффману.Якщо стаття припаде до смаку хабросообществу, то я із задоволенням напишу продовження, так як є ще безліч цікавих речей, що стосуються стиснення без втрат; це як класичні алгоритми, так і попередні перетворення даних (наприклад, перетворення Барроуза-Уіліра), ну і, звичайно, специфічні алгоритми для стиснення звуку, відео і зображень (сама, на мій погляд, цікава тема).
література
- Ватолин Д., Ратушняк А., Смирнов М. Юкін В. Методи стиснення даних. Пристрій архіваторів, стиснення зображень і відео; ISBN 5-86404-170-X; 2003 р
- Д. Селомон. Стиснення даних, зображення і звуку; ISBN 5-94836-027-Х; 2004р.
Принципи стиснення інформації
В основі будь-якого способу стиснення інформації лежить модель джерела інформації, або, більш конкретно, модель надмірності. Іншими словами для стиснення інформації використовуються деякі відомості про те, якого роду інформація стискається - не володіючи нікакмі відомостями про інформацію не можна зробити рівним рахунком ніяких припущень, яке перетворення дозволить зменшити обсяг повідомлення. Ця інформація використовується в процесі стиснення і разжатия. Модель надмірності може також будуватися або параметризрвані на етапі стиснення. Методи, що дозволяють на основі вхідних даних змінювати модель надмірності інформації, називаються адаптивними. Неадаптивними є зазвичай узкоспеціфічние алгоритми, що застосовуються для роботи з добре визначеними і незмінними характеристиками. Переважна частина ж досить універсальних алгоритмів є в тій чи іншій мірі адаптивними.
Будь-який метод стиснення інформації включає в себе два перетворення зворотних один одному:
- перетворення стиснення;
- перетворення расжатія.
Перетворення стиснення забезпечує отримання стисненого повідомлення з вихідного. Разжатие ж забезпечує отримання вихідного повідомлення (або його наближення) з стисненого.
Всі методи стиснення діляться на два основні класи
- без втрат,
- з втратами.
Кардинальне відмінність між ними в тому, що стиснення без втрат забезпечує можливість точного відновлення вихідного повідомлення. Стиснення з втратами ж дозволяє отримати тільки деяке наближення вихідного повідомлення, тобто відрізняється від вихідного, але в межах деяких заздалегідь певних похибок. Ці похибки повинні визначатися іншою моделлю - моделлю приймача, що визначає, які дані і з якою точністю представлені важливі для одержувача, а які допустимо викинути.
Характеристики алгоритмів стиснення і застосовність
коефіцієнт стиснення
Коефіцієнт стиснення - основна характеристика алгоритму стиснення, що виражає основне прикладне якість. Вона визначається як відношення розміру незжатих даних до стисненим, тобто:
k = S o / S c,де k- коефіцієнт стиснення, S o - розмір незжатих даних, а S c - розмір стиснених. Таким чином, чим вище коефіцієнт стиснення, тим алгоритм краще. Слід зазначити:
- якщо k= 1, то алгоритм не виробляє стиснення, тобто отримує вихідну повідомлення розміром, рівним вхідному;
- якщо k < 1, то алгоритм порождает при сжатии сообщение большего размера, нежели несжатое, то есть, совершает «вредную» работу.
ситуація з k < 1 вполне возможна при сжатии. Невозможно получить алгоритм сжатия без потерь, который при любых данных образовывал бы на выходе данные меньшей или равной длины. Обоснование этого факта заключается в том, что количество различных сообщений длиной nШаблон: Е: біт становить рівно 2 n. Тоді кількість різних повідомлень з довжиною меншою або рівною n(При наявності хоча б одного повідомлення меншої довжини) буде менше 2 n. Це означає, що неможливо однозначно зіставити всі вихідні повідомлення стисненим: або деякі вихідні повідомлення не матимуть стисненого уявлення, або декільком вихідним повідомленнями буде відповідати одне і те ж стислий, а значить їх не можна відрізнити.
Коефіцієнт стиснення може бути як постійним коефіцієнтом (деякі алгоритми стиснення звуку, зображення і т. П., Наприклад А-закон, μ-закон, ADPCM), так і змінним. У другому випадку він може бути визначений або для будь-якого конкретного повідомлення, або оцінений за деякими критеріями:
- середнє (зазвичай по деякому тестовому набору даних);
- максимальне (випадок найкращого стиснення);
- мінімальне (випадок найгіршого стиснення);
або будь-яким іншим. Коефіцієнт стиснення з втратами при цьому сильно залежить від допустимої похибки стиснення або його якості, Яке зазвичай виступає як параметр алгоритму.
допустимість втрат
Основним критерієм відмінності між алгоритмами стиснення є описане вище наявність або відсутність втрат. У загальному випадку алгоритми стиснення без втрат універсальні в тому сенсі, що їх можна застосовувати на даних будь-якого типу, в той час як застосування стиснення втрат повинно бути обгрунтовано. Деякі види даних не припускаю яких би то ні було втрат:
- символічні дані, зміна яких неминуче призводить до зміни їх семантики: програми і їх вихідні тексти, виконавчі масиви і т. п .;
- життєво важливі дані, зміни в яких можуть призвести до критичних помилок: наприклад, одержувані з медичної вимірювальної техніки або контрольних приладів літальних, космічних апаратів і т. п.
- дані, багаторазово піддаються стисненню і расжатію: робочі графічні, звукові, відеофайли.
Однак стиснення з втратами дозволяє домогтися набагато більших коефіцієнтів стиснення за рахунок відкидання незначної інформації, яка погано стискається. Так, наприклад алгоритм стиснення звуку без втрат FLAC, дозволяє в більшості випадків стиснути звук в 1,5-2,5 рази, в той час як алгоритм з втратами Vorbis, в залежності від встановленого параметра качетсва може стиснути до 15 разів із збереженням прийнятної якості звучання.
Системні вимоги алгоритмів
Різні алгоритми можуть вимагати різної кількості ресурсів обчислювальної системи, На яких виконуються:
- оперативної пам'яті (під проміжні дані);
- постійної пам'яті (під код програми і константи);
- процесорного часу.
В цілому, ці вимоги залежать від складності і «інтелектуальності» алгоритму. За загальної тенденції, чим краще і універсальніше алгоритм, тим більші вимоги з машині він пред'являє. Однак в специфічних випадках прості і компактні алгоритми можуть працювати краще. Системні вимоги визначають їх споживчі якості: чим менш вимогливий алгоритм, тим на більш простий, а отже, компактною, надійної і дешевої системі він може працювати.
Так як алгоритми стиснення і разжатия працюють в парі, то має значення також співвідношення системних вимогдо них. Нерідко можна ускладнивши один алгоритм можна значно спростити інший. Таким чином ми можемо мати три варіанти:
Алгоритм стиснення набагато більш вимогливим до ресурсів, ніж алгоритм расжатія. Це найбільш поширене співвідношення, і воно може бути застосовано в основному у випадках, коли одноразово стислі дані будуть використовуватися багаторазово. У качетсве приклад можна навести цифрові аудіо-і відеопрогравачі. Алгоритми стиснення і расжатія мають приблизно рівні вимоги. Найбільш прийнятний варіант для лінії зв'язку, коли стиснення і расжатіе відбувається одноразово на двох її кінцях. Наприклад, це можуть бути телефонія. Алгоритм стиснення істотно менш вимогливий, ніж алгоритм разжатия. Досить екзотичний випадок. Може застосовуватися у випадках, коли передавачем є ультрапортативний пристрій, де обсяг доступних ресурсів досить критичний, наприклад, космічний апарат або велика розподілена мережа датчиків, або це можуть бути дані розпакування яких потрібно в дуже малому відсотку випадків, наприклад запис камер відеоспостереження.
Див. також
Wikimedia Foundation. 2010 року.
Дивитися що таке "Стиснення інформації" в інших словниках:
стиснення інформації- ущільнення інформації - [Л.Г.Суменко. Англо російський словник з інформаційних технологій. М .: ДП ЦНДІЗ, 2003.] Тематики інформаційні технології в цілому Синоніми ущільнення інформації EN information reduction ...
СТИСК ІНФОРМАЦІЇ- (стиснення даних) подання інформації (даних) меншим числом бітів в порівнянні з початковою. Засноване на усунення надмірності. Розрізняють С. і. без втрати інформації та з втратою частини інформації, несуттєвою для вирішуваних завдань. До ... ... Енциклопедичний словник з психології та педагогіки
адаптивне стиснення інформації без втрат- - [Л.Г.Суменко. Англо російський словник з інформаційних технологій. М .: ДП ЦНДІЗ, 2003.] Тематики інформаційні технології в цілому EN adaptive lossless data compressionALDC ... Довідник технічного перекладача
ущільнення / стиснення інформації- - [Л.Г.Суменко. Англо російський словник з інформаційних технологій. М .: ДП ЦНДІЗ, 2003.] Тематики інформаційні технології в цілому EN compaction ... Довідник технічного перекладача
цифрове стискання інформації- - [Л.Г.Суменко. Англо російський словник з інформаційних технологій. М .: ДП ЦНДІЗ, 2003.] Тематики інформаційні технології в цілому EN compression ... Довідник технічного перекладача
Звук є простою хвилею, а цифровий сигналє поданням цієї хвилі. Це досягається запам'ятовуванням амплітуди аналогового сигналубезліч разів протягом однієї секунди. Наприклад, в звичайному CD сигнал запам'ятовується 44100 раз за ... ... Вікіпедія
Процес, що забезпечує зменшення обсягу даних шляхом скорочення їх надмірності. Стиснення даних пов'язано з компактним розташуванням порцій даних стандартного розміру. Розрізняють стиснення з втратою і без втрати інформації. За англійськи: Data ... ... Фінансовий словник
стиснення цифрової картографічної інформації- Обробка цифрової картографічної інформації з метою зменшення її об'єму, в тому числі виключення надмірності в межах необхідної точності її подання. [ГОСТ 28441 99] Тематики картографія цифрова Узагальнюючі терміни методи і технології ... ... Довідник технічного перекладача
Мета уроку: розвивати уважність, кмітливість, виховувати інтерес до предмету.
Обладнання: комп'ютери, лабораторні диски, відповідне програмне забезпечення, Карти з тестовим завданням.
Хід уроку
1. Організаційна частина.
2. Актуалізація опорних знань.
3. Вивчення нового матеріалу
4. Закріплення нового матеріалу.
5. Домашнє завдання.
6. Підведення підсумків уроку.
Вивчення нового матеріалу
1. Що таке архівування. Поняття про стиснення даних.
2. Основні види програм-архіваторів.
3. Програма-архіватор WIN-RAR.
4. Як додавати файл в архів, а також витягувати його з архіву.
З розвитком інформаційних технологійгостро постало питання про способи зберігання даних. Починаючи з 40-х років ХХ ст., Вчені розробляють методи представлення даних, при яких простір на носіях інформації використовувався б економніше. Результатом цього стала технологія стиснення даних і архівації даних (backup).
Архівація даних - це злиття декількох файлів або каталогів в єдиний файл-архів.
Стиснення даних - скорочення обсягу вихідних файлів шляхом усунення надлишкової інформації.
Для виконання цих завданнях є програми-архіватори, які забезпечують стиснення даних: зокрема, архівування файлів. За допомогою спеціальних алгоритмів архіватори видаляють з файлів всю надлишкову інформацію, а при зворотних операціях розпаковування вони відновлюють інформацію в первинному вигляді. Розмір стисненого файлувід двох до десяти разів менше файлу-оригіналу. При цьому стиснення та відновлення інформації відбувається без втрат. Стиснення без втрат актуальне при роботі з текстовими і програмними файлами, у задачах криптографії. Існують також методи стиснення з втратами.
Ступінь стиснення залежить від типу файлів і від програми - архіватора. Найбільше стискаються текстові файли, Менш всіх - звукові і відеофайли.
Архівування файлів. завдання
До цих пір мова йшла про одне призначення архівації даних - економніше використання носіїв інформації. Однак за допомогою архівації можна виконувати цілий комплекс завдань:
1. Зменшення обсягу файлів (актуально не тільки для економії місця на носіях, а й для швидкого перенесення файлів по мережі).
2. Створення резервних копій на зовнішні носії для зберігання важливої інформації.
3. Архівація при шифруванні даних з метою зменшення ймовірності злому криптосистеми.
Процес запису інформації в архівний файл називається - архівування.
Витяг файлів з архіву - розархівування.
Перші програми-архіватори з'явилися в середині 80-х років. Вони були орієнтовані на роботу в MS-DOC і підтримували популярні архівні формати: ARC, ICE, ARJ, ZIP і RAR і ін. Існувала також група архіваторів, які упаковували дані в архіви - файли з розширенням. eхе ,. cоm. Для стиснення всього диска були створені резидент архіватори. Вони дозволяли підняти ефективність використання дискового простору шляхом створення великих архівних файлів - «стиснень» дисків.
Значно більш зручною стала робота з архівами при появі Windows і Windows-версій архиваторов. З колишніх архівних форматів серед користувачів Windowsпо-справжньому прижилися ARJ, ZIP - програми які розпаковують файли. Великі за обсягом архівні файли можуть бути розміщені на кількох дискетах (томах). Такі архіви називаються багатотомними.
Том - це складова частинабагатотомного архіву.
Зараз використовується десятки програм-архіваторів, які відрізняються переліком функцій і параметрами роботи, проте найкращі з них мають приблизно однакові характеристики. Ми знаємо, що упаковка і розпакування файлів виконується однією і тією ж програмою, але в деяких випадках це здійснюється різними програмами, Наприклад, програма РКZIP упаковує файли, а РКUNZIP - розпакування файлів.
Програми-архіватори дозволяють створювати такі архіви, для вилучення з яких не потрібні будь-які програми, так як архівні файли містять в собі програму самі розпаковуються. Такі архіви називаються SFX-архівами.
Приміщення файлів в архів: Пуск Програми WINRAR або у вигляді ярлика на Робочому столі.
Універсальний архіватор WINRAR
Архіватор WINRAR також призначений для архівування файлів. Він має зручну графічну оболонку і підтримує технологію Drag and Drop. Програма WINRAR дозволяє працювати не тільки з архівними файлами rar, Але і з іншими архівними форматами: zip, cab, arj, lzh. Запускається WINRAR будь-яким з можливих способів, Передбачених в Windows. Запуск програми за допомогою Головного меню кнопки Пуск Програми WINRAR WINRAR або за допомогою ярлика на Робочому столі.
Тестове опитування з основ роботи з дисками.
Домашнє завдання.
Самоаналіз уроку.
Для виконання цих завданнях є програми-архіватори, які забезпечують як архівування, так і стиснення даних.За допомогою спеціальних алгоритмів архіватори видаляють з файлів всю надлишкову інформацію, а при зворотних операціях розпаковування вони відновлюють інформацію в первинному вигляді. Розмір стиснутого файлу від двох до десяти разів менше файлу-оригіналу.
У наш час багато користувачів замислюються над тим, як здійснюється процес стиснення інформації з метою економії вільного простору на вінчестері, адже це один з найбільш ефективних засобіввикористання корисного простору в будь-якому накопичувачі. Досить часто сучасним користувачам, які стикаються з браком вільного простору на накопичувачі, доводиться видаляти будь-які дані, намагаючись таким чином звільнити потрібне місце, в той час як більш просунуті юзери найчастіше використовують стиснення даних з метою зменшення її об'єму.
Однак багато хто не знає навіть, як називається процес стиснення інформації, не кажучи про те, які використовуються алгоритми і що дає застосування кожного з них.
Чи варто стискати дані?

Стиснення даних є досить важливим на сьогоднішній день і необхідно будь-якому користувачеві. Звичайно, в наш час практично кожен може придбати просунуті накопичувачі даних, що передбачають можливість використання досить великого обсягу вільного простору, а також оснащені високошвидкісними каналами транслювання інформації.
Однак при цьому потрібно правильно розуміти, що з плином часу збільшується також і обсяг тих даних, які необхідно передавати. І якщо буквально десять років тому стандартним для звичайного фільму було прийнято вважати обсяг 700 Мб, то на сьогоднішній день фільми, виконані в HD-якості, можуть мати обсяги, рівні декільком десяткам гігабайт, не кажучи вже про те, скільки вільного місця займають високоякісні картини в форматі Blu-ray.
Коли стиснення даних необхідно?

Звичайно, не варто чекати того, що процес стиснення інформації принесе вам багато користі, проте існує певний ряд ситуацій, при яких деякі методи стиснення інформації є вкрай корисними і навіть необхідними:
- Передача певних документів через електронну пошту. Особливо це стосується тих ситуацій, коли потрібно передати інформацію в великому обсязі, використовуючи різні мобільні пристрої.
- Часто процес стиснення інформації з метою зменшення займаного їй місця використовується при публікації певних даних на різних сайтах, коли потрібно заощадити трафік;
- Економія вільного простору на жорсткому диску в тому випадку, коли немає можливості провести заміну або ж додати нові засоби зберігання даних. Зокрема, найбільш поширеною ситуацією є та, коли присутні певні обмеження в доступному бюджеті, але при цьому не вистачає вільного дискового простору.
Звичайно, крім вищенаведених, є ще величезну кількістьрізних ситуацій, при яких може знадобитися процес стиснення інформації з метою зменшення її об'єму, однак ці є на сьогоднішній день найбільш поширеними.
Як можна стиснути дані?

Сьогодні існують найрізноманітніші методи стиснення інформації, проте всі вони діляться на дві основні групи - це стиснення з певними втратами, а також стиснення без втрат.
Використання останньої групи методів є актуальним тоді, коли дані повинні бути відновлені з гранично високою точністю, аж до одного біта. Такий підхід є єдино актуальним в тому випадку, якщо здійснюється стиснення певного текстового документа.
При цьому варто відзначити той факт, що в деяких ситуаціях немає необхідності в максимально точному відновленні стислих даних, тому передбачається можливість використання таких алгоритмів, при яких стиснення інформації на диску здійснюється з певними втратами. Перевагою стиснення з втратами є те, що така технологія набагато простіша в реалізації, а також забезпечує максимально високу ступінь архівації.
Стиснення з втратами

Інформації з втратами забезпечують на порядок краще стиснення, при цьому зберігаючи достатню якість інформації. У більшості випадків використання таких алгоритмів здійснюється для стиснення аналогових даних, таких як всілякі зображення або ж звуки. У таких ситуаціях розпаковані файли можуть досить сильно відрізнятися від оригінальної інформації, однак для людського ока або ж вуха вони практично не відрізняються.
Стиснення без втрат
Алгоритми стиснення інформації без втрат забезпечують максимально точне відновлення даних, що виключає будь-які втрати стискаються файлів. Однак при цьому потрібно правильно розуміти той факт, що в даному випадку забезпечується не настільки ефективне стиснення файлів.
універсальні методи

Крім усього іншого, існує певний ряд універсальних методів, Якими здійснюється ефективний процес стиснення інформації з метою зменшення займаного їй місця. У загальному випадку можна виділити всього три основних технології:
- Перетворення потоку. В даному випадку опис нової надходить незжатої інформації здійснюється через вже оброблені файли, при цьому не здійснюється обчислення будь-яких ймовірностей, а проводиться кодування символів на основі виключно тих файлів, які вже піддавалися певній обробці.
- Статистичне стиснення. Даний процес стиснення інформації з метою зменшення займаного їй на диску місця розподіляється на дві підкатегорії - адаптивні і блокові методи. Адаптивний варіант передбачає обчислення ймовірностей для нових файлів за інформацією, яка вже оброблялася в процесі кодування. Зокрема, до таких методів слід також віднести різні адаптивні варіанти алгоритмів Шеннона-Фано і Хаффмана. Блоковий алгоритм передбачає окреме вираховування кожного блоку інформації з подальшим додаванням до самого стислому блоку.
- Перетворення блоку. Вхідна інформація розподіляється на кілька блоків, а згодом відбувається цілісне трансформування. При цьому слід сказати про те, що певні методи, особливо ті, які ґрунтуються на перестановці декількох блоків, в кінцевому підсумку можуть привести до значного зниження обсягу сжимаемой інформації. Однак потрібно правильно розуміти, що після проведення такої обробки в кінцевому підсумку відбувається значне поліпшення внаслідок чого проведення подальшого стискання через інші алгоритми здійснюється набагато простіше і швидко.
Стиснення при копіюванні

Одним з найбільш важливих компонентів резервного копіюванняє те пристрій, на яке буде переміщатися потрібна користувачевіінформація. Чим більший обсяг даних вами буде переміщатися, тим більш об'ємне пристрій вам необхідно буде використовувати. Однак якщо вами буде здійснюватися процес стиснення даних, то в такому випадку проблема нестачі вільного простору навряд чи залишиться для вас актуальною.
Навіщо це потрібно?
Можливість проведення стиснення інформації при дозволяє істотно знизити час, який необхідно буде для копіювання потрібних файлів, І при цьому домогтися ефективної економії вільного простору на накопичувачі. Іншими словами, при використанні стиснення інформація буде копіюватися набагато більш компактно і швидко, а ви зможете заощадити свої гроші і фінанси, які необхідні були для покупки більш об'ємного накопичувача. Крім усього іншого, здійснюючи стиснення інформації, ви також скорочуєте час, який знадобиться при транспортуванні всіх даних на сервер або ж їх копіюванні через мережу.
Стиснення даних для резервного копіювання може здійснюватися в один або ж кілька файлів - в даному випадку все буде залежати від того, який саме програмою ви користуєтеся і яку інформацію піддаєте стиску.
Вибираючи утиліту, обов'язково подивіться на те, наскільки обрана вами програма може стискати дані. Це залежить від типу інформації, внаслідок чого ефективність стиснення текстових документів може становити більше 90%, в той час як буде ефективним не більше ніж на 5%.
Як було сказано вище, одним із важливих завдань попередньої підготовкиданих до шифрування є зменшення їх надмірності і вирівнювання статистичних закономірностей застосовуваного мови. Часткове усунення надмірності досягається шляхом стиснення даних.
стиснення інформаціїявляє собою процес перетворення вихідного повідомлення з однієї кодової системи в іншу, в результаті якого зменшується розмір повідомлення. Алгоритми, призначені для стиснення інформації, можна розділити на дві великі групи: реалізують стиснення без втрат (оборотний стиск) і реалізують стиснення з втратами (необоротне стиснення).
оборотний стискмає на увазі абсолютно точне відновлення даних після декодування і може застосовуватися для стиснення будь-якої інформації. Воно завжди призводить до зниження обсягу вихідного потоку інформації без зміни його інформативності, тобто без втрати інформаційної структури. Більш того, з вихідного потоку, за допомогою відновлюючого або декомпресивні алгоритму, можна отримати вхідний, а процес відновлення називається декомпресією або розпакуванням і тільки після процесу розпакування дані придатні для обробки відповідно до їхнього внутрішнього форматом. Стиснення без втрат застосовується для текстів, виконуваних файлів, високоякісного звуку і графіки.
необоротне стисненнямає зазвичай набагато більш високу ступінь стиснення, ніж кодування без втрат, але допускає деякі відхилення декодованих даних від вихідних. На практиці існує широке коло практичних завдань, в яких дотримання вимоги точного відновлення вихідної інформації після декомпресії не є обов'язковим. Це, зокрема, відноситься до стиснення мультимедійної інформації: звуку, фото- або відеозображень. Так, наприклад, широко застосовуються формати мультимедійної інформації JPEG і MPEG, в яких використовується необоротне стиснення. Необоротне стиснення зазвичай не використовується спільно з криптографічним шифруванням, так як основною вимогою до криптосистеме є ідентичність розшифрованих даних вихідним. Однак при використанні мультимедіа-технологій дані, представлені в цифровому вигляді, Часто піддаються незворотною компресії перед подачею в криптографічний систему для шифрування. Після передачі інформації споживачеві та розшифрування мультимедіа-файли використовуються в стислому вигляді (тобто не відновлюються).
Розглянемо докладніше деякі з найбільш поширених способів оборотного стиску даних.
Найбільш відомий простий підхід і алгоритм стиснення інформації оборотним шляхом - це кодування серій послідовностей (Run Length Encoding - RLE). Суть методів даного підходу полягає в заміні ланцюжків або серій повторюваних байтів на один кодує байт -заполнітель і лічильник числа їх повторень. Проблема всіх аналогічних методів полягає лише в визначенні способу, за допомогою якого розпаковувати алгоритм міг би відрізнити в результуючому потоці байтів кодовану серію від інших - не кодованих послідовностей байтів. Рішення проблеми досягається зазвичай простановкой міток спочатку кодованих ланцюжків. Такими позначки можна використати характерні значення бітів в першому байті кодованої серії, значення першого байта кодованого серії. Недоліком методу RLE є досить низька ступінь стиснення або вартість кодування файлів з малим числом серій і, що ще гірше - з малим числом повторюваних байтів в серіях.
При рівномірному кодуванні інформації на повідомлення відводиться одне і те ж число біт, незалежно від ймовірності його появи. Разом з тим логічно припустити, що загальна довжина переданих повідомлень зменшиться, якщо часто зустрічаються повідомлення кодувати короткими кодовими словами, а рідко зустрічаються - довшими. Виникаючі при цьому проблеми пов'язані з необхідністю використання кодів зі змінною довжиною кодового слова. Існує безліч підходів до побудови подібних кодів.
Одними з широко використовуваних на практиці є словникові методи, до основних представників яких відносяться алгоритми сімейства Зива і Лемпела. Їх основна ідея полягає в тому, що фрагменти вхідного потоку ( "фрази") замінюються покажчиком на те місце, де вони в тексті вже раніше з'являлися. У літературі подібні алгоритми позначаються як алгоритми LZ стиснення.
Подібний метод швидко пристосовується до структури тексту і може кодувати короткі функціональні слова, так як вони дуже часто в ньому з'являються. Нові слова і фрази можуть також формуватися з частин раніше зустрінутих слів. Декодування стисненого тексту здійснюється безпосередньо, - відбувається проста заміна покажчика готової фразою зі словника, на яку той вказує. На практиці LZ-метод домагається гарного стиснення, його важливою властивістю є дуже швидка робота декодера.
Іншим підходом до стиснення інформації є код Хаффмана, Кодер і декодер якого мають досить просту апаратну реалізацію. Ідея алгоритму полягає в наступному: знаючи ймовірності входження символів у повідомлення, можна описати процедуру побудови кодів змінної довжини, що складаються з цілого кількості бітів. Символам з більшою ймовірністю присвоюються більш короткі коди, Тоді як рідше зустрічається символам - довші. За рахунок цього досягається скорочення середньої довжини кодового слова і велика ефективність стиснення. Коди Хаффмана мають унікальний префікс (початок кодового слова), що і дозволяє однозначно їх декодувати, незважаючи на їх зміну довжину.
Процедура синтезу класичного коду Хаффмана передбачає наявність апріорної інформації про статистичні характеристики джерела повідомлень. Інакше кажучи, розробнику повинні бути відомі ймовірності виникнення тих чи інших символів, з яких утворюються повідомлення. Розглянемо синтез коду Хаффмана на простому прикладі.
p (S 1) = 0,2, p (S 2) = 0,15, p (S 3) = 0,55, p (S 4) = 0,1. Відсортуємо символи спаданням ймовірності появи і представимо у вигляді таблиці (рис. 14.3, а).
Процедура синтезу коду складається з трьох основних етапів. На першому відбувається згортка рядків таблиці: два рядки, відповідні символам з найменшими ймовірностями виникнення замінюються однією з сумарною ймовірністю, після чого таблиця знову змінювати порядок. Згортка триває до тих пір, поки в таблиці не залишиться лише один рядок з сумарною ймовірністю, яка дорівнює одиниці (рис. 14.3, б).
Мал. 14.3.
На другому етапі здійснюється побудова кодового дерева по згорнутої таблиці (рис. 14.4, а). Дерево будується, починаючи з останнього стовпця таблиці.

Мал. 14.4.
Корінь дерева утворює одиниця, розташована в останньому стовпчику. У розглянутому прикладі ця одиниця утворюється з ймовірностей 0,55 і 0,45, зображуваних у вигляді двох вузлів дерева, пов'язаних з коренем. Перший з них відповідає символу S 3 і, таким чином, подальше розгалуження цього вузла не відбувається.
Другий вузол, маркований ймовірністю 0,45, з'єднується з двома вузлами третього рівня, з вірогідністю 0,25 і 0,2. Імовірність 0,2 відповідає символу S 1, а ймовірність 0,25, в свою чергу, утворюється з ймовірностей 0,15 появи символу S 2 і 0,1 появи символу S 4.
Ребра, що з'єднують окремі вузли кодового дерева, нумеруються цифрами 0 і 1 (наприклад, ліві ребра - 0, а праві - 1). На третьому, заключному етапі, будується таблиця, в якій зіставляються символи джерела і відповідні їм кодові слова коду Хаффмана. Ці кодові слова утворюються в результаті зчитування цифр, якими позначені ребра, що утворюють шлях від кореня дерева до відповідного символу. Для розглянутого прикладу код Хаффмана набуде вигляду, показаний в таблиці праворуч (рис. 14.4, б).
Однак класичний алгоритм Хаффмана має один істотний недолік. Для відновлення вмісту стиснутого повідомлення декодер повинен знати таблицю частот, якою користувався кодер. Отже, довжина стиснутого повідомлення збільшується на довжину таблиці частот, яка повинна надсилатися попереду даних, що може звести нанівець всі зусилля зі стиснення повідомлення.
Інший варіант статичного кодування Хаффманаполягає в перегляді вхідного потоку і побудові кодування на підставі зібраної статистики. При цьому потрібно два проходи по файлу - один для перегляду та збору статистичної інформації, другий - для кодування. У статичному кодуванні Хаффмана вхідним символам (ланцюжках бітів різної довжини) ставляться у відповідність ланцюжка бітів також змінної довжини - їх коди. Довжина коду кожного символу береться пропорційної бінарного логарифму його частоти, взятому з протилежним знаком. А загальний набір всіх зустрілися різних символів становить алфавіт потоку.
Існує інший метод - адаптивного або динамічного кодування Хаффмана. його загальний принципполягає в тому, щоб змінювати схему кодування в залежності від характеру змін вхідного потоку. Такий підхід має однопрохідний алгоритм і не вимагає збереження інформації про використаний кодуванні в явному вигляді. Адаптивне кодування може дати більший ступінь стиснення, в порівнянні зі статичним, оскільки більш повно враховуються зміни частот вхідного потоку. При використанні адаптивного кодування Хаффмана ускладнення алгоритму полягає в необхідності постійного коректування дерева і кодів символів основного алфавіту відповідно до мінливих статистикою вхідного потоку.
Методи Хаффмана дають досить високу швидкість і помірно гарна якістьстиснення. Однак кодування Хаффмана має мінімальну надлишковість за умови, що кожен символ кодується в алфавіті коду символу окремої ланцюжком з двох біт - (0, 1). Основним же недоліком даного методує залежність ступеня стиснення від близькості ймовірностей символів до 2 в деякій негативній ступеня, що пов'язано з тим, що кожен символ кодується цілим числом біт.
Зовсім інше рішення пропонує арифметичне кодування. Цей метод заснований на ідеї перетворення вхідного потоку в одне число з плаваючою комою. Арифметичне кодування є методом, що дозволяє упаковувати символи вхідного алфавіту без втрат за умови, що відомий розподіл частот цих символів.
Передбачувана необхідна послідовність символів при стисненні методом арифметичного кодування розглядається як деякий двійковий дріб з інтервалу)
 Чи можна використовувати Google Play Market на Lumia?
Чи можна використовувати Google Play Market на Lumia? Опис і секрети чинного тарифу нуль сумнівів на Білайні
Опис і секрети чинного тарифу нуль сумнівів на Білайні Опція МТС «Скрізь як удома Росія
Опція МТС «Скрізь як удома Росія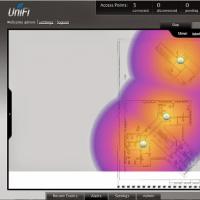 Безшовний Wi-Fi Корисні відгуки про роботу capsman
Безшовний Wi-Fi Корисні відгуки про роботу capsman Як говорити з Алісою Скріншоти Яндекс з Алісою
Як говорити з Алісою Скріншоти Яндекс з Алісою Програма мтс бонус закривається
Програма мтс бонус закривається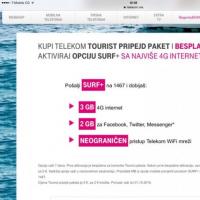 Мобільний зв'язок і інтернет на курортах Чорногорії
Мобільний зв'язок і інтернет на курортах Чорногорії