¿Cuál es el proceso de compresión de datos? Codificación con los árboles de Shannon Fano. Mover y copiar archivos y carpetas comprimidos.
Número de conferencia 4. Comprimir información
Principios de información de compresión.
El propósito de la compresión de datos es proporcionar una representación compacta de los datos generados por la fuente, para su ahorro y transmisión más económicos a través de canales de comunicación.
Tengamos un tamaño de archivo 1 (uno) Megabyte. Necesitamos obtener un archivo más pequeño de él. Nada complicado: lanzar el Archiver, por ejemplo, WinZip, y da como resultado el resultado, por ejemplo, un archivo de 600 kilobytes. ¿Dónde están los 424 kilobytes restantes?
La compresión de la información es una de las formas de codificar. En general, los códigos se dividen en tres grupos grandes: códigos de compresión (códigos efectivos), códigos resistentes al ruido y códigos criptográficos. Los códigos diseñados para comprimir la información se dividen, a su vez, en los códigos sin códigos de pérdida y pérdida. La codificación sin pérdida implica una recuperación de datos absolutamente precisa después de la decodificación y se puede usar para comprimir cualquier información. La codificación de pérdidas suele ser un grado de compresión mucho mayor que la codificación sin pérdida, pero permite algunas desviaciones de los datos decodificados de la fuente.
Tipos de compresión
Todos los métodos de información de compresión se pueden dividir en dos grandes clases de no ciclo: compresión con pérdida Información y compresión. sin pérdida información.
Compresión sin pérdida de información.
Estos métodos de compresión están interesados \u200b\u200ben nosotros primero, ya que son ellos que se utilizan en la transferencia de documentos y programas de texto, al emitir un cliente realizado por el trabajo realizado o al crear copias de copia de seguridad de la información almacenada en una computadora.
Los métodos de compresión de esta clase no pueden permitir la pérdida de información, por lo que se basan únicamente en eliminar su redundancia, y la información tiene una redundancia casi siempre (sin embargo, si alguien ya no lo ha complicado). Si no hubiera redundancia, no habría nada que comprimir.
Aquí hay un ejemplo simple. En ruso, 33 letras, diez dígitos y más sobre una docena de marcas de puntuación y otros caracteres especiales. Para el texto que se registra. solo con letras mayúsculas rusas (Como en los telegramas y los radiogramas), sería suficiente para sesenta valores diferentes. Sin embargo, cada carácter generalmente se codifica por byte, que contiene 8 bits y puede expresar 256 códigos diferentes. Esta es la primera base para la redundancia. Para nuestro texto "Telegraph", sería suficiente para seis bits en un símbolo.
Aquí hay otro ejemplo. En los personajes internacionales de codificación. Ascii. Para codificar cualquier símbolo, se da la misma cantidad de bits (8), mientras que todos tienen tiempo y es bien sabido que los símbolos más comunes tienen sentido codificar menos caracteres. Por lo tanto, por ejemplo, en el "Alfabeto de Morse", las letras "E" y "T", que a menudo se codifican, están codificadas por un signo (respectivamente, este es un punto y un tablero). Y tales letras raras, como "Yu" (- -) y "C" (- -) están codificadas por cuatro signos. La codificación ineficaz es la segunda base para la redundancia. Los programas que comprimen la información pueden ingresar su codificación (diferente para diferentes archivos) y atribuyen una tabla determinada (diccionario) a un archivo comprimido, desde el cual el programa de desempaquete aprende cómo este archivo Esos u otros personajes o sus grupos están codificados. Los algoritmos basados \u200b\u200ben la información de transcodificación se llaman hafman Algorithms.
La presencia de fragmentos repetidos es la tercera base para la redundancia. En los textos es raro, pero en las tablas y en el gráfico, la repetición de los códigos es un fenómeno común. Por ejemplo, si el número 0 se repite veinte veces seguidos, no tiene sentido poner veinte bytes cero. En su lugar, ponen un cero y coeficiente 20. Dichos algoritmos basados \u200b\u200ben repeticiones reveladoras se llaman métodosRLE. (CORRER. Largo. Codificación).
Las grandes secuencias de repetición de los mismos bytes son particularmente diferentes ilustraciones gráficas, pero no fotográficas (hay muchos ruidos y puntos vecinos difieren significativamente en los parámetros), y los que los artistas pintan el color "suave" que en las películas animadas.
Compresión con pérdida de información.
La compresión con la pérdida de información significa que después de desempacar el archivo compactado, recibiremos un documento que es algo diferente al que está al principio. Está claro que cuanto mayor sea el grado de compresión, mayor será el valor de la pérdida y viceversa.
Por supuesto, tales algoritmos no son aplicables para documentos de texto, tablas de bases de datos y especialmente para programas. Las distorsiones menores en un simple texto sin formato se pueden sobrevivir de alguna manera, pero la distorsión de al menos un bit en el programa lo hará absolutamente inoperable.
Al mismo tiempo, hay materiales en los que vale la pena sacrificar un pequeño porcentaje de la información para obtener una compresión de decenas de veces. Estos incluyen ilustración fotográfica, imágenes de video y composiciones musicales. La pérdida de información en la compresión y el desempaque posterior en tales materiales se percibe como la aparición de algún "ruido" adicional. Pero, como cuando se crea estos materiales, un cierto "ruido" todavía está presente, su ligero aumento no siempre parece crítico, y las ganancias en los tamaños otorgan un enorme (10-15 veces en la música, a las 20-30 veces en la foto. y material de metraje de video).
Los algoritmos de compresión con pérdida de información incluyen algoritmos tan conocidos como JPEG y MPEG. El algoritmo JPEG se utiliza al comprimir imágenes fotográficas. Los archivos gráficos comprimidos por este método tienen una extensión JPG. Los algoritmos MPEG se utilizan cuando se comprimen el video y la música. Estos archivos pueden tener diferentes extensiones, dependiendo del programa específico, pero las más famosas son.mpg para el video i.mrz para la música.
Los algoritmos de compresión con pérdida de información se aplican solo para tareas de consumo. Esto significa, por ejemplo, que si la foto se transmite para ver, y la música para la reproducción, entonces se pueden aplicar dichos algoritmos. Si se transmiten para su posterior procesamiento, por ejemplo, para la edición, no es inaceptable ninguna pérdida de información en el material de origen.
La magnitud de la pérdida permisible en la compresión suele ser posible controlar. Esto le permite experimentar y lograr una relación de tamaño / calidad óptimo. En ilustraciones fotográficas destinadas a la reproducción en la pantalla, una pérdida del 5% de la información suele ser no crítica, y en algunos casos se puede permitir 20-25%.
Algoritmos de compresión sin pérdida de información.
Código SHANNON-FANO
Para más razonamiento, será conveniente enviar nuestro archivo original Con texto como fuente de caracteres que aparecen en su salida. No sabemos de antemano qué símbolo será el siguiente, pero sabemos que la letra "A" aparecerá con la probabilidad de P1, con la probabilidad de P2 -BUVA "B", etc.
En el caso más sencillo, consideraremos todos los símbolos de texto independientes entre sí, es decir, La probabilidad de la aparición del siguiente símbolo no depende del valor del símbolo anterior. Por supuesto, por un texto significativo, no lo es, pero ahora estamos considerando una situación muy simplificada. En este caso, la aprobación es verdadera "El símbolo lleva más información, menos probabilidades de aparecer".
Imaginemos el texto, cuyo alfabeto consta de solo 16 letras: a, b, b, g, d, e, z, z, y k, l, m, n, o, p, r. Cada uno de estos Las señales pueden codificar con solo 4 bits: de 0000 a 1111. Ahora imagina que las probabilidades de la apariencia de estos personajes se distribuyen de la siguiente manera:
La suma de estas probabilidades está naturalmente unida. Dividimos estos caracteres en dos grupos para que la probabilidad total de los caracteres de cada grupo sea ~ 0.5 (Fig.). En nuestro ejemplo, será grupos. personajes a-in y señor Los círculos en la figura, indicando grupos de símbolos, se denominan vértices o nodos (nodos), y el diseño mismo de estos nodos es un árbol binario (árbol B). Asignamos su código a cada nodo, que denota un número de nodo 0, y el otro número 1.
Nuevamente, rompemos el primer grupo (A-B) en dos subgrupos para que sus probabilidades totales sean tan más cercanas entre sí. Agregue al código del primer número de subgrupo 0, y al segundo código: dígito 1. 
Repetiremos esta operación hasta que en cada vértice de nuestro "árbol" siga siendo un personaje. El árbol completo para nuestro alfabeto tendrá 31 nodos.
Los códigos de símbolos (gangles de madera extremos extremos) tienen los códigos de longitud desigual. Por lo tanto, la letra A que tiene una probabilidad P \u003d 0.2 para nuestro texto imaginario se codifica con solo dos bits, y la letra P (no se muestra en la figura), con la probabilidad P \u003d 0.013, está codificada con una combinación de seis bits.
Por lo tanto, el principio es obvio: los símbolos comunes están codificados por un número menor de bits, rara vez se encuentran: grandes. Como resultado, la cantidad promedio de bits en el símbolo será igual

donde NI es el número de bits que codifican el símbolo I-TH, PI es la probabilidad de la aparición del símbolo I-TH.
Código Huffman.
El algoritmo Huffman está elegantemente implementa la idea general de la codificación estadística utilizando conjuntos de prefijo y funciona de la siguiente manera:
1. Escribimos todos los símbolos del alfabeto en orden de aumentar o disminuir la probabilidad de su aparición en el texto.
2. Combine constantemente dos personajes con las probabilidades más pequeñas de la aparición de la aparición en un nuevo carácter compuesto, la probabilidad de que asumamos igual a la suma de las probabilidades de los componentes de sus caracteres. Al final, construimos un árbol, cuyo nodo tiene la probabilidad total de todos los nodos debajo de ella.
3. Haga un seguimiento de la ruta a cada hoja de madera, marcando la dirección a cada nodo (por ejemplo, derecha - 1, izquierda - 0). La secuencia resultante le da una palabra de código correspondiente a cada símbolo (Fig.).
Construye un árbol de código para la comunicación con el siguiente alfabeto:

Desventajas de los métodos.
La mayor complejidad con códigos, de la siguiente manera de la discusión anterior, es la necesidad de tener una tabla de probabilidad para cada tipo de datos compresibles. Este no es un problema si se sabe que el texto inglés o ruso está comprimido; Simplemente proporcionamos un árbol de código adecuado del codificador y decodificador para el texto inglés o ruso. En el caso general, cuando se desconoce la probabilidad de símbolos para los datos de entrada, los códigos estáticos de Huffman trabajan ineficientemente.
La solución a este problema es un análisis estadístico de los datos codificados realizados durante la primera pasada de los datos, y la compilación en él se basa en su código de código. En realidad, la codificación se realiza por la segunda pasada.
Otra falta de códigos es que la longitud mínima de la palabra del código para ellos no puede ser inferior a una, mientras que la entropía del mensaje puede ser de 0.1, y 0.01 bits / letra. En este caso, el código se vuelve significativamente redundante. El problema se resuelve utilizando el algoritmo para bloquear los bloques, pero luego el procedimiento de codificación / decodificación es complicado y el árbol de código se expande significativamente, lo que, en última instancia, debe guardarse junto con el código.
Estos códigos no tienen en cuenta las relaciones entre los caracteres que están presentes en casi cualquier texto. Por ejemplo, si en el texto en idioma en Inglés Se nos encuentra en la letra Q, podemos decir con confianza que la letra U lo irá.
Codificación de grupo: codificación de longitud de ejecución (RLE) es uno de los algoritmos de archivo más antiguos y simples. La compresión en la RLE se produce debido a la sustitución de las cadenas del mismo byte en el par "Contador, valor". ("Rojo, rojo, ..., rojo" está escrito como "n rojo").
Una de las implementaciones del algoritmo es: están buscando el byte más frecuentemente ocurrido, lo llaman el prefijo y hacen que reemplace las cadenas de los mismos símbolos en el triple "prefijo, contador, valor". Si se cumple este byte en el archivo de origen una o dos veces seguidas, se reemplaza por un par de "prefijo, 1" o "prefijo, 2". Hay un "prefijo" no utilizado ", 0", que se puede usar como un signo del final de los datos envasados.
Al codificar archivos EXE, puede buscar y empaquetar la secuencia del formulario Axayazawat ... que a menudo se encuentran en los recursos (filas en la codificación Unicode)
Las partes positivas del algoritmo se pueden atribuir a lo que no requiere memoria adicional al trabajar, y se ejecuta rápidamente. El algoritmo se utiliza en los formatos de RCX, TIFF, RMN. Una característica interesante de la codificación del grupo en PCX es que el grado de archivo para algunas imágenes se puede aumentar significativamente solo cambiando el orden de los colores en la paleta de imágenes.
El código de LZW (LEMPEL-ZIV y WELCH) es hoy en día, uno de los códigos de compresión más comunes sin pérdida. Es con la ayuda del código LZW que hay compresión en formatos tan gráficos como TIFF y GIF, con la ayuda de modificaciones LZW, hay muchos archivadores universales. El funcionamiento del algoritmo se basa en la búsqueda en el archivo de entrada de secuencias de símbolos de repetición, que están codificadas por combinaciones con una longitud de 8 a 12 bits. Así, la mayor eficiencia. este algoritmo Tiene archivos de texto y archivos gráficos en los que hay grandes secciones monocromáticas o secuencias de repetición de píxeles.
La ausencia de pérdidas de información con la codificación de LZW condujo a la amplia distribución del formato basado en TIFF según ello. Este formato no impone ninguna restricción sobre el tamaño y la profundidad del color de la imagen y está extendido, por ejemplo, en la impresión. Otro formato basado en LZW: GIF es más primitivo: le permite almacenar imágenes con una profundidad de color de no más de 8 bits / píxeles. Al comienzo del archivo GIF hay una paleta, una tabla que establece la correspondencia entre el índice de color: el número en el rango de 0 a 255 y el valor de color real, de 24 bits.
Algoritmos de compresión con pérdida de información.
El algoritmo JPEG fue desarrollado por un grupo de firmas llamado grupo conjunto de expertos fotográficos. El objetivo del proyecto fue crear un estándar de compresión altamente eficiente para imágenes en blanco y negro y en color, este objetivo y fue logrado por los desarrolladores. Actualmente, JPEG encuentra la aplicación más amplia donde se requiere una relación de alta compresión, por ejemplo, en Internet.
A diferencia del JPEG que codifica el algoritmo LZW está codificando con pérdidas. El algoritmo de codificación en sí se basa en una matemática muy compleja, pero en términos generales se puede describir de la siguiente manera: la imagen se divide en cuadrados de 8 * 8 píxeles, y luego cada cuadrado se convierte en una cadena secuencial de 64 píxeles. A continuación, cada cadena de este tipo se somete a la llamada transformación DCT, que es una de las variedades de transformada de Fourier Discreta. Se encuentra en el hecho de que la secuencia de entrada de píxeles se puede representar como la suma de los componentes sinusoidales y coseno con múltiples frecuencias (los llamados armónicos). En este caso, necesitamos conocer solo las amplitudes de estos componentes para restaurar la secuencia de entrada con un grado suficiente de precisión. Cuanto mayor sea el número de componentes armónicos que conocemos, menos será la discrepancia entre el original y la imagen comprimida. La mayoría de los codificadores JPEG le permiten ajustar la relación de compresión. Esto es muy alcanzado manera simple: Cuanto mayor se establezca el grado de compresión, menor será el armónico presentará cada bloque de 64 píxeles.
Por supuesto, la resistencia de este tipo de codificación es una gran relación de compresión al tiempo que mantiene la profundidad del color original. Es esta propiedad lo que llevó a su uso generalizado en Internet, donde la disminución en el tamaño de los archivos es de suma importancia en las enciclopedias multimedia, donde se requiere el almacenamiento para ser mayor que los gráficos en volumen limitado.
La propiedad negativa de este formato no está relacionada con cualquier medio, inherentemente inherente a la calidad de la imagen. Es este hecho triste que no permite que se utilice en la impresión, donde la calidad se coloca a la cabeza de la esquina.
Sin embargo, el formato JPEG no es el límite de la perfección en el deseo de reducir el tamaño del archivo de destino. EN Últimamente La investigación intensiva está en marcha en el campo de la llamada transformación de wavelet (o transformación de salpicaduras). Sobre la base de los principios matemáticos más complejos, los codificadores de Wavelet permiten obtener una mayor compresión que JPEG, con pérdidas de información más pequeñas. A pesar de la complejidad de las matemáticas de la transformación de Wavelet, en la implementación del software es más fácil que JPEG. Aunque los algoritmos de la compresión de wavelet todavía están en la etapa inicial del desarrollo, se prepara un gran futuro.
Compresión fractal
La compresión de la imagen del fractal es un algoritmo de compresión de imágenes con pérdidas basadas en el uso de funciones icónicas (IFS, como regla general, como resultado de las transformaciones afín) a las imágenes. Este algoritmo se conoce en eso, en algunos casos, permite obtener relaciones de compresión muy altas ( mejores ejemplos - Hasta 1000 veces con capacidad visual aceptable) para fotos reales de objetos naturales, que no está disponible para otros algoritmos de compresión de imágenes en principio. porque situación compleja Con la patente de generalizada el algoritmo no recibió.
El archivo Fractal se basa en el hecho de que el uso de los coeficientes del sistema de las funciones de Idd, la imagen se predica en una forma más compacta. Antes de considerar el proceso de archivo, analizaremos cómo se construye una imagen.
Estrictamente hablando, el IFS es un conjunto de transformaciones afines tridimensionales que traducen una imagen a otra. La transformación se somete a puntos en el espacio tridimensional (coordenada X, en la coordenada, brillo).
La base del método de codificación de fractales es la detección de parcelas similares a sí mismo en la imagen. Por primera vez, la posibilidad de aplicar la teoría de los sistemas de funciones icónicas (IFS) al problema de la compresión de la imagen fue estudiada por Michael Barnsley y Alan Sloan. Patientaron su idea en 1990 y 1991. Jackwin (Jacquin) introdujo un método de codificación de fractales, que utiliza bloques de subimos de dominio y rango (bloques de submemos de dominio y rango), bloques de bloques que cubren toda la imagen. Este enfoque se ha convertido en la base para la mayoría de los métodos de codificación de fractales utilizados hoy. Fue mejorado por Juval Fisher (Yuval Fisher) y una serie de otros investigadores.
De acuerdo con este método, la imagen se divide en una pluralidad de hermanos de clasificación no recíprocos (subimos de rango) y establece un conjunto de discapacidades de dominio superpuestas (subimos de dominio). Para cada bloque de rango, el algoritmo de codificación encuentra la unidad de dominio más adecuada y una conversión afín que traduce esta unidad de dominio a este bloque de rango. La estructura de la imagen se muestra en el sistema de bloques de rango, bloques de dominio y transformaciones.
La idea es la siguiente: Supongamos que la imagen original es un punto fijo de alguna visualización de compresión. Luego, es posible recordar esta pantalla en lugar de la imagen misma, y \u200b\u200bpara restaurarla, se aplica lo suficiente en repetidamente esta pantalla a cualquier imagen de inicio.
En el teorema de Banach, tales iteraciones siempre conducen a un punto fijo, es decir, a la imagen original. En la práctica, toda la dificultad radica en encontrar la pantalla compresiva más adecuada y en su almacenamiento compacto. Como regla general, los algoritmos de mapeo (es decir, los algoritmos de compresión) son en gran medida abrumadores y requieren grandes costos computacionales. Al mismo tiempo, los algoritmos de restauración son bastante efectivos y rápidos.
Brevemente, el método propuesto por Barnesley se puede describir de la siguiente manera. La imagen está codificada por varias transformaciones simples (en nuestro caso afín), es decir, está determinado por los coeficientes de estas transformaciones (en nuestro caso A, B, C, D, E, F).
Por ejemplo, la imagen de la curva Koch se puede codificar por cuatro transformaciones afines, lo determinamos de manera inequívoca con los 24 coeficientes.
Como resultado, el punto definitivamente irá en algún lugar dentro del área negra en la imagen de origen. Habiendo hecho tal operación muchas veces, llenamos todo el espacio negro, restaurando así la imagen.

Las dos imágenes más famosas obtenidas usando IFS: Triángulo de Serpinsky y Fern Barnsley. El primero se establece tres, y el segundo es cinco transformaciones afines (o, en nuestra terminología, lentes). Cada conversión se establece literalmente, lea bytes, mientras que la imagen construida con su ayuda puede ocupar varios megabytes.
Se vuelve claro cómo funciona el Archiver, y por qué necesita tanto tiempo. De hecho, la compresión fractal es la búsqueda de dominios similares a sí mismo en la imagen y la definición de los parámetros de las transformaciones afines para ellos.
En el peor de los casos, si el algoritmo de optimización no se aplica, tomará un busto y comparación de todos los fragmentos posibles de la imagen de diferentes tamaños. Incluso para las imágenes pequeñas, al tener en cuenta la discreción, obtenemos el número astronómico de las opciones trastornadas. Incluso un fuerte estrechamiento de las clases de conversión, por ejemplo, al escalar solo un cierto número de veces, no permitirá lograr un tiempo aceptable. Además, la calidad de la imagen se pierde. La abrumadora mayoría de la investigación en el campo de la compresión fractal ahora está dirigida a reducir el tiempo de archivo requerido para obtener una imagen de alta calidad.
Para un algoritmo de compresión fractal, así como para otros algoritmos de compresión con pérdidas, los mecanismos son muy importantes con los que será posible ajustar el grado de compresión y el grado de pérdidas. Hasta la fecha, se ha desarrollado un gran conjunto de tales métodos. Primero, es posible limitar el número de transformaciones, asegurando deliberadamente la relación de compresión no está por debajo del valor fijo. En segundo lugar, puede exigir que en una situación en la que la diferencia entre el fragmento procesado y la mejor aproximación sea mayor que un cierto valor de umbral, este fragmento se ha aplastado necesariamente (se inician varias lentes). En tercer lugar, es posible prohibir los fragmentos de fragmentos menores que, por ejemplo, cuatro puntos. Al cambiar los valores de umbral y la prioridad de estas condiciones, puede controlar de manera muy flexible la relación de compresión de imágenes: de la conformidad por lotes, a cualquier relación de compresión.
Comparación con JPEG.
Hoy en día, el algoritmo de archivo gráfico más común es JPEG. Compararlo con compresión fractal.
Primero, notamos que ambos, y otro algoritmo operan con imágenes de 8 bits (en grados grises) y 24 bits. Ambos son algoritmos de pérdida de compresión y proporcionan coeficientes de archivo cercanos. Y el algoritmo fractal, y JPEG tienen la oportunidad de aumentar el grado de compresión debido a un aumento de las pérdidas. Además, ambos algoritmos son muy paralelos.
Las diferencias comienzan si consideramos el tiempo que necesita para archivar / descomprimir algoritmos. Por lo tanto, el algoritmo fractal comprime cientos e incluso miles de veces más tiempo que JPEG. Desembalar la imagen, por el contrario, ocurrirá 5-10 veces más rápido. Por lo tanto, si la imagen se comprime solo una vez, y se transfiere a través de la red y se desempaqueta muchas veces, entonces es más rentable usar un algoritmo fractal.
JPEG utiliza la descomposición de la imagen sobre las funciones de coseno, por lo que la pérdida en ella (incluso para las pérdidas mínimas dadas) se manifiesta en ondas y halo en el borde de los colores afilados. Es a este efecto que no le gusta usarlo al comprimir imágenes que se preparan para la impresión de alta calidad: este efecto puede ser muy notable.
El algoritmo fractal está encantado con esta escasez. Además, al imprimir imágenes, cada vez que tenga que realizar la operación de escalado, ya que el dispositivo de impresión del dispositivo de impresión no coincide con la ráster de la imagen. Al convertir, también puede haber varios efectos desagradables con los que puede luchar o escalar la imagen programáticamente (para dispositivos de impresión baratos como láser ordinario y impresoras de inyección de tinta), ya sea proporcionando un dispositivo de impresión con su procesador, disco duro y un conjunto de programas de procesamiento de imágenes (para máquinas fotophonatorias costosas). Como puede adivinar, con el uso de un algoritmo fractal, tales problemas prácticamente no ocurren.
El derrocamiento del algoritmo fractal JPEG en el uso generalizado, pronto sucederá (al menos debido a la velocidad de archivo más baja), pero en el campo de las aplicaciones multimedia, en juegos de computadora Su uso está bastante justificado.
Hoy en día, muchos usuarios piensan en cómo se lleva a cabo el proceso de información de compresión para ahorrar espacio libre en Winchester, ya que es uno de los más herramientas efectivas Uso de espacio útil en cualquier unidad. A menudo es suficiente para los usuarios modernos que enfrentan una escasez de espacio libre en la unidad, debe eliminar los datos, tratando de liberar el lugar deseado de esta manera, mientras que los usuarios más avanzados con mayor frecuencia usan la compresión de datos para reducir su volumen. .
Sin embargo, muchas personas ni siquiera saben cómo se llama el proceso de compresión de información, por no mencionar qué algoritmos se utilizan y lo que le da el uso de cada uno de ellos.
¿Vale la pena comprimir los datos?

La compresión de datos es importante hoy y es necesario para cualquier usuario. Por supuesto, en nuestro tiempo, casi todos pueden adquirir dispositivos de almacenamiento de datos avanzados, proporcionando la posibilidad de usar una cantidad suficientemente grande de espacio libre, así como equipado con canales de traducción de información de alta velocidad.
Sin embargo, es necesario entender correctamente eso con el tiempo, la cantidad de datos que deben transmitirse a lo largo del tiempo. Y si es literalmente hace diez años, un volumen de 700 MB se consideró estándar para una película regular, entonces las películas hechas en la calidad HD pueden tener volúmenes iguales a varias docenas de gigabytes, por no mencionar cuánto espacio libre son pinturas de alta calidad. En Formato de Blu-ray.
¿Cuándo es necesaria la compresión de datos?

Por supuesto, no vale la pena que sea el hecho de que el proceso de información de compresión le brindará mucho uso, pero hay un cierto número de situaciones en las que algunos de los métodos de compresión de información son extremadamente útiles e incluso necesarios:
- Transferencia de ciertos documentos a través de correo electrónico. En particular, esto se refiere a aquellas situaciones en las que necesita transferir información en un gran volumen utilizando varios dispositivos móviles.
- A menudo, el proceso de compresión de información para reducir el lugar ocupado por ella se usa cuando se publica ciertos datos en varios sitios cuando desea ahorrar tráfico;
- Guardar espacio libre en el disco duro cuando no es posible reemplazar o agregar nuevas herramientas de almacenamiento. En particular, la situación más común es la que hay ciertas restricciones en el presupuesto asequible, pero carece de libre. espacio del disco.
Por supuesto, además de lo anterior, todavía hay numero enorme Puede haber diferentes situaciones en las que se puede requerir el proceso de información de compresión para reducir su volumen, pero estos son hoy los más comunes.
¿Cómo puedo comprimir los datos?

Hoy en día, hay una amplia variedad de métodos de compresión de información, pero todos ellos se dividen en dos grupos principales: esta es compresión con ciertas pérdidas, así como la compresión sin pérdida.
El uso del último grupo de métodos es relevante cuando los datos deben restaurarse con una precisión extremadamente alta, hasta un bit. Este enfoque es el único relevante en el caso de que se comprime la compresión de un documento de texto específico.
Cabe señalar que en algunas situaciones no es necesario maximizar la reducción de los datos comprimidos, por lo tanto, es posible usar dichos algoritmos en los que se realiza la compresión de información en el disco con ciertas pérdidas. La ventaja de la compresión con pérdidas es que tal tecnología es mucho más simple en la implementación, y también proporciona el mayor grado posible de archivo.
Compresión con pérdidas

La información con pérdidas garantiza una mejor compresión de la magnitud, al tiempo que mantiene la calidad suficiente de la información. En la mayoría de los casos, el uso de tales algoritmos se lleva a cabo para comprimir datos analógicos, como todo tipo de imágenes o sonidos. En tales situaciones, los archivos desempaquetados pueden diferir con bastante fuerza de la información original, pero prácticamente no son distinguibles para el ojo o el oído humanos.
Compresión sin pérdida
Los algoritmos para la información de compresión sin pérdida proporcionan la recuperación de datos más precisa, eliminando cualquier pérdida de archivos compresibles. Sin embargo, es necesario comprender correctamente el hecho de que, en este caso, no se garantiza una compresión tan efectiva de los archivos.
Métodos universales

Entre otras cosas, hay una serie determinada. métodos universalesque se lleva a cabo un proceso efectivo de información de compresión para reducir el lugar ocupado por ella. En general, puede asignar solo tres tecnologías principales:
- Conversión de flujo. En este caso, se realiza una descripción de la nueva información incomparada entrante a través de archivos ya procesados, y no se calculan las probabilidades, y los símbolos están codificando en función de los únicos archivos que ya han sido sometidos a un determinado procesamiento.
- Compresión estadística. Este proceso de información de compresión para reducir el lugar ocupado en el disco se distribuye en dos subcategorías: métodos de adaptación y bloqueo. La opción adaptativa proporciona el cálculo de la probabilidad de nuevos archivos de acuerdo con la información, que ya se ha procesado durante el proceso de codificación. En particular, tales métodos también deben incluir varias variantes adaptativas de los algoritmos de Shannon Fano y Huffman. El algoritmo de bloque proporciona un cálculo separado de cada bloque de información, seguido de agregar al bloque comprimido en sí.
- Convertir bloque. La información entrante se distribuye a varios bloques, y posteriormente ocurre una transformación holística. Se debe decir que ciertos métodos, especialmente aquellos que se basan en la permutación de varios bloques, en última instancia, pueden llevar a una disminución significativa en el volumen de información compresible. Sin embargo, es necesario comprender correctamente que después de llevar a cabo dicho tratamiento, al final, existe una mejora significativa en la que la compresión posterior a través de otros algoritmos se realiza mucho más sencilla y rápida.
Compresión al copiar

Uno de los componentes más importantes. copia de reserva es el dispositivo para el que se moverá necesario para el usuario información. La mayor cantidad de estos datos se moverá, el dispositivo más volumétrico debe usar. Sin embargo, si se le implementa un proceso de compresión de datos, en este caso, en este caso, es poco probable que el problema de la falta de espacio libre sea relevante para usted.
¿Por qué lo necesitas?
La capacidad de comprimir la información cuando hace posible reducir significativamente el tiempo que desea copiar los archivos necesarios, y al mismo tiempo lograr un ahorro efectivo de espacio libre en la unidad. En otras palabras, cuando se usa la compresión, la información se copiará mucho más compacta y rápidamente, y puede guardar su dinero y las finanzas que fueron necesarias para comprar una unidad más voluminosa. Entre otras cosas, teniendo información comprimida, también reduce el tiempo que necesitará al transportar todos los datos al servidor o copiarlos a través de la red.
La compresión de datos para la copia de seguridad se puede realizar en uno o más archivos, en este caso, todo dependerá de qué tipo de programa utilice y qué información está sujeta a la compresión.
Al elegir una utilidad, asegúrese de ver cómo el programa que eligió puede comprimir los datos. Depende del tipo de información, como resultado, la efectividad de la compresión de los documentos de texto puede ser más del 90%, mientras que es efectivo para no más del 5%.
Antes de comenzar el proceso de comprimir un archivo o carpeta, es muy importante comprender todos los beneficios recibidos de esto, y desmontar los métodos de compresión disponibles en Windows 7:
- Compresión de archivos NTFS
- Carpetas de compresión (zip).
La compresión de datos reduce el tamaño del archivo minimizando sus datos redundantes. EN archivo de texto Con datos redundantes, a menudo hay ciertos signos, como un símbolo espacial o vocales generales (E y A), así como cadenas de caracteres. La compresión de datos crea una versión comprimida del archivo, minimizando estos datos redundantes.
Estos dos métodos de compresión se compararán a continuación. Además, se considerará el impacto. varios archivos y carpetas en la acción de los archivos y carpetas comprimidos.
Archivo sistema NTFS Admite la compresión de archivos basada en un archivo separado. El algoritmo de compresión de archivos aquí es un algoritmo de compresión sin pérdida, esto significa que al comprimir y desempaquetar el archivo, los datos no se pierden. En otros algoritmos en la compresión y la descompresión posterior, parte de los datos se pierde.
Compresión de NTFS disponible en el sistema de archivos NTFS discos durosTiene las siguientes limitaciones y características:
- Compresión: atributo para un archivo o carpeta.
- Carpetas y archivos en el volumen NTFs, o comprimido, o no.
- Los nuevos archivos creados en una carpeta comprimida se limpian de forma predeterminada.
- El estado de una carpeta comprimida no refleja necesariamente el estado de la compresión de los archivos en esta carpeta. Por ejemplo, las carpetas se pueden comprimir sin comprimir su contenido, y algunos o todos los archivos en una carpeta comprimida pueden ser sin pagar.
- Trabajar con archivos comprimidos NTFS sin desembalarlos, ya que son desempaquetados y comprimidos nuevamente sin intervención del usuario.
- Si el archivo comprimido está abierto, el sistema lo desempaqueta automáticamente.
- Al cerrar archivo de Windows De nuevo se aprieta.
- Para simplificar el reconocimiento, los nombres de archivos y carpetas comprimidos de NTFS se muestran en otro color.
- Los archivos y carpetas comprimidos NTFS permanecen en forma comprimida, solo en el volumen NTFS.
- Los archivos comprimidos de NTFS no pueden ser cifrados.
- Los bytes de archivos comprimidos no están disponibles para aplicaciones; Sólo ven solo datos sin comprimir.
- Las aplicaciones que abren archivos comprimidos pueden funcionar con ellos como no se comprimen.
- Los archivos comprimidos no se pueden copiar en otro sistema de archivos.
Nota: Puede usar la herramienta de línea de comandos de línea de comandos para administrar la compresión NTFS.
Mueve y copie archivos y carpetas comprimidos.

Los archivos y carpetas comprimidos desplazados o copiados pueden cambiar su estado de compresión. A continuación se muestran cinco situaciones en las que se considera el impacto de la copia y la mudanza a los archivos y carpetas comprimidos.
Copia dentro de la partición de la sección NTFS.
¿Cómo cambia el estado del archivo o carpeta comprimido, si lo copia dentro de la sección NTFS? Al copiar un archivo o carpeta dentro del sistema de archivos NTFS, una sección, archivo o carpeta hereda el estado de compresión de la carpeta de destino. Por ejemplo, si copia un archivo o carpeta comprimido en una carpeta desempaquetada, un archivo o carpeta se desempaquetará automáticamente.
Moverse dentro de la sección NTFS.
¿Qué sucede con la compresión o carpeta de archivos cuando se mueve dentro de la sección NTFS?
Cuando mueve un archivo o carpeta dentro de la sección NTFS, un archivo o carpeta guarda su estado de compresión inicial. Por ejemplo, al mover un archivo o carpeta comprimido en una carpeta sin comprimir, el archivo permanece comprimido.
Copiando o moviéndose entre secciones NTFS.
¿Qué sucede con un archivo o carpeta comprimido al copiarlo o moverlo entre las secciones NTFS?
Cuando mueve el archivo o la carpeta entre las particiones NTFS, el archivo o la carpeta heredan el estado de compresión de la carpeta de destino. Dado que Windows 7 examina el movimiento entre las secciones como copiando con una operación de eliminación posterior, los archivos heredan el estado de compresión de la carpeta de destino.
Al copiar un archivo en una carpeta que ya contiene un archivo con el mismo nombre, el archivo copiado acepta el atributo de compresión del archivo de destino, independientemente del estado de la compresión de la carpeta.
Copiando o moviendo entre volúmenes de grasa y NTFS.
¿Qué sucede con la compresión de archivos que se copia o se mueve entre los volúmenes de grasa y NTFS?
Los archivos comprimidos copiados en la sección de grasas no están comprimidos, ya que los volúmenes de grasa no admiten la compresión. Sin embargo, si copia o mueve archivos de la sección de grasa a la sección NTFS, heredan el atributo de compresión de la carpeta a la que los copia.
Al copiar archivos, sistema de archivos NTFS calcula el espacio en disco en función del tamaño de un archivo sin comprimir. Esto es importante porque los archivos durante el proceso de copia no se comprimen, y el sistema debe garantizar suficiente espacio. Si está intentando copiar un archivo comprimido a la sección NTFS, y no tiene espacio libre para un archivo sin comprimir, tendrá un mensaje de error que notifique la deficiencia del espacio en disco para el archivo.
Como se mencionó anteriormente, una de las tareas importantes de la preparación preliminar de datos al cifrado es reducir su redundancia y alinear los patrones estadísticos del idioma aplicado. La reducción parcial de la redundancia se logra mediante la compresión de datos.
Comprimir información representa el proceso de convertir el mensaje de origen de un sistema de código a otro, como resultado de lo cual disminuye tamaño del mensaje. Los algoritmos destinados a la compresión de la información se pueden dividir en dos grupos grandes: implementar la compresión sin pérdida (compresión reversible) e implementar la compresión con pérdidas (compresión irreversible).
Compresión reversible Implica una recuperación de datos absolutamente precisa después de la decodificación y se puede aplicar para comprimir cualquier información. Siempre conduce a una disminución en el volumen del flujo de salida de la información sin cambiar su informatividad, es decir, sin pérdida estructura de información. Además, en el flujo de salida, utilizando un algoritmo de restauración o descompresión, puede obtener la entrada, y el proceso de recuperación se llama descompresión o desembalaje y solo después del proceso de desempaquetado, los datos son adecuados para su procesamiento de acuerdo con su formato interno. La compresión sin pérdida se aplica a los textos, archivos ejecutables, sonido y gráficos de alta calidad.
Compresión irreversible Por lo general, es un grado de compresión mucho más alto que la codificación sin pérdida, pero permite algunas desviaciones de los datos decodificados de la fuente. En la práctica, existe una amplia gama de tareas prácticas, en las que no se requiere el cumplimiento del requisito de restauración precisa de la información inicial después de la descompresión. Esto, en particular, se refiere a la compresión de información multimedia: imágenes de sonido, foto o video. Por ejemplo, los formatos de información multimedia JPEG y MPEG se aplican ampliamente, que utilizan compresión irreversible. La compresión irreversible generalmente no se usa junto con el cifrado criptográfico, ya que el requisito principal para el criptosistema es la identidad de los datos descifrados del original. Sin embargo, al utilizar tecnologías multimedia, los datos presentados en video digital, a menudo expuesto a la compresión irreversible antes de servir en el sistema criptográfico para el cifrado. Después de transferir información al consumidor y descifrado, los archivos multimedia se utilizan en un formulario comprimido (es decir, no se restaura).
Considere algunas de las formas más comunes de la compresión de datos reversibles.
El enfoque simple y el algoritmo más conocido para la información de compresión es reversible: esta es la codificación de la serie de secuencias (codificación de longitud de ejecución - RLE). La esencia de los métodos de este enfoque consiste en reemplazar las cadenas o series de bytes repetidos a un ingreso de bytes de codificación y el número de sus repeticiones. El problema de todos los métodos similares es solo en la definición del método, con el cual el algoritmo de desempaquetar podría distinguirse en la corriente resultante de las series codificadas de bytes de otras secuencias de bytes no codificadas. La solución al problema generalmente se logra mediante la expansión de las etiquetas al comienzo de las cadenas codificadas. Dichas etiquetas pueden ser bits característicos en el primer Pape de la serie codificada, los valores del primer byte de la serie codificada. La desventaja del método RLE es una relación de compresión bastante baja o el costo de codificar archivos con un pequeño número de series e incluso peor, con un pequeño número de bytes repetitivos en la serie.
Con la información de codificación uniforme, el mismo bit se asigna al mensaje, independientemente de la probabilidad de su apariencia. Al mismo tiempo, es lógico suponer que la longitud total de los mensajes transmitidos disminuirá si los mensajes frecuentes codificados con palabras de código corto, y rara vez se encontraron, más tiempo. Los problemas que surgen de esto están relacionados con la necesidad de usar. códigos con código de código variable. Hay muchos enfoques para construir tales códigos.
Algunos de los modelos de vocabulario generalizados son métodos de vocabulario, cuyos representantes principales incluyen los algoritmos de la familia ZIVA y los lemplos. Su idea básica es que los fragmentos. flujo de entrada ("Frases") son reemplazadas por un puntero al lugar donde ya han aparecido en el texto. En la literatura, tales algoritmos se indican como algoritmos. Compresión de lz.
Un método similar se adapta rápidamente a la estructura del texto y puede codificar palabras funcionales cortas, ya que aparecen muy a menudo en ella. Las nuevas palabras y frases también se pueden formar a partir de partes de palabras previamente encontradas. La decodificación del texto comprimido se lleva a cabo directamente, - hay un reemplazo simple del puntero a la frase terminada del diccionario al que indica el que indica. En la práctica, el método LZ está logrando una buena compresión, su propiedad importante es muy trabajo rápido descifrador.
Otro enfoque para la compresión de la información es código Hufflman, el codificador y decodificador de los cuales tienen una implementación de hardware bastante simple. La idea del algoritmo consiste en seguir: conocer las probabilidades de ocurrencia de caracteres en un mensaje, puede describir el procedimiento para construir códigos de longitud variable que consiste en un número entero de bits. Los símbolos son más propensos a ser asignados más códigos cortos, mientras que menos a menudo se encuentran personajes más largos. Debido a esto, se logra una reducción en la longitud promedio de la palabra clave y una mayor eficiencia de compresión. Los códigos Huffman tienen un prefijo único (el comienzo de la palabra clave), que le permite decodificarlos inequívocamente, a pesar de su longitud de variable.
El procedimiento para la síntesis del código Khaffman clásico asume la presencia de una información a priori sobre las características estadísticas de la fuente del mensaje. En otras palabras, el desarrollador debe conocer la probabilidad de aquellos u otros personajes, de los cuales se forman mensajes. Considere la síntesis del código de Huffman en un ejemplo simple.
p (S 1) \u003d 0.2, P (S 2) \u003d 0.15, P (S 3) \u003d 0.55, P (S 4) \u003d 0.1. Ordene los símbolos para descender la probabilidad de apariencia e imaginar en forma de tabla (Fig. 14.3, a).
El procedimiento de síntesis del código consta de tres pasos principales. El primer disparador de las filas de la tabla se produce: dos filas correspondientes a los símbolos con las probabilidades más pequeñas de la ocurrencia se reemplazan por una con una probabilidad total, después de lo cual la tabla se reordena de nuevo. La convolución continúa hasta que solo una línea con una probabilidad total igual a una (Fig. 14.3, b) permanece en la tabla.
Higo. 14.3.
En la segunda etapa, el código de código se construye utilizando una mesa plegada (Fig. 14.4, A). El árbol está construido, comenzando con la última columna de la tabla.

Higo. 14.4.
La raíz del árbol forma una unidad ubicada en la última columna. En este ejemplo, esta unidad está formada a partir de las probabilidades de 0.55 y 0,45 representadas en forma de dos nodos del árbol asociado con la raíz. El primero de ellos corresponde al símbolo S 3 y, por lo tanto, no se produce la ramificación adicional de este nodo.
El segundo nodo marcado con una probabilidad de 0.45 está conectado a dos nodos del tercer nivel, con probabilidades 0.25 y 0.2. La probabilidad de 0.2 corresponde al símbolo S 1, y la probabilidad de 0.25, a su vez, se forma a partir de las probabilidades de la apariencia de 0.15 del símbolo S 2 y 0.1 Apariencia del símbolo S 4.
Costillas que conectan los nodos de árbol de código individuales, números 0 y 1 números (por ejemplo, costillas izquierda - 0 y derecha - 1). En la tercera etapa final, se construye una tabla en la que se comparan los símbolos de origen y los códigos del código Huffman. Estas palabras de código se forman como resultado de los números de lectura marcados con nervaduras que forman la ruta de la raíz del árbol al símbolo correspondiente. Para el ejemplo bajo consideración, el código Huffman tomará la vista que se muestra en la tabla a la derecha (Fig. 14.4, B).
Sin embargo, el algoritmo clásico Huffman tiene una desventaja significativa. Para restaurar los contenidos del mensaje comprimido, el decodificador debe conocer la tabla de frecuencia que disfrutó del codificador. Por lo tanto, la longitud del mensaje comprimido aumenta por la longitud de la tabla de frecuencia, que debe enviarse antes de los datos, que pueden no ser reducidos a ningún esfuerzo para comprimir el mensaje.
Otra variante codificación estática Hufffman Es para ver la transmisión de entrada y la codificación de construcción según las estadísticas recopiladas. Esto requiere dos archivos en el archivo, uno para ver y recopilar información estadística, el segundo es para la codificación. En la codificación estática de Huffman, los símbolos de entrada (cadenas de bits de diferentes longitudes) se establecen en la correspondencia de la cadena de bits también las longitudes de variable: sus códigos. La longitud del código de cada símbolo se toma por un logaritmo binario proporcional de su frecuencia tomada con el signo opuesto. Y el conjunto total de todos los que se encuentran con diferentes símbolos es el alfabeto de la corriente.
Hay otro método - adaptativo o codificación dinámica de Huffman. Su principio general Es cambiar el esquema de codificación dependiendo de la naturaleza de los cambios de flujo de entrada. Tal enfoque tiene un algoritmo de un solo paso y no requiere la preservación de la información sobre la codificación utilizada explícitamente. La codificación adaptativa puede dar una mayor proporción de compresión en comparación con estática, ya que los cambios en las frecuencias del flujo de entrada se tienen más plenamente en cuenta. Al usar la codificación de Huffman adaptable, la complicación del algoritmo consiste en la necesidad de ajustar constantemente la madera y los códigos de los símbolos del alfabeto principal de acuerdo con las estadísticas cambiantes del flujo de entrada.
Los métodos de Huffman dan alta velocidad y moderadamente. buena calidad compresión. Sin embargo, la codificación de Huffman tiene una redundancia mínima, siempre que cada carácter esté codificado en el alfabeto del código de símbolo mediante una cadena separada de dos bits - (0, 1). La principal desventaja este método Es la dependencia del grado de compresión de la proximidad de la probabilidad de símbolos a 2 en algún grado negativo, que se debe al hecho de que cada carácter está codificado por un bit entero.
Una solución completamente diferente ofrece codificación aritmética. Este método se basa en la idea de convertir el flujo de entrada a un solo punto flotante. La codificación aritmética es un método que permite que los caracteres de envases del alfabeto de entrada sin pérdidas, siempre que se conoce la distribución de frecuencia de estos caracteres.
La secuencia requerida estimada de símbolos cuando se comprime por el método de codificación aritmética se considera como una fracción binaria del intervalo)
 Celular: lo que es en el iPad y cuál es la diferencia.
Celular: lo que es en el iPad y cuál es la diferencia. Ir a la televisión digital: ¿Qué hacer y cómo prepararse?
Ir a la televisión digital: ¿Qué hacer y cómo prepararse? Encuestas sociales trabajan en internet.
Encuestas sociales trabajan en internet. Savin grabó un mensaje de video a los Tyuments.
Savin grabó un mensaje de video a los Tyuments. Menú de mesas soviéticas, ¿cuál fue el nombre del jueves en cantinas soviéticas?
Menú de mesas soviéticas, ¿cuál fue el nombre del jueves en cantinas soviéticas?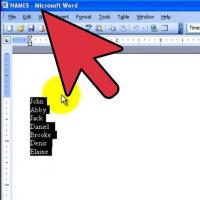 Cómo hacer en la lista "Palabra" alfabéticamente: consejos útiles
Cómo hacer en la lista "Palabra" alfabéticamente: consejos útiles ¿Cómo ver compañeros de clase que se retiran de amigos?
¿Cómo ver compañeros de clase que se retiran de amigos?