Creating a physical database model: Product Design. Creating a physical model of a database: Designing SQL Server Partitioning
Good evening / day / Morning Dear habraloudi! We continue to develop and supplement the blog about my favorite Open Source RDBMS PostgreSQL. It was miraculously so it turned out that the theme of today's topic has never been raised here. I must say that partitioning in PostgreSQL is very well described in the documentation, but will it stop me?).
Introduction
In general, under partitioning, in general, they understand not some technology, but rather approach to the design of the database, which appeared long before the DBMS began to maintain the so-called. Partitioned tables. The thought is very simple - divide the table into several parts of a smaller size. There are two subspecies - horizontal and vertical partitioning.Horizontal partitioning
Parts of the table contain different lines. We set us a table of the logs of a certain abstract application - Logs. We can break it into parts - one for logs in January 2009, the other - for February 2009, etc.Vertical partitioning
Parts of the table contain different columns. Find application for vertical partitioning (when it is really justified) somewhat more complicated than for horizontal. As a spherical horse, I propose to consider this option: the NEWS table has the ID, shorttext, longtext, and let the LongText field is used much less than the first two. In this case, it makes sense to break the NEWS table on columns (create two tables for shorttext and longtext, respectively, related primary keys + Create View News containing both columns). Thus, when we only need a description of the news, the DBMS does not have to read from the disk also the entire text news.Support partitioning in modern DBMS
Most of the modern DBMS supports the partitioning of tables in one form or another.- Oracle - Supports partition starting with 8 version. Working with sections On the one hand is very simple (in general, you can not think about them, you work with a regular table *), and on the other - everything is very flexible. Sections can be broken to "subpartitions", delete, divide, transfer. Different options for indexing the partitioned table are supported (global index partitioned index). Reference to a voluminous description.
- Microsoft SQL Server - Single support appeared recently (in 2005). The first impression of using - "Well, finally !! :)", the second - "works, everything seems to be ok." Documentation on MSDN.
- Mysql - Supports starting from version 5.1. Very good description on Habré
- Etc…
Partitioning in PostgreSQL
Partitioning of tables in PostgreSQL is somewhat different in sales from other databases. The basis for the partition is the inheritance of the tables (the thing inherent exclusively PostgreSQL). That is, we must have a main table (Master Table), and its sections will be the heir tables. We will consider partitioning on the example of a task approximate to reality.Formulation of the problem
The database is used to collect and analyze data on site / site visitors. Data volumes are large enough in order to think about partitioning. When analyzing, in most cases data is used for the last day.1. Create a basic table:
Create Table Analytics.events.
User_ID UUID NOT NULL,
event_type_id Smallint Not Null,
event_time timestamp default now () not ,
URL VARCHAR (1024) NOT NULL,
REFERRER VARCHAR (1024),
IP INET NOT NULL
);
2. We will partition by day by the Event_time field. For every day we will create a new section. We will call the sections according to the rule: analytics.events_ddmmyyyy. For example, a section for January 1, 2010.
Create Table Analytics.events_01012010.
Event_ID Bigint Default NextVal ("Analytics.seq_events") Primary Key,
Check (event_time\u003e \u003d timestamp "2010-01-01 00:00:00" and event_time< TIMESTAMP "2010-01-02 00:00:00" )
) Inherits (Analytics.events);* This Source Code Was Highlighted with Source Code Highlighter.
When creating a section, we explicitly specify the Event_ID field (PRIMARY KEY is not inherited) and create a check constraint on the Event_Time field, in order not to insert too much.
3. Create an index on the Event_Time field. When splitting the table on the section, we mean that most requests to the Events table will use the condition on the event_time field, so that the index on this field will help us very much.
Create index events_01012010_event_time_idx on analytics.events_01012010 Using BTree (event_time);* This Source Code Was Highlighted with Source Code Highlighter.
4. We want to ensure that when inserting into the main table, the data turned out to be the section intended for them. To do this, we make the next Fint - create a trigger that will manage data streams.
CREATE OR REPLACE FUNCTION ANALYTICS.EVENTS_INSERT_TRIGGER ()
RETURNS TRIGGER AS $$
Begin.
If (new .event_time\u003e \u003d TimeStamp "2010-01-01 00:00:00" and
New .Event_time.< TIMESTAMP "2010-01-02 00:00:00" ) THEN
INSERT INTO ANALYTICS.EVENTS_01012010 VALUES (NEW. *);
ELSE.
RAISE EXCEPTION "Date% is out of range. Fix Analytics.events_insert_trigger", New .event_time;
END IF;
RETURN NULL;
End;
$$
Language PlpGSQL;* This Source Code Was Highlighted with Source Code Highlighter.
Create Trigger Events_Before_insert.
Before Insert On Analytics.events
For Each Row Execute Procedure Analytics.events_insert_trigger ();* This Source Code Was Highlighted with Source Code Highlighter.
5. Everything is ready, we now have a partitioned table Analytics.events. We can start violently analyze its data. By the way, check constraints We created not only to protect sections from incorrect data. PostgreSQL can use them when drawing up a request plan (though, with a living index on event_time, the winnings will give it the minimum), it is enough to use the Constraint_Exclusion directive:
Set Constraint_exclusion \u003d ON;
Select * from Analytics.events Where Event_time\u003e Current_Date;* This Source Code Was Highlighted with Source Code Highlighter.
End of the first part
So what do we have? Let's see:1. Events table, divided into sections, analysis of available data over the past day becomes easier and faster.
2. The horror of the realization that all this needs to somehow maintain, create the sections on time, not forgetting to change the trigger accordingly.
About how easy and careless work with partitioned tables will tell in the second part.
UPD1: Replaced partitioning partitioning
UPD2:
According to the comments of one of the readers who do not have, unfortunately, the Account on Habré:
With inheritance, a few moments are connected, which should be taken into account when designing. Sections do not inherit the primary key and external keys on their columns. That is, when creating a section, you need to explicitly create Primary Key and Foreign Keys on the section columns. From myself I note that creating Foreign Key on the columns of the partitioned table is not the best way. In most cases, a partitioned table is the "table of facts" and itself refers to the "Dimension" table.
Good evening / day / Morning Dear habraloudi! We continue to develop and supplement the blog about my favorite Open Source RDBMS PostgreSQL. It was miraculously so it turned out that the theme of today's topic has never been raised here. I must say that partitioning in PostgreSQL is very well described in the documentation, but will it stop me?).
Introduction
In general, under partitioning, in general, they understand not some technology, but rather approach to the design of the database, which appeared long before the DBMS began to maintain the so-called. Partitioned tables. The thought is very simple - divide the table into several parts of a smaller size. There are two subspecies - horizontal and vertical partitioning.Horizontal partitioning
Parts of the table contain different lines. We set us a table of the logs of a certain abstract application - Logs. We can break it into parts - one for logs in January 2009, the other - for February 2009, etc.Vertical partitioning
Parts of the table contain different columns. Find application for vertical partitioning (when it is really justified) somewhat more complicated than for horizontal. As a spherical horse, I propose to consider this option: the NEWS table has the ID, shorttext, longtext, and let the LongText field is used much less than the first two. In this case, it makes sense to break the NEWS table on columns (create two tables for shorttext and longtext, respectively, related primary keys + Create View News containing both columns). Thus, when we only need a description of the news, the DBMS does not have to read from the disk also the entire text news.Support partitioning in modern DBMS
Most of the modern DBMS supports the partitioning of tables in one form or another.- Oracle - Supports partition starting with 8 version. Working with sections On the one hand is very simple (in general, you can not think about them, you work with a regular table *), and on the other - everything is very flexible. Sections can be broken to "subpartitions", delete, divide, transfer. Different options for indexing the partitioned table are supported (global index partitioned index). Reference to a voluminous description.
- Microsoft SQL Server - Single support appeared recently (in 2005). The first impression of using - "Well, finally !! :)", the second - "works, everything seems to be ok." Documentation on MSDN.
- Mysql - Supports starting from version 5.1.
- Etc…
Partitioning in PostgreSQL
Partitioning of tables in PostgreSQL is somewhat different in sales from other databases. The basis for the partition is the inheritance of the tables (the thing inherent exclusively PostgreSQL). That is, we must have a main table (Master Table), and its sections will be the heir tables. We will consider partitioning on the example of a task approximate to reality.Formulation of the problem
The database is used to collect and analyze data on site / site visitors. Data volumes are large enough in order to think about partitioning. When analyzing, in most cases data is used for the last day.1. Create a basic table:
Create Table Analytics.events.
User_ID UUID NOT NULL,
event_type_id Smallint Not Null,
event_time timestamp default now () not ,
URL VARCHAR (1024) NOT NULL,
REFERRER VARCHAR (1024),
IP INET NOT NULL
);
2. We will partition by day by the Event_time field. For every day we will create a new section. We will call the sections according to the rule: analytics.events_ddmmyyyy. For example, a section for January 1, 2010.
Create Table Analytics.events_01012010.
Event_ID Bigint Default NextVal ("Analytics.seq_events") Primary Key,
Check (event_time\u003e \u003d timestamp "2010-01-01 00:00:00" and event_time< TIMESTAMP "2010-01-02 00:00:00" )
) Inherits (Analytics.events);* This Source Code Was Highlighted with Source Code Highlighter.
When creating a section, we explicitly specify the Event_ID field (PRIMARY KEY is not inherited) and create a check constraint on the Event_Time field, in order not to insert too much.
3. Create an index on the Event_Time field. When splitting the table on the section, we mean that most requests to the Events table will use the condition on the event_time field, so that the index on this field will help us very much.
Create index events_01012010_event_time_idx on analytics.events_01012010 Using BTree (event_time);* This Source Code Was Highlighted with Source Code Highlighter.
4. We want to ensure that when inserting into the main table, the data turned out to be the section intended for them. To do this, we make the next Fint - create a trigger that will manage data streams.
CREATE OR REPLACE FUNCTION ANALYTICS.EVENTS_INSERT_TRIGGER ()
RETURNS TRIGGER AS $$
Begin.
If (new .event_time\u003e \u003d TimeStamp "2010-01-01 00:00:00" and
New .Event_time.< TIMESTAMP "2010-01-02 00:00:00" ) THEN
INSERT INTO ANALYTICS.EVENTS_01012010 VALUES (NEW. *);
ELSE.
RAISE EXCEPTION "Date% is out of range. Fix Analytics.events_insert_trigger", New .event_time;
END IF;
RETURN NULL;
End;
$$
Language PlpGSQL;* This Source Code Was Highlighted with Source Code Highlighter.
Create Trigger Events_Before_insert.
Before Insert On Analytics.events
For Each Row Execute Procedure Analytics.events_insert_trigger ();* This Source Code Was Highlighted with Source Code Highlighter.
5. Everything is ready, we now have a partitioned table Analytics.events. We can start violently analyze its data. By the way, check constraints We created not only to protect sections from incorrect data. PostgreSQL can use them when drawing up a request plan (though, with a living index on event_time, the winnings will give it the minimum), it is enough to use the Constraint_Exclusion directive:
Set Constraint_exclusion \u003d ON;
Select * from Analytics.events Where Event_time\u003e Current_Date;* This Source Code Was Highlighted with Source Code Highlighter.
End of the first part
So what do we have? Let's see:1. Events table, divided into sections, analysis of available data over the past day becomes easier and faster.
2. The horror of the realization that all this needs to somehow maintain, create the sections on time, not forgetting to change the trigger accordingly.
About how easy and careless work with partitioned tables will tell in the second part.
UPD1: Replaced partitioning partitioning
UPD2:
According to the comments of one of the readers who do not have, unfortunately, the Account on Habré:
With inheritance, a few moments are connected, which should be taken into account when designing. Sections do not inherit the primary key and external keys on their columns. That is, when creating a section, you need to explicitly create Primary Key and Foreign Keys on the section columns. From myself I note that creating Foreign Key on the columns of the partitioned table is not the best way. In most cases, a partitioned table is the "table of facts" and itself refers to the "Dimension" table.
In the course of the work on large tables, we are constantly faced with problems with the performance of their maintenance and data updates. One of the most productive and convenient solutions of emerging problems is partitioning.
If in general words, the partitioning is partitioning a table or index to blocks. Depending on the partitioning setting, the blocks can be of various sizes, can be stored in different filegroups and files.
Sectioning has both advantages and disadvantages.
The benefits are well painted on the Microsoft website, I will give an excerpt:
« Partitioning of large tables or indexes can give the following advantages in manageability and performance.
- This allows you to quickly and efficiently transfer subsets of data and access them, while maintaining the integrity of the data set. For example, such an operation as the data load from the OLTP into the OLAP system is performed in seconds, and not in minutes and hours, as in the case of non-proof data.
- Service operations can be performed faster with one or more sections. Operations are more efficient, as it is performed only with data conftention, and not with the entire table. For example, you can compress data into one or more sections or rebuild one or more index sections.
- You can enhance the speed of execution of requests depending on requests that are often performed in your hardware configuration. For example, the query optimizer may faster to perform requests for the equitown of two and more partitioned tables if these tables are the same partitioning columns, because you can connect the sections themselves.
In the process of sorting data for I / O operations in SQL Server, data sorting over sections is first. SQL Server can simultaneously contact only one disk, which can reduce performance. To speed up data sorting, it is recommended to distribute data files in sections over multiple hard disks by creating RAID. Thus, despite sorting data by sections, SQL Server will be able to simultaneously access all the hard disks of each section.
In addition, it is possible to increase productivity by using blockages at the sections level, and not the entire table. It can reduce the number of conflicts of locks for the table».
The disadvantages include the complexity in the administration and support of the operation of the partitioned tables.
We will not dwell on the implementation of partitioning, as this issue is very well described on the Microsoft website.
Instead, we will try to show how to optimize the operation of the partitioned tables, and more precisely show the optimal (in our opinion) a way to update data for any time interval.
A large plus partitioned table is the physical distinction of these sections. This property allows us to change the sections in some places or with any other table.
With the usual update of data using the sliding window (for example, for the month), we will need to go through the following steps:
1. Find the desired lines in a large table;
2. Delete the found lines from the table and index;
3. Insert new lines in the table, update the index.
When stored in a table of billions of rows, these operations will take a fairly long time, we can limit yourself to almost one action: just replace the desired section to the table prepared in advance (or section). In this case, we will not need to delete or insert strings, as well as you need to update the index on the entire large table.
Let's go from words to business and show how to implement it.
1. To begin, set up a partitioned table as written in the article specified above.
2. Create tables required for exchange.
To update the data, we will need a mini-copy of the target table. A mini-copy it is because it will be stored data that should be added to the target table, i.e. Data in just 1 month. The third empty table will also need to implement data exchange. Why it is needed - I will explain later.
Hard conditions are put to the mini-copy and table for the exchange:
- Before using the SWITCH operator, both tables should exist. Before performing the switching operation in the database, there must be a table where the section (source table) moves from where the selection table (target table).
- The recipient section must exist and should be empty. If the table is added as a section to an existing partitioned table or section moves from one partitioned table to another, the recipient section must exist and be empty.
- The non-combined recipient table must exist and should be empty. If the section is designed to form a unified non-separated table, then it is necessary that the table receiving a new section existed and was an empty non-transitional table.
- Sections must be from the same column. If the section is switched from one partitioned table to another, both tables must be partitioned by the same column.
- The source and target tables must be in the same file group. The source and target table in the Alter Table ... Switch instructions should be stored in the same file group, as well as their columns with large values. Any respective indexes, index sections or indexed sections should also be stored in the same file group. However, it may differ from the file group for the corresponding tables or other relevant indexes.
I will explain the restrictions on our example:
1. A mini-copy of the table must be partitioned on the same column as the target. If a mini-copy is not a partitioned table, then it must be stored in the same file group as the replacement section.
2. The table for the exchange must be empty and should also be partitioned on the same column or should be stored in the same file group.
3. We implement the exchange.
Now we have the following:
Table with data for all times (Next Table_a)
Table with data for 1 month (Next Table_B)
Empty table (Next Table_C)
First of all, we need to find out in which section we have the data.
You can find it in the query:
SELECT
Count (*) as
, $ Partition. (DT) as
, Rank () Over (Order by $ Partition. (DT))
From DBO. (NOLOCK)
Group by $ Partition. (DT)
In this query, we get sections in which there are rows with information. Quantity can not be counted - we did it to check the need to exchange data. Rank also use so that you can go in the cycle and update several sections in one procedure.
As soon as they found out in which sections, the data is stored - they can be changed in places. Suppose that the data is stored in Section 1.
Then you need to perform the following operations:
Change sections from the target table with a table for exchanging.
Alter table. Switch Partition 1 to. Partition 1.
Now we have the following:
The target table did not have data in the section we need, i.e. The section is empty
Swap sections from the target table and mini-copy
Alter table. Switch Partition 1 to. Partition 1.
Now we have the following:
The target table appeared data for the month, and in mini-copies now emptiness
Clear or delete a table for exchanging.
If you have a cluster index on the table, it is also not a problem. It must be created on all 3 tables with partitioning one by the same column. When changing sections, the index will automatically update, not rebuilding.
Page 23 of 33
Range Partitioning - Sales Information
The nature of the use of sales information is often changeable. As a rule, the current month data is operational data; The data of the previous months is to a large extent data intended for analysis. Most often, the analysis is made monthly, quarterly or annually. Since different analysts may require significant amounts of different analytical data at the same time, the partitioning is best allowed to isolate their activities. In the following scenario, these data flock out of 283 nodes and are supplied as two standard ASCII format files. All files are sent to the central file server no later than 3.00 am the first day of each month. File sizes fluctuate, but on average range is about 86,000 orders per month. Each order on average is 2.63 positions, so orderdetails files are on average by 226180 lines. Each month is added about 25 million new orders and 64 million rows of the nomenclature of orders. The history analysis server supports data in the last 2 years. Data for two years is a little less than 600 million orders and more than 1.5 billion lines in the OrderDetails table. Since the data is often analyzed by comparing the indicators of the same quarters, or the same months for previous years, the range partitioning is selected. A month is chosen as the size of the range.
Based on the schema 11 ("Steps to create a partitioned table"), we decided to partition the table using the Range partitioning on the OrderDate column. Our analysts mainly unite and analyze the last 6 months data, or the last 3 months of the current and last year (for example, January-March 2003 plus January-March 2004). In order to maximize the bundle of discs, and at the same time, isolate most of the data groupings, there will be several file groups on one physical disk, but they will be shifted for six months to reduce the number of conflicts when resource separation. Current month - October 2004, and all 283 separate offices manage their current sales locally. The server stores data from October 2002 to September 2004 inclusive. In order to take advantage of the new 16-processor system and SAN (Storage Area Network - a high-speed network that connects data warehouses), each month will be in its own file group file, and placed on a set of alternating mirrors (RAID 1 + 0). Figure 12 illustrates data placement on logic disks.
Figure 12: Partitioned Orders Table
Each of the 12 logical discs uses the RAID 1 + 0 configuration, so the total number of disks required for the Orders and OrderDetails tables is 48. Despite this, SAN supports up to 78 disks, so the remaining 30 disks are used for Transaction Log, Tempdb, system databases and other small tables, such as Customers (9 million entries) and Products (386,750 entries), etc. Orders and OrderDetails tables will use the same boundary conditions and the same placement on the disk; In fact, they will use the same partitioning scheme. As a result (take a look at two logical disks E: \\ and F: \\ Figure 13) Table data Orders and Orderdetails for the same months will be located on the same disks:
Figure 13: Placing extents of range sections on disk arrays
Although it looks confusing, all this is quite easy to implement. The most difficult thing in creating our partitioned table is data delivery from a large number of sources - 283 repository must have a standard delivery mechanism. However, on the central server there is only one Orders table and one orderdetails table. To turn both tables into the partitions, we must first create a function and a partitioning scheme. The partitioning scheme determines the physical location of sections on the disks, therefore, file groups must also exist. Since file groups are needed for our tables, the next step is their creation. The syntax of the creation of each file group is identical to the above, however, in this way all twenty-four file groups must be created. You can change the names / location of the disks per single disk in order to test and explore the syntax. Make sure you have corrected the file sizes on the MB instead of GB, and have chosen a smaller initial file size, based on the disk space available to you. Twenty-four files and file groups will be created in the SaaleSDB database. All will have similar syntax, with the exception of the location, file name and file name:
| Alter Database Salesdb. |
Once all twenty-four files and file groups are created, you can determine the function and partitioning scheme. Make sure your files and file groups are created, you can using SP_HELPFILE and SP_HELPFILEG system system stored procedures.
The section function will be determined by the OrderDate column with DateTime data type. In order for both tables to be partitioned by the ORDERDATE column, this column must be present in both tables. In fact, the values \u200b\u200bof the key keys of both tables (if both tables are partitioned by one and the same key) will duplicate each other; However, this is necessary to obtain the advantages of alignment, in most cases the size of the key columns will be relatively small (the size of the DateTime field is only 8 bytes). As already been described in the "Create Partition Function for Range Sections" chapter, our function will be a range of partitioning function in which the first boundary condition will be in the first (Left) section.
| CREATE PARTITION FUNCTION TWOYEARDATERANGEPFN (DateTime) |
Since it is extremely left, and extremely right boundary cases are covered, this partitioning function actually creates 25 sections. The table will support the 25th section that will remain empty. For this empty section, no special file group is required, since no data should ever get into it. In order to ensure that no data in it falls, Constraint will limit the range of this table. In order to send data to the corresponding discs, a partitioning scheme that displays the sections to file groups is used. The partitioning scheme will use the explicit definition of file groups for each of the 24 file groups containing the data, and Primary - for the 25th empty section.
| Create Partition Scheme. |
The table can be created with the same syntax that supported previous SQL Server releases - using the default or user-defined file group (to create a non-partitioned table) - either using the scheme (to create a partitioned table). As for what option is preferable (even if this table is partitioned in the future, it all depends on how the table is filling and how many sections are you going to manipulate. Filling a heap (HEAP) and the subsequent creation of a cluster index in it is likely to provide better performance than downloading to a table containing a cluster index. In addition, in multiprocessor systems, you can upload data to the table in parallel, and then also parallel to build indexes. As an example, create the Orders table and load data into it using Insert ... Select statements. To create the Orders table as a partitioned, define the partitioning scheme in the CREATE TABLE OPERATOR.
| CREATE TABLE SALESDB .. |
Since the OrderDetails table is going to use the same scheme, it should include the OrderDate column.
| CREATE TABLE. ( |
In the next step, the data from the new AdventureWorks training database is downloaded. Make sure you have installed the AdventureWorks database.
| INSERT DBO. INSERT DBO. |
Now that you downloaded the data into the partitioned table, you can use the new built-in system function to determine the section on which data will be located. The following request for each of the sections containing data returns information about how many rows is contained in each of the sections, as well as the minimum and maximum value of the orderDate field. Section that does not contain rows does not fall into the final result.
| Select $ Partition.TwoyeardateRangePFN (O.Orderdate) Select $ Partition.twoyeardateRangePFN (OD.OrderDate) |
Finally, now, after you downloaded the data, you can create a cluster index and an external key (Foreign Key) between the OrderDetails and Orders tables. In this case, the cluster index will be built on the primary key (PRIMARY KEY) in the same way as you identify both of these tables by their partition key (for orderdetails to the index you will add the LineNumber column for uniqueness). By default, when constructing indexes on a partitioned table, they are aligned with respect to the partitioned table according to the same partitioning scheme; It is not necessary to specify the scheme.
| ALTER TABLE ORDERS
|
The full syntax that determines the partitioning scheme, would look like this:
| ALTER TABLE ORDERS ALTER TABLE DBO.OrDERDETAILS |
 Error appearance during program launch
Error appearance during program launch FRIGATE plugin for Firefox
FRIGATE plugin for Firefox How to show hidden folders and files in Windows
How to show hidden folders and files in Windows Ways how to make a screen on a laptop brighter or darker
Ways how to make a screen on a laptop brighter or darker How to format a flash drive, disk protection
How to format a flash drive, disk protection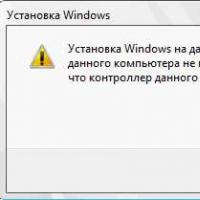 If installing Windows to this disc is not possible
If installing Windows to this disc is not possible During installation of Windows "Make sure that the controller of this disc is included in the computer's BIOS menu.
During installation of Windows "Make sure that the controller of this disc is included in the computer's BIOS menu.