A cuda processzorok számának összehasonlítása. CUDA Rollunk: NVIDIA CUDA technológia. A CUDA fejlesztési története
Arra tervezték, hogy a gazdakódot (fő, vezérlőkód) és az eszközkódot (hardverkódot) (.cu kiterjesztésű fájlok) objektumfájlokká fordítsa, amelyek alkalmasak a végső program vagy könyvtár felépítésére bármilyen programozási környezetben, például NetBeans.
A CUDA architektúra a grid memóriamodellt, a fürtszálakat és a SIMD utasításokat használja. Nemcsak a nagy teljesítményű grafikus számítástechnikára alkalmazható, hanem az nVidia grafikus kártyákat használó különféle tudományos számítástechnikákra is. A tudósok és kutatók széles körben használják a CUDA-t számos területen, beleértve az asztrofizikát, a számítógépes biológiát és a kémiát, a folyadékdinamikai szimulációkat, az elektromágneses kölcsönhatásokat, a számítógépes tomográfiát, a szeizmikus elemzést stb. A CUDA képes OpenGL és Direct3D használatával alkalmazásokhoz csatlakozni. A CUDA egy többplatformos szoftver olyan operációs rendszerekhez, mint a Linux, Mac OS X és Windows.
2010. március 22-én az nVidia kiadta a CUDA Toolkit 3.0-t, amely OpenCL támogatást is tartalmazott.
Felszerelés
A CUDA Platform először a nyolcadik generációs NVIDIA G80 chip kiadásával jelent meg a piacon, és jelen lett a GeForce, Quadro és NVidia Tesla gyorsítócsaládokban használt összes későbbi grafikus chip-sorozatban.
A CUDA SDK-t támogató hardverek első sorozata, a G8x egy 32 bites egyprecíziós vektorprocesszort tartalmazott, amely API-ként a CUDA SDK-t használta (a CUDA támogatja a C double típust, de most a pontosságát 32 bites lebegőre csökkentették pont). A későbbi GT200 processzorok támogatják a 64 bites pontosságot (csak SFU-hoz), de a teljesítmény lényegesen rosszabb, mint a 32 bitesé (annak oka, hogy minden stream multiprocesszorhoz csak két SFU, és nyolc skalár processzor van) . A GPU megszervezi a hardveres többszálú működést, amely lehetővé teszi az összes GPU erőforrás használatát. Így megnyílik a lehetőség egy fizikai gyorsító funkcióinak grafikus gyorsítóra való áthelyezésére (a megvalósításra példa az nVidia PhysX). Szintén széles lehetőségek kínálkoznak a számítógép grafikus berendezéseinek alkalmazására összetett, nem grafikus számítások elvégzésére: például a számítási biológiában és más tudományágakban.
Előnyök
Az általános célú számítástechnika grafikus API-k képességein keresztül történő megszervezésének hagyományos megközelítéséhez képest a CUDA architektúra a következő előnyökkel rendelkezik ezen a területen:
Korlátozások
- Az eszközön végrehajtott összes funkció nem támogatja a rekurziót (a CUDA Toolkit 3.1-ben támogatja a mutatókat és a rekurziót), és van néhány egyéb korlátozás is.
Támogatott GPU-k és grafikus gyorsítók
Az Nvidia berendezésgyártó termékeinek listája, amelyek teljes mértékben támogatják a CUDA technológiát, az Nvidia hivatalos webhelyén található: CUDA-Enabled GPU Products.
Valójában a PC-hardver piacon ma a következő perifériák támogatják a CUDA technológiát:
| Specifikációs verzió | GPU | Videokártyák |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX / Ultra, 9400GT, 9600GT, 9800GT, Tesla C / D / S870, FX4 / 5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS / GT, 8600GT / GTS, 8800GT / GTS, 9600 GSO, 9800GTX / GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17/18,2x,3700x,3700 / 370M, 3/5 / 770M, 16/17/27/28/36/37 / 3800M, NVS420 / 50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370 / 380M, NVS 2 / 3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C / M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S / M2050 / 70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GTX 470, GTX 560, GTX 560, GTX 510, 80 |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce 610M, GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650 Ti, GTX 650, GT 640, GeForce GTX 680MX, GeForce GTX 680M, GeForce GTX 675MX, GeForce GTX 675MX, GeForce GTX 675MX, GeForce GTX 675MX, GeFor7 660 675MX0 GeForce GT 645M, GeForce GT 640M |
| 3.5 | GK110 |
|
|
|
|
|
- A Tesla C1060, Tesla S1070, Tesla C2050 / C2070, Tesla M2050 / M2070, Tesla S2050 modellek segítségével dupla pontossággal végezhet számításokat GPU-n.
Különböző változatok jellemzői és specifikációi
| Funkciótámogatás (a listán nem szereplő funkciók minden számítási képességhez támogatott) |
Számítási képesség (verzió) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
32 bites szavak a globális memóriában |
Nem | Igen | |||
lebegőpontos értékek a globális memóriában |
|||||
| Egész számú atomi függvények működése 32 bites szavak megosztott memóriában |
Nem | Igen | |||
| atomicExch () 32 biten működik lebegőpontos értékek a megosztott memóriában |
|||||
| Egész számú atomi függvények működése 64 bites szavak a globális memóriában |
|||||
| Warp szavazási funkciók | |||||
| Dupla pontosságú lebegőpontos műveletek | Nem | Igen | |||
| 64 biten működő atomi függvények egész értékek a megosztott memóriában |
Nem | Igen | |||
| Lebegőpontos atomi összeadás működik 32 bites szavak a globális és megosztott memóriában |
|||||
| _ballot () | |||||
| _threadfence_system () | |||||
| _syncthreads_count (), _syncthreads_and (), _syncthreads_or () |
|||||
| Felületi funkciók | |||||
| Menetblokk 3D rácsja | |||||
| Műszaki adatok | Számítási képesség (verzió) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
| A menetblokkok rácsának maximális mérete | 2 | 3 | |||
| A menetblokkok rácsának maximális x-, y- vagy z-dimenziója | 65535 | ||||
| A menetblokk maximális mérete | 3 | ||||
| Egy blokk maximális x- vagy y-dimenziója | 512 | 1024 | |||
| Egy blokk maximális z-mérete | 64 | ||||
| A szálak maximális száma blokkonként | 512 | 1024 | |||
| Warm mérete | 32 | ||||
| A rezidens blokkok maximális száma többprocesszoronként | 8 | ||||
| A rezidens vetemítések maximális száma többprocesszoronként | 24 | 32 | 48 | ||
| A rezidens szálak maximális száma többprocesszoronként | 768 | 1024 | 1536 | ||
| 32 bites regiszterek száma többprocesszoronként | 8 K | 16 K | 32 K | ||
| A megosztott memória maximális mennyisége többprocesszoronként | 16 KB | 48 KB | |||
| Megosztott memóriabankok száma | 16 | 32 | |||
| A helyi memória mennyisége szálanként | 16 KB | 512 KB | |||
| Állandó memóriaméret | 64 KB | ||||
| Gyorsítótár munkakészlet többprocesszoronként az állandó memória érdekében | 8 KB | ||||
| Gyorsítótár munkakészlet többprocesszoronként textúra memóriához | Eszközfüggő, 6 KB és 8 KB között | ||||
| Maximális szélesség 1D textúrához |
8192 | 32768 | |||
| Maximális szélesség 1D textúrához lineáris memóriához kötött referencia |
2 27 | ||||
| Maximális szélesség és rétegek száma 1D réteges textúra referenciához |
8192 x 512 | 16384 x 2048 | |||
| Maximális szélesség és magasság 2D-hez textúra referencia kötve lineáris memória vagy CUDA tömb |
65536 x 32768 | 65536 x 65535 | |||
| Maximális szélesség, magasság és szám rétegek 2D réteges textúra referenciához |
8192 x 8192 x 512 | 16384 x 16384 x 2048 | |||
| Maximális szélesség, magasság és mélység lineárishoz kötött 3D textúra referenciához memória vagy CUDA tömb |
2048 x 2048 x 2048 | ||||
| A textúrák maximális száma, amely kernelhez köthető |
128 | ||||
| Maximális szélesség 1D felülethez hivatkozás CUDA tömbhöz van kötve |
Nem támogatott |
8192 | |||
| Maximális szélesség és magasság 2D-hez CUDA tömbhöz kötött felületi hivatkozás |
8192 x 8192 | ||||
| A felületek maximális száma kernelhez köthető |
8 | ||||
| Az utasítások maximális száma per kernel |
2 millió | ||||
Példa
CudaArray * cu_array; struktúra< float , 2 >tex; // Tömb lefoglalása cudaMalloc (& cu_array, cudaCreateChannelDesc< float>(), szélesség magasság); // Képadatok másolása a cudaMemcpy tömbbe (cu_array, kép, szélesség * magasság, cudaMemcpyHostToDevice); // Kösd a tömböt a textúrához cudaBindTexture (text, cu_array); // Kernel dim3 futtatása blockDim (16, 16, 1); dim3 gridDim (szélesség / blockDim.x, magasság / blockDim.y, 1); kernel<<< gridDim, blockDim, 0 >>> (d_adat, szélesség, magasság); cudaUnbindTexture (text); __global__ void kernel (float * odata, int magasság, int szélesség) (előjel nélküli int x = blockIdx.x * blockDim.x + threadIdx.x; unsigned int y = blockIdx.y * blockDim.y + threadIdx.y; float c = texfetch (tex, x, y); odata [y * szélesség + x] = c;)
A pycuda.driver importálása drv-ként import numpy drv.init () dev = drv.Device (0) ctx = dev.make_context () mod = drv.SourceModule ( "" "__global__ void multiply_them (float * dest, float * a, float * b) (const int i = threadIdx.x; dest [i] = a [i] * b [i];)" "") multiply_them = mod.get_function ("multiply_them") a = numpy.random .randn (400) .astype (numpy.float32) b = numpy.random .randn (400) .astype (numpy.float32) dest_like = numpy. (a) multiply_them (drv.Out (dest), drv.In (a), drv.In (b), blokk = (400, 1, 1)) print dest-a * b
A CUDA mint tantárgy az egyetemeken
2009 decembere óta a CUDA programozási modellt 269 egyetemen oktatják szerte a világon. Oroszországban a CUDA képzési kurzusokat a Szentpétervári Politechnikai Egyetemen, a V.I.-ről elnevezett Jaroszlavli Állami Egyetemen oktatják. PG Demidov, Moszkva, Nyizsnyij Novgorod, Szentpétervár, Tver, Kazan, Novoszibirszk, Novoszibirszki Állami Műszaki Egyetem Omszki és Permi Állami Egyetemek, Nemzetközi Társadalom és Man „Dubna” Természettudományi Egyetem, Ivanovo Állami Energiamérnöki Egyetem, Belgorodi Állami Egyetem, MSTU őket. Bauman, RKhTU őket. Mengyelejev, Interregional Supercomputer Center RAS,. Ezenkívül 2009 decemberében bejelentették, hogy elindult az első orosz tudományos és oktatási központ, a "Parallel Computing", amely Dubna városában található, és amelynek feladatai közé tartozik a GPU-n történő összetett számítási problémák megoldására vonatkozó képzés és tanácsadás.
Ukrajnában a CUDA kurzusokat a Kijevi Rendszerelemző Intézetben oktatják.
Linkek
Hivatalos források
- CUDA Zone (orosz) - a CUDA hivatalos oldala
- CUDA GPU Computing – A CUDA számítástechnikával foglalkozó hivatalos webfórumok
Nem hivatalos források
Tom hardvere- Dmitrij Csekanov. nVidia CUDA: GPU számítástechnika vagy CPU halál? ... Tom "s Hardware (2008. június 22.). Archivált
- Dmitrij Csekanov. nVidia CUDA: GPU-benchmarkok a mainstream piac számára. Tom "s Hardware (2009. május 19.). Archiválva: 2012. március 4. Letöltve: 2009. május 19.
- Alekszej Berillo. NVIDIA CUDA – Nem grafikus számítástechnika GPU-kon. 1. rész . iXBT.com (2008. szeptember 23.). Az eredetiből archiválva: 2012. március 4. Letöltve: 2009. január 20.
- Alekszej Berillo. NVIDIA CUDA – Nem grafikus számítástechnika GPU-kon. 2. rész . iXBT.com (2008. október 22.). - Példák az NVIDIA CUDA megvalósítására. Az eredetiből archiválva: 2012. március 4. Letöltve: 2009. január 20.
- Boreskov Alekszej Viktorovics. CUDA Fundamentals (2009. január 20.). Az eredetiből archiválva: 2012. március 4. Letöltve: 2009. január 20.
- Vlagyimir Frolov. Bevezetés a CUDA technológiába. "Számítógépes grafika és multimédia" hálózati magazin (2008. december 19.). Az eredetiből archiválva: 2012. március 4. Letöltve: 2009. október 28..
- Igor Oszkolkov. Az NVIDIA CUDA a megfizethető jegy a nagy számítástechnika világába. Computerra (2009. április 30.). Letöltve: 2009. május 3.
- Vlagyimir Frolov. Bevezetés a CUDA technológiába (2009. augusztus 1.). Az eredetiből archiválva: 2012. március 4. Letöltve: 2010. április 3.
- GPGPU.ru. Grafikus kártyák használata számítástechnikához
- ... Párhuzamos számítástechnikai központ
Jegyzetek (szerkesztés)
Lásd még
| Nvidia | ||||||||
|---|---|---|---|---|---|---|---|---|
| Grafikus processzorok |
| |||||||
A személyi számítógépeket kis szuperszámítógépekké alakító eszközök már régóta léteznek. Még a múlt század 80-as éveiben kínáltak a piacon úgynevezett transzputereket, amelyeket az akkoriban elterjedt ISA bővítőhelyekbe helyeztek be. Eleinte lenyűgöző volt a teljesítményük a megfelelő feladatokban, de aztán felgyorsult az univerzális processzorok sebességének növekedése, megerősítették pozícióikat a párhuzamos számítástechnikában, és nem volt értelme a transzputereknek. Bár ma is léteznek ilyen eszközök, ezek különféle speciális gyorsítók. De gyakran alkalmazási körük szűk, és az ilyen gyorsítókat nem sok elterjedtségben részesítették.
A közelmúltban azonban a párhuzamos számítástechnika fáklyája a tömegpiacra tolódott el, így vagy úgy, hogy a háromdimenziós játékokkal kapcsolatos. A 3D grafikában használt, általános célú többmagos párhuzamos vektoros számítástechnikai eszközök olyan csúcsteljesítményt érnek el, amelyet az általános célú processzorok nem tudnak. Természetesen a maximális sebességet csak számos kényelmes feladatnál érik el, és vannak korlátai, de az ilyen eszközöket már széles körben használják olyan területeken, amelyekre eredetileg nem készültek. Az ilyen párhuzamos processzorok kiváló példája a Sony-Toshiba-IBM szövetség által kifejlesztett és a Sony PlayStation 3-ban használt Cell processzor, valamint a piacvezetők - az Nvidia és az AMD - összes modern videokártyája.
A Cell-hez ma nem nyúlunk, bár korábban megjelent, és egy univerzális processzor, további vektoros képességekkel, ma nem beszélünk róla. A 3D-s videógyorsítók számára néhány éve megjelent a nem grafikus általános célú számítások első technológiája, a GPGPU (General-Purpose compution on GPUs). Hiszen a modern videochipek több száz matematikai végrehajtási egységet tartalmaznak, és ezzel az erővel számos számításigényes alkalmazást jelentősen fel lehet gyorsítani. A GPU-k jelenlegi generációi pedig kellően rugalmas architektúrával rendelkeznek, amely a magas szintű programozási nyelvekkel, valamint az ebben a cikkben tárgyalt hardver- és szoftverarchitektúrákkal együtt feltárja ezeket a lehetőségeket, és sokkal elérhetőbbé teszi őket.
A GPCPU fejlesztését a kellően gyors és rugalmas shader programok megjelenése ösztönözte, amelyek képesek modern videochipek végrehajtására. A fejlesztők úgy döntöttek, hogy a GPU-val nem csak a 3D-s alkalmazásokban található képet számítják ki, hanem más párhuzamos számításokhoz is felhasználják. A GPGPU-ban ehhez grafikus API-kat használtak: OpenGL-t és Direct3D-t, amikor az adatok textúrák formájában kerültek a videochipbe, a számítási programokat pedig shaderek formájában töltötték be. Ennek a módszernek a hátránya a viszonylag nagy programozási bonyolultság, a CPU és a GPU közötti adatcsere alacsony sebessége és egyéb korlátok, amelyeket az alábbiakban tárgyalunk.
A GPU számítástechnika fejlődött, és nagyon gyorsan fejlődik. A jövőben pedig a videochipek két fő gyártója, az Nvidia és az AMD kifejlesztette és bejelentette a megfelelő platformokat CUDA (Compute Unified Device Architecture) és CTM (Close To Metal vagy AMD Stream Computing) néven. A korábbi GPU-programozási modellektől eltérően ezeket a videokártyák hardveres képességeihez való közvetlen hozzáféréssel hajtották végre. A platformok nem kompatibilisek egymással, a CUDA a C programozási nyelv kiterjesztése, a CTM pedig egy összeállítási kódot végrehajtó virtuális gép. Ehelyett mindkét platform megszüntette a korábbi GPGPU-modellek néhány fontos korlátját a hagyományos grafikus folyamat és a megfelelő Direct3D vagy OpenGL interfészek használatával.
Természetesen az OpenGL-t használó nyílt szabványok tűnnek a leginkább hordozhatónak és univerzálisnak, lehetővé teszik ugyanazon kód használatát a különböző gyártók videochipjeihez. De az ilyen módszereknek sok hátránya van, sokkal kevésbé rugalmasak és nem olyan kényelmesek a használatuk. Ezenkívül nem teszik lehetővé bizonyos videokártyák speciális képességeinek használatát, például a modern számítástechnikai processzorokban található gyors megosztott (megosztott) memóriát.
Ezért az Nvidia kiadta a CUDA platformot – egy C-szerű programozási nyelvet, saját fordítóval és könyvtárakkal a GPU-számításhoz. Természetesen a videochipek optimális kódjának megírása korántsem olyan egyszerű, és ez a feladat sok kézi munkát igényel, de a CUDA csak felfedi az összes lehetőséget, és a programozónak nagyobb irányítást ad a GPU hardveres képességei felett. Fontos, hogy a Geforce 8-as, 9-es és 200-as sorozatú grafikus kártyákban használt G8x, G9x és GT2xx lapkák Nvidia CUDA támogatással rendelkezzenek, amelyek igen elterjedtek. Jelenleg a CUDA 2.0 végleges verziója jelent meg, amely néhány újdonságot tartalmaz, például a dupla pontosságú számítások támogatását. A CUDA 32 bites és 64 bites Linux, Windows és MacOS X operációs rendszereken érhető el.
A CPU és a GPU közötti különbség párhuzamos számításokban
Az univerzális processzorok frekvenciájának növekedése a fizikai korlátokba és a nagy fogyasztásba ütközött, teljesítményük pedig egyre inkább nő a több mag egyetlen chipben való elhelyezése miatt. A jelenleg értékesített processzorok legfeljebb négy magot tartalmaznak (a további növekedés nem lesz gyors), és hétköznapi alkalmazásokhoz készültek, használjon MIMD-t - több utasítás- és adatfolyamot. Mindegyik mag külön működik a többitől, és különböző utasításokat hajt végre a különböző folyamatokhoz.
A négykomponensű (egypontos lebegőpontos) és kétkomponensű (dupla pontosságú) vektorokhoz speciális vektorképességek (SSE2 és SSE3) jelentek meg az általános célú processzorokban, elsősorban a grafikus alkalmazások megnövekedett követelményei miatt. Éppen ezért bizonyos feladatoknál kifizetődőbb a GPU-k használata, mert eredetileg ezekre készültek.
Például az Nvidia videochipekben a fő egység egy többprocesszor, nyolc-tíz maggal és összesen több száz ALU-val, több ezer regiszterrel és kis mennyiségű megosztott memóriával. Ezenkívül a videokártya tartalmaz gyors globális memóriát, amelyhez minden többprocesszor hozzáfér, helyi memóriát minden multiprocesszorban, és speciális memóriát az állandók számára.
A legfontosabb, hogy ezek a többprocesszoros magok a GPU-ban SIMD (egy utasításfolyam, több adatfolyam) magok. És ezek a magok ugyanazokat az utasításokat hajtják végre egyszerre, ez a programozási stílus gyakori a grafikus algoritmusoknál és számos tudományos problémánál, de speciális programozást igényel. Ez a megközelítés azonban lehetővé teszi a végrehajtási egységek számának növelését az egyszerűsítésük miatt.
Tehát soroljuk fel a fő különbségeket a CPU és a GPU architektúrák között. A CPU magokat úgy tervezték, hogy egyetlen szekvenciális utasításfolyamot hajtsanak végre maximális teljesítménnyel, míg a GPU-kat úgy tervezték, hogy gyorsan végrehajtsanak nagyszámú egyidejű utasításfolyamot. Az általános célú processzorokat a nagy teljesítményre optimalizálták egyetlen utasításfolyamból, amely egész számokat és lebegőpontos számokat is kezel. Ebben az esetben a memóriához való hozzáférés véletlenszerű.
A CPU-tervezők a teljesítmény javítása érdekében igyekeznek minél több utasítást párhuzamosan futtatni. Erre a célra az Intel Pentium processzoroktól kezdve megjelent a szuperskaláris végrehajtás, amely óránként két utasítás végrehajtását biztosítja, a Pentium Pro pedig az utasítások rendellenes végrehajtásával tűnt ki. De a szekvenciális utasításfolyam párhuzamos végrehajtásának vannak bizonyos alapvető korlátai, és a végrehajtási egységek számának növelésével a sebesség többszörös növelése nem érhető el.
A videochipek esetében a munka egyszerű és kezdetben párhuzamos. A videochip bemenetként egy sokszögcsoportot vesz fel, elvégzi az összes szükséges műveletet, és a kimeneten pixeleket ad ki. A sokszögek és pixelek feldolgozása független, párhuzamosan, egymástól elkülönítve dolgozhatók fel. Ezért a GPU-ban a munka kezdetben párhuzamos megszervezése miatt nagyszámú végrehajtási egységet használnak, amelyek könnyen betölthetők, ellentétben a CPU szekvenciális utasításaival. Ezenkívül a modern GPU-k egynél több utasítást is végrehajthatnak órajelenként (kettős probléma). Így a Tesla architektúra bizonyos feltételek mellett egyszerre indítja el a MAD + MUL vagy a MAD + SFU műveleteket.
A GPU a memóriaelérésben is különbözik a CPU-tól. A GPU-ban beköthető és könnyen kiszámítható - ha a textúra texelét memóriából olvassuk ki, akkor egy idő után eljön a szomszédos texelek ideje is. Igen, és ugyanaz a dolog felvétel közben - egy pixel kerül a framebufferbe, és néhány óraciklus után rögzítésre kerül a mellette lévő. Ezért a memória felépítése eltér a CPU-ban használttól. A videochipnek pedig az univerzális processzorokkal ellentétben egyszerűen nincs szüksége nagy cache-memóriára, a textúrákhoz pedig csak néhány (akár 128-256 a jelenlegi GPU-ban) kilobyte.
És önmagában a GPU és a CPU memóriájával való munka némileg különbözik. Tehát nem minden központi processzor rendelkezik beépített memóriavezérlővel, és minden GPU-nak általában több vezérlője van, legfeljebb nyolc 64 bites csatorna az Nvidia GT200 chipben. A videokártyákon ráadásul gyorsabb memóriát használnak, és ennek köszönhetően a videochipeknek sokszorosa nagyobb memóriasávszélesség áll rendelkezésre, ami szintén nagyon fontos a hatalmas adatfolyamokkal operáló párhuzamos számításoknál.
Az általános célú processzorokban nagy mennyiségű tranzisztor és chipterület jut utasításpufferekhez, hardverágak előrejelzéséhez és hatalmas mennyiségű chip-gyorsítótárhoz. Mindezekre a hardverblokkokra szükség van néhány utasításfolyam végrehajtásának felgyorsításához. A videochipek tranzisztorokat költenek végrehajtó egységek tömbjeire, áramlásvezérlő egységekre, kis megosztott memóriára és memóriavezérlőkre több csatornára. A fentiek nem gyorsítják fel az egyes szálak végrehajtását, lehetővé teszik, hogy a chip egyidejűleg több ezer szálat dolgozzon fel, amelyek a chipen futnak és nagy memória sávszélességet igényelnek.
A gyorsítótárazás különbségeiről. Az általános célú CPU-k gyorsítótárat használnak a teljesítmény növelésére a memóriaelérési késleltetés csökkentésével, míg a GPU-k gyorsítótárat vagy megosztott memóriát használnak a sávszélesség növelésére. A CPU-k nagy gyorsítótárak és elágazási előrejelzések használatával csökkentik a memóriaelérési késleltetést. Ezek a hardver részek foglalják el a chip területének nagy részét, és sok energiát fogyasztanak. A videochipek megkerülik a memóriaelérési késleltetés problémáját azáltal, hogy egyidejűleg több ezer szálat hajtanak végre – miközben az egyik szál adatra vár a memóriából, a videochip várakozás vagy késleltetés nélkül tud számításokat végezni egy másik szálon.
A többszálú támogatásban is sok különbség van. A CPU processzormagonként 1-2 számítási szálat hajt végre, a videochipek pedig akár 1024 szálat is támogathatnak multiprocesszoronként, amiből több is van a chipben. És ha a CPU egyik száláról a másikra való váltás több száz ciklusba kerül, akkor a GPU több szálat vált át egy ciklus alatt.
Ezenkívül a CPU-k SIMD (egy utasítás végrehajtása több adaton) blokkokat használnak a vektorszámításhoz, a videochipek pedig SIMT-et (egy utasítás és több szál) használnak az adatfolyamok skaláris feldolgozásához. A SIMT nem követeli meg a fejlesztőtől, hogy az adatokat vektorokká alakítsa, és lehetővé teszi az önkényes elágazásokat a folyamokban.
Röviden azt mondhatjuk, hogy a modern általános célú CPU-kkal ellentétben a videochipeket párhuzamos számításokhoz tervezték nagyszámú aritmetikai művelettel. És sokkal nagyobb számú GPU-tranzisztor működik a rendeltetésének megfelelően - adattömböket dolgoz fel, és nem irányítja néhány szekvenciális számítási szál végrehajtását (folyamatvezérlését). Ez a diagram azt mutatja, hogy mennyi helyet foglalnak el a különböző logikák a CPU-ban és a GPU-ban:

Ennek eredményeként a GPU teljesítményének tudományos és egyéb nem grafikus számításokban való hatékony felhasználásának alapja az algoritmusok párhuzamosítása a videochipekben elérhető több száz végrehajtási egységre. Például sok molekuláris modellező alkalmazás tökéletesen alkalmas videochipeken történő számításra, nagy számítási teljesítményt igényel, ezért kényelmes a párhuzamos számításokhoz. A több GPU használata pedig még nagyobb számítási teljesítményt biztosít az ilyen problémák megoldásához.
A GPU-n végzett számítások kiváló eredményeket mutatnak a párhuzamos adatfeldolgozást használó algoritmusok esetében. Vagyis amikor ugyanazt a matematikai műveletsort alkalmazzuk nagy mennyiségű adatra. Ebben az esetben a legjobb eredmény akkor érhető el, ha az aritmetikai utasítások számának aránya a memóriaelérések számához képest elég nagy. Ez kisebb igényt támaszt az áramlásszabályozásra, és a matematika nagy sűrűsége és a nagy mennyiségű adat szükségtelenné teszi a CPU-hoz hasonló nagy gyorsítótárak szükségességét.
A fent leírt különbségek eredményeként a videochipek elméleti teljesítménye jelentősen meghaladja a CPU-ét. Az Nvidia a következő grafikont mutatja be a CPU és a GPU teljesítményének növekedéséről az elmúlt néhány évben:

Természetesen ezek az adatok nem mentesek egy adag ravaszságtól. Valójában CPU-n sokkal könnyebb elméleti számadatokat elérni a gyakorlatban, és a számok GPU esetén egyszeri, CPU esetében pedig dupla pontosságra vannak megadva. Mindenesetre néhány párhuzamos feladatnál elég az egyszeri pontosság, az általános célú és a grafikus processzorok között igen nagy a sebességkülönbség, ezért a játék megéri a fáradságot.
Az első próbálkozások a GPU számítástechnika használatára
Hosszú ideig próbálták párhuzamos matematikai számításokban videochipeket használni. Az ilyen alkalmazásokkal kapcsolatos legkorábbi próbálkozások rendkívül primitívek voltak, és néhány hardverfunkció használatára korlátozódtak, mint például a raszterezés és a Z-pufferelés. De ebben a században, a shaderek megjelenésével, elkezdték felgyorsítani a mátrixszámításokat. 2003-ban a SIGGRAPH-nál külön szakaszt jelöltek ki a GPU-számításra, és ezt GPGPU-nak (General-Purpose computing on GPU) nevezték el.
A leghíresebb BrookGPU a Brook streaming programozási nyelv fordítója, amelyet nem grafikus számítások elvégzésére terveztek a GPU-n. Megjelenése előtt a videochipek számítástechnikai képességeit használó fejlesztők a két gyakori API egyikét választották: a Direct3D-t vagy az OpenGL-t. Ez komolyan korlátozta a GPU-k használatát, mert a 3D grafikában shadereket és textúrákat használnak, amiről a párhuzamos programozási szakembereknek nem kötelező tudniuk, szálakat és magokat használnak. Brook segíteni tudott a feladatuk megkönnyítésében. A Stanford Egyetemen kifejlesztett C nyelv streaming-kiterjesztései elrejtették a háromdimenziós API-t a programozók elől, és a videochipet párhuzamos koprocesszorként mutatták be. A fordító elemezte a .br fájlt C ++ kóddal és kiterjesztéssel, így egy DirectX, OpenGL vagy x86 könyvtárhoz kapcsolt kódot hozott létre.
Természetesen Brook-nak sok hibája volt, amelyeknél megálltunk, és amelyekről az alábbiakban részletesebben fogunk beszélni. De már a megjelenése is jelentős mértékben felkeltette ugyanazon Nvidia és ATI figyelmét a GPU-kon történő számítástechnikai kezdeményezésre, mivel ezeknek a képességeknek a fejlesztése a jövőben komolyan megváltoztatta a piacot, és egy teljesen új szektort nyitott meg - párhuzamos számítógépeken. videó chipeken.
Ezt követően a Brook projekt néhány kutatója csatlakozott az Nvidia fejlesztőcsapatához, hogy bevezessenek egy hardver-szoftver párhuzamos számítási stratégiát, új piaci részesedést nyitva ezzel. Ennek az Nvidia kezdeményezésnek pedig az a fő előnye, hogy a fejlesztők a legapróbb részletekig tisztában vannak GPU-ik minden képességével, és nincs szükség a grafikus API használatára, a hardverrel pedig közvetlenül az illesztőprogram segítségével lehet dolgozni. A csapat erőfeszítéseinek eredménye az Nvidia CUDA (Compute Unified Device Architecture), egy új hardver- és szoftverarchitektúra az Nvidia GPU-n történő párhuzamos számításokhoz, amelyről ez a cikk szól.
A párhuzamos GPU számítástechnika alkalmazásai
A számítások videochipekre való átvitelének előnyeinek megértéséhez itt találja a kutatók által a világ minden tájáról származó átlagos adatokat. Átlagosan a számítástechnika GPU-ra történő átvitelekor sok feladatban a gyorsulás 5-30-szoros a gyors, általános célú processzorokhoz képest. A legnagyobb számokat (nagyságrendileg 100-szoros gyorsulás és még több!) olyan kódban érik el, amely nem túl jól alkalmas SSE blokkokkal történő számításokhoz, de a GPU számára meglehetősen kényelmes.
Ez csak néhány példa a szintetikus kód gyorsítására GPU-n, szemben a CPU-n lévő SSE-vektorizált kóddal (az Nvidia szerint):
- Fluoreszcens mikroszkóp: 12x;
- Molekuladinamika (nem kötött erő számítás): 8-16x;
- Elektrosztatika (közvetlen és többszintű Coulomb halmozás): 40-120x és 7x.
És ez egy olyan lemez, amelyet az Nvidia nagyon szeret, és minden bemutatón megmutatja, amelyen a cikk második részében részletesebben foglalkozunk, a CUDA számítástechnika gyakorlati alkalmazásainak konkrét példáival:

Amint látható, a számok nagyon vonzóak, a 100-150-szeres nyereség különösen lenyűgöző. A következő cikkben a CUDA-ról részletesen le fogunk bontani néhány ilyen számot. Most pedig soroljuk fel azokat a fő alkalmazásokat, amelyekben a GPU számítástechnikát jelenleg használják: kép- és jelelemzés és -feldolgozás, fizikai szimuláció, számítási matematika, számítási biológia, pénzügyi számítások, adatbázisok, gáz- és folyadékdinamika, kriptográfia, adaptív sugárterápia, csillagászat, hangfeldolgozás , bioinformatika, biológiai szimulációk, számítógépes látás, adatbányászat, digitális mozi és televízió, elektromágneses szimulációk, földrajzi információs rendszerek, katonai alkalmazások, bányászati tervezés, molekuláris dinamika, mágneses rezonancia képalkotás (MRI), neurális hálózatok, oceanográfiai kutatás, részecskefizika, fehérje hajtogatás szimuláció, kvantumkémia, sugárkövetés, vizualizáció, radar, tározószimuláció, mesterséges intelligencia, műholdadatok elemzése, szeizmikus feltárás, műtét, ultrahang, videokonferencia.
Számos alkalmazás részletei megtalálhatók az Nvidia weboldalán a szoftverek részében. Mint látható, a lista elég hosszú, de ez még nem minden! Folytatható, és minden bizonnyal feltételezhetjük, hogy a jövőben a videochipeken végzett párhuzamos számítások más alkalmazási területei is megtalálhatók lesznek, amiről még nem sejtettük.
Nvidia CUDA jellemzői
A CUDA technológia az Nvidia szoftveres és hardveres számítási architektúrája a C nyelv kiterjesztése alapján, amely lehetővé teszi a grafikus gyorsító utasításkészletéhez való hozzáférés megszervezését és a memória kezelését a párhuzamos számítások szervezésekor. A CUDA segít olyan algoritmusok megvalósításában, amelyek végrehajthatók a Geforce videógyorsítók nyolcadik generációjának (Geforce 8, Geforce 9, Geforce 200 sorozat), valamint Quadro és Tesla GPU-in.
Bár a GPU-programozás bonyolultsága a CUDA-val meglehetősen magas, alacsonyabb, mint a korábbi GPGPU-megoldásoké. Az ilyen programok megkövetelik az alkalmazás felosztását több többprocesszor között, hasonlóan az MPI programozáshoz, de a megosztott videomemóriában tárolt adatok felosztása nélkül. És mivel az egyes többprocesszoros CUDA-programozás hasonló az OpenMP-programozáshoz, szükséges a memóriaszervezés alapos ismerete. De természetesen a fejlesztés és a CUDA-ra történő portolás összetettsége nagymértékben alkalmazásfüggő.
A fejlesztői készlet számos kódpéldát tartalmaz, és jól dokumentált. A tanulási folyamat körülbelül két-négy hetet vesz igénybe azok számára, akik már ismerik az OpenMP-t és az MPI-t. Az API a kiterjesztett C nyelven alapul, és a kód lefordításához erről a nyelvről a CUDA SDK tartalmazza az Open64 nyílt forráskódú fordítón alapuló nvcc parancssori fordítót.
Soroljuk fel a CUDA főbb jellemzőit:
- egységes hardver és szoftver megoldás az Nvidia videochipeken történő párhuzamos számításokhoz;
- támogatott megoldások széles skálája, a mobiltól a multichipig
- szabványos C programozási nyelv;
- Standard Numerical Analysis Libraries FFT (Fast Fourier Transform) és BLAS (Lineáris Algebra)
- optimalizált adatcsere a CPU és a GPU között;
- interakció az OpenGL és DirectX grafikus API-kkal;
- 32 és 64 bites operációs rendszerek támogatása: Windows XP, Windows Vista, Linux és MacOS X;
- az alacsony szintű fejlődés képessége.
Az operációs rendszerek támogatásával kapcsolatban hozzá kell tenni, hogy minden nagyobb Linux disztribúció hivatalosan támogatott (Red Hat Enterprise Linux 3.x / 4.x / 5.x, SUSE Linux 10.x), de a rajongók adataiból ítélve A CUDA remekül működik más összeállításokon: Fedora Core, Ubuntu, Gentoo stb.
A CUDA fejlesztői környezet (CUDA Toolkit) a következőket tartalmazza:
- nvcc fordító;
- FFT és BLAS könyvtárak;
- profilozó;
- gdb hibakereső GPU-hoz;
- CUDA futásidejű illesztőprogram a szabványos Nvidia illesztőprogramokhoz
- programozási útmutató;
- CUDA Developer SDK (forrás, segédprogramok és dokumentáció).
A forráskód példáiban: párhuzamos bitonikus rendezés, mátrix transzpozíció, nagy tömbök párhuzamos prefix összegzése, képkonvolúció, diszkrét wavelet transzformáció, példa az OpenGL és a Direct3D interakciójára, a CUBLAS és CUFFT könyvtárak használata, az opció árának kiszámítása (Black képlete Scholes, binomiális modell, Monte Carlo módszer), párhuzamos véletlenszám generátor Mersenne Twister, nagy tömb hisztogram számítása, zajcsökkentés, Sobel szűrő (határok keresése).
A CUDA előnyei és korlátai
A programozó szemszögéből a grafikus csővezeték feldolgozási szakaszok gyűjteménye. A geometria blokk háromszögeket, a raszterblokk pedig a monitoron megjelenő képpontokat generálja. A hagyományos GPGPU programozási modell így néz ki:

A számítások GPU-kra való átviteléhez egy ilyen modell keretein belül speciális megközelítésre van szükség. Még két vektor elemenkénti összeadásához is meg kell rajzolni az alakzatot a képernyőre vagy egy képernyőn kívüli pufferre. Az alakzat raszterezett, az egyes pixelek színét a megadott program szerint (pixel shader) számítjuk ki. A program minden pixelhez kiolvassa a bemeneti adatokat a textúrákból, hozzáadja azokat és a kimeneti pufferbe ír. És mindezekre a számos műveletre szükség van ahhoz, amit egy hétköznapi programozási nyelvben egyetlen operátor ír le!
Emiatt a GPGPU általános célú számítástechnikai célokra való felhasználásának korlátai vannak, mivel túl sok nehézséget okoz a fejlesztők képzésében. És van még elég megkötés, mert a pixel shader csak egy képlet a végső pixelszín koordinátától való függésére, a pixel shader nyelv pedig egy olyan nyelv, amellyel ezeket a képleteket C-szerű szintaxissal írhatjuk. A korai GPGPU technikák egy trükkös trükk a GPU erejének kihasználására, de minden kényelem nélkül. Az ott található adatokat képek (textúrák) reprezentálják, az algoritmust pedig a raszterizálási folyamat. Meg kell jegyezni egy nagyon specifikus memória- és végrehajtási modellt is.
Az Nvidia GPU-számítástechnikai hardver- és szoftverarchitektúrája abban különbözik a korábbi GPGPU-modellektől, hogy lehetővé teszi a GPU-k számára való programok írását valós C-ben szabványos szintaxissal, mutatókkal, valamint minimális bővítmény szükséges a videochipek számítási erőforrásainak eléréséhez. A CUDA független a grafikus API-któl, és rendelkezik néhány olyan funkcióval, amelyet kifejezetten az általános számítástechnikához terveztek.
A CUDA előnyei a GPGPU számítástechnika hagyományos megközelítésével szemben:
- a CUDA alkalmazásprogramozási felülete a szabványos C programozási nyelven alapszik kiterjesztésekkel, ami leegyszerűsíti a CUDA architektúra tanulásának és megvalósításának folyamatát;
- A CUDA többprocesszoronként 16 KB-os megosztott memóriához biztosít hozzáférést, amely a textúra mintáknál szélesebb sávszélességű gyorsítótár létrehozására használható;
- hatékonyabb adatátvitel a rendszer és a videomemória között
- nincs szükség redundanciával és többletköltséggel rendelkező grafikus API-kra;
- lineáris memóriacímzés, valamint összegyűjtés és szóródás, tetszőleges címekre való írás képessége;
- hardveres támogatás egész és bit műveletekhez.
A CUDA fő korlátai:
- az elvégzett funkciók rekurziós támogatásának hiánya;
- minimális blokkszélesség 32 menet;
- Zárt architektúra CUDA, az Nvidia tulajdona.
A korábbi GPGPU módszereket használó programozás gyengeségei, hogy ezek a módszerek nem használnak vertex shader végrehajtási egységeket a korábbi, nem egységes architektúrákban, az adatok textúrákban tárolódnak, hanem a képernyőn kívüli pufferbe kerülnek, a több lépéses algoritmusok pedig pixel shadert használnak. egységek. A GPGPU korlátozásai a következők lehetnek: a hardver képességeinek elégtelen használata, a memória sávszélességének korlátozása, a szórt műveletek hiánya (csak gyűjtés), a grafikus API kötelező használata.
A CUDA fő előnyei a korábbi GPGPU-módszerekkel szemben abból a tényből fakadnak, hogy ezt az architektúrát a nem grafikus számítástechnika hatékony felhasználására tervezték a GPU-n, és a C programozási nyelvet használja anélkül, hogy az algoritmusokat a koncepciónak megfelelő formába kellene átvinni. egy grafikus csővezetékről. A CUDA a GPU-számítás egy új módját kínálja, amely nem használ grafikus API-kat, és véletlenszerű hozzáférést biztosít a memóriához (szórt vagy gyűjtöget). Ez az architektúra mentes a GPGPU hátrányaitól, és minden végrehajtási egységet használ, valamint bővíti a képességeket az egész szám matematikai és biteltolási műveletei miatt.
Ezenkívül a CUDA megnyit néhány olyan hardverképességet, amely nem érhető el a grafikus API-kból, például a megosztott memóriát. Ez egy kis mennyiségű memória (többprocesszoronként 16 kilobájt), amelyhez szálblokkokkal lehet hozzáférni. Lehetővé teszi a leggyakrabban elért adatok gyorsítótárazását, és nagyobb sebességet biztosít, mint a textúralekérések használata ehhez a feladathoz. Ez viszont számos alkalmazásban csökkenti a párhuzamos algoritmusok sávszélesség-érzékenységét. Például hasznos a lineáris algebra, az FFT és a képfeldolgozó szűrőkhöz.
Kényelmesebb a CUDA-ban és a memóriaelérésben. A grafikus API programkódja 32 egyszeres pontosságú lebegőpontos érték (RGBA értékek egyidejűleg nyolc renderelési célpontban) formájában bocsát ki adatokat előre meghatározott területekre, a CUDA pedig támogatja a szórt rögzítést – korlátlan számú rekord bármilyen címet. Ezek az előnyök lehetővé teszik néhány olyan algoritmus GPU-n történő végrehajtását, amelyet nem lehet hatékonyan megvalósítani grafikus API-kon alapuló GPGPU-módszerekkel.
Ezenkívül a grafikus API-k szükségszerűen textúrákban tárolják az adatokat, ami megköveteli a nagy tömbök előzetes textúrákba történő csomagolását, ami bonyolítja az algoritmust és speciális címzés alkalmazását kényszeríti ki. A CUDA pedig lehetővé teszi az adatok olvasását bármilyen címen. A CUDA másik előnye az optimalizált adatcsere a CPU és a GPU között. Azoknak a fejlesztőknek pedig, akik alacsony szintű hozzáférést szeretnének elérni (például egy másik programozási nyelv írásakor), a CUDA alacsony szintű assembly nyelvű programozás lehetőségét kínálja.
A CUDA fejlesztési története
A CUDA fejlesztését a G80 chippel 2006 novemberében jelentették be, a CUDA SDK nyilvános bétaverziója pedig 2007 februárjában jelent meg. Az 1.0-s verzió 2007 júniusában jelent meg a G80 chipre épülő Tesla megoldások piacra dobásához, amelyeket a nagy teljesítményű számítástechnikai piacra szántak. Aztán az év végén megjelent a CUDA 1.1 béta verziója, amely a verziószám enyhe növekedése ellenére is elég sok újdonságot hozott.
A CUDA 1.1 újdonsága a CUDA funkció beépítése a szokásos Nvidia video-illesztőprogramokba. Ez azt jelentette, hogy bármely CUDA program követelményei között elegendő volt egy Geforce 8 vagy újabb videokártya megadása, valamint a minimális illesztőprogram 169.xx verziója. Ez nagyon fontos a fejlesztők számára, ha ezek a feltételek teljesülnek, a CUDA programok bármelyik felhasználó számára működni fognak. Ezenkívül hozzáadta az aszinkron végrehajtást, valamint az adatok másolását (csak G84, G86, G92 és magasabb chipekhez), aszinkron adatátvitelt a videomemóriába, az atomi memória hozzáférési műveleteket, a 64 bites Windows-verziók támogatását és a többcsipes CUDA működésének lehetőségét SLI-ben. mód.
Jelenleg a Geforce GTX 200 sorozattal együtt megjelent a GT200 - CUDA 2.0 alapú megoldások aktuális verziója, a béta verzió még 2008 tavaszán jelent meg. A második verzió kiegészítve: támogatja a dupla pontosságú számításokat (csak hardveres támogatás a GT200-hoz), végül támogatott Windows Vista (32 és 64 bites verziók) és Mac OS X, hozzáadott hibakereső és profilozó eszközök, támogatott 3D textúrák, optimalizált adatátvitel.
Ami a kettős pontosságú számításokat illeti, ezek sebessége a jelenlegi hardvergeneráción többszöröse az egyszeri pontosságnak. Az okokat a mi cikkünkben tárgyaljuk. Ennek a támogatásnak a megvalósítása a GT200-ban abban rejlik, hogy az FP32 blokkokat nem használják az eredmény négyszer kisebb sebességgel történő eléréséhez; az FP64 számítások támogatására az Nvidia úgy döntött, hogy dedikált számítási blokkokat készít. A GT200-ban pedig tízszer kevesebb van belőlük, mint az FP32 blokkokból (egy dupla precíziós blokk minden multiprocesszorhoz).
A valóságban a teljesítmény még kisebb is lehet, hiszen az architektúra 32 bites memóriából és regiszterekből történő olvasásra van optimalizálva, ráadásul a grafikus alkalmazásoknál nincs szükség dupla pontosságra, a GT200-ban pedig inkább egyszerűvé teszik. A modern négymagos processzorok pedig nem sokkal kisebb valódi teljesítményt mutatnak. De mivel még 10-szer lassabb, mint az egyszeri precizitás, ez a támogatás hasznos vegyes precíziós kialakításokhoz. Az egyik elterjedt technika az, hogy a kezdeti közelítési eredményeket egyszeres pontossággal kapjuk meg, majd dupla pontossággal finomítjuk. Most ezt közvetlenül a videokártyán is megteheti anélkül, hogy közbenső adatokat küldene a CPU-nak.
A CUDA 2.0 másik hasznos funkciója furcsa módon nem kapcsolódik a GPU-hoz. Mostanra lehetséges a CUDA-kódok rendkívül hatékony, többszálú SSE-kódokká való fordítása a CPU-n történő gyors végrehajtás érdekében. Vagyis most ez a funkció nem csak hibakeresésre alkalmas, hanem valós használatra is Nvidia videokártya nélküli rendszereken. Hiszen a CUDA normál kódban való használatát korlátozza, hogy az Nvidia videokártyák, bár a legnépszerűbbek a dedikált videómegoldások között, nem minden rendszerben elérhetőek. A 2.0-s verzió előtt pedig ilyen esetekben két különböző kódot kellett készíteni: a CUDA-hoz és külön a CPU-hoz. És most bármilyen CUDA programot végrehajthat nagy hatékonysággal egy CPU-n, bár kisebb sebességgel, mint a videochipeken.
Megoldások Nvidia CUDA támogatással
Minden CUDA-kompatibilis grafikus kártya segíthet a legigényesebb feladatok felgyorsításában, a hang- és képfeldolgozástól az orvostudományig és a tudományos kutatásig. Az egyetlen valódi korlát az, hogy sok CUDA-program legalább 256 megabájt videomemóriát igényel, ami a CUDA-alkalmazások egyik legfontosabb műszaki specifikációja.
A CUDA-kompatibilis termékek naprakész listájáért látogasson el ide. A cikk írásakor a CUDA számításai támogatták a Geforce 200, Geforce 9 és Geforce 8 sorozat összes termékét, beleértve a Geforce 8400M-től kezdődő mobiltermékeket, valamint a Geforce 8100, 8200 és 8300 lapkakészleteket is. minden Tesla: S1070, C1060, C870, D870 és S870.


Külön megjegyezzük, hogy az új Geforce GTX 260 és 280 grafikus kártyákkal együtt bejelentették a megfelelő megoldásokat a nagy teljesítményű számítástechnika számára: a Tesla C1060 és S1070 (a fenti képen látható), amelyeket idén ősszel lehet megvásárolni. A GPU ugyanaz bennük - GT200, a C1060-ban egy, az S1070-ben - négy. De a játékmegoldásoktól eltérően minden chiphez négy gigabájt memóriát használnak. Az egyetlen hátránya az alacsonyabb memóriafrekvencia és memória sávszélesség, mint a játékkártyáknál, amelyek chipenként 102 GB / s-t biztosítanak.
Nvidia CUDA névsor
A CUDA két API-t tartalmaz: magas szintű (CUDA Runtime API) és alacsony szintű (CUDA Driver API), bár nem lehet mindkettőt egyszerre használni egy programban, vagy az egyiket, vagy a másikat kell használni. A magas szintű az alacsony szintű "felül" működik, minden futásidejű hívás egyszerű utasításokká alakul, amelyeket az alacsony szintű Driver API dolgoz fel. De még a "magas szintű" API is feltételez ismereteket az Nvidia videochipek felépítéséről és működéséről, ott nincs túl magas szintű absztrakció.

Van még egy szint, még magasabb - két könyvtár:
CUBLAS- A BLAS (alapvető lineáris algebrai alprogramok) CUDA verziója, amelyet lineáris algebrai problémák kiszámítására és a GPU-erőforrásokhoz való közvetlen hozzáférésre terveztek;
BIZTOSÍTÁS- A Fast Fourier Transform könyvtár CUDA változata a gyors Fourier transzformáció kiszámításához, amelyet széles körben használnak a jelfeldolgozásban. A következő transzformációs típusok támogatottak: komplex-komplex (C2C), valós-komplex (R2C) és komplex-valós (C2R).
Nézzük meg közelebbről ezeket a könyvtárakat. A CUBLAS a CUDA nyelvre lefordított szabványos lineáris algebrai algoritmusok, jelenleg csak az alapvető CUBLAS függvények bizonyos készlete támogatott. A könyvtár használata nagyon egyszerű: a videokártya memóriájában létre kell hozni egy mátrixot és vektorobjektumokat, ezeket feltölteni adatokkal, meghívni a szükséges CUBLAS függvényeket, majd a videomemóriából vissza kell tölteni az eredményeket a rendszermemóriába. A CUBLAS speciális funkciókat tartalmaz a GPU-memóriában lévő objektumok létrehozására és megsemmisítésére, valamint adatok ebbe a memóriába történő olvasására és írására. Támogatott BLAS-függvények: 1., 2. és 3. szint valós számokhoz, 1. szintű CGEMM a komplex számokhoz. Az 1. szint a vektor-vektor műveletek, a 2. szint a vektor-mátrix műveletek, a 3. szint a mátrix-mátrix műveletek.
Cufft - a Fast Fourier Transform funkció CUDA változata - széles körben használt és nagyon fontos jelelemzésben, szűrésben stb. A CUFFT egyszerű felületet biztosít az FFT hatékony kiszámításához az Nvidia GPU-kon anélkül, hogy saját GPU FFT-t kellene kifejlesztenie. Az FFT CUDA verziója támogatja az összetett és valós adatok 1D, 2D és 3D átalakításait, kötegelt végrehajtást több 1D transzformációhoz párhuzamosan, a 2D és 3D transzformációk méretezhetők, 1D-hez akár 8 millió elem is támogatott.
CUDA programozási alapismeretek
A további szöveg megértéséhez meg kell értenie az Nvidia videochipek alapvető építészeti jellemzőit. A GPU több textúrafeldolgozó klaszterből áll. Mindegyik klaszter textúra minták kinagyított blokkjából és két vagy három streaming multiprocesszorból áll, amelyek mindegyike nyolc számítástechnikai eszközből és két szuperfunkcionális blokkból áll. Minden utasítás a SIMD-elv szerint fut, amikor egy utasítást alkalmazunk a warp összes szálára (a textiliparból származó kifejezés, a CUDA-ban ez egy 32 szálból álló csoport - a többprocesszorok által feldolgozott minimális adatmennyiség). Ezt a végrehajtási módot SIMT-nek (egy utasítás több szál) hívták.

A többprocesszorok mindegyike rendelkezik bizonyos erőforrásokkal. Tehát van egy speciális, 16 kilobájtnyi megosztott memória többprocesszoronként. De ez nem gyorsítótár, mivel a programozó bármilyen igényre használhatja, például a Cell processzorok SPU-jában a Local Store-t. Ez a megosztott memória lehetővé teszi az információcserét ugyanazon blokk szálai között. Fontos, hogy egy blokk összes szálát mindig ugyanaz a multiprocesszor hajtsa végre. És a különböző blokkokból származó adatfolyamok nem cserélhetnek adatot, és emlékeznie kell erre a korlátozásra. A megosztott memória gyakran hasznos, kivéve, ha több szál is hozzáfér ugyanahhoz a memóriabankhoz. A többprocesszorok is hozzáférhetnek a videomemóriához, de nagyobb késleltetéssel és rosszabb sávszélességgel. A hozzáférés felgyorsítása és a videomemória elérésének gyakoriságának csökkentése érdekében a többprocesszorok 8 kilobájt gyorsítótárral rendelkeznek az állandók és a textúraadatok számára.
A többprocesszor 8192-16384 (a G8x / G9x és GT2xx esetén) regisztereket használ, amelyek közösek a rajta végrehajtott összes blokk összes adatfolyamában. A blokkok maximális száma többprocesszoronként a G8x / G9x esetében nyolc, a vetemítések száma pedig 24 (768 szál többprocesszoronként). Összességében a Geforce 8 és 9 sorozat csúcskategóriás videokártyái akár 12288 adatfolyamot is képesek egyszerre feldolgozni. A GT200-ra épülő Geforce GTX 280 akár 1024 szálat kínál többprocesszoronként, 10 fürtje három többprocesszorból áll, amelyek akár 30720 szálat dolgoznak fel. Ezen korlátozások ismerete lehetővé teszi az algoritmusok optimalizálását a rendelkezésre álló erőforrásokhoz.
Egy meglévő alkalmazás CUDA-ba történő portolásának első lépése a profil létrehozása, és a kódban a teljesítményt akadályozó szűk keresztmetszetek azonosítása. Ha az ilyen szakaszok alkalmasak a gyors párhuzamos végrehajtásra, akkor ezek a funkciók a C és CUDA kiterjesztésekre portolódnak a GPU-n való végrehajtáshoz. A programot az Nvidia által szállított fordító segítségével fordítják, amely kódot generál a CPU és a GPU számára is. Egy program végrehajtásakor a központi processzor végrehajtja a kód részeit, a GPU pedig a CUDA kódot hajtja végre a legnehezebb párhuzamos számításokkal. Ezt a GPU-nak szentelt részt kernelnek hívják. A kernel határozza meg az adatokon végrehajtandó műveleteket.
A videochip kap egy magot, és másolatokat készít minden egyes adatelemről. Ezeket a másolatokat szálaknak nevezzük. A stream tartalmazza a számlálót, a regisztereket és az állapotot. Nagy mennyiségű adat, például képfeldolgozás esetén több millió szál fut. A szálak 32-ből álló csoportokban hajtódnak végre, amelyeket warp "s. Warp"-nak neveznek, és meghatározott folyam-multiprocesszorokon való végrehajtásra vannak hozzárendelve. Minden többprocesszor nyolc magból áll – stream processzorokból, amelyek egy MAD utasítást hajtanak végre órajelenként. Egy 32 szálú vetemítés végrehajtásához a multiprocesszor négy órajele szükséges (a shader tartomány frekvenciájáról beszélünk, ami 1,5 GHz és magasabb).
A többprocesszor nem egy hagyományos többmagos processzor, többszálú feldolgozásra is kiválóan alkalmas, egyszerre akár 32 warp-ot is támogat.. A hardver minden órajel ciklusban kiválasztja, hogy melyik warp-ot hajtsa végre, és óraveszteség nélkül vált át egyikről a másikra. A központi processzorhoz hasonlóan ez olyan, mintha 32 programot futtatnánk egyszerre, és minden órajelben váltanánk közöttük a kontextusváltás elvesztése nélkül. A valóságban a CPU magok támogatják egy program egyidejű végrehajtását, és több száz órajel-ciklus késéssel váltanak át a többire.
CUDA programozási modell
A CUDA ismét párhuzamos számítási modellt használ, amikor a SIMD processzorok mindegyike párhuzamosan hajtja végre ugyanazt az utasítást különböző adatelemeken. A GPU egy számítástechnikai eszköz, egy központi processzor (host) társprocesszora (eszköze), amely saját memóriával rendelkezik, és párhuzamosan nagyszámú szálat dolgoz fel. A kernel (kernel) a GPU funkciója, amelyet szálak hajtanak végre (analógia a 3D grafikából - árnyékoló).
Fentebb elmondtuk, hogy a videochip abban különbözik a CPU-tól, hogy több tízezer szálat tud egyszerre feldolgozni, ami általában a jól párhuzamosított grafikákra vonatkozik. Minden adatfolyam skaláris, és nem szükséges az adatokat 4 komponensű vektorokba csomagolni, ami a legtöbb feladatnál kényelmesebb. A logikai szálak és szálblokkok száma meghaladja a fizikai végrehajtási egységek számát, ami jó skálázhatóságot biztosít a vállalati megoldások teljes palettája számára.
A CUDA programozási modell szálcsoportosítást feltételez. A szálak szálblokkokká vannak kombinálva – egydimenziós vagy kétdimenziós szálrácsokká, amelyek megosztott memória és szinkronizálási pontok segítségével kölcsönhatásba lépnek egymással. A program (kernel) szálblokkokból álló rácson fut, lásd az alábbi ábrát. Egyszerre egy háló kerül végrehajtásra. Mindegyik blokk lehet egy-, két- vagy háromdimenziós alakú, és 512 szálat tartalmazhat a jelenlegi hardveren.

A szálblokkokat kis csoportokban, úgynevezett warp-ban hajtják végre, amelyek 32 szál méretűek. Ez a többprocesszorban feldolgozható minimális adatmennyiség. És mivel ez nem mindig kényelmes, a CUDA lehetővé teszi, hogy 64–512 szálat tartalmazó blokkokkal dolgozzon.
A blokkok rácsokba csoportosítása lehetővé teszi, hogy megszabaduljon a korlátozásoktól, és egyetlen hívásban több szálra alkalmazza a kernelt. Segít a méretezésben is. Ha a GPU-nak nincs elég erőforrása, akkor a blokkokat egymás után hajtja végre. Ellenkező esetben a blokkok párhuzamosan is végrehajthatók, ami fontos a munka optimális elosztásához a különböző szintű videochipeken, kezdve a mobil és az integrált chipekkel.
CUDA memória modell
A CUDA memóriamodelljét a bájtcímzés lehetősége, valamint az összegyűjtés és szóródás támogatása jellemzi. Egy-egy stream processzorhoz meglehetősen nagy számú regiszter áll rendelkezésre, akár 1024 darab is. Hozzáférésük nagyon gyors, 32 bites egész számokat vagy lebegőpontos számokat tárolhatunk bennük.
Mindegyik szál a következő típusú memóriákhoz fér hozzá:

Globális memória- az összes többprocesszorhoz elérhető legnagyobb memóriamennyiség egy videochipen, mérete 256 megabájttól 1,5 gigabájtig terjed a jelenlegi megoldásokon (és akár 4 GB a Teslán). Nagy sávszélességgel rendelkezik, több mint 100 gigabájt/s a legjobb Nvidia-megoldásokhoz, de nagyon magas, több száz órajelciklusos késleltetéssel. Nem gyorsítótárazott, támogatja az általános betöltési és tárolási utasításokat, valamint a memóriára mutató rendszeres mutatókat.
Helyi memória Ez egy kis mennyiségű memória, amelyhez csak egyetlen adatfolyam-processzor fér hozzá. Viszonylag lassú – ugyanaz, mint a globális.
Megosztott memória Egy 16 kilobájtos (a jelenlegi architektúra videochipjében) memóriablokk, amelyet egy többprocesszoros összes adatfolyam-processzor megoszt. Ez a memória elég gyors, akárcsak a regiszterek. Biztosítja a szálak együttműködését, közvetlenül a fejlesztő vezérli, és alacsony a késleltetése. Az osztott memória előnyei: az első szintű programozó által vezérelt gyorsítótár formájában történő felhasználás, a végrehajtási egységek (ALU) adatokhoz való hozzáférési késleltetésének csökkentése, a globális memóriába irányuló hívások számának csökkentése.
Az állandók emlékezete- 64 kilobyte-os memóriaterület (ugyanaz a jelenlegi GPU-k esetében), csak olvasható az összes többprocesszor által. Többprocesszoronként 8 kilobájt gyorsítótárban van. Elég lassú - több száz óraciklus késleltetése a szükséges adatok hiányában a gyorsítótárban.
Textúra memória- egy memóriablokk, amely az összes multiprocesszor számára olvasható. Az adatmintavétel a videochip textúra egységeivel történik, így a lineáris adatinterpoláció lehetőségei további költségek nélkül biztosítottak. Minden többprocesszorhoz 8 kilobájt van gyorsítótárban. Lassú, mint a globális – több száz órajel-ciklus a késleltetés, ha nincs adat a gyorsítótárban.
Természetesen a globális, a lokális, a textúra és az állandó memória fizikailag ugyanaz a memória, amelyet a videokártya helyi videomemóriájaként ismerünk. Különbségük a különböző gyorsítótárazási algoritmusokban és hozzáférési modellekben van. A központi processzor csak külső memóriát tud frissíteni és kérni: globális, állandó és textúra.

A fentiekből kitűnik, hogy a CUDA speciális megközelítést feltételez a fejlesztéshez, nem egészen ugyanazt, mint a CPU-hoz készült programokban. Emlékeztetni kell a különféle memóriatípusokkal kapcsolatban, hogy a lokális és a globális memória nincs gyorsítótárazva, és az elérési késleltetés sokkal nagyobb, mint a regisztermemóriáé, mivel fizikailag külön mikroáramkörökben helyezkedik el.
Tipikus, de nem kötelező problémamegoldó minta:
- a feladatot részfeladatokra bontjuk;
- A bemeneti adatok blokkokra vannak osztva, amelyek beleférnek a megosztott memóriába;
- minden blokkot egy szálblokk dolgoz fel;
- az alblokk betöltődik a megosztott memóriába a globálisból;
- a megfelelő számításokat az osztott memóriában lévő adatokon hajtják végre;
- az eredményeket a rendszer a megosztott memóriából visszamásolja a globális memóriába.
Programozási környezet
A CUDA futásidejű könyvtárakat tartalmaz:
- egy közös rész, amely CPU-n és GPU-n támogatott RTL-hívások beépített vektortípusait és részhalmazait biztosítja;
- CPU komponens egy vagy több GPU vezérléséhez;
- GPU-komponens, amely GPU-specifikus funkciókat biztosít.
A CUDA alkalmazás fő folyamata egy univerzális processzoron (host) fut, a kernelfolyamatok több példányát elindítja a videokártyán. A CPU kódja a következőket teszi: inicializálja a GPU-t, lefoglalja a memóriát a videokártyán és a rendszerben, a konstansokat bemásolja a videokártya memóriájába, elindítja a kernelfolyamatok több példányát a videokártyán, az eredményt kimásolja a videóról memória, felszabadítja a memóriát és kilép.
Példaként a megértés érdekében adjuk meg a CPU-kódot a vektorok hozzáadásához, CUDA-ban:

A videochip által végrehajtott függvényekre a következő korlátozások vonatkoznak: nincs rekurzió, a függvényeken belül nincsenek statikus változók és változó számú argumentum. A memóriakezelés két típusa támogatott: a lineáris memória 32 bites mutatókkal, és a CUDA-tömbök, amelyek csak textúra-lekérő funkciókon keresztül érhetők el.
A CUDA programok kölcsönhatásba léphetnek grafikus API-kkal: a programban generált adatok megjelenítéséhez, a renderelési eredmények kiolvasásához és CUDA-eszközökkel történő feldolgozásához (például utófeldolgozási szűrők implementálásakor). Ehhez a grafikus API erőforrásai leképezhetők (az erőforrás címének megszerzésével) a CUDA globális memóriaterébe. A következő grafikus API-erőforrástípusok támogatottak: Pufferobjektumok (PBO / VBO) OpenGL-ben, csúcspufferek és textúrák (2D, 3D és kockatérképek) Direct3D9.
A CUDA-alkalmazás összeállításának szakaszai:

A CUDA C forráskód fájlok az NVCC programmal vannak fordítva, amely egy burkoló a többi eszköz felett, és meghívja őket: cudacc, g ++, cl, stb. Az NVCC előállítja: kódot a központi processzorhoz, amely az alkalmazás többi részével együtt fordít. , tiszta C-vel írva, és a videochip PTX objektumkódja. A CUDA kódot tartalmazó végrehajtható fájlok szükségszerűen megkövetelik a CUDA futásidejű könyvtárát (cudart) és a CUDA központi könyvtárát (cuda).
CUDA programok optimalizálása
Természetesen az áttekintő cikk keretein belül nem lehet komoly optimalizálási kérdéseket mérlegelni a CUDA programozásban. Tehát csak röviden fedjük le az alapokat. A CUDA képességeinek hatékony használatához el kell felejtenie a CPU programjainak szokásos írási módszereit, és azokat az algoritmusokat kell használnia, amelyek jól párhuzamosak több ezer szálhoz. Fontos még megtalálni az optimális helyet az adatok tárolására (regiszterek, megosztott memória stb.), minimalizálni kell a CPU és a GPU közötti adatátvitelt, és pufferelni kell.
Általánosságban elmondható, hogy egy CUDA program optimalizálásakor meg kell próbálni optimális egyensúlyt elérni a mérete és a blokkok száma között. Több szál egy blokkban csökkenti a memória késleltetésének hatását, de csökkenti a rendelkezésre álló regiszterek számát is. Ráadásul az 512 szálból álló blokk nem hatékony, az Nvidia maga javasolja a 128 vagy 256 szálból álló blokkok használatát kompromisszumként az optimális késleltetés és regiszterszám elérése érdekében.
A CUDA programok optimalizálásának főbb pontjai: a megosztott memória legaktívabb használata, mivel sokkal gyorsabb, mint a videokártya globális videomemóriája; A globális memóriából származó olvasási és írási műveleteket lehetőség szerint egyesíteni kell. Ehhez speciális adattípusokat kell használni az egyszerre 32/64/128 adatbit olvasására és írására egy műveletben. Ha az olvasmányokat nehéz kombinálni, próbálkozzon textúra lekéréssel.
következtetéseket
Az Nvidia által bemutatott hardver- és szoftverarchitektúra a CUDA videochipeken történő számításokhoz kiválóan alkalmas számos feladat nagy párhuzamosság melletti megoldására. A CUDA az Nvidia GPU-k széles skáláján fut, és javítja a GPU programozási modelljét azáltal, hogy sokkal egyszerűbbé teszi, és további funkciókat ad hozzá, mint például a megosztott memória, a szálszinkronizálás, a dupla pontosság és az egész műveletek.
A CUDA egy olyan technológia, amely minden szoftverfejlesztő számára elérhető, és bármely programozó használhatja, aki ismeri a C nyelvet. Csak meg kell szoknia a párhuzamos számítástechnikában rejlő eltérő programozási paradigmát. De ha az algoritmus elvileg jól párhuzamos, akkor a CUDA-ban való tanulás és programozásra fordított idő sokszorosan visszatér.
Valószínű, hogy a videokártyák világszerte elterjedt használata miatt a párhuzamos számítástechnika fejlesztése a GPU-n nagymértékben érinti a nagy teljesítményű számítástechnikai ipart. Ezek a lehetőségek már tudományos körökben is nagy érdeklődést váltottak ki, és nem csak bennük. Végtére is, a párhuzamosításra jól alkalmas algoritmusok felgyorsításának lehetősége (a rendelkezésre álló hardveren, ami nem kevésbé fontos) nem olyan gyakran előfordul egyszerre több tucatszor.
Az univerzális processzorok meglehetősen lassan fejlődnek, nincsenek ekkora teljesítményugrások. Alapvetően, bár túl hangosan hangzik, mindenkinek, akinek gyors számítógépekre van szüksége, most egy olcsó személyi szuperszámítógép állhat az asztalán, néha további források befektetése nélkül, mivel az Nvidia grafikus kártyái annyira elterjedtek. Nem is beszélve a GFLOPS / $ és a GFLOPS / Watt teljesítménynövekedésről, amelyeket a GPU-gyártók annyira szeretnek.
Sok számítás jövője egyértelműen a párhuzamos algoritmusokban rejlik, szinte minden új megoldás és kezdeményezés ebbe az irányba irányul. Egyelőre azonban az új paradigmák fejlesztése korai stádiumban van, manuálisan kell szálakat létrehozni és a memória elérését ütemezni, ami megnehezíti a feladatokat a hagyományos programozáshoz képest. Ám a CUDA technológia tett egy lépést a helyes irányba, és jól látszik rajta a sikeres megoldás, különösen, ha az Nvidiának sikerül a lehető legjobban meggyőznie a fejlesztőket előnyeiről és kilátásairól.
De természetesen a GPU-k nem helyettesítik a CPU-kat. Jelenlegi formájukban nem erre valók. Most, hogy a videochipek fokozatosan a CPU felé haladnak, egyre univerzálisabbakká válnak (egy- és dupla pontosságú lebegőpontos számítások, egészszámú számítások), így a CPU-k egyre "párhuzamosabbak", nagyszámú magot, többszálú technológiákat szereznek be, nem is beszélve a SIMD blokkok és a Heterogeneous Processor Projects megjelenéséről. Valószínűleg a GPU és a CPU egyszerűen egyesülni fog a jövőben. Ismeretes, hogy sok vállalat, köztük az Intel és az AMD is dolgozik hasonló projekteken. Nem számít, hogy a GPU-t elnyeli a CPU, vagy fordítva.
A cikkben elsősorban a CUDA előnyeiről beszéltünk. De van légy is a kenőcsben. A CUDA egyik hátránya a rossz hordozhatóság. Ez az architektúra csak a cég videochipjein működik, sőt nem is az összesen, hanem a Geforce 8 és 9 sorozattól, valamint a megfelelő Quadrotól és Teslától kezdve. Igen, nagyon sok ilyen megoldás létezik a világon, az Nvidia 90 millió CUDA-kompatibilis videochipről ad számot. Ez rendben van, de a versenytársak a CUDA-n kívül más megoldásokat is kínálnak. Tehát az AMD-nek van Stream Computing, az Intelnek pedig Ct-je lesz a jövőben.
Melyik technológia fog nyerni, elterjedni és tovább élni, mint mások – csak az idő fogja eldönteni. De a CUDA-nak jó esélyei vannak, hiszen például a Stream Computing-hoz képest fejlettebb és könnyebben használható programozási környezetet képvisel a megszokott C nyelven. Talán egy harmadik fél segíthet a definícióban valamilyen általános megoldással. Például a következő, 11-es verzió alatti DirectX-frissítésben a Microsoft számítástechnikai shadereket ígért, amelyek egyfajta átlagos, mindenkinek, vagy szinte mindenkinek megfelelő megoldássá válhatnak.
Az előzetes adatok alapján ez az új típusú shader sokat kölcsönöz a CUDA modellből. És ha most ebben a környezetben programoz, azonnal megszerezheti az előnyöket és a szükséges készségeket a jövőre nézve. HPC szempontból a DirectX-nek egyértelmű hátránya is van a rossz hordozhatóság formájában, mivel ez az API a Windows platformra korlátozódik. Egy másik szabvány azonban fejlesztés alatt áll - a nyílt többplatformos OpenCL kezdeményezés, amelyet a legtöbb vállalat támogat, köztük az Nvidia, az AMD, az Intel, az IBM és még sokan mások.
Ne feledje, hogy a következő CUDA-cikkben a tudományos és más nem grafikus számítástechnika konkrét gyakorlati alkalmazásait fedezi fel, amelyeket a fejlesztők világszerte végeznek az Nvidia CUDA használatával.
Évtizedek óta érvényben van a Moore-törvény, amely kimondja, hogy egy chipen lévő tranzisztorok száma kétévente megduplázódik. Ez azonban 1965-ben volt, és az elmúlt 5 évben a fizikai többmagos fogyasztói processzorok ötlete gyorsan fejlődni kezdett: 2005-ben az Intel bemutatta a Pentium D-t, az AMD pedig az Athlon X2-t. Ekkor a 2 magot használó alkalmazásokat egy kéz ujjain meg lehetett számolni. Az Intel processzorok következő generációja azonban, amely forradalmat csinált, pontosan 2 fizikai magot tartalmazott. Sőt, 2007 januárjában megjelent a Quad sorozat, ugyanakkor Moore maga is elismerte, hogy törvénye hamarosan megszűnik.
És most? Kétmagos processzorok még a költségvetési irodai rendszerekben is, a 4 fizikai mag pedig mindössze 2-3 év alatt vált megszokottá. A processzorok gyakorisága nem növekszik, de javul az architektúra, nő a fizikai és virtuális magok száma. A több tucat vagy akár több száz számítási "blokk"-tal felszerelt videoadapterek használatának ötlete azonban már régóta létezik.
És bár a GPU-kkal való számítástechnika kilátásai óriásiak, a legnépszerűbb megoldás - az Nvidia CUDA ingyenes, sok dokumentációval rendelkezik, és általában nagyon egyszerűen kivitelezhető, nem sok alkalmazás használja ezt a technológiát. Alapvetően ezek mindenféle speciális számítások, amelyekkel a hétköznapi felhasználó a legtöbb esetben nem törődik. De vannak olyan programok is, amelyeket tömeges felhasználók számára terveztek, és ezekről ebben a cikkben fogunk beszélni.
Kezdésként egy kicsit magáról a technológiáról és arról, hogy mivel eszik. Mivel Egy cikk írásakor az olvasók széles köre vezérel, majd megpróbálom egy érthető nyelven, bonyolult kifejezések nélkül, kissé röviden elmagyarázni.
CUDA(angolul Compute Unified Device Architecture) egy szoftver- és hardverarchitektúra, amely lehetővé teszi a számítástechnikát a GPGPU technológiát támogató NVIDIA grafikus processzorok használatával (tetszőleges számítástechnika a videokártyákon). A CUDA architektúra először a nyolcadik generációs NVIDIA G80 chip kiadásával jelent meg a piacon, és jelen van a GeForce, Quadro és Tesla gyorsítócsaládokban használt összes későbbi grafikus chip-sorozatban. (c) Wikipedia.org
A bejövő streamek feldolgozása egymástól függetlenül történik, azaz. párhuzamos.

Ezenkívül 3 szintre osztható:

Rács- mag. Egy/két/háromdimenziós blokktömböt tartalmaz.
Blokk- sok szálat (szálat) tartalmaz. A különböző blokkokból álló adatfolyamok nem léphetnek kölcsönhatásba egymással. Miért kellett blokkokat bevezetni? Minden blokk alapvetően felelős a saját részfeladatáért. Például egy nagy kép (ami egy mátrix) több kisebb részre (mátrixra) osztható, és párhuzamosan működhet a kép egyes részeivel.
cérna- patak. Az egy blokkon belüli szálak vagy megosztott memórián keresztül, ami egyébként sokkal gyorsabb, mint a globális memórián, vagy szálszinkronizáló eszközökön keresztül léphetnek kapcsolatba.
Warp- ez az interaktív adatfolyamok uniója, minden modern GPU esetében a Warp mérete 32. Következő félláncú, ami egy warp'a fele, hiszen A memória elérése általában külön megy a vetemedés első és második felére.
Mint látható, ez az architektúra kiválóan alkalmas a feladatok párhuzamosításához. És bár a programozás bizonyos megszorításokkal C nyelven történik, a valóságban ez nem ilyen egyszerű, hiszen nem lehet mindent párhuzamosítani. Véletlen számok generálására (vagy inicializálására) szintén nincsenek szabványos funkciók, mindezt külön kell megvalósítani. És bár van elég kész lehetőség, mindez nem okoz örömet. A rekurzió használatának képessége viszonylag új.
Az áttekinthetőség kedvéért egy kis konzolos (a kód minimalizálására) programot írtak, amely két float tömbbel hajt végre műveleteket, pl. nem egész értékekkel. A fenti okok miatt az inicializálást (a tömb kitöltését különféle tetszőleges értékekkel) a CPU végezte. Ezután 25 különböző műveletet végeztünk az egyes tömbök megfelelő elemeivel, a köztes eredményeket a harmadik tömbbe írtuk. A tömb mérete megváltozott, az eredmények a következők:
Összesen 4 tesztet végeztek el:
1024 elem minden tömbben:

Jól látható, hogy ilyen kis számú elem mellett nincs sok értelme a párhuzamos számításoknak, hiszen maguk a számítások sokkal gyorsabbak, mint az előkészítésük.
4096 elem minden tömbben:

És most láthatja, hogy a videokártya 3-szor gyorsabban hajtja végre a műveleteket a tömbökön, mint a processzor. Sőt, ennek a tesztnek a végrehajtási ideje videokártyán nem nőtt (az idő enyhe csökkenése hibának tulajdonítható).
Most minden tömbben 12288 elem található:

A videokártya közötti rés megduplázódott. Ismét vegye figyelembe, hogy a videókártya végrehajtási ideje megnőtt.
jelentéktelen mértékben, de a processzoron több mint 3-szor, i.e. arányos a feladat összetettségével.
És az utolsó teszt - 36864 elem minden tömbben:

Ebben az esetben a gyorsulás lenyűgöző értékeket ér el - videokártyán majdnem 22-szer gyorsabb. És ismét a videókártya végrehajtási ideje jelentéktelenül nőtt, a processzoron pedig - az előírt 3-szor, ami ismét arányos a feladat bonyolultságával.
Ha tovább bonyolítja a számításokat, akkor a videokártya egyre jobban nyer. Bár a példa kissé eltúlzott, általánosságban világosan mutatja a helyzetet. De amint fentebb említettük, nem lehet mindent párhuzamosítani. Például a pi kiszámítása. Csak Monte Carlo módszerrel írt példák vannak, de a számítások pontossága 7 tizedesjegy, i.e. rendes úszó. A számítások pontosságának növelése érdekében hosszú aritmetika szükséges, de itt problémák merülnek fel, mert nagyon-nagyon nehéz hatékonyan megvalósítani. Az interneten nem találtam példát a CUDA használatára és a Pi 1 millió tizedesjegyig való kiszámítására. Voltak már kísérletek ilyen alkalmazás megírására, de a pi kiszámításának legegyszerűbb és leghatékonyabb módja a Brent-Salamin algoritmus vagy a Gauss-képlet. A jól ismert SuperPI-ben valószínűleg (a munka sebességéből és az iterációk számából ítélve) a Gauss-képletet használják. És abból ítélve
A SuperPI egyszálas ténye, a CUDA-ra vonatkozó példák hiánya és a próbálkozásaim kudarca miatt lehetetlen hatékonyan párhuzamosítani a Pi számítását.
Mellesleg láthatja, hogy a számítások végrehajtása során hogyan növekszik a GPU terhelése, valamint a memóriakiosztás.

Most térjünk át a CUDA gyakorlatiasabb előnyeire, nevezetesen a jelenleg létező, ezt a technológiát használó programokra. Ezek többnyire mindenféle audio/video konverter és szerkesztő.
A teszteléshez 3 különböző videófájlt használtunk:
- * Az Avatar című film története - 1920x1080, MPEG4, h.264.
- * "Hazudj nekem" sorozat – 1280x720, MPEG4, h.264.
- * „Philadelphiában mindig süt a nap” sorozat – 624x464, xvid.
Az első két fájl tárolója és mérete mkv és 1,55 gb, az utolsó .avi és 272 mb volt.
Kezdjük egy nagyon szenzációs és népszerű termékkel - Badaboom... A használt verzió: 1.2.1.74 ... A program költsége $29.90 .

A program felülete egyszerű és intuitív - a bal oldalon kiválasztjuk a forrásfájlt vagy lemezt, a jobb oldalon pedig a szükséges eszközt, amelyre kódolni fogunk. Létezik felhasználói mód is, amelyben manuálisan állítják be a paramétereket, és ezt használták.
Kezdésként nézzük meg, hogy a videó milyen gyorsan és hatékonyan kódolódik „önmagába”, azaz. azonos felbontásban és megközelítőleg azonos méretben. A sebességet fps-ben mérik, és nem az eltelt időben - kényelmesebb összehasonlítani és kiszámítani, hogy mennyi tetszőleges hosszúságú videó lesz tömörítve. Mivel ma a "zöld" technológián gondolkodunk, akkor a grafikonok megfelelőek lesznek -)

A kódolási sebesség közvetlenül a minőségtől függ, ez nyilvánvaló. Megjegyzendő, hogy a fényfelbontás (nevezzük hagyományosan - SD) nem okoz gondot a Badaboomnak - a kódolási sebesség 5,5-szerese az eredeti (24 fps) videó képkockasebességének. És még egy nehéz 1080p videót is valós időben konvertál a program. Megjegyzendő, hogy a végleges videó minősége nagyon közel áll az eredeti videóhoz, pl. nagyon-nagyon jó minőségben kódolja a Badaboom-ot.
De általában a videót lekörözik kisebb felbontásra, lássuk, hogy állnak a dolgok ebben a módban. A felbontás csökkentésével a videó bitráta is csökkent. 9500 kbps volt az 1080p kimeneti fájlnál, 4100 kbps a 720p-nél és 2400 kbps a 720x404-nél. A választás a méret/minőség ésszerű aránya alapján történt.

A megjegyzések feleslegesek. Ha 720p-ről normál SD-minőségre másol, akkor körülbelül 30 percet vesz igénybe egy 2 órás film átkódolása. Ugyanakkor a processzor terhelése jelentéktelen lesz, kellemetlen érzés nélkül folytathatja a dolgát.
De mi van akkor, ha a videót mobileszköz formátumára konvertálja? Ehhez válassza ki az iPhone profilt (bitráta 1 Mbps, 480x320), és nézze meg a kódolási sebességet:

Mondanom kell valamit? Egy kétórás film normál iPhone-minőségben kevesebb, mint 15 perc alatt átkódolódik. A HD minőség nehezebb, de még így is elég gyors. A lényeg az, hogy a kimeneti videóanyag minősége meglehetősen magas szinten maradjon a telefon kijelzőjén.
Általánosságban elmondható, hogy a Badaboom benyomásai pozitívak, a munka sebessége tetszik, a felület egyszerű és egyértelmű. A korábbi verziók mindenféle hibája (2008-ban még bétát használtam) ki lett gyógyítva. Egy dolog kivételével - a forrásfájl elérési útja, valamint a kész videó mentési mappája nem tartalmazhat orosz betűket. De a program előnyeihez képest ez a hátrány jelentéktelen.
Mi lesz a következő a sorban Super LoiLoScope... A szokásos verzióra kérik 3280 rubel, a Windows 7 érintéses vezérlését támogató érintőképernyős verzióért pedig annyit kérnek 4440 rubel... Próbáljuk meg kitalálni, miért akar a fejlesztő ennyi pénzt, és miért van szüksége a videószerkesztőnek többérintéses támogatásra. A legújabb verziót használták - 1.8.3.3 .
A program felületét meglehetősen nehéz szavakkal leírni, ezért úgy döntöttem, hogy forgatok egy rövid videót. Azonnal el kell mondanom, hogy mint minden CUDA videokonverterhez, a GPU-gyorsítást csak az MPEG4 videó kimenete támogatja a h.264 kodekkel.
A kódolás során a processzor terhelése 100%, de ez nem okoz kellemetlenséget. A böngésző és más nem nehéz alkalmazások nem lassulnak le.
Most pedig térjünk át a teljesítményre. Először is minden ugyanaz, mint a Badaboom esetében – a videó átkódolása ugyanabba a minőségbe.

Az eredmények sokkal jobbak, mint a Badaboom. A minőség is csúcson van, a különbséget az eredetihez képest csak a képkockák páros nagyító alatti összehasonlításával lehet látni.

Hú, itt a LoiloScope 2,5-szer kerüli meg a Badaboomot. Ezzel párhuzamosan könnyedén vághatunk, kódolhatunk párhuzamosan másik videót, olvashatunk híreket és akár filmet is nézhetünk, sőt a FullHD is gond nélkül lejátszható, igaz a processzorterhelés maximális.
Most próbáljunk meg videót készíteni egy mobileszközre, a profilt ugyanúgy fogjuk elnevezni, mint a Badaboom - iPhone-ban (480x320, 1 Mbps):

Nincs hiba. Mindent többször ellenőriztek, minden alkalommal ugyanaz volt az eredmény. Valószínűleg ez abból az egyszerű okból következik be, hogy az SD-fájlt más kodekkel és más tárolóban írják. Átkódoláskor a videót először dekódolják, meghatározott méretű mátrixokra osztják és tömörítik. Az xvid esetén használt ASP dekóder lassabb, mint az AVC (h.264 esetén) párhuzamos dekódolásnál. A 192 fps azonban 8-szor gyorsabb az eredeti videósebességnél, egy 23 perces sorozatot kevesebb mint 4 perc alatt tömörítenek. A helyzet megismétlődött más xvid / DivX formátumban tömörített fájlokkal.
LoiloScope csak kellemes benyomásokat hagytam magamról - az interfész szokatlansága ellenére kényelmes és funkcionális, a munka sebessége pedig dicsérhetetlen. A viszonylag gyenge funkcionalitás némileg elkeserítő, de sokszor egyszerű szerkesztéssel csak kicsit módosítani kell a színeket, simán át kell állítani a szöveget, át kell fedni a szöveget, és a LoiloScope ezzel kiváló munkát végez. Az ár is kissé ijesztő – a normál verzióért több mint 100 dollár normális külföldön, de ezek a számok még mindig kissé vadnak tűnnek számunkra. Bár bevallom, ha például gyakran forgattam és szerkesztettem házi videókat, akkor lehet, hogy elgondolkodtam a vásárláson. Ezzel egyidőben egyébként ellenőriztem, hogy a HD (vagy inkább AVCHD) tartalmat közvetlenül a kameráról szerkeszthetem anélkül, hogy először konvertáltam volna másik formátumba, a LoiloScope-nak nincs gondja az mts fájlokkal.
Térjünk vissza a történelemhez - vissza 2003-ig, amikor az Intel és az AMD részt vett a közös versenyben a legerősebb processzorért. Alig néhány év alatt ez a verseny az órajelek jelentős növekedését eredményezte, különösen az Intel Pentium 4 megjelenése óta.
De a verseny gyorsan közeledett a határához. Az órajelek hatalmas növekedési hulláma után (2001 és 2003 között a Pentium 4 órajele megduplázódott 1,5-ről 3 GHz-re) a felhasználóknak meg kellett elégedniük a gigahertzes tizedekkel, amit a gyártók ki tudtak kicsikarni (a 2003 és 2005 között az órajel 3-ról 3-ra nőtt, 8 GHz).
Még a nagy órajelre optimalizált architektúrák is – mint például a Prescott – is nehézségekbe ütköztek, és ezúttal nem csak a gyártás során. A chipgyártók egyszerűen belefutottak a fizika törvényeibe. Egyes elemzők még azt is megjósolták, hogy a Moore-törvény nem fog működni. De ez nem történt meg. A törvény eredeti jelentése gyakran torz, de a szilíciummag felületén lévő tranzisztorok számára vonatkozik. A CPU-ban lévő tranzisztorok számának növekedését hosszú ideig a teljesítmény megfelelő növekedése kísérte - ami a jelentés torzulásához vezetett. De aztán a helyzet bonyolultabbá vált. A CPU-architektúra tervezői az erősítéscsökkentés törvényéhez közeledtek: egyre több tranzisztort kellett hozzáadni a kívánt teljesítménynövekedéshez, ami zsákutcába vezetett.
 |
Míg a CPU-gyártók fejük utolsó szőrszálait húzva próbáltak megoldást találni problémáikra, a GPU-gyártók továbbra is figyelemreméltóan profitáltak a Moore-törvény előnyeiből.

Miért nem jutottak el ugyanabba a zsákutcába, mint a CPU-építészek? Az ok nagyon egyszerű: a CPU-kat úgy tervezték, hogy maximális teljesítményt nyújtsanak olyan utasításfolyamokon, amelyek különböző adatokat (egész és lebegőpontos számokat egyaránt) dolgoznak fel, véletlenszerű hozzáférést biztosítanak a memóriához stb. Eddig a fejlesztők igyekeztek az utasítások nagyobb párhuzamosságát biztosítani – vagyis minél több utasítást párhuzamosan végrehajtani. Így például a Pentiumnál megjelent a szuperskaláris végrehajtás, amikor bizonyos feltételek mellett ciklusonként két utasítást lehetett végrehajtani. A Pentium Pro rendellenes utasítás-végrehajtást kapott, ami lehetővé tette a számítási egységek munkájának optimalizálását. A probléma az, hogy a szekvenciális utasításfolyam párhuzamos végrehajtásának nyilvánvaló korlátai vannak, így a számítási egységek számának vak növelése nem jár hasznával, mivel az idő nagy részében továbbra is tétlen marad.
Ezzel szemben a GPU feladata viszonylag egyszerű. Ez abból áll, hogy az egyik oldalon sokszögcsoportot fogadunk el, a másik oldalon pedig pixelcsoportot hozunk létre. A sokszögek és pixelek függetlenek egymástól, így párhuzamosan is feldolgozhatók. Így a GPU-ban a kristály nagy része számítási egységekre bontható, amelyek a CPU-val ellentétben valóban felhasználásra kerülnek.
 |
Kattintson a képre a nagyításhoz.
A GPU nem csak ebben különbözik a CPU-tól. A GPU memóriájához való hozzáférés nagyon kötött - ha egy texel beolvasásra kerül, akkor néhány órajel után a szomszédos texel is beolvasásra kerül; ha egy pixelt rögzítünk, akkor néhány órajel ciklus után a szomszédos is rögzítésre kerül. A memória megfontolt rendszerezésével az elméleti sávszélességhez közeli teljesítmény érhető el. Ez azt jelenti, hogy a GPU a CPU-val ellentétben nem igényel hatalmas gyorsítótárat, hiszen szerepe a textúrázási műveletek felgyorsítása. Csak néhány kilobájtra van szükség, amely több bilineáris és trilineáris szűrőben használt texelt tartalmaz.
|
Kattintson a képre a nagyításhoz.
Éljen a GeForce FX!
A két világ sokáig külön maradt. CPU-t (vagy akár több CPU-t) használtunk az irodai feladatokhoz és az internetes alkalmazásokhoz, a GPU-k pedig csak a renderelés felgyorsítására voltak jók. Egy dolog azonban mindent megváltoztatott: nevezetesen a programozható GPU-k megjelenése. A központi feldolgozó egységeknek eleinte nem kellett félniük. Az első, úgynevezett programozható GPU-k (NV20 és R200) aligha jelentettek veszélyt. Az utasítások száma a programban 10 körül maradt, nagyon egzotikus adattípusokon dolgoztak, például 9 vagy 12 bites fixpontos számokon.
 |
Kattintson a képre a nagyításhoz.
De Moore törvénye ismét megmutatta a legjobb oldalát. A tranzisztorok számának növekedése nemcsak a számítási egységek számát növelte, hanem a rugalmasságukat is javította. Az NV30 megjelenése több okból is jelentős előrelépésnek tekinthető. Természetesen a játékosok nem igazán szerették az NV30-as kártyákat, de az új GPU-k két olyan funkcióra kezdtek támaszkodni, amelyek célja, hogy megváltoztassák a GPU-król alkotott felfogást, nemcsak grafikus gyorsítóként.
- Egyszeri pontosságú lebegőpontos számítások támogatása (még akkor is, ha nem felel meg az IEEE754 szabványnak);
- több mint ezer utasítás támogatása.
Megvan tehát minden olyan feltétel, amely vonzza az úttörő kutatókat, akik mindig további számítási teljesítményre vágynak.
A grafikus gyorsítók matematikai számításokhoz való használatának ötlete nem új. Az első próbálkozások a múlt század 90-es éveiben történtek. Természetesen nagyon primitívek voltak – többnyire bizonyos hardver alapú szolgáltatások használatára korlátozódtak, mint például a raszterezés és a Z-pufferek olyan feladatok gyorsítására, mint az útvonalkeresés vagy a renderelés. Voronoi diagramok .

 |
Kattintson a képre a nagyításhoz.
2003-ban, a továbbfejlesztett shaderek megjelenésével új benchmarkot értek el – ezúttal mátrixszámítással. Ez volt az az év, amikor a SIGGRAPH ("Számítások a GPU-kon") egy teljes részét az IT új területének szentelték. Ezt a korai kezdeményezést GPGPU-nak (General-Purpose compution on GPU) hívták. A korai fordulópont pedig a megjelenés volt.
A BrookGPU szerepének megértéséhez meg kell értenie, hogyan történt minden, mielőtt megjelent. 2003-ban a GPU-erőforrások egyetlen módja a két grafikus API, a Direct3D vagy az OpenGL valamelyikének használata volt. Következésképpen azoknak a fejlesztőknek, akik a GPU-teljesítményt akarták megszerezni számítógépükhöz, az említett két API-ra kellett hagyatkozniuk. A probléma az, hogy nem mindig voltak szakértők a videokártyák programozásában, ami komolyan megnehezítette a technológiához való hozzáférést. Míg a 3D programozók shaderekkel, textúrákkal és töredékekkel dolgoznak, a párhuzamos programozás szakemberei a szálakra, magokra, szórásra stb. Ezért először is analógiákat kellett vonni a két világ között.
- Folyam azonos típusú elemek folyama, a GPU-ban textúrával ábrázolható. Alapvetően a klasszikus programozásban van egy olyan analóg, mint egy tömb.
- Kernel- egy függvény, amely a folyam minden elemére függetlenül kerül alkalmazásra; a pixel shader megfelelője. A klasszikus programozásban a hurok analógiáját meg lehet tenni - nagyszámú elemre alkalmazzák.
- A kernel adatfolyamra történő alkalmazásának eredményeinek olvasásához létre kell hozni egy textúrát. Nincs megfelelője a CPU-n, mivel teljes hozzáférés van a memóriához.
- A rögzítés helye a memóriában (a szórási/szórási műveleteknél) a vertex shader vezérlésén keresztül történik, mivel a pixel shader nem tudja megváltoztatni a feldolgozott pixel koordinátáit.


Amint látható, a feladat még az adott analógiákat figyelembe véve sem tűnik egyszerűnek. És Brook segített. Ez a név a C nyelv kiterjesztésére utal ("C with streams", "C with streams"), ahogy a stanfordi fejlesztők nevezték őket. Lényegében Brook feladata az volt, hogy elrejtse a programozó elől a 3D API minden összetevőjét, ami lehetővé tette a GPU társprocesszorként való bemutatását párhuzamos számításokhoz. Ennek érdekében a Brook fordító feldolgozott egy .br fájlt C ++ kóddal és kiterjesztéssel, majd előállított egy C ++ kódot, amely a különböző kimeneteket (DirectX, OpenGL ARB, OpenGL NV3x, x86) támogató könyvtárhoz kapcsolta.
 |
Kattintson a képre a nagyításhoz.
Brooknak több érdeme is van, ezek közül az első, hogy kihozza a GPGPU-t az árnyékból, hogy a nagyközönség is megismerhesse a technológiát. A projekt bejelentése után azonban számos informatikai oldal túlságosan optimista volt ahhoz, hogy a Brook megjelenése kétségbe vonja a CPU-k létezését, amelyeket hamarosan erősebb GPU-k váltanak fel. De, mint látjuk, ez öt év után nem történt meg. Őszintén szólva nem hisszük, hogy ez valaha is megtörténik. Másrészt az egyre inkább párhuzamosságra orientált CPU-k (több mag, SMT multithreading technológia, SIMD blokkok bővítése), valamint a GPU-k sikeres fejlődését tekintve, amelyek éppen ellenkezőleg, egyre univerzálisabbak. (lebegőpontos számítások szimpla pontosságú, egészszámú számítás támogatása, dupla pontosság támogatása), úgy tűnik, hogy a GPU és a CPU hamarosan egyesül. Akkor mi lesz? Elnyeli a GPU-kat a CPU, mint a matematikai társprocesszoroknál? Könnyen lehetséges. Az Intel és az AMD jelenleg is hasonló projekteken dolgoznak. De még sok minden változhat.

De térjünk vissza témánkhoz. Brook előnye a GPGPU koncepció népszerűsítése volt, jelentősen leegyszerűsítette a GPU erőforrásokhoz való hozzáférést, ami lehetővé tette, hogy egyre több felhasználó sajátítsa el az új programozási modellt. Másrészt a Brook minden tulajdonsága ellenére még hosszú utat kellett megtenni ahhoz, hogy a GPU-erőforrásokat felhasználhassák a számításokhoz.
Az egyik probléma az absztrakció különböző szintjeihez kapcsolódik, és különösen a 3D API által keltett túlzott többletterheléshez kapcsolódik, ami nagyon észrevehető lehet. De ennél komolyabb a kompatibilitási probléma, amivel a Brook fejlesztői nem tudtak mit kezdeni. Éles a verseny a GPU-gyártók között, ezért gyakran optimalizálják illesztőprogramjaikat. Ha ezek az optimalizálások többnyire jók a játékosok számára, egy pillanat alatt véget vethetnek a Brook-kompatibilitásnak. Ezért nehéz elképzelni, hogy ezt az API-t termelési kódban használjuk, amely valahol működni fog. És Brook sokáig a hobbi kutatók és programozók sora maradt.
A Brook sikere azonban elég volt ahhoz, hogy felkeltse az ATI és az nVidia figyelmét, és felkeltette az érdeklődésüket egy ilyen kezdeményezés, mivel ezzel bővülhet a piac, jelentős új szektor nyílik meg a cégek előtt.
A Brook projektben kezdetben részt vevő kutatók gyorsan csatlakoztak a Santa Clara-i fejlesztőcsapatokhoz, hogy bemutassák az új piac fejlesztésének globális stratégiáját. Az ötlet az volt, hogy a GPGPU feladatokra alkalmas hardver és szoftver kombinációját hozzuk létre. Mivel az nVidia fejlesztői ismerik GPU-ik minden titkát, a grafikus API-ra nem lehetett támaszkodni, inkább egy illesztőprogramon keresztül kommunikál a GPU-val. Bár persze ennek megvannak a maga problémái. Tehát a CUDA (Compute Unified Device Architecture) fejlesztőcsapata szoftverréteg-készletet hozott létre a GPU-val való együttműködéshez.
 |
Kattintson a képre a nagyításhoz.
Amint az az ábrán látható, a CUDA két API-t biztosít.
- Magas szintű API: CUDA Runtime API;
- alacsony szintű API: CUDA illesztőprogram API.
Mivel a magas szintű API az alacsony szintű API-n felül van megvalósítva, minden futásidejű függvényhívás egyszerűbb utasításokra van lebontva, amelyeket az illesztőprogram API dolgoz fel. Vegye figyelembe, hogy a két API kölcsönösen kizárja egymást: a programozó használhatja az egyik vagy a másik API-t, de a két API függvényeinek hívásainak keverése nem működik. Általában a „magas szintű API” kifejezés relatív. Még a Runtime API is olyan, hogy sokan alacsony szintűnek tartanák; azonban olyan funkciókat biztosít, amelyek nagyon hasznosak inicializáláshoz vagy kontextuskezeléshez. De ne számítson különösebben magas szintű absztrakcióra – továbbra is jól kell ismernie az nVidia GPU-kat és azok működését.

A Driver API-val még nehezebb dolgozni; több erőfeszítést igényel a GPU-feldolgozás futtatása. Másrészt az alacsony szintű API rugalmasabb, szükség esetén további irányítást ad a programozónak. Két API képes OpenGL vagy Direct3D erőforrásokkal dolgozni (ma még csak a kilencedik verzió). Ennek a funkciónak az előnyei nyilvánvalóak – a CUDA segítségével olyan erőforrásokat hozhatunk létre (geometria, eljárási textúrák stb.), amelyek továbbíthatók a grafikus API-nak, vagy fordítva, a 3D API elküldheti a renderelési eredményeket a CUDA-nak. program, amely viszont elvégzi az utófeldolgozást. Számos példa van ezekre az interakciókra, és az előnye, hogy az erőforrásokat továbbra is a GPU memóriájában tárolják anélkül, hogy át kellene vinni a PCI Express buszt, ami még mindig szűk keresztmetszet.

Azonban meg kell jegyezni, hogy a videomemóriában lévő erőforrások megosztása nem mindig tökéletes, és bizonyos "fejfájásokhoz" vezethet. Például a felbontás vagy a színmélység módosításakor a grafikus adatok élveznek elsőbbséget. Ezért, ha növelni kell az erőforrásokat a framebufferben, akkor az illesztőprogram gond nélkül megteszi a CUDA alkalmazások erőforrásainak rovására, amelyek egyszerűen "felszállnak" egy hibával. Persze nem túl elegáns, de ennek nem szabad túl gyakran előfordulnia. És miközben elkezdtünk beszélni a hátrányokról: ha több GPU-t szeretne használni a CUDA alkalmazásokhoz, akkor először le kell tiltania az SLI módot, különben a CUDA alkalmazások csak egy GPU-t fognak "látni".

Végül a harmadik szoftverréteget a könyvtárak kapják – egészen pontosan kettő.
- CUBLAS, ahol megvannak a szükséges blokkok a lineáris algebra számításához a GPU-n;
- A CUFFT, amely támogatja a Fourier-transzformációk kiszámítását, a jelfeldolgozásban széles körben használt algoritmus.
Mielőtt belemerülnénk a CUDA-ba, hadd definiáljak néhány kifejezést, amelyek szétszórva találhatók az nVidia dokumentációjában. A cég nagyon specifikus terminológiát választott, amelyet nehéz megszokni. Először is vegye figyelembe cérna A CUDA-ban korántsem ugyanazt jelenti, mint a CPU-szál, és nem is a szál megfelelője a GPU-król szóló cikkeinkben. A GPU-szál ebben az esetben a feldolgozandó adatok mögöttes halmaza. A CPU-szálakkal ellentétben a CUDA-szálak nagyon "könnyűek", vagyis a két szál közötti kontextusváltás semmiképpen sem erőforrás-igényes művelet.
A CUDA dokumentációjában gyakran előforduló második kifejezés az vetemedik... Itt nincs félreértés, mivel oroszul nincs analóg (hacsak nem a Start Trek vagy a Warhammer játék rajongója). Valójában a kifejezés a textiliparból származik, ahol a vetülékfonalat áthúzzák a láncfonalon, amelyet a gépre feszítenek. A Warp in CUDA egy 32 szálból álló csoport, és a SIMD módszerrel feldolgozott minimális adatmennyiség a CUDA többprocesszorokban.

De ez a "szemcsésség" nem mindig kényelmes a programozó számára. Ezért a CUDA-ban ahelyett, hogy közvetlenül a vetemítésekkel dolgozna, dolgozhat vele blokkok / blokk 64-512 szálat tartalmaz.
Végül ezek a blokkok összeállnak rácsok / rács... Ennek a csoportosításnak az az előnye, hogy a GPU által egyidejűleg feldolgozott blokkok száma szorosan összefügg a hardver erőforrásokkal, amint azt alább látni fogjuk. A blokkok rácsokba csoportosítása lehetővé teszi, hogy teljesen elvonatkoztassunk ettől a korlátozástól, és egy hívásban több szálra alkalmazzuk a kernelt / kernelt, anélkül, hogy a rögzített erőforrásokra gondolnánk. A CUDA könyvtárak felelősek mindezért. Ráadásul egy ilyen modell jól méretezhető. Ha a GPU-nak kevés erőforrása van, akkor a blokkokat egymás után hajtja végre. Ha a számítási processzorok száma nagy, akkor a blokkok párhuzamosan is végrehajthatók. Vagyis ugyanaz a kód futhat belépő szintű GPU-kon és csúcskategóriás, sőt jövőbeli modelleken is.

A CUDA API-ban van még néhány kifejezés, amelyek a CPU-ra ( házigazda / fogadó) és GPU ( eszköz / eszköz). Ha ez a kis bevezető nem ijesztett meg, akkor itt az ideje, hogy közelebbről is szemügyre vegye a CUDA-t.
Ha rendszeresen olvassa a Tom Hardver útmutatóját, akkor az nVidia legújabb GPU-inak architektúráját ismeri. Ha nem, javasoljuk, hogy tekintse meg a cikket. nVidia GeForce GTX 260 és 280: a grafikus kártyák következő generációja"A CUDA szempontjából az nVidia egy kicsit más módon mutatja be az architektúrát, néhány olyan részletet megjelenítve, amelyek korábban rejtettek voltak.

Amint a fenti ábrán látható, az nVidia shader magja több textúraprocesszor-fürtből áll. (Texture Processor Cluster, TPC)... A 8800 GTX például nyolc klasztert használt, a 8800 GTS hat, és így tovább. Valójában mindegyik klaszter egy textúraegységből és kettőből áll streaming multiprocesszor... Ez utóbbiak közé tartozik az utasításokat beolvasó és dekódoló, valamint végrehajtásra küldő pipeline eleje (front end), valamint a nyolc számítástechnikai eszközből és két szuperfunkcionális eszközből álló pipeline vége (back end). . SFU (szuperfunkciós egység) ahol az utasításokat a SIMD elv szerint hajtják végre, vagyis egy utasítás vonatkozik a warp összes szálára. Az nVidia ezt a módszert nevezi SIMT(egy utasítás több szál, egy utasítás, sok szál). Fontos megjegyezni, hogy a csővezeték vége kétszer akkora gyakorisággal működik, mint a kezdete. Ez a gyakorlatban azt jelenti, hogy ez a rész kétszer olyan "szélesebbnek" tűnik, mint valójában (vagyis nyolccsatornás blokk helyett 16 csatornás SIMD blokknak). A streaming multiprocesszorok a következőképpen működnek: minden órajel ciklusban a folyamat eleje kiválaszt egy végrehajtásra kész warp-ot, és megkezdi az utasítás végrehajtását. Négy óraciklusra lenne szükség ahhoz, hogy az utasítás a warp mind a 32 szálára érvényesüljön, de mivel kétszer akkora frekvencián fut, mint az indítás, mindössze két órajelet vesz igénybe (a csővezeték kezdetét tekintve). Ezért annak érdekében, hogy a csővezeték eleje ne hagyjon üresjáratban egy ciklust, és a hardver a lehető legnagyobb mértékben le legyen terhelve, ideális esetben minden ciklusban váltogathatja az utasításokat - klasszikus utasítás egy ciklusban és utasítás SFU-hoz - egy másik.
Minden többprocesszornak van egy meghatározott erőforráskészlete, amelyet érdemes megérteni. Van egy kis memóriaterület, az úgynevezett "Megosztott memória", 16 KB többprocesszoronként. Ez semmiképpen nem cache memória: a programozó saját belátása szerint használhatja. Vagyis előttünk van valami, ami közel áll az SPU helyi áruházához a Cell processzorokon. Ez a részlet azért érdekes, mert hangsúlyozza, hogy a CUDA szoftver- és hardvertechnológiák kombinációja. Ezt a memóriaterületet nem használják pixel shadereknél, amire az nVidia szellemesen rámutat: "nem szeretjük, ha a pixelek beszélnek egymással".
Ez a memóriaterület megnyitja a lehetőséget a szálak közötti információcserére. egy blokkban... Fontos hangsúlyozni ezt a korlátot: a blokkban lévő összes szálat garantáltan egyetlen multiprocesszor hajtja végre. Ellenkezőleg, a blokkok különböző többprocesszorokhoz kötése egyáltalán nincs előírva, és a különböző blokkokból származó két szál nem tud egymással információt cserélni futás közben. Vagyis a megosztott memória használata nem egyszerű. A megosztott memória azonban továbbra is indokolt, kivéve azokat az eseteket, amikor több szál próbál hozzáférni ugyanahhoz a memóriabankhoz, konfliktust okozva. Más helyzetekben a megosztott memóriához való hozzáférés ugyanolyan gyors, mint a regiszterekhez.

A megosztott memória nem az egyetlen memória, amelyhez a többprocesszorok hozzáférhetnek. Használhatnak videomemóriát, de kisebb sávszélességgel és nagyobb késleltetéssel. Ezért az ehhez a memóriához való hozzáférés gyakoriságának csökkentése érdekében az nVidia a többprocesszorokat gyorsítótárral (körülbelül 8 KB többprocesszoronként) látta el, amely állandókat és textúrákat tárol.

A többprocesszornak 8192 regisztere van, amelyek közösek a többprocesszoron aktív összes blokk összes adatfolyamára. Az aktív blokkok száma többprocesszoronként nem haladhatja meg a nyolcat, az aktív vetemítések száma pedig 24-re (768 szál) van korlátozva. Ezért a 8800 GTX egyszerre akár 12 288 szálat is képes kezelni. Mindezeket a korlátozásokat érdemes volt megemlíteni, mivel lehetővé teszik az algoritmus optimalizálását a rendelkezésre álló erőforrások alapján.
A CUDA program optimalizálása tehát abból áll, hogy optimális egyensúlyt kell elérni a blokkok száma és mérete között. Blokonként több szál hasznos lesz a memória késleltetésének csökkentése érdekében, de a szálanként elérhető regiszterek száma is csökken. Ezenkívül egy 512 szálból álló blokk hatástalan lesz, mivel egy többprocesszoron csak egy blokk lehet aktív, ami 256 szál elvesztéséhez vezet. Ezért az nVidia 128 vagy 256 szálból álló blokkok használatát javasolja, ami a legjobb kompromisszumot nyújtja az alacsonyabb késleltetés és a legtöbb kernel/kernel esetében a regiszterek száma között.
Programozási szempontból a CUDA C-kiterjesztésekből áll, amelyek a BrookGPU-ra emlékeztetnek, valamint számos speciális API-hívásból. A kiterjesztések a függvényekhez és változókhoz kapcsolódó típusleírókat tartalmaznak. Fontos megjegyezni a kulcsszót __globális__, ami a függvény előtt megadva azt mutatja, hogy az utóbbi a kernelre / kernelre vonatkozik - ezt a függvényt a CPU hívja meg, és a GPU-n hajtja végre. Előtag __eszköz__ azt jelzi, hogy a funkció a GPU-n fog végrehajtódni (amit egyébként a CUDA "eszköz/eszköz"-nek hív), de csak a GPU-ból (más szóval egy másik __device__ függvényből vagy a __global__ függvényből) hívható meg. Végül az előtag __házigazda__ opcionális, a CPU által meghívott és a CPU által végrehajtott függvényt jelöl – más szóval egy szabályos függvényt.
Az __device__ és a __global__ függvényeknek számos korlátozása van: nem lehetnek rekurzívak (azaz nem hívhatják meg magukat), és nem rendelkezhetnek változó számú argumentummal. Végül, mivel az __eszköz__ függvényei a GPU memóriájában találhatók, logikus, hogy nem fogja tudni lekérni a címüket. A változóknak számos minősítője is van, amelyek jelzik a memóriaterületet, ahol tárolni fognak. Változó előtaggal __megosztva__ azt jelenti, hogy a streaming multiprocesszor megosztott memóriájában lesz tárolva. A __global__ függvényhívás kissé eltér. A lényeg az, hogy híváskor be kell állítani a végrehajtási konfigurációt - pontosabban annak a rácsnak / gridnek a méretét, amelyre a kernelt / kernelt alkalmazni fogja, valamint az egyes blokkok méretét. Vegyük például a következő aláírással rendelkező kernelt.
| __global__ void Func (float * paraméter); |
Úgy fogják hívni
| Func<<< Dg, Db >>> (paraméter); |
ahol Dg a rács mérete és Db a blokk mérete. Ez a két változó a CUDA-val bevezetett új típusú vektorból származik.
A CUDA API funkciókat tartalmaz a VRAM-ban lévő memóriával való munkavégzéshez: a cudaMalloc a memória lefoglalásához, a cudaFree a felszabadításhoz, a cudaMemcpy pedig a memória másolásához a RAM és a VRAM között, és fordítva.
Ezt az áttekintést egy nagyon érdekes módon fejezzük be, ahogy egy CUDA-programot összeállítunk: a fordítás több lépésben történik. Először a CPU kódot kéri le és továbbítja a szabványos fordítónak. A GPU-specifikus kódot először a PTX köztes nyelvre konvertálják. Hasonlít az assembly nyelvhez, és lehetővé teszi a kód tanulmányozását potenciális hatékonysági hiányosságok után kutatva. Végül az utolsó fázis a köztes nyelv speciális GPU-utasításokká történő lefordítása és egy bináris fájl létrehozása.

Miután átnéztem az nVidia dokumentumokat, a héten szeretném kipróbálni a CUDA-t. Valóban, mi lehet jobb, mint egy API értékelése saját program létrehozásával? Ekkor kell a legtöbb probléma felszínre kerülnie, még akkor is, ha papíron minden tökéletesnek tűnik. Ezenkívül a gyakorlat fogja a legjobban megmutatni, hogy mennyire értette meg a CUDA dokumentációjában felvázolt összes alapelvet.
Nagyon könnyű belemerülni egy ilyen projektbe. Ma már számos ingyenes, de jó minőségű eszköz érhető el letöltésre. Tesztünkhöz Visual C ++ Express 2005-öt használtunk, amelyben minden megtalálható, amire szüksége van. A legnehezebb az volt, hogy olyan programot találjunk, aminek a GPU-ra való portolása nem heteket vesz igénybe, mégis elég szórakoztató ahhoz, hogy erőfeszítéseinket jó formában tartsuk. Végül kiválasztottunk egy olyan kódrészletet, amely egy magasságtérképet vesz fel, és kiszámítja a megfelelő normáltérképet. Nem foglalkozunk részletesen ezzel a funkcióval, mivel ebben a cikkben aligha érdekes. Röviden: a program a területek görbületével foglalkozik: a kiinduló kép minden egyes pixelére beállítunk egy mátrixot, amely egy többé-kevésbé bonyolult képlet segítségével meghatározza a létrejövő képen a szomszédos pixelek által előállított képpont színét. Ennek a funkciónak az az előnye, hogy nagyon könnyű párhuzamosítani, így ez a teszt tökéletesen demonstrálja a CUDA képességeit.


További előny, hogy már van egy implementációnk a CPU-n, így annak eredményét össze tudjuk hasonlítani a CUDA verzióval – és nem találjuk fel újra a kereket.
Még egyszer megismételjük, hogy a teszt célja a CUDA SDK segédprogramok megismerése volt, nem pedig a CPU és a GPU verzióinak összehasonlító tesztelése. Mivel ez volt az első próbálkozásunk egy CUDA program létrehozására, nem sok reményünk volt a nagy teljesítmény elérésére. Mivel a kódnak ez a része nem kritikus, a CPU verzióját nem optimalizálták, így az eredmények közvetlen összehasonlítása aligha érdekes.
Teljesítmény
A végrehajtási időt azonban mértük, hogy megnézzük, van-e előnye a CUDA használatának még a legdurvább implementáció mellett is, vagy hosszú és fárasztó gyakorlatba fog telni, hogy valamiféle nyereséget érjünk el a GPU használatakor. A tesztgépet a fejlesztői laborunkból vettük – egy Core 2 Duo T5450 processzoros laptopot és egy Vistát futtató GeForce 8600M GT grafikus kártyát. Ez messze nem egy szuperszámítógép, de az eredmények elég érdekesek, hiszen a teszt nem a GPU-ra van "élesítve". Mindig jó látni, hogy az nVidia óriási előnyöket ér el a hatalmas GPU-kkal és nagy sávszélességgel rendelkező rendszereken, de a gyakorlatban a PC-piacon jelenleg található 70 millió CUDA-képes GPU közül sok közel sem olyan erős, ezért tesztünknek joga van. az élethez.
Egy 2048 x 2048 pixeles képnél a következő eredményeket kaptuk.
- CPU 1 szál: 1 419 ms;
- CPU 2 szálak: 749 ms;
- CPU 4 szál: 593 ms
- 256 szálból álló GPU (8600M GT) blokkok: 109 ms;
- 128 szálból álló GPU (8600M GT) blokkok: 94 ms;
- GPU (8800 GTX) blokkok 128 szálból / 256 szálból: 31 ms.
Az eredményekből több következtetés is levonható. Kezdjük azzal, hogy a programozók nyilvánvaló lustaságáról szóló beszéd ellenére több szálra módosítottuk a CPU kezdeti verzióját. Mint említettük, a kód ideális erre a helyzetre – mindössze annyit kell tennie, hogy a kezdeti képet annyi zónára kell felosztani, ahány folyam van. Felhívjuk figyelmét, hogy a kétmagos CPU-nkon az egy szálról a kettőre való átmenet gyorsulása szinte lineárisnak bizonyult, ami egyben a tesztprogram párhuzamos jellegét is jelzi. Egészen váratlanul a négy szálas verzió is gyorsabbnak bizonyult, bár ez a mi processzorunkon nagyon furcsa - éppen ellenkezőleg, a további szálak kezelésének többlete miatt a hatékonyság visszaesésére lehetett számítani. Mivel magyarázható ez az eredmény? Nehéz megmondani, de a Windows szálütemezője lehet a hibás; mindenesetre az eredmény megismételhető. Kisebb textúráknál (512x512) a szálakra való felosztásból származó nyereség nem volt annyira markáns (kb. 35% versus 100%), és a négyszálas verzió viselkedése logikusabb volt, növekedés nélkül a kétszálas verzióhoz képest. A GPU továbbra is gyorsabb volt, de nem olyan markáns (a 8600M GT háromszor gyorsabb volt, mint a kétszálas változat).
 |
Kattintson a képre a nagyításhoz.
A második jelentős megfigyelés az, hogy még a leglassabb GPU-megvalósítás is majdnem hatszor gyorsabbnak bizonyult, mint a legjobban teljesítő CPU-verzió. Az első program és az algoritmus optimalizálatlan verziója esetében az eredmény nagyon biztató. Vegye figyelembe, hogy észrevehetően jobb eredményt értünk el kis kockákon, bár az intuíció mást sugallhat. A magyarázat egyszerű - programunk szálonként 14 regisztert használ, 256 szálas blokkoknál pedig blokkonként 3584 regiszterre van szükség, a teljes processzorterheléshez pedig 768 szálra van szükség, amint azt bemutattuk. Esetünkben ez három blokk vagy 10 572 regiszter. De a többprocesszornak csak 8192 regisztere van, így csak két blokkot tud aktívan tartani. Ezzel szemben 128 szálból álló blokkok esetén blokkonként 1792 regiszterre van szükségünk; ha 8 192-t elosztunk 1 792-vel és a legközelebbi egész számra kerekítjük, akkor négy blokkot kapunk. Gyakorlatilag a szálak száma ugyanannyi lesz (multiprocesszoronként 512, bár elméletileg 768 kell a teljes terheléshez), de a blokkok számának növelése a GPU-nak a rugalmasság előnyét adja a memóriaelérésben - ha egy művelet magas késleltetés van folyamatban, az utasítások végrehajtását egy másik blokkból indíthatja el, várva az eredmények beérkezését. Négy blokk egyértelműen csökkenti a késleltetést, különösen azért, mert programunk több memóriaelérést használ.
Elemzés
Végül a fentebb elmondottak ellenére nem tudtunk ellenállni a kísértésnek, és a 8800 GTX-en futtattuk a programot, amely blokkmérettől függetlenül háromszor gyorsabbnak bizonyult, mint a 8600. Azt gondolhatnánk, hogy a gyakorlatban az adott architektúrákon az eredmény négyszer vagy többszöröse lesz: 128 ALU / shader processzor a 32 és magasabb órajelekkel szemben (1,35 GHz versus 950 MHz), de ez nem jött össze. A legvalószínűbb korlátozó tényező a memória hozzáférés volt. Pontosabban, a kezdeti kép többdimenziós CUDA-tömbként érhető el – egy meglehetősen bonyolult kifejezés arra, ami nem más, mint egy textúra. De számos előnye van.
- a hozzáférések a textúra gyorsítótár előnyeit élvezik;
- burkolási módot használunk, aminek nem kell képszegélyeket kezelnie, ellentétben a CPU verzióval.
Emellett kihasználhatjuk az "ingyenes" szűrést a és helyett a normalizált címzéssel, de esetünkben ez aligha hasznos. Mint tudják, a 8600-ban 16 textúraegység van, szemben a 8800 GTX 32-vel. Ezért a két architektúra közötti arány csak kettő az egyhez. Ha ehhez hozzáadjuk a frekvenciák különbségét, megkapjuk a (32 x 0,575) / (16 x 0,475) = 2,4 arányt – közel a „három az egyhez”-hez, amit valójában kapunk. Ez az elmélet azt is megmagyarázza, hogy a blokkméret miért nem változik sokat a G80-on, mivel az ALU továbbra is a textúrablokkokon nyugszik.
 |
Kattintson a képre a nagyításhoz.
Az ígéretes eredmények mellett az első CUDA-val való találkozásunk nagyon jól sikerült, tekintettel a nem túl kedvező feltételekre. A Vista laptopon való fejlesztés azt jelenti, hogy a CUDA SDK 2.0-t kell használni, még mindig béta állapotban, 174.55-ös driverrel, ami szintén béta. Ennek ellenére nem számolhatunk be kellemetlen meglepetésekről, csak a kezdeti hibákról az első hibakeresés során, amikor a programunk, még mindig meglehetősen "hibásan" próbálta megcímezni a memóriát a lefoglalt területen kívül.
A monitor vadul villogott, majd a képernyő elsötétült... amíg a Vista el nem indította a driver javítási szolgáltatást és minden rendben volt. De még mindig némileg meglepő megfigyelni, hogy megszokta-e a tipikus szegmentációs hibát látni az olyan szabványos programokban, mint a miénk. Végezetül egy kis kritika az nVidiával kapcsolatban: a CUDA-hoz elérhető összes dokumentációban nincs olyan kis útmutató, amely lépésről lépésre végigvezeti Önt a Visual Studio fejlesztői környezetének beállításában. Valójában a probléma nem nagy, mivel az SDK-nak teljes példája van, amelyeket tanulmányozhat a CUDA-alkalmazások keretrendszerének megértéséhez, de egy kezdő útmutató hasznos lenne.
 |
Kattintson a képre a nagyításhoz.
Az Nvidia bemutatta a CUDA-t a GeForce 8800-zal. Noha az ígéretek csábítóak voltak akkoriban, a tényleges tesztig kitartottunk a lelkesedésünk mellett. Valóban, akkoriban inkább területi jelölésnek tűnt a GPGPU hullámon maradás. Rendelkezésre álló SDK nélkül nehéz kijelenteni, hogy ez nem csak egy újabb marketing duma, amely megbukik. Nem ez az első eset, hogy egy jó kezdeményezést túl korán jelentettek be, és támogatás hiányában akkor még nem látott napvilágot - főleg egy ilyen versenyszférában. Most, másfél évvel a bejelentés után bátran kijelenthetjük, hogy az nVidia állta a szavát.

Az SDK meglehetősen gyorsan megjelent bétaverzióban 2007 elején, és azóta gyorsan frissítették, ami bizonyítja a projekt értékét az nVidia számára. Ma a CUDA nagyon szépen fejlődik: az SDK már elérhető béta 2.0-s verzióban a fő operációs rendszerekhez (Windows XP és Vista, Linux, illetve 1.1 Mac OS X-hez), az nVidia pedig az oldal egy teljes részét a fejlesztőknek szentelte.


Professzionálisabb szinten a CUDA-val kapcsolatos első lépések benyomása nagyon pozitív volt. Még ha ismeri is a GPU architektúrát, könnyen kitalálhatja. Amikor az API első pillantásra egyértelműnek tűnik, azonnal elkezdi hinni, hogy meggyőző eredményeket fog elérni. De nem fog elpazarolni a számítási időt a CPU-ról GPU-ra való számos átvitel miatt? És hogyan kell használni ezt a több ezer szálat kevés vagy egyáltalán nem szinkronizáló primitívvel? Mindezen félelmek szem előtt tartásával kezdtük meg kísérleteinket. De gyorsan szertefoszlottak, amikor az algoritmusunk első verziója, bár nagyon triviális volt, lényegesen gyorsabbnak bizonyult, mint a CPU-n.
A CUDA tehát nem életmentő a kutatók számára, akik meg akarják győzni az egyetemi tisztviselőket, hogy vásároljanak nekik GeForce-ot. A CUDA egy már teljesen elérhető technológia, amelyet bármely C programozó használhat, ha hajlandó időt és energiát fordítani az új programozási paradigma megszokására. Ez az erőfeszítés nem megy kárba, ha az algoritmusok jól párhuzamosak. Ezúton is szeretnénk köszönetet mondani az nVidiának, amiért teljes és jó minőségű dokumentációt biztosított a CUDA programozók számára, hogy megtalálják a válaszokat.
Mi kell a CUDA-nak ahhoz, hogy felismerhető API legyen? Egy szóval: hordozhatóság. Tudjuk, hogy az IT jövője a párhuzamos számítástechnikában rejlik – ma már mindenki ilyen változásokra készül, és minden kezdeményezés, szoftver és hardver is ebbe az irányba irányul. Jelenleg azonban, ha a paradigmák fejlődését nézzük, még a kezdeti szakaszban vagyunk: manuálisan hozunk létre folyamokat, és próbáljuk megtervezni a megosztott erőforrásokhoz való hozzáférést; mindezzel valahogy meg lehet birkózni, ha egy kéz ujjain meg lehet számolni a magok számát. De néhány éven belül, amikor a processzorok száma több százra tehető, ez a lehetőség már nem lesz meg. A CUDA megjelenésével az nVidia megtette az első lépést a probléma megoldása felé – de természetesen ez a megoldás csak ettől a cégtől származó GPU-kra alkalmas, és akkor sem mindenkinek. Ma már csak a GF8 és 9 (és ezek Quadro/Tesla származékai) működhetnek együtt a CUDA programokkal. És természetesen az új 260/280-as sorozat.

 |
Kattintson a képre a nagyításhoz.
Az Nvidia büszkélkedhet azzal, hogy 70 millió CUDA-kompatibilis GPU-t adott el világszerte, de ez még mindig nem elég ahhoz, hogy de facto szabvány legyen. Figyelembe véve azt a tényt, hogy a versenytársak nem ülnek tétlenül. Az AMD saját SDK-t (Stream Computing) kínál, az Intel pedig megoldást (Ct) jelentett be, bár az még nem elérhető. Szabványháború jön, és nyilvánvalóan nem lesz hely a piacon a három versenytársnak, amíg egy másik szereplő, például a Microsoft nem áll elő egy közös API-val, ami természetesen megkönnyíti a fejlesztők életét.

Ezért az nVidiának sok nehézsége van a CUDA jóváhagyásával kapcsolatban. Bár technológiailag kétségtelenül sikeres megoldásunk van, még mindig meg kell győznünk a fejlesztőket a lehetőségeiről – és ez nem lesz könnyű. A közelmúlt számos API-bejelentése és híre alapján azonban a jövő korántsem tűnik borúsnak.
- alacsony szintű szoftver interfészek készlete ( API) játékok és más nagy teljesítményű multimédiás alkalmazások létrehozásához. Tartalmazza a nagy teljesítmény támogatását 2D- és 3D-grafika, hang és beviteli eszközök.
Direct3D (D3D) - interfész a háromdimenziós kimenethez primitívek(geometriai testek). Tartalmazza .
Opengl(angolból. Nyissa meg a Grafikai könyvtárat, szó szerint - nyílt grafikus könyvtár) egy olyan specifikáció, amely egy programozási nyelvtől független, többplatformos programozási felületet határoz meg kétdimenziós és háromdimenziós számítógépes grafikát használó alkalmazások írásához. Több mint 250 funkciót tartalmaz összetett 3D jelenetek rajzolásához egyszerű primitívekből. Videojátékok létrehozásában, virtuális valóságban, vizualizációban használják a tudományos kutatásban. Az emelvényen ablakok versenyez .
OpenCL(angolból. Nyissa meg a Computing Language lehetőséget, szó szerint - egy nyílt számítástechnikai nyelv) - keretrendszer(szoftverrendszer keretrendszere) párhuzamos számításokhoz kapcsolódó számítógépes programok írására különböző grafikus ( GPU) és ( ). A keretbe OpenCL tartalmaz egy programozási nyelvet és egy alkalmazásprogramozási felületet ( API). OpenCL utasítás- és adatszintű párhuzamosságot biztosít, és a technika megvalósítása GPGPU.
GPGPU(az angolból rövidítve. Általános célú grafikus feldolgozási egységek, szó szerint - GPUáltalános célú) egy technika a grafikus processzor-videokártya általános számításokhoz, amelyeket általában végrehajtanak.
Shader(eng. árnyékoló) - szintetizált képek árnyékolására szolgáló program, amelyet háromdimenziós grafikában használnak egy objektum vagy kép végső paramétereinek meghatározására. Jellemzően tetszőleges komplexitást tartalmaz, amely leírja a fényelnyelést és -szórást, a textúra-leképezést, a visszaverődést és a fénytörést, az árnyékolást, a felületelmozdulást és az utófeldolgozási hatásokat. Az összetett felületek egyszerű geometriai formák segítségével renderelhetők.
Renderelés(eng. renderelés) - vizualizáció, számítógépes grafikában, egy modellből szoftver segítségével kép kinyerésének folyamata.
SDK(az angolból rövidítve. Szoftverfejlesztői csomag) - szoftverfejlesztő eszközök készlete.
CPU(az angolból rövidítve. Központi feldolgozó egység, szó szerint - központi / fő / fő számítási eszköz) - központi (mikro); gépi utasításokat végrehajtó eszköz; egy hardver, amely a számítási műveletek elvégzéséért (az operációs rendszer és az alkalmazási szoftver által meghatározott) és az összes eszköz munkájának koordinálásáért felelős.
GPU(az angolból rövidítve. Grafikus feldolgozó egység, szó szerint - grafikus számítástechnikai eszköz) - grafikus processzor; Külön eszköz vagy játékkonzol, amely grafikus megjelenítést (renderinget) végez. A modern GPU-k nagyon hatékonyan kezelik és jelenítik meg a számítógépes grafikát. A modern videoadapterekben lévő grafikus processzort háromdimenziós grafika gyorsítójaként használják, de bizonyos esetekben számításokhoz is használható ( GPGPU).
Problémák CPU
A hagyományosak teljesítményének növekedése hosszú ideig főként az órajel frekvenciájának szekvenciális növekedésének volt köszönhető (a teljesítmény körülbelül 80% -át az órajel frekvencia határozta meg) az egy kristályon lévő tranzisztorok számának egyidejű növekedésével. . Az órajel-frekvencia további növelése azonban (3,8 GHz-nél nagyobb órajelnél a chipek egyszerűen túlmelegednek!) számos alapvető fizikai akadálynak ütközik (mivel a technológiai folyamat nagyon közel áll az atom méretéhez: és a szilícium atom mérete körülbelül 0,543 nm):
Először is, a kristályméret csökkenésével és az órajel frekvenciájának növekedésével a tranzisztorok szivárgási árama nő. Ez az energiafogyasztás növekedéséhez és a hőkibocsátás növekedéséhez vezet;
Másodszor, a magasabb órajel előnyeit részben ellensúlyozza a memória késleltetése, mivel a memória-hozzáférési idők nem egyeznek a növekvő órajelekkel;
Harmadszor, egyes alkalmazások esetében a hagyományos szekvenciális architektúrák hatástalanná válnak az órajelek növekedésével az úgynevezett "von Neumann szűk keresztmetszet" miatt – ez a teljesítmény korlátozása a számítások szekvenciális folyamatából ered. Ezzel egyidejűleg megnőnek a rezisztív-kapacitív jelátviteli késések, ami további szűk keresztmetszet az órajel frekvenciájának növekedésével kapcsolatban.
Fejlődés GPU
A fejlesztéssel párhuzamosan GPU:
…
2008. november - Intel bevezetett egy 4 magos sort Intel Core i7új generációs mikroarchitektúrán alapul Nehalem... A processzorok 2,6-3,2 GHz-es órajelen működnek. 45 nm-es technológiával készült.
2008. december - 4 magos kellékek AMD Phenom II 940(kód név - Deneb). 3 GHz-es frekvencián működik, 45 nm-es folyamattechnológiával gyártva.
…
2009. május - cég AMD bemutatta a GPU verziót ATI Radeon HD 4890 850 MHz-ről 1 GHz-re emelt mag órajellel. Ez az első grafikus 1 GHz-es processzor. A chip számítási teljesítménye a frekvencia növekedése miatt 1,36-ról 1,6 teraflopra nőtt. A processzor 800 (!) Számítási magot tartalmaz, támogatja a videomemóriát GDDR5, DirectX 10.1, ATI CrossFireXés minden egyéb technológia, amely a modern videokártya modellekben rejlik. A chip 55 nm-es technológia alapján készült.
A fő különbségek GPU
Megkülönböztető tulajdonságok GPU(összehasonlítva ) vannak:
- architektúra, amely maximálisan a textúrák és az összetett grafikai objektumok számítási sebességének növelésére irányul;
- tipikus csúcsteljesítmény GPU sokkal magasabb, mint ;
- a speciális szállítószalag architektúrának köszönhetően, GPU sokkal hatékonyabb a grafikus információk feldolgozásában, mint.
"A műfaj válsága"
"A műfaj válsága" számára 2005-re érlelődött – ekkor jelentek meg. De annak ellenére, hogy a technológia fejlődése, a termelékenység növekedése a hagyományos jelentősen csökkent. Ugyanakkor teljesítmény GPU tovább növekszik. Így 2003-ra ez a forradalmi ötlet kikristályosodott - használja a grafika számítási teljesítményét... A GPU-kat aktívan használják „nem grafikus” számítástechnikára (fizikai szimuláció, jelfeldolgozás, számítási matematika/geometria, adatbázis-műveletek, számítási biológia, számítási közgazdaságtan, számítógépes látás stb.).
A fő probléma az volt, hogy nem volt szabványos interfész a programozáshoz GPU... Használt fejlesztők Opengl vagy Direct3D de nagyon kényelmes volt. Vállalat NVIDIA(az egyik legnagyobb grafikus, média- és kommunikációs processzorok, valamint vezeték nélküli médiaprocesszorok gyártója; 1993-ban alakult) hozzálátott egy egységes és kényelmes szabvány kidolgozásához - és bemutatta a technológiát CUDA.
Hogyan kezdődött
2006 - NVIDIA demonstrálja CUDA™; forradalom kezdete a számítástechnikában GPU.
2007 - NVIDIA architektúrát ad ki CUDA(eredeti verzió CUDA SDK 2007. február 15-én vezették be); "Legjobb újdonság" jelölést a magazintól Népszerű Tudományés az „Olvasók választása” című kiadványból HPCWire.
2008 - technológia NVIDIA CUDA tól a „Technikai Kiválóság” kategóriában nyert PC Magazin.
Mi történt CUDA
CUDA(az angolból rövidítve. Számítsa ki az egyesített eszközarchitektúrát, szó szerint - eszközök egységes számítási architektúrája) - architektúra (szoftver és hardver halmaza), amely lehetővé teszi GPUáltalános célú számítások, míg GPU valójában erős társprocesszorként működik.
Technológia NVIDIA CUDA™ Az egyetlen fejlesztői környezet a programozási nyelvben C, amely lehetővé teszi a fejlesztők számára, hogy bonyolult számítási problémákat rövidebb idő alatt megoldó szoftvereket készítsenek, köszönhetően a GPU-k feldolgozási teljesítményének. Milliók dolgoznak már a világon GPU a támogatással CUDA, és már programozók ezrei használnak (ingyenes!) eszközöket CUDA az alkalmazások felgyorsítására és a legbonyolultabb erőforrás-igényes feladatok megoldására – a videó- és hangkódolástól az olaj- és gázkutatásig, termékmodellezésig, orvosi képalkotásig és tudományos kutatásig.
CUDA lehetőséget ad a fejlesztőnek, hogy saját belátása szerint megszervezze a hozzáférést a grafikus gyorsító utasításkészletéhez és kezelje a memóriáját, komplex párhuzamos számításokat szervezzen rajta. Grafikus gyorsító támogatással CUDA a maihoz hasonló erőteljes programozható nyílt architektúrává válik. Mindez a fejlesztő számára alacsony szintű, elosztott és nagy sebességű hozzáférést biztosít a berendezésekhez, gyártáshoz CUDA szükséges alapok komoly magas szintű eszközök, például fordítók, hibakeresők, matematikai könyvtárak, szoftverplatformok építésekor.
Uralsky, vezető technológiai szakember NVIDIAösszehasonlítása GPUés , ezt mondja: " Egy terepjáró. Bármikor, bárhol vezet, de nem túl gyorsan. A GPU Egy sportautó. Rossz úton egyszerűen nem megy sehova, hanem jó lefedettséget biztosít - és megmutatja az összes sebességét, amiről a SUV nem is álmodott! .. ".
Technológiai képességek CUDA
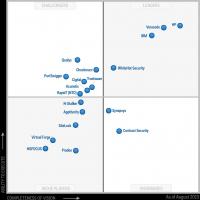 Az örökölt kód elemzése a forráskód elvesztése esetén: tegyen vagy ne?
Az örökölt kód elemzése a forráskód elvesztése esetén: tegyen vagy ne? A Windows nem töltődik be a frissítések telepítése után A laptop nem kapcsol be a Windows 10 frissítése után
A Windows nem töltődik be a frissítések telepítése után A laptop nem kapcsol be a Windows 10 frissítése után A jelszó feltörése: a leggyakoribb módszerek áttekintése
A jelszó feltörése: a leggyakoribb módszerek áttekintése Tiltsa le a titkosítást a táblagépen
Tiltsa le a titkosítást a táblagépen Izzó készítése. Edison izzója. Ki találta fel az első izzót? Miért jutott Edisonhoz minden dicsőség? Az izzólámpa eszközének változástörténete
Izzó készítése. Edison izzója. Ki találta fel az első izzót? Miért jutott Edisonhoz minden dicsőség? Az izzólámpa eszközének változástörténete Hogyan találhatja meg gyorsan telefonját a Google-on, bárhol is legyen
Hogyan találhatja meg gyorsan telefonját a Google-on, bárhol is legyen Az elektromos izzólámpát Oroszországban találták fel
Az elektromos izzólámpát Oroszországban találták fel