A statikus kódellenőrzés módszere. Az örökölt kód elemzése a forráskód elvesztése esetén: tegyen vagy ne? Különböző típusú elemzések munkafolyamatainak kombinálása fejlesztői környezetben
Bevezetés
A szoftvertermékek és a különféle vezérlőrendszerek szabványos képességei a legtöbb ügyfél számára nem elegendőek. Weboldal-kezelő rendszerek (például WordPress, Joomla vagy Bitrix), számviteli programok, ügyfélkezelési rendszerek (CRM), vállalati és termelési rendszerek (például 1C és SAP) bőséges lehetőséget kínálnak a funkcionalitás bővítésére és az egyes ügyfelek igényeihez való alkalmazkodásra. Az ilyen képességeket harmadik féltől származó egyedi modulok vagy a meglévő modulok testreszabása segítségével valósítják meg. Ezek a modulok az egyik beépített programozási nyelven írt programkódok, amelyek kölcsönhatásba lépnek a rendszerrel és megvalósítják az ügyfelek által igényelt funkcionalitást.
Nem minden szervezet gondolja úgy, hogy egy egyedileg készített beágyazott kód vagy webhely súlyos sebezhetőséget tartalmazhat, amelyek kihasználása bizalmas információk kiszivárgásához vezethet, és a programkönyvjelzők olyan speciális kóddarabok, amelyeket a kód által ismert titkos parancsokon bármilyen művelet végrehajtására terveztek. fejlesztő.... Ezenkívül az egyedileg készített kód olyan hibákat is tartalmazhat, amelyek tönkretehetik vagy károsíthatják az adatbázisokat, vagy megzavarhatják a jól működő üzleti folyamatokat.
A fent leírt kockázatokat ismerő cégek a kész modulok elfogadásánál igyekeznek auditorokat, szakembereket bevonni a forráskód elemzésébe, hogy a szakértők meghatározzák a kifejlesztett megoldás biztonságát és megbizonyosodjanak arról, hogy azok mentesek a sebezhetőségektől, hibák és szoftverhibák. Ennek az ellenőrzési módszernek azonban számos hátránya van. Először is, ez a szolgáltatás komolyan megnöveli a fejlesztési költségvetést; másodszor, az ellenőrzés és az elemzés hosszú időt vesz igénybe - egy héttől több hónapig; és harmadszor, egy ilyen megközelítés nem garantálja az elemzett kóddal kapcsolatos problémák teljes hiányát - a kód elfogadása és kihasználása után fennáll az emberi hiba és a korábban ismeretlen támadási vektorok észlelése.
Létezik egy biztonságos fejlesztési módszertan, amely biztosítja az audit és a kódvezérlési folyamatok integrációját a szoftvertermék - SDL (Security Development Lifecycle) - létrehozásának szakaszában. Ezt a módszert azonban csak szoftverfejlesztő alkalmazhatja, ha már vásárlókról beszélünk, akkor az SDL számukra nem alkalmazható, mivel a folyamat a kódgeneráló algoritmusok átstrukturálását vonja maga után, és az elfogadás során már késő alkalmazni. Ezenkívül sok fejlesztés a meglévő kód egy kis részét érinti, amely esetben az SDL szintén nem alkalmazható.
Forráskód-elemzők állnak rendelkezésre a forráskód-auditálás problémájának megoldására, valamint a beágyazott kódokban és webalkalmazásokban lévő sebezhetőségek kihasználása elleni védelemre.
Forráskód-elemzők osztályozása
A forráskód-elemzők a szoftvertermékek egy osztálya, amelyek célja a forráskódok szoftverhibáinak azonosítása és kiaknázása. A forráskód elemzésére szolgáló összes termék nagyjából három típusra osztható:
- Az első csoportba tartoznak a webalkalmazás-kódelemzők és a webhelyek sebezhetőségeinek kiaknázását megakadályozó eszközök.
- A második csoportot a beágyazott kódelemzők alkotják, amelyek a vállalati és termelési rendszerek funkcionalitásának bővítésére tervezett modulok forráskódjában képesek felismerni a problémás területeket. Ezek a modulok az 1C termékcsalád programjait, a CRM-rendszerek kiterjesztését, a vállalatirányítási rendszereket és az SAP-rendszereket tartalmazzák.
- Az utolsó csoport a forráskód elemzésére szolgál különféle programozási nyelveken, amelyek nem kapcsolódnak üzleti alkalmazásokhoz és webes alkalmazásokhoz. Ezek az analizátorok az ügyfelek és a szoftverfejlesztők számára készültek. Az analizátorok ezen csoportja a szoftvertermékek biztonságos fejlesztésének módszertanának alkalmazására is szolgál. A statikus kódelemzők megtalálják a problémákat és a lehetséges sebezhetőségeket a forráskódokban, és javaslatokat tesznek ezek kiküszöbölésére.
Meg kell jegyezni, hogy az analizátorok többsége vegyes típusú, és számos szoftvertermék – webes alkalmazások, beágyazott kód és közönséges szoftverek – elemzésére szolgál. Ennek ellenére ebben az áttekintésben a hangsúly a fejlesztő ügyfelek által használt analizátorokon van, ezért nagyobb figyelmet fordítanak a webalkalmazásokhoz és a beágyazott kódokhoz készült analizátorokra.
Az elemzők különféle elemzési mechanizmusokat tartalmazhatnak, de a legelterjedtebb és univerzális a forráskód statikus elemzése - SAST (Static Application Security Testing), léteznek dinamikus elemzési módszerek is - DAST (Dynamic Application Security Testing), amelyek kódellenőrzést végeznek a folyamat során. végrehajtása, és különféle hibrid lehetőségek, amelyek különböző típusú elemzéseket kombinálnak. A dinamikus elemzés egy független ellenőrzési módszer, amely bővítheti a statikus elemzés lehetőségeit, vagy önállóan használható olyan esetekben, amikor nincs hozzáférés a forráskódhoz. Ez az áttekintés csak a statikus analizátorokkal foglalkozik.
A beágyazott kód és webalkalmazások elemzői számos jellemzőben különböznek egymástól. Nemcsak az elemzés minőségét, valamint a támogatott szoftvertermékek és programozási nyelvek listáját tartalmazza, hanem további mechanizmusokat is: a hibák automatikus kijavításának képességét, olyan funkciók elérhetőségét, amelyek megakadályozzák a hibák kihasználását a kód megváltoztatása nélkül, frissítési lehetőséget. a biztonsági rések és programozási hibák beépített adatbázisa, a megfelelőségi tanúsítványok elérhetősége és a különféle szabályozók követelményeinek való megfelelés lehetősége.
Hogyan működnek a forráskód-elemzők
Az általános működési elvek az analizátorok minden osztályánál hasonlóak: mind a webalkalmazások forráskódjának elemzői, mind a beágyazott kód elemzői. Az ilyen típusú termékek közötti különbség csak abban rejlik, hogy képesek meghatározni a kód végrehajtásának és a külvilággal való interakciójának sajátosságait, ami az elemzők sebezhetőségi adatbázisaiban tükröződik. A piacon lévő analizátorok többsége mindkét osztály funkcióját ellátja, egyformán jól ellenőrzi az üzleti alkalmazásokba beágyazott kódokat és a webes alkalmazások kódját.
A forráskód-elemző bemeneti adatai a programok forráskódjainak tömbje és függőségei (tölthető modulok, használt harmadik féltől származó szoftverek stb.). Munkájuk eredményeként az észlelt sebezhetőségekről és programozási hibákról minden analizátor jelentést ad ki, emellett egyes analizátorok automatikus hibajavítási funkciókat is biztosítanak.
Érdemes megjegyezni, hogy az automatikus hibajavítás nem mindig működik megfelelően, ezért ez a funkció csak webes alkalmazások és beágyazott modulok fejlesztői számára készült, a termék vásárlója csak a végső elemző jelentésre hagyatkozzon, és a kapott adatokat használja fel a döntés a kidolgozott kód elfogadásáról, bevezetéséről, illetve felülvizsgálatra küldéséről.
1. ábra: A forráskód-elemző algoritmusa
A forráskód értékelése során az elemzők különféle adatbázisokat használnak, amelyek a sebezhetőségeket és programozási hibákat tartalmazzák:
- Saját biztonsági rések és programozási hibák - minden forráskód-elemző fejlesztő saját analitikai és kutatási részleggel rendelkezik, amely speciális bázisokat készít fel a programok forráskódjainak elemzésére. Saját bázisunk minősége az egyik legfontosabb kritérium, amely befolyásolja a termék általános minőségét. Ezenkívül a saját adatbázisának dinamikusnak és folyamatosan frissítettnek kell lennie - a támadások új vektorai és a sebezhetőségek kihasználása, valamint a programozási nyelvek és a fejlesztési módszerek változásai megkövetelik az analizátor fejlesztőitől, hogy folyamatosan frissítsék az adatbázist a magas minőség megőrzése érdekében. letapogatás. A statikus, nem frissíthető alappal rendelkező termékek gyakran kudarcot vallanak az összehasonlító teszteken.
- Programozási hibák állapotalapjai - számos sérülékenységi állapot-bázis létezik, amelyek összeállításában és karbantartásában a különböző országok szabályozói vesznek részt. Például az Egyesült Államokban a CWE - Common Weakness Enumeration bázist használják, amelyet a MITER szervezet tart fenn, amelyet többek között az Egyesült Államok Védelmi Minisztériuma is támogat. Oroszország még nem rendelkezik hasonló bázissal, de az orosz FSTEC azt tervezi, hogy a jövőben kiegészíti a sebezhetőségi és fenyegetési alapjait a programozási hibák bázisával. A sebezhetőség-elemzők a CWE-bázis támogatását valósítják meg, beágyazva azt saját sebezhetőségi bázisukba, vagy külön ellenőrző mechanizmusként használják.
- Szabványkövetelmények és ajánlások a védett programozáshoz – Számos kormányzati és iparági szabvány is leírja a biztonságos alkalmazásfejlesztés követelményeit, valamint számos ajánlás és „legjobb gyakorlat” a világ szakértőitől a szoftverfejlesztés és -védelem területén. Ezek a dokumentumok nem írják le közvetlenül a programozási hibákat, ellentétben a CWE-vel, de tartalmazzák azoknak a metódusoknak a listáját, amelyek átalakíthatók statikus forráskód-elemzőben.
Az elemzés minősége, a hamis pozitív eredmények és a kihagyott hibák száma közvetlenül függ attól, hogy az analizátor milyen adatbázisokat használ. Ezenkívül a szabályozási követelményeknek való megfelelés elemzése lehetővé teszi az infrastruktúra és az információs rendszerek külső auditálási eljárásának megkönnyítését és egyszerűsítését abban az esetben, ha a követelmények kötelezőek. Például a PCI DSS követelmények kötelezőek a webes alkalmazásokhoz és a beágyazott kódhoz, amely a bankkártyák fizetési információival működik, míg a PCI DSS megvalósításának külső auditja történik, beleértve a használt szoftvertermékek elemzését.
Világpiac
Számos különböző elemző létezik a világpiacon – mind a jól ismert biztonsági gyártóktól, mind pedig a csak ezzel a termékkategóriával foglalkozó piaci résszel foglalkozó szereplőktől. A Gartner Analytical Center több mint öt éve foglalkozik a forráskód-elemzők osztályozásával és értékelésével, míg 2011-ig a Gartner külön kiemelte az ebben a cikkben tárgyalt statikus analizátorokat, majd egy magasabb osztályba egyesítette őket - Application Security Testing ).
A Gartner Magic Quadrant 2015-ben a HP, a Veracode és az IBM piacvezető a biztonsági auditálás terén. Ugyanakkor a Veracode az egyetlen vezető cég, amely szoftvertermékként nem rendelkezik analizátorral, és a funkcionalitást csak szolgáltatásként biztosítják a Veracode felhőben. A többi vezető cég vagy kizárólag olyan termékeket kínál, amelyek ellenőrzik a felhasználók számítógépét, vagy lehetőséget kínálnak a termék és a felhőszolgáltatás közötti választásra. A HP és az IBM az elmúlt öt évben a világpiaci vezetők maradtak, termékeikről az alábbiakban egy áttekintést adunk. A vezető pozíciókhoz legközelebb a Checkmarx terméke áll, amely csak erre a termékosztályra specializálódott, ezért ez is szerepel a felülvizsgálatban.
2. ábra: Az analitikus mágikus kvadránsA Gartner az Application Security Analysis Market Players által 2015 augusztusában

A ReportsnReports elemzőinek jelentése szerint az Egyesült Államok forráskód-elemzőinek piaca 2014-ben 2,5 milliárd dollárt tett ki, és az előrejelzések szerint 2019-re 14,9%-os éves növekedés mellett megduplázódik, 5 milliárd dollárra. A jelentés elkészítése során megkérdezett szervezetek több mint 50%-a tervezi a forráskód-elemzés költségvetésének elkülönítését és növelését egyedi fejlesztésekhez, és csak 3%-uk beszélt negatívan e termékek használatáról.
A kihívók körzetében található termékek nagy száma megerősíti ennek a termékosztálynak a népszerűségét és az iparág gyors fejlődését. Az elmúlt öt év során a gyártók teljes száma ebben a kvadránsban csaknem megháromszorozódott, és a 2014-es jelentéshez képest három termékkel bővült.
orosz piac
A forráskód-elemzők orosz piaca meglehetősen fiatal - az első nyilvános termékek kevesebb, mint öt éve jelentek meg a piacon. Ugyanakkor a piac két irányból alakult ki - egyrészt olyan vállalatok, amelyek tesztelésre fejlesztenek termékeket, hogy azonosítsák a be nem jelentett lehetőségeket az FSTEC, az FSB és az Orosz Föderáció Védelmi Minisztériuma laboratóriumaiban; másrészt a biztonság különböző területein tevékenykedő vállalatok úgy döntöttek, hogy új termékosztályt adnak portfóliójukhoz.
Az új piac legjelentősebb szereplői a Positive Technologies, az InfoWatch és a Solar Security. A Positive Technologies hosszú ideje szakosodott a sebezhetőségek felkutatására és elemzésére; Portfóliójukban megtalálható a MaxPatrol termék, amely a hazai piac egyik piacvezetője a külső biztonsági ellenőrzés terén, így nem meglepő, hogy a vállalat belső elemzés mellett saját forráskód-elemző fejlesztése mellett döntött. Az InfoWatch DLP-rendszerek fejlesztőjeként fejlődött, végül új piaci rést kereső cégcsoporttá vált. 2012-ben az Appercut csatlakozott az InfoWatch-hez, és egy forráskód-elemzővel egészítette ki az InfoWatch portfólióját. Az InfoWatch befektetése és tapasztalata lehetővé tette számára, hogy gyorsan magas szintre fejlessze a terméket. A Solar Security hivatalosan csak 2015. október végén mutatta be Solar inCode termékét, de már a megjelenéskor négy hivatalos implementációja volt Oroszországban.
Azok a vállalatok, amelyek évtizedek óta fejlesztenek forráskód-elemzőket a tanúsítási teszteléshez, általában nem sietnek elemzőket kínálni üzleti célokra, ezért áttekintésünk csak egy ilyen terméket kínál - az Echelontól. Talán a jövőben sikerül kiszorítani a többi piaci szereplőt, elsősorban ennek a terméknek a fejlesztőinek nagy elméleti és gyakorlati tapasztalatai miatt a sebezhetőségek és a be nem jelentett képességek keresésében.
Az orosz piac másik piaci rése a Digital Security információbiztonsági tanácsadó cég. Az auditok lebonyolításában és az ERP-rendszerek bevezetésében szerzett széleskörű tapasztalattal egy üres rést talált, és hozzálátott az ERP-rendszerek biztonságát elemző termék fejlesztéséhez, amely többek között a beágyazott programok forráskódjainak elemzésére szolgáló mechanizmusokat is tartalmaz.
Az analizátorok áttekintése

Áttekintésünk első forráskód-elemző eszköze a Fortify terméke, amely 2010 óta a Hewlett-Packard tulajdonában van. A HP Fortify termékcsalád a programkódok elemzéséhez különféle termékeket foglal magában: létezik még a Fortify On-Demand SaaS szolgáltatás, amely a forráskód HP felhőbe való feltöltését jelenti, valamint a teljes értékű HP Fortify Static Code Analyzer alkalmazás, amely az ügyfél infrastruktúrájára telepítve van.
A HP Fortify Static Code Analyzer programozási nyelvek és platformok széles skáláját támogatja, beleértve a PHP, Python, Java / JSP, ASP.Net és JavaScript nyelven írt webalkalmazásokat, valamint a beágyazott kódot ABAP-ban (SAP), Action Scriptben és VBScript.
3. ábra: HP Fortify Static Code Analyzer interfész

A termék jellemzői közül érdemes kiemelni a különböző fejlesztésirányítási rendszerekkel való integráció támogatását és a HP Fortify Static Code Analyzer hibakövetését. Ha a kódfejlesztő közvetlen hibajelentést biztosít az ügyfélnek a Bugzillának, a HP Quality Centernek vagy a Microsoft TFS-nek, az elemző automatikusan hibaüzeneteket tud generálni ezeken a rendszereken anélkül, hogy kézi beavatkozásra lenne szüksége.
A termék működése a HP Fortify saját tudásbázisain alapul, amelyet a CWE-bázis adaptálásával alakítottak ki. A termék elemzést hajt végre a DISA STIG, FISMA, PCI DSS és OWASP ajánlások követelményeinek teljesítésére.
A HP Fortify Static Code Analyzer hiányosságai között meg kell jegyezni a termék orosz piacra való lokalizálásának hiányát - az interfész és az angol nyelvű jelentések, a termék orosz nyelvű anyagának és dokumentációjának hiányát, a beágyazott kód elemzését. az 1C és más hazai vállalati szintű termékek esetében nem támogatott.
A HP Fortify statikus kódelemző előnyei:
- híres márka, kiváló minőségű megoldások;
- az elemzett programozási nyelvek és támogatott fejlesztői környezetek nagy listája;
- a fejlesztésirányítási rendszerekkel és más HP Fortify termékekkel való integráció képessége;
- nemzetközi szabványok, iránymutatások és „legjobb gyakorlatok” támogatása.
A Checkmarx CxSAST az amerikai-izraeli Checkmarx cég eszköze, amely forráskód-elemzők fejlesztésére szakosodott. Ez a termék elsősorban elterjedt szoftverek elemzésére szolgál, de a PHP, Python, JavaScript, Perl és Ruby programozási nyelvek támogatása miatt kiválóan alkalmas webes alkalmazások elemzésére. A Checkmarx CxSAST egy sokoldalú elemző, amelynek nincs kifejezett specifitása, ezért a szoftvertermék életciklusának bármely szakaszában - a fejlesztéstől az alkalmazásig - használható.
4. ábra: Checkmarx CxSAST interfész

A Checkmarx CxSAST támogatja a CWE kód alaphibáját, támogatja az OWASP és SANS 25 ajánlásoknak, a PCI DSS, HIPAA, MISRA, FISMA és BSIMM szabványoknak való megfelelés ellenőrzését. A Checkmarx CxSAST által észlelt összes probléma kockázati szint szerint van kategorizálva – a kisebbtől a kritikusig. A termék jellemzői közé tartozik a kód megjelenítésére szolgáló funkciók a végrehajtási útvonalak építési blokkdiagramjaival, valamint ajánlások a grafikus diagramhoz való kötéssel kapcsolatos problémák kijavítására.
A termék hátrányai közé tartozik az üzleti alkalmazásokba beágyazott kód elemzési támogatásának hiánya, a lokalizáció hiánya és a termék használatának nehézsége a szoftverkód vásárlói számára, mivel a megoldás elsősorban fejlesztőknek készült, és szorosan integrált a szoftverkóddal. fejlesztői környezetek.
A Checkmarx CxSAST előnyei:
- nagyszámú támogatott programozási nyelv;
- a termék nagy sebessége, csak a kód megnevezett szakaszainak beolvasása;
- az elemzett kód végrehajtási grafikonjainak megjelenítésének képessége;
- vizuális jelentések és grafikusan formázott forráskód-metrikák.
![]()
Egy jól ismert gyártó másik terméke az IBM Security AppScan forráskód-elemző. Az AppScan termékcsalád számos, biztonságos szoftverfejlesztéssel kapcsolatos terméket tartalmaz, de más termékek nem lesznek alkalmasak a programkód vásárlói számára, mivel sok redundáns funkcióval rendelkeznek. Az IBM Security AppScan Source, mint például a Checkmarx CxSAST, elsősorban fejlesztő szervezeteknek készült, miközben még kevesebb webfejlesztő nyelvet támogat – csak a PHP-t, a Perl-t és a JavaScriptet. A beágyazott kódok programozási nyelvei az üzletági alkalmazásokban nem támogatottak.
5. ábra: IBM Security AppScan Source felület

Az IBM Security AppScan Source szorosan integrálva van az IBM Rational fejlesztői platformmal, így a terméket leggyakrabban a szoftvertermékek fejlesztési és tesztelési szakaszában használják, és nem alkalmas egyéni alkalmazások elfogadására vagy érvényesítésére.
Az IBM Security AppScan Source egyik jellemzője talán az IBM Worklight, a mobil üzleti alkalmazások platformjának programelemzési támogatása. A támogatott szabványok és követelmények listája szűkös – a PCI DSS és DISA és OWASP ajánlások szerint a sebezhetőségi adatbázis korrelálja a talált problémákat a CWE-vel.
Ennek a megoldásnak nem volt különösebb előnye a fejlesztő ügyfelek számára.

A hazai NPO Echelon cég AppChecker egy olyan megoldása, amely a közelmúltban jelent meg a piacon. A termék első verziója alig egy éve jelent meg, de a programkód elemzésénél figyelembe kell venni az Echelon tapasztalatait. Az NPO Echelon az FSTEC, az FSB és az Orosz Föderáció Védelmi Minisztériumának tesztelő laboratóriuma, és nagy tapasztalattal rendelkezik a programforráskódok statikus és dinamikus elemzése terén.
6. ábra: AppChecker Echelon interfész

Az AppChecker számos PHP, Java és C / C ++ nyelven írt szoftver és webalkalmazás elemzésére szolgál. Teljes mértékben támogatja a CWE sebezhetőségi besorolását, és betartja az OWASP, CERT és NISP ajánlásokat. A termék felhasználható a PCI DSS követelményeinek és a Bank of Russia IBBS-2.6-2014 szabványának való megfelelés ellenőrzésére.
A termék hátrányai a megoldás fejlesztésének korai szakaszából fakadnak - nincs elég támogatás a népszerű webfejlesztő nyelvekhez és a beágyazott kód elemzésének képességéhez.
Előnyök:
- a hazai követelményeknek és a PCI DSS-nek megfelelő audit lefolytatásának képessége;
- figyelembe véve a programozási nyelvek sajátosságainak hatását az elemzett projektek rugalmas konfigurációja miatt;
- alacsony költségű.

A PT Application Inspector az orosz Positive Technologies fejlesztő terméke, amelyet a forráskód-elemzési probléma megoldására irányuló megközelítése különböztet meg. A PT Application Inspector elsődleges célja a kód sebezhetőségeinek felkutatása, nem pedig a gyakori programozási hibák azonosítása.
A jelen áttekintésben szereplő többi terméktől eltérően a PT Application Inspector nemcsak jelentések készítésére és a sebezhetőségek kimutatására képes, hanem arra is képes, hogy automatikusan hozzon létre exploitokat bizonyos kategóriák és típusú sebezhetőségek számára – kis végrehajtható modulok, amelyek kihasználják a talált sebezhetőségeket. A létrehozott exploitok segítségével a gyakorlatban lehetőség nyílik a talált sérülékenységek súlyosságának ellenőrzésére, valamint a fejlesztő ellenőrzésére az exploit működésének ellenőrzésével a sérülékenység deklarált bezárása után.
7. ábra: PT Application Inspector interfész

A PT Application Inspector támogatja mind a webalkalmazás-fejlesztő nyelveket (PHP, JavaScript), mind az üzleti alkalmazások beágyazott kódját - SAP ABAP, SAP Java, Oracle EBS Java, Oracle EBS PL / SQL. Ezenkívül a PT Application Inspector termék támogatja a programvégrehajtási útvonalak megjelenítését.
A PT Application Inspector egy egyablakos megoldás mind a fejlesztők, mind az egyedi fejlesztésű webalkalmazásokat és üzleti beépülő modulokat futtató ügyfelek számára. A programkód sebezhetőségeinek és hibáinak bázisa a Positive Technologies cég saját fejlesztéseit, a CWE és a WASC bázisát tartalmazza (a webkonzorcium sebezhetőségeinek bázisa, a CWE analógja webes alkalmazásokhoz).
A PT Application Inspector használatával teljesítheti a PCI DSS, STO BR IBBS szabványok követelményeit, valamint 17 FSTEC-megrendelést és a nem bejelentett képességek hiányára vonatkozó követelményeket (a kódtanúsítás szempontjából).
Előnyök:
- webalkalmazások elemzésének támogatása és számos fejlesztőrendszer üzleti alkalmazásokhoz;
- hazai, honosított termék;
- támogatott kormányzati szabványok széles skálája;
- a WASC webalkalmazás-sebezhetőségi adatbázis és a CWE osztályozó használata;
- a programkód megjelenítésének és a programkönyvjelzők keresésének képessége.
Az InfoWatch Appercut az orosz InfoWatch cég fejlesztette ki. A fő különbség e termék és a kollekció többi terméke között az üzleti alkalmazások ügyfelei számára nyújtott szolgáltatásra specializálódott.
Az InfoWatch Appercut szinte minden olyan programozási nyelvet támogat, amelyen webalkalmazásokat készítenek (JavaScript, Python, PHP, Ruby) és az üzleti javaslatokhoz szükséges beépülő modulokat - 1C, ABAP, X ++ (ERP Microsoft Axapta), Java, Lotus Script. Az InfoWatch Appercut képes alkalmazkodni egy adott alkalmazás sajátosságaihoz és az egyes vállalatok üzleti folyamatainak egyediségéhez.
8. ábra: InfoWatch Appercut interfész

Az InfoWatch Appercut számos követelményt támogat a hatékony és biztonságos programozáshoz, beleértve az általános PCI DSS és HIPPA követelményeket, a CERT és OWAST ajánlásokat és legjobb gyakorlatokat, valamint az üzleti folyamatplatformok gyártóinak ajánlásait – 1C, SAP, Oracle, Microsoft.
Előnyök:
- az orosz FSTEC által tanúsított hazai, honosított termék;
- az egyetlen termék, amely támogatja az Oroszországban népszerű összes üzleti platformot, beleértve az 1C-t, az SAP-t, az Oracle EBS-t, az IBM Collaboration Solutions-t (Lotus) és a Microsoft Axaptát;
- egy gyors szkenner, amely másodpercek alatt elvégzi az ellenőrzéseket, és csak a megváltozott kódot és kódrészleteket képes ellenőrizni.

Digital Security Az ERPScan egy speciális termék az SAP termékekre épített üzleti rendszerek biztonságának elemzésére és figyelésére, az első verzió 2010-ben jelent meg. A konfigurációk, sebezhetőségek és hozzáférés-vezérlés (SOD) elemző modulon kívül az ERPScan tartalmaz egy forráskódos biztonsági értékelési modult is, amely könyvjelzők, kritikus hívások, sebezhetőségek és programozási hibák keresésének funkcióit valósítja meg az ABAP és Java programozási nyelveken. . A termék ugyanakkor figyelembe veszi az SAP platform sajátosságait, a kódban észlelt sérülékenységeket a konfigurációs beállításokkal és hozzáférési jogosultságokkal korrelálja, és jobban végzi az elemzést, mint az azonos programozási nyelvekkel működő, nem speciális termékek.
9. ábra: Digitális biztonsági ERPScan interfész

Az ERPScan további funkciói közé tartozik az észlelt sérülékenységek automatikus javításainak generálása, valamint aláírások generálása a lehetséges támadásokhoz, és ezen aláírások feltöltése a behatolásészlelő és -megelőzési rendszerekbe (a CISCO-val együttműködve). Emellett a rendszer tartalmaz olyan mechanizmusokat is, amelyek a beágyazott kód teljesítményét értékelik, ami kritikus az üzleti alkalmazások számára, mivel a további modulok lassú működése komolyan befolyásolhatja a szervezet üzleti folyamatait. A rendszer támogatja a speciális üzleti alkalmazáskódelemzési irányelvek, például az EAS-SEC és a BIZEC, valamint az általános PCI DSS és OWASP irányelvek szerinti elemzést is.
Előnyök:
- mély specializáció az üzleti alkalmazások egy platformjára, az elemzés és a konfigurációs beállítások és a hozzáférési jogok korrelációjával;
- beágyazott kód teljesítménytesztjei;
- javítások automatikus létrehozása a talált sebezhetőségekhez és virtuális javításokhoz;
- nulladik napi sebezhetőségek keresése.

A Solar inCode egy statikus kódelemző eszköz, amely a szoftverforráskódokban található információbiztonsági sebezhetőségek és nem bejelentett képességek azonosítására szolgál. A termék fő megkülönböztető jellemzője az alkalmazások forráskódjának visszaállítása egy működő fájlból dekompilációs (reverse engineering) technológia segítségével.
A Solar inCode lehetővé teszi a Java, Scala, Java for Android, PHP és Objective C programozási nyelveken írt forráskód elemzését. A legtöbb versenytárstól eltérően a támogatott programozási nyelvek listája fejlesztőeszközöket tartalmaz Android és iOS mobilplatformokhoz.
10. ábra Interfész

Azokban az esetekben, amikor a forráskód nem elérhető, a Solar inCode lehetővé teszi a kész alkalmazások elemzését, ez a funkció támogatja a webalkalmazásokat és a mobil alkalmazásokat. Különösen a mobilalkalmazások esetében egyszerűen másolja be az alkalmazás linkjét a Google Play vagy az Apple Store áruházból a szkennerbe, az alkalmazás automatikusan letöltődik, visszafordításra és ellenőrzésre kerül.
A Solar inCode használata lehetővé teszi a PCI DSS szabványok, az STO BR IBBS, valamint a 17 FSTEC-megrendelés követelményeinek teljesítését, valamint a nem bejelentett képességek hiányára vonatkozó követelményeket (a kódtanúsítás szempontjából).
Előnyök:
- Android és iOS operációs rendszert futtató mobileszközökre vonatkozó alkalmazások elemzésének támogatása;
- támogatja a webalkalmazások és mobilalkalmazások elemzését programok forráskódja nélkül;
- elemzési eredményeket ad konkrét ajánlások formájában a sebezhetőségek kiküszöbölésére;
- részletes ajánlásokat generál a biztonsági eszközök konfigurálásához: SIEM, WAF, FW, NGFW;
- könnyen integrálható a biztonságos szoftverfejlesztés folyamatába a forráskód-tárolókkal való munka támogatásával.
következtetéseket
Az egyedi szoftverek hibái, sérülékenységei és hibái – legyen szó webalkalmazásokról vagy üzleti alkalmazások beépülő moduljairól – jelentős biztonsági kockázatot jelentenek a vállalati adatokra nézve. A forráskód-elemzők használata jelentősen csökkentheti ezeket a kockázatokat, és ellenőrizheti a programkód-fejlesztők által végzett munka minőségét anélkül, hogy további időt és pénzt kellene fordítani a szakértők és külső auditorok szolgáltatásaira. Ugyanakkor a forráskód-elemzők használata leggyakrabban nem igényel speciális képzést, az egyes alkalmazottak kiosztását, és nem okoz egyéb kellemetlenségeket, ha a terméket csak átvételre használják, és a fejlesztő felelős a hibák kijavításáért. Mindezek miatt ez az eszköz kötelezővé válik az egyedi tervek használatakor.
A forráskód-elemző kiválasztásakor a termékek funkcionalitását és munkájuk minőségét kell figyelembe venni. Mindenekelőtt érdemes odafigyelni arra, hogy a termék képes-e ellenőrizni azokat a programozási nyelveket, amelyeken az ellenőrzött forráskódok implementálva vannak. A következő szempont a termékválasztásnál a teszt minősége legyen, amit a fejlesztő cég kompetenciái és a termék demonstrációs működése során határozhatnak meg. A termék kiválasztásának másik tényezője lehet a nemzeti és nemzetközi szabványok követelményeinek való megfelelés ellenőrzésének lehetősége, ha ezek megvalósítása szükséges a vállalati üzleti folyamatokhoz.
Ebben az áttekintésben a külföldi termékek között a programozási nyelv támogatása és a szkennelés minősége tekintetében egyértelműen a HP Fortify Static Code Analyzer megoldás a vezető. A Checkmarx CxSAST is jó termék, de csak általános alkalmazásokat és webalkalmazásokat tud elemezni, az üzleti alkalmazásokhoz való plugineket nem támogatja a termék. Az IBM Security AppScan Source megoldás unalmasnak tűnik a versenytársakhoz képest, és nem különbözik a funkcionalitásban vagy az ellenőrzések minőségében. Ez a termék azonban nem üzleti felhasználóknak készült, és a fejlesztő cégeket célozza meg, ahol nagyobb hatékonyságot tud felmutatni, mint a versenytársak.
Nehéz kiemelni egy egyértelmű vezetőt az orosz termékek közül, a piacot három fő termék képviseli - az InfoWatch Appercut, a PT Application Inspector és a Solar inCode. Ugyanakkor ezek a termékek technológiailag jelentősen eltérnek egymástól, és különböző célközönségnek készültek - az előbbi több üzleti alkalmazásplatformot támogat, és a sérülékenységek kizárólag statikus elemzési módszerekkel történő keresésének köszönhetően nagy teljesítményű. A második a statikus és dinamikus elemzést, valamint ezek kombinációját egyesíti, ami a szkennelés minőségének javításával egyidejűleg a forráskód ellenőrzési idejének növekedéséhez vezet. A harmadik az üzleti felhasználók és az információbiztonsági szakemberek problémáinak megoldására irányul, és lehetővé teszi az alkalmazások ellenőrzését a forráskódhoz való hozzáférés nélkül.
Az "echelon" AppChecker még nem éri utol a versenytársakat, és csekély funkcionalitással rendelkezik, de a termék fejlesztésének korai szakaszában nagyon valószínű, hogy a közeljövőben az értékelések első sorai közé tartozik. forráskód-elemzők.
Digitális biztonság Az ERPScan kiváló termék az SAP platformra szánt üzleti alkalmazások elemzésének rendkívül speciális feladatainak megoldására. A Digital Security kizárólag erre a piacra koncentrálva kifejlesztett egy funkcionalitásában egyedülálló terméket, amely nemcsak a forráskódot elemzi, hanem figyelembe veszi az SAP platform minden sajátosságát, az egyedi konfigurációs beállításokat és az üzleti alkalmazások hozzáférési jogait, és képes automatikusan javításokat készíteni a felfedezett sebezhetőségekre.
annotáció
A statikus elemzés egy módszer a program forráskódjának helyességének ellenőrzésére. A statikus elemzési folyamat három szakaszból áll. Először az elemzett kódot tokenekre bontják – konstansokra, azonosítókra stb. Ezt a műveletet egy lexer hajtja végre. A tokeneket ezután átadják az értelmezőnek, amely ezek alapján kódfát épít fel. Végül elvégezzük a megépített fa statikus elemzését. Ez az áttekintő cikk a statikus elemzés három módszerét írja le: a fa bejárási elemzését, az adatfolyam-elemzést és az útvonal-vezérelt adatfolyam-elemzést.
Bevezetés
A tesztelés az alkalmazásfejlesztési folyamat fontos része. A tesztelésnek sokféle típusa létezik, beleértve a programkódhoz kapcsolódó két típust: a statikus elemzést és a dinamikus elemzést.
Dinamikus elemzést végeznek a lefordított program futtatható kódján. Ez csak a felhasználó-specifikus viselkedést ellenőrzi, pl. csak a teszt során végrehajtott kódot. A dinamikus elemző képes memóriaszivárgást találni, programteljesítményt mérni, hívásveremet kaphat stb.
A statikus elemzés lehetővé teszi a program forráskódjának ellenőrzését a végrehajtás előtt. Különösen minden fordító végez statikus elemzést a fordításkor. Nagy valós projekteknél azonban gyakran szükséges ellenőrizni a teljes kódot, hogy megfelel-e néhány további követelménynek. Ezek a követelmények nagyon sokfélék lehetnek, a változók elnevezésére vonatkozó szabályoktól kezdve a hordozhatóságig (például a kódnak biztonságosan kell futnia x86 és x64 platformon). A leggyakoribb követelmények a következők:
- Megbízhatóság – kevesebb hiba a tesztelt programban.
- Karbantarthatóság – tisztább kód, amely könnyen módosítható és javítható.
- A mobilitás a tesztelt program rugalmassága, amikor különböző platformokon fut.
- Olvashatóság – A kód megértéséhez szükséges idő csökkentése.
A követelmények szabályokra és irányelvekre bonthatók. A szabályok az ajánlásokkal ellentétben kötelezőek. A szabványos fordítókba épített kódelemzők által kiadott hibák és figyelmeztetések hasonlóak a szabályokhoz és ajánlásokhoz.
A szabályok és irányelvek pedig a kódolási szabványt alkotják. Ez a szabvány határozza meg, hogyan kell a programozónak programkódot írnia. A kódolási szabványokat a szoftverfejlesztő szervezetek használják.
A statikus elemző megkeresi a forráskód azon sorait, amelyek állítólag nem felelnek meg az elfogadott kódolási szabványnak, és diagnosztikai üzeneteket jelenít meg, hogy a fejlesztő megérthesse a probléma okát. A statikus elemzési folyamat hasonló a fordításhoz, azzal a különbséggel, hogy sem objektum, sem végrehajtható kód nem jön létre. Ez az áttekintés lépésről lépésre ismerteti a statikus elemzési folyamatot.
Elemzési folyamat
A statikus elemzési folyamat két fő lépésből áll: egy kódfa létrehozása (más néven) és a fa elemzése.
A forráskód elemzéséhez az elemzőnek először ezt a kódot kell „megértenie”, azaz. Szerelje szét összetételében, és hozzon létre egy olyan struktúrát, amely kényelmes formában írja le az elemzett kódot. Ezt az űrlapot kódfának nevezzük. Annak ellenőrzéséhez, hogy a kód megfelel-e a kódolási szabványnak, létre kell hoznia egy ilyen fát.
Általános esetben a fa csak az elemzett kódrészletre épül fel (például egy adott függvényre). A fa létrehozásához először a kódot kell feldolgozni, majd ezután.
A lexer feladata a bemeneti adatok külön tokenekre bontása, valamint ezen tokenek típusának meghatározása és szekvenciális továbbítása az elemzőnek. A lexer soronként olvassa be a forráskód szövegét, majd a kapott sorokat lefoglalt szavakra, azonosítókra és tokennek nevezett konstansokra bontja. A token kézhezvétele után a lexer meghatározza annak típusát.
Tekintsünk egy példaalgoritmust a token típusának meghatározására.
Ha a token első karaktere egy számjegy, akkor a token számnak minősül, ha ez a karakter mínuszjel, akkor negatív szám. Ha a token egy szám, akkor lehet egész vagy tört szám. Ha a szám az exponenciális jelölést meghatározó E betűt vagy tizedesvesszőt tartalmaz, akkor a szám törtnek, ellenkező esetben egész számnak minősül. Vegye figyelembe, hogy ez lexikális hibát eredményezhet – ha az elemzett forráskód tartalmazza a „4xyz” tokent, a lexer 4-es egész számnak tekinti. Ez szintaktikai hibát generál, amelyet az elemző észlelhet. Az ilyen hibákat azonban a lexer is észlelheti.
Ha a token nem szám, akkor lehet karakterlánc is. A karakterlánc-állandók az elemzett nyelv szintaxisától függően egyszeres, dupla idézőjelek vagy más karakterek segítségével ismerhetők fel.
Végül, ha a token nem karakterlánc, akkor annak egy azonosítónak, egy fenntartott szónak vagy egy fenntartott karakternek kell lennie. Ha egy token nem fér bele ezekbe a kategóriákba, lexikai hiba lép fel. A lexer ezt a hibát nem fogja önállóan kezelni – csak azt jelzi az elemzőnek, hogy egy ismeretlen típusú tokent talált. Az elemző kezeli ezt a hibát.
Az elemző megérti a nyelv nyelvtanát. Feladata a szintaktikai hibák észlelése, és az ilyen hibákat nem tartalmazó programok kódfáknak nevezett adatstruktúrákká való konvertálása. Ezek a struktúrák pedig belépnek a statikus analizátor bemenetére, és az feldolgozza őket.
Míg a lexer csak a nyelv szintaxisát érti, az elemző a kontextust is felismeri. Például deklaráljunk egy függvényt C-ben:
Int Func () (vissza 0;)
A Lexer feldolgozza ezt a karakterláncot, és tokenekre bontja az 1. táblázat szerint:
1. táblázat - Az "int Func () (0);" karakterlánc lexémái.
A karakterláncot 8 érvényes tokenként ismeri fel, és ezeket a tokenek átadják az elemzőnek.
Ez az elemző megvizsgálja a kontextust, és megállapítja, hogy az adott tokenek egy olyan függvény deklarációja, amely nem vesz fel paramétereket, egész számot ad vissza, és ez a szám mindig 0.
Az értelmező ezt akkor fogja kitalálni, amikor létrehoz egy kódfát a lexer által biztosított tokenekből, és elemzi azt. Ha a lexémákat és a belőlük felépített fát helyesnek tekintjük, akkor ezt a fát használjuk fel a statikus elemzéshez. Ellenkező esetben az elemző hibaüzenetet ad.
A kódfa felépítésének folyamata azonban nem csupán a tokenek faábrázolása. Nézzük meg közelebbről ezt a folyamatot.
Kódfa
A kódfa a bemeneti adatok lényegét képviseli egy fa formájában, kihagyva a nem lényeges szintaktikai részleteket. Az ilyen fák abban különböznek az adott szintaxisfáktól, hogy nincsenek bennük írásjeleket jelentő csúcsok, például sorvégi pontosvessző vagy vessző, amely a függvény argumentumai között jelenik meg.
A kódfák generálásához használt elemzők írhatók kézzel, vagy létrehozhatók értelmező generátorokkal. A kódfák általában alulról felfelé jönnek létre.
A fa csomópontjainak tervezésekor általában először a modularitás szintjét határozzák meg. Más szóval, meghatározásra kerül, hogy minden nyelvi konstrukciót azonos típusú, értékekkel megkülönböztetett csúcsok képviselnek-e. Példaként tekintsük a bináris aritmetikai műveletek ábrázolását. Az egyik lehetőség, hogy ugyanazokat a csúcsokat használjuk az összes bináris művelethez, amelyek egyik attribútuma a művelet típusa lesz, például "+". Egy másik lehetőség, hogy különböző típusú csúcsokat használunk a különböző műveletekhez. Egy objektumorientált nyelvben ezek lehetnek olyan osztályok, mint az AddBinary, SubstractBinary, MultipleBinary stb., amelyek az absztrakt Binary alaposztályból öröklődnek.
Példaként elemezzünk két kifejezést: 1 + 2 * 3 + 4 * 5 és 1+ 2 * (3 + 4) * 5 (lásd 1. ábra).
Amint az ábrán látható, a kifejezés eredeti formája visszaállítható a fán balról jobbra haladva.
A kódfa létrehozása és tesztelése után a statikus elemző képes meghatározni, hogy a forráskód megfelel-e a kódolási szabványban meghatározott szabályoknak és irányelveknek.
Statikus elemzési módszerek
Számos különböző módszer létezik, különösen a vele végzett elemzés, az adatfolyam-elemzés, az adatfolyam-elemzés útválasztással stb. Ezeknek a módszereknek a megvalósítása a különböző analizátorokban eltérő. A különböző programozási nyelvek statikus elemzői azonban ugyanazt az alapkódot (infrastruktúrát) használhatják. Ezek a keretrendszerek olyan alapvető algoritmusokat tartalmaznak, amelyek különböző kódelemzőkben használhatók, függetlenül az adott feladatoktól és az elemzett nyelvtől. A támogatott módszerek készlete és e módszerek konkrét megvalósítása szintén az adott infrastruktúrától függ. Például a keretrendszer lehetővé teheti olyan elemző egyszerű felépítését, amely fa bejárást használ, de nem támogatja az adatfolyam elemzését.
Bár mindhárom fent felsorolt statikus elemzési módszer az elemző által felépített kódfát használja, ezek a módszerek feladataikban és algoritmusukban különböznek egymástól.
A fa bejárási elemzése, amint azt a neve is sugallja, egy kódfa bejárásával és annak ellenőrzésével történik, hogy a kód megfelel-e egy elfogadott kódolási szabványnak, amely szabályok és irányelvek halmazaként van meghatározva. A fordítók ezt a fajta elemzést végzik.
Az adatfolyam-elemzés úgy írható le, mint az a folyamat, amely során információkat gyűjtenek az elemzett programban lévő adatok felhasználásáról, meghatározásáról és függőségeiről. Az adatfolyam-elemzés egy kódfából előállított parancsfolyam-gráfot használ. Ez a gráf egy adott program végrehajtásának minden lehetséges módját reprezentálja: a csúcsok „egyenes” kódrészleteket jelölnek átmenet nélkül, az élek pedig a vezérlés lehetséges átadását e töredékek között. Mivel az elemzést a tesztelt program elindítása nélkül hajtják végre, lehetetlen meghatározni a végrehajtás pontos eredményét. Más szavakkal, lehetetlen kitalálni, hogy az irányítás milyen módon kerül átadásra. Ezért az adatfolyam-elemző algoritmusok közelítik a lehetséges viselkedést, például az if-then-else utasítás mindkét ágát figyelembe véve, vagy a while ciklus törzsét bizonyos pontossággal végrehajtva. A pontossági megkötés mindig fennáll, hiszen az adatáramlási egyenletek egy bizonyos változóhalmazra vannak felírva, és ezeknek a változóknak a számát korlátozni kell, mivel csak véges operátorkészletű programokkal foglalkozunk. Ezért az ismeretlenek számának mindig van valami felső határa, amely korlátozza a pontosságot. Az utasításfolyamat grafikonja szempontjából a statikus elemzésben minden lehetséges programvégrehajtási utat érvényesnek tekintünk. Emiatt a feltevés miatt az adatfolyam elemzésekor csak közelítő megoldásokat kaphatunk korlátozott számú problémakörre.
A fent leírt adatfolyam elemzésére szolgáló algoritmus nem tesz különbséget az útvonalak között, hiszen minden lehetséges út, függetlenül attól, hogy valós-e vagy sem, gyakran vagy ritkán kerül végrehajtásra, mégis megoldáshoz vezet. A gyakorlatban azonban a lehetséges utaknak csak egy töredékét követik. Ezenkívül a leggyakrabban végrehajtott kód általában az összes lehetséges útvonal még kisebb részhalmazát alkotja. Logikus az elemzett utasításfolyam-gráf csökkentése, és így a számítás mennyiségének csökkentése a lehetséges útvonalak egy bizonyos részhalmazának elemzésével. Az útvonalválasztás elemzése redukált utasításfolyam grafikonon történik, amelyben nincsenek lehetetlen útvonalak és „veszélyes” kódot nem tartalmazó útvonalak. Az útvonalválasztási kritériumok eltérőek a különböző analizátoroknál. Például az analizátor csak a dinamikus tömbdeklarációkat tartalmazó útvonalakat tudja figyelembe venni, az analizátor beállításai szerint az ilyen deklarációkat "veszélyesnek" tekinti.
Következtetés
A statikus elemzési módszerek és maguk az analizátorok száma évről évre növekszik, ami azt jelenti, hogy nő az érdeklődés a statikus kódelemzők iránt. Az érdeklődés oka abban rejlik, hogy a fejlesztés alatt álló szoftverek egyre összetettebbek, így a kód kézi ellenőrzése lehetetlenné válik.
Ez a cikk rövid leírást ad a statikus elemzési folyamatról és az ilyen elemzés végrehajtására szolgáló különféle módszerekről.
Bibliográfiai lista
- Dirk Giesen A statikus elemző eszközök filozófiája és gyakorlati megvalósítása. - Elektronikus adatok. -Dirk Giesen, zsaru. 1998.
- James Alan Farrell fordítói alapismeretek. - Elektronikus adatok. -James Alan Farrell, rendőr 1995. - Hozzáférési mód: http://www.cs.man.ac.uk/~pjj/farrell/compmain.html
- Joel Jones Absztrakt szintaxisfa megvalósítási idiómák. - A 10. konferencia a programok mintanyelveiről 2003, cop 2003.
- Ciera Nicole Christopher Statikus elemzési keretrendszerek értékelése - Ciera Nicole, zsaru. 2006.
- Leon Moonen Az adatfolyam-elemzés általános architektúrája a visszafejtés támogatására. - Az algebrai specifikációk elméletével és gyakorlatával foglalkozó 2. nemzetközi műhely anyaga, cop. 1997.
A statikus elemzés számos különféle hibát és gyengeséget képes észlelni a forráskódban még azelőtt, hogy a kód futásra készen állna. Másrészt a futásidejű elemzés vagy futásidejű elemzés a futó szoftvereken történik, és a felmerülő problémákat észleli, általában kifinomult eszközök használatával. Valaki azzal érvelhet, hogy az elemzés egyik formája megelőzi a másikat, de a fejlesztők mindkét módszert kombinálhatják a fejlesztési és tesztelési folyamatok felgyorsítása, valamint az általuk szállított termék minőségének javítása érdekében.
Ez a cikk először a statikus elemzési módszert tárgyalja. Segít megelőzni a problémákat a fő kód megadása előtt, és biztosíthatja, hogy az új kód megfeleljen a szabványnak. Különféle elemzési technikák, például az absztrakt szintaxisfa (AST) ellenőrzése és a kódútelemzés segítségével a statikus elemző eszközök rejtett sebezhetőségeket, logikai hibákat, megvalósítási hibákat és egyéb problémákat fedezhetnek fel. Ez történhet az egyes munkaállomások fejlesztési szakaszában és a rendszerépítés során is. Továbbá a cikk egy dinamikus elemzési módszert vizsgál, amely a modulfejlesztés és a rendszerintegráció szakaszában használható, és lehetővé teszi a statikus elemzés során kimaradt problémák azonosítását. A dinamikus elemzés nemcsak a mutatókkal kapcsolatos hibákat és egyéb hibásságokat észleli, hanem a CPU-ciklusok, a RAM, a flash memória és egyéb erőforrások felhasználásának optimalizálására is lehetőség nyílik.
A cikk a statikus és a dinamikus elemzés kombinálásának lehetőségeit is tárgyalja, hogy megelőzze a fejlesztés korábbi szakaszaiba való visszaesést a termék érésekor. Ez a két technikát egyszerre alkalmazó megközelítés segít elkerülni a legtöbb probléma megnyilvánulását még a fejlesztés korai szakaszában is, amikor azok a legkönnyebben és legolcsóbban javíthatók.
A két világ legjobbjait ötvözi
A statikus elemző eszközök a hibákat a projekt létrehozásának korai szakaszában találják meg, általában a végrehajtható fájl létrehozása előtt. Ez a korai felismerés különösen hasznos a nagy beágyazott rendszerprojekteknél, ahol a fejlesztők nem használhatják a dinamikus elemzési eszközöket, amíg a szoftver eléggé kész a célrendszeren való futtatáshoz.
A statikus elemzési szakasz azonosítja és leírja a forráskód gyenge pontjait, beleértve a rejtett sebezhetőségeket, logikai hibákat, megvalósítási hibákat, a párhuzamos műveletek helytelenségét, ritkán előforduló peremfeltételeket és sok más problémát. Például a Klocwork Insight statikus elemző eszközök a forráskód mélyreható elemzését végzik szintaktikai és szemantikai szinten. Ezek az eszközök a vezérlés és az adatfolyamok kifinomult eljárásközi elemzését is elvégzik, és fejlett hamis útvonalmetszési technikákat alkalmaznak, kiértékelik a változókat felvevő értékeket, és szimulálják a program lehetséges viselkedését futás közben.
A fejlesztők a fejlesztési szakaszban bármikor használhatják a statikus elemző eszközöket, még akkor is, ha a projektnek csak töredékei vannak megírva. Azonban minél teljesebb a kód, annál jobb. A statikus elemzés során a kódvégrehajtás összes lehetséges útvonala megtekinthető – a rendszeres tesztelés során ez ritkán fordul elő, kivéve, ha a projekt 100%-os kódlefedettséget igényel. A statikus elemzés például képes észlelni a peremfeltételekkel kapcsolatos szoftverhibákat vagy a tervezéskor nem tesztelt útvonalhibákat.
Mivel a statikus elemzés a program viselkedését a forráskód-modell alapján próbálja megjósolni, néha olyan "hibát" találnak, amely valójában nem létezik - ez az úgynevezett "hamis pozitív". Számos modern statikus elemző eszköz továbbfejlesztett technikákat alkalmaz a probléma elkerülése és rendkívül pontos elemzések elvégzése érdekében.
| Statikus elemzés: A profik | Statikus elemzés: Hátrányok |
| A szoftver életciklusának korai szakaszában használatos, mielőtt a kód készen állna a végrehajtásra és a tesztelés megkezdése előtt. A már tesztelt, létező kódbázisok elemezhetők. Az eszközök integrálhatók a fejlesztői környezetbe az éjszakai összeállításokban használt komponens részeként és a fejlesztői munkaterület eszközkészletének részeként. Alacsony költség: nincs szükség tesztprogramok vagy álmodulok (csonkok) létrehozására; a fejlesztők lefuttathatják saját elemzéseiket. |
Olyan szoftverhibák és sérülékenységek észlelhetők, amelyek nem feltétlenül okozzák a program összeomlását vagy befolyásolják a program viselkedését a tényleges végrehajtás során. A „téves pozitív” valószínűsége nem nulla. |
Asztal 1- Érvek a statikus elemzés mellett és ellen.
A dinamikus elemző eszközök észlelik a hibákat a végrehajtásra futtatott kódban. Ugyanakkor a fejlesztőnek lehetősége van megfigyelni vagy diagnosztizálni az alkalmazás viselkedését annak végrehajtása során, ideális esetben közvetlenül a célkörnyezetben.
Sok esetben egy dinamikus elemző eszköz módosítja az alkalmazás forrását vagy binárisát, hogy beállítsa a műszeres mérésekhez szükséges horgokat vagy horgokat. Ezekkel a horgokkal futás közben észlelheti a programhibákat, elemezheti a memóriahasználatot, a kódlefedettséget és egyéb feltételeket. A dinamikus elemző eszközök pontos információkat generálhatnak a verem állapotáról, így a hibakeresők megtalálhatják a hiba okát. Ezért amikor a dinamikus elemző eszközök hibát találnak, az valószínűleg valódi hiba, amelyet a programozó gyorsan azonosítani és kijavítani tud. Meg kell jegyezni, hogy ahhoz, hogy hibahelyzetet hozzon létre a futási szakaszban, pontosan meg kell teremteni a szükséges feltételeket, amelyek között a szoftverhiba megnyilvánul. Ennek megfelelően a fejlesztőknek létre kell hozniuk valamilyen tesztesetet egy adott forgatókönyv megvalósításához.
| Dinamikus elemzés: A profik | Dinamikus elemzés: a hátrányok |
| Ritkán vannak "téves pozitívumok" - magas termelékenység a hibák megtalálásában Teljes verem és futásidejű nyomkövetés használható a hiba okának felderítésére. A hibákat a rendszer egy futó rendszer kontextusában rögzíti, mind a valós életben, mind a szimulációs módban. |
A rendszer valós idejű viselkedése zavart okoz; a beavatkozás mértéke a felhasznált betétek számától függ. Ez nem mindig vezet problémákhoz, de ezt szem előtt kell tartani, amikor időkritikus kóddal dolgozik. A hibaelemzés teljessége a kódlefedettség mértékétől függ. Így a hibát tartalmazó kódútvonalon be kell járni, és a tesztesetben meg kell teremteni a szükséges feltételeket a hibahelyzet létrehozásához. |
2. táblázat- Érvek a dinamikus elemzés mellett és ellen.
Korai hibafelismerés a fejlesztési költségek csökkentése érdekében
Minél előbb fedezik fel a szoftverhibát, annál gyorsabban és olcsóbban javítható. Ezért a statikus és dinamikus elemző eszközök valódi értéket képviselnek, lehetővé téve a hibák megtalálását a szoftver életciklusának korai szakaszában. Az ipari termékekre vonatkozó különféle tanulmányok azt mutatják, hogy a probléma kijavítása a rendszer tesztelésének szakaszában (a munka minőségének megerősítése, minőségbiztosítás) vagy a rendszer leszállítása után több nagyságrenddel drágább, mint ugyanazon problémák kijavítása a rendszer tesztelésének szakaszában. szoftverfejlesztés. Sok szervezet saját becsléssel rendelkezik a hibák megszüntetésének költségeiről. ábrán. Az 1. ábrán Capers Jones gyakran idézett könyvéből vett adatok láthatók a tárgyalt kérdésről. Alkalmazott szoftver mérése.
Rizs. egy„A projekt előrehaladtával a szoftverhibák kijavításának költségei exponenciálisan növekedhetnek. A statikus és dinamikus elemző eszközök segítenek megelőzni ezeket a költségeket azáltal, hogy a hibákat a szoftver életciklusának korai szakaszában észlelik.
Statikus elemzés
A statikus elemzést majdnem olyan régóta használják a szoftverfejlesztési gyakorlatban, mint magát a szoftverfejlesztést. Eredeti formájában az elemzés a programozási stílus szabványoknak való megfelelés ellenőrzésére redukálódott (lint). A fejlesztők ezt közvetlenül a munkahelyükön használták. Amikor a szoftverhibák észleléséről volt szó, a korai statikus elemző eszközök arra összpontosítottak, ami a felszínen van: a programozási stílusra és a gyakori szintaktikai hibákra. Például még a legegyszerűbb statikus elemző eszközök is képesek észlelni ezt a fajta hibát:
Int foo (int x, int * ptr) (if (x & 1); (* ptr = x; return;) ...)
Itt egy extra pontosvessző hibás használata potenciálisan katasztrofális eredményekhez vezethet: a függvény bemeneti paraméter-mutatója váratlan körülmények között újradefiniálódik. A mutató mindig újradefiniálva van, függetlenül az ellenőrzött feltételtől.
A korai elemző eszközök elsősorban a szintaktikai hibákra összpontosítottak. Ezért bár lehetséges volt komoly hibákat találni ennek során, a legtöbb talált probléma viszonylag triviális volt. Ezenkívül az eszközöket elég kis kódkörnyezettel látták el, hogy pontos eredményeket lehessen várni. Ennek az az oka, hogy a munkát egy tipikus fordítási/linkelési fejlesztési ciklus során végezték, és amit a fejlesztő csinált, az csak egy kis kódrészlet volt egy nagy szoftverrendszerben. Ez a hiba oda vezetett, hogy az elemző eszközök becsléseket és hipotéziseket fogalmaztak meg arról, hogy mi történhet a fejlesztő homokozóján kívül. Ez viszont megnövekedett mennyiségű „téves pozitív” jelentéshez vezetett.
A statikus elemző eszközök következő generációi észrevették ezeket a hiányosságokat, és kiterjesztették hatókörüket az elemzésen és a szemantikai elemzésen túl. Az új eszközökben a generált kód kibővített nézete vagy modellje készült (valami hasonló a fordítási fázishoz), majd a modellnek megfelelően modellezték a kódvégrehajtás összes lehetséges útját. Ezen túlmenően a logikai folyamok leképezése ezekre az útvonalakra történt, az adatobjektumok létrehozásának, felhasználásának és megsemmisítésének egyidejű szabályozásával. A szoftvermodulok elemzése során a folyamatközi vezérlést és az adatáramlást elemző eljárások összekapcsolhatók. Ugyanakkor a "téves pozitívumok" is minimálisra csökkennek azáltal, hogy új megközelítéseket alkalmaznak a hamis útvonalak kiküszöbölésére, a változók által felvehető értékek értékelésére, és valós időben történő munkavégzés során a lehetséges viselkedés szimulálására. Az ilyen szintű adatok statikus elemző eszközökben történő előállításához elemezni kell a projekt teljes kódbázisát, egy integrált rendszerelrendezést kell végrehajtani, és nem csak a fejlesztő asztalán lévő "homokozóban" kapott eredményekkel kell dolgozni.
Az ilyen kifinomult elemzési formák elvégzéséhez a statikus elemző eszközök a kódellenőrzés két fő típusával foglalkoznak:
- Absztrakt szintaxisfa érvényesítése- a kód alapvető szintaxisának és szerkezetének ellenőrzésére.
- Kódútvonal-elemzés- egy teljesebb elemzés elvégzése, amely a programadat-objektumok állapotának megértésétől függ a kódvégrehajtás útvonalának egy adott pontján.
Absztrakt szintaxis fák
Az absztrakt szintaktikai fa egyszerűen a forráskód fa szerkezetű reprezentációja, amint azt a fordító előzetes szakaszaiban elő lehet állítani. A fa tartalmazza a kód szerkezetének részletes, egyértelmű bontását, lehetővé téve az eszközöknek, hogy egyszerű keresést hajtsanak végre a rendellenes helyekre a szintaxisban.
Nagyon egyszerű olyan ellenőrző programot készíteni, amely ellenőrzi az elnevezési konvencióknak és a függvényhívásokra vonatkozó korlátozásoknak való megfelelést, például a nem biztonságos könyvtárakat. Az AST-ellenőrzések végrehajtásának célja általában az, hogy a kódból mint olyanból valamilyen következtetést lehessen levonni, a kód végrehajtási viselkedésének ismerete nélkül.
Számos eszköz kínál AST-alapú érvényesítést számos nyelvhez, beleértve a nyílt forráskódú eszközöket, például a PMD for Java-t. Egyes eszközök az X-path nyelvtant vagy egy X-útvonalból származó nyelvtant használják a programok vezérlése szempontjából érdekes feltételek meghatározására. Más eszközök fejlett mechanizmusokat biztosítanak, amelyek lehetővé teszik a felhasználók számára, hogy saját AST-alapú érvényesítőket hozzanak létre. Ez a fajta felülvizsgálat viszonylag könnyen végrehajtható, és sok szervezet hoz létre új ilyen típusú felülvizsgálati programokat a vállalati kódolási szabványok vagy az iparág által ajánlott legjobb gyakorlatok betartásának ellenőrzésére.
Kódútvonal-elemzés
Nézzünk egy összetettebb példát. Most ahelyett, hogy a programozási stílus megsértésének eseteit keresnénk, azt szeretnénk ellenőrizni, hogy a mutató hivatkozási megkísérlése megfelelően működik-e, vagy sikertelen lesz:
Ha (x & 1) ptr = NULL; * ptr = 1;
A töredék felületes vizsgálata arra a nyilvánvaló következtetésre vezet, hogy a ptr változó NULL lehet, ha az x változó páratlan, és ez a feltétel, ha dereferáljuk, elkerülhetetlenül a nulla oldal meghívásához vezet. Azonban nagyon problémás ilyen programozási hibát találni egy AST alapú ellenőrző létrehozásakor. Vegyük fontolóra az AST fát (az egyértelműség kedvéért leegyszerűsítve), amely a fenti kódrészlethez jön létre:
Utasításblokk If-utasítás Ellenőrző-kifejezés Bináris operátor & x 1 True-Branch Expression-utasítás Assignment-operator = ptr 0 Kifejezés-utasítás Assignment-operator = Dereference-pointer - ptr 1 Ilyen esetekben nincs fakeresés vagy egyszerű csomópont a felsorolás nem érzékeli ésszerűen általánosított formában a ptr mutató hivatkozási kísérletét (legalábbis néha érvénytelen). Ennek megfelelően az elemző eszköz nem tud egyszerűen keresni a szintaktikai modellben. Ezenkívül elemeznie kell az adatobjektumok életciklusát, amint megjelennek, és futás közben a vezérlőlogikán belül használatosak.
A kódútvonalak elemzésekor a végrehajtási útvonalakon belüli objektumok nyomon követhetők, aminek eredményeként az ellenőrző programok meg tudják határozni, hogy az adatok mennyire egyértelműen és helyesen kerülnek felhasználásra. A kódútelemzés alkalmazása kibővíti a statikus elemzés során megválaszolható kérdések körét. Ahelyett, hogy egyszerűen elemezné a program kódjának helyességét, a kódútvonal-elemzés megpróbálja meghatározni a kód "szándékát", és ellenőrizni, hogy a kód ennek a szándéknak megfelelően van-e megírva. Ebben az esetben a következő kérdésekre kaphatunk választ:
- Az újonnan létrehozott objektumot felszabadították, mielőtt az összes hivatkozást eltávolították volna a hatókörből?
- Érvényes értéktartomány ellenőrzése megtörtént néhány adatobjektumnál, mielőtt az objektumot átadták volna egy operációs rendszer függvénynek?
- Ellenőrizték a karakterláncban, hogy vannak-e speciális karakterek, mielőtt a karakterláncot SQL-lekérdezésként adták volna át?
- A másolási művelet puffertúlcsordulást okoz?
- Biztonságos most ezt a függvényt hívni?
Ezen a kódvégrehajtási útvonalak elemzésén keresztül, mind az eseményindítótól a célszkriptig, mind az eseményindítótól a szükséges adatinicializálásig ellentétes irányban az eszköz képes lesz választ adni a kérdésekre. feltéve, és hibajelentést ad ki, ha a célszkript vagy az inicializálás a várt módon vagy nem a várt módon fut.
Ennek a képességnek a megvalósítása elengedhetetlen a fejlett forráskódelemzés végrehajtásához. Ezért a fejlesztőknek olyan eszközöket kell keresniük, amelyek fejlett kódútelemzést használnak a memóriaszivárgások, a mutatók helytelen hivatkozásának megszüntetése, a nem biztonságos vagy érvénytelen adatátvitel, a párhuzamosság megsértése és sok más problémát okozó körülmény észlelésére.
A statikus elemzés lépései
A statikus elemzés a fejlesztési folyamat két kulcsfontosságú pontján képes felderíteni a problémákat: a munkahelyi programírás során és a rendszer-összekapcsolási szakaszban. Ahogy arról korábban szó volt, az eszközök jelenlegi generációja elsősorban a rendszerkapcsolati szakaszban működik, amikor lehetőség nyílik a teljes rendszer kódfolyamának elemzésére, ami nagyon pontos diagnosztikai eredményekhez vezet.
A Klocwork Insight, a maga nemében egyedülálló termék, lehetővé teszi az adott fejlesztő munkahelyén létrehozott kód elemzését, miközben elkerüli az ilyen eszközökre általában jellemző pontatlan diagnosztikával kapcsolatos problémákat. A Klocwork biztosítja a Connected Desktop Analysist, amely elemzi a fejlesztő kódját az összes rendszerfüggőség megértésével. Ez olyan helyi elemzéshez vezet, amely ugyanolyan pontos és hatékony, mint a központi rendszerelemzés, de mindez még a kód teljes összeállítása előtt megtörténik.
Az elemzési folyamat szempontjából ez a képesség lehetővé teszi a fejlesztő számára, hogy a fejlesztési életciklus legkorábbi szakaszában pontos és jó minőségű statikus elemzést végezzen. A Klockwork Insight eszköz üzeneteket küld az integrált fejlesztési környezetnek (IDE) vagy a parancssornak bármilyen problémáról, miközben a fejlesztő kódot ír, és rendszeresen fordít/linkel. Ezeket az üzeneteket és jelentéseket a rendszer a dinamikus elemzés futtatása előtt bocsátja ki, és mielőtt az összes fejlesztő összeállította volna a kódját.
Rizs. 2- A statikus elemzés sorrendje.Dinamikus elemzési technológia
A szoftverhibák észlelésére a dinamikus elemző eszközök gyakran kis kódrészleteket illesztenek be vagy közvetlenül a program forráskódjába (beszúrás a forráskódba), vagy a végrehajtható kódba (beszúrás az objektumkódba). Ezek a kódszegmensek "józanság-ellenőrzést" hajtanak végre a program állapotában, és hibákat jelentenek, ha valami hibás vagy nem működőképes dolog található. Az ilyen eszközök más funkciókat is magukban foglalhatnak, például a memóriafoglalás és -használat nyomon követését az idő múlásával.
A dinamikus elemzési technológia a következőket tartalmazza:
- Beszúrások elhelyezése a forráskódban az előfeldolgozási szakaszban- egy speciális kódrészletet szúrnak be az alkalmazás forráskódjába a fordítás előtt a hibák észlelésére. Ez a megközelítés nem igényli a futási környezet részletes ismeretét, ezért ez a módszer népszerű a beágyazott rendszerek tesztelő és elemző eszközei között. Ilyen eszköz például az IBM Rational Test RealTime.
- Beszúrások elhelyezése az objektumkódban- egy ilyen dinamikus elemző eszközhöz kellő ismeretekkel kell rendelkeznie a futási környezetről ahhoz, hogy közvetlenül be tudjon illeszteni kódot futtatható fájlokba és könyvtárakba. Ezzel a megközelítéssel nem kell hozzáférnie a program forráskódjához, vagy nem kell újra csatolnia az alkalmazást. Ilyen eszköz például az IBM Rational Purify.
- Kód beszúrása fordításkor- a fejlesztő speciális fordítókapcsolókat (opciókat) használ a forráskódba való beágyazáshoz. A fordító azon képességét használja, hogy észleli a hibákat. Például a GNU C / C ++ 4.x fordító Mudflap technológiát használ a mutatóműveletekkel kapcsolatos problémák azonosítására.
- Speciális futásidejű könyvtárak- Az átadott paraméterek hibáinak észlelésére a fejlesztő a rendszerkönyvtárak hibakeresési verzióit használja. Az olyan függvények, mint az strcpy () arról híresek, hogy futás közben nulla vagy hibás mutatókat adhatnak. A könyvtárak hibakeresési verzióinak használatakor ilyen "rossz" paraméterek találhatók. Ez a technológia nem igényli az alkalmazás újraépítését, és kevésbé befolyásolja a teljesítményt, mint a forrás-/objektumkódba történő beillesztések teljes körű használata. Ezt a technológiát a QNX® Momentics® IDE RAM-elemző eszköze használja.
Ebben a cikkben megvizsgáljuk a QNX Momentics fejlesztői eszközeiben használt technológiákat, különös tekintettel a GCC Mudflapre és a speciális futásidejű könyvtárakra.
GNU C / C ++ Mudflap: fordítási idejű forrásbefecskendezés
A Mudflap eszköz, amely a GNU C / C ++ Compiler (GCC) 4.x verziójában található, fordítási idejű forrásinjektálást használ. Ugyanakkor a végrehajtás során a struktúrák ellenőrzése megtörténik, ami potenciálisan hibalehetőséget hordoz magában. A Mudflap a mutatóműveletekre összpontosít, mivel ezek a C és C ++ programok futásidejű hibáinak forrásai.
A Mudflap bevonásával a GCC fordítónak van még egy lépése a mutatóműveletek ellenőrző kódjának beszúrásával. A beszúrt kód általában ellenőrzi az átadott mutatóértékek érvényességét. Az érvénytelen mutatóértékek miatt a GCC fordító üzeneteket nyomtat a szabványos konzol hibaeszközre (stderr). A Mudflap pointer watchdog eszköze nem csak a mutatók nullát ellenőrzi: adatbázisa memóriacímeket tárol az érvényes objektumokhoz és az objektum tulajdonságaihoz, mint például a forrás helye, a dátum/időbélyeg, a verem visszakövetése a memóriafoglaláskor és a felszabadításkor. Egy ilyen adatbázis lehetővé teszi a szükséges adatok gyors megszerzését a program forráskódjában található memóriaelérési műveletek elemzésekor.
A könyvtári függvények, például az strcpy () nem ellenőrzik az átadott paramétereket. Ezt a funkciót a Mudflap sem teszteli. A Mudflapben azonban létrehozhat egy szimbólumburkolót a statikusan csatolt könyvtárakhoz, vagy egy beszúrást a dinamikus könyvtárakhoz. Ezzel a technológiával egy további réteg jön létre az alkalmazás és a könyvtár között, amely lehetővé teszi a paraméterek megbízhatóságának ellenőrzését és az eltérések megnyilvánulásáról szóló üzenet kiadását. A Mudflap eszköz az alkalmazás által használt memóriahatárok (kupac, verem, kód- és adatszegmensek stb.) ismeretén alapuló heurisztikus algoritmus segítségével határozza meg a visszaadott mutatók helyes értékét.
A GCC fordító parancssori kapcsolóival a fejlesztő csatlakoztathatja a Mudflap képességeket kódrészletek beszúrásához és a viselkedés szabályozásához, például a szabálysértések (határok, értékek) kezelése, további ellenőrzések és beállítások elvégzése, heurisztikus módszerek és öndiagnosztika összekapcsolása. Például az -fmudflap kapcsolókombináció beállítja az alapértelmezett Mudflap konfigurációt. A Mudflap által észlelt jogsértésekről szóló fordítóüzenetek a kimeneti konzolra (stderr) vagy a parancssorba kerülnek kinyomtatásra. A bőbeszédű kimenet információt nyújt a jogsértésről, az érintett változókról, funkciókról és a kód helyéről. Ez az információ automatikusan importálható az IDE-be, ahol a rendszer rendereli és veremkövetést hajt végre. Ezen adatok felhasználásával a fejlesztő gyorsan a megfelelő helyre ugorhat a program forráskódjában.
ábrán. A 3. ábra egy példát mutat be egy hibát mutató IDE-re a kapcsolódó visszakövetési információkkal együtt. A Backtrace a forráskód ragasztójaként működik, lehetővé téve a fejlesztő számára, hogy gyorsan diagnosztizálja a probléma kiváltó okát.
A Mudflap eszköz használata növelheti a kapcsolódási időt és a teljesítményt futás közben. A „Mudflap: Pointer Use Checking for C / C ++” (“Mudflap: a pointerek használatának ellenőrzése C / C ++ nyelveknél”) című cikkben bemutatott adatok arra utalnak, hogy a Mudflap csatlakoztatása esetén a kapcsolódási idő megnő 3 . .. 5-ször, és a program 1,25-5-ször lassabban indul el. Nyilvánvaló, hogy az időkritikus alkalmazások fejlesztőinek óvatosan kell használniuk ezt az eszközt. Ennek ellenére a Mudflap hatékony eszköz a hibára hajlamos és potenciálisan végzetes kódok azonosítására A QNX azt tervezi, hogy a Mudflap eszközt használja dinamikus elemző eszközeinek jövőbeli verzióiban.

Rizs. 3- A QNX Momentics IDE-ben megjelenő visszakövetési információk felhasználása a hiba forrásának megtalálásához.
Futóidejű könyvtárak hibakeresési verziói
A futásidejű könyvtárakban a speciális hibakereső beillesztésekkel együtt, amelyek jelentős többletmemória- és időfelhasználáshoz vezetnek a hivatkozási és futási szakaszok során, a fejlesztők használhatnak előre beszerelt futásidejű könyvtárakat. Az ilyen könyvtárakban a függvényhívások köré valamilyen kód kerül hozzáadásra, melynek célja a bemeneti paraméterek érvényesítése. Vegyük például a karakterláncok másolásának régi ismerős funkcióját:
strcpy (a, b);
Két paramétert foglal magában, mindkettő a típusra mutat char: egy az eredeti karakterlánchoz ( b), és egy másik az eredmény karakterlánchoz ( a). Az egyszerűség ellenére ez a funkció számos hiba forrása lehet:
- ha a mutató értéke a nulla vagy érvénytelen, akkor a másolás erre a célra a memória hozzáférés megtagadva hibát eredményez;
- ha a mutató értéke b egyenlő nullával vagy érvénytelen, akkor az információ olvasása erről a címről memória-hozzáférési megtagadási hibát eredményez;
- ha a sor végén b a „0” befejező karaktert kihagyjuk, akkor a vártnál több karakter kerül a cél karakterláncba;
- ha vonalméret b több memória van lefoglalva a karakterlánc számára a akkor a vártnál több bájt lesz írva a megadott címre (tipikus puffertúlcsordulási forgatókönyv).
A könyvtár hibakeresési verziójában a paraméterértékek ellenőrzésre kerülnek. a' és ' b’. A húrok hosszát is ellenőrzik, hogy megbizonyosodjanak arról, hogy kompatibilisek. Ha érvénytelen paramétert talál, megfelelő riasztási üzenet jelenik meg. A QNX Momentics programban a hibaüzenet-adatok importálódnak a célrendszerből, és megjelennek. A QNX Momentics memóriafoglalási és felosztási nyomkövetési technológiát is használ a RAM használatának mélyreható elemzéséhez.
A könyvtár hibakereső verziója minden olyan alkalmazással működik, amely a funkcióit használja; nincs szükség további módosításokra a kódon. Ezenkívül a fejlesztő hozzáadhatja a könyvtárat az alkalmazás indításakor. A könyvtár ezután lecseréli a teljes szabványos könyvtár megfelelő részeit, így nincs szükség a teljes könyvtár hibakereső verziójának használatára. A QNX Momentics IDE-ben a fejlesztő a program indításakor hozzáadhat egy ilyen könyvtárat egy normál interaktív hibakeresési munkamenet részeként. ábrán. A 4. ábra egy példát mutat be arra, hogy a QNX Momentics hogyan észleli és jelenti a memóriahibákat.
A könyvtárak hibakeresési verziói bevált "nem agresszív" módszert kínálnak a könyvtári függvények hívásakor előforduló hibák észlelésére. Ez a technika ideális a RAM elemzéséhez és más olyan elemzési módszerekhez, amelyek konzisztens híváspárokon alapulnak, például malloc () és free (). Más szóval, ez a technológia csak a könyvtárhívásokkal rendelkező kódnál képes futás közbeni hibákat észlelni. Ez nem észlel sok gyakori hibát, például a soron belüli mutatóhivatkozásokat vagy a hibás mutatóaritmetikát. Általában a rendszerhívásoknak csak egy részhalmazát figyeli a rendszer a hibakeresés során. Erről többet megtudhat a cikkben.

Rizs. 4- A RAM elemzése csapdák elhelyezésével történik a memóriaeléréshez kapcsolódó API-hívások területén.
Dinamikus elemzési sorozat
Röviden, a dinamikus elemzés magában foglalja a beágyazott célrendszer megsértésével vagy más jelentős eseményeivel kapcsolatos események rögzítését, ezen információk importálását a fejlesztői környezetbe, majd vizualizációs eszközök használatával a hibákat tartalmazó kódrészletek gyors azonosítására.
ábrán látható módon. 5, a dinamikus elemzés nem csak a hibák észlelését teszi lehetővé, hanem segít felhívni a fejlesztő figyelmét a memóriafogyasztás, a CPU-ciklusok, a lemezterület és egyéb erőforrások részleteire. Az elemzési folyamat több lépésből áll, és egy jó dinamikus elemző eszköz megbízható támogatást nyújt minden lépéshez:
- Megfigyelés- Először is rögzíti a futásidejű hibákat, észleli a memóriaszivárgást és megjeleníti az összes eredményt az IDE-ben.
- Beállítás- akkor a fejlesztőnek lehetősége van minden hibát visszavezetni a jogsértő forrássorig. Ha jól integrálódik az IDE-be, minden hiba megjelenik a képernyőn. A fejlesztő egyszerűen rákattint a hibasorra, és a forráskódrészlet megnyílik a sértő sorral. Sok esetben a fejlesztő gyorsan kijavíthatja a problémát a rendelkezésre álló veremkövetés és az IDE-ben található további forráskód-eszközök (függvényhívás-megjelenítők, híváskövetők stb.) használatával.
- Profilalkotás- Az észlelt hibák és memóriaszivárgások kiküszöbölésével a fejlesztő elemezheti az erőforrás-használatot az idő múlásával, beleértve a csúcshelyzeteket, az átlagos terhelést és az erőforrások túlhasználatát. Ideális esetben az elemző eszköz vizuálisan mutatja be a hosszú távú erőforrás-kihasználást, lehetővé téve a memóriafoglalási csúcsok és egyéb anomáliák azonnali azonosítását.
- Optimalizálás- A profilalkotási szakaszból származó információk felhasználásával a fejlesztő most "finom" elemzést végezhet a program erőforrás-használatáról. Többek között az ilyen optimalizálás minimalizálhatja az erőforrás-csúcsokat és az elpazarolt erőforrásokat, beleértve a RAM-on való futást és a CPU-idő használatát.

Rizs. 5- Tipikus munkafolyamat dinamikus elemzéshez
Különböző típusú elemzések munkafolyamatainak kombinálása fejlesztői környezetben
A statikus és dinamikus elemzési eszközök mindegyikének megvannak a maga erősségei. Ennek megfelelően a fejlesztőcsapatoknak ezeket az eszközöket párhuzamosan kell használniuk. Például a statikus elemző eszközök képesek észlelni azokat a hibákat, amelyeket a dinamikus elemző eszközök kihagynak, mivel a dinamikus elemző eszközök csak akkor rögzítenek hibát, ha a hibás kódrészletet a tesztelés során végrehajtják. Másrészt a dinamikus elemző eszközök a végső futási folyamat során észlelik a szoftverhibákat. Aligha kell egy hibáról beszélni, ha már észlelték a null pointer használatát.
Ideális esetben a fejlesztő mindkét elemző eszközt használja a mindennapi munkája során. A feladatot nagyban megkönnyíti, ha az eszközök jól integrálódnak a munkahelyi fejlesztő környezetbe.
Íme egy példa arra, hogyan lehet kétféle eszközt együtt használni:
- A nap elején a fejlesztő áttekinti az éjszakai összeállítás eredményjelentését. Ez a jelentés tartalmazza a tényleges összeállítási hibákat és a felépítés során végzett statikus elemzés eredményeit.
- A statikus elemzési jelentés felsorolja a talált hibákat, valamint olyan információkat, amelyek segíthetnek a javításukban, beleértve a forráskódra mutató hivatkozásokat. Az IDE használatával a fejlesztő minden helyzetet valódi hibaként vagy „hamis pozitívként” jelölhet meg. Ezt követően a tényleges hibákat kijavítják.
- A fejlesztő helyileg az IDE-n belül menti a változtatásokat az új kódrészletekkel együtt. A fejlesztő ezeket a változtatásokat nem teszi vissza a forrásvezérlő rendszerbe mindaddig, amíg a változtatásokat át nem vizsgálták és tesztelték.
- A fejlesztő elemzi és javítja az új kódot egy statikus elemző eszköz segítségével a helyi munkahelyen. A jó minőségű hibaészlelés és a "hamis pozitívumok" hiánya érdekében az elemzés fejlett, rendszerszintű információkat használ. Ez az információ az éjszakai építési/elemzési folyamat adataiból származik.
- Az új kódok elemzése és tisztítása után a fejlesztő beszúrja a kódot egy helyi tesztképbe vagy végrehajtható fájlba.
- A dinamikus elemzési eszközök segítségével a fejlesztő teszteket futtat az elvégzett változtatások ellenőrzésére.
- Az IDE segítségével a fejlesztő gyorsan azonosíthatja és kijavíthatja a dinamikus elemző eszközökön keresztül jelentett hibákat. A kód akkor tekinthető véglegesnek és használatra késznek, ha átesett statikus elemzésen, egységteszten és dinamikus elemzésen.
- A fejlesztő végrehajtja a változtatásokat a forrásvezérlő rendszerben; a módosított kód ezután részt vesz a következő éjszakai összeállítási folyamatban.
Ez a munkafolyamat hasonló a közepes és nagy projekteknél használthoz, amelyek már éjszakai elrendezéseket, forráskódkezelést és személyes kódfelelősséget használnak. Mivel az eszközök integrálva vannak az IDE-be, a fejlesztők gyorsan végezhetnek statikus és dinamikus elemzést anélkül, hogy eltérnének a tipikus munkafolyamattól. Ennek eredményeként a kód minősége már a forráskód elkészítésének szakaszában jelentősen megnő.
Az RTOS architektúra szerepe
A statikus és dinamikus elemzési eszközök tárgyalása során az RTOS architektúra említése helytelennek tűnhet. De kiderül, hogy egy jól megtervezett RTOS nagyban megkönnyítheti számos szoftverhiba észlelését, lokalizálását és feloldását.
Például egy mikrokernel RTOS-ban, mint a QNX Neutrino, minden alkalmazás, eszközillesztő, fájlrendszer és hálózati verem a kernelen kívül, külön címterekben található. Ennek eredményeként mindegyik el van szigetelve a magtól és egymástól. Ez a megközelítés biztosítja a legnagyobb fokú hibaszigetelést: az egyik komponens meghibásodása nem vezet a rendszer egészének összeomlásához. Sőt, kiderül, hogy a RAM-mal kapcsolatos hibát, vagy más logikai hibát könnyen lokalizálhat egészen a hibát okozó összetevőig.
Például, ha egy eszköz-illesztőprogram a folyamattárolón kívül próbál meg memóriát elérni, az operációs rendszer azonosítani tudja a folyamatot, rámutat a hiba helyére, és létrehozhat egy kiíratási fájlt, amely a forráskód hibakeresésével megtekinthető. Addig is a rendszer többi része tovább fog működni, a fejlesztő pedig elkülönítheti a problémát, és dolgozhat a javításon.

Rizs. 6- Mikrokernel operációs rendszerben az illesztőprogramok, protokollveremek és egyéb szolgáltatások RAM-jának meghibásodása nem zavarja meg a többi folyamatot vagy a kernelt. Sőt, az operációs rendszer azonnal észleli a memória-hozzáférési kísérletet, és jelzi, hogy melyik kódból történt ez a kísérlet.
A hagyományos operációs rendszermaghoz képest a mikrokernel szokatlanul gyors Mean Time to Repair (MTTR) idővel rendelkezik. Fontolja meg, mi történik, ha egy eszközillesztő meghibásodik: az operációs rendszer leállíthatja az illesztőprogramot, visszaállíthatja az illesztőprogram által használt erőforrásokat, és újraindíthatja az illesztőprogramot. Ez általában néhány milliszekundumot vesz igénybe. Egy tipikus monolitikus operációs rendszerben az eszközt újra kell indítani – ez a folyamat néhány másodperctől több percig is eltarthat.
Záró megjegyzések
A statikus elemző eszközök még a kód futtatása előtt is észlelhetik a programhibákat. Még azokat a hibákat is észlelik, amelyeket az egység, a rendszer tesztelésének, valamint az integráció szakaszában nem észlelnek, mert nagyon nehéz és költséges a komplex alkalmazások teljes kódlefedettsége. Ezenkívül a fejlesztőcsapatok statikus elemző eszközöket használhatnak a rendszeres rendszerépítés során, hogy biztosítsák az új kód minden darabjának elemzését.
Mindeközben a dinamikus elemző eszközök támogatják az integrációs és tesztelési fázisokat azáltal, hogy jelentik a programvégrehajtás során fellépő hibákat (vagy lehetséges problémákat) a fejlesztői környezetnek. Ezek az eszközök teljes körű információt nyújtanak a hiba helyének visszakereséséhez. Ezen információk felhasználásával a fejlesztők lényegesen rövidebb idő alatt utólag hibakereshetik a rejtélyes programhibákat vagy a rendszer összeomlását. A veremnyomokon és változókon keresztül végzett dinamikus elemzés feltárhatja a probléma kiváltó okát – nem pedig az „if (ptr! = NULL)” utasítások széles körben elterjedt használatát az összeomlások megelőzésére és elkerülésére.
A korai felismerés, a jobb és teljes tesztkód lefedettség, valamint a hibajavítás révén a fejlesztők jobb minőségű szoftvereket hozhatnak létre rövidebb időn belül.
Bibliográfia
- Eigler, Frank Ch., „Mudflap: Pointer Use Checking for C / C ++”, Proceedings of the GCC Developers Summit 2003, p. 57-70. http://www.linux.org.uk/~ajh/gcc/gccsummit-2003-proceedings.pdf
- „Heap Analysis: A memóriahibák a múlté”, QNX Neutrino RTOS programozói útmutató. http://pegasus.ott.qnx.com/download/download/16853/neutrino_prog.pdf
A QNX szoftverrendszerekről
A QNX Software Systems a Harman International leányvállalata, és a beágyazott rendszerek innovatív technológiáinak vezető globális szállítója, beleértve a köztesszoftvert, fejlesztőeszközöket és operációs rendszereket. A QNX® Neutrino® RTOS, a QNX Momentics® Development Kit és a QNX Aviage® köztes szoftver, amelyek mindegyike moduláris architektúrán alapul, a legrobusztusabb és leginkább méretezhető szoftvercsomagot kínálja a nagy teljesítményű beágyazott rendszerek számára. A vezető globális vállalatok, mint például a Cisco, a Daimler, a General Electric, a Lockheed Martin és a Siemens széles körben alkalmazzák a QNX technológiát hálózati útválasztókban, orvosi eszközökben, járműtelematikában, biztonsági és védelmi rendszerekben, ipari robotokban és más, kritikus fontosságú alkalmazásokban. A cég székhelye Ottawában (Kanada) található, a termékek forgalmazói pedig a világ több mint 100 országában találhatók.
A Klocworkről
A Klocwork termékeket statikus kódok automatizált elemzésére, szoftverhibák és biztonsági problémák észlelésére és megelőzésére tervezték. Termékeink eszközöket biztosítanak a fejlesztőcsapatoknak a szoftverminőségi és biztonsági hiányosságok kiváltó okainak azonosításához, valamint ezen hiányosságok nyomon követéséhez és megelőzéséhez a fejlesztési folyamat során. A Klocwork szabadalmaztatott technológiáját 1996-ban hozták létre, és magas befektetési megtérülést (ROI) biztosított több mint 80 ügyfélnek, amelyek közül sok a Fortune 500 vállalat, és a világ legkeresettebb szoftverfejlesztési környezetét kínálja. A Klocwork magántulajdonban van Burlingtonban, San Joséban, Chicagóban, Dallasban (USA) és Ottawában (Kanada).
A bináris kód, vagyis a gép által közvetlenül végrehajtott kód elemzése nem triviális feladat. A legtöbb esetben, ha egy bináris kód elemzésére van szükség, először szétszedéssel, majd valamilyen magas szintű reprezentációra való visszafordítással visszaállítják, majd az eredményt elemzik.
Itt el kell mondanunk, hogy a visszaállított kód szöveges megjelenítésében alig van közös a programozó által eredetileg megírt és végrehajtható fájlba lefordított kóddal. Lehetetlen pontosan visszaállítani a lefordított programozási nyelvekből, például C / C ++, Fortran bináris fájlt, mivel ez egy algoritmikusan nem formalizált feladat. A programozó által megírt forráskódnak a gép által végrehajtott programmá való konvertálása során a fordító visszafordíthatatlan konverziókat hajt végre.
A múlt század 90-es éveiben elterjedt volt az a vélemény, hogy a fordító az eredeti programot húsdarálóhoz hasonlóan darálja, és a helyreállítási feladat hasonló a kos kolbászból való visszaállításának feladatához.
Azonban nem minden olyan rossz. A kolbász megszerzése során a kos elveszti funkcionalitását, míg a bináris program megtartja. Ha a kapott kolbász futni és ugrálni tudna, a feladatok hasonlóak lennének.
Tehát, mivel egy bináris program megőrizte funkcionalitását, elmondhatjuk, hogy lehetséges a végrehajtható kód visszaállítása magas szintű reprezentációra úgy, hogy a bináris program funkcionalitása, amelynek eredeti reprezentációja nem létezik, és a program , amelynek szöveges ábrázolását kaptuk, egyenértékűek.
Definíció szerint két program funkcionálisan egyenértékű, ha ugyanazon a bemeneti adaton mindkettő befejezi vagy nem fejezi be a végrehajtását, és ha a végrehajtás véget ér, ugyanazt az eredményt adják vissza.
A szétszerelési feladatot általában félautomata módban oldják meg, vagyis egy szakember kézi helyreállítást végez interaktív eszközökkel, például IdaPro interaktív szétszerelővel, radarral vagy más eszközzel. Ezenkívül a dekompiláció félautomata módban is megtörténik. A dekompilációhoz a szakembert segítő eszközként használjunk HexRays-t, SmartDecompiler-t vagy más, az adott visszafejtési probléma megoldására alkalmas dekompilátort.
A program eredeti szöveges megjelenítésének visszaállítása a byte-kódból meglehetősen pontosan elvégezhető. Az olyan értelmezett nyelvek esetében, mint a Java vagy a .NET család nyelvei, amelyeket bájtkódba fordítanak le, a dekompiláció problémája másként oldódik meg. Ebben a cikkben nem foglalkozunk ezzel a kérdéssel.
Tehát a bináris programokat dekompilációval elemezheti. Ezt az elemzést általában azért hajtják végre, hogy megértsék egy program viselkedését, hogy lecseréljék vagy módosítsák azt.
Az örökölt programokkal való munka gyakorlatából
Néhány szoftver, amelyet 40 évvel ezelőtt írtak alacsony szintű C és Fortran nyelvek családjában, vezérli az olajtermelő berendezéseket. Ennek a berendezésnek a meghibásodása kritikus lehet a gyártás szempontjából, ezért nagyon nem kívánatos a szoftver cseréje. Az évek során azonban a forráskódok elvesztek.Az információbiztonsági osztály új munkatársa, akinek feladatai közé tartozott, hogy megértse a működését, felfedezte, hogy a szenzorvezérlő program bizonyos rendszerességgel ír valamit a lemezre, de nem világos, hogy mit ír, és hogyan lehet ezeket az információkat felhasználni. Arra is gondolt, hogy a berendezések megfigyelését egyetlen nagy képernyőn is meg lehetne jeleníteni. Ehhez érteni kellett, hogyan működik a program, mit és milyen formátumban ír lemezre, hogyan értelmezhető ez az információ.
A probléma megoldására dekompilációs technológiát alkalmaztak a helyreállított kód utólagos elemzésével. Eleinte egyenként szétszedtük a szoftverösszetevőket, majd lokalizáltuk az információbevitelért/kiadásért felelős kódot, és fokozatosan elkezdtük a visszaállítást ebből a kódból a függőségek figyelembevételével. Ezután helyreállt a program logikája, amely lehetővé tette a biztonsági szolgálat minden, az elemzett szoftverrel kapcsolatos kérdésének megválaszolását.
Ha elemeznie kell egy bináris programot annak érdekében, hogy visszaállítsa működési logikáját, részben vagy teljesen visszaállítsa a bemeneti adatok kimenetekké alakításának logikáját stb., akkor ezt kényelmesen megteheti egy decompiler segítségével.
Az ilyen feladatokon kívül a gyakorlatban vannak bináris programok információbiztonsági követelmények elemzésének feladatai. Ugyanakkor az ügyfél nem mindig tudja, hogy ez az elemzés nagyon munkaigényes. Úgy tűnik, hogy vissza kell fordítania és le kell futtatnia a kapott kódot egy statikus elemzővel. De a kvalitatív elemzés eredményeként ez szinte soha nem fog működni.
Először is, a talált sebezhetőségeket nemcsak megtalálni, hanem megmagyarázni is tudni kell. Ha egy magas szintű nyelvi programban sérülékenységet találtak, abban egy elemző vagy egy kódelemző eszköz megmutatja, hogy mely kódrészletek tartalmaznak bizonyos hibákat, amelyek megléte okozta a sérülékenység megjelenését. Mi van, ha nincs forráskód? Hogyan lehet megmutatni, hogy melyik kód okozta a sebezhetőséget?
A decompiler helyreállítja a helyreállítási műtermékekkel "teleszórt" kódot, és az észlelt sebezhetőséget felesleges ilyen kódra leképezni, továbbra sem világos. Ezenkívül a helyreállított kód rosszul strukturált, ezért nem használható kódelemző eszközökkel. A sebezhetőség bináris programmal való magyarázata is nehézkes, mert akinek a magyarázatot készítik, annak jól kell ismernie a programok bináris ábrázolását.
Másodszor, az IS-követelmények szerinti bináris elemzést úgy kell elvégezni, hogy megértsük, mit kell tenni a kapott eredménnyel, mivel nagyon nehéz egy bináris kódban lévő sebezhetőséget kijavítani, de nincs forráskód.
A bináris programok IS követelményeknek megfelelő statikus elemzésének minden sajátossága és nehézsége ellenére sok olyan helyzet adódik, amikor ilyen elemzést kell végezni. Ha valamilyen oknál fogva nincs forráskód, és a bináris program olyan funkciókat hajt végre, amelyek kritikusak az információbiztonsági követelmények szempontjából, akkor azt ellenőrizni kell. Ha sérülékenységet találnak, lehetőség szerint el kell küldeni egy ilyen alkalmazást felülvizsgálatra, vagy készíteni kell hozzá egy további "shell"-et, amely lehetővé teszi az érzékeny információk mozgásának ellenőrzését.
Amikor a biztonsági rés egy bináris fájlban volt elrejtve
Ha a program által végrehajtott kód magas szintű kritikussággal rendelkezik, még akkor is, ha a program forráskódja magas szintű nyelvű, hasznos a bináris fájl auditálása. Ez segít kiküszöbölni azokat a furcsaságokat, amelyeket a fordító a konverziók optimalizálása során okozhat. Így 2017 szeptemberében széles körben megvitatták a Clang fordító által végrehajtott optimalizálási átalakítást. Az eredmény egy olyan függvény hívása, amelyet soha nem szabad meghívni.#beleértve
Az optimalizálási átalakítások eredményeként a fordító a következő összeállítási kódot kapja. A példát Linux X86 alatt fordították le -O2 jelzővel.
Szöveg .globl NeverCalled .align 16, 0x90 .type NeverCalled, @ function NeverCalled: # @NeverCalled retl .Lfunc_end0: .size NeverCalled, .Lfunc_end0-NeverCalled .globl main .align 16, type 0x, @0 main function main subl $ 12,% esp movl $ .L.str, (% esp) calll system addl $ 12,% esp retl .Lfunc_end1: .size main, .Lfunc_end1-main .type .L.str, @ object # @ . str. szakasz .rodata.str1.1, "aMS", @ progbits, 1 .L.str: .asciz "rm -rf /" .size .L.str, 9
A forráskódban meghatározatlan viselkedés található. A NeverCalled () függvény meghívása a fordító által végrehajtott optimalizálási konverziók miatt történik. Az optimalizálás során nagy valószínűséggel allias elemzést végez, és ennek eredményeként a Do () függvény megkapja a NeverCalled () függvény címét. És mivel a main () metódus meghívja a Do () függvényt, ami definiálatlan, ami definiálatlan viselkedés, az eredmény a következő: meghívódik az EraseAll () függvény, amely végrehajtja az "rm -rf /" parancsot.
A következő példa: a fordító optimalizálási konverziói következtében elvesztettük a NULL-ra mutató mutató ellenőrzését a hivatkozás megszüntetése előtt.
#beleértve
Mivel a 3. sor a mutató hivatkozását megszünteti, a fordító azt feltételezi, hogy a mutató nem nulla. Ezt követően az "elérhetetlen kód kiküszöbölése" optimalizálás eredményeként a 4. sort töröltük, mivel az összehasonlítás redundánsnak minősül, majd ezt követően a 3. sort is törölte a fordító a "holt kód megszüntetése" optimalizálás eredményeként. Csak az 5. sor maradt meg. Az alábbiakban látható a gcc 7.3 Linux x86 alatti -O2 kapcsolóval történő fordításával kapott assembler kód.
Szöveg .p2align 4.15 .globl _Z7CheckerPi .type _Z7CheckerPi, @function _Z7CheckerPi: movl 4 (% esp),% eax movl $ 8, (% eax) ret
A fordítóoptimalizálás működésére vonatkozó fenti példák az UB kódban definiálatlan viselkedésének az eredménye. Ez azonban teljesen normális kód, amelyet a legtöbb programozó biztonságosnak tart. Ma a programozók időt áldoznak arra, hogy kiküszöböljék a nem definiált viselkedést egy programban, míg 10 évvel ezelőtt nem figyeltek rá. Ennek eredményeként az örökölt kód az UB jelenlétével kapcsolatos sebezhetőségeket tartalmazhat.
A legtöbb modern statikus forráskód-elemző nem észleli az UB-vel kapcsolatos hibákat. Ezért, ha a kód az információbiztonsági követelmények szempontjából kritikus funkcionalitást hajt végre, ellenőrizni kell mind a forráskódját, mind a közvetlenül végrehajtandó kódot.
annotáció
Jelenleg számos eszközt fejlesztettek ki a programok sebezhetőségeinek keresésének automatizálására. Ez a cikk ezek közül néhányat ismertet.
Bevezetés
A statikus kódelemzés olyan szoftverelemzés, amelyet a programok forráskódján hajtanak végre, és anélkül hajtanak végre, hogy ténylegesen végrehajtanák a vizsgált programot.
A szoftverek gyakran tartalmaznak különféle sebezhetőségeket a programkód hibái miatt. A programok fejlesztése során elkövetett hibák bizonyos helyzetekben a program meghibásodásához vezetnek, és emiatt a program normál működése megszakad: ilyenkor gyakran előfordul adatváltozás, sérülés, a program vagy akár a rendszer leállása. A sérülékenységek többsége a kívülről kapott adatok hibás feldolgozásával, vagy azok nem megfelelő ellenőrzésével kapcsolatos.
A sérülékenységek azonosítására különféle eszközöket használnak, például a program forráskódjának statikus elemzőit, amelyek áttekintését ebben a cikkben adjuk meg.
A biztonsági rések osztályozása
Ha a program minden lehetséges bemeneti adaton megfelelő működésére vonatkozó követelmény megsérül, akkor lehetségessé válik az úgynevezett biztonsági rések megjelenése. A biztonsági rések oda vezethetnek, hogy egyetlen program segítségével az egész rendszer biztonsági korlátait le lehet küzdeni.
A védelmi sebezhetőségek osztályozása szoftverhibáktól függően:
- Puffer túlcsordulás. Ez a sérülékenység abból adódik, hogy a program végrehajtása során nem lehet ellenőrizni a memóriában lévő tömb határait. Ha egy túl nagy adatcsomag túlcsordul egy korlátozott méretű puffert, az idegen memóriacellák tartalma felülíródik, a program összeomlik és kilép. A puffernek a folyamatmemóriában való elhelyezkedése alapján puffertúlcsordulások vannak a veremben (verem puffer túlcsordulás), a kupacban (heap puffer túlcsordulás) és a statikus adatok területén (bss puffer túlcsordulás).
- Sebezhetőségek (szennyezett beviteli sebezhetőség). Sebezhetőségek merülhetnek fel, ha a felhasználói bevitel megfelelő ellenőrzés nélkül kerül át valamilyen külső nyelv (általában a Unix shell vagy SQL) értelmezőjébe. Ebben az esetben a felhasználó megadhatja a bemeneti adatokat úgy, hogy az elindított interpreter a sérülékeny program készítői által szándékolttól teljesen eltérő parancsot hajtson végre.
- Formázási karakterlánc sebezhetőségi hibák. Az ilyen típusú biztonsági rés a sebezhetőség egy alosztálya. Ez az elégtelen paramétervezérlés miatt fordul elő, amikor a C szabványkönyvtár printf, fprintf, scanf stb. formátumú I / O függvényeit használja. Ezek a függvények az egyik paraméterként egy karakterláncot vesznek fel, amely meghatározza a függvény későbbi argumentumainak bemeneti vagy kimeneti formátumát. Ha a felhasználó meg tudja adni a formázás típusát, akkor ez a sérülékenység a karakterlánc formázási funkciók sikertelen használatából eredhet.
- Időzítési hibák (versenykörülmények) következményeként fellépő sebezhetőségek. A többfeladatos működéssel kapcsolatos problémák a következő helyzetekhez vezetnek: egy program, amelyet nem multitasking környezetben való futtatásra terveztek, azt gondolhatja, hogy például az általa használt fájlokat egy másik program nem tudja megváltoztatni. Ennek eredményeként egy támadó, aki időben lecseréli ezeknek a munkafájloknak a tartalmát, bizonyos műveletek végrehajtására kényszerítheti a programot.
Természetesen a felsoroltakon kívül vannak más osztályok is a biztonsági réseknek.
A meglévő analizátorok áttekintése
A következő eszközöket használják a programok biztonsági résének észlelésére:
- Dinamikus hibakeresők. Eszközök, amelyek lehetővé teszik a program hibakeresését annak végrehajtása során.
- Statikus elemzők (statikus hibakeresők). Eszközök, amelyek a program statikus elemzése során felhalmozott információkat használják fel.
A statikus analizátorok jelzik a program azon helyeit, ahol a hiba található. Ezek a gyanús kódrészletek hibát tartalmazhatnak, vagy teljesen biztonságosak.
Ez a cikk áttekintést nyújt több létező statikus analizátorról. Nézzük meg mindegyiket közelebbről.
1. BOON
Egy olyan eszköz, amely mély szemantikai elemzés alapján automatizálja a C-források vizsgálatának folyamatát a puffertúlcsorduláshoz vezető sebezhetőségek felkutatása érdekében. A lehetséges hibákat úgy észleli, hogy feltételezi, hogy bizonyos értékek egy adott puffermérettel rendelkező implicit típus részei.
2. CQual
Elemző eszköz a C programok hibáinak észlelésére. A program a C nyelvet további felhasználó által definiált típusleírókkal bővíti. A programozó a megfelelő specifikációkkal kommentálja a programját, és a cqual ellenőrzi a hibákat. A helytelen megjegyzések lehetséges hibákat jeleznek. A Qual a lehetséges formátumkarakterlánc-sebezhetőségek észlelésére használható.
3. MOPS
(Model checking Programs for Security) egy eszköz a C-programok biztonsági réseinek felderítésére. Célja a C program dinamikus frissítése, hogy illeszkedjen a statikus modellhez. A MOPS szoftver-auditálási modellt használ annak meghatározására, hogy egy program megfelel-e a biztonságos szoftver létrehozásához meghatározott szabályoknak.
4. ITS4, RATS, PScan, Flawfinder
A következő statikus analizátorok használhatók a puffertúlcsordulás és a formázási karakterlánc hibák keresésére:
- ... Egy egyszerű eszköz, amely statikusan ellenőrzi a C / C ++ forráskódot, hogy észlelje a lehetséges biztonsági réseket. Megjegyzi a potenciálisan veszélyes függvények, például az strcpy / memcpy hívásait, és felületes szemantikai elemzést végez, megpróbálja felmérni, mennyire veszélyes az ilyen kód, és tanácsokat ad a javításához.
- ... A RATS (Rough Auditing Tool for Security) segédprogram C / C ++ nyelven írt kódot dolgoz fel, és képes Perl, PHP és Python parancsfájlokat is feldolgozni. A RATS megvizsgálja a forráskódot potenciálisan veszélyes függvényhívások után kutatva. Ennek az eszköznek nem az a célja, hogy véglegesen megtalálja a hibákat, hanem érvényes következtetéseket vonjon le, amelyek alapján a szakember manuálisan ellenőrizheti a kódot. A RATS a biztonsági ellenőrzések kombinációját használja az ITS4 szemantikai ellenőrzésétől a mély szemantikai elemzésig a MOPS-ből származó puffertúlcsordulási hibák keresésére.
- ... Ellenőrzi a C-forrásokat a printf-szerű funkciókkal való esetleges visszaélések után, és felfedi a formátumkarakterlánc-sebezhetőségeket.
- ... A RATS-hez hasonlóan ez is egy statikus C / C ++ forráskód-szkenner. Megkeresi a leggyakrabban visszaélt funkciókat, kockázati pontszámokat rendel hozzájuk (például az átadott paraméterek alapján), és összeállítja a lehetséges sebezhetőségek listáját, kockázat szerint rendezve.
Mindezek az eszközök hasonlóak, és csak lexikális és alapvető elemzést használnak. Ezért az ezen programok által előállított eredmények akár 100%-ban hamis üzeneteket is tartalmazhatnak.
5. Csomó
A C-programok elemzésére és megjelenítésére szolgáló eszköz, amely egy függőségi gráfot épít fel, hogy segítse az auditort a program moduláris felépítésének megértésében.
6. UNO
Egy egyszerű forráskód-elemző. Úgy tervezték, hogy megtalálja a hibákat, például az inicializálatlan változókat, a nulla mutatókat és a tömbtúllépéseket. Az UNO lehetővé teszi a vezérlési folyamatok és az adatfolyamok egyszerű elemzését, mind az eljáráson belüli, mind az eljárások közötti elemzést, valamint a felhasználói tulajdonságok megadását. De ez az eszköz nincs véglegesítve valódi alkalmazások elemzésére, nem támogat sok szabványos könyvtárat, és a fejlesztés ezen szakaszában nem teszi lehetővé komoly programok elemzését.
7. Flexelint (PC-Lint)
Ez az elemző a forráskód elemzésére szolgál a különféle típusú hibák észlelése érdekében. A program a forráskód szemantikai elemzését, az adatfolyamok elemzését és az ellenőrzést végzi.
A munka végén több fő típusú üzenet jelenik meg:
- Lehetséges null mutató;
- Memóriakiosztási problémák (pl. nincs szabad () a malloc () után);
- Problémás vezérlési folyamat (például elérhetetlen kód);
- Puffer túlcsordulás, aritmetikai túlcsordulás lehetséges;
- Rossz és potenciálisan veszélyes kódstílusú figyelmeztetések.
8. Viva64
Egy eszköz, amely segít a szakembernek nyomon követni a C / C ++ programok forráskódjában a 32 bites rendszerről 64 bitesre való átálláshoz kapcsolódó potenciálisan veszélyes töredékeket. A Viva64 a Microsoft Visual Studio 2005/2008 környezetbe van beágyazva, ami megkönnyíti a kényelmes munkát ezzel az eszközzel. Az elemző segít helyes és optimalizált kód megírásában 64 bites rendszerekhez.
9. Parasoft C ++ teszt
Egy speciális Windows-eszköz, amely lehetővé teszi a C ++ kód minőségének elemzését. A C ++ tesztcsomag elemzi a projektet, és kódot generál a projektben található összetevők teszteléséhez. A C ++ tesztcsomag nagyon fontos feladatot lát el a C ++ osztályok elemzésében. A projekt betöltése után be kell állítania a tesztelési módszereket. A szoftver megvizsgál minden metódus argumentumot, és visszaadja a megfelelő értékek típusát. Ezeknél az egyszerű típusoknál az alapértelmezett argumentumértékek behelyettesítésre kerülnek; tesztadatokat definiálhat a felhasználó által definiált típusokhoz és osztályokhoz. Felülbírálhatja az alapértelmezett C ++ teszt argumentumokat, és visszaadhatja a teszt értékeit. Külön kiemelendő a C ++ Test azon képessége, hogy tesztelni tudja a befejezetlen kódot. A szoftver csonkkódot generál minden olyan módszerhez és funkcióhoz, amely még nem létezik. A külső eszközök és a felhasználó által definiált bemenetek szimulációja támogatott. Mindkét funkció újratesztelhető. Az összes módszer tesztparamétereinek meghatározása után a C ++ tesztcsomag készen áll a futtatható kód futtatására. A csomag tesztkódot generál a Visual C ++ fordító meghívásával annak előkészítéséhez. Lehetőség van tesztek kialakítására metódus, osztály, fájl és projekt szintjén.
10. Takarás
Eszközöket használnak a biztonsági és minőségi hibák azonosítására és kijavítására a kritikus fontosságú alkalmazásokban. A Coverity technológiája megszünteti az összetett szoftverek írásának és telepítésének akadályait azáltal, hogy automatizálja a kritikus szoftverhibák és biztonsági hibák keresését és kijavítását a fejlesztési folyamat során. A Coverity eszköze több tízmillió kódsor kezelésére képes minimális pozitív hibával, 100%-os sávlefedettséget biztosítva.
11. KlocWork K7
A cég termékeit automatizált statikus kódelemzésre, szoftverhibák és biztonsági problémák észlelésére és megelőzésére tervezték. A cég eszközei a szoftverminőségi és biztonsági hiányosságok kiváltó okainak azonosítását, illetve ezen hiányosságok nyomon követését és megelőzését szolgálják a fejlesztési folyamat során.
12. Frama-C
Nyílt, integrált eszközkészlet a C forráskód elemzéséhez. A készlet tartalmazza az ANSI / ISO C specifikációs nyelvet (ACSL), egy speciális nyelvet, amely lehetővé teszi a C függvények specifikációinak részletes leírását, például egy funkció érvényes bemeneti értékeinek és a normál kimeneti tartományának megadását. értékeket.
Ez az eszköztár a következő műveletek végrehajtásában segít:
- Végezze el a kód formális felülvizsgálatát;
- Keresse meg a lehetséges végrehajtási hibákat;
- Auditálja vagy tekintse át a kódot;
- Fejtse fel a kódot a szerkezet megértésének javítása érdekében;
- Formális dokumentáció készítése.
13. CodeSurfer
Programelemző eszköz, amelyet nem kifejezetten a biztonsági rések keresésére terveztek. Fő előnyei a következők:
- Mutatóelemzés;
- Az adatáramlás különféle elemzései (változók használata és meghatározása, adatfüggőség, hívási gráf készítése);
- Szkriptnyelv.
A CodeSurfer használható a forráskód hibáinak felderítésére, a forráskód megértésének javítására és a programok újratervezésére. A CodeSurfer keretein belül elkészült a biztonsági rések felderítésére szolgáló prototípus eszköz, de a kifejlesztett eszközt csak a fejlesztő szervezeten belül használják.
14. FxCop
Eszközt biztosít a .NET-szerelvények automatikus érvényesítésére a Microsoft .NET-keretrendszer tervezési irányelvei szerint. A lefordított kód ellenőrzése tükrözési mechanizmusok, MSIL elemzés és hívásgráf elemzés segítségével történik. Ennek eredményeként az FxCop több mint 200 hibát (vagy hibát) képes észlelni a következő területeken:
- Könyvtári architektúra;
- Lokalizáció;
- Elnevezési szabályok;
- Teljesítmény;
- Biztonság.
Az FxCop lehetőséget biztosít saját szabályok létrehozására egy speciális SDK segítségével. Az FxCop a grafikus felületen és a parancssorban is működhet.
15. JavaChecker
Ez a TermWare technológián alapuló statikus elemző a Java programok számára.
Ez az eszköz lehetővé teszi a kód hibáinak azonosítását, például:
- a kivételek gondatlan kezelése (üres fogásblokkok, általános kivételek dobása stb.);
- nevek elrejtése (például amikor egy osztálytag neve megegyezik egy metódus formális paraméterének nevével);
- stílussértések (programozási stílust reguláris kifejezések készletével adhat meg);
- szabványos használati szerződések megsértése (például ha az egyenlő metódus felül van írva, de a hashCode nem);
- szinkronizálási megsértések (például ha egy szinkronizált változóhoz való hozzáférés a szinkronizált blokkon kívül van).
Az ellenőrzések halmaza vezérlő megjegyzésekkel vezérelhető.
A JavaChecker az ANT szkriptből hívható meg.
16. Simian
Hasonlósági elemző, amely egyszerre több fájlban is keresi a szintaxis ismétlődését. A program megérti a különböző programozási nyelvek, köztük a C #, a T-SQL, a JavaScript és a Visual BasicR szintaxisát, és szöveges fájlokban is képes keresni a duplikált töredékeket. Számos testreszabási lehetőség lehetővé teszi a duplikált kód keresési szabályainak finomhangolását. Például a küszöb paraméter határozza meg, hogy hány ismétlődő kódsor minősül ismétlődőnek.
A Simian egy kis eszköz, amelyet a kódismétlések hatékony megtalálására terveztek. Hiányzik a grafikus felület, de elindítható parancssorból vagy programozottan elérhető. Az eredmények szöveges formában jelennek meg, és a beépített formátumok egyikében (például XML) is megjeleníthetők. Míg a Simian karcsú felülete és korlátozott kimeneti lehetőségei némi képzést igényelnek, segít megőrizni a termék integritását és hatékonyságát. A Simian alkalmas duplikált kód megtalálására nagy és kis projektekben egyaránt.
A duplikált kód csökkenti a projekt karbantarthatóságát és frissíthetőségét. A Simian segítségével gyorsan megtalálhatja a kód ismétlődő darabjait több fájlban egyszerre. Mivel a Simian parancssorból is futtatható, beépíthető az építési folyamatba, hogy figyelmeztetéseket kapjon, vagy leállítsa a folyamatot, ha a kód ismétlődik.
Következtetés
Tehát ebben a cikkben a forráskód statikus elemzőit vettük figyelembe, amelyek a programozó segédeszközei. Mindegyik eszköz más és más, és segít nyomon követni a szoftver legkülönfélébb biztonsági résosztályait. Megállapítható, hogy a statikus analizátoroknak pontosnak és érzékenynek kell lenniük. De sajnos a statikus hibakereső eszközök nem adhatnak abszolút megbízható eredményt.
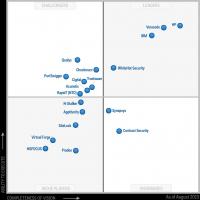 Az örökölt kód elemzése a forráskód elvesztése esetén: tegyen vagy ne?
Az örökölt kód elemzése a forráskód elvesztése esetén: tegyen vagy ne? A Windows nem töltődik be a frissítések telepítése után A laptop nem kapcsol be a Windows 10 frissítése után
A Windows nem töltődik be a frissítések telepítése után A laptop nem kapcsol be a Windows 10 frissítése után A jelszó feltörése: a leggyakoribb módszerek áttekintése
A jelszó feltörése: a leggyakoribb módszerek áttekintése Tiltsa le a titkosítást a táblagépen
Tiltsa le a titkosítást a táblagépen Izzó készítése. Edison izzója. Ki találta fel az első izzót? Miért jutott Edisonhoz minden dicsőség? Az izzólámpa eszközének változástörténete
Izzó készítése. Edison izzója. Ki találta fel az első izzót? Miért jutott Edisonhoz minden dicsőség? Az izzólámpa eszközének változástörténete Hogyan találhatja meg gyorsan telefonját a Google-on, bárhol is legyen
Hogyan találhatja meg gyorsan telefonját a Google-on, bárhol is legyen Az elektromos izzólámpát Oroszországban találták fel
Az elektromos izzólámpát Oroszországban találták fel