Universal PHP content parser. We write content parser on PHP. Reading a file in php line with fgets ()
I decided to give an article to the actual form. Earlier, the Universal HTML Page PHP was presented on this page. But for more than 4 years has passed, I have worked more experience in the field of parser development. And I decided to lay out a new example of PHP Parser with a detailed analysis of the work algorithm.
Parser last version wore a proud title of universal, but it was a very subjective designation. The script had many restrictions, for its full use, knowledge was required in regular expressions on PHP and JS.
I thought, I thought and decided that a more versatile decision would be to show an example of a parser on PHP and tell how it works. So programmers who previously did not write parsers will be able to solve their tasks. And customers will be able to understand the possibilities of PHP in the field of site parceration and what can actually require programmers.
Parser. - This is a program that analyzes input text data, retrieves the necessary information and based on the data obtained gives the result in a given format.
The general PHP PARSING algorithm assumes that your script makes a query at a given address, receives a response from the server as an HTML page, or in some other text format, such as CSV, JSON, XML. Further, the information obtained is analyzed, from it is retrieved (parsing) the necessary data on the basis of which the result is formed. The data obtained can be displayed on the screen, or write to a file or database.
Example of a simple PHP Paraser HTML Content
Suppose we need to resort the price of goods on the site gearbest.com. The script reads the specified page, then through regular expressions it analyzes its content and highlights the slices of HTML code you need. Next, the result is displayed on the screen.
/ US "; $ buffer \u003d array (); preg_match ($ REGEXP, $ Page, $ buffer); $ RES_Arr [" Price_List "] [" Currency "] \u003d $ buffer; $ RES_Arr [" error "] \u003d" "; ) ELSE ($ res_arr ["Price"] \u003d 0; $ RES_Arr ["Currency"] \u003d "nodata"; $ RES_Arr ["Error"] \u003d "page load error";) Return $ res_arr;) / * 1.4 --- Data Output in HTML * / / * --- 1.4.1 --- Translation of the prices * / Function price_list_html ($ Price_List) (Echo
Price: "$ Price_List [" Price "]." "$ Price_List [" Currency "]."
";) / * --- 1.4.2 --- Error output * / FUNCTION ERROR_LIST_HTML ($ error) (if (! Empty ($ error)) (Echo"During the processing of the query, the following errors occur:
\\ n "; echo"- \\ N "; Foreach ($ Error As $ error_row) (Echo"
- ". $ error_row." \\ n ";) echo"
Status: Fail
\\ n ";) ELSE (Echo"Status: OK.
\\ n ";)) / * --- 1.4.3 --- Disposition of page load errors * / function error_page_list_html ($ error_page) (if (! Empty ($ error_page)) (Echo"- \\ n "; foreach ($ error_page as $ error_row) (echo"
- [". $ error_row."] "$ ERROR_ROW" - ". $ error_row." \\ n ";) echo"
PARRER PRICES Items on Gearbest.com
index.php. - The main PHP file of the parser script. Parser code is relevant at the time of publication. Over time, the HTML site code of the source may change and regular expressions will no longer be approached.
There are different ways to install the script. I worked with him from under XAMPP. But you can run the parser straight with. Just pour file index.php. To your site in any folder and access to it through the address bar of the browser. Suppose you snapped the script to the My folder -Parser. In the root directory of your hosting. Then you need to dial the URL in the address bar: http: //vashdomen.ru/my-parser/.
Screenshot of the main page of Parser Prices from Gearbest.com:
1. On the main page of the Parser, we must enter the address of the product page. After clicking on the "Start" button, the page restarts, the form data on the server and the PHP script makes a query at a given address using the CURL library.
For this action responds function curl_get_contents ()which is analogue standard php function file_Get_Contents ()but with curl-based extended functionality.
curl - This is an extension for PHP, which provides LIBCURL functions support. This feature set allows you to form POST and PUT requests, download files. Different HTTP, HTTPS, FTP protocols are supported. You can use proxy servers, cookies and user authentication. In general, an excellent tool for imitating user actions in the browser.
the CURL is a very useful thing for the development of HTML parser, and in one of I will tell you more detail about the receptions of working with it for the purpose of the parsing.
 Please note that the script sees a page in text format and analyze its HTML code.
Please note that the script sees a page in text format and analyze its HTML code.
3. The next step is formed and displayed on the screen resulting based on data after parsing. In our case, this is the currency and the price of goods.
Thus, for the successful development of parsers on the PHP programmer, you need to be able to work with the CURL Library and PHP regular expressions.
How to Poule encrypted data
In some cases, the server gives HTML pages in a compressed or protected form, such as Accept-Encoding: GZIP. In this case, the connection of supported compression formats in the query may not affect the response format.
In such cases, you need to decrypt the answer, for example, standard PHP function gZDECODE (). And then you can work on the old scheme.
Data across the BASE64 algorithm can be decrypted by the function bASE64_ENCODE ().
PHP Parser HTML site for free
Actually the answer to the question where to take PHP parser sites for free, simple - write it yourself. The base algorithm of the work of parsers, I described above in detail.
You can search for already ready, written by someone's solutions for your task. But to make a parser who would approach all options on the machine, probably impossible. Under each type of task, you need to develop your specific product.
And for those who do not want to bathe with regular expressions and parser settings, I am ready to make it refinement for you, but, of course, it will cost money :-).
The final cost of development services is determined after receiving a specific technical task. The price is set strictly before starting the work, during the workflow, the financial conditions do not change. I work in 100% prepayment. Minimum order is 2000 rubles.
Often the price of Parser is quite high, and this is due to the fact that the development is obtained unique, sharpened under a specific customer. Miscellaneous There are options for entrance melon, an individual output result is required.
In this case, you can also form a parser for yourself. For example, the price of the development of the parser turned out to be 9,000 rubles. You are looking for 9 people with a similar problem and collect 1000 rubles from them, order the development of a parser. Then you make 10 copies, 1 ourselves and 9 give your acquaintances.
In the next cycle of articles, I will show examples of the implementation of more complex parsers, etc.
In general, my dear readers, than I could help, read, learn and do not forget to link to the blog.
If you need to make a PARSING HTML document, regular expressions are not the best way for this. In addition, their writing, labor-intensive process, and they reduce the speed of the PHP application. In this article, you will learn how to use your free HTML parser, to read, change, extract some DOM elements from HTML pages. Moreover, an HTML resource may be an external source. That is, the address of HTML pages on another domain. Using as an example, site sitear.ruYou will learn how to get and display a list of all published materials on the site's main page. In other words, you will do what you need, HTML PARS using PHP. In this case, PHP is implied by the Simple HTML DOM library.
Just follow all the steps of the article, and learn a lot of new and useful for yourself!
Step 1 - Preparation
To begin with, you need to download a copy simple Html DOMlibraries. Download free.
In the archive you will find several files, but we need only one - simple_html_dom.php.. All others, these are examples and documentation.
Step 2 - Parsing HTML Basics
This library is very easy to use, but still, it is necessary to disassemble some basics before using it.
$ HTML \u003d new simple_html_dom (); // Load from a string $ HTML-\u003e Load ("Hello WORLD!
"); // Load a File $ HTML-\u003e LOAD_FILE (" http: // Site / ");Everything is simple, you can create an object by downloading HTML from the string. Or download HTML code from the file. You can download the file by the URL address, or with your local file system (server).
Important to remember:Load_file () method works on using PHP File_Get_Contents features. If in your php.ini file, the Allow_URL_FOPEN parameter is not set as true, you will not be able to receive HTML files at a remote address. But, you can upload these files using the CURL library. Next, read the content using the Load () method.
Get access to HTML DOM objects

Suppose we already have a DOM object, a structure, as in the picture above. You can start working with it using the Find () method, and creating collections. Collections are groups of objects found using selectors - syntax in something similar to jQuery.
Hello WORLD!
WE "RE HERE.
Using this example of HTML code, we learn how to access the information prisoner in the second paragraph (P). Also, we will change the information received and derive the result on the display.
// Creating a parser object and receiving HTML Include ("Simple_HTML_DOM.PHP"); $ HTML \u003d new simple_html_dom (); $ HTML-\u003e LOAD ("
Hello WORLD!
"); // Obtaining arrays of paragraphs $ Element \u003d $ HTML-\u003e FIND (" P "); // Changing information within the paragraph of $ Element-\u003e InnerText. \u003d" and we "Re Here to Stay."; // Output Echo $ HTML-\u003e SAVE ();
As you can see to implement PHP parsing of HTML document, it is very easy using Simple HTML DOM library. In principle, in this piece of PHP code, everything can be understood intuitively, but if you doubt something, we will look at the code.
Line 2-4: Connect the library, create a class object and load HTML code from the line.
Line 7: With this line, we find everything
tags in HTML code, and we save in a variable as an array. The first paragraph will have index 0, the remaining paragraphs will be indexed according to 1,2,3 ...
Line 10: We get the contents of the second paragraph in our collection. Its index will be 1. We also make changes to the text using the InNERTEXT attribute. The InNERTEXT attribute changes all the contents inside the specified tag. We can also change the tag itself using the OUTERTEXT attribute.
Let's add another PHP code line with which we assign the style class to our paragraph.
$ Element-\u003e Class \u003d "class_name"; Echo $ HTML-\u003e SAVE ();
The result of the execution of our code will be the next HTML document:
Hello WORLD!
WE "RE HERE AND WE" RE HERE TO STAY.
Other selectors
Below are other examples of selectors. If you used jQuery, then in the Simple HTML DOM library, the syntax is slightly similar.
// Get the first element with id \u003d "foo" $ Single \u003d $ HTML-\u003e FIND ("# Foo", 0); // receives all elements with class \u003d "foo" $ collection \u003d $ HTML-\u003e FIND when parseing); // gets all tags With the $ collection \u003d $ HTML-\u003e FIND ("A") parsing; // gets all tags who are placed in the tag $ Collection \u003d $ HTML-\u003e FIND ("H1 A"); // Gets all images with title \u003d "(! Lang: Himom"
$collection = $html->find("img");
!}
Using the first selector with PHP PARS HTML document, very simple and understandable. Its uniqueness is that it returns only one HTML element, unlike others that return an array (collection). The second parameter (0), we indicate that we need only the first element of our collection. I hope you understand all the variants of the Simple HTML DOM selector selectors if you do not understand something, try the method of scientific experiment. If he did not help, contact the article.
Simple HTML DOM documentation
Full documentation for using the Simple HTML DOM library can be found at this address:
http://simplehtmldom.sourceforge.net/manual.htm.
Just give you an illustration that shows the possible properties of the selected HTML DOM element.

Step 3 - Real EXAMPLE PHP PARSING HTML Document
For the example of the parsing, and bring the HTML DOM into action, we will write graver materials on the site website. Next, we will withdraw all articles in the form of a list in which the names of the articles will be indicated. When writing grabrov, remember, the theft of the content is prosecuted! But not in the case when the page is worth an active reference to the source document.

Include ("Simple_html_dom.php"); $ articles \u003d array (); GetArticles ("http: // Site /");
Start with the library connection and function call getArticles Which will pass HTML documents according to the address of the page that is transmitted as a function parameter.
We also specify a global array in which all information about articles will be stored. Before starting the PARSING HTML document, let's see how it looks.
This is the basic template of this page. When writing a parser HTML, you need to carefully examine the document, since comments, such as, these are also descendants. In other words, in the eyes of the Simple HTML DOM library, these are elements that are equivalent to other tags of the page.
Step 4 - Write the main feature of PHP Paraser HTML
Function GetArticles ($ Page) (Global $ Articles; $ HTML \u003d New Simple_HTML_DOM (); $ HTML-\u003e LOAD_FILE ($ Page); // ... Next ...)Initially, we call our global array that we have indicated earlier. Create a new Simple_HTML_DOM object. Next, download the page that we will pars.
Step 5 - Find the desired information
$ items \u003d $ HTML-\u003e FIND ("DIV"); Foreach ($ Items As $ Names) ($ Articles \u003d Array ($ Post-\u003e Children (0) -\u003e PlainText);)In this piece of code, everything is extremely simple, we find all the div with Class \u003d Name_Material. Next, we read the collection of elements and choose the names of the materials. All materials will be saved in the array in this form:
$ articles \u003d "material name 1"; $ articles \u003d "material name 2"; ...
Step 6 - Display Parside Result
To begin with, we will install some styles, for the beauty of the displayed information that received during Parsing.
Item (Padding: 10px; Color: # 600; Font: Bold 40px / 38px Helvetica, Verdana, Sans-Serif;)
"Echo $ Item; Echo"
The result of the execution of this script will be a list of titles of articles on the site site.
Conclusion
So we learned the PHP parting HTML documents. Remember that Parsing is a long process. One page can parse about one second. If you do a large number of HTML documents, your server can reverse the script operation in connection with the expiration of the time set for execution. This can be corrected using the set_time_limit (240) function; 240 - this time in seconds, allocated to execute the script.
This article is intended to form the basic concepts of the HTML page by PHP. There are other libraries and parsing methods. If you know those, share in the comments. I will be glad to know what instruments and HTML methods of the Parsing are you.
In order to parsing the website page (that is, to disassemble her HTML code), it should be obtained for starters. And then the received code can be disassembled using regular expressions and, or somehow analyze it, or save it to the database or both.
Getting Site Pages using File_Get_Contents
So, for starters, let's get together to receive the pages of sites into the PHP variable. This is done using the function. file_Get_contents.which is most often used to obtain data from the file, however, can be used to get the site page - if you cannot transfer it to the file to the file, but the URL of the site page.
Note that this feature is not perfect and there is a more powerful analogue - library Curlwhich allows you to work with cookies, with headlines, allows you to send shapes and proceed by redirects. All this file_Get_contents. Does not know how, however, for the beginning, she will come down, and work with Curl We will analyze in the next lesson.
So, let's get the main page of my site for example and bring it to the screen (do it):
What you will receive as a result: on the screen you will see the page of my site, however, most likely without CSS styles and pictures (whether CSS and pictures will work - it depends on the site, why it is so will look later).
Let's now bring the site page, but its source code. We write it to the variable $ STR. and bring to the screen using var_Dump:
Note that var_Dump Must be configured correctly in the PHP configuration (see the previous lesson for this). Correctly - it means you should see tags and there should be no restrictions on the length of the string (the site page code can be very large and desirable to see it all).
So, if everything is done well, and you see the source code of the site page - it's time to get to his parting with regular expressions.
If you do not know regular expressions or doubt your knowledge - it's time to learn the textbook on regular expressions, and then return to the study of this Partsing Guide.
Allow_url_fopen directive must be enabled http://php.net/manual/ru/fileSystem.configuration.php#ini.allow-url-fopen
Parsing with regular expressions
When trying to disassemble the HTML code with the help of regular expressions you will be waiting for some pitfalls. Their presence is most often due to the fact that regular expressions are not intended to disarm tags - there are more advanced tools for this, for example, the phpquery library, which we will disassemble in the following lessons.
However, be able to use regular Parside Expressions It is also important - first, regularly it is simple (if you already know them - then a simple) and a popular tool for parsing, secondly, regularly work an order faster than any libraries (often it is critical), well, and Third, even when using special libraries, the need is still there anyway.
Underwater rocks
First The surprise that awaits you when using preg_match and preg_match_all. - This is what they work only for tags, entirely located on the same line (that is, they do not have a pressed enter). If you try to resign a multi-line tag - you will not succeed until you turn on single-line mode Using modifier s.. So this way:
Second The surprise is waiting for you when you try to work with Cyrillic - in this case you need not forget to write a modifier u. (U small, not to be confused with great), like this:
What other pitfalls are waiting for you - we will disassemble gradually during this lesson.
Let's try to disassemble tags
Let we somehow (for example, through file_Get_contents.) Received HTML site code. Here it is:
Let's deal with his analysis. First, let's get the contents of the tag
Content
:(.+?)#SU ", $ str, $ Res); var_dump ($ res);?\u003e
Content
: (.+?)
#SU ", $ str, $ Res); var_dump ($ res);?\u003e
In general, there is nothing complicated, only note that both the corners of the tags and the plane from the closing tag should not be shielded (the latter is true if the regular regular limiter is not silent /, but, for example, the lattice. now).
However, in fact, our regular regularities are not perfect. Under some conditions, they just refuse to work. You must be prepared for this - sites that you will be painted - different (often they are still outdated), and what works well on one site, it may well stop working on the other.
What do we do wrong? Actually tag
- The same tag, as well as the rest and in it may well be attributes. Most often it is the Class attribute, but others may be (for example, onLoad. To execute javascript).So, rewrite the regular card with the attributes:
(.+?)
#SU ", $ str, $ Res); var_dump ($ res);?\u003e
But here we are mistaken, with more errors. First - should not be put plus + , and star * because plus suggests availability at least one symbol - But after all the attributes in the tag may not be - and in this case between the title of the tag body. And there will be no symbols with the corner - and our regularly will save (it is not clear what I wrote here - Teach regularly).
We will replant this problem and return to further discussion:
(.+?)
 Cellular - what it is on the iPad and what's the difference
Cellular - what it is on the iPad and what's the difference Go to digital television: What to do and how to prepare?
Go to digital television: What to do and how to prepare? Social polls work on the Internet
Social polls work on the Internet Savin recorded a video message to the Tyuments
Savin recorded a video message to the Tyuments Menu of Soviet tables What was the name of Thursday in Soviet canteens
Menu of Soviet tables What was the name of Thursday in Soviet canteens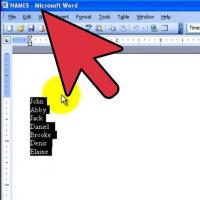 How to make in the "Word" list alphabetically: useful tips
How to make in the "Word" list alphabetically: useful tips How to see classmates who retired from friends?
How to see classmates who retired from friends?