Crearea unui model de bază de date fizic: Designul produsului. Crearea unui model fizic al unei baze de date: Proiectarea partiționării serverului SQL
Bună seara / zi / dimineață Dragă Habraloudi! Continuăm să dezvoltăm și să completăm blogul despre RDBMS-ul meu Open Postgresql. A fost în mod miraculos, așa că sa dovedit că tema subiectului de astăzi nu a fost niciodată ridicată aici. Trebuie să spun că partiționarea în postgreSQL este foarte bine descrisă în documentație, dar mă va opri?).
Introducere
În general, în conformitate cu partiționarea, în general, ei înțeleg nu o tehnologie, ci mai degrabă abordarea de proiectarea bazei de date, care a apărut cu mult înainte ca DBM-urile să înceapă așa-numitul. Mese partiționate. Gândul este foarte simplu - împărțiți tabelul în mai multe părți de dimensiuni mai mici. Există două subspecii - partiționarea orizontală și verticală.Partiționarea orizontală
Părțile din tabel conțin diferite linii. Ne-am stabilit o masă a jurnalelor unei anumite aplicații abstracte - jurnale. O putem sparge în părți - unul pentru bușteni în ianuarie 2009, celălalt - pentru februarie 2009 etc.Partiționarea verticală
Părțile din tabel conțin diferite coloane. Găsiți aplicația pentru partiționarea verticală (când este într-adevăr justificată) oarecum mai complicată decât pentru orizontală. Ca un cal sferic, propun să ia în considerare această opțiune: Tabelul de știri are ID-ul, scurtatul, longtextul și lasa câmpul Longtext este folosit mult mai puțin decât primele două. În acest caz, este logic să spargeți tabelul de știri pe coloane (creați două mese pentru scurtext și lungime, respectiv, chei primare legate + creați știri de vizualizare care conțin ambele coloane). Astfel, când avem nevoie doar de o descriere a știrilor, DBMS nu trebuie să citească de pe disc, de asemenea, întreaga știri text.Sprijinirea partiționării în DBMS moderne
Majoritatea DBM-urilor moderne suportă împărțirea tabelelor într-o formă sau alta.- Oracol - Suportă partiția începând cu 8 versiuni. Lucrul cu secțiunile pe de o parte este foarte simplu (în general, nu vă puteți gândi la ele, lucrați cu o masă obișnuită *), iar pe cealaltă - totul este foarte flexibil. Secțiunile pot fi rupte la "subpartiții", ștergeți, împărțiți, transferați. Sunt acceptate diferite opțiuni pentru indexarea tabelului partiționat (indexul global partiționat). Referire la o descriere voluminoasă.
- Microsoft SQL Server. - Suportul unic a apărut recent (în 2005). Prima impresie de utilizare - "Ei bine, în cele din urmă! :)", a doua - "Lucrări, totul pare să fie în regulă". Documentație pe MSDN.
- Mysql. - Sprijină pornind de la versiunea 5.1. Descriere foarte bună pe Habré
- Etc ...
Partiționarea în postgresql.
Partiționarea tabelelor din PostgreSQL este oarecum diferită în vânzările din alte baze de date. Baza pentru partiție este moștenirea tabelelor (lucrul inerent exclusiv postgresc). Adică, trebuie să avem o masă principală (masterat), iar secțiunile sale vor fi mesele moștenite. Vom lua în considerare partiționarea cu privire la exemplul unei sarcini aproximativă de realitate.Formularea problemei
Baza de date este utilizată pentru colectarea și analizarea datelor pe site-ul / site-ul vizitatorilor. Volumele de date sunt suficient de mari pentru a gândi la partiționare. Atunci când analizați, în majoritatea cazurilor, datele sunt utilizate pentru ultima zi.1. Creați un tabel de bază:
Creați analitică de tabel.events.
User_id uuid nu nul,
event_type_id mic nu este nul,
Event_Time Timestamp Implicit acum () nu nul,
URL Varchar (1024) Nu NULL,
Referitor Varchar (1024),
IP INET NU NULL
);
2. Vom partiționa pe zi de către câmpul Event_Time. Pentru fiecare zi vom crea o nouă secțiune. Vom numi secțiunile în conformitate cu regula: analitics.events_ddmmyyyyy. De exemplu, o secțiune pentru 1 ianuarie 2010.
Creați tabelul Analytics.events_01012010.
EVENT_ID BIGINT implicit NextVal ("analytics.seq_events") cheie primară,
Verificați (Event_Time\u003e \u003d Timestamp "2010-01-01 00:00:00" și Event_Time< TIMESTAMP "2010-01-02 00:00:00" )
) Moștenirea (analitics.events);* Acest cod sursă a fost evidențiat cu evidența codului sursă.
Când creați o secțiune, specificăm în mod explicit câmpul Event_ID (cheia primară nu este moștenită) și creați o constrângere de verificare pe câmpul Event_Time, pentru a nu introduce prea mult.
3. Creați un index în câmpul Event_Time. Când împărțiți masa de pe secțiune, înțelegem că majoritatea solicitărilor la tabelul Evenimente vor folosi condiția pe câmpul Event_Time, astfel încât indexul din acest câmp ne va ajuta foarte mult.
Creați index Evenimente_01012010_Event_Time_idx pe Analytics.events_01012010 utilizând BTERE (Event_Time);* Acest cod sursă a fost evidențiat cu evidența codului sursă.
4. Vrem să ne asigurăm că atunci când introduceți în tabelul principal, datele s-au dovedit a fi secțiunea destinată acestora. Pentru a face acest lucru, facem următoarea faimă - creați un declanșator care va gestiona fluxurile de date.
Creați sau înlocuiți funcția Analytics.events_insert_trigger ()
Returnează declanșatorul ca $$
Începe.
Dacă (New .event_Time\u003e \u003d Timestamp "2010-01-01 00:00:00" și
New .event_time.< TIMESTAMP "2010-01-02 00:00:00" ) THEN
Introduceți valorile Analytics.events_01012010 (noi *);
Altfel.
Ridicați excepția "Date% este în afara domeniului. Fix Analytics.events_Insert_trigger", New .event_time;
Terminați dacă;
Întoarceți null;
Sfârșit;
$$
Limba plpgsql;* Acest cod sursă a fost evidențiat cu evidența codului sursă.
Creați Trigger Events_BoFore_Insert.
Înainte de introducerea pe analitics.events
Pentru fiecare procedură de executare a rândurilor Analytics.events_insert_trigger ();* Acest cod sursă a fost evidențiat cu evidența codului sursă.
5. Totul este gata, acum avem un analitic de masă partiționat. Events. Putem începe să analizăm violent datele sale. Apropo, verificați constrângerile pe care le-am creat nu numai pentru a proteja secțiunile din date incorecte. PostgreSQL le poate folosi atunci când elaborează un plan de solicitare (deși, cu un indice viu pe Event_time, câștigurile vor da minimul), este suficient să se utilizeze Directiva Constraint_exclusion:
Setați constrângere_exclusion \u003d activat;
Selectați * de la Analytics.events Unde Event_Time\u003e Current_Date;* Acest cod sursă a fost evidențiat cu evidența codului sursă.
Sfârșitul primei părți
Deci, ce avem? Sa vedem:1. Tabelul de evenimente, împărțit în secțiuni, analiza datelor disponibile în ziua trecută devine mai ușoară și mai rapidă.
2. Horror de realizare că toate astea trebuie să mențină într-un fel, să creeze secțiunile la timp, fără a uita să schimbe declanșatorul corespunzător.
Despre cât de ușor și neglijent munca cu mesele partiționate va spune în a doua parte.
UPD1: Partiționarea de partiționare înlocuită
UPD2:
Potrivit observațiilor unuia dintre cititorii care nu au, din păcate, contul pe Habré:
Cu moștenire, sunt conectate câteva momente, care ar trebui luate în considerare la proiectarea. Secțiunile nu moștenesc cheile primare și cheile externe pe coloanele lor. Adică, atunci când creați o secțiune, trebuie să creați în mod explicit cheia primară și cheile străine pe coloanele secțiunii. De la mine am observat că crearea de chei străine pe coloanele mesei partiționate nu este cea mai bună cale. În majoritatea cazurilor, o masă partiționată este "tabelul faptelor" și se referă la tabelul "Dimensiune".
Bună seara / zi / dimineață Dragă Habraloudi! Continuăm să dezvoltăm și să completăm blogul despre RDBMS-ul meu Open Postgresql. A fost în mod miraculos, așa că sa dovedit că tema subiectului de astăzi nu a fost niciodată ridicată aici. Trebuie să spun că partiționarea în postgreSQL este foarte bine descrisă în documentație, dar mă va opri?).
Introducere
În general, în conformitate cu partiționarea, în general, ei înțeleg nu o tehnologie, ci mai degrabă abordarea de proiectarea bazei de date, care a apărut cu mult înainte ca DBM-urile să înceapă așa-numitul. Mese partiționate. Gândul este foarte simplu - împărțiți tabelul în mai multe părți de dimensiuni mai mici. Există două subspecii - partiționarea orizontală și verticală.Partiționarea orizontală
Părțile din tabel conțin diferite linii. Ne-am stabilit o masă a jurnalelor unei anumite aplicații abstracte - jurnale. O putem sparge în părți - unul pentru bușteni în ianuarie 2009, celălalt - pentru februarie 2009 etc.Partiționarea verticală
Părțile din tabel conțin diferite coloane. Găsiți aplicația pentru partiționarea verticală (când este într-adevăr justificată) oarecum mai complicată decât pentru orizontală. Ca un cal sferic, propun să ia în considerare această opțiune: Tabelul de știri are ID-ul, scurtatul, longtextul și lasa câmpul Longtext este folosit mult mai puțin decât primele două. În acest caz, este logic să spargeți tabelul de știri pe coloane (creați două mese pentru scurtext și lungime, respectiv, chei primare legate + creați știri de vizualizare care conțin ambele coloane). Astfel, când avem nevoie doar de o descriere a știrilor, DBMS nu trebuie să citească de pe disc, de asemenea, întreaga știri text.Sprijinirea partiționării în DBMS moderne
Majoritatea DBM-urilor moderne suportă împărțirea tabelelor într-o formă sau alta.- Oracol - Suportă partiția începând cu 8 versiuni. Lucrul cu secțiunile pe de o parte este foarte simplu (în general, nu vă puteți gândi la ele, lucrați cu o masă obișnuită *), iar pe cealaltă - totul este foarte flexibil. Secțiunile pot fi rupte la "subpartiții", ștergeți, împărțiți, transferați. Sunt acceptate diferite opțiuni pentru indexarea tabelului partiționat (indexul global partiționat). Referire la o descriere voluminoasă.
- Microsoft SQL Server. - Suportul unic a apărut recent (în 2005). Prima impresie de utilizare - "Ei bine, în cele din urmă! :)", a doua - "Lucrări, totul pare să fie în regulă". Documentație pe MSDN.
- Mysql. - Sprijină pornind de la versiunea 5.1.
- Etc ...
Partiționarea în postgresql.
Partiționarea tabelelor din PostgreSQL este oarecum diferită în vânzările din alte baze de date. Baza pentru partiție este moștenirea tabelelor (lucrul inerent exclusiv postgresc). Adică, trebuie să avem o masă principală (masterat), iar secțiunile sale vor fi mesele moștenite. Vom lua în considerare partiționarea cu privire la exemplul unei sarcini aproximativă de realitate.Formularea problemei
Baza de date este utilizată pentru colectarea și analizarea datelor pe site-ul / site-ul vizitatorilor. Volumele de date sunt suficient de mari pentru a gândi la partiționare. Atunci când analizați, în majoritatea cazurilor, datele sunt utilizate pentru ultima zi.1. Creați un tabel de bază:
Creați analitică de tabel.events.
User_id uuid nu nul,
event_type_id mic nu este nul,
Event_Time Timestamp Implicit acum () nu nul,
URL Varchar (1024) Nu NULL,
Referitor Varchar (1024),
IP INET NU NULL
);
2. Vom partiționa pe zi de către câmpul Event_Time. Pentru fiecare zi vom crea o nouă secțiune. Vom numi secțiunile în conformitate cu regula: analitics.events_ddmmyyyyy. De exemplu, o secțiune pentru 1 ianuarie 2010.
Creați tabelul Analytics.events_01012010.
EVENT_ID BIGINT implicit NextVal ("analytics.seq_events") cheie primară,
Verificați (Event_Time\u003e \u003d Timestamp "2010-01-01 00:00:00" și Event_Time< TIMESTAMP "2010-01-02 00:00:00" )
) Moștenirea (analitics.events);* Acest cod sursă a fost evidențiat cu evidența codului sursă.
Când creați o secțiune, specificăm în mod explicit câmpul Event_ID (cheia primară nu este moștenită) și creați o constrângere de verificare pe câmpul Event_Time, pentru a nu introduce prea mult.
3. Creați un index în câmpul Event_Time. Când împărțiți masa de pe secțiune, înțelegem că majoritatea solicitărilor la tabelul Evenimente vor folosi condiția pe câmpul Event_Time, astfel încât indexul din acest câmp ne va ajuta foarte mult.
Creați index Evenimente_01012010_Event_Time_idx pe Analytics.events_01012010 utilizând BTERE (Event_Time);* Acest cod sursă a fost evidențiat cu evidența codului sursă.
4. Vrem să ne asigurăm că atunci când introduceți în tabelul principal, datele s-au dovedit a fi secțiunea destinată acestora. Pentru a face acest lucru, facem următoarea faimă - creați un declanșator care va gestiona fluxurile de date.
Creați sau înlocuiți funcția Analytics.events_insert_trigger ()
Returnează declanșatorul ca $$
Începe.
Dacă (New .event_Time\u003e \u003d Timestamp "2010-01-01 00:00:00" și
New .event_time.< TIMESTAMP "2010-01-02 00:00:00" ) THEN
Introduceți valorile Analytics.events_01012010 (noi *);
Altfel.
Ridicați excepția "Date% este în afara domeniului. Fix Analytics.events_Insert_trigger", New .event_time;
Terminați dacă;
Întoarceți null;
Sfârșit;
$$
Limba plpgsql;* Acest cod sursă a fost evidențiat cu evidența codului sursă.
Creați Trigger Events_BoFore_Insert.
Înainte de introducerea pe analitics.events
Pentru fiecare procedură de executare a rândurilor Analytics.events_insert_trigger ();* Acest cod sursă a fost evidențiat cu evidența codului sursă.
5. Totul este gata, acum avem un analitic de masă partiționat. Events. Putem începe să analizăm violent datele sale. Apropo, verificați constrângerile pe care le-am creat nu numai pentru a proteja secțiunile din date incorecte. PostgreSQL le poate folosi atunci când elaborează un plan de solicitare (deși, cu un indice viu pe Event_time, câștigurile vor da minimul), este suficient să se utilizeze Directiva Constraint_exclusion:
Setați constrângere_exclusion \u003d activat;
Selectați * de la Analytics.events Unde Event_Time\u003e Current_Date;* Acest cod sursă a fost evidențiat cu evidența codului sursă.
Sfârșitul primei părți
Deci, ce avem? Sa vedem:1. Tabelul de evenimente, împărțit în secțiuni, analiza datelor disponibile în ziua trecută devine mai ușoară și mai rapidă.
2. Horror de realizare că toate astea trebuie să mențină într-un fel, să creeze secțiunile la timp, fără a uita să schimbe declanșatorul corespunzător.
Despre cât de ușor și neglijent munca cu mesele partiționate va spune în a doua parte.
UPD1: Partiționarea de partiționare înlocuită
UPD2:
Potrivit observațiilor unuia dintre cititorii care nu au, din păcate, contul pe Habré:
Cu moștenire, sunt conectate câteva momente, care ar trebui luate în considerare la proiectarea. Secțiunile nu moștenesc cheile primare și cheile externe pe coloanele lor. Adică, atunci când creați o secțiune, trebuie să creați în mod explicit cheia primară și cheile străine pe coloanele secțiunii. De la mine am observat că crearea de chei străine pe coloanele mesei partiționate nu este cea mai bună cale. În majoritatea cazurilor, o masă partiționată este "tabelul faptelor" și se referă la tabelul "Dimensiune".
În cursul lucrării pe mese mari, ne confruntăm în mod constant cu probleme cu performanța actualizărilor de întreținere și de date. Una dintre soluțiile cele mai productive și convenabile ale problemelor emergente este partiționarea.
Dacă în cuvinte, în general, partiționarea este partiționarea unei mese sau indexuri pentru blocuri. În funcție de setarea de partiționare, blocurile pot fi de diferite dimensiuni, pot fi stocate în diferite grupuri de fișiere și fișiere.
Secționarea are atât avantaje, cât și dezavantaje.
Beneficiile sunt bine vopsite pe site-ul Microsoft, voi da un extras:
« Partiționarea meselor sau a indiciilor mari poate oferi următoarele avantaje în gestionabilitate și performanță.
- Acest lucru vă permite să transferați rapid și eficient subseturile de date și să le accesați, menținând în același timp integritatea setului de date. De exemplu, o astfel de operație ca încărcare de date din OLTP în sistemul OLAP se efectuează în câteva secunde și nu în câteva minute și ore, ca în cazul datelor care nu sunt probă.
- Operațiile de service pot fi efectuate mai repede cu una sau mai multe secțiuni. Operațiunile sunt mai eficiente, deoarece se efectuează numai cu confidențialitatea datelor și nu cu întregul tabel. De exemplu, puteți comprima date în una sau mai multe secțiuni sau puteți reconstrui una sau mai multe secțiuni index.
- Puteți îmbunătăți viteza de execuție a cererilor în funcție de solicitările care sunt adesea efectuate în configurația dvs. hardware. De exemplu, Query Optimizer poate fi mai rapid să efectueze solicitări pentru echiparea a două și mai multe tabele partiționate dacă aceste tabele sunt aceleași coloane de partiționare, deoarece puteți conecta secțiunile în sine.
În procesul de sortare a datelor pentru operațiile I / O în SQL Server, sortarea datelor pe secțiuni este mai întâi. Serverul SQL poate contacta simultan doar un disc, care poate reduce performanța. Pentru a accelera sortarea datelor, se recomandă distribuirea fișierelor de date în secțiuni pe mai multe discuri dure prin crearea RAID. Astfel, în ciuda datelor de sortare pe secțiuni, SQL Server va putea accesa simultan toate discurile dure ale fiecărei secțiuni.
În plus, este posibilă creșterea productivității prin utilizarea blocajelor la nivelul secțiunilor, și nu întregul tabel. Poate reduce numărul de conflicte de încuietori pentru masă».
Dezavantajele includ complexitatea în administrarea și susținerea funcționării tabelelor partiționate.
Nu vom locui la implementarea partiționării, deoarece această problemă este foarte bine descrisă pe site-ul Microsoft.
În schimb, vom încerca să arătăm cum să optimizăm funcționarea tabelelor partiționate și să arătăm mai precis cea mai optimă (în opinia noastră) o modalitate de a actualiza datele pentru orice interval de timp.
O masă mare plus partiționată este distincția fizică a acestor secțiuni. Această proprietate ne permite să modificăm secțiunile în unele locuri sau cu orice altă masă.
Cu actualizarea obișnuită a datelor utilizând fereastra glisantă (de exemplu, pentru lună), va trebui să trecem prin următorii pași:
1. Găsiți liniile dorite într-o masă mare;
2. Ștergeți liniile găsite din tabel și index;
3. Introduceți noi linii în tabel, actualizați indexul.
Când sunt stocate într-o masă de miliarde de rânduri, aceste operațiuni vor avea o perioadă destul de lungă, vă putem limita la aproape o acțiune: înlocuiți secțiunea dorită la tabelul preparat în avans (sau secțiunea). În acest caz, nu va trebui să ștergem sau să inserați șiruri, precum și trebuie să actualizați indexul pe întreaga masă mare.
Să mergem de la cuvinte la afaceri și să arătăm cum să o punem în aplicare.
1. Începeți, configurați o masă partiționată așa cum este scrisă în articolul specificat mai sus.
2. Creați tabele necesare pentru schimb.
Pentru a actualiza datele, vom avea nevoie de o mini-copie a tabelului țintă. O mini-copie se datorează faptului că vor fi stocate date care ar trebui adăugate la tabelul țintă, adică. Date în doar o lună. Al treilea tabel gol va trebui, de asemenea, să implementeze schimbul de date. De ce este necesar - voi explica mai târziu.
Condițiile grele sunt puse la mini-copie și masă pentru schimb:
- Înainte de a utiliza operatorul de comutare, ar trebui să existe ambele tabele. Înainte de a efectua operația de comutare în baza de date, trebuie să existe un tabel în care secțiunea (tabelul sursă) se deplasează de unde tabelul de selecție (tabelul țintă).
- Secțiunea destinatară trebuie să existe și ar trebui să fie goală. Dacă tabelul este adăugat ca o secțiune la o masă partiționată existentă sau o secțiune se deplasează de la o masă partiționată la alta, secțiunea destinatarului trebuie să existe și să fie goală.
- Tabelul recipient ne-combinat trebuie să existe și ar trebui să fie gol. Dacă secțiunea este proiectată pentru a forma o masă unificată neapară, atunci este necesar ca tabelul care primească o nouă secțiune și a fost o masă netra tranziție goală.
- Secțiunile trebuie să fie din aceeași coloană. Dacă secțiunea este comutată de la o masă partiționată la alta, ambele tabele trebuie împărțite prin aceeași coloană.
- Tabelele sursă și țintă trebuie să fie în același grup de fișiere. Sursa și tabelul țintă din tabelul Alter ... instrucțiunile de comutare trebuie să fie stocate în același grup de fișiere, precum și coloanele lor cu valori mari. Orice indici respectivi, secțiuni de index sau secțiuni indexate ar trebui, de asemenea, să fie stocate în același grup de fișiere. Cu toate acestea, poate diferi de grupul de fișiere pentru tabelele corespunzătoare sau al altor indici relevanți.
Voi explica restricțiile privind exemplul nostru:
1. O mini-copie a tabelului trebuie împărțită pe aceeași coloană ca și țintă. Dacă o mini-copie nu este o masă partiționată, atunci trebuie să fie stocată în același grup de fișiere ca și secțiunea de înlocuire.
2. Tabelul pentru schimb trebuie să fie gol și ar trebui să fie partiționat în aceeași coloană sau trebuie depozitat în același grup de fișiere.
3. Implementăm schimbul.
Acum avem următoarele:
Tabel cu date pentru totdeauna (următoarea table_a)
Tabel cu date pentru o lună (următoarea table_b)
Tabelul gol (următoarea table_c)
În primul rând, trebuie să aflăm în ce secțiune avem datele.
Puteți găsi în interogare:
SELECTAȚI
Conteaza ca
, $ Partiție. (Dt) ca
, Rang () peste (comanda prin partiția de $ (DT))
De la dbo. (Nolock)
Grup de partiție de $ (dt)
În această interogare, primim secțiuni în care există rânduri cu informații. Cantitatea nu poate fi luată în considerare - am făcut-o pentru a verifica necesitatea schimbului de date. Clasament, de asemenea, utilizați astfel încât să puteți merge în ciclu și să actualizați mai multe secțiuni într-o singură procedură.
De îndată ce au aflat în ce secțiuni, datele sunt stocate - ele pot fi schimbate în locuri. Să presupunem că datele sunt stocate în secțiunea 1.
Apoi, trebuie să efectuați următoarele operații:
Schimbați secțiunile din tabelul țintă cu o masă pentru schimbul.
Alter tabel. Comutați partiția 1 la. Partiția 1.
Acum avem următoarele:
Tabelul țintă nu a avut date în secțiunea de care avem nevoie, adică Secțiunea este goală
Schimbați secțiunile din tabelul țintă și mini-copie
Alter tabel. Comutați partiția 1 la. Partiția 1.
Acum avem următoarele:
Tabelul țintă a apărut date pentru lună, iar în mini-copii acum gol
Ștergeți sau ștergeți un tabel pentru schimbul.
Dacă aveți un indice de cluster pe masă, nu este, de asemenea, o problemă. Trebuie să fie creată pe toate cele 3 tabele cu separarea unul prin aceeași coloană. La schimbarea secțiunilor, indexul va actualiza automat, fără a reconstrui.
Pagina 23 din 33
Interval de partiționare - Informații despre vânzări
Natura utilizării informațiilor de vânzări este adesea schimbabilă. De regulă, datele curente ale lunii sunt date operaționale; Datele din lunile anterioare sunt în mare măsură date destinate analizei. Cel mai adesea, analiza este făcută lunar, trimestrială sau anuală. Deoarece diferiți analiști pot necesita în același timp cantități semnificative de date analitice diferite, partiționarea este mai bine autorizată să-și izoleze activitățile. În scenariul următor, aceste date se scufundă din 283 de noduri și sunt furnizate ca două fișiere de format standard ASCII. Toate fișierele sunt trimise la serverul de fișiere centrale, cel târziu la 3.00, în prima zi a fiecărei luni. Dimensiunile fișierelor fluctuează, dar în gama medie este de aproximativ 86.000 de comenzi pe lună. Fiecare comandă în medie este de 2,63 poziții, astfel încât fișierele de ordonare sunt în medie cu 226180 de linii. În fiecare lună se adaugă aproximativ 25 de milioane de comenzi noi și 64 milioane de rânduri ale nomenclaturii comenzilor. Serverul de analiză a istoriei acceptă date în ultimii 2 ani. Datele de doi ani sunt puțin mai puțin de 600 de milioane de comenzi și mai mult de 1,5 miliarde de linii în tabelul OrdedeDetails. Deoarece datele sunt adesea analizate prin compararea indicatorilor acelorași trimestre sau în aceleași luni pentru anii precedenți, este selectată partiționarea intervalului. O lună este aleasă ca dimensiune a intervalului.
Pe baza schemei 11 ("Pașii pentru a crea o masă partiționată"), am decis să partiționăm tabelul utilizând intervalul de partiționare pe coloana Orderdate. Analiștii noștri se unesc și analizează ultimele 6 luni, sau ultimele 3 luni ale actualei și anul trecut (de exemplu, ianuarie-martie 2003 plus ianuarie-martie 2004). Pentru a maximiza pachetul de discuri și, în același timp, izolați majoritatea grupărilor de date, vor exista mai multe grupuri de fișiere pe un disc fizic, dar acestea vor fi deplasate timp de șase luni pentru a reduce numărul de conflicte la separarea resurselor . Luna curentă - octombrie 2004, iar toate cele 283 de birouri separate își gestionează vânzările curente la nivel local. Serverul stochează date din octombrie 2002 până în septembrie 2004 inclusiv. Pentru a profita de noul sistem de 16 procesor și de San (rețea de depozitare - o rețea de mare viteză care conectează depozitele de date), fiecare lună va fi în propriul fișier de fișiere de fișiere și plasat pe un set de oglinzi alternante ( RAID 1 + 0). Figura 12 ilustrează plasarea datelor pe discuri logice.
Figura 12: Tabelul comenzilor partiționate
Fiecare dintre cele 12 discuri logice utilizează configurația RAID 1 + 0, astfel încât numărul total de discuri necesare pentru comenzi și tabelele de ordonare este de 48. În ciuda acestui fapt, SAN suportă până la 78 de discuri, astfel încât celelalte 30 de discuri sunt utilizate pentru jurnalul de tranzacții , TEMPDB, baze de date de sistem și alte tabele mici, cum ar fi clienții (9 milioane de intrări) și produse (386.750 de intrări) etc. Comenzile și tabelele de ordonare vor folosi aceleași condiții de graniță și aceeași plasare pe disc; De fapt, ei vor folosi aceeași schemă de împărțire. Ca rezultat (aruncați o privire la două discuri logice E: \\ și F: \\ Figura 13) Comenzile de date de masă și ordonările pentru aceleași luni vor fi amplasate pe aceleași discuri:
Figura 13: Plasarea amplorii secțiunilor de interval pe ariele de discuri
Deși pare confuz, toate acestea sunt destul de ușor de implementat. Cel mai dificil lucru în crearea tabelului nostru partiționat este livrarea de date dintr-un număr mare de surse - 283 depozit trebuie să aibă un mecanism standard de livrare. Cu toate acestea, pe serverul central există doar o masă de comenzi și un tabel de ordonare. Pentru a transforma ambele tabele în partiții, trebuie mai întâi să creăm o funcție și o schemă de partiționare. Schema de partiționare determină locația fizică a secțiunilor pe discuri, prin urmare, trebuie să existe și grupurile de fișiere. Deoarece grupurile de fișiere sunt necesare pentru mesele noastre, următorul pas este crearea lor. Sintaxa creației fiecărui grup de fișiere este identică cu cele de mai sus, totuși, în acest fel trebuie create toate cele douăzeci și patru de grupuri de fișiere. Puteți modifica numele / locația discurilor pe un singur disc pentru a testa și a explora sintaxă. Asigurați-vă că ați corectat dimensiunile fișierului pe MB în loc de GB și ați ales o dimensiune inițială mai mică a fișierului, pe baza spațiului pe disc disponibil pentru dvs. Douăzeci și patru de fișiere și grupuri de fișiere vor fi create în baza de date SaAlesdB. Toate vor avea sintaxă similară, cu excepția locației, a numelui fișierului și a numelui fișierului:
| ALTER WIRSDB. |
Odată ce toate cele douăzeci și patru de fișiere și grupuri de fișiere sunt create, puteți determina schema de funcționare și de partiționare. Asigurați-vă că fișierele și grupurile de fișiere sunt create, puteți utiliza procedurile stocate SP_HELPFILE și SP_HELPFILEG.
Funcția secțiunii va fi determinată prin coloana Orderdate cu tip de date date. Pentru ca ambele tabele să fie împărțite prin coloana Orderdate, această coloană trebuie să fie prezentă în ambele tabele. De fapt, valorile cheilor-cheie ale ambelor tabele (dacă ambele tabele sunt împărțite de una și aceeași cheie) se vor duplica reciproc; Cu toate acestea, acest lucru este necesar pentru a obține avantajele alinierii, în cele mai multe cazuri dimensiunea coloanelor cheie va fi relativ mică (dimensiunea câmpului DataTime este de numai 8 octeți). După cum sa descris deja în capitolul "Creare partiție pentru secțiunile de interval", funcția noastră va fi o gamă de funcții de partiționare în care prima condiție limită va fi în prima secțiune (stânga).
| Creați funcția de partiție DouăyeardateRengePfn (DateTime) |
Deoarece este extrem de stânga, sunt acoperite cazuri de frontieră extrem de dreptate, această funcție de partiționare creează de fapt 25 de secțiuni. Tabelul va susține secțiunea 25 care va rămâne goală. Pentru această secțiune goală, nu este necesar un grup de fișiere speciale, deoarece nu ar trebui să intre vreodată date. Pentru a se asigura că nu există date în el, constrângerea va limita gama din acest tabel. Pentru a trimite date pe discurile corespunzătoare, se utilizează o schemă de partiționare care afișează secțiunile grupurilor de fișiere. Schema de partiționare va utiliza definiția explicită a grupurilor de fișiere pentru fiecare dintre cele 24 de grupuri de fișiere care conțin datele și primare - pentru secțiunea 25 goală.
| Creați schema de partiții. |
Tabelul poate fi creat cu aceeași sintaxă care a acceptat versiunile anterioare SQL Server - utilizând grupul de fișiere implicit sau definit de utilizator (pentru a crea o tabelă neplăcută) - fie folosind schema (pentru a crea o masă partiționată). În ceea ce privește ce opțiune este preferabilă (chiar dacă acest tabel este împărțit în viitor, totul depinde de modul în care se umple tabelul și câte secțiuni veți manipula. Umplerea unui heap (HAP) și crearea ulterioară a unui indice de cluster este probabil să ofere performanțe mai bune decât descărcarea la un tabel care conține un indice de cluster. În plus, în sistemele multiprocesoare, puteți încărca date pe masă în paralel și apoi paralel pentru a construi indexuri. De exemplu, creați tabelul comenzilor și încărcați datele în acesta utilizând Inserare ... Selectați instrucțiuni. Pentru a crea tabelul comenzilor ca fiind partiționat, definiți schema de partiționare din cadrul operatorului de masă.
| Creați vânzător de masă .. |
Deoarece tabelul OrdedeDetails va folosi aceeași schemă, acesta ar trebui să includă coloana Orderdate.
| Creați tabelul. ( |
În etapa următoare, datele din noua bază de date de formare a New AdventureWorkworks sunt descărcate. Asigurați-vă că ați instalat baza de date AdventureWorks.
| Introduceți dbo. Introduceți dbo. |
Acum că ați descărcat datele în tabelul partiționat, puteți utiliza noua funcție de sistem încorporată pentru a determina secțiunea pe care vor fi localizate datele. Următoarea solicitare pentru fiecare dintre secțiunile care conțin date returnează informații despre câte rânduri sunt conținute în fiecare secțiune, precum și valoarea minimă și maximă a câmpului Orderdate. Secțiunea care nu conține rânduri nu se încadrează în rezultatul final.
| Selectați $ partition.twoyeardateragepfn (O.OrderDate) Selectați $ partition.twoyearDateRengepfn (Od.oderdate) |
În cele din urmă, acum, după ce ați descărcat datele, puteți crea un indice de cluster și o cheie externă (cheie străină) între tabelele de ordonare și comenzi. În acest caz, indicele clusterului va fi construit pe cheia primară (cheie primară) în același mod în care identificați ambele tabele prin cheia lor de partiție (pentru ordedetailurile la indexul pe care îl veți adăuga coloana de linenumblare pentru unicitate). În mod implicit, la construirea indexurilor pe o tabelă partiționată, acestea sunt aliniate în ceea ce privește tabelul partiționat în conformitate cu aceeași schemă de împărțire; Nu este necesar să specificați schema.
| Alter comenzi de masă
|
Sintaxa completă care determină schema de partiționare, ar arăta astfel:
| Alter comenzi de masă Alter tabel dbo.ordedetails. |
 Celular - ceea ce este pe iPad și care este diferența
Celular - ceea ce este pe iPad și care este diferența Du-te la televiziunea digitală: Ce să faci și cum să te pregătești?
Du-te la televiziunea digitală: Ce să faci și cum să te pregătești? Sondajele sociale lucrează pe Internet
Sondajele sociale lucrează pe Internet Savin a înregistrat un mesaj video către taiaturi
Savin a înregistrat un mesaj video către taiaturi Meniu de tabele sovietice Care a fost numele joiului în cantinele sovietice
Meniu de tabele sovietice Care a fost numele joiului în cantinele sovietice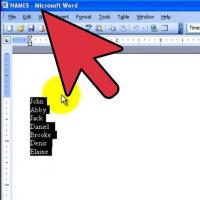 Cum se face în lista "Word" alfabetic: Sfaturi utile
Cum se face în lista "Word" alfabetic: Sfaturi utile Cum să vezi colegii de clasă care s-au retras de la prieteni?
Cum să vezi colegii de clasă care s-au retras de la prieteni?