Qu'est-ce que la validité du code ? Vérification de la validité des données. Vérification des fichiers locaux
Effectue plusieurs vérifications sur votre code. Les principaux sont :
Le principal argument contre la validation est qu'elle est trop stricte et ne correspond pas au fonctionnement réel des navigateurs. Oui, HTML peut être invalide, mais tous les navigateurs peuvent gérer du code invalide de la même manière. Si je suis prêt à assumer la responsabilité du mauvais code que j'écris, je n'ai pas à me soucier de la validation. La seule chose dont je dois me soucier, c'est que cela fonctionne.
Ma position C'est l'une des rares occasions où j'énonce publiquement ma position sur quelque chose. J'ai toujours été parmi les opposants à la validation, en me basant sur le fait que le validateur est trop strict pour être pratique dans des applications réelles. Il y a des choses qui sont prises en charge par la plupart des navigateurs ( dans , après ) qui ne sont pas valides mais qui sont parfois très nécessaires pour fonctionner correctement.En général, mon plus gros problème de validation est la validation #4 (pour les éléments superflus). Je suis fan de l'utilisation d'attributs personnalisés dans les balises HTML pour stocker des métadonnées supplémentaires liées à un élément particulier. Selon ma compréhension, il s'agit, par exemple, d'ajouter l'attribut foo lorsque j'ai des données (bar) que je dois associer à un élément spécifique. Parfois, les gens surchargent les attributs existants à cette fin uniquement pour réussir la validation malgré l'utilisation abusive de l'attribut. Pour moi c'est vide de sens.
Le secret des navigateurs est qu'ils ne vérifient jamais si le code HTML correspond à la DTD spécifiée. Le doctype que vous spécifiez dans le document fait passer l'analyseur du navigateur dans un certain mode, mais il ne charge pas le doctype et ne vérifie pas le code par rapport à celui-ci. Autrement dit, l'analyseur du navigateur traite le HTML avec certaines hypothèses d'invalidation, comme les balises à fermeture automatique et les éléments de bloc dans les éléments en ligne (je suis sûr qu'il y en a d'autres).
Dans le cas des attributs personnalisés, tous les navigateurs analysent et reconnaissent les attributs syntaxiquement corrects comme valides. Cela permet d'accéder à ces attributs via le DOM en utilisant Javascript. Alors, pourquoi devrais-je me soucier de la validité ? Je vais continuer à utiliser mes attributs et je suis très content que HTML5 les formalise.
Le meilleur exemple d'une technologie qui entraîne un code HTML invalide mais qui fait une énorme différence est ARIA. ARIA fonctionne en ajoutant de nouveaux attributs à HTML 4. Ces attributs fournissent une signification sémantique supplémentaire aux éléments HTML et le navigateur est capable de transmettre cette sémantique aux dispositifs d'assistance pour aider les personnes handicapées. Tous les principaux navigateurs prennent désormais en charge le balisage ARIA. Cependant, si vous utilisez ces attributs, vous aurez un code HTML invalide.
En ce qui concerne les balises personnalisées, je pense qu'il n'y a rien de mal à ajouter de nouvelles balises syntaxiquement correctes à la page, mais je ne vois pas beaucoup d'intérêt pratique à le faire.
Pour clarifier ma position : je crois que les vérifications #1 et #2 sont très importantes et doivent toujours être faites. Le contrôle #3 est également important, mais pas aussi important que les deux premiers. La vérification #4 est très discutable pour moi car elle touche les attributs personnalisés. Je pense que, tout au plus, les attributs personnalisés devraient être signalés comme des avertissements (plutôt que des erreurs) dans les résultats de validation afin que je puisse vérifier si j'ai mal saisi le nom de l'attribut. Signaler les balises personnalisées comme des erreurs est probablement une bonne idée, mais pose également certains problèmes, par exemple lors de l'intégration de contenu dans un autre balisage - SVG ou MathML.
Validation pour validation ? Je pense que la validation pour le bien de la validation est extrêmement stupide. Un code HTML valide signifie uniquement que les 4 vérifications ont réussi sans erreur. Il y a quelques choses importantes qu'un HTML valide ne garantit pas :- un HTML valide ne garantit pas l'accessibilité ;
- un HTML valide ne garantit pas une bonne UX (expérience utilisateur) ;
- un code HTML valide ne garantit pas un site fonctionnel ;
- Un HTML valide ne garantit pas l'affichage correct du site.
Je sais que c'est un sujet controversé pour beaucoup, alors s'il vous plaît, évitez d'être purement émotionnel dans les commentaires.
UPD : merci pour le karma, déplacé vers thématique. Je répète les mots de l'auteur: je comprends qu'il s'agit d'un sujet controversé, mais veuillez vous abstenir de commentaires purement émotionnels, donnez des arguments.
Vérifier la validité du code HTML du site est un must dans mon . Mais ne surestimez pas l'importance des erreurs de validation pour la promotion SEO - c'est très petit. Sur n'importe quel sujet, il y aura des sites dans le TOP avec un grand nombre d'erreurs de ce type et ils vivront très bien.
MAIS! L'absence d'erreurs techniques sur le site est un facteur de classement, et donc cette possibilité ne doit pas être négligée. Il vaut mieux le réparer, ça ne va certainement pas s'aggraver. Les moteurs de recherche verront vos efforts et vous donneront un petit plus en karma.
Comment vérifier la validité du code HTML sur le site WebLa validation du code du site est vérifiée à l'aide du service en ligne W3C HTML Validator. S'il y a des erreurs, le service vous en donne une liste. Je vais maintenant analyser les types d'erreurs les plus courants que j'ai vus sur les sites Web.
- Erreur : ID en double min_value_62222

Et derrière cette erreur se cache un avertissement.
- Avertissement : La première occurrence de l'ID min_value_62222 était ici

Cela signifie que l'identifiant d'identification de style est dupliqué, ce qui, selon les règles de validité html, doit être unique. Vous pouvez utiliser CLASS au lieu d'ID pour les objets en double.
Corriger cela est souhaitable, mais pas très critique. S'il y a beaucoup d'erreurs de ce type, il est préférable de les corriger.
De même, il peut y avoir d'autres options :
- Erreur : ID en double placeWorkTimes
- Erreur : ID en double callbackCss-css
- Erreur : ID en double Capa_1
Ce qui suit est un avertissement très courant.
- Avertissement : L'attribut type n'est pas nécessaire pour les ressources JavaScript
Il s'agit d'une erreur très courante lors de la vérification de la validation du site Web. Selon les règles HTML5, l'attribut type de la balise de script n'est pas nécessaire, c'est un élément obsolète.
De même, cet avertissement pour les styles :
- Avertissement : L'attribut type de l'élément de style n'est pas nécessaire et doit être omis
La correction de ces avertissements est souhaitable, mais pas critique. Avec une grande quantité, il vaut mieux le réparer.
- Avertissement : Pensez à éviter les valeurs de fenêtre d'affichage qui empêchent les utilisateurs de redimensionner les documents
Cet avertissement indique que vous ne pouvez pas augmenter la taille de la page sur mobile ou tablette. C'est-à-dire que l'utilisateur voulait regarder de plus près les images ou le très petit texte et ne peut pas le faire.
Je considère cet avertissement très indésirable, c'est gênant pour l'utilisateur, c'est un inconvénient pour les comportementaux. Éliminé en supprimant ces éléments - maximum-scale=1.0 et user-scalable=no.
- Erreur : L'attribut itemprop a été spécifié, mais l'élément n'est la propriété d'aucun élément
Il s'agit d'un micro-balisage, l'attribut itemprop doit être à l'intérieur de l'élément itemscope. Je considère que cette erreur n'est pas critique et peut être laissée telle quelle.
- Avertissement : Les documents ne doivent pas utiliser about:legacy-compat, sauf s'ils sont générés par des systèmes hérités qui ne peuvent pas générer le doctype standard
La ligne about:legacy-compat n'est nécessaire que pour les générateurs html. Ici, il vous suffit de le faire, mais l'erreur n'est pas du tout critique.
- Erreur : source de balise de fin erronée

Si vous regardez dans le code du site lui-même et trouvez cet élément, vous pouvez voir qu'une seule balise est enregistrée en tant que balise de paire - ce n'est pas vrai.
En conséquence, vous devez supprimer la balise de fermeture du code. Semblable à cette erreur, il peut y avoir des balises
- Erreur : Un élément img doit avoir un attribut alt, sauf sous certaines conditions. Pour plus de détails, consultez les conseils sur la fourniture d'alternatives textuelles pour les images
Toutes les images doivent avoir un attribut alt, je considère cette erreur critique, elle doit être corrigée.
- Erreur : L'élément ol n'est pas autorisé en tant qu'enfant de l'élément ul dans ce contexte. (Suppression d'autres erreurs de cette sous-arborescence.)

L'imbrication des balises est incorrectement énoncée ici. DANS
- devrait être seulement
- . Dans cet exemple, ces éléments ne sont pas du tout nécessaires.

De même, il peut y avoir d'autres erreurs :
- L'élément h2 n'est pas autorisé en tant qu'enfant de l'élément ul dans ce contexte.
- L'élément a n'est pas autorisé en tant qu'enfant de l'élément ul dans ce contexte.
- L'élément noindex n'est pas autorisé en tant qu'enfant de l'élément li dans ce contexte.
- L'élément div n'est pas autorisé en tant qu'enfant de l'élément ul dans ce contexte.
Tout cela doit être corrigé.
- Erreur : L'attribut http-equiv n'est pas autorisé sur la méta de l'élément à ce stade
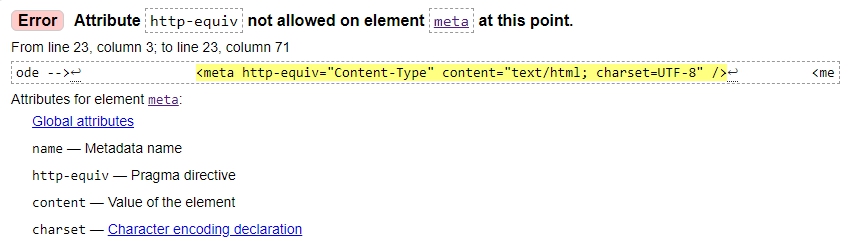
L'attribut http-equiv n'est pas destiné à l'élément meta, il doit être supprimé ou remplacé.
Erreurs similaires :
- Erreur : L'attribut n2-lightbox n'est pas autorisé sur l'élément a à ce stade.
- Erreur : L'attribut asyncsrc n'est pas autorisé sur le script d'élément à ce stade.
- Erreur : Le prix de l'attribut n'est pas autorisé sur l'option d'élément à ce stade.
- Erreur : La chaîne de hachage d'attribut n'est pas autorisée sur l'étendue de l'élément à ce stade.
Ici, vous devez également supprimer les attributs n2-lightbox, asyncsrc, price, hashstring ou les remplacer par d'autres options.
- Erreur : Balise de début incorrecte dans img dans head
Ou comme ceci :
- Erreur : Balise de début incorrecte dans div dans head

Les balises img et div ne doivent pas être au format . Cette erreur doit être corrigée.
- Erreur : CSS : erreur d'analyse

Dans ce cas, il ne devrait pas y avoir de point-virgule après la parenthèse dans les styles.
Eh bien, une telle erreur, une bagatelle, mais pas agréable) Voyez par vous-même si vous devez l'enlever ou non, cela n'aura aucun rôle dans la promotion du site Web.
- Avertissement : L'attribut charset de l'élément de script est obsolète
Les scripts n'ont plus besoin de prescrire l'encodage, c'est un élément obsolète. L'avertissement n'est pas critique, à votre discrétion.
- Erreur : le script d'élément ne doit pas avoir d'attribut charset à moins que l'attribut src ne soit également spécifié
Dans cette erreur, vous devez supprimer l'attribut charset="uft-8" du script, car il affiche l'encodage en dehors du script. Je pense que cette erreur doit être corrigée.
- Attention : rubrique vide

Voici un en-tête h1 vide. Vous devez supprimer les balises ou mettre un titre entre elles. L'erreur est critique.
- Erreur : Balise de fin br

La balise br est simple, mais elle est faite comme s'il s'agissait d'une paire de fermeture. Vous devez supprimer le / de la balise.
- Erreur : la référence du caractère nommé ne se terminait pas par un point-virgule. (Ou & aurait dû être échappé comme &.)

Ce sont des caractères spéciaux HTML, vous devez les écrire correctement ou les copier. Il vaut mieux corriger cette erreur.
- Erreur fatale : impossible de récupérer après la dernière erreur. Toute autre erreur sera ignorée
C'est une grave erreur :
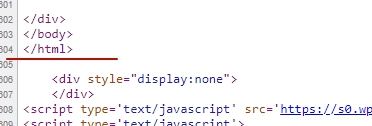
Après cela, il ne devrait plus rien y avoir, puisqu'il s'agit de la dernière balise de fermeture de la page. Vous devez supprimer tout ce qui suit ou le déplacer au-dessus.
- Erreur : CSS : à droite : seul 0 peut être une unité. Vous devez mettre une unité après votre numéro
Vous devez écrire la valeur en px :

Voici une erreur similaire :
- Erreur : CSS : margin-top : seul 0 peut être une unité. Vous devez mettre une unité après votre numéro
- Erreur : élément non fermé a
Vous avez probablement entendu l'expression "validité du code" à plusieurs reprises. Et savez-vous ce que c'est ? Si tel est le cas, parcourez cet article en diagonale, vous trouverez peut-être encore quelque chose d'intéressant. Pour ceux qui ne connaissent pas, lisez la suite. Je vais parler de la façon dont j'ai vérifié la validité du code de mon blog, comment j'ai corrigé les balises incorrectes, et bien plus encore.
Si vous avez votre propre site Web ou blog, vous y écrivez probablement des articles uniques, vous en faites la promotion dans les moteurs de recherche, etc. Mais avez-vous pensé au code source de votre site ? Ceci est également très important, car les moteurs de recherche voient le code source des pages et en extraient les textes des articles et autres éléments de ressources. Si le code source est incorrect et ne respecte pas les normes, il sera difficile pour les robots d'évaluer correctement la qualité du texte et, par exemple, la navigation sur le site.
Donc, validité du code- c'est la conformité du code source du site avec les règles et réglementations décrites par le World Wide Web Consortium ou W3C en abrégé. Pour vérifier la conformité de votre blog à ces normes, vous devez vous rendre sur le lien : validator.w3.org. Entrez l'adresse souhaitée et voyez les résultats.J'ai rencontré des erreurs dans la mise en page de mon thème, ainsi que des erreurs que j'ai moi-même faites lors de l'installation du compteur depuis liveinternet. En fait, je les connaissais depuis longtemps, je n'y attachais tout simplement aucune importance. Et tout récemment, je n'avais rien à faire et j'ai décidé d'obtenir la validité du code de mon blog. Je ne pense pas que ça fasse mal =)
Pour commencer, je dirai qu'il y avait 12 erreurs, mais 10 d'entre elles appartenaient à la même balise, à savoir à
Rel="balise de catégorie"
Après avoir tapé cette balise dans Google, j'ai réalisé qu'il n'y avait aucun espoir pour les sites en russe, car il n'y a pas une seule mention de cette balise dans Runet. Eh bien, pas de problème, nous allons chercher en anglais, car il n'y a rien de compliqué à ce sujet. Donc, après avoir lu les sujets sur wordpress.org, je me suis rendu compte que je n'en avais pas souffre de cette étiquette. Sur l'un des sites bourgeois j'ai trouvé comment le réparer, si quelqu'un en a besoin, alors on insère ce code dans le fichier functions.php :
Add_filter("the_category", "add_nofollow_cat"); function add_nofollow_cat($text) ( $text = str_replace("rel="tag de catégorie"", "", $text); return $text; )
Après cela, 10 erreurs ont immédiatement disparu, mais deux autres sont restées. Le premier était tout aussi facile à réparer. Vous voyez les boutons d'abonnement RSS et Twitter dans l'en-tête de mon blog ? Ils sont faits comme des images, mais j'ai oublié de définir le paramètre alt. J'ai écrit sur l'importance du paramètre alt pour les images dans le sujet sur l'optimisation interne, mais il s'avère qu'il est généralement requis. Le voici fixé. Il reste une erreur.
Lorsque j'ai installé le compteur sur le site, je l'ai mis dans la barre latérale (la colonne de droite avec la navigation), pour ainsi dire, à la hâte. Auparavant, je l'entourais d'une balise centrale pour l'aligner. Mais, comme il s'est avéré, ce n'est pas le Feng Shui et le validateur maudit, disent-ils, supprimez cette balise et rendez tout beau - avec des divs. OK, les divas sont des divas. J'ai longtemps voulu enlever le comptoir du sous-sol pour la beauté, le laisser traîner là-bas. Et juste comme ça, il y avait une raison de le faire. Je l'ai retiré du pied de page et l'ai aligné à l'aide de float: juste sur le bord droit, je l'ai même aimé moi-même, et c'est le principal :)
C'est tout, maintenant mon site est entièrement conforme ! Le prochain objectif est CSS, vous pouvez tout vérifier sur le même service, le lien vers lequel j'ai donné au début de l'article.
Vlad Merjevitch
Il existe de nombreuses façons de vérifier les pages Web pour les erreurs et les commentaires. Classiquement, ils sont divisés en en ligne et local. Ceux en ligne sont conçus pour vérifier les pages à l'aide d'un navigateur sur Internet, tandis que les locaux sont utilisés pour vérifier les documents sur l'ordinateur actuel. Ensuite, considérez les méthodes populaires de validation de documents.
validator.w3.org Installation de l'extensionAprès avoir téléchargé le fichier, vous pouvez installer l'extension de plusieurs manières.
1. Via le gestionnaire d'extensions
Lancez Firefox et ouvrez le menu Outils > Extensions. Faites glisser le fichier téléchargé (il porte l'extension xpi) dans la fenêtre qui s'ouvre. L'extension sera alors installée automatiquement.
2. En ouvrant un fichier
Sélectionnez Fichier > Ouvrir un fichier... dans le menu Firefox et spécifiez le chemin d'accès au fichier avec l'extension, le navigateur effectuera lui-même d'autres actions.
3. Copier le fichier dans le dossier d'extension
Ouvrez le dossier sur le lecteur où Firefox est installé (par exemple, c:\Program Files\Mozilla Firefox) et recherchez-y le sous-dossier d'extension, dans lequel copiez l'extension. Après le lancement du navigateur, la poursuite de l'installation aura lieu indépendamment.
Toutes les méthodes d'installation ci-dessus nécessitent que vous redémarriez votre navigateur après avoir installé l'extension. Le validateur HTML démarre immédiatement après le redémarrage de Firefox.
Si ces méthodes n'ont pas aidé pour une raison quelconque, vous pouvez contacter le site d'assistance du navigateur Mozilla Firefox et en savoir plus sur toutes les méthodes possibles pour installer des extensions sur
Utilisation du validateur HTML
http://forum.mozilla-russia.org/doku.php?id=general:extensions_installingLorsque vous ouvrez une page Web, HTML Validator démarre son travail immédiatement et le résultat de la vérification s'affiche dans la barre d'état, dans son coin inférieur droit sous forme de petite image. L'image dépend de l'état du contrôle et est illustrée à la fig. 14.6.



Riz. 14.6. Types d'images affichées lors de la vérification d'un document
Un cercle avec une coche (Fig. 14.6a) indique que le document est valide, un triangle jaune avec un point d'exclamation (Fig. 14.6b) - il y a des commentaires sur le code qui peuvent être corrigés automatiquement. Un cercle rouge avec une croix (Fig. 14.6c) avertit qu'il y a des erreurs graves.
Vous pouvez afficher toutes les erreurs de deux manières. Tout d'abord, regardez le code HTML du document via le menu Affichage > Code source de la page ou faites un clic droit et sélectionnez Afficher le code source de la page dans le menu contextuel (Fig. 14.7).

Riz. 14.7. Menu contextuel avec option de sélection du code source
La fenêtre du code source de la page Web est divisée en trois sections (Figure 14-8), la section supérieure contenant le code HTML réel. Le bloc en bas à gauche affiche une liste d'erreurs et des commentaires ou des messages d'information dans le cas d'un document valide. Le bloc en bas à droite contient des conseils détaillés sur les remarques actuelles.

Riz. 14.8. Le résultat de l'extension HTML Validator
Un code HTML valide est un code conforme à toutes les normes W3C (World Wide Web Consortium). Partout il y a des normes: sur Internet - validité, dans les langues - grammaire, chez les invités des entreprises.
Les blogs/sites qui vérifieront la validité du code et avec le meilleur succès réduiront au minimum les erreurs, respecteront les normes du World Wide Web, ces sites s'afficheront correctement dans tous les navigateurs, les téléchargements augmenteront, ce qui avoir un bon effet sur les facteurs comportementaux et les classements des moteurs de recherche à l'avenir. Le code HTML d'un site comportant de nombreuses erreurs HTML et CSS est considéré comme invalide.
Mon blog avait 340 erreurs et 240 avertissements. Pendant une semaine entière, je n'ai pas pu écrire d'articles, mon humeur était nulle, j'ai ouvert site après site, lu, mais je n'ai pas pu aller au fond des choses. Environ sur le centième site, maintenant je ne donnerai même pas de lien vers le site, c'est dommage, bien sûr, l'auteur a si bien décrit l'essence du problème que même un débutant le comprendrait.
Au début, il y avait des pensées: "Elle a foiré." Mais lorsque j'ai lentement supprimé erreur après erreur, j'ai réalisé que j'avais reçu beaucoup en cadeau des maquettistes ou de l'auteur du modèle.
Comment créer un code html valide en ligneVous pouvez vérifier la validité du code HTML du site auprès du validateur officiel de la norme W3C. Suivez le lien >>> vers le service en ligne. Vérifiez le balisage (HTML, XHTML, ...) des documents Web. Dans la barre d'adresse, saisissez l'url de votre site, cliquez sur « Vérifier ».
Comment corriger les erreurs de validité du code htmlDans l'article, je décrirai ma méthode de création de code valide. Nous allons sur la page principale de notre blog et ouvrons le code source du site en appuyant sur Ctrl + U. Nous regardons quelle ligne d'erreurs et d'avertissements dans le validateur

Nous trouvons la ligne souhaitée dans le code source, la copions, ouvrons n'importe quel éditeur visuel de code HTML en ligne, collons le code dans l'éditeur et voyons le résultat.
erreur "édition rapide"
Recherchez la chaîne et collez-la dans un éditeur HTML en ligne. Erreur - bouton pour une édition rapide des gadgets. J'ai un modèle tiers, mais spécifiquement pour la plateforme Blogger (Blogspot), un cadeau de l'auteur du modèle.

Les boutons n'étaient pas visibles dans la vraie vie, mais les codes sont restés dans le modèle. J'ai personnellement eu 15 boutons.
Solution . Nous ouvrons le blog, allons au modèle, faisons une sauvegarde, supprimons tous les boutons. Trouver le code
et supprimer.
Il peut y avoir plusieurs codes de ce type, afin de tout supprimer, sélectionnez le code dans la zone de recherche et appuyez sur Entrée.
S'il vous plaît rappelez-vous! Chaque fois qu'un widget ou un gadget est ajouté au blog, le code du bouton apparaîtra dans le modèle et générera une erreur dans le validateur.
Résultat : 15 suppressions de code et moins 50 bugs
Je tiens à souligner que vous comprendriez plus vite, cela vaut la peine de supprimer une ligne et d'autres lignes de validité peuvent être supprimées. Dans le validateur, les erreurs se répètent.
Si possible, n'exécutez pas votre modèle, tout ce qui ne fonctionne pas correctement est très mauvais. En fait, par exemple, ces boutons ne me dérangeaient pas, je ne les voyais pas, ils ne me dérangeaient pas, mais ils augmentaient la taille du code du modèle.
La deuxième erreur et moins 42 erreurs dans le validateur.
Je vais de la même manière à travers le générateur de code de l'éditeur HTML en temps réel. Je colle le code de la page d'origine dans l'éditeur et le problème est résolu. Ceci est juste le code pour le formulaire de recherche de blog sur la page de publication.
Solution et correction d'erreur : J'ai une recherche de blog de Yandex, ce qui signifie que le code n'est pas avec. Comment trouver la bonne publication ? Je demande dans ma recherche la requête " Recherche de blog"Et je trouve un article. Dans l'éditeur de message, je supprime le code et le rajoute.
Le validateur a l'erreur suivante
J'ouvre le code source du blog avec le raccourci clavier Ctrl + U et cherche la ligne 666, qui indique une erreur dans le validateur.
Je suis sur le point de corriger à nouveau les erreurs. Je copie le code et le colle dans l'éditeur HTML en ligne.
Et que vois-je ? C'est triste, insultant, énervant, mais bon, à cause du principe, je ne corrigerai cette erreur qu'en des temps meilleurs.

Alors vous, mes chers visiteurs, ne vous souciez pas trop des erreurs dans le code. Ils affectent naturellement le chargement du site, mais Google ne gronde pas particulièrement ses enfants pour les erreurs. L'ordre doit être mis en ordre, mais autant que je sache, il y a des erreurs mineures sur les sites officiels des moteurs de recherche.
Il est souhaitable de corriger les violations flagrantes, mais je ne supprimerai pas la recherche de Yandex, et je n'ai pas pris le code de mon doigt, mais sur le site officiel et la recherche de blog fonctionne bien. Si vous ne me croyez pas, jetez un œil ! :-)
Si vous ne pouvez pas corriger les erreurs, mais que vous devez absolument le faire, je vous conseille de contacter des indépendants, le service coûtera de 100 à 300 roubles. Il faut beaucoup de temps pour corriger le code html par vous-même.
 Vérification de la validité des données
Vérification de la validité des données Suppression, réorganisation et ajout de diapositives
Suppression, réorganisation et ajout de diapositives Que faire s'il n'y a pas de son sur l'ordinateur
Que faire s'il n'y a pas de son sur l'ordinateur FAT32 ou NTFS : quel système de fichiers choisir pour une clé USB ou un disque dur externe
FAT32 ou NTFS : quel système de fichiers choisir pour une clé USB ou un disque dur externe DVR avec détecteur de radar Highscreen Black Box Radar-HD : (ne pas) dépasser
DVR avec détecteur de radar Highscreen Black Box Radar-HD : (ne pas) dépasser Comment distribuer l'Internet mobile depuis un smartphone via Wi-Fi ?
Comment distribuer l'Internet mobile depuis un smartphone via Wi-Fi ? Bouton power, mute, volume ne fonctionne pas
Bouton power, mute, volume ne fonctionne pas