Mysql соединить две таблицы
Что выполняется раньше - JOIN или GROUP BY? Этот неявный вопрос не возникал у меня до тех пор, пока ответ на него не всплыл в виде ошибочных данных, возвращаемых моим запросом. Разумеется, JOIN выполняется раньше, он и в запросах пишется до GROUP BY. Но что, если мне нужно объединить таблицы уже после группировки? Рассмотрим простой пример, когда это может потребоваться.
Представим себе не слишком удобную, но очень простую систему бухгалтерии, состоящую из двух таблиц: Income - таблица доходов и Outlay - таблица расходов. В обеих таблицах по 3 поля: id (INT), time (DATETIME), sum (INT):
# Income (доходы) # Outlay (расходы) id time sum id time sum 1 2014-01-01 00:00:00 100 1 2014-01-02 00:00:00 100 2 2014-01-01 23:59:59 100 2 2014-01-02 23:59:59 100 3 2014-01-02 00:00:00 500
Как видите, 1 января у нас было две продажи по 100 рублей, а 2 января - продажа на 500 и два расхода по 100 рублей.
Объединяем, агрегируем, группируем
Вообразим, что перед нами стоит задача вывести таблицу ежедневных доходов. Всё просто, мы должны сложить суммы, выполнив группировку по дате:
# Суммируем доходы и группируем их по дням SELECT DATE(`income`.`time`) `date`, SUM(`income`.`sum`) `inSum` FROM `Income` `income` GROUP BY DATE(`income`.`time`); # Результат выполнения - сумма доходов по дням date inSum 2014-01-01 200 2014-01-02 500
Ну а теперь напротив каждой даты мне захотелось вывести сумму расходов. И вот что я, наивный, написал:
# Объединяем таблицы доходов и расходов по дате, суммируем доходы и расходы, группируя по дням # Так писать НЕ НАДО: SELECT DATE(`income`.`time`) `date`, SUM(`income`.`sum`) `inSum`, SUM(`outlay`.`sum`) `outSum` FROM `Income` `income` LEFT JOIN `Outlay` `outlay` ON DATE(`income`.`time`) = DATE(`outlay`.`time`) GROUP BY DATE(`income`.`time`); # Ёлки-палки! Прибыль на 2 января увеличилась в 2 раза! date inSum outSum 2014-01-01 200 NULL 2014-01-02 1000(!) 200
Как видите, в ответе вернулся абсолютный ужас - доходы на 2 января увеличились в 2 раза. Как уже было отмечено в начале статьи, JOIN выполняется до GROUP BY, соответственно, из-за того, что 2 января у нас было две статьи расходов, статьи доходов продублировались при объединении таблиц, что привело к задвоению доходов при суммировании. Логика подсказывает, что для исправления проблемы мы должны объединять таблицы, уже сгруппированные по дате.
Ранняя группировка при объединении таблиц MySQL при помощи вложенного запроса
В пределах одного запроса мы не можем сперва сгруппировать, а затем связать таблицы, но мы можем осуществить отложенное объединение с результатом вложенного запроса, а группировку выполнить заранее в нём. Делается это так:
# Заранее группируем данные в таблице Outlay, затем производим объединение с таблицей Income SELECT DATE(`income`.`time`) `date`, SUM(`income`.`sum`) `inSum`, `outlayGroupped`.`outSum` FROM `Income` `income` LEFT JOIN (# Наш вложенный запрос с группировкой SELECT SUM(`outlay`.`sum`) `outSum`, DATE(`outlay`.`time`) `outDate` FROM `Outlay` `outlay` GROUP BY DATE(`outlay`.`time`)) `outlayGroupped` ON DATE(`income`.`time`) = `outlayGroupped`.`outDate` GROUP BY DATE(`income`.`time`); # Прибыли конечно меньше, чем в прошлый раз, но зато цифры правильные:) date inSum outSum 2014-01-01 200 NULL 2014-01-02 500 200
Обычно такие неявные проблемы требуют столь же неявных решений в двух случаях - когда не совсем корректно поставлена задача или когда архитектура проекта оставляет желать лучшего. В данном случае конечно структура базы данных притянута за уши ради примера.
Ну и давайте не забывать, что вложенные запросы - это всегда не есть хорошо, ведь они выполняются отдельно и независимо от внешних. Поэтому, работая с какой-то крупной статистикой, не забывайте их оптимизировать и проставлять лимиты. А ещё лучше - поразмыслите над своей :)
Оператор языка SQL JOIN предназначен для соединения двух или более таблиц базы данных по совпадающему условию. Этот оператор существует только в реляционных базах данных. Именно благодаря JOIN реляционные базы данных обладают такой мощной функциональностью, которая позволяет вести не только хранение данных, но и их, хотя бы простейший, анализ с помощью запросов. Разберём основные нюансы написания SQL-запросов с оператором JOIN, которые являются общими для всех СУБД (систем управления базами данных). Для соединения двух таблиц оператор SQL JOIN имеет следующий синтаксис:
SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ_1 JOIN ИМЯ_ТАБЛИЦЫ_2 ON УСЛОВИЕ
После одного или нескольких звеньев с оператором JOIN может следовать необязательная секция WHERE или HAVING, в которой, также, как в простом SELECT-запросе, задаётся условие выборки. Общим для всех СУБД является то, что в этой конструкции вместо JOIN может быть указано INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, FULL OUTER JOIN, CROSS JOIN (или, как вариант, запятая).
INNER JOIN (внутреннее соединение)
Запрос с оператором INNER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON.
То же самое делает и просто JOIN. Таким образом, слово INNER - не обязательное.
Пример 1. Есть база данных портала объявлений. В ней есть таблица Categories (категории объявлений) и Parts (части, или иначе - рубрики, которые и относятся к категориям). Например, части Квартиры, Дачи относятся к категории Недвижимость, а части Автомобили, Мотоциклы - к категории Транспорт. Эти таблицы с заполненными данными имеют следующий вид.
Таблица Parts:
Заметим, что в таблице Parts Книги имеют Cat - ссылку на категорию, которой нет в таблице Categories, а в таблице Categories Техника имеет Cat_ID - первичный ключ, ссылки на который нет в таблице Parts. Требуется соединить данные этих двух таблиц так, чтобы в результирующей таблице были поля Part (Часть), Cat (Категория) и Price (Цена подачи объявления) и чтобы данные полностью пересекались по условию. Условие - совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts. Для этого пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS INNER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
В результирующей таблице нет Книг, так как эта запись ссылается на категорию, которой нет в таблице Categories, и Техники, так как эта запись имеет внешний ключ в таблице Categories, на который нет ссылки в таблице Parts.
В ряде случаев при соединениях таблиц составить менее громоздкие запросы можно с помощью предиката EXISTS и без использования JOIN.
Есть база данных "Театр". Таблица Play содержит данные о постановках. Таблица Team - о ролях актёров. Таблица Actor - об актёрах. Таблица Director - о режиссёрах. Поля таблиц, первичные и внешние ключи можно увидеть на рисунке ниже (для увеличения нажать левой кнопкой мыши).

Пример 3. Вывести список актеров, которые в одном спектакле играют более одной роли, и количество их ролей.
Оператор JOIN использовать 1 раз. Использовать HAVING, GROUP BY .
Подсказка. Оператор HAVING применяется к числу ролей, подсчитанных агрегатной функцией COUNT.
LEFT OUTER JOIN (левое внешнее соединение)
Запрос с оператором LEFT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой по порядку (левой) таблицы, даже если они не соответствуют условию. У записей левой таблицы, которые не соответствуют условию, значение столбца из правой таблицы будет NULL (неопределённым).

Пример 4. База данных и таблицы - те же, что и в примере 1.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Parts, которые не соответствуют условию, пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS LEFT OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
В результирующей таблице, в отличие от таблицы из примера 1, есть Книги, но значение столбца Цены (Price) у них - NULL, так как эта запись имеет идентификатор категории, которой нет в таблице Categories.
RIGHT OUTER JOIN (правое внешнее соединение)
Запрос с оператором RIGHT OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из второй по порядку (правой) таблицы, даже если они не соответствуют условию. У записей правой таблицы, которые не соответствуют условию, значение столбца из левой таблицы будет NULL (неопределённым).

Пример 5.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS RIGHT OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| NULL | 45 | 65,00 |
В результирующей таблице, в отличие от таблицы из примера 1, есть запись с категорией 45 и ценой 65,00, но значение столбца Части (Part) у неё - NULL, так как эта запись имеет идентификатор категории, на которую нет ссылок в таблице Parts.
FULL OUTER JOIN (полное внешнее соединение)
Запрос с оператором FULL OUTER JOIN предназначен для соединения таблиц и вывода результирующей таблицы, в которой данные полностью пересекаются по условию, указанному после ON, и дополняются записями из первой (левой) и второй (правой) таблиц, даже если они не соответствуют условию. У записей, которые не соответствуют условию, значение столбцов из другой таблицы будет NULL (неопределённым).

Пример 6. База данных и таблицы - те же, что и в предыдущих примерах.
Для получения результирующей таблицы, в которой данные из двух таблиц полностью пересекаются по условию и дополняются всеми данными как из таблицы Parts, так и из таблицы Categories, которые не соответствуют условию, пишем следующий запрос:
SELECT PARTS.Part, CATEGORIES.Cat_ID AS Cat, CATEGORIES.Price FROM PARTS FULL OUTER JOIN CATEGORIES ON PARTS.Cat = CATEGORIES.Cat_ID
Результатом выполнения запроса будет следующая таблица:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
| Книги | 160 | NULL |
| NULL | 45 | 65,00 |
В результирующей таблице есть записи Книги (из левой таблицы) и с категорией 45 (из правой таблицы), причём у первой из них неопределённая цена (столбец из правой таблицы), а у второй - неопределённая часть (столбец из левой таблицы).
Псевдонимы соединяемых таблиц
В предыдущих запросах мы указывали с названиями извлекаемых столбцов из разных таблиц полные имена этих таблиц. Такие запросы выглядят громоздко: одно и то же слово повторяется несколько раз. Нельзя ли как-то упростить конструкцию? Оказывается, можно. Для этого следует использовать псевдонимы таблиц - их сокращённые имена. Псевдоним может состоять и из одной буквы. Возможно любое количество букв в псевдониме, главное, чтобы запрос после сокращения был понятен Вам самим. Общее правило: в секции запроса, определяющей соединение, то есть вокруг слова JOIN нужно указать полные имена таблиц, а за каждым именем должен следовать псевдоним таблицы.
Пример 7. Переписать запрос из примера 1 с использованием псевдонимов соединяемых таблиц.
Запрос будет следующим:
SELECT P.Part, C.Cat_ID AS Cat, C.Price FROM PARTS P INNER JOIN CATEGORIES C ON P.Cat = C.Cat_ID
Запрос вернёт то же самое, что и запрос в примере 1, но он гораздо компактнее.
JOIN и соединение более двух таблиц
Реляционные базы данных должны подчиняться требованиям целостности и неизбыточности данных, в связи с чем данные об одном бизнес-процессе могут содержаться не только в одной, двух, но и в трёх и более таблицах. В этих случаях для анализа данных используются цепочки соединённых таблиц: например, в одной (первой) таблице содержится некоторый количественный показатель, вторую таблицу с первой и третьей связывают внешние ключи - данные пересекаются, но только третья таблица содержит условие, в зависимости от которого может быть выведен количественный показатель из первой таблицы. И таблиц может быть ещё больше. При помощи оператора SQL JOIN в одном запросе можно соединить большое число таблиц. В таких запросах за одной секцией соединения следует другая, причём каждый следующий JOIN соединяет со следующей таблицей таблицу, которая была второй в предыдущем звене цепочки. Таким образом, синтаксис SQL запроса для соединения более двух таблиц следующий:
SELECT ИМЕНА_СТОЛБЦОВ (1..N) FROM ИМЯ_ТАБЛИЦЫ_1 JOIN ИМЯ_ТАБЛИЦЫ_2 ON УСЛОВИЕ JOIN ИМЯ_ТАБЛИЦЫ_3 ON УСЛОВИЕ... JOIN ИМЯ_ТАБЛИЦЫ_M ON УСЛОВИЕ
Пример 8. База данных - та же, что и в предыдущих примерах. К таблицам Categories и Parts в этом примере добавится таблица Ads, содержащая данные об опубликованных на портале объявлениях. Приведём фрагмент таблицы Ads, в котором среди записей есть записи о тех объявлениях, срок публикации которых истекает 2018-04-02.
| A_Id | Part_ID | Date_start | Date_end | Text |
| 21 | 1 | "2018-02-11" | "2018-04-20" | "Продаю..." |
| 22 | 1 | "2018-02-11" | "2018-05-12" | "Продаю..." |
| ... | ... | ... | ... | ... |
| 27 | 1 | "2018-02-11" | "2018-04-02" | "Продаю..." |
| 28 | 2 | "2018-02-11" | "2018-04-21" | "Продаю..." |
| 29 | 2 | "2018-02-11" | "2018-04-02" | "Продаю..." |
| 30 | 3 | "2018-02-11" | "2018-04-22" | "Продаю..." |
| 31 | 4 | "2018-02-11" | "2018-05-02" | "Продаю..." |
| 32 | 4 | "2018-02-11" | "2018-04-13" | "Продаю..." |
| 33 | 3 | "2018-02-11" | "2018-04-12" | "Продаю..." |
| 34 | 4 | "2018-02-11" | "2018-04-23" | "Продаю..." |
Представим, что сегодня "2018-04-02", то есть это значение принимает функция CURDATE() - текущая дата . Требуется узнать, к каким категориям принадлежат объявления, срок публикации которых истекает сегодня. Названия категорий есть только в таблице CATEGORIES, а даты истечения срока публикации объявлений - только в таблице ADS. В таблице PARTS - части категорий (или проще, подкатегории) опубликованных объявлений. Но внешним ключом Cat_ID таблица PARTS связана с таблицей CATEGORIES, а таблица ADS связана внешним ключом Part_ID с таблицей PARTS. Поэтому соединяем в одном запросе три таблицы и этот запрос можно с максимальной корректностью назвать цепочкой.
Запрос будет следующим:
Результат запроса - таблица, содержащая названия двух категорий - "Недвижимость" и "Транспорт":
| Cat_name |
| Недвижимость |
| Транспорт |
CROSS JOIN (перекрестное соединение)
Использование оператора SQL CROSS JOIN в наиболее простой форме - без условия соединения - реализует операцию декартова произведения в реляционной алгебре . Результатом такого соединения будет сцепление каждой строки первой таблицы с каждой строкой второй таблицы. Таблицы могут быть записаны в запросе либо через оператор CROSS JOIN, либо через запятую между ними.
Пример 9. База данных - всё та же, таблицы - Categories и Parts. Реализовать операцию декартова произведения этих двух таблиц.
Запрос будет следующим:
SELECT (*) Categories CROSS JOIN Parts
Или без явного указания CROSS JOIN - через запятую:
SELECT (*) Categories , Parts
Запрос вернёт таблицу из 5 * 5 = 25 строк, фрагмент которой приведён ниже:
| Cat_ID | Cat_name | Price | Part_ID | Part | Cat |
| 10 | Стройматериалы | 105,00 | 1 | Квартиры | 505 |
| 10 | Стройматериалы | 105,00 | 2 | Автомашины | 205 |
| 10 | Стройматериалы | 105,00 | 3 | Доски | 10 |
| 10 | Стройматериалы | 105,00 | 4 | Шкафы | 30 |
| 10 | Стройматериалы | 105,00 | 5 | Книги | 160 |
| ... | ... | ... | ... | ... | ... |
| 45 | Техника | 65,00 | 1 | Квартиры | 505 |
| 45 | Техника | 65,00 | 2 | Автомашины | 205 |
| 45 | Техника | 65,00 | 3 | Доски | 10 |
| 45 | Техника | 65,00 | 4 | Шкафы | 30 |
| 45 | Техника | 65,00 | 5 | Книги | 160 |
Как видно из примера, если результат такого запроса и имеет какую-либо ценность, то это, возможно, наглядная ценность в некоторых случаях, когда не требуется вывести структурированную информацию, тем более, даже самую простейшую аналитическую выборку. Кстати, можно указать выводимые столбцы из каждой таблицы, но и тогда информационная ценность такого запроса не повысится.
Но для CROSS JOIN можно задать условие соединения! Результат будет совсем иным. При использовании оператора "запятая" вместо явного указания CROSS JOIN условие соединения задаётся не словом ON, а словом WHERE.
Пример 10. Та же база данных портала объявлений, таблицы Categories и Parts. Используя перекрестное соединение, соединить таблицы так, чтобы данные полностью пересекались по условию. Условие - совпадение идентификатора категории в таблице Categories и ссылки на категорию в таблице Parts.
Запрос будет следующим:
Запрос вернёт то же самое, что и запрос в примере 1:
| Part | Cat | Price |
| Квартиры | 505 | 210,00 |
| Автомашины | 205 | 160,00 |
| Доски | 10 | 105,00 |
| Шкафы | 30 | 77,00 |
И это совпадение не случайно. Запрос c перекрестным соединением по условию соединения полностью аналогичен запросу с внутренним соединением - INNER JOIN - или, учитывая, что слово INNER - не обязательное, просто JOIN.
Таким образом, какой вариант запроса использовать - вопрос стиля или даже привычки специалиста по работе с базой данных. Возможно, перекрёстное соединение с условием для двух таблиц может представляться более компактным. Но преимущество перекрестного соединения для более чем двух таблиц (это также возможно) весьма спорно. В этом случае WHERE-условия пересечения перечисляются через слово AND. Такая конструкция может быть громоздкой и трудной для чтения, если в конце запроса есть также секция WHERE с условиями выборки.
Реляционные базы данных и язык SQL
SQL - Урок 6. Объединение таблиц (внутреннее объединение)
Предположим, мы хотим узнать, какие темы, и какими авторами были созданы. Для этого проще всего обратиться к таблице Темы (topics):
Но, что если нам необходимо, чтобы в ответе на запрос были не идентификаторы авторов, а их имена? Вложенные запросы нам не помогут, т.к. в конечном итоге они выдают данные из одной таблицы. А нам надо получить данные из двух таблиц (Темы и Пользователи) и объединить их в одну. Запросы, которые позволяют это сделать, в SQL называются Объединениями .
Синтаксис самого простого объединения следующий:
SELECT имена_столбцов_таблицы_1, имена_столбцов_таблицы_2 FROM имя_таблицы_1, имя_таблицы_2;
Давайте создадим простое объединение:

Получилось не совсем то, что мы ожидали. Такое объединение научно называется декартовым произведением, когда каждой строке первой таблицы ставится в соответствие каждая строка второй таблицы. Возможно, бывают случаи, когда такое объединение полезно, но это явно не наш случай.
Чтобы результирующая таблица выглядела так, как мы хотели, необходимо указать условие объединения. Мы связываем наши таблицы по идентификатору автора, это и будет нашим условием. Т.е. мы укажем в запросе, что необходимо выводить только те строки, в которых значения поля id_author таблицы topics совпадают со значениями поля id_user таблицы users:

На схеме будет понятнее:
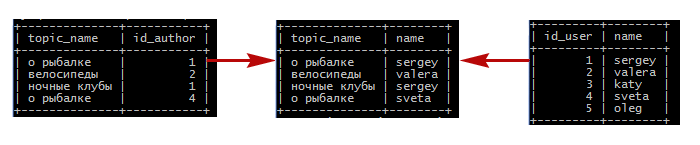
Т.е. мы в запросе сделали следующее условие: если в обеих таблицах есть одинаковые идентификаторы, то строки с этим идентификатором необходимо объединить в одну результирующую строку.
Обратите внимание на две вещи:
- Если в одной из объединяемых таблиц есть строка с идентификатором, которого нет в другой объединяемой таблице, то в результирующей таблице строки с таким идентификатором не будет. В нашем примере есть пользователь Oleg (id=5), но он не создавал тем, поэтому в результате запроса его нет.
- При указании условия название столбца пишется после названия таблицы, в которой этот столбец находится (через точку). Это сделано во избежание путаницы, ведь столбцы в разных таблицах могут иметь одинаковые названия, и MySQL может не понять, о каких конкретно столбцах идет речь.
SELECT имя_таблицы_1.имя_столбца1_таблицы_1, имя_таблицы_1.имя_столбца2_таблицы_1, имя_таблицы_2.имя_столбца1_таблицы_2, имя_таблицы_2.имя_столбца2_таблицы_2 FROM имя_таблицы_1, имя_таблицы_2 WHERE имя_таблицы_1.имя_столбца_по_которому_объединяем = имя_таблицы_2.имя_столбца_по_которому_объединяем;
Если имя столбца уникально, то название таблицы можно опустить (как мы делали в примере), но делать это не рекомендуется.
Как вы понимаете, объединения дают возможность выбирать любую информацию из любых таблиц, причем объединяемых таблиц может быть и три, и четыре, да и условие для объединения может быть не одно.
Для примера давайте создадим запрос, который покажет нам все сообщения, к каким темам они относятся и авторов этих сообщений. Конечно, вся эта информация хранится в таблице Сообщения (posts):
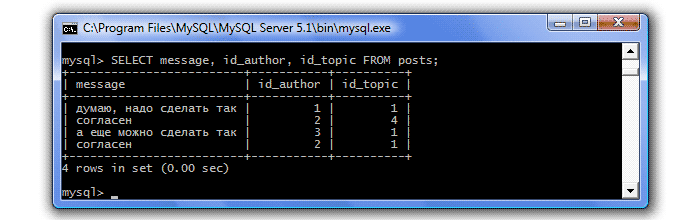
Но чтобы вместо идентификаторов отображались имена и названия, нам придется сделать объединение трех таблиц:

Т.е. мы объединили таблицы Сообщения и Пользователи условием posts.id_author=users.id_user, а таблицы Сообщения и Темы - условием posts.id_topic=topics.id_topic

Объединения, которые мы сегодня рассматривали, называются Внутренними объединениями . Такие объединения связывают строки одной таблицы со строками другой таблицы (а может еще и третьей таблицы). Но бывают ситуации, когда необходимо, чтобы в результат были включены строки, не имеющие связанных. Например, когда мы создавали запрос, какие темы и какими авторами были созданы, пользователь Oleg в результирующую таблицу не попал, т.к. тем не создавал, а потому и связанной строки в объединяемой таблице не имел.
Поэтому, если нам потребуется составить несколько иной запрос - вывести всех пользователей и темы, которые они создавали, если таковые имеются - то нам придется воспользоваться Внешним объединением , позволяющим выводить все строки одной таблицы и имеющиеся связанные с ними строки из другой таблицы. О таких объединениях мы и будем говорить в следующем уроке.
SQL - Урок 7. Объединение таблиц (внешнее объединение)
Итак, в продолжение прошлого урока, нам надо вывести всех пользователей и темы, которые они создавали, если таковые имеются. Если мы воспользуемся внутренним объединением, рассмотренным на прошлом уроке, то получим в итоге следующее: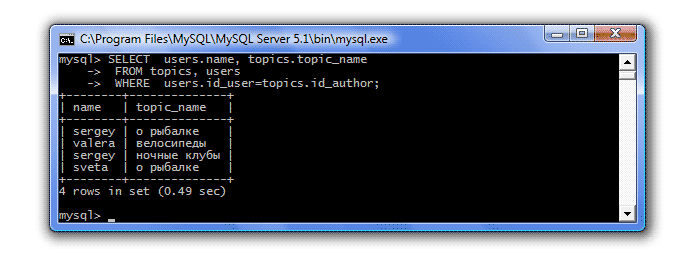
То есть в результирующей таблице есть только те пользователи, которые создавали темы. А нам надо, чтобы выводились все имена. Для этого мы немного изменим запрос:
SELECT users.name, topics.topic_name FROM users LEFT OUTER JOIN topics ON users.id_user=topics.id_author;
И получим желаемый результат - все пользователи и темы, ими созданные. Если пользователь не создавал тему, но в соответствующем столбце стоит значение NULL.

Итак, мы добавили в наш запрос ключевое слово - LEFT OUTER JOIN , указав тем самым, что из таблицы слева надо взять все строки, и поменяли ключевое слово WHERE на ON . Кроме ключевого слова LEFT OUTER JOIN может быть использовано ключевое слово RIGHT OUTER JOIN . Тогда будут выбираться все строки из правой таблицы и имеющиеся связанные с ними из левой таблицы. И наконец, возможно полное внешнее объединение, которое извлечет все строки из обеих таблиц и свяжет между собой те, которые могут быть связаны. Ключевое слово для полного внешнего объединения - FULL OUTER JOIN .
Давайте поменяем в нашем запросе левостороннее объединение на правостороннее:
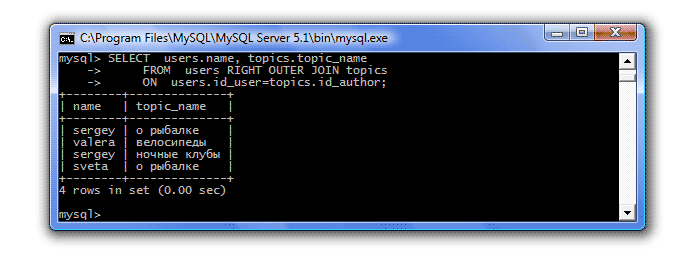
Как видите, теперь у нас есть все темы (все строки из правой таблицы), а вот пользователи только те, которые темы создавали (т.е. из левой таблицы выбираются только те строки, которые связаны с правой таблицей).
К сожалению полное объединение СУБД MySQL не поддерживает.
Подведем итог этого короткого урока. Синтаксис для внешнего объединения следующий.
 Работа со звуком на платформе Макинтош (Mac OS X)
Работа со звуком на платформе Макинтош (Mac OS X) Arduino и четырехразрядный семисегментный индикатор
Arduino и четырехразрядный семисегментный индикатор Способы проверки задолженности за телефон и интернет от ростелеком
Способы проверки задолженности за телефон и интернет от ростелеком Как повысить производительность компьютера за минимальные деньги
Как повысить производительность компьютера за минимальные деньги Электронная почта — где можно ее создать, как зарегистрировать почтовый ящик и выбрать лучший из бесплатных Email сервисов
Электронная почта — где можно ее создать, как зарегистрировать почтовый ящик и выбрать лучший из бесплатных Email сервисов SHA256 – алгоритм хеширования
SHA256 – алгоритм хеширования Установить прошивку CyanogenMod с помощью инсталлятора CyanogenMod Влияние на гарантию
Установить прошивку CyanogenMod с помощью инсталлятора CyanogenMod Влияние на гарантию