Surveillance professionnelle complète des demandes d'écho. Moniteur de ping EMCO. Assistant d'administration gratuit Qui en a besoin et pourquoi
A l'apparition de cette optique, passant par la forêt jusqu'au collecteur, on peut conclure que l'installateur n'a pas suivi un peu la technologie. La monture sur la photo suggère également qu'il s'agit probablement d'un marin - un nœud marin.
Je fais partie de l'équipe de santé du réseau physique, en d'autres termes, le support technique, qui est chargé de s'assurer que les voyants des routeurs clignotent comme il se doit. Nous avons sous notre aile diverses grandes entreprises avec des infrastructures à travers le pays. Nous ne montons pas à l'intérieur de leur entreprise, notre tâche est de nous assurer que le réseau fonctionne au niveau physique et que le trafic passe comme il se doit.
Le sens général du travail est l'interrogation constante des nœuds, la suppression de la télémétrie, les tests (par exemple, la vérification des paramètres pour trouver des vulnérabilités), la garantie de la santé, la surveillance des applications, le trafic. Parfois inventaires et autres perversions.
Je vais vous raconter comment c'est organisé et quelques histoires de voyages.
Comme c'est généralement le cas
Notre équipe se trouve dans un bureau à Moscou et prend la télémétrie du réseau. En fait, ce sont des pings constants de nœuds, ainsi que la réception de données de surveillance si le matériel est intelligent. La situation la plus courante est que le ping ne passe pas plusieurs fois de suite. Dans 80 % des cas pour une chaîne de magasins, par exemple, cela s'avère être une panne de courant, alors nous, voyant cette image, faisons ce qui suit :- Nous appelons d'abord le fournisseur au sujet des accidents
- Puis - à la centrale à propos de l'arrêt
- Ensuite, nous essayons d'établir une connexion avec quelqu'un de l'établissement (ce n'est pas toujours possible, par exemple, à 2 heures du matin)
- Et, enfin, si ce qui précède n'a pas aidé en 5 à 10 minutes, nous nous quittons ou envoyons un «avatar» - un ingénieur contractuel assis quelque part à Izhevsk ou à Vladivostok, si le problème est là.
- Nous restons en contact permanent avec "l'avatar" et le "menons" à travers l'infrastructure - nous avons des capteurs et des manuels d'entretien, il a des pinces.
- Ensuite, l'ingénieur nous envoie un rapport avec une photo de ce que c'était.
Le dialogue se déroule parfois ainsi :
- Donc, la connexion est perdue entre les bâtiments numéro 4 et 5. Vérifiez le routeur dans le cinquième.
- Commande, inclus. Il n'y a pas de connexion.
- Ok, longez le câble jusqu'au quatrième bâtiment, il y a un autre nœud.
-… Opa !
- Ce qui s'est passé?
- Ici la 4ème maison a été démolie.
- Quoi??
- Je joins une photo au rapport. Je ne peux pas restaurer la maison dans SLA.

Mais le plus souvent, il s'avère toujours de trouver une pause et de restaurer le canal.
Environ 60% des trajets sont "dans le lait", car soit l'alimentation électrique est interrompue (par une pelle, un contremaître, des intrus), soit le prestataire n'est pas au courant de sa panne, soit un problème de courte durée est éliminé avant l'installateur arrive. Cependant, il y a des moments où nous découvrons le problème avant les utilisateurs et avant les services informatiques du client, et communiquons la solution avant même qu'ils ne réalisent que quelque chose s'est produit. Le plus souvent, de telles situations surviennent la nuit, lorsque l'activité des entreprises clientes est faible.
Qui en a besoin et pourquoi
En règle générale, toute grande entreprise possède son propre service informatique, qui comprend clairement les spécificités et les tâches. Dans les moyennes et grandes entreprises, le travail des "enikeev" et des ingénieurs réseau est souvent externalisé. C'est juste bénéfique et pratique. Par exemple, un détaillant a ses propres informaticiens très cool, mais ils sont loin de remplacer les routeurs et de localiser les câbles.Qu'est-ce que nous faisons
- Nous travaillons sur les demandes - tickets et appels de panique.
- Nous faisons de la prévention.
- Nous suivons les recommandations des fournisseurs de matériel, par exemple sur les conditions de maintenance.
- Nous nous connectons au suivi du client et lui supprimons des données afin de se déplacer en cas d'incidents.
La première façon - de simples vérifications - est juste une machine qui envoie un ping à tous les nœuds du réseau et s'assure qu'ils répondent correctement. Une telle implémentation ne nécessite aucun changement ou des changements cosmétiques minimes dans le réseau du client. En règle générale, dans un cas très simple, nous installons Zabbix directement chez nous dans l'un des centres de données (heureusement, nous en avons deux dans le bureau du CROC à Volochaevskaya). Dans un cas plus complexe, par exemple, si vous utilisez votre propre réseau sécurisé - vers l'une des machines du centre de données du client :

Zabbix peut être utilisé plus compliqué, par exemple, il a des agents qui sont installés sur les nœuds * nix et win et affichent la surveillance du système, ainsi qu'un mode de vérification externe (avec prise en charge du protocole SNMP). Néanmoins, si une entreprise a besoin de quelque chose de similaire, soit elle a déjà sa propre surveillance, soit une solution plus riche en fonctionnalités est choisie. Bien sûr, ce n'est plus open source et cela coûte de l'argent, mais même un inventaire précis et banal réduit déjà les coûts d'environ un tiers.
Nous le faisons aussi, mais c'est l'histoire de collègues. Ici, ils ont envoyé quelques captures d'écran d'Infosim :


Je suis un opérateur d'avatar, je vais donc vous en dire plus sur mon travail.
À quoi ressemble un incident typique ?
Devant nous se trouvent des écrans avec l'état général suivant :
Sur cet objet, Zabbix collecte pour nous pas mal d'informations : numéro de lot, numéro de série, utilisation CPU, description de l'appareil, disponibilité des interfaces, etc. Toutes les informations nécessaires sont disponibles depuis cette interface.
Un incident ordinaire commence généralement par le fait que l'un des canaux menant, par exemple, au magasin du client (dont il possède 200 à 300 pièces à travers le pays) tombe en panne. Le commerce de détail est maintenant bien développé, pas comme il y a sept ans, donc le box-office continuera de fonctionner - il y a deux canaux.
On décroche les téléphones et on passe au moins trois appels : au fournisseur, à la centrale électrique et aux gens sur place (« Oui, on a chargé des raccords ici, le câble de quelqu'un a été touché... Ah, le vôtre ? Bon, c'est bien ça nous l'avons trouvé").
En règle générale, sans surveillance, des heures ou des jours s'écouleraient avant une escalade - les mêmes canaux de secours ne sont pas toujours vérifiés. On sait tout de suite et on part tout de suite. S'il existe des informations supplémentaires en plus des pings (par exemple, un modèle de pièce de fer buggy), nous complétons immédiatement l'ingénieur de terrain avec les pièces nécessaires. De plus déjà en place.
Le deuxième appel régulier le plus fréquent est la panne de l'un des terminaux des utilisateurs, par exemple un téléphone DECT ou un routeur Wi-Fi qui distribuait le réseau au bureau. Ici, nous apprenons le problème grâce à la surveillance et recevons presque immédiatement un appel avec des détails. Parfois l'appel n'apporte rien de nouveau ("Je décroche le téléphone, quelque chose ne sonne pas"), parfois il est très utile ("On l'a laissé tomber de la table"). Il est clair que dans le second cas ce n'est clairement pas un saut de ligne.
L'équipement à Moscou provient de nos entrepôts de réserve chaude, nous en avons plusieurs types:

Les clients ont généralement leurs propres stocks de composants fréquemment défaillants - combinés de bureau, blocs d'alimentation, ventilateurs, etc. Si vous devez livrer quelque chose qui n'est pas en place, pas à Moscou, nous y allons généralement nous-mêmes (parce que l'installation). Par exemple, j'ai fait un voyage nocturne à Nizhny Tagil.
Si le client dispose de sa propre surveillance, il peut nous envoyer des données. Parfois, nous déployons Zabbix en mode polling, juste pour assurer la transparence et le contrôle SLA (ceci est également gratuit pour le client). Nous n'installons pas de capteurs supplémentaires (ceci est fait par des collègues qui assurent la continuité des processus de production), mais nous pouvons nous y connecter si les protocoles ne sont pas exotiques.
En général, nous ne touchons pas à l'infrastructure du client, nous la soutenons telle quelle.
Par expérience, je peux dire que les dix derniers clients sont passés à l'assistance externe en raison du fait que nous sommes très prévisibles en termes de coûts. Budgétisation claire, bonne gestion des dossiers, rapport sur chaque demande, SLA, rapports d'équipement, maintenance préventive. Idéalement, bien sûr, nous sommes pour le CIO d'un client tel que les nettoyeurs - nous venons le faire, tout est propre, nous ne distrayons pas.
Une autre chose à noter est que dans certaines grandes entreprises, l'inventaire devient un véritable problème, et parfois nous sommes attirés uniquement pour le réaliser. De plus, nous effectuons le stockage des configurations et leur gestion, ce qui est pratique pour les différents déménagements et reconnexions. Mais, encore une fois, dans les cas difficiles, ce n'est pas non plus moi - nous avons une équipe spéciale qui transporte les centres de données.
Et un autre point important : notre ministère ne s'occupe pas d'infrastructures critiques. Tout ce qui se trouve à l'intérieur des centres de données et tout ce qui concerne les banques, les assurances et les opérateurs, ainsi que les systèmes de base de la vente au détail - c'est une équipe X. Voici les gars.
Plus d'entraînement
De nombreux appareils modernes sont capables de fournir de nombreuses informations de service. Par exemple, pour les imprimantes réseau, il est très facile de surveiller le niveau de toner dans la cartouche. Vous pouvez compter sur la période de remplacement à l'avance, recevoir une notification de 5 à 10 % (si le bureau commence soudainement à taper furieusement pas dans le calendrier standard) - et envoyer immédiatement une enikey avant que le service comptable ne commence à paniquer.Très souvent, des statistiques annuelles nous sont retirées, ce qui est fait par le même système de surveillance plus nous. Dans le cas de Zabbix, il s'agit simplement de planifier les coûts et de comprendre ce qui est allé où, et dans le cas d'Infosim, c'est également un matériau pour calculer la mise à l'échelle pendant un an, charger les administrateurs et toutes sortes d'autres choses. Il y a la consommation d'énergie dans les statistiques - l'année dernière, presque tout le monde a commencé à lui demander, apparemment pour répartir les coûts internes entre les départements.
Parfois, de véritables sauvetages héroïques sont obtenus. De telles situations sont très rares, mais d'après ce dont je me souviens cette année, nous avons vu vers 3 heures du matin que la température montait à 55 degrés sur le commutateur cisco. Dans la salle des serveurs distante, il y avait des climatiseurs "stupides" sans surveillance, et ils ont échoué. Nous avons immédiatement appelé un ingénieur en refroidissement (pas le nôtre) et appelé l'administrateur du client en service. Il a mis en place des services non critiques et a protégé la salle des serveurs de l'arrêt thermique jusqu'à l'arrivée du type avec un climatiseur mobile, puis les services réguliers ont été réparés.
Les Polycoms et autres équipements de visioconférence coûteux surveillent très bien le niveau de charge de la batterie avant les conférences, ce qui est également important.
Tout le monde a besoin de surveillance et de diagnostic. En règle générale, il est long et difficile à mettre en œuvre sans expérience : les systèmes sont soit extrêmement simples et pré-configurés, soit de la taille d'un porte-avions et avec un tas de rapports standards. Aiguiser avec un fichier pour l'entreprise, inventer la mise en œuvre de leurs tâches pour le service informatique interne et afficher les informations dont ils ont le plus besoin, ainsi que tenir à jour tout l'historique est un râteau s'il n'y a pas d'expérience de mise en œuvre. Lorsque nous travaillons avec des systèmes de surveillance, nous choisissons le juste milieu entre les solutions gratuites et les meilleures - en règle générale, pas les fournisseurs les plus populaires et les plus "épais", mais résolvons clairement le problème.
Il était une fois un traitement plutôt atypique. Le client devait donner le routeur à certaines de ses divisions distinctes, et exactement selon l'inventaire. Le routeur avait un module avec le numéro de série spécifié. Lorsque le routeur a commencé à se préparer pour la route, il s'est avéré que ce module manquait. Et personne ne peut le trouver. Le problème est légèrement exacerbé par le fait que l'ingénieur qui a travaillé avec cette branche l'année dernière est déjà à la retraite et est parti vivre avec ses petits-enfants dans une autre ville. Ils nous ont contactés et nous ont demandé de regarder. Heureusement, le matériel a fourni des rapports sur les numéros de série, et Infosim a fait un inventaire, nous avons donc trouvé ce module dans l'infrastructure en quelques minutes, décrit la topologie. Le fugitif a été retrouvé par câble - il se trouvait dans une autre salle de serveurs dans un placard. L'histoire du mouvement a montré qu'il y est arrivé après l'échec d'un module similaire.

Une image d'un long métrage sur Hottabych, décrivant avec précision l'attitude de la population envers les caméras
Beaucoup d'incidents de caméra. Une fois, 3 caméras ont échoué en même temps. Rupture de câble dans l'un des tronçons. L'installateur en souffla un nouveau dans l'ondulation, deux des trois chambres se levèrent après une série de chamanisme. Et le troisième ne l'est pas. De plus, on ne sait pas du tout où elle se trouve. Je monte le flux vidéo - les dernières images juste avant la chute - 4 heures du matin, trois hommes portant des foulards sur le visage se présentent, quelque chose de brillant en dessous, la caméra tremble beaucoup, tombe.
Une fois que nous avons mis en place la caméra, qui devrait se concentrer sur les "lièvres" grimpant par-dessus la clôture. Pendant la conduite, nous avons réfléchi à la façon dont nous désignerions le point où l'intrus devrait apparaître. Cela n'a pas été utile - dans les 15 minutes que nous avons passées là-bas, 30 personnes sont entrées dans l'objet uniquement au point dont nous avions besoin. Table droite.
Comme j'ai déjà donné un exemple ci-dessus, l'histoire du bâtiment démoli n'est pas une blague. Une fois le lien vers l'équipement disparu. En place - il n'y a pas de pavillon où le cuivre est passé. Le pavillon a été démoli, le câble a disparu. Nous avons vu que le routeur était mort. L'installateur est arrivé, a commencé à regarder - et la distance entre les nœuds est de quelques kilomètres. Il a un testeur Vipnet dans son ensemble, le standard - ça sonnait d'un connecteur, ça sonnait d'un autre - il est allé chercher. Habituellement, le problème est immédiatement visible.

Suivi du câble: c'est de l'optique ondulée, une suite de l'histoire du tout en haut du post sur le nœud. Ici, au final, en plus de l'installation absolument époustouflante, le problème était que le câble s'était éloigné des supports. Ici escaladez les uns et les autres, et desserrez les structures métalliques. Environ cinq millième représentant du prolétariat a cassé l'optique.
Dans une installation, tous les nœuds étaient éteints environ une fois par semaine. Et en même temps. Nous cherchions un modèle depuis un certain temps. Le programme d'installation a trouvé les éléments suivants :
- Le problème survient toujours dans le quart de travail de la même personne.
- Il diffère des autres en ce qu'il porte un manteau très épais.
- Une machine automatique est montée derrière un cintre.
- Quelqu'un a pris le couvert de la machine il y a longtemps, à l'époque préhistorique.
- Lorsque ce camarade arrive dans l'établissement, il raccroche ses vêtements et elle éteint les machines.
- Il les rallume immédiatement.
L'équipement a été éteint à une seule et même heure à la même heure la nuit. Il s'est avéré que des artisans locaux se sont connectés à notre alimentation électrique, ont sorti une rallonge et y ont collé une bouilloire et une cuisinière électrique. Lorsque ces appareils fonctionnent simultanément, tout le pavillon est assommé.
Dans l'un des magasins de notre vaste pays, tout le réseau tombait constamment avec la fermeture du quart de travail. L'installateur a vu que toute la puissance était amenée à la ligne d'éclairage. Dès que l'éclairage zénithal du hall (qui consomme beaucoup d'énergie) est éteint dans le magasin, tous les équipements du réseau sont éteints.
Il y a eu un cas où le concierge a interrompu le câble avec une pelle.
Souvent, nous ne voyons que du cuivre couché avec une ondulation déchirée. Une fois, entre deux ateliers, des artisans locaux faisaient simplement suivre un câble à paire torsadée sans aucune protection.
Loin de la civilisation, les employés se plaignent souvent d'être exposés à « nos » équipements. Les standards de certains sites distants peuvent se trouver dans la même pièce que la personne de service. En conséquence, à quelques reprises, nous avons rencontré des grands-mères nuisibles qui, de gré ou de force, les ont éteintes au début du quart de travail.
Une autre ville lointaine accroché une vadrouille sur l'optique. Ils ont détaché l'ondulation du mur et ont commencé à l'utiliser comme attaches pour l'équipement.

Dans ce cas, il y a clairement des problèmes de nutrition.
Ce que la "grande" surveillance peut faire
Je parlerai brièvement des capacités de systèmes plus sérieux, en prenant l'exemple des installations d'Infosim.Il existe 4 solutions combinées en une seule plate-forme :- Gestion des pannes - contrôle des pannes et corrélation des événements.
- Gestion des performances.
- Inventaire et découverte automatique de la topologie.
- Gestion de la configuration.
Séparément, à propos de l'inventaire. Le module affiche non seulement la liste, mais construit également la topologie elle-même (au moins dans 95 % des cas, il essaie et réussit). Il vous permet également d'avoir à portée de main une base de données à jour des équipements informatiques usagés et inutilisés (réseau, équipements serveurs, etc.), de remplacer à temps les équipements obsolètes (EOS/EOL). En général, c'est pratique pour les grandes entreprises, mais dans les petites entreprises, une grande partie de cela se fait à la main.
Exemples de rapports :
- Rapports dans le contexte des types de systèmes d'exploitation, des micrologiciels, des modèles et des fabricants d'équipements ;
- Rapport sur le nombre de ports libres sur chaque commutateur du réseau / par fabricant sélectionné / par modèle / par sous-réseau, etc. ;
- Rapport sur les appareils nouvellement ajoutés pour une période spécifiée ;
- Avertissement de faible niveau de toner de l'imprimante ;
- Évaluation de l'adéquation du canal de communication au trafic sensible aux retards et aux pertes, méthodes actives et passives ;
- Suivi de la qualité et de la disponibilité des canaux de communication (SLA) - génération de rapports sur la qualité des canaux de communication, ventilés par opérateurs télécoms ;
- La fonctionnalité de contrôle des pannes et de corrélation des événements est mise en œuvre via le mécanisme d'analyse des causes profondes (sans que les administrateurs aient besoin d'écrire des règles) et le mécanisme de la machine d'état d'alarme. L'analyse des causes premières est une analyse de la cause première d'un accident basée sur les procédures suivantes : 1. détection et localisation automatiques du site de la défaillance ; 2. réduire le nombre d'événements d'urgence à une seule clé ; 3. identifier les conséquences d'un échec - qui et quoi a été affecté par l'échec.

Stablenet - Embedded Agent (SNEA) - un ordinateur un peu plus grand qu'un paquet de cigarettes.
L'installation est effectuée dans des guichets automatiques ou des segments de réseau dédiés où des tests d'accessibilité sont nécessaires. Avec leur aide, des tests de charge sont effectués.
Surveillance en nuage
Un autre modèle d'installation est le SaaS dans le cloud. Fabriqué pour un client mondial (une entreprise avec un cycle de production continu avec une géographie de distribution de l'Europe à la Sibérie).Des dizaines d'installations, dont des usines et des entrepôts de produits finis. Si leurs canaux tombaient et que leur soutien était assuré à partir de bureaux étrangers, des retards d'expédition commençaient, ce qui, le long de la vague, entraînait de nouvelles pertes. Tout le travail a été effectué sur demande et beaucoup de temps a été consacré à enquêter sur l'incident.
Nous avons mis en place un suivi spécifiquement pour eux, puis l'avons terminé sur un certain nombre de sites en fonction des spécificités de leur routage et de leur matériel. Tout cela a été fait dans le cloud CROC. Ils ont réalisé et livré le projet très rapidement.
Le résultat est:
- Grâce au transfert partiel de la gestion de l'infrastructure réseau, il a été possible d'optimiser au moins 50 %. Inaccessibilité des équipements, charge des canaux, dépassement des paramètres recommandés par le constructeur : tout cela est enregistré en 5 à 10 minutes, diagnostiqué et éliminé en une heure.
- Lorsqu'il reçoit un service du cloud, le client convertit les coûts d'investissement du déploiement de son système de surveillance de réseau en coûts d'exploitation moyennant des frais d'abonnement à notre service, qui peuvent être annulés à tout moment.
L'avantage du cloud est que dans notre décision, nous nous tenons, pour ainsi dire, au-dessus de leur réseau et pouvons regarder tout ce qui se passe de manière plus objective. À ce moment-là, si nous étions à l'intérieur du réseau, nous ne verrions l'image que jusqu'au nœud défaillant, et ce qui se passe derrière, nous ne le saurions plus.
Quelques dernières photos
C'est le "casse-tête du matin":
Et voici le trésor que nous avons trouvé :

Voici ce qu'il y avait dans le coffre :

Et enfin, à propos de la sortie la plus drôle. Une fois, je suis allé dans un magasin de détail.
Il s'est passé ce qui suit : d'abord, il a commencé à couler du toit sur le faux plafond. Puis un lac s'est formé dans le faux plafond, qui s'est érodé et a traversé l'une des tuiles. En conséquence, tout cela a jailli chez l'électricien. Ensuite, je ne sais pas exactement ce qui s'est passé, mais quelque part dans la pièce voisine, il y a eu un court-circuit et un incendie s'est déclaré. D'abord, les extincteurs à poudre ont fonctionné, puis les pompiers sont arrivés et ont tout rempli de mousse. Je suis arrivé après eux pour le démontage. Je dois dire que le tsiska 2960 a bien réussi après tout cela - j'ai pu récupérer la configuration et envoyer l'appareil en réparation.
Une fois de plus, lors du déclenchement du système de poudre, le Tsiskovsky 3745 dans une boîte était presque entièrement rempli de poudre. Toutes les interfaces étaient pleines - 2 x 48 ports. Il devait être inclus sur place. Nous nous sommes souvenus du dernier cas, avons décidé d'essayer d'enlever les configs "à chaud", l'avons secoué, nettoyé du mieux que nous pouvions. Nous l'avons allumé - au début, l'appareil a dit "pff" et nous a éternué avec un grand jet de poudre. Et puis il a grondé et s'est levé.
demande d'écho
Une requête d'écho (ping) est un outil de diagnostic utilisé pour savoir si un hôte particulier est accessible sur un réseau IP. La demande d'écho est faite à l'aide du protocole ICMP (Internet Control Message Protocol). Ce protocole est utilisé pour envoyer une requête d'écho à l'hôte en cours de vérification. L'hôte doit être configuré pour accepter les paquets ICMP.
Examen
par demande d'écho
PRTG est un outil de surveillance de ping et de réseau pour Windows. Il est compatible avec tous les principaux systèmes Windows, y compris Windows Server 2012 R2 et Windows 10.
PRTG est un outil puissant pour l'ensemble du réseau. Pour les serveurs, les routeurs, les commutateurs, la disponibilité et les connexions cloud, PRTG garde une trace de tout afin que vous puissiez simplifier l'administration. Le capteur ping, ainsi que les capteurs SNMP , NetFlow et de reniflage de paquets sont utilisés pour recueillir des informations détaillées sur la disponibilité et la charge de travail du réseau.
PRTG dispose d'un système d'alarme intégré personnalisable qui vous avertit rapidement des problèmes. Le capteur ping est configuré comme capteur principal pour les périphériques réseau. Si ce capteur tombe en panne, tous les autres capteurs de l'appareil sont mis en mode veille. Cela signifie qu'au lieu d'un flux de messages d'alerte, vous ne recevrez qu'une seule notification.
À tout moment, un aperçu rapide peut être affiché sur le tableau de bord PRTG. Vous verrez immédiatement si tout est en ordre. Le tableau de bord est personnalisable pour répondre à vos besoins spécifiques. En dehors du lieu de travail, comme lorsque vous travaillez dans une salle de serveurs, l'accès à PRTG est possible via une application pour smartphone, et vous ne manquerez jamais un seul événement.
La surveillance initiale est configurée immédiatement lors de l'installation. Ceci est possible grâce à la fonction de découverte automatique : PRTG envoie un ping à vos adresses IP privées et crée automatiquement des capteurs pour les appareils disponibles. Lorsque vous ouvrez PRTG pour la première fois, vous pouvez immédiatement vérifier la disponibilité de votre réseau.
Le programme PRTG a un modèle de licence transparent. Vous pouvez tester PRTG gratuitement. Le capteur de ping et la fonction d'alarme sont également inclus dans la version gratuite et ont une durée d'utilisation illimitée. Si votre entreprise ou votre réseau a besoin de plus de fonctionnalités, il est facile de mettre à niveau votre licence.
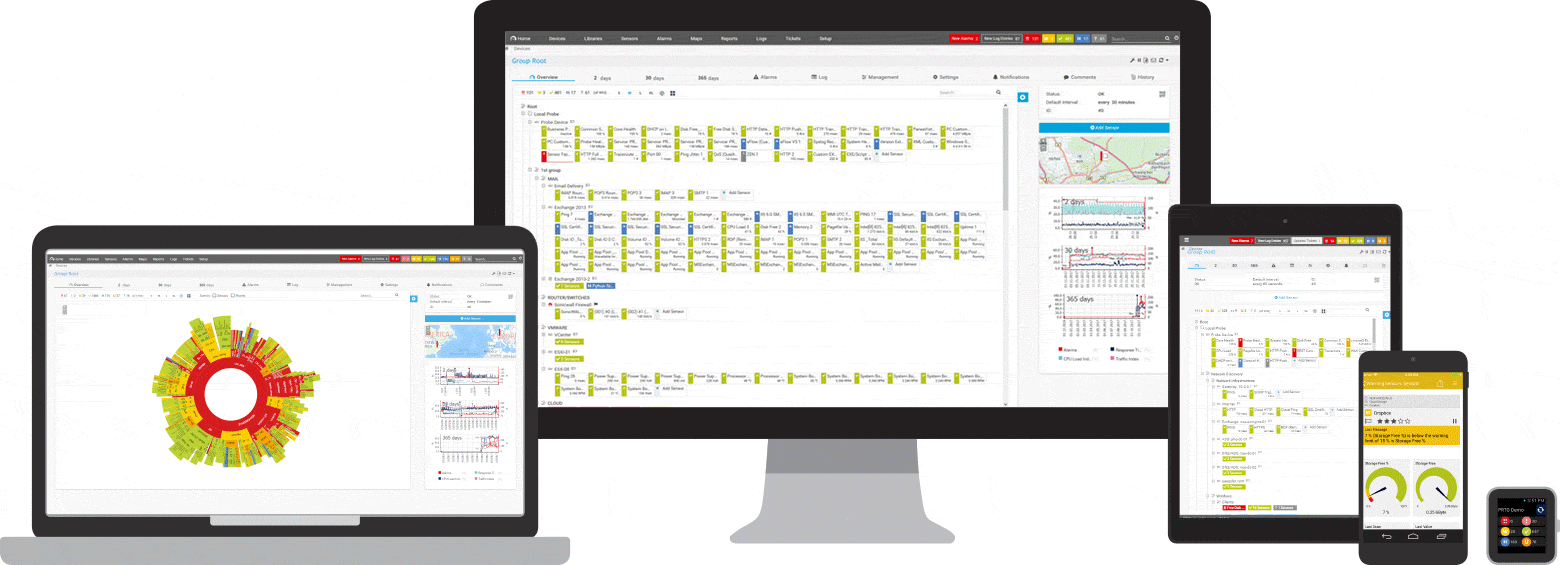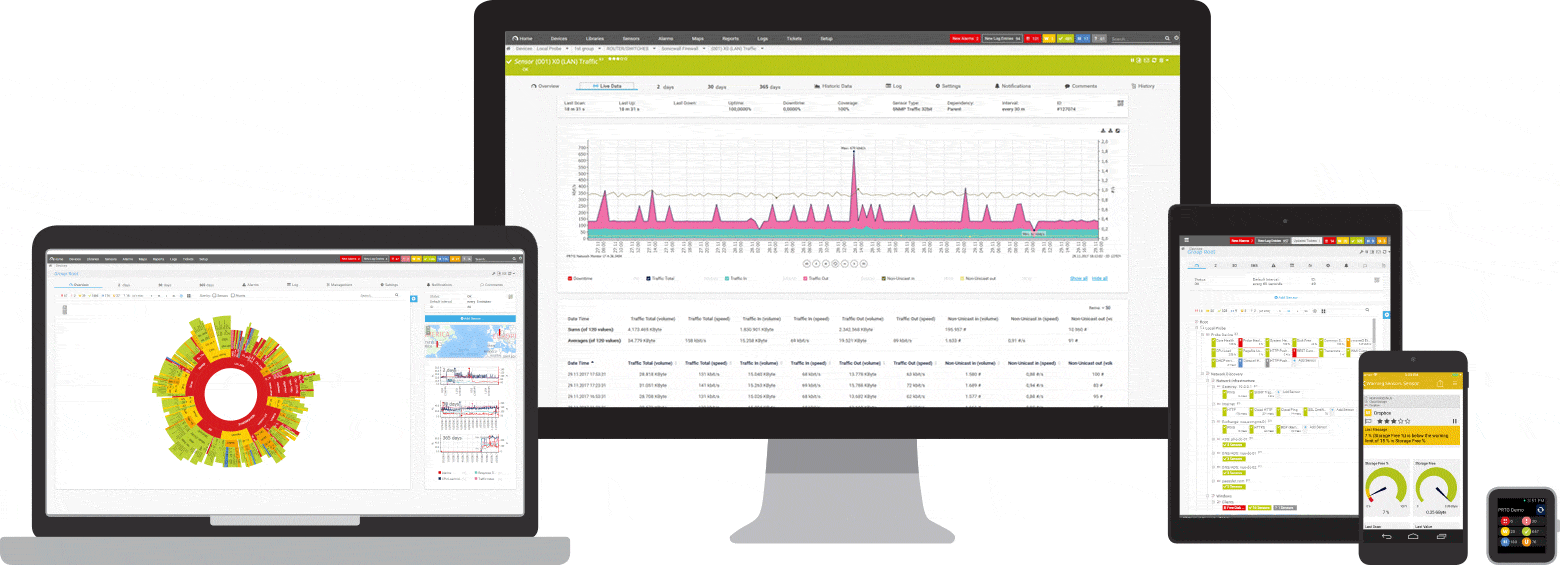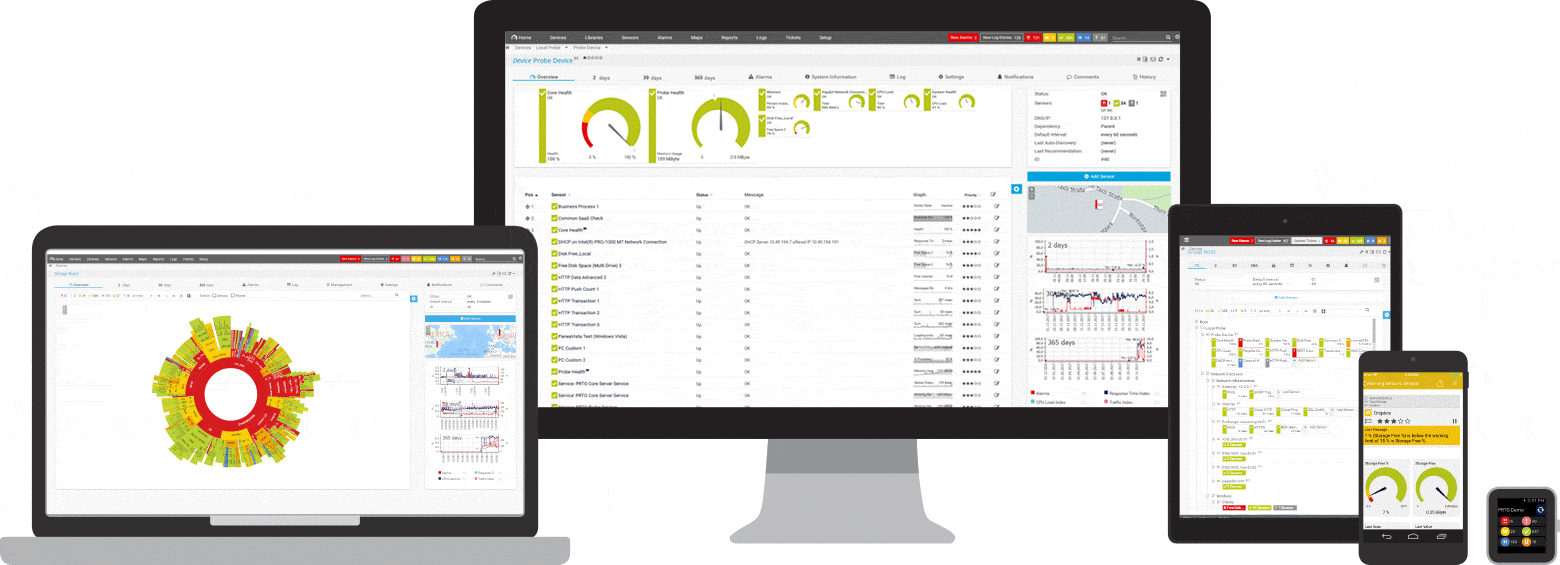
Captures d'écran
Une brève introduction à PRTG : Surveillance du ping



Vos capteurs de ping en pleine vue
- même en déplacement
PRTG s'installe en quelques minutes et est compatible avec la plupart des appareils mobiles.
PRTG contrôle pour vous ces fabricants et applications ainsi que de nombreux autres
Trois capteurs PRTG pour la surveillance du ping
Capteur
demandes d'écho
du nuage
Le Cloud Ping Sensor utilise le cloud PRTG pour mesurer le temps nécessaire pour envoyer un ping à votre réseau à partir de divers endroits dans le monde. Ce capteur vous permet de voir la disponibilité de votre réseau en Asie, en Europe et en Amérique. En particulier, cet indicateur est très important pour les entreprises internationales. .
En achetant le logiciel PRTG, vous bénéficierez d'une assistance complète et gratuite. Notre tâche est de résoudre vos problèmes le plus rapidement possible ! Spécialement pour cela, avec d'autres matériaux, nous avons préparé des vidéos de formation et un guide complet. Notre objectif est de répondre à tous les tickets d'assistance dans les 24 heures (en semaine). Vous trouverez des réponses à de nombreuses questions dans notre base de connaissances. Par exemple, la requête de recherche « ping monitoring » renvoie 700 résultats. Quelques exemples :
« J'ai besoin d'un capteur de ping qui collecte uniquement des informations sur la disponibilité de l'appareil, sans modifier son état. Est-il possible?"
"Puis-je construire un capteur de demande d'écho inverse ?"

"Avec PRTG, nous sommes beaucoup plus à l'aise en sachant que nos systèmes sont surveillés en permanence."
Markus Puke, administrateur réseau, clinique Schüchtermann (Allemagne)
- Version complète de PRTG pendant 30 jours
- Après 30 jours - version gratuite
- Pour la version étendue - licence commerciale

| Logiciel de surveillance réseau - Version 19.2.50.2842 (15 mai 2019) | |
|
Hébergement |
Version cloud également disponible (PRTG dans le cloud) |
Langues |
Anglais, allemand, russe, espagnol, français, portugais, néerlandais, japonais et chinois simplifié |
Des prix |
Gratuit jusqu'à 100 capteurs (prix) |
Surveillance complète |
Périphériques réseau, bande passante, serveurs, applications, environnements virtuels, systèmes distants, IoT et plus encore. |
Fournisseurs et applications pris en charge |
Surveillance du réseau et du ping avec PRTG : trois études de cas pratiques
200 000 administrateurs dans le monde font confiance au programme PRTG. Ces administrateurs peuvent provenir de différentes industries, mais ils ont tous une chose en commun : le désir d'assurer et d'améliorer la disponibilité et les performances de leurs réseaux. Trois cas d'utilisation :

Aéroport de Zürich
L'aéroport de Zurich est le plus grand aéroport de Suisse, il est donc particulièrement important que tous ses systèmes électroniques fonctionnent correctement. Pour rendre cela possible, le service informatique a implémenté le logiciel PRTG Network Monitor de Paessler AG. Avec plus de 4 500 capteurs, cet outil garantit que les problèmes sont immédiatement détectés et résolus immédiatement par l'équipe informatique. Dans le passé, le service informatique utilisait une variété de programmes de surveillance. Mais finalement, la direction a conclu que le logiciel n'était pas adapté à une surveillance spécialisée par le personnel d'exploitation et de maintenance. Exemple d'utilisation.

Université Bauhaus, Weimar
Les systèmes informatiques de l'Université Bauhaus de Weimar sont utilisés par 5 000 étudiants et 400 employés. Dans le passé, une solution isolée basée sur Nagios était utilisée pour surveiller le réseau universitaire. Le système était techniquement obsolète et n'était pas en mesure de répondre aux besoins de l'infrastructure informatique de l'établissement d'enseignement. Les mises à niveau des infrastructures seraient extrêmement coûteuses. Au lieu de cela, l'université s'est tournée vers de nouvelles solutions de surveillance du réseau. Les responsables informatiques souhaitaient un produit logiciel complet, convivial, facile à installer et économique. C'est pourquoi ils ont choisi PRTG. Exemple d'utilisation.

Services publics de la ville de Frankenthal
Un peu plus de 200 employés des services publics de la ville de Frankenthal sont responsables de la fourniture d'électricité, de gaz et d'eau aux consommateurs privés et aux organisations. L'organisation, avec tous ses bâtiments, dépend également d'une infrastructure distribuée localement, qui se compose d'environ 80 serveurs et 200 appareils connectés. Les responsables informatiques de Frankenthal recherchaient un logiciel abordable pour répondre à leurs besoins spécifiques. Tout d'abord, le service informatique a mis en place un essai gratuit de PRTG. Les services publics de Frankenthal utilisent actuellement environ 1 500 capteurs pour surveiller, entre autres, les piscines publiques. Exemple d'utilisation.

Conseils pratiques. Dites-moi, Greg, avez-vous des recommandations pour surveiller les pings ?
« Les capteurs Pingback sont probablement les éléments les plus importants de la surveillance du réseau. Ils doivent être correctement configurés, en particulier compte tenu de vos connexions. Si, par exemple, vous surveillez une machine virtuelle, il est utile de placer un capteur ping sur la connexion à son hôte. Si un nœud tombe en panne, vous ne recevrez pas de notification pour chaque machine virtuelle qui lui est connectée. De plus, les capteurs de ping peuvent être de bons indicateurs que le chemin réseau vers l'hôte ou Internet fonctionne correctement, en particulier dans les scénarios de haute disponibilité ou de basculement.
Greg Campion, administrateur système, PAESSLER AG
A l'apparition de cette optique, passant par la forêt jusqu'au collecteur, on peut conclure que l'installateur n'a pas suivi un peu la technologie. La monture sur la photo suggère également qu'il s'agit probablement d'un marin - un nœud marin.
Je fais partie de l'équipe de santé du réseau physique, en d'autres termes, le support technique, qui est chargé de s'assurer que les voyants des routeurs clignotent comme il se doit. Nous avons sous notre aile diverses grandes entreprises avec des infrastructures à travers le pays. Nous ne montons pas à l'intérieur de leur entreprise, notre tâche est de nous assurer que le réseau fonctionne au niveau physique et que le trafic passe comme il se doit.
Le sens général du travail est l'interrogation constante des nœuds, la suppression de la télémétrie, les tests (par exemple, la vérification des paramètres pour trouver des vulnérabilités), la garantie de la santé, la surveillance des applications, le trafic. Parfois inventaires et autres perversions.
Je vais vous raconter comment c'est organisé et quelques histoires de voyages.
Comme c'est généralement le cas
Notre équipe se trouve dans un bureau à Moscou et prend la télémétrie du réseau. En fait, ce sont des pings constants de nœuds, ainsi que la réception de données de surveillance si le matériel est intelligent. La situation la plus courante est que le ping ne passe pas plusieurs fois de suite. Dans 80 % des cas pour une chaîne de magasins, par exemple, cela s'avère être une panne de courant, alors nous, voyant cette image, faisons ce qui suit :- Nous appelons d'abord le fournisseur au sujet des accidents
- Puis - à la centrale à propos de l'arrêt
- Ensuite, nous essayons d'établir une connexion avec quelqu'un de l'établissement (ce n'est pas toujours possible, par exemple, à 2 heures du matin)
- Et, enfin, si ce qui précède n'a pas aidé en 5 à 10 minutes, nous nous quittons ou envoyons un «avatar» - un ingénieur contractuel assis quelque part à Izhevsk ou à Vladivostok, si le problème est là.
- Nous restons en contact permanent avec "l'avatar" et le "menons" à travers l'infrastructure - nous avons des capteurs et des manuels d'entretien, il a des pinces.
- Ensuite, l'ingénieur nous envoie un rapport avec une photo de ce que c'était.
Le dialogue se déroule parfois ainsi :
- Donc, la connexion est perdue entre les bâtiments numéro 4 et 5. Vérifiez le routeur dans le cinquième.
- Commande, inclus. Il n'y a pas de connexion.
- Ok, longez le câble jusqu'au quatrième bâtiment, il y a un autre nœud.
-… Opa !
- Ce qui s'est passé?
- Ici la 4ème maison a été démolie.
- Quoi??
- Je joins une photo au rapport. Je ne peux pas restaurer la maison dans SLA.
Mais le plus souvent, il s'avère toujours de trouver une pause et de restaurer le canal.
Environ 60% des trajets sont "dans le lait", car soit l'alimentation électrique est interrompue (par une pelle, un contremaître, des intrus), soit le prestataire n'est pas au courant de sa panne, soit un problème de courte durée est éliminé avant l'installateur arrive. Cependant, il y a des moments où nous découvrons le problème avant les utilisateurs et avant les services informatiques du client, et communiquons la solution avant même qu'ils ne réalisent que quelque chose s'est produit. Le plus souvent, de telles situations surviennent la nuit, lorsque l'activité des entreprises clientes est faible.
Qui en a besoin et pourquoi
En règle générale, toute grande entreprise possède son propre service informatique, qui comprend clairement les spécificités et les tâches. Dans les moyennes et grandes entreprises, le travail des "enikeev" et des ingénieurs réseau est souvent externalisé. C'est juste bénéfique et pratique. Par exemple, un détaillant a ses propres informaticiens très cool, mais ils sont loin de remplacer les routeurs et de localiser les câbles.Qu'est-ce que nous faisons
- Nous travaillons sur les demandes - tickets et appels de panique.
- Nous faisons de la prévention.
- Nous suivons les recommandations des fournisseurs de matériel, par exemple sur les conditions de maintenance.
- Nous nous connectons au suivi du client et lui supprimons des données afin de se déplacer en cas d'incidents.
La première façon - de simples vérifications - est juste une machine qui envoie un ping à tous les nœuds du réseau et s'assure qu'ils répondent correctement. Une telle implémentation ne nécessite aucun changement ou des changements cosmétiques minimes dans le réseau du client. En règle générale, dans un cas très simple, nous installons Zabbix directement chez nous dans l'un des centres de données (heureusement, nous en avons deux dans le bureau du CROC à Volochaevskaya). Dans un cas plus complexe, par exemple, si vous utilisez votre propre réseau sécurisé - vers l'une des machines du centre de données du client :
Zabbix peut être utilisé plus compliqué, par exemple, il a des agents qui sont installés sur les nœuds * nix et win et affichent la surveillance du système, ainsi qu'un mode de vérification externe (avec prise en charge du protocole SNMP). Néanmoins, si une entreprise a besoin de quelque chose de similaire, soit elle a déjà sa propre surveillance, soit une solution plus riche en fonctionnalités est choisie. Bien sûr, ce n'est plus open source et cela coûte de l'argent, mais même un inventaire précis et banal réduit déjà les coûts d'environ un tiers.
Nous le faisons aussi, mais c'est l'histoire de collègues. Ici, ils ont envoyé quelques captures d'écran d'Infosim :
Je suis un opérateur d'avatar, je vais donc vous en dire plus sur mon travail.
À quoi ressemble un incident typique ?
Devant nous se trouvent des écrans avec l'état général suivant :
Sur cet objet, Zabbix collecte pour nous pas mal d'informations : numéro de lot, numéro de série, utilisation CPU, description de l'appareil, disponibilité des interfaces, etc. Toutes les informations nécessaires sont disponibles depuis cette interface.
Un incident ordinaire commence généralement par le fait que l'un des canaux menant, par exemple, au magasin du client (dont il possède 200 à 300 pièces à travers le pays) tombe en panne. Le commerce de détail est maintenant bien développé, pas comme il y a sept ans, donc le box-office continuera de fonctionner - il y a deux canaux.
On décroche les téléphones et on passe au moins trois appels : au fournisseur, à la centrale électrique et aux gens sur place (« Oui, on a chargé des raccords ici, le câble de quelqu'un a été touché... Ah, le vôtre ? Bon, c'est bien ça nous l'avons trouvé").
En règle générale, sans surveillance, des heures ou des jours s'écouleraient avant une escalade - les mêmes canaux de secours ne sont pas toujours vérifiés. On sait tout de suite et on part tout de suite. S'il existe des informations supplémentaires en plus des pings (par exemple, un modèle de pièce de fer buggy), nous complétons immédiatement l'ingénieur de terrain avec les pièces nécessaires. De plus déjà en place.
Le deuxième appel régulier le plus fréquent est la panne de l'un des terminaux des utilisateurs, par exemple un téléphone DECT ou un routeur Wi-Fi qui distribuait le réseau au bureau. Ici, nous apprenons le problème grâce à la surveillance et recevons presque immédiatement un appel avec des détails. Parfois l'appel n'apporte rien de nouveau ("Je décroche le téléphone, quelque chose ne sonne pas"), parfois il est très utile ("On l'a laissé tomber de la table"). Il est clair que dans le second cas ce n'est clairement pas un saut de ligne.
L'équipement à Moscou provient de nos entrepôts de réserve chaude, nous en avons plusieurs types:
Les clients ont généralement leurs propres stocks de composants fréquemment défaillants - combinés de bureau, blocs d'alimentation, ventilateurs, etc. Si vous devez livrer quelque chose qui n'est pas en place, pas à Moscou, nous y allons généralement nous-mêmes (parce que l'installation). Par exemple, j'ai fait un voyage nocturne à Nizhny Tagil.
Si le client dispose de sa propre surveillance, il peut nous envoyer des données. Parfois, nous déployons Zabbix en mode polling, juste pour assurer la transparence et le contrôle SLA (ceci est également gratuit pour le client). Nous n'installons pas de capteurs supplémentaires (ceci est fait par des collègues qui assurent la continuité des processus de production), mais nous pouvons nous y connecter si les protocoles ne sont pas exotiques.
En général, nous ne touchons pas à l'infrastructure du client, nous la soutenons telle quelle.
Par expérience, je peux dire que les dix derniers clients sont passés à l'assistance externe en raison du fait que nous sommes très prévisibles en termes de coûts. Budgétisation claire, bonne gestion des dossiers, rapport sur chaque demande, SLA, rapports d'équipement, maintenance préventive. Idéalement, bien sûr, nous sommes pour le CIO d'un client tel que les nettoyeurs - nous venons le faire, tout est propre, nous ne distrayons pas.
Une autre chose à noter est que dans certaines grandes entreprises, l'inventaire devient un véritable problème, et parfois nous sommes attirés uniquement pour le réaliser. De plus, nous effectuons le stockage des configurations et leur gestion, ce qui est pratique pour les différents déménagements et reconnexions. Mais, encore une fois, dans les cas difficiles, ce n'est pas non plus moi - nous en avons un spécial qui transporte les centres de données.
Et un autre point important : notre ministère ne s'occupe pas d'infrastructures critiques. Tout ce qui se trouve à l'intérieur des centres de données et tout ce qui concerne les banques, les assurances et les opérateurs, ainsi que les systèmes de base de la vente au détail - c'est une équipe X. ces gars.
Plus d'entraînement
De nombreux appareils modernes sont capables de fournir de nombreuses informations de service. Par exemple, pour les imprimantes réseau, il est très facile de surveiller le niveau de toner dans la cartouche. Vous pouvez compter sur la période de remplacement à l'avance, recevoir une notification de 5 à 10 % (si le bureau commence soudainement à taper furieusement pas dans le calendrier standard) - et envoyer immédiatement une enikey avant que le service comptable ne commence à paniquer.Très souvent, des statistiques annuelles nous sont retirées, ce qui est fait par le même système de surveillance plus nous. Dans le cas de Zabbix, il s'agit simplement de planifier les coûts et de comprendre ce qui est allé où, et dans le cas d'Infosim, c'est également un matériau pour calculer la mise à l'échelle pendant un an, charger les administrateurs et toutes sortes d'autres choses. Il y a la consommation d'énergie dans les statistiques - l'année dernière, presque tout le monde a commencé à lui demander, apparemment pour répartir les coûts internes entre les départements.
Parfois, de véritables sauvetages héroïques sont obtenus. De telles situations sont très rares, mais d'après ce dont je me souviens cette année, nous avons vu vers 3 heures du matin que la température montait à 55 degrés sur le commutateur cisco. Dans la salle des serveurs distante, il y avait des climatiseurs "stupides" sans surveillance, et ils ont échoué. Nous avons immédiatement appelé un ingénieur en refroidissement (pas le nôtre) et appelé l'administrateur du client en service. Il a mis en place des services non critiques et a protégé la salle des serveurs de l'arrêt thermique jusqu'à l'arrivée du type avec un climatiseur mobile, puis les services réguliers ont été réparés.
Les Polycoms et autres équipements de visioconférence coûteux surveillent très bien le niveau de charge de la batterie avant les conférences, ce qui est également important.
Tout le monde a besoin de surveillance et de diagnostic. En règle générale, il est long et difficile à mettre en œuvre sans expérience : les systèmes sont soit extrêmement simples et pré-configurés, soit de la taille d'un porte-avions et avec un tas de rapports standards. Aiguiser avec un fichier pour l'entreprise, inventer la mise en œuvre de leurs tâches pour le service informatique interne et afficher les informations dont ils ont le plus besoin, ainsi que tenir à jour tout l'historique est un râteau s'il n'y a pas d'expérience de mise en œuvre. Lorsque nous travaillons avec des systèmes de surveillance, nous choisissons le juste milieu entre les solutions gratuites et les meilleures - en règle générale, pas les fournisseurs les plus populaires et les plus "épais", mais résolvons clairement le problème.
Il était une fois un traitement plutôt atypique. Le client devait donner le routeur à certaines de ses divisions distinctes, et exactement selon l'inventaire. Le routeur avait un module avec le numéro de série spécifié. Lorsque le routeur a commencé à se préparer pour la route, il s'est avéré que ce module manquait. Et personne ne peut le trouver. Le problème est légèrement exacerbé par le fait que l'ingénieur qui a travaillé avec cette branche l'année dernière est déjà à la retraite et est parti vivre avec ses petits-enfants dans une autre ville. Ils nous ont contactés et nous ont demandé de regarder. Heureusement, le matériel a fourni des rapports sur les numéros de série, et Infosim a fait un inventaire, nous avons donc trouvé ce module dans l'infrastructure en quelques minutes, décrit la topologie. Le fugitif a été retrouvé par câble - il se trouvait dans une autre salle de serveurs dans un placard. L'histoire du mouvement a montré qu'il y est arrivé après l'échec d'un module similaire.
Une image d'un long métrage sur Hottabych, décrivant avec précision l'attitude de la population envers les caméras
Beaucoup d'incidents de caméra. Une fois, 3 caméras ont échoué en même temps. Rupture de câble dans l'un des tronçons. L'installateur en souffla un nouveau dans l'ondulation, deux des trois chambres se levèrent après une série de chamanisme. Et le troisième ne l'est pas. De plus, on ne sait pas du tout où elle se trouve. Je monte le flux vidéo - les dernières images juste avant la chute - 4 heures du matin, trois hommes portant des foulards sur le visage se présentent, quelque chose de brillant en dessous, la caméra tremble beaucoup, tombe.
Une fois que nous avons mis en place la caméra, qui devrait se concentrer sur les "lièvres" grimpant par-dessus la clôture. Pendant la conduite, nous avons réfléchi à la façon dont nous désignerions le point où l'intrus devrait apparaître. Cela n'a pas été utile - dans les 15 minutes que nous avons passées là-bas, 30 personnes sont entrées dans l'objet uniquement au point dont nous avions besoin. Table droite.
Comme j'ai déjà donné un exemple ci-dessus, l'histoire du bâtiment démoli n'est pas une blague. Une fois le lien vers l'équipement disparu. En place - il n'y a pas de pavillon où le cuivre est passé. Le pavillon a été démoli, le câble a disparu. Nous avons vu que le routeur était mort. L'installateur est arrivé, a commencé à regarder - et la distance entre les nœuds est de quelques kilomètres. Il a un testeur Vipnet dans son ensemble, le standard - ça sonnait d'un connecteur, ça sonnait d'un autre - il est allé chercher. Habituellement, le problème est immédiatement visible.
Suivi du câble: c'est de l'optique ondulée, une suite de l'histoire du tout en haut du post sur le nœud. Ici, au final, en plus de l'installation absolument époustouflante, le problème était que le câble s'était éloigné des supports. Ici escaladez les uns et les autres, et desserrez les structures métalliques. Environ cinq millième représentant du prolétariat a cassé l'optique.
Dans une installation, tous les nœuds étaient éteints environ une fois par semaine. Et en même temps. Nous cherchions un modèle depuis un certain temps. Le programme d'installation a trouvé les éléments suivants :
- Le problème survient toujours dans le quart de travail de la même personne.
- Il diffère des autres en ce qu'il porte un manteau très épais.
- Une machine automatique est montée derrière un cintre.
- Quelqu'un a pris le couvert de la machine il y a longtemps, à l'époque préhistorique.
- Lorsque ce camarade arrive dans l'établissement, il raccroche ses vêtements et elle éteint les machines.
- Il les rallume immédiatement.
L'équipement a été éteint à une seule et même heure à la même heure la nuit. Il s'est avéré que des artisans locaux se sont connectés à notre alimentation électrique, ont sorti une rallonge et y ont collé une bouilloire et une cuisinière électrique. Lorsque ces appareils fonctionnent simultanément, tout le pavillon est assommé.
Dans l'un des magasins de notre vaste pays, tout le réseau tombait constamment avec la fermeture du quart de travail. L'installateur a vu que toute la puissance était amenée à la ligne d'éclairage. Dès que l'éclairage zénithal du hall (qui consomme beaucoup d'énergie) est éteint dans le magasin, tous les équipements du réseau sont éteints.
Il y a eu un cas où le concierge a interrompu le câble avec une pelle.
Souvent, nous ne voyons que du cuivre couché avec une ondulation déchirée. Une fois, entre deux ateliers, des artisans locaux faisaient simplement suivre un câble à paire torsadée sans aucune protection.
Loin de la civilisation, les employés se plaignent souvent d'être exposés à « nos » équipements. Les standards de certains sites distants peuvent se trouver dans la même pièce que la personne de service. En conséquence, à quelques reprises, nous avons rencontré des grands-mères nuisibles qui, de gré ou de force, les ont éteintes au début du quart de travail.
Une autre ville lointaine accroché une vadrouille sur l'optique. Ils ont détaché l'ondulation du mur et ont commencé à l'utiliser comme attaches pour l'équipement.
Dans ce cas, il y a clairement des problèmes de nutrition.
Ce que la "grande" surveillance peut faire
Je parlerai brièvement des capacités de systèmes plus sérieux, en prenant l'exemple des installations d'Infosim.Il existe 4 solutions combinées en une seule plate-forme :- Gestion des pannes - contrôle des pannes et corrélation des événements.
- Gestion des performances.
- Inventaire et découverte automatique de la topologie.
- Gestion de la configuration.
Séparément, à propos de l'inventaire. Le module affiche non seulement la liste, mais construit également la topologie elle-même (au moins dans 95 % des cas, il essaie et réussit). Il vous permet également d'avoir à portée de main une base de données à jour des équipements informatiques usagés et inutilisés (réseau, équipements serveurs, etc.), de remplacer à temps les équipements obsolètes (EOS/EOL). En général, c'est pratique pour les grandes entreprises, mais dans les petites entreprises, une grande partie de cela se fait à la main.
Exemples de rapports :
- Rapports dans le contexte des types de systèmes d'exploitation, des micrologiciels, des modèles et des fabricants d'équipements ;
- Rapport sur le nombre de ports libres sur chaque commutateur du réseau / par fabricant sélectionné / par modèle / par sous-réseau, etc. ;
- Rapport sur les appareils nouvellement ajoutés pour une période spécifiée ;
- Avertissement de faible niveau de toner de l'imprimante ;
- Évaluation de l'adéquation du canal de communication au trafic sensible aux retards et aux pertes, méthodes actives et passives ;
- Suivi de la qualité et de la disponibilité des canaux de communication (SLA) - génération de rapports sur la qualité des canaux de communication, ventilés par opérateurs télécoms ;
- La fonctionnalité de contrôle des pannes et de corrélation des événements est mise en œuvre via le mécanisme d'analyse des causes profondes (sans que les administrateurs aient besoin d'écrire des règles) et le mécanisme de la machine d'état d'alarme. L'analyse des causes premières est une analyse de la cause première d'un accident basée sur les procédures suivantes : 1. détection et localisation automatiques du site de la défaillance ; 2. réduire le nombre d'événements d'urgence à une seule clé ; 3. identifier les conséquences d'un échec - qui et quoi a été affecté par l'échec.
Stablenet - Embedded Agent (SNEA) - un ordinateur un peu plus grand qu'un paquet de cigarettes.
L'installation est effectuée dans des guichets automatiques ou des segments de réseau dédiés où des tests d'accessibilité sont nécessaires. Avec leur aide, des tests de charge sont effectués.
Surveillance en nuage
Un autre modèle d'installation est le SaaS dans le cloud. Fabriqué pour un client mondial (une entreprise avec un cycle de production continu avec une géographie de distribution de l'Europe à la Sibérie).Des dizaines d'installations, dont des usines et des entrepôts de produits finis. Si leurs canaux tombaient et que leur soutien était assuré à partir de bureaux étrangers, des retards d'expédition commençaient, ce qui, le long de la vague, entraînait de nouvelles pertes. Tout le travail a été effectué sur demande et beaucoup de temps a été consacré à enquêter sur l'incident.
Nous avons mis en place un suivi spécifiquement pour eux, puis l'avons terminé sur un certain nombre de sites en fonction des spécificités de leur routage et de leur matériel. Tout cela a été fait dans le cloud CROC. Ils ont réalisé et livré le projet très rapidement.
Le résultat est:
- Grâce au transfert partiel de la gestion de l'infrastructure réseau, il a été possible d'optimiser au moins 50 %. Inaccessibilité des équipements, charge des canaux, dépassement des paramètres recommandés par le constructeur : tout cela est enregistré en 5 à 10 minutes, diagnostiqué et éliminé en une heure.
- Lorsqu'il reçoit un service du cloud, le client convertit les coûts d'investissement du déploiement de son système de surveillance de réseau en coûts d'exploitation moyennant des frais d'abonnement à notre service, qui peuvent être annulés à tout moment.
L'avantage du cloud est que dans notre décision, nous nous tenons, pour ainsi dire, au-dessus de leur réseau et pouvons regarder tout ce qui se passe de manière plus objective. À ce moment-là, si nous étions à l'intérieur du réseau, nous ne verrions l'image que jusqu'au nœud défaillant, et ce qui se passe derrière, nous ne le saurions plus.
Quelques dernières photos
C'est le "casse-tête du matin":
Et voici le trésor que nous avons trouvé :
Voici ce qu'il y avait dans le coffre :
Et enfin, à propos de la sortie la plus drôle. Une fois, je suis allé dans un magasin de détail.
Il s'est passé ce qui suit : d'abord, il a commencé à couler du toit sur le faux plafond. Puis un lac s'est formé dans le faux plafond, qui s'est érodé et a traversé l'une des tuiles. En conséquence, tout cela a jailli chez l'électricien. Ensuite, je ne sais pas exactement ce qui s'est passé, mais quelque part dans la pièce voisine, il y a eu un court-circuit et un incendie s'est déclaré. D'abord, les extincteurs à poudre ont fonctionné, puis les pompiers sont arrivés et ont tout rempli de mousse. Je suis arrivé après eux pour le démontage. Je dois dire que le tsiska 2960 a bien réussi après tout cela - j'ai pu récupérer la configuration et envoyer l'appareil en réparation.
Une fois de plus, lors du déclenchement du système de poudre, le Tsiskovsky 3745 dans une boîte était presque entièrement rempli de poudre. Toutes les interfaces étaient pleines - 2 x 48 ports. Il devait être inclus sur place. Nous nous sommes souvenus du dernier cas, avons décidé d'essayer d'enlever les configs "à chaud", l'avons secoué, nettoyé du mieux que nous pouvions. Nous l'avons allumé - au début, l'appareil a dit "pff" et nous a éternué avec un grand jet de poudre. Et puis il a grondé et s'est levé.
Moniteur de ping EMCO. Assistant administratif gratuit
Si votre infrastructure comporte jusqu'à 5 hôtes de virtualisation, vous pouvez utiliser la version gratuite.
Ping Monitor : outil de surveillance de l'état de la connexion réseau (gratuit pour 5 hôtes)
Info:
Outil de surveillance fiable pour vérifier automatiquement la connexion au réseau des hôtes en exécutant une commande ping.
wiki :
Ping est un utilitaire permettant de tester les connexions sur les réseaux TCP/IP, ainsi que le nom commun de la requête elle-même.
L'utilitaire envoie des requêtes (ICMP Echo-Request) du protocole ICMP à l'hôte spécifié et capture les réponses entrantes (ICMP Echo-Reply). Le temps entre l'envoi d'une requête et la réception d'une réponse (RTT, de l'anglais Round Trip Time) vous permet de déterminer les délais d'aller-retour (RTT) le long de la route et la fréquence de perte de paquets, c'est-à-dire de déterminer indirectement la charge sur les canaux de données et appareils intermédiaires.
Le programme ping est l'un des principaux outils de diagnostic des réseaux TCP / IP et est inclus dans la livraison de tous les systèmes d'exploitation de réseau modernes.
https://ru.wikipedia.org/wiki/Ping
Le programme, en envoyant des requêtes ICMP régulières, surveille les connexions réseau et vous informe de la restauration / suppression de canaux détectée. EMCO Ping Monitor fournit des données statistiques de connexion, y compris la disponibilité, les interruptions de service, les échecs de ping, etc.


Un outil de surveillance de ping robuste pour vérifier automatiquement la connexion aux hôtes du réseau. En faisant des pings réguliers, il surveille les connexions réseau et vous informe des hauts/bas détectés. EMCO Ping Monitor fournit également des informations sur les statistiques de connexion, y compris la disponibilité, les pannes, les échecs de ping, etc. Vous pouvez facilement étendre les fonctionnalités et configurer EMCO Ping Monitor pour exécuter des commandes personnalisées ou lancer des applications lorsque les connexions sont perdues ou restaurées.
Qu'est-ce qu'EMCO Ping Monitor ?
EMCO Ping Monitor peut fonctionner en mode 24h/24 et 7j/7 pour suivre les états de la connexion d'un ou de plusieurs hôtes. L'application analyse les réponses ping pour détecter les pannes de connexion et rapporter les statistiques de connexion. Il peut détecter automatiquement les pannes de connexion et afficher les bulles de la barre d'état Windows, jouer des sons et envoyer des notifications par e-mail. Il peut également générer des rapports et les envoyer par e-mail ou les enregistrer sous forme de fichiers PDF ou HTML.
Le programme vous permet d'obtenir des informations sur les statuts de tous les hôtes, de vérifier les statistiques détaillées d'un hôte sélectionné et de comparer les performances de différents hôtes. Le programme stocke les données de ping collectées dans la base de données, de sorte que vous pouvez vérifier les statistiques pour une période de temps sélectionnée. Les informations disponibles incluent le temps de ping min/max/moy, l'écart de ping, la liste des pannes de connexion, etc. Ces informations peuvent être représentées sous forme de données de grille et de graphiques.
EMCO Ping Monitor : comment ça marche ?
EMCO Ping Monitor peut être utilisé pour effectuer une surveillance ping de quelques hôtes seulement ou de milliers d'hôtes. Tous les hôtes sont surveillés en temps réel par des threads de travail dédiés, de sorte que vous pouvez obtenir des statistiques et des notifications en temps réel sur les changements d'état de connexion pour chaque hôte. Le programme n'a pas d'exigences particulières en matière de matériel - vous pouvez surveiller quelques milliers d'hôtes sur un PC moderne typique.
Le programme utilise des pings pour détecter les pannes de connexion. Si quelques pings échouent dans un raw - il signale une panne et vous informe du problème. Lorsque la connexion est établie et que les pings commencent à passer, le programme détecte la fin de la panne et vous en informe. Vous pouvez personnaliser les conditions de détection de panne et de restauration ainsi que les notifications utilisées par le programme.
Comparez les fonctionnalités et sélectionnez l'édition
Le programme est disponible en trois éditions avec les différents ensembles de fonctionnalités.
Comparer les éditions
L'édition gratuite permet d'effectuer une surveillance ping de jusqu'à 5 hôtes. Il ne permet aucune configuration spécifique pour les hôtes. Il s'exécute comme un programme Windows, de sorte que la surveillance est arrêtée si vous fermez l'interface utilisateur ou si vous vous déconnectez de Windows.
Gratuit pour un usage personnel et commercial
Edition Professionnelle
L'édition professionnelle permet de surveiller jusqu'à 250 hôtes simultanément. Chaque hôte peut avoir une configuration personnalisée telle que la notification des destinataires de courrier électronique ou des actions personnalisées à exécuter en cas de perte de connexion et d'événements de restauration. Il s'exécute en tant que service Windows, de sorte que la surveillance continue même si vous fermez l'interface utilisateur ou vous déconnectez de Windows.
Edition pour entreprise
L'édition Enterprise n'a pas de limitations sur le nombre d'hôtes surveillés. Sur un PC moderne, il est possible de surveiller plus de 2500 hôtes en fonction de la configuration matérielle.
Cette édition inclut toutes les fonctionnalités disponibles et fonctionne en tant que client/serveur. Le serveur fonctionne comme un service Windows pour assurer la surveillance du ping en mode 24/7. Le client est un programme Windows qui peut se connecter à un serveur exécuté sur un PC local ou à un serveur distant via un réseau local ou Internet. Plusieurs clients peuvent se connecter au même serveur et travailler simultanément.
Cette édition comprend également des rapports Web, qui permettent de consulter les statistiques de surveillance de l'hôte à distance dans un navigateur Web.
Les principales caractéristiques d'EMCO Ping Monitor
Surveillance du ping multi-hôtes
L'application peut surveiller plusieurs hôtes simultanément. L'édition gratuite de l'application permet de surveiller jusqu'à cinq hôtes ; l'édition professionnelle n'a aucune limite pour le nombre d'hôtes surveillés. La surveillance de chaque hôte fonctionne indépendamment des autres hôtes. Vous pouvez surveiller des dizaines de milliers d'hôtes à partir d'un PC moderne.
Détection des interruptions de connexion
L'application envoie des demandes d'écho ping ICMP et analyse les réponses d'écho ping pour surveiller l'état de la connexion en mode 24/7. Si le nombre prédéfini de pings échoue à la suite, l'application détecte une panne de connexion et vous informe du problème. L'application suit toutes les pannes, afin que vous puissiez voir quand un hôte était hors ligne.
Analyse de la qualité de la connexion
Lorsque l'application envoie un ping à un hôte surveillé, elle enregistre et agrège des données sur chaque ping, afin que vous puissiez obtenir des informations sur les temps de réponse ping minimum, maximum et moyen et l'écart de réponse ping par rapport à la moyenne pour toute période de rapport. Cela vous permet d'estimer la qualité de la connexion réseau.
Notifications flexibles
Si vous souhaitez recevoir des notifications sur la connexion perdue, la connexion restaurée et d'autres événements détectés par l'application, vous pouvez configurer l'application pour envoyer des notifications par e-mail, émettre des sons et afficher les bulles de la barre d'état Windows. L'application peut envoyer une seule notification de n'importe quel type ou répéter les notifications plusieurs fois.
Graphiques et rapports
Toutes les informations statistiques collectées par l'application peuvent être représentées visuellement par des graphiques. Vous pouvez voir les statistiques de ping et de disponibilité pour un seul hôte et comparer les performances de plusieurs hôtes sur des graphiques. L'application peut générer automatiquement des rapports dans différents formats sur une base régulière pour représenter les statistiques de l'hôte.
Actions personnalisées
Vous pouvez intégrer l'application à un logiciel externe en exécutant des scripts externes ou des fichiers exécutables lorsque les connexions sont perdues ou restaurées ou en cas d'autres événements. Par exemple, vous pouvez configurer l'application pour qu'elle exécute un outil de ligne de commande externe afin d'envoyer des notifications par SMS concernant toute modification des statuts de l'hôte.
 Amplificateur Bluetooth compact Ce dont vous avez besoin
Amplificateur Bluetooth compact Ce dont vous avez besoin Vue d'ensemble Highscreen Zera S Power
Vue d'ensemble Highscreen Zera S Power FAT32 ou NTFS : quel système de fichiers choisir pour une clé USB ou un disque dur externe
FAT32 ou NTFS : quel système de fichiers choisir pour une clé USB ou un disque dur externe Son manquant sur Galaxy S9 ?
Son manquant sur Galaxy S9 ? Mettre à jour flash player vers la nouvelle version
Mettre à jour flash player vers la nouvelle version Mettre à jour flash player vers la nouvelle version
Mettre à jour flash player vers la nouvelle version Daemon Tools Lite Lecteur virtuel pour les images de disque
Daemon Tools Lite Lecteur virtuel pour les images de disque