Метод статичної перевірки коду. Аналіз успадкованого коду, коли вихідний код втрачено: робити чи робити? Комбінування послідовності дій різних видів аналізу серед розробки
Вступ
Стандартні можливості програмних продуктів та різних систем керування недостатні для більшості замовників. Системи управління веб-сайтами (наприклад, WordPress, Joomla або Bitrix), бухгалтерські програми, системи управління клієнтами (CRM), підприємством та виробництвом (наприклад, 1С та SAP) надають широкі можливості щодо розширення функціональності та адаптації під потреби конкретних замовників. Такі можливості реалізуються за допомогою сторонніх модулів, виконаних на замовлення або кастомізації існуючих. Ці модулі є програмним кодом, написаним однією з вбудованих мов програмування, що взаємодіє із системою і реалізує необхідні замовникам функціональні можливості.
Не всі організації замислюються, що виконаний на замовлення код або веб-сайт може містити серйозні вразливості, експлуатація яких зловмисником може призвести до витоку конфіденційної інформації, і програмні закладки - спеціальні ділянки коду, призначені для виконання будь-яких операцій за секретними командами, відомими розробнику коду . Крім того, виконаний на замовлення код може містити помилки, здатні знищити або пошкодити бази даних або призвести до порушень налагоджених бізнес-процесів.
Компанії, які знайомі з описаними вище ризиками, намагаються залучати до приймання готових модулів аудиторів та фахівців з аналізу вихідних текстів програм, щоб експерти визначили безпеку розробленого рішення та переконалися у відсутності в них уразливостей, помилок та програмних закладок. Але цей метод контролю має низку недоліків. По-перше, ця послуга серйозно збільшує бюджет на розробку; по-друге, проведення аудиту та аналізу займає тривалий час - від тижня до кількох місяців; і по-третє, такий підхід не гарантує повної відсутності проблем з аналізованим кодом – є ймовірність людської помилки та виявлення раніше невідомих векторів атак вже після приймання та початку експлуатації коду.
Існує методологія захищеної розробки, що передбачає вбудовування процесів аудиту та контролю коду на етапі створення програмного продукту – SDL (Security Development Lifecycle, захищений життєвий цикл розробки). Однак застосувати цю методологію може тільки розробник програмного забезпечення, якщо говорити про замовників, то SDL для них не застосовується, тому що процес передбачає перебудову алгоритмів створення коду і використовувати його при прийманні вже пізно. Крім того, багато розробок зачіпають невелику частину вже існуючого коду, і в цьому випадку SDL також не застосовується.
Для вирішення проблеми аудиту вихідного коду та забезпечення захисту від експлуатації вразливостей у кодах і веб-додатках, що вбудовуються, існують аналізатори вихідного коду.
Класифікація аналізаторів вихідного коду
Аналізатори вихідного коду - клас програмних продуктів, створених виявлення і запобігання експлуатації програмних помилок у вихідних кодах. Всі продукти, спрямовані на аналіз вихідного коду, можна умовно поділити на три типи:
- Перша група включає аналізатори коду веб-додатків і засоби запобігання експлуатації вразливостей веб-сайтів.
- Друга група - аналізатори коду, що вбудовується, що дозволяють виявити проблемні місця у вихідних текстах модулів, призначених для розширення функціональності корпоративних і виробничих систем. До таких модулів відносяться програми для лінійки продуктів 1С, розширення CRM-систем, систем керування підприємством та систем SAP.
- Остання група призначена для аналізу вихідного коду різними мовами програмування, які не стосуються бізнес-додатків та веб-додатків. Такі аналізатори призначені для замовників та розробників програмного забезпечення. У тому числі дана група аналізаторів використовується для використання методології захищеної розробки програмних продуктів. Аналізатори статичного коду знаходять проблеми та потенційно вразливі місця у вихідних кодах та видають рекомендації для їх усунення.
Варто зазначити, що більшість аналізаторів відносяться до змішаних типів і виконують функції з аналізу широкого спектру програмних продуктів - веб-додатків, коду, що вбудовується, і звичайного програмного забезпечення. Проте в даному огляді акцент робиться на застосуванні аналізаторів замовниками розробки, тому більша увага приділяється аналізаторам веб-додатків і вбудованого коду.
Аналізатори можуть містити різні механізми аналізу, але найпоширенішим і універсальним є статичний аналіз вихідного коду – SAST (Static Application Security Testing), також існують методи динамічного аналізу – DAST (Dynamic Application Security Testing), що виконують перевірки коду при його виконанні, та різні гібридні. варіанти, що поєднують різні типи аналізів. p align="justify"> Динамічний аналіз є самостійним методом перевірки, який може розширювати можливості статичного аналізу або застосовуватися самостійно в тих випадках, коли доступ до вихідних текстів відсутній. У цьому огляді розглядаються лише статичні аналізатори.
Аналізатори вбудованого коду та веб-додатків розрізняються за набором параметрів. До нього входять не лише якість аналізу та перелік підтримуваних програмних продуктів та мов програмування, але й додаткові механізми: можливість здійснення автоматичного виправлення помилок, наявність функцій щодо запобігання експлуатації помилок без змін коду, можливість оновлення вбудованої бази вразливостей та помилок програмування, наявність сертифікатів відповідності та можливість виконання вимог різних регуляторів.
Принципи роботи аналізаторів вихідного коду
Загальні принципи роботи схожі всім класів аналізаторів: і аналізаторів вихідного коду веб-додатків, і аналізаторів вбудованого коду. Відмінність між цими типами продуктів - лише у можливості визначити особливості виконання та взаємодії коду із зовнішнім світом, що відображається в базах уразливостей аналізаторів. Більшість аналізаторів, представлених на ринку, виконує функції обох класів, однаково добре перевіряючи як вбудований в бізнес-програми код, так і код веб-додатків.
Вхідними даними для аналізатора вихідного коду є масив вихідних текстів програм та його залежностей (підвантажуваних модулів, використовуваного стороннього програмного забезпечення тощо). Як результати роботи всі аналізатори видають звіт про виявлені вразливості та помилки програмування, додатково деякі аналізатори надають функції з автоматичного виправлення помилок.
Варто зазначити, що автоматичне виправлення помилок не завжди працює коректно, тому даний функціонал призначений тільки для розробників веб-додатків та вбудованих модулів, замовник продукту повинен спиратися лише на фінальний звіт аналізатора та використовувати отримані дані для прийняття рішення щодо приймання та впровадження розробленого коду або надсилання його на доопрацювання.
Рисунок 1. Алгоритм роботи аналізатора вихідних кодів
При проведенні оцінки вихідних текстів аналізатори використовують різні бази даних, що містять опис уразливостей та помилок програмування:
- Власна база вразливостей та помилок програмування – у кожного розробника аналізаторів вихідних кодів є свої відділи аналітики та досліджень, які готують спеціалізовані бази для аналізу вихідних текстів програм. Якість своєї бази - одне із ключових критеріїв, що впливає загальне якість роботи товару. Крім того, власна база повинна бути динамічною та постійно оновлюваною - нові вектори атак та експлуатації вразливостей, а також зміни в мовах програмування та методах розробки вимагають від розробників аналізаторів виконувати постійні оновлення бази для збереження високої якості перевірки. Продукти зі статичною неоновлюваною базою найчастіше програють у порівняльних тестах.
- Державні основи помилок програмування - існує низка державних основ уразливостей, складанням та підтримкою яких займаються регулятори різних країн. Наприклад, США використовується база CWE - Common Weakness Enumeration, обслуговуванням якої займається організація MITRE, підтримувана зокрема Міністерством оборони США. У Росії її поки що відсутня аналогічна база, але ФСТЭК Росії у майбутньому планує доповнити свої бази вразливостей і загроз базою помилок програмування. Аналізатори вразливостей реалізують підтримку бази CWE, вбудовуючи їх у власну базу вразливостей чи використовуючи як окремий механізм перевірки.
- Вимоги стандартів та рекомендації щодо захищеного програмування - існує як низка державних та галузевих стандартів, що описують вимоги до безпечної розробки додатків, так і низка рекомендацій та «кращих практик» від світових експертів у галузі розробки та захисту програмного забезпечення. Дані документи безпосередньо не описують помилки програмування, на відміну CWE, але містять перелік методів, які можуть бути перетворені для використання в статичному аналізаторі вихідного коду.
Від того, які бази використовуються в аналізаторі, залежить якість проведення аналізу, кількість помилкових спрацьовувань і пропущених помилок. Крім того, аналіз на відповідність вимогам регуляторів дозволяє полегшити та просити процедуру зовнішнього аудиту інфраструктури та інформаційної системи у тому випадку, якщо вимоги є обов'язковими. Наприклад, вимоги PCI DSS обов'язкові для веб-додатків і вбудованого коду, що працює з платіжною інформацією за банківськими картками, причому проведення зовнішнього аудиту по виконанню PCI DSS здійснюється в тому числі з аналізом застосовуваних програмних продуктів.
Світовий ринок
На світовому ринку представлено безліч різних аналізаторів - як від відомих вендорів у сфері безпеки, так і нішевих гравців, які займаються даним класом продуктів. Аналітичний центр Gartner веде класифікацію та оцінку аналізаторів вихідних кодів вже понад п'ять років, при цьому до 2011 року Gartner виділяв окремо статичні аналізатори, про які йдеться в цій статті, пізніше об'єднавши їх у більш високий клас - засоби перевірки захищеності додатків (Application Security Testing) ).
У магічному квадранті Gartner у 2015 році лідерами ринку перевірки захищеності є компанії HP, Veracode та IBM. При цьому Veracode – єдина з компаній-лідерів, у якої відсутня аналізатор як програмний продукт, а функціональність надається лише як послуга у хмарі компанії Veracode. Інші компанії-лідери пропонують або виключно продукти, що перевіряють на комп'ютерах користувачів, або можливість вибору між продуктом і хмарною послугою. Лідерами світового ринку протягом останніх п'яти років залишаються компанії HP та IBM, огляд їх продуктів наведено нижче. Найбільш близький до лідируючих позицій продукт компанії Checkmarx, що спеціалізується лише на даному класі коштів, тому він також включений до огляду.
2. Магічний квадрант аналітиків.Gartner за гравцями ринку аналізу захищеності додатків у серпні 2015 року

За даними звіту аналітиків ReportsnReports, у США обсяг ринку аналізаторів вихідних кодів у 2014 році склав $2,5 млрд, до 2019 року прогнозується дворазове зростання до $5 млрд зі щорічним зростанням на 14,9%. Понад 50% організацій, опитаних у ході складання звіту, планують виділення та збільшення бюджетів на аналіз вихідного коду при замовленій розробці, і лише 3% негативно висловилися щодо застосування цих продуктів.
Велика кількість товарів, що у сфері претендентів (challengers), підтверджує популярність даного класу товарів хороший і розвиток галузі. За останні п'ять років загальна кількість виробників у цьому квадранті збільшилася майже втричі, а порівняно зі звітом за 2014 рік додалося три продукти.
Російський ринок
Російський ринок аналізаторів вихідних текстів досить молодий - перші громадські товари почали з'являтися над ринком менше п'яти років тому. При цьому ринок сформувався з двох напрямків - з одного боку, компанії, що розробляють продукти для проведення випробувань щодо виявлення недекларованих можливостей у лабораторіях ФСТЕК, ФСБ та Міноборони РФ; з іншого боку - компанії, що займаються різними областями безпеки та вирішили додати у своє портфоліо новий клас продуктів.
Найбільш помітні гравці нового ринку – компанії Positive Technologies, InfoWatch, а також Solar Security. Positive Technologies тривалий час спеціалізувалися на пошуку та аналізі вразливостей; в їхньому портфоліо є продукт MaxPatrol - один з лідерів вітчизняного ринку із зовнішнього контролю захищеності, тому не дивно, що в компанії вирішили зайнятися і внутрішнім аналізом і розробляти власний аналізатор вихідних кодів. Компанія InfoWatch розвивалася як розробник DLP-систем, згодом перетворившись на групу компаній, що перебуває у пошуках нових ринкових ніш. У 2012 році до складу InfoWatch увійшла компанія Appercut, додавши до портфельу InfoWatch засіб аналізу вихідного коду. Інвестиції та досвід InfoWatch дозволили швидко розвинути продукт до високого рівня. Solar Security офіційно представили свій продукт Solar inCode лише наприкінці жовтня 2015 року, але вже на момент виходу мали чотири офіційні впровадження в Росії.
Компанії, які протягом десятиліть розробляли аналізатори вихідних текстів для проведення сертифікаційних випробувань, загалом не поспішають пропонувати аналізатори для бізнесу, тому в нашому огляді наводиться лише один такий продукт – від компанії «Ешелон». Можливо, у майбутньому, він буде здатний потіснити решту гравців ринку, насамперед за рахунок великого теоретичного та практичного досвіду розробників даного продукту у сфері пошуку вразливостей та недекларованих можливостей.
Ще одним нішевим гравцем російського ринку є Digital Security – консалтингова компанія в галузі інформаційної безпеки. Маючи великий досвід проведення аудитів і впроваджень ERP-систем, вона намацала незайняту нішу і взялася за розробку продукту для аналізу безпеки ERP-систем, серед інших функцій, що містить механізми аналізу вихідних кодів для програм, що вбудовуються.
Короткий огляд аналізаторів

Перший засіб аналізу вихідного коду в нашому огляді – продукт компанії Fortify, що з 2010 року належить Hewlett-Packard. У лінійці HP Fortify є різні продукти для аналізу програмних кодів: є і SaaS-сервіс Fortify On-Demand, що передбачає завантаження вихідного коду в хмару HP, і повноцінний додаток HP Fortify Static Code Analyzer, що встановлюється в інфраструктурі замовника.
HP Fortify Static Code Analyzer підтримує велику кількість мов програмування та платформ, включаючи веб-застосунки, написані на PHP, Python, Java/JSP, ASP.Net та JavaScript, і вбудований код мовами ABAP (SAP), Action Script і VBScript.
Малюнок 3. Інтерфейс HP Fortify Static Code Analyzer

З особливостей продукту варто виділити наявність у HP Fortify Static Code Analyzer підтримки інтеграції з різними системами управління розробкою та відстеження помилок. Якщо розробник програмного коду надає замовнику доступ до прямої передачі повідомлень про помилки в Bugzilla, HP Quality Center або Microsoft TFS, аналізатор може автоматично створювати повідомлення про помилки в цих системах без необхідності ручних дій.
Робота продукту заснована на базах знань HP Fortify, сформованих адаптацією бази CWE. У продукті реалізований аналіз виконання вимог DISA STIG, FISMA, PCI DSS і рекомендацій OWASP.
З недоліків HP Fortify Static Code Analyzer слід відзначити відсутність локалізації продукту для російського ринку – інтерфейс та звіти англійською мовою, відсутність матеріалів та документації на продукт російською мовою, не підтримується аналіз вбудованого коду для 1С та інших вітчизняних продуктів enterprise-рівня.
Переваги HP Fortify Static Code Analyzer:
- відомий бренд, висока якість рішення;
- великий перелік аналізованих мов програмування та підтримуваних середовищ розробки;
- наявність можливості інтеграції із системами керування розробкою та іншими продуктами HP Fortify;
- підтримка міжнародних стандартів, рекомендацій та «кращих практик».
Checkmarx CxSAST – засіб американо-ізраїльської компанії Сheckmarx, що спеціалізується на розробці аналізаторів вихідних кодів. Цей продукт призначений насамперед для аналізу звичайного програмного забезпечення, але за рахунок підтримки мов програмування PHP, Python, JavaScript, Perl та Ruby відмінно підходить для аналізу веб-застосунків. Checkmarx CxSAST це універсальний аналізатор, що не має яскраво вираженої специфіки і тому підходить для будь-яких етапів життєвого циклу програмного продукту - від розробки до застосування.
Рисунок 4. Інтерфейс Checkmarx CxSAST

У Checkmarx CxSAST реалізована підтримка бази помилок програмного коду CWE, підтримуються перевірки на відповідність рекомендаціям OWASP та SANS 25, стандартам PCI DSS, HIPAA, MISRA, FISMA та BSIMM. Усі виявлені Checkmarx CxSAST проблеми поділяються за рівнем ризику – від незначного до критичного. З особливостей продукту - наявність функцій із візуалізації коду з побудовою блок-схем маршрутів виконання та рекомендаціями щодо виправлення проблем із прив'язкою до графічної схеми.
До недоліків продукту можна віднести відсутність підтримки аналізу вбудованого в бізнес-додатки коду, відсутність локалізації та труднощі застосування продукту для замовників програмного коду, оскільки рішення призначене насамперед для розробників та тісно інтегрується із середовищами розробки.
Переваги Checkmarx CxSAST:
- велика кількість підтримуваних мов програмування;
- висока швидкість роботи продукту; можливість проводити сканування тільки по іменних ділянках коду;
- можливість візуалізації графів виконання аналізованого коду;
- наочні звіти та графічно оформлені метрики вихідних кодів.
![]()
Ще один продукт від відомого вендора – аналізатор вихідних кодів IBM Security AppScan Source. Лінійка AppScan включає безліч продуктів, пов'язаних з безпечною розробкою програмного забезпечення, але для застосування у замовників програмного коду інші продукти не підійдуть, оскільки мають велику кількість зайвого функціоналу. IBM Security AppScan Source, як і Checkmarx CxSAST, в першу чергу призначений для організацій-розробників, при цьому підтримує навіть менше мов веб-розробки - тільки PHP, Perl і JavaScript. Мови програмування для коду, що вбудовується в бізнес-додатки, не підтримуються.
Рисунок 5. Інтерфейс IBM Security AppScan Source

IBM Security AppScan Source тісно інтегрується з платформою для розробки IBM Rational, тому продукт найчастіше використовується на етапі розробки та тестування програмних продуктів і не дуже добре підходить для виконання приймання або перевірки розробленого на замовлення програми.
Особливістю IBM Security AppScan Source є хіба підтримка аналізу програм для IBM Worklight - платформи для мобільних бізнес-додатків. Перелік підтримуваних стандартів та вимог мізерний - PCI DSS та рекомендації DISA та OWASP, база вразливостей зіставляє знайдені проблеми з CWE.
Особливих переваг цього рішення для замовників розробки не виявлено.

AppChecker від вітчизняної компанії ЗАТ "НВО Ешелон" - рішення, що з'явилося на ринку зовсім недавно. Перша версія продукту вийшла лише рік тому, але при цьому слід враховувати досвід компанії Ешелон в аналізі програмного коду. «НВО Ешелон» є випробувальною лабораторією ФСТЕК, ФСБ та Міністерства оборони РФ і має великий досвід у галузі проведення статичного та динамічного аналізу вихідних текстів програм.
Рисунок 6. Інтерфейс "Ешелон" AppChecker

AppChecker призначений для аналізу різноманітного програмного забезпечення та веб-додатків, написаних мовами PHP, Java та C/C++. Повністю підтримує класифікацію вразливостей CWE та враховує рекомендації OWASP, CERT та NISP. Продукт можна використовувати для виконання аудиту на відповідність вимогам PCI DSS та стандарту Банку Росії ІББС-2.6-2014.
Недоліки продукту обумовлені ранньою стадією розвитку рішення - не вистачає підтримки популярних мов веб-розробки та можливості аналізу коду, що вбудовується.
Переваги:
- наявність можливості проведення аудиту за вітчизняними вимогами та PCI DSS;
- облік впливу особливостей мов програмування з допомогою гнучкої конфігурації аналізованих проектів;
- низька вартість.

PT Application Inspector - продукт російського розробника Positive Technologies, який відрізняється своїм підходом до вирішення проблеми аналізу вихідного коду. PT Application Inspector орієнтований насамперед на пошук вразливостей у коді, а не на виявлення загальних програмних помилок.
На відміну від решти продуктів у даному огляді, PT Application Inspector має не тільки можливість складання звіту та демонстрації вразливих місць, але й здатність автоматично створювати експлоїти для окремих категорій та видів вразливостей - невеликі модулі, що виконуються, що експлуатують знайдені вразливості. За допомогою створених експлоїтів можна на практиці перевіряти небезпеку знайдених уразливостей, а також контролювати розробника, перевіривши роботу експлоїту після декларованого закриття вразливості.
Рисунок 7. Інтерфейс PT Application Inspector

PT Application Inspector підтримує як мови розробки веб-додатків (PHP, JavaScript), так і вбудований код для бізнес-програм - SAP ABAP, SAP Java, Oracle EBS Java, Oracle EBS PL/SQL. Також PT Application Inspector підтримує візуалізацію маршрутів виконання програм.
PT Application Inspector є універсальним рішенням як для розробників, так і для замовників, що експлуатують розроблені на замовлення веб-додатки та модулі для бізнес-додатків. База вразливостей та помилок у програмному коді містить власні напрацювання компанії Positive Technologies, базу CWE та WASC (база вразливостей веб-консорціуму, аналог CWE для веб-додатків).
Використання PT Application Inspector дозволяє виконати вимоги стандартів PCI DSS, СТО БР ІББС, а також 17 наказів ФСТЕК та вимоги щодо відсутності недекларованих можливостей (актуально під час сертифікації коду).
Переваги:
- підтримка аналізу веб-додатків та великого набору систем розробки для бізнес-додатків;
- вітчизняний, локалізований продукт;
- широкий набір державних стандартів, що підтримуються;
- використання бази вразливостей веб-додатків WASC та класифікатора CWE;
- можливість візуалізації програмного коду та пошуку програмних закладок.
InfoWatch Appercut розроблено російською компанією InfoWatch. Основна відмінність даного продукту від інших у цій добірці - спеціалізація на наданні сервісу для замовників бізнес-додатків.
InfoWatch Appercut підтримує практично всі мови програмування, якими створюються веб-додатки (JavaScript, Python, PHP, Ruby) і вбудовані модулі для бізнес-пропозицій - 1С, ABAP, X++ (ERP Microsoft Axapta), Java, Lotus Script. InfoWatch Appercut має здатність підлаштовуватися під специфіку конкретної програми та унікальність бізнес-процесів кожної компанії.
Рисунок 8. Інтерфейс InfoWatch Appercut

InfoWatch Appercut підтримує багато вимог щодо ефективного та безпечного програмування, включаючи загальні вимоги PCI DSS та HIPPA, рекомендації та «кращі практики» CERT та OWAST, а також рекомендації виробників платформ бізнес-процесів – 1С, SAP, Oracle, Microsoft.
Переваги:
- вітчизняний, локалізований продукт, сертифікований ФСТЕК Росії;
- єдиний продукт, який підтримує всі популярні в Росії бізнес-платформи, включаючи 1С, SAP, Oracle EBS, IBM Collaboration Solutions (Lotus) та Microsoft Axapta;
- швидкий сканер, що виконує перевірки за лічені секунди та здатний перевіряти лише змінений код та фрагменти коду.

Digital Security ERPScan – спеціалізований продукт для аналізу та моніторингу захищеності бізнес-систем, побудованих на продуктах SAP, перша версія випущена у 2010 році. До складу ERPScan входить крім модуля аналізу конфігурацій, вразливостей та контролю доступу (SOD) модуль оцінки безпеки вихідного коду, що реалізує функції пошуку закладок, критичних викликів, уразливостей та помилок програмування в коді мовами програмування ABAP та Java. При цьому продукт враховує специфіку платформи SAP, проводить кореляцію виявлених уразливостей у коді з налаштуваннями конфігурації та правами доступу та виконує аналіз краще, ніж неспеціалізовані продукти, що працюють з тими самими мовами програмування.
Рисунок 9. Інтерфейс Digital Security ERPScan

З додаткових функцій ERPScan можна відзначити можливість автоматичної генерації виправлень для виявлених уразливостей, а також генерацію сигнатур для можливих атак та вивантаження цих сигнатур у системи виявлення та запобігання вторгненням (у партнерстві з CISCO). Крім того, в системі присутні механізми оцінки продуктивності вбудованого коду, що є критичним для бізнес-додатків, оскільки повільна робота додаткових модулів може серйозно позначитися на бізнес-процесах в організації. Система також підтримує аналіз відповідно до специфічних рекомендацій щодо аналізу коду бізнес-додатків, таких, як EAS-SEC та BIZEC, а також загальними рекомендаціями PCI DSS та OWASP.
Переваги:
- глибока спеціалізація на одній платформі бізнес-додатків з кореляцією аналізу з налаштуваннями конфігурації та правами доступу;
- тести продуктивності вбудованого коду;
- автоматичне створення виправлень до знайдених уразливостей та віртуальних патчів;
- пошук уразливостей нульового дня.

Solar inCode – інструмент статичного аналізу коду, призначений для виявлення вразливостей інформаційної безпеки та недекларованих можливостей у вихідних текстах програмного забезпечення. Основною відмінністю продукту є можливість відновлювати вихідний код додатків з робочого файлу з використанням технології декомпіляції (зворотної інженерії).
Solar inCode дозволяє проводити аналіз вихідного коду, написаного мовами програмування Java, Scala, Java для Android, PHP і Objective C. На відміну від більшості конкурентів, у списку мов програмування присутні засоби розробки для мобільних платформ Android і iOS.
Рисунок 10. Інтерфейс

У випадках, коли вихідний код недоступний, Solar inCode дозволяє здійснити аналіз готових програм, ця функціональність підтримує веб-програми та мобільні програми. Зокрема, для мобільних програм достатньо просто скопіювати в сканер посилання на програму з Google Play або Apple Store, програма буде автоматично завантажена, декомпільована і перевірена.
Використання Solar inCode дозволяє виконати вимоги стандартів PCI DSS, СТО БР ІББС, а також 17 наказів ФСТЕК та вимоги щодо відсутності недекларованих можливостей (актуально під час сертифікації коду).
Переваги:
- Підтримка аналізу програм для мобільних пристроїв під керуванням Android та iOS;
- підтримує аналіз веб-додатків та мобільних програм без використання вихідних текстів програм;
- видає результати аналізу у форматі конкретних рекомендацій щодо усунення вразливостей;
- формує детальні рекомендації щодо настроювання засобів захисту: SIEM, WAF, FW, NGFW;
- легко інтегрується у процес безпечної розробки програмного забезпечення за рахунок підтримки роботи з репозиторіями вихідних текстів.
Висновки
Наявність програмних помилок, вразливостей та закладок у програмному забезпеченні, яке розробляється на замовлення, будь то веб-додатки або модулі для бізнес-додатків, є серйозним ризиком для безпеки корпоративних даних. Використання аналізаторів вихідних кодів дозволяє суттєво знизити ці ризики та тримати під контролем якість виконання роботи розробниками програмного коду без необхідності додаткових витрат часу та коштів на послуги експертів та зовнішніх аудиторів. При цьому використання аналізаторів вихідних кодів, найчастіше, не вимагає спеціальної підготовки, виділення окремих співробітників і не завдає інших незручностей, якщо продукт використовується тільки для приймання та виправлення помилок виконує розробник. Все це робить цей інструмент обов'язковим до застосування при використанні розробок на замовлення.
При виборі аналізатора вихідного коду слід відштовхуватися від функціональних можливостей продуктів та якості їхньої роботи. Насамперед варто звернути увагу на можливості продукту здійснювати перевірки для мов програмування, на яких реалізовані вихідні коди, що перевіряються. p align="justify"> Наступним критерієм у виборі продукту має бути якість перевірки, визначити яке можна за компетенціями компанії-розробника і в ході демонстраційної експлуатації продукту. Ще одним фактором для вибору продукту може бути можливість проведення аудиту на відповідність вимогам державних і міжнародних стандартів, якщо їх виконання потрібне для корпоративних бізнес-процесів.
У цьому огляді явним лідером серед іноземних продуктів з підтримки мов програмування та якості сканування є рішення HP Fortify Static Code Analyzer. Також хорошим продуктом є Checkmarx CxSAST, але він здатний аналізувати лише звичайні програми та веб-програми, підтримка вбудованих модулів для бізнес-додатків у продукті відсутня. Рішення IBM Security AppScan Source на тлі конкурентів виглядає блякло і не відрізняється ні функціональністю, ні якістю перевірок. Втім, цей продукт не призначений для бізнес-користувачів і спрямований на використання у компаніях-розробниках, де він може показувати більшу ефективність, ніж конкуренти.
Серед російських продуктів складно виділити однозначного лідера, ринок представляють три основні продукти – InfoWatch Appercut, PT Application Inspector та Solar inCode. При цьому дані продукти суттєво розрізняються технологічно і призначені для різних цільових аудиторій - перший підтримує більше платформ бізнес-додатків та відрізняється великою швидкодією за рахунок пошуку вразливостей виключно статичними методами аналізу. Другий - поєднує в собі статичний та динамічний аналіз, а також їх комбінацію, що одночасно з покращенням якості сканування призводить до збільшення часу перевірки вихідного коду. Третій спрямований на вирішення проблем бізнес-користувачів та фахівців з інформаційної безпеки, а також дозволяє перевіряти програми без доступу до вихідного коду.
"Ешелон" AppChecker поки не дотягує до конкурентів і має невеликий набір функціональних можливостей, але, враховуючи ранню стадію розвитку продукту, цілком можливо, що найближчим часом він може претендувати на верхні рядки в рейтингах аналізаторів вихідних текстів.
Digital Security ERPScan є чудовим продуктом для вирішення вузькоспеціалізованого завдання аналізу бізнес-додатків для платформи SAP. Сконцентрувавшись тільки на цьому ринку, компанія Digital Security розробила унікальний за своєю функціональністю продукт, який не тільки проводить аналіз вихідного коду, а й враховує всю специфіку платформи SAP, конкретних налаштувань конфігурації та прав доступу бізнес-додатків, а також має можливість автоматичного створення виправлень до виявлених уразливостей.
Анотація
Статичний аналіз це спосіб перевірки вихідного коду програми на коректність. Процес статичного аналізу складається із трьох етапів. Спочатку аналізований код розбивається на лексеми - константи, ідентифікатори і т. д. Ця операція виконується лексером. Потім лексеми передаються синтаксичному аналізатору, який вибудовує по цих лексем дерево коду. Зрештою, проводиться статичний аналіз збудованого дерева. У даній оглядовій статті наведено опис трьох методів статичного аналізу: аналіз з обходом дерева коду, аналіз потоку даних та аналіз потоку даних із вибором шляхів.
Вступ
Тестування є важливою частиною процесу розробки програм. Існує безліч різних видів тестування, у тому числі два види, що стосуються програмного коду: статичний аналіз і динамічний аналіз.
Динамічний аналіз проводиться над виконуваним кодом скомпільованої програми. У цьому перевіряється лише поведінка, що залежить від користувача, тобто. тільки код, який виконується під час тесту. Динамічний аналізатор може знаходити витоку пам'яті, вимірювати продуктивність програми, отримувати стек викликів тощо.
Статичний аналіз дозволяє перевіряти вихідний код програми до виконання. Зокрема будь-який компілятор проводить статичний аналіз при компіляції. Проте, у великих реальних проектах часто виникає необхідність перевірити весь код щодо відповідності деяким додатковим вимогам. Ці вимоги можуть бути дуже різноманітні, починаючи від правил іменування змінних і закінчуючи мобільністю (наприклад, код повинен виконуватися на платформах х86 і х64). Найбільш поширеними вимогами є:
- Надійність - менша кількість помилок у програмі, що тестується.
- Зручність супроводу - зрозуміліший код, який легко змінювати та вдосконалити.
- Мобільність - гнучкість програми, що тестується при запуску на різних платформах.
- Зручність - скорочення часу, необхідного для розуміння коду.
Вимоги можна розбити на правила та рекомендації. Правила, на відміну рекомендацій, обов'язкові до виконання. Аналогом правил та рекомендацій є помилки та попередження, що видаються аналізаторами коду, вбудованими у стандартні компілятори.
Правила та рекомендації, у свою чергу, формують стандарт кодування. Цей стандарт визначає, як програміст повинен писати програмний код. Стандарти кодування застосовуються в організаціях, що займаються розробкою програмного забезпечення.
Статичний аналізатор знаходить рядки вихідного коду, які, ймовірно, не відповідають прийнятому стандарту кодування та відображає діагностичні повідомлення, щоб розробник міг зрозуміти причину проблеми. Процес статичного аналізу аналогічний компіляції, тільки при цьому не генерується ні об'єктний, ні код, що виконується. У цьому огляді наводиться покроковий опис процесу статичного аналізу.
Процес аналізу
Процес статичного аналізу і двох основних кроків: створення дерева коду (також званого ) і цього дерева.
Щоб проаналізувати вихідний код, аналізатор повинен спочатку " зрозуміти " цей код, тобто. розібрати його за складом і створити структуру, що описує аналізований код у зручній формі. Ця форма називається деревом коду. Щоб перевірити, чи код відповідає стандарту кодування, необхідно побудувати таке дерево.
В загальному випадку дерево будується тільки для фрагмента коду, що аналізується (наприклад, для якоїсь конкретної функції). Для того щоб створити дерево код обробляється спочатку, а потім.
Лексер відповідає за розбиття вхідних даних на окремі лексеми, а також за визначення типу цих лексем та їх послідовну передачу синтаксичному аналізатору. Лексер зчитує текст вихідного коду рядок за рядком, а потім розбиває отримані рядки на зарезервовані слова, ідентифікатори та константи, які називаються лексемами. Після одержання лексеми лексер визначає її тип.
Розглянемо зразковий алгоритм визначення типу лексеми.
Якщо перший символ лексеми є цифрою, лексема вважається числом, якщо це символ є знаком " мінус " , це - негативне число. Якщо лексема є числом, може бути числом цілим чи дробовим. Якщо в числі міститься буква E, що визначає експоненційне уявлення, або десяткова точка, число вважається дробовим, інакше - цілим. Зауважимо, що при цьому може виникнути лексична помилка - якщо в аналізованому вихідному коді міститься лексема "4xyz", лексер визнає її цілим числом 4. Це породить синтаксичну помилку, яку зможе виявити синтаксичний аналізатор. Проте подібні помилки можуть бути і лексером.
Якщо лексема не є числом, то вона може бути рядком. Строкові константи можуть розпізнаватись по одинарних лапках, подвійних лапках, або будь-яким іншим символам, залежно від синтаксису аналізованої мови.
Нарешті, якщо лексема є рядком, вона має бути ідентифікатором, зарезервованим словом, чи зарезервованим символом. Якщо лексема не підходить і під ці категорії, виникає лексична помилка. Лексер не оброблятиме цю помилку самостійно - він лише повідомить синтаксичному аналізатору, що виявлено лексему невідомого типу. Опрацюванням цієї помилки займеться синтаксичний аналізатор.
Синтаксичний аналізатор розуміє граматику мови. Він відповідає за виявлення синтаксичних помилок і за перетворення програми, в якій такі помилки відсутні, структури даних, звані деревами коду. Ці структури у свою чергу надходять на вхід статичного аналізатора та обробляються ним.
Тоді як лексер розуміє лише синтаксис мови, синтаксичний аналізатор також розпізнає контекст. Наприклад, оголосимо функцію мовою Сі:
Int Func()(return 0;)
Лексер обробить цей рядок і розіб'є її на лексеми як показано в таблиці 1:
Таблиця 1 - Лексема рядка "int Func()(return 0);".
Рядок буде розпізнано як 8 коректних лексем, і ці лексеми будуть передані синтаксичному аналізатору.
Цей аналізатор перегляне контекст і з'ясує, що цей набір лексем є оголошенням функції, яка не приймає жодних параметрів, повертає ціле число, і це завжди дорівнює 0.
Синтаксичний аналізатор з'ясує це, коли створить дерево коду з лексем, наданих лексером, та проаналізує це дерево. Якщо лексеми та побудоване з них дерево будуть вважатися правильними – це дерево буде використане при статичному аналізі. В іншому випадку синтаксичний аналізатор видасть повідомлення про помилку.
Однак процес побудови дерева коду не зводиться до простого уявлення лексем у вигляді дерева. Розглянемо цей процес докладніше.
Дерево коду
Дерево коду являє собою суть поданих на вхід даних у формі дерева, опускаючи несуттєві деталі синтаксису. Такі дерева відрізняються від конкретних дерев синтаксису тим, що в них немає вершин, що представляють розділові знаки на кшталт крапки з комою, що завершує рядок, або комою, яка ставиться між аргументами функції.
Синтаксичні аналізатори, що використовуються для створення дерев коду, можуть бути написані вручну, а можуть створюватися генераторами синтаксичних аналізаторів. Дерева коду зазвичай створюються знизу догори.
Під час створення вершин дерева насамперед зазвичай визначається рівень модульності. Іншими словами, визначається, чи всі конструкції мови представлені вершинами одного типу, що розрізняються за значеннями. Як приклад розглянемо уявлення бінарних арифметичних операцій. Один варіант - використовувати для всіх бінарних операцій однакові вершини, одним із атрибутів яких буде тип операції, наприклад, "+". Інший варіант – використовувати для різних операцій вершини різного типу. В об'єктно-орієнтованій мові це можуть бути класи на кшталт AddBinary, SubstractBinary, MultipleBinary тощо, які успадковуються від абстрактного базового класу Binary.
Як приклад розберемо два вирази: 1 + 2 * 3 + 4 * 5 і 1 + 2 * (3 + 4) * 5 (див. рисунок 1).
Як видно з малюнка, оригінальний вид виразу може бути відновлений при обході дерева зліва направо.
Після того, як дерево коду створено та перевірено, статичний аналізатор може визначити, чи відповідає вихідний код правилам та рекомендаціям, зазначеним у стандарті кодування.
Методи статичного аналізу
Існує безліч різних методів, зокрема, аналіз, аналіз потоку даних, аналіз потоку даних з вибором шляху і т. д. Конкретні реалізації цих методів різні в різних аналізаторах. Проте, статичні аналізатори для різних мов програмування можуть використовувати той самий базовий код (інфраструктуру). Ці інфраструктури містять набір основних алгоритмів, які можуть використовуватися в різних аналізаторах коду незалежно від конкретних завдань та аналізованої мови. Набір методів, що підтримуються, і конкретна реалізація цих методів, знову ж таки, залежатиме від конкретної інфраструктури. Наприклад, інфраструктура може легко створювати аналізатор, що використовує обхід дерева коду, але не підтримувати аналіз потоку даних .
Хоча всі три перераховані вище методи статичного аналізу використовують дерево коду, побудоване синтаксичним аналізатором, ці методи розрізняються за своїми завданнями та алгоритмами.
Аналіз з обходом дерева, як видно з назви, виконується шляхом обходу дерева коду та проведення перевірок на предмет відповідності коду прийнятому стандарту кодування, зазначеному у вигляді набору правил та рекомендацій. Саме цей тип аналізу проводять компілятори.
Аналіз потоку даних можна описати як процес збору інформації про використання, визначення та залежності даних в аналізованої програмі. При аналізі потоку даних використовується граф потоку команд, що генерується з урахуванням дерева коду. Цей граф представляє всі можливі шляхи виконання даної програми: вершини позначають "прямолінійні", без будь-яких переходів, фрагменти коду, а ребра - можливу передачу управління між цими фрагментами. Оскільки аналіз виконується без запуску програми, що перевіряється, точно визначити результат її виконання неможливо. Іншими словами, неможливо з'ясувати, яким саме шляхом передаватиметься управління. Тому алгоритми аналізу потоку даних апроксимують можливу поведінку, наприклад, розглядаючи обидві гілки оператора if-then-else або виконуючи з певною точністю тіло циклу while. Обмеження точності існує завжди, оскільки рівняння потоку даних записуються для деякого набору змінних, і кількість змінних має бути обмежена, оскільки ми розглядаємо лише програми з кінцевим набором операторів. Отже, для кількості невідомих завжди існує певна верхня межа, що дає обмеження точності. З погляду графа потоку команд при статичному аналізі всі можливі шляхи виконання програми вважаються дійсними. Через це припущення під час аналізу потоку даних можна лише приблизні рішення для обмеженого набору завдань .
Описаний вище алгоритм аналізу потоку даних не розрізняє шляхів, оскільки всі можливі шляхи, незалежно від того чи реальні вони, чи ні, чи будуть вони виконуватися часто, або рідко, все одно призводять до вирішення. Насправді, проте, виконується лише мала частина потенційно можливих шляхів. Більш того, найчастіше виконуваний код, як правило, становить ще менше підмножини всіх можливих шляхів. Логічно скоротити аналізований граф потоку команд і зменшити в такий спосіб обсяг обчислень, аналізуючи лише деяке підмножина можливих шляхів. Аналіз із вибором шляхів проводиться за скороченим графом потоку команд, у якому немає неможливих шляхів та шляхів, що не містять "небезпечного" коду. Критерії вибору шляхів різні у різних аналізаторах. Наприклад, аналізатор може розглядати лише шляхи, що містять оголошення динамічних масивів, вважаючи такі оголошення "небезпечними" згідно з налаштуваннями аналізатора.
Висновок
Число методів статичного аналізу та самих аналізаторів зростає рік у рік, і це означає, що інтерес до статичним аналізаторам коду зростає. Причина зацікавленості полягає в тому, що програмне забезпечення, що розробляється, стає все більш і більш складним і, отже, перевіряти код вручну стає неможливо.
У цій статті було наведено короткий опис процесу статичного аналізу та різних методів проведення такого аналізу.
бібліографічний список
- Dirk Giesen Philosophy and practical implementation of static analyzer tools. -Electronic data. -Dirk Giesen, cop. 1998.
- James Alan Farrell Compiler Basics. -Electronic data. -James Alan Farrell, cop 1995. -Access mode: http://www.cs.man.ac.uk/~pjj/farrell/compmain.html
- Joel Jones Abstract syntax tree implementation idioms. -Proceedings of the 10th Conference on Pattern Languages of Programs 2003, cop 2003.
- Ciera Nicole Christopher Evaluating Static Analysis Frameworks.- Ciera Nicole, cop. 2006.
- Leon Moonen Generic Architecture for Data Flow Analysis to Support Reverse Engineering. - Процедури 2-го міжнародного робітника на теоріях і практиках з алгебраїчних специфічностей, cop. 1997.
При статичному аналізі (static analysis) можна знайти багато різноманітних дефектів і слабких місць вихідного коду до того, як код буде готовий для запуску. З іншого боку, динамічний аналіз (runtime analysis), або аналіз під час виконання, відбувається на працюючому програмному забезпеченні та виявляє проблеми у міру їх виникнення, зазвичай використовуючи складні інструментальні засоби. Хтось може заперечити, що одна форма аналізу випереджає іншу, але розробники можуть комбінувати обидва способи для прискорення процесів розробки та тестування, а також для підвищення якості продукту, що видається.
У статті спочатку розглядається метод статичного аналізу. З його допомогою можна запобігти проблемам їх проникнення до складу основного програмного коду і гарантувати, що новий код відповідає стандарту. Використовуючи різні техніки аналізу, наприклад, перевірку абстрактного синтаксичного дерева (abstract syntax tree, AST) та аналіз кодових шляхів, інструменти статичного аналізу можуть виявити приховані вразливості, логічні помилки, дефекти реалізації та інші проблеми. Це може бути як на етапі розробки на кожному робочому місці, так і під час компонування системи. Далі у статті досліджується метод динамічного аналізу, який можна використовувати на етапі розробки модулів та системної інтеграції, який дозволяє виявити проблеми, пропущені при статичному аналізі. При динамічному аналізі не тільки виявляються помилки, пов'язані з вказівниками та іншими некоректностями, але є можливість також оптимізувати використання циклів ЦПУ, ОЗУ, флеш-пам'яті та інших ресурсів.
У статті обговорюються також варіанти комбінування статичного та динамічного аналізу, що допоможе запобігати поверненню до більш ранніх етапів розробки в міру "дозрівання" продукту. Такий підхід з використанням одразу двох методик допомагає уникнути прояву більшості проблем ще на ранніх етапах розробки, коли їх найлегше і найдешевше виправити.
Об'єднуючи найкраще із двох світів
Інструменти статичного аналізу знаходять програмні помилки ще ранній фазі створення проекту, зазвичай перед тим, як створюється виконуваний файл. Таке раннє виявлення особливо корисно для проектів великих вбудовуваних систем, де розробники не можуть використовуватися засоби динамічного аналізу, поки програмне забезпечення не буде завершено настільки, щоб його можна було запустити на цільовій системі.
На етапі статичного аналізу виявляються і описуються області вихідного коду зі слабкими місцями, включаючи приховані вразливості, логічні помилки, дефекти реалізації, некоректності при виконанні паралельних операцій, граничні умови, що рідко виникають, і багато інших проблем. Наприклад, інструменти статичного аналізу Klocwork Insight виконують глибокий аналіз вихідного коду на синтаксичному та семантичному рівнях. Ці інструментальні засоби виконують також складний міжпроцедурний аналіз керуючих потоків і потоків даних та використовують удосконалену техніку відсікання хибних шляхів, оцінюють значення, які прийматимуть змінні та моделюють потенційну поведінку програми під час виконання.
Розробники можуть використовувати інструменти статичного аналізу у час на етапі розробки, навіть коли написані лише фрагменти проекту. Проте, чим більш завершеним є код, тим краще. При статичному аналізі можуть проглядатися всі потенційні шляхи виконання коду – при звичайному тестуванні таке відбувається рідко, якщо в проекті не потрібно забезпечення 100% покриття коду. Наприклад, при статичному аналізі можна виявити програмні помилки, пов'язані з крайовими умовами чи помилками шляхів, які не тестуються під час розробки.
Оскільки під час статичного аналізу робиться спроба передбачити поведінку програми, засновану на моделі вихідного коду, іноді виявляється "помилка", якої фактично не існує - це так зване "хибне спрацьовування" (false positive). Багато сучасних засобів статичного аналізу реалізують покращену техніку, щоб уникнути подібної проблеми та виконати виключно точний аналіз.
| Статичний аналіз: аргументи "за" | Статичний аналіз: аргументи "проти" |
| Використовується вже на ранніх етапах життєвого циклу програмного забезпечення, перш ніж код готовий до виконання і до початку тестування. Можуть аналізуватись існуючі бази кодів, які вже пройшли тестування. Кошти можуть бути інтегровані в середу розробки як частину компонента, що використовується при "нічних складаннях" (nightly builds) і як частина інструментального набору робочого місця розробника. Низькі вартісні витрати: немає потреби створювати тестові програми або фіктивні модулі (stubs); розробники можуть запускати власні види аналізу. |
Можуть виявлятися програмні помилки та вразливості, які обов'язково призводять до відмови програми або впливають на поведінку програми під час її реального виконання. Ненульова ймовірність "хибного спрацьовування". |
Таблиця 1- Аргументи "за" та "проти" статичного аналізу.
Інструменти динамічного аналізу виявляють програмні помилки в коді, запущеному на виконання. При цьому розробник має можливість спостерігати або діагностувати поведінку програми під час її виконання, в ідеальному випадку безпосередньо в цільовому середовищі.
У багатьох випадках в інструменті динамічного аналізу проводиться модифікація вихідного або бінарного коду програми, щоб встановити пастки або процедури-перехоплювачі (hooks) для проведення інструментальних вимірювань. За допомогою цих пасток можна виявити програмні помилки на етапі виконання, проаналізувати використання пам'яті, покриття коду та перевірити інші умови. Інструменти динамічного аналізу можуть генерувати точну інформацію про стан стека, що дозволяє відладчикам знайти причину помилки. Тому, коли інструменти динамічного аналізу знаходять помилку, то швидше за все це справжня помилка, яку програміст може швидко ідентифікувати та виправити. Слід зазначити, що для створення помилкової ситуації на етапі виконання повинні існувати необхідні умови, за яких проявляється програмна помилка. Відповідно, розробники повинні створити певний контрольний приклад реалізації конкретного сценарію.
| Динамічний аналіз: аргументи "за" | Динамічний аналіз: аргументи "проти" |
| Рідко виникають "хибні спрацьовування" - висока продуктивність знаходження помилок Для відстеження причини помилки може бути проведена повна трасування стека та середовища виконання. Захоплюються помилки у тих працюючої системи, як у реальних умовах, і у режимі імітаційного моделювання. |
Відбувається втручання у поведінку системи у реальному часі; ступінь втручання залежить від кількості використовуваних інструментальних вставок. Це не завжди призводить до виникнення проблем, але про це потрібно пам'ятати при роботі з критичним на час кодом. Повнота аналізу помилок залежить від рівня покриття коду. Таким чином, кодовий шлях, що містить помилку, повинен бути обов'язково пройдено, а в контрольному прикладі повинні створюватися необхідні умови для створення помилкової ситуації. |
Таблиця 2- Аргументи "за" та "проти" динамічного аналізу.
Раннє виявлення помилок зменшення витрат на розробку
Чим раніше виявляється програмна помилка, тим швидше і дешевше її можна виправити. Тому інструменти статичного та динамічного аналізу становлять реальну цінність, забезпечуючи пошук помилок на ранніх етапах життєвого циклу програмного забезпечення. Різні дослідження промислових продуктів показують, що корекція проблеми на етапі тестування системи (для підтвердження якості її роботи, QA) або вже після поставки системи виявляється на кілька порядків дорожчою, ніж усунення тих самих проблем на етапі розробки програмного забезпечення. Багато організацій мають оціночні показники щодо витрат на усунення дефектів. На рис. 1 наведені дані з обговорюваної проблеми, взяті з книги Каперса Джонса (Capers Jones), що часто цитується "Applied Software Measurement" ("Прикладні вимірювання програмного забезпечення").
Рис. 1- У міру просування проекту, вартість усунення дефектів програмного забезпечення може експоненційно зростати. Інструменти статичного та динамічного аналізу допомагають запобігти цим витратам завдяки виявленню програмних помилок на ранніх етапах життєвого циклу програмного забезпечення.
Статичний аналіз
Статичний аналіз використовується в практиці програмних розробок майже так довго, як існує сама розробка програмного забезпечення. У початковому вигляді аналіз зводився до контролю відповідності стандартам стилю програмування (lint). Розробники користувалися цим безпосередньо на своєму робочому місці. Коли справа сягала виявлення програмних помилок, то ранніх інструментах статичного аналізу основну увагу зверталося те що, що лежить на поверхні: стиль програмування і часто виникаючі синтаксичні помилки. Наприклад, навіть найпростіші інструменти статичного аналізу зможуть виявити таку помилку:
Int foo(int x, int* ptr) ( if(x & 1); ( *ptr = x; return; ) ... )
Тут помилкове вживання зайвої точки з комою призводить до потенційно катастрофічних результатів: покажчик вхідного параметра функції перевизначається за неочікуваних умов. Покажчик перевизначається завжди, незалежно від умови, що перевіряється.
Ранні інструменти аналізу звертали увагу головним чином на синтаксичні помилки. Тому, хоча при цьому і можна було виявити серйозні помилки, все ж більшість проблем, що виявлялися, виявлялися відносно тривіальними. Крім того, для інструментів надавався досить невеликий кодовий контекст, щоб очікувати точних результатів. Це відбувалося тому, що робота проводилася протягом типового циклу компіляції/компонування при розробці, а те, що робив розробник, було лише невеликою частиною коду великої програмної системи. Такий недолік приводив до того, що в інструменти аналізу закладалися оцінки та гіпотези щодо того, що може відбуватися за межами "пісочниці" розробника. А це, у свою чергу, призводило до генерації підвищеного обсягу звітів із "хибними спрацьовуваннями".
Наступні покоління інструментів статичного аналізу звертали увагу на ці недоліки та розширювали сферу свого впливу за межі синтаксичного та семантичного аналізу. У нових інструментах будувалося розширене уявлення або модель коду (щось схоже на фазу компіляції), а далі моделювалися всі можливі шляхи виконання коду відповідно до моделі. Далі проводилося відображення на ці шляхи логічних потоків з одночасним контролем того, як і де створюються, використовуються та знищуються об'єкти даних. У процесі аналізу програмних модулів можуть підключатися процедури аналізу міжпроцедурного керування та потоку даних. При цьому також мінімізуються "хибні спрацьовування" за рахунок використання нових підходів для відсікання хибних шляхів, оцінки значень, які можуть набувати змінних, моделювання потенційної поведінки при роботі в реальному часі. Для генерації даних такого рівня в інструментах статичного аналізу необхідно аналізувати всю кодову базу проекту, проводити інтегральне системне компонування, а не просто працювати з результатами, що отримуються в "пісочниці" на робочому столі розробника.
Для виконання таких витончених форм аналізу в інструментах статичного аналізу мають справу з двома основними типами перевірок коду:
- Перевірка абстрактного синтаксичного дерева- для перевірки базового синтаксису та структури коду.
- Аналіз кодових шляхів- для виконання повнішого аналізу, який залежить від розуміння стану програмних об'єктів даних у конкретній точці на шляху виконання коду.
Анотація синтаксичних дерев
Абстрактне синтаксичне дерево просто є уявленням вихідного коду у вигляді деревоподібної структури, як це може генеруватися на попередніх стадіях роботи компілятора. Дерево містить докладне однозначне розкладання структури коду, що дозволяє інструментам виконати простий пошук аномальних місць синтаксису.
Дуже просто побудувати програму контролю, яка перевіряє дотримання стандартів щодо угоди щодо присвоєння імен та обмежень щодо функціональних викликів, наприклад, контроль небезпечних бібліотек. Мета виконання перевірок з AST зазвичай полягає у отриманні будь-яких логічних висновків на підставі коду як такого без використання знань про поведінку коду у процесі виконання.
Багато інструментів пропонують перевірки на основі AST для багатьох мов, включаючи інструменти з відкритим вихідним кодом, наприклад, PMD для Java. Деякі інструменти використовують граматику Х-шляхів або похідну від Х-шляхів граматику, щоб визначати умови, які становлять інтерес для програм контролю. Інші інструменти надають розширені механізми, що дозволяють користувачам створювати свої власні програми перевірки на основі AST. Такий тип перевірки відносно просто проводити, і багато організацій створюють нові програми перевірки такого типу, щоб перевірити дотримання корпоративних стандартів написання коду або рекомендованих галузі кращих методів організації робіт.
Аналіз кодових шляхів
Розглянемо складніший приклад. Тепер замість пошуку випадків порушення стилю програмування ми хочемо перевірити, чи приведе спроба розіменування покажчика до правильної роботи або до збою:
If(x & 1) ptr = NULL; *ptr = 1;
Поверхневий розгляд фрагмента призводить до очевидного висновку, що змінна ptr може набувати значення NULL, якщо змінна x - непарна, і ця умова при розіменуванні неминуче призведе до звернення до нульової сторінки. Тим не менш, при створенні програми перевірки на основі AST знайти таку програмну помилку дуже проблематично. Розглянемо дерево AST (у спрощеному вигляді для ясності), яке було б створено для наведеного вище фрагмент коду:
Statement Block If-statement Check-Expression Binary-operator & x 1 Увага! не зможуть виявити в розумно узагальненій формі спробу (щонайменше, іноді неприпустиму) розіменування покажчика ptr. Відповідно, інструмент аналізу не може просто проводити пошук за синтаксичною моделлю. Необхідно також аналізувати життєвий цикл об'єктів даних у міру їх появи та використання усередині керуючої логіки у процесі виконання.
При аналізі кодових шляхів простежуються об'єкти всередині шляхів виконання, у результаті програми перевірки можуть визначити, наскільки чітко та коректно використовуються дані. Використання аналізу кодових шляхів розширює коло питань, куди можна отримати відповіді у процесі проведення статичного аналізу. Замість того щоб просто аналізувати правильність написання коду програми, при аналізі кодових шляхів робиться спроба визначити "намір" коду і перевірити, чи написаний код відповідно до цих намірів. При цьому можуть бути отримані відповіді на такі запитання:
- Чи не був новостворений об'єкт звільнений перш, ніж з області видимості були видалені всі посилання, що до нього звертаються?
- Чи проводилася для деякого об'єкта даних перевірка дозволеного діапазону значень, як об'єкт передається функції ОС?
- Чи перевірявся рядок символів на наявність у ньому спеціальних символів перед передачею цього рядка як SQL-запит?
- Чи не призведе операція копіювання до переповнення буфера?
- Чи безпечно зараз викликати цю функцію?
За допомогою подібного аналізу шляхів виконання коду, як у прямому напрямку від запуску події до цільового сценарію, так і у зворотному напрямку від запуску події до необхідної ініціалізації даних, інструментальний засіб зможе дати відповіді на поставлені запитання та видати звіт про помилки у випадку, якщо цільовий сценарій або ініціалізація виконуються або виконуються так, як очікується.
Реалізація такої можливості істотна виконання розширеного аналізу вихідного коду. Тому розробники повинні шукати інструменти, в яких використовується розширений аналіз кодових шляхів для виявлення витоків пам'яті, неправильного розіменування покажчиків, передачі небезпечних або неправильних даних, порушень паралелізму та інших умов, що призводять до виникнення проблем.
Послідовність дій під час виконання статичного аналізу
При статичному аналізі можуть бути виявлені проблеми у двох ключових точках процесу розробки: під час написання програми на робочому місці та на етапі системного компонування. Як мовилося раніше, поточне покоління інструментальних засобів працює, головним чином, на етапі системної компоновки, коли є можливість проаналізувати кодовий потік всієї системи загалом, що зумовлює дуже точним діагностичним результатам.
Унікальний продукт Klocwork Insight дозволяє проводити аналіз коду, створюваного на робочому місці конкретного розробника, при цьому уникати проблем, пов'язаних з неточністю діагностики, що зазвичай властиве інструментам подібного роду. Компанія Klocwork надає можливість проведення зв'язкового аналізу коду на робочому місці (Connected Desktop Analysis), коли виконується аналіз коду розробника з урахуванням розуміння всіх системних залежностей. Це призводить до проведення локального аналізу, який є такою ж мірою точним і потужним, як і централізований системний аналіз, але все це виконується до повного складання коду.
З погляду перспектив щодо послідовності дій при аналізі, дана здатність дозволяє розробнику провести точний та високоякісний статичний аналіз на ранньому етапі життєвого циклу розробки. Інструмент Klockwork Insight видає в інтегроване середовище розробника (IDE) або командний рядок повідомлення з усіх проблем у міру написання розробником коду та періодичного виконання ним операцій компіляції/компонування. Видача таких повідомлень та звітів відбувається до виконання динамічного аналізу та до того, як усі розробники зведуть свої коди докупи.
Рис. 2- послідовність виконання статичного аналізу.Технологія динамічного аналізу
Для виявлення програмних помилок в інструментах динамічного аналізу часто проводиться вставка невеликих фрагментів коду або безпосередньо у вихідний текст програми (вставка у вихідний код), або виконуваний код (вставка в об'єктний код). У таких кодових сегментах виконується "санітарна перевірка" стану програми та видається звіт про помилки, якщо виявляється щось некоректне чи непрацездатне. У таких інструментах можуть бути задіяні інші функції, наприклад, відстеження розподілу пам'яті та її використання в часі.
Технологія динамічного аналізу включає:
- Розміщення вставок у вихідний код на етапі препроцесорної обробки– у вихідний текст програми до початку компіляції вставляється спеціальний фрагмент коду виявлення помилок. При такому підході не потрібно детального знання середовища виконання, внаслідок чого такий метод користується популярністю серед інструментів тестування та аналізу систем, що вбудовуються. Як приклад такого інструменту можна навести продукт IBM Rational Test RealTime.
- Розміщення вставок в об'єктний код– для такого інструменту динамічного аналізу необхідно мати достатні знання щодо середовища виконання, щоб мати можливість вставляти код безпосередньо у виконувані файли та бібліотеки. При цьому підході не потрібно мати доступ до вихідного тексту програми або робити перекомпонування програми. Як приклад такого інструменту можна навести продукт IBM Rational Purify.
- Вставка коду під час компіляції- Розробник використовує спеціальні ключі (опції) компілятора для впровадження у вихідний код. Використовується здатність компілятора виявляти помилки. Наприклад, у компіляторі GNU C/C++ 4.x використовується технологія Mudflap для виявлення проблем, що стосуються операцій із покажчиками.
- Спеціалізовані бібліотеки етапу виконання– для виявлення помилок у параметрах, що передаються, розробник використовує налагоджувальні версії системних бібліотек. Поганою славою користуються функції типу strcpy() через можливість появи нульових або помилкових покажчиків під час виконання. У разі використання налагоджувальних версій бібліотек такі "погані" параметри виявляються. Ця технологія не вимагає перекомпонування програми та меншою мірою впливає на продуктивність, ніж повноцінне використання вставок у вихідний/об'єктний код. Ця технологія використовується в інструменті аналізу ОЗУ QNX® Momentics® IDE.
У цій статті ми розглянемо технології, що використовуються в інструментах розробника QNX Momentics, особливо звертаючи увагу на GCC Mudflap та спеціалізовані бібліотеки етапу виконання.
GNU C/C++ Mudflap: впровадження у вихідний код на етапі компіляції
В інструментальному засобі Mudflap, що є у версії 4.х компілятора GNU C/C++ (GCC), використовується впровадження у вихідний код під час компіляції. При цьому під час виконання відбувається перевірка конструкцій, що потенційно несуть можливість появи помилок. Основна увага в засобі Mudflap звертається на операції з покажчиками, оскільки є джерелом багатьох помилок на етапі виконання для програм, написаних мовами C і C++.
З підключенням засобу Mudflap у роботі компілятора GCC з'являється ще один прохід, коли вставляється код перевірки для операцій з покажчиками. Код, що вставляється, зазвичай виконує перевірку на достовірність значень вказівників. Неправильні значення покажчиків призведуть до видачі компілятором GCC повідомлень стандартний пристрій видачі помилок консолі (stderr). Засіб Mudflap для контролю за вказівниками не просто перевіряє вказівники на нульове значення: у його базі даних зберігаються адреси пам'яті для дійсних об'єктів та властивості об'єктів, наприклад, місцезнаходження у вихідному коді, мітка дати/часу, зворотне трасування стека при виділенні та звільненні пам'яті. Така база даних дозволяє швидко отримати необхідні дані під час аналізу операцій доступу до пам'яті у вихідному коді програми.
У бібліотечних функціях, подібних до strcpy(), не виконується перевірка параметрів, що передаються. Такі функції не перевіряються засобом Mudflap. Тим не менш, в Mudflap можна створити символьну оболонку (symbol wrapper) для статичних бібліотек, що підключаються, або вставку для динамічних бібліотек. За такої технології між програмою та бібліотекою створюється додатковий шар, що дає змогу провести перевірку достовірності параметрів та видати повідомлення про прояв відхилень. У засобі Mudflap використовується евристичний алгоритм, заснований на знанні меж пам'яті, що використовуються додатком (динамічна пам'ять, стек, сегменти коду та даних тощо), щоб визначити правильність значень вказівників, що повертаються.
Використовуючи ключі командного рядка компілятора GCC, розробник може підключити можливості Mudflap для вставки кодових фрагментів та управління поведінкою, наприклад, управління порушеннями (меж, значень), проведення додаткових перевірок та налаштувань, підключення евристичних методів та самодіагностики. Наприклад, комбінація ключів -fmudflap встановлює конфігурацію Mudflap за промовчанням. Повідомлення компілятора про виявлені засобом Mudflap порушення видаються на вихідну консоль (stderr) або командний рядок. У докладному висновку надається інформація про порушення та про задіяні при цьому змінні, функції, а також місцезнаходження коду. Ця інформація може автоматично імпортуватися в середовище IDE, де відбувається її візуалізація, і виконується трасування стека. Користуючись цими даними, розробник може швидко перейти до місця вихідного коду програми.
На рис. 3 показаний приклад представлення помилки в середовищі IDE разом з відповідною інформацією щодо зворотного трасування. Зворотне трасування працює як сполучна ланка з вихідним кодом, що дозволяє розробнику швидко діагностувати причину проблеми.
При використанні засобу Mudflap може зрости час на компонування і може зменшитися продуктивність під час виконання. Дані, представлені у статті “Mudflap: Pointer Use Checking for C/C++” ("Засіб Mudflap: перевірка використання покажчиків для мов C/C++") свідчать, що з підключенням Mudflap час компонування зростає в 3...5 разів, а програма починає працювати повільніше в 1.25 … 5 разів.. Зовсім ясно, що розробники критичних за часом виконання додатків повинні користуватися цим засобом з обережністю, проте Mudflap є потужним засобом для виявлення схильних до помилок і потенційно фатальних кодових конструкцій. майбутні версії своїх інструментів динамічного аналізу.

Рис. 3- Використання інформації зворотного трасування, що відображається в середовищі QNX Momentics IDE для пошуку вихідного коду, що спричинив помилку.
Налагоджувальні версії бібліотек етапу виконання
Поряд із використанням спеціальних налагоджувальних вставок у бібліотеки етапу виконання, які призводять до значних додаткових витрат пам'яті та часу на етапах компонування та виконання, розробники можуть використовувати попередньо підготовлені (pre-instrumented) бібліотеки етапу виконання. У таких бібліотеках навколо функціональних викликів додається певний код, мета якого полягає у перевірці достовірності вхідних параметрів. Наприклад, розглянемо стару знайому – функцію копіювання рядків:
strcpy(a,b);
У ній беруть участь два параметри, які є вказівниками на тип char: один для вихідного рядка ( b), а інший для рядка-результату ( a). Незважаючи на таку простоту, ця функція може бути джерелом багатьох помилок:
- якщо значення вказівника aодно нулю або є недійсним, то копіювання на цю адресу призначення призведе до помилки заборони доступу до пам'яті;
- якщо значення вказівника bдорівнює нулю або є недійсним, читання інформації з цієї адреси призведе до помилки заборони доступу до пам'яті;
- якщо в кінці рядка bпропущено завершальний рядок символ "0", то в рядок призначення буде скопійовано більше символів, ніж очікується;
- якщо розмір рядка bбільше розміру пам'яті, виділеного під рядок a, то вказаною адресою буде записано більше байт, ніж передбачалося (типовий сценарій переповнення буфера).
У версії налагодження бібліотеки проводиться перевірка значень параметрів ‘ a' і ' b’. Перевіряються також довжини рядків, щоб переконатися у сумісності. Якщо виявляється недійсний параметр, видається відповідне аварійне повідомлення. У QNX Momentics дані повідомлення про помилки імпортуються з цільової системи та відображаються на екрані. У середовищі QNX Momentics використовується також технологія стеженнями за випадками виділення та звільнення пам'яті, що дозволяє виконувати глибокий аналіз використання ОЗУ.
Налагоджувальна версія бібліотеки працюватиме з будь-яким додатком, у якому використовуються її функції; не потрібно вносити жодних додаткових змін до коду. Більше того, розробник може додати бібліотеку під час запуску програми. Тоді бібліотека замінить відповідні частини повної стандартної бібліотеки, усуваючи необхідність використовувати версію налагодження повної бібліотеки. У QNX Momentics IDE розробник може додати таку бібліотеку під час запуску програми як елемент нормального інтерактивного сеансу налагодження. На рис. 4 показаний приклад того, як у середовищі QNX Momentics відбувається виявлення та видача повідомлень про помилки роботи з пам'яттю.
У налагоджувальній версії бібліотек надається перевірений "неагресивний" метод виявлення помилок при викликах бібліотечних функцій. Така технологія ідеальна для аналізу ОЗУ та інших методів аналізу, які залежать від узгоджених пар викликів, наприклад, malloc() і free(). Іншими словами, дана технологія може виявляти помилки на етапі виконання лише для кодів із бібліотечними викликами. При цьому не виявляється багато типових помилок, таких як вбудований код розіменування посилання (inline pointer dereferences) або некоректні арифметичні операції з покажчиками. Зазвичай при налагодженні здійснюється контроль лише деякої підмножини системних викликів. Докладніше з цим можна ознайомитись у статті.

Рис. 4- Аналіз ОЗУ відбувається шляхом розташування пасток в області викликів API, пов'язаних із зверненням до пам'яті.
Послідовність дій за динамічного аналізу
Якщо говорити коротко, то динамічний аналіз включає захоплення подій про порушення або інші значні події у цільовій системі, що вбудовується, імпорт цієї інформації в середу розробки, після чого використовуються засоби візуалізації для швидкої ідентифікації що містять помилку ділянок коду.
Як показано на рис. 5, динамічний аналіз не тільки дозволяє виявити помилки, але й допомагає звернути увагу розробника на подробиці пам'яті, циклів ЦПУ, дискового простору та інших ресурсів. Процес аналізу складається з декількох кроків, і хороший інструмент динамічного аналізу надає надійну підтримку кожного кроку:
- Спостереження– насамперед, відбувається захоплення помилок середовища виконання, виявлення місць витоку пам'яті та відображення всіх результатів у середовищі IDE.
- Коригування– далі розробник має можливість провести трасування кожної помилки назад до рядка вихідного тексту, що порушує роботу. При хорошій інтеграції в середу IDE, кожна помилка буде відображатися на екрані. Розробнику потрібно просто клацнути мишею на рядку помилки, і відкриється фрагмент вихідного коду з рядком, який порушує роботу. У багатьох випадках розробник може швидко усунути проблему, використовуючи доступне трасування стека та додаткові інструменти роботи з вихідним кодом у середовищі IDE (засоби перегляду функцій дзвінків, засоби трасування дзвінків тощо).
- Профілювання– усунувши виявлені помилки та витоку пам'яті, розробник може проаналізувати використання ресурсів у часі, включаючи пікові ситуації, середнє завантаження та надмірне витрачання ресурсів. В ідеальному випадку інструмент аналізу видасть візуальне уявлення довгострокового використання ресурсів, дозволяючи негайно ідентифікувати сплески у розподілі пам'яті та інші аномалії.
- Оптимізація- Використовуючи інформацію етапу профілювання, розробник може тепер провести "тонкий" аналіз використання ресурсів програмою. Серед іншого, подібна оптимізація може мінімізувати випадки пікового використання ресурсів та їх надмірне витрачання, включаючи роботу з ОЗУ та використання часу ЦПУ.

Рис. 5- Типова послідовність дій під час динамічного аналізу
Комбінування послідовності дій різних видів аналізу серед розробки
Кожен із інструментів статичного та динамічного аналізу має свої сильні сторони. Відповідно команди розробників повинні використовувати ці інструменти в тандемі. Наприклад, інструменти статичного аналізу здатні виявляти помилки, що пропускаються інструментами динамічного аналізу, тому що інструменти динамічного аналізу фіксують помилку лише у випадку, якщо під час тестування помилковий фрагмент коду виконується. З іншого боку, інструменти динамічного аналізу виявляють програмні помилки кінцевого процесу. Навряд чи потрібно влаштовувати дискусію щодо помилки, якщо вже виявлено використання покажчика з нульовим значенням.
В ідеальному випадку розробник у щоденній роботі використовуватиме обидва інструменти аналізу. Завдання значно полегшується, якщо інструменти добре інтегровані в середу розробки на робочому місці.
Ось який можна запропонувати приклад спільного використання двох видів інструментів:
- На початку робочого дня розробник переглядає звіт про результати нічного компонування. До цього звіту включаються як помилки компонування, так і результати статичного аналізу, проведеного під час компонування.
- У звіті статистичного аналізу наводяться виявлені дефекти поряд з інформацією, яка допоможе в їх усуненні, у тому числі посилання на вихідний код. Використовуючи середовище IDE, розробник може помітити кожну ситуацію або як знайдену помилку, або як "хибне спрацьовування". Після цього провадиться виправлення фактично присутніх помилок.
- Розробник локально, всередині IDE, зберігає внесені зміни разом з будь-якими новими фрагментами коду. Розробник не передає ці зміни назад до системи керування вихідними текстами доти, доки зміни не будуть проаналізовані та протестовані.
- Розробник аналізує та коригує новий код, використовуючи інструмент статичного аналізу на локальному робочому місці. Для того щоб бути впевненим у якісному виявленні помилок та відсутності "хибних спрацьовувань", в аналізі використовується розширена інформація на рівні системи. Ця інформація береться з даних виконаного вночі процес компонування/аналізу.
- Після аналізу та "чистки" будь-якого нового коду розробник вбудовує код у локальний тестовий образ або файл, що виконується.
- Використовуючи інструменти динамічного аналізу, розробник запускає тести для перевірки змін.
- За допомогою середовища IDE розробник може швидко виявити та виправити помилки, про які повідомляється через інструменти динамічного аналізу. Код вважається остаточним та готовим до використання, коли він пройшов через статичний аналіз, блочне тестування та динамічний аналіз.
- Розробник передає зміни до системи управління вихідними текстами; після цього змінений код бере участь у процесі наступного нічного компонування.
Подібна послідовність дій схожа на застосовувану у проектах середнього та великого розмірів, де вже використовуються нічні компонування, система управління вихідними кодами та персональна відповідальність за коди. Оскільки інструменти інтегровані у середовище IDE, розробники швидко виконують статичний та динамічний аналіз, не відхиляючись від типової послідовності дій. В результаті якість коду суттєво зростає вже на етапі створення вихідних текстів.
Роль архітектури ОСРВ
У рамках дискусії про інструменти статичного та динамічного аналізу згадка про архітектуру ОСРВ може здатися недоречною. Але виявляється, що правильно побудована ОСРВ може значно полегшити виявлення, локалізацію та вирішення багатьох програмних помилок.
Наприклад, у мікроядерній ОСРВ типу QNX Neutrino всі додатки, драйвери пристроїв, файлові системи та мережеві стеки розташовуються за межами ядра в окремих адресних просторах. У результаті вони виявляються ізольованими від ядра і друг від друга. Такий підхід забезпечує найвищий рівень локалізації збоїв: відмова одного з компонентів не призводить до краху системи в цілому. Більш того, виявляється, що можна легко локалізувати помилку, пов'язану з ОЗУ, або іншу логічну помилку з точністю до компонента, який викликав цю помилку.
Наприклад, якщо драйвер пристрою робить спробу доступу до пам'яті за межами свого контейнера процесу, то ОС може ідентифікувати такий процес, вказати місце помилки та створити дамп-файл, який можна переглянути засобами налагодження вихідного коду. У той же час решта системи продовжить свою роботу, а розробник може локалізувати проблему і зайнятися її усуненням.

Рис. 6- У мікроядерній ОС збої в ОЗУ для драйверів, стеків протоколів та інших служб не призведуть до порушення роботи інших процесів чи ядра. Більш того, ОС може миттєво виявити невирішену спробу доступу до пам'яті та вказати, з боку якого коду ця спроба.
Порівняно із звичайним ядром ОС мікроядру властиво надзвичайно малий середній час відновлення після збою (Mean Time to Repair, MTTR). Розглянемо, що відбувається при збої в роботі драйвера пристрою: ОС може завершити роботу драйвера, відновити ресурси, що використовуються драйвером, і перезапустити драйвер. Зазвичай на це йде кілька мілісекунд. У звичайній монолітній операційній системі пристрій має бути перезавантажено – цей процес може тривати від кількох секунд до кількох хвилин.
Заключні зауваження
Інструменти статичного аналізу можуть виявляти програмні помилки ще до того, як код запускається виконання. Виявляються навіть ті помилки, які виявляються не виявленими на етапах тестування блоку, системи, а також на етапі інтеграції, тому що забезпечити повне покриття коду для складних програм виявляється дуже важко, і це потребує значних витрат. Крім того, команди розробників можуть використовувати інструменти статичного аналізу під час регулярних компоновок системи, щоб бути впевненим у тому, що проаналізовано кожну ділянку нового коду.
Тим часом інструменти динамічного аналізу підтримують етапи інтеграції та тестування, повідомляючи в середу розробки про помилки (або потенційні проблеми), що виникають при виконанні програми. Ці інструменти надають також повну інформацію щодо зворотного трасування до місця виникнення помилки. Використовуючи цю інформацію, розробники можуть виконати "посмертне" налагодження таємничої відмови програми або краху системи за значно менший інтервал часу. При динамічному аналізі через трасування стека та змінних можуть бути виявлені основні причини проблеми – ця краще, ніж використовувати оператори “if (ptr != NULL)” для запобігання та обходу аварійних ситуацій.
Використання раннього виявлення, кращого та повного тестового покриття коду спільно з корекцією помилок допомагає розробникам створювати програмне забезпечення кращої якості та у більш короткі терміни.
Бібліографія
- Eigler, Frank Ch., “Mudflap: Pointer Use Checking for C/C++”, Proceedings of the GCC Developers Summit 2003, pg. 57-70. http://www.linux.org.uk/~ajh/gcc/gccsummit-2003-proceedings.pdf
- “Heap Analysis: Making Memory Errors Thing of the Past”, QNX Neutrino RTOS Programmer's Guide. http://pegasus.ott.qnx.com/download/download/16853/neutrino_prog.pdf
Про компанію QNX Software Systems
QNX Software Systems є однією з дочірніх компаній Harman International і провідним глобальним постачальником інноваційних технологій для систем, що вбудовуються, включаючи сполучне ПЗ, інструментальні засоби розробки та операційні системи. ОСРВ QNX® Neutrino®, комплект розробника QNX Momentics® і сполучне програмне забезпечення QNX Aviage®, засновані на модульній архітектурі, утворюють найнадійніший і масштабований програмний комплекс для створення високопродуктивних вбудованих систем. Глобальні компанії-лідери, такі як Cisco, Daimler, General Electric, Lockheed Martin і Siemens, широко використовують технології QNX у мережевих маршрутизаторах, медичній апаратурі, телематичних блоках автомобілів, системах безпеки та захисту, у промислових роботах та інших додатках для відповідальних та критично важливих задач. Головний офіс компанії знаходиться в м. Оттава (Канада), а дистриб'ютори продукції розташовані у більш ніж 100 країнах світу.
Про компанію Klocwork
Продукти Klocwork призначені для автоматизованого аналізу статичного коду, виявлення та запобігання дефектам програмного забезпечення та проблем безпеки. Наша продукція надає колективам розробників інструментарій для виявлення корінних причин недоліків якості та безпеки програмного забезпечення, для відстеження та запобігання цим недолікам протягом усього процесу розробки. Запатентована технологія компанії Klocwork була створена в 1996 р. і забезпечила високий коефіцієнт окупності інвестицій (ROI) для більш ніж 80 клієнтів, багато з яких входять до рейтингу найбільших 500 компаній журналу Fortune і пропонують середовище розробки програмного забезпечення, яке має найбільший попит у світі. Klocwork є приватною компанією та має офіси в Берлінгтоні, Сан Хосе, Чикаго, Далласі (США) та Оттаві (Канада).
Аналіз бінарного коду, тобто коду, який виконується безпосередньо машиною – нетривіальне завдання. Найчастіше, якщо треба проаналізувати бінарний код, його відновлюють спочатку у вигляді дизассемблирования, та був декомпіляції у деяке високорівневе уявлення, а далі вже аналізують те, що вийшло.
Тут треба сказати, що код, який відновили, за текстовим уявленням має мало спільного з тим кодом, який спочатку написаний програмістом і скомпільований у виконуваний файл. Відновити точно бінарний файл, отриманий від мов програмування типу C/C++, Fortran, не можна, оскільки це алгоритмічно неформалізоване завдання. У процесі перетворення вихідного коду, який написав програміст, програму, яку виконує машина, компілятор виконує незворотні перетворення.
У 90-ті роки минулого століття було поширене судження про те, що компілятор як м'ясорубка перемелює вихідну програму, і завдання відновити її схоже на завдання відновлення барана з сосиски.
Проте не так усе погано. У процесі отримання сосиски баран втрачає свою функціональність, тоді як бінарна програма її зберігає. Якби отримана в результаті сосиска могла бігати і стрибати, завдання були б схожі.
Отже, якщо бінарна програма зберегла свою функціональність, можна говорити, що є можливість відновити код, що виконується, у високорівневе уявлення так, щоб функціональність бінарної програми, вихідного представлення якої немає, і програми, текстове уявлення якої ми отримали, були еквівалентними.
За визначенням дві програми функціонально еквівалентні, якщо на тих самих вхідних даних обидві завершують або не завершують своє виконання і, якщо виконання завершується, видають однаковий результат.
Завдання дизассемблирования зазвичай вирішується у напівавтоматичному режимі, тобто фахівець робить відновлення вручну з допомогою інтерактивних інструментів, наприклад, інтерактивним дизассемблером IdaPro , radare чи іншим інструментом. Далі також у напівавтоматичному режимі виконується декомпіляція. Як інструментальний засіб декомпіляції на допомогу спеціалісту використовують HexRays, SmartDecompiler або інший декомпілятор, який підходить для вирішення цієї задачі декомпіляції.
Відновлення вихідного текстового представлення програми з byte-коду можна зробити досить точним. Для мов, що інтерпретуються типу Java або мов сімейства.NET, трансляція яких виконується в byte-код, завдання декомпіляції вирішується по-іншому. Це питання ми у цій статті не розглядаємо.
Отже, аналізувати бінарні програми можна за допомогою декомпіляції. Зазвичай такий аналіз виконують, щоб розібратися у поведінці програми з її заміни чи модифікації.
З практики роботи з успадкованими програмами
Деяке програмне забезпечення, написане 40 років тому на сімействі низькорівневих мов С та Fortran, керує обладнанням з видобутку нафти. Збій цього обладнання може бути критичним для виробництва, тому змінювати програмне забезпечення вкрай небажано. Проте за давністю років вихідні коди було втрачено.Новий співробітник відділу інформаційної безпеки, в обов'язки якого входило розуміти, як працює, виявив, що програма контролю датчиків з деякою регулярністю щось пише на диск, а що пише і як цю інформацію можна використовувати, незрозуміло. Також у нього виникла ідея, що моніторинг роботи обладнання можна вивести на великий екран. Для цього треба було розібратися, як працює програма, що й у якому форматі вона пише на диск, як цю інформацію можна інтерпретувати.
Для вирішення завдання було застосовано технологію декомпіляції з подальшим аналізом відновленого коду. Ми спочатку дизассемблювали програмні компоненти по одному, далі зробили локалізацію коду, який відповідав за введення-виведення інформації, і стали поступово від цього коду виконувати відновлення з огляду на залежності. Потім була відновлена логіка роботи програми, що дозволило відповісти на всі питання безпеки щодо аналізованого програмного забезпечення.
Якщо потрібен аналіз бінарної програми з метою відновлення логіки її роботи, часткового або повного відновлення логіки перетворення вхідних даних у вихідні, зручно робити це за допомогою декомпілятора.
Крім таких завдань, практично зустрічаються завдання аналізу бінарних програм з вимогам інформаційної безпеки. При цьому замовник не завжди має розуміння, що цей аналіз дуже трудомісткий. Здавалося б, зроби декомпіляцію і прожени код статичним аналізатором, що вийшов. Але в результаті якісного аналізу практично ніколи не вдасться.
По-перше, знайдені вразливості треба вміти як знаходити, а й пояснювати. Якщо вразливість була знайдена у програмі мовою високого рівня, аналітик чи інструментальний засіб аналізу коду показують у ній, які фрагменти коду містять ті чи інші недоліки, наявність яких спричинила появу вразливості. Що робити, якщо вихідного коду немає? Як показати, який код спричинив появу вразливості?
Декомпілятор відновлює код, який "засмічений" артефактами відновлення, і робити відображення виявленої вразливості на такий код марно, все одно нічого не зрозуміло. Понад те, відновлений код погано структурований і тому погано піддається інструментальним засобам аналізу коду. Пояснювати вразливість у термінах бінарної програми теж складно, адже той, для кого робиться пояснення, має добре розумітися на бінарному представленні програм.
По-друге, бінарний аналіз за вимогами ІБ треба проводити з розумінням, що робити з результатом, тому що поправити вразливість у бінарному коді дуже складно, а вихідного коду немає.
Незважаючи на всі особливості та складності проведення статичного аналізу бінарних програм за вимогами ІБ, ситуацій, коли такий аналіз потрібно виконувати, багато. Якщо вихідного коду з якихось причин немає, а бінарна програма виконує функціонал, критичний на вимоги ІБ, її треба перевіряти. Якщо вразливості виявлено, таку програму треба оправляти на доопрацювання, якщо це можливо, або робити для нього додаткову «оболонку», яка дозволить контролювати рух чутливої інформації.
Коли вразливість сховалась у бінарному файлі
Якщо код, який виконує програма, має високий рівень критичності, навіть за наявності вихідного тексту програми мовою високого рівня, корисно зробити аудит бінарного файлу. Це допоможе виключити особливості, які може привнести компілятор, оптимізуючи перетворення. Так, у вересні 2017 року широко обговорювалися оптимізаційне перетворення, виконане компілятором Clang. Його результатом став виклик функції, яка ніколи не повинна викликатись.#include
В результаті оптимізаційних перетворень компілятором буде отримано такий асемблерний код. Приклад скомпілювали під ОС Linux X86 з прапором -O2.
Text .globl NeverCalled .align 16, 0x90 .type NeverCalled,@function NeverCalled: # @NeverCalled retl .Lfunc_end0: .size NeverCalled, .Lfunc_end0-NeverCalled .globl main. main subl $12, %esp movl $.L.str, (%esp) call system addl $12, %esp retl .Lfunc_end1: .size main, .Lfunc_end1-main .type .L.str,@object # @.str . section .rodata.str1.1,"aMS",@progbits,1 .L.str: .asciz "rm -rf /" .size .L.str, 9
У вихідному коді є undefined behavior. Функція NeverCalled() викликається через оптимізаційні перетворення, які виконує компілятор. У процесі оптимізації він швидше за все виконує аналіз аліасу, і в результаті функція Do() отримує адресу функції NeverCalled(). Оскільки в методі main() викликається функція Do(), яка визначена, що є невизначене стандартом поведінка (undefined behavior), виходить такий результат: викликається функція EraseAll(), яка виконує команду «rm -rf /».
Наступний приклад: в результаті оптимізаційних перетворень компілятора ми втратили перевірку покажчика на NULL перед його розйменуванням.
#include
Оскільки в рядку 3 виконується розименування покажчика, компілятор припускає, що покажчик ненульовий. Далі рядок 4 була видалена в результаті виконання оптимізації «видалення недосяжного коду», так як порівняння вважається надлишковим, а після рядок 3 була видалена компілятором в результаті оптимізації «видалення мертвого коду» (dead code elimination). Залишається лише рядок 5. Асемблерний код, отриманий в результаті компіляції gcc 7.3 під ОС Linux x86 з прапором -O2, наведено нижче.
Text .p2align 4,15 .globl _Z7CheckerPi .type _Z7CheckerPi, @function _Z7CheckerPi: movl 4(%esp), %eax movl $8, (%eax) ret
Наведені вище приклади роботи оптимізації компілятора – результат наявності коду undefined behavior UB. Однак це цілком нормальний код, який більшість програмістів сприймуть за безпечний. Сьогодні програмісти приділяють час виключенню невизначеної поведінки у програмі, тоді як ще 10 років тому не звертали на це уваги. В результаті успадкований код може містити вразливість, пов'язану з наявністю UB.
Більшість сучасних статичних аналізаторів вихідного коду не виявляють помилок, пов'язаних з UB. Отже, якщо код виконує критичний за вимогами інформаційної безпеки функціонал, треба перевіряти його вихідники, і безпосередньо той код, який виконуватиметься.
Анотація
В даний час розроблено велику кількість інструментальних засобів, призначених для автоматизації пошуку вразливостей програм. У цій статті будуть розглянуті деякі з них.
Вступ
Статичний аналіз коду - це аналіз програмного забезпечення, який проводиться над вихідним кодом програм і реалізується без виконання досліджуваної програми.
Програмне забезпечення часто містить різноманітні вразливості через помилки у коді програм. Помилки, допущені розробки програм, у деяких ситуаціях призводять до збою програми, отже, порушується нормальна робота програми: у своїй часто виникає зміна і псування даних, зупинення програми і навіть системи. Більшість уразливостей пов'язані з неправильною обробкою даних, одержуваних ззовні, чи недостатньо суворе їх перевіркою.
Для виявлення вразливостей використовують різні інструментальні засоби, наприклад статичні аналізатори вихідного коду програми, огляд яких наведено в даній статті.
Класифікація вразливостей захисту
Коли вимога коректної роботи програми всіх можливих вхідних даних порушується, стає можливим поява про вразливостей захисту (security vulnerability). Вразливість захисту може призвести до того, що одна програма може використовуватися для подолання обмежень захисту всієї системи в цілому.
Класифікація вразливостей захисту залежно від програмних помилок:
- Переповнення буфера (buffer overflow). Ця вразливість виникає через відсутність контролю над виходом межі масиву у пам'яті під час виконання програми. Коли надто великий пакет даних переповнює буфер обмеженого розміру, вміст сторонніх осередків пам'яті перезаписується, і відбувається збій та аварійний вихід із програми. За місцем розташування буфера в пам'яті процесу розрізняють переповнення буфера в стеку (stack buffer overflow), купі (heap buffer overflow) та області статичних даних (bss buffer overflow).
- Вразливості (tainted input vulnerability). Вразливості можуть виникати у випадках, коли дані, що вводяться користувачем, без достатнього контролю передаються інтерпретатору деякої зовнішньої мови (зазвичай це мова Unix shell або SQL). У цьому випадку користувач може таким чином задати вхідні дані, що запущений інтерпретатор виконає зовсім не ту команду, яку передбачали автори вразливої програми.
- Помилки форматних рядків (format string vulnerability). Цей тип уразливостей захисту є підкласом уразливості. Він виникає через недостатній контроль параметрів при використанні функцій форматного введення-виводу printf, fprintf, scanf і т. д. стандартної бібліотеки мови Сі. Ці функції приймають як один із параметрів символьний рядок, що задає формат введення або виведення наступних аргументів функції. Якщо користувач може задати вид форматування, то ця вразливість може виникнути в результаті невдалого застосування функцій форматування рядків.
- Вразливість як наслідок помилок синхронізації (race conditions). Проблеми, пов'язані з багатозадачністю, призводять до ситуацій, званим: програма, не розрахована виконання у багатозадачному середовищі, вважатимуться, що, наприклад, використовувані нею під час роботи файли неспроможна змінити інша програма. Як наслідок, зловмисник, який вчасно підміняє вміст цих робочих файлів, може нав'язати програмі виконання певних дій.
Звичайно, крім перерахованих, існують і інші класи вразливостей захисту.
Огляд існуючих аналізаторів
Для виявлення вразливостей захисту у програмах застосовують такі інструментальні засоби:
- Динамічні налагоджувачі. Інструменти, які дозволяють проводити налагодження програми в процесі виконання.
- Статичні аналізатори (статичні налагоджувачі). Інструменти, які використовують інформацію, накопичену під час статичного аналізу програми.
Статичні аналізатори вказують на ті місця в програмі, в яких може бути помилка. Ці підозрілі фрагменти коду можуть як містити помилку, так і виявитися абсолютно безпечними.
У цій статті запропоновано огляд кількох статичних аналізаторів. Розглянемо докладніше кожен із них.
1. BOON
Інструмент , який з урахуванням глибокого семантичного аналізу автоматизує процес сканування вихідних текстів на Сі у пошуках вразливих місць, здатних призводити до переповнення буфера. Він виявляє можливі дефекти, припускаючи, деякі значення є частиною неявного типу з конкретним розміром буфера.
2. CQual
Інструмент аналізу для виявлення помилок у Сі-програмах. Програма розширює мову Сі додатковими специфікаторами типу, що визначаються користувачем. Програміст коментує свою програму з відповідними специфікаторами і cqual перевіряє помилки. Неправильні інструкції вказують на потенційні помилки. Сqual може використовуватися, щоб виявити потенційну вразливість форматного рядка.
3. MOPS
(MOdel checking Programs for Security) - інструмент пошуку вразливостей у захисті програм на Сі. Його призначення: динамічне коригування, що забезпечує відповідність програми на си статичної моделі. MOPS використовує модель аудиту програмного забезпечення, яка покликана допомогти з'ясувати, чи програма відповідає набору правил, визначеному для створення безпечних програм.
4. ITS4, RATS, PScan, Flawfinder
Для пошуку помилок переповнення буфера та помилок форматних рядків використовують такі статичні аналізатори:
- . Простий інструмент, який статично переглядає вихідний Сі/Сі++ код для виявлення потенційних вразливостей захисту. Він наголошує на викликах потенційно небезпечних функцій, таких, наприклад, як strcpy/memcpy, і виконує поверхневий семантичний аналіз, намагаючись оцінити, наскільки небезпечний такий код, а також дає поради щодо його поліпшення.
- . Утиліта RATS (Rough Auditing Tool for Security) обробляє код, написаний на Сі/Сі++, також може обробити ще й скрипти на Perl, PHP і Python. RATS переглядає вихідний текст, знаходячи потенційно небезпечні звернення до функцій. Мета цього інструменту - не знайти помилки, а забезпечити обґрунтовані висновки, спираючись на які фахівець зможе вручну виконувати перевірку коду. RATS використовує поєднання перевірок надійності захисту від семантичних перевірок ITS4 до глибокого семантичного аналізу в пошуках дефектів, здатних призвести до переповнення буфера, отриманих з MOPS.
- . Сканує вихідні тексти на Сі у пошуках потенційно некоректного використання функцій, аналогічних printf, та виявляє вразливі місця у рядках формату.
- . Як і RATS, це статичний сканер вихідних текстів програм, написаних Сі/Сі++. Виконує пошук функцій, які найчастіше використовуються некоректно, привласнює їм коефіцієнти ризику (спираючись на таку інформацію, як параметри, що передаються) і складає список потенційно вразливих місць, впорядковуючи їх за ступенем ризику.
Всі ці інструменти схожі і використовують лише лексичний та найпростіший синтаксичний аналіз. Тому результати, видані цими програмами, можуть містити до 100% неправдивих повідомлень.
5. Bunch
Засіб аналізу та візуалізації програм на Сі, яке будує граф залежностей, що допомагає аудитору розібратися у модульній структурі програми.
6. UNO
Простий аналізатор вихідного коду. Він був розроблений для знаходження таких помилок, як неініціалізовані змінні, нульові покажчики та вихід за межі масиву. UNO дозволяє виконувати нескладний аналіз потоку керування та потоків даних, здійснювати як внутрішньо-, так і міжпроцедурний аналіз, специфікувати властивості користувача. Але цей інструмент не доопрацьований для аналізу реальних додатків, не підтримує багато стандартних бібліотек і на даному етапі розробки не дозволяє аналізувати якісь серйозні програми.
7. FlexeLint (PC-Lint)
Цей аналізатор призначений для аналізу вихідного коду для виявлення помилок різного типу. Програма проводить семантичний аналіз вихідного коду, аналіз потоків даних та управління.
Наприкінці роботи видаються повідомлення кількох основних типів:
- Можливий нульовий покажчик;
- Проблеми із виділенням пам'яті (наприклад, немає free() після malloc());
- Проблемний потік управління (наприклад, недосяжний код);
- Можливе переповнення буфера, арифметичне переповнення;
- Попередження про поганий і потенційно небезпечний стиль коду.
8. Viva64
Інструмент , який допомагає фахівцеві відстежувати у вихідному коді Сі/Сі++-програм потенційно небезпечні фрагменти, пов'язані з переходом від 32-бітних систем до 64-бітних. Viva64 вбудовується в середу Microsoft Visual Studio 2005/2008, що сприяє зручній роботі з цим інструментом. Аналізатор допомагає писати коректний та оптимізований код для 64-бітних систем.
9. Parasoft C++ Test
Спеціалізований інструмент для Windows, що дозволяє автоматизувати аналіз якості коду C++. Пакет C++Test аналізує проект і генерує код, призначений для перевірки компонентів, що містяться в проекті. Пакет C++Test робить дуже важливу роботу з аналізу класів C++. Після того, як проект завантажений, необхідно налаштувати методи тестування. Програмне забезпечення вивчає кожен аргумент методу та повертає типи відповідних значень. Для цих простих типів підставляються значення аргументів за замовчуванням; можна визначити тестові дані для певних користувачем типів та класів. Можна перевизначити аргументи C++Test, які використовуються за замовчуванням, і видати значення, отримані в результаті тестування. На особливу увагу заслуговує здатність C++Test тестувати незавершений код. Програмне забезпечення генерує код-заглушку для будь-якого методу та функції, які ще не існують. Підтримується імітація зовнішніх пристроїв та вхідних даних, що задаються користувачем. І та й інша функція допускають можливість повторного тестування. Після визначення тестових параметрів всім методів пакет C++Test готовий до запуску виконуваного коду. Пакет генерує тестовий код, викликаючи для підготовки компілятор Visual C++. Можливе формування тестів лише на рівні методу, класу, файлу та проекту.
10. Coverity
Інструменти використовуються для виявлення та виправлення дефектів безпеки та якості у програмах критичного призначення. Технологія компанії Coverity усуває бар'єри у написанні та впровадженні складного ПЗ за допомогою автоматизації пошуку та усунення критичних програмних помилок та недоліків безпеки під час процесу розробки. Інструмент компанії Coverity здатний з мінімальною позитивною похибкою обробляти десятки мільйонів рядків коду, забезпечуючи 100% покриття траси.
11. KlocWork K7
Продукти компанії призначені для автоматизованого статичного аналізу коду, виявлення та запобігання дефектам програмного забезпечення та проблем безпеки. Інструменти цієї компанії служать для виявлення корінних причин недоліків якості та безпеки програмного забезпечення, для відстеження та запобігання цим недолікам протягом усього процесу розробки.
12. Frama-C
Відкритий інтегрований набір інструментів для аналізу вихідного коду мовою Сі. Набір включає ACSL (ANSI/ISO C Specification Language) - спеціальну мову, що дозволяє докладно описувати специфікації функцій Сі, наприклад, вказати діапазон допустимих вхідних значень функції та діапазон нормальних вихідних значень.
Цей інструментарій допомагає робити такі дії:
- Здійснювати формальну перевірку коду;
- Шукати потенційні помилки виконання;
- Здійснити аудит або рецензування коду;
- Проводити реверс-інжиніринг коду для покращення розуміння структури;
- Генерувати формальну документацію.
13. CodeSurfer
Інструмент аналізу програм, який не призначається безпосередньо для пошуку помилок уразливості захисту. Його основними перевагами є:
- Аналіз покажчиків;
- Різні аналізи потоку даних (використання та визначення змінних, залежність даних, побудова графа викликів);
- Скриптова мова.
CodeSurfer може бути використаний для пошуку помилок у вихідному коді, для покращення розуміння вихідного коду, та для реінженерії програм. В рамках середовища CodeSurfer велася розробка прототипу інструментального засобу виявлення вразливостей захисту, проте розроблений інструментальний засіб використовується тільки всередині організації розробників.
14. FxCop
Надає засоби автоматичної перевірки.NET-складання на відповідність правилам Microsoft .NET Framework Design Guidelines. Відкомпільований код перевіряється за допомогою механізмів рефлексії, парсингу MSIL та аналізу графа викликів. В результаті FxCop здатний виявити понад 200 недоліків (або помилок) у таких областях:
- Архітектура бібліотеки;
- Локалізація;
- Правила іменування;
- продуктивність;
- Безпека.
FxCop передбачає можливість створення своїх правил за допомогою спеціального SDK. FxCop може працювати як у графічному інтерфейсі, так і в командному рядку.
15. JavaChecker
Це статичний аналізатор Java програм, що базується на технології TermWare.
Цей засіб дозволяє виявляти дефекти коду, такі як:
- недбала обробка винятків (порожні catch-блоки, генерування винятків загального виду тощо);
- приховування імен (наприклад, коли ім'я члена класу збігається з ім'ям формального параметра методу);
- порушення стилю (ви можете задавати стиль програмування за допомогою набору регулярних виразів);
- порушення стандартних контрактів використання (наприклад, коли перевизначено метод equals, але не hashCode);
- порушення синхронізації (наприклад, коли доступ до синхронізованої змінної знаходиться поза synchronized блоком).
Набором перевірок можна керувати за допомогою керуючих коментарів.
Виклик JavaChecker можна здійснювати з скрипту ANT.
16. Simian
Аналізатор подібності, який шукає синтаксис, що повторюється, в декількох файлах одночасно. Програма розуміє синтаксис різних мов програмування, включаючи C#, T-SQL, JavaScript і Visual BasicR, а також може шукати фрагменти, що повторюються, в текстових файлах. Багато можливостей налаштування дозволяє точно настроювати правила пошуку коду, що дублюється. Наприклад, параметр порога (threshold) визначає, яку кількість рядків коду, що повторюються, вважати дублікатом.
Simian – це невеликий інструмент, розроблений для ефективного пошуку повторень коду. У нього немає графічного інтерфейсу, але його можна запустити з командного рядка або звернутися до нього програмно. Результати виводяться в текстовому вигляді та можуть бути представлені в одному із вбудованих форматів (наприклад, XML). Хоча мізерний інтерфейс та обмежені можливості виведення результатів Simian вимагають деякого навчання, він допомагає зберегти цілісність та ефективність продукту. Simian підходить для пошуку коду, що повторюється, як у великих, так і в маленьких проектах.
Код, що повторюється, знижує підтримуваність і оновлюваність проекту. Можна використовувати Simian для швидкого пошуку фрагментів коду, що дублюються, в багатьох файлах одночасно. Оскільки Simian може бути запущений з командного рядка, його можна включити в процес збирання, щоб отримати попередження або зупинити процес у разі повторення коду.
Висновок
Отже, у статті були розглянуті статичні аналізатори вихідного коду, які є допоміжними інструментами програміста. Всі інструментальні засоби різні і допомагають відстежувати різні класи вразливостей захисту в програмах. Можна зробити висновок, що статичні аналізатори мають бути точними, сприйнятливими. Але, на жаль, статичні засоби налагодження не можуть дати абсолютно надійного результату.
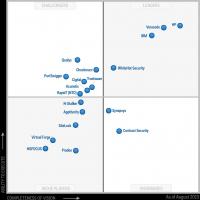 Аналіз успадкованого коду, коли вихідний код втрачено: робити чи робити?
Аналіз успадкованого коду, коли вихідний код втрачено: робити чи робити? Не завантажується Windows після інсталяції оновлень Не вмикається ноутбук після оновлення windows 10
Не завантажується Windows після інсталяції оновлень Не вмикається ноутбук після оновлення windows 10 Як зламати пароль: огляд найпоширеніших способів
Як зламати пароль: огляд найпоширеніших способів Відключаємо на планшеті шифрування
Відключаємо на планшеті шифрування Створення лампочки. Лампочка Едісона. Хто винайшов першу лампочку? Чому вся слава дісталася Едісон? Історія зміни пристрою лампи розжарювання
Створення лампочки. Лампочка Едісона. Хто винайшов першу лампочку? Чому вся слава дісталася Едісон? Історія зміни пристрою лампи розжарювання Як швидко знайти свій телефон через google, де б він не був
Як швидко знайти свій телефон через google, де б він не був Електричну лампу розжарювання винайшли у Росії
Електричну лампу розжарювання винайшли у Росії