Ce este P2P? Tehnologii peer-to-Peer - de la Cenușăreasa la prințese Peer to technology
Și în timp ce stăm aici ne întrebăm unde să ne plasăm reclamele, ceva ciudat se întâmplă în Palo Alto. Acolo, angajații Hassett Ace Hardware, un mic magazin de hardware, arată cum înțelepciunea străveche conform căreia „oamenii nu au fost creați pentru a aduna, ci pentru a împărtăși” poate prinde viață.
Se numește „Repair Cafe”. În fiecare weekend, lângă magazin se deschide un site unde oricine poate repara orice gratuit. Dar, în același timp, va trebui să-și aducă contribuția la ceea ce se întâmplă pe acest site. În timp ce managerul magazinului este ocupat cu vânzările regulate, alți cinci angajați organizează mulțimi de oameni care vor să „repare”, atrăgându-i la alte reparații.
Toată lumea împărtășește cunoștințe, sfaturi și bună dispoziție. Vânzările sunt în creștere (reparațiile necesită adesea piese care trebuie cumpărate dintr-un magazin). În aprilie, județul a reparat aproximativ 130 de echipamente, inclusiv o fântână gigantică de lavă de grădină și o mașină de cusut veche de 200 de ani. Toți cei care sunt reparați la o locație Hassett Ace Hardware primesc un steag pentru biciclete cu sigla companiei. Și o iau cu plăcere, pentru că serviciul grozav este un lucru al naibii de plăcut și de neuitat.
Această economie a beneficiului reciproc a primit denumirea de „peer-to-peer” sau „peer-to-peer” pe marginea marketingului. Este construită nu doar pe bani, ci și pe un grad ridicat de satisfacție emoțională, iar în cazul magazinelor mici precum Hassett Ace Hardware, tot pe construirea unei relații aproape intime cu clienții. Există zvonuri că astfel de giganți precum Pepsi, Chevrolet și Unilever „snifing” deja această tehnologie.
„Am învățat un lucru interesant: tinerii cumpărători, înainte de a veni la dealer să cumpere o mașină, caută paginile vânzătorilor noștri pe rețelele de socializare pentru a le studia interesele și a găsi o persoană apropiată în spirit. Îl găsesc și se consultă cu el pentru că știu că ajutorul va fi mai prietenos decât managerial”, spune Christy Landy, manager de marketing la General Motors. Chiar și opinia experților poate face obiectul unui schimb reciproc avantajos.
O privire rapidă asupra literaturii dezvăluie multe interpretări diferite ale conceptului Peer-to-Peer, care diferă în principal în gama de caracteristici incluse.
Cele mai stricte definiții ale unei rețele peer-to-peer „pure” o tratează ca pe un sistem complet distribuit în care toate nodurile sunt absolut egale în ceea ce privește funcționalitatea și sarcinile efectuate. Sistemele bazate pe ideea de „supernoduri” (noduri care acționează ca mini-servere locale alocate dinamic), cum ar fi Kazaa, nu îndeplinesc această definiție (deși acest lucru nu o împiedică să fie acceptată pe scară largă ca o rețea P2P sau un sistem care utilizează o infrastructură de server centralizată pentru a efectua subseturi de sarcini auxiliare: auto-ajustare, managementul ratingului reputației etc.).
Prin definiție mai largă, P2P este o clasă de aplicații care utilizează resurse - hard disk-uri, cicluri de procesor, conținut - disponibile la marginea cloud-ului Internet. În același timp, este potrivit și pentru sistemele care folosesc servere centralizate pentru funcționarea lor (precum SETI@home, sisteme de mesagerie instant, sau chiar infama rețea Napster), precum și diverse aplicații din domeniul grid computing.
Drept urmare, pentru a fi sincer, nu există un punct de vedere unic asupra a ceea ce este și ce nu este o rețea P2P. Definițiile multiple se datorează probabil faptului că sistemele sau aplicațiile sunt numite P2P nu din cauza operațiunilor sau arhitecturii lor interne, ci din cauza modului în care apar în exterior, adică dacă oferă impresia unei comunicări directe de la computer la computer.
În același timp, mulți sunt de acord că principalele caracteristici pentru arhitectura P2P sunt următoarele:
- partajarea resurselor informatice prin schimb direct fără ajutorul intermediarilor. Uneori, serverele centralizate pot fi folosite pentru a îndeplini sarcini specifice (auto-configurare, adăugarea de noi noduri, obținerea de chei globale pentru criptarea datelor). Deoarece nodurile dintr-o rețea peer-to-peer nu se pot baza pe un server central pentru a coordona partajarea conținutului și operațiunile în întreaga rețea, li se cere să își asume, în mod independent și unilateral, un rol activ în realizarea unor sarcini precum căutarea altor noduri, localizarea sau stocarea în cache a conținutului și rutarea informațiilor și a mesajelor, conexiunea cu nodurile învecinate și terminarea acesteia, criptarea și verificarea conținutului etc.;
- capacitatea de a accepta instabilitatea și inconstanța conexiunilor ca normă, adaptându-se automat la întreruperile și defecțiunile computerului acestora, precum și la un număr variabil de noduri.
Pe baza acestor cerințe, un număr de experți propun următoarea definiție (stilul său amintește oarecum de un brevet, dar dacă încercați să îl simplificați, nu va fi decât mai rău): O rețea P2P este un sistem distribuit care conține noduri interconectate capabile să se autoorganizeze într-o topologie de rețea pentru a partaja resurse precum conținut, cicluri de procesor, dispozitive de stocare și lățime de bandă, adaptându-se la defecțiuni și la un număr variabil de noduri, menținând în același timp un nivel acceptabil de conectivitate și performanță fără a fi nevoie de intermediari sau de suportul unui server central global.
Aici este momentul să vorbim despre caracteristicile de calcul în sistemele grid și P2P. Ambele reprezintă două abordări ale calculului distribuit folosind resurse partajate într-o comunitate de calcul la scară largă.
Grilele de calcul sunt sisteme distribuite care asigură utilizarea coordonată și partajarea la scară largă a resurselor distribuite geografic, bazate pe infrastructuri de servicii permanente, standardizate și concepute în primul rând pentru calculul de înaltă performanță. Pe măsură ce aceste sisteme se extind, încep să necesite soluții la problemele de auto-configurare și toleranță la erori. La rândul lor, sistemele P2P sunt inițial concentrate pe instabilitate, un număr variabil de noduri în rețea, toleranță la erori și autoadaptare. Până în prezent, dezvoltatorii P2P au creat în mare parte aplicații integrate pe verticală și nu s-au obosit să definească protocoale comune și cadre standardizate pentru interoperabilitate.
Cu toate acestea, pe măsură ce tehnologia P2P se maturizează și sunt utilizate aplicații mai complexe, cum ar fi distribuția de conținut structurat, colaborarea cu PC și grid computing, este de așteptat convergența P2P și grid computing.
Clasificarea aplicațiilor P2P
Arhitecturile P2P au fost folosite pentru multe aplicații din diferite categorii. Iată o scurtă descriere a unora dintre ele.
Comunicații și colaborare. Această categorie include sisteme care oferă o infrastructură pentru comunicare și colaborare directă, de obicei în timp real, între computere de la egal la egal. Exemplele includ chatul și mesageria instantanee.
Calcul distribuit. Scopul acestor sisteme este de a pune în comun puterea de calcul a colegilor pentru a rezolva probleme intensive de calcul. Pentru a face acest lucru, sarcina este împărțită într-un număr de subsarcini mici, care sunt distribuite pe diferite noduri. Rezultatul muncii lor este apoi returnat gazdei. Exemple de astfel de sisteme sunt SETI@home, genome@home și alte câteva proiecte.
Sisteme de baze de date. S-au depus eforturi considerabile pentru dezvoltarea bazelor de date distribuite bazate pe infrastructura P2P. În special, a fost propus un Model Relațional Local, care presupune că setul tuturor datelor stocate într-o rețea P2P este format din baze de date relaționale locale incompatibile (adică cele care nu îndeplinesc constrângerile de integritate specificate), interconectate folosind „intermediari”, care determina regulile de traducere și dependențele semantice dintre ele.
Distribuție de conținut. Cele mai multe rețele P2P moderne se încadrează în această categorie, cuprinzând sisteme și infrastructuri concepute pentru a partaja informații audiovizuale digitale și alte date între utilizatori. Aceste sisteme de distribuție de conținut variază de la aplicații relativ simple pentru partajarea directă a fișierelor și se extind până la cele mai complexe care creează medii de stocare distribuite care asigură organizarea, indexarea, căutarea, actualizarea și preluarea datelor sigure și eficiente. Exemplele includ rețeaua Napster, Gnutella, Kazaa, Freenet și Groove. În cele ce urmează, ne vom concentra asupra acestei clase de rețele.
Distribuție de conținut în rețele P2P
În cel mai tipic caz, astfel de sisteme oferă un mediu de stocare distribuit în care fișierele pot fi publicate, căutate și preluate de utilizatorii acelei rețele. Pe măsură ce complexitatea crește, poate introduce caracteristici nefuncționale precum securitatea, anonimatul, corectitudinea, scalabilitatea, gestionarea resurselor și capabilitățile organizaționale. Tehnologiile moderne P2P pot fi clasificate după cum urmează.
aplicații P2P. Această categorie include sisteme de distribuție de conținut bazate pe tehnologia P2P. În funcție de scopul și complexitatea lor, este oportun să le împărțim în două subgrupe:
- sisteme de partajare a fișierelor, destinat unui schimb simplu unic între computere. Astfel de sisteme creează o rețea de colegi și oferă un mijloc de căutare și transfer de fișiere între ei. În mod obișnuit, acestea sunt aplicații QoS ușoare, cu cele mai bune eforturi, fără nicio preocupare pentru securitate, disponibilitate sau supraviețuire;
- sisteme de publicare și stocare a conținutului. Astfel de sisteme oferă un mediu de stocare distribuit în care utilizatorii pot publica, stoca și distribui conținut, menținând în același timp securitatea și fiabilitatea. Accesul la un astfel de conținut este controlat și nodurile trebuie să aibă privilegii adecvate pentru a-l primi. Obiectivele principale ale unor astfel de sisteme sunt asigurarea securității datelor și a supraviețuirii rețelei și, adesea, scopul lor principal este acela de a crea mijloace de identificare, anonimat și gestionarea conținutului (actualizare, ștergere, control al versiunilor).
- Determinarea adresei și rutarea. Orice sistem de distribuție de conținut P2P se bazează pe o rețea peer-to-peer, în cadrul căreia nodurile și conținutul trebuie să fie localizate eficient, cererile și răspunsurile trebuie direcționate, asigurând în același timp toleranța la erori. Au fost dezvoltate diverse cadre și algoritmi pentru a îndeplini aceste cerințe;
- asigurarea anonimatului. Sistemele de infrastructură bazate pe P2P ar trebui concepute pentru a asigura anonimatul utilizatorilor;
- managementul reputației. Rețelelor P2P le lipsește o autoritate centrală care să gestioneze informațiile despre reputație despre utilizatori și comportamentul acestora. Prin urmare, este situat pe multe noduri diferite. Pentru a vă asigura că este sigur, actualizat și disponibil în întreaga rețea, trebuie să existe o infrastructură sofisticată de gestionare a reputației.
Localizarea și rutarea obiectelor distribuite în rețele P2P
Funcționarea oricărui sistem de distribuție de conținut P2P se bazează pe noduri și conexiuni între ele. Această rețea este formată deasupra și independent de bază (de obicei IP) și, prin urmare, este adesea numită suprapunere. Topologia, structura, gradul de centralizare a rețelei de suprapunere, mecanismele de localizare și rutare pe care le utilizează pentru a transporta mesaje și conținut sunt critice pentru funcționarea sistemului, deoarece afectează toleranța la erori, performanța, scalabilitatea și securitatea acestuia. Rețelele suprapuse variază în ceea ce privește gradul de centralizare și structură.
Centralizare. Deși cea mai strictă definiție presupune că rețelele suprapuse sunt complet descentralizate, în practică acest lucru nu este întotdeauna respectat și se găsesc sisteme cu grade diferite de centralizare. În special, există trei categorii:
- arhitecturi complet descentralizate. Toate nodurile din rețea îndeplinesc aceleași sarcini, acționând ca servere și clienți, și nu există un centru care să le coordoneze activitățile;
- arhitecturi parțial centralizate. Baza aici este aceeași ca și în cazul precedent, dar unele dintre noduri joacă un rol mai important, acționând ca indici centrali locali pentru fișierele partajate de nodurile locale. Modul în care acestor supernoduri li se atribuie rolul lor în rețea variază de la un sistem la altul. Este important de menționat, totuși, că aceste supernoduri nu reprezintă un singur punct de defecțiune pentru rețeaua P2P, deoarece sunt alocate dinamic și în caz de defecțiune, rețeaua își transferă automat funcțiile către alte noduri;
- arhitecturi hibride descentralizate. Astfel de sisteme au un server central care facilitează comunicarea între noduri prin gestionarea unui director de metadate care descrie fișierele partajate stocate pe ele. Deși comunicarea și schimbul de la capăt la capăt pot avea loc direct între două noduri, serverele centrale facilitează acest proces prin vizualizarea și identificarea nodurilor care stochează fișiere.
Evident, în aceste arhitecturi există un singur punct de eșec - serverul central.
Structura rețelei caracterizează dacă rețeaua de suprapunere este creată nedeterminist (ad-hoc), pe măsură ce se adaugă noduri și conținut, sau pe baza unor reguli speciale. Din punct de vedere al structurii, rețelele P2P sunt împărțite în două categorii:
- nestructurat. Plasarea conținutului (fișierelor) în ele nu are nimic de-a face cu topologia rețelei de suprapunere, în cazurile tipice, aceasta trebuie să fie localizată. Mecanismele de căutare variază de la metode de forță brută, cum ar fi inundarea interogărilor într-o manieră pe lățimea întâi sau pe adâncime până la găsirea conținutului dorit, până la strategii mai sofisticate care implică utilizarea metodei de mers aleatoriu și indexarea rutelor. Mecanismele de căutare utilizate în rețelele nestructurate au implicații evidente pentru disponibilitate, scalabilitate și fiabilitate.
Sistemele nestructurate sunt mai potrivite pentru rețele cu un număr variabil de noduri. Exemple sunt Napster, Gnutella, Kazaa, Edutella și câteva altele;
- structurat. Apariția unor astfel de rețele a fost asociată în primul rând cu încercările de a rezolva problemele de scalabilitate cu care s-au confruntat inițial sistemele nestructurate. În rețelele structurate, topologia de suprapunere este strict controlată, iar fișierele (sau pointerii către ele) sunt plasate în locații strict definite. Aceste sisteme oferă în esență o mapare între conținut (să zicem un ID de fișier) și locația acestuia (să zicem o adresă de nod) sub forma unui tabel de rutare distribuit, astfel încât cererile să poată fi direcționate eficient către nodul cu conținutul căutat.
Sistemele structurate (inclusiv Chord, CAN (Content Addressable Network), Tapestry și o serie de altele) oferă soluții scalabile pentru căutări cu potrivire exactă, adică pentru interogări în care este cunoscut identificatorul exact al datelor dorite. Dezavantajul lor este complexitatea managementului structurii necesar pentru a direcționa eficient mesajele într-un mediu cu un număr variabil de noduri.
Rețelele care ocupă o poziție intermediară între structurat și nestructurat sunt numite slab structurate. Deși nu indică pe deplin localizarea conținutului, ele contribuie totuși la căutarea rutei (un exemplu tipic de astfel de rețea este Freenet).
Acum vom discuta mai detaliat rețelele suprapuse în ceea ce privește structura și gradul de centralizare.
Arhitecturi nestructurate
Sa incepem cu arhitecturi complet descentralizate(vezi definiția de mai sus). Cel mai interesant reprezentant al unor astfel de rețele este Gnutella. La fel ca majoritatea sistemelor P2P, construiește o rețea virtuală suprapusă cu propriul mecanism de rutare, permițând utilizatorilor să partajeze fișiere. Rețeaua lipsește orice coordonare centrală a operațiunilor, iar nodurile se conectează între ele direct folosind un software care funcționează atât ca client, cât și ca server (utilizatorii săi sunt numiți servitori - de la SERVERI + CLIENȚI).
Gnutella folosește IP ca protocol de rețea de bază, în timp ce comunicațiile între noduri sunt definite de un protocol de nivel de aplicație care acceptă patru tipuri de mesaje:
- Ping- o cerere către o anumită gazdă pentru a se anunța;
- Pong- răspuns la un mesaj Ping care conține adresa IP, portul gazdei solicitate, precum și numărul și dimensiunea fișierelor partajate;
- Interogare- interogare de căutare. Include un șir de căutare și cerințe minime de viteză pentru gazda care răspunde;
- Afișări de interogare- răspuns la o cerere Interogare, include adresa IP, portul și viteza de transmisie a gazdei care răspunde, numărul de fișiere găsite și un set de indecși ai acestora.
După ce se alătură rețelei Gnutella (prin comunicarea cu gazdele găsite în baze de date precum gnutellahosts.com), gazda trimite un mesaj Ping unor gazde asociate cu aceasta. Ei răspund cu un mesaj Pong, identificându-se și trimite un mesaj Ping vecinilor tăi.
Într-un sistem nestructurat precum Gnutella, singura modalitate de a localiza un fișier era printr-o căutare nedeterministă, deoarece nodurile nu aveau cum să ghicească unde se află.
Arhitectura Gnutella a folosit inițial un mecanism de inundare (sau difuzare) pentru a distribui cererile PingȘi Interogare: Fiecare nod a redirecționat mesajele primite către toți vecinii săi, iar răspunsurile au urmat calea inversă. Pentru a limita fluxul de mesaje în rețea, toate au conținut un câmp Time-to-Live (TTL) în antet. La nodurile de tranzit, valoarea acestui câmp a fost scăzută, iar când a ajuns la valoarea 0, mesajul a fost șters.
Mecanismul descris a fost implementat prin atribuirea de ID-uri unice mesajelor și având tabele de rutare dinamică cu ID-uri de mesaje și adrese de noduri în gazde. Când răspunsurile conțin același ID ca și mesajele trimise, gazda consultă tabelul de rutare pentru a determina prin ce canal să direcționeze răspunsul pentru a întrerupe bucla.
| Orez. 1. Exemplu de mecanism de căutare într-un sistem nestructurat |
Dacă un nod primește un mesaj Lovitură de interogare, care indică faptul că fișierul pe care îl căutați se află pe un anumit computer, inițiază descărcarea printr-o conexiune directă între cele două noduri. Mecanismul de căutare este prezentat în fig. 1.
Sisteme parțial centralizate sunt în multe privințe similare cu cele complet descentralizate, dar folosesc conceptul de supernoduri - computere cărora li se atribuie dinamic sarcina de a servi o mică parte a rețelei de suprapunere prin indexarea și memorarea în cache a fișierelor pe care le conține. Acestea sunt selectate automat pe baza puterii de procesare și a lățimii de bandă.
Supernoduri indexează fișierele partajate de nodurile conectate la acestea și, ca servere proxy, efectuează căutări în numele lor. Prin urmare, toate cererile sunt inițial direcționate către supernoduri.
Sistemele parțial centralizate au două avantaje:
- timp de căutare redus în comparație cu sistemele anterioare în absența unui singur punct de defecțiune;
- utilizarea eficientă a eterogenității inerente rețelelor P2P. În sistemele complet descentralizate, toate nodurile sunt încărcate în mod egal, indiferent de puterea lor de procesare, lățimea de bandă a canalului sau capacitățile de stocare. În sistemele parțial centralizate, supernodurile preiau cea mai mare parte a sarcinii rețelei.
Un sistem parțial centralizat este rețeaua Kazaa.
Orez. Figura 2 ilustrează un exemplu de arhitectură tipică P2P cu descentralizare hibridă. Fiecare computer client stochează fișiere care sunt partajate cu restul rețelei de suprapunere. Toți clienții sunt conectați la un server central, care gestionează tabele de date despre utilizatorii înregistrați (adresă IP, lățime de bandă etc.) și liste de fișiere deținute de fiecare utilizator și partajate în rețea împreună cu metadatele fișierelor (de exemplu, numele, ora). creație etc.).
Un computer care dorește să se alăture comunității se conectează la serverul central și îi spune despre fișierele pe care le conține. Nodurile client trimit cereri despre ele către server. Căută în tabelul index și returnează o listă de utilizatori care le au.
Avantajul sistemelor hibride descentralizate este că sunt simplu de implementat, iar recuperarea fișierelor este rapidă și eficientă. Principalele dezavantaje includ vulnerabilitatea la control, cenzură și acțiuni legale, atacuri și defecțiuni tehnice, deoarece conținutul partajat, sau cel puțin descrierea acestuia, este controlat de o singură organizație, companie sau utilizator. Mai mult, un astfel de sistem nu se scalează bine, deoarece capacitățile sale sunt limitate de dimensiunea bazei de date a serverului și de capacitatea sa de a răspunde la interogări. Un exemplu în acest caz ar fi Napster.
Arhitecturi structurate
O varietate de sisteme structurate de distribuție a conținutului utilizează diferite mecanisme pentru a direcționa mesajele și a localiza datele. Ne vom concentra pe cel mai familiar utilizatorilor ucraineni - Freenet.
Această rețea de suprapunere este una dintre cele slab structurate. Să reamintim că principala lor caracteristică este capacitatea nodurilor de a determina (nu central!) unde este cel mai probabil stocat acest sau acel conținut pe baza tabelelor de rutare, care indică corespondența dintre conținut (identificatorul fișierului) și localizarea acestuia ( adresa nodului). Acest lucru le oferă posibilitatea de a evita solicitările de difuzare orbește. În schimb, se folosește o metodă de înlănțuire, în care fiecare nod ia o decizie locală cu privire la unde să redirecționeze următorul mesaj.
Freenet este un exemplu tipic de sistem de distribuție de conținut complet descentralizat, semi-structurat. Funcționează ca o rețea peer-to-peer, care se organizează automat, reunind spațiul pe disc neutilizat pe computere pentru a crea un sistem de fișiere virtual partajat.
Fișierele de pe Freenet sunt identificate folosind chei binare unice. Sunt acceptate trei tipuri de chei, dintre care cea mai simplă se bazează pe aplicarea unei funcții hash unui șir scurt de text descriptiv care însoțește orice fișier stocat online de proprietarul său.
Fiecare nod Freenet își gestionează propria stocare locală de date, făcându-l lizibil și scris de către alții, precum și un tabel dinamic de rutare care conține adresele altor noduri și fișierele pe care le stochează. Pentru a găsi un fișier, utilizatorul trimite o solicitare care conține cheia și o valoare indirectă a duratei de viață exprimată în termeni de număr maxim de hop-to-live permis.
Freenet folosește următoarele tipuri de mesaje, fiecare incluzând un ID de nod (pentru detectarea buclei), o valoare de hop-to-live și ID-uri sursă și destinație:
- Inserarea datelor- un nod care plasează date noi în rețea (mesajul conține cheia și datele (fișierul));
- Solicitare de date- cererea unui fisier anume (include o cheie);
- Răspuns la date- răspuns când fișierul este găsit (fișierul este inclus în mesaj);
- Datele au eșuat- eroare la căutarea unui fișier (se indică nodul și cauza erorii).
Pentru a se alătura Freenetului, calculatoarele stabilesc mai întâi adresa unuia sau mai multor noduri existente și apoi trimit mesaje Inserarea datelor.
Pentru a pune un fișier nou în rețea, un nod își calculează mai întâi cheia binară și trimite un mesaj Inserarea datelor pentru tine. Orice nod care primește un astfel de mesaj verifică mai întâi dacă cheia este deja utilizată. Dacă nu, îl caută pe cel mai apropiat (în termeni de distanță lexicografică) în tabelul său de rutare și direcționează mesajul (cu date) către nodul corespunzător. Folosind mecanismul descris, fișierele noi sunt plasate pe noduri care dețin deja fișiere cu chei similare.
Aceasta continuă până când se atinge limita hop-a-trai. În acest fel, fișierul distribuit va fi localizat pe mai multe noduri. În același timp, toate nodurile implicate în proces își vor actualiza tabelele de rutare - acesta este mecanismul prin care noile noduri își anunță prezența în rețea. Dacă limita hop-a-trai se realizează fără o coliziune a valorii cheie, un mesaj „tot corect” va fi livrat înapoi la sursă, informând-o că fișierul a fost plasat cu succes în rețea. Dacă cheia este deja utilizată, nodul returnează fișierul existent ca și cum ar fi cel solicitat. Astfel, o încercare de falsificare a fișierelor va duce la distribuirea ulterioară a acestora.
Când un nod primește o solicitare pentru un fișier stocat pe el, căutarea se oprește și datele sunt trimise inițiatorului său. Dacă fișierul necesar nu există, nodul transmite cererea unui vecin pe care este probabil să fie localizat. Adresa este căutată în tabelul de rutare folosind cea mai apropiată cheie etc. Rețineți că aici este un algoritm de căutare simplificat care oferă doar o imagine generală a funcționării rețelei Freenet.
Aici vom termina probabil scurta noastră revizuire a tehnologiilor P2P și vom aborda subiectul utilizării lor în afaceri. Este ușor de evidențiat o serie de avantaje ale arhitecturii P2P față de arhitectura client-server, care vor fi solicitate în mediul de afaceri:
- fiabilitate și disponibilitate ridicată a aplicațiilor în sistemele descentralizate, care se explică prin absența unui singur punct de defecțiune și natura distribuită a stocării informațiilor;
- o mai bună utilizare a resurselor, fie că este vorba de lățimea de bandă de comunicare, ciclurile procesorului sau spațiul pe hard disk. Dublarea informațiilor de lucru reduce semnificativ (dar nu elimină complet) nevoia de backup;
- simplitatea implementării sistemului și ușurința în utilizare datorită faptului că aceleași module software îndeplinesc atât funcții de client, cât și de server - mai ales când vine vorba de lucrul pe o rețea locală.
Potențialul rețelelor P2P era atât de mare încât Hewlett-Packard, IBM și Intel au inițiat crearea unui grup de lucru pentru standardizarea tehnologiei pentru uz comercial. Noua versiune de Microsoft Windows Vista va avea instrumente de colaborare încorporate, permițând laptopurilor să partajeze date cu cei mai apropiați vecini ai lor.
Primii susținători ai tehnologiei, cum ar fi gigantul aerospațial Boeing, compania petrolieră Amerada Hess și Intel însăși, spun că utilizarea acesteia reduce nevoia de a achiziționa sisteme de calcul de ultimă generație, inclusiv mainframe. De asemenea, sistemele P2P pot relaxa cerințele de lățime de bandă a rețelei, ceea ce este important pentru companiile care au probleme cu acest lucru.
Intel a început să folosească tehnologia P2P în 1990 într-un efort de a reduce costurile de dezvoltare a cipurilor. Compania și-a creat propriul sistem, numit NetBatch, care conectează peste 10 mii de computere, oferind inginerilor acces la resurse de calcul distribuite la nivel global.
Boeing folosește calcularea distribuită pentru a efectua teste de testare care necesită mult resurse. Compania folosește un model de rețea asemănător Napster, în care serverele direcționează traficul către nodurile desemnate. „Nu există un singur computer care să îndeplinească cerințele noastre”, spune Ken Neves, directorul diviziei de cercetare.
Potențialul tehnologiilor P2P a atras și atenția capitalului de risc. Astfel, Softbank Venture Capital a investit 13 milioane de dolari în United Device, o companie care dezvoltă tehnologii pentru trei piețe: de calcul pentru industria biotehnologică, calitatea serviciului (QoS) și teste de încărcare pentru site-uri web, precum și indexarea conținutului bazată pe metoda de căutare a viermilor. , utilizat de o serie de mașini de pe Internet.
În orice caz, cinci domenii de aplicare cu succes a rețelelor P2P sunt deja evidente astăzi. Acestea includ partajarea fișierelor, separarea aplicațiilor, integritatea sistemului, calculul distribuit și interoperabilitatea dispozitivelor. Nu există nicio îndoială că vor fi și mai mulți dintre ei în curând.
Client P2P gratuit, open source pentru lucrul cu rețeaua Direct Connect. Vă permite să descărcați gratuit fișiere partajate de alți utilizatori ai acestei rețele.
Despre rețelele peer-to-peer (p2p)
Rețeaua Direct Connect amintește oarecum de BitTorrent în structura sa.
Hub Hub (hub englezesc, butuc de roată, centru) este un nod de rețea.Tracker- un server al rețelei BitTorrent care își coordonează clienții.
De asemenea, nu există un sistem de căutare centralizat și, pentru a găsi orice fișier, trebuie să vizitați unul dintre serverele speciale - hub-uri (asemănătoare cu trackerele de pe BitTorrent).
După conectarea la hub, veți primi o listă de utilizatori conectați la acesta. Cu toate acestea, conexiunea poate să nu aibă loc dacă nu ați partajat (încărcat) cantitatea necesară de informații. De obicei, de la 2 la 10 GB.
Dacă conexiunea are loc, atunci aveți posibilitatea fie să introduceți numele fișierului care vă interesează în căutare, fie să efectuați o căutare manual, mergând la fiecare utilizator.
Principiul de funcționare a rețelei trebuie înțeles în termeni generali. Acum să ne uităm la clientul Direct Connection în sine.
Instalarea StrongDC++
După descărcarea arhivei cu programul, rulați fișierul executabil și programul va fi instalat în folderul „Fișiere program” de pe computer.
Dacă la sfârșitul instalării nu ați debifat caseta corespunzătoare, programul va porni automat.
Această versiune este deja în rusă, dar dacă ați descărcat versiunea în engleză, puteți rusifica programul folosind fișierul corespunzător cu extensia xml, aflat în arhiva noastră cu programul.
Când crack-ul este descărcat, trebuie să îl instalați. Pentru a face acest lucru, selectați elementul „Aspect” din meniul de setări ale programului și din câmp Fișier de limbă faceți clic pe butonul „Răsfoiți” pentru a selecta locația fișierului sDC++russian.xml(numele fișierului crack).
După ce ați efectuat toate manipulările, reporniți programul și obțineți o versiune rusă complet funcțională!
Configurarea StrongDC++
Acum să setăm versiunea rusă a Strong DC++.
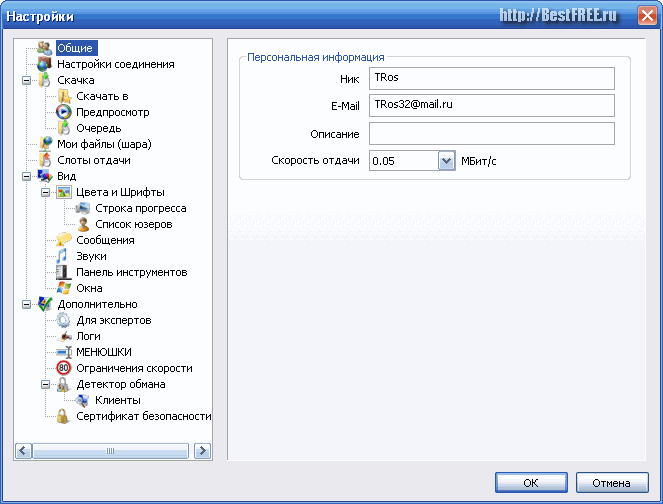
În meniul „General”, trebuie să specificați porecla, e-mailul și viteza de încărcare a fișierului. Câmpul „Descriere” poate fi lăsat gol (acesta este ca comentariul tău).
adresa IP- adresa digitală a unui computer din rețea, de exemplu: 192.0.3.244.În „Setări de conectare” puteți specifica adresa IP și alte date. O atenție deosebită trebuie acordată „Setărilor de conectare de intrare”.
Este mai bine să utilizați o conexiune pasivă printr-un firewall (în caz contrar, fișierele altor utilizatori nu vor fi afișate pentru dvs.).
Server proxy- server intermediar.Traficul conexiunilor de ieșire poate fi redirecționat către serverul proxy sau poate fi lăsat direct (viteza va fi mai mare).
Apoi selectați elementul „Descărcare” și configurați folderele implicite pentru descărcări și pentru stocarea fișierelor temporare.
Și acum - cel mai important lucru!!! Trebuie să vă partajați fișierele. Pentru a face acest lucru, accesați meniul „Fișierele mele (bilul)” și în fereastra care se deschide în dreapta, selectați fișierele și folderele la care doriți să deschideți accesul.

După ce selectați un fișier, veți vedea următoarea fereastră de progres.

Noțiuni introductive cu StrongDC++
După hashing fișierele, puteți începe să lucrați direct cu programul. Faceți clic pe butonul „OK” din partea de jos și fereastra principală a programului va apărea în fața dvs.

Pentru a începe să căutați fișierele de care aveți nevoie, primul lucru pe care trebuie să-l faceți este să vă conectați la unul dintre numeroasele hub-uri.
Pentru a face acest lucru, faceți clic pe butonul „Internet hub-uri” de pe bara de instrumente, apoi selectați una dintre listele de Internet hub-uri și faceți clic pe butonul „Actualizare”.

Dacă știți numele hub-ului sau al utilizatorului specific de care aveți nevoie, este mai ușor să căutați folosind un filtru.
Când este găsit hub-ul dorit, puteți accesa el făcând dublu clic pe butonul stâng al mouse-ului pe numele acestuia. Dacă cantitatea de date pe care ați partajat-o îndeplinește cerințele hub-ului, atunci veți vedea ceva de genul acesta:

Acordați atenție prezenței marcajelor sub fereastra principală. Toată navigarea în Strong DC++ se realizează folosind aceste marcaje. Puteți gestiona marcajele făcând clic dreapta.
Interfață puternică DC++
Spațiul principal este ocupat de chat - un lucru foarte profitabil. Va fi util, de la „doar conversație” până la abilitatea de a întreba pe alții unde să găsească această sau acea informație dacă căutarea nu a ajutat.
În dreapta chat-ului există o listă de utilizatori care sunt prezenți în prezent pe hub. Culorile în care sunt scrise numele de utilizator conțin informații suplimentare.

Căutarea manuală a fișierelor de descărcat
Să luăm în considerare interacțiunea folosind căutarea manuală. Lângă fiecare utilizator există un indicator al numărului de fișiere partajate. Dacă viteza de conectare nu este foarte mare, atunci este mai bine să-i alegeți pe cei care au volume de fișiere mai mici.

Acum, când apare un semnal în „Stare” că lista de fișiere a fost descărcată, mai jos se va deschide o altă filă, unde puteți vedea ce fișiere se află pe computerul utilizatorului pe care l-ați ales.
Pentru a descărca fișierul selectat, faceți clic dreapta pe el și selectați „Descărcare”.

Facem același lucru când folosim căutarea. În bara de căutare, introduceți numele fișierului de care avem nevoie și așteptați.
După ce căutarea este completă, mai jos veți vedea o listă de utilizatori care au acest fișier. Selectați unul dintre ele, vă conectați la el și descărcați datele necesare.
concluzii
În ciuda numeroaselor avantaje ale rețelei DC++, există și unele dezavantaje. Sunt două dintre ele în mod specific. Imposibilitatea de a descărca un fișier dacă sursa (cel care are acest fișier) s-a deconectat. Iar al doilea dezavantaj este, uneori, o coadă foarte lungă pentru descărcare.
În general, sistemul este foarte interesant, iar ceea ce îl face convenabil este utilizarea programului StrongDC++.
P.S. Se acordă permisiunea de a copia și cita în mod liber acest articol, cu condiția ca un link activ deschis către sursă să fie indicat și paternitatea lui Ruslan Tertyshny să fie păstrată.
P.P.S. Predecesorii rețelei P2P au fost serverele FTP, care sunt cel mai convenabil conectate la utilizarea acestui program:
Client FTP FileZilla https://www..php
Tehnologii peer-to-peer
Efectuat:
Student în anul I al programului de Master Fizică și Matematică
Kulacenko Nadejda Sergheevna
Verificat:
Cernîșenko Serghei Viktorovici
Moscova 2011
Introducere
Pe măsură ce internetul se dezvoltă, tehnologiile de partajare a fișierelor devin din ce în ce mai interesante în rândul utilizatorilor. Rețeaua, care este mai accesibilă decât înainte, și disponibilitatea canalelor de acces largi fac mult mai ușor să găsiți și să descărcați fișierele de care aveți nevoie. Nu cel mai mic rol în acest proces îl au tehnologiile moderne și principiile de construire a comunității, care fac posibilă construirea unor sisteme foarte eficiente atât din punctul de vedere al organizatorilor, cât și al utilizatorilor rețelelor de partajare a fișierelor. Astfel, acest subiect este actual astăzi, deoarece Apar constant rețele noi, iar cele vechi fie nu mai funcționează, fie sunt modificate și îmbunătățite. Potrivit unor date, în prezent, mai mult de jumătate din tot traficul de pe Internet este trafic din rețele peer-to-peer de partajare de fișiere. Dimensiunile celor mai mari dintre ele au depășit pragul unui milion de noduri care funcționează simultan. Numărul total de participanți înregistrați în astfel de rețele de partajare a fișierelor din întreaga lume este de aproximativ 100 de milioane.
Peer-to-peer (în engleză: egal cu egal) este un principiu străvechi al samurailor japonezi și al socialiștilor utopici. A câștigat o reală popularitate la sfârșitul secolului al XX-lea. Acum acest principiu este folosit de milioane de utilizatori de Internet, discutând cu prietenii din țări îndepărtate, descarcând fișiere de la utilizatori cu care nu s-au întâlnit niciodată.
Tehnologiile peer-to-peer (P2P) sunt unul dintre cele mai populare subiecte astăzi. Popularitatea obținută cu programe precum Skype, Bittorrent, DirectConnect și lista cu astfel de programe continuă și continuă confirmă potențialul sistemelor peer-to-peer.
În această lucrare, voi lua în considerare principiile individuale ale funcționării resurselor pe această temă, principiile de funcționare a rețelelor populare peer-to-peer care sunt utilizate în mod activ pentru schimbul de fișiere, precum și problemele utilizării lor.
1. Napster și Gnutella - primele rețele peer-to-peer
Prima rețea peer-to-peer Napster a apărut în 1999 și a devenit imediat cunoscută întregii comunități de internet. Autorul clientului a fost Sean Fanning, în vârstă de optsprezece ani. Napster a conectat mii de computere la resurse deschise. Inițial, utilizatorii Napster au schimbat fișiere mp3.
Napster a permis crearea unui mediu interactiv multi-utilizator pentru o anumită interacțiune specifică. Napster oferă tuturor utilizatorilor conectați la acesta posibilitatea de a schimba fișiere muzicale în format mp3 aproape direct: serverele centrale ale Napster oferă posibilitatea de a căuta în computerele tuturor utilizatorilor conectați la ei, iar schimbul are loc ocolind serverele centrale, folosind un utilizator. schema către utilizator. Multe dintre înregistrările care circulă în mediul Napster sunt protejate de legea dreptului de autor, dar sunt distribuite gratuit. Napster a existat în liniște timp de cinci luni, devenind un serviciu foarte popular.
Pe 7 decembrie, Asociația Industriei de Înregistrări din America (RIAA) a dat în judecată Napster pentru „încălcare directă și indirectă a drepturilor de autor”.
În cele din urmă, Napster a fost vândut mai întâi unei companii europene, apoi a fost închis complet.
Gnutella a fost creat în 2000 de către programatorii Nullsoft ca succesor al Napster. Funcționează și astăzi, deși din cauza unor defecte serioase ale algoritmului, utilizatorii preferă în prezent rețeaua Gnutella2. Această rețea funcționează fără un server (descentralizare completă).
La conectare, clientul primește de la nodul cu care a putut să se conecteze o listă de cinci noduri active; Li se trimite o solicitare de a căuta o resursă folosind un cuvânt cheie. Nodurile caută resurse care se potrivesc cu cererea și, dacă nu le găsesc, înaintează cererea către nodurile active în sus „arborele” (topologia rețelei are o structură grafică „arborele”) până când este găsită o resursă sau numărul maxim de pași este depășită. Această căutare se numește interogare de interogare.
Este clar că o astfel de implementare duce la o creștere exponențială a numărului de solicitări și, în consecință, la nivelurile superioare ale „arborei” poate duce la o refuzare a serviciului, care a fost observată de multe ori în practică. Dezvoltatorii au îmbunătățit algoritmul și au introdus reguli conform cărora cererile pot fi trimise în „arborele” doar de către anumite noduri - așa-numitele ultrapeers (frunze) le pot solicita doar pe acestea din urmă. A fost introdus și un sistem de noduri de cache.
Rețeaua funcționează și astăzi sub această formă, deși deficiențele algoritmului și capacitățile slabe de extensibilitate duc la o scădere a popularității sale.
Deficiențele protocolului Gnutella au inițiat dezvoltarea unor algoritmi fundamental noi pentru căutarea rutelor și resurselor și au condus la crearea unui grup de protocoale DHT (Distributed Hash Tables) - în special, protocolul Kademlia, care este acum utilizat pe scară largă în cele mai mari. retelelor.
Solicitările din rețeaua Gnutella sunt trimise prin TCP sau UDP, iar fișierele sunt copiate prin HTTP. Recent, au apărut extensii pentru programele client care vă permit să copiați fișiere prin UDP și să faceți cereri XML pentru metainformații despre fișiere.
În 2003, a fost creat un protocol Gnutella2 fundamental nou și au fost creați primii clienți care îl suportau, care erau compatibile cu clienții Gnutella. În conformitate cu acesta, unele noduri devin hub-uri, în timp ce restul sunt noduri obișnuite (frunze). Fiecare nod obișnuit are o conexiune la unul sau două hub-uri. Și un hub este conectat la sute de noduri obișnuite și la zeci de alte hub-uri. Fiecare nod trimite periodic către hub o listă de identificatori de cuvinte cheie care pot fi utilizați pentru a găsi resursele publicate de acest nod. ID-urile sunt stocate într-un tabel comun pe hub. Când un nod „dorește” să găsească o resursă, trimite o interogare de cuvinte cheie către hub-ul său, care fie găsește resursa în tabelul său și returnează ID-ul nodului care deține resursa, fie returnează o listă de alte hub-uri, pe care node interogă din nou la rândul său la întâmplare. O astfel de căutare se numește căutare folosind metoda de mers aleatoriu.
O caracteristică notabilă a rețelei Gnutella2 este capacitatea de a reproduce informații despre un fișier din rețea fără a copia fișierul în sine, ceea ce este foarte util din punctul de vedere al urmăririi virușilor. Pentru pachetele transmise în rețea, a fost dezvoltat un format proprietar similar XML, care implementează în mod flexibil capacitatea de a crește funcționalitatea rețelei prin adăugarea de informații suplimentare de serviciu. Interogările și listele de ID-uri de cuvinte cheie sunt trimise către hub-uri prin UDP.
2. Tehnologii P2P. Principiul „client-client”.
O rețea peer-to-peer, descentralizată sau peer-to-peer (din engleză peer-to-peer, P2P - egal cu egal) este o rețea de calculatoare suprapusă bazată pe egalitatea participanților. Într-o astfel de rețea nu există servere dedicate, iar fiecare nod (peer) este atât client, cât și server. Spre deosebire de arhitectura client-server, această organizare permite rețelei să rămână operațională cu orice număr și orice combinație de noduri disponibile. Participanții la rețea sunt colegi.
Termenul de peer-to-peer a fost folosit pentru prima dată în 1984 de IBM la dezvoltarea unei arhitecturi de rețea pentru rutarea dinamică a traficului prin rețele de calculatoare cu o topologie arbitrară (Advanced Peer to Peer Networking). Tehnologia se bazează pe principiul descentralizării: toate nodurile din rețeaua P2P au drepturi egale, i.e. Fiecare nod poate acționa simultan atât ca client (destinatar de informații) cât și ca server (furnizor de informații). „Acest lucru oferă astfel de avantaje ale tehnologiei P2P față de abordarea client-server, precum toleranța la erori în cazul pierderii conexiunii cu mai multe noduri de rețea, viteza crescută de achiziție a datelor datorită copierii simultane din mai multe surse, capacitatea de a partaja resurse fără a fi „legat” la anumite adrese IP, la rețele de energie enorme, în general, etc.”[2]
Fiecare nod peer interacționează direct doar cu un anumit subset de noduri de rețea. Dacă este necesar să se transfere fișiere între nodurile de rețea care nu sunt direct în contact, transferul de fișiere se realizează fie prin noduri intermediare, fie printr-o conexiune directă stabilită temporar (este special stabilită pentru perioada de transfer). În activitatea lor, rețelele de partajare de fișiere folosesc propriul set de protocoale și software, care este incompatibil cu protocoalele FTP și HTTP și are îmbunătățiri și diferențe importante. În primul rând, fiecare client al unei astfel de rețele, prin descărcarea datelor, permite altor clienți să se conecteze la ea. În al doilea rând, serverele P2P (spre deosebire de HTTP și FTP) nu stochează fișiere pentru schimb, iar funcțiile lor se reduc în principal la coordonarea colaborării utilizatorilor dintr-o rețea dată. Pentru a face acest lucru, ei mențin un fel de bază de date în care sunt stocate următoarele informații:
Ce adresă IP are acesta sau acel utilizator de rețea?
Ce fișiere sunt găzduite de ce client;
Ce fragmente din care fișiere se află unde;
Statistici despre cine a descărcat cât pentru ei înșiși și l-a dat altora pentru a-l descărca.
Lucrul într-o rețea tipică de partajare a fișierelor este structurat după cum urmează:
Clientul solicită fișierul necesar în rețea (înainte de aceasta, este posibil să căutați fișierul necesar folosind datele stocate pe servere).
Dacă fișierul necesar este disponibil și găsit, serverul oferă clientului adresele IP ale altor clienți pentru care a fost găsit fișierul.
Clientul care a solicitat fișierul stabilește o conexiune „directă” cu clientul sau clienții care au fișierul dorit și începe să îl descarce (dacă clientul nu este deconectat de la rețea în acest moment sau nu este supraîncărcat). Mai mult, în majoritatea rețelelor P2P este posibil să descărcați un fișier din mai multe surse simultan.
Clienții informează serverul despre toți clienții care se conectează la ei și despre fișierele pe care le solicită.
Serverul înregistrează în baza sa de date cine a descărcat ce (chiar dacă fișierele nu sunt descărcate complet).
Rețelele construite pe tehnologia Peer-to-Peer se mai numesc și peer-to-peer, peer-to-peer sau descentralizate. Și deși acum sunt folosite în principal pentru separarea fișierelor, există multe alte domenii în care această tehnologie este, de asemenea, utilizată cu succes. Acestea sunt transmisii de televiziune și audio, programare paralelă, stocarea în cache distribuită a resurselor pentru a descărca servere, trimiterea de notificări și articole, susținerea sistemului de nume de domeniu, indexarea și căutarea resurselor distribuite, backup și crearea de stocare de date distribuite rezistente, mesagerie, crearea de sisteme rezistente. la atacuri de tip denial of service, distribuție de module software.
3. Principalele vulnerabilități ale P2P
Implementarea și utilizarea sistemelor distribuite are nu numai avantaje, ci și dezavantaje asociate caracteristicilor de securitate. Obținerea controlului asupra unei structuri atât de extinse și mari precum o rețea P2P sau exploatarea lacunelor în implementarea protocolului pentru propriile nevoi, este un obiectiv de dorit pentru hackeri. În plus, este mai dificil să protejezi o structură distribuită decât un server centralizat.
O cantitate atât de mare de resurse disponibile în rețelele P2P este dificil de criptat/decriptat, astfel încât majoritatea informațiilor despre adresele IP și resursele participanților sunt stocate și transmise necriptate, făcându-le susceptibile de interceptare. Atunci când este interceptat, atacatorul nu numai că primește informațiile în sine, ci învață și despre nodurile pe care este stocată, ceea ce este și periculos.
Numai recent clienții majorității rețelelor mari au început să rezolve această problemă prin criptarea antetelor pachetelor și a informațiilor de identificare. Apar clienți care suportă tehnologia SSL, sunt introduse mijloace speciale de protejare a informațiilor despre locația resurselor etc.
O problemă serioasă este răspândirea „viermilor” și falsificarea ID-urilor resurselor pentru a le falsifica. De exemplu, clientul Kazaa folosește funcția hash UUHash, care vă permite să găsiți rapid ID-uri pentru fișiere mari, chiar și pe computere slabe, dar lasă totuși posibilitatea de a manipula fișiere și de a scrie un fișier corupt cu același ID.
Pentru a face față problemei descrise, clienții ar trebui să utilizeze funcții hash de încredere („arbori cu funcții hash” dacă fișierul este copiat în părți), cum ar fi SHA-1, Whirlpool, Tiger și numai pentru sarcini cu o valoare critică scăzută - sume de control CRC. Pentru a reduce volumul de date trimise și a facilita criptarea, puteți utiliza compresia. Pentru a vă proteja împotriva virușilor, trebuie să puteți stoca metainformații de identificare despre viermi, așa cum se face, în special, în rețeaua Gnutella2.
O altă problemă este posibilitatea de a falsifica ID-urile serverului și nodului. În absența unui mecanism de verificare a autenticității mesajelor de serviciu redirecționate, de exemplu folosind certificate, există posibilitatea de falsificare a serverului sau a nodului (multe noduri). Deoarece nodurile fac schimb de informații, manipularea unora dintre ele va compromite întreaga rețea sau o parte a acesteia. Software-ul închis pentru client și server nu este o soluție la problemă, deoarece există o oportunitate de inginerie inversă a protocoalelor și programelor.
Unii clienți doar copiază fișierele altora, dar nu oferă nimic pentru ca alții să le copieze (leechers).
În rețelele de domiciliu din Moscova, pentru fiecare câțiva activiști care pun la dispoziție mai mult de 100 GB de informații, sunt aproximativ o sută care postează mai puțin de 1 GB. Pentru a combate acest lucru sunt folosite diferite metode. eMule folosește metoda creditelor: dacă ai copiat un fișier, creditul tău ar scădea dacă ai permite copierea fișierului tău, creditul tău ar crește (xMule este un sistem de creditare care încurajează distribuirea fișierelor rare). Rețeaua eDonkey încurajează multiplicarea surselor Bittorrent implementează schema „câte blocuri dintr-un fișier s-au dat, atâtea” etc.
4. Unele rețele peer-to-peer
4.1 DirectConnect
torrent de rețea peer-to-peer peer-to-peer
Direct Connect este o rețea parțial centralizată de partajare a fișierelor (P2P) bazată pe un protocol special dezvoltat de NeoModus.
NeoModus a fost fondată de Jonathan Hess în noiembrie 1990 ca o companie care a făcut bani din programul adware Direct Connect. Primul client terță parte a fost „DClite”, care nu a suportat niciodată pe deplin protocolul. Noua versiune de Direct Connect necesita deja o cheie de criptare simplă pentru a inițializa conexiunea, ceea ce spera să blocheze clienții terți. Cheia a fost spartă și autorul DClite a lansat o nouă versiune a programului său, compatibilă cu noul software de la NeoModus. În curând, codul DClite a fost rescris și programul a fost redenumit Open Direct Connect. Printre altele, interfața sa de utilizator a devenit multi-document (MDI) și a devenit posibilă utilizarea pluginurilor pentru protocoalele de partajare a fișierelor (ca în MLDonkey). De asemenea, Open Direct Connect nu a avut suport complet pentru protocol, dar a apărut sub Java. Puțin mai târziu, au început să apară și alți clienți: DCTC (Direct Connect Text Client), DC++ etc.
Rețeaua funcționează după cum urmează. Clienții se conectează la unul sau mai multe servere, așa-numitele hub-uri, pentru a căuta fișiere care de obicei nu sunt conectate între ele (unele tipuri de hub-uri pot fi conectate parțial sau complet în rețea folosind scripturi specializate sau programul Hub-Link) și servesc la căutare pentru fișiere și surse pentru descărcarea acestora. Hub-urile cel mai des folosite sunt PtokaX, Verlihub, YnHub, Aquila, DB Hub, RusHub. Pentru a comunica cu alte hub-uri, așa-numitele. link-uri dchub:
dchub://[ nume de utilizator ]@[ IP sau domeniu hub ]:[ port hub ]/[cale fișier]/[nume fișier]
Diferențele față de alte sisteme P2P:
1. Condiționat de structura rețelei
· Chat multi-utilizator dezvoltat
· Un server de rețea (hub) poate fi dedicat unui anumit subiect (de exemplu, muzică dintr-un anumit gen), ceea ce facilitează găsirea utilizatorilor cu subiectul necesar al fișierelor
· Prezența utilizatorilor privilegiați - operatori care au un set extins de capabilități de gestionare a hub-ului, în special, monitorizarea conformității utilizatorilor cu regulile de chat și de partajare a fișierelor
2. Dependent de client
· Posibilitatea de a descărca directoare întregi
· Rezultatele căutării nu numai după numele fișierelor, ci și după directoare
· Restricții privind cantitatea minimă de material partajat (în funcție de volum)
· Suport pentru scripturi cu posibilități potențial nelimitate atât pe partea client, cât și pe partea hub (nu este valabil pentru toate hub-urile și clienții)
Pentru a rezolva probleme specifice, autorii clientului DC++ au dezvoltat un protocol fundamental nou numit Advanced Direct Connect (ADC), al cărui scop este de a crește fiabilitatea, eficiența și securitatea rețelei de partajare a fișierelor. Pe 2 decembrie 2007, a fost lansată versiunea finală a protocolului ADC 1.0. Protocolul continuă să fie dezvoltat și completat.
Torrent pe 4.2 biți
BitTorrent (literal în engleză „bit stream”) este un protocol de rețea peer-to-peer (P2P) pentru partajarea cooperativă de fișiere pe Internet.
Fișierele sunt transferate pe părți, fiecare client torrent, primind (descărcând) aceste părți, în același timp le dă (încărcă) altor clienți, ceea ce reduce încărcarea și dependența de fiecare client sursă și asigură redundanța datelor. Protocolul a fost creat de Bram Cohen, care a scris primul client torrent, BitTorrent, în Python pe 4 aprilie 2001. Lansarea primei versiuni a avut loc pe 2 iulie 2001.
Pentru fiecare distribuție, este creat un fișier de metadate cu extensia .torrent, care conține următoarele informații:
URL de urmărire;
Informații generale despre fișierele (nume, lungime etc.) din această distribuție;
Sume de control (mai precis, sume hash SHA1) ale segmentelor de fișiere distribuite;
Cheia de acces a utilizatorului, dacă acesta este înregistrat pe acest tracker. Lungimea cheii este setată de tracker.
Nu este necesar:
Sume hash ale fișierelor întregi;
Surse alternative care nu folosesc protocolul BitTorrent. Cel mai comun suport este așa-numitele web seeds (protocol HTTP), dar sunt acceptate și ftp, ed2k, magnet URI.
Fișierul de metadate este un dicționar în format bencode. Fișierele de metadate pot fi distribuite prin orice canale de comunicare: ele (sau link-uri către acestea) pot fi postate pe servere web, plasate pe paginile de start ale utilizatorilor rețelei, trimise prin e-mail, publicate în bloguri sau fluxuri de știri RSS. De asemenea, este posibil să primiți partea informativă a unui fișier public de metadate direct de la alți participanți la distribuție datorită extensiei de protocol „Extensie pentru ca peers să trimită fișiere de metadate”. Acest lucru vă permite să vă descurcați publicând doar un link magnet. După ce a primit cumva un fișier cu metadate, clientul poate începe descărcarea.
Înainte de a începe descărcarea, clientul se conectează la tracker la adresa specificată în fișierul torrent, îi spune adresa și cantitatea hash a fișierului torrent, ca răspuns la care clientul primește adresele altor clienți care descarcă sau distribuie același fișier. fişier. În continuare, clientul informează periodic tracker-ul despre progresul procesului și primește o listă actualizată de adrese. Acest proces se numește anunț.
Clienții se conectează între ei și schimbă segmente de fișiere fără participarea directă a unui tracker, care stochează doar informațiile primite de la clienții conectați la schimb, o listă de clienți înșiși și alte informații statistice. Pentru ca rețeaua BitTorrent să funcționeze eficient, este necesar ca cât mai mulți clienți să poată accepta conexiuni de intrare. Configurarea incorectă a NAT sau firewall poate împiedica acest lucru.
Când se conectează, clienții schimbă imediat informații despre segmentele pe care le au. Un client care dorește să descarce un segment (leecher) trimite o solicitare și, dacă al doilea client este gata să descarce, primește acest segment. Clientul verifică apoi suma de verificare a segmentului. Dacă se potrivește cu cel înregistrat în fișierul torrent, atunci segmentul este considerat descărcat cu succes, iar clientul anunță toți colegii conectați despre prezența acestui segment. Dacă sumele de verificare diferă, atunci segmentul începe să fie descărcat din nou. Unii clienți interzic colegii care trimit segmente incorecte prea des.
Astfel, cantitatea de informații despre serviciu (dimensiunea fișierului torrent și dimensiunea mesajelor cu o listă de segmente) depinde direct de numărul și, prin urmare, de dimensiunea segmentelor. Prin urmare, atunci când alegeți un segment, este necesar să mențineți un echilibru: pe de o parte, cu o dimensiune mare a segmentului, cantitatea de informații despre serviciu va fi mai mică, dar în cazul unei erori de verificare a sumei de control, va trebui să descărcați din nou mai multe informații. Pe de altă parte, cu o dimensiune mică, erorile nu sunt atât de critice, deoarece este necesar să redescărcați un volum mai mic, dar dimensiunea fișierului torrent și a mesajelor despre segmentele existente devine mai mare.
Când descărcarea este aproape completă, clientul intră într-un mod special numit joc final. În acest mod, solicită toate segmentele rămase de la toți colegii conectați, ceea ce evită încetinirea sau înghețarea completă a unei descărcări aproape finalizate din cauza mai multor clienți lenți.
Specificația protocolului nu specifică când exact trebuie să intre clientul în modul final de joc, dar există un set de practici general acceptate. Unii clienți intră în acest mod atunci când nu mai sunt blocuri nesolicitate, alții atâta timp cât numărul de blocuri rămase este mai mic decât numărul de blocuri transmise și nu mai mult de 20. Există o credință nespusă că este mai bine să păstrați numărul. de blocuri așteptate scăzute (1 sau 2) pentru a minimiza redundanța și asta atunci când cererile aleatoare au șanse mai mici de a primi duplicate ale aceluiași bloc.
Dezavantaje și limitări
· Indisponibilitatea distribuției – dacă nu există utilizatori distribuitori (semințe);
· Lipsa anonimatului:
Utilizatorii sistemelor neprotejate și clienții cu vulnerabilități cunoscute pot fi supuși unui atac.
Este posibil să aflați adresele utilizatorilor care fac schimb de conținut contrafăcut și să îi dați în judecată.
· Problema lipitorilor - clienți care distribuie mult mai puțin decât descarcă. Acest lucru duce la o scădere a productivității.
· Problema trișorilor – utilizatori care modifică informații despre cantitatea de date descărcate/transferate.
Personalizare – protocolul nu acceptă porecle, chat sau vizualizarea unei liste de fișiere utilizator.
Concluzie
Rețelele moderne peer-to-peer au suferit o evoluție complexă și au devenit, în multe privințe, produse software perfecte. Acestea garantează transferul fiabil și de mare viteză a unor cantități mari de date. Au o structură distribuită și nu pot fi distruse dacă mai multe noduri sunt deteriorate.
Tehnologiile testate în rețele peer-to-peer sunt acum utilizate în multe programe din alte domenii:
Pentru distribuția rapidă a distribuțiilor de programe open source (open source);
Pentru rețele de date distribuite, cum ar fi Skype și Joost.
Cu toate acestea, sistemele de schimb de date sunt adesea folosite în zone ilegale: sunt încălcate legile dreptului de autor, cenzura etc. Putem spune următoarele: dezvoltatorii de rețele peer-to-peer au înțeles perfect pentru ce vor fi folosite și s-au ocupat de ușurința de utilizare, de anonimatul clienților și de invulnerabilitatea sistemului în ansamblu. Programele și sistemele de schimb de date sunt adesea clasificate drept zona „gri” a Internetului - o zonă în care legile sunt încălcate, dar este fie dificil, fie imposibil să se dovedească vinovăția celor implicați în încălcare.
Programele și rețelele de schimb de date sunt situate undeva la „periferia” Internetului. Nu au sprijinul marilor companii, uneori nimeni nu îi ajută deloc; creatorii lor sunt de obicei hackeri cărora nu le plac standardele de internet. Producătorii de firewall-uri, routere și echipamente similare, precum și furnizorii de servicii de internet (ISP) nu le plac programele de schimb de date - rețelele „hacker” le iau o parte semnificativă din resursele prețioase. Prin urmare, furnizorii încearcă în toate modurile posibile să înlocuiască și să interzică sistemele de schimb de date sau să le limiteze activitățile. Cu toate acestea, ca răspuns la aceasta, creatorii sistemelor de schimb de date încep din nou să caute contramăsuri și obțin adesea rezultate excelente.
Implementarea și utilizarea sistemelor distribuite are nu numai avantaje, ci și dezavantaje asociate caracteristicilor de securitate. Obținerea controlului asupra unei structuri atât de extinse și mari precum o rețea P2P sau exploatarea lacunelor în implementarea protocolului pentru propriile nevoi, este un obiectiv de dorit pentru hackeri. În plus, este mai dificil să protejezi o structură distribuită decât un server centralizat.
O cantitate atât de mare de resurse disponibile în rețelele P2P este dificil de criptat/decriptat, astfel încât majoritatea informațiilor despre adresele IP și resursele participanților sunt stocate și transmise necriptate, făcându-le susceptibile de interceptare. Atunci când este interceptat, atacatorul nu numai că primește informațiile în sine, ci învață și despre nodurile pe care este stocată, ceea ce este și periculos.
Numai recent clienții majorității rețelelor mari au început să rezolve această problemă prin criptarea antetelor pachetelor și a informațiilor de identificare. Apar clienți care suportă tehnologia SSL, sunt introduse mijloace speciale de protejare a informațiilor despre locația resurselor etc.
O problemă serioasă este răspândirea „viermilor” și falsificarea ID-urilor resurselor pentru a le falsifica. De exemplu, clientul Kazaa folosește funcția hash UUHash, care vă permite să găsiți rapid ID-uri pentru fișiere mari, chiar și pe computere slabe, dar lasă totuși posibilitatea de a manipula fișiere și de a scrie un fișier corupt cu același ID.
În prezent, serverele și nodurile dedicate schimbă periodic informații de verificare între ele și, dacă este necesar, adaugă servere/noduri false la lista neagră de blocare a accesului.
De asemenea, se lucrează la crearea de proiecte care să combine rețele și protocoale (de exemplu, JXTA - dezvoltatorul Bill Joy).
Bibliografie
1. Yu N. Gurkin, Yu A. Semenov. „Rețele de partajare a fișierelor P2P: principii de bază, protocoale, securitate” // „Rețele și sisteme de comunicații”, nr. 11 2006
06/02/2011 17:23 http://www.ccc.ru/magazine/depot/06_11/read.html?0302.htm
2. A. Gryzunova Napster: istoricul cazului Revista Internet, numărul 22 06/02/2011 15:30 http://www.gagin.ru/internet/22/7.html
3. Rețele moderne de calculatoare Rezumat 06/02/2011 15:49 http://5ballov.qip.ru/referats/preview/106448
4. 28.01.2011 16:56 http://ru.wikipedia.org/wiki/Peer-to-peer
5. http://style-hitech.ru/peer-to-peer_i_tjekhnologii_fajloobmjena
28/01/2011 15:51
Instituția de învățământ de stat din Moscova Tehnologii peer-to-peer Completat de: student în anul I al programului de masterat în fizică și matematică Kulachenko Nadezhda Sergeevna Verificat de: Chernyshenko Sergey ViktorovichUna dintre primele rețele peer-to-peer, creată în 2000. Este încă în funcțiune, deși din cauza unor defecte serioase ale algoritmului, utilizatorii preferă în prezent rețeaua Gnutella2.
La conectare, clientul primește de la nodul cu care a putut să se conecteze o listă de cinci noduri active; Li se trimite o solicitare de a căuta o resursă folosind un cuvânt cheie. Nodurile caută resurse care se potrivesc cu cererea și, dacă nu le găsesc, înaintează cererea către nodurile active în sus „arborele” (topologia rețelei are o structură grafică „arborele”) până când este găsită o resursă sau numărul maxim de pași este depășită. Această căutare se numește interogare de interogare.
Este clar că o astfel de implementare duce la o creștere exponențială a numărului de solicitări și, în consecință, la nivelurile superioare ale „arborei” poate duce la o refuzare a serviciului, care a fost observată de multe ori în practică. Dezvoltatorii au îmbunătățit algoritmul și au introdus reguli conform cărora cererile pot fi trimise în „arborele” doar de către anumite noduri - așa-numitele ultrapeers (frunze) le pot solicita doar pe acestea din urmă. A fost introdus și un sistem de noduri de cache.
Rețeaua funcționează și astăzi sub această formă, deși deficiențele algoritmului și capacitățile slabe de extensibilitate duc la o scădere a popularității sale.
Deficiențele protocolului Gnutella au inițiat dezvoltarea unor algoritmi fundamental noi pentru căutarea rutelor și resurselor și au condus la crearea unui grup de protocoale DHT (Distributed Hash Tables) - în special, protocolul Kademlia, care este acum utilizat pe scară largă în cele mai mari. retelelor.
Solicitările din rețeaua Gnutella sunt trimise prin TCP sau UDP, iar fișierele sunt copiate prin HTTP. Recent, au apărut extensii pentru programele client care vă permit să copiați fișiere prin UDP și să faceți cereri XML pentru metainformații despre fișiere.
În 2003, a fost creat un protocol Gnutella2 fundamental nou și au fost creați primii clienți care îl suportau, care erau compatibile cu clienții Gnutella. În conformitate cu acesta, unele noduri devin hub-uri, în timp ce restul sunt noduri obișnuite (frunze). Fiecare nod obișnuit are o conexiune la unul sau două hub-uri. Și un hub este conectat la sute de noduri obișnuite și la zeci de alte hub-uri. Fiecare nod trimite periodic către hub o listă de identificatori de cuvinte cheie care pot fi utilizați pentru a găsi resursele publicate de acest nod. ID-urile sunt stocate într-un tabel comun pe hub. Când un nod „dorește” să găsească o resursă, trimite o interogare de cuvinte cheie către hub-ul său, care fie găsește resursa în tabelul său și returnează ID-ul nodului care deține resursa, fie returnează o listă de alte hub-uri, pe care node interogă din nou la rândul său la întâmplare. O astfel de căutare se numește căutare folosind metoda de mers aleatoriu.
O caracteristică notabilă a rețelei Gnutella2 este capacitatea de a reproduce informații despre un fișier din rețea fără a copia fișierul în sine, ceea ce este foarte util din punctul de vedere al urmăririi virușilor. Pentru pachetele transmise în rețea, a fost dezvoltat un format proprietar similar XML, care implementează în mod flexibil capacitatea de a crește funcționalitatea rețelei prin adăugarea de informații suplimentare de serviciu. Interogările și listele de ID-uri de cuvinte cheie sunt trimise către hub-uri prin UDP.
Iată o listă cu cele mai comune programe client pentru Gnutella și Gnutella2: Shareaza, Kiwi, Alpha, Morpheus, Gnucleus, Adagio Pocket G2 (Windows Pocket PC), FileScope, iMesh, MLDonkey
 Cum să introduceți o cartelă SIM în Xiaomi - instrucțiuni pas cu pas
Cum să introduceți o cartelă SIM în Xiaomi - instrucțiuni pas cu pas Tehnologii peer-to-Peer - de la Cenușăreasa la prințese Peer to technology
Tehnologii peer-to-Peer - de la Cenușăreasa la prințese Peer to technology Efectuăm backup, arhivare și recuperare de date
Efectuăm backup, arhivare și recuperare de date Regulile pentru furnizarea de servicii poștale s-au modificat Regulile pentru furnizarea de servicii poștale
Regulile pentru furnizarea de servicii poștale s-au modificat Regulile pentru furnizarea de servicii poștale Vulnerabilitatea VKontakte: acces la previzualizări ale fotografiilor din dialoguri și albume ascunse ale oricărui utilizator Fotografii VK private și private
Vulnerabilitatea VKontakte: acces la previzualizări ale fotografiilor din dialoguri și albume ascunse ale oricărui utilizator Fotografii VK private și private Google Play Market nu funcționează - ce să faci?
Google Play Market nu funcționează - ce să faci? Cum să măriți memoria internă pe un smartphone Lenovo A328 folosind micro SD Creați un fișier de schimb pentru a crește memoria RAM pe Android
Cum să măriți memoria internă pe un smartphone Lenovo A328 folosind micro SD Creați un fișier de schimb pentru a crește memoria RAM pe Android