Kártya használatával. Számítások a GPU-n. Hogyan válasszunk ki egy videokártyát a bányászathoz
GPU használata a C ++ amp segítségével
Eddig párhuzamos programozási technikák megvitatása során csak a processzor magokat vettük figyelembe. A több processzorral kapcsolatos programok párhuzamosításának néhány képességét szereztük be, szinkronizáljuk a megosztott erőforrásokhoz való hozzáférést, és a nagysebességű szinkronizálási primitívek használatát zárolások nélkül használhatják.
Azonban van egy másik módja a programok párhuzamosítására - grafikus processzorok (GPU)Nagyszámú magot tart, mint a nagy teljesítményű processzorok. A grafikus processzorok magjai tökéletesen alkalmasak a párhuzamos adatfeldolgozási algoritmusok megvalósítására, valamint nagy mennyiségükre, mint a rájuk nyújtott programok kényelmetlensége. Ebben a cikkben megismerjük a grafikus processzor programok végrehajtásának egyik módját, a C ++ nyelvi bővítmény használatával C ++ AMP.
A C ++ AMP kiterjesztések a C ++ nyelveken alapulnak, és ezért a C ++ nyelven szereplő példák ebben a cikkben jelennek meg. Azonban az interakciós mechanizmus mérsékelt használatával. Net, a C ++ AMP algoritmusokat használhatja a .NET programban. De erről beszélünk a cikk végén.
Bevezetés a C ++ AMP-hez
Lényegében a grafikus processzor ugyanaz a processzor, mint bármely más, de különleges utasítások, nagyszámú mag és memória hozzáférési protokoll. Azonban nagy különbségek vannak a modern grafikai és rendes processzorok között, és megértése kulcsfontosságú olyan programok létrehozásának kulcsa, amelyek hatékonyan használják a grafikus processzor számítástechnikai erejét.
A modern grafikus processzorok nagyon kis utasítások vannak. Ez bizonyos korlátozásokat jelent: a hívófunkciók függvényének hiánya, a támogatott adattípusok korlátozott készlete, könyvtári funkciók és mások nincsenek. Néhány művelet, mint például a feltételes átmenetek, jelentősen többet jelenthetnek a hagyományos processzorokon végzett hasonló műveleteknél. Nyilvánvaló, hogy a nagy mennyiségű kódot a processzorból a grafikus processzorra ilyen körülmények között jelentős erőfeszítéseket igényel.
Az átlagos grafikus processzorban lévő magok száma sokkal nagyobb, mint a rendszeres processzor átlaga. Azonban néhány feladat túl kicsi, vagy nem teszi lehetővé, hogy megszakítsa magukat elég nagyszámú Az alkatrészek, hogy a grafikus processzor alkalmazását élvezhesse.
Az egyik feladatot végrehajtó grafikus processzor magok közötti szinkronizálás támogatása nagyon szűkös, és teljesen hiányzik a grafikus processzorok magjai között különböző feladatok. Ez a körülmény egy grafikus processzor szinkronizálását igényli hagyományos processzorral.
Közvetlenül felmerül a kérdés, hogy milyen feladatok alkalmasak a grafikus processzor megoldására? Ne feledje, hogy nem minden algoritmus alkalmas a grafikus processzor végrehajtására. Például a grafikus processzorok nem férnek hozzá az I / O eszközökhöz, így nem tudják javítani a program teljesítményét, amely az RSS szalagot az internetről kivonja, grafikus processzor segítségével. Azonban számos számítástechnikai algoritmus átvihető a grafikus processzorba, és tömeges párhuzamosságot biztosít. Az alábbiakban több példa van ilyen algoritmusokra (ez a lista nem teljes):
a képek élességének növekedése és csökkenése és más átalakulások;
gyors Fourier transzformáció;
mátrixok átültetése és szorzása;
rendezési számok;
a hash "homlokában" inverziója.
A további példák kiváló forrása a Microsoft Native Concrongrency Blog, ahol a C ++ AMP-en végrehajtott különböző algoritmusokra és magyarázatokra vonatkoznak.
A C ++ AMP egy keret, amely része Vizuális Stúdió. 2012-ben, így a fejlesztők, hogy a C ++ egy egyszerű módja annak, hogy végezze el a számításokat grafikus processzor, és csupán a rendelkezésre álló DirectX vezérlőt 11. A Microsoft kiadta a C ++ AMP, mint egy nyitott szabvány, amely bármely gyártó fordítóprogramok lehet végrehajtani.
A C ++ AMP keretrendszer lehetővé teszi a kód végrehajtását grafikus gyorsítók (gyorsítók)amelyek számítástechnikai eszközök. A DirectX illesztőprogram 11 használatával a C ++ AMP keretrendszer dinamikusan érzékeli az összes gyorsítót. A C ++ AMP tartalmaz egy gyorsító szoftver emulátort és egy emulátort, amely rendszeres processzor, Warp, amely a grafikus processzor nélküli rendszerek nélkül vagy grafikus processzor nélkül szolgál, de a DirectX meghajtó meghajtó hiányában 11 , és több magot és a SIMD utasításokat használ.
És most folytatjuk az algoritmus tanulmányát, amely könnyen párhuzamos lehet a grafikus processzor végrehajtásához. Az alábbi megvalósítás két azonos hosszúságú vektort vesz igénybe, és kiszámítja a kísérletet. Nehéz elképzelni bármit egyértelműen:
Void VectorADDEXPPointWise (float * első, úszó * második, úszó * eredmény, int hossz) (az (int i \u003d 0; i)< length; ++i) { result[i] = first[i] + exp(second[i]); } }
Ahhoz, hogy a rendszeres processzoron lássák ezt az algoritmust, meg kell szakítania az iterációk tartományát több alsávba, és mindegyiküket egy lépéssel futtatni kell. A korábbi cikkekben nagyon sok időt szenteltünk a korábbi cikkekben, hogy párhuzamosan párhuzamosan párhuzamosan megtaláljuk az egyszerű számok megtalálásának első példáját - láttuk, hogy hogyan tehetjük meg, és manuálisan készítheti el a folyamatokat az áramlási medencével és a párhuzamos használatával. automatikus párhuzamosításra. Ne feledje, hogy a szokásos processzor hasonló algoritmusainak párhuzamával, különösen gondoskodtunk, hogy ne felosztjuk a feladatot túl kicsi feladatokra.
A grafikus processzor esetében ezek a figyelmeztetések nem szükségesek. A grafikus feldolgozóknak számos olyan rendszermagja van, amelyek nagyon gyorsan végzik az áramlást, és a kontextus átkapcsolásának költsége lényegesen alacsonyabb, mint a hagyományos processzorokban. Az alábbiakban egy töredék, amely megpróbálja használni a funkciót párhuzamos_for_each. A C ++ AMP keretrendszerből:
#Inlude.
Most külön megvizsgáljuk a kód minden részét. Azonnal megjegyezzük, hogy az általános formája a fő ciklus maradt fenn, de az eredetileg használt ciklust helyébe a PARALLEL_FOR_EACH funkciót. Valójában a ciklusnak a függvényhez vagy módszerhez való átalakításának elve nem új - egy ilyen vétel a paralisztus alkalmazásával. () És párhuzamos. A TPL könyvtárából már bizonyították.
Ezután a bemeneti adatok (az első, a második és az eredmény paraméterei) példányokkal vannak csomagolva array_View.. Az Array_View Osztályát a grafikus processzor (gyorsító) által továbbított adatok csomagolására használják. A sablon paramétere meghatározza az adattípusokat és azok dimenzióját. A grafikus processzor utasításainak végrehajtásához, amelyek a szokásos processzoron eredetileg feldolgozott adatokhoz vonzódnak, valaki vagy valami gondoskodnia kell az adatok másolására egy grafikus processzorba, mivel a legtöbb modern grafikus kártya különálló eszközök a saját memóriájukkal. Array_View példányok megoldják ezt a feladatot - adnak másolási adatokat a keresletre, és csak akkor, ha valóban szükségesek.
Ha a grafikus processzor végrehajtja a feladatot, az adatokat másolják vissza. Az Array_View példány létrehozásával a verseny típusú argumentummal garantáljuk, hogy az első és a második másolódik a grafikus processzor memóriájába, de nem lesz másolva. Hasonlóképpen, okozza discard_data (), Kizárjuk a másolás eredményeit a normál processzor memóriából a gyorsító memóriába, de ezeket az adatokat az ellenkező irányba másolja.
A párhuzamos_for_each szolgáltatás olyan mértékű objektumot kap, amely meghatározza a feldolgozott adatok formáját és a függvényt az egyes elemekhez való használathoz. A fenti példában egy lambda funkciót használtunk, amelynek támogatása az ISO C ++ 2011 szabványban (C ++ 11) jelent meg. A korlátozás (AMP) Kulcsszóbejegyzések A fordítót ellenőrizheti a grafikus processzoron lévő test funkció végrehajtásának képességét, és a C ++ szintaxis nagy részét kikapcsolja, amelyet a grafikus processzor utasításaiban nem lehet összeállítani.
Lambda funkció paraméter, index<1> Az objektum egydimenziós indexet jelent. Meg kell felelnie a használt objektumnak - ha kétdimenziós objektumot (például a forrásadatok formájának meghatározását kétdimenziós mátrix formájában) kell megadni), az indexnek is kettőnek kell lennie -dimenziós. Az ilyen helyzet egyik példája az alábbiakban található.
Végül hívjon egy módszert szinkronizálás () A VektoradDexpoCeWise módszer végén garantálja az Array_View Avresult által a grafikus processzor által gyártott számítás eredményeinek másolását, vissza az eredmény tömbjéhez.
Ezen azt befejezni az első ismerős a C ++ AMP világon, és most már készen áll a részletes kutatás, valamint több érdekes példát bemutató használatának előnyeit párhuzamos számítási grafikus processzor. Vektorok hozzáadása - nem a legsikeresebb algoritmus, és nem a legjobb jelölt, amely bemutatja a grafikus processzor használatát az adatok másolásának nagy költsége miatt. A következő alfejezet két érdekes példát mutat.
Mátrix szorzás
Az első "valódi" példa, amelyet a mátrixok szorzása. Megvalósítani, mi lesz egy egyszerű köbös szorzás algoritmus mátrixok, és nem a Strassen algoritmus, amelynek végrehajtási idő közel köbös ~ O (N 2,807). Két mátrix esetében: mátrix Matrix Matrix M x W és mátrix B A W x n méret, a következő program végzi a szorzást, és visszaadja az eredményt - a mátrix m x n méretű:
Void matrixmully (int * a, int m, int w, int * b, int n, int * c) (az (int i \u003d 0; i)< m; ++i) { for (int j = 0; j < n; ++j) { int sum = 0; for (int k = 0; k < w; ++k) { sum += A * B; } C = sum; } } }
Ezt a megvalósítást többféleképpen is kiválaszthatja, és ha paralilit szeretne a kódjegyhez, akkor lehetőség lenne külső ciklusú párhuzamosságot kapni a szokásos processzoron. A grafikus processzor azonban elegendő számú maggal rendelkezik, és párhuzamosan csak a külső ciklusban, nem tudunk elegendő számú feladatot létrehozni az összes magvak betöltéséhez. Ezért van értelme párhuzamos két külső ciklus, így a belső ciklus érintetlen:
Void Matrixmully (INT * A, INT M, INT W, INT * B, INT N, INT * C) (Array_View
Ezt a végrehajtást még mindig szorosan emlékezteti a mátrixok szorzásának következetes megvalósításával és a fenti vektorok hozzáadására, kivéve az index kivételével, amely most kétdimenziós, és a belső ciklusban elérhető a operátor. Mennyibe kerül ez a verzió gyorsabb, mint a szokásos processzoron végzett következetes alternatíva? Szorzás: két mátrix (egész számok) 1024 x 1024 A szokásos processzor szekvenciális verziója átlagosan 7350 milliszekundumot hajt végre, míg a grafikus processzor verziója - tartsa a keményen - 50 milliszekundum, 147-szer gyorsabb!
A részecskék mozgásának modellezése
Példák a fent bemutatott grafikus processzorra vonatkozó problémák megoldására, nagyon egyszerű végrehajtás a belső ciklusban. Nyilvánvaló, hogy nem lesz mindig. A natív párhuzamos blog, amelyre már a fenti hivatkozás, bemutatja a részecskék közötti gravitációs kölcsönhatások modellezésének példáját. A szimuláció végtelen számú lépést tartalmaz; Minden lépésnél az egyes részecskékre vonatkozó gyorsulási vektor elemeinek új értékeit kiszámítjuk, majd meghatározzuk az új koordinátákat. Itt a részecskevektor párhuzamosításnak van kitéve - elég nagy számú részecskékkel (több ezer és annál nagyobb), létrehozhat egy elég nagy számú feladatot, hogy betöltse a grafikus processzor összes magját.
Az algoritmus alapja a két részecske közötti kölcsönhatások eredményének meghatározása, az alábbiak szerint, amely könnyen átvihető a grafikus processzorra:
// itt a Float4 négy elemet tartalmazó vektorok, // a műveletekben résztvevő részecskék, amelyek részt vesznek a műveletekben Void Bodybody_intaction (Float4 & Acceleration, CONST FLOAT4 P1, CONSTHOOD4 P2) korlátozva (Float4 Dist \u003d P2 - P1; / / nem float Abddist \u003d dist.x * dist.x + dist.y * dist.y + dist.z * dist.z; float invist \u003d 1,0f / sqrt (abdist); float invistcube \u003d invis * invist * invwist; gyorsítás + \u003d dist * Particle_MASS * INVDISTCUBE;)
A kezdeti adatok minden egyes modellezés lépésben egy tömb koordinátákkal és sebességgel a részecskék mozgásának, és ennek eredményeként a számítások, egy új tömb jön létre koordinátákkal és a részecske arányok:
Strukturális részecske (float4 pozíció, sebesség; // konstruktor megvalósítása, másolás konstruktor és // operátor \u003d korlátozás (amp), hogy a hely megtakarítása érdekében); Void Simulation_step (Array
A megfelelő grafikus felület vonzerejével a szimuláció nagyon érdekes lehet. A C ++ AMP fejlesztői csapatának teljes példája megtalálható a natív egységesítő blogon. Az Intel Core I7 processzorral és a GeForce GT 740m videokártyával rendelkező rendszeren a 10 000 részecskék mozgási modellezését a második másodpercenkénti sebességgel (másodpercenkénti lépések) végezzük, a rendszeres processzoron futó soros verzióval, és 160 képkocka másodpercenként optimalizált verziókkal futó grafikus processzoron - a termelékenység hatalmas növekedése.
A szakasz befejezése előtt meg kell mondania a C ++ AMP keretrendszer másik fontos jellemzőjét, amely még nagyobb növelheti a grafikus processzoron végrehajtott kód termelékenységét. Grafikus processzorok támogatása programozható gyorsítótáradatok (gyakran hívják megosztott memória). A Kesche-ban tárolt értékeket az egyik mozaik (csempe) végrehajtási folyamainak megosztják. Hála a mozaik memória szervezése, a C ++ AMP keret alapú program tudja olvasni az adatokat a grafikus kártya memória megosztott memória mozaik majd elérni őket több végrehajtási szál nélkül újra kitermelése az adatokat a grafikus kártya memóriájában. A mozaik megosztott memóriájához való hozzáférés körülbelül 10-szer gyorsabb, mint a grafikus kártya memóriájához. Más szóval, van oka az olvasás folytatása.
A párhuzamos ciklus mozaikverziójának végrehajtásának biztosítása érdekében a párhuzamos_for_each módszert továbbítják domain tiled_extentamelyek a multidimenzionális mozaikfragmensek és a Lambda paraméter Tiled_index, amely meghatározza a mozaik belsejében lévő globális és helyi áramlási azonosítót. Például egy 16x16 mátrix osztható 2x2 mozaik töredékek (amint az az alábbi ábrán), és átviheti az ParlelLel_For_each funkciók:
Mérték<2> Mátrix (16,16); tiled_extent<2,2> Tiledmatrix \u003d mátrix.<2,2> (); Parallal_for_Each (TiledMatrix, [\u003d] (tiled_index)<2,2> IDX) korlátozza (AMP) (// ...));

Az ugyanazon mozaikhoz tartozó négy végrehajtás mindegyike megoszthatja a blokkban tárolt adatokat.
Mátrixokkal végzett műveletek végrehajtása során a grafikus processzor magjában a szabványos index index helyett<2>Mint a fenti példákban, használhatja idx.global. A helyi mozaikmemória és a helyi indexek illetékes felhasználása jelentős teljesítménynövekedést biztosít. A mozaikmemória kijelentése, amely az összes végrehajtásfolyamat megosztja egy mozaikban, a helyi változók a Tile_Static specifierrel deklarálhatók.
A gyakorlatban gyakran használják a megosztott memória nyilatkozatának elfogadására és az egyéni blokkok inicializálására különböző végrehajtási folyamatokban:
Parallal_for_Each (TiledMatrix, [\u003d] (tiled_index)<2,2> IDX) Korlátozás (AMP) (// 32 bájtot osztanak meg a Tile_Static In Helyi egység összes szála; // hozzárendelje az értéket az áramláshoz tartozó elemhez \u003d 42;
Nyilvánvaló, hogy a megosztott memória használatából származó bármilyen előny csak a memóriához való hozzáférés szinkronizálása esetén érhető el; Vagyis az áramok nem kezelhetik a memóriát, amíg az egyikük inicializálja. A mozaikban lévő patakok szinkronizálása objektumok segítségével történik tile_barrier (A TPL-könyvtárból származó akadályosztályhoz hasonlítva) - csak a Tile_Barrier.wait () módszer hívása után folytathatják a végrehajtását, amely csak akkor fog visszatérni az ellenőrzést, ha az összes patak hívja a tile_barrier.wait. Például:
Parallal_for_Each (Tiledmatrix, (Tiled_index)<2,2> IDX) korlátozza (AMP) (// 32 bájt, amelyet a Tile_Static Int helyi blokkban megosztott összes szálak osztanak meg; // most ez a patak hozzáférhet a "helyi" tömböt, // az egyéb futásidejű indexek használatával);
Most itt az ideje, hogy megtestesítsük a konkrét példában szerzett tudásokat. Visszatérjen a mátrixok sokszorosításának megvalósításához, mozaikmemória szervezet használata nélkül, és adja hozzá a leírt optimalizálást. Tegyük fel, hogy a 256 mattanácsszám mérete 16 x 16-os blokkokkal dolgozik. A mátrixok jellege lehetővé teszi rövid távú szorzásukat, és kihasználhatjuk ezt a funkciót (valójában a mátrixok megosztása) A blokkok a mátrixok multiplózis algoritmusának tipikus optimalizálása, amely hatékonyabb felhasználásával hatékonyabb felhasználásával).
A vétel lényege a következőkre csökken. Ahhoz, hogy megtalálja a C I, J (az I. karakterláncban és az eredmény oszlopban az eredménymátrixban), meg kell számolnia a skaláris terméket az AI, * (II vonal az első mátrix) és a b *, j (j-th) között oszlop a második mátrixban). Ez azonban megegyezik a részleges skaláris karakterlánc és oszlop kiszámításával az eredmények későbbi összegzésével. Ezt a körülményt használhatjuk, hogy átalakítsa a szorzási algoritmust a mozaikos verzióra:
Void Matrixmully (INT * A, INT M, INT W, INT * B, INT N, INT * C) (Array_View A leírt optimalizálás lényege, hogy a mozaikban (a 16 x 16 blokkhoz 256 szálat hoznak létre), az A és B forrásmátrixok fragmenseinek helyi példányait inicializálja. Minden mozaikban lévő áramlás csak egy Vonal és egy oszlop ezekből a blokkokból, de az összes patak együttesen hozzáfér az egyes sorokhoz és minden egyes oszlophoz 16 alkalommal. Ez a megközelítés jelentősen csökkenti a fő memóriára való hivatkozások számát. Az (I, J) elem kiszámításához az adott mátrixban az algoritmus az első mátrix teljes I-I vonalát és a második mátrix J-TH oszlopát igényli. Amikor a szálak a mozaik 16x16, az ábrán bemutatott és a K \u003d 0, az árnyékolt területek az első és a második mátrixok fogják olvasni az osztott memóriában. A végrehajtás adatfolyam, a számító eleme (i, j) az eredmény mátrix, kiszámítja a részleges skalár termék az első k elemek az i-edik sor és a j-edik oszlopa az eredeti mátrixok. Ebben a példában a mozaik szervezet használata óriási termelékenységi nyereséget biztosít. A mátrixok sokszorosításának mozaikos változata sokkal gyorsabban történik, mint egy egyszerű verzió, és körülbelül 17 milliszekundumot foglal el (ugyanazon a kezdeti 1024 x 1024-es kezdeti mátrixoknál), amely 430 gyorsabb, mint a szokásos processzoron végzett verzió. Mielőtt befejeznénk a C ++ AMP keretrendszer megvitatását, szeretnénk megemlíteni a fejlesztők rendelkezésére álló eszközöket (Visual Studio). A Visual Studio 2012 hibakeresést kínál egy grafikus processzorhoz (GPU), amely lehetővé teszi a vezérlési pontok telepítését, feltárja a hívások kihívását, olvassa el és módosítsa a helyi változók értékeit (egyes gyorsítók támogatják a GPU hibakeresését; más vizuális A Studio szoftverszimulátort használ), és egy profiler értékeli az alkalmazás által kapott előnyöket a grafikus processzor segítségével. További információ a hibakereső funkciók a Visual Studio, olvassa el a cikk „Step-by-Step Guide. Debugging C ++ AMP alkalmazások »az MSDN weboldalán. Eddig ebben a cikkben a példákat csak a C ++ nyelven mutatjuk be, azonban számos módon használhatjuk a grafikus processzor teljesítményét a kezelt alkalmazásokban. Az egyik módja annak, hogy olyan interakciós eszközöket használjunk, amelyek lehetővé teszik, hogy a grafikus processzor magjával való áttérés az alacsony szintű C ++ komponensekhez. Ez a megoldás nagyszerű azok számára, akik C ++ AMP keretrendszereket kívánnak használni, vagy képesek a C ++ AMP kész alkatrészeket kezelni a kezelt alkalmazásokban. Egy másik módja annak, hogy egy grafikus processzorral működő könyvtárat használjon egy kezelt kódból. Jelenleg számos ilyen könyvtár van. Például a GPU.NET és a Cudafy.net (mindkettő kereskedelmi ajánlatok). Az alábbiakban egy példa a GPU.NET Github tárolóból, amely bemutatja a két vektor skaláris termékének megvalósítását: Nyilvános statikus üreg multiplyaddgpu (Dupla A, Double B, Double C) (int Threadid \u003d blockdimension.x * blockindex.x + threadindex.x; int totalthreads \u003d blockdimension.x * griddimension.x; az (int elementidx \u003d threadid; Tartom azt a véleményemet, hogy sokkal könnyebb és hatékonyabb a nyelv kiterjesztése (C ++ AMP alapján), mint a könyvtári szinten való kölcsönhatás megszervezése, vagy jelentős változások az IL-ben. Így, miután áttekintettük a lehetőségeket Párhuzamos programozás V.Net és használata GPU, akkor minden bizonnyal nem kétséges, hogy a szervezet a párhuzamos számítási fontos módja, hogy növelje a termelékenységet. Sok szerverek és munkaállomások a világ, vannak kihasználatlan érvénytelen számítási teljesítmény rendes és grafikus processzorok, mert alkalmazásokat egyszerűen nem használja őket. A Task Parallel Library könyvtár ad nekünk egy egyedülálló lehetőség, hogy tartalmazza az összes rendelkezésre álló magok a központi processzor, bár meg kell oldani néhány igen érdekes problémát a szinkronizálás, a túlzott aprítás feladatok és egyenlőtlen munkamegosztás a folyamok között a végrehajtás. A C ++ AMP keretrendszer és a párhuzamos számítástechnika más többcélú könyvtárai sikeresen alkalmazhatók a számítások párhuzamosítására a több száz grafikus processzor mag között. Végül van egy felderítetlen korábbi, a termelékenység megszerzésének képessége az elosztott számítástechnika felhőtechnológiáinak használatából, amely a közelmúltban továbbított az információs technológiák fejlesztésének egyik fő irányába. A kérdés gyakran elkezdett megjelenni: Miért nincs GPU gyorsulás az Adobe Media Encoder CC programban? És az a tény, hogy az Adobe Media Encoder GPU gyorsulást használ, megtudtuk, és megjegyezte a használatának árnyalatát is. A jóváhagyás is megtalálható: az Adobe Media Encoder CC program eltávolította a GPU gyorsításának támogatását. Ez a hibás vélemény és az az a tény, hogy az Adobe Premiere Pro CC alapvető program mostantól előírt és ajánlott videokártya nélkül működhet, és bekapcsolhatja a GPU-motorot az Adobe Media Encoder CC-ben, a videokártyát a dokumentumok tartalmazza: Cuda_Supported_Cards vagy opencl_supported_cards. Ha az NVIDIA chipsets segítségével minden világos, csak vegye be a chipset nevét, és írja be a CUDA_SUPPORTED_CARDS dokumentumba. Ez az AMD videokártyák használatakor nem szükséges a chipkészlet nevének előírása, de a kódoló kód neve. Tehát nézzük a gyakorlatban, mint az ASUS N71JQ laptop egy diszkrét menetrend ATI Mobility Radeon HD 5730 GPU Engedélyezze a motor az Adobe Media Encoder CC. Az ATI mobilitás technikai adatai Radeon HD 5730 grafikus adapter a GPU-Z segédprogramban: Futtassa az Adobe Premiere Pro CC programot, és kapcsolja be a motort: \u200b\u200bhigany lejátszási motor GPU gyorsítás (OpenCL). Három DSLR videó az idővonalon, egymás között, kettő, létrehozza a kép hatását a képen. Ctrl + M, válassza az MPEG2-DVD előre, távolítsa el a fekete csíkok az oldalán a skála segítségével, hogy töltse ki a lehetőséget. A GPU nélkül is megemelt minőséget is tartalmazunk: MRQ (maximális renderelés). Kattintson a: Export gombra. Processzor letöltése Legfeljebb 20% és RAM 2.56 GB. Az ATI mobilitás Radeon HD 5730 GPU 97% és 35,2b fedélzeti video memória. A laptopot az akkumulátorból való működés során teszteltük, ezért a grafikus mag / memória alacsony frekvenciákon működik: 375/810 MHz. Az eredményváltozás kimeneti ideje: 1 perc és 55 másodperc (Be / Ki MRQ A motor GPU használatakor nem befolyásolja az eredményidőt). Jelenlegi óra frekvenciák az akkumulátorról: 930 MHz. AMEENCODINGLOG-t futtatunk, és megnézzük a hibás összefüggés végső arányát: 5 perc és 14 másodperc. Ismételjük a tesztet, de már egy donkeeperrel használja a maximális renderelést, nyomja meg a gombot: Queue. Az eredményváltozás kimeneti ideje: 1 perc és 17 másodperc. Most viszont a GPU motor Adobe Media Encoder CC futtassa az Adobe Premiere Pro CC programot, nyomja meg a billentyűkombinációt: Ctrl + F12, végezze Konzol\u003e Konzol megtekintése és a Command a területen, kattintson GPUSniffer nyomja meg az ENTER gombot. Kiosztjuk és másoljuk a nevét a GPU számítási információban. Az Adobe Premiere Pro CC programban megnyitja az OpenCL_SUPPORTED_CARDS dokumentumot, és az ábécé sorrendben meghajtja a chipset kódnevét, Ctrl + S. Kattintson a gombra: Queue, és GPU gyorsulása az Adobe Premiere Pro CC projekt az Adobe Media Encoder CC-ben. Végső idő: 1 perc és 55 másodperc. Csatlakoztatjuk a laptopot a kimenethez, és ismételje meg a hibáskulációk eredményeit. Queue, DAW MRQ eltávolította, anélkül, hogy bekapcsolná a motort, a RAM letöltése egy kicsit nőtt: Jelenlegi óra frekvenciák: 1,6 GHz, amikor a kimenetről és a bekapcsolás üzemmód: nagy teljesítmény. Végső idő: 46 másodperc. Kapcsolja be a motort: \u200b\u200bMercury Playback Engine GPU gyorsítás (OpenCL), Amint a hálózatról látható, laptop video kártya működik az alapfrekvenciáján, az Adobe Media Encoder CC GPU terhelése eléri a 95% -ot. Az eredményváltozás kimeneti ideje, csökkent 1 perc 55 másodperckorábban 1 perc és 5 másodperc. * Az Adobe Media Encoder CC vizualizációjához egy grafikus processzort (GPU) használnak. A CUDA és az OpenCL szabványok támogatottak. Az Adobe Media Encoder CC-ben a GPU-motorot a következő vizualizációs folyamatokra használják: Olvastunk a rejtett partícióról az ASUS N71JQ laptop rendszerlemezén. A magok nem sokat jelentenek ... A modern GPU-k szörnyű feltérképezési állatok, amelyek gigabájtokat tudnak rágni. Azonban egy emberi ember, és nem számít, mennyi számítástechnikai hatalom nőtt fel, felmerül feladatok Minden bonyolultabb és nehezebb, így egy pillanatra jön, amikor szomorúsággal kell állnia - kell optimalizálnod 🙁 Ez a cikk leírja a fő fogalmakat annak érdekében, hogy könnyebben navigáljon a GPU-optimalizálás elmélete és az alapvető szabályok elméletében annak érdekében, hogy ezeket a fogalmakat kevésbé gyakori módon kezeljük. Az okok, amelyeknek a GPU hatékonyan dolgozik a feldolgozást igénylő nagy mennyiségű adatokkal: Memória sávszélesség (memória sávszélesség) - Ez az, hogy mennyi információ van egy kicsit vagy a gigabájt - időnként a második vagy a processzor tapintat. Az egyik optimalizálási feladat az, hogy a maximalizálási kapacitást használja - növelje a mutatókat Átjáró.(Ideális esetben egyenlőnek kell lennie a memória sávszélességével). A sávszélesség használatának javítása: Késleltetés - Az idő intervallum a pont, amikor a szabályozó igényelt specifikus memória cella, és abban a pillanatban, amikor az adat vált elérhetővé a processzor utasítások végrehajtására. Nem befolyásolhatjuk a késedelmet - ezek a korlátozások a hardver szintjén vannak jelen. Ennek a késleltetésnek a rovására van, hogy a processzor egyidejűleg több patakot is szolgálhat - míg az áramlás és a memória elosztására kérte, az áramlás B számolhat valamit, és a kért adatok várakozásra kerülnek. A késleltetés csökkentése (késleltetés) Ha szinkronizálást használ: Az optimalizálásról szóló magas tercier beszélgetések gyakran villognak a kifejezéssel - gPU kihasználtság vagy kernel foglaltsága - tükrözi a videokártya-erőforrások használatának hatékonyságát. Külön, megjegyzem - ha az összes forrást is használod - ez nem jelenti azt, hogy helyesen használja őket. A GPU számítástechnikai teljesítmény több száz mohó processzor, mielőtt a számítástechnika, a program létrehozásakor - a rendszermag (kernel) - a programozó vállára helyezi a terhelés terjesztését. A hiba arra a tényre vezethet, hogy az értékes erőforrások többsége céltalanul szembesülhet. Most megmagyarázom, miért. Indítsa el távolról. Hadd emlékeztessem meg, hogy a lánc ( warp.
Az NVIDIA terminológiában, hullámfront.
- AMD terminológiában) - olyan adatfolyamok készlete, amelyek egyszerre hajtják végre a processzor azonos feszített Cernel funkcióját. A blokkokban lévő programozó által kombinált patakok a meleges tervező áramokra vannak osztva (külön-külön minden egyes többprocesszorra) - Míg egy láncszem, a második várja a memóriára irányuló kérések feldolgozását stb. Ha a Warp bármelyike \u200b\u200btovábbra is számít számításokat, míg mások már mindent megtettek, hogy hatástalanítanák a számítástechnikai erőforrás - az emberek, akik a megkönnyítő kapacitást nevezik. Minden egyes szinkronizációs pont, mindegyik logika elágazása ilyen leállást generálhat.
A maximális eltérés (a végrehajtás logikájának elágazása) a lánc méretétől függ. Az NVIDIA GPU 32, az AMD - 64 esetében. Annak érdekében, hogy csökkentse az egyszerű többprocesszort a lánc végrehajtása során: A probléma hatékony megoldásához értelme megérteni - hogyan képződik a lánc kialakulása (több dimenzióval rendelkező eset). Tény, hogy a megrendelés egyszerű - először X, majd Y és utolsó, Z. a rendszermag 64 × 16-os dimenzióval rendelkező blokkokkal kezdődik, a patakok az X, Y, Z - I.E. Az első 64 elem két láncra, majd a második stb. A rendszermag 16 × 64 blokkokkal kezdődik. Az első és a második elemek az első lánchoz, a második lánccal - harmadik és negyedik stb. Hogyan lehet csökkenteni az eltérést (emlékezz - elágazás - nem mindig a kritikus teljesítményvesztés oka) A GPU erőforrások maximális használata GPU erőforrások sajnos is vannak korlátozások. És szigorúan beszélve a kernel funkció elindítása előtt, érdemes meghatározni a határértékeket, és amikor a terhelést elosztják, ezek a határértékek figyelembe veszik. Miért fontos? A videokártyák korlátozzák a teljes szálak számát, amelyek egy multiprocesszort, a maximális áramlási számok maximális számát végezhetik egy blokkban, az egyik processzor maximális számának maximális száma, korlátozások a különböző típusú memóriakártyákon és hasonlókon. Mindezek az információkat programozhatják, a megfelelő API-n keresztül és az SDK segédprogramok előzetes használatával. (Élő modulok Nvidia eszközökhöz, Clinfo - AMD videokártyákhoz). Általános gyakorlat: Emlékeztetni kell arra, hogy az abszolút minimum - 3-4 Warp / Beefront egyidejűleg forogjon az egyes processzoroknál, a bölcs útmutatók tájékoztatják a megfontolást - legalább hét vebronátot. Ugyanakkor - ne felejtsd el a korlátozásokat a mirigyen! A fejemben mindezen részletek gyorsan unatkoznak, mert a GPU-foglaltság kiszámításához Nvidia váratlan eszközt kínál - Exesel (!) Számológép, amely makróval csomagolt. Akkor információt ad meg a maximális számú folyam SM, a regiszterek száma és mérete közös (megosztott) szabad memória a streaming processzor, és a funkciók kiindulási funkciókat használnak - és ez ad egy százalékát az erőforrás-felhasználás hatékonyságának (és te szakad a fejedre, hogy rájöjjön, hogy mit használjon az összes magja, akinek nincs regisztrálja). információ a használatról: GPU és memória műveletek A videokártyák 128 bites memória műveletekhez vannak optimalizálva. Azok. Ideális esetben minden egyes manipuláció memóriával, ideális esetben meg kell változtatnia a 4 négybájt értéket. A programozó fő baja, hogy a GPU-k modern fordulatai nem tudják, hogyan optimalizálhatják az ilyen dolgokat. Ez közvetlenül a funkciókódba kell tennie, és átlagosan átlagosan növeli a teljesítmény növekedését. A teljesítményre gyakorolt \u200b\u200bsokkal nagyobb hatással van a memória kérések gyakoriságára. A probléma a következő - minden kérés adagot ad vissza egy többszörös 128 bit méretére. És minden adatfolyam csak egynegyedét használja (rendszeres négybájtos változó esetében). Ha a szomszédos áramok egyidejűleg dolgoznak a memóriatűsejtekben lévő adatokkal, csökkenti a memória fellebbezésének teljes számát. Ezt a jelenséget - kombinált olvasási és írási műveletek ( coalsced Access - Good! Olvasni és írni) - és a megfelelő szervezeti kóddal ( lépjen kapcsolatba a memória szomszédos darabjához - rossz!) Ez jelentősen javíthatja a teljesítményt. Ha a szervező a mag - emlékszik - szomszédos hozzáférés - belül az elemek egy memória húr, a munka az oszlop elemei már nem annyira hatékony. További részleteket szeretne? Tetszett ez a PDF - vagy a Google a témához " memória koalátum technikák.
“. A "keskeny hely" jelölés vezető pozíciója egy másik memória műveletet tartalmaz - adatok másolása a gazdagép memóriájából GPU-ban
. A másolás nem történik meg, mint egy speciálisan dedikált vezető- és memóriakártyáról: amikor az adatokat másolásból kéri - a rendszer először másolja ezeket az adatokat, és csak akkor töltse ki őket a GPU-ban. Az adatátviteli sebességet a PCI Express XN busz sávszélessége (ahol n az adatvonalak száma) korlátozza, amelyen keresztül a modern videokártyák kommunikálnak a gazdagépekkel. Azonban a lassú memória felesleges másolása a fogadóban néha indokolatlan költségek. Kilépés - használja az úgynevezett rögzített memória.
- Egy speciálisan megjelölt memóriaterületen, így az operációs rendszernek nincs lehetősége arra, hogy bármilyen műveletet végezzen vele (például a swap / mozgást a saját belátása szerint stb.). Az adatátvitel a fogadóból a videokártyán az operációs rendszer részvétele nélkül történik - aszinkron módon Dma
(Közvetlen memória hozzáférés). És végül egy kicsit többet a memóriáról. A többprocesszorra vonatkozó megosztott memóriát általában 32 bites szóval rendelkező memória-bankokként szervezik. A bankok jó hagyományok száma változik az egyik generációs GPU-tól a másikra - 16/32, ha minden egyes szálat az adatokra külön bankba kell kezelni - minden rendben van. Ellenkező esetben számos olvasási / írási kérés van egy jarra, és konfliktusokat kapunk ( megosztott memória bank konfliktus). Az ilyen konfliktuskezelőket sorosítják, és következetesen hajtják végre, és nem párhuzamosan. Ha az összes patakot egy banknak kell címezni - egy sugárzott választ használ ( adás.) Nincs konfliktus. Számos módon lehet hatékonyan kezelni a hozzáférési konfliktusokat, tetszett a memóriakártyákhoz való hozzáférésű konfliktusokból származó főbb módszerek leírása
– . Hogyan készítsünk a matematikai műveleteket még gyorsabban? Emlékezz arra: A CUDA-fejlesztők számára értelme, hogy szoros figyelmet fordítson a koncepcióra cuda patak,lehetővé teszi, hogy több magfunkciót futtatjon egyszerre egy eszközön, vagy az aszinkron másolási adatokat kombinálja a gazdagépről a készülékre a funkciók végrehajtása közben. OpenCL, most, ez a funkcionális nem ad 🙁 Util profilozáshoz: Az NVIFIA Visual Profiler érdekes segédprogram, elemzi a kerneleket CUDA és OpenCL-ben. P. S. Mint egy kiterjedtebb optimalizálási útmutató, javasolhatom a Google mindenfajta számára a legjobb gyakorlatok útmutatója
Az OpenCL és a CUDA számára. A GPU párhuzamos számítástechnikájáról beszélünk, emlékezzünk arra, hogy mikor élünk, ma, amikor mindent a világban felgyorsul, hogy elveszítjük a számláját veled, anélkül, hogy észrevennénk, hogyan rohan. Mindaz, amit csinálunk, az információfeldolgozás nagy pontosságával és sebességével járunk, ilyen körülmények között mindenképpen szükségünk van olyan eszközökre, amelyek kezelhetjük azokat az információt, amelyeket az adatokhoz kapcsolunk és konvertálunk az adatokhoz, emellett emlékeznünk kell olyan feladatokra, amelyeket ezek a feladatok nem szükségesek csak nagy szervezetek vagy mega-társaságok, valamint a hétköznapi felhasználók, akik megoldják a létfontosságú feladatokat magas technológiák Otthon a személyi számítógépeken! Az NVIDIA CUDA megjelenése nem meglepő, de inkább indokolt, mert rövid idő alatt jelentősen több időigényes feladatokat kell feldolgozni a számítógépen, mint korábban. A korábban elfoglalt munka, amelyet sok időt vesz igénybe, most néhány percet vesz igénybe, ez befolyásolja az egész világ általános képét! A GPU számításai a GPU használata a technikai, tudományos, hazai problémák kiszámításához. A GPU kiszámítása a CPU és a GPU használatát tartalmazza heterogén mintával köztük, nevezetesen: a programok következetes része a CPU-t veszi át, míg az időigényes számítástechnikai feladatok továbbra is GPU maradnak. Ennek köszönhetően a feladatok párhuzamosítása következik be, ami az információfeldolgozás gyorsításához vezet, és csökkenti a végrehajtási időt, a rendszer termelékenyebbé válik, és egyidejűleg több feladatot is kezelhet, mint korábban. Annak érdekében azonban, hogy az ilyen sikert egyedül a hardvertámogatással lehessen elérni, ez nem feltétlenül szükséges, ebben az esetben a támogatást is szükség lehet arra, hogy az alkalmazás átruházhatja a leginkább időigényes számításokat a GPU-ra. CUDA - programozási technológia az SI algoritmusok egyszerűsített nyelvén, amelyeket a GeForce GeForce grafikus processzorok és az idősebbek, valamint az Nvidia megfelelő Quadro és Tesla kártyákon végeznek. A CUDA lehetővé teszi, hogy sajátos funkciókat tartalmazzon az SI szövegében. Ezeket a funkciókat egyszerűsített SI programozási nyelven írják, és grafikus processzoron hajtják végre. A CUDA SDK kezdeti verzióját 2007. február 15-én képviselték. A sikeres sugárzási kód ezen a nyelven, a CUDA SDK magában foglalja saját SI fordítóját. parancs sor NVCC NVIDIA cégek. Az NVCC fordító az Open64 Open Compileren alapul, és úgy van kialakítva, hogy a fogadó kód (fő, vezérlő kód) és az eszközkód (hardverkód) (hardverkód) (a .cu kiterjesztésű fájlokat) sugározza az összeszerelés folyamatában Végső program vagy könyvtár bármely programozási környezetben, mint például a Microsoft Visual Studio. A program leginkább fogyasztása egy tinktúra. A program konzol felületén van, de a programhoz csatolt utasításnak köszönhetően használható. A program létrehozásának rövid utasítása. Mi fogjuk ellenőrizni a program teljesítményét, és összehasonlítani egy másik hasonló programmal, amely nem használja az NVIDIA CUDA-t, ebben az esetben ez a jól ismert program "Advanced Archive Password Recovery". A repedt CRARK Archívumból csak három fájlra van szükségünk: crark.exe, crark-hp.exe és password.def. A Circlak.exe egy konzolos segédprogram a jelszavak megnyitásához RAR 3.0 anélkül, hogy titkosított fájlok nincsenek az archívumon belül (azaz az archívum felfedése, a nevet látjuk, de nem csomagolhatjuk meg az archívumot jelszó nélkül). Circa-hp.exe egy konzolos segédprogram nyitó jelszó RAR 3.0 egészében titkosított archív (azaz felfedi az archív, nem látunk semmilyen nevet, sem a levéltár magukat, és nem tudja kicsomagolni az archívum jelszó nélkül). Password.DEF bármely átnevezett szövegfájl, nagyon alacsony (például: 1. sor: ## 2. sor :? *, ebben az esetben, a jelszó megnyitása minden karakter használatával történik). A jelszó.def a CRARK program vezetője. A fájl tartalmazza a jelszó megnyitására vonatkozó szabályokat (vagy a crark.exe által használt karakterek területét). További információk a lehetőségek kiválasztásával ezek a jelek van írva egy szöveges fájlban érkezik, amikor nyitás le a helyszínen a szerző a program CRARK: russian.def. Azonnal azt mondom, hogy a program csak akkor működik, ha a videokártya a GPU-n alapul, amely támogatja a CUDA 1.1 gyorsulási szintjét. Tehát a G80 chipen alapuló videokártya, például a GeForce 8800 GTX, eltűnik, mivel a CUDA 1.0 gyorsítás hardvertámogatása van. A program felveszi a CUDA csak jelszavakat a RAR 3.0+ archívumokon. Szükséges a CUDA-hoz társított szoftvert, nevezetesen: Hozzon létre bármilyen mappát bárhol (például egy lemezen :), és hívjon semmilyen nevet például "3.2". A fájlokat ott helyezzük el: crark.exe, crark-hp.exe and password.def és parrette / titkosított rar archívum. Ezután futtassa a parancskonzolot windows húrok És menj hozzá a létrehozott mappához. A Windows Vista és a 7, hívja a "Start" menüt, és írja be a "Cmd.exe" keresési mezőbe, a Windows XP rendszerben a Start menüben először hívja a "Run" párbeszédablakot, és már írja be a "cmd.exe" -t. A konzol megnyitása után írja be a Típus parancsot: CD C: \\ mappa \\, CD C: \\ 3.2 Ebben az esetben. B. szöveg szerkesztő Két sor (akkor is menteni a szöveget, mint a .bat fájlt a mappában CRARK) válassza jelszava passerous RAR nem titkosított fájlokat: visszhangzik; jelszó jelszavának kiválasztása és titkosított RAR archívuma: visszhangzik; Másolja át a szövegfájl 2 sorát a konzolba, és nyomja meg az Enter (vagy Run.bat fájlt) gombot. A dekódolási folyamat az ábrán látható: A CRARK kiválasztási sebessége CUDA használatával 1625 jelszó / másodperc volt. Egy percig, harminchat másodpercre, a 3 jelszóval rendelkező jelszó volt kiválasztva: "Q) $." Összehasonlításképpen: az oltás sebessége a fejlett archívum jelszó helyreállításában a belvárosomon athlon processzor A 3000+ egyenlő, legfeljebb 50 jelszó / másodperc, és a mellszobor 5 órát kell tartania. Azaz, a kiválasztás Bruteforce a CRARK RAR a GeForce 9800 GTX + videokártya fordul 30-szor gyorsabb, mint a CPU. Azok számára, akiknek egy Intel processzorral rendelkeznek, egy jó rendszerfedél a rendszerbusz (FSB 1600 MHz) nagyfrekvenciájával, a Rate CPU jelzővel és a keresés méretével magasabb lesz. És ha van egy négy magos processzor, és egy pár GEFORCE 280 GTX videokártyák, akkor a sebesség jelszavakat felgyorsul időnként. Összefoglalva a példát, azt kell mondanom, hogy ezt a feladatot a Cuda Technology segítségével minden 2 percig 5 óra helyett mindössze 2 percig megoldották, ami nagy lehetőségeket jelent a technológia számára! Miután ma tekintettük a párhuzamos CUDA számítások technológiáját. Vizuálisan láttuk az összes hatalmat és óriási potenciált a technológia fejlesztésére a program példáján a RAR archívumok jelszavának helyreállítására. Meg kell mondanom a technológia kilátásairól, ez a technológia minden bizonnyal megtalálja a helyet minden olyan személy életében, aki megoldja azt, hogy a tudományos feladatok vagy a videofeldolgozáshoz kapcsolódó feladatok, vagy akár olyan gazdasági feladatok, amelyek gyors pontosságot igényelnek Számítás, mindez az elkerülhetetlen növekedéshez vezet, amelyet nem lehet észrevenni. A mai napig a "Home SuperComputer" kifejezés már elkezdődik a lexikonba; Teljesen nyilvánvaló, hogy egy ilyen tétel megvalósítása minden házban van, már van egy CUDA nevű eszköz. Mivel a G80-as chipen alapuló térképek kimenete (2006) nagy mennyiség Nvidia gyorsítók támogatják a CUDA technológiát, amely képes megtapasztalni az álmokat a szuperszámítógépekről a valóságban. A CUDA technológiájának előmozdítása, az NVIDIA az ügyfelek szemében az ügyfelek szemében adja meg további jellemzők Azok, amelyeket sokan már megvásároltak. Csak azt kell hinni, hogy hamarosan a CUDA nagyon gyorsan fejlődik, és biztosítja a felhasználók számára, hogy teljes mértékben kihasználják a párhuzamos számítástechnika összes képességét a GPU-n. AMD / ATI RADEON Építészeti jellemzők Ez hasonló az új biológiai fajok születéséhez, amikor az élő lények fejlődnek az élőhely élőhelyeinek fejlesztésében, hogy javítsák a médium alkalmazkodóképességét. Így és a GPU, kezdve gyorsulás raszterizációs és állományjavító háromszögek kifejlesztett további teljesítéséhez szükséges shader programokat festéséhez ezek leginkább háromszög. Ezek a képességek a keresletben és az írástudatlan számításokban kiderültek, ahol egyes esetekben jelentős teljesítményt nyújtanak a hagyományos megoldásokhoz képest. Analógiát végezzünk tovább - egy hosszú evolúció után a földön, az emlősök behatoltak a tengerbe, ahol szokásos tengeri lakosokat toltunk. A versenyszerű küzdelem, emlősök egyaránt használható új, fejlett képességeit, hogy megjelent a Föld felszínét, és kifejezetten szerzett alkalmazkodni az élet a vízben. Hasonlóképpen, a GPU, az építészet előnyei alapján 3D-s grafika, egyre inkább a különleges funkcionalitásHasznos a távoli feladatok távoli problémáinak végrehajtásához. Tehát, mi lehetővé teszi a GPU számára, hogy jogosult legyen saját szektorára az általános célú programok területén? A GPU mikroarchitektúra épül egészen más, mint a szokásos CPU-k és bizonyos előnyökkel eredetileg megállapított benne. A diagram feladatok független párhuzamos adatfeldolgozást vállalnak, és a GPU eredetileg szaporodott. De ez a párhuzamosság csak öröm. A mikroarchitektúra célja a rendelkezésre álló nagyszámú szálak működtetése. A GPU áll, több tucat (30 NVIDIA GT200, 20 - az Evergreen, 16 - a Fermi) processzor magok, amelyek úgynevezett Streaming többprocesszoros a NVIDIA terminológia, és ATI-SIMD Engine terminológiát. Ennek részeként a cikkben fogjuk hívni őket mini-feldolgozók, mert végre több száz programot szálak és tudja, hogyan kell szinte minden ugyanaz, mint a szokásos CPU, de nem minden. A marketing nevek összezavarodtak - számukra jelentős fontosságú, jelezze a levonható és megszorozódó funkcionális modulok számát: például 320 Vector "magvak" (magja). Ezek a magok inkább szemek. Jobb, ha a GPU-t többmagos processzorként ábrázolják, nagyszámú maggal, amelyek egyidejűleg különböző szálakat végeznek. Mindegyik miniprocesszornak helyi memóriája van, a 16 kb méretű GT200, 32 KB-ra - az Evergreen és a 64 kB - Fermi számára (valójában ez egy programozható L1 gyorsítótár). Hasonlóan a szokásos CPU hozzáférési idő első szintjével rendelkezik, és a nagyobb adatszállítás hasonló funkcióit végzi a funkcionális modulokhoz. A Fermi-architektúrában a helyi memória része szokásos gyorsítótárként konfigurálható. A GPU-ban a helyi memória gyorsan cseréli az adatokat a végrehajtó szálak között. A szokásos GPU programrendszer egyike: a helyi memória elején a GPU globális memóriájából származó adatok betöltődnek. Ez csak egy hétköznapi video memória (valamint rendszermemória) Külön a „z” processzor - abban az esetben, videó, ültették be több chip a Textolit a videokártya. Ezután több száz szál működik ezekkel az adatokkal a helyi memóriában, és írja az eredményt a globális memóriába, amely után továbbítják a CPU-nak. A programozó felelőssége tartalmazza a helyi memóriából származó adatok letöltésére és kirakodására vonatkozó utasításokat. Valójában ez az adatok particionálása [ különleges feladat] Párhuzamos feldolgozásra. A GPU is támogatja atomi bejegyzések / olvasási utasításokat, de ezek hatástalanok, és általában a kereslet a végső szakaszban a „ragasztás” eredmények kiszámításához minden miniprocessors. A helyi memória gyakori a mini-processzorban végzett összes szál esetében, ezért például az NVIDIA terminológiában is megosztott, és a helyi memória kifejezést az ellenkezője jelzi, nevezetesen: az a Külön szál a globális memóriában, látható és hozzáférhető csak hozzá. De a helyi memória mellett egy mini-processzorban van egy másik memória terület, minden architektúrában körülbelül négyszer nagy mennyiségben. Ugyanígy oszlik meg az összes végrehajtó szál között, ezek nyilvántartások a változók tárolására és a számítások közbenső eredményeire. Minden szál több tucat regiszterre számít. A pontos összeg attól függ, hogy hány szálat végez egy miniprocesszor. Ez az összeg nagyon fontos, mivel a globális memória késleltetése nagyon nagy, több száz óra, és a gyorsítótár hiányában nincs hely a köztes számítások köztes eredményeinek tárolására. És a GPU egyik legfontosabb jellemzője: "puha" vektor. Minden miniprocesszornak számos számítástechnikai modulja van (8 GT200, 16 Radeon és 32 Fermi számára), de mindössze ugyanazokat az utasításokat lehet végrehajtani egy szoftvercímekkel. Az operandok eltérőek lehetnek, a különböző szálak sajátjuk. Például az utasítás hajtsa be a két regiszter tartalmát: Az összes számítástechnikai eszköz egyidejűleg végrehajtja, de a regiszterek különbözőek. Feltételezzük, hogy a GPU program összes hányada, amely párhuzamos adatfeldolgozást végez, általában a programkód párhuzamos pályán mozog. Így minden számítástechnikai modul egyenletesen van betöltve. És ha a szálak a program fióktelepei miatt megosztották a kód végrehajtásának módját, akkor az úgynevezett szerializáció következik be. Ezután nem minden számítástechnikai modulot használnak, mivel a szálakat különböző utasítások végrehajtásához nyújtják be, és a számítástechnikai modulok blokkja végrehajtható, ahogy azt mondtuk, csak egy címmel rendelkező utasításokat. És természetesen a teljesítmény csökken a maximálishoz képest. Az előny az, hogy a vektorizálás automatikusan automatikusan automatikusan automatikusan, ez nem programozás SSE, MMX és így tovább. És a GPU maga az eltéréseket feldolgozza. Elméletileg általában programokat írhat a GPU számára, anélkül, hogy a végrehajtó modulok vektor jellegére gondolna, de az ilyen program sebessége nem lesz nagyon magas. A mínusz a vektor nagy szélességében fekszik. Ez nagyobb, mint a funkcionális modulok névleges száma, és 32 a GPU Nvidia és a 64 Radeon számára. A szálakat a megfelelő méretű blokkok feldolgozzák. NVIDIA hívja ezt a szálas blokkot egy lánccal, az AMD - hullám első, hogy ugyanaz. Így 16 számítástechnikai eszközök "hullámfront" 64 hosszú szálat feldolgoznak négy óra (az utasítás szokásos hossza alapján). A szerző inkább ebben az esetben a kifejezés Warp, mivel a Szövetség a tenger kifejezés Warp, amely azt a kötelet kapcsolódó kötél kapcsolatos kötelek. Tehát a szálak "csavart", és szilárd szalagot alkotnak. Azonban a hullámfront is társulhat a tengerhez: az utasítások is megérkeznek a végrehajtó eszközökhöz, mint a hullámok egymás után a többi hengerelt partra. Ha az összes szál ugyanolyan előrehaladott a program végrehajtásában (egy helyen van), és így egy utasítást hajt végre, akkor minden rendben van, de ha nem - lassul. Ebben az esetben az egyik láncból vagy hullámfrontból származó szálak a program különböző területeiben találhatók, azok olyan szálcsoportokra vannak osztva, amelyek azonos számú utasításszámmal rendelkeznek (más szavakkal, az utasítás mutatója (utasítás mutató)) . És még mindig csak egy időben végeznek, csak az azonos csoport szálai - minden teljesít ugyanazt az utasítást, de különböző operandusokkal. Ennek eredményeképpen a Warp olyan sokszor lassabb, ha hány csoport van törve, és a csoportban lévő szálak száma nem rendelkezik. Még ha a csoport mindegyik szálból áll, akkor továbbra is ugyanaz, mint a teljes lánc. A mirigyben bizonyos szálak maszkolása, azaz az utasítások formálisan végrehajtásra kerülnek, de a végrehajtásuk eredményeit nem rögzítik bárhol, és a jövőben nem használják. Bár az idő minden pillanatában minden egyes miniprocesszor (Streaming Multiprocessor vagy SIMD motor) csak egy lánccal (kapcsolata a szálak) tartozó utasításokat hajt végre, több tucat aktív lánccal rendelkezik a végrehajtható medencében. Az egyetlen lánc utasításainak kitöltésével a miniprocesszor végzi el a lánc utasításait, de az utasításokat valaki más a lánc. Ez a lánc egy teljesen más programhelyzetben lehet, nem befolyásolja a sebességet, mivel csak az összes szál láncos utasításaiban kötelesek teljes mértékben a teljes sebességgel. Ebben az esetben a 20 SIMD-motor mindegyike négy aktív hullámfront, mindegyikben 64 szál. Minden szálat rövid vonal jelzi. Összesen: 64 × 4 × 20 \u003d 5120 szál Így, tekintettel arra, hogy minden egyes deformálhatja vagy hullám előtt áll 32-64 szálak, a miniprocessor több száz aktív szálak, amelyek végrehajtódnak szinte egyszerre. Az alábbiakban látni fogjuk, amely az építészeti előnyök ilyen nagyszámú párhuzamos szálakat, de először azt, ami a korlátozások az alkatrészeket a GPU mini-processzorok. A fő dolog az, hogy a GPU-ban nincs köteg, ahol a funkciók paraméterei és helyi változók tárolhatók. A köteg nagy mennyiségű szálának köszönhetően egyszerűen nincs hely a kristályon. Sőt, mivel a GPU egyidejűleg végzi a sorrendben 10.000 szálak, a méret a köteg egy szál 100 KB, a teljes mennyiség 1 GB lesz, amely egyenlő a standard térfogatú teljes videomemória. Különösen nincs lehetőség arra, hogy a GPU-kernel bármilyen jelentős méretét elhelyezzük. Ha például egy 1000 bájtot helyez a szálra, akkor csak egy mini-processzor szükséges 1 MB memóriát, amely majdnem ötször több, mint a mini-processzor és a memória helyi memóriájának teljes összege A nyilvántartások tárolása. Ezért nincs rekurzió a GPU programban, és a funkciókkal nem lesz különösen kibontakozás. Minden funkció közvetlenül helyettesíti a kódot a program összeállításakor. Ez korlátozza a GPU alkalmazási körét a számítástechnikai feladatokhoz. Néha lehet, hogy egy korlátozott vetélkedés a verem segítségével globális memória rekurzív algoritmusok egy ismert kis iterációs mélység, de ez egy tipikus alkalmazás a GPU. Ehhez kifejezetten egy algoritmust kell kifejleszteni, hogy megvalósításának lehetősége legyen a sikeres gyorsulás garanciája nélkül a CPU-hoz képest. A Fermi-ben először virtuális funkciókat használhatunk, de a használatukat az egyes szálak nagy gyors gyorsítótárának hiányára korlátozhatja. A 1536 szálban 48 kb-t vagy 16 kb L1-et tartalmaz, azaz a program virtuális funkciói viszonylag ritkán használhatók, különben a verem lassú globális memóriát is használ, amely lelassítja a végrehajtást, és valószínűleg nem fogja Előnyök a CPU opcióhoz képest. Így a GPU képviselteti magát, mint számítástechnikai koprocesszor, amelyben az adatok betöltése, azok feldolgozása néhány algoritmus, és az eredményt ki. De nagyon gyorsan tartja a GPU-t. És ebben, hogy segíti a magas multiplowitását. A nagy számú aktív szál lehetővé teszi részben, hogy elrejtse a nagyobb latenciát, amely külön-külön globális video memóriát tartalmaz, ami körülbelül 500 órát jelent. Különösen jól kiegyenlített kód, amely nagy sűrűségű aritmetikai műveletekkel rendelkezik. Így nem igényel drága az L1-L2-L3 gyorsítótár tranzisztorai hierarchiájának szempontjából. Ahelyett, hogy sok számítástechnikai modul található a kristályon, biztosítva a kiemelkedő aritmetikai teljesítményt. Időközben az egyik szál vagy lánc utasításai teljesülnek, a többi száz szál csendesen várja az adatokat. A Fermi-ben egy második szintű gyorsítótárat vezettek be körülbelül 1 MB méretű, de nem hasonlítható össze a modern processzorok gyorsítótárjával, hosszabb a magok és a különböző szoftver trükkök közötti kommunikációhoz. Ha a méretét több tucat több ezer szál között osztják meg, mindegyiknek mindenkinek jelentéktelen mennyiségben kell lennie. De a globális emlékezet késleltetése mellett még mindig sok látens látens a számítástechnikai eszközön, amelyet elrejteni kell. Ez az adatátvitel latenciája a Crystal belsejében a számítástechnikai eszközökről az első szintű gyorsítótárba, azaz a helyi GPU memóriára, valamint a regiszterekre, valamint az utasítások gyorsítótárra. A nyilvántartás fájlt, mint a helyi memóriát, külön helyezkedik el a funkcionális modulok, valamint a hozzáférés sebessége az őket körülbelül egy évszázaddal a taway. És ismét számos szál, aktív lánc, lehetővé teszi, hogy hatékonyan elrejtse ezt a késleltetést. Ezenkívül a teljes GPU helyi memóriájához való hozzáférés teljes sávszélessége (sávszélesség), figyelembe véve a mini-processzorok összetevőinek számát, sokkal nagyobb, mint az első szintű gyorsítótár-hozzáférés sávszélessége a modern CPU-ban. A GPU jelentősen több adatot tud újrahasznosítani. Azonnal azt mondhatja, hogy ha a GPU-t nem tartalmaz nagy számú párhuzamos szál, akkor szinte nulla teljesítményű lesz, mert ugyanolyan ütemben fog működni, mintha teljesen betöltődik, hanem sokkal kisebb munkát végez. Például, hagyja, hogy csak egy 10 000 szál helyett legyen: a teljesítmény körülbelül ezer alkalommal esik, mert nem csak az összes blokk betöltődik, de minden késleltetés hatással lesz. Az Ortre és a modern nagyfrekvenciás CPU-k késleltetésének problémája, kifinomult módon használják a mély csővezetékek kiküszöbölésére, az utasítások rendkívüli végrehajtása (rendelés). Ehhez komplex tervezők szükségesek az utasítások végrehajtásának, különböző puffereknek stb., Ami a kristályon történik. Minden szükséges legjobb teljesítmény Egyszálú üzemmódban. De a GPU esetében mindez nem szükséges, építészeti szempontból gyorsabb a számítási problémák nagyszámú szálakkal. De a multithreading teljesítményt alakítja át, mivel filozófus kője aranyba vezet. A GPU eredetileg kialakított optimális végrehajtását shader programokat pixel háromszögek, melyek nyilvánvalóan független és lehet párhuzamosan végrehajtani. És ebből az állapotból, akkor alakult ki úgy, hogy különböző képességeket (és helyi memória címezhető hozzáférést videomemória, valamint a szövődmények az utasításkészlet) egy nagyon erős számítástechnikai eszköz, amely továbbra is hatékonyan alkalmazható csak algoritmusok, amelyek lehetővé teszik a nagy -Parallel megvalósítás korlátozott helyi kötet memóriával. A GPU egyik legklasszikusabb feladata az N testek kölcsönhatásának kiszámításának feladata, gravitációs mező létrehozása. De ha például ki kell számolni a földhold-naprendszer fejlődését, akkor a GPU rossz asszisztens: kevés tárgyat. Minden objektumhoz szükség van az összes többi objektummal való kölcsönhatás kiszámítására, és csak kettő van. A naprendszer mozgása esetén a bolygókkal és a lunával (néhány száz objektumról), a GPU még mindig nem túl hatékony. Azonban a multi-core processzor miatt a magas rezsi áramlik folyamvezérléshez vagy szintén nem képes megmutatni az összes erő, fog működni egy menetes mód. De itt is, ha ki kell számolnia az üstökös övek üstökösjeinek és tárgyainak pályáit is, akkor már feladat a GPU számára, mivel az objektumok elegendőek ahhoz, hogy létrehozzák a szükséges számú párhuzamos számítási áramlást. A GPU is jól mozog, ha ki kell számolni a golyós klaszterek ütközését több százezer csillagból. Egy másik lehetőség, hogy a GPU-teljesítményt használja a feladat n testületeiben, akkor jelenik meg, ha az egyedi feladatok különböző feladatokat kell kiszámítani, még kis mennyiségű tel. Például, ha ki szeretné kiszámolni az egyik rendszer fejlődésének változatát különböző opciókkal a kezdeti sebességekhez. Ezután hatékonyan használja a GPU-t problémamentesen. Megvizsgáltuk a GPU szervezet alapelveit, közösek az összes gyártó video-gyorsítójaival, mivel kezdetben egy célfeladat - Shader programok voltak. Azonban a gyártók megtalálta a lehetőséget arra, hogy eloszlassa a részleteket microarchctural végrehajtását. Bár a különböző gyártók CPU-k néha nagyon eltérőek, még kompatibilisek is, például Pentium 4 és Athlon vagy mag. Az NVIDIA architektúra már jól ismert, most nézzük meg Radeon és kiemelje a fő különbség a megközelítések ilyen szolgáltatók. Az AMD videokártyák teljes körű támogatást kaptak az általános célú számítástechnika az örökzöld családtól kezdve, amelyben a DirectX 11 specifikációt először is végrehajtották. A 47xx-es családi kártyáknak számos jelentős korlátozása van, amelyeket az alábbiakban tárgyalunk. A helyi memória méretének különbségei (32 kb Radeon vs. 16 kb a GT200 és a 64 kb-ban Fermiben) általában nem alapvető fontosságúak. Mint a hullámfront mérete 64 szálban az AMD-nél 32 szálat az NVIDIA-ban. Majdnem bármilyen GPU program könnyen konfigurálható és konfigurálható ezeknek a paramétereknek. A teljesítmény több tucat százalékra válthat, de a GPU esetében nem annyira alapvetően, hogy a GPU program általában tízszer lassabban működik, mint az analóg a CPU-hoz, vagy tízszer gyorsabban működik, vagy egyáltalán nem működik. Fontosabb a AMD technológia VLIW (nagyon hosszú utasításos szó). Az NVIDIA Skalar egyszerű utasításokat használ, amelyek skaláris regiszterekkel működnek. A gyorsítója egyszerű klasszikus Riscot valósít meg. Az AMD videokártyák ugyanolyan számú regiszterrel rendelkeznek, mint GT200, de a regiszterek 128 bites regiszterek. Minden VLIW utasítás több négykomponensű 32 bites regiszterben működik, amelyek hasonlítanak SSE-re, de a VLIW funkciók sokkal szélesebbek. Ez NEM SIMD, mint az SSE - Itt utasítások minden egyes operandus más lehet, és akár függő is lehet! Például, hagyja, hogy az A regiszter összetevőit A1, A2, A3, A4-nek nevezzük; A B regiszter hasonló. Kiszámítható egy olyan utasítás alkalmazásával, amelyet egy óra, például az A1 × B1 + A2 × B2 + A3 × B3 + A4 × B4 vagy kétdimenziós vektor (A1 × B1 + A2 × B2, A3 × B3 + A4 × B4). Ezt lehetővé tette az alacsonyabb GPU-gyakoriságnak köszönhetően, mint a CPU, és az elmúlt években a folyamat erős csökkenése. Nem igényel semmilyen tervezőt, szinte mindent a tapintat végez. A vektoros utasításoknak köszönhetően a Radeon csúcs teljesítménye az egyes pontossági számokban nagyon magas, és már alkotja a terápolyát. Egy vektor-nyilvántartás helyett négy számú egypontos pontosságot tárolhat egy számú kettős pontosságot. És egy VLIW utasítást sem szeres két pár dupla szám, vagy két számot, vagy két számot, és karba a harmadik. Így a páros csúcs teljesítménye körülbelül ötször alacsonyabb, mint az úszóban. A radeon modellek esetében megfelel az NVIDIA TESLA teljesítményének az új Fermi-architektúrán és sokkal magasabb, mint a GT200 architektúrán lévő kettős kártyák teljesítményével. A FERMI-n alapuló fogyasztói GeForce videokártyáknál a kettős számítás maximális sebessége négyszer csökkent. A GPU gyártók, ellentétben a CPU gyártókkal (elsősorban az X86-kompatibilis) nem kapcsolódnak a kompatibilitási problémákhoz. A GPU program első összeállítani egy bizonyos köztes kódot, és amikor a vezető elkezdi a vezető állítja össze ezt a kódot a gépi utasítások egy specifikus modell. Mint fentebb említettük, a GPU-gyártók kihasználták ezt, feltalálás kényelmes ISA (Instruction Set Architecture) annak GPU és azok módosítása generációról generációra. Ez minden esetben a hiány hiánya miatt hozzáadott néhány százalékot (szükségtelen) dekóder miatt. De az AMD még tovább ment, feltalva saját formátumát a gépkód utasításainak helyén. Ezek nem következetesen (a program felsorolása szerint) és szakaszok szerint vannak elhelyezve. Először is, a szekcionált átmeneti utasításokat követték, amelyek hivatkoznak a folyamatos aritmetikai utasítások egységeire, amelyek megfelelnek a különböző átmeneti ágazatoknak. Ezeket VLIW kötegek (VLIW-oktatási ligamentumok). Ezek a szakaszok csak aritmetikai utasításokat tartalmaznak a nyilvántartásokból vagy a helyi memóriából származó adatokkal. Egy ilyen szervezet leegyszerűsíti az utasítások áramlását és a végrehajtó eszközöknek történő szállítását. Ez sokkal hasznosabb, mivel a VLIW utasítások viszonylag nagy méretűek. Vannak szekciók is a memória fellebbezésére. A GPU mind a gyártók (és az Nvidia és az AMD) is beépített gyorsszámítási utasításokat is tartalmaznak több alapvető matematikai funkcióra, négyzetgyökérre, kiállítókra, logaritmusokra, szinárokra és koszinókra egyetlen pontossági számokra. Ehhez speciális számítástechnikai blokkok vannak. Ők "bekövetkeztek" annak szükségességétől, hogy végrehajtsák ezeket a funkciók gyors közelítését a geometriai szörfösökben. Ha még valaki sem tudta, hogy a GPU-t a grafika használták, és csak megismerkedtek technikai sajátosságokEnnek alapján tudta kitalálni, hogy ezek a számítástechnikai társprocesszorokat történt Video forrásokból. Hasonlóképpen, a tengeri emlősök bizonyos mértéke szerint a tudósok rájöttek, hogy őseik földi lények voltak. De egy nyilvánvalóbb tulajdonság, amely kiadja a készülék grafikai eredetét, ezek a kétdimenziós és háromdimenziós textúrák olvasása a bilineáris interpolációhoz. A GPU-programokban széles körben használják őket, mivel gyorsított és egyszerűsített olvasást adnak a Diad-csak adathordozóknak. A GPU alkalmazás egyik standard viselkedése a forrásadat-tömböket olvasja, feldolgozza azokat a számítástechnikai kernelekben és rögzíti az eredményt egy másik tömbbe, amelyet tovább továbbítanak a CPU-hoz. Egy ilyen rendszer szabványos és elosztott, mert kényelmes a GPU architektúrához. Igénylő feladatok intenzíven írni és olvasni az egyik nagy területen a globális memóriából, így attól függően, hogy az adatok, nehéz parallerate és hatékonyan hajtsák végre a GPU. Emellett teljesítményük nagymértékben függ a globális memória késleltetésétől, ami nagyon nagy. De ha a feladatot az "Adat-olvasás - feldolgozás - felvétel - rögzítés" sablon írja le, akkor szinte biztosan nagy növekedést kaphat a GPU végrehajtására. A GPU-ban lévő texturális adatok esetében az első és a második szint kis gyorsítótárak külön hierarchiája van. Gyorsulást biztosít a textúrák használatából. Ez a hierarchia eredetileg megjelent a grafikus processzorok használata érdekében a településen való hozzáférés textúrák: Nyilvánvaló, hogy a feldolgozás után egy pixel egy szomszédos pixel (nagy valószínűséggel), akkor meg kell szorosan található textúra adatokat. De a rendes számítások sok algoritmusai hasonló jellegűek az adatokhoz való hozzáféréshez. Tehát a grafikákból származó textúrák nagyon hasznosak lesznek. Bár az NVIDIA L1-L2 gyorsítótárak mérete és az AMD kártyák nagyjából hasonlóak, amelyet nyilvánvalóan az optimális követelmények a játékgrafikák szempontjából az optimális követelmények miatt jelentősen változik. Az NVIDIA Access Latencia több, és a GeForce texturális gyorsítótárak elsősorban segítenek csökkenteni a rakományt a memóriabuszon, és nem közvetlenül felgyorsítják az adatokhoz való hozzáférést. Nem észrevehető a grafikus programokban, de fontos az általános célú programok esetében. A Radeonban az alábbi texturális gyorsítótár késleltetése, de a miniprocesszorok helyi emlékének késleltetése felett. Ez a példa is adható: az optimális szaporodása mátrixok NVIDIA kártya, akkor jobb, ha a helyi memóriát használó, be a mátrix tömb, valamint a Jobb támaszkodjon egy alacsony határozott textúrájú gyorsítótárra, olvassa el a mátrix elemeit. De már elég jó optimalizálás, és az algoritmus már lefordított a GPU-n. Ez a különbség a 3D-s textúrák használata esetén is megjelenik. A GPU kiszámításának egyik első referenciaértéke, amely komoly előnyt mutatott az AMD-nek, csak a 3D-s textúrákat használta, mivel háromdimenziós adatgyűjtéssel dolgozott. És a Radeon textúrákhoz való hozzáférés késleltetése jelentősen gyorsabb, és a 3D-tok tovább optimalizálva vannak a mirigyben. A vasaló maximális teljesítményének megszerzése különböző cégekből, egy adott kártya keretében egy bizonyos hangolásra van szükség, de ez egy nagyságrendű, kevésbé szignifikáns, mint a GPU architektúra algoritmusának kialakulása. Ebben a családban a GPU-n történő számítástechnika hiányos. Megjegyezhető három fontos pont. Először is, nincs helyi memória, azaz fizikailag ott van, de nem képes a modern GPU program szabványos egyetemes hozzáférésére. A globális memóriában emulálódik, azaz a teljes funkcionalitású GPU-val ellentétben nem fog járni. A második pont a memóriával és szinkronizációs utasításokkal kapcsolatos különböző utasítások korlátozott támogatása. És a harmadik pont az utasítások kis méretű gyorsítótár: a program bizonyos méretétől kezdve a sebesség lelassul. Vannak más kisebb korlátozások is. Csak tökéletesen alkalmas arra, hogy a GPU programok jól működjenek ezen a videokártyán. Rendes vizsgálati programokamelyek csak a nyilvántartások, a videokártya tudja mutatni egy jó eredmény gigaflop, valami bonyolult hatékonyan programozni problémásnak. Ha összehasonlítja az AMD és az NVIDIA termékeket, akkor a GPU-n található számítások szempontjából az 5xxx sorozat nagyon erős GT200-nak tűnik. Egy ilyen erős dolog a csúcs teljesítményen túllépi a fermi-t mintegy két és félszer. Különösen az új NVIDIA videokártyák paraméterei után a magok száma csökken. De a Fermi Cache L2 megjelenése egyszerűsíti a GPU egyes algoritmusainak megvalósítását, ezáltal bővíti a GPU-hatókörét. Ami érdekes, hogy a jól optimalizált az előző generáció GT200 CUDA programok Fermi építészeti újítások gyakran nem tett semmit. A számítástechnikai modulok számának növekedésével felgyorsultak, azaz kevesebb, mint kétszerese (az egyes pontosságok száma), és még kevesebb, mert a memória PSP nem nőtt (vagy más okok miatt). És olyan feladatokban, amelyek a GPU-k építészetére kifejtettek, kifejezett vektor jellegű (például mátrixok szorzása), Radeon viszonylag közel áll az elméleti csúcsteljesítményhez és a Fermi túlterheléséhez. Nem is beszélve a többmagos CPU-ról. Különösen az egyetlen pontossággal rendelkező számokkal rendelkező feladatokban. De Radeonnak van egy kisebb kristályterülete, kevesebb hőtermelés, energiafogyasztás, nagyobb teljesítményű és ennek megfelelően kevesebb költség. És közvetlenül a feladatok 3D grafika nyerő Fermi, ha ez általában sokkal kevesebb különbség a kristály területen. Ez nagyrészt annak köszönhető, hogy a Radeon számítástechnikai architektúra 16 számítástechnikai eszköz per miniprocesszoronként, a hullámfront mérete 64 fonal és vektor Vliw utasítások gyönyörű a fő feladat - számítás grafikus árnyékolók. A hétköznapi felhasználók abszolút többsége, a játékok termelékenysége és az ár elsőbbséget élvez. A szempontból a szakmai, tudományos program, a Radeon architektúra biztosítja a legjobb ár-teljesítmény arány, teljesítmény Watt és abszolút teljesítmény feladatokat, amely elvileg alkalmas a GPU architektúra, hogy a párhuzamosság és vektorizáláshoz. Például a Radeon kulcs kiválasztása teljes mértékben párhuzamos egyszerűen vectorized feladata többször gyorsabb, mint a GeForce és több tucatszor gyorsabb, mint a CPU. Ez megfelel az általános AMD Fusion koncepció, amely szerint a GPU kell egészítenie a CPU, és a jövőben integrált CPU kernel maga, mint egy matematikai koprocesszor átkerült egy külön kristályt a processzor mag (ez történt húsz éve az első Pentium processzorok előtt). A GPU integrált grafikus mag és vektoros kopprocesszor lesz a streaming feladatokhoz. A Radeon a funkcionális modulok végrehajtása során a különböző hullámfrontól eltérő hullámok keverésére használja a trükkös technikát. Könnyen megtehető, mivel az utasítások teljesen függetlenek. Az elv hasonlít a modern CPU-k független utasításainak szállítójához. Nyilvánvaló, hogy lehetővé teszi, hogy hatékonyan teljesítse a komplexumot, sok bájtot, vektoros vliw utasításokat foglaljon el. A CPU-t, ehhez egy komplex ütemező azonosítani független utasításokat vagy a Hyper-Threading technológiát, amely ellátja CPU szándékosan független utasításokat a különböző források. 128 A két hullám elülső utasításai, amelyek mindegyike 64 műveletből áll, 16 VLIW modulból áll, nyolc óra. Van egy váltakozás, és a valóság minden modulnak két órája van az egész utasítás megvalósításával kapcsolatban, feltéve, hogy új, hogy egy újat hajtson végre a második tapintáson. Valószínű, hogy segít gyorsan elvégezni a VLIW utasításokat, mint az A1 × A2 + B1 × B2 + C1 × C2 + D1 × D2, azaz nyolc óra számára nyolc utasítás teljesítéséhez. (Formálisan kiderül, az egyik a tapintat.) Az NVIDIA-ban látszólag nincs ilyen technológia. És a VLIW hiányában a nagy teljesítményű skaláris utasítások segítségével nagy gyakoriságra van szükség, amely automatikusan növeli a hőelvezetést, és nagy igényeket támaszt a technológiai folyamaton (annak érdekében, hogy a rendszert nagyobb gyakorisággal kényszerítsük). A Radeon hiánya a GPU-számítások szempontjából nagy nem tetszik az elágazáshoz. A GPU általában nem panaszkodik az elágazással a fent leírt utasítások végrehajtási technológiája miatt: azonnal egy szálcsoport egy szoftvercímmel. (By the way, ezt a technikát SIMT-nek nevezik: egy utasítás - többszörös szálak (egy utasítás - sok szál), a SIMD analógiával, ahol az egyik utasítás egy műveletet hajt végre különböző adatokkal. Ugyanakkor a Radeon elágazás nem tetszik ez : Ez egy nagy izzási ligament méret. Nyilvánvaló, hogy ha a program nem teljesen vektor, annál nagyobb a nagyobb méret a lánc vagy a hullám elülső, annál rosszabb, mivel az elutasítások, több csoportot kell végrehajtani egymás után (sorozatos) az ösvényen. Tegyük fel, hogy a szálak szétszóródnak, majd a Warp méretben 32 szálban, a program 32-szerese lassabb lesz. És a 64-es méret esetében, mint Radeonban, - 64-szer lassabb. Ez észrevehető, de nem az "ellenségesség" egyetlen megnyilvánulása. Az NVIDIA videokártyákon minden egyes funkcionális modul, más néven Cuda Core, speciális ág-feldolgozó egységgel rendelkezik. És Radeon videokártyákon 16 számítástechnikai modulban - csak két ágvezérlő egység (az aritmetikai blokkok tartományából származik). Tehát a feltételes átmenet utasításának egyszerű feldolgozása, hagyja eredményét, és ugyanazt az összes szálra a hullámfront, extra időt vesz igénybe. És Speed \u200b\u200bSarses. Az AMD is produkálja a CPU-kat. Úgy vélik, hogy a nagy mennyiségű ágú programok esetében a CPU még mindig jobban megfelel, és a GPU tiszta vektoros programokra készült. Tehát a Radeon általában kevesebb lehetőséget biztosít a hatékony programozáshoz, de sok esetben jobb termelékenységi arányt biztosít. Más szóval, olyan programok, amelyek hatékonyak lehetnek (előnyösek) Fordítás a CPU-ról Radeonra, kevesebb, mint a hatékonyan működő programok. De azok, amelyek hatékonyan átadhatók, sok jelentésben hatékonyabban fognak dolgozni Radeonon. A Radeon Műszaki adatok önmagukban nézni vonzó, akkor is, ha nem idealizált és absolutize a számításokat a GPU. A GPU program kidolgozásához és végrehajtásához szükséges teljesítményű szoftverekhez hasonlóan fontos, hogy magas szintű és futási időnyelvű, vagyis olyan illesztőprogram, amely kölcsönhatásba lép a CPU-nál futó program és közvetlenül a GPU között. Még fontosabb, mint a CPU esetében: A CPU esetében nincs szüksége olyan illesztőprogramra, amely adatátviteli menedzsmentet végez, és a GPU-fordító szempontjából több arrogikusan van. Például a fordítónak a köztes számítási eredmények tárolására szolgáló nyilvántartások minimális számával kell ellátnia, valamint óvatosan beágyazza a funkciók hívásait, ismét minimális regiszter használatával. Végtére is, annál kevesebb regiszter használja a szálat, annál több szál indítható el, és a GPU teljesen terhelhető, jobb, ha elrejti a memória hozzáférési idejét. És itt van a Radeon termékek szoftver támogatása, miközben elmarad a vas fejlődésének mögött. (Ellentétben az Nvidia helyzetével, ahol a vasbevitel elhalasztásra került, és a terméket egy vágott formában szabadították fel.) Újabban az AMD által gyártott OpenCl-fordítónak volt béta állapota, sokféle hibával. Túl gyakran hibás kódot generált, vagy nem volt hajlandó összeállítani a kódot a helyes forrásszövegből, vagy maga is munkavégzést adott ki, és függött. Csak a tavasz végén kijött egy nagy teljesítményű kiadás. Nem is hiányzik a hibák, de sokkal kisebbek lettek, és általában az oldalirányban merülnek fel, amikor megpróbálnak valamit programozni a helyesség szélén. Például az Uchar4 típusú, amely a 4 bájt négykomponensű változót állítja be. Ez a típus az OpenCL specifikációiban van, de nem érdemes dolgozni Radeon-on, mert a regiszterek 128 bitesek: ugyanaz a négy komponens, de 32 bites. És egy ilyen változó Uchar4 még egy egész nyilvántartásban, csak a további csomagolási műveletek lesz szükség, és hozzáférést biztosít az egyes byte alkatrészeket. A fordítónak nincs hibája, de nincsenek fordítók hibák nélkül. Még az Intel fordító után 11 változat után összeállási hibákat tartalmaz. Az azonosított hibák a következő kiadásban vannak rögzítve, amely közelebb kerül az őszhez. De még mindig vannak olyan dolgok, amelyek finomítást igényelnek. Például a Radeon szabványos GPU-vezetője nem rendelkezik a GPU számítástechnikával az OpenCL használatával. A felhasználónak további speciális csomagot kell feltöltenie és telepítenie kell. De a legfontosabb dolog a funkciók könyvtárak hiánya. A kettős pontosság valódi számához sem sinus, koszinusz és kiállítók is vannak. Nos, továbbá, a mátrixok szorzása nem szükséges, de ha valami bonyolultabb programot szeretne programozni, meg kell írnia az összes funkciót a semmiből. Vagy várjon az új SDK kiadásra. Hamarosan az ACML (AMD Core Math Library) meg kell adnia az Evergreen GPU család számára, amely támogatja a fő mátrix funkciókat. Jelenleg a cikk szerzője szerint igazi programozás videokártyák Radeon. Kiválasztja a közvetlen kiszámolás 5,0 API használatát, természetesen figyelembe véve a korlátozásokat: Orientáció a Windows 7 és a Windows Vista platformon. A Microsoftnak sok tapasztalata van a fordítók létrehozásában, és hamarosan teljesen hatékony kiadást várhat, a Microsoft érdekli ezt. De a közvetlen számítás az interaktív alkalmazások igényeire koncentrál: kiszámítani valamit, és azonnal vizualizálja az eredményt - például a folyadék áramlását a felületen. Ez nem jelenti azt, hogy nem használható egyszerűen a számításokhoz, de ez nem az ő természetes célja. Például a Microsoft nem tervezi a könyvtári funkciókat a közvetlen számításhoz - csak azok, amelyek jelenleg nincsenek az AMD-ben. Azaz, ami most már hatékonyan kiszámítani Radeon - néhány nem túl bonyolult programok, akkor lehet végrehajtani az Direct Compute, ami sokkal könnyebb OpenCL és nagyobb stabilitást eredményez. Plusz, ez teljes mértékben hordozható, működni fog az NVIDIA és az AMD, így kell összeállítani a programot csak egyszer, míg a végrehajtása OpenCL SDK vállalatok NVIDIA és az AMD nem teljesen kompatibilisek. (Abban az értelemben, hogy ha fejleszteni egy OpenCL program AMD rendszer segítségével az AMD OpenCL SDK, akkor nem megy olyan könnyen NVIDIA. Szükség lehet lefordítani az azonos szöveget NVIDIA SDK. És persze, épp ellenkezőleg. ) Ezután OpenCL sok felesleges funkciók, mivel OpenCL fogant, mint egy univerzális programozási nyelv és az API széles köre számára a rendszerek. És GPU, és CPU és cella. Tehát abban az esetben, ha csak egy programot kell írnia egy tipikus felhasználói rendszerhez (processzor, plusz egy videokártya), az OpenCL nem jelenik meg, így beszélni, "nagyon produktív". Minden funkció tíz paramétert, és kilenc közülük kell állítani 0-ra, és annak érdekében, hogy állítsa be az egyes paraméterek, meg kell hívni egy speciális funkció, amely szintén paramétereket. És a legfontosabb jelenlegi és közvetlen számítás - a felhasználónak nem kell speciális csomagot telepíteni: Minden, amire szüksége van, a DirectX 11-ben létezik. Ha szférát veszel személyi számítógépekA helyzet olyan: nincs olyan sok feladat, amelyre a nagy számítási teljesítmény szükséges, és nincs elég a szokásos kétmagos processzor. Mintha a tengertől, egy nagy, telhetetlen, de hatalmas szörnyek kijöttek a tengerből, és szinte semmi köze a földhöz. És az ősi kolostor a Föld felszínének mérete csökken, megtanulják kevésbé fogyasztanak kevesebbet, mint mindig a hiány a természeti erőforrásokat. Ha most már ugyanezen szükség van a teljesítményre, 10-15 évvel ezelőtt, a GPU-számítástechnika egy bummot vesz fel. És így a kompatibilitási problémák és a GPU programozás relatív komplexitása előtérbe kerül. Jobb, ha olyan programot írhat, amely minden olyan rendszeren dolgozik, mint egy gyorsan működő program, de csak a GPU-nál kezdődik. Néhány jobb GPU kilátás a professzionális alkalmazásokban és a munkaállomás-ágazatokban, mivel több teljesítményigény van. Pluginok a 3D-s szerkesztők számára GPU-támogatással: például a sugarak nyomon történő megjelenítéséhez - nem szabad összetéveszteni a szokásos GPU-renderelést! Valami megjelenik a 2D szerkesztők és a bemutató szerkesztők számára, a komplex hatások létrehozásának gyorsításával. A videomegjelenítési programok szintén fokozatosan megszerzik a GPU támogatását. A fenti feladatok szem előtt tartva a párhuzamos entitásuk jó a GPU-architektúrában, de most már egy nagyon nagy kód kódot hoznak létre, amely minden CPU funkcióhoz optimalizálva van, így szükség van az időre, hogy jó GPU implementációk megjelenjen. Ebben a szegmensben a GPU gyengesége szintén nyilvánul meg, mint korlátozott mennyiségű video memória - körülbelül 1 GB a hagyományos GPU-k esetében. Az egyik fő tényező, amely csökkenti a teljesítményt GPU programok szükségességét közötti adatcserére CPU és a GPU egy lassú busz, valamint amiatt, hogy kevés a memória, akkor továbbítja több adat. Ezután az AMD koncepciója a GPU és a CPU egy modulban történő kombinációjában ígéretes: feláldozhatja a grafikus memória nagy sávszélességét a könnyű és egyszerű hozzáférés a teljes memóriához, ráadásul a kevésbé késleltetéssel. Ez a magas PSP az aktuális video memória DDR5 sokkal több keresletben közvetlenül grafikus programokmint a legtöbb GPU-számítástechnikai program. Általánosságban elmondható, hogy az Általános GPU és a CPU memória egyszerűen bővíti a GPU hatókörét, lehetővé teszi számítási lehetőségeinek használatát a programok kis részkészleteiben. És a legtöbb GPU kereslet a tudományos számítástechnika területén. A GPU-n alapuló többszörös szuperszámítógépek, amelyek nagyon nagy eredményt mutatnak a mátrix műveletek tesztjében. A tudományos feladatok olyan sokszínűek és számos, hogy mindig van egy olyan készlet, amely tökéletesen esik a GPU architektúrára, amelyhez a GPU használata megkönnyíti a nagy teljesítményt. Ha a modern számítógépek összes feladata közül választhat, akkor számítógépes grafika lesz - a világ képe, amelyben élünk. És az optimális architektúra erre a célra nem lehet rossz. Annyira fontos és alapvető feladat, amelyet a vas által tervezett vasnak sokoldalúnak kell lennie, és optimális a különböző feladatokhoz. Különösen mivel a videokártyák sikeresen fejlődnek.
A V.NET grafikus processzorainak számításainak alternatívái
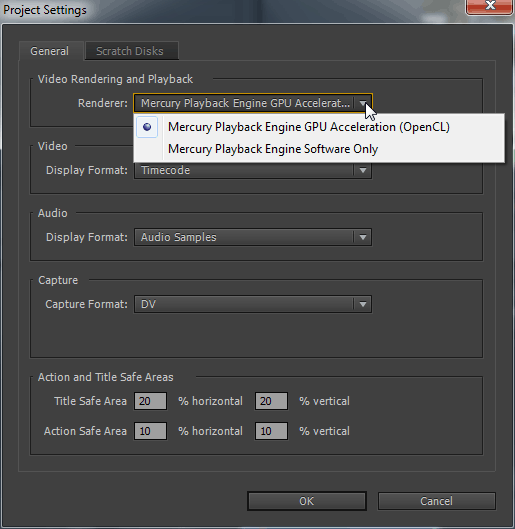


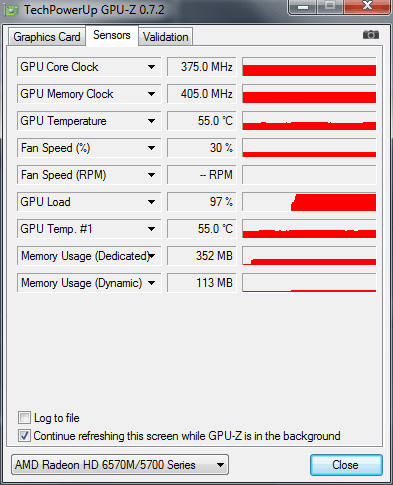
Ha a felhasználás maximális megjelenítési minősége telepítve van, kattintson a: Queue gombra. 


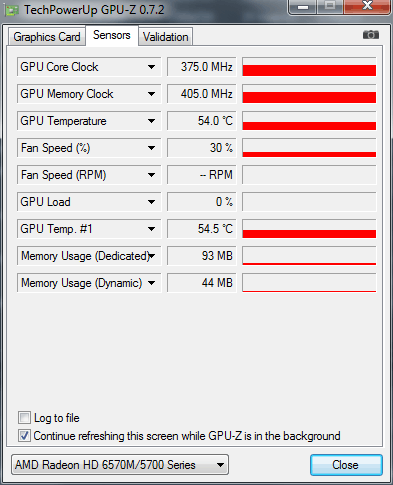




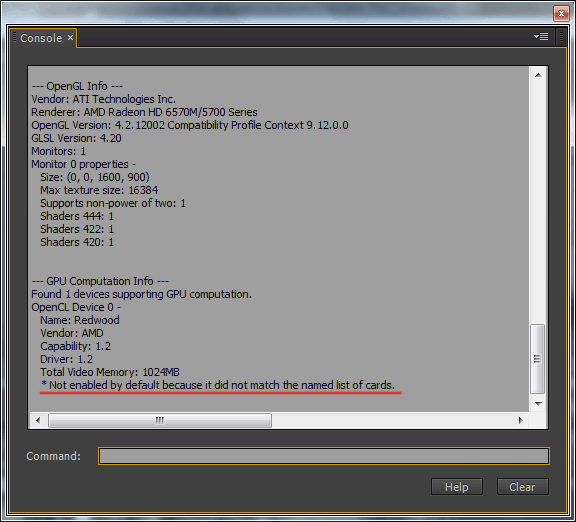

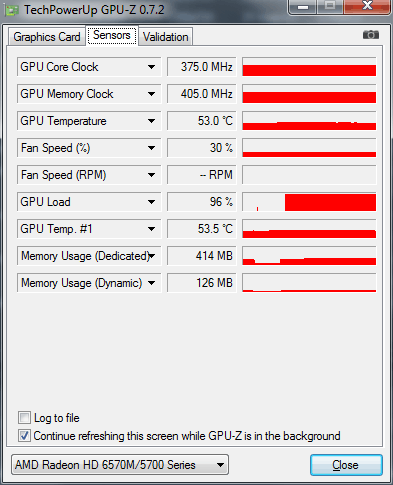






- Az egyértelműség megváltozása (magasra a standardra és fordítva).
- Időkódszűrő.
- Pixel formátumú konverzió.
- Terjesztés.
Ha a Premiere Pro projekt látható, az AME vizualizációs beállításokat használ a projekthez megadott GPU-val. Ugyanakkor a Premiere Pro-ban végrehajtott GPU-val való vizualizáció lehetősége. Az AME projektek vizualizálásához korlátozott számú megjelenítési funkciót használnak a GPU-val. Ha a szekvenciát az eredeti támogatás segítségével vizualizálják, az AME-ről származó GPU beállítást alkalmazzák, a projektbeállítás figyelmen kívül marad. Ebben az esetben a GPU Premiere Pro összes vizualizációs funkcióját közvetlenül az AME-hez használják. Ha a projekt harmadik féltől származó VST-t tartalmaz, akkor a projekt GPU telepítést használnak. A szekvenciát pproeheadless segítségével kódolják, mint az AME korábbi verzióiban. Ha az Enable Native Premiere Pro szekvencia behozatali jelölőnégyzetet eltávolítják, a pproHeadless és GPU beállításokat mindig használják. GPU erőforrások használata a teljes - GPU foglaltsághoz

http://docs.nvidia.com/cuda/cuda-c-best-practices-guide/#calculating-occuplyMi a számítás a GPU-n
Mi a cuda
Technológiai lehetőségek
A technológia előnyei
Példa a technológia alkalmazására
cRARK.
Készítmény
cmd / k crirk (archiválási név) .rar
cmd / k CRARK-HP (Archívum neve) .rareredmények


következtetések
Az építészet előnyei
Példa
AMD Radeon Microarchitecture Részletek

Radeon munka koncepciója. Csak egy miniprocesszor 20 párhuzamos munkaA feltételes átmeneti utasítások szakasza
0. szakasz. Ág 0. Link a folyamatos aritmetikai utasítások 3. szakaszához
1. szakasz. Ág 1. Link a 4. szakaszra
2. szakasz. Ág 2. Link az 5. szakaszra
A folyamatos aritmetikai utasítások részei
3. szakasz. VLIW utasítás 0 VLIW utasítás 1 VLIW utasítás 2 VLIW utasítás 3
4. szakasz. VLIW utasítás 4 VLIW utasítás 5
5. szakasz. VLIW utasítás 6 VLIW utasítás 7 VLIW utasítás 8 VLIW utasítás 9
A Radeon 47xx sorozat korlátozása
Az örökzöld előnyei és hátrányai
tact 0. tapintó 1. tact 2. 3. tut. tUT 4. tUT 5. tUT 6. tUT 7. VLIW modul
wave front 0 wave front 1. wave front 0 wave front 1. wave front 0 wave front 1. wave front 0 wave front 1.
→
műszer 0. műszer 0. műszer tizenhat műszer tizenhat műszer 32. műszer 32. műszer 48. műszer 48. Vliw0.
→
műszer egy …
…
…
…
…
…
…
Vliw1
→
műszer 2. …
…
…
…
…
…
…
Vliw2.
→
műszer 3. …
…
…
…
…
…
…
Vliw3.
→
műszer négy …
…
…
…
…
…
…
Vliw4.
→
műszer öt …
…
…
…
…
…
…
Vliw5.
→
műszer 6. …
…
…
…
…
…
…
VLIW6.
→
műszer 7. …
…
…
…
…
…
…
VLIW7.
→
műszer nyolc …
…
…
…
…
…
…
Vliw8.
→
műszer kilenc …
…
…
…
…
…
…
VLIW9.
→
műszer 10 …
…
…
…
…
…
…
Vliw10
→
műszer tizenegy …
…
…
…
…
…
…
Vliw11
→
műszer 12 …
…
…
…
…
…
…
Vliw12.
→
műszer 13 …
…
…
…
…
…
…
Vliw13.
→
műszer tizennégy …
…
…
…
…
…
…
Vliw14
→
műszer tizenöt …
…
…
…
…
…
…
Vliw15
API a GPU számítástechnikához
A GPU-számítások fejlesztésének problémái
 A Flash Player miért nem működik, és hibaelhárítás
A Flash Player miért nem működik, és hibaelhárítás Maga a laptop kikapcsol, mit kell tennie?
Maga a laptop kikapcsol, mit kell tennie? HP Pavilion DV6: Jellemzők és vélemények
HP Pavilion DV6: Jellemzők és vélemények Formázási pont ábrázolása lebegőpontos számok Hogyan tárolják a negatív számokat a számítógép memóriájában
Formázási pont ábrázolása lebegőpontos számok Hogyan tárolják a negatív számokat a számítógép memóriájában Számítógépes krumplit, és nem kapcsolja be, mit tegyen?
Számítógépes krumplit, és nem kapcsolja be, mit tegyen? Miért nem működik az egér egy laptopon vagy egéren?
Miért nem működik az egér egy laptopon vagy egéren? Hogyan lehet növelni vagy csökkenteni az oldal méretét (betűtípus) az osztálytársakban?
Hogyan lehet növelni vagy csökkenteni az oldal méretét (betűtípus) az osztálytársakban?