Cómo trabajar en el programa Ebby Fine Rider. Cómo usar el programa Abbyy FineReader. Escaneo en PDF.
Historia Abbyy FineReader ha pasado más de 20 años. La compañía Aniversario 2013 notó el lanzamiento del completo (en comparación con la edición expresa desde 2009) Abbyy FineReader Pro para Mac, y después de un par de meses, en febrero de 2014, su "regalo" recibió y usuarios de Windows - Abbyy FineReader 12 Profesional y Corporativo. Permítanme recordarle que la versión anterior apareció en 2011, y dos años y medio mucho tiempo, comprendamos cómo son los cambios significativos.
información general
Requisitos del sistema para nueva versión No cambiado completamente. La plataforma puede servir ventanas o Servidor de windows A partir de XP y 2003, respectivamente. Consultas de hardware En los horarios actuales y no son modestos: un procesador de cualquier bit con una frecuencia de 1 GHz, RAM al menos 1 GB más 512 MB para cada kernel de computación, etc. Varios solo aumentaron la necesidad de espacio en disco, ahora no es Se requiere instalar 700, y 850 MB (más, aún, otros 700 MB para los archivos de trabajo).
Naturalmente, estamos hablando en los requisitos mínimos; Completamente Abbyy FineReader 12 Professional será revelado solo por relativamente sistemas modernos. En particular, le recuerdo que el programa puede paralelar efectivamente el procesamiento de páginas individuales, utiliza todos los kernels del procesador y cargan cualquier procesador en casi el 100%. Pero realmente no es codicioso para el carnero, e incluso permanece 32 bits.
El procedimiento de instalación no ha cambiado: el mínimo de preguntas y opciones. Incluido con Abbyy FineReader 12 Professional, todavía hay un lector de capturas de pantalla de Abbyy, que se vuelve eficiente solo después de registrar al usuario.

Después de eso, el acceso al soporte técnico también se abrirá.

Incluso sobre la base de esta modesta información, se puede suponer que tenemos el resultado de la evolución. En consecuencia, en el futuro me concentro en la descripción de los cambios en comparación con versión previaque se puede dividir en dos grupos principales: trabajar con el programa (interfaz, herramientas auxiliares, facilidad de uso) y OCR (calidad y rendimiento del reconocimiento real).
Trabajando con el programa
Abbyy FineReader 12 Professional demuestra un poco de refinamiento en la interfaz de usuario. Esto es inmediatamente notable en la ventana de tareas que se abre de forma predeterminada cuando se inicia el programa. Obviamente, imita el concepto de las baldosas Windows 8.x y se adapta para controlar los dedos, especialmente porque el programa también soporta los gestos principales como el desplazamiento y la escala. De hecho, los cambios afectados solo a la "fachada", e incluso en parte, junto a los azulejos, están adyacentes a los controles habituales y, en el proceso de configuración, deberán lidiar con los cuadros de diálogo estándar. Trabajar con ellos es bastante problemático, especialmente en 8-10 pantallas, que se están volviendo populares entre las tabletas con Windows.

Para enviar que el usuario de dicha tableta equipado con la cámara puede querer "en la marcha" para introducir algún tipo de documento impreso, realmente fácil. Mientras tanto, toda la historia de las ventanas, comenzando con la primera edición de Tablet PC, confirma la falta de sentido de la adaptación al control sensorial de la interfaz de escritorio estándar. Aparentemente, para estos fines, es mucho más correcto crear una cáscara especial que corresponda a todos los cánones de metro, pero utilizando el mismo "motor". Un ejemplo de tal solución sirve Explorador de Internet. De Windows 8.x. Además, ABBYY incluso tiene una parte posterior en la forma de Abbyy FineReader Touch para Windows 8, que utiliza el servicio en la nube de la compañía.
Si distraes de la entrada sensorial, entonces habrá más cambios. esta clase - de la actualización muy esperada de la apertura / preservación de documentos, que, entre otras cosas, proporciona un fácil acceso a almacenamiento en la nube (Si hay un agente y carpeta apropiados en el sistema), hasta varios más importantes y útiles.

El procesamiento de la página en Abbyy FineReader 12 Professional ahora se realiza en el fondo. Esto implica la ausencia de la ventana modal anterior con el estado de las operaciones (ahora este papel Reproduce la cadena de estado en la parte inferior de la pantalla) y, en consecuencia, la presencia de acceso a la interfaz. Por lo tanto, el usuario tiene la capacidad de trabajar con el programa en paralelo al proceso de reconocimiento (si ciertamente es lo suficientemente largo), por ejemplo, copiar fragmentos del texto resultante o incluso ajustar la marca de las páginas: este último estará en el cola y procesada.

A diferencia de la versión anterior, tampoco apaga las páginas, ya que se reconoce o cuando se inicia el documento, si el reconocimiento automático está deshabilitado. En Abbyy FineReader 12 Professional, el documento se carga y se divide en páginas casi al instante, y sus bocetos se construyen solo cuando se desplazan manualmente en el panel izquierdo. Entre otras cosas, ahorra así recursos computacionalesAdemás, bastante notable en grandes documentos de múltiples páginas.
Los cambios restantes en esta clase no son tan interesantes, aunque pueden ser útiles en algunos escenarios, por lo que son breves sobre ellos.
Si necesita que no procese el documento por completo, pero solo para citar lugares individuales, puede desactivar todas las operaciones automáticas y seleccionar los fragmentos necesarios de cualquier tipo, copiándolos inmediatamente al Portapapeles, con el análisis y el reconocimiento se realizará en la mosca.


Para obtener un resultado con una estructura más sencilla que el original, puede desactivar la conciliación de pies de página, notas al pie y otros elementos de diseño. Esto puede ser útil, por ejemplo, al preparar libros electrónicos.

Continuando por libros electronicos - Abbyy FineReader 12 Professional Admite epub 2.0.1 y formatos 3.0.

Los parámetros de conversión en XLSX se extienden, por ejemplo, tiene la capacidad de limpiar el formato o guardar imágenes.

Al guardar los documentos resultantes en el PDF con una capa de texto, ahora puede usar nueva tecnología Abbyy Precise Scan, que es para suavizar los caracteres en las imágenes de las páginas originales. Está disponible, por cierto, solo en modo de color.

El efecto de su trabajo es bastante notable, aunque no siempre, digamos, "académico". Sin embargo, la legibilidad de caracteres alisados \u200b\u200ben cualquier caso debe ser mayor, y en este ejemplo El original es realmente de muy baja calidad.


LOC
Ahora vamos a tratar qué mejoras ocurrieron en los mecanismos de reconocimiento.
Los desarrolladores informan la siguiente etapa de la mejora de la tecnología ADRT, que, recuerde, analiza y recrea la estructura lógica del documento. Se declara que comenzó a trabajar mucho más preciso, especialmente con tablas, listas, diagramas. Demostrar que estos ejemplos adecuados no son tan simples, pero no son imposibles. Aquí, por ejemplo, los resultados del reconocimiento (con la configuración predeterminada) de la misma página en Abbyy FineReader 11 Professional (en la parte superior) y Abbyy FineReader 12 Professional (fondo).


La versión anterior asignó y procesó solo el bloque de texto principal, posiblemente debido a la baja calidad del original, considere los elementos restantes "basura". Nuevo, por el contrario, identificó correctamente la lista e intentó recrearlo. El resultado, sin embargo, no es ideal: el hecho de que no todos los marcadores pueden ser reconocidos, nuevamente, atribuidos a la calidad de la imagen, pero el programa, aparentemente, todavía no entendió que estaría delante de ella, de lo contrario. No interpretaría los números como letras. Sin embargo, el progreso está en los originales más cualitativos de dichas quejas, puede que no haya sido.
Pero cómo se procesa la tabla "implícita" sin líneas divisorias - Abbyy FineReader 11 Professional (en la parte superior) y Abbyy FineReader 12 Professional (abajo).


Se ve claramente que la versión anterior, en contraste con lo nuevo, no vio la estructura de la tabla y se limitó a un conjunto de bloques de texto no relacionados. No sea perezoso para hacer clic en las imágenes y comparar los resultados del reconocimiento: Abbyy FineReader 12 Professional está cerca del ideal.
Desafortunadamente, no siempre sucede y ya en las páginas vecinas de Abbyy FineReader 12 Professional mostró resultados similares a Abbyy FineReader 11 Professional. Aunque el ADRT debe realizar un seguimiento de las mismas "tapas" y entender que delante de él es un tipo de mesa que fluye.

Pero aún así es claramente notable que los algoritmos actualizados prestan atención a más detalles que antes. En el proceso de pruebas de Abbyy FineReader 12, se observó un profesional, por ejemplo, incluso un intento de interpretar como una tabla con una colocación ordenada de información de texto. Mucho más a menudo, la nueva versión también está tratando de recrear varios gráficos y esquemas basados \u200b\u200ben el patrón de fondo, y no de los bloques gráficos y de texto individuales.
Hay algunos productos nuevos diseñados para mejorar en la calidad del reconocimiento profesional de Abbyy FineReader 12. Como saben, uno de los requisitos previos para esta es la calidad del original, especialmente si se obtiene utilizando un no escáner, pero cámaras. Por eso, a la vez, apareció un medio de pre-procesamiento de originales en FineReader. En la nueva versión, su lista se ha extendido, recortando a lo largo de los bordes de las páginas, aligerando y alineando el brillo de fondo, la eliminación de los elementos de color. Este último puede ser útil, por ejemplo, para procesar documentos con sellos y sellos. Además, ahora el usuario puede conectar varios métodos individualmente.

El soporte lingüístico también se mejora. Primero, el alfabeto ruso apareció con estrés, en segundo lugar, se declara un aumento en la calidad del reconocimiento de chino, japonés y coreano (hasta el 20%), árabe (hasta un 60%), hebreo (hasta un 10%) - Esto se logra, aparentemente, al mejorar y clasificadores de capacitación adicionales.

Bueno, finalmente, uno de los problemas más quemados para muchos lectores: ¿Se ha crecido la velocidad del programa? Es razonable responder a esta pregunta, especialmente con los números, no tan simples, demasiados idiomas, cada uno de los cuales tiene sus propios matices; una gran variedad de originales; Demasiados factores desconocidos de influencia en el trabajo de los algoritmos. Por lo tanto, incluso los propios desarrolladores están bastante restringidos sobre el desempeño de Abbyy FineReader 12 Rendimiento profesional en un 10-15%.
Dichos números generalmente se obtienen por los resultados del procesamiento de matrices suficientemente grandes de documentos y, en consecuencia, son algo así como la "temperatura promedio en el hospital". Por lo tanto, es útil con más detalle cualquier caso de demostración, por ejemplo, similar a los dos siguientes:
- escaneado en color con una resolución de 300 dpi 10 páginas de un folleto de formato A4 a todo color. Buena calidad, idiomas ruso e inglés, simulacro complejo;
- PDF S. imágenes gráficas 138 páginas de un libro que contiene una pequena cantidad de Ilustraciones de color y blanco y negro, varias mesas. La calidad es baja (comenzando, aparentemente, con la impresión "ciega" en un libro de papel), idiomas ucraniano y ruso, un diseño simple.
Ambos documentos fueron reconocidos en modo color, y el segundo también se encuentra en blanco y negro, que estaba destinado a imitar el proceso de preparar el libro electrónico. Todas las configuraciones predeterminadas se dejaron sin cambios, con la excepción del conjunto de idiomas y, en consecuencia, los modos de funcionamiento. Como un polígono de prueba, se utilizó una PC con un procesador I5-3450 y 8 GB de memoria. Los resultados se presentan en la siguiente tabla:
Como se puede ver, para la aceleración de PDF, incluso excede el 15% prometido, quizás, es solo una de las ocasiones especiales que son bien adecuadas para las últimas optimizaciones en algoritmos de reconocimiento. Debe tenerse en cuenta que los programas, en general, han hecho una cantidad diferente de trabajo. Mira al menos en la ilustración por encima del procesamiento de las tablas: es difícil decir cuál de las versiones tenía que ser más difícil.
En cuanto al número de errores, casi coincidió en ambas versiones, aunque fue notable que a veces las dudas causan diferentes fragmentos y símbolos, parece ser evidencia de algoritmos de capacitación. En cualquier caso, la mayoría de los personajes inciertos reconocidos se identificaron absolutamente correctamente utilizando diccionarios, y los errores "gruesos" (la interpretación incorrecta de símbolos especiales y decorativos, texto en la tabla, etc.) coincidió. Así que la diferencia se puede considerar desapareciendo.
Otra pregunta es ¿cuánto es importante el aumento del rendimiento? Aparentemente, las ganancias están a medio minuto en 138 páginas que deben revisarse de todos modos y pueden corregirse, hay un poco de vale la pena. Si se supone que los trabajos similares a las tareas de prueba se deben llevar a cabo en ocasiones en el caso, entonces el rendimiento no puede preocuparse con precisión. Otra cosa es, si se trata del procesamiento fuera de línea de grandes cantidades de documentos, que está disponible en Abbyy FineReader 12 corporativo. En este caso, los ahorros del 15% del tiempo ya son bastante notables.
Resumen
A pesar de que la nueva FineReader 12 de Abbyy 12 Profesional no prometió nada revolucionario, al menos algunos cambios en ella merecen todo tipo de alabanzas. En primer lugar, son las mejoras en la tecnología ADRT en términos de reconocimiento de tabla, diagramas y en general la estructura lógica de las páginas, que en algunos casos le permite obtener mejores resultados cardinales también modo de fondo Procesamiento que abre nuevas características para trabajos interactivos con grandes documentos.
También hay muchos otros cambios, aunque son menos significativos. El movimiento hacia el soporte del control sensorial está seguramente justificado, pero la ruta se selecciona por viciosa, para proporcionar en una interfaz por igual trabajo conveniente El mouse y los dedos son poco probables tal vez. Sin embargo, mientras que las tabletas de Windows simplemente están tratando de entrar en el mercado, y los desarrolladores de Abbyy todavía tienen tiempo.
Precios de Abbyy FineReader 12 Professional:
- versión en caja: 4990 rublos;
- descargar la versión: 4490 rublos;
- actualización: 2690 rublos.
Como de costumbre, la respuesta a la pregunta "vale la pena cambiar versión antigua ¿A la nueva? " depende de la situación. En cualquier caso, vale la pena considerar que el ciclo de vida de FineReader es bastante largo, y si alguna de las mejoras descritas desempeña cualquier papel importante para usted, en 2-3 años, los costos de actualización seguramente pagarán, si no Material, entonces moralmente. Para resolver, esta pregunta finalmente ayudará.
El trabajo en reconocimiento de imágenes consiste en los siguientes pasos:
- Obtener imágenes escaneadas (escaneos).
- Abríalos en el programa OCR (FineReader).
- Haz el diseño de páginas a los bloques. Es decir, dividir la página en el área, cada uno de los cuales será de texto, o imágenes o tablas, u otro contenido homogéneo.
- En realidad el reconocimiento.
- Remoto reconocido, la conciliación del texto resultante y las exploraciones de origen.
- Guardar los resultados obtenidos en uno de los formatos documentales (DOC, RTF, PDF, HTML, etc.).
Cuando reconozca los textos, dos opciones son posibles: o escanea el material usted mismo o trabaja con el texto ya escaneado.
En el primer caso, las etapas "Obtener imágenes" y "Abrir imágenes" se combinan en una ventanal de FineReader recibidas de inmediato se abre de inmediato en su paquete. En el segundo caso, el paso "Obtener imágenes" ya ha pasado, solo es necesario abrirlos en el programa.
Considere ambas opciones a su vez.
Escanear texto en FineReader
El escaneo comienza a través de "Archivo → Páginas de escaneo" o "SCAN", o MENU CTRL-K.
Higo. 1 interfaz de escaneo
Sin embargo, antes de comenzar a escanear, sería bueno averiguar cómo obtener las exploraciones son las más óptimas para el reconocimiento. Y para hacer esto, entender que "bueno" (desde el punto de vista de FineReader), Skan difiere de "no muy bueno".
Para un reconocimiento de alta calidad, el programa requiere tres cosas. Primero, la capacidad de distinguir de manera confiable texto e ilustraciones desde el fondo de la página. En segundo lugar, las letras, los números y otros contenidos son claros y legibles, de modo que no surgen situaciones "aquí y el ojo humano no siempre entenderá lo que se imprime". En tercer lugar, las cadenas del texto en el escaneo deben ir tan suavemente, ya que están impresas en la página del libro, sin distorsión y distorsión. También hay otros requisitos para una exploración cualitativa, pero estos pueden considerarse clave.
1. Para una distinción confiable, "aquí se requiere el texto, y aquí los antecedentes de las páginas" para asegurarse de que la transición entre los temas y la otra sea afilada, no borrosa. Aquí hay muestras de páginas con mal y con buena claridad. En el primer caso, naturalmente, será reconocido peor, con gran cantidad Errores.

Higo. 2. Límites limitadores borrosos

Higo. 3. Borrar límites de limitador
La causa habitual de los bordes de fondo borrosos de texto está escaneando con un enfoque perturbado, lo que comúnmente se llama "no enfoque". Por lo tanto, antes de comenzar a trabajar, es deseable verificar su escáner en este momento.
Otra razón que puede interferir con la distinción del texto y el fondo es demasiado "denso" de fondo. Normalmente, debe ser o blanco puro, o blanco con una pequeña impureza de algún color. Si los libros de las viejas ediciones se escanean, donde el papel a menudo se colorea, el fondo también puede ser amarillento (pero moderadamente).
Si el fondo se ve notablemente sobrevalorado, estas páginas volverán a ser reconocidas nuevamente.
El tipo de fondo estará en el fondo depende del brillo de la exploración mostrada. Se puede ajustar a través del motor "Brillo". Para empezar, tiene sentido poner un 50%, verifique que sea, si es necesario, correcto.
2. Obstabilidad El litro de texto depende principalmente de la resolución de brillo y escaneo.
Si el brillo es demasiado grande, se desgarrarán las líneas de letras, se caerán como si se desmoronaban en piezas separadas. Si el brillo es pequeño, los detalles de las letras comienzan a fusionarse entre sí, surgen manchas sin forma. Ambos no son "alimentos" muy comestibles para los programas de reconocimiento.
El brillo se ajusta aquí de la misma manera que en el caso anterior, ponemos un 50% en la interfaz de escaneo, y luego en la situación.

Higo. 4. Página con un brillo demasiado grande.

Higo. 5. Página con brillo demasiado pequeño (fondo de página de sobremesa)

Higo. 6. Pero la misma página, pero en forma normal.
La resolución de escaneo determina cuántos píxeles en el escaneo tendrán que venir a cada letra. Si estos píxeles son suficientes para extraer el esquema de la letra, entonces no habrá problemas en el reconocimiento. Si no es suficiente, las letras pueden ser mal distinguibles incluso para los ojos humanos, sin mencionar los programas de reconocimiento.

Higo. 8. Lo mismo, pero 200 puntos.

Higo. 9. Lo mismo, pero por 400 puntos.
Al elegir una resolución generalmente se guía por las siguientes reglas:
- Se eligen 300 puntos para libros de publicaciones masivas (páginas llenas de texto del tamaño habitual, casi sin patrones);
- Se seleccionan 400 puntos para libros y revistas con un volumen notable de texto con tazones pequeños (notas, firmas debajo de las imágenes, tablas, inserciones con texto pequeño);
- Se eligen 600 puntos para los libros impresos por tazones muy pequeños (muchos libros de referencia y enciclopedias, libros en miniatura). O con patrones finamentelatares, por ejemplo, grabados. Esto también debe incluir muchos libros de ediciones de la década de 1990, luego los editores guardados en papel y, a menudo, se imprimen con letras completamente crujientes.
La interfaz de escaneo en FineReader le permite seleccionar solo 300 puntos o 600 (resolución de cadena "). Por lo tanto, si tiene mucho material, lo que es deseable hacer 400 puntos, es mejor escanear no de debajo de FineReader, sino del programa que viene junto con el escáner.
O en la configuración de FineReader, cambie de su propia interfaz de programa en la interfaz TWAIN de su escáner ("Servicio → Configuración → Bookmark" Scan / Open "→ Haga clic en la parte inferior de la" interfaz de escáner de uso "). Luego, puede escanear desde FineReader, pero trabajará en la interfaz del escáner (generalmente hay una mayor cantidad de configuraciones y funciones).
3. Las líneas de texto suaves y de aspecto cuidadosamente se aseguran principalmente por la precesión de la imagen ("pre-", en este caso, "ejecutado después del escaneo, pero antes del reconocimiento"). Después de realizar correctamente posibles, los contenidos de las páginas se reconocerán con mayor calidad.
FineReader tiene un conjunto bastante rico de funciones que se pueden ver en la configuración del programa en la pestaña Escanear / Abrir. Además, esta ventana se puede llamar a través del botón "Configuración" en la ventana de la interfaz de escaneo.

Higo. 10. Configuraciones de precalación
"Compartir una reversión del libro" debe ser elegida cuando el libro no tenga miedo, sino la inversión. Luego, para el reconocimiento, se cortarán Chaproof.
"Determine la orientación de las páginas" si el libro fue escaneado por el lado opuesto. Luego se implementará en su posición normal. Pero si hay páginas en el libro que se imprimen, se convierten en 90 grados en relación con el a granel, entonces la marca aquí es mejor eliminar. De lo contrario, cuando el PDF se deriva en PDF, puede obtener parte de las páginas en la orientación "Libro" y parte en el "Paisaje". Gire las páginas deseadas en este caso es mejor manualmente, en el editor de imágenes incorporado
"Fijar el secado" elimina bloques de páginas. El ajuste es de forma única, pero debe tenerse en cuenta que el "texto de PDF bajo la imagen de la página" recibido de tales exploraciones tendrá una especie no muy limpia: cuñas grises alrededor de los bordes de la página (donde se hizo un turno ).
"Para fijar distorsiones de cadena", líneas las curvas de líneas, que cuando el escaneo a menudo se forma cerca de la unión (también se llaman "bigote").

Higo. 11. Un ejemplo de una página de flexión.
"Eliminar las distorsiones trapezoides" corrige la deformación de las páginas que aparecen si el libro no está muy ajustado, presionada con la copa del escáner.
Se necesita "Invertir imágenes" si hay un montón de texto "letras brillantes sobre un fondo oscuro" en un material escaneado y desea convertirlos a "letras oscuras en un fondo claro".
"Eliminar elementos de colores" es útil si está en la página de las "letras negras sobre un fondo blanco", debe eliminar diferentes innecesarios, como marcar el asa en los campos, firmas y sellos (documentación de la oficina), e incluso solo lugares. Pero si está en la misma página, hay algún tipo de "necesidad": gráficos, gráficos o fotos en la misma página, entonces no puede poner la garrapata. De lo contrario, serán eliminados.
"Fije la resolución de la imagen" es un elemento que requiere una explicación más detallada que las anteriores. El hecho es que el proceso de reconocimiento en FineReader es muy sensible a qué permiso se establece en las propiedades de esta imagen. A partir de esto, depende significativamente de cómo se determinará exactamente el texto del texto, interbustos y distancias atrasadas y otras similitudes. Por lo tanto, la marca aquí es necesaria. Además, no debe sorprenderse si constantemente recibirá mensajes de FineReader "en la página, de modo que incorrectamente establece el permiso y sería bueno corregirlo".
Además de la configuración de preprocesamiento en la pestaña Escanear / Abrir, hay un bloque de configuración "General". Aquí establece un conjunto de acciones básicas que se completarán por encima de las páginas abiertas. Las opciones para tales acciones pueden ser las siguientes:
- simplemente abre imágenes escaneadas, sin hacer nada con ellos. Para hacer esto, debe eliminar la casilla de verificación "Procese automáticamente las páginas agregadas".
Esto tiene sentido solo si tiene una exploración de alta calidad que ni siquiera los mejoran. Puede enviarlo inmediatamente al reconocimiento. Sucede, por supuesto que, pero mucho menos a menudo, qué me gustaría :-), por lo que la garrapata es mejor irse. - abra las imágenes, ejecute una predicción, pero a su equipo mientras que nada más que hacer. Para hacer esto, debe seleccionar la "Posibilidad de preparación".
Por lo general, lo hace, si necesita que no comience el reconocimiento inmediatamente, pero primero vea lo que sucedió como resultado del preprocesamiento, en la medida en que funcionó bien por este conjunto Imágenes. - abra las imágenes, ejecute las predicciones, realice marcas en bloques, reconocimiento hasta que comience. Para hacer esto, seleccione el elemento "Análisis de las imágenes (incluyendo POSTPACK)".
La opción seleccionada más frecuentemente. Tienes una exploración de calidad completamente decente, el hecho de que harás un predefinido con ellos. Te imaginas bien, verifique después de que no sea necesario. Así que nos conectamos a una tres etapas descritas anteriormente y comenzamos a observar qué tan bien se hace el marcado. - todas las etapas de reconocimiento son automáticamente, sin ningún control intermedio. Inmediatamente recibes un resultado preparado y empieza a leerlo. Para hacer esto, seleccione el elemento "Reconocimiento de imágenes (incluida la posición)". Por lo tanto, tiene sentido hacer solo si tiene exploraciones de buena calidad y con un aspecto muy simple, por ejemplo, un texto sólido en un idioma y nada más. En todos los demás casos, es mejor elegir la opción 2 o 3. especialmente si tiene páginas con formato complejo, tablas, diagramas, figuras, etc.

Higo. 12. Un ejemplo de una página con un diseño complejo.

Higo. 13. Un ejemplo de una página con un diseño complejo.
Ver imágenes en FineReader
Esta es la segunda opción para trabajar con imágenes: No los escanee usted mismo, y obtenga la forma preparada y abierta en FineReader. Se realiza a través del botón "Abrir" en el menú de la ventana principal o a través de "Archivo → Abrir PDF o imagen", o a través de CTRL-O.

Higo. 14. Ventana "Imagen abierta"
En la ventana de conductores abiertos que se abre, seleccione las imágenes, configure el botón Configuración necesaria ("Configuración" y haga clic en "Abrir". Los ajustes aquí se utilizan lo mismo que se describe para escanear, es necesario trabajar con ellos lo mismo.
Cuando las páginas están abiertas en FineReader, el paquete predeterminado es creado por Nameless ("Documento sin nombre") y se almacena en la carpeta TMP, solo dentro de la sesión actual. Para no perder accidentalmente los resultados del trabajo, se recomienda inmediatamente después de crear guardar el paquete bajo un nombre permanente ("Archivo → Guardar FineReader" Documento).
Marcado de páginas a bloques.
Después de abrir las exploraciones, debe marcar los bloques de bloques a los bloques. Esto se hace a través del "Documento → Análisis de documentos" o a través de CTRL-SHIFT-E.
Los principales objetivos de trabajo en el markup dos.
Primero, separe el hecho de que la página tiene texto, del hecho de que el texto no lo es. "Texto" en este caso es todo lo que FineReader es capaz de reconocer. "No-texto" en consecuencia, todo se considera que no se considera reconocer. Básicamente, esta es una parte ilustrativa de la página: dibujos, dibujos, gráficos, diagramas, etc. Las fórmulas, los registros manuscritos y las notas desde este punto de vista también se consideran que no se consideran de texto, para reconocer que su FineReader no pueda reconocer. Entonces, al marcarlos, deben ser etiquetados como una "imagen".
En segundo lugar, todavía es necesario que haya texto, publicación por categoría: solo texto, tablas, notas (notas al pie), pies de página, tabla de contenido y similares. Para entonces cuando lees reconocido en editor de textoTodos estos elementos se verían exactamente en la forma en que está acostumbrado (sería formateado en consecuencia).
La página publicada puede tener sobre el siguiente tipo:

Higo. 15. Ventana de imagen "Imagen" con una página marcada
Ahora necesita ver el marcado realizado por el programa en cada una de las páginas y, si es necesario, corríjalo.
Los errores de marcado suelen ser las siguientes especies.
1. Algunas partes del contenido de la página (texto, dibujo, etc.) se resaltan correctamente en el sentido de los límites de la región, pero no se asigna los contenidos. Por ejemplo, un fragmento de texto está marcado como un dibujo o viceversa.
En este caso, debe hacer clic en dicho área, abra el menú contextual, seleccione "Cambiar tipo de área" en él, en el submenú Submendizo, seleccione el tipo requerido ("Texto", "Tabla", "Imagen", " Imagen de fondo "," Stroke el código ").

Higo. 16. Menú contextual "Cambiar tipo de área"
Vea rápidamente dónde puede estar en los marcos de color. El "Texto" se destaca por los marcos de un color verde oscuro, "Tabla" - Blue, "Imagen" - un rojo claro, "imagen de fondo" - rojo oscuro, "código de barras" - verde claro.
2. En el sentido de los contenidos, el área se asigna correctamente, pero en el sentido de las dimensiones (límites) no se requería todo lo que en este caso. O, por el contrario, cayó una pieza de la zona vecina con otro contenido.

Higo. 17. Página con marcado incorrecto
Al área superior de la "imagen", las firmas circundantes que lo rodean (deben marcarse como "texto").
Una parte de la imagen no golpeó la "imagen" de la zona inferior.
Para solucionarlo, primero debe hacer clic en la ventana "Imagen" en el botón "Flecha".
Y luego haga clic en cada área incorrecta marcada y mueva sus bordes. Aproximadamente de la misma manera, como generalmente mueve los bordes de los programas abiertos.
3. En general, se pierde algo de los contenidos del marcado de página, no se metió en ninguna de las áreas creadas.

Higo. 18. La fórmula se cayó de la marca (no entré en uno de los bloques)
Aquí será necesario crear un área nueva en la página (resalte la parte faltante del marco de la página) y luego asigne el área creada de tipo deseado.
Para hacer esto, primero haga clic en la ventana "Imagen" en el icono "Seleccionar zona de reconocimiento"
Después de eso, para rodear la sección deseada del marco (como de costumbre en editor gráfico Seleccione parte de la figura) y finalmente configure el tipo de área. La última operación ya está descrita en el párrafo 1.
Si necesita una parte de texto de la página, así como texto sólido (que más suele suceder), esto es suficiente. Si desea en Word, los diversos elementos de la Declaración de páginas reconocidas (notas, pies de página, pies de página) se verían exactamente como notas y pies de página, entonces necesita verificar y este momento.
Se ajusta a través del menú contextual. Haga clic en el área de texto deseada en la página que se está marcando, en el menú contextual, selecciona el elemento "Propósito del texto", consulte qué elemento es una marca de verificación (generalmente "Detección automática"). Si no es donde sea necesario, cambie al elemento deseado.

Higo. 19. Menú contextual "Propósito del texto"
Reconocimiento
Después de corregir los errores en el marcado, se puede iniciar el reconocimiento. Esto se hace a través del "Documento → Reconocer el documento" o a través de Ctrl-Shift-R. Antes de eso, no olvide establecer el lenguaje de reconocimiento y establecer la configuración necesaria.
El idioma se establece a través de la ventana "Idioma del documento" en el panel Botón de la ventana del programa principal.

Higo. 20. Seleccione Idioma a través del menú principal
O en la configuración ("Servicio → Configuración → Bookmark" Documento ").

Higo. 21. Seleccione Idioma a través de la configuración de FineReader
Si no hay ningún idioma que necesite en la lista que necesita, luego haga clic en "Seleccionar idiomas" en la parte inferior de la lista y en la ventana que se abre, marque la casilla contra el idioma que necesita (Establecer idiomas). Después de eso, se agregará a la lista.
En la configuración del reconocimiento ("Servicio → Configuración → pestaña de reconocimiento), el modo de reconocimiento es mejor dejar de forma predeterminada (" reconocimiento exhaustivo "). "Rápido reconocimiento" tiene sentido poner solo si tiene algo simple en apariencia y con una muy buena calidad de escaneo. Por ejemplo, un documento de texto escaneado en blanco y negro sin ilustraciones.

Higo. 22. Configuraciones, pestaña "Reconocer"
Desde el resto de la configuración, el grupo "Definición de elementos estructurales" tiene un significado básico. Aquí están los detalles del diseño de la página: notas al pie (notas), página de página, listas, contenidos de tabla. Cuando se establece una marca de verificación contra el elemento, se reconocerá y se guardará en DOC / RTF / DOCX, no solo como parte del texto en la página, a saber, como nota de pie de página, página de pie de página, lista o tabla de contenidos.
Simplemente no olvides al mismo tiempo momento importante. Si tiene que reconocer áreas con un contenido similar, una casilla de verificación en la configuración del marcador "reconocible" puede resultar un poco. Además, todavía se requiere en la etapa de marcado, marque correctamente estas áreas "propósito del texto" en el menú contextual.
Subtagnar
La deducción del texto reconocido en FineReader se puede hacer de dos maneras. O usando la función "Comprobar", o de la manera habitual, visualizando las páginas en el editor de FineReader incorporado. A través de la ventana "Primer plano" con un escáner, donde hay errores, correctos.
La función "Comprobar" se inicia con el botón en la esquina superior derecha del menú o a través de CTRL-F7. Su trabajo se basa en el hecho de que durante las marcas de reconocimiento de FineReader, los caracteres y las palabras que han sido reconocidas con un alto nivel de confiabilidad. Es decir, el programa para su ocasión es alguna duda "Tal vez este sea, de hecho, el carácter que se le presentan, pero tal vez algo más". Durante la inspección, se muestran a los lugares dudos dudosos a su vez para que lo corrija si es necesario.
La ventana de cheque es lo suficientemente simple. En la parte superior, muestra un fragmento de una página en la que se verifica el carácter. La parte inferior del texto reconocido se muestra en la parte inferior con este símbolo, así como varios botones para una fácil edición.

Higo. 23. Ventana "Comprobar"
Si todo está bien, el carácter se define correctamente, luego haga clic en "Skip". Si se define incorrectamente, ingresamos el valor correcto o usamos el teclado, o si no hay dicho teclado, luego usando el botón "Pegar un símbolo" (letra griega "Omega). Después de eso, haga clic en "Confirmar".
Del mismo modo, actúe si el símbolo se reconoce correctamente, pero su formato es incorrecto. Por ejemplo, en el texto del libro en algún lugar está apuntando, pero reconoció como una fuente regular. Para reformatear, use los botones en la parte inferior de la ventana.
Pero las posibilidades de la ventana de control aún son bastante limitadas. Y por qué tamaño se puede mostrar una pieza de la página en la parte superior de la ventana, y mediante la edición de capacidades que están aquí. Por lo tanto, todos los movimientos en el texto, desde un punto de verificación a otro, también se rastrean en el "Texto" y las ventanas "Close-Up". Todo el tiempo, mientras trabajan, los cursores en el "texto" y el "primer plano" se mueven sincrónicamente a su posición en la "verificación".
Si la página (en su escaneo) de repente necesitaba ver más de unas pocas palabras que se muestran en el "cheque", puedes hacerlo en un "primer plano". Si se requieren capacidades del editor para editar el error actual, puede cambiarlo por un tiempo (simplemente haga clic en su ventana), haga el trabajo necesario y regrese a la "Cheque" (haciendo clic en su ventana). Después de regresar a la "verificación", se mostrará todos los cambios que realizó en el "Texto".

Higo. 24. Un ejemplo de trabajo al mismo tiempo. ventanas abiertas "Marque", "texto" y "primer plano"
Si tiene una ventana de "cheque" con ella características limitadas No es muy conveniente (solía trabajar con todas las comodidades de los editores de texto y no vas a cambiar el hábito), entonces puede hacer este trabajo desde el principio en la ventana "Texto".
Los lugares que requieren verificaciones se muestran en su totalidad: estos son símbolos y palabras asignados por azul claro. La capacidad de pasar de un error a un error sin navegar por completo de la página completa, también existe los botones "Siguiente Error" y "Error anterior" en el panel del botón en el lado izquierdo de la ventana.
Teóricamente, por el plan de los creadores de FineReader, la ventana "Comprobar" debe ser suficiente para una deducción completa de texto reconocido. Todos los lugares dudosos están marcados, moviéndose a lo largo de ellos, las reglas del error, obtenemos un texto completamente sidrantado en la salida.
Pero, como ocurre a menudo, la teoría aquí disipa con la práctica laboral cotidiana. En los textos reconocidos, los lugares erróneos se encuentran sistemáticamente, lo que, como errores, no están marcados. Es decir, FineReader reconoce incorrectamente algún símbolo / palabra, pero con total confianza que se reconoce correctamente.
Por lo tanto, para una fusión de pleno derecho, la ventana "Verificación" generalmente no es suficiente, especialmente si hay muchos términos científicos o técnicos en el texto, la jerga profesional y la "no conservación". También debemos pasar a través de los reconocidos manualmente de manera manual, verlo con cuidado en la ventana "Texto" y verifique todos los espacios dudosos.
El final del texto en la ventana "Texto" no es muy diferente del trabajo de diseño habitual. Configure la ventana "Texto" y "primer plano" para que ocuparon la mayor parte de la ventana de trabajo del programa, vaya a la página siguiente que se está verificando, vea su texto. Si encuentra un lugar dudoso o explícitamente erróneo, luego haga clic en él, mientras que el cursor en el "primer plano" se establece exactamente en el mismo lugar del original (escaneo). Compare la regla original y reconocida, si es necesario, que se está moviendo.

Higo. 25. Remoto con el "Texto" y las ventanas "Close-Up"
La funcionalidad del texto del texto "texto" no es particularmente diferente de la funcionalidad de ningún editor textual del grado promedio de complejidad. La apariencia de los botones en el menú es bastante típica, no debe haber problemas cuando se trabaje con ellos. Si necesita corregir algún carácter, que falta en el teclado, como en la ventana "Comprobar", debe hacer clic en el botón con el "Omega" griego y seleccione la necesaria en la tabla.
Resultados de ahorro
Cuando el material escaneado es reconocido y calculado, se debe guardar en uno de los formatos documentales - DOC, DOCX, RTF, PDF, HTML, etc. Esto se realiza a través de "Archivo → Guardar el documento como → Seleccione el formato deseado" o A través del botón "Guardar" en el Menú principal FineReader.
En la ventana del conductor abierto, seleccione el formato, a través del botón "Configuración", configure los parámetros Guardar, haga clic en "Aceptar". Si desea ver de inmediato si no hay errores notables en la apariencia del texto guardado, marque el "Documento Abrir después de guardar". Luego se abrirá inmediatamente en el editor (navegador, visor).

Higo. 26. Ventana de conservación de texto reconocido.
La práctica habitual del reconocimiento es ingresar al texto escaneado del libro o registro, en la salida, todas sus páginas se guardan en el archivo con el nombre de este libro. Es esta configuración "Crear un solo archivo para todas las páginas" es predeterminado en la cadena "Opciones de archivo". Si no es reconocido por un texto de una sola pieza, pero simplemente un rasguño de páginas (por ejemplo, documentación de oficina), entonces será necesario establecer "Guardar archivo separado. Para cada página ".
Configuraciones de conservación en DOC, DOCX, formatos RTF

Higo. 27. Configuraciones de conservación en DOC / DOCX / RTF
La clave y lo más importante que necesita elegir es con qué grado de precisión en el documento guardado se mostrará la apariencia del original (uno de los modos de conservación en el "Diseño de documentos"). Todos los demás ajustes no son más que el refinamiento y detallando este artículo.
Las opciones de selección aquí son cuatro: "Copia precisa", "Copia editable", "texto formateado" y "texto simple".
1. "Copia precisa".
Según el plan de desarrolladores, debería haber habido una imagen prácticamente espejo de una página reconocida. Por eso se llama. Con una reproducción precisa de las fuentes, el tamaño de las letras (kegles), las distancias entre las letras en las palabras, las distancias entre las palabras, las filas y los párrafos y otros detalles de diseño. La idea, en general, no es mala, pero la oportunidad de darse cuenta en el volumen planificado de FineReader se suele perder.
Las fuentes y su dibujo (normal, cursiva, audaz) a menudo se reproducen de acuerdo con el principio "como sale y tendrá éxito". Se puede transmitir exactamente. Puede suceder que la fuente utilizada en la página reconocida se sustituya con otra fuente (similar a la vista, pero otras). Puede suceder que la inscripción normal será reconocida como audaz o viceversa. Y así sucesivamente y así sucesivamente.
Con la reproducción de kegos, distancias y otros formatos, la situación no es mucho mejor, más o menos la reproducción con precisión la apariencia (diseño) de la página reconocida generalmente se administra en casos de algo no muy complejo.
Como resultado, resulta que no está muy claro qué: un documento de Word solo se puede leer (bueno y copiar el texto desde allí). Edítalo fuera del "Par de letras para eliminar, un par de letras insertar" locamente. Y es necesario editar lo mismo, continuará en algún tipo de trabajo, lo que significa que será necesario rehacer el formato para la necesidad de uso futuro.
Por un lado, todo el texto aquí es Raskidanadan en numerosos marcos, que bonitos complican el trabajo con él. Por otro lado, durante el reconocimiento, el programa genera un grupo de estilos de Word'Ovo: todo el formato en el texto se realiza exclusivamente a través de estilos. Por lo general, es cuando se generan unos pocos cientos de estilos diferentes en el texto del libro de medianos (300-400 páginas). Lo que más complica la edición.
Resumen: no tiene ningún sentido particular para elegir este modo de preservar un sentido especial, es bastante inconveniente trabajar con el texto guardado.
Si necesita una reproducción completa de la apariencia del original, es más sencillo, y es más práctico realizar en forma de "texto en la página" o PDF "solo texto e imágenes" (sobre estos métodos de salida son ligeramente más bajos) .
2. "Copia editable".
En significado, esta es una versión liviana de la "copia precisa". Apariencia El original se reproduce no con tal grado de meticulosidad, como en el caso anterior, los marcos con texto son notablemente más pequeños (aunque se encuentran periódicamente). Sin embargo, al menos esta opción se llama "editable", trabaje con él también, para no decir cómodo.
Si se necesita el documento de Word, como es, solo para ver su contenido y copiar el fragmento deseado del texto, también puede usar esta opción. Si necesita rehacer mucho, reformatear, etc., es mejor elegir algo más.
La razón es la misma que es demasiado de la conversión de texto del tipo que se emitirá la "copia editable", según la vista que puede necesitar. Todavía había algún número de texto en marcos, la tendencia aún se conserva en el formateo de la apariencia (diseño) del original. Sí, y el hábito de generar un montón de estilos no está haciendo ninguna parte.
Resumen: trabajar con el texto aquí no es tan problemático como en la "copia precisa", pero aún deja mucho que desear.
3. "Texto formateado".
El grado de cumplimiento del original aquí se minimiza: la reproducción de fuentes y kegles, ubicación aproximada del material en las páginas del original, vista general Texto y mesas.
Trabajar con esta opción es notablemente más fácil que con los anteriores, pero aún es difícil porque gran número Estilos. Pero es suficiente para ser tratado, puede pasar rápidamente el texto e imponer su propio conjunto de estilos.
4. "texto simple".
Aunque se llama "texto simple", pero aquí puede ahorrar tanto el texto como el texto con imágenes. El formateo en esta opción se reduce a los párrafos mínimos de la palabra ordinaria de un borde de la página a otra, más la estufa entre las imágenes. Atención de las opciones anteriores, tampoco se genera muchos estilos.
Pero si lo desea, incluso aquí puede dejar el desglose original en las cuerdas y en las páginas. Además, mantenga el dibujo de la fuente es normal, cursiva, negrita.
Por lo general, se selecciona o se selecciona o "texto formateado", o "texto simple", dependiendo de lo que va a hacer a continuación y cómo usarlo reconocido.
Ahora sobre las otras configuraciones de esta ventana.
- "Tamaño de papel predeterminado".
Aquí está la configuración de la palabra "Configuración de página → Tamaño de papel", es decir, en papel de qué formato hará una impresión. Generalmente se establece A4. Pero debe tenerse en cuenta que en la "copia precisa" y los modos "Copia editable" uno a uno se almacenan, no solo se almacenan los contenidos de la página reconocida, sino también su tamaño inicial. Como resultado, si pone un formato de papel aquí, más que el tamaño de la página, luego, cuando se imprime alrededor del texto, habrá campos vacíos. Si pone un formato más pequeño, se puede perder parte del material de la página (resulta más allá de los límites de la hoja de papel). - "Guarda la transferencia y la decisión de las líneas".
Si se establece la garrapata, entonces se guardará el desglose en la cadena, que está en el original. Las transferencias de fila en este caso se hacen suaves. Si no coloca las casillas de verificación, entonces el texto irá párrafos ordinarios de palabras-buey, con filas de un borde de la página a otra. - "Guardar división a las páginas".
Si se establece la casilla de verificación, entonces se guardará el desglose en la página, que se guardará en el original. Si las casillas de verificación no se ponen, entonces el texto en la página romperá la palabra en sí. - "Guardar pies y números de página".
Si se entrega la garrapata, se guardará el texto marcado y reconocido como pieadores de página y números de página y se colocarán en los campos correspondientes de la muñeca de palabras. Si no pone una garrapata, entonces esta parte del texto no se muestra en absoluto. - "Guardar números de cadena".
Si se establece la casilla de verificación, entonces la numeración de estas filas se guardará en las listas con cadenas numeradas. - "Mantenga el color de fondo y las letras".
Si se entrega la garrapata, se derivará el texto impreso en color (o en un fondo de color), como en el original. Si las casillas de verificación no se colocan, entonces todo el texto se emitirá de la manera habitual: negro sobre un fondo blanco (o en blanco sobre un fondo negro). - "Guarde una fuente audaz, cursiva y subrayada en el texto simple".
La salida al "texto simple" se puede hacer de acuerdo con el principio de "toda la misma intensidad, normal", y es posible preservar el dibujo, que estaba en el original. Aquí solo este momento y regulado. - "Seleccione símbolos de reconocimiento insuficiente".
Esta casilla de verificación debe instalarse si prefiere deducir el texto reconocido, no en FineReader, sino en algún editor de texto. Luego, todas las marcas de los personajes y las palabras que tenían en la ventana "Texto" se jugarán en el documento guardado. - "Guardar fotos".
Se determinará si las imágenes también se guardarán. - "Calidad de las imágenes".
Aquí se determina el grado de compresión de imágenes del original. Puede ajustarse en tres direcciones, a través de varios algoritmos de compresión, a través de la resolución de la imagen de rescate y a través de la profundidad del color. Los detalles se pueden ver si selecciona la opción "Personalizada" en la cadena "Calidad de la imagen". Es más práctico usarlo, y no presets "tamaño pequeño (150 dpi)" y " Alta calidad (Resolución de la imagen de origen). "
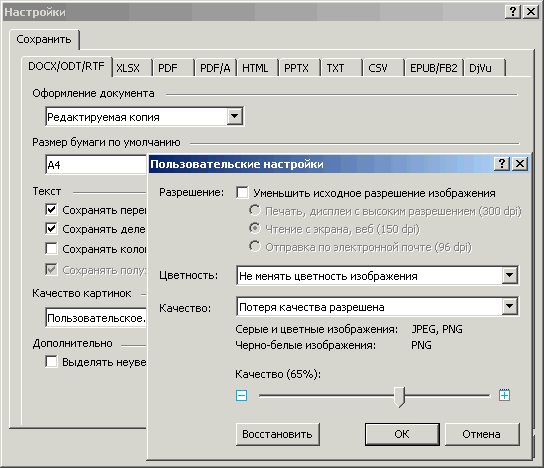
Higo. 28. Ventana de configuración de calidad de imagen
Dado que con una disminución en la resolución inicial y la compresión posterior, son posibles distorsiones poco previsibles, la casilla de verificación "Reduce la resolución de la imagen original" se elimina mejor.
Profundidad de color por la situación. Si se necesitan las imágenes, como es, elige "No cambiar el color de la imagen". Si simplemente es simplemente un tipo común, la reproducción exacta de los colores no es necesaria, elige "Convertir imágenes en color en gris". La conversión de color y imágenes grises en blanco y negro es mejor no elegir, porque la binarización puede dar mucha distorsión (y mal predecible). El artículo "automáticamente" también es mejor no elegir, no está muy claro qué lógica del trabajo se siente y que recibirá en la salida.
Configuración de conservación en PDF y PDF / A Formatos

Higo. 29. Configuraciones de conservación en PDF
Los modos Guardar Aquí también son cuatro: "Solo texto e imágenes", "texto en la parte superior de la imagen de la página", "texto debajo de la imagen de una página", "solo una imagen".
- "Solo texto e imágenes".
Aquí, en realidad, obtiene la opción PDF de lo que se emite en la "copia precisa", el texto y la ilustración reconocidos en la ventana "Texto" en el formulario lo más cerca posible del original. La calidad de la reproducción original aquí es más alta que en DOC / DOCX / RTF, ya que el formato PDF tiene más posibilidades para esto. - "Texto en la parte superior de la página de la página".
Este PDF que consta de dos capas es la imagen original (capa inferior) a la que se aplica texto reconocido (capa superior). Esta opción es bastante conveniente si PDF se editará más tarde. - "Texto bajo la imagen de la página".
Este PDF compilado de las mismas dos capas es la imagen original y el texto reconocido. Solo que van en orden inverso, la imagen de la capa superior, el texto de abajo (invisible) capa. Este método de salida también se denomina "PDF con un sustrato de texto" y se usa cuando es necesario obtener, por un lado, la copia exacta de la apariencia del original, y, por otro lado, la posibilidad de copiar el texto de este original. . - "Sólo una imagen".
Este es un PDF ensamblado de imágenes de origen. Además de las imágenes, no hay nada allí.
Ahora sobre el resto de la configuración de esta ventana.
1. "El tamaño de papel predeterminado".
En PDF-SALIDA, el significado de esta configuración es el mismo que en el caso anterior: el formato de hoja en el que se imprimirá la página.
En el caso anterior, se dijo acerca de la regla "Si una página es más pequeña que el formato especificado, entonces habrá campos vacíos alrededor del texto, si se reducirá más del texto". En PDF, todavía se cumple aún más rígidamente, porque aquí la página original se reproduce en cualquier opción uno a uno. Por lo tanto, es más razonable poner aquí "Use el tamaño del original".
2. "Mantenga el color de fondo y las letras".
3. "Guardar pies".
El significado de estos dos ajustes es el mismo que en el caso anterior.
4. "Crea una tabla de contenidos".
Si una marca de verificación "Definición de elementos estructurales → Tabla de contenido" se estableció en la configuración del reconocimiento, los contenidos del libro reconocidos de esta manera se pueden utilizar para creación automática Tabla de contenidos en el archivo PDF.
5. "Permitir etiquetas PDF".
En las etiquetas PDF, este es un análogo funcional de estilos de palabras, el método de marcado estructural de los contenidos del archivo PDF. Con su ayuda, la información se almacena en el desglose del texto en los capítulos, encabezados, sucezas, ilustraciones, tablas, notas, hipervínculos, fórmulas matemáticas Y de lo contrario como.
Si necesita copiar a menudo desde piezas de texto PDF, entonces la marca aquí vale la pena. Luego, el texto copiado será mucho más coincidir con lo que parece en la página PDF.
También las etiquetas son útiles si PDF tiene que verse en pantallas diferentes tamaños - De escritorios a teléfonos inteligentes. En tales casos, los lectores PDF tienen que reformatear los contenidos de las páginas en el tamaño de la pantalla actual y con el marcado de etiquetas, pasa de manera mucho más precisa, sin distorsiones notables del tipo inicial.
6. "Use contenido ráster mixto (MRC)".
MRC (contenido de ráster mixto) es el nombre de la tecnología de compresión capaz de dar multiplicidades notablemente grandes de la compresión que la conocida JPEG y el JPEG 2000. Muchos están familiarizados con él en el formato DJVU: se basa en la base de datos MRC. La elección de "necesidad de poner una marca o no" aquí es ambigua y se determina sobre la base de su conclusión.
El principal más es el tamaño del PDF resultante. Puede ser varias veces menos que el PDF obtenido con la misma configuración de compresión, pero sin MRC.
¿Qué podrían ser menos?
La compresión de MRC está organizada que cuando el trabajo siempre le da un número mal previsible de distorsión. Debido al hecho de que las distorsiones aquí solo dependen de la configuración de compresión, y en una medida justo del contenido de la página. Texto, dibujos, gráficos, fotos - con compresión de MRC, todos se comportan de manera marcada de manera diferente y dan un número diferente de distorsión.
Intensidad de recursos notablemente grande al comprimir y ver dicho PDF. Incluso en las computadoras de hoy, MRC-PDF se puede abrir y desplazarse sin familiarse sin problemas, y salta, cuando se muestra la página siguiente en la pantalla, no todos a la vez, sino en partes.
7. "Guardar fotos".
8. "Calidad de la imagen".
El significado de estos ajustes es el mismo que en el caso anterior: es necesario o no es necesario al crear PDF para guardar imágenes y con qué nivel de compresión para guardarlos. Las recomendaciones también son similares, para eliminar la marca de verificación de "Reducir la resolución inicial", el color es mejor no cambiar, el motor "Calidad" está configurado por analogía con compresión en JPEG 2000.
9. "Fuentes".
Si pones "uso fuentes de Windows"El reconocimiento y la salida posterior utilizarán el conjunto de fuentes que están instaladas en su computadora. Si pone "Fuentes predefinidas de uso", solo un conjunto de fuentes que se instala cuando se instala FineReader.
Es preferible establecer la primera opción, ya que se utilizará una variedad de fuentes mucho mayor y el programa será más fácil seleccionar el cumplimiento de las fuentes de libros reconocibles.
10. "Incrustar fuentes".
Si lo necesita, al ver un archivo PDF en otra computadora, fue visible exactamente cómo lo obtuvo (fue en estas fuentes), entonces necesita poner una marca aquí.
11. "Parámetros de protección PDF".
Aquí puedes exhibir protección de contraseña sobre el ver PDF., Imprimiendo, copiando de texto y dibujos, edición.
Si tiene preguntas sobre el trabajo de FineReader, para el cual no ha encontrado una respuesta en el texto del artículo, puede especificar los desarrolladores del programa.
La conversación se realizará sobre el programa Abbyy FineReader 12, es decir, sobre su última versión. No se ve demasiado lejos, elegimos el producto más famoso de ABBYY, que, a su mérito, está perfectamente ruso. Ya a primera vista, Fine Reader (FR) da la impresión de un programa con un buen apoyo de habla rusa: en este sentido, de hecho, todo se realiza en un nivel muy digno, incluida la información de referencia.
Inicialmente - retiro. La pregunta siempre es relevante cómo traducir todo o parte del archivo en un formato digital (y que, de hecho, para entender bajo la palabra "DIGITAL"). Apenas comprar el escáner resuelve todos los problemas. Por supuesto, un disco o varios con la marca se completa con la documentación del escáner. software. Sin embargo, ya en la etapa de saneamiento, resulta que la calidad del programa de escaneo deja mucho que desear o un formato en el que se guarda, desafortunadamente, no es adecuado para el almacenamiento. ¿Por qué? La mayoría de los formatos gráficos no separan el texto del espacio no intestino del documento, y por lo tanto, la copia de cualquier extracto de dicho archivo no sea posible.
Es en tales casos que los programas funcionales de los "reconocimientos" del texto llegan a los ingresos, las posibilidades de las cuales, en particular, incluyen la extracción de texto de la imagen.
Conocimiento con FineReader Abbyy
Paquete Abbyy FineReader 12. - Sistema de reconocimiento de texto óptico (reconocimiento de caracteres ópticos - OCR). Diseñado tanto para ingresar automáticamente documentos impresos a la computadora y convertir documentos PDF y fotos a formatos editables. (desde el manual del programa)
La abreviatura "OCR" es aplicable a todas las solicitudes de reconocimiento de datos (y no solo texto). La fuente de extracción de datos se puede imprimir o documento electrónico. Una vez que no sea durante mucho tiempo sobre OCR, de una forma u otra, pocas personas lo sabían, y el proceso de traducción de texto al formulario electrónico se convirtió en una especie de rutina, hasta la reimpresión manual del texto del original. Hoy, poseiendo escáner de tabletas (utilice manualmente unidades en casa) y fineReader 12.- Asegúrese de que no surja ninguna dificultad en el escaneo y el reconocimiento.
Comenzando con la sexta versión, FineReader admite importación y exportación a formato PDF, patentado por Adobe. Probablemente muchos lectores se enfrentaron con las dificultades de transferencia de este formato en cualquier otra (doc, etc.), ya que no hay tanto programas útiles en esta área (la atención es digna. Es la subsidiaria de Abbyy - Transformer PDF). El hecho es que tales programas se realizan mediante el reconocimiento del texto solo una vez, como resultado de lo cual la "identidad" del resultado es en absoluto pequeña (dependiendo de la complejidad del documento), más el formato de documento.
En el caso de FineReader, todo es diferente. La novena versión del programa introdujo una tecnología llamada Documento OCR. Se basa en el principio del reconocimiento sólido del documento: se analiza y se reconoce en su conjunto, y no se pospuesta. Al mismo tiempo, todo tipo de columnas, pies de página, fuentes, estilos, notas al pie y imágenes permanecen intactas o reemplazadas cerca del original.
Instalación de un paquete
La versión demo-Version FineReader 12 se puede descargar en el sitio web abyy.ru, en la sección de descargas, la versión con licencia completa se distribuye en el CD. Acerca de la forma de comprar se puede encontrar en el mismo sitio en la sección "Comprar".
En el sitio web de Abbyy Developers, puede descargar la versión de demostración del paquete de Abbyy FineReader versión 12 (u otro, relevante hoy)
Abbyy FineReader se extiende a varias versiones: edición profesional, edición corporativa, edición de licencia del sitio y otros. Diferencia versión de profesional El resto es lo que está diseñado para trabajar. red corporativa Con la capacidad de colaborar en reconocer documentos. De lo contrario, la diferencia es insignificante y depende de la elección de los términos del acuerdo de licencia.
Es difícil imaginar que hace 12 años existió FineReader 2.0, que ocupó aproximadamente 10 MB de espacio en disco. Con el tiempo, el paquete "cultivado" diez veces y ahora en el formulario prescrito toma hasta 300 MB. Es mucho o un pequeño juicio por ti mismo. El nuevo FR es compatible con 179 idiomas de reconocimiento, entre los que hay idiomas artificiales poco conocidos (Ido, Interningwa, Occidental y Eserario), lenguajes de programación, fórmulas, etc. No nos olvidaremos del apoyo de varios formatos, escenarios. Por lo tanto, si por alguna razón desea limitar el lugar ocupado por el paquete, verifique solo aquellos componentes que estarán en demanda al trabajar.
La selección de componentes afecta la duración de la instalación, que, sin embargo, no debe llevar mucho tiempo. En el proceso de instalación, estará familiarizado con las posibilidades principales de FR. Después de la activación (en Internet, por correo electrónico, utilizando el código recibido, etc.), el programa está listo para el trabajo con todas las funciones. En el modo de demostración, seguramente encontrará varias restricciones, lo que, lamentablemente, no permitirá el uso completo del paquete.
Interfaz de FineReader. Funcionalidad
El acceso a las capacidades del programa está disponible tanto utilizando escenarios que aparecerán en el menú principal inmediatamente después del proceso de instalación y, de hecho, a través de la interfaz principal.
 Screensaver cuando se inició FineReader
Screensaver cuando se inició FineReader La aparición del programa de la versión a la versión no se somete a cambios especiales: los desarrolladores no ven el sentido de cambiarlo radicalmente. Se presta atención considerable a la ergonomía, que es notable en todos los productos de Abbyy (Lingvo, Transformador PDF, Flexicapture ...). En otras palabras, la fina interfaz de lector 12 está bien pensada y está predispuesta a todos los usuarios, no excluyendo novatos. El principio de "obtener el resultado de una pulsación" tendrá que probar a quienes no se usan para personalizar algo y cambiar. Por otro lado, los usuarios más experimentados pueden configurar cuidadosamente FineReader a través del cuadro de diálogo Configuración (Servicio -\u003e Opciones ...). El único matiz: es recomendable que el trabajo cómodo en la aplicación establezca la resolución de la pantalla en 1280? 800 para que todas las herramientas siempre hayan sido, lo que se llama, en cuestión.
Después de iniciar el programa Fine Rider, aparecerá una ventana con los botones. acceso rapido a las funciones del programa. Este menú También disponible a través del menú Herramientas:\u003e Abbyy FineReader, el botón "Escenarios básicos" en la esquina extrema derecha del programa o a través de una combinación de teclas CTRL + N (por analogía con Word, donde se llama este documento nuevo).
Escanear en Microsoft Word: En la novena versión de FineReader, el soporte aún no ha tenido tiempo de convertirse en popular Microsoft Word 2007. A su vez, en la barra de herramientas en las aplicaciones de Microsoft Office, en la sección complementaria después de instalar el FR, aparece el icono rojo "Marcado".
 Menú para exportar el documento reconocido de FineReader
Menú para exportar el documento reconocido de FineReader  Seleccione el idioma para el escaneo y el reconocimiento de documentos.
Seleccione el idioma para el escaneo y el reconocimiento de documentos. Además de Microsoft Office, FR es compatible con Microsoft Outlook Integration, proporciona resultados de exportación de reconocimiento a la misma Microsoft Word, Excel, Lotus Word Pro, Corel Wordperect y Adobe Acrobat. Estas oportunidades se deteriorarán hasta cierto punto y acelerarán el trabajo con el programa, especialmente si tiene que trabajar regularmente.
PDF o imagen en Microsoft Word: Reconozca los datos de un PDF, o un archivo gráfico de otro tipo, compatible con FineReader 12 versión. Cabe señalar que la tecnología para extraer texto de PDF -File en FR no es solo "pelado", se puede faltar el llenado textual (capa de texto en PDF) de gráficos. De hecho, la tecnología de reconocimiento es bastante difícil: después de analizar el contenido del documento, el programa decide eso y cómo hacerlo con el texto: simplemente extraer o reconocer, y así como se aplica a cada fragmento de texto.
Escanear B. Microsoft Excel.: El escaneo XLS (Formato de Microsoft Excel) se puede justificar si la imagen escaneada contiene tablas.
Escanear en PDF: Puede haber muchas razones para escanear en PDF. Uno de ellos es la seguridad: este es el único formato, familiar FR, en la configuración del cual puede establecer un bloqueo de contraseña. La contraseña está configurada no solo para abrir el documento, sino también para imprimir y otras operaciones. Es posible elegir uno de los tres niveles de cifrado: 40 bits, 128 bits basado en estándar RC4, nivel de 128 bits basado en el AES (estándar de cifrado avanzado).
Convertir foto en Microsoft Word: Traducción de un archivo desde un formato gráfico (y esto puede ser PDF o una imagen de varias páginas) en DOC / DOCX.
Abierto en buen jinete: Abra el archivo gráfico (PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG) para el reconocimiento de FineReader.
Trabajo en FineReader.
Ahora, brevemente sobre las características del programa. Todo el proceso se divide en escaneo, reconocimiento y preservación de resultados. Una vez que haya seleccionado el tipo de acción del programa, el archivo o el dispositivo para escanear, el FineReader realiza fasantemente su tarea, por cierto, es bastante intensivo por el procesador central.
Si usted es un propietario feliz de un procesador de doble núcleo, luego trabaje en el paquete Fine Reader 12, puede evaluar la potencia del rendimiento de la computadora. El hecho es que fr, encontrar un procesador de doble núcleo, reconoce que no es uno, sino a la vez dos páginas del documento paralelo. Trifle - pero agradable.
Al principio, escanear, luego reconocer y exportar un documento temporal al formato seleccionado.
 PDF Proceso de reconocimiento de documentos
PDF Proceso de reconocimiento de documentos Exploración. Nic entornos preliminares En la aplicación FineReader (a excepción de la selección del lector), no necesita hacerlo antes de escanear. Es por eso que se inventaron los escenarios: están diseñados para simplificar la implementación del mismo tipo de acciones.
Reconocimiento. Simplificación tocada en otras pequeñas cosas. Entonces, si recuerda las versiones anteriores del programa, antes de que tuviéramos que cambiar manualmente el idioma (idiomas, si hubiera varios) del documento. Ahora sucede automáticamente, aunque no siempre. En este último caso, la FR se ofrece de manera discreta para verificar el idioma del documento.
Volviendo a la Tecnología de reconocimiento de FR: ¿Por qué el programa es el primer documento en todo el documento, y no después del posponimiento? Como ya se mencionó, se reconoce el texto, según el contenido completo: se seleccionan similares a las fuentes de tamaño / auricular, las tablas y los límites, sangrías, etc.
No se sorprenda si el programa FineReader 12 le dará un mensaje, dicen, la página no se puede reconocer, ya que no se encontró ningún área de texto. Por el bien del experimento, fotografiamos en un teléfono móvil desde la pantalla LCD, un área de documentos de texto (sin embargo, sabiendo, el resultado ya es de anticipación). FINE LECTOR 12El reconoció el texto de la imagen, ya que era claramente de esta cualidad, lo que claramente no es suficiente para esto. Con el segundo enfoque, fotografiamos una página de cámara digital con texto durante la iluminación normal.
FineReader reconoció el extracto sin problemas, reteniendo el formato y marcando los marcadores de algunos momentos o símbolos dudosos que pueden ser una escritura variable.
Como se puede ver en la imagen, principalmente este punto, guiones, comas, en general, personajes pequeños. Además, se ve claramente que el programa de desigualidad, la curva de la página fotografiada y niveló las cadenas de texto. CONCLUSIÓN - FR, perfectamente se enfrió a su propia tarea, incluso una tarea muy difícil.
Ocasionalmente, pueden permanecer inadvertidos por el programa Fine Rider algunos momentos menores, pero se corrigen fácilmente. Afortunadamente, hay un WYSIWYG en el paquete, cuyas capacidades son suficientes para hacer la edición final del documento. El corrector ortográfico también está disponible.
¿Cómo mejorar la precisión del reconocimiento para luego en menor medida para participar en el texto de edición? Primero, puede conectar el diccionario de usuario de Microsoft Word. Es cierto, es difícil juzgar el aumento de la precisión, excepto que el aumento en el vocabulario del Spelchkeker (Módulo inspeccionando la ortografía y la gramática). Entre otras cosas, tiene sentido mejorar el reconocimiento de familiarizarse con la configuración del programa (Servicio -\u003e Opciones) y seleccione uno de los dos modos:
reconocimiento cuidadoso - Se puede elegir al reconocer documentos de cualquier "complejidad": con tablas sin líneas de malla, texto, gráficos, tablas sobre fondo de color, etc. También puede ayudar también con una fuente de calidad deficiente para el reconocimiento
reconocimiento rápido - Se recomienda este modo para procesar grandes cantidades de documentos con diseño simple o en caso de que el tiempo no permita un reconocimiento cuidadoso. En la mayoría de los casos, cuando tiene con texto impreso negro sobre un fondo blanco, puede detenerse en un rápido reconocimiento.
En general, mejorar la calidad de la operación FineReader es un tema separado para la conversación, cuyos detalles pueden aprender de la ayuda oficial, a saber, en la sección "Cómo mejorar los resultados obtenidos".
Guardar un documento. La última etapa del trabajo en el programa Fine Reader 12 es guardar el resultado final en un formato gráfico / texto específico. Pre-configuración de la Guardar Puede especificarse en el FR: Service -\u003e Opciones, Guardar pestaña. Para cada formato proporciona su configuración. Al guardar en formato DOCX, la compatibilidad de formatos (los archivos DOCX no se reconocen en Word 2003<). В txt-файлах не забудьте проверить правильность кодировки (особенно в случае с текстом в кириллице).
Lector de captura de pantalla de Abbyy.
Muchos paquetes a granel son muy a menudo desarrolladores, les gusta agregar servicios públicos de servicio menores. Por ejemplo, una aplicación conocida para grabar los discos Nero incluye un conjunto de 3 a 5 utilidades, lo que permite algo que incluso Nerón no puede. Revisión (aquí también puede descargarlo como parte del Fine Rider 12).
En cuanto a FineReader, una pequeña aplicación de lectores de captura de pantalla se encuentra en su composición. Con él, puede tomar una instantánea de la pantalla y la traducirá rápidamente al formato deseado por fr. El programa está disponible a través del menú Inicio (Inicio -\u003e Todos los programas -\u003e Abbyy FineReader 12.0 -\u003e Lector de captura de pantalla de Abbyy.).
Las capacidades del lector de capturas de pantalla son algo más anchas de lo que parecen a primera vista. (Y, de lo contrario, sería posible hacer con una pulsación simple de la tecla "PISTRISTA" en el teclado). Además del hecho de que el lector de captura de pantalla toma la captura de pantalla (o, más precisamente, el área de pantalla seleccionada), el programa está estrechamente integrado con fr.
Cuando hace clic en el botón "Snapshot" en el panel Reader de captura de pantalla, el cursor cambia el formulario y la herramienta de selección de pantalla está activada. El área seleccionada de la imagen es el marco para el reconocimiento de texto adicional (se inicia automáticamente).
En la lista desplegable, puede elegir la acción deseada: de hecho, el lector de capturas de pantalla dupite escenarios rápidos de FR con la diferencia que en lugar de una imagen del escáner "en la entrada" ingresa a la captura de pantalla.
Cabe destacar, el programa, junto con todo el paquete, requiere activación. Al registrar un producto Abbyy FineReReder 12 Professional Edition Screenshot Reader es gratuito, como "Bonus".
Conclusión
Buen lector - un programa indispensable Para escanear y reconocer los datos gráficos. La interfaz rusa y la disponibilidad de la configuración no asustará a un usuario inexperto. Soporte para los últimos formatos, tecnologías innovadoras y, como resultado, el reconocimiento de alta calidad realiza el programa con una opción óptima, especialmente porque los competidores en esta área aún no están previstos.
Keys FineReader 12
- Crea un nuevo documento de Abbyy FineReader - Ctrl + n
- Abierto Abbyy FineReader Document 12 - CTRL + MAYÚS + N
- Guardar páginas - Ctrl + S
- Guardar imagen en archivo - Ctrl + Alt + S
- Reconocer todas las páginas de documentos. - CTRL + MAYÚS + R
- Cerrar la página actual - Ctrl + F4
- Reconocer Dediced Abbyy FineReader Document Pages - Ctrl + R
- Administrador de escenario abierto - Ctrl + t
- Opción de diálogo abierto "Fine Rider"- Ctrl + Shift + O
- Certificado abierto - F1.
- Ir a la ventana del documento - Alt +1
- Ir a la imagen de la ventana - Alt +2.
- Ir a la ventana de texto - Alt +3.
- Ir a la ventana de primer plano - Alt +4.
La traducción al texto al formato digital es una tarea bastante común para aquellos que trabajan con documentos. Abbyy FineReader ayudará a ahorrar mucho tiempo, transferir automáticamente las inscripciones de imágenes rasteras o "lectores" al texto editable.
En este artículo, considere cómo usar Abbyy FineReader para reconocer los textos.
Cómo reconocer el texto de la imagen con Abbyy FineReader
Para reconocer el texto en imagen de la trama, Simplemente descarguelo al programa, y \u200b\u200bAbbyy FineReader reconoce automáticamente el texto. Solo puede editarlo, resaltar el deseado y guardar en el formato deseado o copiar al editor de texto.
Reconocer el texto puede ser directamente desde el escáner conectado.
Lea más en nuestro sitio web.
Cómo crear un documento PDF y FB2 usando Abbyy FineReader
El programa Abbyy FineReader le permite convertir imágenes a un formato PDF universal y formato FB2 para leer en libros electrónicos y tabletas.
El proceso de crear dichos documentos es similar.
1. En el menú principal del programa, seleccione la sección E-Book y presione FB2. Seleccione el tipo de documento de origen: escaneo, documento o foto.

2. Busque y abra el documento requerido. Se iniciará en la Carta del Programa (puede tomar algún tiempo).
3. Cuando se complete el proceso de reconocimiento, el programa se propondrá para seleccionar el formato para guardar. Seleccione FB2. Si es necesario, vaya a "Opciones" e ingrese información adicional (Autor, Nombre, indicio, descripción).

Después de ahorrar, puede permanecer en el modo de edición de texto y traducirlo en formato de palabra. o PDF.
Características de edición de texto en Abbyy FineReader
Para el texto que reconoció a Abbyy FineReader tiene varias opciones.
En el resultado del documento, guarde las imágenes y los pies de página para que se muevan a un nuevo documento.

Realice un análisis de documentos para saber qué errores y problemas pueden ocurrir durante el proceso de conversión.

Editar imagen de la página. Opciones para cultivos, corrección de fotos, cambios de resolución están disponibles.

Así que le dijimos a cómo usar Abbyy FineReader. Tiene una edición de texto bastante amplia y capacidades de conversión. Deje que este programa ayude a crear cualquier documento que necesite.
Hola. Hoy hablaré sobre cómo usar el programa Abbyy FineReader para reconocer la imagen de texto C que podría obtener como resultado del escaneo. ¡Su texto escaneado estará completamente en el documento de Microsoft Word y este texto reconocido se puede editar! Reconocer el texto con Abbyy FineReader puede ser útil para aquellos que estudian, funcionan con textos y traducciones. El programa, lamentablemente, se paga. De alguna manera he estado tratando de probar una de las opciones gratuitas. programas similares¡Pero el texto muy bien escaneado es simplemente terrible ... y reconocer el texto en FineReader Abbyy, resulta de muy alta calidad! Ahora le mostraré cómo usar Abbyy FineReader para reconocer rápidamente el texto de la imagen.
Abbyy FineReader tiene versión de prueba Durante 30 días con la capacidad de reconocer hasta 100 páginas y ahorrar más de 3 páginas del documento. Esos. Durante este tiempo, puede ver las posibilidades del programa y tomar una solución ponderada, ya sea que le necesite si vale la pena comprarlo o no.
¡Cómo instalar Abbyy FineReader!
Antes de usar Abbyy FineReader, debe estar instalado. Considere el proceso de instalación de este programa ...
Para empezar, seleccione el idioma del programa. Haga clic en Aceptar".
Aceptamos los términos del acuerdo de licencia (si lo desea, puede leer el acuerdo de licencia si está interesado en lo que está allí). Haga clic en Siguiente".
A continuación, debe seleccionar el modo de instalación. En el modo normal, el programa no le preguntará y establece lo que se especifica el programa de forma predeterminada, a saber, todos los componentes: el programa Abbyy FineReader en sí mismo para el reconocimiento de texto, componente para los programas de Microsoft Office y un componente para el Explorador de Windows (lo que le permite rápidamente Reconocer imágenes sin abrir el programa por separado). Le aconsejo que marque una instalación selectiva para configurar lo que necesita. Especialmente no toma 15 minutos :) debajo de la carpeta se indica dónde se instalará el programa. Es recomendable dejar la selección predeterminada para que no haya problemas al usar el programa. Haga clic en Siguiente".
Componentes del programa. Esta ventana aparecerá en caso de que seleccione la configuración "Personalizada". Los componentes son algo así como aplicaciones de aplicaciones auxiliares. El primer componente "Integración con los programas de Microsoft Office y Conductor de Windows" Este componente se mostrará en el menú Microsoft Office y, si hace clic en la imagen en su computadora, haga clic con el botón derecho, luego habrá un artículo con este programa. Así es como se verá su menú en Microsoft Office después de agregar este componente.
Pero lo que sucederá si hace clic con el botón derecho en la imagen:
Esos. Aparece un menú en el que puede hacer un reconocimiento de texto rápido con el envío de resultados en Word, Excel o PDF.
El segundo componente le permitirá reconocer el texto de la pantalla de la computadora. Esto significa que puede hacer una captura de pantalla y también reconocer el texto. Si no desea instalar uno de estos componentes, o no desea instalar ambos, debe hacer clic en la flecha hacia abajo y seleccionar "Este componente no estará disponible". Luego, no se instalará el componente. Me dejé ambos.
Siguiente 4 puntos. El 1º significa que la información sobre cómo utiliza el programa Abbyy FineReader será transferido al desarrollador. Este artículo aconsejo que no tenga en cuenta que el programa se publique una vez más en Internet por el hecho de enviar información sobre cómo trabajar con él. Además, nunca se sabe qué otra información se enviará :) 2do artículo crea un acceso directo de programa en el escritorio. 3RD significa que el programa se iniciará cuando la computadora esté encendida, y el 4º revisará las actualizaciones del programa. Solo dejo el segundo y lo opuesto, deja una garrapata. Cierre todas las aplicaciones de Microsoft Office, porque requiere el instalador y haga clic en "Conjunto".
Necesitas esperar un par de minutos para arrancar y hacer clic en "Siguiente".
¡Toda la instalación se completa! Presione "LISTO".
¿Cómo reconocer el texto con un escaneo o cualquier otra imagen usando Abbyy FineReader?
Considere cómo usar el programa. Por ejemplo, has escaneado texto. Ahora, para reconocer el texto en FineReader Abbyy, abra el programa. Haga clic en "Abrir".
Elija la imagen que necesita y haga clic en Abrir.
Cuando abre el documento deseado, Abbyy FineReader comenzará a reconocer el texto. Cuanto más documento, más tiempo tendrá el reconocimiento. El reconocimiento de una sola página puede tardar unos segundos.
Después de reconocer el texto, solo guardará el resultado en documento de Microsoft Palabra para que puedas editar cualquier cosa en ella. Para hacer esto, haga clic en el botón "Guardar" en la parte superior de la barra de herramientas, después de lo cual selecciona qué carpeta se guardará palabra de documento y bajo el nombre.
Si está conectado a un escáner de computadora, puede comenzar a escanear directamente desde el programa, y \u200b\u200bdespués de lo cual se reconocerá inmediatamente el documento escaneado. Para hacer esto, en la barra de herramientas superior, haga clic en el botón Escanear. A continuación, las acciones dependerán del programa de conductor para su impresora. Solo necesita seguir las instrucciones del asistente de escaneo.
Como puedes ver, todo es muy simple y rápido. ¡Ahora sabes cómo usar Abbyy FineReader para reconocer el texto de las imágenes! Espero que esta información ayude enormemente a muchos :) ¡Buena suerte!
 Cómo pagar un nombre de dominio
Cómo pagar un nombre de dominio Zona de dominio de las islas Tokelau
Zona de dominio de las islas Tokelau ¿Qué es el dominio qué problemas pueden ser?
¿Qué es el dominio qué problemas pueden ser? YANDEX WORDSTAT: Instrucciones detalladas para usar los operadores de servicio y agrupación y una solicitud complicada
YANDEX WORDSTAT: Instrucciones detalladas para usar los operadores de servicio y agrupación y una solicitud complicada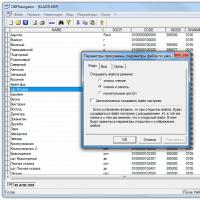 Edición de archivos DBF
Edición de archivos DBF Xenu Link Sleuth: ¿Qué es este programa cómo usar el programa XENU?
Xenu Link Sleuth: ¿Qué es este programa cómo usar el programa XENU? Métodos Copia e inserte texto desde el teclado sin usar el mouse
Métodos Copia e inserte texto desde el teclado sin usar el mouse