¿Qué es P2P? Tecnologías peer-to-peer: desde Cenicienta hasta princesas Peer to technology
Y mientras estamos aquí sentados preguntándonos dónde colocar nuestra publicidad, algo extraño está sucediendo en Palo Alto. Allí, los empleados de Hassett Ace Hardware, una pequeña ferretería, muestran cómo puede cobrar vida la antigua sabiduría de que “los humanos no fueron creados para atesorar, sino para compartir”.
Se llama "Café de reparación". Cada fin de semana se abre un sitio al lado de la tienda donde cualquiera puede reparar cualquier cosa de forma gratuita. Pero al mismo tiempo tendrá que aportar su contribución a lo que sucede en este sitio. Mientras el gerente de la tienda está ocupado con las ventas regulares, otros cinco empleados organizan multitudes de personas que quieren “arreglar”, atrayendo a otras reparaciones.
Todos comparten conocimientos, consejos y buen humor. Las ventas están aumentando (las reparaciones a menudo requieren piezas que deben comprarse en una tienda). En abril, el condado reparó alrededor de 130 equipos, incluida una fuente de lava gigante en el jardín y una máquina de coser de 200 años. Todos los que son reparados en una ubicación de Hassett Ace Hardware reciben una bandera de bicicleta con el logotipo de la empresa. Y lo toman con mucho gusto, porque un buen servicio es algo muy agradable e inolvidable.
Esta economía de beneficio mutuo recibió el nombre de “peer-to-peer” o “peer to peer” en el ámbito del marketing. Se basa no sólo en el dinero, sino también en un alto grado de satisfacción emocional y, en el caso de tiendas pequeñas como Hassett Ace Hardware, también en la construcción de una relación casi íntima con los clientes. Hay rumores de que gigantes como Pepsi, Chevrolet y Unilever ya están "olfateando" esta tecnología.
“Aprendimos algo interesante: los compradores jóvenes, antes de venir al concesionario a comprar un coche, buscan las páginas de nuestros vendedores en las redes sociales para estudiar sus intereses y encontrar una persona cercana en espíritu. Lo encuentran y consultan con él porque saben que la ayuda será más amigable que gerencial”, dice Christy Landy, gerente de marketing de General Motors. Incluso la opinión de expertos puede ser objeto de un intercambio mutuamente beneficioso.
Un vistazo rápido a la literatura revela muchas interpretaciones diferentes del concepto Peer-to-Peer, que difieren principalmente en la gama de características incluidas.
Las definiciones más estrictas de una red peer-to-peer "pura" la tratan como un sistema totalmente distribuido en el que todos los nodos son absolutamente iguales en términos de funcionalidad y tareas realizadas. Los sistemas basados en la idea de “supernodos” (nodos que actúan como miniservidores locales asignados dinámicamente), como Kazaa, no cumplen con esta definición (aunque esto no impide que sea ampliamente aceptado como una red P2P, o un sistema que utiliza alguna infraestructura de servidor centralizado para realizar subconjuntos de tareas auxiliares: autoajuste, gestión de calificación de reputación, etc.).
Por definición más amplia, P2P es una clase de aplicaciones que utilizan recursos (discos duros, ciclos de procesador, contenido) disponibles en el borde de la nube de Internet. Al mismo tiempo, también es adecuado para sistemas que utilizan servidores centralizados para su funcionamiento (como SETI@home, sistemas de mensajería instantánea o incluso la infame red Napster), así como para diversas aplicaciones en el campo de la computación grid.
Como resultado, para ser honesto, no existe un punto de vista único sobre qué es y qué no es una red P2P. Las múltiples definiciones probablemente se deban al hecho de que los sistemas o aplicaciones se denominan P2P no por sus operaciones o arquitectura internas, sino por cómo aparecen externamente, es decir, si dan la impresión de comunicación directa de computadora a computadora.
Al mismo tiempo, muchos coinciden en que las principales características de la arquitectura P2P son las siguientes:
- compartir recursos informáticos mediante intercambio directo sin la ayuda de intermediarios. En ocasiones, se pueden utilizar servidores centralizados para realizar tareas específicas (autoconfiguración, agregar nuevos nodos, obtener claves globales para el cifrado de datos). Debido a que los nodos en una red peer-to-peer no pueden depender de un servidor central para coordinar el intercambio de contenido y las operaciones en toda la red, se les exige que asuman de manera independiente y unilateral un papel activo en la realización de tareas como buscar otros nodos, localizar o almacenamiento en caché de contenido y enrutamiento de información y mensajes, conexión con nodos vecinos y su terminación, cifrado y verificación de contenido, etc.;
- la capacidad de aceptar la inestabilidad e inconstancia de las conexiones como norma, adaptándose automáticamente a sus roturas y fallos informáticos, así como a un número variable de nodos.
A partir de estos requisitos, varios expertos proponen la siguiente definición (su estilo recuerda algo a una patente, pero si intentas simplificarla, resultará peor): Una red P2P es un sistema distribuido que contiene nodos interconectados capaces de autoorganizarse en una topología de red para compartir recursos como contenido, ciclos de procesador, dispositivos de almacenamiento y ancho de banda, adaptándose a fallas y a un número variable de nodos, manteniendo un nivel aceptable de conectividad y rendimiento sin necesidad de intermediarios ni el soporte de un servidor central global.
Este es el momento de hablar sobre las características de la informática en sistemas grid y P2P. Ambos representan dos enfoques de la informática distribuida que utilizan recursos compartidos en una comunidad informática a gran escala.
Las redes informáticas son sistemas distribuidos que permiten el uso coordinado a gran escala y el intercambio de recursos distribuidos geográficamente, basados en infraestructuras de servicios permanentes y estandarizados y diseñados principalmente para computación de alto rendimiento. A medida que estos sistemas se expanden, comienzan a requerir soluciones a los problemas de autoconfiguración y tolerancia a fallas. Por su parte, los sistemas P2P se centran inicialmente en la inestabilidad, un número variable de nodos en la red, la tolerancia a fallos y la autoadaptación. Hasta la fecha, los desarrolladores de P2P han creado en su mayoría aplicaciones integradas verticalmente y no se han molestado en definir protocolos comunes y marcos estandarizados para la interoperabilidad.
Sin embargo, a medida que la tecnología P2P madure y se utilicen aplicaciones más complejas, como la distribución de contenido estructurado, la colaboración de PC y la computación grid, se espera la convergencia de P2P y la computación grid.
Clasificación de aplicaciones P2P
Las arquitecturas P2P se han utilizado para muchas aplicaciones de diferentes categorías. A continuación se ofrece una breve descripción de algunos de ellos.
Comunicaciones y colaboración. Esta categoría incluye sistemas que proporcionan una infraestructura para la comunicación y colaboración directa, generalmente en tiempo real, entre computadoras pares. Los ejemplos incluyen chat y mensajería instantánea.
Computación distribuída. El objetivo de estos sistemas es aunar la potencia informática de sus pares para resolver problemas computacionalmente intensivos. Para ello, la tarea se divide en una serie de pequeñas subtareas, que se distribuyen en diferentes nodos. Luego, el resultado de su trabajo se devuelve al anfitrión. Ejemplos de tales sistemas son los proyectos SETI@home, genome@home y varios otros.
Sistemas de bases de datos. Se ha invertido un esfuerzo considerable en desarrollar bases de datos distribuidas basadas en infraestructura P2P. En particular, se ha propuesto un modelo relacional local, que supone que el conjunto de todos los datos almacenados en una red P2P consta de bases de datos relacionales locales incompatibles (es decir, aquellas que no satisfacen restricciones de integridad específicas), interconectadas mediante "intermediarios", que determinar reglas de traducción y dependencias semánticas entre ellas.
Distribución de contenidos. La mayoría de las redes P2P modernas entran en esta categoría y comprenden sistemas e infraestructuras diseñadas para compartir información audiovisual digital y otros datos entre usuarios. Estos sistemas de distribución de contenido varían desde aplicaciones relativamente simples para compartir archivos directamente hasta otras más complejas que crean entornos de almacenamiento distribuido que brindan organización, indexación, búsqueda, actualización y recuperación de datos segura y eficiente. Los ejemplos incluyen la última red Napster, Gnutella, Kazaa, Freenet y Groove. A continuación nos centraremos en esta clase de redes.
Distribución de contenidos en redes P2P
En el caso más típico, estos sistemas proporcionan un entorno de almacenamiento distribuido en el que los usuarios de esa red pueden publicar, buscar y recuperar archivos. A medida que aumenta la complejidad, puede introducir características no funcionales como seguridad, anonimato, equidad, escalabilidad, gestión de recursos y capacidades organizativas. Las tecnologías P2P modernas se pueden clasificar de la siguiente manera.
Aplicaciones P2P. Esta categoría incluye los sistemas de distribución de contenidos basados en tecnología P2P. En función de su finalidad y complejidad, conviene dividirlos en dos subgrupos:
- sistemas para compartir archivos, destinado al intercambio simple y único entre computadoras. Estos sistemas crean una red de pares y proporcionan un medio para buscar y transferir archivos entre ellos. Por lo general, se trata de aplicaciones QoS ligeras y de mejor esfuerzo sin preocuparse por la seguridad, la disponibilidad o la capacidad de supervivencia;
- Sistemas para publicar y almacenar contenidos.. Dichos sistemas proporcionan un entorno de almacenamiento distribuido en el que los usuarios pueden publicar, almacenar y distribuir contenido manteniendo la seguridad y la confiabilidad. El acceso a dicho contenido está controlado y los nodos deben tener los privilegios adecuados para recibirlo. Los principales objetivos de dichos sistemas son garantizar la seguridad de los datos y la supervivencia de la red y, a menudo, su objetivo principal es crear medios para la identificación, el anonimato y la gestión de contenidos (actualización, eliminación, control de versiones).
- determinación de direcciones y enrutamiento. Cualquier sistema de distribución de contenido P2P se basa en una red peer-to-peer, dentro de la cual los nodos y el contenido deben localizarse de manera eficiente, las solicitudes y las respuestas deben enrutarse, al tiempo que se garantiza la tolerancia a fallas. Se han desarrollado varios marcos y algoritmos para cumplir con estos requisitos;
- asegurando el anonimato. Los sistemas de infraestructura basados en P2P deberían diseñarse para garantizar el anonimato del usuario;
- manejo de reputación. Las redes P2P carecen de una autoridad central para gestionar la información de reputación de los usuarios y su comportamiento. Por lo tanto, se encuentra en muchos nodos diferentes. Para garantizar que sea segura, esté actualizada y esté disponible en toda la red, debe existir una infraestructura sofisticada de gestión de la reputación.
Localización y enrutamiento de objetos distribuidos en redes P2P.
El funcionamiento de cualquier sistema de distribución de contenidos P2P se basa en nodos y conexiones entre ellos. Esta red se forma sobre la base (normalmente IP) e independientemente de ella y, por lo tanto, a menudo se la denomina superposición. La topología, estructura, grado de centralización de la red superpuesta, los mecanismos de localización y enrutamiento que utiliza para transportar mensajes y contenido son críticos para el funcionamiento del sistema, ya que afectan su tolerancia a fallos, rendimiento, escalabilidad y seguridad. Las redes superpuestas varían en su grado de centralización y estructura.
Centralización. Aunque la definición más estricta supone que las redes superpuestas están completamente descentralizadas, en la práctica esto no siempre se cumple y se encuentran sistemas con distintos grados de centralización. En particular, hay tres categorías:
- Arquitecturas completamente descentralizadas. Todos los nodos de la red realizan las mismas tareas, actuando como servidores y clientes, y no existe ningún centro que coordine sus actividades;
- Arquitecturas parcialmente centralizadas. La base aquí es la misma que en el caso anterior, pero algunos de los nodos juegan un papel más importante, actuando como índices centrales locales para archivos compartidos por nodos locales. La forma en que se asigna su función a estos supernodos en la red varía según el sistema. Es importante señalar, sin embargo, que estos supernodos no son un único punto de falla para la red P2P, ya que se asignan dinámicamente y en caso de falla, la red transfiere automáticamente sus funciones a otros nodos;
- Arquitecturas híbridas descentralizadas. Dichos sistemas tienen un servidor central que facilita la comunicación entre nodos mediante la administración de un directorio de metadatos que describe los archivos compartidos almacenados en ellos. Aunque la comunicación y el intercambio de un extremo a otro pueden ocurrir directamente entre dos nodos, los servidores centrales facilitan este proceso al ver e identificar los nodos que almacenan archivos.
Obviamente, en estas arquitecturas hay un único punto de falla: el servidor central.
Estructura de red Caracteriza si la red superpuesta se crea de forma no determinista (ad hoc), a medida que se agregan nodos y contenido, o en base a reglas especiales. En términos de estructura, las redes P2P se dividen en dos categorías:
- desestructurado. Colocar contenido (archivos) en ellos no tiene nada que ver con la topología de la red superpuesta; en casos típicos es necesario localizarlo. Los mecanismos de búsqueda van desde métodos de fuerza bruta, como inundar las consultas primero en amplitud o en profundidad hasta encontrar el contenido deseado, hasta estrategias más sofisticadas que implican el uso del método de caminata aleatoria y rutas de indexación. Los mecanismos de búsqueda utilizados en redes no estructuradas tienen implicaciones obvias para la disponibilidad, escalabilidad y confiabilidad.
Los sistemas no estructurados son más adecuados para redes con un número variable de nodos. Algunos ejemplos son Napster, Gnutella, Kazaa, Edutella y varios otros;
- estructurado. El surgimiento de tales redes se asoció principalmente con intentos de resolver los problemas de escalabilidad que enfrentaron inicialmente los sistemas no estructurados. En las redes estructuradas, la topología de superposición está estrictamente controlada y los archivos (o punteros a ellos) se colocan en ubicaciones estrictamente definidas. Básicamente, estos sistemas proporcionan un mapeo entre el contenido (por ejemplo, un ID de archivo) y su ubicación (por ejemplo, una dirección de nodo) en forma de una tabla de enrutamiento distribuida para que las solicitudes se puedan enrutar de manera eficiente al nodo con el contenido que se busca.
Los sistemas estructurados (incluidos Chord, CAN (Content Addressable Network), Tapestry y muchos otros) proporcionan soluciones escalables para búsquedas de coincidencias exactas, es decir, para consultas en las que se conoce el identificador exacto de los datos deseados. Su desventaja es la complejidad de la gestión de la estructura necesaria para enrutar mensajes de manera eficiente en un entorno con un número variable de nodos.
Las redes que ocupan una posición intermedia entre estructuradas y no estructuradas se denominan débilmente estructuradas. Aunque no indican completamente la localización del contenido, contribuyen a la búsqueda de rutas (un ejemplo típico de una red de este tipo es Freenet).
Ahora analizaremos las redes superpuestas con más detalle en términos de su estructura y grado de centralización.
Arquitecturas no estructuradas
Empecemos con arquitecturas completamente descentralizadas(ver definición arriba). El representante más interesante de este tipo de redes es Gnutella. Como la mayoría de los sistemas P2P, crea una red superpuesta virtual con su propio mecanismo de enrutamiento, lo que permite a sus usuarios compartir archivos. La red carece de coordinación central de operaciones y los nodos se conectan entre sí directamente mediante un software que funciona como cliente y servidor (sus usuarios se denominan servidores, de SERVers + clients).
Gnutella utiliza IP como protocolo de red base, mientras que las comunicaciones entre nodos se definen mediante un protocolo de capa de aplicación que admite cuatro tipos de mensajes:
- Silbido- una solicitud a un anfitrión específico para anunciarse;
- Apestar- respuesta a un mensaje Ping que contiene la dirección IP, el puerto del host solicitado, así como el número y tamaño de los archivos compartidos;
- Consulta- consulta de busqueda. Incluye una cadena de búsqueda y requisitos mínimos de velocidad para el host que responde;
- Resultados de consultas- respuesta a una solicitud Consulta, incluye la dirección IP, el puerto y la velocidad de transmisión del host que responde, la cantidad de archivos encontrados y un conjunto de sus índices.
Después de unirse a la red Gnutella (al comunicarse con hosts que se encuentran en bases de datos como gnutellahosts.com), el host envía un mensaje Ping a algunos hosts asociados con él. Responden con un mensaje Apestar, identificándose y enviando un mensaje Silbido a tus vecinos.
En un sistema no estructurado como Gnutella, la única forma de localizar un archivo era mediante una búsqueda no determinista, ya que los nodos no tenían forma de adivinar dónde estaba.
La arquitectura Gnutella originalmente usaba un mecanismo de inundación (o transmisión) para distribuir solicitudes. Silbido Y Consulta: Cada nodo reenvía los mensajes recibidos a todos sus vecinos y las respuestas siguen el camino inverso. Para limitar el flujo de mensajes en la red, todos contenían un campo de tiempo de vida (TTL) en el encabezado. En los nodos de tránsito, el valor de este campo disminuyó y cuando alcanzó el valor 0, el mensaje se eliminó.
El mecanismo descrito se implementó asignando ID únicos a los mensajes y teniendo tablas de enrutamiento dinámico con ID de mensajes y direcciones de nodo en los hosts. Cuando las respuestas contienen el mismo ID que los mensajes salientes, el host consulta la tabla de enrutamiento para determinar a través de qué canal enrutar la respuesta para romper el bucle.
| Arroz. 1. Ejemplo de mecanismo de búsqueda en un sistema no estructurado. |
Si un nodo recibe un mensaje Consulta de éxito, que indica que el archivo que buscas está en una computadora específica, inicia la descarga a través de una conexión directa entre los dos nodos. El mecanismo de búsqueda se muestra en la Fig. 1.
Sistemas parcialmente centralizados son en muchos aspectos similares a los totalmente descentralizados, pero utilizan el concepto de supernodos: computadoras a las que se les asigna dinámicamente la tarea de servir a una pequeña parte de la red superpuesta indexando y almacenando en caché los archivos que contiene. Se seleccionan automáticamente en función de su potencia de procesamiento y ancho de banda.
Los supernodos indexan archivos compartidos por nodos conectados a ellos y, como servidores proxy, realizan búsquedas en su nombre. Por lo tanto, todas las solicitudes se enrutan inicialmente a los supernodos.
Los sistemas parcialmente centralizados tienen dos ventajas:
- tiempo de búsqueda reducido en comparación con sistemas anteriores en ausencia de un único punto de falla;
- uso efectivo de la heterogeneidad inherente de las redes P2P. En sistemas totalmente descentralizados, todos los nodos se cargan por igual, independientemente de su potencia de procesamiento, ancho de banda del canal o capacidades de almacenamiento. En sistemas parcialmente centralizados, los supernodos asumen la mayor parte de la carga de la red.
Un sistema parcialmente centralizado es la red Kazaa.
Arroz. La Figura 2 ilustra un ejemplo de una arquitectura P2P típica con Descentralización híbrida. Cada computadora cliente almacena archivos que se comparten con el resto de la red superpuesta. Todos los clientes están conectados a un servidor central, que administra tablas de datos sobre usuarios registrados (dirección IP, ancho de banda, etc.) y listas de archivos propiedad de cada usuario y compartidos en la red junto con metadatos de archivos (por ejemplo, nombre, hora). creación, etcétera).
Una computadora que quiere unirse a la comunidad se conecta al servidor central y le informa sobre los archivos que contiene. Los nodos cliente envían solicitudes sobre ellos al servidor. Busca en la tabla de índice y devuelve una lista de usuarios que los tienen.
La ventaja de los sistemas híbridos descentralizados es que son fáciles de implementar y la recuperación de archivos es rápida y eficiente. Las principales desventajas incluyen vulnerabilidad al control, censura y acciones legales, ataques y fallas técnicas, ya que el contenido compartido, o al menos su descripción, está controlado por una única organización, empresa o usuario. Además, un sistema de este tipo no se escala bien, ya que sus capacidades están limitadas por el tamaño de la base de datos del servidor y su capacidad para responder a consultas. Un ejemplo en este caso sería Napster.
Arquitecturas estructuradas
Una variedad de sistemas de distribución de contenido estructurado utilizan diferentes mecanismos para enrutar mensajes y localizar datos. Nos centraremos en el más familiar para los usuarios ucranianos: Freenet.
Esta red superpuesta es una de las más débilmente estructuradas. Recordemos que su característica principal es la capacidad de los nodos para determinar (¡no de forma centralizada!) dónde es más probable que se almacene tal o cual contenido basándose en tablas de enrutamiento, que indican la correspondencia entre el contenido (identificador de archivo) y su localización ( dirección de nodo). Esto les da la posibilidad de evitar solicitudes de transmisión a ciegas. En su lugar, se utiliza un método de encadenamiento, en el que cada nodo toma una decisión local sobre dónde reenviar el mensaje a continuación.
Freenet es un ejemplo típico de un sistema de distribución de contenidos semiestructurado y completamente descentralizado. Funciona como una red peer-to-peer autoorganizada, que agrupa el espacio en disco no utilizado en las computadoras para crear un sistema de archivos virtual compartido.
Los archivos en Freenet se identifican mediante claves binarias únicas. Se admiten tres tipos de claves, la más simple de las cuales se basa en aplicar una función hash a una breve cadena de texto descriptivo que acompaña a cualquier archivo almacenado en línea por su propietario.
Cada nodo de Freenet gestiona su propio almacenamiento de datos local, haciéndolo legible y escribible por otros, así como una tabla de enrutamiento dinámica que contiene las direcciones de otros nodos y los archivos que almacenan. Para encontrar un archivo, el usuario envía una solicitud que contiene la clave y un valor de vida indirecto expresado en términos del número máximo de saltos de vida permitidos.
Freenet utiliza los siguientes tipos de mensajes, cada uno de los cuales incluye un ID de nodo (para detección de bucle), un valor de saltos de vida e ID de origen y destino:
- Insertar datos- un nodo que coloca nuevos datos en la red (el mensaje contiene la clave y los datos (archivo));
- Solicitud de datos- solicitud de un archivo específico (incluye una clave);
- Respuesta de datos- respuesta cuando se encuentra el archivo (el archivo se incluye en el mensaje);
- Error de datos- error al buscar un archivo (se indican el nodo y la causa del error).
Para unirse a Freenet, las computadoras primero determinan la dirección de uno o más nodos existentes y luego envían mensajes. Insertar datos.
Para colocar un nuevo archivo en la red, un nodo primero calcula su clave binaria y envía un mensaje Insertar datos a ti mismo. Cualquier nodo que reciba dicho mensaje primero verifica si la clave ya está en uso. De lo contrario, busca el más cercano (en términos de distancia lexicográfica) en su tabla de enrutamiento y enruta el mensaje (con datos) al nodo apropiado. Utilizando el mecanismo descrito, los archivos nuevos se colocan en nodos que ya poseen archivos con claves similares.
Esto continúa hasta que se alcanza el límite. salto para vivir. De esta forma, el archivo distribuido se ubicará en más de un nodo. Al mismo tiempo, todos los nodos involucrados en el proceso actualizarán sus tablas de enrutamiento; este es el mecanismo mediante el cual los nuevos nodos anuncian su presencia en la red. si el limite salto para vivir se logra sin una colisión de valores clave, se enviará un mensaje "todo correcto" a la fuente, informándole que el archivo se colocó en la red con éxito. Si la clave ya está en uso, el nodo devuelve el archivo existente como si fuera el solicitado. Por lo tanto, un intento de falsificar archivos conducirá a su posterior distribución.
Cuando un nodo recibe una solicitud de un archivo almacenado en él, la búsqueda se detiene y los datos se envían a su iniciador. Si el archivo requerido no existe, el nodo pasa la solicitud a un vecino en el que probablemente esté ubicado. La dirección se busca en la tabla de enrutamiento usando la clave más cercana, etc. Tenga en cuenta que aquí hay un algoritmo de búsqueda simplificado que solo brinda una imagen general del funcionamiento de la red Freenet.
Aquí probablemente terminaremos nuestra breve revisión de las tecnologías P2P y abordaremos el tema de su uso en los negocios. Es fácil destacar una serie de ventajas de la arquitectura P2P sobre la arquitectura cliente-servidor, que tendrán demanda en el entorno empresarial:
- alta confiabilidad y disponibilidad de aplicaciones en sistemas descentralizados, que se explica por la ausencia de un único punto de falla y la naturaleza distribuida del almacenamiento de información;
- mejor utilización de los recursos, ya sea ancho de banda de comunicación, ciclos de procesador o espacio en el disco duro. La duplicación de la información de trabajo también reduce significativamente (pero no elimina por completo) la necesidad de realizar copias de seguridad;
- simplicidad de implementación del sistema y facilidad de uso debido al hecho de que los mismos módulos de software realizan funciones de cliente y servidor, especialmente cuando se trata de trabajar en una red local.
El potencial de las redes P2P era tan grande que Hewlett-Packard, IBM e Intel iniciaron la creación de un grupo de trabajo para estandarizar la tecnología para uso comercial. La nueva versión de Microsoft Windows Vista tendrá herramientas de colaboración integradas, que permitirán a las computadoras portátiles compartir datos con sus vecinos más cercanos.
Los primeros defensores de la tecnología, como el gigante aeroespacial Boeing, la petrolera Amerada Hess y la propia Intel, dicen que su uso reduce la necesidad de comprar sistemas informáticos de alta gama, incluidos mainframes. Los sistemas P2P también pueden relajar los requisitos de ancho de banda de la red, lo cual es importante para las empresas que tienen problemas con esto.
Intel comenzó a utilizar la tecnología P2P en 1990 en un esfuerzo por reducir los costos de desarrollo de chips. La empresa creó su propio sistema, llamado NetBatch, que conecta más de 10 mil computadoras, brindando a los ingenieros acceso a recursos informáticos distribuidos globalmente.
Boeing utiliza computación distribuida para realizar pruebas de prueba que requieren muchos recursos. La empresa utiliza un modelo de red similar a Napster en el que los servidores dirigen el tráfico a nodos designados. "No existe ningún ordenador que satisfaga nuestras necesidades", afirma Ken Neves, director de la división de investigación.
El potencial de las tecnologías P2P también ha atraído la atención del capital riesgo. Así, Softbank Venture Capital invirtió 13 millones de dólares en United Device, empresa que desarrolla tecnologías para tres mercados: informática para la industria biotecnológica, calidad de servicio (QoS) y pruebas de carga para sitios web, así como indexación de contenidos basada en el método de búsqueda por gusanos. , utilizado por varias máquinas en Internet.
En cualquier caso, hoy ya son evidentes cinco áreas de aplicación exitosa de las redes P2P. Estos incluyen el intercambio de archivos, la separación de aplicaciones, la integridad del sistema, la computación distribuida y la interoperabilidad de dispositivos. No hay duda de que pronto habrá más.
Cliente P2P gratuito y de código abierto para trabajar con la red Direct Connect. Le permite descargar libremente archivos compartidos por otros usuarios de esta red.
Acerca de las redes peer-to-peer (p2p)
La red Direct Connect recuerda algo a BitTorrent en su estructura.
Centro Hub (inglés hub, wheel hub, center) es un nodo de red.Rastreador- un servidor de la red BitTorrent que coordina a sus clientes.
Tampoco existe un sistema de búsqueda centralizado y, para encontrar cualquier archivo, debe visitar uno de los servidores especiales: concentradores (similares a los rastreadores en BitTorrent).
Después de conectarse al centro, recibirá una lista de los usuarios conectados a él. Sin embargo, es posible que la conexión no se produzca si no ha compartido (cargado) la cantidad de información requerida. Normalmente de 2 a 10 GB.
Si se produce la conexión, entonces tiene la oportunidad de ingresar el nombre del archivo que le interesa en la búsqueda o realizar una búsqueda manualmente, dirigiéndose a cada usuario.
El principio de funcionamiento de la red debe entenderse en términos generales. Ahora veamos el propio cliente de Direct Connection.
Instalación de StrongDC++
Después de descargar el archivo con el programa, ejecute el archivo ejecutable y el programa se instalará en la carpeta "Archivos de programa" de su computadora.
Si al finalizar la instalación no desmarcaste la casilla correspondiente, el programa se iniciará automáticamente.
Esta versión ya está en ruso, pero si descargaste la versión en inglés, puedes rusificar el programa usando el archivo correspondiente con la extensión XML, ubicado en nuestro archivo con el programa.
Cuando se descarga el crack, debes instalarlo. Para hacer esto, seleccione el elemento "Apariencia" en el menú de configuración del programa y en el campo Archivo de idioma haga clic en el botón "Examinar" para seleccionar la ubicación del archivo sDC+++ruso.xml(nombre del archivo crack).
Después de realizar todas las manipulaciones, reinicie el programa y obtenga una versión rusa completamente funcional.
Configurando StrongDC++
Ahora configuremos la versión rusa de Strong DC++.
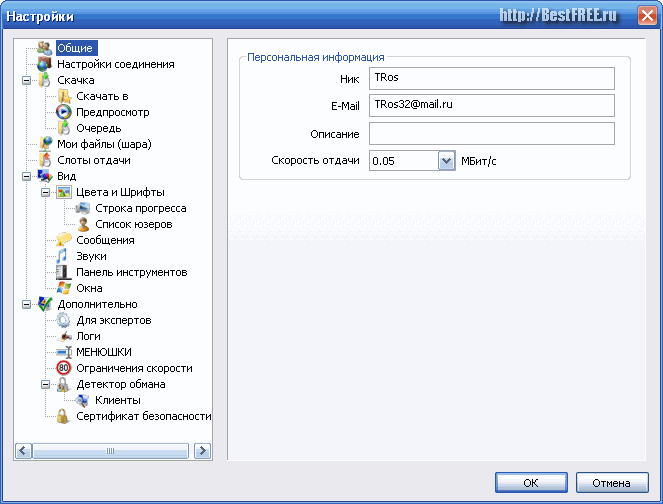
En el menú "General" debes especificar tu apodo, correo electrónico y velocidad de carga de archivos. El campo "Descripción" se puede dejar vacío (esto es como tu comentario).
dirección IP- dirección digital de una computadora en la red, por ejemplo: 192.0.3.244.En “Configuración de conexión” puede especificar su dirección IP y algunos otros datos. Se debe prestar especial atención a la "Configuración de la conexión entrante".
Es mejor utilizar una conexión pasiva a través de un firewall (de lo contrario, no se le mostrarán los archivos de otros usuarios).
Servidor proxy- servidor intermedio.El tráfico de las conexiones salientes se puede redirigir al servidor proxy o dejarlo directamente (la velocidad será mayor).
Luego seleccione el elemento "Descargar" y configure las carpetas predeterminadas para descargas y para almacenar archivos temporales.
Y ahora lo más importante!!! Necesitas compartir tus archivos. Para hacer esto, vaya al menú “Mis archivos (bola)” y en la ventana que se abre a la derecha, seleccione los archivos y carpetas a los que desea abrir el acceso.

Después de seleccionar un archivo, verá la siguiente ventana de progreso.

Empezando con StrongDC++
Después de realizar el hash de los archivos, puede comenzar a trabajar directamente con el programa. Haga clic en el botón "Aceptar" en la parte inferior y la ventana principal del programa aparecerá frente a usted.

Para comenzar a buscar los archivos que necesita, lo primero que debe hacer es conectarse a uno de los muchos centros.
Para hacer esto, haga clic en el botón "Centros de Internet" en la barra de herramientas, luego seleccione una de las listas de centros de Internet y haga clic en el botón "Actualizar".

Si conoce el nombre del centro o el usuario específico que necesita, es más fácil buscar usando un filtro.
Cuando encuentre el centro deseado, puede acceder a él haciendo doble clic con el botón izquierdo del mouse en su nombre. Si la cantidad de datos que compartió cumple con los requisitos del centro, verá algo como esta ventana:

Preste atención a la presencia de marcadores debajo de la ventana principal. Toda la navegación en Strong DC++ se realiza utilizando estos marcadores. Puede administrar los marcadores haciendo clic con el botón derecho del mouse.
Interfaz fuerte DC++
El espacio principal lo ocupa el chat, algo muy rentable. Será útil, desde “simplemente charlar” hasta la posibilidad de preguntar a otros dónde encontrar tal o cual información si la búsqueda no ayudó.
A la derecha del chat hay una lista de usuarios que están presentes actualmente en el centro. Los colores en los que están escritos los nombres de usuario contienen información adicional.

Búsqueda manual de archivos para descargar
Consideremos la interacción mediante la búsqueda manual. Al lado de cada usuario hay un indicador de la cantidad de archivos compartidos. Si la velocidad de su conexión no es muy alta, es mejor elegir aquellos que tengan volúmenes de archivos más pequeños.

Ahora, cuando aparezca una señal en “Estado” de que la lista de archivos ha sido descargada, se abrirá otra pestaña debajo, donde podrás ver qué archivos hay en la computadora del usuario que has elegido.
Para descargar el archivo seleccionado, haga clic derecho sobre él y seleccione "Descargar".

Hacemos lo mismo cuando utilizamos la búsqueda. En la barra de búsqueda ingresamos el nombre del archivo que necesitamos y esperamos.
Una vez completada la búsqueda, a continuación verá una lista de usuarios que tienen este archivo. Seleccionas uno de ellos, te conectas a él y descargas los datos necesarios.
conclusiones
A pesar de las muchas ventajas de la red DC++, también existen algunas desventajas. Hay dos de ellos específicamente. Imposibilidad de descargar un archivo si la fuente (la que tiene este archivo) se ha desconectado. Y el segundo inconveniente es, en ocasiones, una cola muy larga para la descarga.
En general, el sistema es muy interesante y lo que lo hace conveniente es el uso del programa StrongDC++.
PD Se concede permiso para copiar y citar libremente este artículo, siempre que se indique un enlace activo abierto a la fuente y se conserve la autoría de Ruslan Tertyshny.
P.P.S. Los predecesores de la red P2P fueron los servidores FTP, que se conectan más cómodamente mediante este programa:
Cliente FTP FileZilla https://www..php
Tecnologías de igual a igual
Realizado:
Estudiante de 1er año de la Maestría en Física y Matemáticas
Kulachenko Nadezhda Sergeevna
Comprobado:
Chernyshenko Serguéi Viktorovich
Moscú 2011
Introducción
A medida que Internet se desarrolla, las tecnologías para compartir archivos se vuelven cada vez más interesantes entre los usuarios. La Red, que es más accesible que antes, y la disponibilidad de amplios canales de acceso hacen que sea mucho más fácil encontrar y descargar los archivos que necesita. Un papel importante en este proceso lo desempeñan las tecnologías modernas y los principios de construcción de comunidades, que permiten construir sistemas que son muy efectivos tanto desde el punto de vista de los organizadores como de los usuarios de las redes de intercambio de archivos. Por lo tanto, este tema es relevante hoy, porque Constantemente aparecen nuevas redes y las antiguas dejan de funcionar o se modifican y mejoran. Según algunos datos, actualmente más de la mitad de todo el tráfico en Internet proviene de redes de intercambio de archivos entre pares. El tamaño de los más grandes superó la marca del millón de nodos que funcionan simultáneamente. El número total de participantes registrados en este tipo de redes de intercambio de archivos en todo el mundo es de unos 100 millones.
Peer-to-peer (inglés: igual a igual) es un antiguo principio de los samuráis japoneses y los socialistas utópicos. Ganó verdadera popularidad a finales del siglo XX. Ahora, este principio lo utilizan millones de usuarios de Internet, hablan con amigos de países lejanos y descargan archivos de usuarios que nunca han conocido.
Las tecnologías peer-to-peer (P2P) son uno de los temas más populares en la actualidad. La popularidad alcanzada con programas como Skype, Bittorrent, DirectConnect y la lista interminable de programas de este tipo confirma el potencial de los sistemas peer-to-peer.
En este trabajo, consideraré los principios individuales del funcionamiento de los recursos sobre este tema, los principios del funcionamiento de las redes populares peer-to-peer que se utilizan activamente para el intercambio de archivos, así como los problemas de su uso.
1. Napster y Gnutella: las primeras redes peer-to-peer
La primera red peer-to-peer, Napster, apareció en 1999 e inmediatamente se hizo conocida por toda la comunidad de Internet. El autor del cliente era Sean Fanning, de dieciocho años. Napster conectó miles de computadoras para abrir recursos. Inicialmente, los usuarios de Napster intercambiaban archivos mp3.
Napster permitió la creación de un entorno interactivo multiusuario para alguna interacción específica. Napster ofrece a todos los usuarios conectados a él la posibilidad de intercambiar archivos de música en formato mp3 casi directamente: los servidores centrales de Napster ofrecen la posibilidad de buscar en los ordenadores de todos los usuarios conectados a ellos, y el intercambio se produce sin pasar por los servidores centrales, utilizando un usuario- esquema a usuario. Gran parte de las grabaciones que circulan en el entorno Napster están protegidas por la ley de derechos de autor, pero se distribuyen de forma gratuita. Napster existió silenciosamente durante cinco meses y se convirtió en un servicio muy popular.
El 7 de diciembre, la Recording Industry Association of America (RIAA) demandó a Napster por “infracción directa e indirecta de derechos de autor”.
Al final, Napster primero se vendió a alguna empresa europea y luego se cerró por completo.
Gnutella fue creado en el año 2000 por programadores de Nullsoft como sucesor de Napster. Todavía funciona hoy en día, aunque debido a graves fallos en el algoritmo, los usuarios prefieren actualmente la red Gnutella2. Esta red funciona sin servidor (descentralización completa).
Al conectarse, el cliente recibe del nodo con el que pudo conectarse una lista de cinco nodos activos; Se les envía una solicitud para buscar un recurso utilizando una palabra clave. Los nodos buscan recursos que coincidan con la solicitud y, si no los encuentran, reenvían la solicitud a los nodos activos en el "árbol" (la topología de la red tiene una estructura gráfica de "árbol") hasta que se encuentra un recurso o se alcanza el número máximo de pasos. se supera. Esta búsqueda se llama inundación de consultas.
Está claro que tal implementación conduce a un aumento exponencial en el número de solicitudes y, en consecuencia, en los niveles superiores del "árbol" puede conducir a una denegación de servicio, lo que se ha observado muchas veces en la práctica. Los desarrolladores mejoraron el algoritmo e introdujeron reglas según las cuales las solicitudes solo pueden ser enviadas al "árbol" por ciertos nodos; los llamados ultrapeers, otros nodos (hojas) solo pueden solicitar estos últimos; También se ha introducido un sistema de nodos de almacenamiento en caché.
La red todavía funciona de esta forma hoy en día, aunque las deficiencias del algoritmo y las débiles capacidades de extensibilidad conducen a una disminución de su popularidad.
Las deficiencias del protocolo Gnutella iniciaron el desarrollo de algoritmos fundamentalmente nuevos para buscar rutas y recursos y llevaron a la creación de un grupo de protocolos DHT (Distributed Hash Tables), en particular, el protocolo Kademlia, que ahora se usa ampliamente en los más grandes. redes.
Las solicitudes en la red Gnutella se envían a través de TCP o UDP y los archivos se copian a través de HTTP. Recientemente, han aparecido extensiones para programas cliente que permiten copiar archivos a través de UDP y realizar solicitudes XML de metainformación sobre archivos.
En 2003, se creó un protocolo Gnutella2 fundamentalmente nuevo y se crearon los primeros clientes que lo soportaban, que eran compatibles con versiones anteriores de los clientes Gnutella. De acuerdo con esto, algunos nodos se convierten en centros, mientras que el resto son nodos ordinarios (hojas). Cada nodo regular tiene una conexión a uno o dos concentradores. Y un centro está conectado a cientos de nodos regulares y docenas de otros centros. Cada nodo envía periódicamente al centro una lista de identificadores de palabras clave que se pueden utilizar para buscar recursos publicados por este nodo. Los ID se almacenan en una tabla común en el centro. Cuando un nodo "quiere" encontrar un recurso, envía una consulta de palabra clave a su centro, que encuentra el recurso en su tabla y devuelve el ID del nodo propietario del recurso, o devuelve una lista de otros centros, que el El nodo vuelve a realizar consultas por turnos al azar. Esta búsqueda se denomina búsqueda mediante el método de paseo aleatorio.
Una característica notable de la red Gnutella2 es la capacidad de reproducir información sobre un archivo en la red sin copiar el archivo en sí, lo cual es muy útil desde el punto de vista del seguimiento de virus. Para los paquetes transmitidos en la red, se ha desarrollado un formato propietario similar a XML, que implementa de manera flexible la capacidad de aumentar la funcionalidad de la red agregando información de servicio adicional. Las consultas y listas de ID de palabras clave se envían a los concentradores a través de UDP.
2. Tecnologías P2P. El principio "cliente-cliente"
Una red peer-to-peer, descentralizada o peer-to-peer (del inglés peer-to-peer, P2P - igual a igual) es una red informática superpuesta basada en la igualdad de los participantes. En dicha red no hay servidores dedicados y cada nodo (par) es al mismo tiempo un cliente y un servidor. A diferencia de la arquitectura cliente-servidor, esta organización permite que la red permanezca operativa con cualquier número y combinación de nodos disponibles. Los participantes de la red son pares.
El término peer-to-peer fue utilizado por primera vez en 1984 por IBM al desarrollar una arquitectura de red para el enrutamiento dinámico del tráfico a través de redes informáticas con una topología arbitraria (Advanced Peer to Peer Networking). La tecnología se basa en el principio de descentralización: todos los nodos de la red P2P tienen los mismos derechos, es decir. Cada nodo puede actuar simultáneamente como cliente (destinatario de información) y servidor (proveedor de información). “Esto proporciona ventajas de la tecnología P2P sobre el enfoque cliente-servidor, como la tolerancia a fallas en caso de pérdida de conexión con varios nodos de la red, una mayor velocidad de adquisición de datos debido a la copia simultánea de varias fuentes, la capacidad de compartir recursos sin ser “vinculados” a direcciones IP específicas, enormes redes eléctricas en general, etc.”[2]
Cada nodo par interactúa directamente solo con un determinado subconjunto de nodos de la red. Si es necesario transferir archivos entre nodos de la red que no están en contacto directo, la transferencia de archivos se realiza a través de nodos intermediarios o a través de una conexión directa establecida temporalmente (está especialmente establecida para el período de transferencia). En su trabajo, las redes de intercambio de archivos utilizan su propio conjunto de protocolos y software, que es incompatible con los protocolos FTP y HTTP y presenta importantes mejoras y diferencias. En primer lugar, cada cliente de dicha red, al descargar datos, permite que otros clientes se conecten a ella. En segundo lugar, los servidores P2P (a diferencia de HTTP y FTP) no almacenan archivos para intercambiar y sus funciones se reducen principalmente a coordinar la colaboración de los usuarios en una red determinada. Para ello mantienen una especie de base de datos en la que se almacena la siguiente información:
¿Qué dirección IP tiene este o aquel usuario de la red?
Qué archivos están alojados en qué cliente;
Qué fragmentos de qué archivos se encuentran y dónde;
Estadísticas de quién descargó cuánto para sí mismo y se lo dio a otros para que lo descargaran.
El trabajo en una red típica de intercambio de archivos se estructura de la siguiente manera:
El cliente solicita el archivo requerido en la red (antes de hacer esto, es posible buscar el archivo requerido utilizando los datos almacenados en los servidores).
Si el archivo requerido está disponible y se encuentra, el servidor le proporciona al cliente las direcciones IP de otros clientes para los cuales se encontró el archivo.
El cliente que solicitó el archivo establece una conexión “directa” con el cliente o clientes que tienen el archivo deseado y comienza a descargarlo (si el cliente no está desconectado de la red en ese momento o no está sobrecargado). Además, en la mayoría de las redes P2P es posible descargar un archivo de varias fuentes a la vez.
Los clientes informan al servidor sobre todos los clientes que se conectan a ellos y los archivos que solicitan.
El servidor registra en su base de datos quién descargó qué (incluso si los archivos no se descargaron en su totalidad).
Las redes construidas con tecnología Peer-to-Peer también se denominan peer-to-peer, peer-to-peer o descentralizadas. Y aunque ahora se utilizan principalmente para la separación de archivos, hay muchos otros ámbitos en los que esta tecnología también se utiliza con éxito. Se trata de transmisiones de televisión y audio, programación paralela, almacenamiento en caché distribuido de recursos para descargar servidores, envío de notificaciones y artículos, soporte del sistema de nombres de dominio, indexación y búsqueda de recursos distribuidos, copia de seguridad y creación de almacenamiento de datos distribuidos resilientes, mensajería, creación de sistemas resistentes. a ataques de tipo denegación de servicio, distribución de módulos de software.
3. Principales vulnerabilidades del P2P
La implementación y uso de sistemas distribuidos no sólo tiene ventajas, sino también desventajas asociadas con las características de seguridad. Obtener control sobre una estructura tan extensa y grande como una red P2P, o explotar las brechas en la implementación del protocolo para sus propias necesidades, es un objetivo deseable para los piratas informáticos. Además, es más difícil proteger una estructura distribuida que un servidor centralizado.
Una cantidad tan enorme de recursos disponibles en las redes P2P es difícil de cifrar/descifrar, por lo que la mayor parte de la información sobre las direcciones IP y los recursos de los participantes se almacena y transmite sin cifrar, lo que la hace susceptible de interceptación. Cuando es interceptado, el atacante no sólo recibe la información en sí, sino que también aprende sobre los nodos en los que está almacenada, lo que también es peligroso.
Sólo recientemente los clientes de la mayoría de las redes grandes han comenzado a abordar este problema cifrando los encabezados de los paquetes y la información de identificación. Están apareciendo clientes que admiten la tecnología SSL, se están introduciendo medios especiales para proteger la información sobre la ubicación de los recursos, etc.
Un problema grave es la propagación de "gusanos" y la falsificación de identificaciones de recursos para falsificarlas. Por ejemplo, el cliente Kazaa utiliza la función hash UUHash, que le permite encontrar rápidamente ID de archivos grandes, incluso en computadoras débiles, pero aún deja la posibilidad de alterar archivos y escribir un archivo corrupto con la misma ID.
Para solucionar el problema descrito, los clientes deben utilizar funciones hash confiables ("árboles de funciones hash" si el archivo se copia en partes), como SHA-1, Whirlpool, Tiger y solo para tareas poco críticas: sumas de verificación CRC. Para reducir el volumen de datos enviados y facilitar el cifrado, puede utilizar la compresión. Para protegerse contra los virus, es necesario poder almacenar metainformación que identifique a los gusanos, como se hace, en particular, en la red Gnutella2.
Otro problema es la posibilidad de falsificar las identificaciones de servidores y nodos. En ausencia de un mecanismo para verificar la autenticidad de los mensajes de servicio reenviados, por ejemplo mediante certificados, existe la posibilidad de falsificación del servidor o del nodo (muchos nodos). Dado que los nodos intercambian información, la manipulación de algunos de ellos comprometerá toda la red o parte de ella. El software cerrado de cliente y servidor no es una solución al problema, ya que existe la posibilidad de realizar ingeniería inversa de protocolos y programas.
Algunos clientes sólo copian los archivos de otras personas, pero no ofrecen nada para que otros copien (leechers).
En las redes domésticas de Moscú, por cada pocos activistas que ponen a disposición más de 100 GB de información, hay alrededor de cien que publican menos de 1 GB. Se utilizan varios métodos para combatir esto. eMule utiliza el método de créditos: si copia un archivo, su crédito disminuirá; si permite que su archivo sea copiado, su crédito aumentará (xMule es un sistema de crédito que fomenta la distribución de archivos raros). La red eDonkey fomenta la multiplicación de fuentes, Bittorrent implementa el esquema "cuántos bloques de un archivo se recibieron, tantos se regalaron", etc.
4. Algunas redes peer-to-peer
4.1 Conexión directa
red peer-to-peer torrent peer-to-peer
Direct Connect es una red de intercambio de archivos (P2P) parcialmente centralizada basada en un protocolo especial desarrollado por NeoModus.
NeoModus fue fundada por Jonathan Hess en noviembre de 1990 como una empresa que ganaba dinero con el programa publicitario Direct Connect. El primer cliente de terceros fue "DClite", que nunca admitió completamente el protocolo. La nueva versión de Direct Connect ya requería una clave de cifrado simple para inicializar la conexión, que se esperaba bloquearía a los clientes de terceros. La clave fue descifrada y el autor de DClite lanzó una nueva versión de su programa, compatible con el nuevo software de NeoModus. Pronto, se reescribió el código DClite y el programa pasó a llamarse Open Direct Connect. Entre otras cosas, su interfaz de usuario se volvió multidocumento (MDI) y fue posible utilizar complementos para protocolos de intercambio de archivos (como en MLDonkey). Open Direct Connect tampoco tenía soporte completo para el protocolo, pero apareció en Java. Un poco más tarde empezaron a aparecer otros clientes: DCTC (Direct Connect Text Client), DC++, etc.
La red funciona de la siguiente manera. Los clientes se conectan a uno o más servidores, los llamados concentradores, para buscar archivos que normalmente no están conectados entre sí (algunos tipos de concentradores pueden conectarse parcial o totalmente en red mediante scripts especializados o el programa Hub-Link) y sirven para buscar. para archivos y fuentes para descargarlos. Los hubs más utilizados son PtokaX, Verlihub, YnHub, Aquila, DB Hub, RusHub. Para comunicarse con otros centros, los llamados. enlaces de dchub:
dchub://[ nombre de usuario ]@[ IP o dominio del concentrador ]:[ puerto del concentrador ]/[ruta del archivo]/[nombre del archivo]
Diferencias con otros sistemas P2P:
1. Condicionado por la estructura de la red
· Chat multiusuario desarrollado
· Se puede dedicar un servidor de red (hub) a un tema específico (por ejemplo, música de un género particular), lo que facilita encontrar usuarios con el tema de archivos requerido.
· La presencia de usuarios privilegiados: operadores que tienen un conjunto ampliado de capacidades de administración de centros, en particular, monitorear el cumplimiento de los usuarios con las reglas de chat y uso compartido de archivos.
2. Dependiente del cliente
· Posibilidad de descargar directorios completos
· Resultados de búsqueda no sólo por nombres de archivos, sino también por directorios
· Restricciones sobre la cantidad mínima de material compartido (por volumen)
· Soporte para scripts con posibilidades potencialmente ilimitadas tanto en el lado del cliente como en el lado del hub (no es válido para todos los hubs y clientes)
Para resolver problemas específicos, los autores del cliente DC++ desarrollaron un protocolo fundamentalmente nuevo llamado Advanced Direct Connect (ADC), cuyo objetivo es aumentar la confiabilidad, eficiencia y seguridad de la red de intercambio de archivos. El 2 de diciembre de 2007 se publicó la versión final del protocolo ADC 1.0. El protocolo continúa desarrollándose y complementándose.
Torrente de 4,2 bits
BitTorrent (literalmente en inglés "bit stream") es un protocolo de red peer-to-peer (P2P) para compartir archivos de forma cooperativa a través de Internet.
Los archivos se transfieren en partes, cada cliente de torrent, al recibir (descargar) estas partes, al mismo tiempo las entrega (carga) a otros clientes, lo que reduce la carga y la dependencia de cada cliente de origen y garantiza la redundancia de datos. El protocolo fue creado por Bram Cohen, quien escribió el primer cliente torrent, BitTorrent, en Python el 4 de abril de 2001. El lanzamiento de la primera versión se produjo el 2 de julio de 2001.
Para cada distribución se crea un archivo de metadatos con extensión .torrent, que contiene la siguiente información:
URL del rastreador;
Información general sobre los archivos (nombre, longitud, etc.) de esta distribución;
Sumas de comprobación (más precisamente, sumas hash SHA1) de segmentos de archivos distribuidos;
Clave de acceso del usuario, si está registrado en este rastreador. La longitud de la clave la establece el rastreador.
No es necesario:
Sumas hash de archivos completos;
Fuentes alternativas que no utilizan el protocolo BitTorrent. El soporte más común son las llamadas semillas web (protocolo HTTP), pero también se aceptan ftp, ed2k y magnet URI.
El archivo de metadatos es un diccionario en formato bencode. Los archivos de metadatos se pueden distribuir a través de cualquier canal de comunicación: ellos (o enlaces a ellos) pueden publicarse en servidores web, colocarse en las páginas de inicio de los usuarios de la red, enviarse por correo electrónico, publicarse en blogs o canales de noticias RSS. También es posible recibir la parte de información de un archivo de metadatos público directamente de otros participantes de la distribución gracias a la extensión del protocolo "Extensión para que Peers envíe archivos de metadatos". Esto le permite arreglárselas publicando solo un enlace magnético. Habiendo recibido de alguna manera un archivo con metadatos, el cliente puede comenzar a descargarlo.
Antes de iniciar la descarga, el cliente se conecta al rastreador en la dirección especificada en el archivo torrent, le indica su dirección y la cantidad de hash del archivo torrent, en respuesta a lo cual el cliente recibe las direcciones de otros clientes que descargan o distribuyen el mismo. archivo. A continuación, el cliente informa periódicamente al rastreador sobre el progreso del proceso y recibe una lista actualizada de direcciones. Este proceso se llama anunciar.
Los clientes se conectan entre sí e intercambian segmentos de archivos sin la participación directa de un rastreador, que solo almacena información recibida de los clientes conectados al intercambio, una lista de los propios clientes y otra información estadística. Para que la red BitTorrent funcione eficazmente, es necesario que el mayor número posible de clientes puedan aceptar conexiones entrantes. La configuración incorrecta de NAT o firewall puede impedir esto.
Al conectarse, los clientes intercambian inmediatamente información sobre los segmentos que tienen. Un cliente que quiere descargar un segmento (leecher) envía una solicitud y, si el segundo cliente está listo para descargar, recibe este segmento. Luego, el cliente verifica la suma de verificación del segmento. Si coincide con el registrado en el archivo torrent, entonces el segmento se considera descargado exitosamente y el cliente notifica a todos los pares conectados sobre la presencia de este segmento. Si las sumas de verificación difieren, el segmento comienza a descargarse nuevamente. Algunos clientes prohíben a sus pares que envían segmentos incorrectos con demasiada frecuencia.
Así, la cantidad de información del servicio (el tamaño del archivo torrent y el tamaño de los mensajes con una lista de segmentos) depende directamente del número y, por tanto, del tamaño de los segmentos. Por tanto, a la hora de elegir un segmento es necesario mantener el equilibrio: por un lado, con un tamaño de segmento grande, la cantidad de información del servicio será menor, pero en caso de error en la verificación de la suma de verificación, tendrás que descargar más información nuevamente. Por otro lado, con un tamaño pequeño, los errores no son tan críticos, ya que es necesario volver a descargar un volumen más pequeño, pero el tamaño del archivo torrent y los mensajes sobre los segmentos existentes aumentan.
Cuando la descarga está casi completa, el cliente ingresa a un modo especial llamado final del juego. En este modo, solicita todos los segmentos restantes de todos los pares conectados, lo que evita ralentizar o congelar por completo una descarga casi completa debido a varios clientes lentos.
La especificación del protocolo no especifica cuándo exactamente el cliente debe ingresar al modo final del juego, pero existe un conjunto de prácticas generalmente aceptadas. Algunos clientes ingresan a este modo cuando no quedan bloques no solicitados, otros siempre que el número de bloques restantes sea menor que el número de bloques que se transmiten y no más de 20. Existe la creencia tácita de que es mejor mantener el número. de bloques esperados bajos (1 o 2) para minimizar la redundancia, y que cuando las solicitudes aleatorias tienen una menor probabilidad de recibir duplicados del mismo bloque.
Desventajas y limitaciones
· Indisponibilidad de distribución – si no hay usuarios distribuidores (semillas);
· Falta de anonimato:
Los usuarios de sistemas desprotegidos y clientes con vulnerabilidades conocidas pueden estar sujetos a ataques.
Es posible averiguar las direcciones de los usuarios que intercambian contenidos falsificados y demandarlos.
· El problema de los leechers: clientes que distribuyen mucho menos de lo que descargan. Esto conduce a una caída de la productividad.
· El problema de los tramposos: usuarios que modifican la información sobre la cantidad de datos descargados/transferidos.
Personalización: el protocolo no admite apodos, chat ni visualización de una lista de archivos de usuario.
Conclusión
Las modernas redes peer-to-peer han experimentado una evolución compleja y se han convertido, en muchos aspectos, en productos de software perfectos. Garantizan una transferencia fiable y de alta velocidad de grandes cantidades de datos. Tienen una estructura distribuida y no pueden destruirse si se dañan varios nodos.
Las tecnologías probadas en redes peer-to-peer ahora se utilizan en muchos programas de otras áreas:
Para la distribución rápida de distribuciones de programas de código abierto (código abierto);
Para redes de datos distribuidas como Skype y Joost.
Sin embargo, los sistemas de intercambio de datos se utilizan a menudo en ámbitos ilegales: se violan las leyes de derechos de autor, censura, etc. Podemos decir lo siguiente: los desarrolladores de redes peer-to-peer entendieron perfectamente para qué se utilizarían y se preocuparon por la facilidad de uso, el anonimato de los clientes y la invulnerabilidad del sistema en su conjunto. Los programas y sistemas de intercambio de datos a menudo se clasifican como la zona "gris" de Internet, una zona en la que se violan las leyes, pero es difícil o imposible demostrar la culpabilidad de los involucrados en la violación.
Los programas y las redes de intercambio de datos se encuentran en algún lugar de las “periferias” de Internet. No cuentan con el apoyo de grandes empresas, a veces nadie les ayuda en absoluto; sus creadores suelen ser piratas informáticos a quienes no les gustan los estándares de Internet. A los fabricantes de firewalls, enrutadores y equipos similares, así como a los proveedores de servicios de Internet (ISP), no les gustan los programas de intercambio de datos: las redes de "hackers" les quitan una parte importante de sus valiosos recursos. Por lo tanto, los proveedores están intentando por todos los medios desplazar y prohibir los sistemas de intercambio de datos o limitar sus actividades. Sin embargo, en respuesta a esto, los creadores de sistemas de intercambio de datos nuevamente comienzan a buscar contramedidas y, a menudo, logran excelentes resultados.
La implementación y uso de sistemas distribuidos no sólo tiene ventajas, sino también desventajas asociadas con las características de seguridad. Obtener control sobre una estructura tan extensa y grande como una red P2P, o explotar las brechas en la implementación del protocolo para sus propias necesidades, es un objetivo deseable para los piratas informáticos. Además, es más difícil proteger una estructura distribuida que un servidor centralizado.
Una cantidad tan enorme de recursos disponibles en las redes P2P es difícil de cifrar/descifrar, por lo que la mayor parte de la información sobre las direcciones IP y los recursos de los participantes se almacena y transmite sin cifrar, lo que la hace susceptible de interceptación. Cuando es interceptado, el atacante no sólo recibe la información en sí, sino que también aprende sobre los nodos en los que está almacenada, lo que también es peligroso.
Sólo recientemente los clientes de la mayoría de las redes grandes han comenzado a abordar este problema cifrando los encabezados de los paquetes y la información de identificación. Están apareciendo clientes que admiten la tecnología SSL, se están introduciendo medios especiales para proteger la información sobre la ubicación de los recursos, etc.
Un problema grave es la propagación de "gusanos" y la falsificación de identificaciones de recursos para falsificarlas. Por ejemplo, el cliente Kazaa utiliza la función hash UUHash, que le permite encontrar rápidamente ID de archivos grandes, incluso en computadoras débiles, pero aún deja la posibilidad de alterar archivos y escribir un archivo corrupto con la misma ID.
Actualmente, los servidores y nodos dedicados intercambian periódicamente información de verificación entre sí y, si es necesario, agregan servidores/nodos falsos a la lista negra de bloqueo de acceso.
También se está trabajando para crear proyectos que combinen redes y protocolos (por ejemplo, JXTA - desarrollador Bill Joy).
Bibliografía
1. Yu. N. Gurkin, Yu. “Redes de intercambio de archivos P2P: principios básicos, protocolos, seguridad” // “Redes y sistemas de comunicación”, No. 11 2006
02/06/2011 17:23 http://www.ccc.ru/magazine/depot/06_11/read.html?0302.htm
2. A. Gryzunova Napster: Historia del caso Revista InterNet, número 22 02/06/2011 15:30 http://www.gagin.ru/internet/22/7.html
3. Redes informáticas modernas Resumen 02/06/2011 15:49 http://5ballov.qip.ru/referats/preview/106448
4. 28/01/2011 16:56 http://ru.wikipedia.org/wiki/Peer-to-peer
5. http://style-hitech.ru/peer-to-peer_i_tjekhnologii_fajloobmjena
28/01/2011 15:51
Institución educativa estatal de Moscú Tecnologías peer-to-peer Completado por: Estudiante de 1er año de la Maestría en Física y Matemáticas Kulachenko Nadezhda Sergeevna Revisado por: Chernyshenko Sergey ViktorovichUna de las primeras redes peer-to-peer, creada en el año 2000. Todavía está en funcionamiento, aunque debido a graves fallos en el algoritmo, los usuarios actualmente prefieren la red Gnutella2.
Al conectarse, el cliente recibe del nodo con el que pudo conectarse una lista de cinco nodos activos; Se les envía una solicitud para buscar un recurso utilizando una palabra clave. Los nodos buscan recursos que coincidan con la solicitud y, si no los encuentran, reenvían la solicitud a los nodos activos en el "árbol" (la topología de la red tiene una estructura gráfica de "árbol") hasta que se encuentra un recurso o se alcanza el número máximo de pasos. se supera. Esta búsqueda se llama inundación de consultas.
Está claro que tal implementación conduce a un aumento exponencial en el número de solicitudes y, en consecuencia, en los niveles superiores del "árbol" puede conducir a una denegación de servicio, lo que se ha observado muchas veces en la práctica. Los desarrolladores mejoraron el algoritmo e introdujeron reglas según las cuales las solicitudes solo pueden ser enviadas al "árbol" por ciertos nodos; los llamados ultrapeers, otros nodos (hojas) solo pueden solicitar estos últimos; También se ha introducido un sistema de nodos de almacenamiento en caché.
La red todavía funciona de esta forma hoy en día, aunque las deficiencias del algoritmo y las débiles capacidades de extensibilidad conducen a una disminución de su popularidad.
Las deficiencias del protocolo Gnutella iniciaron el desarrollo de algoritmos fundamentalmente nuevos para buscar rutas y recursos y llevaron a la creación de un grupo de protocolos DHT (Distributed Hash Tables), en particular, el protocolo Kademlia, que ahora se usa ampliamente en los más grandes. redes.
Las solicitudes en la red Gnutella se envían a través de TCP o UDP y los archivos se copian a través de HTTP. Recientemente, han aparecido extensiones para programas cliente que permiten copiar archivos a través de UDP y realizar solicitudes XML de metainformación sobre archivos.
En 2003, se creó un protocolo Gnutella2 fundamentalmente nuevo y se crearon los primeros clientes que lo soportaban, que eran compatibles con versiones anteriores de los clientes Gnutella. De acuerdo con esto, algunos nodos se convierten en centros, mientras que el resto son nodos ordinarios (hojas). Cada nodo regular tiene una conexión a uno o dos concentradores. Y un centro está conectado a cientos de nodos regulares y docenas de otros centros. Cada nodo envía periódicamente al centro una lista de identificadores de palabras clave que se pueden utilizar para buscar recursos publicados por este nodo. Los ID se almacenan en una tabla común en el centro. Cuando un nodo "quiere" encontrar un recurso, envía una consulta de palabra clave a su centro, que encuentra el recurso en su tabla y devuelve el ID del nodo propietario del recurso, o devuelve una lista de otros centros, que el El nodo vuelve a realizar consultas por turnos al azar. Esta búsqueda se denomina búsqueda mediante el método de paseo aleatorio.
Una característica notable de la red Gnutella2 es la capacidad de reproducir información sobre un archivo en la red sin copiar el archivo en sí, lo cual es muy útil desde el punto de vista del seguimiento de virus. Para los paquetes transmitidos en la red, se ha desarrollado un formato propietario similar a XML, que implementa de manera flexible la capacidad de aumentar la funcionalidad de la red agregando información de servicio adicional. Las consultas y listas de ID de palabras clave se envían a los concentradores a través de UDP.
Aquí hay una lista de los programas cliente más comunes para Gnutella y Gnutella2: Shareaza, Kiwi, Alpha, Morpheus, Gnucleus, Adagio Pocket G2 (Windows Pocket PC), FileScope, iMesh, MLDonkey
 Cómo insertar una tarjeta SIM en Xiaomi: instrucciones paso a paso
Cómo insertar una tarjeta SIM en Xiaomi: instrucciones paso a paso Tecnologías peer-to-peer: desde Cenicienta hasta princesas Peer to technology
Tecnologías peer-to-peer: desde Cenicienta hasta princesas Peer to technology Realizamos copias de seguridad, archivado y recuperación de datos.
Realizamos copias de seguridad, archivado y recuperación de datos. Las reglas para la prestación de servicios postales han cambiado. Las reglas para la prestación de servicios postales han cambiado.
Las reglas para la prestación de servicios postales han cambiado. Las reglas para la prestación de servicios postales han cambiado. Vulnerabilidad de VKontakte: acceso a vistas previas de fotos desde diálogos y álbumes ocultos de cualquier usuario Fotos VK privadas y privadas
Vulnerabilidad de VKontakte: acceso a vistas previas de fotos desde diálogos y álbumes ocultos de cualquier usuario Fotos VK privadas y privadas Google Play Market no funciona: ¿qué hacer?
Google Play Market no funciona: ¿qué hacer? Cómo aumentar la memoria interna en un teléfono inteligente Lenovo A328 usando micro SD Crear un archivo de intercambio para aumentar la RAM en Android
Cómo aumentar la memoria interna en un teléfono inteligente Lenovo A328 usando micro SD Crear un archivo de intercambio para aumentar la RAM en Android