Створення семантичного ядра. Як скласти семантичне ядро з нуля? Скільки запитів має містити семантичне ядро
Вітаю вас любі мої читачі!
Я впевнений, що багато хто з вас не те, що б не чув, а навіть і не здогадується, що є таке поняття як семантичне ядро! І що це таке запитаєте ви? - Постараюся пояснити вам простими словами. Семантичне ядро – це набір ключових слів, словосполучень, простих речень, фраз тощо, які видає пошукова система (далі – ПС) під час введення вами запиту у рядку браузера.
Для чого потрібне семантичне ядро? Семантичне ядро сайту - це основа просування та розкручування, воно необхідне для внутрішньої оптимізації. Без семантичного ядра просування вашого проекту (сайту) буде неефективним. Чим грамотніше складено семантичне ядро сайту, тим менше грошей вам знадобиться для його успішного просування. Нічого поки не зрозуміло, адже? Не лякайтеся, далі я постараюся, як можна докладно розкласти все по поличках. Читайте уважно і все зрозумієте!
Як скласти семантичне ядро!
Перше, що вам необхідно зробити після того, як ви визначилися з тематикою блогу, скласти семантичне ядро. Для цього потрібно взяти зошит та ручку та записати всі слова, словосполучення, речення, які характеризують тематику вашого блогу. Кожне слово, словосполучення чи пропозиція це, по суті, будуть майбутні заголовки для ваших постів, і чим більше слів ви придумаєте, тим надалі у вас буде більший вибір при написанні статей.
А щоб скласти солідний список (200-300 слів) у вас на це піде чимало часу. Тому для зручності ми скористаємося спеціальними сервісами, такими як Yandex wordstat, Google adwords, Rambler adstat, вони нам значно спростять завдання при . Звичайно, можна було б обійтися лише Yandex та Google, т.к. це гіганти в пошуку ключових запитів у порівнянні з Rambler, але статистика говорить про те, що 5-6% людей все ж таки використовують як пошукову систему Rambler, тому не будемо її нехтувати.
Що б вам було набагато легше освоїти матеріал, показуватиму все на конкретних прикладах. Погодьтеся, теорія це добре, але коли справа доходить до практики у багатьох починаються проблеми. Тому ми з вами разом складемо семантичне ядро, щоб надалі ви з легкістю змогли перенести отримані знання та досвід на тематику вашого блогу. Допустимо, тема вашого блогу «фотошоп » і все, що з ним пов'язане. Тому як було написано вище, ви повинні придумати і записати в зошит якнайбільше слів, словосполучень, фраз, виразів – можете як завгодно їх називати. Ось ті слова, які у мене характеризуються тематикою блогу про фотошоп. Звичайно ж, я не перераховуватиму весь список слів, а лише частину, щоб вам був зрозумілий сам зміст складання семантичного ядра:
кисті для фотошоп
кисті для photoshop
кисті фотошоп
кисті photoshop
ефекти фотошоп
ефекти photoshop
фотоефект
малюнки фотошоп
малюнки photoshop
колаж
фотоколаж
фотомонтаж
рамки для світлин
фото дизайн
Список складено. Ну що ж, почнемо. Відразу обмовлюся, ваш список може набагато відрізнятися від мого і повинен бути набагато більшим. Цей список слів я склав для наочності, щоб ви вловили саму суть, як скласти семантичне ядро.
Статистика ключових слів Yandex wordstat
Після того як ваш список сформований необхідно відсіяти всі не потрібні нам слова, за якими ми точно не просуватимемо наш блог. Я наприклад не буду просуватися за такими словами як (пензлі для фотошопу торрент, кисті для фотошопу макіяж), ці фрази для мене взагалі не зрозумілі, так само відсіваємо схожі словосполучення такі як (кисті для фотошопу безкоштовно і безкоштовно для фотошопу). Я думаю, сенс відбору ключових слів вам зрозумілий.
Далі ви бачите, що в Yandex wordstat є два стовпці. Стовпець зліва показує вам, що шукали люди, вбиваючи, в пошуковий рядок, у нашому випадку фразу «пензля для фотошоп». Правий стовпець показує, що ще шукали люди, які шукали фразу "пензлі для фотошоп", раджу вам не ігнорувати правий стовпець, а вибрати з нього всі слова, які підходять для вашої тематики.
Добре, з цим теж розібралися, ідемо далі. Ще один дуже важливий момент, як ви бачите за результатом пошуку «пензля для фотошоп» ми спостерігаємо величезну цифру 61134 запиту! Але це не означає, що фразу «пензля для фотошоп» вбивали стільки разів на місяць у пошуковий рядок Яндекс. Yandex wordstat влаштований таким чином, що якщо допустимо вбити словосполучення «пензля для фотошоп» він вам видасть кількість запитів, яка означатиме, скільки разів люди шукали будь-які словоформи (кисті фотошоп, кисті для фотошоп) а, кіст ьфотошопу і.т.д.), словосполучення (пропозиції) (безкоштовні кисті для фотошоп, скачати кисті фотошоп безкоштовно і т.д.), в яких є фраза «кисті для фотошоп». Я думаю, це теж зрозуміло.
Для того щоб Yandex wordstat видавав нам (щодо) точну кількість запитів, існують спеціальні оператори, такі як («», «!»). Якщо ви вводите словосполучення «пензлі для фотошоп» у лапках, ви побачите зовсім іншу цифру, яка вам показує скільки разів люди шукали словосполучення «кисті для фотошоп» у різних словоформах (кисті для фотошоп аі т.д.).

При введенні словосполучення «!кисті!для!фотошоп» в лапках і з знаком оклику ми отримаємо точну кількість запитів «!кисті!для!фотошоп» у такому вигляді в якому воно є, тобто. без будь-яких відмін, словоформ і словосполучень. Я думаю, ви зрозуміли сенс, розжував як зміг.

Так ось після того як у вас сформувався значний список в excel, вам необхідно застосувати до кожного слова (словосполучення) оператор «!». Коли ви все зробите, у вас з'явиться список з точним числом запитів на місяць, який потрібно буде знову підкоригувати.
Але про це трохи пізніше, після того, як ми розглянемо дві інші системи підбору ключових слів (Google adwords і Rambler adstat). Оскільки після їх розгляду ваш список ключових слів суттєво поповниться.
Добір ключових слів Google adwords
Для підбору ключових слів також використовують Google adwords, це аналогічний сервіс з Yandex wordstat. Давайте так само перейдемо ось. Перед нами відкриється вікно вибору ключових слів Google Adwords. Так само вбиваємо в пошуковому рядку першу фразу з нашого списку «пензлі для фотошоп». Зверніть увагу, що в Google adwords немає жодних операторів, а достатньо поставити галочку навпроти слова [Точне] у стовпці Типи відповідності. Як бачимо, кількість запитів/на місяць у Google adwords істотно відрізняється від Yandex wordstat. Це говорить про те, що все ж таки більше людей використовують пошукову систему Yandex. Але якщо переглянути весь список, то можна знайти ключові слова, які Yandex wordstat взагалі не показує.
Також у Google adwords можна дізнатися ще багато чого цікавого (наприклад, приблизна ціна за клік), що також слід враховувати під час відбору ключових слів. Чим більша ціна за клік – тим більший конкурентний запит. Докладно зупинятися тут я не буду, принцип відбору ключових слів схожий на Yandex wordstat і трохи покопавшись, ви і самі зможете з усім розібратися. Йдемо далі.
Статистика пошукових запитів Rambler adstat
Як я вже згадував вище, що Rambler adstat набагато поступається двом попереднім сервісам, але все ж таки з нього теж можна, почерпнути деяку інформацію. Давайте так само перейдемо ось і введемо в пошуковому рядку першу фразу з нашого списку «пензли для фотошоп». Тут я гадаю, теж докладно зупинятися не варто. Повторюся ще раз принцип відбору ключових слів у всіх трьох систем схожий.
Ми з вами ознайомилися з трьома сервісами щодо підбору ключових слів. У результаті у вас з'явився величезний список, сформований з усіх трьох сервісів, в якому ви вже зробили відбір за тими запитами, за якими ви не плануєте просуватися і дублерам. Про це я вже писав вище. Але це лише півдороги у складанні семантичного ядра. У вас, напевно, вже закипіли мізки, але насправді якщо це вникнути і розібратися, то тут немає нічого складного. Повірте, краще один раз правильно скласти семантичне ядро, ніж надалі доведеться все виправляти. А виправляти набагато складніше, ніж робити все з нуля. Тому запасіться терпінням і йдемо далі.
ВЧ, СЧ та НЧ запити або ВЧЗ, СЧЗ та НЧЗ
При складанні семантичного ядра існують ще такі поняття як високочастотні, середньочастотні та низькочастотні запити або їх називають ВЧ, СЧ і НЧ запити, також можуть зустрічатися ВЧЗ, СЧЗ і НЧЗ. Це запити, які люди вводять у пошукові системи. Чим більше людей введе той самий запит у пошуковий рядок, тим високочастотнішим буде запит (ВЧ запит), те саме з СЧ і НЧ запитами. Сподіваюся, це теж зрозуміло.
Тепер запам'ятайте один дуже важливий момент. На початковому етапі розвитку блогу його слід просувати тільки за НЧ запитами, іноді використовують і СЧ запити, це буде залежати від конкурентності запиту. За запитами ВЧ ви навряд чи зможете, у вас просто не вистачить на це грошей. Не лякайтеся за НЧ запитами вийти в ТОП можливо та без вкладення коштів. У вас швидше за все постало питання, а які запити вважати ВЧ запитами, СЧ запитами та НЧ запитами?
Тут точна відповідь я думаю, не може дати ніхто! У блогів різних тематик він буде різним. Є тематики дуже популярні, в яких точна кількість запитів («!») досягає 20 тис. показів/на місяць і більше (наприклад, «! уроки! фотошопу»), а є менш популярні, в яких точна кількість запитів не досягає і 2000 показів/на місяць (наприклад «! уроки! англійської»).
Я в цьому випадку дотримуюся простої формули, яку вирахував для себе, продемонструю на прикладі «! Уроки! Фотошопу»:
ВК, СК та ПК запити ВКЗ, СКЗ та НКЗ
За повз ВЧ, СЧ та НЧ запитів існує ще одна категорія. Це високо конкурентні (ВК), середньо конкурентні (СК) та низько конкурентні (НК) запити, також можуть зустрічатися ВКЗ, СКЗ та НКЗ. У цьому випадку нам потрібно буде визначити конкурентність тих запитів, за якими ми плануємо просуватися в ТОП, але про це буде окрема посада, на тему «». . А поки що давайте вважати, що ВЧ запити є ВК запитами, СЧ – СК та НЧ – ПК. У більшості випадків ця формула працює, але бувають і винятки, коли, наприклад, НЧ запити є високо конкурентними (ВК) і навпаки ВЧ запити є ПК. Все залежить від тематики блогу.
Схема складання семантичного ядра
Для наочності давайте подивимося на схематичний приклад семантичного ядра. Приблизно так має виглядати стандартна схема семантичного ядра.
Але не варто прив'язуватися до цієї схеми, т.к. у міру ведення блогу вона може змінюватися. На початковому етапі у вас можливо, допустимо всього чотири рубрики, що містять по три НЧ запити, а згодом може все змінитися.
Ось нічого не зрозуміло скаже більшість із вас, особливо хто вперше стикається з семантичним ядром. Нічого страшного, я теж спочатку не розумів багато речей, поки не вивчив тему дуже добре. Не хочу сказати, що я профі в цій темі, але багато чого засвоїв. І, як і обіцяв, давайте розбирати все на конкретному прикладі та згідно з нашою темою.
Відразу хочу сказати, що я не фахівець у «фотошопі», просто ця тема мені спала на думку при написанні посту. Тому я підбирав запити за змістом. Добре, яка схема семантичного ядра в мене вийшла на тему «фотошоп». У вас має вийти щось на кшталт:
Види запитів
Всі запити (наші ключові слова) можна поділити на три категорії:
- Первинні запити– це запити, які одним-двома словами можуть дати загальне визначення вашого ресурсу чи його частини. Первинні запити, які найбільше охоплюють загальну тематику вашого блогу, краще залишити на головній сторінці. У нашому випадку це: уроки фотошоп, ефекти фотошоп, як зробити фотоколаж.
Первинні запити, що менш охоплюють загальну тематику вашого блогу, але найбільш точно характеризують його якусь частину, рекомендується використовувати як окремі рубрики вашого блогу. У нашому випадку це: фотошоп, фотошоп, фотошоп, фотошоп, фото дизайн.
- Основні запити- Це ті запити, які досить точно визначають тематику вашого проекту і здатні дати корисну інформацію читачеві, навчити його тому, що він хоче, або відповісти на питання, що часто задається ЯК??? Тобто, в нашому випадку це: як додати пензлі у фотошопі, як зробити шаблон у фотошопі, як зробити фотоколаж у фотошопі і т.д. Основні запити по суті повинні бути заголовками наших майбутніх статей.
- Додаткові (допоміжні) запити або ще їх називають асоціативними– це запити, які люди вводили в пошуковий рядок браузера при пошуку основного запиту. Тобто. це ключові фрази, що є частиною основного запиту. Вони будуть доповнювати основний запит, і будуть ключовими словами при просуванні її в ТОП. Наприклад: фотошоп для початківців онлайн, фотошоп прибрати ефект червоних очей, колаж із кількох фотографій. Я думаю, це зрозуміло.
Стратегія складання семантичного ядра
Тепер нам необхідно розбити весь список сторінок. Тобто. потрібно зі всіх ваших ключових слів вибрати первинні запити, які будуть рубриками вашого блогу і зробити окремі вкладки в excel. Далі, вибрати основні і допоміжні запити, що відносяться до них, і розмістити їх по різних сторінках у створеному вами документі excel (тобто за рубриками). Ось що в мене вийшло:
Як я вже писав вище: на початковому етапі варто просувати свій блог за НЧ чи ПК запитами. А що ж робити із СЧ (СК) та ВЧ (ВК) запитами, запитаєте ви? Пояснюю.
Просуватись по ВЧ (ВК) запитам у вас навряд чи вийде, тому їх можна видалити, але рекомендується залишити один-два ВЧ (ВК) запиту для головної сторінки. Відразу обмовлюся: не треба кидатися на самий ВЧ запит, такий як «фотошоп», у якого точне число показів/на місяць становить – 163384. Наприклад, ви хочете за допомогою вашого блогу навчити людей роботі у фотошопі. Ось і візьміть за основу ВЧ запиту – «уроки фотошоп», у якого точна кількість показів/на місяць становить – 7110. Цей запит характеризує вашу тему і по ньому вам буде легше просунутися.
А ось СЧ (СК) запити можна помістити на окремій сторінці Excel. У міру того як ваш блог буде підніматися в очах ПС вони (СЧ (СК) запити) будуть потроху ставати затребуваними.
Я знаю, що новачки зараз взагалі не розуміють, про що я говорю, раджу вам почитати статтю про те, вивчивши яку вам стане все зрозуміло.
Висновок
Ось у принципі, мабуть, і все. Звичайно ж, є програми, які допоможуть вам у складанні семантичного ядраяк платні (Key Kollektor), так і безкоштовні (Словоєб, Словодер), але про них я писати в цьому пості не буду. Можливо, якось напишу про них окрему статтю. Але вони вам тільки підберуть ключові слова, а рознести їх за рубриками і постами вам доведеться самостійно.
А як ви складаєте семантичне ядро? А може ви його взагалі не складаєте? Які використовуєте програми та послуги при складанні? Радий почути ваші відповіді у коментарях!
І насамкінець подивіться цікаве відео.
Генератор Продажів
Час читання: 14 хвилин
Відправимо матеріал вам на:
З цієї статті ви дізнаєтесь:
- Як скласти семантичне ядро сайту
- Які програми для цього використовувати
- Як проаналізувати семантичне ядро сайту конкурентів
- Які помилки найчастіше припускаються у складанні семантичного ядра
- Скільки коштує замовити готове семантичне ядро сайту
Семантичне ядро – основа будь-якого інтернет-ресурсу, запорука його успішного просування та залучення цільової аудиторії. Як правильно створити семантичне ядро сайту та яких помилок уникнути, ви дізнаєтесь із цієї статті.
Що таке семантичне ядро сайту
Найпростіший і при цьому ефективний спосіб залучити відвідувачів на ваш сайт – зробити так, щоб вони виявили інтерес до нього, перейшовши за посиланням з пошукової системи Яндекс або Google. Для цього потрібно з'ясувати, що цікавить вашу цільову аудиторію, яким чином користувачі шукають необхідну інформацію. У цьому вам допоможе семантичне ядро.
Семантичне ядро – сукупність окремих слів чи словосполучень, що характеризують тематику та структуру вашого сайту. Семантика - спочатку - галузь філології, що має справу зі змістом слів. Нині найчастіше сприймається як вивчення сенсу взагалі.
З цього можна дійти невтішного висновку, що поняття «семантичне ядро» і «смислове ядро» – синоніми.
Мета створення семантичного ядра сайту – наповнення його контентом, привабливим користувачам. Для цього необхідно дізнатися, за якими ключовими словами вони шукатимуть інформацію, розміщену на вашому сайті.

Залишити заявку
Підбір семантичного ядра сайту передбачає розподіл пошукових запитів або груп запитів на сторінках таким чином, щоб вони максимально задовольняли цільову аудиторію.
Цього можна досягти двома способами. Перший – проаналізувати пошукові фрази користувачів та на їх основі створити структуру сайту. Другий спосіб – спочатку вигадати каркас майбутнього сайту, а потім, після аналізу, розподілити по ньому ключові слова.
Кожен спосіб має право на існування, але другий логічніше: спочатку ви створюєте структуру сайту, а потім наповнюєте його пошуковими запитами, за якими потенційні клієнти зможуть знайти потрібний їм контент через пошукові системи.
Так ви виявляєте якість проактивності - самостійно визначаєте, яку інформацію донести до відвідувачів сайту. В іншому випадку, створюючи структуру сайту на основі ключових слів, ви лише підлаштовуєтеся до навколишньої дійсності.
Є кардинальна відмінність між підходом до створення семантичного ядра сайту спеціаліста з SEO та маркетолога.
Класичний оптимізатор скаже вам: щоб створити сайт, потрібно відібрати фрази та слова із пошукових запитів, за якими можна потрапити до ТОП пошукової видачі. Потім на їх основі сформувати структуру майбутнього сайту та розподілити ключові слова на сторінках. Контент сторінок створюється під вибрані ключові слова.
Маркетолог чи підприємець підійде до питання створення сайту інакше. Спочатку він замислиться над тим, навіщо потрібен сайт, яку інформацію він нестиме користувачам. Потім вигадає орієнтовну структуру сайту та перелік сторінок. На наступному етапі він займеться створенням семантичного ядра сайту, щоб зрозуміти, за якими пошуковими запитами потенційні клієнти шукають інформацію.
Які недоліки роботи з семантичним ядром з позиції спеціаліста з SEO? Насамперед, за такого підходу якість інформації на сайті значно погіршується.
Компанія повинна сама вирішувати, що говорити клієнтам, а не видавати контент як реакцію на найбільш популярні пошукові запити. Подібна сліпа оптимізація може призвести до того, що відсіється частина перспективних запитів із низькими показниками частотності.
Результатом створення семантичного ядра є перелік ключових слів, які розподілені на сторінках сайту. У цьому списку вказується URL-адреса сторінок, ключові слова та рівень частоти запитів.
Приклад семантичного ядра сайту

Як скласти семантичне ядро сайту: покрокова інструкція
Крок 1. Складаємо початковий перелік запитів
Для початку потрібно відібрати найпопулярніші пошукові запити на тематику вашого сайту. Є два варіанти, як це зробити:
1. Метод мозкового штурму- коли протягом невеликого проміжку часу ви самостійно або з колегами записуєте всі слова та словосполучення, за якими, на вашу думку, користувачі шукатимуть інформацію, розміщену на вашому сайті.
Записуйте всі можливі варіанти, зокрема:
- варіації написання назви продукту чи послуги, синонімічні слова, способи написання назви латинськими літерами та кирилицею;
- повні назви та скорочені позначення;
- жаргонні слова;
- згадки складових елементів товару чи послуги, наприклад, будматеріали – пісок, цегла, профнастил, шпаклівка та ін;
- прикметники, що відбивають значущі характеристики товару чи послуги (якісний ремонт, швидка доставка, безболісне лікування зубів).
2. Проаналізуйте сайти ваших конкурентів. Відкрийте браузер у режимі інкогніто у вашому регіоні. Подивіться сайти конкурентів, які вам покаже пошукова видача на вашу тематику. Знайдіть усі потенційні ключові слова. Визначити семантичне ядро сайту конкурента можна за допомогою сервісів com і bukvarix.com.
Проаналізуйте рекламні оголошення.Самостійно або за допомогою спеціалізованих сервісів (наприклад, spywords.ru або advodka.com) вивчіть семантичне ядро чужого сайту та з'ясуйте, які ключові слова використовують конкуренти.
Застосувавши всі три підходи, ви отримаєте чималий список ключових слів. Але його все одно буде недостатньо для створення ефективного семантичного ядра.
Крок 2. Розширюємо список, що вийшов.
На цьому етапі вам допоможуть сервіси Яндекс.Вордстат та Google AdWords. Якщо буде по черзі вводити слова зі списку ключів, сформованого на першому етапі, в пошуковий рядок будь-якого з цих сервісів, то на виході отримаєте перелік уточнених і асоціативних пошукових запитів.
Уточнені запити можуть містити не лише ваше слово, але й інші слова або фрази. Наприклад, якщо ввести ключове слово "собака", то сервіс видасть вам 11 115 538 запитів із цим словом, до яких входять такі запити за останній місяць, як "фото собак", "лікування собак", "породи собак" та ін.

Асоціативні запити – слова чи фрази, які користувачі шукали разом із вашим запитом. Наприклад, одночасно з ключовим словом "собака" користувачі вводили: "сухий корм", "роял канін", "тибетський мастиф" та ін. Ці пошукові запити теж можуть стати у нагоді вам.

Крім того, є спеціальні програми для створення семантичного ядра сайту, наприклад: KeyCollector, SlovoEB та онлайн-сервіси – Топвізор, serpstat.com та ін. Вони дозволяють не лише підбирати ключові слова, а й аналізувати їх та проводити угруповання пошукових запитів.
Щоб максимально розширити список ключів, перегляньте, що показують пошукові підказки сервісу. Там ви знайдете найпопулярніші пошукові запити, що починаються з тих самих букв або слів, що і ваш.
Крок 3. Видаляємо зайві запити
Пошукові запити можна класифікувати по-різному. Залежно від частоти запити бувають:
- високочастотні (понад 1500 запитів на місяць);
- середньочастотні (600-1500 запитів на місяць);
- низькочастотні (100-200 запитів на місяць).
Ця класифікація дуже умовна. Віднесення запиту до тієї чи іншої категорії залежить від тематики конкретного сайту.
Останніми роками спостерігається тенденція зростання показників низькочастотних запитів. Тому для просування сайту семантичне ядро має включати середньо- та низькочастотні запити.
Конкуренція серед них менша, тому підняти сайт на першу сторінку пошукової видачі буде набагато простіше, ніж під час роботи з високочастотними запитами. До того ж, багато пошукових систем вітають, коли сайти застосовують низькочастотні ключові слова.
Інша класифікація пошукових запитів – за метою пошуку:
- Інформаційні– ключові слова, які користувачі вводять у пошуку певної інформації. Наприклад: "як самостійно приклеїти плитку у ванній", "як підключити посудомийку".
- Транзакційні– ключові слова, які вводять користувачі, які планують вчинити якусь дію. Наприклад: «дивитися фільм онлайн безкоштовно», «завантажити гру», «купити будматеріали».
- Вітальні- Запити, які вводять користувачі в пошуках конкретного сайту. Наприклад: "Сбербанк онлайн", "купити холодильник на Яндекс.Маркет", "вакансії на Head hunters".
- Інші (загальні)– решта пошукових запитів, за якими можна зрозуміти, що шукає користувач. Наприклад, запит «автомобіль» може ввести, якщо хоче продати, купити або відремонтувати машину.
Тепер настав час видалити зі списку ключових слів усі зайві, які:
- не відповідають тематиці вашого сайту;
- включають назви торгових марок конкурентів;
- включають назви інших регіонів (наприклад, купити айфон у Москві, якщо ваш сайт працює тільки на Західний Сибір);
- містять помилки або помилки (якщо ви напишете в пошуковій системі «сабака», а не «собака», він врахує це як окремий пошуковий запит).
Крок 4. Визначаємо конкурентні запити
Щоб ефективно розподілити ключові слова на сторінках сайту, їх потрібно відфільтрувати за значимістю. І тому використовують індекс ефективності ключових слів – KEI (Keyword Effectiveness Index). Формула розрахунку:
KEI = P 2 /C,
де P – це частота показів ключового слова останній місяць; С – кількість сайтів, оптимізована під даний пошуковий запит.
З формули видно, що чим популярніше ключове слово, то вище KEI, тим більше цільового трафіку ви залучите на ваш сайт. Висока конкуренція за пошуковим запитом ускладнює просування сайту по ньому, що відбивається на значенні KEI.
Таким чином, чим вищий KEI, тим популярніший пошуковий запит, і навпаки: чим нижчий індекс ефективності ключових слів, тим вища за ним конкуренція.
Є спрощена варіація цієї формули:
KEI = P 2 /U,
де замість С використовується показник U – кількість сторінок, оптимізованих під дане ключове слово.
Розглянемо з прикладу, як використовувати індекс ефективності ключових слів KEI. Визначимо частоту запитів за допомогою сервісу Яндекс Wordstat:

На наступному кроці подивимося, скільки сторінок у пошуковій видачі за пошуковим запитом, що цікавить нас, за останній місяць.

Підставимо у формулу знайдені значення змінних та розрахуємо індекс ефективності ключових слів KEI:
KEI = (206146 * 206146) / 70000000 = 607
Як оцінювати значення KEI:
- якщо KEI менше 10, пошукові запити неефективні;
- якщо KEI від 10 до 100, то пошукові запити ефективні, залучатимуть цільову аудиторію на сайт;
- якщо KEI від 100 до 400, то пошукові запити дуже ефективні, залучатимуть значну частку трафіку;
- при KEI більше 400 пошукові запити мають максимальну ефективність і залучать величезну кількість користувачів.
Майте на увазі, що градація значень індексу ефективності ключових слів KEI визначається тематикою сайту. Тому наведена шкала значень не може застосовуватися для всіх інтернет-ресурсів, оскільки для одних значення KEI > 400 може бути недостатнім, а для вузькотематичних сайтів ця класифікація взагалі не застосовується.
Крок 5. Групуємо ключові слова на сайті
Кластеризація семантичного ядра сайту є процесом групування пошукових запитів з логічних міркувань і на основі результатів пошукових систем. Перед тим як приступити до угруповання, важливо переконатися, що фахівець, який його проводитиме, розбирається у всіх тонкощах компанії та продукту, знає їх специфіку.
Ця робота потребує великих витрат, особливо якщо йдеться про наповнення багатосторінкового інтернет-ресурсу. Але зовсім не обов'язково робити її вручну. Можна провести кластеризацію семантичного ядра сайту автоматично за допомогою спеціальних сервісів, таких як Топвізор, Seranking.ru та ін.
Але отримані результати краще перевіряти ще раз, тому що логіка поділу ключів на групи у програм може не збігатися з вашою. Зрештою, ви отримаєте остаточну структуру сайту. Тепер ви чітко розумітимете, які сторінки потрібно створити, а які ліквідувати.
У яких випадках необхідний аналіз семантичного ядра сайту конкурентів
- Під час запуску нового проекту.
Ви працюєте над новим проектом і займаєтесь формуванням семантичного ядра сайту з нуля. Для цього ви вирішили проаналізувати ключові слова, які використовують конкуренти для просування сайтів.
Багато хто підходить і вам, тому ви використовуєте їх для поповнення семантичного ядра. Варто враховувати нішу, у якій працюють конкуренти. Якщо ви плануєте зайняти невелику частку ринку, а конкуренти працюють на федеральному рівні, то не можна просто взяти і повністю скопіювати їхнє семантичне ядро.
- При розширенні семантичного ядра працюючого сайту.
Ви маєте сайт, який потрібно просувати. Семантичне ядро було давно сформоване, але працює неефективно. Потрібна оптимізація сайту, його реструктуризація, оновлення контенту для збільшення трафіку. З чого почати?
Насамперед можна проаналізувати семантичне ядро на конкуруючих сайтах за допомогою спеціалізованих сервісів.
Як використовувати ключові слова з сайтів конкурентів найефективнішим способом?
Ось кілька нескладних правил. По-перше, враховуйте відсоток збігів за ключами з вашого сайту та з чужих інтернет-ресурсів. Якщо ваш сайт поки що на стадії розробки, то вибирайте будь-який конкуруючий сайт, проводьте його аналіз та використовуйте ключові слова як основу для створення вашого семантичного ядра.
Надалі ви просто порівнюватимете, наскільки перетинаються ваші еталонні ключі з ключами з сайтів конкурентів. Найпростіший спосіб - вивантажити за допомогою сервісу перелік всіх сайтів, що конкурують, і відфільтрувати їх за відсотком перетинів.
Потім потрібно завантажити семантичні ядра перших кількох сайтів у програму Excel або Key Collector і доповнити новими ключовими словами семантичне ядро вашого сайту.
По-друге, перед тим, як скопіювати ключі з сайту-донора, обов'язково проведіть його візуальну перевірку.
- Купуючи готовий сайт з метою подальшого розвитку або перепродажу.
Розглянемо приклад: ви бажаєте придбати певний веб-сайт, але перед прийняттям остаточного рішення вам необхідно оцінити його потенціал. Найпростіше це зробити, вивчивши семантичне ядро, ви зможете порівняти поточне охоплення сайту з сайтами конкурентів.
Як стандарт берете найсильнішого конкурента і порівнюєте його показники видимості з результатами інтернет-ресурсу, який ви плануєте придбати. Якщо відставання від еталонного сайту суттєво, це гарний знак: отже, ваш сайт має потенціал для розширення семантичного ядра і залучення нового трафіку.
Плюси та мінуси аналізу семантичного ядра конкурентів через спеціальні сервіси
Принцип роботи багатьох сервісів щодо визначення ключових слів на чужих сайтах наступний:
- формується список найпопулярніших пошукових запитів;
- кожного ключа відбирається 1-10 сторінок видачі (SERP);
- такий збір видачі ключових фраз повторюють із певною періодичністю (щотижня, щомісяця чи щороку).
Недоліки такого підходу:
- послуги видають лише видиму частину пошукових запитів на сайтах конкуруючих організацій;
- послуги зберігають у себе своєрідний «зліпок» видачі, створений під час збору ключових слів;
- послуги можуть визначити видимість лише тих пошукових запитів, що є у тому базах;
- послуги показують ті ключові слова, які їм відомі.
- щоб отримати достовірні дані про ключові слова на конкурувальному сайті, необхідно знати, коли проводився збір пошукових запитів (аналіз видимості);
- не всі запити відображаються в пошуковій видачі, тому їх сервіс не бачить. Причини можуть бути різні: сторінки сайту ще не проіндексовані, пошуковик не ранжує сторінки через те, що вони довго вантажаться, містять віруси тощо;
- Традиційно немає інформації про те, які ключі входять до складу бази сервісу, що використовується для збору пошукової видачі.
Таким чином, сервіс формує не реальне семантичне ядро, яке лежить в основі сайту, а лише невелику його видиму частину.
На основі викладеного можна зробити такі висновки:
- Семантичне ядро сайту конкурентів, сформоване за допомогою спеціальних сервісів, не дає повної актуальної картини.
- Перевірка семантичного ядра сайту конкурента допомагає доповнити семантику вашого інтернет-ресурсу або проаналізувати маркетингову політику конкуруючих компаній.
- Чим більша база ключових слів сервісу, тим повільніше процес обробки видачі і нижче рівень актуальності семантики. Поки сервіс збирає пошукову видачу на початку бази, дані до кінця бази застарівають.
- Сервіси не розголошують інформацію про рівень актуальності їх баз та дату останнього оновлення. Тому ви не можете знати, наскільки відібрані сервісом ключові слова із сайту конкурента відображають його реальне семантичне ядро.
- Значною перевагою такого підходу є отримання доступу до великого переліку ключових слів конкурентів, багато з яких можна використовувати для розширення семантичного ядра власного сайту.
ТОП-3 платних сервісу, де можна дізнатися семантичне ядро конкурентів
Megaindex Premium Analytics

Цей сервіс має багатий арсенал для аналізу семантичного ядра конкуруючих сайтів. За допомогою модуля «Видимість сайту»ви можете знайти та завантажити список ключових фраз, виявити сайти з аналогічною тематикою, які можна використовувати для розширення семантичного ядра вашого сайту.
Один із мінусів Megaindex Premium Analytics – неможливість фільтрувати списки ключів у самій програмі, спочатку потрібно завантажити їх у Excel.
Коротка характеристика сервісу:
Keys.so

Для того щоб проаналізувати семантичне ядро за допомогою сервісу keys.so, потрібно вставити url сайту-конкурента, вибрати відповідні сайти виходячи з кількості ключових фраз, що збігаються, проаналізувати їх і завантажити список пошукових запитів, за якими вони просуваються. Сервіс робить це легко та просто. Приємний бонус – найсучасніший інтерфейс програми.
Мінуси: невеликий розмір бази пошукових фраз, недостатня частота поновлення видимості.
Короткий звіт про сервіс:
Spywords.ru

Цей сервіс не тільки аналізує видимість, але й видає статистику рекламних оголошень в Яндекс.Директ. Спочатку складно розібратися з інтерфейсом spywords.ru, він перевантажений функціоналом, але загалом свою роботу виконує добре.
За допомогою сервісу можна провести аналіз сайтів, що конкурують, виявити перетину за ключовими фразами, вивантажити список ключів конкурентів. Основний мінус - недостатня база сервісу (близько 23 млн пошукових фраз).
Короткий звіт про сервіс:
Завдяки спеціальним програмам сайти та їх семантичні ядра більше вам не загадка. Ви можете легко проаналізувати будь-які цікаві для вас інтернет-ресурси конкурентів. Ось кілька порад щодо використання отриманої інформації:
- Використовуйте ключові слова лише з сайтів з аналогічною тематикою(що більше перетинів з вашим, то краще).
- Не аналізуйте портали,у них надто великі семантичні ядра. У результаті ви не доповните власне ядро, а лише розширіть його. А це, як ви знаєте, можна робити нескінченно.
- При покупці сайту орієнтуйтесь на показники його поточної видимості у пошуковій системі, порівняйте їх із сайтами, що входять у ТОП, щоб оцінити потенціал розвитку.
- Беріть ключові слова із сайтів конкурентів для доповнення семантичного ядра вашого сайту, а не формування його з нуля.
- Чим більша база сервісу, який ви використовуєте, тим повноціннішим буде ваше семантичне ядро.Але звертайте увагу на частоту поновлення баз пошукових фраз.
7 сервісів, які допоможуть скласти семантичне ядро сайту з нуля онлайн
Планувальник ключових слів Google

Якщо ви замислилися над питанням, як створити семантичне ядро сайту, зверніть увагу на цей сервіс. Його можна використовувати не тільки в Рунеті, але і в інших сегментах, де працює AdWords.
Відкрийте Google AdWords. У верхній панелі у розділі «Інструменти»клацніть по параметру "Планувальник ключових слів".З'явиться нове меню, де потрібно вибрати розділ «Пошук нових ключових слів за фразою, сайтом або категорією».Тут можна налаштувати такі параметри:
- ключове слово чи словосполучення, якими буде проходити пошук;
- тематику товару чи послуги;
- регіон пошукових запитів;
- мову, якою користувачі вводять пошукові запити;
- систему пошуку ключових фраз;
- мінус-слова (не повинні бути присутніми у ключових фразах).
Далі клацаєте по кнопці «Отримати варіанти»,після цього Google AdWords видасть вам можливі синоніми вашого ключового слова або словосполучення. Отримані дані можна вивантажити до Google-документів або CSV.
Переваги використання Google AdWords:
- можливість підбору синонімів до ключової фрази;
- використання мінус-слів для уточнення пошукового запиту;
- доступ до величезної бази запитів пошукової системи Google.
Головний недолік сервісу: якщо у вас безкоштовний обліковий запис, то Google AdWords надаватиме неточні дані про частотність пошукових запитів. Похибка настільки значна, що на ці показники неможливо спиратися при просуванні сайту. Вихід - купувати доступ до платного облікового запису або використовувати інший сервіс.
Serpstat

Цей сервіс дозволяє комплексно збирати пошукові запити користувачів за ключовими словами та доменами сайтів. Serplast постійно розширює кількість баз регіонів.
Сервіс дозволяє виявити ключових конкурентів вашого сайту, визначити пошукові фрази, якими вони просуваються, і сформувати їх перелік для подальшого використання в семантичному ядрі вашого інтернет-ресурсу.
Переваги сервісу Serplast:
- великий вибір інструментів аналізу семантичного ядра сайтів конкурентів;
- інформативні форми звітності, що відображають показники частотності обраного регіону;
- опція розвантаження пошукових запитів на конкретних сторінках сайту.
Мінуси сервісу Serplast:
- незважаючи на те, що дані баз сервісу постійно актуалізуються, немає гарантій, що в проміжок між останніми оновленнями будуть надані реалістичні дані щодо частотності пошукових запитів;
- в повному обсязі пошукові фрази з низькою частотністю відображаються сервісом;
- обмеженість мов та країн, з якими працює сервіс.
Key Collector

Цей сервіс допоможе вам розібратися не лише з питанням, як зібрати семантичне ядро сайту, але й вирішити проблему його розширення, чищення та кластеризації. Key Collector вміє збирати пошукові запити, надавати дані про рівень їхньої частотності по вибраних регіонах, робити обробку семантики.
Програма шукає ключові фрази за стартовими списками. Її можна використовувати для роботи з базами даних різних форматів.
Key Collector може показати частотність ключових даних, вивантажених з Serpstat, Yandex Wordstat та інших сервісів.
Semrush

Складання семантичного ядра сайту в програмі Semrush обійдеться абсолютно безкоштовно. Але ви отримаєте не більше 10 ключових запитів з даними щодо їх частотності за вибраним регіоном. Крім того, за допомогою сервісу можна дізнатися, які пошукові запити вводять по вашому ключовику користувачі в інших регіонах.
Плюси сервісу Semrush:
- працює у всьому світі, можна збирати дані щодо частотності пошукових запитів у західному регіоні;
- для кожної ключової фрази видає ТОП сайтів у пошуковій видачі. Ви можете орієнтуватися на них у подальшому, при формуванні семантичного ядра власного сайту.
Мінуси сервісу Semrush:
- якщо бажаєте отримати більше 10 ключових фраз, потрібно придбати платну версію за 100 доларів;
- неможливо повністю завантажити список ключових фраз.
Keywordtool

Цей сервіс дозволяє зібрати ключові фрази для семантичного ядра сайту із іноземних інтернет-ресурсів у широкій відповідності. Також Keywordtool дає можливість підібрати пошукові підказки та фрази, які містять базовий ключ.
Якщо ви використовуєте безкоштовну версію програми, то за одну сесію зможете отримати не більше 1000 пошукових фраз без даних про рівень їхньої частотності.
Переваги сервісу Keywordtool:
- працює з різними мовами та у багатьох країнах світу;
- показує пошукові запити не тільки з пошукових систем, а й популярних інтернет-магазинів (Amazon, eBay, App Store) та найбільшого сервісу відеохостингу YouTube;
- широта пошуку пошукових фраз перевищує аналогічний показник у Google AdWords;
- сформований перелік пошукових запитів можна легко скопіювати до таблиці будь-якого формату.
Недоліки сервісу Keywordtool:
- безкоштовна версія не надає даних про частотність пошукових запитів;
- немає можливості завантажити ключові слова одразу списком;
- шукає ключові слова тільки за фразами, до яких вони можуть входити, не враховує можливі синоніми
Ubersuggest

Семантичне ядро сайту в сервісі Ubersuggest можна створити на основі пошукових запитів користувачів практично з будь-якої країни світу будь-якою мовою. Якщо ви користуєтеся безкоштовною версією, то на один запит отримаєте до 750 пошукових фраз.
Перевагою сервісу є можливість сортування списку ключових слів у алфавітному порядку з урахуванням приставки. Всі пошукові запити автоматично групуються, що полегшує роботу з ними під час формування семантичного ядра сайту.
Як недолік Ubersuggest можна виділити некоректні дані про частотність пошукових запитів у безкоштовній версії програми та відсутність можливості пошуку за синонімами ключовика.
Ahrefs Keywords Explorer

Цей сервіс може збирати ключові слова для вашого семантичного ядра у широкій, фразовій та точній відповідності у вибраному регіоні з урахуванням рівня частотності.
Є опція вибору мінус-слів та перегляду ТОП-пошукової видачі в Google за вашими головними ключами.
Основні мінуси Ahrefs Keywords Explorer – лише платна версія програми та залежність точності даних від ступеня актуальності баз.
Часті питання щодо складання семантичного ядра сайту
- Якої кількості ключів достатньо створення семантичного ядра сайту (100, 1000, 100 000)?
На це питання не можна дати однозначної відповіді. Все залежить від специфіки сайту, його структури, дій конкурентів. Оптимальна кількість ключів визначається в індивідуальному порядку.
- Чи варто використовувати готові основи ключових фраз для формування семантичного ядра сайту?
В Інтернеті ви можете знайти багато різних ресурсів із тематичними базами ключів. Наприклад, База Пастухова, UP Base, Мутаген, KeyBooster тощо. буд. Не можна сказати, що користуватися такими джерелами не варто. У подібних базах знаходяться значні архіви пошукових запитів, які стануть вам у нагоді для просування сайту.
Але пам'ятайте про такі показники, як конкурентність та актуальність ключів. Також майте на увазі, що ваші конкуренти також можуть використовувати готові бази. Ще один недолік таких джерел - вірогідність відсутності важливих для вас ключових фраз.
- Як використати семантичне ядро сайту?
Ключові фрази, відібрані до створення семантичного ядра, використовують із складання карти релевантності. До неї входять теги title, description та заголовки h1-h6, які потрібні для просування сайту. Також ключі беруть за основу написання SEO текстів для сторінок сайту.
- Чи варто брати запити із нульовою частотністю для семантичного ядра сайту?
Це доцільно у таких випадках:
- Якщо для створення сторінок з такими ключами ви витратите мінімум ресурсів та часу.Наприклад, створення сторінок SEO-фільтрів в автоматичному режимі в інтернет-магазинах.
- Нульова частотність не є абсолютноютобто на момент збору інформації рівень частотності дорівнює нулю, але історія пошукової системи показує запити за цим словом або фразою.
- Нульова частотність лише у вибраному регіоні, в інших регіонах рівень частотності за цим ключем вищий.
5 типових помилок при збиранні семантичного ядра для сайту
- Уникнення ключових фраз із високою конкурентністю.Адже це не зобов'язує вас будь-що виводити сайт в ТОР за цим ключем. Ви можете використовувати таку пошукову фразу як доповнення до семантичного ядра, як контент-ідеї.
- Відмова від застосування ключів із низькою частотністю. Ви також можете використовувати подібні пошукові запити у вигляді контент-ідей.
- Створення інтернет-сторінок під окремі запити.Напевно, ви бачили сайти, де для схожих запитів (наприклад, «купити весільний торт» і «зробити весільний торт на замовлення») є своя сторінка. Але користувач, який вводить ці запити, насправді хоче одного й того самого. Нема рації робити кілька сторінок.
- Створювати семантичне ядро сайту лише за допомогою сервісів.Звісно, збирання ключів в автоматизованому режимі полегшує життя. Але їхня цінність буде мінімальною, якщо ви не проаналізуєте результат. Адже тільки ви розумієте особливості галузі, рівень конкуренції та знаєте все про заходи вашої компанії.
- Надмірний фокус на збиранні ключів. Якщо у вас невеликий сайт, почніть зі збору семантики за допомогою сервісів Яндекса або Google. Не варто відразу займатися аналізом семантичного ядра на сайтах конкурентів або збиранням ключів із різних пошукових систем. Всі ці способи вам знадобляться тоді, коли ви зрозумієте, що настав час розширювати ядро.
А може краще замовити складання семантичного ядра сайту?
Ви можете спробувати самостійно скласти семантичне ядро за допомогою безкоштовних сервісів, про які ми розповіли. Наприклад, «Планувальник ключових слів від Google» може дати вам непоганий результат. Але якщо ви зацікавлені у створенні великого якісного семантичного ядра, заплануйте цю статтю видатків у вашому бюджеті.
У середньому розробка семантичного ядра сайту коштуватиме від 30 до 70 тисяч рублів. Як ви пам'ятаєте, підсумкова ціна залежить від тематики бізнесу та оптимальної кількості пошукових запитів.
Щоб не купити кота в мішку
Якісне семантичне ядро обійдеться недешево. Щоб переконатися, що виконавець знається на цій роботі і зробить усе на високому рівні, попросіть його зібрати пробну семантику за одним запитом. Зазвичай це робиться безкоштовно.
Для перевірки отриманих результатів пропустіть список ключів через Мутаген і проаналізуйте, скільки серед них високочастотних та низькокурентних. Нерідко виконавці надають списки з великою кількістю ключових фраз, багато з яких не придатні для подальшого використання.
Array ( => 21 [~ID] => 21 => 28.09.2019 13:01:03 [~TIMESTAMP_X] => 28.09.2019 13:01:03 => 1 [~MODIFIED_BY] => 1 => 21.09. 2019 10:35:17 [~DATE_CREATE] => 21.09.2019 10:35:17 => 1 [~CREATED_BY] => 1 => 6 [~IBLOCK_ID] => 6 => [~IBLOCK_SECTION_ID] => => Y [~ACTIVE] => Y => Y [~GLOBAL_ACTIVE] => Y => 500 [~SORT] => 500 => Статті Дмитра Свистунова [~NAME] => Статті Дмитра Свистунова => 11076 [~PICTURE] = > 11076 => 7 [~LEFT_MARGIN] => 7 => 8 [~RIGHT_MARGIN] => 8 => 1 [~DEPTH_LEVEL] => 1 => Дмитро Свистунов [~DESCRIPTION] => Дмитро Свистунов => text [~DESCRIPTION_TYPE ] => text => Статті Дмитра Свистунова Дмитро Свистунов [~SEARCHABLE_CONTENT] => Статті Дмитра Свистунова Дмитро Свистунов => statyi-dmitriya-svistunova [~CODE] => statyi-dmitriya-svistunova => [~XML_ID] => => [~TMP_ID] => => [~DETAIL_PICTURE] => => [~SOCNET_GROUP_ID] => => /blog/index.php?ID=6 [~LIST_PAGE_URL] => /blog/index.php?ID=6 => /blog/list.php? SECTION_ID=21 [~SECTION_PAGE_URL] => /blog/list.php?SECTION_ID=21 => blog [~IBLOCK_TYPE_ID] => blog => blog [~IBLOCK_CODE] => blog => [~IBLOCK_EXTERNAL_ID] => => [ ~EXTERNAL_ID] =>)
Напишемо просте ядро, яке можна завантажити за допомогою бутлоадера GRUB x86-системи. Це ядро відображатиме повідомлення на екрані та чекатиме.
Як завантажується система x86?
Перш ніж почнемо писати ядро, давайте розберемося, як система завантажується і передає управління ядру.
Більшість регістрів процесора під час запуску вже є певні значення. Регістр, що вказує на адресу інструкцій (Instruction Pointer, EIP), зберігає адресу пам'яті, яким лежить виконувана процесором інструкція. EIP за замовчуванням дорівнює 0xFFFFFFF0. Таким чином, x86-процесори на апаратному рівні розпочинають роботу з адреси 0xFFFFFFF0. Насправді це останні 16 байт 32-бітного адресного простору. Ця адреса називається вектором перезавантаження (reset vector).
Тепер картка пам'яті чіпсету гарантує, що 0xFFFFFFF0 належить певній частині BIOS, не RAM. У цей час BIOS копіює себе в RAM для швидшого доступу. Адреса 0xFFFFFFF0 міститиме лише інструкцію переходу на адресу в пам'яті, де зберігається копія BIOS.
Так починається виконання коду BIOS. Спочатку BIOS шукає пристрій, з якого можна завантажитись, у встановленому порядку. Шукається магічне число, що визначає, чи є пристрій завантажувальним (511 і 512 байти першого сектора повинні дорівнювати 0xAA55).
Коли BIOS знаходить завантажувальний пристрій, вона копіює вміст першого сектора пристрою в RAM, починаючи з фізичної адреси 0x7c00; потім переходить на адресу та виконує завантажений код. Цей код називається бутлоадером.
Бутлоадер завантажує ядро на фізичну адресу 0x100000. Ця адреса використовується як стартова у всіх великих ядрах на x86-системах.
Всі x86-процесори починають роботу в простому 16-бітному режимі, що називається реальним режимом. Бутлоадер GRUB перемикає режим у 32-бітовий захищений режим, встановлюючи нижній біт регістра CR0 1 . Таким чином, ядро завантажується у 32-бітному захищеному режимі.
Зауважте, що у випадку з ядром Linux GRUB бачить протоколи завантаження Linux і завантажує ядро в реальному режимі. Ядро самостійно перемикається у захищений режим.
Що нам потрібно?
- x86-комп'ютер;
- Linux;
- ld (GNU Linker);
Задаємо точку входу на асемблері
Як би не хотілося обмежитися одним Сі, щось доведеться писати на асемблері. Ми напишемо на ньому невеликий файл, який буде вихідною точкою для нашого ядра. Все, що він робитиме – викликати зовнішню функцію, написану на Сі, та зупиняти потік програми.
Як нам зробити так, щоб цей код обов'язково був саме вихідною точкою?
Ми будемо використовувати скрипт-лінковник, який з'єднує об'єктні файли для створення кінцевого файлу. У цьому скрипті ми вкажемо, що хочемо завантажити дані за адресою 0x100000.
Ось код на асемблері:
kernel.asm bits 32 ;nasm directive - 32 bit секції . .bss resb 8192 ;8KB for stack stack_space:
Перша інструкція, bits 32 не є x86-ассемблерів інструкцією. Це директива асемблеру NASM, що задає генерацію коду процесора, що працює в 32-бітному режимі. У нашому випадку це не обов'язково, але загалом корисно.
З другого рядка починається секція із кодом.
Global - це ще одна директива NASM, що робить символи вихідного коду глобальними. Таким чином, лінковник знає, де знаходиться символ start – наша точка входу.
kmain - це функція, яка буде визначена у файлі kernel.c. extern означає, що функцію оголошено десь у іншому місці.
Потім йде функція start, що викликає функцію kmain і зупиняє процесор інструкцією hlt. Саме тому ми заздалегідь відключаємо переривання інструкцією cli.
В ідеалі нам потрібно виділити небагато пам'яті та вказати на неї покажчиком стека (esp). Однак, схоже, що GRUB вже зробив це за нас. Тим не менш, ви все одно виділимо трохи місця в секції BSS і перемістимо на її початок покажчик стека. Ми використовуємо інструкцію resb, яка резервує вказану кількість байт. Відразу перед викликом kmain покажчик стека (esp) встановлюється на потрібне місце інструкцією mov .
Ядро на Сі
У kernel.asm ми здійснили виклик функції kmain(). Таким чином, наш “сишний” код має розпочати виконання з kmain() :
/* * kernel.c */ void kmain(void) ( const char *str = "my first kernel"; char *vidptr = (char*)0xb8000; //video mem begins here. unsigned int i = 0; unsigned int j = 0;< 80 * 25 * 2) { /* blank character */ vidptr[j] = " "; /* attribute-byte - light grey on black screen */ vidptr = 0x07; j = j + 2; } j = 0; /* this loop writes the string to video memory */ while(str[j] != "\0") { /* the character"s ascii */ vidptr[i] = str[j]; /* attribute-byte: give character black bg and light grey fg */ vidptr = 0x07; ++j; i = i + 2; } return; }
Все, що зробить наше ядро – очистить екран та виведе рядок “my first kernel”.
Спершу ми створюємо покажчик vidptr, який вказує на адресу 0xb8000. З цієї адреси в захищеному режимі починається відеопам'ять. Для виведення тексту на екран ми резервуємо 25 рядків по 80 символів ASCII, починаючи з 0xb8000.
Кожен символ відображається не звичними 8 бітами, а 16. У першому байті зберігається сам символ, а в другому - attribute-byte. Він визначає форматування символу, наприклад, його колір.
Для виведення символу зеленого кольору на чорному тлі ми запишемо цей символ в перший байт і значення 0x02 в другий. 0 означає чорне тло, 2 - зелений колір тексту.
Ось таблиця кольорів:
0 - Black, 1 - Blue, 2 - Green, 3 - Cyan, 4 - Red, 5 - Magenta, 6 - Brown, 7 - Light Grey, 8 - Dark Grey, 9 - Light Blue, 10/a - Light Green, 11/b - Light Cyan, 12/c - Light Red, 13/d - Light Magenta, 14/e - Light Brown, 15/f - White.
У нашому ядрі ми будемо використовувати світло-сірий текст на чорному тлі, тому наш байт-атрибут матиме значення 0x07.
У першому циклі програма виводить порожній символ у всій зоні 80×25. Це очистить екран. У наступному циклі в "відеопамять" записуються символи з нуль-термінованого рядка "my first kernel" з байтом-атрибутом, що дорівнює 0x07. Це виведе рядок на екран.
Сполучна частина
Ми повинні зібрати kernel.asm в об'єктний файл за допомогою NASM; потім за допомогою GCC скомпілювати kernel.c ще один об'єктний файл. Потім їх потрібно приєднати до завантажувального ядра, що виконується.
Для цього ми будемо використовувати зв'язуючий скрипт, який передається ld як аргумент.
/* * link.ld */ OUTPUT_FORMAT(elf32-i386) ENTRY(start) SECTIONS ( . = 0x100000; .text: ( *(.text) ) .data: ( *(.data) ) .bss: ( *( .bss) ) )
Спершу ми поставимо формат виводуяк 32-бітовий Executable and Linkable Format (ELF). ELF – це стандартний формат бінарних файлів Unix-систем архітектури x86. ENTRYприймає один аргумент, що визначає ім'я символу, що є точкою входу. SECTIONS- це найважливіша частина. У ній визначається розмітка нашого файлу, що виконується. Ми визначаємо, як мають з'єднуватися різні секції та де їх розмістити.
У дужках після SECTIONS точка (.) відображає лічильник положення за промовчанням 0x0. Його можна змінити, що ми робимо.
Дивимося наступний рядок: .text: ( *(.text) ) . Зірочка (*) - це спеціальний символ, який збігається з будь-яким ім'ям файлу. Вираз *(.text) означає всі секції.text із усіх вхідних файлів.
Таким чином, лінковник з'єднує всі секції коду об'єктних файлів в одну секцію файлу, що виконується за адресою в лічильнику положення (0x100000). Після цього значення лічильника дорівнюватиме 0x100000 + розмір отриманої секції.
Аналогічно відбувається і з іншим секціями.
Grub та Multiboot
Тепер усі файли готові до створення ядра. Але лишився ще один крок.
Існує стандарт завантаження x86-ядер із використанням бутлоадера, що називається Multiboot specification. GRUB завантажить наше ядро лише тоді, коли воно задовольняє цим специфікаціям .
Наслідуючи їх, ядро має містити заголовок у своїх перших 8 кілобайтах. Крім того, цей заголовок повинен містити 3 поля, які є 4 байтами:
- магічнеполе: містить магічне число 0x1BADB002для ідентифікації ядра.
- поле flags: нам воно не потрібно, встановимо в нуль
- поле checksum: якщо скласти його з попередніми двома, повинен вийти нуль.
Наш kernel.asm стане таким:
;;kernel.asm ;nasm directive - 32 bit bits 32 section .text ;multiboot spec align 4 dd 0x1BADB002 ;magic dd 0x00 ;flags dd - (0x1BADB002 + 0x00) ;checksum. m+f+c повинен бути 0 Global start extern kmain ;kmain is defined in the c file start: cli ;block interrupts mov esp, stack_space ;set stack pointer call kmain hlt ;halt the CPU section .bss resb 8192 ;8KB for stack stack_space:
Будуємо ядро
Тепер ми створимо об'єктні файли з kernel.asm та kernel.c та зв'яжемо їх, використовуючи наш скрипт.
Nasm -f elf32 kernel.asm -o kasm.o
Цей рядок запустить асемблер для створення об'єктного файлу kasm.o у форматі ELF-32.
Gcc -m32 -c kernel.c -o kc.o
Опція "-c" гарантує, що після компіляції не буде прихованого лінкування.
Ld -m elf_i386 -T link.ld -o kernel kasm.o kc.o
Це запустить лінковник з нашим скриптом і створить файл, що називається kernel.
Налаштовуємо grub та запускаємо ядро
GRUB вимагає, щоб ім'я ядра задовольняло шаблону kernel-
Тепер помістіть його в директорію /boot. Для цього знадобляться права суперкористувача.
У конфігураційному файлі GRUB grub.cfg додайте наступне:
Title myKernel root (hd0,0) kernel /boot/kernel-701 ro
Не забудьте прибрати директиву hiddenmenu, якщо вона є.
Перезавантажте комп'ютер, і ви побачите список ядер з вашим у тому числі. Виберіть його, і ви побачите:

Це ваше ядро! Додамо систему введення/виведення.
P.S.
- Для будь-яких фокусів із ядром краще використовувати віртуальну машину.
- Для запуску ядра в grub2конфіг повинен виглядати так: menuentry "kernel 7001" (set root="hd0,msdos1" multiboot /boot/kernel-7001 ro
- якщо ви хочете використовувати емулятор qemu , використовуйте: qemu-system-i386 -kernel kernel
Самі запити можна поділити на три групи:
- Первинні запитихарактеризують сайт загалом. Наприклад, для мого сайту: заробіток вдома, заробіток в Інтернеті, робота в Інтернеті.
- Основні запитивходять у семантичне ядро і з них варто просувати сайт. Наприклад: заробіток в інтернеті без вкладень, робота в інтернеті для мам.
- Допоміжні запитичи асоціативні, тобто. схожі за змістом із основними. Наприклад, ким працювати у декреті, підробіток для мами у декреті.
Складаємо семантичне ядро своїми руками онлайн
wordstat.yandex.ruнайдоступніший спосіб створення СЯ. На цьому сайті показується, скільки разів на місяць люди вбивають у пошук ту чи іншу фразу (ключовий запит).
Працювати досить просто – в головне поле введіть первинний запит, який охарактеризує сайт загалом або потрібну сторінку/розділ сайту. Наприклад, «заробіток в інтернеті».
Зліва ви отримаєте список основних запитів (заробіток в інтернеті без вкладень) та допоміжних (заробіток у мережі, додатковий дохід).
Майте на увазі, що ці цифри показують скільки разів зустрічався даний запит, але не саме в такому вигляді. Так, наприклад, люди шукали не заробіток без вкладень, а заробіток в інтернеті без вкладень, заробіток грошей без вкладень тощо.
Щоб зрозуміти, скільки разів люди шукали конкретну фразу, потрібно взяти її в лапки і поставити на початку знак оклику: «!заробіток без вкладень». Значення стало у кілька разів менше, але ви знаєте точну частотність, тобто. скільки людей вбивають у пошук саме цю фразу.
Аналогічно відбувається підбір ключових запитів для гугла (Google.Adwords) та рамблера (Rambler.Adstat). Інші пошукові системи надто незначні, щоб підбирати під них запити.
Але погодьтеся, вручну підбирати всі ці запити дуже складно, нудно і довго. Тому краще скористатися програмами.
Складаємо семантичне ядро: програми
- На верхній панелі натисніть на шестерню та зайдіть у налаштування. Тут багато всього можна підлаштувати під себе, але зараз перейдіть в останню вкладку Yandex.Direct;
- Введіть логін та пароль від Яндекса (створіть додаткову скриньку, тому що його можуть забанити);
- Натисніть на створення нового проекту, назвіть і збережіть його;
- Натисніть «Пакетний збір слів з лівої колонки Yandex Wordstat»;
- Внесіть первинний запит і пару основних, потім натисніть Почати збір;
- Перегляньте видачу і позначте галочкою всі, які не підходять для вас, потім клацніть правою кнопкою миші та Видалити зазначені рядки;
- Натисніть «Збір частотності із сервісу Yandex.Wordstat» — Зібрати частотність «!».
- Орієнтуйтеся саме на стовпець «Частотність!» - це конкретна кількість запитів саме цієї фрази (на місяць). Можна відфільтрувати за зростанням, і відразу відкинути всі КЗ із частотністю нижче 30 – це лише 1 запит на день.
- Експортуйте дані до Excel – натисніть на верхній панелі відповідний значок.
- Платна програма (близько 1700 рублів). З ним працюють професійні сеошники. Якщо ви хочете просто підібрати СЯ для невеликого блогу і все не варто платити такі гроші за програму, краще використовувати Словоєб. Найчастіше її купують досвідчені блогери з безліччю сайтів або веб-райтери, які займаються сео-статтями.
Працювати з програмою дуже просто:
- Розпочати новий проект;
- Вибрати регіон Росія + СНД (або інше);
- Введіть пошуковий запит і натисніть кнопку Яндекс.Вордстат (1 виділена зеленим кнопка);
- Перегляньте варіанти та виберіть відповідні;
- Перенесіть відповідні запити у 2 та 3 кнопки, виділені зеленим на скрині;
- Отримайте відповідні ключі.
Сама програма досить проста у використанні + є інструкції в Інтернеті. За бажання можна купити та користуватися.
Складаємо семантичне ядро своїми руками
Підберіть вищезазначеними способами відповідні ключові запити. Не варто відразу набирати 2000, можна обмежитись 200 запитами, а потім розвивати. Посидіть та подумайте, які ключі можна використовувати та складіть повний список. Вам потрібно набрати ключі для першої сторінки та ще кількох статей.
Відсійте слова та запити, за якими ви не плануєте просуватися. У мене часто трапляються запити на кшталт «робота вдома Перм» або в інших містах, тому їх відразу викидаю. Оцінюйте відразу – що хочуть отримати люди на цей запит і чи зможете ви це дати?
Забирайте висококонкурентні запити, за якими ви не зможете пробитися до ТОП10. У разі виникнення сумнівів подивіться на сайті Мутаген рівень конкуренції. Ну чи вручну оцінюйте видачу – популярні запити видно одразу.
Розподіліть запити по сайту. Середньочастотні запити йдуть на головну сторінку, низькочастотні згрупуйте за змістом та використовуйте у статтях чи розділах. Використовуйте їх як ключові слова у статтях (1 середньочастотний головний, пара низькочастотних у статті та підзаголовках, та розбавте по тексту допоміжними). Вписуйте в середньому 1-2 ключі на 2000 знаків, не частіше.
Деякі не створюють СЯ і все одно досягають успіху. Але краще знати, як скласти семантичне ядро своїми руками, програми для підбору слів зроблять це практично на автоматі (слово). А вам потім буде набагато простіше розвиватися і писати статті.
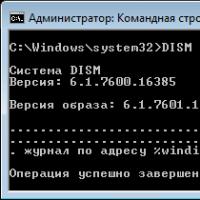 Як виправити помилки під час інсталяції оновлень Windows за допомогою вбудованого відновлення компонентів
Як виправити помилки під час інсталяції оновлень Windows за допомогою вбудованого відновлення компонентів Безкоштовні програми для Windows скачати безкоштовно
Безкоштовні програми для Windows скачати безкоштовно Перевірені способи зняття захисту з накопичувача
Перевірені способи зняття захисту з накопичувача Як змінити мелодію запуску Windows Як встановити мелодію на windows
Як змінити мелодію запуску Windows Як встановити мелодію на windows Нокія люмія чорний список в однокласниках
Нокія люмія чорний список в однокласниках Як зробити заміну телефону за гарантією
Як зробити заміну телефону за гарантією Sony Xperia Tablet S - Технічні характеристики
Sony Xperia Tablet S - Технічні характеристики