Знаходимо N'е число Фібоначчі трьома способами за прийнятний час: основи динамічного програмування. Числа Фібоначчі: циклом і рекурсією Фібоначчі c рекурсія
Дуже часто на різноманітних олімпіадах трапляються завдання на зразок цієї, які, як здається на перший погляд, можна вирішити за допомогою простого перебору. Але якщо ми підрахуємо кількість можливих варіантів, То відразу переконаємося в неефективності такого підходу: наприклад, проста рекурсивна функція, наведена нижче, буде споживати істотні ресурси вже на 30-ом числі Фібоначчі, тоді як на олімпіадах час вирішення часто обмежена 1-5 секундами.
Int fibo (int n) (if (n \u003d\u003d 1 || n \u003d\u003d 2) (return 1;) else (return fibo (n - 1) + fibo (n - 2);))
Давайте подумаємо, чому так відбувається. Наприклад, для обчислення fibo (30) ми спочатку обчислюємо fibo (29) і fibo (28). Але при цьому наша програма «забуває», що fibo (28) ми вже обчислювали при пошуку fibo (29).
Основна помилка такого підходу «в лоб» в тому, що однакові значення аргументів функції обчислюються багаторазово - але ж це досить ресурсомісткі операції. Позбутися від повторюваних обчислень нам допоможе метод динамічного програмування - це прийом, при використанні якого завдання розбивається на загальні і повторювані підзадачі, кожна з яких вирішується тільки 1 раз - це значно підвищує ефективність програми. Цей метод докладно описаний в, там же є і приклади розв'язання інших завдань.
Самий просто варіант поліпшення нашої функції - запам'ятовувати, які значення ми вже обчислювали. Для цього потрібно ввести додатковий масив, який буде служити як би «кешем» для наших обчислень: перед обчисленням нового значення ми будемо перевіряти, чи не обчислювали його раніше. Якщо вираховували, то будемо брати з масиву готове значення, а якщо не обчислювали - доведеться рахувати його на основі попередніх і запам'ятовувати на майбутнє:
Int cache; int fibo (int n) (if (cache [n] \u003d\u003d 0) (if (n \u003d\u003d 1 || n \u003d\u003d 2) (cache [n] \u003d 1;) else (cache [n] \u003d fibo (n - 1) + fibo (n - 2);)) return cache [n];)
Так як в цьому завданню для обчислення N-ого значення нам гарантовано знадобиться (N-1) -е, то не важко буде переписати формулу в ітераційний вид - просто будемо заповнювати наш масив поспіль до тих пір, поки не дійдемо до потрібної комірки:
<= n; i++) { cache[i] = cache + cache; } cout << cache;
Тепер ми можемо помітити, що коли ми обчислюємо значення F (N), то значення F (N-3) нам уже гарантовано ніколи не знадобиться. Тобто нам досить зберігати в пам'яті лише два значення - F (N-1) і F (N-2). Причому, як тільки ми вирахували F (N), зберігання F (N-2) втрачає будь-який сенс. Спробуємо записати ці роздуми у вигляді коду:
// Два попередніх значення: int cache1 \u003d 1; int cache2 \u003d 1; // Нове значення int cache3; for (int i \u003d 2; i<= n; i++) { cache3 = cache1 + cache2; //Вычисляем новое значение //Абстрактный cache4 будет равен cache3+cache2 //Значит cache1 нам уже не нужен?.. //Отлично, значит cache1 -- то значение, которое потеряет актуальность на следующей итерации. //cache5 = cache4 - cache3 => через ітерацію втратить актуальність cache2, тобто він і повинен стати cache1 // Іншими словами, cache1 - f (n-2), cache2 - f (n-1), cache3 - f (n). // Нехай N \u003d n + 1 (номер, який ми обчислюємо на наступній ітерації). Тоді n-2 \u003d N-3, n-1 \u003d N-2, n \u003d N-1. // У відповідно до нових реалій ми і переписуємо значення наших змінних: cache1 \u003d cache2; cache2 \u003d cache3; ) cout<< cache3;
Бувалому програмісту зрозуміло, що код вище, в общем-то дурниця, так як cache3 ніколи не використовується (він відразу записується в cache2), і всю ітерацію можна переписати, використовуючи всього один вислів:
Cache \u003d 1; cache \u003d 1; for (int i \u003d 2; i<= n; i++) { cache = cache + cache; //При i=2 устареет 0-й элемент //При i=3 в 0 будет свежий элемент (обновили его на предыдущей итерации), а в 1 -- ещё старый //При i=4 последним элементом мы обновляли cache, значит ненужное старьё сейчас в cache //Интуитивно понятно, что так будет продолжаться и дальше } cout << cache;
Для тих, хто не може зрозуміти, як працює магія із залишком від ділення, або просто хоче побачити більш неочевидні формулу, існує ще одне рішення:
Int x \u003d 1; int y \u003d 1; for (int i \u003d 2; i< n; i++) { y = x + y; x = y - x; } cout << "Число Фибоначчи: " << y;
Спробуйте простежити за виконанням цієї програми: ви переконаєтеся в правильності алгоритму.
P.S. Взагалі, існує єдина формула для обчислення будь-якого числа Фібоначчі, яка не вимагає ніяких ітерацій або рекурсії:
Const double SQRT5 \u003d sqrt (5); const double PHI \u003d (SQRT5 + 1) / 2; int fibo (int n) (return int (pow (PHI, n) / SQRT5 + 0.5);)
Але, як можете здогадатися, підступ в тому, що ціна обчислення ступенів нецілих чисел досить велика, як і їх похибка.
числа Фібоначчі - це ряд чисел, в якому кожне наступне число дорівнює сумі двох попередніх: 1, 1, 2, 3, 5, 8, 13, .... Іноді ряд починають з нуля: 0, 1, 1, 2, 3, 5, .... В даному випадку ми будемо дотримуватися першого варіанту.
Формула:
F 1 \u003d 1
F 2 \u003d 1
F n \u003d F n-1 + F n-2
Приклад обчислення:
F 3 \u003d F 2 + F 1 \u003d 1 + 1 \u003d 2
F 4 \u003d F 3 + F 2 \u003d 2 + 1 \u003d 3
F 5 \u003d F 4 + F 3 \u003d 3 + 2 \u003d 5
F 6 \u003d F 5 + F 4 \u003d 5 + 3 \u003d 8
...
Обчислення n-го числа ряду Фібоначчі за допомогою циклу while
- Присвоїти змінним fib1 і fib2 значення двох перших елементів ряду, тобто привласнити змінним одиниці.
- Запросити у користувача номер елемента, значення якого він хоче отримати. Присвоїти номер змінної n.
- Виконувати такі дії n - 2 разів, так як перші два елементи вже враховані:
- Скласти fib1 і fib2, присвоївши результат змінної для тимчасового зберігання даних, наприклад, fib_sum.
- Змінної fib1 привласнити значення fib2.
- Змінної fib2 привласнити значення fib_sum.
- Вивести на екран значення fib2.
Примітка. Якщо користувач вводить 1 або 2, тіло циклу жодного разу не виконується, на екран виводиться вихідне значення fib2.
fib1 \u003d 1 fib2 \u003d 1 n \u003d input () n \u003d int (n) i \u003d 0 while i< n - 2 : fib_sum = fib1 + fib2 fib1 = fib2 fib2 = fib_sum i = i + 1 print (fib2)
Компактний варіант коду:
fib1 \u003d fib2 \u003d 1 n \u003d int (input ( "Номер елемента ряду Фібоначчі:")) - 2 while n\u003e 0: fib1, fib2 \u003d fib2, fib1 + fib2 n - \u003d 1 print (fib2)
Висновок чисел Фібоначчі циклом for
В даному випадку виводиться не тільки значення шуканого елемента ряду Фібоначчі, але і всі числа до нього включно. Для цього висновок значення fib2 поміщений в цикл.
fib1 \u003d fib2 \u003d 1 n \u003d int (input ()) if n< 2 : quit() print (fib1, end= " " ) print (fib2, end= " " ) for i in range (2 , n) : fib1, fib2 = fib2, fib1 + fib2 print (fib2, end= " " ) print ()
Приклад виконання:
10 1 1 2 3 5 8 13 21 34 55
Рекурсивне обчислення n-го числа ряду Фібоначчі
- Якщо n \u003d 1 або n \u003d 2, повернути в зухвалу гілку одиницю, так як перший і другий елементи ряду Фібоначчі рівні одиниці.
- У всіх інших випадках викликати цю ж функцію з аргументами n - 1 і n - 2. Результат два дзвінки скласти і повернути в зухвалу гілку програми.
def fibonacci (n): if n in (1, 2): return 1 return fibonacci (n - 1) + fibonacci (n - 2) print (fibonacci (10))
Припустимо, n \u003d 4. Тоді відбудеться рекурсивний виклик fibonacci (3) і fibonacci (2). Другий поверне одиницю, а перший призведе до ще двох викликів функції: fibonacci (2) і fibonacci (1). Обидва виклику повернуть одиницю, в сумі буде два. Таким чином, виклик fibonacci (3) повертає число 2, яке підсумовується з числом 1 від виклику fibonacci (2). Результат 3 повертається в основну гілку програми. Четвертий елемент ряду Фібоначчі дорівнює трьом 1 1 2 3.
Програмістам числа Фібоначчі повинні вже набриднути. Приклади їх обчислення використовуються всюди. Все від того, що ці числа надають найпростіший приклад рекурсії. А ще вони є хорошим прикладом динамічного програмування. Але чи треба обчислювати їх так в реальному проекті? Не треба. Ні рекурсія, ні динамічне програмування не є ідеальними варіантами. І не замкнута формула, яка використовує числа з плаваючою комою. Зараз я розповім, як правильно. Але спочатку пройдемося по всіх відомих варіантів рішення.Код призначений для Python 3, хоча повинен йти і на Python 2.
Для початку - нагадаю визначення:
F n \u003d F n-1 + F n-2
І F 1 \u003d F 2 \u003d 1.
замкнута формула
Припустимо деталі, але бажаючі можуть ознайомитися з висновком формули. Ідея в тому, щоб припустити, що є якийсь x, для якого F n \u003d x n, а потім знайти x.Що означає
![]()
Скорочуємо x n-2
![]()
Вирішуємо квадратне рівняння:

Звідки і росте «золотий перетин» φ \u003d (1 + √5) / 2. Підставивши вихідні значення і виконавши ще обчислення, ми отримуємо:

Що і використовуємо для обчислення F n.
From __future__ import division import math def fib (n): SQRT5 \u003d math.sqrt (5) PHI \u003d (SQRT5 + 1) / 2 return int (PHI ** n / SQRT5 + 0.5)
гарне:
Швидко і просто для малих n
погане:
Потрібні операції з плаваючою комою. Для великих n буде потрібно велика точність.
зле:
Використання комплексних чисел для обчислення F n красиво з математичної точки зору, але потворно - з комп'ютерної.
рекурсія
Найочевидніше рішення, яке ви вже багато разів бачили - швидше за все, в якості прикладу того, що таке рекурсія. Повторю його ще раз, для повноти. В Python її можна записати в один рядок:Fib \u003d lambda n: fib (n - 1) + fib (n - 2) if n\u003e 2 else 1
гарне:
Дуже проста реалізація, що повторює математичне визначення
погане:
Експоненціальне час виконання. Для великих n дуже повільно
зле:
переповнення стека
запам'ятовування
У рішення з рекурсією є велика проблема: пересічні обчислення. Коли викликається fib (n), то підраховуються fib (n-1) і fib (n-2). Але коли вважається fib (n-1), вона знову незалежно підрахує fib (n-2) - тобто, fib (n-2) підрахувати двічі. Якщо продовжити міркування, буде видно, що fib (n-3) буде підрахована тричі, і т.д. Занадто багато перетинів.Тому треба просто запам'ятовувати результати, щоб не підраховувати їх знову. Час і пам'ять у цього рішення витрачаються лінійним чином. У рішенні я використовую словник, але можна було б використовувати і простий масив.
M \u003d (0: 0, 1: 1) def fib (n): if n in M: return M [n] M [n] \u003d fib (n - 1) + fib (n - 2) return M [n]
(В Python це можна також зробити за допомогою декоратора, functools.lru_cache.)
гарне:
Просто перетворити рекурсию в рішення із запам'ятовуванням. Перетворює експоненціальне час виконання в лінійне, для чого витрачає більше пам'яті.
погане:
Витрачає багато пам'яті
зле:
Можливо переповнення стека, як і у рекурсії
динамічне програмування
Після рішення із запам'ятовуванням стає зрозуміло, що нам потрібні не всі попередні результати, а тільки два останніх. Крім цього, замість того, щоб починати з fib (n) і йти назад, можна почати з fib (0) і йти вперед. У наступного коду лінійний час виконання, а використання пам'яті - фіксоване. На практиці швидкість рішення буде ще вище, оскільки тут відсутні рекурсивні виклики функцій і пов'язана з цим робота. І код виглядає простіше.Це рішення часто наводиться як приклад динамічного програмування.
Def fib (n): a \u003d 0 b \u003d 1 for __ in range (n): a, b \u003d b, a + b return a
гарне:
Швидко працює для малих n, простий код
погане:
Все ще лінійний час виконання
зле:
Так особливо нічого.
матрична алгебра
І, нарешті, найменш висвітлене, але найбільш правильне рішення, грамотно використовує як час, так і пам'ять. Його також можна розширити на будь-яку однорідну лінійну послідовність. Ідея в використанні матриць. Досить просто бачити, що
А узагальнення цього говорить про те, що

Два значення для x, отриманих нами раніше, у тому числі одне представляло собою золотий перетин, є власними значеннями матриці. Тому, ще одним способом виведення замкнутої формули є використання матричного рівняння і лінійної алгебри.
Так чому ж корисна таке формулювання? Тим, що зведення в ступінь можна зробити за логарифмічна час. Це робиться через зведення в квадрат. Суть в тому, що

Де перший вираз використовується для парних A, друге для непарних. Залишилося тільки організувати перемноження матриць, і все готово. Виходить наступний код. Я організував рекурсивную реалізацію pow, оскільки її простіше зрозуміти. Ітеративну версію дивіться тут.
Def pow (x, n, I, mult): "" "Повертає x в ступені n. Передбачає, що I - це одинична матриця, яка перемножується з mult, а n - позитивне ціле" "" if n \u003d\u003d 0: return I elif n \u003d\u003d 1: return x else: y \u003d pow (x, n // 2, I, mult) y \u003d mult (y, y) if n% 2: y \u003d mult (x, y) return y def identity_matrix (n): "" "Повертає одиничну матрицю n на n" "" r \u003d list (range (n)) return [for j in r] def matrix_multiply (A, B): BT \u003d list (zip (* B) ) return [for row_a in A] def fib (n): F \u003d pow ([,], n, identity_matrix (2), matrix_multiply) return F
гарне:
Фіксований обсяг пам'яті, логарифмічна час
погане:
код складніше
зле:
Доводиться працювати з матрицями, хоча вони не такі вже й погані
порівняння швидкодії
Порівнювати варто тільки варіант динамічного програмування і матриці. Якщо порівнювати їх за кількістю знаків в числі n, то вийде, що матричне рішення лінійно, а рішення з динамічним програмуванням - експоненціально. Практичний приклад - обчислення fib (10 ** 6), числа, у якого буде більше двохсот тисяч знаків.N \u003d 10 ** 6
Обчислюємо fib_matrix: у fib (n) всього 208988 цифр, розрахунок зайняв 0.24993 секунд.
Обчислюємо fib_dynamic: у fib (n) всього 208988 цифр, розрахунок зайняв 11.83377 секунд.
теоретичні зауваження
Чи не безпосередньо торкаючись наведеного вище коду, дане зауваження все-таки має певний інтерес. Розглянемо наступний граф:
Підрахуємо кількість шляхів довжини n від A до B. Наприклад, для n \u003d 1 у нас є один шлях, 1. Для n \u003d 2 у нас знову є один шлях, 01. Для n \u003d 3 у нас є два шляхи, 001 і 101 . Досить просто можна показати, що кількість шляхів довжини n від А до в одно в точності F n. Записавши матрицю суміжності для графа, ми отримаємо таку ж матрицю, яка була описана вище. Це відомий результат з теорії графів, що при заданій матриці суміжності А, входження в А n - це кількість шляхів довжини n в графі (одне із завдань, згадуваних у фільмі «Розумниця Уілл Хантінг»).
Чому на ребрах стоять такі позначення? Виявляється, що при розгляді нескінченної послідовності символів на нескінченній в обидві сторони послідовності шляхів на графі, ви отримаєте щось під назвою "подсдвігі кінцевого типу", що представляє собою тип системи символічної динаміки. Саме цей подсдвіг кінцевого типу відомий, як «зрушення золотого перетину», і задається набором «заборонених слів» (11). Іншими словами, ми отримаємо нескінченні в обидві сторони виконавчі послідовності і ніякі пари з них не будуть суміжними. Топологічна ентропія цієї динамічної системи дорівнює золотому перетину φ. Цікаво, як це число періодично з'являється в різних областях математики.
 Поява помилки під час запуску програм
Поява помилки під час запуску програм Плагін friGate для Firefox
Плагін friGate для Firefox Як показати приховані папки і файли в Windows
Як показати приховані папки і файли в Windows Способи, як зробити екран на ноутбуці яскравіше або темніше
Способи, як зробити екран на ноутбуці яскравіше або темніше Як форматувати флешку, диск захищений від запису
Як форматувати флешку, диск захищений від запису Якщо установка Windows на даний диск неможлива
Якщо установка Windows на даний диск неможлива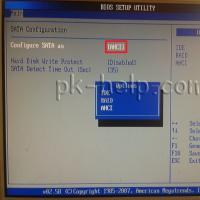 Під час установки Windows «Переконайтеся що контролер даного диска включений в меню bios комп'ютера
Під час установки Windows «Переконайтеся що контролер даного диска включений в меню bios комп'ютера