Мова r що. Мова програмування R і його місце серед статистичних програм. Як виглядає середу R
Давайте трохи поговоримо про мову програмування під назвою R. У Останнім часомви могли у нас в блогах прочитати статті про та, тих сферах, де просто необхідно під рукою мати потужний мову для роботи зі статистикою та графіками. І R якраз з таких. Новачкові в світі програмування буде досить непросто в це повірити, але сьогодні R вже популярнішим SQL, він активно використовується в комерційних організаціях, дослідницьких і університетах.
Не заглиблюючись в правила, синтаксис і конкретні області застосування, просто давайте розглянемо основні книги і ресурси, які допоможуть вам з нуля вивчити R.
Що таке мова R, навіщо він вам потрібен і як його можна використовувати з розумом, можна дізнатися з прекрасного Руслана Купцова, який він провів трохи менше року тому в рамках GeekWeek-2015.
книги
Тепер, коли в голові є певний порядок, можна приступати до читання літератури, благо її більш ніж достатньо. Почнемо з вітчизняних авторів:

Інтернет ресурси
Будь-яка людина, що бажає вивчити будь-якої мова програмування обов'язково повинен відвідати в пошуках знань два ресурси: офіційний сайт його розробників і найбільше онлайн співтовариство. Що ж. не робитимемо виключення і для R:
Але знову перейнявшись турботою до тих, хто англійська мовавивчити ще не встиг, а ось вивчити R ну дуже хоче, згадаємо кілька російських ресурсів:
А поки довершили картину невеликим списком англомовних, але від цього не менш пізнавальних сайтів:
CRAN - власне, місце де можна завантажити до себе на комп'ютер середу розробки R. Крім того мануали, приклади та інше корисне чтиво;
Quick-R - коротко і зрозуміло про статистику, методи її обробки і мову R;
Burns-Stat - про R і про попередника його S з величезною кількістюприкладів;
R for Data Science - ще одна книга від Гаррета Гроулмунда (Garrett Grolemund), перекладена в формат онлайн підручника;
Awesome R - добірка кращого кодуз офіційного сайту, розміщена на нашому улюбленому GitHub;
Mran - мова R від Microsoft;
Tutorial R - ще один ресурс з впорядкованою інформацією з офіційного сайту.
На написання цієї статті мене спонукав наступний топік: У пошуках ідеального поста, або загадки Хабра. Справа в тому, що після ознайомлення з мовою R я вкрай скоса дивлюся на будь-які спроби, щось порахувати в екселя. Але треба визнати, що і з R я познайомився лише тиждень тому.
Мета: Зібрати засобами мови R дані з улюбленого HabraHabr "а й провести, власне те, для чого і була створена мова R, а саме: статистичний аналіз.
Отже, прочитавши цей топік ви дізнаєтеся:
- Як можна використовувати R для отримання даних з Web ресурсів
- Як перетворювати дані для подальшого аналізу
- Які ресурси вкрай рекомендуються до прочитання всім бажаючим познайомитися з R ближче
Очікується, що читач досить самостійний, щоб самому ознайомитися з основними конструкціями мови. Для цього як ніяк краще підійдуть посилання в кінці статті.
підготовка
Нам знадобляться наступні ресурси:Після установки ви повинні побачити щось типу цього:
У правій нижній панелі на вкладці Packages ви можете знайти список встановлених пакетів. Нам знадобиться додатково встановити наступні:
- Rcurl - для роботи з мережею. Всі хто працював з CURL відразу зрозуміє всі можливості, що відкриваються.
- XML - пакет для роботи з DOM деревом XML документа. Нам знадобиться функціонал знаходження елементів по xpath
отримуємо дані
Щоб отримати DOM об'єкт документа отриманого з інтернету досить виконати наступні рядки:url<-"http://habrahabr.ru/feed/posts/habred/page10/" cookie<-"Мои сверхсекретные печеньки" html<-getURL(url, cookie=cookie) doc<-htmlParse(html)
Зверніть увагу на передані cookie. Якщо ви захочете повторити експеременту, то вам треба буде підставити свої cookie, які отримує ваш браузер після авторизації на сайті. Далі нам треба отримати цікаві для нас дані, а саме:
- Коли запис була опублікована
- Скільки було переглядів
- Скільки людей занесло запис в обрані
- Скільки було натискань на +1 і -1 (сумарно)
- Скільки було +1 натискань
- скільки -1
- Поточний рейтинг
- кількість коментарів
published<-xpathSApply(doc, "//div[@class="published"]", xmlValue) pageviews<-xpathSApply(doc, "//div[@class="pageviews"]", xmlValue) favs<-xpathSApply(doc, "//div[@class="favs_count"]", xmlValue) scoredetailes<-xpathSApply(doc, "//span[@class="score"]", xmlGetAttr, "title") scores<-xpathSApply(doc, "//span[@class="score"]", xmlValue) comments<-xpathSApply(doc, "//span[@class="all"]", xmlValue) hrefs<-xpathSApply(doc, "//a[@class="post_title"]", xmlGetAttr, "href")
Тут ми використовували пошук елементів і атрибутів за допомогою xpath.
Далі вкрай рекомендується сформувати з отриманих даних data.frame - це аналог таблиць бази даних. Можна буде робити запити різного рівня складності. Іноді диву даєшся, як елегантно можна зробити в R ту чи іншу річ.
posts<-data.frame(hrefs, published, scoredetailes, scores, pageviews, favs, comments)
Після формування data.frame необхідно буде підправити отримані дані: перетворити рядки в числа, отримати реальну дату в нормальному форматі і т.д. Робимо це таким чином:
Posts $ comments<-as.numeric(as.character(posts$comments)) posts$scores<-as.numeric(as.character(posts$scores)) posts$favs<-as.numeric(as.character(posts$favs)) posts$pageviews<-as.numeric(as.character(posts$pageviews)) posts$published<-sub(" декабря в ","/12/2012 ",as.character(posts$published)) posts$published<-sub(" ноября в ","/11/2012 ",posts$published) posts$published<-sub(" октября в ","/10/2012 ",posts$published) posts$published<-sub(" сентября в ","/09/2012 ",posts$published) posts$published<-sub("^ ","",posts$published) posts$publishedDate<-as.Date(posts$published, format="%d/%m/%Y %H:%M")
Так само корисно додати додаткові поля, які обчислюються з уже отриманих:
scoressplitted<-sapply(strsplit(as.character(posts$scoredetailes), "\\D+", perl=TRUE),unlist)
if(class(scoressplitted)=="matrix" && dim(scoressplitted)==4)
{
scoressplitted<-t(scoressplitted)
posts$actions<-as.numeric(as.character(scoressplitted[,1]))
posts$plusactions<-as.numeric(as.character(scoressplitted[,2]))
posts$minusactions<-as.numeric(as.character(scoressplitted[,3]))
}
posts$weekDay<-format(posts$publishedDate, "%A")
Тут ми всім відомі повідомлення виду «Всього 35: 29 і ↓ 6» перетворили в масив даних по тому, скільки взагалі було вироблено дій, скільки було плюсів і скільки було мінусів.
На цьому, можна сказати, що всі дані отримані і перетворені до готового для аналізу формату. Код вище я оформив у вигляді функції готової до використання. В кінці статті ви зможете знайти посилання на исходник.
Але уважний читач уже помітив, що таким чином, ми отримали дані лише для однієї сторінки, щоб отримати для цілого ряду. Щоб отримати дані для цілого списку сторінок була написана наступна функція:
GetPostsForPages<-function(pages, cookie, sleep=0)
{
urls<-paste("http://habrahabr.ru/feed/posts/habred/page", pages, "/", sep="")
ret<-data.frame()
for(url in urls)
{
ret<-rbind(ret, getPosts(url, cookie))
Sys.sleep(sleep)
}
return(ret)
}
Тут ми використовуємо системну функцію Sys.sleep, щоб не влаштувати випадково хабраеффект самому Хабре :)
Дану функцію пропонується використовувати такий спосіб:
posts<-getPostsForPages(10:100, cookie,5)
Таким чином ми завантажуємо всі сторінки з 10 по 100 з паузою в 5 секунд. Сторінки до 10 нам не цікаві, тому що оцінки там ще не видно. Після декількох хвилин очікування всі наші дані знаходяться в змінної posts. Рекомендую їх тут же зберегти, щоб кожен раз не турбувати Хабр! Робиться це в такий спосіб:
write.csv (posts, file = "posts.csv")
А зчитуємо наступним чином:
posts<-read.csv("posts.csv")
Ура! Ми навчилися отримувати статистичні дані з Хабра і зберігати їх локально для наступного аналізу!
аналіз даних
Цей розділ я залишу недомовленим. Пропоную читачеві самому погратися з даними і отримати свої долеко йдуть. Наприклад, спробуйте проаналізувати залежність настрою плюси і мінуси в залежності від дня тижня. Наведу лише 2 цікавих висновки, які я зробив.Користувачі Хабра значно охочіше плюсують, ніж мінусують.
Це видно за наступним графіком. Зауважте, на скільки «хмара» мінусів рівномірніше і ширше, ніж розкид плюсів. Кореляція плюсів від кількості переглядів значно сильніше, ніж для мінусів. Іншими словами: плюсуем не думаючи, а мінусуем за справу!(Прошу вибачення за написи на графіках: поки не розібрався, як виводити їх правильно російською мовою)

Дійсно є кілька класів постів
Це твердження в згаданому пості використовувалося як даність, але я хотів переконатися в цьому в дійсності. Для цього достатньо порахувати середню частку плюсів до загальної кількості дій, те ж саме для мінусів і розділити друге першу. Якби все було однорідно, то безліч локальних піків на гістограмі ми не повинні спостерігати, проте вони там є.
Як ви можете помітити, є виражені піки в районі 0.1, 0.2 і 0.25. Пропоную читачеві самому знайти і «назвати» ці класи.
Хочу зауважити, що R багата алгоритмами для кластеризації даних, для апроксимації, для перевірки гіпотез і т.п.
Корисні ресурси
Якщо ви дійсно хочете зануритися в світ R, то рекомендую наступні посилання. Будь ласка, поділіться в коментарях вашими цікавими блогами і сайтами на тему R. Есть кто-нибудь пише про R російською?Хочу розповісти про використання вільного середовища статистичного аналізу R. Розглядаю її як альтернативу статистичних пакетів типу SPSS Statistics. На мій превеликий жаль, вона абсолютно невідома на просторах нашої Батьківщини, а даремно. Вважаю, що можливість написання додаткових процедур статистичного аналізу на мові S робить систему R корисним інструментом аналізу даних.
У весняному семестрі 2010 мені довелося читати лекції і проводити практичні заняття з курсу «Статистичний аналіз даних» для студентів відділення інтелектуальних систем РДГУ.
Мої студенти попередньо вивчали семестровий курс теорії ймовірностей, що покриває основи дискретних імовірнісних просторів, умовні ймовірності, теорему Байеса, закон «великих чисел», деякі відомості про нормальний закон і Центральну граничну теорему.
Років п'ять тому я вже проводив заняття з (тоді ще об'єднаному) семестрового курсу «Основи теорії ймовірностей і математичної статистики», тому я розширив свої замітки (видаються перед кожним заняттям студентам) по статистиці. Зараз, коли в РДГУ є студентський сервер isdwiki.rsuh.ru відділення, я паралельно викладаю їх на FTP.
Стало зрозуміло: яку програму використовувати, для проведення практичних занять в комп'ютерному класі? Часто використовується Microsoft Excel був відхилений як через пропрієтарного, так і з-за некоректність реалізації деяких статистичних процедур. Про це можна прочитати, наприклад, в книзі А.А.Макарова і Ю.Н.Тюріна «Статистичний аналіз даних на комп'ютері». Електронні таблиці Calc з безкоштовного офісного пакету Openoffice.org русифікували так, що мені ніяк не вдається знайти потрібну опцію (їх назви ще й скоротили огидно).
Найбільш часто використовується пакет SPSS Statistics. В даний час фірма SPSS поглинена фірмою IBM. Серед переваг IBM SPSS Statistics виділю:
- Зручне завантаження даних різних форматів (Excel, SAS, через OLE DB, через ODBC Direct Driver);
- Наявність як командного мови, так і розгалуженої системи меню для прямого доступу до багатьох процедур статистичного аналізу;
- Графічні засоби виведення результатів;
- Вбудований модуль Statistics Coach, інтерактивним чином пропонує адекватний метод аналізу.
- Платність навіть для студентів;
- Необхідність отримання (додатково оплачуваних) модулів, що містять спеціальні процедури;
- Підтримка тільки 32-розрядних операційних систем Linux, хоча Windows підтримуються як 32-розрядні, так і 64-розрядні.
Перевагами обговорюваної системи я вважаю:
- Поширення програми під GNU Public License;
- Доступність як вихідних текстів, так і бінарних модулів у великій мережі репозитаріїв CRAN (The Comprehensive R Archive Network). Для Росії - це сервер cran.gis-lab.info;
- Наявність установчого пакета під Windows (працює як на 32-х, так і на 64-х розрядної Vista). Випадково з'ясувалося, що установка не вимагає прав адміністратора під Windows XP;
- Можливість установки з репозитария в Linux (у мене працює на 64-розрядної версії Ubuntu 9.10);
- Наявність власної мови програмування статистичних процедур R, фактично став стандартом. Він, наприклад, повністю підтримується новою системою IBM SPSS Statistics Developer;
- Ця мова є розширенням мови S, розробленим в Bell Labs, в даний час складають основу комерційної системи S-PLUS. Більшість програм, написаних для S-PLUS, може легко бути виконано в середовищі R;
- Можливість обміну даними з електронними таблицями;
- Можливість збереження всієї історії обчислень для цілей документування.
Перше заняття було присвячено встановленню і навчання користуватися пакетом, знайомство з синтаксисом мови R. В якості тестової задачі використовувалися обчислення інтегралів методом Монте-Карло. Ось приклад обчислення ймовірності С.В. з експоненціальним розподілом з параметром 3 прийняти значення менше 0.5 (10000 - число спроб).
> X = runif (10000,0,0.5)
> Y = runif (10000,0,3)
> T = y<3*exp(-3*x)
> U = x [t]
> V = y [t]
> Plot (u, v)
> I = 0.5 * 3 * length (u) / 10000
Перші два рядки задають рівномірний розподіл точок в прямокутнику x, потім відбираються ті точки, які потрапили під графік експоненціальної щільності 3 * exp (-3 * x), функція plot відображає точки у вікні графічного виведення, нарешті, обчислюється шуканий інтеграл.
Друге заняття було присвячено обчисленню описових статистик (квантиль, медіані, середнього, дисперсії, кореляції і коваріації) і висновку графіків (гістограми, ящик-з-вусами).
У наступних заняттях використовувалася бібліотека «Rcmdr». Це - графічний інтерфейс користувача (GUI) для середовища R. Бібліотека створюється зусиллями професора Джона Фокса з університету McMaster в Канаді.
Установка цієї бібліотеки проводиться виконанням команди install.packages ( «Rcmdr», dependencies = TRUE) всередині середовища R. Якщо саме середовище - інтерпретатор мови R, то надбудова «Rcmdr» - це додаткове вікно, забезпечене системою меню, що містить велику кількість команд, відповідних стандартним статистичним процедурам. Це особливо зручно для курсів, де головне - навчити студента натискати на кнопочки (на мій жаль, такі зустрічаються зараз все в більшій кількості).
З попереднього мого курсу були розширені замітки до семінарів. Вони також доступні через FTP з сайту isdwiki.rsuh.ru. Ці нотатки містили таблиці критичних значень, які використовувалися для обчислень у дошки. Цього року студентам пропонувалося вирішувати ці завдання на комп'ютері, а також перевіряти таблиці, використавши (нормальні) апроксимації, також зазначені в нотатках.
Були і деякі мої промахи. Наприклад, я надто пізно зрозумів, що Rcmdr дозволяє імпортувати дані з завантажених пакетів, тому відносно великі вибірки оброблялися тільки на заняттях, присвячених регрессионному аналізу. При викладі непараметрических тестів дані студенти вводили руками, використовуючи мої замітки. Іншим недоліком, як я зараз розумію, було недостатнє число домашніх завдань на написання досить складних програм на мові R.
Слід зазначити, що на мої заняття ходили кілька студентів старших курсів, а деякі скачували матеріали лекцій і семінарів. Студенти відділення інтелектуальних систем РДГУ отримують фундаментальну підготовку з математики та програмування, тому використання середовища R (замість електронних таблиць і статистичних пакетів з фіксованими статистичними процедурами) видається мені дуже корисним.
Якщо перед Вами стоїть завдання вивчення статистики, а особливо написання нестандартних процедур статистичної обробки даних, то рекомендую звернути свою увагу на пакет R.
Статистичний аналіз є невід'ємною частиною наукового дослідження. Якісна обробка даних підвищує шанси опублікувати статтю в солідному журналі, і вивести дослідження на міжнародний рівень. Існує багато програм, здатних забезпечити якісний аналіз, однак більшість з них платні, і часто ліцензія коштує від кількох сотень доларів і вище. Але сьогодні ми поговоримо про статистичної середовищі, за яку не треба платити, а її надійність і популярність конкурують з кращими комерційними стат. пакетами: ми познайомимося з R!
Що таке R?
Перш ніж дати чітке визначення, слід зазначити, що R - це щось більше, ніж просто програма: це і середовище, і мову, і навіть рух! Ми розглянемо R з різних ракурсів.
R - це середовище обчислень, Розроблена вченими для обробки даних, математичного моделювання та роботи з графікою. R можна використовувати як простий калькулятор, можна, можна проводити прості статистичні аналізи (наприклад, ANOVA або регресійний аналіз) і більш складні тривалі обчислення, перевіряти гіпотези, будувати векторні графіки і карти. Це далеко не повний перелік того, що можна робити в цьому середовищі. Варто відзначити, що вона поширюється безкоштовно і може бути встановлена як на Windows, так і на операційні системи класу UNIX (Linux і MacOS X). Іншими словами, R - це вільний і багатоплатформовий продукт.
R - це мова програмування, Завдяки чому можна писати власні програми ( скрипти) За допомогою, а також використовувати і створювати спеціалізовані розширення ( пакети). Пакет - це набір, файлів з довідковою інформацією і прикладами, зібраних разом в одному архіві. грають важливу роль, так як вони використовуються як додаткові розширення на базі R. Кожен пакет, як правило, присвячений конкретній темі, наприклад: пакет "ggplot2" використовується для побудови красивих векторних графіків певного дизайну, а пакет "qtl" ідеально підходить для генетичного картування . Таких пакетів в бібліотеці R налічується на даний момент більше 7000! Всі вони перевірені на предмет помилок і знаходяться у відкритому доступі.

R - це спільнота / рух.
Так як R - це безкоштовний продукт з відкритим кодом, то його розробкою, тестуванням і налагодженням займається не окрема компанія з найнятим персоналом, а самі користувачі. За два десятиліття з ядра розробників і ентузіастів сформувалося величезне співтовариство. За останніми даними, понад 2 млн осіб так чи інакше допомагали розвивати і просувати R на добровільній основі, починаючи від переказів документації, створення навчальних курсів і закінчуючи розробкою нових додатків для науки і промисловості. В інтернеті існує величезна кількість форумів, на яких можна знайти відповіді на більшість питань, пов'язаних з R.
Як виглядає середу R?
Існує багато "оболонок" для R, зовнішній вигляд і функціональність яких можуть сильно відрізнятися. Але ми коротко розглянемо лише три найбільш популярних варіанти: Rgui, Rstudio і R, запущений в терміналі Linux / UNIX у вигляді командного рядка.

Мова R в світі статистичних програм
На даний момент налічуються десятки якісних статистичних пакетів, серед яких явними лідерами є SPSS, SAS і MatLab. Однак, в 2013 році, незважаючи на високу конкуренцію, R став найбільш використовуваним програмним продуктом для статистичного аналізу в наукових публікаціях (http://r4stats.com/articles/popularity/). Крім того, в останнє десятиліття R стає все більш затребуваним і в бізнес-секторі: такі компанії-гіганти, як Google, Facebook, Ford і New York Times активно використовують його для збору, аналізу та візуалізації даних (http: //www.revolutionanalytics .com / companies-using-r). Для того щоб зрозуміти причини зростаючої популярності мови R, звернемо увагу на його загальні риси та відмінності від інших статистичних продуктів.
В цілому більшість статистичних інструментів можна розділити на три типи:
- програми з графічним інтерфейсом, Засновані на принципі "кликни тут, тут і отримай готовий результат";
- статистичні мови програмування, В роботі з якими необхідні базові навички програмування;
- "Змішаний", В яких є і графічний інтерфейс ( GUI), І можливість створення скриптових програм (наприклад: SAS, STATA, Rcmdr).

Особливості програм з GUI
Програми з графічним інтерфейсом мають звичний для звичайного користувача вид і легкі в освоєнні. Але для вирішення нетривіальних завдань вони не підходять, так як мають обмежений набір стат. методів і в них неможливо писати власні алгоритми. Змішаний тип поєднує в собі зручність GUI оболонки і міць мов програмування. Однак, при детальному порівнянні статистичних можливостей з мовами програмування SAS і STATA програють і R, і MatLab (порівняння статистичних методів R, MatLab, STATA, SAS, SPSS). До того ж за ліцензію для цих програм доведеться викласти пристойну суму грошей, а єдиним безкоштовної альтернативою є Rcmdr: оболонка для R з GUI (Rcommander).
Порівняння R з мовами програмування MatLab, Python і Julia
Серед мов програмування, використовуваних в статистичних розрахунках, лідируючі позиції займають R і Matlab. Вони схожі між собою, як за зовнішнім виглядом, так і по функціональності; але мають різні лобі користувачів, що і визначає їх специфіку. Історично MatLab був орієнтований на прикладні науки інженерних спеціальностей, тому його сильними сторонами є мат. моделювання та розрахунки, до того ж він набагато швидше R! Але так як R розроблявся як вузькопрофільний мову для статистичної обробки даних, то багато експериментальні стат. методи з'являлися і закріплювалися саме в ньому. Цей факт і нульова вартість зробили R ідеальним майданчиком для розробки та використання нових пакетів, що застосовуються в фундаментальних науках.
Іншими "конкуруючими" мовами є Python і Julia. На мою думку, Python, будучи універсальний мовою програмування, більше підходить для обробки даних і збору інформації із застосуванням веб-технологій, ніж для статистичного аналізу та візуалізації (основні відмінності R від Python добре описані). А ось статистичний мову Julia - досить молодий і претензійний проект. Основною особливістю цієї мови є швидкість обчислень, в деяких тестах перевищує R в 100 разів! Поки Julia знаходиться на ранній стадії розвитку і має мало додаткових пакетів і послідовників, але в віддалений перспективі Julia - це, мабуть, єдиний потенційний конкурент R.
висновок
Таким чином, в даний час мова R є одним з провідних статистичних інструментів в світі. Він активно застосовується в генетиці, молекулярній біології та біоінформатики, науках про навколишнє середовище (екологія, метеорологія) та сільськогосподарських дисциплінах. Також R все більше використовується в обробці медичних даних, витісняючи з ринку такі комерційні пакети, як SAS і SPSS.
Переваги середовища R:
- безкоштовна і кроссплатформенная;
- багатий арсенал стат. методів;
- якісна векторна графіка;
- більше 7000 перевірених пакетів;
- гнучка у використанні:
- дозволяє створювати / редагувати скрипти і пакети,
- взаємодіє з іншими мовами, такими: C, Java і Python,
- може працювати з форматами даних для SAS, SPSS та STATA; - активна спільнота користувачів та розробників;
- регулярні оновлення, хороша документація і тих. підтримка.
недоліки:
- невеликий обсяг інформації російською мовою (хоча за останні п'ять років з'явилося кілька навчальних курсів і цікавих книг);
- відносна складність у використанні для користувача, незнайомого з мовами програмування. Частково це можна згладити працюючи в GUI оболонці Rcmdr, про яку я писав вище, але для нестандартних рішень все ж слід скористатися командним рядком.
Список корисних джерел
- Офіційний сайт: http://www.r-project.org/
- Сайт для початківців: http://www.statmethods.net/
- Один з кращих довідників: The R Book, 2nd Edition by Michael J. Crawley, 2012
- Список доступної літератури російською + хороший блог
Programming on R. Level 1. Basics
Мова R - найпопулярніший в світі інструмент статистичного аналізу даних. Він містить найширший спектр можливостей для аналізу даних, їх візуалізації, а також створення документів і веб-додатків. Хочете освоїти цей потужний мову під керівництвом досвідченого наставника? Запрошуємо вас на курс «Програмування на мові R. Рівень 1. Базові знання».
Цей курс призначений для широкого кола фахівців, яким необхідно шукати закономірності у великій кількості даних, візуалізувати їх і будувати статистично коректні висновки: соціологів, менеджерів клінічних випробувань / фармакологів, дослідників (астрономія, фізика, біологія, генетика, медицина і т.д.) , IT-аналітиків, бізнес-аналітиків, фінансових аналітиків, маркетологів. Курс також сподобається фахівцям, яким не підходить функціонал (або платність) /.
На заняттях ви отримаєте основні навички аналізу та візуалізації даних в середовищі R. Велика частина часу відводиться практичним завданням і роботі з реальними наборами даних. Ви вивчіть всі нові інструменти роботи з даними і навчитеся їх застосовувати в своїй роботі.
Після курсу видається посвідчення про підвищення кваліфікації центру.
 Чи можна використовувати Google Play Market на Lumia?
Чи можна використовувати Google Play Market на Lumia? Опис і секрети чинного тарифу нуль сумнівів на Білайні
Опис і секрети чинного тарифу нуль сумнівів на Білайні Опція МТС «Скрізь як удома Росія
Опція МТС «Скрізь як удома Росія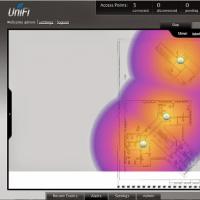 Безшовний Wi-Fi Корисні відгуки про роботу capsman
Безшовний Wi-Fi Корисні відгуки про роботу capsman Як говорити з Алісою Скріншоти Яндекс з Алісою
Як говорити з Алісою Скріншоти Яндекс з Алісою Програма мтс бонус закривається
Програма мтс бонус закривається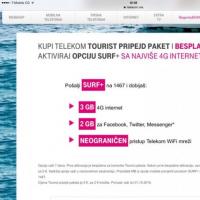 Мобільний зв'язок і інтернет на курортах Чорногорії
Мобільний зв'язок і інтернет на курортах Чорногорії