V teórii relačných databáz sa tabuľka nazýva tzv. Teória relačnej databázy: normalizácia, vzťahy a spojenia. Kľúče vo vzťahu
Relačná algebra je založená na teórii množín a je základom logiky databázy.
Keď som ešte len študoval štruktúru databáz a SQL, predbežné oboznámenie sa s relatívnou algebrou veľmi pomohlo mojim ďalším vedomostiam dostať to do poriadku v hlave a pokúsim sa, aby tento článok mal podobný efekt.
Takže ak sa chystáte začať študovať v tejto oblasti alebo vás len zaujali, prosím, pod kat.
Relačná databáza
Na začiatok si predstavíme koncept relačnej databázy, v ktorej budeme vykonávať všetky akcie.
Relačná databáza je množina vzťahov, ktoré obsahujú všetky informácie, ktoré musia byť v databáze uložené. V tejto definícii nás zaujíma pojem vzťah, no nateraz ho necháme bez striktnej definície.
Poďme si lepšie predstaviť tabuľku produktov.
Tabuľka PRODUKTY
| ID | NÁZOV | SPOLOČNOSŤ | CENA |
| 123 | Cookies | LLC "The Dark Side" | 190 |
| 156 | Čaj | LLC "The Dark Side" | 60 |
| 235 | Ananás | JSC "Ovocie" | 100 |
| 623 | Paradajky | LLC "Zelenina" | 130 |
Tabuľka pozostáva zo 4 riadkov, riadok v tabuľke je v relačnej teórii n-tica. Súbor usporiadaných n-tic sa nazýva vzťah.
Pred definovaním vzťahu si predstavme ešte jeden pojem – doménu. Domény vo vzťahu k tabuľke sú stĺpce.
Pre prehľadnosť teraz zavedieme striktnú definíciu vzťahu.
Nech je daných N množín D1, D2,…. Dn (domény), vzťah R nad týmito množinami je množinou usporiadaných N-tic tvaru
Každý prvok n-tice predstavuje hodnotu jedného z atribútov zodpovedajúcich jednej z domén.
Kľúče vo vzťahu
Čo sa týka požiadavky, všetky n-tice musia byť odlišné. Primárny kľúč existuje na jedinečnú identifikáciu n-tice. Primárny kľúč je atribút alebo súbor minimálneho počtu atribútov, ktorý jednoznačne identifikuje konkrétnu n-tku a neobsahuje ďalšie atribúty.Z toho vyplýva, že všetky atribúty v primárnom kľúči musia byť potrebné a postačujúce na identifikáciu konkrétnej n-tice a vylúčenie ktoréhokoľvek z atribútov v kľúči by to znamenalo, že nebude stačiť na identifikáciu.
Napríklad v takejto tabuľke bude kľúčom kombinácia atribútov z prvého a druhého stĺpca.
Tabuľka VODIČOV
Je zrejmé, že organizácia môže mať niekoľko vodičov a na jedinečnú identifikáciu vodiča je potrebná hodnota zo stĺpca „Názov organizácie“ aj zo stĺpca „Meno vodiča“. Takýto kľúč sa nazýva zložený kľúč.
V relačnej databáze sú tabuľky prepojené a súvisia navzájom ako nadriadené a podriadené. Vzťah medzi hlavnou a podriadenou tabuľkou sa uskutočňuje prostredníctvom primárneho kľúča hlavnej tabuľky a cudzieho kľúča podriadenej tabuľky.
Cudzí kľúč je atribút alebo súbor atribútov, ktorý je primárnym kľúčom v hlavnej tabuľke.
Táto prípravná teória vám postačí na oboznámenie sa so základnými operáciami relačnej algebry.
Operácie relačnej algebry
Osem hlavných operácií relačnej algebry navrhol E. Codd.- Združenie
- Prechod
- Odčítanie
- karteziánsky súčin
- Ukážka
- Projekcia
- Zlúčenina
- divízie
Pre pochopenie je dôležité mať na pamäti, že výsledkom akejkoľvek operácie algebry nad vzťahmi je ďalší vzťah, ktorý je potom možné použiť aj v iných operáciách.
Vytvorme si ďalšiu tabuľku, ktorá sa nám bude hodiť v príkladoch.
Tabuľka PREDAJCOV
| ID | PREDAJCA |
| 123 | oOO "šípka" |
| 156 | OJSC "Bucket" |
| 235 | JSC "Vegetable Baza" |
| 623 | JSC "Firma" |
Dohodnime sa, že v tejto tabuľke je ID cudzí kľúč spojený s primárnym kľúčom tabuľky PRODUKTY.
Začnime tým, že sa pozrieme na najjednoduchšiu operáciu – názov vzťahu. Jeho výsledkom bude rovnaký vzťah, teda vykonaním operácie PRODUKTY získame kópiu vzťahu PRODUKT.
Projekcia
Projekcia je operácia, pri ktorej sa atribúty zo vzťahu vyberú len zo zadaných domén, to znamená, že sa z tabuľky vyberú len požadované stĺpce, a ak sa získa niekoľko rovnakých n-tic, zostane v poli iba jedna inštancia takejto n-tice. výsledný vzťah.Urobme napríklad projekciu na tabuľku PRODUKTY tak, že z nej vyberieme ID a CENU.
Syntax operácie:
π (ID, CENA) PRODUKTY
Vo výberovej podmienke môžeme použiť ľubovoľný logický výraz. Urobme ďalšiu vzorku s cenou vyššou ako 90 a ID produktu menším ako 300:
σ (CENA> 90 ^ ID<300) PRODUCTS
Násobenie
Násobenie alebo karteziánsky súčin je operácia vykonaná na dvoch vzťahoch, v dôsledku čoho z dvoch počiatočných vzťahov získame vzťah so všetkými doménami. N-tice v týchto doménach budú predstavovať všetky možné kombinácie n-tic z počiatočného vzťahu. Príklad to objasní.Zoberme si karteziánske produkty tabuliek PRODUKTY a PREDAJCOVIA.
Syntax operácie:
PRODUKTY × PREDAJCOVIA
Všimnete si, že tieto dve tabuľky majú rovnaké ID domény. V tejto situácii majú domény s rovnakým názvom predponu s názvom zodpovedajúceho vzťahu, ako je uvedené nižšie.
Pre stručnosť nenásobíme úplné vzťahy, ale vzorky s ID podmienky<235
(rovnaké n-tice sú farebne zvýraznené)
| PRODUCTS.ID | NÁZOV | SPOLOČNOSŤ | CENA | SELLERS.ID | PREDAJCA |
| 123 | Cookies | LLC "The Dark Side" | 190 | 123 | oOO "šípka" |
| 156 | Čaj | LLC "The Dark Side" | 60 | 156 | OJSC "Bucket" |
| 123 | Cookies | LLC "The Dark Side" | 190 | 156 | OJSC "Bucket" |
| 156 | Čaj | LLC "The Dark Side" | 60 | 123 | oOO "šípka" |
Pre príklad použitia tejto operácie si predstavme potrebu výberu predajcov s cenami nižšími ako 90. Bez produktu by bolo potrebné najskôr získať ID produktov z prvej tabuľky, potom použiť tieto ID z druhej tabuľky. získať potrebné mená PREDAJCOV a pri použití produktu sa zobrazí nasledujúci dotaz:
π (SELLER) σ (RODUCTS.ID = SELLERS.ID ^ CENA<90) PRODUCTS × SELLERS
V dôsledku tejto operácie dostaneme vzťah:
| PREDAJCA |
| OJSC "Bucket" |
Lepenie a prirodzené spojenie
Operácia spojenia je opakom operácie projekcie a vytvára nový vzťah z dvoch existujúcich. Nový vzťah sa získa zreťazením n-tic prvého a druhého vzťahu a zreťazením vzťahov, v ktorých sa hodnoty daných atribútov zhodujú. Najmä ak vstúpite do vzťahov PRODUKTY a PREDAJCOVIA, tieto atribúty sú atribútmi ID domén.Taktiež si pre názornosť môžete prepojenie predstaviť ako výsledok dvoch operácií. Najprv sa vezme súčin pôvodných tabuliek a následne z výsledného vzťahu urobíme výber s podmienkou rovnosti atribútov z rovnakých domén. V tomto prípade je podmienkou rovnosť PRODUCTS.ID a SELLERS.ID.
Skúsme prepojiť vzťahy PRODUKTY a PREDAJCOVIA a získajme vzťah.
| PRODUCTS.ID | NÁZOV | SPOLOČNOSŤ | CENA | SELLERS.ID | PREDAJCA |
| 123 | Cookies | LLC "The Dark Side" | 190 | 123 | oOO "šípka" |
| 156 | Čaj | LLC "The Dark Side" | 60 | 156 | OJSC "Bucket" |
| 235 | Ananás | JSC "Ovocie" | 100 | 235 | JSC "Vegetable Baza" |
| 623 | Paradajky | LLC "Zelenina" | 130 | 623 | JSC "Firma" |
Prirodzené spojenie dostane podobný vzťah, ale ak máme v databáze správne nakonfigurovanú schému (v tomto prípade je primárny kľúč tabuľky PRODUCTS ID prepojený s cudzím kľúčom tabuľky SELLERS ID), potom výsledný vzťah opustí jedno ID domény.
Syntax operácie:
PRODUKTY ⋈ PREDAJCOVIA;
Získate tento postoj:
| PRODUCTS.ID | NÁZOV | SPOLOČNOSŤ | CENA | PREDAJCA |
| 123 | Cookies | LLC "The Dark Side" | 190 | oOO "šípka" |
| 156 | Čaj | LLC "The Dark Side" | 60 | OJSC "Bucket" |
| 235 | Ananás | JSC "Ovocie" | 100 | JSC "Vegetable Baza" |
| 623 | Paradajky | LLC "Zelenina" | 130 | JSC "Firma" |
Priesečník a odčítanie.
Výsledkom operácie prieniku bude vzťah pozostávajúci z n-tic, ktoré sú úplne zahrnuté v oboch vzťahoch.Výsledkom odčítania je relácia pozostávajúca z n-tic, ktoré sú n-ticami prvého vzťahu a nie sú n-ticami druhého vzťahu.
Tieto operácie sú podobné tým istým operáciám na množinách, preto si myslím, že ich netreba podrobne popisovať.
Zdroje informácií
- Základy používania a navrhovania databáz - V. M. Iľjušečkin
- kurz prednášok Úvod do databáz - Jennifer Widom, Stanford University
Budem vďačný za dobre zdôvodnené komentáre.
Databáza (DB) je organizovaný súbor údajov. Usporiadanie údajov má zvyčajne odrážať skutočný vzťah medzi uloženými údajmi takým spôsobom, aby sa uľahčilo spracovanie týchto informácií.
DBMS - databázové systémy sú špecializovaný softvér určený podľa očakávania na správu databáz. To sa dosiahne interakciou s používateľom na jednej strane a so samotnou databázou na strane druhej.
Univerzálny DBMS by mal byť schopný definovať, vytvárať, upravovať, spravovať a dotazovať sa na databázu.
Príklady DBMS zahŕňajú také dobre známe balíky ako
- MySQL
- PostgreSQL
- Microsoft SQL Server
- Oracle
- IBM DB2
- Microsoft Access
- SQLite
Databázy zvyčajne nie sú prenosné medzi rôznymi DBMS, ale interoperabilita medzi DBMS (a s vlastným softvérom) je možná pomocou rôznych štandardov, ako sú SQL, ODBC alebo JDBC.
DBMS sú často klasifikované podľa dátového modelu, ktorý podporujú. Od 80. rokov 20. storočia prakticky všetky populárne DBMS podporujú relačný dátový model reprezentovaný štandardom dotazovacieho jazyka SQL (hoci NoSQL si v posledných rokoch získava na popularite).
Medzi hlavné úlohy, ktoré vykonáva DBMS, teda patria
Definovanie dátovej schémy Vytváranie, úprava a mazanie štruktúr, ktoré určujú organizáciu všetkých ostatných dát v databáze Úprava dát Pridávanie, úprava a mazanie samotných dát Získavanie dát Poskytovanie informácií vo forme vhodnej na priame použitie inými aplikáciami. Správa databázy Registrácia a správa používateľov, bezpečnosť údajov, údržba integrity, obnova informácií, kontrola súbežného prístupu, monitorovanie výkonu atď.
DBMS sú široko používané v bankovníctve, dopravných spoločnostiach, vzdelávacích inštitúciách, telekomunikáciách, na správu finančných informácií a ľudských zdrojov. Majte tiež na pamäti, že väčšina webových backendov používa nejakú formu systému správy databáz.
Jednou z hlavných čŕt vývoja databáz je skutočnosť, že neexistujú žiadne hotové riešenia a algoritmy. Každá databáza je špecifická pre úlohu, na ktorú je navrhnutá. To odlišuje vývoj databázy od vývoja typických aplikácií, pre ktoré sa algoritmy a návrhové vzory vyvíjajú už dlho a nemusíte vymýšľať nič špeciálne. Aj keď, samozrejme, techniky návrhu databázy sú spoločné pre všetky aplikácie.
DB modely
Ako už bolo uvedené, najpoužívanejším dátovým modelom je relačný model. Vzniku relačného modelu však predchádzali najmä iné
- Hierarchický alebo navigačný model
- Sieťový model
Hierarchický model bol široko používaný v DBMS dodaných IBM v 60. rokoch. Hlavnou myšlienkou je, že záznam v takejto databáze môže mať niekoľko „detí“ a jedného „rodiča“. Celkovo to vyzerá podozrivo ako hierarchický súborový systém. Na získanie záznamu v takejto databáze je často potrebné prejsť celý strom.
Sieťový model je flexibilnejšou verziou rovnakého prístupu. Umožňuje vám mať viacero „rodičovských“ záznamov. Tento model, ktorý sa objavil na začiatku sedemdesiatych rokov, sa nerozšíril a čoskoro bol nahradený relačným modelom.
V 70. rokoch Edgar Codd (zamestnanec IBM) navrhol relačný model, ktorý výrazne uľahčil úlohu hľadania informácií v databáze. Relačný model si možno predstaviť ako „tabuľky“, v ktorých „riadky“ sú záznamy v databáze. Záznamy v relačnej databáze sa tiež nazývajú n-tice a skupiny záznamov („tabuľky“) sa nazývajú vzťahy. Relačný model je schopný vyjadrovať vzťahy medzi hierarchickým a sieťovým modelom a má pridané vlastné vzťahy zodpovedajúce tabuľkovému modelu.
Na základe návrhov Codda bol System R vyvinutý v polovici 70. rokov a ku koncu mal podporu pre štandardizovaný dopytovací jazyk SQL.
V osemdesiatych rokoch, s príchodom objektovo orientovaného programovania, bolo čoraz ťažšie prekladať objekty do relačného modelu. Nakoniec to viedlo k vzniku prístupov NoSQL a NewSQL, ktoré sa v súčasnosti iba vyvíjajú. Príkladmi implementácie NoSQL prístupu môžu byť tzv. dokumentovo orientované databázy postavené na báze XML. Hlavnou výhodou NoSQL je vysoká horizontálna škálovateľnosť, t.j. schopnosť zvýšiť výkon pridaním serverov. S príchodom cloudových technológií sa NoSQL stalo obzvlášť žiadaným.
Napriek tomu je stále najrozšírenejší relačný model, preto sa mu budeme venovať podrobnejšie.
Relačný model
Relačný model funguje v zmysle záznamov, atribútov a vzťahov. Vzťah si možno predstaviť ako dvojrozmernú tabuľku, potom atribúty sú stĺpce tabuľky (presnejšie názvy stĺpcov) a záznamy sú riadky tabuľky.
Relačný model vyžaduje presné definovanie štruktúry údajov uložených v databáze, to znamená, že vzťahy a atribúty pre danú databázu sú pevné.
Uveďme niekoľko definícií.
Doména Množina obsahujúca kompletnú množinu všetkých možných hodnôt pre niektorú premennú. Domény sa často označujú ako Dátový typ... Atribút objednaného páru názvy atribútov a doména \ (D_j \). Tuple Konečná usporiadaná množina \ ((d_1, d_2, \ ldots, d_n) \) Názov (schéma) vzťahu Tuple \ ((A_1, A_2, \ ldots, A_n) \), kde \ (A_j \) sú atribúty. Hodnota atribútu Špecifická hodnota, ktorá patrí do domény atribútu. Telo vzťahu Množina n-tic, kde \ (d ^ i_j \ v D_j \), \ (D_j \) sú domény. Record Tuple \ ((d ^ i_1, d ^ i_2, \ ldots, d ^ i_n) \) s pevným \ (i \). Vzťah Súbor hlavičky vzťahu a tela vzťahu. Databázová schéma Množina schém všetkých relácií zahrnutých v databáze.
Vzťah môžete znázorniť vo forme tabuľky. Potom telom vzťahu je telo tabuľky, hlavička vzťahu je hlavička tabuľky, atribúty sú názvy stĺpcov, záznamy sú riadky a hodnoty atribútov sú v bunkách. :
| \ (A_1 \) | \ (A_2 \) | \ (\ ldots \) | \ (A_n \) | ← Názov |
|---|---|---|---|---|
| \ (d ^ 1_1 \) | \ (d ^ 1_2 \) | \ (\ ldots \) | \ (d ^ 1_n \) | ← Nahrávanie |
| \ (d ^ 2_1 \) | \ (d ^ 2_2 \) | \ (\ ldots \) | \ (d ^ 2_n \) | ← Nahrávanie |
| \ (\ ldots \) | \ (\ ldots \) | \ (\ ldots \) | \ (\ ldots \) | ← Nahrávanie |
| \ (d ^ m_1 \) | \ (d ^ m_2 \) | \ (\ ldots \) | \ (d ^ m_n \) | ← Nahrávanie |
Relačný model kladie na vzťahy tieto dodatočné požiadavky:
Je jasné, že atribúty (presnejšie ich hodnoty) na sebe akosi závisia – inak sa vzťah ukáže len ako neštruktúrovaný súbor údajov. Na definovanie závislostí medzi atribútmi sa používa koncept funkčná závislosť.
Funkčná závislosť množiny atribútov \ (B \) funkčne závisí od množiny atribútov \ (A \) (písané \ (A \ šípka vpravo B \)), ak pre ľubovoľné dva záznamy majú rovnaké hodnoty \ ( A \), ich hodnoty \ ( B \) sa zhodujú. V opačnom prípade každá hodnota \ (A \) zodpovedá jednej hodnote \ (B \) (nie nevyhnutne jedinečná, je jediná).
Inými slovami, ak nejaká množina atribútov \ (A \) jednoznačne určuje (v rámci tohto vzťahu) hodnoty atribútov \ (B \), potom \ (B \) funkčne závisí od \ (A \ ).
Ako bežnejší príklad funkčnej závislosti môžeme uviesť matematickú definíciu funkcie. Pre funkciu má každá hodnota argumentu jednu funkčnú hodnotu. Opak vo všeobecnosti neplatí, napríklad pre funkciu \ (y = sin (x) \) akákoľvek hodnota \ (y \) z domény \ (1 \ geq y \ geq -1 \) zodpovedá nekonečnej množine hodnôt \ (x \ ), ale pre každú hodnotu \ (x \) existuje práve jedna hodnota \ (y \), takže \ (x \ až y \). Všimnite si, že koncept funkčnej závislosti je použiteľný aj pre funkcie mnohých premenných. Pre nich hodnota funkcie funkčne závisí od všetky argumenty súčasne... Napríklad pre funkciu \ (z = f (x, y) \) je splnené FZ \ ((x, y) \ až z \), alebo v skratke \ (xy \ až z \).
Vzťahy v tomto kontexte možno považovať za nejaký druh tabuľkový alebo diskrétne funkcie.
Práca s federálnym zákonom
Pre prácu so vzťahmi FZ platia určité formálne pravidlá.
Formálne pravidlá úzko súvisia s pojmami uzávery a neredukovateľný FZ.
Armstrongove axiómy
Existujú pravidlá pre odobratie nových FZ z existujúcich, tzv podľa Armstrongových axióm.
Armstrongove axiómy
- Pravidlo reflexivity: ak \ (B \ podmnožina A \), potom \ (A \ šípka doprava B \)
- Doplňte pravidlo: ak \ (A \ šípka doprava B \), potom \ (AC \ šípka doprava BC \)
- Pravidlo prechodnosti: ak \ (A \ šípka doprava B \) a \ (B \ šípka doprava C \), potom \ (A \ šípka doprava C \)
Z týchto axióm možno odvodiť aj nasledujúce dodatočné pravidlá:
- Pravidlo sebaurčenia: \ (A \ šípka doprava A \)
- Pravidlo rozkladu: Ak \ (A \ šípka doprava BC \), potom \ (A \ šípka doprava B \) a \ (A \ šípka doprava C \)
- Pravidlo únie: Ak \ (A \ šípka doprava B \) a \ (A \ šípka doprava C \), potom \ (A \ šípka doprava BC \)
- Pravidlo zloženia: Ak \ (A \ šípka doprava B \) a \ (C \ šípka doprava D \), potom \ (AC \ šípka doprava BD \)
Je možné poznamenať, že vďaka pravidlu reflexivity každá množina atribútov \ (A \) implikuje FD v tvare \ (A \ až A \). Takéto FZ, ako aj nasledujúce, nie sú zaujímavé a nazývajú sa triviálnymi.
Triviálna funkčná závislosť ФЗ \ (A \ až B \), taká, že \ (B \ podmnožina A \).
V zásade tieto pravidlá postačujú na nájdenie všetkých FD, ktoré vyplývajú z údajov. V tejto súvislosti sa zavádza pojem výluka súpravy FZ.
Uzavretie množiny FD Uzavretie množiny FD je množina FD, ktorá zahŕňa všetky FD pôvodnej sady, ako aj všetky tie, ktoré z nich vyplývajú. Inými slovami, pre vzťah \ (R \) s funkčnými závislosťami \ (S \), uzáver \ (S ^ + \) je množina všetkých FZ možných pre \ (R \), počnúc od \ (S \ ).
Spravidla je potrebné určiť, či určitá ФЗ \ (X \ šípka vpravo Y \) bude vyplývať z danej množiny ФЗ \ (S \). Ukazuje sa, že je to možné vtedy a len vtedy, ak množina atribútov \ (Y \) je podmnožinou uzavretia atribútov \ (X ^ + \) v \ (S \).
Uzavretie atribútov Uzavretie atribútov \ (X ^ + \) \ (X \) množinou ФЗ \ (S \) je množina všetkých atribútov, ktoré funkčne závisia od nejakej podmnožiny \ (X \).
Na výpočet uzavretia množiny atribútov \ (X ^ + \) množinou ФЗ \ (S \) platí nasledujúce pravidlo: pre každú ФЗ \ (A \ šípka vpravo B \) v \ (S \), if \ (A \ podmnožina X ^ + \), potom \ (B \ podmnožina X ^ + \), a stačí začať s predpokladom, že \ (X ^ + = X \).
Treba poznamenať, že pre každý uzáver \ (X ^ + \) existujú FD v tvare \ (X \ až B \), kde \ (B \ podmnožina X ^ + \), teda uzávery všetkých atribútov vzťahu podľa jeho FZ popísať uzatvorenie FZ tohto vzťahu.
Toto pravidlo sa používa na výpočet neredukovateľného súboru FD ekvivalentných danému (v zmysle ekvivalencie ich uzáverov). Zníženie počtu FD pri zachovaní uzavretia (a tým aj internej logiky opísanej FD) je dôležitým krokom pri návrhu databázy.
Súbor FZ sa nazýva neredukovateľný, ak:
- Pravá strana každého FZ obsahuje iba jeden prvok
- Žiadny z atribútov žiadnej ľavej strany súpravy FZ nie je možné odstrániť bez zmeny uzáveru
- Bez výmeny uzáveru nie je možné odstrániť žiadne FZ súpravy.
Pre každú množinu FZ existuje aspoň jedna ekvivalentná neredukovateľná množina. Takáto zostava je tzv minimálne pokrytie.
Anotácia: Táto a ďalšie dve prednášky sú venované teórii relačných databáz. Keďže celý smer relačného prístupu k organizovaniu databáz je čisto praktický, táto teória je hlavne pragmatická. Hlavným problémom, ktorý sa teória relačných databáz snaží vyriešiť, je objavenie užitočných vlastností niektorých databázových schém a navrhnutie spôsobov, ako takéto schémy skonštruovať. Je zvykom tento problém stručne nazvať problémom návrhu relačnej databázy.
Úvod
Napriek svojmu praktickému zameraniu teória relačných databáz je samostatná vedecká oblasť, v ktorej pôsobilo (a pôsobí) mnoho známych výskumníkov, ktorých mená nájdete v našich prednáškach. Nemali sme v pláne v tomto kurze podrobne popísať hlavné výsledky v teréne. Naším cieľom je poskytnúť iba definície a vyhlásenia potrebné na všeobecné pochopenie procesu návrh relačnej databázy na základe normalizácie.
Keďže najdôležitejšie vlastnosti relačných databáz z praktického hľadiska vychádzajú z konceptu funkčná závislosť, vyčlenili sme krátku diskusiu o relevantných teoretických otázkach v samostatnej prednáške. Spomedzi týchto otázok sú najzaujímavejšie uzávery a pokrytie množín funkčných závislostí, Armstrongove axiómy a Heathova veta o postačujúcej podmienke bezstratový rozklad vzťahu... Koncepty a tvrdenia tejto prednášky sú skutočne potrebné na to, aby sme si osvojili materiál z prednášky 7, ale pokúsili sme sa čitateľom na jednoduchých príkladoch ukázať, čo teória relačných databáz, aká je úroveň jeho zložitosti a nakoľko je intuitívny.
Upozorňujeme, že sme nevyčlenili teoretický materiál týkajúci sa viachodnotové závislosti a závislosti pripojenia... Stalo sa tak z dvoch dôvodov. Po prvé, tieto typy závislostí sú v modelovaní menej bežné predmetná oblasť prostredníctvom databáz. Preto sme považovali za dostatočné prezentovať v rámci prednášky 8 len základy zodpovedajúceho teoretického materiálu. Po druhé, hoci teória viachodnotové závislosti a závislosti pripojenia v skutočnosti nie je oveľa zložitejšia ako teória funkčné závislosti, jeho definície a vyhlásenia sú pre tento kurz príliš ťažkopádne.
Funkčné závislosti
Najdôležitejšie z praktického hľadiska normálne vzťahy sú založené na základných teória relačných databáz predstavy funkčná závislosť... Pre ďalšiu prezentáciu potrebujeme niekoľko definícií a tvrdení (v priebehu prezentácie ich vysvetlíme a znázorníme).
Všeobecné definície
Nech je to dané vzťahová premenná r a X a Y sú ľubovoľné podmnožiny hlavičky r ("zložené" atribúty).
Vo význame variabilný pomer r atribút Y funkčne závisí od atribútu X vtedy a len vtedy, ak každá hodnota X zodpovedá práve jednej hodnote Y. V tomto prípade sa tiež hovorí, že atribút X funkčne definuje atribút Y (X je determinant ( determinant) pre Y a Y je závislé od X). Označíme ho ako r.X-> r.Y.
Napríklad použijeme vzťah EMPLOYEE_PROJECTS (SLU_NOM, SLU_NAME, SLU_ZARP, PRO_NOM, PROJECT_HANDS)(obr. 6.1). Samozrejme, ak je SLU_NOM primárny kľúč vzťahu ZAMESTNANCI, potom je tento vzťah spravodlivý funkčná závislosť (FD) SLU_NOM-> SLU_NAME.
Vlastne pre telo vzťahu EMPLOYEE_PROJECTS v podobe, v akej je znázornená na obr. 6.1 sú splnené aj tieto rámcové rozhodnutia (1):
Ryža. 6.1.
SLU_NOM-> SLU_NAME SLU_NOM-> SLU_ZARP SLU_NOM-> ABOUT_SLU_NOM-> PROJECT_HANDS (SLU_NOM, SLU_NAME) -> SLU_ZARP (SLU_NOOL, SLU_NAME) -> ABOUT_YE_SUFF_SUFF_SUFFY
Keďže mená všetkých zamestnancov sú odlišné, vykonajú sa aj nasledujúce FD (2):
SLU_NAME-> SLU_NOMY_NAME-> SLU_ZARP SLU_NAME-> PRO_NOM atď.
Navyše, napríklad na obr. 6.1 drží a FD (3):
SLU_ZARP-> PRO_NOM
Všimnite si však, že povaha FD skupiny (1) sa líši od povahy FD skupín (2) a (3). Je logické predpokladať, že identifikačné čísla zamestnancov by mali byť vždy iné a každý projekt má len jedného manažéra. Preto FD skupiny (1) musia byť pravdivé pre akúkoľvek platnú hodnotu variabilný pomer EMPLOYEE_PROJECTS a môže byť videný ako invarianty, alebo integritné obmedzenia toto variabilný pomer.
Skupiny FD (2) vychádzajú z menej prirodzeného predpokladu, že mená všetkých zamestnancov sú odlišné. To platí pre príklad na obr. 6.1, ale je možné, že časom skupiny FD (2) nebudú splnené pre žiadnu hodnotu variabilný pomer EMPLOYEE_PROJECTS.
Napokon, FD skupiny (3) je založené na úplne neprirodzenom predpoklade, že žiadni dvaja zamestnanci zúčastňujúci sa na rôznych projektoch nedostávajú rovnakú mzdu. Tento predpoklad opäť platí pre príklad na obr. 6.1, ale to je s najväčšou pravdepodobnosťou náhoda.
V budúcnosti nás budú zaujímať len tie funkčné závislosti vykonať pre všetky možné hodnoty vzťahové premenné.
Všimnite si, že ak atribút A vzťahu r je možný kľúč, potom pre ktorýkoľvek atribút B tohto vzťahu vždy platí
Životný cyklus informačných systémov
Analýza situácie (zložitosť vývoja IS, neefektívne využívanie IS), ktorú vykonali vedci, ukázala, že tento stav bol spôsobený tým, že pri vývoji softvéru neboli dodržané veľmi dôležité požiadavky. :
· Chýbajúca úplná špecifikácia všetkých požiadaviek;
· nedostatok akceptovateľnej metodiky (systému metód) rozvoja IS;
· Absencia rozdelenia všeobecného globálneho projektu na samostatné komponenty, ktoré je možné efektívne monitorovať a riadiť.
Životný cyklus (LC) informačných systémov je štruktúrovaný prístup k vývoju softvéru.
(nejaká schéma) na 26. 9. 2012
1. Plánovanie rozvoja IS. Prípravné akcie, ktoré umožňujú realizovať etapy životného cyklu IS s maximálnou efektivitou. Tri hlavné zložky: odhad rozsahu práce; posúdenie požadovaných zdrojov; odhadnúť celkové náklady na projekt.
2. Stanovenie systémových požiadaviek. Určenie rozsahu a hraníc databázovej aplikácie, funkcií, jej používateľov a rozsahov.
3. Zhromažďovanie a analýza požiadaviek používateľov. Zhromažďovanie a analýza informácií o tej časti organizácie, ktorej práca bude podporovaná pomocou vytvoreného IS, stanovenie užívateľských požiadaviek na systém. Zdroje: prieskum a dotazník; pozorovanie; štúdium dokumentov; predošlé skúsenosti.
4. Návrh databázy. Vytvorenie databázového projektu. Existujú dva hlavné prístupy k navrhovaniu databázových systémov: „ zostupne" a " vzostupne».
5. Výber cieľového DBMS. Výber správneho typu DBMS na podporu databázovej aplikácie, ktorú vytvárate.
6. Vývoj aplikácií. Návrh používateľského rozhrania a aplikácií pre prácu s databázou.
7. Vytvorenie prototypu. Vytvorte pracovný model pre svoju databázovú aplikáciu.
8. Implementácia. Fyzická implementácia databázy a vyvinutých aplikácií.
9. Konverzia a načítanie údajov. Prenos existujúcich údajov do novej databázy, načítanie a úprava existujúcich aplikácií za účelom organizácie spoločnej práce s novou databázou.
10. Testovanie. Proces spúšťania aplikačných programov s cieľom nájsť chyby. Stratégie testovania: testovanie zhora nadol; testovanie zdola nahor; testovacie prúdy; intenzívne testovanie.
11. Prevádzka a údržba. Monitorovanie systému a podpora jeho normálneho fungovania: kontrola výkonu; údržbu a modernizáciu aplikácií.
Teória relačnej databázy
Terminológia
V roku 1970 relačný model prvýkrát navrhol E.F. Coddom.
V relačnej DBMS sa predpokladá, že používateľ vníma databázu ako súbor tabuliek (a nie inak).
Matematické vzťahy.
Teória relačných databáz vychádza z matematickej teórie vzťahov.
Nech D1, D2,... Dn sú nejaké množiny.
Kartézsky súčin D1 D2… Dn = ((X1, X2,…, Xn) | X1 D1, X2 D2,… Xn Dn)
Pomer je podmnožinou R D1 * D2 *… * Dn
Napríklad n = 2, D1 = (2,4) a D2 = (1,3,5), D1 * D2 = ((2,1), (2,3), (2,5), (4 , 1), (4,3), (4,5)), R = ((2,1), (4,1))
Podskupina m. B. daný podmienkou, napr.
R = ((x1, x2) | x1 D1, x2 D2, X2 = 1), A1, A2,… An sú názvy atribútov s doménami D1, D2,… Wb, potom sa vzťah zapíše ako:
R (A1: D1, A2: D2,... An: Dn)
Vlastnosti vzťahu:
· Vzťah má jedinečný názov;
· Každý atribút má jedinečný názov (vo vzťahu k);
· Každá bunka vzťahu obsahuje iba atómovú hodnotu a neexistujú žiadne opakujúce sa skupiny (vzťah je normalizovaný);
D1 - študenti
D2 - disciplíny: Matematika, Informatika
· Na poradí atribútov nezáleží;
· Poradie n-tic je ľubovoľné;
· Každá n-tica je jedinečná.
Relačné kľúče
Relačné kľúče sa používajú na jedinečnú identifikáciu n-tice popisujúcej vzťahy medzi vzťahmi.
Vzťahová integrita.
Relačná algebra
Výsledok operácie možno použiť ako operand pre inú operáciu, čo umožňuje vytvárať vnorené výrazy (PA uzáver).
Relačná algebra je jazyk, v ktorom sú všetky n-tice spracované jedinou inštrukciou.
Päť základných operácií:
Vzorkovanie,
projekcia,
karteziánsky súčin,
· združenie,
· Rozdiel.
Na základe týchto operácií je možné získať ďalšie:
spojenia,
križovatky,
· Divízie.
V predikáte možno použiť symboly logických operácií ^ (And), v (Alebo), ~ (nie).
Príklad. Získajte zoznam všetkých zamestnancov s platom nad 300.
Projekcia.
Definuje vzťah, ktorého atribúty sú attr1, ..., attrn a obsahuje iba jedinečné n-tice.
karteziánsky súčin
Kartézsky súčin sa používa zriedka, selekcia sa aplikuje na výsledok.
Združenie
Rozdiel
Operácie pripojenia.
Theta spojenie
Prirodzené spojenie
Externé pripojenie
Potom sa pri ľavom vonkajšom spojení zachovajú všetky pôvodné informácie zo vzťahu R. Podobne môžete definovať aj pravé vonkajšie spojenie.
Polovičné spojenie
Operáciu polovičného spojenia je možné definovať pomocou operátorov projekcie a spojenia.
Prechod
zastupovanie
Účel zobrazenia:
· Poskytuje flexibilný mechanizmus na ochranu databázy skrytím niektorých jej častí pred určitými používateľmi;
· Umožňuje organizovať prístup používateľov k údajom pre nich najvhodnejším spôsobom;
· Umožňuje zjednodušiť zložité operácie so základnými vzťahmi.
Pravidlá, ktoré treba splniť
relačný DBMS
Na určenie, či je SUBO relačné, Codd (1985) navrhol 13 pravidiel, ktoré musia spĺňať.
| № | Pravidlo | |
| Základné pravidlo. Relačný DBMS musí byť schopný spravovať databázy výlučne pomocou svojich relačných funkcií. | ||
| Prezentácia informácií. Všetky informácie v relačnej databáze sú explicitne reprezentované na logickej úrovni iba jedným spôsobom - vo forme hodnôt v tabuľkách. Vrátane metadát. | ||
| Garantovaný prístup. Pre každú údajovú položku v relačnej databáze musí byť zaručený logický prístup na základe kombinácie názvu tabuľky, hodnoty primárneho kľúča a názvu stĺpca. | ||
| Podpora pre nedefinované hodnoty. DBMS podporuje hodnoty null. | ||
| Katalóg relačných systémov. Opis databázy by mal byť prezentovaný na logickej úrovni rovnakým spôsobom ako bežné údaje, čo používateľom umožňuje používať rovnaký relačný jazyk na odkazovanie na ne. | ||
| Komplexný dátový podjazyk. relačný DBMS môže podporovať viacero jazykov. Musí však existovať aspoň jeden jazyk, ktorého operátori umožnia vykonávať nasledujúce funkcie: 1. Definícia údajov; 2. Definícia pohľadov; 3. Príkazy na manipuláciu s údajmi; 4. Obmedzenia integrity; 5. Autorizácia užívateľa; 6. Organizácia transakcií | ||
| Operácie na vysokej úrovni extrahovať, vkladať, mazať, aktualizovať. Schopnosť DBMS vykonávať operácie načítania údajov príkazov vloženia, vymazania a aktualizácie ako jedinú operáciu. | ||
| Fyzická nezávislosť od údajov. Zo spôsobu skladovania | ||
| Logická dátová nezávislosť. Nezávislosť aplikácie od zmien základných tabuliek. | ||
| Integrita obmedzuje nezávislosť. Obmedzenia integrity musia byť definované v podjazyku relačných údajov a uložené v systémovom katalógu, nie v aplikačných programoch. | ||
| Nezávislosť distribúcie údajov. | ||
| Pravidlo zákazu obchádzky. Ak má DBMS nízkoúrovňový jazyk (so sekvenčným riadkovým spracovaním), nemalo by to umožňovať obchádzanie pravidiel a obmedzení integrity popísaných v relačnom jazyku na vysokej úrovni. |
Dátové modelovanie založené na procese normalizácie
Cieľ normalizácie.
Proces normalizácie navrhol v roku 1972 E. F. Codd – tri normálne formy (NF): prvá (1NF), druhá (2NF) a tretia (3NF).
Presnejšia definícia tretej NF (R. Boyes a E. F. Codd, 1974) je Boyes-Codd normálna forma (NFBK).
Redundancia a anomálie spracovania.
Nedostatok normalizácie má za následok:
Redundancia údajov
Anomálie vkladania (nemožno pridať záznamy)
Anomálie pri odstraňovaní (pri odstraňovaní informácií sa stratia ďalšie informácie)
Aktualizovať anomálie (treba aktualizovať veľa záznamov)
· Vlastnosti bezstratovej ochrany a zachovania závislosti.
Funkčné závislosti
 Kryptomena Ripple: Kompletná príručka pre investorov Existuje Ripple Mining
Kryptomena Ripple: Kompletná príručka pre investorov Existuje Ripple Mining Potrebujú teda banky naozaj blockchain?
Potrebujú teda banky naozaj blockchain? Token, čo to je, jednoduchými slovami Čo token znamená
Token, čo to je, jednoduchými slovami Čo token znamená Vzdialený prístup k počítaču
Vzdialený prístup k počítaču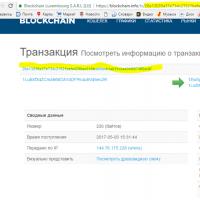 Čas potvrdenia bitcoinovej transakcie: ako dlho čakať?
Čas potvrdenia bitcoinovej transakcie: ako dlho čakať?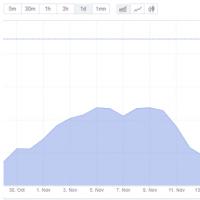 Verzie dôvodov kolapsu trhu s kryptomenami
Verzie dôvodov kolapsu trhu s kryptomenami Platené prieskumy, prieskumy za peniaze
Platené prieskumy, prieskumy za peniaze