Porovnanie počtu procesorov cuda. CUDA We're Rolling: Technológia NVIDIA CUDA. História vývoja CUDA
A je navrhnutý tak, aby preložil kód hostiteľa (hlavný, riadiaci kód) a kód zariadenia (hardvérový kód) (súbory s príponou .cu) do objektových súborov vhodných na zostavenie finálneho programu alebo knižnice v akomkoľvek programovacom prostredí, napríklad v NetBeans. .
Architektúra CUDA využíva mriežkový pamäťový model, klastrové vlákna a SIMD inštrukcie. Použiteľné nielen pre vysokovýkonné grafické výpočty, ale aj pre rôzne vedecké výpočty pomocou grafických kariet nVidia. Vedci a výskumníci využívajú CUDA vo veľkej miere v rôznych oblastiach, vrátane astrofyziky, výpočtovej biológie a chémie, simulácií dynamiky tekutín, elektromagnetických interakcií, počítačovej tomografie, seizmickej analýzy a ďalších. CUDA má schopnosť pripojiť sa k aplikáciám pomocou OpenGL a Direct3D. CUDA je multiplatformový softvér pre operačné systémy ako Linux, Mac OS X a Windows.
22. marca 2010 nVidia vydala CUDA Toolkit 3.0, ktorý obsahoval podporu OpenCL.
Vybavenie
Platforma CUDA Prvýkrát sa objavila na trhu s uvedením ôsmej generácie čipu NVIDIA G80 a stala sa prítomnou vo všetkých nasledujúcich sériách grafických čipov používaných v rodinách akcelerátorov GeForce, Quadro a NVidia Tesla.
Prvá séria hardvéru podporujúca CUDA SDK, G8x, mala 32-bitový vektorový procesor s jednoduchou presnosťou využívajúci CUDA SDK ako API (CUDA podporuje typ C double, ale teraz bola jeho presnosť znížená na 32-bitové plávajúce bod). Neskoršie procesory GT200 majú podporu pre 64-bitovú presnosť (iba pre SFU), ale výkon je výrazne horší ako pre 32-bitovú presnosť (kvôli skutočnosti, že na stream multiprocesoru sú len dve SFU a existuje osem skalárnych procesorov). GPU organizuje hardvérové multithreading, čo umožňuje využitie všetkých zdrojov GPU. Otvára sa tak perspektíva presunu funkcií fyzického akcelerátora na grafický akcelerátor (príkladom implementácie je nVidia PhysX). Taktiež existujú široké možnosti využitia grafického vybavenia počítača na vykonávanie zložitých negrafických výpočtov: napríklad vo výpočtovej biológii av iných vedných odboroch.
Výhody
V porovnaní s tradičným prístupom k organizovaniu všeobecných výpočtov pomocou možností grafických API má architektúra CUDA v tejto oblasti nasledujúce výhody:
Obmedzenia
- Všetky funkcie vykonávané na zariadení nepodporujú rekurziu (v CUDA Toolkit 3.1 podporuje ukazovatele a rekurziu) a majú niektoré ďalšie obmedzenia
Podporované GPU a grafické akcelerátory
Zoznam zariadení od výrobcu zariadení Nvidia s deklarovanou plnou podporou technológie CUDA je uvedený na oficiálnej stránke Nvidia: CUDA-Enabled GPU Products.
V skutočnosti na dnešnom trhu s PC hardvérom podporujú technológiu CUDA nasledujúce periférie:
| Verzia špecifikácie | GPU | Video karty |
|---|---|---|
| 1.0 | G80, G92, G92b, G94, G94b | GeForce 8800GTX / Ultra, 9400GT, 9600GT, 9800GT, Tesla C / D / S870, FX4 / 5600, 360M, GT 420 |
| 1.1 | G86, G84, G98, G96, G96b, G94, G94b, G92, G92b | GeForce 8400GS / GT, 8600GT / GTS, 8800GT / GTS, 9600 GSO, 9800GTX / GX2, GTS 250, GT 120/30/40, FX 4/570, 3/580, 17200x28,3 / 370 M, 3/5 / 770 M, 16/17/27/28/36/37 / 3800 M, NVS420 / 50 |
| 1.2 | GT218, GT216, GT215 | GeForce 210, GT 220/40, FX380 LP, 1800M, 370/380M, NVS 2/3100M |
| 1.3 | GT200, GT200b | GeForce GTX 260, GTX 275, GTX 280, GTX 285, GTX 295, Tesla C / M1060, S1070, Quadro CX, FX 3/4/5800 |
| 2.0 | GF100, GF110 | GeForce (GF100) GTX 465, GTX 470, GTX 480, Tesla C2050, C2070, S / M2050 / 70, Quadro Plex 7000, Quadro 4000, 5000, 6000, GeForce (GF1604, G5804TX, G5804TX, G59TX, G504TX |
| 2.1 | GF104, GF114, GF116, GF108, GF106 | GeForce 610M, GT 430, GT 440, GTS 450, GTX 460, GTX 550 Ti, GTX 560, GTX 560 Ti, 500M, Quadro 600, 2000 |
| 3.0 | GK104, GK106, GK107 | GeForce GTX 690, GTX 680, GTX 670, GTX 660 Ti, GTX 660, GTX 650 Ti, GTX 650, GT 640, GeForce GTX 680MX, GeForce GTX 680M, GeForce GTX 6750MX, GeForce GTX 6750MX, GeTXM70Force GTX66 GeForce GT 645M, GeForce GT 640M |
| 3.5 | GK110 |
|
|
|
|
|
- Modely Tesla C1060, Tesla S1070, Tesla C2050 / C2070, Tesla M2050 / M2070, Tesla S2050 umožňujú vykonávať výpočty na GPU s dvojnásobnou presnosťou.
Vlastnosti a špecifikácie rôznych verzií
| Podpora funkcií (neuvedené funkcie sú podporované pre všetky výpočtové možnosti) |
Výpočtová schopnosť (verzia) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
32-bitové slová v globálnej pamäti |
nie | Áno | |||
hodnoty s pohyblivou rádovou čiarkou v globálnej pamäti |
|||||
| Celočíselné atómové funkcie fungujúce na 32-bitové slová v zdieľanej pamäti |
nie | Áno | |||
| atomicExch () pracujúci na 32-bit hodnoty s pohyblivou rádovou čiarkou v zdieľanej pamäti |
|||||
| Celočíselné atómové funkcie fungujúce na 64-bitové slová v globálnej pamäti |
|||||
| Funkcie warp hlasovania | |||||
| Operácie s pohyblivou rádovou čiarkou s dvojitou presnosťou | nie | Áno | |||
| Atómové funkcie pracujúce na 64-bit celočíselné hodnoty v zdieľanej pamäti |
nie | Áno | |||
| Atómová adícia s pohyblivou rádovou čiarkou funguje 32-bitové slová v globálnej a zdieľanej pamäti |
|||||
| _hlasovací lístok () | |||||
| _threadfence_system () | |||||
| _syncthreads_count (), _syncthreads_and (), _syncthreads_or () |
|||||
| Funkcie povrchu | |||||
| 3D mriežka bloku závitov | |||||
| Technické špecifikácie | Výpočtová schopnosť (verzia) | ||||
|---|---|---|---|---|---|
| 1.0 | 1.1 | 1.2 | 1.3 | 2.x | |
| Maximálna rozmernosť rastra závitových blokov | 2 | 3 | |||
| Maximálny rozmer x, y alebo z mriežky blokov závitov | 65535 | ||||
| Maximálna rozmernosť závitového bloku | 3 | ||||
| Maximálny rozmer x alebo y bloku | 512 | 1024 | |||
| Maximálny z-rozmer bloku | 64 | ||||
| Maximálny počet vlákien na blok | 512 | 1024 | |||
| Veľkosť osnovy | 32 | ||||
| Maximálny počet rezidentných blokov na jeden multiprocesor | 8 | ||||
| Maximálny počet rezidentných warpov na multiprocesor | 24 | 32 | 48 | ||
| Maximálny počet rezidentných vlákien na multiprocesor | 768 | 1024 | 1536 | ||
| Počet 32-bitových registrov na jeden multiprocesor | 8 K | 16 K | 32 tis | ||
| Maximálne množstvo zdieľanej pamäte na jeden multiprocesor | 16 kB | 48 kB | |||
| Počet bánk zdieľanej pamäte | 16 | 32 | |||
| Množstvo lokálnej pamäte na vlákno | 16 kB | 512 kB | |||
| Konštantná veľkosť pamäte | 64 kB | ||||
| Pracovná súprava vyrovnávacej pamäte na multiprocesor pre stálu pamäť | 8 kB | ||||
| Pracovná súprava vyrovnávacej pamäte na multiprocesor pre pamäť textúr | V závislosti od zariadenia, medzi 6 KB a 8 KB | ||||
| Maximálna šírka pre 1D textúru |
8192 | 32768 | |||
| Maximálna šírka pre 1D textúru referencia viazaná na lineárnu pamäť |
2 27 | ||||
| Maximálna šírka a počet vrstiev pre referenciu 1D vrstvenej textúry |
8192 x 512 | 16384 x 2048 | |||
| Maximálna šírka a výška pre 2D odkaz na textúru viazaný na lineárna pamäť alebo pole CUDA |
65536 x 32768 | 65536 x 65535 | |||
| Maximálna šírka, výška a počet vrstiev pre referenciu 2D vrstvenej textúry |
8192 x 8192 x 512 | 16384 x 16384 x 2048 | |||
| Maximálna šírka, výška a hĺbka pre referenciu 3D textúry viazanú na lineárnu pamäť alebo pole CUDA |
2048 x 2048 x 2048 | ||||
| Maximálny počet textúr, ktoré môžu byť viazané na jadro |
128 | ||||
| Maximálna šírka pre 1D povrch odkaz viazaný na pole CUDA |
nie podporované |
8192 | |||
| Maximálna šírka a výška pre 2D povrchová referencia viazaná na pole CUDA |
8192 x 8192 | ||||
| Maximálny počet plôch, ktoré môžu byť viazané na jadro |
8 | ||||
| Maximálny počet pokynov na jadro |
2 milióny | ||||
Príklad
CudaArray * cu_array; textúra< float , 2 >tex; // Pridelenie poľa cudaMalloc (& cu_array, cudaCreateChannelDesc< float>(), šírka výška); // Kopírovanie údajov obrázka do poľa cudaMemcpy (cu_array, obrázok, šírka * výška, cudaMemcpyHostToDevice); // Naviazať pole na textúru cudaBindTexture (tex, cu_array); // Spustite kernel dim3 blockDim (16, 16, 1); dim3 gridDim (šírka / blockDim.x, výška / blockDim.y, 1); jadro<<< gridDim, blockDim, 0 >>> (d_odata, sirka, vyska); cudaUnbindTexture (tex); __global__ void kernel (float * odata, int height, int width) (unsigned int x = blockIdx.x * blockDim.x + threadIdx.x; unsigned int y = blockIdx.y * blockDim.y + threadIdx.y; float c = texfetch (tex, x, y); odata [y * šírka + x] = c;)
Importovať pycuda.driver ako drv import numpy drv.init () dev = drv.Device (0) ctx = dev.make_context () mod = drv.SourceModule ( "" "__global__ void multiply_them (float * dest, float * a, float * b) (const int i = threadIdx.x; dest [i] = a [i] * b [i];)" "") multiply_them = mod.get_function ("multiply_them") a = numpy.random .randn (400) .astype (numpy.float32) b = numpy.random .randn (400) .astype (numpy.float32) dest = numpy.zeros (a) multiply_them (drv.Out (dest), drv.In (a), drv.In (b), block = (400, 1, 1)) print dest-a * b
CUDA ako predmet na univerzitách
Od decembra 2009 sa programovací model CUDA vyučuje na 269 univerzitách po celom svete. V Rusku sa školiace kurzy CUDA vyučujú na Petrohradskej polytechnickej univerzite, Yaroslavl State University pomenovanej po V.I. PG Demidov, Moskva, Nižný Novgorod, Petrohrad, Tver, Kazaň, Novosibirsk, Novosibirská štátna technická univerzita Omsk a Permské štátne univerzity, Medzinárodná univerzita prírody spoločnosti a človeka „Dubna“, Ivanovská štátna energetická univerzita, Belgorodská štátna univerzita, MSTU ich. Bauman, RKhTU im. Mendelejev, Medziregionálne superpočítačové centrum RAS,. Okrem toho bolo v decembri 2009 oznámené, že bolo spustené prvé ruské vedecké a vzdelávacie centrum „Parallel Computing“, ktoré sa nachádza v meste Dubna, medzi ktorého úlohy patrí školenie a poradenstvo pri riešení zložitých výpočtových problémov na GPU.
Na Ukrajine sa kurzy CUDA vyučujú na Kyjevskom inštitúte pre systémovú analýzu.
Odkazy
Oficiálne zdroje
- Zóna CUDA (ruština) - oficiálna stránka CUDA
- CUDA GPU Computing - Oficiálne webové fóra venované počítačom CUDA
Neoficiálne zdroje
Tomov hardvér- Dmitrij Čekanov. nVidia CUDA: Výpočet GPU alebo smrť CPU? ... Tom's Hardware (22. júna 2008). Archivované
- Dmitrij Čekanov. nVidia CUDA: GPU benchmarky pre bežný trh. Tom's Hardware (19. máj 2009). Archivované 4. marca 2012. Získané 19. mája 2009.
- Alexey Berillo. NVIDIA CUDA – Negrafické výpočty na GPU. Časť 1 . iXBT.com (23. september 2008). Archivované z originálu 4. marca 2012. Získané 20. januára 2009.
- Alexey Berillo. NVIDIA CUDA – Negrafické výpočty na GPU. Časť 2 . iXBT.com (22. októbra 2008). - Príklady implementácie NVIDIA CUDA. Archivované z originálu 4. marca 2012. Získané 20. januára 2009.
- Boreskov Alexej Viktorovič. Základy CUDA (20. januára 2009). Archivované z originálu 4. marca 2012. Získané 20. januára 2009.
- Vladimír Frolov.Úvod do technológie CUDA. Sieťový časopis „Počítačová grafika a multimédiá“ (19. decembra 2008). Archivované z originálu 4. marca 2012. Získané 28. októbra 2009.
- Igor Oskolkov. NVIDIA CUDA je cenovo dostupná vstupenka do sveta veľkých počítačov. Computerra (30. apríla 2009). Získané 3. mája 2009.
- Vladimír Frolov.Úvod do technológie CUDA (1. augusta 2009). Archivované z originálu 4. marca 2012. Získané 3. apríla 2010.
- GPGPU.ru. Používanie grafických kariet na prácu s počítačom
- ... Centrum pre paralelné výpočty
Poznámky (upraviť)
pozri tiež
| Nvidia | ||||||||
|---|---|---|---|---|---|---|---|---|
| Grafický spracovateľov |
| |||||||
Zariadenia na premenu osobných počítačov na malé superpočítače existujú už dlho. Ešte v 80. rokoch minulého storočia boli na trhu ponúkané takzvané transputery, ktoré sa vkladali do vtedy rozšírených rozširujúcich slotov ISA. Spočiatku bol ich výkon v zodpovedajúcich úlohách pôsobivý, ale potom sa zrýchlil rast rýchlosti univerzálnych procesorov, posilnili svoje pozície v paralelných výpočtoch a transputáty nemali zmysel. Aj keď takéto zariadenia existujú dodnes, ide o rôzne špecializované urýchľovače. Rozsah ich aplikácie je však často úzky a takéto urýchľovače nie sú veľmi rozšírené.
Nedávno sa však pochodeň paralelných výpočtov presunul na masový trh, tak či onak spojený s trojrozmernými hrami. Viacjadrové paralelné vektorové výpočtové zariadenia na všeobecné účely používané v 3D grafike dosahujú špičkový výkon, ktorý procesory na všeobecné použitie nedokážu. Samozrejme, maximálna rýchlosť sa dosahuje iba v množstve pohodlných úloh a má určité obmedzenia, ale takéto zariadenia sa už začali široko používať v oblastiach, pre ktoré neboli pôvodne určené. Vynikajúcim príkladom takéhoto paralelného procesora je procesor Cell, vyvinutý alianciou Sony-Toshiba-IBM a používaný v Sony PlayStation 3, ako aj všetky moderné grafické karty od lídrov na trhu - Nvidia a AMD.
Cellu sa dnes nedotkneme, hoci sa objavil už skôr a ide o univerzálny procesor s ďalšími vektorovými schopnosťami, dnes o ňom nehovoríme. Pre 3D video akcelerátory sa pred niekoľkými rokmi objavili prvé technológie negrafických všeobecných výpočtov GPGPU (General-Purpose computation on GPUs). Koniec koncov, moderné video čipy obsahujú stovky matematických vykonávacích jednotiek a túto silu je možné využiť na výrazné zrýchlenie mnohých výpočtovo náročných aplikácií. A súčasné generácie GPU majú dostatočne flexibilnú architektúru, ktorá spolu s programovacími jazykmi na vysokej úrovni a softvérovými a hardvérovými architektúrami, ako je tá, o ktorej sa hovorí v tomto článku, odhaľuje tieto možnosti a robí ich oveľa dostupnejšími.
Vývoj GPCPU podnietil vznik dostatočne rýchlych a flexibilných shader programov, ktoré sú schopné vykonávať moderné video čipy. Vývojári sa rozhodli prinútiť GPU počítať nielen obraz v 3D aplikáciách, ale použiť ho aj v iných paralelných výpočtoch. V GPGPU na to slúžili grafické API: OpenGL a Direct3D, kedy sa dáta prenášali na video čip vo forme textúr a načítavali sa výpočtové programy vo forme shaderov. Nevýhodou tejto metódy je pomerne veľká náročnosť programovania, nízka rýchlosť výmeny dát medzi CPU a GPU a ďalšie obmedzenia, ktoré si rozoberieme nižšie.
GPU computing sa vyvíjal a vyvíja veľmi rýchlo. A v budúcnosti dvaja hlavní výrobcovia video čipov, Nvidia a AMD, vyvinuli a oznámili zodpovedajúce platformy s názvom CUDA (Compute Unified Device Architecture) a CTM (Close To Metal alebo AMD Stream Computing). Na rozdiel od predchádzajúcich modelov programovania GPU boli tieto vykonávané s priamym prístupom k hardvérovým možnostiam grafických kariet. Platformy nie sú navzájom kompatibilné, CUDA je rozšírenie programovacieho jazyka C a CTM je virtuálny stroj, ktorý vykonáva montážny kód. Namiesto toho obe platformy odstránili niektoré dôležité obmedzenia predchádzajúcich modelov GPGPU pomocou tradičného grafického potrubia a zodpovedajúcich rozhraní Direct3D alebo OpenGL.
Samozrejme, otvorené štandardy využívajúce OpenGL sa zdajú byť najprenosnejšie a univerzálnejšie, umožňujú používať rovnaký kód pre video čipy od rôznych výrobcov. Takéto metódy však majú veľa nevýhod, sú oveľa menej flexibilné a nie sú také vhodné na použitie. Okrem toho neumožňujú využívať špecifické schopnosti určitých grafických kariet, ako je napríklad rýchla zdieľaná (zdieľaná) pamäť, ktorá sa nachádza v moderných počítačových procesoroch.
Preto Nvidia vydala platformu CUDA – programovací jazyk podobný C s vlastným kompilátorom a knižnicami pre prácu s GPU. Samozrejme, napísanie optimálneho kódu pre video čipy nie je vôbec také jednoduché a táto úloha si vyžaduje dlhú manuálnu prácu, no CUDA len odkrýva všetky možnosti a dáva programátorovi väčšiu kontrolu nad hardvérovými možnosťami GPU. Dôležité je, že čipy G8x, G9x a GT2xx používané v grafických kartách Geforce 8, 9 a 200 majú podporu Nvidia CUDA, ktorá je veľmi rozšírená. Aktuálne bola vydaná finálna verzia CUDA 2.0, ktorá prináša niektoré nové funkcie, napríklad podporu výpočtov s dvojitou presnosťou. CUDA je k dispozícii na 32-bitových a 64-bitových operačných systémoch Linux, Windows a MacOS X.
Rozdiel medzi CPU a GPU pri paralelnom výpočte
Nárast frekvencie univerzálnych procesorov narážal na fyzické obmedzenia a vysokú spotrebu a ich výkon sa čoraz viac zvyšuje vďaka umiestneniu niekoľkých jadier v jednom čipe. Predávané procesory teraz obsahujú až štyri jadrá (ďalší rast už nebude rýchly) a sú určené pre bežné aplikácie, využívajú MIMD - viacnásobný tok inštrukcií a dát. Každé jadro funguje oddelene od ostatných a vykonáva rôzne inštrukcie pre rôzne procesy.
Špecializované vektorové schopnosti (SSE2 a SSE3) pre štvorzložkové (s jednoduchou presnosťou s pohyblivou rádovou čiarkou) a dvojzložkové (s dvojitou presnosťou) vektory sa objavili vo všeobecných procesoroch predovšetkým kvôli zvýšeným požiadavkám grafických aplikácií. Preto je pre určité úlohy použitie GPU výhodnejšie, pretože boli pôvodne vyrobené pre ne.
Napríklad vo videočipoch Nvidia je hlavnou jednotkou multiprocesor s ôsmimi až desiatimi jadrami a celkovo stovkami ALU, niekoľkými tisíckami registrov a malým množstvom zdieľanej pamäte. Okrem toho grafická karta obsahuje rýchlu globálnu pamäť s prístupom pre všetky multiprocesory, lokálnu pamäť v každom multiprocesore a špeciálnu pamäť pre konštanty.
Najdôležitejšie je, že tieto viacnásobné viacprocesorové jadrá v GPU sú jadrá SIMD (single inštrukcie stream, multiple data streams). A tieto jadrá vykonávajú rovnaké inštrukcie v rovnakom čase, tento štýl programovania je bežný pre grafické algoritmy a mnohé vedecké problémy, ale vyžaduje špecifické programovanie. Tento prístup vám však umožňuje zvýšiť počet vykonávacích jednotiek vďaka ich zjednodušeniu.
Poďme si teda vymenovať hlavné rozdiely medzi architektúrami CPU a GPU. Jadrá CPU sú navrhnuté tak, aby vykonávali jeden tok sekvenčných inštrukcií pri maximálnom výkone, zatiaľ čo GPU sú navrhnuté tak, aby rýchlo vykonávali veľké množstvo súbežných tokov inštrukcií. Procesory na všeobecné použitie sú optimalizované pre vysoký výkon z jedného toku inštrukcií, ktoré spracovávajú celé čísla aj čísla s pohyblivou rádovou čiarkou. V tomto prípade je prístup k pamäti náhodný.
Dizajnéri CPU sa snažia získať čo najviac inštrukcií na paralelný chod, aby sa zlepšil výkon. Na tento účel sa počnúc procesormi Intel Pentium objavilo superskalárne vykonávanie, ktoré zaisťuje vykonanie dvoch inštrukcií na takt a Pentium Pro sa vyznamenalo mimoriadkovým vykonávaním inštrukcií. Ale paralelné vykonávanie sekvenčného prúdu inštrukcií má určité základné obmedzenia a zvýšením počtu vykonávacích jednotiek nie je možné dosiahnuť niekoľkonásobné zvýšenie rýchlosti.
Pre video čipy je práca jednoduchá a spočiatku paralelná. Video čip berie ako vstup skupinu polygónov, vykonáva všetky potrebné operácie a na výstupe vydáva pixely. Spracovanie polygónov a pixelov je nezávislé, možno ich spracovávať paralelne, oddelene od seba. Preto sa kvôli pôvodne paralelnej organizácii práce v GPU používa veľké množstvo vykonávacích jednotiek, ktoré sa na rozdiel od sekvenčného toku inštrukcií pre CPU jednoducho načítavajú. Okrem toho môžu moderné GPU vykonávať aj viac ako jednu inštrukciu za cyklus hodín (duálny problém). Architektúra Tesla teda za určitých podmienok spúšťa operácie MAD + MUL alebo MAD + SFU súčasne.
GPU sa líši od CPU aj z hľadiska prístupu k pamäti. V GPU je to prepojené a ľahko predvídateľné - ak sa texel textúry načíta z pamäte, tak po chvíli príde čas aj na susedné texely. Áno, a to isté počas nahrávania - pixel sa zapíše do framebufferu a po niekoľkých taktovacích cykloch sa zaznamená ten, ktorý sa nachádza vedľa neho. Preto je organizácia pamäte odlišná od organizácie používanej v CPU. A video čip na rozdiel od univerzálnych procesorov jednoducho nepotrebuje veľkú vyrovnávaciu pamäť a textúry vyžadujú len niekoľko (až 128 – 256 v súčasných GPU) kilobajtov.
A sama o sebe je práca s pamäťou pre GPU a CPU trochu iná. Takže nie všetky centrálne procesory majú vstavané pamäťové radiče a všetky GPU majú zvyčajne niekoľko radičov, až osem 64-bitových kanálov v čipe Nvidia GT200. Okrem toho sa na grafických kartách používa rýchlejšia pamäť a v dôsledku toho majú videočipy k dispozícii mnohonásobne väčšiu šírku pásma pamäte, čo je tiež veľmi dôležité pre paralelné výpočty pracujúce s obrovskými dátovými tokmi.
V procesoroch na všeobecné účely sa veľké množstvo tranzistorov a oblasti čipu dostane do vyrovnávacej pamäte inštrukcií, predikcie hardvérových vetví a obrovského množstva vyrovnávacej pamäte na čipe. Všetky tieto hardvérové bloky sú potrebné na urýchlenie vykonávania malého počtu tokov inštrukcií. Video čipy využívajú tranzistory na polia vykonávacích jednotiek, jednotiek riadenia toku, malej zdieľanej pamäte a pamäťových radičov pre niekoľko kanálov. Vyššie uvedené nezrýchľuje vykonávanie jednotlivých vlákien, umožňuje čipu spracovať niekoľko tisíc vlákien súčasne vykonávaných na čipe a vyžadujúcich veľkú šírku pásma pamäte.
O rozdieloch vo vyrovnávacej pamäti. Univerzálne CPU používajú vyrovnávaciu pamäť na zvýšenie výkonu znížením latencie prístupu k pamäti, zatiaľ čo GPU používajú vyrovnávaciu pamäť alebo zdieľanú pamäť na zvýšenie šírky pásma. CPU znižujú latenciu prístupu do pamäte použitím veľkých vyrovnávacích pamätí a predikcie vetvenia. Tieto hardvérové časti zaberajú väčšinu plochy čipu a spotrebúvajú veľa energie. Video čipy obchádzajú problém oneskorenia prístupu do pamäte súčasným vykonávaním tisícok vlákien - zatiaľ čo jedno z vlákien čaká na dáta z pamäte, videočip môže vykonávať výpočty na inom vlákne bez čakania alebo oneskorení.
Existuje tiež veľa rozdielov v podpore multithreadingu. CPU vykonáva 1-2 výpočtové vlákna na jadro procesora a video čipy môžu podporovať až 1024 vlákien na multiprocesor, ktorých je v čipe niekoľko. A ak prepínanie z jedného vlákna na druhé pre CPU stojí stovky cyklov, potom GPU prepne niekoľko vlákien v jednom cykle.
Okrem toho CPU používajú SIMD (jedna inštrukcia sa vykonáva na viacerých dátach) bloky na vektorové výpočty a video čipy používajú SIMT (jedna inštrukcia a viacero vlákien) na skalárne spracovanie tokov. SIMT nevyžaduje, aby vývojár konvertoval dáta na vektory a umožňuje ľubovoľné vetvenie v prúdoch.
Stručne povedané, môžeme povedať, že na rozdiel od moderných univerzálnych CPU sú video čipy navrhnuté pre paralelné výpočty s veľkým počtom aritmetických operácií. A oveľa väčší počet tranzistorov GPU pracuje na svoj zamýšľaný účel - spracovanie dátových polí a neriadi vykonávanie (riadenie toku) niekoľkých sekvenčných výpočtových vlákien. Toto je schéma toho, koľko miesta v CPU a GPU zaberajú rôzne logiky:

Výsledkom je, že základom efektívneho využitia výkonu GPU vo vedeckých a iných negrafických výpočtoch je paralelizácia algoritmov do stoviek vykonávacích jednotiek dostupných vo video čipoch. Napríklad mnohé aplikácie molekulárneho modelovania sa dokonale hodia na výpočty na video čipoch, vyžadujú veľa výpočtového výkonu, a preto sú vhodné na paralelné výpočty. A použitie viacerých GPU dáva ešte väčší výpočtový výkon na riešenie takýchto problémov.
Vykonávanie výpočtov na GPU ukazuje vynikajúce výsledky v algoritmoch, ktoré využívajú paralelné spracovanie údajov. To znamená, keď sa rovnaká postupnosť matematických operácií aplikuje na veľké množstvo údajov. V tomto prípade sa najlepšie výsledky dosiahnu, ak je pomer počtu aritmetických inštrukcií k počtu prístupov do pamäte dostatočne veľký. To kladie menšie nároky na riadenie toku a vysoká hustota matematiky a veľké množstvo údajov odstraňuje potrebu veľkých vyrovnávacích pamätí, ako je napríklad CPU.
V dôsledku všetkých vyššie opísaných rozdielov teoretický výkon video čipov výrazne prevyšuje výkon CPU. Nvidia poskytuje tento graf rastu výkonu CPU a GPU za posledných niekoľko rokov:

Prirodzene, tieto údaje nie sú bez dávky lsti. V skutočnosti je na CPU oveľa jednoduchšie dosiahnuť teoretické čísla v praxi a čísla sú uvedené pre jednoduchú presnosť v prípade GPU a pre dvojnásobnú presnosť v prípade CPU. V každom prípade na niektoré paralelné úlohy stačí jediná presnosť a rozdiel v rýchlosti medzi univerzálnym a grafickým procesorom je veľmi veľký, a preto hra stojí za námahu.
Prvé pokusy o využitie GPU computingu
V paralelných matematických výpočtoch sa dlho pokúšali využívať video čipy. Najskoršie pokusy o takúto aplikáciu boli extrémne primitívne a obmedzovali sa na použitie niektorých hardvérových funkcií, ako je rasterizácia a Z-buffering. Ale v tomto storočí, s príchodom shaderov, začali zrýchľovať maticové výpočty. V roku 2003 bola na SIGGRAPH vyčlenená samostatná sekcia pre GPU computing a dostala názov GPGPU (General-Purpose computation on GPU).
Najznámejším BrookGPU je kompilátor programovacieho jazyka Brook streaming určený na vykonávanie negrafických výpočtov na GPU. Pred jeho objavením si vývojári využívajúci možnosti video čipov na výpočtovú techniku vybrali jedno z dvoch bežných rozhraní API: Direct3D alebo OpenGL. To vážne obmedzilo použitie GPU, pretože v 3D grafike sa používajú shadery a textúry, o ktorých špecialisti na paralelné programovanie nemusia vedieť, používajú vlákna a jadrá. Brook im mohol pomôcť uľahčiť ich úlohu. Tieto streamingové rozšírenia do jazyka C vyvinuté na Stanfordskej univerzite skryli pred programátormi trojrozmerné API a predstavili video čip ako paralelný koprocesor. Kompilátor analyzoval súbor .br s kódom C++ a príponami, čím vytvoril kód prepojený s knižnicou DirectX, OpenGL alebo x86.
Prirodzene, Brook mal veľa nedostatkov, pri ktorých sme sa zastavili a o ktorých si podrobnejšie povieme nižšie. Ale aj jeho samotný vzhľad spôsobil významný prílev pozornosti tých istých Nvidia a ATI k iniciatíve výpočtovej techniky na GPU, pretože vývoj týchto schopností v budúcnosti vážne zmenil trh a otvoril jeho úplne nový sektor - paralelné počítače založené na na video čipoch.
Následne sa niektorí výskumníci z projektu Brook pripojili k vývojovému tímu Nvidia, aby predstavili hardvérovo-softvérovú stratégiu paralelných výpočtov, čím sa otvoril nový podiel na trhu. A hlavnou výhodou tejto iniciatívy Nvidia je, že vývojári dobre poznajú všetky možnosti svojich GPU do najmenších detailov a nie je potrebné používať grafické API a s hardvérom môžete pracovať priamo pomocou ovládača. Výsledkom úsilia tohto tímu je Nvidia CUDA (Compute Unified Device Architecture), nová hardvérová a softvérová architektúra pre paralelné výpočty na GPU Nvidia, o ktorej je tento článok.
Aplikácie paralelných GPU výpočtov
Aby ste pochopili výhody prenosu výpočtov na video čipy, uvádzame priemerné údaje získané výskumníkmi z celého sveta. V priemere, keď sa výpočtové výpočty prenesú na GPU, v mnohých úlohách je zrýchlenie 5-30-násobné v porovnaní s rýchlymi univerzálnymi procesormi. Najväčšie čísla (rádovo 100-násobné zrýchlenie a ešte viac!) sa dosahujú v kóde, ktorý nie je príliš vhodný na výpočty pomocou blokov SSE, ale je celkom vhodný pre GPU.
Toto sú len niektoré príklady zrýchlenia syntetického kódu na GPU oproti SSE-vektorizovanému kódu na CPU (podľa Nvidie):
- Fluorescenčná mikroskopia: 12x;
- Molekulárna dynamika (výpočet neviazaných síl): 8-16x;
- Elektrostatika (priame a viacúrovňové stohovanie Coulomb): 40-120x a 7x.
A toto je tanier, ktorý Nvidia veľmi miluje a ukazuje ho na všetkých prezentáciách, ktorým sa budeme podrobnejšie venovať v druhej časti článku, venovanej konkrétnym príkladom praktických aplikácií výpočtovej techniky CUDA:

Ako môžete vidieť, čísla sú veľmi atraktívne, obzvlášť pôsobivé sú 100-150x zisky. V ďalšom článku o CUDA si niektoré z týchto čísel podrobne rozoberieme. Uveďme si teraz zoznam hlavných aplikácií, v ktorých sa v súčasnosti používa výpočtová technika GPU: analýza a spracovanie obrazu a signálu, fyzikálna simulácia, výpočtová matematika, výpočtová biológia, finančné výpočty, databázy, dynamika plynov a kvapalín, kryptografia, adaptívna radiačná terapia, astronómia, spracovanie zvuku , bioinformatika, biologické simulácie, počítačové videnie, dolovanie údajov, digitálne kino a televízia, elektromagnetické simulácie, geografické informačné systémy, vojenské aplikácie, plánovanie ťažby, molekulárna dynamika, magnetická rezonancia (MRI), neurónové siete, oceánografický výskum, časticová fyzika, proteín skladacia simulácia, kvantová chémia, sledovanie lúčov, vizualizácia, radar, simulácia nádrží, umelá inteligencia, analýza satelitných údajov, seizmický prieskum, chirurgia, ultrazvuk, videokonferencie.
Podrobnosti o mnohých aplikáciách nájdete na webovej stránke Nvidia v sekcii softvéru. Ako vidíte, zoznam je pomerne dlhý, ale to nie je všetko! Dá sa pokračovať a určite sa dá predpokladať, že v budúcnosti sa nájdu aj ďalšie oblasti aplikácie paralelných výpočtov na video čipoch, o ktorých sme zatiaľ ani len netušili.
Funkcie Nvidia CUDA
Technológia CUDA je softvérová a hardvérová výpočtová architektúra spoločnosti Nvidia založená na rozšírení jazyka C, ktorá umožňuje organizovať prístup k sade inštrukcií grafického akcelerátora a spravovať jeho pamäť pri organizovaní paralelných výpočtov. CUDA pomáha implementovať algoritmy, ktoré sú spustiteľné na GPU ôsmej generácie video akcelerátorov Geforce (Geforce 8, Geforce 9, Geforce 200 séria), ako aj Quadro a Tesla.
Aj keď je zložitosť programovania GPU s CUDA pomerne vysoká, je nižšia ako u predchádzajúcich riešení GPGPU. Takéto programy vyžadujú rozdelenie aplikácie medzi niekoľko multiprocesorov podobne ako programovanie MPI, ale bez rozdelenia údajov, ktoré sú uložené v zdieľanej videopamäti. A keďže programovanie CUDA pre každý multiprocesor je podobné programovaniu OpenMP, vyžaduje si dobré pochopenie organizácie pamäte. Ale, samozrejme, zložitosť vývoja a portovania na CUDA do veľkej miery závisí od aplikácie.
Vývojárska súprava obsahuje veľa príkladov kódu a je dobre zdokumentovaná. Proces učenia bude trvať asi dva až štyri týždne pre tých, ktorí už poznajú OpenMP a MPI. API je založené na rozšírenom jazyku C a na preklad kódu z tohto jazyka obsahuje CUDA SDK kompilátor príkazového riadku nvcc založený na kompilátore Open64 s otvoreným zdrojom.
Uveďme si hlavné charakteristiky CUDA:
- jednotné hardvérové a softvérové riešenie pre paralelné výpočty na video čipoch Nvidia;
- široká škála podporovaných riešení, od mobilných až po multičipové
- štandardný programovací jazyk C;
- Štandardné knižnice numerickej analýzy FFT (Fast Fourier Transform) a BLAS (Linear Algebra);
- optimalizovaná výmena dát medzi CPU a GPU;
- interakcia s grafickými API OpenGL a DirectX;
- podpora pre 32- a 64-bitové operačné systémy: Windows XP, Windows Vista, Linux a MacOS X;
- schopnosť rozvíjať sa na nízkej úrovni.
K podpore operačného systému treba dodať, že oficiálne sú podporované všetky hlavné distribúcie Linuxu (Red Hat Enterprise Linux 3.x / 4.x / 5.x, SUSE Linux 10.x), ale súdiac podľa údajov nadšencov, CUDA funguje skvele na iných zostavách: Fedora Core, Ubuntu, Gentoo atď.
Vývojové prostredie CUDA (CUDA Toolkit) obsahuje:
- kompilátor nvcc;
- knižnice FFT a BLAS;
- profilovač;
- gdb debugger pre GPU;
- Runtime ovládač CUDA je súčasťou štandardných ovládačov Nvidia
- programová príručka;
- CUDA Developer SDK (zdroj, nástroje a dokumentácia).
V príkladoch zdrojového kódu: paralelné bitonické triedenie, maticová transpozícia, paralelná sumacia prefixov veľkých polí, konvolúcia obrazu, diskrétna vlnková transformácia, príklad interakcie s OpenGL a Direct3D, použitie knižníc CUBLAS a CUFFT, výpočet ceny opcie (Blackov vzorec Scholes, binomický model, metóda Monte Carlo), paralelný generátor náhodných čísel Mersenne Twister, výpočet histogramu veľkého poľa, redukcia šumu, Sobelov filter (hľadanie hraníc).
Výhody a obmedzenia CUDA
Z pohľadu programátora je grafický pipeline súborom fáz spracovania. Geometrický blok generuje trojuholníky a rastrový blok generuje pixely zobrazené na monitore. Tradičný programovací model GPGPU vyzerá takto:

Na prenos výpočtov na GPU v rámci takéhoto modelu je potrebný špeciálny prístup. Dokonca aj pridanie dvoch vektorov po jednotlivých prvkoch bude vyžadovať nakreslenie tvaru na obrazovku alebo do vyrovnávacej pamäte mimo obrazovky. Tvar je rastrovaný, farba každého pixelu je vypočítaná podľa zadaného programu (pixel shader). Program načíta vstupné dáta z textúr pre každý pixel, pridá ich a zapíše do výstupnej vyrovnávacej pamäte. A všetky tieto početné operácie sú potrebné na to, čo je v bežnom programovacom jazyku napísané jedným operátorom!
Preto má použitie GPGPU na univerzálne výpočty obmedzenie v podobe príliš veľkých ťažkostí pri školení vývojárov. A je tu dosť ďalších obmedzení, pretože pixel shader je len vzorec pre závislosť výslednej farby pixelu od jeho súradnice a jazyk pixel shader je jazyk na písanie týchto vzorcov so syntaxou podobnou C. Skoré techniky GPGPU sú zložitým trikom na využitie výkonu GPU, ale bez akéhokoľvek pohodlia. Dáta sú tam reprezentované obrázkami (textúrami) a algoritmus je reprezentovaný procesom rasterizácie. Treba tiež poznamenať veľmi špecifický model pamäte a vykonávania.
Hardvérová a softvérová architektúra Nvidie pre prácu s GPU sa líši od predchádzajúcich modelov GPGPU tým, že umožňuje písať programy GPU v reálnom C so štandardnou syntaxou, ukazovateľmi a potrebou minimálneho rozšírenia pre prístup k výpočtovým zdrojom video čipov. CUDA je nezávislý od grafických rozhraní API a má niektoré funkcie špeciálne navrhnuté pre všeobecné výpočty.
Výhody CUDA oproti tradičnému prístupu k výpočtovej technike GPGPU:
- aplikačné programovacie rozhranie CUDA je založené na štandardnom programovacom jazyku C s rozšíreniami, čo zjednodušuje proces učenia a implementácie architektúry CUDA;
- CUDA poskytuje prístup k 16KB zdieľanej pamäti na multiprocesor, ktorú možno použiť na vytvorenie vyrovnávacej pamäte so širšou šírkou pásma ako vzorky textúr;
- efektívnejší prenos dát medzi systémom a video pamäťou
- nie sú potrebné grafické API s redundanciou a réžiou;
- lineárne adresovanie pamäte a zhromažďovanie a rozptyl, schopnosť zapisovať na ľubovoľné adresy;
- hardvérová podpora celočíselných a bitových operácií.
Hlavné obmedzenia CUDA:
- nedostatok podpory rekurzie pre vykonávané funkcie;
- minimálna šírka bloku 32 závitov;
- Uzavretá architektúra CUDA, ktorú vlastní Nvidia.
Slabé stránky programovania pomocou predchádzajúcich metód GPGPU spočívajú v tom, že tieto metódy nepoužívajú vykonávacie jednotky vertex shader v predchádzajúcich nezjednotených architektúrach, dáta sú uložené v textúrach, ale výstup do vyrovnávacej pamäte mimo obrazovky a viacpriechodové algoritmy používajú pixel shader. Jednotky. Obmedzenia GPGPU môžu zahŕňať: nedostatočné využitie hardvérových možností, obmedzenia šírky pásma pamäte, žiadna operácia rozptylu (iba zber), povinné používanie grafického API.
Hlavné výhody CUDA oproti predchádzajúcim metódam GPGPU vyplývajú zo skutočnosti, že táto architektúra je navrhnutá pre efektívne využitie negrafických výpočtov na GPU a využíva programovací jazyk C bez potreby prenosu algoritmov do formy vhodnej pre daný koncept. grafického potrubia. CUDA ponúka nový spôsob výpočtu GPU, ktorý nepoužíva grafické rozhrania API a ponúka náhodný prístup k pamäti (rozptyl alebo zhromaždenie). Táto architektúra je zbavená nevýhod GPGPU a využíva všetky vykonávacie jednotky a tiež rozširuje možnosti vďaka celočíselnej matematike a operáciám bitového posunu.
Okrem toho CUDA otvára niektoré hardvérové funkcie, ktoré nie sú dostupné z grafických rozhraní API, ako je napríklad zdieľaná pamäť. Ide o malé množstvo pamäte (16 kilobajtov na multiprocesor), ku ktorej môžu pristupovať bloky vlákien. Umožňuje vám ukladať najčastejšie používané údaje do vyrovnávacej pamäte a môže poskytnúť vyššiu rýchlosť ako použitie načítania textúr pre túto úlohu. To zase znižuje citlivosť na šírku pásma paralelných algoritmov v mnohých aplikáciách. Napríklad je užitočný pre lineárnu algebru, FFT a filtre na spracovanie obrazu.
Pohodlnejšie v CUDA a prístupe k pamäti. Programový kód v grafickom rozhraní API vydáva dáta vo forme 32 s jednoduchou presnosťou hodnôt s pohyblivou rádovou čiarkou (hodnoty RGBA súčasne v ôsmich cieľoch vykresľovania) do preddefinovaných oblastí a CUDA podporuje bodové nahrávanie - neobmedzený počet záznamov pri akúkoľvek adresu. Tieto výhody umožňujú vykonávať na GPU niektoré algoritmy, ktoré nemožno efektívne implementovať pomocou metód GPGPU založených na grafických API.
Grafické API tiež nevyhnutne ukladajú dáta do textúr, čo si vyžaduje predbežné zabalenie veľkých polí do textúr, čo komplikuje algoritmus a núti použitie špeciálneho adresovania. A CUDA vám umožňuje čítať dáta na akejkoľvek adrese. Ďalšou výhodou CUDA je optimalizovaná výmena dát medzi CPU a GPU. A pre vývojárov, ktorí chcú získať nízkoúrovňový prístup (napríklad pri písaní iného programovacieho jazyka), CUDA ponúka možnosť nízkoúrovňového programovania v assembleri.
História vývoja CUDA
Vývoj CUDA bol oznámený s čipom G80 v novembri 2006 a verejná beta verzia CUDA SDK bola vydaná vo februári 2007. Verzia 1.0 bola vydaná v júni 2007 pre spustenie riešení Tesla založených na čipe G80 a určených pre trh s vysokovýkonnými počítačmi. Koncom roka potom vyšla beta verzia CUDA 1.1, ktorá aj napriek miernemu nárastu čísla verzie priniesla pomerne veľa noviniek.
Novinkou v CUDA 1.1 je zahrnutie funkcionality CUDA do bežných ovládačov videa Nvidia. To znamenalo, že v požiadavkách na akýkoľvek CUDA program stačilo špecifikovať grafickú kartu Geforce 8 alebo vyššiu, ako aj minimálnu verziu ovládača 169.xx. To je veľmi dôležité pre vývojárov, ak sú splnené tieto podmienky, CUDA programy budú fungovať pre každého používateľa. Pridal tiež asynchrónne vykonávanie spolu s kopírovaním údajov (len pre čipy G84, G86, G92 a vyššie), asynchrónny prenos údajov do videopamäte, operácie prístupu k atómovej pamäti, podporu pre 64-bitové verzie Windows a možnosť viacčipovej prevádzky CUDA v SLI. režim.
Momentálne je aktuálna verzia pre riešenia založené na GT200 - CUDA 2.0, vydaná spolu s radom Geforce GTX 200. Beta verzia bola vydaná ešte na jar 2008. Druhá verzia prináša: podporu výpočtov s dvojitou presnosťou (hardvérová podpora len pre GT200), konečne sú podporované Windows Vista (32 a 64-bitové verzie) a Mac OS X, pridané sú nástroje na ladenie a profilovanie, podporované sú 3D textúry, optimalizované dáta prevod.
Čo sa týka výpočtov s dvojnásobnou presnosťou, ich rýchlosť na súčasnej generácii hardvéru je niekoľkonásobne nižšia ako jednoduchá presnosť. Dôvody sú diskutované v našom. Implementácia tejto podpory v GT200 spočíva v tom, že bloky FP32 sa nepoužívajú na získanie výsledku štvornásobne nižšou rýchlosťou; na podporu výpočtov FP64 sa Nvidia rozhodla vytvoriť vyhradené výpočtové bloky. A v GT200 je ich desaťkrát menej ako blokov FP32 (jeden blok s dvojitou presnosťou pre každý multiprocesor).
V skutočnosti môže byť výkon ešte nižší, keďže architektúra je optimalizovaná pre 32-bitové čítanie z pamäte a registrov, navyše nie je potrebná dvojitá presnosť v grafických aplikáciách a v GT200 je pravdepodobnejšie, že bude jednoduchá. A moderné štvorjadrové procesory nevykazujú oveľa menej skutočného výkonu. Táto podpora je však dokonca 10-krát pomalšia ako jednoduchá presnosť, a preto je užitočná pre návrhy so zmiešanou presnosťou. Jednou z bežných techník je získať počiatočné výsledky aproximácie s jednoduchou presnosťou a potom ich spresniť s dvojnásobnou presnosťou. Teraz to možno urobiť priamo na grafickej karte bez odosielania medziľahlých údajov do CPU.
Ďalšia užitočná funkcia CUDA 2.0 nesúvisí s GPU, napodiv. Práve teraz je možné skompilovať kód CUDA do vysoko efektívneho viacvláknového kódu SSE pre rýchle vykonávanie na CPU. To znamená, že teraz je táto funkcia vhodná nielen na ladenie, ale aj na skutočné použitie v systémoch bez grafickej karty Nvidia. Koniec koncov, použitie CUDA v bežnom kóde je obmedzené skutočnosťou, že grafické karty Nvidia, hoci sú najobľúbenejšie medzi špecializovanými video riešeniami, nie sú dostupné vo všetkých systémoch. A pred verziou 2.0 by ste v takýchto prípadoch museli vytvoriť dva rôzne kódy: pre CUDA a samostatne pre CPU. A teraz môžete vykonávať akýkoľvek CUDA program na CPU s vysokou účinnosťou, aj keď pri nižšej rýchlosti ako na video čipoch.
Riešenia s podporou Nvidia CUDA
Všetky grafické karty s podporou CUDA môžu pomôcť urýchliť najnáročnejšie úlohy, od spracovania zvuku a videa až po medicínu a vedecký výskum. Jediným skutočným obmedzením je, že mnohé programy CUDA vyžadujú najmenej 256 megabajtov video pamäte, čo je jedna z najdôležitejších technických špecifikácií pre aplikácie CUDA.
Aktuálny zoznam produktov s podporou CUDA nájdete na. V čase písania tohto článku výpočty CUDA podporovali všetky produkty radu Geforce 200, Geforce 9 a Geforce 8, vrátane mobilných produktov počínajúc Geforce 8400M, ako aj čipsetov Geforce 8100, 8200 a 8300. Tiež moderné Quadro a všetky Tesla: S1070, C1060, C870, D870 a S870.


Zvlášť poznamenávame, že spolu s novými grafickými kartami Geforce GTX 260 a 280 boli ohlásené zodpovedajúce riešenia pre vysokovýkonné výpočty: Tesla C1060 a S1070 (zobrazené na fotografii vyššie), ktoré budú k dispozícii na kúpu túto jeseň. GPU je v nich rovnaké - GT200, v C1060 je to jedno, v S1070 - štyri. Na rozdiel od herných riešení však využívajú štyri gigabajty pamäte pre každý čip. Jedinou nevýhodou je nižšia frekvencia pamäte a šírka pásma pamäte ako u herných kariet, ktoré poskytujú 102 GB/s na čip.
Súpiska Nvidia CUDA
CUDA obsahuje dve API: vysokú úroveň (CUDA Runtime API) a nízku úroveň (CUDA Driver API), aj keď nie je možné použiť obe súčasne v jednom programe, musíte použiť jedno alebo druhé. Vysoká úroveň funguje "navrchu" nízkej úrovne, všetky runtime volania sú preložené do jednoduchých inštrukcií spracovaných nízkoúrovňovým Driver API. Ale aj „vysokoúrovňové“ API predpokladá znalosti o štruktúre a fungovaní video čipov Nvidia, nie je tam príliš vysoká miera abstrakcie.

Existuje ešte jedna úroveň, ešte vyššia - dve knižnice:
CUBLAS- CUDA verzia BLAS (Basic Linear Algebra Subprograms), určená na výpočet problémov lineárnej algebry a využitie priameho prístupu k zdrojom GPU;
CUFFT- CUDA verzia knižnice Fast Fourier Transform na výpočet rýchlej Fourierovej transformácie, ktorá je široko používaná pri spracovaní signálov. Podporované sú nasledujúce typy transformácií: komplexná-komplexná (C2C), reálna-komplexná (R2C) a komplexná-reálna (C2R).
Pozrime sa bližšie na tieto knižnice. CUBLAS sú štandardné algoritmy lineárnej algebry preložené do jazyka CUDA, v súčasnosti je podporovaná len určitá množina základných funkcií CUBLAS. Knižnica sa používa veľmi jednoducho: musíte vytvoriť maticu a vektorové objekty v pamäti grafickej karty, naplniť ich údajmi, zavolať požadované funkcie CUBLAS a načítať výsledky z video pamäte späť do systémovej pamäte. CUBLAS obsahuje špeciálne funkcie na vytváranie a ničenie objektov v pamäti GPU, ako aj na čítanie a zápis dát do tejto pamäte. Podporované funkcie BLAS: úrovne 1, 2 a 3 pre reálne čísla, úroveň 1 CGEMM pre komplexné čísla. Úroveň 1 sú operácie vektor-vektor, úroveň 2 sú operácie vektor-matica, úroveň 3 sú operácie matice-matice.
CUFFT - CUDA variant funkcie rýchlej Fourierovej transformácie - široko používaný a veľmi dôležitý pri analýze signálu, filtrovaní atď. CUFFT poskytuje jednoduché rozhranie na efektívny výpočet FFT na GPU Nvidia bez toho, aby ste museli vyvíjať svoj vlastný GPU FFT. CUDA verzia FFT podporuje 1D, 2D a 3D transformácie komplexných a reálnych dát, dávkové vykonávanie pre niekoľko 1D transformácií paralelne, 2D a 3D transformácie je možné dimenzovať, pre 1D je podporovaných až 8 miliónov prvkov.
Základy programovania CUDA
Aby ste porozumeli ďalšiemu textu, mali by ste pochopiť základné architektonické vlastnosti video čipov Nvidia. GPU pozostáva z niekoľkých klastrov na spracovanie textúr. Každý klaster pozostáva zo zväčšeného bloku vzoriek textúr a dvoch alebo troch streamovacích multiprocesorov, z ktorých každý pozostáva z ôsmich výpočtových zariadení a dvoch superfunkčných blokov. Všetky inštrukcie sú vykonávané na princípe SIMD, kedy je jedna inštrukcia aplikovaná na všetky vlákna v osnove (pojem z textilného priemyslu, v CUDA je to skupina 32 vlákien – minimálne množstvo dát spracovávaných multiprocesormi). Tento spôsob vykonávania sa nazýval SIMT (single inštrukcie multiple threads).

Každý z multiprocesorov má určité zdroje. Existuje teda špeciálna zdieľaná pamäť 16 kilobajtov na multiprocesor. Toto však nie je vyrovnávacia pamäť, pretože programátor ju môže použiť na akúkoľvek potrebu, ako napríklad lokálny obchod v SPU procesorov Cell. Táto zdieľaná pamäť umožňuje výmenu informácií medzi vláknami rovnakého bloku. Je dôležité, aby všetky vlákna jedného bloku vždy vykonával rovnaký multiprocesor. A streamy z rôznych blokov si nemôžu vymieňať dáta a toto obmedzenie si musíte zapamätať. Zdieľaná pamäť je často užitočná, okrem prípadov, keď viaceré vlákna pristupujú k rovnakej pamäťovej banke. Multiprocesory môžu tiež pristupovať k videopamäti, ale s vyššou latenciou a horšou šírkou pásma. Na urýchlenie prístupu a zníženie frekvencie prístupu k videopamäti majú multiprocesory 8 kilobajtov vyrovnávacej pamäte pre konštanty a dáta textúr.
Multiprocesor používa registre 8192-16384 (pre G8x / G9x, respektíve GT2xx) spoločné pre všetky toky všetkých na ňom vykonávaných blokov. Maximálny počet blokov na multiprocesor pre G8x / G9x je osem a počet warp je 24 (768 vlákien na multiprocesor). Celkovo dokážu špičkové grafické karty zo série Geforce 8 a 9 spracovať až 12288 streamov naraz. Geforce GTX 280 na báze GT200 ponúka až 1024 vlákien na multiprocesor, má 10 klastrov troch multiprocesorov, ktoré spracovávajú až 30720 vlákien. Poznanie týchto obmedzení vám umožňuje optimalizovať algoritmy pre dostupné zdroje.
Prvým krokom pri portovaní existujúcej aplikácie do CUDA je jej profilovanie a identifikácia úzkych miest v kóde, ktoré bránia výkonu. Ak sú takéto sekcie vhodné na rýchle paralelné vykonávanie, tieto funkcie sa prenesú do rozšírení C a CUDA na vykonávanie na GPU. Program je kompilovaný pomocou kompilátora dodávaného spoločnosťou Nvidia, ktorý generuje kód pre CPU aj GPU. Pri vykonávaní programu centrálny procesor vykonáva svoje časti kódu a GPU vykonáva kód CUDA s najťažšími paralelnými výpočtami. Táto časť venovaná GPU sa nazýva jadro. Jadro definuje operácie, ktoré sa budú vykonávať s údajmi.
Video čip prijíma jadro a vytvára kópie pre každú dátovú položku. Tieto kópie sa nazývajú vlákna. Prúd obsahuje počítadlo, registre a stav. Pre veľké množstvo údajov, ako je spracovanie obrazu, sú spustené milióny vlákien. Vlákna sa vykonávajú v skupinách po 32, ktoré sa nazývajú warp "s. Warp" a sú priradené k vykonávaniu na špecifických prúdových multiprocesoroch. Každý multiprocesor pozostáva z ôsmich jadier – stream procesorov, ktoré vykonajú jednu MAD inštrukciu za takt. Na vykonanie jedného 32-vláknového warpu sú potrebné štyri taktovacie cykly multiprocesora (hovoríme o frekvencii shader domény, ktorá je 1,5 GHz a viac).
Multiprocesor nie je tradičný viacjadrový procesor, je vhodný pre multithreading, podporuje až 32 warpov naraz.Hardvér si pri každom takte vyberie, ktorý warp vykoná, a prepne z jedného na druhý bez straty taktu. Analogicky s centrálnym procesorom je to ako spustenie 32 programov súčasne a prepínanie medzi nimi v každom takte bez straty prepínania kontextu. V skutočnosti jadrá CPU podporujú súčasné vykonávanie jedného programu a prepínajú sa na iné s oneskorením stoviek hodinových cyklov.
Programovací model CUDA
CUDA opäť používa paralelný výpočtový model, keď každý z procesorov SIMD paralelne vykonáva rovnakú inštrukciu na rôznych dátových položkách. GPU je výpočtové zariadenie, koprocesor (zariadenie) pre centrálny procesor (hostiteľ), ktorý má vlastnú pamäť a paralelne spracováva veľké množstvo vlákien. Jadro (kernel) je funkcia pre GPU, ktorú vykonávajú vlákna (analógia 3D grafiky - shader).
Vyššie sme povedali, že video čip sa líši od CPU v tom, že dokáže spracovať desiatky tisíc vlákien súčasne, čo je zvyčajne pre grafiku, ktorá je dobre paralelizovaná. Každý tok je skalárny a nevyžaduje balenie údajov do 4-zložkových vektorov, čo je pre väčšinu úloh pohodlnejšie. Počet logických vlákien a blokov vlákien prevyšuje počet fyzických vykonávacích jednotiek, čo poskytuje dobrú škálovateľnosť pre celý rad riešení spoločnosti.
Programovací model CUDA predpokladá zoskupovanie vlákien. Vlákna sa kombinujú do blokov vlákien - jednorozmerných alebo dvojrozmerných mriežok vlákien, ktoré navzájom spolupracujú pomocou zdieľanej pamäte a synchronizačných bodov. Program (kernel) beží na mriežke blokov vlákien, pozri obrázok nižšie. Jedna sieť sa vykonáva naraz. Každý blok môže mať jedno-, dvoj- alebo trojrozmerný tvar a môže mať 512 vlákien na aktuálnom hardvéri.

Bloky vlákien sa vykonávajú v malých skupinách nazývaných warp, ktoré majú veľkosť 32 vlákien. Ide o minimálne množstvo údajov, ktoré je možné spracovať vo viacerých procesoroch. A keďže to nie je vždy vhodné, CUDA vám umožňuje pracovať s blokmi obsahujúcimi od 64 do 512 vlákien.
Zoskupenie blokov do mriežok vám umožní zbaviť sa obmedzení a použiť jadro na viac vlákien v jednom volaní. Pomáha aj pri škálovaní. Ak GPU nemá dostatok zdrojov, vykoná bloky postupne. V opačnom prípade môžu byť bloky vykonávané paralelne, čo je dôležité pre optimálne rozloženie práce na video čipoch rôznych úrovní, počnúc mobilnými a integrovanými.
Pamäťový model CUDA
Pamäťový model v CUDA sa vyznačuje možnosťou bajtového adresovania, podporou zberu aj rozptylu. Pre každý stream procesor je k dispozícii pomerne veľký počet registrov, až 1024 kusov. Prístup k nim je veľmi rýchly, môžete do nich uložiť 32-bitové celé čísla alebo čísla s pohyblivou rádovou čiarkou.
Každé vlákno má prístup k nasledujúcim typom pamäte:

Globálna pamäť- najväčšie množstvo pamäte dostupnej pre všetky multiprocesory na video čipe s veľkosťou od 256 megabajtov do 1,5 gigabajtu na súčasných riešeniach (a až 4 GB na Tesle). Má veľkú šírku pásma, viac ako 100 gigabajtov/s pre špičkové riešenia Nvidia, ale veľmi vysoké latencie niekoľko stoviek hodinových cyklov. Neukladá sa do vyrovnávacej pamäte, podporuje všeobecné pokyny na načítanie a ukladanie a bežné ukazovatele na pamäť.
Lokálna pamäť Je to malé množstvo pamäte, ku ktorej má prístup iba jeden stream procesor. Je pomerne pomalý – rovnaký ako ten globálny.
Zdieľaná pamäť Je 16-kilobajtový (vo video čipoch súčasnej architektúry) blok pamäte, ktorý je zdieľaný všetkými stream procesormi v multiprocesore. Táto pamäť je pomerne rýchla, rovnako ako registre. Poskytuje interoperabilitu vlákien, je priamo riadený vývojárom a má nízku latenciu. Výhody zdieľanej pamäte: využitie vo forme programátorom riadenej cache prvej úrovne, zníženie oneskorení v prístupe exekučných jednotiek (ALU) k dátam, zníženie počtu volaní do globálnej pamäte.
Pamäť konštánt- 64 kilobajtová pamäťová oblasť (rovnaká pre súčasné GPU), len na čítanie všetkými multiprocesormi. Je uložená vo vyrovnávacej pamäti s veľkosťou 8 kilobajtov na multiprocesor. Pomerne pomalé - oneskorenie niekoľkých stoviek hodinových cyklov pri absencii požadovaných údajov vo vyrovnávacej pamäti.
Pamäť textúry- blok pamäte dostupný na čítanie všetkými multiprocesormi. Vzorkovanie údajov sa vykonáva pomocou textúrnych jednotiek video čipu, preto sú možnosti lineárnej interpolácie údajov poskytované bez dodatočných nákladov. Pre každý multiprocesor je uložených 8 kilobajtov. Pomalé ako globálne – stovky hodinových cyklov latencie pri absencii údajov vo vyrovnávacej pamäti.
Prirodzene, globálna, lokálna, textúrová a konštantná pamäť sú fyzicky rovnaká pamäť, známa ako lokálna video pamäť grafickej karty. Ich rozdiely sú v rôznych cachovacích algoritmoch a prístupových modeloch. Centrálny procesor môže aktualizovať a požadovať iba externú pamäť: globálnu, konštantnú a textúru.

Z vyššie uvedeného je zrejmé, že CUDA predpokladá špeciálny prístup k vývoju, nie úplne rovnaký ako v programoch pre CPU. Pri rôznych typoch pamäte je potrebné pamätať na to, že lokálna a globálna pamäť sa neukladá do vyrovnávacej pamäte a latencia pri prístupe k nej je oveľa vyššia ako latencia registrovej pamäte, pretože je fyzicky umiestnená v samostatných mikroobvodoch.
Typický, ale nie povinný vzor riešenia problémov:
- úloha je rozdelená na čiastkové úlohy;
- vstupné dáta sú rozdelené do blokov, ktoré sa zmestia do zdieľanej pamäte;
- každý blok je spracovaný blokom vlákien;
- podblok sa načíta do zdieľanej pamäte z globálnej;
- zodpovedajúce výpočty sa vykonajú na dátach v zdieľanej pamäti;
- výsledky sa skopírujú zo zdieľanej pamäte späť do globálnej pamäte.
Programovacie prostredie
CUDA obsahuje runtime knižnice:
- spoločná časť poskytujúca vstavané vektorové typy a podmnožiny RTL hovorov podporovaných na CPU a GPU;
- Komponent CPU na ovládanie jedného alebo viacerých GPU;
- Komponent GPU, ktorý poskytuje funkcie špecifické pre GPU.
Hlavný proces aplikácie CUDA beží na univerzálnom procesore (hostiteľ), spúšťa niekoľko kópií procesov jadra na grafickej karte. Kód pre CPU robí nasledovné: inicializuje GPU, prideľuje pamäť na grafickej karte a v systéme, skopíruje konštanty do pamäte grafickej karty, spúšťa niekoľko kópií procesov jadra na grafickej karte, skopíruje výsledok z videa pamäť, uvoľní pamäť a ukončí sa.
Ako príklad na pochopenie uveďme kód CPU na pridávanie vektorov, uvedený v CUDA:

Funkcie vykonávané video čipom majú nasledujúce obmedzenia: neexistuje žiadna rekurzia, vo funkciách nie sú žiadne statické premenné a premenlivý počet argumentov. Podporované sú dva typy správy pamäte: lineárna pamäť s prístupom pomocou 32-bitových ukazovateľov a polia CUDA s prístupom iba prostredníctvom funkcií načítania textúr.
Programy CUDA môžu interagovať s grafickými API: na vykresľovanie údajov generovaných v programe, na čítanie výsledkov vykresľovania a ich spracovanie pomocou nástrojov CUDA (napríklad pri implementácii filtrov na následné spracovanie). Za týmto účelom môžu byť zdroje grafického API mapované (so získaním adresy zdroja) do globálneho pamäťového priestoru CUDA. Podporované sú nasledujúce typy prostriedkov grafického rozhrania API: Objekty vyrovnávacej pamäte (PBO / VBO) v OpenGL, vyrovnávacie pamäte vrcholov a textúry (2D, 3D a mapy kocky) Direct3D9.
Etapy kompilácie aplikácie CUDA:

Súbory zdrojového kódu CUDA C sú kompilované pomocou programu NVCC, ktorý je obalom iných nástrojov a volá ich: cudacc, g ++, cl atď. NVCC generuje: kód pre centrálny procesor, ktorý sa kompiluje spolu so zvyškom aplikácie , napísaný v čistom C a objektový kód PTX pre video čip. Spustiteľné súbory s kódom CUDA nevyhnutne vyžadujú knižnicu runtime CUDA (cudart) a knižnicu jadra CUDA (cuda).
Optimalizácia programov CUDA
Prirodzene, v rámci prehľadového článku nemožno uvažovať o závažných otázkach optimalizácie v programovaní CUDA. Poďme si teda v krátkosti priblížiť základy. Ak chcete efektívne využívať možnosti CUDA, musíte zabudnúť na obvyklé metódy písania programov pre CPU a použiť tie algoritmy, ktoré sú dobre paralelizované s tisíckami vlákien. Dôležité je tiež nájsť optimálne miesto na ukladanie dát (registre, zdieľaná pamäť a pod.), minimalizovať prenos dát medzi CPU a GPU a využívať vyrovnávaciu pamäť.
Vo všeobecnosti by ste sa pri optimalizácii programu CUDA mali snažiť dosiahnuť optimálnu rovnováhu medzi veľkosťou a počtom blokov. Viac vlákien v bloku zníži dopad latencie pamäte, ale tiež zníži počet dostupných registrov. Blok 512 vlákien je navyše neefektívny, samotná Nvidia odporúča používať bloky 128 alebo 256 vlákien ako kompromis pre dosiahnutie optimálnej latencie a počtu registrov.
Medzi hlavné body optimalizácie programov CUDA: najaktívnejšie využitie zdieľanej pamäte, pretože je oveľa rýchlejšie ako globálna video pamäť grafickej karty; Operácie čítania a zápisu z globálnej pamäte by mali byť spojené vždy, keď je to možné. Na to je potrebné použiť špeciálne dátové typy na čítanie a zápis naraz 32/64/128 dátových bitov v jednej operácii. Ak sa čítania ťažko kombinujú, môžete skúsiť použiť načítanie textúr.
závery
Hardvérová a softvérová architektúra prezentovaná spoločnosťou Nvidia pre výpočty na video čipoch CUDA sa dobre hodí na riešenie širokého spektra úloh s vysokým paralelizmom. CUDA beží na širokej škále GPU Nvidia a vylepšuje programovací model GPU tým, že je oveľa jednoduchší a pridáva ďalšie funkcie, ako je zdieľaná pamäť, synchronizácia vlákien, dvojitá presnosť a celočíselné operácie.
CUDA je technológia dostupná pre každého vývojára softvéru a môže ju používať každý programátor, ktorý ovláda jazyk C. Musíte si len zvyknúť na inú programovaciu paradigmu, ktorá je vlastná paralelným výpočtom. Ale ak je algoritmus v princípe dobre paralelizovaný, potom sa štúdium a čas strávený programovaním v CUDA mnohonásobne vráti.
Je pravdepodobné, že vzhľadom na rozšírené používanie grafických kariet vo svete vývoj paralelných výpočtov na GPU výrazne ovplyvní priemysel vysokovýkonných počítačov. Tieto možnosti už vyvolali veľký záujem vo vedeckých kruhoch, a nielen v nich. Koniec koncov, potenciál pre zrýchlenie algoritmov, ktoré sa hodia na paralelizáciu (na dostupnom hardvéri, čo je nemenej dôležité), nie sú tak často desiatky naraz.
Univerzálne procesory sa vyvíjajú skôr pomaly, nemajú také výkonnostné skoky. V podstate, hoci to znie príliš nahlas, každý, kto potrebuje rýchle počítače, môže mať teraz na svojom stole lacný osobný superpočítač, niekedy dokonca bez investovania ďalších finančných prostriedkov, keďže grafické karty Nvidia sú tak rozšírené. Nehovoriac o zvýšení efektívnosti v GFLOPS / $ a GFLOPS / Watt, ktoré výrobcovia GPU tak milujú.
Budúcnosť mnohých výpočtov je jednoznačne v paralelných algoritmoch, takmer všetky nové riešenia a iniciatívy smerujú týmto smerom. Zatiaľ je však vývoj nových paradigiem v ranom štádiu, musíte manuálne vytvárať vlákna a plánovať prístup do pamäte, čo v porovnaní s konvenčným programovaním komplikuje úlohy. Technológia CUDA ale urobila krok správnym smerom a úspešné riešenie je na nej jasne vidieť, najmä ak sa Nvidii podarí čo najviac presvedčiť vývojárov o svojich výhodách a perspektívach.
Ale, samozrejme, GPU nenahradia CPU. V súčasnej podobe na to nie sú určené. Teraz, keď sa video čipy postupne posúvajú smerom k CPU, stávajú sa čoraz univerzálnejšími (výpočty s jednou a dvojitou presnosťou s pohyblivou rádovou čiarkou, výpočty celých čísel), takže CPU sú čoraz viac „paralelnejšie“, získavajú veľké množstvo jadier, multivláknové technológie, nehovoriac o vzhľade blokov SIMD a projektov heterogénnych procesorov. S najväčšou pravdepodobnosťou sa GPU a CPU v budúcnosti jednoducho spoja. Je známe, že na podobných projektoch pracuje mnoho spoločností vrátane Intelu a AMD. Je jedno, či GPU pohltí CPU, alebo naopak.
V článku sme hovorili najmä o výhodách CUDA. Ale je tu aj mucha. Jednou z mála nevýhod CUDA je slabá prenosnosť. Táto architektúra funguje iba na video čipoch od tejto spoločnosti a dokonca nie na všetkých, ale počnúc sériami Geforce 8 a 9 a zodpovedajúcimi Quadro a Tesla. Áno, takýchto riešení je na svete veľa, Nvidia udáva cifru 90 miliónov CUDA-kompatibilných video čipov. To je v poriadku, ale konkurenti ponúkajú svoje riešenia iné ako CUDA. Takže AMD má Stream Computing, Intel bude mať Ct v budúcnosti.
Ktorá z technológií zvíťazí, rozšíri sa a bude žiť dlhšie ako ostatné – to ukáže až čas. Ale CUDA má dobré šance, napríklad v porovnaní s Stream Computing predstavuje rozvinutejšie a ľahko použiteľné programovacie prostredie v bežnom jazyku C. Možno tretia strana môže pomôcť pri definícii vydaním nejakého všeobecného riešenia. Microsoft napríklad v ďalšej aktualizácii DirectX pod verziou 11 sľúbil výpočtové shadery, ktoré sa môžu stať akýmsi priemerným riešením vyhovujúcim každému, alebo takmer každému.
Na základe predbežných údajov si tento nový typ shadera veľa požičiava z modelu CUDA. A programovaním v tomto prostredí už teraz môžete získať výhody okamžite a potrebné zručnosti do budúcnosti. Z pohľadu HPC má DirectX aj jasnú nevýhodu v podobe zlej prenosnosti, keďže toto API je obmedzené na platformu Windows. Vyvíja sa však ďalší štandard – otvorená multiplatformová iniciatíva OpenCL, ktorú podporuje väčšina spoločností vrátane Nvidie, AMD, Intelu, IBM a mnohých ďalších.
Majte na pamäti, že v nasledujúcom článku CUDA preskúmate konkrétne praktické aplikácie vedeckých a iných negrafických výpočtov, ktoré vykonávajú vývojári z celého sveta pomocou Nvidia CUDA.
Desaťročia platí Moorov zákon, ktorý hovorí, že počet tranzistorov na čipe sa každé dva roky zdvojnásobí. Bolo to však už v roku 1965 a za posledných 5 rokov sa myšlienka fyzického viacjadra v procesoroch spotrebiteľskej triedy začala rýchlo rozvíjať: v roku 2005 Intel predstavil Pentium D a AMD - Athlon X2. Potom by sa aplikácie využívajúce 2 jadrá dali spočítať na prstoch jednej ruky. Ďalšia generácia procesorov Intel, ktorá urobila revolúciu, však mala rovno 2 fyzické jadrá. Navyše, v januári 2007 sa objavila séria Quad, súčasne Moore sám priznal, že jeho zákon čoskoro prestane fungovať.
Čo teraz? Dvojjadrové procesory aj v rozpočtových kancelárskych systémoch a 4 fyzické jadrá sa stali normou len za 2-3 roky. Frekvencia procesorov sa nezvyšuje, ale zlepšuje sa architektúra, zvyšuje sa počet fyzických a virtuálnych jadier. Myšlienka použitia video adaptérov vybavených desiatkami alebo dokonca stovkami výpočtových „blokov“ však existuje už dlho.
A hoci sú vyhliadky na prácu s GPU obrovské, najobľúbenejšie riešenie - Nvidia CUDA je zadarmo, má veľa dokumentácie a vo všeobecnosti je veľmi jednoduché na implementáciu, nie je veľa aplikácií, ktoré využívajú túto technológiu. V podstate ide o všelijaké špecializované výpočty, ktoré bežného používateľa vo väčšine prípadov nezaujímajú. Existujú však aj programy určené pre masového používateľa a o nich si povieme v tomto článku.
Na úvod trochu o samotnej technológii a o tom, čím sa jedáva. Pretože Pri písaní článku ma vedie široká škála čitateľov, potom sa ho pokúsim vysvetliť prístupným jazykom bez zložitých pojmov a trochu stručne.
CUDA(English Compute Unified Device Architecture) je softvérová a hardvérová architektúra, ktorá umožňuje prácu s grafickými procesormi NVIDIA, ktoré podporujú technológiu GPGPU (arbitrary computing na grafických kartách). Architektúra CUDA sa prvýkrát objavila na trhu s uvedením ôsmej generácie čipu NVIDIA G80 a je prítomná vo všetkých nasledujúcich sériách grafických čipov používaných v rodinách akcelerátorov GeForce, Quadro a Tesla. (c) Wikipedia.org
Prichádzajúce toky sú spracovávané nezávisle na sebe, t.j. paralelný.

Okrem toho existuje rozdelenie do 3 úrovní:

Mriežka- jadro. Obsahuje jedno / dvoj / trojrozmerné pole blokov.
Blokovať- obsahuje veľa vlákien (vlákno). Prúdy rôznych blokov nemôžu navzájom interagovať. Prečo ste potrebovali zaviesť bloky? Každý blok je v podstate zodpovedný za svoju vlastnú podúlohu. Napríklad veľký obrázok (ktorý je maticou) možno rozdeliť na niekoľko menších častí (matíc) a pracovať paralelne s každou časťou obrázka.
Niť- Prúd. Vlákna v rámci jedného bloku môžu interagovať buď prostredníctvom zdieľanej pamäte, ktorá je mimochodom oveľa rýchlejšia ako globálna pamäť, alebo prostredníctvom nástrojov na synchronizáciu vlákien.
Warp- toto je spojenie interagujúcich streamov, pre všetky moderné GPU je veľkosť Warpu 32. Ďalej prichádza polovičná osnova, čo je polovica warp'a, keďže prístup do pamäte zvyčajne prebieha oddelene pre prvú a druhú polovicu warpu.
Ako vidíte, táto architektúra je skvelá na paralelizáciu úloh. A hoci sa programovanie vykonáva v jazyku C s určitými obmedzeniami, v skutočnosti to nie je také jednoduché nie všetko sa dá paralelizovať. Neexistujú ani štandardné funkcie na generovanie náhodných čísel (alebo inicializáciu), to všetko je potrebné implementovať samostatne. A hoci existuje dostatok hotových možností, to všetko neprináša radosť. Možnosť použiť rekurziu je relatívne nová.
Pre názornosť bol napísaný malý konzolový (pre minimalizáciu kódu) program, ktorý vykonáva operácie s dvomi float poliami, t.j. s neceločíselnými hodnotami. Z vyššie uvedených dôvodov inicializáciu (naplnenie poľa rôznymi ľubovoľnými hodnotami) vykonal CPU. Potom sa vykonalo 25 rôznych operácií so zodpovedajúcimi prvkami z každého poľa a medzivýsledky sa zapísali do tretieho poľa. Veľkosť poľa sa zmenila, výsledky sú nasledovné:
Celkovo boli vykonané 4 testy:
1024 prvkov v každom poli:

Je jasne vidieť, že pri takom malom počte prvkov nemajú paralelné výpočty zmysel samotné výpočty sú oveľa rýchlejšie ako ich príprava.
4096 prvkov v každom poli:

A teraz môžete vidieť, že grafická karta vykonáva operácie na poliach 3-krát rýchlejšie ako procesor. Okrem toho sa čas vykonania tohto testu na grafickej karte nezvýšil (mierne skrátenie času možno pripísať chybe).
Teraz je v každom poli 12288 prvkov:

Medzera medzi grafickou kartou sa zdvojnásobila. Opäť si uvedomte, že čas vykonania na grafickej karte sa zvýšil.
nepodstatne, ale na procesore viac ako 3x, t.j. úmerné zložitosti úlohy.
A posledný test - 36864 prvkov v každom poli:

V tomto prípade dosahuje zrýchlenie pôsobivé hodnoty - takmer 22-krát rýchlejšie na grafickej karte. A opäť sa čas vykonávania na grafickej karte nevýznamne zvýšil a na procesore - predpísané 3-krát, čo je opäť úmerné komplikácii úlohy.
Ak budete naďalej komplikovať výpočty, grafická karta vyhráva čoraz viac. Hoci je príklad trochu prehnaný, vo všeobecnosti jasne ukazuje situáciu. Ale ako bolo spomenuté vyššie, nie všetko sa dá paralelizovať. Napríklad výpočet pi. Sú tam len príklady napísané metódou Monte Carlo, ale presnosť výpočtov je na 7 desatinných miest, t.j. pravidelný plavák. Na zvýšenie presnosti výpočtov je potrebná dlhá aritmetika, ale tu vznikajú problémy, pretože je veľmi, veľmi ťažké efektívne implementovať. Na internete som nenašiel príklady s použitím CUDA a výpočtu Pi na 1 milión desatinných miest. Boli urobené pokusy napísať takúto aplikáciu, ale najjednoduchšou a najefektívnejšou metódou na výpočet pi je Brent-Salaminov algoritmus alebo Gaussov vzorec. V známom SuperPI sa s najväčšou pravdepodobnosťou (súdiac podľa rýchlosti práce a počtu iterácií) používa Gaussov vzorec. A súdiac podľa
skutočnosť, že SuperPI je jednovláknová, nedostatok príkladov pre CUDA a zlyhanie mojich pokusov, nie je možné efektívne paralelizovať výpočet Pi.
Mimochodom, môžete vidieť, ako sa v procese vykonávania výpočtov zvyšuje zaťaženie GPU, ako aj alokácia pamäte.

Teraz prejdime k praktickejším výhodám CUDA, a to k aktuálne existujúcim programom využívajúcim túto technológiu. Z väčšej časti ide o všetky druhy audio / video prevodníkov a editorov.
Na testovanie sme použili 3 rôzne video súbory:
- * História filmu Avatar - 1920x1080, MPEG4, h.264.
- * Séria "Lie to me" - 1280 x 720, MPEG4, h.264.
- * Séria „Vo Philadelphii je vždy slnečno“ – 624 x 464, xvid.
Kontajner a veľkosť prvých dvoch súborov boli mkv a 1,55 gb a posledný bol .avi a 272 mb.
Začnime s veľmi senzačným a obľúbeným produktom - Badaboom... Použitá verzia bola - 1.2.1.74 ... Cena programu je $29.90 .

Rozhranie programu je jednoduché a intuitívne - vľavo vyberieme zdrojový súbor alebo disk a vpravo - požadované zariadenie, pre ktoré budeme kódovať. Nechýba ani užívateľský režim, v ktorom sa parametre nastavujú manuálne a ten sa používal.
Na začiatok si povedzme, ako rýchlo a efektívne sa video zakóduje „do seba“, t.j. v rovnakom rozlíšení a približne rovnakej veľkosti. Rýchlosť sa bude merať v fps, a nie v uplynutom čase - je pohodlnejšie porovnať a vypočítať, koľko videa ľubovoľnej dĺžky bude komprimované. Pretože dnes uvažujeme o technológii „zelenej“, potom budú vhodné grafy -)

Rýchlosť kódovania priamo závisí od kvality, to je zrejmé. Treba si uvedomiť, že svetelné rozlíšenie (nazvime to tradične – SD) nie je pre Badaboom problém – rýchlosť kódovania je 5,5-krát vyššia ako pôvodná (24 fps) snímková frekvencia videa. A dokonca aj ťažké 1080p video program skonvertuje v reálnom čase. Treba si uvedomiť, že kvalita výsledného videa je veľmi blízka pôvodnému videu, t.j. kóduje Badaboom veľmi, veľmi kvalitne.
Väčšinou sa ale video predbieha na nižšie rozlíšenie, pozrime sa, ako sa veci majú v tomto režime. So znížením rozlíšenia klesol aj bitový tok videa. Bolo to 9500 kbps pre výstupný súbor 1080p, 4100 kbps pre 720p a 2400 kbps pre 720x404. Výber bol urobený na základe rozumného pomeru veľkosť / kvalita.

Komentáre sú zbytočné. Ak stiahnete zo 720p na normálnu kvalitu SD, prekódovanie 2-hodinového filmu bude trvať asi 30 minút. A zároveň bude zaťaženie procesora zanedbateľné, môžete podnikať bez pocitu nepohodlia.
Čo ak však video skonvertujete do formátu pre mobilné zariadenie? Ak to chcete urobiť, vyberte profil iPhone (bitová rýchlosť 1 Mbps, 480 x 320) a pozrite sa na rýchlosť kódovania:

Musím niečo povedať? Dvojhodinový film v bežnej kvalite pre iPhone sa prekóduje za menej ako 15 minút. HD kvalita je náročnejšia, ale stále dosť rýchla. Hlavná vec je, že kvalita výstupného video materiálu zostáva pri pohľade na displej telefónu na pomerne vysokej úrovni.
Vo všeobecnosti sú dojmy z Badaboom pozitívne, rýchlosť práce poteší, rozhranie je jednoduché a priamočiare. Všetky druhy chýb v predchádzajúcich verziách (v roku 2008 som stále používal beta) boli odstránené. Až na jednu vec - cesta k zdrojovému súboru, ako aj k priečinku, do ktorého sa ukladá hotové video, by nemala obsahovať ruské písmená. Ale na pozadí predností programu je táto nevýhoda zanedbateľná.
Ďalší v poradí budeme mať Super LoiLoScope... Pýtajú sa na bežnú verziu 3 280 rubľov a za dotykovú verziu podporujúcu dotykové ovládanie vo Windows 7 si pýtajú toľko 4 440 rubľov... Skúsme prísť na to, prečo chce vývojár také peniaze a prečo editor videa potrebuje multitouch podporu. Bola použitá najnovšia verzia - 1.8.3.3 .
Je dosť ťažké opísať rozhranie programu slovami, preto som sa rozhodol natočiť krátke video. Hneď musím povedať, že ako všetky video konvertory pre CUDA, aj GPU akcelerácia je podporovaná len pre video výstup v MPEG4 s kodekom h.264.
Počas kódovania je zaťaženie procesora 100%, ale to nespôsobuje nepohodlie. Prehliadač a ďalšie nenáročné aplikácie sa nespomalia.
Teraz prejdime k výkonu. Na začiatok je všetko rovnaké ako pri Badaboom – prekódovanie videa do rovnakej kvality.

Výsledky sú oveľa lepšie ako Badaboom. Kvalita má tiež navrch, rozdiel oproti originálu je vidieť len pri porovnaní rámikov vo dvojici pod lupou.

Páni, tu LoiloScope obchádza Badaboom 2,5-krát. Zároveň môžete jednoducho paralelne strihať a kódovať ďalšie video, čítať správy a dokonca pozerať film a bez problémov sa dá prehrať aj FullHD, hoci zaťaženie procesora je maximálne.
Teraz skúsme spraviť video pre mobilné zariadenie, profil pomenujeme tak, ako sa volal v Badaboom – iPhone (480x320, 1 Mbps):

Nemá to chybu. Všetko bolo niekoľkokrát kontrolované, zakaždým bol výsledok rovnaký. S najväčšou pravdepodobnosťou sa to stane z jednoduchého dôvodu, že súbor SD je napísaný s iným kodekom a v inom kontajneri. Pri transkódovaní sa video najskôr dekóduje, rozdelí na matice určitej veľkosti a skomprimuje. ASP dekodér použitý v prípade xvid je pomalší ako AVC (pre h.264) pri paralelnom dekódovaní. 192 fps je však 8-krát rýchlejšia ako pôvodná rýchlosť videa, 23-minútový zhluk je komprimovaný za menej ako 4 minúty. Situácia sa opakovala s ďalšími súbormi komprimovanými v xvid / DivX.
LoiloScope zanechal o sebe len príjemné dojmy - rozhranie je napriek svojej nezvyčajnosti pohodlné a funkčné a rýchlosť práce je mimo chvály. Pomerne slabá funkcionalita je trochu frustrujúca, ale často pri jednoduchej úprave stačí mierne upraviť farby, urobiť plynulé prechody, prekryť text a LoiloScope si s tým poradí vynikajúco. Trochu desivá je aj cena – viac ako 100 dolárov za bežnú verziu je v zahraničí normálne, no aj tak sa nám takéto čísla zdajú byť trochu divoké. Aj keď, priznám sa, že keby som napríklad často natáčal a strihal domáce videá, možno by som rozmýšľal nad kúpou. Zároveň som si mimochodom overil možnosť úpravy HD (či skôr AVCHD) obsahu priamo z videokamery bez predchádzajúcej konverzie do iného formátu, LoiloScope nemá problémy so súbormi mts.
Vráťme sa do histórie – späť do roku 2003, kedy sa Intel a AMD zúčastnili spoločných pretekov o najvýkonnejší procesor. V priebehu niekoľkých rokov viedli tieto preteky k výraznému zvýšeniu rýchlosti hodín, najmä od vydania Intel Pentium 4.
Ale preteky sa rýchlo blížili k svojmu limitu. Po vlne obrovského nárastu taktov (v rokoch 2001 až 2003 sa takt Pentia 4 zdvojnásobil z 1,5 na 3 GHz) sa používatelia museli uspokojiť s desatinami gigahertzov, ktoré výrobcovia dokázali vyžmýkať (od r. 2003 až 2005 sa taktovanie zvýšilo iba z 3 na 3, 8 GHz).
Dokonca aj architektúry optimalizované pre vysoké takty, ako Prescott, začali mať ťažkosti, a tentoraz nielen produkčné. Výrobcovia čipov jednoducho narazili na fyzikálne zákony. Niektorí analytici dokonca predpovedali, že Mooreov zákon prestane fungovať. To sa však nestalo. Pôvodný význam zákona je často skreslený, ale týka sa počtu tranzistorov na povrchu kremíkového jadra. Po dlhú dobu bol nárast počtu tranzistorov v CPU sprevádzaný zodpovedajúcim nárastom výkonu - čo viedlo k skresleniu významu. Potom sa však situácia skomplikovala. Konštruktéri architektúry CPU pristúpili k zákonu redukcie zisku: počet tranzistorov, ktoré bolo potrebné pridať pre požadované zvýšenie výkonu, bol čoraz viac, čo viedlo k slepej uličke.
 |
Zatiaľ čo výrobcovia CPU si ťahali posledné vlasy na hlave a snažili sa nájsť riešenia svojich problémov, výrobcovia GPU naďalej pozoruhodne ťažili z výhod Moorovho zákona.

Prečo sa nedostali do rovnakej slepej uličky ako architekti CPU? Dôvod je veľmi jednoduchý: CPU sú navrhnuté pre maximálny výkon v toku inštrukcií, ktoré spracúvajú rôzne dáta (celé čísla aj čísla s pohyblivou rádovou čiarkou), vykonávajú náhodný prístup do pamäte atď. Doteraz sa vývojári snažia poskytovať viac paralelizmu inštrukcií – teda vykonávať paralelne čo najviac inštrukcií. Napríklad pri Pentiu sa objavilo superskalárne vykonávanie, keď za určitých podmienok bolo možné vykonať dve inštrukcie za cyklus. Pentium Pro dostalo mimo poradie vykonávanie inštrukcií, čo umožnilo optimalizovať prácu výpočtových jednotiek. Problém je v tom, že paralelné vykonávanie sekvenčného toku inštrukcií má zjavné obmedzenia, takže slepé zvýšenie počtu výpočtových jednotiek neprináša žiadnu výhodu, pretože budú väčšinu času stále nečinné.
Naproti tomu úloha GPU je pomerne jednoduchá. Pozostáva z prijatia skupiny polygónov na jednej strane a generovania skupiny pixelov na druhej strane. Polygóny a pixely sú na sebe nezávislé, takže je možné ich spracovávať paralelne. V GPU sa teda dá veľká časť kryštálu rozdeliť na výpočtové jednotky, ktoré sa na rozdiel od CPU aj reálne využijú.
 |
Pre zväčšenie kliknite na obrázok.
GPU sa od CPU líši nielen v tomto. Prístup k pamäti v GPU je veľmi viazaný - ak sa číta texel, potom sa po niekoľkých hodinových cykloch prečíta susedný texel; keď sa zaznamená pixel, po niekoľkých hodinových cykloch sa zaznamená susedný pixel. Rozumným usporiadaním pamäte môžete dosiahnuť výkon blízko teoretickej šírky pásma. To znamená, že GPU na rozdiel od CPU nevyžaduje obrovskú vyrovnávaciu pamäť, keďže jeho úlohou je zrýchliť operácie textúrovania. Všetko, čo je potrebné, je niekoľko kilobajtov obsahujúcich niekoľko texelov používaných v bilineárnych a trilineárnych filtroch.
|
Pre zväčšenie kliknite na obrázok.
Nech žije GeForce FX!
Tieto dva svety zostali na dlhý čas oddelené. Na kancelárske úlohy a internetové aplikácie sme používali CPU (alebo dokonca viacero CPU) a GPU boli dobré len na zrýchlenie vykresľovania. Jedna vec však všetko zmenila: konkrétne príchod programovateľných GPU. Centrálne procesorové jednotky sa spočiatku nemali čoho báť. Prvé takzvané programovateľné GPU (NV20 a R200) boli sotva hrozbou. Počet inštrukcií v programe zostal obmedzený na približne 10, pracovalo sa s veľmi exotickými dátovými typmi, ako sú 9- alebo 12-bitové čísla s pevným bodom.
 |
Pre zväčšenie kliknite na obrázok.
Moorov zákon však opäť ukázal svoju najlepšiu stránku. Nárast počtu tranzistorov zvýšil nielen počet výpočtových jednotiek, ale zlepšil aj ich flexibilitu. Vzhľad NV30 možno považovať za výrazný krok vpred z viacerých dôvodov. Samozrejme, hráčom sa karty NV30 veľmi nepáčili, no nové GPU sa začali spoliehať na dve funkcie, ktoré mali zmeniť vnímanie GPU nielen ako grafických akcelerátorov.
- Podpora výpočtov s jedinou presnosťou s pohyblivou rádovou čiarkou (aj keď nevyhovuje štandardu IEEE754);
- podpora pre viac ako tisíc pokynov.
Máme teda všetky podmienky, ktoré môžu prilákať priekopníckych výskumníkov, ktorí vždy hľadajú dodatočný výpočtový výkon.
Myšlienka použitia grafických akcelerátorov na matematické výpočty nie je nová. Prvé pokusy sa uskutočnili už v 90. rokoch minulého storočia. Samozrejme, boli veľmi primitívne – väčšinou obmedzené na použitie niektorých hardvérových funkcií, ako je rasterizácia a Z-buffery na urýchlenie úloh, ako je hľadanie trasy alebo vykresľovanie. Voronoiove diagramy .

 |
Pre zväčšenie kliknite na obrázok.
V roku 2003, s príchodom evoluovaných shaderov, bol dosiahnutý nový benchmark - tentoraz vykonávanie maticových výpočtov. V tomto roku bola celá časť SIGGRAPH („Výpočty na GPU“) venovaná novej oblasti IT. Táto skorá iniciatíva sa nazývala GPGPU (General-Purpose computation on GPU). A skorým zlomom bol vzhľad.
Aby ste pochopili úlohu BrookGPU, musíte pochopiť, ako sa všetko stalo predtým, ako sa objavil. Jediný spôsob, ako získať zdroje GPU v roku 2003, bolo použiť jedno z dvoch grafických API, Direct3D alebo OpenGL. V dôsledku toho sa vývojári, ktorí chceli získať výkon GPU pre svoje výpočty, museli spoliehať na dve uvedené rozhrania API. Problém je v tom, že neboli vždy odborníkmi na programovanie grafických kariet, čo vážne sťažovalo prístup k technológiám. Kým 3D programátori pracujú s shadermi, textúrami a fragmentmi, špecialisti v oblasti paralelného programovania sa spoliehajú na vlákna, jadrá, rozptyl atď. Preto bolo najprv potrebné načrtnúť analógie medzi týmito dvoma svetmi.
- Prúd je prúd prvkov rovnakého typu, v GPU môže byť reprezentovaný textúrou. V podstate v klasickom programovaní existuje taký analóg ako pole.
- Kernel- funkcia, ktorá bude aplikovaná nezávisle na každom prvku prúdu; je ekvivalentom pixel shaderu. V klasickom programovaní sa dá urobiť analógia slučky - aplikuje sa na veľké množstvo prvkov.
- Ak chcete čítať výsledky aplikácie jadra na prúd, musíte vytvoriť textúru. Na CPU neexistuje žiadny ekvivalent, pretože existuje úplný prístup k pamäti.
- Miesto v pamäti, kde sa vykoná záznam (v operáciách rozptyl/rozptyl) je riadené vertex shaderom, keďže pixel shader nemôže meniť súradnice spracovávaného pixelu.


Ako vidíte, aj keď vezmeme do úvahy uvedené analógie, úloha nevyzerá jednoducho. A Brook prišiel na pomoc. Tento názov označuje rozšírenia jazyka C („C with streams“, „C with streams“), ako ich nazvali vývojári zo Stanfordu. V jadre bolo úlohou Brooka ukryť pred programátorom všetky komponenty 3D API, čo umožnilo prezentovať GPU ako koprocesor pre paralelné výpočty. Na tento účel kompilátor Brook spracoval súbor .br s kódom C++ a príponami a potom vygeneroval kód C++, ktorý bol prepojený s knižnicou s podporou rôznych výstupov (DirectX, OpenGL ARB, OpenGL NV3x, x86).
 |
Pre zväčšenie kliknite na obrázok.
Brook má viacero zásluh, prvou z nich je vyviesť GPGPU z tieňa, aby sa s technológiou mohla zoznámiť široká verejnosť. Po oznámení projektu však bolo množstvo IT stránok príliš optimistických, že vydanie Brooka spochybňuje existenciu CPU, ktoré budú čoskoro nahradené výkonnejšími GPU. Ako však vidíme, po piatich rokoch sa tak nestalo. Úprimne povedané, nemyslíme si, že sa to niekedy stane. Na druhej strane, pri pohľade na úspešnú evolúciu CPU, ktoré sa čoraz viac orientujú na paralelizmus (viac jadier, SMT multithreading technológia, rozširovanie SIMD blokov), ako aj GPU, ktoré sú naopak čoraz univerzálnejšie. (podpora výpočtov s pohyblivou rádovou čiarkou s jednoduchou presnosťou, celočíselným výpočtom, podporou dvojitej presnosti), vyzerá to, že GPU a CPU sa čoskoro zlúčia. čo sa stane potom? Pohltí GPU CPU, ako sa to stalo v prípade matematických koprocesorov? Je to celkom možné. Intel a AMD v súčasnosti pracujú na podobných projektoch. Ale stále je toho veľa, čo sa môže zmeniť.

Ale späť k našej téme. Výhodou Brooka bola popularizácia konceptu GPGPU, výrazne to zjednodušilo prístup k zdrojom GPU, čo umožnilo čoraz viac používateľov zvládnuť nový programovací model. Na druhej strane, napriek všetkým kvalitám Brooka, k využitiu zdrojov GPU na výpočty bola ešte dlhá cesta.
Jeden z problémov je spojený s rôznymi úrovňami abstrakcie a tiež najmä s nadmerným dodatočným zaťažením vytváraným 3D API, ktoré môže byť dosť citeľné. Závažnejší je však problém s kompatibilitou, s ktorým vývojári z Brook nemohli nič urobiť. Medzi výrobcami GPU existuje silná konkurencia, takže často optimalizujú svoje ovládače. Ak sú tieto optimalizácie pre hráčov z väčšej časti dobré, o chvíľu by mohli ukončiť kompatibilitu s Brookom. Preto je ťažké si predstaviť použitie tohto API v produkčnom kóde, ktorý bude niekde fungovať. A Brook zostal na dlhú dobu partiou nadšených výskumníkov a programátorov.
Úspech Brooka však stačil na to, aby pritiahol pozornosť spoločností ATI a nVidia a o takúto iniciatívu prejavili záujem, pretože by mohla rozšíriť trh a otvoriť nový významný sektor pre spoločnosti.
Výskumníci pôvodne zapojení do projektu Brook sa rýchlo pripojili k vývojovým tímom v Santa Clare, aby predstavili globálnu stratégiu rozvoja nového trhu. Cieľom bolo vytvoriť kombináciu hardvéru a softvéru vhodnej pre úlohy GPGPU. Keďže vývojári nVidia poznajú všetky tajomstvá svojich GPU, nedalo sa spoliehať na grafické API, ale skôr komunikovať s GPU cez ovládač. Aj keď to má, samozrejme, svoje problémy. Vývojový tím CUDA (Compute Unified Device Architecture) teda vytvoril sadu softvérových vrstiev pre prácu s GPU.
 |
Pre zväčšenie kliknite na obrázok.
Ako môžete vidieť na diagrame, CUDA poskytuje dve API.
- API vysokej úrovne: CUDA Runtime API;
- nízkoúrovňové API: CUDA Driver API.
Pretože vysokoúrovňové rozhranie API je implementované nad nízkoúrovňovým rozhraním API, každé volanie funkcie runtime je rozdelené do jednoduchších pokynov, ktoré spracováva rozhranie Driver API. Upozorňujeme, že tieto dve rozhrania API sa navzájom vylučujú: programátor môže použiť jedno alebo druhé rozhranie API, ale zmiešavanie volaní funkcií týchto dvoch rozhraní API nebude fungovať. Vo všeobecnosti je pojem „rozhranie API na vysokej úrovni“ relatívny. Dokonca aj Runtime API je také, že by ho mnohí považovali za nízkoúrovňové; poskytuje však funkcie, ktoré sú celkom užitočné pri inicializácii alebo správe kontextu. Nečakajte však obzvlášť vysokú úroveň abstrakcie – stále musíte mať dobré znalosti o GPU nVidia a o tom, ako fungujú.

S Driver API je ešte ťažšie pracovať; spustenie spracovania GPU si vyžaduje viac úsilia. Na druhej strane je nízkoúrovňové API flexibilnejšie a v prípade potreby poskytuje programátorovi dodatočnú kontrolu. Dve API sú schopné pracovať so zdrojmi OpenGL alebo Direct3D (zatiaľ iba deviata verzia). Výhody tejto funkcie sú zrejmé - CUDA sa dá použiť na vytváranie zdrojov (geometria, procedurálne textúry atď.), ktoré je možné odovzdať grafickému API, alebo naopak, môžete nechať 3D API posielať výsledky vykresľovania do CUDA. program, ktorý zase vykoná následné spracovanie. Existuje mnoho príkladov týchto interakcií a výhodou je, že zdroje sú naďalej uložené v pamäti GPU bez toho, aby museli prejsť cez zbernicu PCI Express, ktorá je stále úzkym miestom.

Je však potrebné poznamenať, že zdieľanie zdrojov vo videopamäti nie je vždy dokonalé a môže viesť k určitým „bolestiam hlavy“. Napríklad pri zmene rozlíšenia alebo farebnej hĺbky majú prednosť grafické dáta. Ak teda potrebujete navýšiť zdroje vo framebufferi, tak to ovládač bez problémov spraví na úkor zdrojov CUDA aplikácií, ktoré sa s chybou jednoducho „rozbehnú“. Nie veľmi elegantné, samozrejme, ale to by sa nemalo stávať príliš často. A keď sme začali hovoriť o nevýhodách: ak chcete použiť viacero GPU pre aplikácie CUDA, musíte najskôr vypnúť režim SLI, inak aplikácie CUDA budú môcť „vidieť“ iba jeden GPU.

Napokon, tretiu vrstvu softvéru dostávajú knižnice – presnejšie dve.
- CUBLAS, kde sú potrebné bloky na výpočet lineárnej algebry na GPU;
- CUFFT, ktorý podporuje výpočet Fourierových transformácií, čo je algoritmus široko používaný pri spracovaní signálov.
Predtým, ako sa ponoríme do CUDA, dovoľte mi definovať niekoľko pojmov roztrúsených v dokumentácii nVidia. Spoločnosť zvolila veľmi špecifickú terminológiu, na ktorú si ťažko zvyká. V prvom rade si to všimnite vlákno v CUDA má ďaleko od rovnakého významu ako vlákno CPU, ani to nie je ekvivalent vlákna v našich článkoch o GPU. Vlákno GPU je v tomto prípade základnou sadou údajov, ktoré je potrebné spracovať. Na rozdiel od vlákien CPU sú vlákna CUDA veľmi „ľahké“, to znamená, že prepínanie kontextu medzi dvoma vláknami nie je v žiadnom prípade operácia náročná na zdroje.
Druhý výraz, ktorý sa často nachádza v dokumentácii CUDA, je osnova... Nie je tu žiadny zmätok, pretože v ruštine neexistuje žiadny analóg (pokiaľ nie ste fanúšikom Start Trek alebo hry Warhammer). V skutočnosti je pojem prevzatý z textilného priemyslu, kde sa útková priadza preťahuje cez osnovnú priadzu, ktorá sa napína na stroji. Warp v CUDA je skupina 32 vlákien a predstavuje minimálne množstvo dát spracovávaných metódou SIMD v CUDA multiprocesoroch.

Ale táto "zrnitosť" nie je vždy vhodná pre programátora. Preto v CUDA namiesto priamej práce s osnovami môžete pracovať s bloky / blok obsahuje 64 až 512 vlákien.
Nakoniec sa tieto bloky spoja mriežky / mriežka... Výhodou tohto zoskupenia je, že počet blokov súčasne spracovaných GPU úzko súvisí s hardvérovými prostriedkami, ako uvidíme nižšie. Zoskupovanie blokov do mriežok vám umožňuje úplne abstrahovať od tohto obmedzenia a aplikovať jadro/kernel na viac vlákien v jednom volaní bez toho, aby ste museli premýšľať o pevných zdrojoch. Za toto všetko sú zodpovedné knižnice CUDA. Navyše, takýto model sa dobre škáluje. Ak má GPU málo zdrojov, bloky bude vykonávať postupne. Ak je počet výpočtových procesorov veľký, potom je možné bloky vykonávať paralelne. To znamená, že rovnaký kód môže bežať na GPU základnej úrovne aj na špičkových a dokonca budúcich modeloch.

Existuje niekoľko ďalších výrazov v CUDA API, ktoré odkazujú na CPU ( hostiteľ / hostiteľ) a GPU ( zariadenie / zariadenie). Ak vás tento malý úvod nevystrašil, potom je čas pozrieť sa na CUDA bližšie.
Ak pravidelne čítate Tomovu príručku k hardvéru, architektúra najnovších GPU od nVidie je vám známa. Ak nie, odporúčame vám prečítať si tento článok. nVidia GeForce GTX 260 a 280: ďalšia generácia grafických kariet„Pokiaľ ide o CUDA, nVidia prezentuje architektúru trochu iným spôsobom, ukazuje niektoré detaily, ktoré boli predtým skryté.

Ako môžete vidieť na obrázku vyššie, jadro shadera nVidia sa skladá z viacerých klastrov procesorov textúr. (Texture Processor Cluster, TPC)... Napríklad 8800 GTX používal osem klastrov, 8800 GTS šesť atď. Každý klaster sa v skutočnosti skladá z textúrovej jednotky a dvoch streamovací multiprocesor... Tie zahŕňajú začiatok potrubia (predný koniec), ktorý číta a dekóduje inštrukcie, ako aj ich odosielanie na vykonanie, a koniec potrubia (zadný koniec), ktorý pozostáva z ôsmich výpočtových zariadení a dvoch superfunkčných zariadení. . SFU (superfunkčná jednotka) kde sa inštrukcie vykonávajú podľa princípu SIMD, to znamená, že jedna inštrukcia platí pre všetky vlákna vo warpe. nVidia tento spôsob nazýva SIMT(jedna inštrukcia viac vlákien, jedna inštrukcia, veľa vlákien). Je dôležité poznamenať, že koniec potrubia pracuje s dvojnásobnou frekvenciou jeho začiatku. V praxi to znamená, že táto časť vyzerá dvakrát tak "širšie", ako v skutočnosti je (teda ako 16-kanálový SIMD blok namiesto osemkanálového bloku). Streamovacie multiprocesory fungujú nasledovne: každý cyklus hodín, začiatok pipeline vyberie warp pripravený na vykonanie a začne vykonávať inštrukciu. Trvalo by štyri hodinové cykly, kým by sa inštrukcia aplikovala na všetkých 32 vlákien vo warpe, ale keďže beží s dvojnásobnou frekvenciou štartu, trvá to len dva hodinové cykly (v zmysle spustenia pipeline). Preto, aby začiatok pipeline nestál cyklus a hardvér bol čo najviac zaťažený, v ideálnom prípade môžete každý cyklus striedať inštrukcie - klasická inštrukcia v jednom cykle a inštrukcia pre SFU - v ďalší.
Každý multiprocesor má špecifický súbor prostriedkov, ktoré stojí za pochopenie. Existuje malá oblasť pamäte tzv "Zdieľaná pamäť", 16 KB na multiprocesor. V žiadnom prípade nejde o vyrovnávaciu pamäť: programátor ju môže použiť podľa vlastného uváženia. To znamená, že máme pred sebou niečo blízke lokálnemu úložisku procesorov SPU on Cell. Tento detail je zvláštny, pretože zdôrazňuje, že CUDA je kombináciou softvérových a hardvérových technológií. Táto pamäťová oblasť sa nevyužíva pre pixel shadery, na čo nVidia vtipne poukazuje „nepáči sa nám, keď sa pixely medzi sebou rozprávajú“.
Táto oblasť pamäte otvára možnosť výmeny informácií medzi vláknami. v jednom bloku... Je dôležité zdôrazniť toto obmedzenie: všetky vlákna v bloku sú zaručene vykonávané jedným multiprocesorom. Naopak, viazanie blokov na rôzne multiprocesory nie je stanovené vôbec a dve vlákna z rôznych blokov si za behu nemôžu vymieňať informácie. To znamená, že používanie zdieľanej pamäte nie je jednoduché. Zdieľaná pamäť je však stále opodstatnená, s výnimkou prípadov, keď sa niekoľko vlákien pokúša o prístup k rovnakej pamäťovej banke, čo spôsobuje konflikt. V iných situáciách je prístup k zdieľanej pamäti rovnako rýchly ako k registrom.

Zdieľaná pamäť nie je jedinou pamäťou, ku ktorej majú multiprocesory prístup. Môžu používať video pamäť, ale s nižšou šírkou pásma a vyššou latenciou. Preto, aby sa znížila frekvencia prístupu k tejto pamäti, nVidia vybavila multiprocesory cache (cca 8KB na multiprocesor), v ktorej sú uložené konštanty a textúry.

Multiprocesor má 8192 registrov, ktoré sú spoločné pre všetky prúdy všetkých blokov aktívnych na multiprocesore. Počet aktívnych blokov na multiprocesor nemôže presiahnuť osem a počet aktívnych warpov je obmedzený na 24 (768 vlákien). Preto 8800 GTX zvládne naraz až 12 288 vlákien. Všetky tieto obmedzenia stoja za zmienku, pretože umožňujú optimalizáciu algoritmu na základe dostupných zdrojov.
Optimalizácia programu CUDA teda spočíva v získaní optimálnej rovnováhy medzi počtom blokov a ich veľkosťou. Viac vlákien na blok bude užitočných na zníženie latencie pamäte, ale zníži sa aj počet dostupných registrov na vlákno. Navyše blok 512 vlákien bude neúčinný, pretože na multiprocesore môže byť aktívny iba jeden blok, čo povedie k strate 256 vlákien. Preto nVidia odporúča používať bloky 128 alebo 256 vlákien, čo poskytuje najlepší kompromis medzi nižšou latenciou a počtom registrov pre väčšinu jadier / jadier.
Z programového hľadiska pozostáva CUDA zo sady rozšírení C, ktoré pripomínajú BrookGPU, ako aj niekoľkých špecifických volaní API. Rozšírenia zahŕňajú špecifikátory typu súvisiace s funkciami a premennými. Dôležité je zapamätať si kľúčové slovo __globálny__, ktorá je uvedená pred funkciou a ukazuje, že táto funkcia sa týka jadra / jadra - túto funkciu zavolá CPU a vykoná sa na GPU. Predpona __zariadenie__ označuje, že funkcia bude vykonaná na GPU (ktorý, mimochodom, CUDA volá „device / device“), ale dá sa volať len z GPU (inými slovami, z inej funkcie __device__ alebo z funkcie __global__). Nakoniec predpona __hostiteľ__ voliteľné, označuje funkciu, ktorá je volaná CPU a vykonávaná CPU - inými slovami, bežná funkcia.
Funkcie __device__ a __global__ majú množstvo obmedzení: nemôžu byť rekurzívne (to znamená volať samy seba) a nemôžu mať premenlivý počet argumentov. Nakoniec, keďže funkcie __device__ sú umiestnené v pamäťovom priestore GPU, dáva zmysel, že nebudete môcť získať ich adresu. Premenné majú tiež niekoľko kvalifikátorov, ktoré označujú oblasť pamäte, kde budú uložené. Premenná s predponou __zdieľaný__ znamená, že bude uložený v zdieľanej pamäti streamovacieho multiprocesora. Volanie funkcie __global__ je mierne odlišné. Ide o to, že pri volaní je potrebné nastaviť konfiguráciu vykonávania - konkrétnejšie veľkosť mriežky / mriežky, na ktorú sa jadro / jadro bude aplikovať, ako aj veľkosť každého bloku. Vezmite si napríklad jadro s nasledujúcim podpisom.
| __global__ void Func (float * parameter); |
Bude sa volať ako
| Func<<< Dg, Db >>> (parameter); |
kde Dg je veľkosť mriežky a Db je veľkosť bloku. Tieto dve premenné sú nového typu vektora zavedeného pomocou CUDA.
CUDA API obsahuje funkcie na prácu s pamäťou vo VRAM: cudaMalloc na pridelenie pamäte, cudaFree na uvoľnenie a cudaMemcpy na kopírovanie pamäte medzi RAM a VRAM a naopak.
Tento prehľad zakončíme veľmi zaujímavým spôsobom, akým sa zostavuje program CUDA: kompilácia prebieha v niekoľkých krokoch. Najprv sa získa kód CPU a odovzdá sa štandardnému kompilátoru. Kód špecifický pre GPU sa najskôr skonvertuje do stredného jazyka PTX. Je podobný jazyku symbolických inštrukcií a umožňuje vám študovať váš kód a hľadať potenciálne neefektívnosti. Nakoniec poslednou fázou je preloženie medzijazyka do špecifických inštrukcií GPU a vytvorenie binárneho súboru.

Po prečítaní dokumentov nVidia chcem tento týždeň vyskúšať CUDA. Naozaj, čo môže byť lepšie ako vyhodnotenie API vytvorením vlastného programu? Vtedy by mala väčšina problémov vyplávať na povrch, aj keď na papieri vyzerá všetko perfektne. Okrem toho prax najlepšie ukáže, ako dobre ste pochopili všetky princípy načrtnuté v dokumentácii CUDA.
Ponoriť sa do takéhoto projektu je celkom jednoduché. Dnes je k dispozícii na stiahnutie veľké množstvo bezplatných, no kvalitných nástrojov. Na náš test sme použili Visual C ++ Express 2005, ktorý má všetko, čo potrebujete. Najťažšie bolo nájsť program, ktorého portovanie na GPU netrvalo týždne, no bol dostatočne zábavný, aby udržal naše úsilie v dobrej kondícii. Nakoniec sme vybrali kus kódu, ktorý vezme výškovú mapu a vypočíta zodpovedajúcu normálnu mapu. Nebudeme sa podrobne zaoberať touto funkciou, pretože v tomto článku je sotva zaujímavá. Stručne povedané, program sa zaoberá zakrivením oblastí: pre každý pixel počiatočného obrázka vložíme maticu, ktorá pomocou viac či menej zložitého vzorca určuje farbu výsledného pixelu vo vygenerovanom obrázku podľa susedných pixelov. Výhodou tejto funkcie je veľmi jednoduchá paralelizácia, takže tento test dokonale demonštruje možnosti CUDA.


Ďalšou výhodou je, že už máme implementáciu na CPU, takže jej výsledok môžeme porovnať s verziou CUDA – a nie znovu vymýšľať koleso.
Ešte raz zopakujeme, že cieľom testu bolo zoznámiť sa s utilitami CUDA SDK a nie porovnávať verzie pre CPU a GPU. Keďže to bol náš prvý pokus o vytvorenie programu CUDA, mali sme malú nádej na dosiahnutie vysokého výkonu. Keďže táto časť kódu nie je kritická, verzia pre CPU nebola optimalizovaná, takže priame porovnanie výsledkov je sotva zaujímavé.
Výkon
Zmerali sme však čas vykonania, aby sme zistili, či existuje výhoda používania CUDA aj pri najhrubšej implementácii, alebo či to bude trvať dlhý a únavný tréning, kým sa získa nejaký GPU zisk. Testovací stroj bol prevzatý z nášho vývojového laboratória – notebook s procesorom Core 2 Duo T5450 a grafickou kartou GeForce 8600M GT so systémom Vista. Od superpočítača to má ďaleko, no výsledky sú celkom zaujímavé, keďže test nie je „nabrúsený“ pre GPU. Vždy je pekné vidieť, že nVidia dosahuje obrovské zisky na systémoch s obrovskými GPU a veľkou šírkou pásma, ale v praxi mnohé zo 70 miliónov GPU s podporou CUDA na dnešnom trhu s počítačmi nie sú ani zďaleka tak výkonné, a preto má náš test právo života.
Pre obrázok s rozmermi 2 048 x 2 048 pixelov sme získali nasledujúce výsledky.
- CPU 1 vlákno: 1 419 ms;
- CPU 2 vlákna: 749 ms;
- CPU 4 vlákna: 593 ms
- GPU (8600M GT) bloky 256 vlákien: 109 ms;
- GPU (8600M GT) bloky 128 vlákien: 94 ms;
- GPU (8800 GTX) bloky 128 vlákien / 256 vlákien: 31 ms.
Z výsledkov možno vyvodiť niekoľko záverov. Začnime tým, že napriek rečiam o evidentnej lenivosti programátorov sme upravili prvotnú verziu CPU pre viacero vlákien. Ako sme spomenuli, kód je pre túto situáciu ideálny – všetko, čo je potrebné, je rozdeliť počiatočný obrázok na toľko zón, koľko je streamov. Upozorňujeme, že zrýchlenie z prechodu z jedného vlákna na dva na našom dvojjadrovom CPU sa ukázalo byť takmer lineárne, čo tiež naznačuje paralelný charakter testovacieho programu. Celkom nečakane sa rýchlejšia ukázala aj verzia so štyrmi vláknami, aj keď na našom procesore je to veľmi zvláštne – naopak, dalo by sa očakávať pokles efektivity kvôli réžii správy ďalších vlákien. Ako možno vysvetliť tento výsledok? Ťažko povedať, ale na vine môže byť plánovač vlákien systému Windows; v každom prípade je výsledok opakovateľný. Pri menších textúrach (512x512) nebol zisk z rozdelenia na vlákna taký výrazný (asi 35 % verzus 100 %) a logickejšie bolo správanie verzie so štyrmi vláknami, bez navýšenia oproti verzii pre dve vlákna. GPU bol stále rýchlejší, ale nie taký výrazný (8600M GT bol trikrát rýchlejší ako dvojvláknová verzia).
 |
Pre zväčšenie kliknite na obrázok.
Druhým významným postrehom je, že aj najpomalšia implementácia GPU sa ukázala byť takmer šesťkrát rýchlejšia ako najvýkonnejšia verzia CPU. Pre prvý program a neoptimalizovanú verziu algoritmu je výsledok veľmi povzbudivý. Všimnite si, že sme dosiahli výrazne lepší výsledok na malých blokoch, hoci intuícia môže naznačovať opak. Vysvetlenie je jednoduché – náš program používa 14 registrov na vlákno a pri 256-vláknových blokoch je potrebných 3 584 registrov na blok a na plné zaťaženie procesora je potrebných 768 vlákien, ako sme si ukázali. V našom prípade ide o tri bloky alebo 10 572 registrov. Ale multiprocesor má len 8192 registrov, takže dokáže udržať aktívne iba dva bloky. Naproti tomu pri blokoch so 128 vláknami potrebujeme 1 792 registrov na blok; ak 8 192 vydelíme 1 792 a zaokrúhlime na najbližšie celé číslo, dostaneme štyri bloky. V praxi bude počet vlákien rovnaký (512 na jeden multiprocesor, aj keď teoreticky je potrebných 768 na plné zaťaženie), ale zvýšenie počtu blokov dáva GPU výhodu flexibility v prístupe k pamäti - keď operácia s prebiehajú vysoké latencie, môžete spustiť vykonávanie pokynov z iného bloku a čakať na prijatie výsledkov. Štyri bloky jasne znižujú latenciu, najmä preto, že náš program používa viacero prístupov do pamäte.
Analýza
Nakoniec, napriek tomu, čo sme povedali vyššie, neodolali sme pokušeniu a spustili sme program na 8800 GTX, ktorý sa ukázal byť trikrát rýchlejší ako 8600, bez ohľadu na veľkosť bloku. Možno by ste si mysleli, že v praxi na príslušných architektúrach bude výsledok štyri a viackrát vyšší: 128 ALU / shader procesorov verzus 32 a vyššie takty (1,35 GHz verzus 950 MHz), no nevyšlo to. Najpravdepodobnejším limitujúcim faktorom bol prístup k pamäti. Aby sme boli presnejší, k počiatočnému obrázku sa pristupuje ako k multidimenzionálnemu poľu CUDA – pomerne komplikovaný výraz pre to, čo nie je nič iné ako textúra. Existuje však niekoľko výhod.
- prístupy ťažia z vyrovnávacej pamäte textúr;
- používame režim zalamovania, ktorý na rozdiel od verzie s procesorom nemusí spracovávať okraje obrázkov.
Okrem toho môžeme využiť „bezplatné“ filtrovanie s normalizovaným adresovaním medzi a namiesto, ale v našom prípade je to sotva užitočné. Ako viete, 8600 má 16 textúrových jednotiek v porovnaní s 32 pre 8800 GTX. Preto je pomer medzi týmito dvoma architektúrami iba dva ku jednej. Pripočítajme k tomu rozdiel vo frekvenciách a dostaneme pomer (32 x 0,575) / (16 x 0,475) = 2,4 - blízko k "tri ku jednej", ktorú skutočne dostaneme. Táto teória tiež vysvetľuje, prečo sa veľkosť bloku na G80 príliš nemení, pretože ALU stále spočíva na blokoch textúr.
 |
Pre zväčšenie kliknite na obrázok.
Okrem sľubných výsledkov, naša prvá expozícia CUDA prebehla veľmi dobre, vzhľadom na zvolené nie príliš priaznivé podmienky. Vývoj na notebooku Vista znamená použitie CUDA SDK 2.0, stále v beta verzii, s ovládačom 174.55, ktorý je tiež beta. Napriek tomu nemôžeme hlásiť žiadne nemilé prekvapenia - iba prvotné chyby pri prvom ladení, kedy sa náš program, ešte dosť "zabugovaný", snažil adresovať pamäť mimo prideleného priestoru.
Monitor divoko blikal, potom obrazovka stmavla ... kým Vista nespustila službu opravy ovládačov a všetko bolo v poriadku. Stále je však trochu prekvapujúce pozorovať, ak ste zvyknutí vidieť typickú chybu segmentácie na štandardných programoch, ako je ten náš. Na záver malá kritika smerom k nVidii: v celej dokumentácii dostupnej pre CUDA sa nenachádza žiadny malý návod, ktorý by vás krok za krokom previedol, ako nastaviť vývojové prostredie pre Visual Studio. V skutočnosti problém nie je veľký, pretože SDK má celý súbor príkladov, ktoré si môžete preštudovať, aby ste pochopili rámec pre aplikácie CUDA, ale užitočná by bola príručka pre začiatočníkov.
 |
Pre zväčšenie kliknite na obrázok.
Nvidia predstavila CUDA s GeForce 8800. Aj keď boli vtedajšie sľuby lákavé, my sme svoje nadšenie vydržali až do skutočného testu. Skutočne, v tom čase sa zdalo, že ide skôr o územnú prirážku zostať na vlne GPGPU. Bez dostupného SDK ťažko povedať, že to nie je len ďalšia marketingová atrapa, ktorá neuspeje. Nie je to prvýkrát, čo bola dobrá iniciatíva ohlásená príliš skoro a nevyšla vtedy najavo pre nedostatočnú podporu – najmä v takom konkurenčnom sektore. Teraz, rok a pol po oznámení, môžeme s istotou povedať, že nVidia dodržala slovo.

SDK sa objavilo pomerne rýchlo v beta verzii začiatkom roku 2007 a odvtedy sa rýchlo aktualizovalo, čo dokazuje hodnotu tohto projektu pre nVidia. Dnes sa CUDA vyvíja veľmi dobre: SDK je už dostupné v beta verzii 2.0 pre hlavné operačné systémy (Windows XP a Vista, Linux a 1.1 pre Mac OS X) a nVidia vyhradila celú časť stránky pre vývojárov.


Na profesionálnejšej úrovni bol dojem z prvých krokov s CUDA veľmi pozitívny. Aj keď ste oboznámení s architektúrou GPU, môžete to ľahko zistiť. Keď API vyzerá na prvý pohľad priamočiaro, okamžite začnete veriť, že získate presvedčivé výsledky. Nebude však plytvanie výpočtovým časom pri početných prenosoch z CPU na GPU? A ako použiť tieto tisíce vlákien s malým alebo žiadnym synchronizačným primitívom? Svoje experimenty sme začali so všetkými týmito obavami. Rýchlo sa však rozplynuli, keď sa prvá verzia nášho algoritmu, aj keď veľmi triviálna, ukázala byť výrazne rýchlejšia ako na CPU.
CUDA teda nie je záchranou pre výskumníkov, ktorí chcú presvedčiť predstaviteľov univerzity, aby im kúpili GeForce. CUDA je už plne dostupná technológia, ktorú môže použiť každý programátor v jazyku C, ak je ochotný venovať čas a námahu zvykaniu si na novú programovaciu paradigmu. Toto úsilie nebude zbytočné, ak budú vaše algoritmy dobre paralelné. Tiež by sme sa chceli poďakovať spoločnosti nVidia za poskytnutie kompletnej a vysokokvalitnej dokumentácie pre začínajúcich programátorov CUDA, aby našli odpovede.
Čo vyžaduje CUDA, aby sa stalo rozpoznateľným API? Jedným slovom: prenosnosť. Vieme, že budúcnosť IT je v paralelných výpočtoch – dnes sa na takéto zmeny každý pripravuje a všetky iniciatívy, softvérové aj hardvérové, smerujú týmto smerom. Ak sa však v tejto chvíli pozrieme na vývoj paradigiem, sme stále v počiatočnej fáze: toky vytvárame manuálne a snažíme sa plánovať prístup k zdieľaným zdrojom; s tým všetkým sa dá nejako vyrovnať, ak sa počet jadierok dá spočítať na prstoch jednej ruky. Ale o pár rokov, keď sa počet procesorov bude pohybovať v stovkách, táto možnosť už nebude. S vydaním CUDA urobila nVidia prvý krok k vyriešeniu tohto problému – ale, samozrejme, toto riešenie je vhodné len pre GPU od tejto spoločnosti a aj to nie pre každého. Len GF8 a 9 (a ich deriváty Quadro / Tesla) dnes dokážu pracovať s programami CUDA. A samozrejme nový rad 260/280.

 |
Pre zväčšenie kliknite na obrázok.
Nvidia sa môže pochváliť, že celosvetovo predala 70 miliónov GPU kompatibilných s CUDA, no stále to nestačí na to, aby sa stala de facto štandardom. S prihliadnutím na fakt, že konkurenti nesedia nečinne. AMD ponúka vlastné SDK (Stream Computing) a Intel ohlásil riešenie (Ct), aj keď ešte nie je dostupné. Prichádza vojna o štandardy a na trhu zjavne nezostane miesto pre troch konkurentov, kým ďalší hráč, napríklad Microsoft, nepríde so zdieľaným API, čo vývojárom samozrejme uľahčí život.

Preto má nVidia veľa problémov so schvaľovaním CUDA. Hoci technologicky máme bezpochyby úspešné riešenie, stále zostáva presvedčiť vývojárov o jeho perspektívach - a to nebude jednoduché. Avšak, súdiac podľa mnohých nedávnych oznámení a noviniek API, budúcnosť nevyzerá ani zďaleka pochmúrne.
- súbor nízkoúrovňových softvérových rozhraní ( API) na vytváranie hier a iných vysokovýkonných multimediálnych aplikácií. Zahŕňa podporu pre vysoký výkon 2D- a 3D-grafika, zvuk a vstupné zariadenia.
Direct3D (D3D) - rozhranie pre trojrozmerný výstup primitívov(geometrické telesá). Zahrnuté v .
Opengl(z angl. Otvorte grafickú knižnicu, doslova - otvorená grafická knižnica) je špecifikácia, ktorá definuje multiplatformové programovacie rozhranie nezávislé od programovacieho jazyka na písanie aplikácií využívajúcich dvojrozmernú a trojrozmernú počítačovú grafiku. Obsahuje viac ako 250 funkcií na kreslenie zložitých 3D scén z jednoduchých primitív. Používa sa pri tvorbe videohier, virtuálnej reality, vizualizácie vo vedeckom výskume. Na platforme Windows súťaží s .
OpenCL(z angl. Otvorte počítačový jazyk, doslova - otvorený počítačový jazyk) - rámec(rámec softvérového systému) na písanie počítačových programov súvisiacich s paralelnými výpočtami na rôznych grafických ( GPU) a ( ). Do rámca OpenCL obsahuje programovací jazyk a aplikačné programovacie rozhranie ( API). OpenCL poskytuje paralelizmus na úrovni inštrukcií a údajov a je implementáciou tejto techniky GPGPU.
GPGPU(skrátene z angličtiny. G rafické spracovateľské jednotky na všeobecné použitie, doslova - GPU všeobecný účel) je technika na použitie grafického procesora a grafickej karty na všeobecné výpočty, ktoré sa zvyčajne vykonávajú.
Shader(angl. shader) - program na tieňovanie na syntetizovaných obrázkoch, ktorý sa používa v trojrozmernej grafike na určenie konečných parametrov objektu alebo obrázku. Typicky zahŕňa ľubovoľnú zložitosť opisujúcu absorpciu a rozptyl svetla, mapovanie textúr, odraz a lom, tieňovanie, posun povrchu a efekty následného spracovania. Zložité povrchy je možné vykresliť pomocou jednoduchých geometrických tvarov.
Vykresľovanie(angl. vykresľovanie) - vizualizácia, v počítačovej grafike, proces získavania obrazu z modelu pomocou softvéru.
SDK(skrátene z angličtiny. Súprava na vývoj softvéru) - súbor nástrojov na vývoj softvéru.
CPU(skrátene z angličtiny. Centrálna procesorová jednotka, doslova - centrálne / hlavné / hlavné výpočtové zariadenie) - centrálne (mikro); zariadenie, ktoré vykonáva strojové inštrukcie; hardvér, ktorý je zodpovedný za vykonávanie výpočtových operácií (špecifikovaných operačným systémom a aplikačným softvérom) a koordináciu práce všetkých zariadení.
GPU(skrátene z angličtiny. Jednotka grafického spracovania, doslova - grafické výpočtové zariadenie) - grafický procesor; Samostatné zariadenie alebo herná konzola, ktorá vykonáva vykresľovanie grafiky (renderovanie). Moderné GPU zvládajú a vykresľujú počítačovú grafiku veľmi efektívne. Grafický procesor v moderných grafických adaptéroch sa používa ako akcelerátor pre trojrozmernú grafiku, ale v niektorých prípadoch sa dá použiť aj na výpočty ( GPGPU).
Problémy CPU
Po dlhú dobu bol nárast výkonu tradičných spôsobený najmä postupným zvyšovaním taktovacej frekvencie (asi 80% výkonu bolo určených hodinovou frekvenciou) so súčasným nárastom počtu tranzistorov na jednom kryštáli. . Ďalšie zvýšenie taktovacej frekvencie (pri frekvencii vyššej ako 3,8 GHz sa čipy jednoducho prehrievajú!) však naráža na množstvo základných fyzických prekážok (keďže technologický proces je veľmi blízky veľkosti atómu: a veľkosť atómu kremíka je asi 0,543 nm):
Po prvé, keď sa veľkosť kryštálu zmenšuje a frekvencia hodín sa zvyšuje, zvodový prúd tranzistorov sa zvyšuje. To vedie k zvýšeniu spotreby energie a zvýšeniu emisií tepla;
Po druhé, výhody vyšších rýchlostí hodín sú čiastočne kompenzované oneskorením pamäte, pretože časy prístupu do pamäte nezodpovedajú zvyšujúcim sa rýchlostiam hodín;
Po tretie, pre niektoré aplikácie sa tradičné sekvenčné architektúry stávajú neefektívne so zvyšujúcou sa frekvenciou hodín v dôsledku takzvaného „von Neumannovho úzkeho miesta“ – obmedzenia výkonu vyplývajúceho zo sekvenčného toku výpočtov. Súčasne sa zväčšujú oneskorenia prenosu odporovo-kapacitného signálu, čo je ďalšie úzke miesto spojené so zvýšením taktovacej frekvencie.
rozvoj GPU
Súbežne s rozvojom GPU:
…
november 2008 - Intel predstavil rad 4 jadier Intel Core i7 založené na mikroarchitektúre novej generácie Nehalem... Procesory pracujú na frekvencii 2,6-3,2 GHz. Vyrobené podľa 45nm procesnej technológie.
December 2008 - dodávky 4-jadra AMD Phenom II 940(krycie meno - Deneb). Pracuje na frekvencii 3 GHz, vyrába sa 45nm procesnou technológiou.
…
máj 2009 - spol AMD predstavila verziu GPU Grafická karta ATI Radeon HD 4890 s taktovacou frekvenciou jadra zvysenou z 850 MHz na 1 GHz. Toto je prvé grafický 1 GHz procesor. Výpočtový výkon čipu sa vďaka zvýšeniu frekvencie zvýšil z 1,36 na 1,6 teraflopov. Procesor obsahuje 800 (!) Výpočtových jadier, podporuje video pamäť GDDR5, DirectX 10.1, ATI CrossFireX a všetky ostatné technológie vlastné moderným modelom grafických kariet. Čip je vyrobený na báze 55nm technológie.
Hlavné rozdiely GPU
Charakteristické rysy GPU(v porovnaní s ) sú:
- architektúra, maximálne zameraná na zvýšenie rýchlosti výpočtu textúr a zložitých grafických objektov;
- typický špičkový výkon GPU oveľa vyššia ako ;
- vďaka špecializovanej architektúre dopravníka, GPU oveľa efektívnejšie pri spracovaní grafických informácií ako.
"Kríza žánru"
„Kríza žánru“ pre dozreli v roku 2005 - vtedy sa objavili. Ale napriek rozvoju technológie, zvýšenie produktivity konvenčných výrazne klesla. Zároveň výkon GPU naďalej rastie. Takže v roku 2003 sa táto revolučná myšlienka vykryštalizovala - využiť výpočtový výkon grafiky... GPU sa začali aktívne používať na „negrafické“ výpočty (fyzikálna simulácia, spracovanie signálov, výpočtová matematika/geometria, operácie s databázami, výpočtová biológia, výpočtová ekonómia, počítačové videnie atď.).
Hlavným problémom bolo, že neexistovalo štandardné rozhranie na programovanie GPU... Vývojári použili Opengl alebo Direct3D ale bolo to veľmi pohodlné. korporácie NVIDIA(jeden z najväčších výrobcov grafických, mediálnych a komunikačných procesorov, ako aj bezdrôtových mediálnych procesorov; založený v roku 1993) sa pustil do vývoja jednotného a pohodlného štandardu - a predstavil technológiu CUDA.
Ako to začalo
2006 - NVIDIA demonštruje CUDA™; začiatok revolúcie vo výpočtovej technike GPU.
2007 - NVIDIA uvoľňuje architektúru CUDA(originálna verzia CUDA SDK bol predstavený 15. februára 2007); nominácia "Najlepšia novinka" z časopisu Populárna veda a „Voľba čitateľov“ z publikácie HPCWire.
2008 - technológia NVIDIA CUDA vyhral v kategórii „Technická dokonalosť“ od PC magazín.
Čo sa stalo CUDA
CUDA(skrátene z angličtiny. Zjednotená architektúra zariadení Compute, doslova - jednotná výpočtová architektúra zariadení) - architektúra (súbor softvéru a hardvéru), ktorá umožňuje GPU všeobecné výpočty, zatiaľ čo GPU v skutočnosti funguje ako výkonný koprocesor.
technológie NVIDIA CUDA™ Je jediným vývojovým prostredím v programovacom jazyku C, ktorá umožňuje vývojárom vytvárať softvér na riešenie zložitých výpočtových problémov v kratšom čase, vďaka výpočtovému výkonu GPU. Vo svete už fungujú milióny GPU s podporou CUDA a tisíce programátorov už používajú (bezplatné!) nástroje CUDA na urýchlenie aplikácií a riešenie najzložitejších úloh náročných na zdroje – od kódovania videa a zvuku až po prieskum ropy a zemného plynu, modelovanie produktov, lekárske zobrazovanie a vedecký výskum.
CUDA dáva vývojárovi možnosť podľa vlastného uváženia organizovať prístup k súboru inštrukcií grafického akcelerátora a spravovať jeho pamäť, organizovať na ňom zložité paralelné výpočty. Grafický akcelerátor s podporou CUDA sa stáva výkonnou programovateľnou otvorenou architektúrou ako dnes. To všetko poskytuje vývojárom nízkoúrovňový, distribuovaný a vysokorýchlostný prístup k zariadeniam, vytváranie CUDA nevyhnutný základ pri budovaní serióznych nástrojov na vysokej úrovni, ako sú kompilátory, debuggery, matematické knižnice, softvérové platformy.
Uralsky, popredný technologický špecialista NVIDIA porovnávanie GPU a , hovorí takto: " Je SUV. Jazdí kedykoľvek a kdekoľvek, no nie veľmi rýchlo. A GPU Je športové auto. Na zlej ceste jednoducho nikam nepôjde, ale poskytne dobré pokrytie - a ukáže všetku svoju rýchlosť, o ktorej SUV ani nesnívalo! .. “.
Technologické schopnosti CUDA
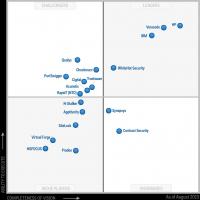 Analýza staršieho kódu, keď sa zdrojový kód stratí: urobiť alebo nie?
Analýza staršieho kódu, keď sa zdrojový kód stratí: urobiť alebo nie? Po inštalácii aktualizácií sa systém Windows nenačítava Prenosný počítač sa po aktualizácii systému Windows 10 nezapne
Po inštalácii aktualizácií sa systém Windows nenačítava Prenosný počítač sa po aktualizácii systému Windows 10 nezapne Ako prelomiť heslo: prehľad najbežnejších metód
Ako prelomiť heslo: prehľad najbežnejších metód Zakázať šifrovanie na tablete
Zakázať šifrovanie na tablete Vytvorenie žiarovky. Edisonova žiarovka. Kto vynašiel prvú žiarovku? Prečo sa Edisonovi dostalo všetkej slávy? História zmien zariadenia žiarovky
Vytvorenie žiarovky. Edisonova žiarovka. Kto vynašiel prvú žiarovku? Prečo sa Edisonovi dostalo všetkej slávy? História zmien zariadenia žiarovky Ako rýchlo nájsť svoj telefón na Googli, nech je kdekoľvek
Ako rýchlo nájsť svoj telefón na Googli, nech je kdekoľvek Elektrická žiarovka bola vynájdená v Rusku
Elektrická žiarovka bola vynájdená v Rusku