Prezentare generală a sistemelor distribuite. Arhitectură de sistem distribuită Platformă Cloud IoT la scară largă
Adesea, la definirea unui sistem distribuit, accentul se pune pe împărțirea funcțiilor acestuia între mai multe computere. Cu această abordare, orice este distribuit sistem de calcul unde prelucrarea datelor este împărțită între două sau mai multe computere. Pe baza definiției lui E. Tanenbaum, un sistem oarecum mai restrâns distribuit poate fi definit ca un ansamblu de calculatoare independente conectate prin canale de comunicație, care, din punctul de vedere al unui utilizator al unor programe, arată ca un singur întreg.
Această abordare a definirii unui sistem distribuit are dezavantajele sale. De exemplu, tot ce este folosit într-un astfel de sistem distribuit software ar putea funcționa pe un singur computer, dar din punctul de vedere al definiției de mai sus, un astfel de sistem nu va mai fi distribuit. Prin urmare, conceptul de sistem distribuit ar trebui probabil să se bazeze pe analiza software-ului care formează un astfel de sistem.
Ca bază pentru descrierea interacțiunii a două entități, luați în considerare modelul general de interacțiune client-server, în care una dintre părți (clientul) inițiază schimbul de date prin trimiterea unei cereri celeilalte părți (server). Serverul procesează cererea și, dacă este necesar, trimite un răspuns clientului (Fig. 1.1).
Orez. 1.1.
Interacțiunea în cadrul modelului client-server poate fi fie sincronă, când clientul așteaptă ca serverul să-și proceseze cererea, fie asincronă, în care clientul trimite o cerere către server și își continuă execuția fără a aștepta cererea serverului. raspuns. Modelul client și server poate fi folosit ca bază pentru descrierea diferitelor interacțiuni. Pentru acest curs este importantă interacțiunea părților constitutive ale software-ului care formează un sistem distribuit.

Orez. 1.2.
Luați în considerare o anumită aplicație tipică, care, în conformitate cu conceptele moderne, poate fi împărțită în următoarele niveluri logice (Fig. 1.2): interfața cu utilizatorul(PI), logica aplicației (LP) și accesul la date (DD), lucrând cu baza de date (DB). Utilizatorul sistemului interacționează cu acesta prin interfața cu utilizatorul, baza de date stochează date care descriu domeniul aplicației, iar stratul logic al aplicației implementează toți algoritmii legați de domeniul subiectului.
Deoarece, în practică, diferiți utilizatori ai sistemului sunt de obicei interesați să acceseze aceleași date, cea mai simplă separare a funcțiilor unui astfel de sistem între mai multe computere va fi separarea straturilor logice ale aplicației între o parte de server a aplicației. , care este responsabil pentru accesarea datelor, și a părților client situate pe mai multe computere.implementarea interfeței cu utilizatorul. Logica aplicației poate fi atribuită serverului, clienților sau partajată între aceștia (Figura 1.3).

Orez. 1.3.
Arhitectura aplicațiilor construite pe acest principiu se numește client-server sau pe două niveluri. În practică, astfel de sisteme nu sunt adesea clasificate ca fiind distribuite, dar formal pot fi considerate cei mai simpli reprezentanți ai sistemelor distribuite.
Dezvoltarea arhitecturii client-server este o arhitectură cu trei niveluri, în care interfața cu utilizatorul, logica aplicației și accesul la date sunt separate în componente independente ale sistemului care pot rula pe computere independente (Fig. 1.4).

Orez. 1.4.
Solicitarea utilizatorului în astfel de sisteme este procesată secvenţial de partea client a sistemului, serverul logic al aplicaţiei şi serverul bazei de date. Cu toate acestea, un sistem distribuit este de obicei înțeles ca un sistem cu o arhitectură mai complexă decât una cu trei niveluri.
În capitolul anterior, am analizat sistemele multiprocesoare strâns cuplate cu memorie partajată, structuri de date ale nucleului partajat și un pool partajat din care sunt invocate procesele. Adesea, totuși, este de dorit să se aloce procesoarele în așa fel încât să fie autonome față de mediul de operare și condițiile de operare în scopul partajării resurselor. Să presupunem, de exemplu, că un utilizator al unui computer personal trebuie să acceseze fișierele aflate pe o mașină mai mare, dar în același timp să păstreze controlul asupra computerului personal. Deși unele programe, cum ar fi uucp, acceptă transferul de fișiere în rețea și alte funcții de rețea, utilizarea lor nu va fi ascunsă utilizatorului, deoarece utilizatorul este conștient că folosește rețeaua. În plus, trebuie remarcat faptul că programe precum editorii de text nu funcționează cu fișierele șterse, ca în cazul celor obișnuite. Utilizatorii ar trebui să aibă setul standard de funcții ale sistemului UNIX și, în afară de potențialul blocaj de performanță, nu ar trebui să simtă trecerea granițelor mașinii. Deci, de exemplu, activitatea funcțiilor de sistem deschise și citite cu fișiere de pe mașini la distanță nu ar trebui să difere de munca lor cu fișiere aparținând sistemelor locale.
Arhitectura sistemului distribuit este prezentată în Figura 13.1. Fiecare computer prezentat în figură este o unitate autonomă constând dintr-un procesor, memorie și periferice. Modelul nu se strică deși computerul nu are un sistem de fișiere local: trebuie să aibă dispozitive periferice pentru a comunica cu alte mașini, iar toate fișierele care îi aparțin pot fi localizate pe alt computer. Memoria fizică disponibilă pentru fiecare mașină este independentă de procesele care rulează pe alte mașini. În acest sens, sistemele distribuite diferă de sistemele multiprocesoare strâns cuplate discutate în capitolul anterior. În consecință, nucleul sistemului de pe fiecare mașină funcționează independent de condițiile externe de funcționare ale mediului distribuit.
Figura 13.1. Model de sistem de arhitectură distribuită
Sistemele distribuite, bine descrise în literatură, se încadrează în mod tradițional în următoarele categorii:
Sisteme periferice, care sunt grupuri de mașini care au o comunitate puternică și sunt asociate cu o singură mașină (de obicei mai mare). Procesoarele periferice își împart sarcina cu procesorul central și redirecționează toate apelurile către sistemul de operare către acesta. Scopul unui sistem periferic este de a crește performanța generală a rețelei și de a oferi capacitatea de a aloca un procesor unui singur proces într-un mediu de operare UNIX. Sistemul pornește ca un modul separat; Spre deosebire de alte modele de sisteme distribuite, sistemele periferice nu au autonomie reală, cu excepția cazurilor legate de dispecerarea proceselor și alocarea memoriei locale.
Sisteme distribuite precum „Newcastle”, permițând comunicarea la distanță prin numele fișierelor de la distanță din bibliotecă (numele este preluat din articolul „The Newcastle Connection” – vezi). Fișierele șterse au un BOM (nume distinctiv) care, în calea de căutare, conține caractere speciale sau o componentă de nume opțională care precede rădăcina sistemului de fișiere. Implementarea acestei metode nu presupune efectuarea de modificări la nucleul sistemului și, prin urmare, este mai simplă decât celelalte metode discutate în acest capitol, dar mai puțin flexibilă.
Sistemele distribuite sunt complet transparente, în care numele distinctive standard sunt suficiente pentru a face referire la fișierele aflate pe alte mașini; depinde de kernel să recunoască aceste fișiere ca fiind șterse. Căile de căutare a fișierelor specificate în numele lor compuse traversează granițele mașinii la punctele de montare, indiferent câte astfel de puncte sunt formate atunci când sistemele de fișiere sunt montate pe discuri.
În acest capitol, ne vom uita la arhitectura fiecărui model; toate informațiile furnizate nu se bazează pe rezultatele unor dezvoltări specifice, ci pe informații publicate în diferite articole tehnice. Aceasta presupune că modulele de protocol și driverele de dispozitiv sunt responsabile pentru adresare, rutare, controlul fluxului și detectarea și corectarea erorilor - cu alte cuvinte, că fiecare model este independent de rețeaua utilizată. Exemplele de utilizare a funcțiilor de sistem prezentate în secțiunea următoare pentru sisteme periferice funcționează într-un mod similar pentru sisteme precum Newcastle și pentru sisteme complet transparente, care vor fi discutate mai târziu; prin urmare, le vom analiza în detaliu o dată, iar în secțiunile dedicate altor tipuri de sisteme, ne vom concentra în principal pe caracteristicile care disting aceste modele de toate celelalte.
13.1 PROCESATORE PERIFERICE
Arhitectura sistemului periferic este prezentată în Figura 13.2. Scopul acestei configurații este de a îmbunătăți performanța generală a rețelei prin realocarea proceselor care rulează între CPU și procesoarele periferice. Fiecare dintre procesoarele periferice nu are la dispoziție alte dispozitive periferice locale, altele decât cele de care are nevoie pentru a comunica cu unitatea centrală de procesare. Sistemul de fișiere și toate dispozitivele sunt la dispoziția procesorului central. Să presupunem că toate procesele utilizatorului sunt executate pe procesorul periferic și nu se deplasează între procesoarele periferice; odată transferate la procesor, acestea rămân pe acesta până la finalizare. Procesorul periferic conține o versiune ușoară a sistemului de operare concepută pentru a gestiona apelurile locale către sistem, gestionarea întreruperilor, alocarea memoriei, protocoale de rețea și un driver pentru comunicarea cu procesorul central.
Când sistemul este inițializat pe procesorul central, nucleul încarcă sistemul de operare local pe fiecare dintre procesoarele periferice prin intermediul liniilor de comunicație. Orice proces care rulează la periferie este asociat cu un proces satelit aparținând procesorului central (vezi); când un proces care rulează pe un procesor periferic apelează o funcție de sistem care necesită doar serviciile procesorului central, procesul periferic comunică cu satelitul său și cererea este trimisă procesorului central pentru procesare. Procesul satelit îndeplinește o funcție de sistem și trimite rezultatele înapoi la procesorul periferic. Relația unui proces periferic cu satelitul său este similară cu relația client-server pe care am discutat în detaliu în Capitolul 11: procesul periferic acționează ca un client al satelitului său, care suportă funcțiile de lucru cu sistemul de fișiere. În acest caz, procesul serverului la distanță are un singur client. În secțiunea 13.4 ne vom uita la procesele serverului cu mai mulți clienți.

Figura 13.2. Configurarea sistemului periferic

Figura 13.3. Formate de mesaje
Când un proces periferic apelează o funcție de sistem care poate fi procesată local, nucleul nu trebuie să trimită o solicitare procesului satelit. Deci, de exemplu, pentru a obține memorie suplimentară, un proces poate apela funcția sbrk pentru execuție locală. Cu toate acestea, dacă serviciile procesorului central sunt necesare, de exemplu, pentru a deschide un fișier, nucleul codifică informații despre parametrii trecuți funcției apelate și condițiile de execuție a procesului într-un mesaj trimis procesului satelit (Figura 13.3). Mesajul include un semn din care rezultă că funcția sistemului este realizată de procesul satelit în numele clientului, parametrii trecuți funcției și date despre mediul de execuție a procesului (de exemplu, coduri de identificare a utilizatorului și a grupului), care sunt diferite pentru funcții diferite. Restul mesajului sunt date de lungime variabilă (de exemplu, un nume de fișier compus sau date care trebuie scrise cu funcția de scriere).
Procesul satelit așteaptă cereri de la procesul periferic; atunci când se primește o solicitare, acesta decodifică mesajul, determină tipul funcției sistemului, îl execută și convertește rezultatele într-un răspuns trimis procesului periferic. Răspunsul, în plus față de rezultatele execuției funcției sistemului, include mesajul de eroare (dacă există), numărul semnalului și o matrice de date cu lungime variabilă care conține, de exemplu, informații citite dintr-un fișier. Procesul periferic este suspendat până când se primește un răspuns, după ce îl primește, acesta decriptează și transmite rezultatele utilizatorului. Aceasta este schema generală de gestionare a apelurilor către sistemul de operare; acum să trecem la o analiză mai detaliată a funcțiilor individuale.
Pentru a explica cum funcționează sistemul periferic, luați în considerare o serie de funcții: getppid, open, write, fork, exit și semnal. Funcția getppid este destul de simplă, deoarece se ocupă de formulare simple de solicitare și răspuns care sunt schimbate între periferic și CPU. Nucleul de pe procesorul periferic generează un mesaj care are un semn, din care rezultă că funcția solicitată este funcția getppid, și trimite cererea către procesorul central. Procesul satelit de pe procesorul central citește mesajul de la procesorul periferic, decriptează tipul de funcție de sistem, îl execută și obține identificatorul părintelui său. Apoi generează un răspuns și îl transmite unui proces periferic aflat la celălalt capăt al liniei de comunicație. Când procesorul periferic primește un răspuns, acesta îl transmite procesului care a numit funcția de sistem getppid. Dacă procesul periferic stochează date (cum ar fi ID-ul de proces al părintelui) în memoria locală, nu trebuie să comunice deloc cu însoțitorul său.
Dacă este apelată funcția de sistem deschis, procesul periferic trimite un mesaj către însoțitorul său, care include numele fișierului și alți parametri. Dacă are succes, procesul însoțitor alocă un index și un punct de intrare tabelului de fișiere, alocă o intrare în tabelul descriptor al fișierului utilizator în spațiul său și returnează descriptorul fișierului procesului periferic. În tot acest timp, la celălalt capăt al liniei de comunicație, procesul periferic așteaptă un răspuns. Nu are la dispoziție nicio structură care să stocheze informații despre dosarul deschis; Descriptorul returnat de open este un pointer către o intrare din procesul însoțitor din tabelul descriptor al fișierului utilizator. Rezultatele executării funcției sunt prezentate în Figura 13.4.

Figura 13.4. Apelarea funcției deschise dintr-un proces periferic
Dacă se efectuează un apel la funcția de scriere a sistemului, procesorul periferic generează un mesaj constând dintr-un semn al funcției de scriere, un descriptor de fișier și cantitatea de date de scris. Apoi, din spațiul procesului periferic, copiază datele în procesul satelit prin linia de comunicație. Procesul satelit decriptează mesajul primit, citește datele de pe linia de comunicație și le scrie în fișierul corespunzător (descriptorul conținut în mesaj este folosit ca indicator la al cărui index și înregistrarea despre care se utilizează în tabelul de fișiere ); toate aceste acțiuni sunt efectuate pe procesorul central. La sfârșitul lucrării, procesul satelit trimite procesului periferic un mesaj care confirmă primirea mesajului și conține numărul de octeți de date care au fost copiați cu succes în fișier. Operația de citire este similară; satelitul informează procesul periferic despre numărul de octeți citiți efectiv (în cazul citirii datelor de la un terminal sau de pe un canal, acest număr nu coincide întotdeauna cu cantitatea specificată în cerere). Pentru a efectua una sau cealaltă funcție, poate fi necesar să trimiteți mesaje de informații de mai multe ori prin rețea, care este determinată de cantitatea de date trimisă și de dimensiunea pachetelor de rețea.
Singura funcție care trebuie schimbată în timp ce rulează pe CPU este funcția sistemului de furcă. Când un proces execută această funcție pe CPU, nucleul selectează un procesor periferic pentru acesta și trimite un mesaj unui proces special - server, informându-l pe acesta din urmă că va începe descărcarea procesului curent. Presupunând că serverul a acceptat cererea, nucleul folosește fork pentru a crea un nou proces periferic, alocând o intrare în tabelul de proces și un spațiu de adrese. Procesorul central descarcă o copie a procesului care a numit funcția fork către procesorul periferic, suprascriind spațiul de adresă nou alocat, generează un satelit local pentru a comunica cu noul proces periferic și trimite un mesaj către periferic pentru a inițializa contorul de program pentru noul proces. Procesul satelit (pe CPU) este un descendent al procesului care a numit fork; un proces periferic este din punct de vedere tehnic un descendent al procesului server, dar logic este un descendent al procesului care a numit funcția fork. Procesul serverului nu are nicio conexiune logică cu copilul când se termină fork; singura sarcină a serverului este să ajute la descărcarea copilului. Datorită conexiunii puternice dintre componentele sistemului (procesoarele periferice nu au autonomie), procesul periferic și procesul satelit au același cod de identificare. Relația dintre procese este prezentată în Figura 13.5: linia continuă arată relația părinte-copil, iar linia punctată arată relația dintre egali.

Figura 13.5. Executarea unei funcții de furcă pe CPU
Când un proces execută funcția fork pe procesorul periferic, acesta trimite un mesaj către satelitul său de pe CPU, care apoi execută întreaga secvență de acțiuni descrise mai sus. Satelitul selectează un nou procesor periferic și face pregătirile necesare pentru descărcarea imaginii vechiului proces: trimite o solicitare procesului periferic părinte pentru a-și citi imaginea, în răspuns la care transferul datelor solicitate începe la celălalt capăt. a canalului de comunicare. Satelitul citește imaginea transmisă și o suprascrie la descendentul periferic. Când descărcarea imaginii este terminată, satelitul procesează bifurcația, creându-și copilul pe CPU și transmite valoarea contorului programului copilului periferic pentru ca acesta din urmă să știe de la ce adresă să înceapă execuția. Evident, ar fi mai bine ca copilul procesului însoțitor să fie atribuit copilului periferic ca părinte, dar în cazul nostru, procesele generate sunt capabile să ruleze pe alte procesoare periferice, nu doar pe cel pe care sunt create. Relația dintre procesele de la sfârșitul funcției de furcă este prezentată în Figura 13.6. Când procesul periferic își termină activitatea, trimite un mesaj corespunzător procesului satelit, iar acesta se termină. Un proces însoțitor nu poate iniția o oprire.

Figura 13.6. Executarea unei funcții de furcă pe un procesor periferic
Atât în sistemele multiprocesor, cât și în cele uniprocesoare, procesul trebuie să răspundă la semnale în același mod: procesul fie finalizează execuția funcției sistemului înainte de a verifica semnalele, fie, dimpotrivă, la recepția semnalului, iese imediat din starea suspendată și întrerupe brusc activitatea sistemului, dacă aceasta este în concordanță cu prioritatea.cu care a fost suspendat. Deoarece procesul satelit îndeplinește funcții de sistem în numele procesului periferic, trebuie să răspundă la semnale în coordonare cu acesta din urmă. Dacă, pe un sistem uniprocesor, un semnal determină un proces să anuleze funcția, procesul însoțitor pe un sistem multiprocesor ar trebui să se comporte în același mod. Același lucru se poate spune despre cazul în care semnalul solicită procesului să-și încheie activitatea folosind funcția de ieșire: procesul periferic se termină și trimite mesajul corespunzător procesului satelit, care, desigur, se termină și el.
Atunci când un proces periferic apelează funcția de sistem de semnal, acesta stochează informațiile curente în tabele locale și trimite un mesaj către satelitul său informându-l dacă semnalul specificat trebuie primit sau ignorat. Procesului satelit nu îi pasă dacă interceptează semnalul sau acțiunea implicită. Reacția unui proces la un semnal depinde de trei factori (Figura 13.7): dacă un semnal este primit în timp ce procesul execută o funcție de sistem, dacă se face o indicație folosind funcția semnal pentru a ignora semnalul, dacă semnalul apare pe același procesor periferic sau pe altul. Să trecem la luarea în considerare a diferitelor posibilități.
algoritm sighandle / * algoritm de procesare a semnalului * /
dacă (procesul curent este însoțitorul cuiva sau are un prototip)
dacă (semnalul este ignorat)
dacă (semnalul a venit în timpul execuției unei funcții de sistem)
pune un semnal în fața procesului satelit;
trimite un mesaj semnal către un proces periferic;
else (/ * proces periferic * /
/ * dacă un semnal a fost primit în timpul execuției unei funcții de sistem sau nu * /
trimite un semnal către procesul satelit;
algoritm satelit_end_of_syscall / * terminarea unei funcții de sistem numită de un proces periferic * /
informații de intrare: absent
amprenta: niciuna
if (o întrerupere a fost primită în timpul execuției unei funcții de sistem)
trimite mesaj de întrerupere, semnal către procesul periferic;
else / * execuția funcției de sistem nu a fost întreruptă * /
trimite răspuns: activează steagul care arată sosirea semnalului;
Figura 13.7. Prelucrarea semnalului în sistemul periferic
Să presupunem că un proces periferic și-a suspendat activitatea în timp ce procesul satelit îndeplinește o funcție de sistem în numele său. Dacă semnalul apare în altă parte, procesul satelit îl detectează mai devreme decât procesul periferic. Sunt posibile trei cazuri.
1. Dacă, în așteptarea unui eveniment, procesul satelit nu a intrat în starea suspendată, din care ar ieși la primirea unui semnal, îndeplinește funcția de sistem până la capăt, trimite rezultatele execuției către procesul periferic și arată care dintre semnalele pe care le-a primit.
2. Dacă procesul a instruit să ignore acest tip de semnal, satelitul continuă să urmeze algoritmul de execuție a funcției sistemului fără a ieși din starea suspendată prin longjmp. În răspunsul trimis către procesul periferic, nu va exista niciun mesaj de semnal primit.
3. Dacă, la primirea unui semnal, procesul satelit întrerupe execuția unei funcții de sistem (prin longjmp), informează procesul periferic despre aceasta și îl informează despre numărul semnalului.
Procesul periferic caută informații despre primirea semnalelor în răspunsul primit și, dacă există, procesează semnalele înainte de a ieși din funcția sistemului. Astfel, comportamentul unui proces într-un sistem multiprocesor corespunde exact comportamentului său într-un sistem uniprocesor: fie iese fără a ieși din modul kernel, fie apelează o funcție personalizată de procesare a semnalului, fie ignoră semnalul și finalizează cu succes funcția sistemului.

Figura 13.8. Întreruperea în timpul execuției unei funcții de sistem
Să presupunem, de exemplu, că un proces periferic apelează o funcție de citire de la un terminal conectat la procesorul central și își întrerupe activitatea în timp ce procesul satelit îndeplinește funcția (Figura 13.8). Dacă utilizatorul apasă tasta break, nucleul procesorului trimite un semnal către procesul satelit. Dacă satelitul era într-o stare suspendată, așteptând o porțiune de date de la terminal, iese imediat din această stare și termină funcția de citire. În răspunsul său la o solicitare din partea unui proces periferic, satelitul furnizează un cod de eroare și un număr de semnal corespunzător întreruperii. Procesul periferic analizează răspunsul și, din moment ce mesajul spune că a sosit o întrerupere, își trimite semnalul. Înainte de a ieși din funcția de citire, nucleul periferic verifică semnalizarea, detectează un semnal de întrerupere din procesul satelitului și îl procesează ca de obicei. Dacă, ca urmare a primirii unui semnal de întrerupere, procesul periferic își încheie activitatea folosind funcția de ieșire, această funcție se ocupă de omorârea procesului satelit. Dacă procesul periferic interceptează semnalele de întrerupere, apelează funcția de gestionare a semnalului definită de utilizator și returnează utilizatorului un cod de eroare la ieșirea din funcția de citire. Pe de altă parte, dacă satelitul execută funcția sistemului statistic în numele procesului periferic, acesta nu va întrerupe execuția acesteia atunci când primește un semnal (funcția statistică este garantată să iasă din orice pauză, deoarece are un timp de așteptare limitat al resurselor). ). Satelitul finalizează execuția funcției și returnează numărul semnalului procesului periferic. Procesul periferic își trimite un semnal și îl primește la ieșirea din funcția de sistem.
Dacă pe procesorul periferic apare un semnal în timpul execuției unei funcții de sistem, procesul periferic va fi în întuneric dacă va reveni în curând la control din procesul satelitului sau acesta din urmă va intra într-o stare suspendată pe termen nelimitat. Procesul periferic trimite satelitului un mesaj special, informându-l despre apariția unui semnal. Miezul de pe CPU decriptează mesajul și trimite un semnal către satelit, a cărui reacție la primirea semnalului este descrisă în paragrafele precedente (încetarea anormală a execuției funcției sau finalizarea acesteia). Procesul periferic nu poate trimite un mesaj direct către satelit, deoarece satelitul este ocupat cu o funcție de sistem și nu citește date de pe linia de comunicație.
Referindu-ne la exemplul citit, trebuie remarcat că procesul periferic habar nu are dacă însoțitorul său așteaptă intrarea de la terminal sau efectuează alte acțiuni. Procesul periferic trimite un mesaj de semnal către satelit: dacă satelitul este într-o stare suspendată cu o prioritate întreruptabilă, iese imediat din această stare și încetează funcția sistemului; în caz contrar, funcția este reportată până la finalizarea cu succes.
În sfârșit, luăm în considerare cazul sosirii unui semnal la un moment care nu este asociat cu execuția unei funcții de sistem. Dacă un semnal provine de la un alt procesor, satelitul îl primește mai întâi și trimite un mesaj semnal către procesul periferic, indiferent dacă semnalul se referă la procesul periferic sau nu. Nucleul periferic decriptează mesajul și trimite un semnal procesului, care reacționează la acesta în mod obișnuit. Dacă semnalul provine de la procesorul periferic, procesul efectuează acțiuni standard fără a recurge la serviciile satelitului său.
Când un proces periferic trimite un semnal către alte procese periferice, acesta codifică un mesaj de apel kill și îl trimite procesului satelit, care execută funcția apelată local. Dacă unele dintre procesele pentru care este destinat semnalul sunt localizate pe alte procesoare periferice, sateliții lor vor primi semnalul (și vor reacționa la el așa cum este descris mai sus).
13.2 TIP DE COMUNICARE NEWCASTLE
În secțiunea anterioară, am considerat un tip de sistem strâns cuplat, care se caracterizează prin trimiterea tuturor apelurilor către funcțiile subsistemului de gestionare a fișierelor care apar pe procesorul periferic către un procesor (central) de la distanță. Ne întoarcem acum la luarea în considerare a sistemelor cu o conexiune mai slabă, care constau în mașini care efectuează apeluri către fișiere situate pe alte mașini. Într-o rețea de computere personale și stații de lucru, de exemplu, utilizatorii accesează adesea fișierele aflate pe o mașină mare. În următoarele două secțiuni, ne vom uita la configurațiile sistemului în care toate funcțiile sistemului sunt efectuate în subsisteme locale, dar în același timp este posibil să accesăm fișiere (prin funcțiile subsistemului de gestionare a fișierelor) aflate pe alte mașini.
Aceste sisteme folosesc una dintre următoarele două căi pentru a identifica fișierele șterse. Pe unele sisteme, un caracter special este adăugat numelui de fișier compus: componenta de nume care precede acest caracter identifică mașina, restul numelui este fișierul de pe acea mașină. Deci, de exemplu, numele distins
"sftig! / fs1 / mjb / rje"
identifică fișierul „/ fs1 / mjb / rje” de pe mașina „sftig”. Această schemă de identificare a fișierelor urmează convenția uucp pentru transferul de fișiere între sisteme asemănătoare UNIX. Într-o altă schemă, fișierele șterse sunt identificate prin adăugarea unui prefix special la nume, de exemplu:
/../sftig/fs1/mjb/rje
unde „/../” este un prefix care indică faptul că fișierul este șters; a doua componentă a numelui fișierului este numele mașinii de la distanță. Această schemă folosește sintaxa familiară a numelor de fișiere UNIX, astfel încât, spre deosebire de prima schemă, programele utilizator nu trebuie să se adapteze la utilizarea numelor cu construcție neobișnuită (vezi).

Figura 13.9. Formularea cererilor către serverul de fișiere (procesor)
Vom dedica restul acestei secțiuni unui model de sistem care utilizează o legătură Newcastle, în care nucleul nu este preocupat de recunoașterea fișierelor șterse; această funcție este complet atribuită subrutinelor din biblioteca standard C, care în acest caz joacă rolul interfeței de sistem. Aceste rutine analizează prima componentă a numelui fișierului, care în ambele metode de identificare descrise conține un semn al distanței fișierului. Aceasta este o abatere de la rutina în care rutinele bibliotecii nu analizează numele fișierelor. Figura 13.9 arată cum sunt formulate cererile către un server de fișiere. Dacă fișierul este local, nucleul de sistem local procesează cererea în mod normal. Luați în considerare cazul opus:
deschide ("/../ sftig / fs1 / mjb / rje / fisier", O_RDONLY);
Subrutina deschisă din biblioteca C analizează primele două componente ale numelui de fișier distins și știe să caute fișierul pe mașina de la distanță „sftig”. Pentru a avea informații despre dacă procesul a avut anterior o conexiune cu o anumită mașină, subrutina pornește o structură specială în care își amintește acest fapt, iar în cazul unui răspuns negativ, stabilește o conexiune cu serverul de fișiere care rulează pe telecomandă. mașinărie. Atunci când procesul își formulează prima cerere de prelucrare la distanță, serverul la distanță confirmă cererea, dacă este necesar, înregistrările în câmpurile codurilor de identificare utilizator și grup și creează un proces satelit care va acționa în numele procesului client.
Pentru a îndeplini cererile clientului, satelitul trebuie să aibă aceleași permisiuni de fișiere pe mașina de la distanță ca și clientul. Cu alte cuvinte, utilizatorul „mjb” trebuie să aibă aceleași drepturi de acces atât la fișierele de la distanță, cât și la cele locale. Din păcate, este posibil ca codul de identificare a clientului „mjb” să coincidă cu codul de identificare al altui client de pe mașina de la distanță. Astfel, administratorii de sistem de pe mașinile care rulează în rețea ar trebui fie să se asigure că fiecărui utilizator i se atribuie un cod de identificare unic pentru întreaga rețea, fie să efectueze conversia codului în momentul formulării unei cereri de servicii de rețea. Dacă acest lucru nu se face, procesul însoțitor va avea drepturile unui alt client pe mașina de la distanță.
O problemă mai delicată este obținerea drepturilor de superutilizator în legătură cu lucrul cu fișiere de la distanță. Pe de o parte, clientul superutilizator nu ar trebui să aibă aceleași drepturi asupra sistemului de la distanță pentru a nu induce în eroare controalele de securitate ale sistemului de la distanță. Pe de altă parte, unele dintre programe, dacă nu li se acordă drepturi de superutilizator, pur și simplu nu vor putea funcționa. Un exemplu de astfel de program este programul mkdir (vezi Capitolul 7), care creează un director nou. Sistemul la distanță nu ar permite clientului să creeze un director nou, deoarece drepturile de superutilizator nu sunt în vigoare la ștergere. Problema creării directoarelor la distanță servește ca un motiv serios pentru revizuirea funcției de sistem mkdir în direcția extinderii capacităților sale în stabilirea automată a tuturor conexiunilor necesare utilizatorului. Cu toate acestea, este încă o problemă comună faptul că programele setuid (cum ar fi programul mkdir) câștigă privilegii de superutilizator asupra fișierelor de la distanță. Poate cea mai bună soluție la această problemă ar fi să setați caracteristici suplimentare pentru fișierele care descriu accesul la acestea de către superutilizatorii de la distanță; din păcate, acest lucru ar necesita modificări ale structurii indexului discului (în ceea ce privește adăugarea de noi câmpuri) și ar crea prea multă mizerie în sistemele existente.
Dacă subrutina deschisă reușește, biblioteca locală lasă o notă corespunzătoare despre aceasta într-o structură accesibilă utilizatorului care conține adresa nodului de rețea, ID-ul procesului procesului satelit, descriptorul fișierului și alte informații similare. Rutinele bibliotecii de citire și scriere determină, pe baza descriptorului de fișier, dacă fișierul este șters și, dacă da, trimit un mesaj către satelit. Procesul client interacționează cu însoțitorul său în toate cazurile de accesare a funcțiilor sistemului care necesită serviciile unei mașini la distanță. Dacă un proces accesează două fișiere situate pe aceeași mașină la distanță, folosește un satelit, dar dacă fișierele sunt localizate pe mașini diferite, sunt deja utilizați doi sateliți: unul pe fiecare mașină. Doi sateliți sunt, de asemenea, utilizați atunci când două procese accesează un fișier de pe o mașină la distanță. Prin invocarea funcției sistemului prin satelit, procesul generează un mesaj care include numărul funcției, numele căii de căutare și alte informații necesare, similare cu cele incluse în structura mesajului în sistemul cu procesoare periferice.
Mecanismul de efectuare a operațiunilor pe directorul curent este mai complex. Când procesul selectează un director la distanță ca fiind cel curent, rutina bibliotecii trimite un mesaj către satelit, care schimbă directorul curent, iar rutina își amintește că directorul este șters. În toate cazurile în care numele căii de căutare începe cu un alt caracter decât o bară oblică (/), subrutina trimite numele către mașina de la distanță, unde procesul satelit îl direcționează din directorul curent. Dacă directorul curent este local, rutina transmite pur și simplu numele căii de căutare nucleului de sistem local. Funcția de sistem chroot pe un director la distanță este similară, dar trece neobservată pentru nucleul local; strict vorbind, procesul poate ignora această operație, deoarece doar biblioteca înregistrează execuția acesteia.
Când un proces apelează la fork, rutina de bibliotecă corespunzătoare trimite mesaje fiecărui satelit. Procesele sateliților se ramifică și își trimit ID-urile copilului către clientul părinte. Procesul client rulează funcția de sistem fork, care transferă controlul copilului pe care îl generează; copilul local este în dialog cu copilul satelit la distanță ale cărui adrese sunt stocate de rutina bibliotecii. Această interpretare a funcției de furcă ușoară pentru procesele satelit să controleze fișierele deschise și directoarele curente. Când procesul de lucru cu fișiere de la distanță iese (prin apelarea funcției de ieșire), subrutina trimite mesaje către toți sateliții săi la distanță, astfel încât aceștia să facă același lucru atunci când primesc mesajul. Anumite aspecte ale implementării funcțiilor sistemului exec și exit sunt discutate în exerciții.
Avantajul unei legături Newcastle este că accesul unui proces la fișierele de la distanță devine transparent (invizibil pentru utilizator), fără a fi nevoie de a face modificări nucleului de sistem. Cu toate acestea, această dezvoltare are o serie de dezavantaje. În primul rând, în timpul implementării sale, este posibilă o scădere a performanței sistemului. Datorită utilizării bibliotecii C extinse, dimensiunea memoriei utilizate de fiecare proces crește, chiar dacă procesul nu accesează fișierele de la distanță; biblioteca dublează funcțiile kernelului și necesită mai mult spațiu de memorie. Creșterea dimensiunii proceselor prelungește perioada de pornire și poate crea mai multe dispute pentru resursele de memorie, creând condiții pentru descărcarea și paginarea mai frecventă a sarcinilor. Cererile locale vor fi executate mai lent datorita cresterii duratei fiecarui apel catre kernel, iar procesarea cererilor de la distanta poate fi si ele incetinita, costul trimiterii lor prin retea creste. Procesarea suplimentară a cererilor de la distanță la nivel de utilizator crește numărul de comutări de context, operațiuni de descărcare și schimb. În sfârșit, pentru a accesa fișierele de la distanță, programele trebuie recompilate folosind noile biblioteci; programele vechi și modulele obiect livrate nu vor putea funcționa cu fișiere de la distanță fără ele. Toate aceste dezavantaje sunt absente din sistemul descris în secțiunea următoare.
13.3 SISTEME DE FIȘIERE DISTRIBUITE „TRASPARENTE”.
Termenul „alocare transparentă” înseamnă că utilizatorii de pe o mașină pot accesa fișierele de pe o altă mașină fără să-și dea seama că trec granițele mașinii, la fel cum sunt pe mașina lor când trec de la un sistem de fișiere la altul traversează punctele de montare. Numele prin care procesele se referă la fișierele aflate pe mașini la distanță sunt similare cu numele fișierelor locale: nu există caractere distinctive în ele. În configurația prezentată în Figura 13.10, directorul „/ usr / src” aparținând mașinii B este „montat” în directorul „/ usr / src” aparținând mașinii A. același cod sursă de sistem, întâlnit în mod tradițional în „/ directorul usr / src". Utilizatorii care rulează pe mașina A pot accesa fișierele aflate pe mașina B folosind sintaxa familiară de scriere a numelor de fișiere (de exemplu: „/usr/src/cmd/login.c”), iar nucleul însuși decide dacă fișierul este la distanță sau local. . Utilizatorii care rulează pe mașina B au acces la fișierele lor locale (neștiind că utilizatorii mașinii A pot accesa aceleași fișiere), dar, la rândul lor, nu au acces la fișierele situate pe mașina A. Desigur, sunt posibile și alte opțiuni, în în special, cele în care toate sistemele la distanță sunt montate la rădăcina sistemului local, astfel încât utilizatorii să poată accesa toate fișierele de pe toate sistemele.

Figura 13.10. Sisteme de fișiere după montarea de la distanță
Asemănările dintre montarea sistemelor de fișiere locale și permiterea accesului la sistemele de fișiere la distanță au determinat adaptarea funcției de montare la sistemele de fișiere la distanță. În acest caz, nucleul are la dispoziție un tabel de montare în format extins. Executând funcția de montare, nucleul organizează o conexiune de rețea cu o mașină de la distanță și stochează informații care caracterizează această conexiune în tabelul de montare.
O problemă interesantă are de-a face cu numele căilor care includ „..”. Dacă un proces realizează directorul curent dintr-un sistem de fișiere la distanță, atunci folosirea caracterelor „..” în nume va returna procesul la sistemul de fișiere local, mai degrabă decât accesarea fișierelor de deasupra directorului curent. Revenind din nou la Figura 13.10, rețineți că atunci când un proces aparținând mașinii A, având selectat anterior directorul curent „/ usr / src / cmd” aflat în sistemul de fișiere la distanță, va executa comanda
directorul curent va fi directorul rădăcină al mașinii A, nu al mașinii B. Algoritmul namei care rulează în nucleul sistemului la distanță, după primirea secvenței de caractere „..”, verifică dacă procesul de apelare este un agent al clientului proces și, dacă da, stabilește dacă clientul tratează directorul de lucru curent ca rădăcină a sistemului de fișiere la distanță.
Comunicarea cu o mașină de la distanță ia una dintre două forme: un apel de procedură de la distanță sau un apel de funcție de sistem de la distanță. În prima formă, fiecare procedură de nucleu care se ocupă de indexuri verifică dacă indexul indică un fișier la distanță și, dacă da, trimite o solicitare mașinii la distanță pentru a efectua operația specificată. Această schemă se încadrează în mod firesc în structura abstractă de suport pentru sisteme de fișiere de diferite tipuri, descrisă în partea finală a capitolului 5. Astfel, un acces la un fișier la distanță poate iniția transferul mai multor mesaje prin rețea, al căror număr este determinat de numarul de operatiuni implicite asupra dosarului, cu cresterea corespunzatoare a timpului de raspuns la cerere, tinand cont de timpul de asteptare acceptat in retea. Fiecare set de operații de la distanță include cel puțin acțiuni pentru blocarea indexului, numărarea referințelor etc. Pentru îmbunătățirea modelului, au fost propuse diverse soluții de optimizare legate de combinarea mai multor operații într-o singură interogare (mesaj) și punerea în buffer a celor mai importante date (cm. ).

Figura 13.11. Deschiderea unui fișier de la distanță
Luați în considerare un proces care deschide un fișier la distanță „/usr/src/cmd/login.c”, unde „src” este punctul de montare. Analizând numele fișierului (folosind schema namei-iget), nucleul detectează că fișierul este șters și trimite o solicitare mașinii gazdă pentru a obține indexul blocat. După ce a primit răspunsul dorit, nucleul local creează o copie a indexului în memorie corespunzătoare fișierului de la distanță. Apoi, nucleul verifică drepturile de acces necesare la fișier (pentru citire, de exemplu) trimițând un alt mesaj către mașina de la distanță. Algoritmul deschis continuă în deplină conformitate cu planul prezentat în Capitolul 5, trimițând mesaje către mașina de la distanță după cum este necesar, până când algoritmul este complet și indexul este eliberat. Relația dintre structurile de date ale nucleului la finalizarea algoritmului deschis este prezentată în Figura 13.11.
Dacă clientul apelează funcția de citire a sistemului, nucleul clientului blochează indexul local, emite o blocare pe indexul de la distanță, o solicitare de citire, copiază datele în memoria locală, emite o solicitare pentru eliberarea indexului la distanță și eliberează indexul local . Această schemă este în concordanță cu semantica nucleului uniprocesor existent, dar frecvența de utilizare a rețelei (apeluri multiple către fiecare funcție de sistem) reduce performanța întregului sistem. Cu toate acestea, pentru a reduce fluxul de mesaje în rețea, mai multe operațiuni pot fi combinate într-o singură solicitare. În exemplul cu funcția de citire, clientul poate trimite serverului o cerere generală de „citire”, iar serverul însuși decide să apuce și să elibereze indexul atunci când este executat. Reducerea traficului de rețea poate fi realizată și prin utilizarea bufferelor la distanță (așa cum am discutat mai sus), dar trebuie avut grijă să vă asigurați că funcțiile fișierelor de sistem care utilizează aceste buffere sunt executate corect.
În a doua formă de comunicare cu o mașină la distanță (un apel către o funcție de sistem la distanță), nucleul local detectează că funcția de sistem este legată de un fișier la distanță și trimite parametrii specificați în apelul său către sistemul de la distanță, care execută funcția și returnează rezultatele clientului. Mașina client primește rezultatele execuției funcției și iese din starea de apel. Majoritatea funcțiilor sistemului pot fi efectuate folosind o singură cerere de rețea și primind un răspuns după un timp rezonabil, dar nu toate funcțiile se încadrează în acest model. Deci, de exemplu, la primirea anumitor semnale, nucleul creează un fișier pentru procesul numit „core” (Capitolul 7). Crearea acestui fișier nu este asociată cu o anumită funcție de sistem, dar ajunge să efectueze mai multe operațiuni, cum ar fi crearea unui fișier, verificarea permisiunilor și efectuarea unei serii de scrieri.
În cazul funcției de sistem deschis, cererea de executare a funcției trimisă către mașina de la distanță include partea din numele fișierului rămasă după excluderea componentelor numelui căii de căutare care disting fișierul la distanță, precum și diverse steaguri. În exemplul anterior de deschidere a fișierului „/usr/src/cmd/login.c”, kernel-ul trimite numele „cmd / login.c” mașinii de la distanță. Mesajul include, de asemenea, acreditări, cum ar fi codurile de identificare a utilizatorului și a grupului, care sunt necesare pentru a verifica permisiunile fișierelor pe o mașină de la distanță. Dacă se primește un răspuns de la mașina de la distanță care indică o funcție deschisă cu succes, nucleul local preia un index liber în memoria mașinii locale și îl marchează ca index de fișier la distanță, stochează informații despre mașina la distanță și indexul de la distanță și alocă în mod obișnuit o nouă intrare în tabelul de fișiere. În comparație cu indexul real de pe mașina de la distanță, indexul deținut de mașina locală este formal și nu încalcă configurația modelului, care este în general aceeași cu configurația utilizată la apelarea procedurii de la distanță (Figura 13.11). Dacă o funcție apelată de un proces accesează un fișier la distanță prin descriptorul său, nucleul local știe din indexul (local) că fișierul este la distanță, formulează o cerere care include funcția apelată și o trimite mașinii la distanță. Cererea conține un pointer către indexul de la distanță prin care procesul satelit poate identifica fișierul de la distanță în sine.
După ce a primit rezultatul executării oricărei funcții de sistem, nucleul poate recurge la serviciile unui program special pentru a o procesa (la finalizarea căruia nucleul va termina de lucrat cu funcția), deoarece procesarea locală a rezultatelor utilizate într-un sistem uniprocesor nu este întotdeauna potrivit pentru un sistem cu mai multe procesoare. Ca urmare, sunt posibile modificări în semantica algoritmilor de sistem, menite să ofere suport pentru execuția funcțiilor sistemului de la distanță. Totuși, în același timp, în rețea circulă un flux minim de mesaje, asigurând timpul minim de răspuns al sistemului la solicitările primite.
13.4 MODEL DISTRIBUIT FĂRĂ PROCESE DE TRANSFER
Utilizarea proceselor de transfer (procese satelit) într-un sistem distribuit transparent facilitează urmărirea fișierelor șterse, dar tabelul de procese al sistemului de la distanță este supraîncărcat cu procese satelit care sunt inactive de cele mai multe ori. În alte scheme, procesele speciale de server sunt folosite pentru a procesa cererile de la distanță (vezi și). Sistemul de la distanță are un set (pool) de procese server pe care le atribuie din când în când pentru a procesa cererile de la distanță primite. După procesarea cererii, procesul serverului revine în pool și intră într-o stare gata să proceseze alte cereri. Serverul nu salvează contextul utilizatorului între două apeluri, deoarece poate procesa cereri de la mai multe procese simultan. Prin urmare, fiecare mesaj care sosește de la un proces client trebuie să includă informații despre mediul său de execuție și anume: coduri de identificare a utilizatorului, directorul curent, semnale etc. funcții.
Când un proces deschide un fișier la distanță, nucleul la distanță atribuie un index pentru link-urile ulterioare către fișier. Mașina locală menține un tabel de descriptor de fișier personalizat, un tabel de fișiere și un tabel de index cu un set obișnuit de înregistrări, cu o intrare de tabel de index care identifică mașina de la distanță și indexul de la distanță. În cazurile în care o funcție de sistem (de exemplu, citire) utilizează un descriptor de fișier, nucleul trimite un mesaj care indică indexul de la distanță atribuit anterior și transferă informații legate de proces: codul de identificare a utilizatorului, dimensiunea maximă a fișierului etc. Procesul serverului la dispoziția sa, interacțiunea cu clientul ia forma descrisă mai devreme, totuși, conexiunea dintre client și server se stabilește doar pe durata funcției sistemului.
Utilizarea serverelor în loc de procese prin satelit poate face mai dificilă gestionarea traficului de date, a semnalelor și a dispozitivelor de la distanță. Un număr mare de cereri către o mașină de la distanță în absența unui număr suficient de servere ar trebui să fie puse în coadă. Acest lucru necesită un protocol de nivel mai înalt decât cel utilizat în rețeaua principală. În modelul satelit, pe de altă parte, suprasaturarea este eliminată deoarece toate cererile clienților sunt procesate sincron. Un client poate avea cel mult o cerere în așteptare.
Procesarea semnalelor care întrerup execuția unei funcții de sistem este, de asemenea, complicată atunci când se utilizează servere, deoarece mașina de la distanță trebuie să caute serverul corespunzător care deservește execuția funcției. Este chiar posibil ca, din cauza aglomerației tuturor serverelor, o solicitare pentru o funcție de sistem să fie în așteptarea procesării. Condițiile pentru apariția concurenței apar și atunci când serverul returnează rezultatul funcției sistemului procesului de apelare, iar răspunsul serverului include trimiterea unui mesaj de semnalizare corespunzător prin rețea. Fiecare mesaj trebuie marcat astfel încât sistemul de la distanță să-l poată recunoaște și, dacă este necesar, să încheie procesele serverului. La folosirea sateliților, procesul care se ocupă de îndeplinirea cererii clientului este identificat automat, iar în cazul sosirii unui semnal nu este greu de verificat dacă cererea a fost procesată sau nu.
În cele din urmă, dacă o funcție de sistem apelată de client face ca serverul să se întrerupă pe termen nelimitat (de exemplu, la citirea datelor de la un terminal la distanță), serverul nu poate procesa alte solicitări pentru a elibera pool-ul de servere. Dacă mai multe procese accesează simultan dispozitive de la distanță și dacă numărul de servere este limitat de sus, există un blocaj destul de tangibil. Acest lucru nu se întâmplă cu sateliții, deoarece un satelit este alocat fiecărui proces client. O altă problemă legată de utilizarea serverelor pentru dispozitive la distanță va fi tratată în Exercițiul 13.14.
În ciuda avantajelor pe care le oferă utilizarea proceselor satelit, nevoia de intrări gratuite în tabelul de procese devine în practică atât de acută încât, în majoritatea cazurilor, serviciile proceselor server sunt încă folosite pentru a procesa cererile de la distanță.

Figura 13.12. Diagrama conceptuală a interacțiunii cu fișierele de la distanță la nivel de kernel
13.5 CONCLUZII
În acest capitol, am luat în considerare trei scheme de lucru cu fișiere situate pe mașini la distanță, tratând sistemele de fișiere la distanță ca pe o extensie a celui local. Diferențele arhitecturale dintre aceste amenajări sunt prezentate în Figura 13.12. Toate, la rândul lor, diferă de sistemele multiprocesoare descrise în capitolul anterior prin faptul că procesoarele de aici nu împart memoria fizică. Un sistem de procesor periferic constă dintr-un set strâns cuplat de procesoare care partajează resursele de fișiere ale procesorului central. O conexiune de tip Newcastle oferă acces ascuns („transparent”) la fișierele de la distanță, dar nu prin intermediul nucleului sistemului de operare, ci prin utilizarea unei biblioteci C speciale. Din acest motiv, toate programele care intenționează să utilizeze acest tip de legături trebuie să fie recompilate, ceea ce, în general, este un dezavantaj serios al acestei scheme. Depărtarea unui fișier este indicată folosind o secvență specială de caractere care descrie mașina pe care se află fișierul și acesta este un alt factor care limitează portabilitatea programelor.
În sistemele distribuite transparente, o modificare a funcției sistemului de montare este utilizată pentru a accesa fișierele de la distanță. Indecșii de pe sistemul local sunt marcați ca fișiere la distanță, iar nucleul local trimite un mesaj către sistemul de la distanță care descrie funcția de sistem solicitată, parametrii acesteia și indexul de la distanță. Comunicarea într-un sistem distribuit „transparent” este suportată în două forme: sub forma unui apel către o procedură la distanță (se trimite un mesaj către mașina de la distanță care conține o listă de operațiuni asociate cu indexul) și sub forma unui apel. la o funcție de sistem de la distanță (mesajul descrie funcția solicitată). Partea finală a capitolului discută probleme legate de procesarea cererilor de la distanță folosind procese și servere satelit.
13.6 EXERCIȚII
*1. Descrieți implementarea funcției sistemului de ieșire într-un sistem cu procesoare periferice. Care este diferența dintre acest caz și când procesul iese la primirea unui semnal necaptat? Cum ar trebui nucleul să arunce conținutul memoriei?
2. Procesele nu pot ignora semnalele SIGKILL; Explicați ce se întâmplă în sistemul periferic atunci când procesul primește un astfel de semnal.
* 3. Descrieți implementarea funcției de sistem exec pe un sistem cu procesoare periferice.
*4. Cum ar trebui procesorul central să distribuie procesele între procesoarele periferice pentru a echilibra sarcina totală?
*5. Ce se întâmplă dacă procesorul periferic nu are suficientă memorie pentru a găzdui toate procesele descărcate în el? Cum ar trebui să se facă descărcarea și schimbarea proceselor din rețea?
6. Luați în considerare un sistem în care solicitările către un server de fișiere la distanță sunt trimise dacă se găsește un prefix special în numele fișierului. Lăsați procesul să apeleze execl ("/../ sftig / bin / sh", "sh", 0); Executabilul se află pe o mașină la distanță, dar trebuie să ruleze pe sistemul local. Explicați cum este migrat modulul la distanță în sistemul local.
7. Dacă administratorul trebuie să adauge mașini noi la un sistem existent cu o conexiune precum Newcastle, atunci care este cea mai bună modalitate de a informa modulele bibliotecii C despre aceasta?
*opt. În timpul execuției funcției exec, nucleul suprascrie spațiul de adrese al procesului, inclusiv tabelele de bibliotecă utilizate de legătura Newcastle pentru a urmări link-urile către fișierele de la distanță. După executarea funcției, procesul trebuie să păstreze capacitatea de a accesa aceste fișiere prin vechii lor descriptori. Descrieți implementarea acestui punct.
*nouă. După cum se arată în secțiunea 13.2, apelarea funcției de sistem de ieșire pe sistemele cu o conexiune Newcastle are ca rezultat trimiterea unui mesaj către procesul însoțitor, forțând pe acesta din urmă să se încheie. Acest lucru se face la nivelul rutinelor bibliotecii. Ce se întâmplă când un proces local primește un semnal care îi spune să iasă în modul kernel?
*zece. Într-un sistem cu o legătură Newcastle, în care fișierele la distanță sunt identificate prin prefixarea numelui cu un prefix special, cum poate un utilizator, specificând „..” (directorul părinte) ca componentă a numelui fișierului, să traverseze punctul de montare la distanță?
11. Din capitolul 7 știm că diverse semnale determină procesul să arunce conținutul memoriei în directorul curent. Ce ar trebui să se întâmple dacă directorul curent provine din sistemul de fișiere la distanță? Ce răspuns ați da dacă sistemul folosește o relație precum Newcastle?
*12. Ce implicații pentru procesele locale ar avea dacă toate procesele satelit sau server ar fi eliminate din sistem?
*13. Luați în considerare modul de implementare a algoritmului de legătură într-un sistem distribuit transparent, ai cărui parametri pot fi două nume de fișiere la distanță, precum și algoritmul exec, asociat cu efectuarea mai multor operațiuni interne de citire. Luați în considerare două forme de comunicare: un apel de procedură de la distanță și un apel de funcție de sistem la distanță.
*paisprezece. La accesarea dispozitivului, procesul serverului poate intra în starea suspendată, din care va fi scos de driverul dispozitivului. Desigur, dacă numărul de servere este limitat, sistemul nu va mai putea satisface solicitările mașinii locale. Vino cu o schemă fiabilă prin care nu toate procesele serverului sunt suspendate în timp ce se așteaptă finalizarea I/E-urilor legate de dispozitiv. Funcția de sistem nu se va opri în timp ce toate serverele sunt ocupate.

Figura 13.13. Configurare Terminal Server
*15. Când un utilizator se conectează la sistem, disciplina de linie terminală stochează informația că terminalul este un terminal operator care conduce un grup de procese. Din acest motiv, atunci când utilizatorul apasă tasta „break” de pe tastatura terminalului, toate procesele din grup primesc semnalul de întrerupere. Luați în considerare o configurație de sistem în care toate terminalele sunt conectate fizic la o singură mașină, dar înregistrarea utilizatorului este implementată în mod logic pe alte mașini (Figura 13.13). În fiecare caz, sistemul creează un proces getty pentru terminalul la distanță. Dacă cererile către un sistem la distanță sunt procesate de un set de procese server, rețineți că atunci când procedura deschisă este executată, serverul nu mai așteaptă o conexiune. Când funcția de deschidere se termină, serverul revine la pool-ul de servere, întrerupând conexiunea la terminal. Cum se declanșează un semnal de întrerupere prin apăsarea tastei „break” trimis la adresele proceselor incluse în același grup?
*16. Partajarea memoriei este o caracteristică inerentă mașinilor locale. Din punct de vedere logic, alocarea unei zone comune de memorie fizică (locală sau la distanță) poate fi efectuată pentru procese aparținând diferitelor mașini. Descrieți implementarea acestui punct.
* 17. Algoritmii de paginare a procesului și de paginare discutați în Capitolul 9 presupun utilizarea unui pager local. Ce modificări ar trebui făcute acestor algoritmi pentru a putea suporta dispozitive de descărcare la distanță?
*optsprezece. Să presupunem că mașina (sau rețeaua) de la distanță se confruntă cu o prăbușire fatală și protocolul nivelului de rețea local înregistrează acest fapt. Dezvoltați o schemă de recuperare pentru un sistem local care face cereri către un server la distanță. În plus, dezvoltați o schemă de recuperare pentru un sistem server care și-a pierdut contactul cu clienții.
*19. Când un proces accesează un fișier de la distanță, este posibil ca procesul să traverseze mai multe mașini în căutarea fișierului. Luați numele „/ usr / src / uts / 3b2 / os” ca exemplu, unde „/ usr” este directorul care aparține mașinii A, „/ usr / src” este punctul de montare al rădăcinii mașinii B, „ / usr / src / uts / 3b2 „este punctul de montare al rădăcinii mașinii C. Mersul prin mai multe mașini până la destinația sa finală se numește multihop. Cu toate acestea, dacă există o conexiune directă la rețea între mașinile A și C, trimiterea datelor prin mașina B ar fi ineficientă. Descrieți caracteristicile implementării „multishopping” într-un sistem cu o conexiune Newcastle și într-un sistem distribuit „transparent”.
V exploatații mari zeci de mii de utilizatori lucrează în filiale. Fiecare organizație are propriile sale procese interne de afaceri: aprobarea documentelor, emiterea de instrucțiuni etc. În același timp, unele procese depășesc granițele unei companii și afectează angajații alteia. De exemplu, șeful sediului central emite un ordin filialei sau un angajat al filialei trimite spre aprobare un acord cu avocații societății-mamă. Acest lucru necesită o arhitectură complexă care utilizează mai multe sisteme.
Mai mult, în interior o singură companie multe sisteme sunt folosite pentru a rezolva diferite probleme: un sistem ERP pentru operațiuni contabile, instalații separate de sisteme ECM pentru documentația organizatorică și administrativă, pentru devizele de proiectare etc.
Sistemul DIRECTUM va ajuta la asigurarea interacțiunii diferitelor sisteme atât în cadrul exploatației, cât și la nivelul unei singure organizații.
DIRECTUM oferă instrumente convenabile pentru construcție arhitectură distribuită gestionată organizarea si rezolvarea urmatoarelor sarcini:
- organizarea proceselor de afaceri end-to-end și sincronizarea datelor între mai multe sisteme ale aceleiași companii și din holding;
- asigurarea accesului la date din diferite instalații ale sistemelor ECM. De exemplu, căutați un document în mai multe sisteme specializate: cu documentație financiară, cu documentație de proiectare și deviz etc.
- administrarea multor sisteme și servicii dintr-un singur punct de management și crearea unei infrastructuri IT confortabile;
- distribuirea convenabilă a dezvoltării către sistemele de producție distribuită.

Componentele unei arhitecturi distribuite gestionate
Mecanisme de interconectare (DCI)
Mecanismele DCI sunt folosite pentru a organiza procesele de afaceri end-to-end și pentru a sincroniza datele între diferite sisteme din cadrul uneia sau mai multor organizații (holding).

Soluția conectează procesele locale de afaceri existente în companii într-un singur proces end-to-end. Angajații și managerii lor lucrează cu interfața deja familiară de sarcini, documente și cărți de referință. În același timp, acțiunile angajaților sunt transparente în fiecare etapă: aceștia pot vedea textul corespondenței cu o companie afiliată, pot vedea stadiul aprobării documentului cu organizația-mamă etc.
Diverse instalații DIRECTUM și alte clase de sisteme (ERP, CRM etc.) pot fi conectate la DCI. De regulă, instalațiile sunt împărțite pe domenii de activitate, ținând cont de localizarea teritorială sau legală a organizațiilor și de alți factori.
Împreună cu DCI, componentele de dezvoltare sunt furnizate cu o descriere detaliată și exemple de cod, datorită cărora un dezvoltator poate crea un algoritm pentru procesele de afaceri ale organizației sale.
Mecanismele DCI sunt capabile să transmită cantități mari de date și să reziste la sarcini de vârf. În plus, oferă toleranță la erori în cazul erorilor de comunicare și protecția datelor transmise.
Căutare federată
Cu căutarea federată, puteți găsi sarcinile sau documentele de care aveți nevoie simultan în toate sistemele individuale DIRECTUM. De exemplu, începeți o căutare simultan în sistemul de lucru și în sistemul cu documente arhivate.

Căutarea federată vă permite să:
- vizualiza prin clientul web progresul aprobării unui document de ieșire într-o filială;
- găsiți acorduri încheiate cu o contraparte în toate filialele, de exemplu, pentru pregătirea negocierilor. În acest caz, puteți merge la sarcinile în care sunt anexate contractele;
- verifica starea de executare a comenzii transmise de organizația-mamă către filială, sau documentele și sarcinile create pe aceasta;
- găsi documente simultan în mai multe sisteme cu specializări diferite, de exemplu, cu documente organizatorice și administrative și cu contracte;
- găsiți documente contabile primare pentru audit sau reconciliere cu o contraparte imediat în sistemul de lucru și în sistemul cu arhivă de documente;
- schimbă link-uri către rezultatele căutării cu colegii.
Administratorul poate modifica căutările standard, poate adăuga altele noi și, de asemenea, poate personaliza sistemele care vor fi vizibile pentru utilizator.
Centrul de Administrare Servicii DIRECTUM
Sistemul DIRECTUM rezolvă multe sarcini diferite: interacțiunea angajaților, stocarea documentelor etc. Acest lucru este posibil datorită funcționării fiabile a serviciilor sale. Și în companiile mari, ei alocă instalații întregi ale sistemului DIRECTUM cu propriul set de servicii pentru o sarcină specifică, de exemplu, pentru stocarea documentelor de arhivă. Instalațiile și serviciile sunt implementate pe mai multe servere. Această infrastructură trebuie administrată.
Centrul de administrare a serviciilor DIRECTUM este un singur punct de intrare administrativ pentru configurarea, monitorizarea și gestionarea serviciilor și sistemelor DIRECTUM. Centrul este un site pentru instrumente de management pentru Server de sesiune, Serviciu flux de lucru, Serviciu de evenimente, Serviciu de stocare fișiere, Servicii de intrare și transformare, Căutare federată și Ajutor web.

Configurarea vizuală convenabilă a sistemelor și serviciilor de la distanță simplifică munca administratorului. Nu trebuie să meargă la fiecare server și să facă manual modificări la fișierele de configurare.
Serviciile sunt oprite și activate cu un singur clic. Starea serviciilor este afișată instantaneu pe ecran.
Lista setărilor poate fi completată și filtrată. În mod implicit, site-ul afișează doar setările de bază. În același timp, pentru toate setările, puteți vedea sfaturi cu recomandări pentru umplere.
Sistemul DIRECTUM organizează eficient munca organizațiilor distribuite și oferă utilizatorilor un schimb transparent de documente, sarcini și înregistrări de director.
Fiecare componentă a unei Arhitecturi distribuite gestionate poate fi utilizată separat, dar împreună pot aduce o valoare comercială mai mare organizației dumneavoastră.
În prezent, toate SI dezvoltate în scop comercial au o arhitectură distribuită, ceea ce presupune utilizarea rețelelor globale și/sau locale.
Din punct de vedere istoric, arhitectura serverului de fișiere a fost prima răspândită, deoarece logica sa este simplă și este cel mai ușor să transferați la o astfel de arhitectură IS-urile care sunt deja în uz. Apoi a fost transformat într-o arhitectură server-client, care poate fi interpretată ca o continuare logică. Sistemele moderne utilizate în rețeaua globală INTERNET se referă în principal la arhitectura obiectelor distribuite (vezi Fig. III‑15 )
IS poate fi imaginat constând din următoarele componente (Fig. III-16)
III.03.2. a Aplicații server de fișiere.
Din punct de vedere istoric, este prima arhitectură distribuită (Fig. III-17). Este organizat foarte simplu: există doar date pe server și totul aparține mașinii client. Deoarece rețelele locale sunt destul de ieftine și datorită faptului că cu o astfel de arhitectură software-ul aplicației este autonom, o astfel de arhitectură este adesea folosită astăzi. Putem spune că aceasta este o variantă a arhitecturii client-server, în care pe server se află doar fișierele de date. Diferitele computere personale interacționează doar prin intermediul unui depozit comun de date, prin urmare programele scrise pentru un computer sunt cel mai ușor de adaptat la o astfel de arhitectură.
Pro:
Avantajele unei arhitecturi de server de fișiere:
Ușurință de organizare;
Nu contravine cerințelor necesare pentru ca baza de date să mențină integritatea și fiabilitatea.
congestionarea rețelei;
Răspuns imprevizibil la o solicitare.
Aceste dezavantaje se explică prin faptul că orice solicitare către baza de date duce la transferul unor cantități semnificative de informații prin rețea. De exemplu, pentru a selecta unul sau mai multe rânduri din tabele, întregul tabel este descărcat pe computerul client și DBMS-ul selectează deja acolo. Traficul semnificativ de rețea este plin în special de organizarea accesului de la distanță la baza de date.
III.03.2. b Aplicații client-server.
În acest caz, există o distribuție a responsabilităților între server și client. În funcție de modul în care sunt separate, distingeți grasși client slab.
În modelul thin client, toate lucrările aplicației și gestionarea datelor se fac pe server. Interfața cu utilizatorul din aceste sisteme „migrează” către un computer personal, iar aplicația software în sine îndeplinește funcțiile unui server, adică. rulează toate procesele aplicației și gestionează datele. Modelul de client subțire poate fi implementat și acolo unde clienții sunt computere sau stații de lucru. Dispozitivele de rețea rulează browserul de internet și interfața de utilizator implementată în sistem.
Principal defect modele de client subțiri - încărcare mare de server și rețea. Toate calculele sunt efectuate pe server, iar acest lucru poate duce la un trafic de rețea semnificativ între client și server. Există suficientă putere de calcul în computerele moderne, dar practic nu este folosită în modelul / clientul subțire al băncii
În schimb, modelul client gros folosește puterea de procesare a mașinilor locale: aplicația în sine este plasată pe computerul client. Un exemplu de acest tip de arhitectură sunt sistemele ATM, în care ATM-ul este clientul, iar serverul este computerul central care deservește baza de date a conturilor clienților.
III.03.2. c Arhitectură client-server cu două și trei niveluri.
Toate arhitecturile discutate mai sus sunt pe două niveluri. Ei fac diferența între nivelul de client și cel de server. Strict vorbind, CI constă din trei niveluri logice:
· Nivel de utilizator;
Nivel de aplicare:
· Stratul de date.
Prin urmare, într-un model cu două niveluri, în care sunt implicate doar două niveluri, există probleme de scalabilitate și performanță dacă este ales modelul de client subțire sau probleme de management al sistemului dacă este ales modelul de client gros. Aceste probleme pot fi evitate dacă aplicăm un model format din trei niveluri, unde două dintre ele sunt servere (Fig. III-21).
| Server de date |
De fapt, serverul de aplicații și serverul de date pot fi amplasate pe aceeași mașină, dar nu pot îndeplini funcțiile unul altuia. Lucrul frumos despre modelul cu trei niveluri este că separă în mod logic execuția aplicației și gestionarea datelor.
Tabelul III-5 Aplicarea diferitelor tipuri de arhitecturi
| Arhitectură | Aplicație |
| Client subțire pe două niveluri | 1 Sisteme vechi în care nu este recomandabil să se separe execuția aplicației și gestionarea datelor. 2 Aplicații intensive de calcul cu o gestionare redusă a datelor. 3 Aplicații cu cantități mari de date, dar puține calcule. |
| Client gros pe două niveluri | 1 Aplicații în care utilizatorul necesită o prelucrare intensivă a datelor, adică vizualizarea datelor. 2 Aplicații cu un set relativ constant de funcții de utilizator aplicate unui mediu de sistem bine gestionat. |
| Server-client pe trei niveluri | 1 Aplicații mari cu celule și mii de clienți 2 Aplicații în care atât datele, cât și metodele de procesare se schimbă frecvent. 3 Aplicații care integrează date din mai multe surse. |
Acest model este potrivit pentru multe tipuri de aplicații, dar limitează dezvoltatorii IS care trebuie să decidă unde să ofere servicii, să ofere suport pentru scalabilitate și să dezvolte instrumente pentru a conecta noi clienți.
III.03.2. d Arhitectura obiectelor distribuite.
O abordare mai generală este oferită de o arhitectură de obiecte distribuite, din care obiectele sunt componentele principale. Ei oferă un set de servicii prin interfețele lor. Alte obiecte trimit cereri fără a face diferența între client și server. Obiectele pot fi localizate pe diferite computere din rețea și interacționează prin middleware, similar magistralei de sistem, care vă permite să conectați diferite dispozitive și să sprijine comunicarea între dispozitivele hardware.
| … |
| Manager de drivere ODBC |
| Șoferul 1 |
| Șoferul K |
| DB 1 |
| DB K |
| Lucrul cu SQL |
| … |
Arhitectura ODBC include componente:
1. Aplicație (de ex. IS). Îndeplinește sarcini: solicită o conexiune la sursa de date, trimite interogări SQL la sursa de date, descrie zona de stocare și formatul pentru interogările SQL, gestionează erorile și notifică utilizatorul despre acestea, comite sau derulează tranzacții, solicită o conexiune la sursă de date.
2. Manager dispozitive. Încarcă drivere la cererea aplicațiilor, oferă o singură interfață pentru toate aplicațiile, iar interfața de administrator ODBC este aceeași și indiferent de ce DBMS va interacționa aplicația. Managerul de drivere furnizat de Microsoft este o bibliotecă cu încărcare dinamică (DLL).
3. Driverul depinde de SGBD. Un driver ODBC este o bibliotecă de legături dinamice (DLL) care implementează funcții ODBC și interacționează cu o sursă de date. Un driver este un program care procesează o solicitare pentru o funcție specifică unui SGBD (poate modifica cereri în conformitate cu SGBD) și returnează rezultatul aplicației. Fiecare SGBD care acceptă tehnologia ODBC trebuie să ofere dezvoltatorilor de aplicații un driver pentru acel SGBD.
4. Sursa de date conține informațiile de control specificate de utilizator, informații despre sursa de date și este folosită pentru a accesa un anumit SGBD. În acest caz, sunt utilizate mijloacele sistemului de operare și platforma de rețea.
Model dinamic
Acest model presupune multe aspecte, pentru care se folosesc cel puțin 5 diagrame în UML, vezi pp. 2.04.2- 2.04.5.
Luați în considerare aspectul managementului. Modelul de guvernare completează modelele structurale.
Indiferent de modul în care este descrisă structura sistemului, acesta constă dintr-un set de unități structurale (funcții sau obiecte). Pentru ca acestea să funcționeze ca un întreg, trebuie să fie controlate și nu există informații de control în diagramele statice. Modelele de control proiectează fluxul de control între sisteme.
Există două tipuri principale de control în sistemele software.
1. Management centralizat.
2. Management bazat pe evenimente.
Managementul centralizat poate fi:
· Ierarhic- pe baza principiului „call-return” (așa funcționează cel mai adesea programele educaționale)
· Model de dispecer care este folosit pentru sistemele paralele.
V modele de dispecer se presupune că una dintre componentele sistemului este un dispecer. Gestionează atât pornirea și oprirea sistemelor, cât și coordonarea restului proceselor din sistem. Procesele pot rula în paralel unul cu celălalt. Un proces se referă la un program, subsistem sau procedură care rulează în prezent. Acest model poate fi aplicat și în sisteme secvențiale, unde programul de control apelează subsisteme individuale în funcție de unele variabile de stare (prin operator caz).
Management de evenimenteîși asumă absența oricărei subrutine responsabile de management. Controlul este efectuat de evenimente externe: apăsarea unui buton al mouse-ului, apăsarea unei tastaturi, modificarea citirilor senzorului, modificarea citirilor temporizatorului etc. Fiecare eveniment extern este codificat și plasat în coada de evenimente. Dacă este furnizată o reacție la un eveniment din coadă, atunci este apelată procedura (subrutină), care realizează reacția la acest eveniment. Evenimentele la care reacționează sistemul pot avea loc fie în alte subsisteme, fie în mediul extern al sistemului.
Un exemplu de astfel de management este organizarea aplicațiilor în Windows.
Toate modelele structurale descrise anterior pot fi implementate folosind managementul centralizat sau managementul bazat pe evenimente.
Interfața cu utilizatorul
Atunci când se dezvoltă un model de interfață, ar trebui să se ia în considerare nu numai sarcinile software-ului proiectat, ci și caracteristicile creierului asociate cu percepția informațiilor.
III.03.4. a Caracteristicile psihofizice ale unei persoane asociate cu percepția și procesarea informațiilor.
Partea creierului, care poate fi numită în mod convențional un procesor al percepției, în mod constant, fără participarea conștiinței, procesează informațiile primite, o compară cu experiența trecută și o depozitează.
Când o imagine vizuală ne atrage atenția, atunci informațiile care ne interesează ajung în memoria de scurtă durată. Daca nu ne-a fost atrasa atentia, atunci informatia din depozit dispare, fiind inlocuita cu urmatoarele portiuni.
În fiecare moment de timp, focalizarea atenției poate fi fixată la un moment dat, așa că dacă devine necesară urmărirea simultană a mai multor situații, atunci focalizarea se mută de la un obiect urmărit la altul. În același timp, atenția este împrăștiată, iar unele detalii pot fi trecute cu vederea. De asemenea, este semnificativ faptul că percepția se bazează în mare măsură pe motivație.
Când schimbi cadrul, creierul este blocat pentru un timp: stăpânește o nouă imagine, evidențiind cele mai semnificative detalii. Aceasta înseamnă că, dacă aveți nevoie de un răspuns rapid din partea utilizatorului, atunci nu ar trebui să schimbați brusc imaginile.
Memoria pe termen scurt este blocajul în sistemul de procesare a informațiilor unei persoane. Capacitatea sa este de 7 ± 2 obiecte neconectate. Informațiile nerevendicate sunt stocate în el timp de cel mult 30 de secunde. Pentru a nu uita nicio informație importantă pentru noi, de obicei o repetăm nouă, actualizând informațiile în memoria de scurtă durată. Astfel, la proiectarea interfețelor, trebuie avut în vedere faptul că majorității covârșitoare le este greu, de exemplu, să-și amintească și să introducă numere care conțin mai mult de cinci cifre pe alt ecran.
Deși capacitatea și timpul de stocare a memoriei pe termen lung sunt nelimitate, accesul la informații nu este ușor. Mecanismul de extragere a informațiilor din memoria pe termen lung este de natură asociativă. Pentru a îmbunătăți memorarea informațiilor, aceasta este legată de datele pe care memoria le stochează deja și le face ușor de obținut. Deoarece accesul la memoria pe termen lung este dificil, este recomandabil să vă așteptați ca utilizatorul să nu-și amintească informațiile, ci pe faptul că utilizatorul le va recunoaște.
III.03.4. b Criterii de bază pentru evaluarea interfețelor
Numeroase sondaje și sondaje efectuate de firme de dezvoltare software de top au arătat că utilizatorii valorifică într-o interfață:
1) ușurința de stăpânire și memorare - estimați în mod specific timpul de stăpânire și durata păstrării informațiilor și memoriei;
2) viteza de obținere a rezultatelor la utilizarea sistemului, care este determinată de numărul de comenzi și setări introduse sau selectate de mouse;
3) satisfacția subiectivă față de funcționarea sistemului (ușurință în utilizare, oboseală etc.).
Mai mult, pentru utilizatorii profesioniști care lucrează constant cu același pachet, al doilea și al treilea criteriu ajung rapid pe primul loc, iar pentru utilizatorii neprofesioniști care lucrează periodic cu software și efectuează sarcini relativ simple - primul și al treilea.
Din acest punct de vedere, astăzi cele mai bune caracteristici pentru utilizatorii profesioniști sunt interfețele cu navigare gratuită, iar pentru utilizatorii neprofesioniști - interfețele de manipulare directă. S-a observat de mult că atunci când efectuează o operațiune de copiere a fișierelor, toate celelalte lucruri fiind egale, majoritatea profesioniștilor folosesc shell-uri precum Far, în timp ce neprofesioniștii folosesc Windows „drag and drop”.
III.03.4. c Tipuri de interfeţe utilizator
Se disting următoarele tipuri de interfețe utilizator:
Primitiv
Navigare gratuită
Manipulare directă.
Interfața este primitivă
Primitiv se numeste interfata care organizeaza interactiunea cu utilizatorul si este folosita in modul consola. Singura abatere de la procesul secvenţial pe care îl oferă datele este trecerea în buclă prin mai multe seturi de date.
Interfață de meniu.
Spre deosebire de interfața primitivă, permite utilizatorului să selecteze o operație dintr-o listă specială afișată de program. Aceste interfețe presupun implementarea multor scenarii de lucru, succesiunea acțiunilor în care este determinată de utilizatori. Organizarea sub formă de arbore a meniului sugerează că găsirea unui articol în mai mult de meniuri cu două niveluri este dificilă.
Principiile creării unui sistem de procesare a informațiilor la nivelul întregii întreprinderi
Istoria dezvoltării tehnologiei informatice (și, în consecință, a software-ului) a început cu sisteme separate, autonome. Oamenii de știință și inginerii au fost preocupați de crearea primelor computere și au fost în principal nedumeriți de modul în care să funcționeze aceste roiuri de tuburi vidate. Cu toate acestea, această stare de lucruri nu a durat mult - ideea de a combina puterea de calcul era destul de evidentă și era în aer, saturată de zumzetul dulapurilor metalice ale primelor ENIAK și mărci. La urma urmei, ideea de a combina eforturile a două sau mai multe computere pentru a rezolva sarcini complexe, insuportabile pentru fiecare dintre ele separat, se află la suprafață.
Orez. 1. Schema de calcul distribuit
Cu toate acestea, implementarea practică a ideii de conectare a calculatoarelor în clustere și rețele a fost împiedicată de lipsa soluțiilor tehnice și, în primul rând, de necesitatea creării de standarde și protocoale de comunicare. După cum știți, primele computere au apărut la sfârșitul anilor patruzeci ai secolului XX, iar prima rețea de calculatoare ARPANet, care a conectat mai multe computere din Statele Unite, abia în 1966, aproape douăzeci de ani mai târziu. Desigur, o astfel de combinație de capabilități de calcul ale arhitecturii moderne distribuite semăna foarte vag, dar totuși a fost primul pas în direcția corectă.
Apariția rețelelor locale de-a lungul timpului a condus la dezvoltarea unei noi zone de dezvoltare software - crearea de aplicații distribuite. A trebuit să facem asta de la zero, după cum se spune, dar, din fericire, marile companii, a căror structură de business necesita astfel de soluții, s-au arătat imediat interesate de astfel de aplicații. În etapa creării aplicațiilor distribuite corporative s-au format cerințele de bază și s-au dezvoltat arhitecturile principale ale unor astfel de sisteme, care sunt utilizate și astăzi.
Treptat, mainframe-urile și terminalele au evoluat către o arhitectură client-server, care a fost în esență prima versiune a unei arhitecturi distribuite, adică un sistem distribuit pe două niveluri. Într-adevăr, în aplicațiile client-server o parte din operațiunile de calcul și logica de afaceri a fost transferată în partea clientului, ceea ce, de fapt, a devenit punctul culminant, semnul distinctiv al acestei abordări.
În această perioadă a devenit evident că principalele avantaje ale aplicațiilor distribuite sunt:
· Scalabilitate bună – dacă este necesar, puterea de calcul a unei aplicații distribuite poate fi crescută cu ușurință fără a-i modifica structura;
· Capacitatea de a gestiona încărcarea - nivelurile intermediare ale unei aplicații distribuite fac posibilă gestionarea fluxurilor de solicitări ale utilizatorilor și redirecționarea acestora către servere mai puțin încărcate pentru procesare;
· Globalitate - o structură distribuită vă permite să urmăriți distribuția spațială a proceselor de afaceri și să creați stații de lucru client în punctele cele mai convenabile.
Pe măsură ce trecea timpul, micile insule de rețele universitare, guvernamentale și corporative s-au extins, s-au fuzionat în sisteme regionale și naționale. Și apoi a apărut jucătorul principal pe scenă - Internetul.
Elogiile elogioase despre World Wide Web au fost mult timp un loc obișnuit pentru publicațiile pe subiecte informatice. Într-adevăr, Internetul a jucat un rol esențial în dezvoltarea calculului distribuit și a făcut din această zonă destul de specifică a dezvoltării software-ului punctul central al unei armate de programatori profesioniști. Astăzi, extinde în mod semnificativ utilizarea aplicațiilor distribuite, permițând utilizatorilor la distanță să se conecteze și făcând disponibile funcțiile aplicațiilor peste tot.
Aceasta este istoria problemei. Acum să aruncăm o privire la ce sunt aplicațiile distribuite.
Paradigma de calcul distribuit
Imaginează-ți o unitate de producție, o companie comercială sau un furnizor de servicii destul de mare. Toate diviziile lor au deja propriile baze de date și software specific. Oficiul central colectează cumva informații despre activitățile curente ale acestor departamente și furnizează managerilor informații pe baza cărora aceștia iau decizii de management.
Să mergem mai departe și să presupunem că organizația pe care o luăm în considerare se dezvoltă cu succes, deschide filiale, dezvoltă noi tipuri de produse sau servicii. Mai mult, la ultima intalnire, directorii progresisti au decis sa organizeze o retea de statii de lucru la distanta de la care clientii sa primeasca cateva informatii despre onorarea comenzilor lor.
În situația descrisă, rămâne doar să-i fie milă șefului departamentului IT dacă nu s-a ocupat în prealabil de construirea unui sistem general de management al fluxului de afaceri, deoarece fără el va fi foarte dificil să se asigure dezvoltarea eficientă a organizației. Mai mult, nu se poate face fără un sistem de procesare a informațiilor la nivel de întreprindere, conceput ținând cont de încărcătura în creștere și, în plus, corespunzător principalelor fluxuri de afaceri, deoarece toate departamentele trebuie să își îndeplinească nu numai sarcinile, ci și, dacă este necesar, să proceseze cererile. din alte departamente și chiar (coșmar pentru un manager de proiect!) clienți.
Așadar, suntem gata să formulăm cerințele de bază pentru aplicațiile moderne la scară întreprindere dictate de însăși organizarea procesului de producție.
Separarea spațială. Diviziile organizației sunt dispersate în spațiu și au adesea un software slab unificat.
Conformitate structurală. Software-ul ar trebui să reflecte în mod adecvat structura informațională a întreprinderii - ar trebui să corespundă principalelor fluxuri de date.
Orientare către informații externe. Întreprinderile moderne sunt forțate să acorde o atenție sporită lucrului cu clienții. Prin urmare, software-ul pentru întreprinderi trebuie să poată funcționa cu un nou tip de utilizator și cu nevoile acestora. Astfel de utilizatori au drepturi limitate cu bună știință și au acces la un tip de date strict definit.
Toate cerințele de mai sus pentru software-ul la nivel de întreprindere sunt îndeplinite de sistemele distribuite - schema de distribuție a calculelor este prezentată în Fig. 1.
Desigur, aplicațiile distribuite nu sunt lipsite de defecte. În primul rând, sunt costisitoare de operat, iar în al doilea rând, crearea unor astfel de aplicații este un proces laborios și complex, iar costul unei erori în etapa de proiectare este foarte mare. Cu toate acestea, dezvoltarea aplicațiilor distribuite progresează bine - jocul merită lumânarea, deoarece un astfel de software ajută la îmbunătățirea eficienței organizației.
Deci, paradigma calculului distribuit presupune prezența mai multor centre (servere) de stocare și procesare a informațiilor, implementând diverse funcții și distanțate între ele. Aceste centre, pe lângă solicitările clienților sistemului, trebuie să îndeplinească și cerințele unul altuia, deoarece în unele cazuri, rezolvarea primei sarcini poate necesita eforturile comune ale mai multor servere. Pentru gestionarea cererilor complexe și a funcționării sistemului în ansamblu, este necesar un software de control specializat. Și în sfârșit, întregul sistem trebuie să fie „cufundat” într-un fel de mediu de transport care să asigure interacțiunea părților sale.
Sistemele de calcul distribuite au proprietăți comune precum:
· Gestionabilitate - implică capacitatea sistemului de a-și controla eficient componentele. Acest lucru se realizează prin utilizarea unui software de control;
· Performanta - asigurata datorita posibilitatii de redistribuire a sarcinii pe serverele sistemului folosind software-ul de control;
Scalabilitate – dacă este necesară creșterea fizică a productivității, un sistem distribuit poate integra cu ușurință noi resurse de calcul în mediul său de transport;
· Extensibilitate – la aplicațiile distribuite pot fi adăugate noi componente (software server) cu funcții noi.
Accesul la date din aplicațiile distribuite este posibil din software-ul client și alte sisteme distribuite pot fi organizate la diferite niveluri - de la software-ul client și protocoalele de transport până la protecția serverelor de baze de date.

Orez. 2. Principalele niveluri ale arhitecturii unei aplicații distribuite
Proprietățile enumerate ale sistemelor distribuite sunt un motiv suficient pentru a suporta complexitatea dezvoltării lor și costul ridicat de întreținere.
Arhitectura aplicațiilor distribuite
Luați în considerare arhitectura unei aplicații distribuite care îi permite să îndeplinească funcții complexe și variate. Surse diferite oferă opțiuni diferite pentru construirea de aplicații distribuite. Și toți au dreptul să existe, deoarece astfel de aplicații rezolvă cea mai largă gamă de probleme în multe domenii, iar dezvoltarea ireprimabilă a instrumentelor și tehnologiilor de dezvoltare împinge pentru îmbunătățirea continuă.
Cu toate acestea, există cea mai generală arhitectură a unei aplicații distribuite, conform căreia aceasta este împărțită în mai multe straturi logice, straturi de procesare a datelor. Aplicațiile, după cum știți, sunt concepute pentru a procesa informații și aici putem distinge trei funcții principale ale acestora:
· Prezentarea datelor (nivel de utilizator). Aici utilizatorii aplicației pot vizualiza datele necesare, pot trimite o cerere de execuție, pot introduce date noi în sistem sau le pot edita;
· Prelucrarea datelor (nivel intermediar, middleware). La acest nivel se concentrează logica de business a aplicației, se controlează fluxurile de date și se organizează interacțiunea părților aplicației. Concentrarea tuturor funcțiilor de prelucrare și control a datelor la un nivel este considerată principalul avantaj al aplicațiilor distribuite;
· Stocarea datelor (stratul de date). Acesta este nivelul serverului de baze de date. Serverele în sine, bazele de date, instrumentele de acces la date și diverse instrumente auxiliare se află aici.
Această arhitectură este adesea denumită arhitectură cu trei niveluri sau trei niveluri. Și de foarte multe ori pe baza acestor „trei balene” se creează structura aplicației dezvoltate. Se remarcă întotdeauna că fiecare nivel poate fi subdivizat în mai multe subniveluri. De exemplu, nivelul utilizatorului poate fi împărțit în interfața de utilizator reală și reguli pentru validarea și procesarea datelor de intrare.
Desigur, dacă luăm în considerare posibilitatea împărțirii în subniveluri, atunci orice aplicație distribuită poate fi inclusă în arhitectura cu trei niveluri. Dar aici nu se poate ignora o altă trăsătură caracteristică inerentă aplicațiilor distribuite - aceasta este gestionarea datelor. Importanța acestei caracteristici este evidentă deoarece este foarte dificil să se creeze o aplicație distribuită în lumea reală (cu toate stațiile client, middleware, servere de baze de date etc.) care să nu gestioneze cererile și răspunsurile sale. Prin urmare, o aplicație distribuită trebuie să aibă un alt strat logic - stratul de gestionare a datelor.

Orez. 3. Distribuția logicii de afaceri pe nivelurile unei aplicații distribuite
Prin urmare, este indicat să se împartă nivelul intermediar în două independente: nivelul de prelucrare a datelor (întrucât este necesar să se țină cont de avantajul important pe care îl oferă - concentrarea regulilor de business pentru prelucrarea datelor) și nivelul de management al datelor. Acesta din urmă asigură controlul asupra executării cererilor, menține lucrul cu fluxurile de date și organizează interacțiunea părților sistemului.
Astfel, există patru straturi principale ale unei arhitecturi distribuite (vezi Fig. 2):
· Prezentarea datelor (nivel de utilizator);
· Reguli de logica de afaceri (nivelul de prelucrare a datelor);
· Managementul datelor (nivelul de management al datelor);
· Stocarea datelor (stratul de stocare a datelor).
Trei dintre cele patru niveluri, excluzând primul, sunt direct implicate în prelucrarea datelor, iar stratul de prezentare a datelor vă permite să le vizualizați și să le editați. Cu ajutorul acestui strat, utilizatorii primesc date din stratul de prelucrare a datelor, care, la rândul său, preia informații din depozite și efectuează toate transformările de date necesare. După introducerea de informații noi sau editarea datelor existente, fluxurile de date sunt direcționate înapoi: de la interfața cu utilizatorul prin stratul de reguli de afaceri până la depozit.
Un alt nivel - managementul datelor - iese în afară de coloana vertebrală a datelor, dar asigură buna funcționare a întregului sistem, gestionând cererile și răspunsurile și interacțiunea unor părți ale aplicației.
Separat, este necesar să se ia în considerare opțiunea de vizualizare a datelor în modul „numai citire”. În acest caz, stratul de procesare a datelor nu este utilizat în schema generală de transfer de date, deoarece nu este nevoie să faceți nicio modificare. Iar fluxul de informații în sine este unidirecțional - de la stocare până la nivelul de prezentare a datelor.
Structura fizică a aplicațiilor distribuite
Acum să ne întoarcem la straturile fizice ale aplicațiilor distribuite. Topologia unui sistem distribuit implică împărțirea în mai multe servere de baze de date, servere de procesare a datelor și o colecție de clienți locali și la distanță. Toate pot fi amplasate oriunde: în aceeași clădire sau pe alt continent. În orice caz, părțile unui sistem distribuit trebuie să fie conectate prin linii de comunicație fiabile și sigure. În ceea ce privește rata de transfer de date, aceasta depinde în mare măsură de importanța conexiunii dintre cele două părți ale sistemului în ceea ce privește prelucrarea și transmiterea datelor și, într-o măsură mai mică, de distanța lor.
Distribuția logicii de afaceri între nivelurile de aplicații distribuite
Acum este momentul să trecem la o descriere detaliată a nivelurilor unui sistem distribuit, dar mai întâi să spunem câteva cuvinte despre distribuția funcționalității aplicației pe niveluri. Logica de afaceri poate fi implementată la oricare dintre nivelurile arhitecturii pe trei niveluri.
Serverele de baze de date nu numai că pot stoca date în baze de date, ci și pot conține o parte din logica de afaceri a aplicației în proceduri stocate, declanșatoare etc.
Aplicațiile client pot implementa și reguli de prelucrare a datelor. Dacă setul de reguli este minim și se reduce în principal la proceduri de verificare a corectitudinii introducerii datelor, avem de-a face cu un client „subțire”. În schimb, un client gros conține o mare parte din funcționalitatea aplicației.
Nivelul de prelucrare a datelor este de fapt destinat să implementeze logica de afaceri a aplicației, iar aici sunt concentrate toate regulile de bază pentru prelucrarea datelor.
Astfel, în cazul general, funcționalitatea aplicației este „untată” în întreaga aplicație. Toată varietatea distribuției logicii de afaceri între nivelurile de aplicație poate fi reprezentată ca o curbă netedă care arată proporția regulilor de procesare a datelor concentrate într-un anumit loc. Curbele din fig. 3 sunt de natură calitativă, dar vă permit totuși să vedeți cum modificările în structura aplicației pot afecta distribuția regulilor.
Iar practica confirmă această concluzie. La urma urmei, vor exista întotdeauna câteva reguli care trebuie implementate în procedurile stocate ale serverului de baze de date și este foarte adesea convenabil să transferați unele operațiuni inițiale cu date către partea clientului - cel puțin pentru a preveni procesarea cererilor incorecte.
Stratul de prezentare
Stratul de prezentare a datelor este singurul disponibil pentru utilizatorul final. Acest strat simulează stațiile de lucru client ale unei aplicații distribuite și software-ul corespunzător. Capacitățile stației de lucru client sunt determinate în primul rând de capacitățile sistemului de operare. În funcție de tipul de interfață cu utilizatorul, software-ul client este împărțit în două grupuri: clienți care utilizează capabilități GUI (de exemplu, Windows) și clienți web. Dar, în orice caz, aplicația client trebuie să ofere următoarele funcții:
· Primirea datelor;
· Prezentarea datelor pentru vizualizare de către utilizator;
· Editarea datelor;
· Verificarea corectitudinii datelor introduse;
· Salvarea modificărilor efectuate;
· Gestionarea excepțiilor și afișarea informațiilor despre erori pentru utilizator.
Este de dorit să se concentreze toate regulile de afaceri la nivelul de prelucrare a datelor, dar în practică acest lucru nu este întotdeauna posibil. Apoi vorbesc despre două tipuri de software client. Clientul subțire conține un set minim de reguli de afaceri, în timp ce clientul gros implementează o parte semnificativă a logicii aplicației. În primul caz, o aplicație distribuită este mult mai ușor de depanat, modernizat și extins, în al doilea, puteți minimiza costul creării și menținerii unui nivel de management al datelor, deoarece unele dintre operațiuni pot fi efectuate pe partea clientului și numai transferul de date cade pe middleware.
Stratul de prelucrare a datelor
Stratul de procesare a datelor combină părțile care implementează logica de business a aplicației și este un intermediar între stratul de prezentare și stratul de stocare. Toate datele trec prin el și suferă modificări în el, datorită problemei care se rezolvă (vezi Fig. 2). Funcțiile acestui nivel includ următoarele:
· Prelucrarea fluxurilor de date în conformitate cu regulile de afaceri;
· Interacțiunea cu nivelul de prezentare a datelor pentru a primi cereri și a returna răspunsuri;
· Interacțiunea cu stratul de stocare a datelor pentru a trimite cereri și a primi răspunsuri.
Cel mai adesea, stratul de procesare a datelor este echivalat cu middleware-ul unei aplicații distribuite. Această situație este pe deplin adevărată pentru un sistem „ideal” și doar parțial pentru aplicații reale (vezi Fig. 3). Cât despre acestea din urmă, middleware-ul pentru ei conține o mare parte de reguli de procesare a datelor, dar unele dintre ele sunt implementate în serverele SQL sub formă de proceduri stocate sau declanșatoare, iar unele sunt incluse în software-ul client.
O astfel de „încețoșare” a logicii de afaceri este justificată, deoarece permite simplificarea unora dintre procedurile de prelucrare a datelor. Să luăm un exemplu clasic de instrucțiune de comandă. Poate include numele acelor produse care sunt în stoc. Prin urmare, atunci când adăugați un anumit articol la comandă și determinați cantitatea acestuia, numărul corespunzător trebuie scăzut din restul acestui articol din depozit. Evident, cel mai bun mod de a implementa această logică este prin intermediul serverului DB - fie o procedură stocată, fie un declanșator.
Stratul de gestionare a datelor
Stratul de gestionare a datelor este necesar pentru a se asigura că aplicația rămâne coerentă, rezistentă și fiabilă, are capacitatea de a se moderniza și de a scala. Asigură executarea sarcinilor de sistem, fără el, părți ale aplicației (servere de baze de date, servere de aplicații, middleware, clienți) nu vor putea interacționa între ele, iar conexiunile care au fost întrerupte în timpul unei creșteri a încărcăturii nu pot fi restaurate.
În plus, la nivel de management al datelor pot fi implementate diverse servicii de sistem ale aplicației. La urma urmei, există întotdeauna funcții comune întregii aplicații care sunt necesare pentru funcționarea tuturor nivelurilor aplicației, prin urmare, acestea nu pot fi localizate pe niciunul dintre celelalte niveluri.
De exemplu, un serviciu de marcare temporală oferă tuturor părților unei aplicații marcaje temporale ale sistemului care le mențin sincronizate. Imaginați-vă că o aplicație distribuită are un server care trimite clienților sarcini cu un anumit termen limită. Dacă termenul limită este ratat, sarcina trebuie înregistrată cu calcularea timpului de întârziere. Dacă stațiile de lucru client sunt situate în aceeași clădire cu serverul, sau pe o stradă adiacentă, nicio problemă, algoritmul de contabilitate este simplu. Dar ce se întâmplă dacă clienții sunt localizați în fusuri orare diferite - în alte țări sau chiar în străinătate? În acest caz, serverul trebuie să poată calcula diferența ținând cont de fusurile orare la trimiterea joburilor și la primirea răspunsurilor, iar clienților li se va cere să adauge informații despre serviciu despre ora locală și fusul orar la rapoarte. Dacă într-o aplicație distribuită este inclus un singur serviciu, atunci această problemă pur și simplu nu există.
Pe lângă serviciul unic, nivelul de gestionare a datelor poate conține servicii pentru stocarea informațiilor generale (informații despre aplicație în ansamblu), generarea de rapoarte generale etc.
Deci, funcțiile stratului de gestionare a datelor includ:
· Gestionarea părților unei aplicații distribuite;
· Managementul conexiunilor și canalelor de comunicare între părți ale aplicației;
· Controlul fluxurilor de date între clienți și servere și între servere;
· Controlul sarcinii;
· Implementarea serviciilor de sistem ale aplicației.
Trebuie remarcat faptul că adesea stratul de gestionare a datelor este creat pe baza unor soluții gata făcute furnizate pieței de software de diverși producători. Dacă dezvoltatorii au ales arhitectura CORBA pentru aplicația lor, atunci aceasta include un Object Request Broker (ORB), dacă platforma este Windows, au la dispoziție o varietate de instrumente: tehnologia COM + (dezvoltarea tehnologiei Microsoft Transaction Server, MTS), tehnologia de procesare a cozilor de mesaje MSMQ, tehnologia Microsoft BizTalk etc.
Stratul de stocare a datelor
Nivelul de stocare reunește serverele SQL și bazele de date utilizate de aplicație. Oferă o soluție pentru următoarele sarcini:
· Stocarea datelor intr-o baza de date si mentinerea lor in stare de functionare;
· Prelucrarea cererilor de nivel de prelucrare a datelor si returnarea rezultatelor;
· Implementarea unei părți a logicii de business a unei aplicații distribuite;
· Managementul bazelor de date distribuite folosind instrumente administrative ale serverelor de baze de date.
Pe lângă funcțiile evidente - stocarea datelor și procesarea interogărilor, un strat poate conține o parte din logica de afaceri a aplicației în proceduri stocate, declanșatoare, constrângeri etc. Și însăși structura bazei de date a aplicației (tabele și câmpurile acestora, indici, străini). chei etc.) ) există o implementare a structurii de date cu care funcționează aplicația distribuită și implementarea unor reguli de logica de afaceri. De exemplu, utilizarea unei chei străine într-un tabel de bază de date necesită crearea unei restricții corespunzătoare privind manipulările de date, deoarece înregistrările tabelului principal nu pot fi șterse dacă există înregistrări corespunzătoare legate de cheia străină a tabelului.
Majoritatea serverelor de baze de date suportă o varietate de proceduri de administrare, inclusiv gestionarea bazelor de date distribuite. Acestea includ replicarea datelor, arhivarea de la distanță, instrumente pentru accesarea bazelor de date la distanță etc. Abilitatea de a utiliza aceste instrumente ar trebui luată în considerare atunci când dezvoltați structura propriei aplicații distribuite.
Conectarea la bazele de date SQL Server se face în primul rând cu software-ul client server. În plus, pot fi utilizate în plus diverse tehnologii de acces la date, de exemplu, ADO (ActiveX Data Objects) sau ADO.NET. Dar la proiectarea unui sistem, este necesar să se țină cont de faptul că tehnologiile de acces la date intermediare funcțional nu aparțin nivelului de stocare a datelor.
Extensii de nivel de bază
Nivelurile de mai sus ale arhitecturii aplicațiilor distribuite sunt de bază. Ele formează structura aplicației create în ansamblu, dar, în același timp, desigur, nu pot asigura implementarea vreunei aplicații - domeniile și sarcinile sunt prea vaste și diverse. Pentru astfel de cazuri, arhitectura unei aplicații distribuite poate fi extinsă cu straturi suplimentare care sunt concepute pentru a reflecta caracteristicile aplicației create.
Printre altele, există două dintre cele mai frecvent utilizate extensii de nivel de bază.
Stratul de interfață de afaceri este situat între stratul de interfață cu utilizatorul și stratul de procesare a datelor. Acesta ascunde de aplicațiile client detaliile structurii și implementării regulilor de afaceri ale stratului de procesare a datelor, oferind abstracția codului aplicației client din caracteristicile de implementare ale logicii aplicației.
Ca rezultat, dezvoltatorii de aplicații client folosesc un anumit set de funcții necesare - un analog al unei interfețe de programare a aplicațiilor (API). Acest lucru face ca software-ul client să fie independent de implementarea stratului de procesare a datelor.
Desigur, atunci când faceți modificări serioase ale sistemului, nu puteți face fără modificări globale, dar nivelul interfeței de afaceri vă permite să nu faceți acest lucru decât dacă este absolut necesar.
Stratul de acces la date este situat între stratul de stocare a datelor și stratul de procesare a datelor. Vă permite să faceți structura aplicației independentă de o anumită tehnologie de stocare a datelor. În astfel de cazuri, obiectele software ale stratului de prelucrare a datelor trimit cereri și primesc răspunsuri folosind mijloacele tehnologiei de acces la date alese.
La implementarea aplicațiilor pe platforma Windows, tehnologia de acces la date ADO este folosită cel mai adesea deoarece oferă o modalitate universală de acces la o mare varietate de surse de date - de la servere SQL la foi de calcul. Pentru aplicațiile pe platforma .NET se folosește tehnologia ADO.NET.
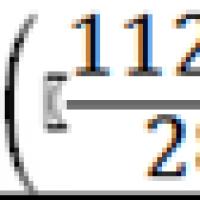 Calculul caracteristicilor de stabilitate ale sistemului operațional de comunicații
Calculul caracteristicilor de stabilitate ale sistemului operațional de comunicații Software pentru crearea PDF
Software pentru crearea PDF Canal discret. Interferență în canalele de comunicare
Canal discret. Interferență în canalele de comunicare Cum să utilizați QoS pentru a asigura calitatea accesului la Internet Unde este programatorul de pachete qos
Cum să utilizați QoS pentru a asigura calitatea accesului la Internet Unde este programatorul de pachete qos Instalare și configurare de bază Sendmail pe Ubuntu Server
Instalare și configurare de bază Sendmail pe Ubuntu Server Instalați VPN în conexiune Ubuntu Vpn ubuntu
Instalați VPN în conexiune Ubuntu Vpn ubuntu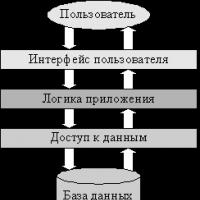 Arhitectură de sistem distribuită Platformă Cloud IoT la scară largă
Arhitectură de sistem distribuită Platformă Cloud IoT la scară largă