Az elosztott rendszerek áttekintése. Elosztott rendszerarchitektúra, nagyszabású felhő IoT-platform
Az elosztott rendszer meghatározásakor gyakran a funkcióinak több számítógép közötti felosztására helyezik a hangsúlyt. Ezzel a megközelítéssel bármelyik el van osztva számítástechnikai rendszer ahol az adatfeldolgozás két vagy több számítógép között megoszlik. E. Tanenbaum definíciója alapján valamivel szűkebben elosztott rendszert úgy határozhatunk meg, mint kommunikációs csatornákkal összekapcsolt, független számítógépek összességét, amelyek egyes szoftverek felhasználója szempontjából egységes egésznek tűnnek.
Az elosztott rendszer meghatározásának ez a megközelítése megvannak a maga hátrányai. Például mindent, amit egy ilyen elosztott rendszerben használnak szoftver működhetne egyetlen számítógépen, de a fenti definíció szempontjából ilyen rendszer már nem lesz terjesztve. Ezért az elosztott rendszer koncepciójának valószínűleg az ilyen rendszert alkotó szoftver elemzésén kell alapulnia.
Két entitás interakciójának leírásának alapjául vegyük a kliens-szerver interakció általános modelljét, amelyben az egyik fél (a kliens) úgy kezdeményezi az adatcserét, hogy kérést küld a másik félnek (a szervernek). A szerver feldolgozza a kérést, és szükség esetén választ küld a kliensnek (1.1. ábra).
Rizs. 1.1.
A kliens-szerver modell keretein belüli interakció lehet szinkron, amikor a kliens arra vár, hogy a szerver feldolgozza a kérését, vagy aszinkron, amelyben a kliens kérést küld a szervernek és annak végrehajtását anélkül folytatja, hogy megvárná a szerver kérését. válasz. A kliens és a szerver modellje alapul szolgálhat különféle interakciók leírásához. Ennél a kurzusnál fontos az elosztott rendszert alkotó szoftver alkotórészeinek interakciója.

Rizs. 1.2.
Tekintsünk egy bizonyos tipikus alkalmazást, amely a modern koncepcióknak megfelelően a következő logikai szintekre osztható (1.2. ábra): felhasználói felület(PI), alkalmazáslogikát (LP) és adatelérést (DD), az adatbázissal (DB) való munkavégzést. A rendszerfelhasználó a felhasználói felületen keresztül lép kapcsolatba vele, az adatbázis az alkalmazási tartományt leíró adatokat tárolja, az alkalmazáslogikai réteg pedig megvalósítja az összes kapcsolódó algoritmust. tárgykörben.
Mivel a gyakorlatban általában a rendszer különböző felhasználói érdekeltek ugyanazon adatok elérésében, egy ilyen rendszer funkcióinak legegyszerűbb szétválasztása több számítógép között az alkalmazás logikai rétegeinek szétválasztása lesz az alkalmazás egy szerver része között. , amely az adatok eléréséért felelős, illetve a több számítógépen elhelyezkedő kliens részek.a felhasználói felület megvalósítása. Az alkalmazáslogika hozzárendelhető a szerverhez, a kliensekhez, vagy megosztható közöttük (1.3. ábra).

Rizs. 1.3.
Az ezen az elven felépített alkalmazások architektúráját kliens-szervernek vagy kétszintűnek nevezik. A gyakorlatban az ilyen rendszereket gyakran nem minősítik elosztottnak, de formálisan az elosztott rendszerek legegyszerűbb képviselőinek tekinthetők.
A kliens-szerver architektúra fejlesztése egy háromszintű architektúra, amelyben a felhasználói felület, az alkalmazáslogika és az adatelérés a rendszer független, független számítógépeken működő komponenseire különül el (1.4. ábra).

Rizs. 1.4.
Az ilyen rendszerekben a felhasználó kérését a rendszer kliens része, az alkalmazáslogikai szerver és az adatbázisszerver egymás után dolgozza fel. Az elosztott rendszeren azonban általában olyan rendszer értendő, amely összetettebb architektúrával rendelkezik, mint egy háromszintű.
Az előző fejezetben szorosan összekapcsolt többprocesszoros rendszereket vizsgáltunk megosztott memóriával, megosztott kernel adatstruktúrákkal és megosztott készlettel, ahonnan a folyamatok meghívásra kerülnek. Gyakran azonban kívánatos a processzorok oly módon történő kiosztása, hogy azok függetlenek legyenek a működési környezettől és a működési feltételektől az erőforrás-megosztás érdekében. Tegyük fel például, hogy egy személyi számítógép felhasználójának hozzá kell férnie egy nagyobb gépen található fájlokhoz, ugyanakkor meg kell őriznie az irányítást a személyi számítógép felett. Bár egyes programok, mint például az uucp, támogatják a hálózati fájlátvitelt és egyéb hálózati funkciókat, használatuk nem marad elrejtve a felhasználó elől, mivel a felhasználó tudatában van annak, hogy a hálózatot használja. Ezenkívül meg kell jegyezni, hogy az olyan programok, mint a szövegszerkesztők, nem működnek a törölt fájlokkal, mint a hagyományos fájlokkal. A felhasználóknak rendelkezniük kell a szabványos UNIX rendszerfunkciókkal, és a potenciális teljesítmény szűk keresztmetszetétől eltekintve nem szabad átlépniük a gépek határait. Így például a távoli gépeken lévő fájlokkal megnyitott és olvasott rendszerfunkciók nem különbözhetnek a helyi rendszerekhez tartozó fájlokkal végzett munkájuktól.
Az elosztott rendszer architektúrája a 13.1. ábrán látható. Az ábrán látható minden számítógép egy önálló egység, amely CPU-ból, memóriából és perifériákból áll. A modell akkor sem törik meg, ha a számítógépnek nincs helyi fájlrendszere: perifériás eszközökkel kell kommunikálnia más gépekkel, és a hozzá tartozó összes fájl egy másik számítógépen is elhelyezhető. Az egyes gépek rendelkezésére álló fizikai memória független a többi gépen futó folyamatoktól. Ebben a tekintetben az elosztott rendszerek eltérnek az előző fejezetben tárgyalt, szorosan csatolt többprocesszoros rendszerektől. Ennek megfelelően minden gépen a rendszer magja az elosztott környezet külső működési feltételeitől függetlenül működik.
13.1. ábra. Elosztott architektúra rendszermodell
A szakirodalomban jól leírt elosztott rendszerek hagyományosan a következő kategóriákba sorolhatók:
Perifériás rendszerek, amelyek olyan gépcsoportok, amelyeknek erős a közös vonása, és egy (általában nagyobb) géphez kapcsolódnak. A perifériás processzorok megosztják terhelésüket a központi processzorral, és az operációs rendszer minden hívását arra továbbítják. A perifériás rendszerek célja az általános hálózati teljesítmény növelése, valamint a processzorok egyetlen folyamathoz való hozzárendelésének lehetősége UNIX operációs környezetben. A rendszer külön modulként indul el; Az elosztott rendszerek más modelljeivel ellentétben a perifériás rendszerek nem rendelkeznek valódi autonómiával, kivéve a folyamatelosztással és a helyi memóriafoglalással kapcsolatos eseteket.
Elosztott rendszerek, mint például a "Newcastle", amelyek lehetővé teszik a távoli kommunikációt a könyvtárban lévő távoli fájlok nevei alapján (a név a "The Newcastle Connection" cikkből származik - lásd). A törölt fájloknak van egy BOM-ja (megkülönböztetett név), amely a keresési útvonalon speciális karaktereket vagy egy opcionális névösszetevőt tartalmaz, amely megelőzi a fájlrendszer gyökerét. Ennek a módszernek a megvalósítása nem jár változtatásokkal a rendszermagban, ezért egyszerűbb, mint a fejezetben tárgyalt többi módszer, de kevésbé rugalmas.
Az elosztott rendszerek teljesen átlátszóak, amelyekben a szabványos megkülönböztető nevek elegendőek ahhoz, hogy más gépeken található fájlokra hivatkozzanak; a kernel feladata, hogy ezeket a fájlokat töröltként ismerje fel. Az összetett nevükben megadott fájlkeresési útvonalak a csatlakoztatási pontokon keresztezik a gép határait, függetlenül attól, hogy hány ilyen pont jön létre, amikor a fájlrendszereket lemezekre csatlakoztatják.
Ebben a fejezetben megvizsgáljuk az egyes modellek architektúráját; minden közölt információ nem konkrét fejlesztések eredményein, hanem különböző műszaki cikkekben megjelent információkon alapul. Ez azt feltételezi, hogy a protokollmodulok és az eszközmeghajtók felelősek a címzésért, az útválasztásért, az áramlásvezérlésért, valamint a hibaészlelésért és -javításért – más szóval, hogy minden modell független a használt hálózattól. A következő részben bemutatott példák a perifériás rendszerekre vonatkozó rendszerfunkciók használatára hasonló módon működnek az olyan rendszerek esetében, mint a Newcastle és a teljesen transzparens rendszerek, amelyekről később lesz szó; ezért ezeket egyszer részletesen megvizsgáljuk, és a más típusú rendszerekkel foglalkozó részekben elsősorban azokra a jellemzőkre koncentrálunk, amelyek megkülönböztetik ezeket a modelleket az összes többitől.
13.1 PERIFÉRIÁLIS PROCESSZOROK
A periféria rendszer architektúráját a 13.2. ábra mutatja. Ennek a konfigurációnak a célja az általános hálózati teljesítmény javítása a futó folyamatok átcsoportosításával a CPU és a perifériás processzorok között. A perifériaprocesszorok egyike sem rendelkezik más helyi perifériaeszközzel, kivéve azokat, amelyekre a központi feldolgozóegységgel való kommunikációhoz szükségük van. A fájlrendszer és az összes eszköz a központi processzor rendelkezésére áll. Tegyük fel, hogy minden felhasználói folyamat a perifériás processzoron fut, és nem mozog a periféria processzorok között; a processzorra átvitel után a befejezésig rajta maradnak. A perifériás processzor az operációs rendszer egy könnyed verzióját tartalmazza, amelyet a rendszer helyi hívásainak kezelésére, megszakításkezelésre, memóriafoglalásra, hálózati protokollokkal való együttműködésre és a központi processzorral való kommunikációhoz szükséges eszközillesztő-programra terveztek.
Amikor a rendszert a központi processzoron inicializálják, a mag kommunikációs vonalakon keresztül betölti a helyi operációs rendszert az egyes perifériás processzorokra. A periférián futó bármely folyamat a központi processzorhoz tartozó műholdfolyamathoz kapcsolódik (lásd); amikor egy perifériás processzoron futó folyamat olyan rendszerfunkciót hív meg, amely csak a központi processzor szolgáltatásait igényli, a perifériafolyamat kommunikál a műholdjával, és a kérést elküldi a központi processzornak feldolgozásra. A műholdas folyamat rendszerfunkciót hajt végre, és az eredményeket visszaküldi a perifériás processzornak. A perifériás folyamat és a műhold kapcsolata hasonló ahhoz a kliens-szerver kapcsolathoz, amelyet a 11. fejezetben részletesen tárgyaltunk: a periféria folyamat a műholdjának klienseként működik, amely támogatja a fájlrendszerrel való munkavégzés funkcióit. Ebben az esetben a távoli szerver folyamatnak csak egy kliense van. A 13.4 szakaszban a több klienssel működő szerverfolyamatokat fogjuk megvizsgálni.

13.2. ábra. Perifériás rendszer konfigurációja

13.3. ábra. Üzenetformátumok
Amikor egy periféria folyamat meghív egy helyben feldolgozható rendszerfüggvényt, a kernelnek nem kell kérést küldenie a műholdfolyamatnak. Így például, hogy további memóriát szerezzen, egy folyamat meghívhatja az sbrk függvényt helyi végrehajtásra. Ha azonban a központi processzor szolgáltatásai szükségesek például egy fájl megnyitásához, akkor a kernel a hívott függvénynek átadott paraméterekről és a folyamatvégrehajtási feltételekről szóló információkat a szatellit folyamatnak küldött üzenetbe kódolja (13.3. ábra). Az üzenet tartalmaz egy jelet, amelyből az következik, hogy a rendszerfunkciót a műholdfolyamat látja el a kliens nevében, a funkciónak átadott paramétereket és a folyamatvégrehajtási környezetre vonatkozó adatokat (például felhasználói és csoportazonosító kódokat), amelyek különböző funkciókhoz. Az üzenet többi része változó hosszúságú adat (például összetett fájlnév vagy az írási funkcióval írandó adat).
A műholdas folyamat a perifériás folyamattól érkező kérésekre vár; kérés érkezésekor dekódolja az üzenetet, meghatározza a rendszerfunkció típusát, végrehajtja azt, és az eredményeket a perifériás folyamatnak küldött válaszlá alakítja. A válasz a rendszerfunkció végrehajtásának eredményein kívül tartalmazza a hibaüzenetet (ha van), a jel számát, valamint egy változó hosszúságú adattömböt, amely például fájlból kiolvasott információkat tartalmaz. A periféria folyamat a válasz beérkezéséig felfüggesztésre kerül, annak beérkezése után dekódolja és az eredményeket továbbítja a felhasználónak. Ez az operációs rendszer hívásainak kezelésének általános sémája; most térjünk át az egyes funkciók részletesebb vizsgálatára.
A periféria működésének magyarázatához vegye figyelembe a következő funkciókat: getppid, open, write, fork, exit és signal. A getppid függvény meglehetősen egyszerű, mivel a periféria és a CPU között cserélhető egyszerű kérés- és válaszűrlapokkal foglalkozik. A perifériás processzor magja generál egy üzenetet, aminek előjele van, amiből az következik, hogy a kért függvény a getppid függvény, és elküldi a kérést a központi processzornak. A központi processzoron lévő műholdfolyamat beolvassa a perifériás processzor üzenetét, visszafejti a rendszerfunkció típusát, végrehajtja azt, és megkapja a szülő azonosítóját. Ezután választ generál, és továbbadja egy függőben lévő perifériás folyamatnak a kommunikációs vonal másik végén. Amikor a periféria processzor választ kap, átadja azt a getppid rendszerfüggvényt hívó folyamatnak. Ha a perifériás folyamat adatokat (például a szülő folyamatazonosítóját) tárolja a helyi memóriában, akkor egyáltalán nem kell kommunikálnia a társával.
A nyílt rendszer függvény meghívása esetén a periféria folyamat üzenetet küld a társának, amely tartalmazza a fájl nevét és egyéb paramétereit. Ha sikeres, a kísérőfolyamat hozzárendel egy indexet és egy belépési pontot a fájltáblához, lefoglal egy bejegyzést a felhasználói fájlleíró táblában annak területén, és visszaadja a fájlleírót a perifériafolyamatnak. Mindvégig a kommunikációs vonal másik végén a perifériás folyamat válaszra vár. Nem áll rendelkezésére olyan struktúra, amely információkat tárolna a megnyitott fájlról; Az open által visszaadott leíró egy mutató a kísérőfolyamat bejegyzésére a felhasználói fájlleíró táblában. A függvény végrehajtásának eredményeit a 13.4. ábra mutatja.

13.4. ábra. A nyitott függvény meghívása perifériás folyamatból
Ha megtörténik a rendszer írási funkciójának hívása, a periféria processzor egy üzenetet generál, amely az írási funkció előjeléből, egy fájlleíróból és az írandó adatmennyiségből áll. Ezután a perifériás folyamat teréből a kommunikációs vonalon át másolja az adatokat a műholdas folyamatba. A műholdfolyamat dekódolja a fogadott üzenetet, beolvassa a kommunikációs vonalról érkező adatokat és beírja a megfelelő fájlba (az üzenetben található leíró mutatóként szolgál arra, hogy melyik indexet és melyik rekordot használja a fájltáblázatban ); mindezeket a műveleteket a központi processzor hajtja végre. A munka végén a műholdfolyamat egy üzenetet küld a perifériás folyamatnak, amely megerősíti az üzenet fogadását, és tartalmazza a fájlba sikeresen másolt adatok bájtjainak számát. Az olvasási művelet hasonló; a műhold tájékoztatja a perifériás folyamatot a ténylegesen beolvasott bájtok számáról (terminálról vagy csatornáról történő adatolvasás esetén ez a szám nem mindig esik egybe a kérésben megadott mennyiséggel). Az egyik vagy a másik funkció végrehajtásához szükség lehet többszöri információs üzenetek küldésére a hálózaton keresztül, amit az elküldött adatok mennyisége és a hálózati csomagok mérete határoz meg.
Az egyetlen funkció, amelyet a CPU-n való futás közben módosítani kell, az a fork system funkció. Amikor egy folyamat végrehajtja ezt a funkciót a CPU-n, a kernel kiválaszt egy perifériás processzort, és üzenetet küld egy speciális folyamatnak - a szervernek, amely tájékoztatja az utóbbit, hogy megkezdi az aktuális folyamat kiürítését. Feltételezve, hogy a szerver elfogadta a kérést, a kernel fork segítségével hoz létre egy új perifériás folyamatot, lefoglalva egy folyamattábla bejegyzést és címteret. A központi processzor betölti a fork függvényt hívó folyamat egy példányát a periféria processzorába, felülírva az újonnan lefoglalt címteret, létrehoz egy helyi műholdat, hogy kommunikáljon az új perifériafolyamattal, és üzenetet küld a perifériának, hogy inicializálja a programszámlálót. az új folyamat. A műholdas folyamat (a CPU-n) a fork nevű folyamat leszármazottja; a perifériás folyamat technikailag a szerverfolyamat leszármazottja, de logikailag a fork függvénynek nevezett folyamat leszármazottja. A kiszolgáló folyamatnak nincs logikai kapcsolata a gyermekkel, amikor a fork befejeződik; a szerver egyetlen feladata, hogy segítsen kirakni a gyereket. A rendszerelemek közötti erős kapcsolat miatt (a perifériás processzorok nem rendelkeznek autonómiával) a periféria és a műholdas folyamat azonos azonosító kóddal rendelkezik. A folyamatok közötti kapcsolatot a 13.5. ábra mutatja: a folytonos vonal a szülő-gyermek viszonyt, a szaggatott vonal pedig a társak közötti kapcsolatot mutatja.

13.5. ábra. Fork funkció végrehajtása a CPU-n
Amikor egy folyamat végrehajtja a fork funkciót a perifériás processzoron, üzenetet küld a CPU-n lévő műholdjának, amely ezután végrehajtja a fent leírt műveletek teljes sorozatát. A műhold kiválaszt egy új perifériaprocesszort, és megteszi a szükséges előkészületeket a régi folyamat képének kirakásához: kérést küld a szülő perifériafolyamatnak, hogy olvassa be a képét, amelyre válaszul a másik végén megkezdődik a kért adatok átvitele. a kommunikációs csatornáról. A műhold beolvassa a továbbított képet, és felülírja a perifériás leszármazottra. Amikor a képkitöltés befejeződött, a műhold elágazik, létrehozva gyermekét a CPU-n, és átadja a programszámláló értékét a periféria gyermekének, hogy az tudja, melyik címről kezdje meg a végrehajtást. Nyilván jobb lenne, ha a kísérőfolyamat gyermeke a periféria gyermekéhez lenne szülőként hozzárendelve, de esetünkben a generált folyamatok képesek más periféria processzorokon is futni, nem csak azon, amelyiken létrejöttek. A folyamatok közötti kapcsolat a fork függvény végén a 13.6. ábrán látható. Amikor a perifériás folyamat befejezi munkáját, egy megfelelő üzenetet küld a műholdfolyamatnak, és ez is véget ér. Egy társfolyamat nem kezdeményezhet leállást.

13.6. ábra. Fork funkció végrehajtása perifériás processzoron
Mind a többprocesszoros, mind az egyprocesszoros rendszerekben a folyamatnak azonos módon kell reagálnia a jelekre: a folyamat vagy befejezi a rendszerfunkció végrehajtását a jelek ellenőrzése előtt, vagy éppen ellenkezőleg, a jel vétele után azonnal kilép a felfüggesztett állapotból, hirtelen megszakítja a rendszerfunkció munkáját, ha ez összhangban van azzal a prioritással, amellyel felfüggesztették. Mivel a műholdas folyamat a perifériás folyamat nevében látja el a rendszerfunkciókat, a jelekre az utóbbival koordinálva kell reagálnia. Ha egy egyprocesszoros rendszeren egy jel hatására egy folyamat megszakítja a funkciót, akkor a többprocesszoros rendszeren a kísérőfolyamatnak is hasonlóan kell viselkednie. Ugyanez mondható el arról az esetről is, amikor a jel az exit funkció segítségével a folyamat befejezésére készteti: a periféria folyamat befejeződik, és elküldi a megfelelő üzenetet a műholdfolyamatnak, amely természetesen szintén leáll.
Amikor egy periféria folyamat meghívja a jelrendszer funkciót, az aktuális információkat helyi táblákban tárolja, és üzenetet küld a műholdjának, amelyben tájékoztatja, hogy a megadott jelet fogadni kell-e vagy figyelmen kívül kell hagyni. A műholdas folyamatot nem érdekli, hogy elfogja-e a jelet vagy az alapértelmezett műveletet. Egy folyamat jelre adott reakciója három tényezőtől függ (13.7. ábra): hogy érkezik-e jel, miközben a folyamat egy rendszerfunkciót hajt végre, történik-e jelzés a jelfüggvénnyel a jel figyelmen kívül hagyására, hogy a jel megjelenik-e ugyanazon a periféria processzoron vagy máson. Térjünk át a különféle lehetőségek mérlegelésére.
sighandle algoritmus / * jelfeldolgozó algoritmus * /
ha (az aktuális folyamat valakinek a társa, vagy van prototípusa)
ha (a jel figyelmen kívül hagyva)
if (a jel egy rendszerfunkció végrehajtása közben érkezett)
helyezzen jelet a műholdas folyamat elé;
jelüzenet küldése egy perifériás folyamatnak;
else (/ * perifériás folyamat * /
/ * hogy egy rendszerfunkció végrehajtása közben érkezett-e jel vagy sem * /
küldjön jelet a műholdfolyamatnak;
algoritmus satellite_end_of_syscall / * egy perifériás folyamat által meghívott rendszerfunkció befejezése * /
bemeneti információ: hiányzik
impresszum: nincs
if (rendszerfunkció végrehajtása közben megszakítás érkezett)
megszakítási üzenet, jelzés küldése a perifériás folyamatnak;
különben / * a rendszerfunkció végrehajtása nem szakadt meg * /
válasz küldése: engedélyezze a jelzés érkezését jelző zászlót;
13.7. ábra. Jelfeldolgozás a perifériás rendszerben
Tegyük fel, hogy egy periféria folyamat felfüggesztette a munkáját, miközben a műholdas folyamat egy rendszerfunkciót hajt végre a nevében. Ha a jel máshol fordul elő, a műholdas folyamat korábban észleli, mint a perifériás folyamat. Három eset lehetséges.
1. Ha valamilyen eseményre várva a műholdfolyamat nem került felfüggesztett állapotba, ahonnan jel vételekor kilépne, a rendszer funkcióját a végéig ellátja, a végrehajtás eredményét elküldi a perifériás folyamatnak és megmutatja hogy a jelek közül melyiket fogadta.
2. Ha a folyamat az ilyen típusú jel figyelmen kívül hagyására utasítja, a műhold továbbra is követi a rendszerfunkció-végrehajtási algoritmust anélkül, hogy longjmp-vel kilépne a felfüggesztett állapotból. A perifériás folyamatnak küldött válaszban nem lesz jel fogadott üzenet.
3. Ha egy jel vételekor a műholdfolyamat megszakítja egy rendszerfunkció végrehajtását (longjmp-vel), akkor erről tájékoztatja a perifériás folyamatot és tájékoztatja a jel számáról.
A periféria folyamat információt keres a fogadott válaszban a jelek fogadásáról, és ha van ilyen, feldolgozza a jeleket, mielőtt kilép a rendszerfunkcióból. Így egy folyamat viselkedése egy többprocesszoros rendszerben pontosan megfelel az egyprocesszoros rendszerben tapasztalható viselkedésének: vagy kilép anélkül, hogy kilépne a kernel módból, vagy meghív egy egyéni jelfeldolgozó függvényt, vagy figyelmen kívül hagyja a jelet és sikeresen befejezi a rendszerfunkciót.

13.8. ábra. Megszakítás egy rendszerfunkció végrehajtása közben
Tegyük fel például, hogy egy periféria folyamat meghív egy olvasási funkciót a központi processzorhoz csatlakoztatott terminálról, és szünetelteti a munkáját, amíg a szatellit folyamat végrehajtja a funkciót (13.8. ábra). Ha a felhasználó megnyomja a szünet billentyűt, a CPU mag jelet küld a műholdas folyamatnak. Ha a műhold felfüggesztett állapotban volt, és várt a termináltól érkező adatok egy részére, azonnal kilép ebből az állapotból, és leállítja az olvasási funkciót. A perifériás folyamat kérésére válaszolva a műhold a megszakításnak megfelelő hibakódot és jelszámot ad meg. A perifériás folyamat elemzi a választ, és mivel az üzenet szerint megszakítás érkezett, elküldi magának a jelet. Az olvasási funkcióból való kilépés előtt a perifériamag ellenőrzi a jelzéseket, észleli a műholdfolyamatból származó megszakítási jelet, és a szokásos módon feldolgozza azt. Ha egy megszakítási jel vétele következtében a periféria az exit funkcióval leállítja a munkáját, akkor ez a funkció gondoskodik a műholdfolyamat leállításáról. Ha a periféria folyamat elfogja a megszakítási jeleket, akkor meghívja a felhasználó által definiált jelkezelő függvényt, és hibakódot küld a felhasználónak, amikor kilép az olvasási funkcióból. Másrészt, ha a műhold végrehajtja a stat rendszer funkciót a perifériás folyamat nevében, akkor nem szakítja meg a végrehajtását, amikor jelet kap (a stat funkció garantáltan kilép minden szünetből, mivel korlátozott az erőforrás várakozási ideje ). A műhold befejezi a funkció végrehajtását, és visszaküldi a jel számát a periféria folyamatnak. A perifériás folyamat jelet küld magának, és a rendszerfunkcióból való kilépéskor veszi azt.
Ha egy rendszerfunkció végrehajtása közben jel érkezik a perifériás processzoron, akkor a periféria folyamata homályban marad, hogy hamarosan visszakerül-e az irányítás a műholdfolyamatból, vagy az utóbbi korlátlan ideig felfüggesztett állapotba kerül. A perifériás folyamat speciális üzenetet küld a műholdnak, tájékoztatva a jel előfordulásáról. A CPU-n lévő mag dekódolja az üzenetet, és jelet küld a műholdra, amelynek reakcióját a jel vételére az előző bekezdésekben ismertetjük (a funkció végrehajtásának rendellenes leállása vagy befejezése). A perifériás folyamat nem tud közvetlenül üzenetet küldeni a műholdra, mert a műhold egy rendszerfunkció végrehajtásával van elfoglalva, és nem olvas adatokat a kommunikációs vonalról.
Az olvasási példára hivatkozva meg kell jegyezni, hogy a perifériás folyamatnak fogalma sincs arról, hogy társa a terminál inputjára vár, vagy más műveleteket hajt végre. A perifériás folyamat jelüzenetet küld a műholdnak: ha a műhold felfüggesztett állapotban van, megszakítható prioritással, azonnal kilép ebből az állapotból és leállítja a rendszerműködést; ellenkező esetben a funkció a sikeres befejezésig továbbítódik.
Végezetül nézzük meg azt az esetet, amikor egy jel olyan időpontban érkezik, amely nem kapcsolódik egy rendszerfunkció végrehajtásához. Ha egy jel egy másik processzorról származik, akkor a műhold először veszi azt, és jelüzenetet küld a perifériás folyamatnak, függetlenül attól, hogy a jel a perifériás folyamatra vonatkozik-e vagy sem. A perifériás mag dekódolja az üzenetet, és jelet küld a folyamatnak, amely a szokásos módon reagál rá. Ha a jel a perifériás processzorról származik, a folyamat szabványos műveleteket hajt végre anélkül, hogy a műhold szolgáltatásait igénybe venné.
Amikor egy periféria folyamat jelet küld más perifériás folyamatoknak, akkor kódol egy tiltó hívás üzenetet, és elküldi a műhold folyamatnak, amely helyileg végrehajtja a hívott funkciót. Ha egyes folyamatok, amelyekhez a jelet szánják, más perifériás processzorokon helyezkednek el, ezek műholdjai veszik a jelet (és reagálnak rá a fent leírtak szerint).
13.2 KOMMUNIKÁCIÓS TÍPUS NEWCASTLE
Az előző részben a szorosan csatolt rendszer típusát vizsgáltuk, amelyre jellemző, hogy a perifériás processzoron fellépő összes fájlkezelő alrendszer funkcióira irányuló hívást egy távoli (központi) processzorra küldi. Most rátérünk a gyengébb kapcsolattal rendelkező rendszerekre, amelyek olyan gépekből állnak, amelyek más gépeken található fájlokat hívnak meg. A személyi számítógépek és munkaállomások hálózatában például a felhasználók gyakran hozzáférnek egy nagy gépen található fájlokhoz. A következő két részben azokat a rendszerkonfigurációkat tekintjük át, amelyekben az összes rendszerfunkciót helyi alrendszerekben látják el, ugyanakkor lehetőség van más gépeken található fájlok elérésére (a fájlkezelő alrendszer funkcióin keresztül).
Ezek a rendszerek a következő két útvonal egyikét használják a törölt fájlok azonosítására. Egyes rendszereken speciális karaktert adnak az összetett fájlnévhez: az ezt a karaktert megelőző névkomponens azonosítja a gépet, a név többi része az adott gépen lévő fájl. Tehát például a megkülönböztetett név
"sftig! / fs1 / mjb / rje"
azonosítja a "/ fs1 / mjb / rje" fájlt az "sftig" gépen. Ez a fájlazonosító séma az uucp-konvenciót követi a UNIX-szerű rendszerek közötti fájlok átvitelére. Egy másik sémában a törölt fájlok azonosítása speciális előtag hozzáadásával történik a névhez, például:
/../sftig/fs1/mjb/rje
ahol a "/../" egy előtag, amely a fájl törlését jelzi; a fájlnév második összetevője a távoli gép neve. Ez a séma az ismert UNIX fájlnév szintaxist használja, így az első sémával ellentétben a felhasználói programoknak nem kell alkalmazkodniuk a szokatlan felépítésű nevek használatához (lásd).

13.9. ábra. Kérések megfogalmazása a fájlszervernek (processzornak)
Ennek a szakasznak a további részét egy Newcastle hivatkozást használó rendszer modelljének szenteljük, amelyben a kernel nem foglalkozik a törölt fájlok felismerésével; ez a funkció teljesen hozzá van rendelve a szubrutinokhoz a szabványos C könyvtárból, amelyek jelen esetben a rendszer interfész szerepét töltik be. Ezek a rutinok elemzik a fájlnév első komponensét, amely mindkét leírt azonosítási módszernél a fájl távoliságának jelét tartalmazza. Ez eltér attól a rutintól, amelyben a könyvtári rutinok nem elemzik a fájlneveket. A 13.9. ábra bemutatja, hogyan fogalmazódnak meg a fájlkiszolgálóhoz intézett kérések. Ha a fájl helyi, akkor a helyi rendszermag normálisan dolgozza fel a kérést. Tekintsük az ellenkező esetet:
open ("/../ sftig / fs1 / mjb / rje / file", O_RDONLY);
A C könyvtárban lévő nyitott szubrutin elemzi a megkülönböztetett fájlnév első két összetevőjét, és tudja, hogy megkeresse a fájlt az „sftig” távoli gépen. Annak érdekében, hogy információhoz jusson arról, hogy a folyamatnak volt-e korábban kapcsolata egy adott géppel, a szubrutin elindít egy speciális struktúrát, amelyben megjegyzi ezt a tényt, és nemleges válasz esetén kapcsolatot létesít a távoli számítógépen futó fájlszerverrel. gép. Amikor a folyamat megfogalmazza az első kérését a távoli feldolgozásra, a távoli szerver megerősíti a kérést, szükség esetén rögzíti a felhasználói és csoportazonosító kódok mezőit, és létrehoz egy műholdas folyamatot, amely a kliens folyamat nevében fog eljárni.
Az ügyfél kéréseinek teljesítéséhez a műholdnak ugyanazokkal a fájlengedélyekkel kell rendelkeznie a távoli gépen, mint az ügyfélnek. Más szóval, az "mjb" felhasználónak azonos hozzáférési jogokkal kell rendelkeznie a távoli és a helyi fájlokhoz. Sajnos előfordulhat, hogy az "mjb" kliens azonosító kódja egybeeshet egy másik kliens azonosító kódjával a távoli gépen. Így a hálózaton futó gépek rendszergazdáinak vagy gondoskodniuk kell arról, hogy minden felhasználóhoz a teljes hálózatra egyedi azonosító kódot rendeljenek, vagy a hálózati szolgáltatási kérés megfogalmazásakor végre kell hajtani a kódkonverziót. Ha ez nem történik meg, a kísérőfolyamat egy másik kliens jogaival rendelkezik a távoli gépen.
Kényesebb probléma a távoli fájlokkal való munkavégzéshez kapcsolódó szuperfelhasználói jogok megszerzése. Egyrészt a szuperfelhasználói kliensnek nem szabad ugyanolyan jogokkal rendelkeznie a távoli rendszer felett, hogy ne vezesse félre a távoli rendszer biztonsági vezérlőit. Másrészt a programok egy része, ha nem kapnak szuperfelhasználói jogokat, egyszerűen nem fog működni. Ilyen program például az mkdir program (lásd a 7. fejezetet), amely egy új könyvtárat hoz létre. A távoli rendszer nem engedi, hogy az ügyfél új könyvtárat hozzon létre, mert a törléskor nem érvényesek a felettes felhasználói jogok. A távoli könyvtárak létrehozásának problémája komoly okként szolgál az mkdir rendszerfunkció felülvizsgálatára, annak érdekében, hogy kibővítse képességeit a felhasználó számára szükséges összes kapcsolat automatikus létrehozásában. Azonban továbbra is gyakori probléma, hogy a setuid programok (például az mkdir program) szuperfelhasználói jogosultságokat szereznek a távoli fájlokhoz. Talán a legjobb megoldás erre a problémára az lenne, ha további jellemzőket állítana be a fájlokhoz, amelyek leírják a távoli szuperfelhasználók hozzáférését; sajnos ehhez a lemezindex szerkezetének módosítására lenne szükség (új mezők hozzáadásával), és túl sok rendetlenséget okozna a meglévő rendszerekben.
Ha a nyitott szubrutin sikeresen befejeződik, a helyi könyvtár megfelelő megjegyzést hagy erről egy felhasználó által elérhető struktúrában, amely tartalmazza a hálózati csomópont címét, a műholdas folyamat folyamatazonosítóját, a fájlleírót és más hasonló információkat. A könyvtár olvasási és írási rutinjai a leíró alapján meghatározzák, hogy a fájl törlésre került-e, és ha igen, üzenetet küld a műholdra. Az ügyfélfolyamat minden olyan rendszerfunkcióhoz való hozzáférés esetén kölcsönhatásba lép a társával, amely távoli gép szolgáltatásait igényli. Ha egy folyamat két, ugyanazon a távoli gépen található fájlhoz fér hozzá, akkor egy műholdat használ, de ha a fájlok különböző gépeken találhatók, akkor már két műhold van használatban: mindegyik gépen egy. Két műhold akkor is használatos, ha két folyamat hozzáfér egy fájlhoz egy távoli gépen. A rendszerfunkció műholdon keresztüli meghívásával a folyamat egy üzenetet generál, amely tartalmazza a funkció számát, a keresési útvonal nevét és egyéb szükséges információkat, hasonlóan ahhoz, amit a perifériás processzorokkal rendelkező rendszerben az üzenetstruktúra tartalmaz.
Az aktuális könyvtáron végzett műveletek mechanizmusa összetettebb. Amikor a folyamat egy távoli könyvtárat választ ki aktuálisként, a könyvtári rutin üzenetet küld a műholdra, amely megváltoztatja az aktuális címtárat, és a rutin emlékszik, hogy a címtárat törölték. Minden olyan esetben, amikor a keresési útvonal neve perjeltől (/) eltérő karakterrel kezdődik, az alprogram elküldi a nevet a távoli gépnek, ahol a műholdfolyamat az aktuális könyvtárból továbbítja azt. Ha az aktuális könyvtár helyi, a rutin egyszerűen átadja a keresési útvonal nevét a helyi rendszermagnak. A rendszer chroot függvénye egy távoli könyvtárban hasonló, de a helyi kernelnél észrevétlen marad; szigorúan véve a folyamat figyelmen kívül hagyhatja ezt a műveletet, mivel csak a könyvtár rögzíti a végrehajtását.
Amikor egy folyamat hívja a forkot, a megfelelő könyvtári rutin üzeneteket küld minden műholdra. A műholdak folyamatai szétágaznak, és elküldik gyermekazonosítóikat a szülő kliensnek. Az ügyfélfolyamat a fork rendszerfüggvényt futtatja, amely átadja az irányítást az általa létrehozott gyermeknek; a helyi gyermek párbeszédet folytat a távoli műholdas gyermekkel, akinek a címeit a könyvtári rutin tárolja. A fork funkció ezen értelmezése megkönnyíti a műholdas folyamatok számára a megnyitott fájlok és aktuális könyvtárak vezérlését. Amikor a távoli fájlokkal dolgozó folyamat kilép (a kilépési funkció meghívásával), az alprogram üzeneteket küld az összes távoli műholdjának, így azok is ugyanezt teszik, amikor megkapják az üzenetet. A gyakorlatok az exec és exit rendszer funkciók megvalósításának bizonyos szempontjait tárgyalják.
A Newcastle-hivatkozás előnye, hogy a folyamat távoli fájlokhoz való hozzáférése átlátszóvá (láthatatlanná) válik a felhasználó számára, anélkül, hogy a rendszermagot módosítani kellene. Ennek a fejlesztésnek azonban számos hátránya van. Először is, a megvalósítás során a rendszer teljesítményének csökkenése lehetséges. A kiterjesztett C könyvtár használata miatt az egyes folyamatok által használt memória mérete megnő, még akkor is, ha a folyamat nem éri el a távoli fájlokat; a könyvtár megkettőzi a kernel függvényeit, és több memóriát igényel. A folyamatok méretének növelése meghosszabbítja az indítási időszakot, és nagyobb versenyt kelthet a memória-erőforrásokért, megteremtve a feltételeket a feladatok gyakoribb ki- és lapozásához. A helyi kérések az egyes kernelhívások időtartamának növekedése miatt lassabban fognak teljesíteni, illetve a távoli kérések feldolgozása is lelassulhat, megnő a hálózaton keresztüli küldés költsége. A távoli kérések felhasználói szinten történő további feldolgozása megnöveli a kontextusváltások, a kirakodási és csereműveletek számát. Végül a távoli fájlok eléréséhez a programokat újra kell fordítani az új könyvtárak használatával; a régi programok és a szállított objektummodulok enélkül nem fognak tudni dolgozni távoli fájlokkal. Mindezek a hátrányok hiányoznak a következő részben ismertetett rendszerből.
13.3 „ÁTLÁTSZÓ” OSZTOTT FÁJLRENDSZEREK
Az "átlátszó kiosztás" kifejezés azt jelenti, hogy az egyik gépen a felhasználók hozzáférhetnek egy másik gépen lévő fájlokhoz anélkül, hogy észrevennék, hogy átlépik a gép határait, éppúgy, mint a saját gépükön, amikor egyik fájlrendszerről a másikra váltanak, áthaladva a csatolási pontokon. Azok a nevek, amelyekkel a folyamatok a távoli gépeken található fájlokra hivatkoznak, hasonlóak a helyi fájlok nevéhez: nincsenek bennük megkülönböztető karakterek. A 13.10. ábrán látható konfigurációban a B géphez tartozó "/ usr / src" könyvtár az A géphez tartozó "/ usr / src" könyvtárba van "csatolva". ugyanaz a rendszerforráskód, amely hagyományosan a "/ usr / src" könyvtárba. Az A gépen futó felhasználók a B gépen található fájlokhoz a szokásos fájlnevek írási szintaxisával érhetik el (például: "/usr/src/cmd/login.c"), és a kernel maga dönti el, hogy a fájl távoli vagy helyi. . A B gépen futó felhasználók hozzáférhetnek a helyi fájljaikhoz (nem tudják, hogy az A gép felhasználói hozzáférhetnek ugyanazokhoz a fájlokhoz), viszont nem férnek hozzá az A gépen található fájlokhoz. Természetesen más lehetőségek is lehetségesek, különösen azok, amelyekben az összes távoli rendszer a helyi rendszer gyökeréhez van csatlakoztatva, így a felhasználók hozzáférhetnek az összes fájlhoz az összes rendszeren.

13.10. ábra. Fájlrendszerek távoli csatlakoztatás után
A helyi fájlrendszerek csatlakoztatása és a távoli fájlrendszerekhez való hozzáférés engedélyezése közötti hasonlóságok arra késztették, hogy a mount funkciót távoli fájlrendszerekhez igazítsák. Ebben az esetben a kernelnek van egy kiterjesztett formátumú csatolótáblája. A mount funkciót végrehajtva a kernel hálózati kapcsolatot szervez egy távoli géppel, és a csatlakozást jellemző információkat tárolja a csatolási táblában.
Egy érdekes probléma a "..."-t tartalmazó elérési útnevekkel kapcsolatos. Ha egy folyamat egy távoli fájlrendszerből hozza létre az aktuális könyvtárat, akkor a ".." karakterek használata a névben nagyobb valószínűséggel téríti vissza a folyamatot a helyi fájlrendszerbe, nem pedig az aktuális könyvtár feletti fájlokhoz. Visszatérve a 13.10. ábrához, vegye figyelembe, hogy amikor az A géphez tartozó folyamat, miután korábban kiválasztotta a távoli fájlrendszerben található "/ usr / src / cmd" könyvtárat, végrehajtja a parancsot.
az aktuális könyvtár az A gép gyökérkönyvtára lesz, nem a B gép. A távoli rendszer kernelében futó namei algoritmus a „..” karaktersorozat fogadása után ellenőrzi, hogy a hívó folyamat a kliens ügynöke-e folyamatot, és ha igen, beállítja, hogy az ügyfél az aktuális munkakönyvtárat kezeli-e a távoli fájlrendszer gyökereként.
A távoli géppel való kommunikáció két formája lehet: távoli eljáráshívás vagy távoli rendszerfunkció hívás. Az első formában minden indexekkel foglalkozó kerneleljárás ellenőrzi, hogy az index egy távoli fájlra mutat-e, és ha igen, akkor kérést küld a távoli gépnek a megadott művelet végrehajtására. Ez a séma természetesen illeszkedik a különféle típusú fájlrendszerek támogatásának absztrakt struktúrájába, amelyet az 5. fejezet utolsó részében ismertetünk. Így egy távoli fájlhoz való hozzáférés több üzenet továbbítását kezdeményezheti a hálózaton keresztül, amelyek száma a fájlon végrehajtott implikált műveletek száma határozza meg, a válaszidő ennek megfelelő növekedésével a kérésre, figyelembe véve a hálózatban elfogadott várakozási időt. A távoli műveletek mindegyike tartalmaz legalább indexzárolási, referenciaszámlálási stb. műveleteket. A modell fejlesztése érdekében különféle optimalizálási megoldásokat javasoltak, amelyek több műveletet egy lekérdezésbe (üzenetbe) kombináltak, és a legfontosabb adatokat (cm. ).

13.11. ábra. Távoli fájl megnyitása
Tekintsünk egy folyamatot, amely megnyit egy távoli „/usr/src/cmd/login.c” fájlt, ahol az „src” a csatlakoztatási pont. A fájlnév elemzésével (a namei-iget séma használatával) a kernel észleli a fájl törlését, és kérést küld a gazdagépnek a zárolt index lekérésére. Miután megkapta a kívánt választ, a helyi kernel létrehozza a távoli fájlnak megfelelő index másolatát a memóriában. Ezután a kernel ellenőrzi a szükséges hozzáférési jogokat a fájlhoz (például olvasáshoz) úgy, hogy újabb üzenetet küld a távoli gépnek. A nyitott algoritmus az 5. fejezetben vázolt tervnek megfelelően folytatódik, szükség szerint üzeneteket küldve a távoli gépnek, amíg az algoritmus be nem fejeződik és az index fel nem szabadul. A kernel adatstruktúrái közötti kapcsolatot a nyitott algoritmus befejezése után a 13.11. ábra mutatja.
Ha a kliens meghívja a read system funkciót, a kliens kernel zárolja a helyi indexet, zárolást ad ki a távoli indexre, olvasási kérelmet ad ki, az adatokat a helyi memóriába másolja, kérelmet ad ki a távoli index felszabadítására, és felszabadítja a helyi indexet. . Ez a séma összhangban van a meglévő egyprocesszoros kernel szemantikájával, de a hálózathasználat gyakorisága (több hívás minden rendszerfunkcióhoz) csökkenti a teljes rendszer teljesítményét. A hálózaton lévő üzenetek áramlásának csökkentése érdekében azonban több műveletet is össze lehet vonni egyetlen kérelemben. Az olvasási függvény példájában a kliens egy általános "olvasási" kérést küldhet a szervernek, és a szerver maga dönti el, hogy megragadja és felszabadítja az indexet, amikor az végrehajtódik. A hálózati forgalom csökkentése távoli pufferek használatával is elérhető (ahogyan fentebb tárgyaltuk), de ügyelni kell arra, hogy az ezeket a puffereket használó rendszerfájl-funkciók megfelelően végrehajtásra kerüljenek.
A távoli géppel való kommunikáció második formájában (a távoli rendszer függvényének hívása) a helyi kernel észleli, hogy a rendszerfüggvény egy távoli fájlhoz kapcsolódik, és elküldi a hívásakor megadott paramétereket a távoli rendszernek, amely végrehajtja a függvényt, és visszaküldi az eredményeket az ügyfélnek. Az ügyfélgép megkapja a függvény végrehajtásának eredményét, és kilép a hívási állapotból. A legtöbb rendszerfunkció végrehajtható egyetlen hálózati kéréssel és ésszerű időn belüli válasz fogadásával, de nem minden funkció fér bele ebbe a modellbe. Így például bizonyos jelek vételekor a kernel létrehoz egy fájlt a folyamathoz, amelyet "core"-nak neveznek (7. fejezet). Ennek a fájlnak a létrehozása nem kapcsolódik egy adott rendszerfunkcióhoz, hanem több műveletet hajt végre, például egy fájl létrehozását, az engedélyek ellenőrzését és egy sor írást.
Nyitott rendszer funkció esetén a távoli gépre küldött függvény végrehajtási kérése tartalmazza a fájlnévnek azt a részét, amely a távoli fájlt megkülönböztető keresési útvonalnév-összetevők, valamint a különböző jelzők kizárása után megmarad. A „/usr/src/cmd/login.c” fájl megnyitásának korábbi példájában a kernel a „cmd / login.c” nevet küldi a távoli gépnek. Az üzenet olyan hitelesítő adatokat is tartalmaz, mint például a felhasználói és csoportazonosító kódok, amelyek a távoli gépen lévő fájlengedélyek ellenőrzéséhez szükségesek. Ha a távoli gépről válasz érkezik, amely jelzi a sikeres megnyitási funkciót, a helyi kernel lekér egy szabad indexet a helyi gép memóriájában, és távoli fájlindexként jelöli meg, információkat tárol a távoli gépről és a távoli indexről, és rutinszerűen hozzárendel egy új bejegyzést a fájltáblázatban. A távoli gépen lévő valós indexhez képest a helyi gép tulajdonában lévő index formális, és nem sérti a modell konfigurációját, amely nagyjából megegyezik a távoli eljárás hívásakor használt konfigurációval (13.11. ábra). Ha egy folyamat által meghívott függvény a leírója alapján hozzáfér egy távoli fájlhoz, a helyi kernel a (helyi) indexből tudja, hogy a fájl távoli, megfogalmaz egy kérést, amely tartalmazza a meghívott függvényt, és elküldi azt a távoli gépnek. A kérés tartalmaz egy mutatót a távoli indexre, amellyel a műholdfolyamat magát a távoli fájlt azonosítani tudja.
Miután megkapta bármely rendszerfunkció végrehajtásának eredményét, a kernel egy speciális program szolgáltatásait veheti igénybe annak feldolgozásához (amelynek befejezése után a kernel befejezi a funkcióval való munkát), mivel az egyprocesszoros rendszerben az eredmények helyi feldolgozása történik. nem mindig alkalmas több processzoros rendszerhez. Ennek eredményeként a rendszeralgoritmusok szemantikájának változtatásai lehetségesek, amelyek célja a távoli rendszerfunkciók végrehajtásának támogatása. Ugyanakkor egy minimális üzenetáramlás kering a hálózatban, biztosítva a rendszer minimális válaszidejét a bejövő kérésekre.
13.4 FORGALMAZOTT MODELL ÁTVITELI FOLYAMATOK NÉLKÜL
Az átviteli folyamatok (műholdas folyamatok) alkalmazása egy átlátszó elosztott rendszerben megkönnyíti a törölt fájlok nyomon követését, de a távoli rendszer folyamattáblája túlterhelt a legtöbbször tétlen műholdas folyamatokkal. Más sémákban speciális szerverfolyamatokat használnak a távoli kérések feldolgozására (lásd és). A távoli rendszernek van egy szerverfolyamat-készlete (készlete), amelyet időről időre hozzárendel a bejövő távoli kérések feldolgozásához. A kérés feldolgozása után a kiszolgálófolyamat visszatér a készlethez, és készen áll a többi kérés feldolgozására. A szerver nem menti el a felhasználói kontextust két hívás között, mert egyszerre több folyamat kérését is képes feldolgozni. Ezért minden ügyfélfolyamatból érkező üzenetnek tartalmaznia kell a végrehajtási környezetére vonatkozó információkat, nevezetesen: felhasználói azonosító kódokat, aktuális könyvtárat, jeleket stb.
Amikor egy folyamat megnyit egy távoli fájlt, a távoli kernel indexet rendel a fájlra mutató későbbi hivatkozásokhoz. A helyi gép egy egyéni fájlleíró táblát, egy fájltáblázatot és egy indextáblát tart karban szokásos rekordkészlettel, egy indextábla-bejegyzéssel, amely azonosítja a távoli gépet és a távoli indexet. Azokban az esetekben, amikor egy rendszerfunkció (például olvasás) fájlleírót használ, a kernel üzenetet küld, amely a korábban hozzárendelt távoli indexre mutat, és továbbítja a folyamattal kapcsolatos információkat: felhasználóazonosító kód, maximális fájlméret stb. szerver folyamat áll rendelkezésére, a klienssel való interakció a korábban leírt formát ölti, azonban a kapcsolat a kliens és a szerver között csak a rendszer működésének idejére jön létre.
A műholdas folyamatok helyett szerverek használata megnehezítheti az adatforgalom, a jelek és a távoli eszközök kezelését. Elegendő számú kiszolgáló hiányában a távoli gépekre érkező nagyszámú kérést sorba kell helyezni. Ehhez magasabb szintű protokollra van szükség, mint a főhálózaton használtnál. A műholdas modellben ezzel szemben a túltelítettség megszűnik, mivel minden ügyfélkérést szinkronban dolgoznak fel. Egy ügyfélnek legfeljebb egy kérése lehet függőben.
A rendszerfunkció végrehajtását megszakító jelek feldolgozása is bonyolult szerverek használatakor, mivel a távoli gépnek meg kell keresnie a funkció végrehajtását kiszolgáló megfelelő szervert. Még az is lehetséges, hogy az összes szerver elfoglaltsága miatt egy rendszerfunkcióra vonatkozó kérés feldolgozás alatt áll. A verseny kialakulásának feltételei akkor is felmerülnek, ha a szerver visszaküldi a rendszerfunkció eredményét a hívó folyamatnak, és a szerver válasza egy megfelelő jelzőüzenetet küld a hálózaton keresztül. Minden üzenetet meg kell jelölni, hogy a távoli rendszer felismerje és szükség esetén leállíthassa a szerver folyamatokat. Műholdak használatakor automatikusan beazonosítható a kliens kérésének teljesítését kezelő folyamat, jelzés érkezése esetén pedig nem nehéz ellenőrizni, hogy a kérés feldolgozásra került-e vagy sem.
Végül, ha az ügyfél által meghívott rendszerfüggvény miatt a kiszolgáló határozatlan ideig szünetel (például amikor adatokat olvas egy távoli terminálról), a kiszolgáló nem tud más kéréseket feldolgozni a kiszolgálókészlet felszabadítására. Ha egyszerre több folyamat is hozzáfér a távoli eszközökhöz, és ha felülről korlátozzák a szerverek számát, akkor egy egészen kézzelfogható szűk keresztmetszet áll fenn. Ez nem fordul elő műholdak esetében, mivel minden ügyfélfolyamathoz hozzá van rendelve egy műhold. A szerverek távoli eszközökhöz való használatával kapcsolatos másik problémát a 13.14. gyakorlat tárgyalja.
A műholdas folyamatok használatának előnyei ellenére a gyakorlatban a folyamattábla szabad bejegyzéseinek igénye olyan akuttá válik, hogy a legtöbb esetben továbbra is a szerverfolyamatok szolgáltatásait veszik igénybe a távoli kérések feldolgozására.

13.12. ábra. A távoli fájlokkal való interakció fogalmi diagramja kernel szinten
13.5 KÖVETKEZTETÉSEK
Ebben a fejezetben három sémát vettünk figyelembe a távoli gépeken található fájlokkal való munkavégzéshez, amelyek a távoli fájlrendszereket a helyi fájl kiterjesztéseként kezelik. Az ezen elrendezések közötti építészeti különbségeket a 13.12. ábra mutatja. Mindegyik abban különbözik az előző fejezetben ismertetett többprocesszoros rendszerektől, hogy az itteni processzorok nem osztoznak a fizikai memórián. A perifériás processzorrendszer szorosan összekapcsolt processzorokból áll, amelyek megosztják a központi processzor fájlerőforrásait. A Newcastle típusú kapcsolat rejtett ("átlátszó") hozzáférést biztosít távoli fájlokhoz, de nem az operációs rendszer kernelén keresztül, hanem egy speciális C könyvtár használatával. Emiatt minden olyan programot újra kell fordítani, amely ilyen típusú hivatkozást kíván használni, ami általánosságban ennek a sémának komoly hátránya. A fájl távoli helyzetét egy speciális karaktersorozat jelzi, amely leírja a gépet, amelyen a fájl található, és ez egy másik tényező, amely korlátozza a programok hordozhatóságát.
Átlátszó elosztott rendszerekben a mount system funkció módosítása használatos a távoli fájlok eléréséhez. A helyi rendszeren lévő indexek távoli fájlként vannak megjelölve, és a helyi kernel üzenetet küld a távoli rendszernek, amelyben leírja a kért rendszerfunkciót, annak paramétereit és a távoli indexet. Az "átlátszó" elosztott rendszerben a kommunikáció két formában támogatott: távoli eljárás hívása (üzenet küldése a távoli gépnek, amely tartalmazza az indexhez kapcsolódó műveletek listáját) és hívás formájában. távoli rendszerfunkcióhoz (az üzenet leírja a kért funkciót). A fejezet utolsó része a távoli kérések műholdas folyamatok és szerverek segítségével történő feldolgozásával kapcsolatos kérdéseket tárgyalja.
13.6 GYAKORLATOK
*1. Ismertesse a kilépési rendszer funkció megvalósítását perifériás processzorokkal rendelkező rendszerben! Mi a különbség ez az eset és az, hogy mikor fejeződik be a folyamat, amikor nem fogott jelet kap? Hogyan kell a kernelnek kiírnia a memória tartalmát?
2. A folyamatok nem hagyhatják figyelmen kívül a SIGKILL jeleket; Magyarázza el, mi történik a perifériás rendszerben, amikor a folyamat ilyen jelet kap!
* 3. Ismertesse az exec rendszerfunkció megvalósítását perifériás processzorokkal rendelkező rendszeren.
*4. Hogyan kell a központi processzornak elosztani a folyamatokat a perifériás processzorok között, hogy kiegyensúlyozza a teljes terhelést?
*5. Mi történik, ha a perifériás processzornak nincs elég memóriája ahhoz, hogy befogadja az összes rátöltött folyamatot? Hogyan történjen a hálózatban a folyamatok ki- és felcserélése?
6. Tekintsünk egy olyan rendszert, amelyben a távoli fájlszervernek küldenek kéréseket, ha a fájlnévben speciális előtag található. Hagyja, hogy a folyamat meghívja az execl parancsot ("/../ sftig / bin / sh", "sh", 0); A végrehajtható fájl egy távoli gépen van, de a helyi rendszeren kell futnia. Magyarázza el, hogyan kerül áttelepítésre a távoli modul a helyi rendszerre.
7. Ha az adminisztrátornak új gépeket kell hozzáadnia egy meglévő rendszerhez olyan kapcsolattal, mint a Newcastle, akkor mi a legjobb módja annak, hogy tájékoztassa erről a C könyvtár moduljait?
*nyolc. Az exec függvény végrehajtása során a kernel felülírja a folyamat címterét, beleértve a Newcastle hivatkozás által a távoli fájlokra mutató hivatkozások nyomon követésére használt könyvtártáblákat is. A funkció végrehajtása után a folyamatnak meg kell őriznie a hozzáférést ezekhez a fájlokhoz a régi leíróik alapján. Ismertesse ennek a pontnak a végrehajtását.
*kilenc. Ahogy a 13.2. szakaszban látható, a kilépési rendszerfüggvény meghívása Newcastle-kapcsolattal rendelkező rendszereken üzenetet küld a kísérőfolyamatnak, amely az utóbbi leállására kényszeríti. Ez a könyvtári rutinok szintjén történik. Mi történik, ha egy helyi folyamat olyan jelet kap, amely felszólítja, hogy kernel módban lépjen ki?
*tíz. Egy Newcastle-hivatkozással rendelkező rendszerben, ahol a távoli fájlok azonosítása úgy történik, hogy a nevet egy speciális előtaggal látják el, hogyan tud a felhasználó a „..” (szülőkönyvtár) fájlnév-összetevőként megadva a távoli csatlakoztatási ponton keresztülhaladni?
11. A 7. fejezetből tudjuk, hogy különböző jelek hatására a folyamat a memória tartalmát az aktuális könyvtárba írja. Mi történik, ha az aktuális könyvtár a távoli fájlrendszerből származik? Mit válaszolna, ha a rendszer olyan kapcsolatot használ, mint a Newcastle?
*12. Milyen következményekkel járna a helyi folyamatokra, ha az összes műhold- vagy szerverfolyamatot eltávolítanák a rendszerből?
*13. Fontolja meg, hogyan valósítható meg a link algoritmus egy transzparens elosztott rendszerben, amelynek paraméterei lehet két távoli fájlnév, valamint az exec algoritmus, amely több belső olvasási művelet végrehajtásához kapcsolódik. Tekintsünk két kommunikációs formát: egy távoli eljáráshívást és egy távoli rendszerfunkció hívást.
*tizennégy. Az eszköz elérésekor a szerver folyamat felfüggesztett állapotba kerülhet, amelyből az eszközillesztő kiveszi. Természetesen, ha a szerverek száma korlátozott, a rendszer már nem tudja kielégíteni a helyi gép kéréseit. Dolgozzon ki egy megbízható sémát, amely szerint nem minden kiszolgálói folyamat függ fel, amíg az eszközhöz kapcsolódó I/O befejezésére vár. A rendszerfunkció nem fejeződik be, amíg az összes szerver foglalt.

13.13. ábra. Terminálkiszolgáló konfigurációja
*15. Amikor egy felhasználó bejelentkezik a rendszerbe, a terminálvonali diszciplína tárolja azt az információt, hogy a terminál egy kezelőterminál, amely folyamatok csoportját vezeti. Emiatt, amikor a felhasználó megnyomja a "break" gombot a terminál billentyűzetén, a csoport összes folyamata megkapja a megszakítási jelet. Vegyünk egy olyan rendszerkonfigurációt, amelyben az összes terminál fizikailag egy géphez csatlakozik, de a felhasználói regisztráció logikailag más gépeken valósul meg (13.13. ábra). A rendszer minden esetben létrehoz egy getty folyamatot a távoli terminál számára. Ha a távoli rendszerhez intézett kéréseket szerverfolyamatok dolgozzák fel, vegye figyelembe, hogy a nyílt eljárás végrehajtásakor a szerver nem vár a kapcsolatra. Amikor a megnyitás funkció befejeződik, a szerver visszatér a kiszolgálókészlethez, megszakítva a kapcsolatot a terminállal. Hogyan indítható el megszakítási jel a "break" gomb megnyomásával az azonos csoportba tartozó folyamatok címére?
*16. A memória megosztása a helyi gépek sajátossága. Logikai szempontból a fizikai memória közös területének (helyi vagy távoli) kiosztása elvégezhető a különböző gépekhez tartozó folyamatokhoz. Ismertesse ennek a pontnak a végrehajtását.
* 17. A 9. fejezetben tárgyalt folyamatlapozási és lapozási algoritmusok helyi személyhívó használatát feltételezik. Milyen változtatásokat kell végrehajtani ezeken az algoritmusokon, hogy támogassák a távoli tehermentesítési eszközöket?
*tizennyolc. Tegyük fel, hogy a távoli gép (vagy hálózat) végzetes összeomlást szenved, és a helyi hálózati réteg protokollja rögzíti ezt a tényt. Készítsen helyreállítási sémát egy távoli kiszolgálónak kérelmező helyi rendszerhez. Ezenkívül dolgozzon ki helyreállítási sémát egy olyan szerverrendszer számára, amely elvesztette a kapcsolatot az ügyfelekkel.
*19. Amikor egy folyamat hozzáfér egy távoli fájlhoz, lehetséges, hogy a folyamat több gépet is bejár a fájl keresése során. Vegyük például a "/ usr / src / uts / 3b2 / os" nevet, ahol a "/ usr" az A géphez tartozó könyvtár, az "/ usr / src" pedig a B gép gyökerének csatolási pontja, " A / usr / src / uts / 3b2 "a C gép gyökerének beillesztési pontja. A több gépen keresztüli gyaloglást a végső célig multihopnak nevezzük. Ha azonban közvetlen hálózati kapcsolat van az A és C gép között, a B gépen keresztüli adatküldés nem lenne hatékony. Ismertesse a "multishopping" megvalósításának jellemzőit Newcastle kapcsolattal rendelkező rendszerben és "transzparens" elosztott rendszerben!
V nagy birtokok több tízezer felhasználó dolgozik a leányvállalatokban. Minden szervezetnek megvannak a saját belső üzleti folyamatai: dokumentumok jóváhagyása, utasítások kiadása stb. Ugyanakkor bizonyos folyamatok túllépnek az egyik vállalat határain, és egy másik vállalat alkalmazottait érintik. Például a központi iroda vezetője megbízást ad a leányvállalatnak, vagy a leányvállalat alkalmazottja jóváhagyásra küld megállapodást az anyavállalat jogászaival. Ez több rendszert használó összetett architektúrát igényel.
Ráadásul belül egy cég sok rendszert használnak különböző problémák megoldására: ERP rendszer a könyvelési műveletekhez, külön ECM rendszerek telepítése a szervezeti és adminisztratív dokumentációhoz, a tervezési becslésekhez stb.
A DIRECTUM rendszer elősegíti a különböző rendszerek interakciójának biztosítását mind a holdingon belül, mind egy szervezet szintjén.
A DIRECTUM kényelmes eszközöket biztosít az építkezéshez felügyelt elosztott architektúra az alábbi feladatok megszervezése és megoldása:
- végpontok közötti üzleti folyamatok megszervezése és adatszinkronizálás ugyanazon vállalat több rendszere között és a holdingban;
- hozzáférés biztosítása az ECM rendszerek különböző telepítéseiből származó adatokhoz. Például keressen egy dokumentumot több speciális rendszerben: pénzügyi dokumentációval, tervezési és becslési dokumentációval stb.
- számos rendszer és szolgáltatás adminisztrációja egyetlen felügyeleti pontról és kényelmes informatikai infrastruktúra létrehozása;
- a fejlesztés kényelmes elosztása az elosztott termelési rendszerek között.

Egy menedzselt elosztott architektúra összetevői
Összekapcsolási mechanizmusok (DCI)
A DCI mechanizmusok az üzleti folyamatok végpontok közötti megszervezésére és az adatok szinkronizálására szolgálnak egy vagy több szervezeten belüli különböző rendszerek között (holding).

A megoldás a vállalatoknál meglévő helyi üzleti folyamatokat egyetlen végponttól végpontig terjedő folyamattá kapcsolja össze. Az alkalmazottak és vezetőik a már megszokott feladatok, dokumentumok és segédkönyvek felületén dolgoznak. Ugyanakkor a munkavállalók lépései minden szakaszban átláthatóak: láthatják a kapcsolt céggel folytatott levelezés szövegét, láthatják az anyaszervezettel történt dokumentumok jóváhagyásának állapotát stb.
Különféle DIRECTUM-telepítések és egyéb rendszerosztályok (ERP, CRM stb.) csatlakoztathatók a DCI-hez. A létesítményeket általában üzleti területek szerint osztják fel, figyelembe véve a szervezetek területi vagy jogi elhelyezkedését és egyéb tényezőket.
A DCI-vel együtt a fejlesztési komponenseket részletes leírással és kódpéldákkal látják el, amelyeknek köszönhetően a fejlesztő algoritmust készíthet szervezete üzleti folyamataihoz.
A DCI mechanizmusok nagy mennyiségű adat továbbítására képesek, és ellenállnak a csúcsterhelésnek. Ezen kívül hibatűrést biztosítanak kommunikációs hibák esetén és a továbbított adatok védelmét.
Összevont keresés
Az egyesített kereséssel az összes DIRECTUM rendszerben egyszerre megtalálhatja a szükséges feladatokat vagy dokumentumokat. Például egyszerre indítson keresést a működő rendszerben és az archivált dokumentumokat tartalmazó rendszerben.

Az egyesített keresés lehetővé teszi a következőket:
- megtekintheti a webes kliensen keresztül egy kimenő dokumentum jóváhagyásának folyamatát egy leányvállalatnál;
- minden leányvállalatnál megtalálja a partnerrel kötött megállapodásokat, például a tárgyalások előkészítésére. Ebben az esetben mehet azokhoz a feladatokhoz, amelyekhez a szerződések mellékelve vannak;
- ellenőrzi az anyaszervezettől a leányvállalatnak küldött megbízás, illetve az azon keletkezett dokumentumok, feladatok teljesítésének állapotát;
- egyszerre több, különböző szakterületű rendszerben találhat dokumentumokat, például szervezeti és adminisztratív dokumentumokat, szerződéseket;
- azonnal megtalálja az elsődleges számviteli bizonylatokat az ellenőrzéshez vagy a partnerrel való egyeztetéshez a működő rendszerben és a dokumentumtárat tartalmazó rendszerben;
- keresési eredményekre mutató hivatkozások cseréje kollégáival.
Az adminisztrátor módosíthatja a szokásos kereséseket, újakat adhat hozzá, és azt is személyre szabhatja, hogy mely rendszerek legyenek láthatók a felhasználó számára.
DIRECTUM Services Administration Center
A DIRECTUM rendszer számos különféle feladatot old meg: munkatársak interakciója, dokumentumok tárolása stb. Ezt szolgáltatásainak megbízható működése teszi lehetővé. A nagyvállalatoknál pedig a DIRECTUM rendszer teljes telepítését saját szolgáltatáskészletükkel osztják ki egy adott feladatra, például archív dokumentumok tárolására. A telepítések és a szolgáltatások több kiszolgálón vannak telepítve. Ezt az infrastruktúrát adminisztrálni kell.
A DIRECTUM Services Administration Center egyetlen adminisztratív belépési pont a DIRECTUM szolgáltatások és rendszerek konfigurálásához, figyeléséhez és kezeléséhez. A központ a munkamenet-kiszolgáló, a munkafolyamat-szolgáltatás, az eseményfeldolgozási szolgáltatás, a fájltároló szolgáltatás, a beviteli és átalakítási szolgáltatások, az egyesített keresés és a webes súgó felügyeleti eszközeinek webhelye.

A távoli rendszerek és szolgáltatások kényelmes vizuális konfigurálása leegyszerűsíti a rendszergazda munkáját. Nem kell minden kiszolgálóra felmennie és manuálisan módosítania a konfigurációs fájlokat.
A szolgáltatások egy kattintással leállnak és engedélyezhetők. A szolgáltatások állapota azonnal megjelenik a képernyőn.
A beállítások listája feltölthető és szűrhető. Alapértelmezés szerint a webhely csak az alapvető beállításokat jeleníti meg. Ugyanakkor az összes beállításhoz tippeket láthat a kitöltésre vonatkozó javaslatokkal.
A DIRECTUM rendszer hatékonyan szervezi az elosztott szervezetek munkáját, és biztosítja a felhasználók számára a dokumentumok, feladatok és címtárrekordok átlátható cseréjét.
A felügyelt elosztott architektúra minden összetevője külön-külön is használható, de együtt nagyobb üzleti értéket hozhatnak a szervezet számára.
Jelenleg minden kereskedelmi célra kifejlesztett IS elosztott architektúrával rendelkezik, ami globális és/vagy helyi hálózatok használatát jelenti.
Történelmileg a fájlszerver architektúra volt az első, amely elterjedt, mivel logikája egyszerű, és ilyen architektúrába a legkönnyebb átvinni a már használatban lévő IS-eket. Ezután szerver-kliens architektúrává alakították át, ami annak logikai folytatásaként is értelmezhető. Az INTERNET globális hálózatban használt modern rendszerek főként az elosztott objektumok architektúrájára vonatkoznak (lásd az ábrát). III‑15 )
Az IS a következő összetevőkből állva képzelhető el (III-16. ábra)
III.03.2. a Fájlkiszolgáló alkalmazások.
Történelmileg ez az első elosztott építészet (III-17. ábra). Nagyon egyszerűen van megszervezve: csak adat van a szerveren, minden más pedig a kliens gépé. Mivel a helyi hálózatok meglehetősen olcsók, és mivel egy ilyen architektúra mellett az alkalmazásszoftver autonóm, ma gyakran használnak ilyen architektúrát. Elmondhatjuk, hogy ez a kliens-szerver architektúra egy olyan változata, amelyben csak adatfájlok találhatók a szerveren. A különböző személyi számítógépek csak egy közös adattáron keresztül lépnek kapcsolatba egymással, ezért az egy számítógépre írt programokat egy ilyen architektúrához lehet a legkönnyebben adaptálni.
Előnyök:
A fájlszerver architektúra előnyei:
Könnyű szervezés;
Nem mond ellent az adatbázis integritásának és megbízhatóságának megőrzéséhez szükséges követelményeknek.
Hálózati torlódások;
Kiszámíthatatlan válasz egy kérésre.
Ezeket a hátrányokat az magyarázza, hogy az adatbázishoz intézett bármely kérés jelentős mennyiségű információ átviteléhez vezet a hálózaton keresztül. Ha például egy vagy több sort szeretne kijelölni a táblákból, a teljes tábla letöltődik az ügyfélgépre, és a DBMS már ott választ ki. A jelentős hálózati forgalom különösen az adatbázis távelérésének megszervezésével jár.
III.03.2. b Kliens-szerver alkalmazások.
Ebben az esetben a felelősség megoszlik a szerver és a kliens között. Attól függően, hogy hogyan különböznek egymástól zsírés vékony kliens.
A vékonykliens modellben minden alkalmazási munka és adatkezelés a szerveren történik. A felhasználói felület ezekben a rendszerekben egy személyi számítógépre "vándorol", a szoftveralkalmazás pedig maga látja el a szerver funkcióit, pl. lefuttatja az összes alkalmazási folyamatot és kezeli az adatokat. A vékonykliens modell ott is megvalósítható, ahol az ügyfelek számítógépek vagy munkaállomások. A hálózati eszközökön az Internet böngésző és a rendszeren belül megvalósított felhasználói felület fut.
Fő hiba vékony kliens modellek - magas szerver- és hálózati terhelés. Minden számítás a szerveren történik, és ez jelentős hálózati forgalomhoz vezethet a kliens és a szerver között. A modern számítógépekben elegendő számítási teljesítmény van, de gyakorlatilag nem használják a bank modelljében / vékony kliensében
Ezzel szemben a vastag kliens modell a helyi gépek feldolgozási teljesítményét használja: maga az alkalmazás kerül a kliens számítógépre. Ilyen típusú architektúra például az ATM rendszerek, amelyekben az ATM a kliens, a szerver pedig az ügyfélszámla-adatbázist kiszolgáló központi számítógép.
III.03.2. c Két- és háromszintű kliens-szerver architektúra.
A fent tárgyalt architektúrák mindegyike kétszintű. Különbséget tesznek a kliens és a szerver szint között. Szigorúan véve az IC három logikai szintből áll:
· Felhasználói szint;
Alkalmazási szint:
· Adatréteg.
Ezért egy kétrétegű modellben, ahol csak két rétegről van szó, skálázhatósági és teljesítményproblémák lépnek fel, ha vékony kliens modellt választanak, vagy rendszerkezelési problémákat, ha vastag kliens modellt választanak. Ezek a problémák elkerülhetők, ha egy három szintből álló modellt alkalmazunk, amelyek közül kettő szerver (III-21. ábra).
| Adatszerver |
Valójában az alkalmazásszerver és az adatszerver elhelyezhető egy gépen, de nem tudják ellátni egymás funkcióit. A háromszintű modellben az a szép, hogy logikusan elválasztja egymástól az alkalmazás-végrehajtást és az adatkezelést.
III-5. táblázat Különböző típusú architektúrák alkalmazása
| Építészet | Alkalmazás |
| Kétszintű vékony kliens | 1 Hagyományos rendszerek, amelyekben nem célszerű elkülöníteni az alkalmazás-végrehajtást és az adatkezelést. 2 Intenzív alkalmazások számítása kevés adatkezeléssel. 3 Alkalmazások nagy mennyiségű adattal, de kevés számítással. |
| Kétrétegű vastag kliens | 1 Olyan alkalmazások, ahol a felhasználó intenzív adatfeldolgozást, azaz adatvizualizációt igényel. 2 Alkalmazások viszonylag állandó felhasználói funkciókkal, jól menedzselt rendszerkörnyezetben alkalmazva. |
| Háromszintű szerver-kliens | 1 Nagy alkalmazások cellákkal és több ezer klienssel 2 Olyan alkalmazások, amelyekben mind az adatok, mind a feldolgozási módszerek gyakran változnak. 3 Alkalmazások, amelyek több forrásból származó adatokat integrálnak. |
Ez a modell sokféle alkalmazáshoz alkalmas, de korlátozza az IS fejlesztők körét, akiknek el kell dönteniük, hol nyújtanak szolgáltatást, támogatniuk kell a skálázhatóságot, és eszközöket kell kifejleszteniük az új ügyfelek összekapcsolásához.
III.03.2. d Elosztott objektum architektúra.
Általánosabb megközelítést biztosít az elosztott objektum architektúra, amelynek fő összetevői az objektumok. Interfészeiken keresztül egy sor szolgáltatást nyújtanak. Más objektumok kéréseket küldenek anélkül, hogy különbséget tennének az ügyfél és a szerver között. Az objektumok a hálózat különböző számítógépein helyezkedhetnek el, és köztes szoftveren keresztül léphetnek kapcsolatba egymással, hasonlóan a rendszerbuszhoz, amely lehetővé teszi különböző eszközök csatlakoztatását és a hardvereszközök közötti kommunikáció fenntartását.
| … |
| ODBC illesztőprogram-kezelő |
| sofőr 1 |
| sofőr K |
| DB 1 |
| DB K |
| Munka SQL-el |
| … |
Az ODBC architektúra a következő összetevőket tartalmazza:
1. Jelentkezés (pl. IS). Feladatokat hajt végre: csatlakozást kér az adatforráshoz, SQL lekérdezéseket küld az adatforráshoz, leírja az SQL lekérdezések tárolási területét és formátumát, kezeli a hibákat és értesíti azokról a felhasználót, végrehajtja vagy visszagörgeti a tranzakciókat, kapcsolatot kér a adatforrás.
2. Eszközkezelő. Az alkalmazások igénye szerint betölti az illesztőprogramokat, egyetlen interfészt kínál az összes alkalmazáshoz, és az ODBC adminisztrátori felület ugyanaz, függetlenül attól, hogy az alkalmazás melyik DBMS-sel fog kommunikálni. A Microsoft által biztosított Driver Manager egy dinamikus betöltésű könyvtár (DLL).
3. Az illesztőprogram a DBMS-től függ. Az ODBC-illesztőprogram egy dinamikus hivatkozási könyvtár (DLL), amely ODBC-funkciókat valósít meg, és kölcsönhatásba lép egy adatforrással. Az illesztőprogram egy olyan program, amely egy DBMS-re jellemző funkcióra vonatkozó kérést dolgoz fel (a DBMS-nek megfelelően módosíthatja a kéréseket), és az eredményt visszaküldi az alkalmazásnak. Minden ODBC technológiát támogató DBMS-nek biztosítania kell az alkalmazásfejlesztők számára az adott DBMS-hez illesztőprogramot.
4. Az adatforrás tartalmazza a felhasználó által megadott vezérlő információkat, információkat az adatforrásról, és egy adott DBMS elérésére szolgál. Ebben az esetben az operációs rendszer és a hálózati platform eszközeit használják.
Dinamikus modell
Ez a modell sok szempontot feltételez, amelyekre az UML-ben legalább 5 diagramot használnak, lásd pp. 2.04.2- 2.04.5.
Vegye figyelembe a menedzsment szempontját. Az irányítási modell kiegészíti a strukturális modelleket.
Bárhogyan is írjuk le a rendszer felépítését, az szerkezeti egységek (funkciók vagy objektumok) halmazából áll. Ahhoz, hogy összességében működjenek, vezérelni kell őket, és a statikus diagramokon nincs vezérlő információ. A szabályozási modellek a rendszerek közötti vezérlési áramlást tervezik.
A szoftverrendszerekben a vezérlésnek két fő típusa van.
1. Központosított irányítás.
2. Esemény alapú menedzsment.
A központosított irányítás lehet:
· Hierarchikus- a "hívás-visszaküldés" elve alapján (az oktatási programok leggyakrabban így működnek)
· Diszpécser modell amelyet párhuzamos rendszerekre használnak.
V diszpécser modellek feltételezzük, hogy a rendszer egyik összetevője egy diszpécser. Felügyeli mind a rendszerek indítását és leállítását, mind a rendszer többi folyamatának koordinálását. A folyamatok párhuzamosan futhatnak egymással. A folyamat egy jelenleg futó programra, alrendszerre vagy eljárásra utal. Ez a modell szekvenciális rendszerekben is alkalmazható, ahol a vezérlőprogram egyes állapotváltozók függvényében (az operátoron keresztül) egyedi alrendszereket hív meg ügy).
Rendezvényszervezés feltételezi a menedzsmentért felelős szubrutin hiányát. A vezérlést külső események hajtják végre: egérgomb megnyomása, billentyűzet lenyomása, érzékelők leolvasásának módosítása, időzítő leolvasásának módosítása stb. Minden külső esemény kódolva van, és az eseménysorba kerül. Ha a sorban lévő eseményre adott reakció, akkor az eljárás (szubrutin) meghívásra kerül, amely erre az eseményre reagál. Az események, amelyekre a rendszer reagál, előfordulhatnak más alrendszerekben vagy a rendszer külső környezetében.
Az ilyen kezelésre példa az alkalmazások Windows rendszerben való szervezése.
A korábban leírt szerkezeti modellek mindegyike megvalósítható központosított vagy eseményalapú menedzsmenttel.
Felhasználói felület
Az interfészmodell kialakításánál nem csak a tervezett szoftver feladatait kell figyelembe venni, hanem az agy információérzékeléssel összefüggő sajátosságait is.
III.03.4. a Az információ észlelésével és feldolgozásával kapcsolatos pszichofizikai jellemzők.
Az agynak az a része, amelyet hagyományosan az észlelés feldolgozójának nevezhetünk, folyamatosan, a tudat részvétele nélkül feldolgozza a beérkező információkat, összehasonlítja a múltbeli tapasztalatokkal és raktárba helyezi.
Amikor egy vizuális kép felkelti a figyelmünket, akkor a minket érdeklő információ a rövid távú memóriába érkezik. Ha figyelmünket nem keltettük fel, akkor a tárolóban lévő információk eltűnnek, helyükre a következő részek lépnek.
A figyelem fókusza minden pillanatban egy ponton rögzíthető, így ha több helyzet egyidejű követése válik szükségessé, akkor a fókusz egyik követett tárgyról a másikra kerül. Ugyanakkor a figyelem szétszóródik, és néhány részlet figyelmen kívül maradhat. Az is lényeges, hogy az észlelés nagyrészt a motiváción alapul.
Amikor megváltoztatja a keretet, az agy egy ideig blokkolva van: új képet készít, kiemelve a legjelentősebb részleteket. Ez azt jelenti, hogy ha gyors válaszra van szüksége a felhasználótól, akkor ne változtassa meg hirtelen a képeket.
A rövid távú memória a szűk keresztmetszet az ember információfeldolgozó rendszerében. Kapacitása 7 ± 2 nem összekapcsolt objektum. A nem igényelt információkat legfeljebb 30 másodpercig tárolják benne. Annak érdekében, hogy a számunkra fontos információkat ne felejtsük el, általában magunknak ismételjük, frissítve az információkat a rövid távú memóriában. Így az interfészek tervezésénél figyelembe kell venni, hogy a túlnyomó többség nehezen tudja például megjegyezni és más képernyőn öt számjegynél többet tartalmazó számokat bevinni.
Bár a hosszú távú memória kapacitása és tárolási ideje korlátlan, az információkhoz való hozzáférés nem egyszerű. A hosszú távú memóriából való információ kinyerésének mechanizmusa asszociatív jellegű. Az információk memorizálásának javítása érdekében a memória már tárolt adatokhoz kötődik, és megkönnyíti a megszerzését. Mivel a hosszú távú memóriához való hozzáférés nehézkes, célszerű elvárni, hogy a felhasználó ne az információra emlékezzen, hanem arra, hogy felismerje azt.
III.03.4. b Az interfészek értékelésének alapvető kritériumai
A vezető szoftverfejlesztő cégek által végzett számos felmérés és felmérés kimutatta, hogy a felhasználók értékelik a felületet:
1) könnyű elsajátítás és memorizálás - konkrétan becsülje meg a mastering idejét, valamint az információ és a memória megőrzésének időtartamát;
2) az eredmények elérésének sebessége a rendszer használata során, amelyet az egérrel bevitt vagy kiválasztott parancsok és beállítások száma határoz meg;
3) szubjektív elégedettség a rendszer működésével (könnyű használhatóság, fáradtság stb.).
Sőt, azon professzionális felhasználók számára, akik folyamatosan ugyanazzal a csomaggal dolgoznak, a második és a harmadik kritérium gyorsan az első helyre kerül, és a nem professzionális felhasználók számára, akik rendszeresen dolgoznak szoftverekkel és viszonylag egyszerű feladatokat hajtanak végre - az első és a harmadik.
Ebből a szempontból ma a professzionális felhasználók számára a legjobb jellemzők az ingyenes navigációval rendelkező felületek, a nem professzionális felhasználók számára pedig a közvetlen manipulációs felületek. Régóta megfigyelhető, hogy a fájlmásolási műveletek végrehajtása során, ha minden más dolog nem változik, a legtöbb szakember olyan shell-eket használ, mint a Far, míg a nem profik a Windows "húzással".
III.03.4. c Felhasználói felületek típusai
A következő típusú felhasználói felületek különböztethetők meg:
Primitív
Ingyenes navigáció
Közvetlen manipuláció.
A felület primitív
Primitív az interfész, amely a felhasználóval való interakciót szervezi, és konzol módban használatos. Az adatok által biztosított szekvenciális folyamattól való egyetlen eltérés a több adathalmazon való hurokolás.
Menü felület.
A primitív felülettel ellentétben ez lehetővé teszi a felhasználó számára, hogy a program által megjelenített speciális listából válasszon ki egy műveletet. Ezek az interfészek számos munkaforgatókönyv megvalósítását feltételezik, amelyekben a műveletek sorrendjét a felhasználók határozzák meg. Az étlap faszerű felépítése azt sugallja, hogy a kétszintnél több menüben nehéz megtalálni az elemet.
A vállalati szintű információfeldolgozó rendszer létrehozásának elvei
A számítástechnika (és ennek megfelelően a szoftverek) fejlődésének története különálló, autonóm rendszerekkel kezdődött. A tudósokat és mérnököket az első számítógépek megalkotása foglalkoztatta, és főleg azon törték a fejüket, hogyan lehet működésre bírni ezeket a vákuumcsövek rajokat. Ez az állapot azonban nem tartott sokáig - a számítási teljesítmény kombinálásának ötlete teljesen nyilvánvaló volt, és ott volt a levegőben, telítve az első ENIAK-ok és Marks fémszekrényeinek zümmögésével. Végül is a felszínen rejlik az ötlet, hogy két vagy több számítógép erőfeszítéseit kombinálják összetett, elviselhetetlen feladatok mindegyikének külön-külön történő megoldására.
Rizs. 1. Az elosztott számítástechnika sémája
A számítógépek klaszterekbe és hálózatokba történő összekapcsolásának gondolatának gyakorlati megvalósítását azonban hátráltatta a műszaki megoldások hiánya, és mindenekelőtt a szabványok és kommunikációs protokollok létrehozásának szükségessége. Mint ismeretes, az első számítógépek a huszadik század negyvenes éveiben jelentek meg, az első számítógépes hálózat, az ARPANet, amely több számítógépet is összekapcsolt az Egyesült Államokban, csak 1966-ban, csaknem húsz évvel később. Természetesen a modern elosztott architektúra számítási képességeinek ilyen kombinációja nagyon homályosan hasonlított, de ennek ellenére ez volt az első lépés a helyes irányba.
A helyi hálózatok idővel történő megjelenése a szoftverfejlesztés új területének kifejlesztéséhez vezetett - az elosztott alkalmazások létrehozásához. Ezt, ahogy mondani szokás, a nulláról kellett megtenni, de szerencsére a nagy cégek, amelyek üzleti felépítése ilyen megoldásokat igényelt, azonnal érdeklődést mutattak az ilyen alkalmazások iránt. A vállalati elosztott alkalmazások létrehozásának szakaszában alakították ki az alapvető követelményeket, és fejlesztették ki az ilyen rendszerek fő architektúráit, amelyeket ma is használnak.
Fokozatosan a mainframe-ek és a terminálok a kliens-szerver architektúra felé fejlődtek, amely lényegében az elosztott architektúra, azaz egy kétszintű elosztott rendszer első változata volt. Valójában a kliens-szerver alkalmazásokban került át a számítási műveletek és az üzleti logika egy része a kliens oldalára, ami tulajdonképpen ennek a megközelítésnek a fénypontja, ismertetőjele lett.
Ebben az időszakban vált nyilvánvalóvá, hogy az elosztott alkalmazások fő előnyei a következők:
· Jó skálázhatóság – szükség esetén egy elosztott alkalmazás számítási teljesítménye könnyen növelhető anélkül, hogy a szerkezetét megváltoztatnánk;
· A terhelés kezelésének képessége – az elosztott alkalmazások köztes szintjei lehetővé teszik a felhasználói kérések áramlásának kezelését és feldolgozás céljából kevésbé terhelt szerverekre irányítását;
· Globalitás – az elosztott struktúra lehetővé teszi az üzleti folyamatok térbeli eloszlásának nyomon követését és ügyfélmunkaállomások létrehozását a legkényelmesebb pontokon.
Az idő előrehaladtával az egyetemi, kormányzati és vállalati hálózatok kis szigetei bővültek, egyesültek regionális és nemzeti rendszerekbe. És ekkor megjelent a színen a főszereplő - az internet.
A világhálóról szóló dicsérő laudáció már régóta gyakori helye a számítógépes témájú publikációknak. Valójában az internet kulcsszerepet játszott az elosztott számítástechnika fejlesztésében, és a szoftverfejlesztésnek ezt a meglehetősen specifikus területét professzionális programozók hadának fókuszába helyezte. Ma már jelentősen kibővíti az elosztott alkalmazások használatát, lehetővé téve a távoli felhasználók csatlakozását, és mindenhol elérhetővé teszi az alkalmazásfunkciókat.
Ez a probléma története. Most pedig nézzük meg, melyek azok az elosztott alkalmazások.
Elosztott számítástechnikai paradigma
Képzeljünk el egy meglehetősen nagy gyártóüzemet, kereskedelmi céget vagy szolgáltatót. Minden részlegük rendelkezik már saját adatbázissal és speciális szoftverrel. A központi iroda valamilyen módon információkat gyűjt ezen osztályok aktuális tevékenységéről, és olyan információkkal látja el a vezetőket, amelyek alapján vezetői döntéseket hoznak.
Menjünk tovább, és tegyük fel, hogy az általunk vizsgált szervezet sikeresen fejlődik, fiókokat nyit, új típusú termékeket vagy szolgáltatásokat fejleszt. Sőt, a legutóbbi találkozón a haladó gondolkodású vezetők úgy döntöttek, hogy megszervezik a távoli munkaállomások hálózatát, ahonnan az ügyfelek tájékoztatást kaphatnak megrendeléseik teljesítéséről.
A leírt helyzetben már csak az informatikai osztály vezetőjét kell sajnálni, ha nem gondoskodott előzetesen egy általános üzleti folyamatirányítási rendszer kiépítéséről, mert enélkül nagyon nehéz lesz biztosítani a szervezet hatékony fejlesztését. Sőt, nem nélkülözhető az egész vállalatra kiterjedő, a növekvő terhelés figyelembevételével kialakított, ráadásul a fő üzleti folyamatoknak megfelelő információfeldolgozó rendszer, hiszen minden részlegnek nemcsak a feladatait kell ellátnia, hanem szükség esetén a kéréseket is feldolgoznia. más részlegektől, sőt (projektmenedzser rémálma!) ügyfelektől is.
Így készen állunk arra, hogy megfogalmazzuk azokat az alapvető követelményeket, amelyeket a gyártási folyamat szervezése diktál a modern vállalati szintű alkalmazásokhoz.
Térbeli elválasztás. A szervezet részlegei térben szétszórtan helyezkednek el, és gyakran rosszul egységes szoftverrel rendelkeznek.
Strukturális megfelelőség. A szoftvernek megfelelően tükröznie kell a vállalat információs szerkezetét - meg kell felelnie a fő adatfolyamoknak.
Tájékozódás a külső információkhoz. A modern vállalkozások kénytelenek fokozott figyelmet fordítani az ügyfelekkel való együttműködésre. Ezért a vállalati szoftvereknek képesnek kell lenniük az új típusú felhasználókkal és azok igényeivel való együttműködésre. Az ilyen felhasználók tudatosan korlátozott jogokkal rendelkeznek, és szigorúan meghatározott típusú adatokhoz férnek hozzá.
A vállalati szintű szoftverekkel szemben támasztott összes fenti követelménynek eleget tesznek az elosztott rendszerek – a számítási elosztási sémát az ábra mutatja. 1.
Természetesen az elosztott alkalmazások nem mentesek a hibáktól. Egyrészt költséges a működtetésük, másrészt az ilyen alkalmazások létrehozása fáradságos és összetett folyamat, és a tervezési szakaszban bekövetkező hiba költsége nagyon magas. Ennek ellenére az elosztott alkalmazások fejlesztése jól halad – a játék megéri a gyertyát, mert az ilyen szoftverek hozzájárulnak a szervezet hatékonyságának javításához.
Tehát az elosztott számítástechnika paradigmája magában foglalja több központ (szerver) jelenlétét az információk tárolására és feldolgozására, különböző funkciók megvalósítására, és egymástól távol. Ezeknek a központoknak a rendszer klienseinek kérésein túl egymás kéréseit is teljesíteniük kell, hiszen esetenként az első feladat megoldása több szerver közös erőfeszítését is igényelheti. Az összetett kérések kezeléséhez és a rendszer egészének működéséhez speciális vezérlő szoftverre van szükség. És végül az egész rendszert "el kell meríteni" valamilyen közlekedési környezetbe, amely biztosítja részeinek kölcsönhatását.
Az elosztott számítástechnikai rendszerek olyan közös tulajdonságokkal rendelkeznek, mint:
· Kezelhetőség – a rendszer azon képességét jelenti, hogy hatékonyan tudja irányítani az összetevőit. Ez vezérlőszoftver használatával érhető el;
· Teljesítmény - a rendszer szervereinek terhelésének a vezérlőszoftver segítségével történő újraelosztásának lehetősége miatt;
Skálázhatóság - ha szükséges a termelékenység fizikai növelése, egy elosztott rendszer könnyen integrálhat új számítási erőforrásokat a szállítási környezetébe;
· Bővíthetőség – az elosztott alkalmazásokhoz új komponensek (szerverszoftver) új funkciókkal egészíthetők ki.
Az elosztott alkalmazásokban lévő adatokhoz kliensszoftverről lehet hozzáférni, más elosztott rendszerek pedig különböző szinteken szervezhetők – a kliensszoftvertől és a szállítási protokolloktól az adatbázis-kiszolgálók védelméig.

Rizs. 2. Az elosztott alkalmazás architektúrájának főbb szintjei
Az elosztott rendszerek felsorolt tulajdonságai elegendő okot adnak arra, hogy megtűrjük fejlesztésük bonyolultságát és magas karbantartási költségét.
Elosztott alkalmazás architektúra
Tekintsük egy elosztott alkalmazás architektúráját, amely lehetővé teszi összetett és változatos funkciók végrehajtását. A különböző források különböző lehetőségeket kínálnak az elosztott alkalmazások létrehozására. És mindegyiknek létjogosultsága van, mert az ilyen alkalmazások számos témakörben a legszélesebb körű problémákat oldják meg, és a fejlesztő eszközök és technológiák visszatarthatatlan fejlődése folyamatos fejlesztést sürget.
Ennek ellenére létezik egy elosztott alkalmazás legáltalánosabb architektúrája, amely szerint több logikai rétegre, adatfeldolgozási rétegre oszlik. Az alkalmazások, mint tudják, információk feldolgozására szolgálnak, és itt három fő funkciójukat különböztethetjük meg:
· Adatok bemutatása (felhasználói szint). Itt az alkalmazás felhasználói megtekinthetik a szükséges adatokat, végrehajtási kérelmet küldhetnek, új adatokat vihetnek be a rendszerbe vagy szerkeszthetik azokat;
· Adatfeldolgozás (középszintű, middleware). Ezen a szinten koncentrálódik az alkalmazás üzleti logikája, az adatfolyamok vezérlése és az alkalmazásrészek interakciója szerveződik. Az elosztott alkalmazások fő előnyének az összes adatfeldolgozási és vezérlési funkció egy szinten való koncentrálását tekintik;
· Adattárolás (adatréteg). Ez az adatbázis-kiszolgáló szintje. Itt találhatóak maguk a szerverek, adatbázisok, adatelérési eszközök és különféle segédeszközök.
Ezt az architektúrát gyakran három- vagy háromrétegű architektúrának nevezik. És nagyon gyakran ez a "három bálna" alapján jön létre a kifejlesztett alkalmazás szerkezete. Mindig meg kell jegyezni, hogy minden szint további alszintre osztható. Például a felhasználói szint lebontható a tényleges felhasználói felületre és a bemeneti adatok érvényesítésének és feldolgozásának szabályaira.
Természetesen, ha figyelembe vesszük az alszintekre bontás lehetőségét, akkor bármilyen elosztott alkalmazás bekerülhet a háromrétegű architektúrába. De itt nem lehet figyelmen kívül hagyni az elosztott alkalmazásokban rejlő másik jellemző tulajdonságot - ez az adatkezelés. Ennek a funkciónak a jelentősége nyilvánvaló, mert nagyon nehéz olyan valós elosztott alkalmazást létrehozni (minden kliens állomással, köztes szoftverrel, adatbázis-kiszolgálóval stb.), amely nem kezeli a kéréseit és válaszait. Ezért egy elosztott alkalmazásnak rendelkeznie kell egy másik logikai réteggel - az adatkezelési réteggel.

Rizs. 3. Az üzleti logika elosztása az elosztott alkalmazások szintjei között
Ezért célszerű a középső szintet két független szintre osztani: az adatfeldolgozási szintre (mivel figyelembe kell venni azt a fontos előnyt, amit ez jelent - az adatkezelésre vonatkozó üzleti szabályok koncentrációját) és az adatkezelési szintre. Ez utóbbi biztosítja a kérések végrehajtásának vezérlését, az adatfolyamokkal végzett munkát és a rendszer részeinek interakcióját szervezi.
Így az elosztott architektúrának négy fő rétege van (lásd 2. ábra):
· Adatok bemutatása (felhasználói szint);
· Üzleti logikai szabályok (adatfeldolgozási réteg);
· Adatkezelés (adatkezelési réteg);
· Adattárolás (adattároló réteg).
A négy szint közül három, az első kivételével, közvetlenül részt vesz az adatfeldolgozásban, és az adatmegjelenítési réteg lehetővé teszi ezek megjelenítését és szerkesztését. Ennek a rétegnek a segítségével a felhasználók adatokat kapnak az adatfeldolgozó rétegtől, amely viszont lekéri az információkat a tárolókból, és elvégzi az összes szükséges adatátalakítást. Az új információk bevitele vagy a meglévő adatok szerkesztése után az adatfolyamok visszafelé irányulnak: a felhasználói felületről az üzleti szabályok rétegén keresztül a tárolóba.
Egy másik réteg - az adatkezelés - kívül esik az adatgerinctől, de ez biztosítja a teljes rendszer zavartalan működését, a kérések és válaszok kezelését, valamint az alkalmazás egyes részeinek interakcióját.
Külön meg kell fontolni az adatok "csak olvasható" módban történő megtekintésének lehetőségét. Ebben az esetben az adatfeldolgozó réteg nem kerül felhasználásra az általános adatátviteli sémában, mivel nincs szükség változtatásra. Maga az információáramlás pedig egyirányú – a tárolástól az adatmegjelenítés szintjéig.
Elosztott alkalmazások fizikai felépítése
Most térjünk át az elosztott alkalmazások fizikai rétegeire. Az elosztott rendszer topológiája magában foglalja a felosztást több adatbázis-kiszolgálóra, adatfeldolgozó szerverre, valamint helyi és távoli kliensek gyűjteményére. Mindegyik bárhol elhelyezhető: ugyanabban az épületben vagy egy másik kontinensen. Mindenesetre az elosztott rendszer részeit megbízható és biztonságos kommunikációs vonalakkal kell összekötni. Ami az adatátviteli sebességet illeti, az nagyban függ a rendszer két része közötti kapcsolat fontosságától az adatfeldolgozás és -továbbítás szempontjából, illetve kisebb mértékben a távolságuktól.
Az üzleti logika elosztása az elosztott alkalmazási szintek között
Itt az ideje, hogy áttérjünk az elosztott rendszer szintjeinek részletes leírására, de először ejtsünk néhány szót az alkalmazási funkciók szintek közötti elosztásáról. Az üzleti logika a háromszintű architektúra bármelyik szintjén megvalósítható.
Az adatbázis-szerverek nemcsak adatbázisokban tárolhatnak adatokat, hanem az alkalmazás üzleti logikájának egy részét is tartalmazhatják a tárolt eljárásokban, triggerekben stb.
Az ügyfélalkalmazások adatfeldolgozási szabályokat is megvalósíthatnak. Ha a szabályrendszer minimális és főként az adatbevitel helyességének ellenőrzésére irányul, akkor "vékony" kliensről van szó. Ezzel szemben egy vastag kliens az alkalmazás funkcióinak nagy részét tartalmazza.
Az adatfeldolgozás szintje tulajdonképpen az alkalmazás üzleti logikáját hivatott megvalósítani, itt összpontosul az adatkezelés minden alapvető szabálya.
Így általános esetben az alkalmazás funkcionalitása "elkenődik" az egész alkalmazásban. Az üzleti logika alkalmazási szintek közötti eloszlásának sokfélesége sima görbeként ábrázolható, amely megmutatja az adatfeldolgozási szabályok egy adott helyen koncentrált arányát. ábra görbéi. 3 minőségi jellegűek, de ennek ellenére lehetővé teszik, hogy megnézze, hogy az alkalmazás szerkezetében bekövetkezett változások hogyan befolyásolhatják a szabályok elosztását.
A gyakorlat pedig megerősíti ezt a következtetést. Hiszen az adatbázis-szerver tárolt eljárásaiban mindig lesz egy-két szabály, amit végre kell hajtani, és nagyon gyakran célszerű néhány kezdeti műveletet adatokkal átvinni a kliens oldalra - legalábbis azért, hogy elkerüljük a hibás kérések feldolgozása.
Bemutató réteg
Az adatmegjelenítési réteg az egyetlen, amely elérhető a végfelhasználó számára. Ez a réteg szimulálja egy elosztott alkalmazás kliens munkaállomásait és a megfelelő szoftvert. A kliens munkaállomás képességeit elsősorban az operációs rendszer képességei határozzák meg. A felhasználói felület típusától függően az ügyfélszoftverek két csoportra oszthatók: grafikus felhasználói felületet használó kliensekre (például Windows) és webes kliensekre. De minden esetben az ügyfélalkalmazásnak biztosítania kell a következő funkciókat:
· Adatok fogadása;
· Adatok megjelenítése a felhasználó számára;
· Adatszerkesztés;
· A bevitt adatok helyességének ellenőrzése;
· A végrehajtott változtatások mentése;
· Kivételek kezelése és a hibákkal kapcsolatos információk megjelenítése a felhasználó számára.
Kívánatos az összes üzleti szabályt az adatfeldolgozás szintjén koncentrálni, de a gyakorlatban ez nem mindig lehetséges. Aztán kétféle kliens szoftverről beszélnek. A vékony kliens minimális üzleti szabályokat tartalmaz, míg a vastag kliens az alkalmazáslogika jelentős részét valósítja meg. Az első esetben az elosztott alkalmazás sokkal könnyebben hibakereshető, modernizálható és bővíthető, a másodikban pedig minimalizálható az adatkezelési réteg létrehozásának és karbantartásának költségei, hiszen a műveletek egy része a kliens oldalon is elvégezhető, ill. csak az adatátvitel esik a köztes szoftverre.
Adatfeldolgozási réteg
Az adatfeldolgozó réteg egyesíti az alkalmazás üzleti logikáját megvalósító részeket, és közvetítő a megjelenítési réteg és a tárolóréteg között. Minden adat áthalad rajta, és a probléma megoldása miatt megváltozik benne (lásd a 2. ábrát). Ennek a szintnek a funkciói a következők:
· Adatfolyamok feldolgozása az üzleti szabályoknak megfelelően;
· Interakció az adatmegjelenítési réteggel a kérések fogadása és a válaszok visszaküldése érdekében;
· Interakció az adattároló réteggel kérések küldéséhez és válaszok fogadásához.
Leggyakrabban az adatfeldolgozási réteget egy elosztott alkalmazás köztes szoftverével azonosítják. Ez a helyzet teljesen igaz egy "ideális" rendszerre, és csak részben igaz a valós alkalmazásokra (lásd 3. ábra). Utóbbiakat illetően a hozzájuk tartozó köztes szoftverek nagy arányban tartalmaznak adatfeldolgozási szabályokat, de ezek egy része SQL szervereken van implementálva tárolt eljárások vagy triggerek formájában, és van, amelyik a kliensszoftverben is megtalálható.
Az üzleti logika ilyen „összemosása” indokolt, mivel lehetővé teszi az adatfeldolgozási eljárások egy részének egyszerűsítését. Vegyünk egy klasszikus példát a rendelési utasításra. Csak a raktáron lévő termékek nevét tartalmazhatja. Ezért egy adott cikk rendeléshez történő hozzáadásakor és mennyiségének meghatározásakor a megfelelő számot le kell vonni a raktárban lévő cikk maradékából. Nyilvánvaló, hogy ennek a logikának a megvalósításának legjobb módja a DB-kiszolgáló – akár egy tárolt eljárás, akár egy trigger.
Adatkezelési réteg
Az adatkezelési rétegre azért van szükség, hogy az alkalmazás koherens, rugalmas és megbízható maradjon, valamint modernizálható és méretezhető legyen. Biztosítja a rendszerfeladatok végrehajtását, enélkül az alkalmazás egyes részei (adatbázis szerverek, alkalmazásszerverek, middleware, kliensek) nem tudnak egymással kommunikálni, a terhelésnövekedés során megszakadt kapcsolatokat nem lehet helyreállítani.
Emellett az alkalmazás különféle rendszerszolgáltatásai is megvalósíthatók adatkezelési szinten. Hiszen mindig vannak a teljes alkalmazásban közös funkciók, amelyek az alkalmazás minden szintjének működéséhez szükségesek, ezért nem helyezhetők el a többi szinten.
Például egy időbélyegző szolgáltatás az alkalmazás minden részét rendszeridőbélyegekkel látja el, amelyek szinkronban tartják azokat. Képzelje el, hogy egy elosztott alkalmazásnak van egy kiszolgálója, amely meghatározott határidővel küldi el az ügyfeleknek a feladatokat. A határidő elmulasztása esetén a feladatot a késleltetési idő számításával kell rögzíteni. Ha a kliens munkaállomások a szerverrel egy épületben vagy egy szomszédos utcában helyezkednek el, akkor nincs probléma, a könyvelési algoritmus egyszerű. De mi van akkor, ha az ügyfelek különböző időzónákban találhatók – más országokban vagy akár a tengerentúlon? Ebben az esetben a szervernek tudnia kell a különbséget az időzónák figyelembevételével kiszámítani a feladatok küldésekor és a válaszok fogadásakor, az ügyfeleknek pedig a helyi időre és időzónára vonatkozó szolgáltatási információkat kell hozzáadniuk a jelentésekhez. Ha egy elosztott alkalmazás egyetlen egyszeri szolgáltatást tartalmaz, akkor ez a probléma egyszerűen nem létezik.
Az adatkezelési szint az egyszeri szolgáltatáson túl általános információk tárolására (az alkalmazás egészére vonatkozó információk), általános jelentések készítésére stb.
Tehát az adatkezelési réteg funkciói a következők:
· Elosztott alkalmazás részeinek kezelése;
· Az alkalmazás részei közötti kapcsolatok és kommunikációs csatornák kezelése;
· Az ügyfelek és szerverek közötti, valamint a szerverek közötti adatáramlás szabályozása;
· Terhelésvezérlés;
· Az alkalmazás rendszerszolgáltatásainak megvalósítása.
Megjegyzendő, hogy az adatkezelési réteget gyakran a különböző gyártók által a szoftverpiacra szállított kész megoldások alapján hozzák létre. Ha a fejlesztők a CORBA architektúrát választották az alkalmazásukhoz, akkor ez tartalmaz egy Object Request Broker-t (ORB), ha a platform Windows, akkor sokféle eszköz áll szolgálatukban: COM + technológia (Microsoft Transaction Server technológia fejlesztése, MTS), feldolgozási technológia MSMQ üzenetsorok, Microsoft BizTalk technológia stb.
Adattároló réteg
A tárolási réteg egyesíti az alkalmazás által használt SQL-kiszolgálókat és adatbázisokat. A következő feladatokra nyújt megoldást:
· Adatok tárolása adatbázisban és működőképes állapotban tartása;
· Adatfeldolgozási szintű kérelmek feldolgozása és eredményvisszaadás;
· Elosztott alkalmazás üzleti logikájának egy részének megvalósítása;
· Elosztott adatbázisok kezelése adatbázis-kiszolgálók adminisztrációs eszközeivel.
A nyilvánvaló funkciókon – adatok tárolásán és lekérdezések feldolgozásán – túlmenően egy réteg tartalmazhatja az alkalmazás üzleti logikájának egy részét tárolt eljárásokban, triggerekben, megszorításokban stb. És maga az alkalmazás adatbázisának szerkezete (táblák és mezőik, indexek, idegen kulcsok stb.) ) van egy olyan adatstruktúra implementációja, amellyel az elosztott alkalmazás működik, valamint néhány üzleti logikai szabály megvalósítása. Például egy idegen kulcs használata egy adatbázistáblában megköveteli az adatkezelés megfelelő korlátozását, mivel a főtábla rekordjai nem törölhetők, ha vannak megfelelő rekordok, amelyeket a tábla idegen kulcsa kapcsol össze.
A legtöbb adatbázis-kiszolgáló számos adminisztrációs eljárást támogat, beleértve az elosztott adatbázis-kezelést. Ide tartozik az adatreplikáció, a távoli archiválás, a távoli adatbázisok elérésére szolgáló eszközök stb. A saját elosztott alkalmazás szerkezetének kialakításakor figyelembe kell venni ezen eszközök használatának lehetőségét.
Az SQL Server adatbázisokhoz való csatlakozás elsősorban a szerver kliens szoftverrel történik. Ezenkívül különféle adatelérési technológiák is használhatók, például az ADO (ActiveX Data Objects) vagy az ADO.NET. De a rendszer tervezésénél figyelembe kell venni, hogy a funkcionálisan köztes adatelérési technológiák nem tartoznak az adattárolási szinthez.
Alapszintű bővítmények
Az elosztott alkalmazásarchitektúra fenti szintjei alapvetőek. Ezek alkotják az elkészült alkalmazás egészének szerkezetét, ugyanakkor természetesen egyetlen pályázat megvalósítását sem tudják biztosítani - a tantárgyi területek és feladatok túlságosan kiterjedtek és szerteágazóak. Ilyen esetekben az elosztott alkalmazás architektúrája kibővíthető további rétegekkel, amelyek a létrehozandó alkalmazás jellemzőit tükrözik.
Többek között két leggyakrabban használt alapszintű bővítmény található.
Az üzleti felület réteg a felhasználói felület réteg és az adatfeldolgozó réteg között található. Elrejti a kliens alkalmazások elől az adatfeldolgozó réteg felépítésének és üzleti szabályainak megvalósításának részleteit, biztosítva az ügyfélalkalmazás kódjának absztrakcióját az alkalmazáslogika megvalósítási jellemzőitől.
Ennek eredményeként az ügyfélalkalmazások fejlesztői a szükséges funkciók bizonyos készletét használják - az alkalmazásprogramozási felület (API) analógját. Ez függetlenné teszi a kliens szoftvert az adatfeldolgozó réteg megvalósításától.
Természetesen a rendszer komoly változtatásainál nem nélkülözhetjük a globális változtatásokat, de az üzleti felület szintje lehetővé teszi, hogy ezt ne tegyük meg, hacsak nem feltétlenül szükséges.
Az adatelérési réteg az adattároló réteg és az adatfeldolgozó réteg között helyezkedik el. Lehetővé teszi, hogy az alkalmazás szerkezetét függetlenítse egy adott adattárolási technológiától. Ilyen esetekben az adatfeldolgozó réteg szoftverobjektumai a választott adatelérési technológia eszközeivel küldenek kéréseket és fogadnak válaszokat.
Az alkalmazások Windows platformon való implementálásakor leggyakrabban az ADO adatelérési technológiát használják, mivel ez univerzális módot biztosít az adatforrások széles skálájának elérésére - az SQL szerverektől a táblázatokig. A .NET platformon lévő alkalmazásokhoz az ADO.NET technológia használatos.
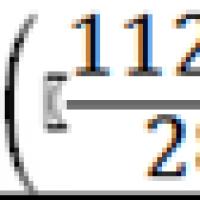 Az operatív kommunikációs rendszer stabilitási jellemzőinek számítása
Az operatív kommunikációs rendszer stabilitási jellemzőinek számítása PDF készítő szoftver
PDF készítő szoftver Diszkrét csatorna. Zavar a kommunikációs csatornákban
Diszkrét csatorna. Zavar a kommunikációs csatornákban A QoS használata az internet-hozzáférés minőségének biztosítására Hol van a qos csomagütemező
A QoS használata az internet-hozzáférés minőségének biztosítására Hol van a qos csomagütemező A Sendmail alapvető telepítése és konfigurálása az Ubuntu kiszolgálón
A Sendmail alapvető telepítése és konfigurálása az Ubuntu kiszolgálón Telepítse a VPN-t az Ubuntu Vpn ubuntu kapcsolatba
Telepítse a VPN-t az Ubuntu Vpn ubuntu kapcsolatba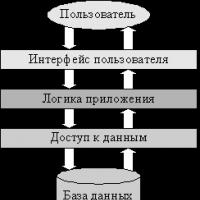 Elosztott rendszerarchitektúra, nagyszabású felhő IoT-platform
Elosztott rendszerarchitektúra, nagyszabású felhő IoT-platform