Supervisión integral profesional de las solicitudes de eco. Monitor de ping de EMCO. Asistente administrativo gratuito Quién lo necesita y por qué
Por la apariencia de esta óptica, atravesando el bosque hasta el colector, podemos concluir que el instalador no siguió un poco la tecnología. La montura de la foto también sugiere que probablemente sea un marinero, un nudo marino.
Estoy en el equipo de salud de la red física, es decir, el soporte técnico, que se encarga de que las luces de los routers parpadeen como deben. Tenemos bajo nuestro ala varias grandes empresas con infraestructura en todo el país. No nos metemos dentro de su negocio, nuestra tarea es asegurarnos de que la red funcione a nivel físico y el tráfico pase como debe.
El significado general del trabajo es el sondeo constante de los nodos, la eliminación de la telemetría, las ejecuciones de prueba (por ejemplo, verificar la configuración para encontrar vulnerabilidades), garantizar la salud, monitorear las aplicaciones, el tráfico. A veces inventarios y otras perversiones.
Te cuento como se organiza y un par de anécdotas de los viajes.
Como suele ser el caso
Nuestro equipo se sienta en una oficina en Moscú y toma telemetría de red. En realidad, estos son pings constantes de nodos, además de recibir datos de monitoreo si el hardware es inteligente. La situación más común es que el ping no pase varias veces seguidas. En el 80% de los casos para una cadena minorista, por ejemplo, esto resulta ser un corte de energía, por lo que, al ver esta imagen, hacemos lo siguiente:- Primero llamamos al proveedor sobre accidentes.
- Entonces - a la planta de energía sobre el cierre
- Luego tratamos de establecer una conexión con alguien en la instalación (esto no siempre es posible, por ejemplo, a las 2 am)
- Y, finalmente, si lo anterior no ayudó en 5-10 minutos, nos dejamos o enviamos un "avatar": un ingeniero contratado sentado en algún lugar de Izhevsk o Vladivostok, si el problema está ahí.
- Nos mantenemos en contacto constante con el "avatar" y lo "guiamos" a través de la infraestructura: tenemos sensores y manuales de servicio, él tiene alicates.
- Luego el ingeniero nos envía un informe con una foto de lo que fue.
El diálogo a veces es así:
- Entonces, la conexión se pierde entre los edificios número 4 y 5. Verifique el enrutador en el quinto.
- Pedido, incluido. No hay conexión.
- Ok, ve por el cable hasta el cuarto edificio, hay otro nodo.
-… ¡Opa!
- ¿Qué ha pasado?
- Aquí se demolió la cuarta casa.
- ¿¿Qué??
- Adjunto una foto al informe. No puedo restaurar la casa en SLA.

Pero más a menudo, todavía resulta encontrar un descanso y restaurar el canal.
Aproximadamente el 60% de los viajes están “en la leche”, porque o se interrumpe el suministro eléctrico (por una pala, capataz, intrusos), o el proveedor no sabe de su falla, o se elimina un problema coyuntural antes que el instalador. llega Sin embargo, hay ocasiones en las que nos enteramos del problema antes que los usuarios y antes que los servicios TI del cliente, y comunicamos la solución antes incluso de que se den cuenta de que algo ha pasado. En la mayoría de los casos, estas situaciones ocurren por la noche, cuando la actividad en las empresas de los clientes es baja.
Quién lo necesita y por qué
Como regla general, cualquier gran empresa tiene su propio departamento de TI, que comprende claramente los detalles y las tareas. En las empresas medianas y grandes, el trabajo de los "enikeevs" y los ingenieros de redes a menudo se subcontrata. Es simplemente beneficioso y conveniente. Por ejemplo, un minorista tiene su propia gente de TI muy interesante, pero están lejos de reemplazar los enrutadores y rastrear los cables.Que estamos haciendo
- Trabajamos en las solicitudes - entradas y llamadas de pánico.
- Hacemos prevención.
- Seguimos las recomendaciones de los proveedores de hardware, por ejemplo, en términos de mantenimiento.
- Nos conectamos al seguimiento del cliente y le quitamos datos para poder viajar en caso de incidencias.
La primera forma, comprobaciones simples, es simplemente una máquina que hace ping a todos los nodos de la red y se asegura de que respondan correctamente. Dicha implementación no requiere cambios en absoluto o cambios cosméticos mínimos en la red del cliente. Como regla general, en un caso muy simple, instalamos Zabbix directamente en uno de los centros de datos (afortunadamente, tenemos dos en la oficina de CROC en Volochaevskaya). En uno más complejo, por ejemplo, si usa su propia red segura, a una de las máquinas en el centro de datos del cliente:

Zabbix se puede usar de manera más complicada, por ejemplo, tiene agentes que se instalan en * nix y ganan nodos y muestran el monitoreo del sistema, así como el modo de verificación externa (con soporte para el protocolo SNMP). Sin embargo, si una empresa necesita algo similar, entonces ya tiene su propio monitoreo o se elige una solución funcionalmente más rica. Por supuesto, esto ya no es de código abierto y cuesta dinero, pero incluso un inventario preciso banal ya supera los costos en aproximadamente un tercio.
También hacemos esto, pero esta es la historia de los colegas. Aquí enviaron un par de capturas de pantalla de Infosim:


Soy operadora de avatares, así que les contaré más sobre mi trabajo.
¿Cómo es un incidente típico?
Ante nosotros hay pantallas con el siguiente estado general:
En este objeto, Zabbix recopila bastante información para nosotros: número de lote, número de serie, uso de CPU, descripción del dispositivo, disponibilidad de interfaces, etc. Toda la información necesaria está disponible desde esta interfaz.
Un incidente ordinario suele comenzar con el hecho de que uno de los canales que conducen, por ejemplo, a la tienda del cliente (de la que tiene 200-300 piezas en todo el país) se cae. El comercio minorista ahora está bien desarrollado, no como hace siete años, por lo que la taquilla seguirá funcionando: hay dos canales.
Cogemos los teléfonos y hacemos al menos tres llamadas: al proveedor, a la central y a la gente del lugar (“Sí, aquí cargamos herrajes, a alguien le tocaron el cable… Ah, ¿el tuyo? Bueno, qué bueno que lo encontramos").
Como regla general, sin monitoreo, pasarían horas o días antes de una escalada; no siempre se verifican los mismos canales de respaldo. Lo sabemos de inmediato y nos vamos de inmediato. Si hay información adicional además de los pings (por ejemplo, un modelo de una pieza de hierro del buggy), completamos de inmediato al ingeniero de campo con las piezas necesarias. Además ya en su lugar.
La segunda llamada habitual más frecuente es la avería de uno de los terminales de los usuarios, por ejemplo, un teléfono DECT o un router Wi-Fi que distribuía la red a la oficina. Aquí aprendemos sobre el problema del monitoreo y casi de inmediato recibimos una llamada con detalles. A veces la llamada no aporta nada nuevo ("Cojo el teléfono, algo no suena"), a veces es muy útil ("Se nos cae de la mesa"). Está claro que en el segundo caso esto claramente no es un salto de línea.
El equipo en Moscú se toma de nuestros almacenes de reserva caliente, tenemos varios tipos de ellos:

Los clientes suelen tener sus propias existencias de componentes que fallan con frecuencia: teléfonos de oficina, fuentes de alimentación, ventiladores, etc. Si necesita entregar algo que no está en su lugar, no a Moscú, generalmente vamos solos (porque la instalación). Por ejemplo, tuve un viaje nocturno a Nizhny Tagil.
Si el cliente tiene su propio seguimiento, puede subirnos datos. A veces implementamos Zabbix en modo de sondeo, solo para garantizar la transparencia y el control de SLA (esto también es gratuito para el cliente). No instalamos sensores adicionales (esto lo hacen colegas que aseguran la continuidad de los procesos de producción), pero podemos conectarnos a ellos si los protocolos no son exóticos.
En general, no tocamos la infraestructura del cliente, solo la apoyamos tal como está.
Por experiencia puedo decir que los últimos diez clientes cambiaron a soporte externo debido al hecho de que somos muy predecibles en términos de costos. Presupuesto claro, buen manejo de casos, reporte de cada solicitud, SLA, reportes de equipos, mantenimiento preventivo. Idealmente, por supuesto, somos para el CIO de un cliente como los limpiadores: venimos y lo hacemos, todo está limpio, no distraemos.
Otra cosa a destacar es que en algunas grandes empresas el inventario se convierte en un verdadero problema, y en ocasiones nos atrae puramente llevarlo a cabo. Además, hacemos el almacenamiento de configuraciones y su gestión, lo cual es conveniente para diferentes reubicaciones y reconexiones. Pero, nuevamente, en casos difíciles, este tampoco soy yo: tenemos un equipo especial que transporta centros de datos.
Y un punto más importante: nuestro departamento no se ocupa de la infraestructura crítica. Todo lo que se encuentra dentro de los centros de datos y todo lo relacionado con la banca, los seguros y el operador, además de los sistemas centrales minoristas: este es un equipo X. Aquí están los chicos.
Más práctica
Muchos dispositivos modernos pueden brindar mucha información de servicio. Por ejemplo, las impresoras de red son muy fáciles de controlar el nivel de tóner en el cartucho. Puede contar con el período de reemplazo por adelantado, además de recibir una notificación del 5-10% (si la oficina de repente comienza a escribir furiosamente fuera del horario estándar), e inmediatamente envíe un enikey antes de que el departamento de contabilidad comience a entrar en pánico.Muy a menudo, nos quitan las estadísticas anuales, lo que hace el mismo sistema de monitoreo más nosotros. En el caso de Zabbix, se trata de una simple planificación de costos y la comprensión de qué fue a dónde, y en el caso de Infosim, también es material para calcular la escala durante un año, cargar administradores y todo tipo de otras cosas. Hay consumo de energía en las estadísticas: en el último año, casi todos comenzaron a preguntarle, aparentemente para distribuir los costos internos entre los departamentos.
A veces se obtienen auténticos rescates heroicos. Tales situaciones son muy raras, pero por lo que recuerdo este año, vimos alrededor de las 3 am que la temperatura subió a 55 grados en el interruptor de Cisco. En la sala de servidores distante había acondicionadores de aire "estúpidos" sin monitoreo, y fallaron. Inmediatamente llamamos a un ingeniero de refrigeración (no el nuestro) y llamamos al administrador del cliente de turno. Apagó algunos servicios no críticos y evitó que la sala de servidores se apagara térmicamente hasta que llegó el tipo con un aire acondicionado móvil, y luego se arreglaron los regulares.
Polycom y otros equipos de videoconferencia costosos controlan muy bien el nivel de carga de la batería antes de las conferencias, lo que también es importante.
Todos necesitan monitoreo y diagnóstico. Como regla, es largo y difícil de implementar sin experiencia: los sistemas son extremadamente simples y preconfigurados, o del tamaño de un portaaviones y con un montón de informes estándar. Afilar con un archivo para la empresa, inventar la implementación de sus tareas para el departamento de TI interno y mostrar la información que más necesitan, además de mantener todo el historial actualizado es un rastrillo si no hay experiencia en implementación. Cuando trabajamos con sistemas de monitoreo, elegimos el medio dorado entre soluciones gratuitas y superiores; por regla general, no los proveedores más populares y "gruesos", pero claramente resuelven el problema.
Una vez hubo un tratamiento bastante atípico.. El cliente tuvo que entregar el enrutador a algunas de sus divisiones separadas, y exactamente de acuerdo con el inventario. El enrutador tenía un módulo con el número de serie especificado. Cuando el enrutador comenzó a prepararse para el camino, resultó que faltaba este módulo. Y nadie puede encontrarlo. El problema se agrava un poco por el hecho de que el ingeniero que trabajó en esta rama el año pasado ya está jubilado y se ha ido a vivir con sus nietos a otra ciudad. Nos contactaron y pidieron mirar. Afortunadamente, el hardware proporcionó informes sobre los números de serie e Infosim hizo un inventario, por lo que encontramos este módulo en la infraestructura en un par de minutos y describimos la topología. El fugitivo fue rastreado por cable: estaba en otra sala de servidores en un armario. La historia del movimiento mostró que llegó allí después del fracaso de un módulo similar.

Un fotograma de un largometraje sobre Hottabych, que describe con precisión la actitud de la población hacia las cámaras.
Muchos incidentes de cámara. Una vez 3 cámaras fallaron a la vez. Rotura de cable en uno de los tramos. El instalador sopló uno nuevo en la ondulación, dos de las tres cámaras se levantaron después de una serie de chamanismo. Y el tercero no lo es. Además, no está claro dónde está en absoluto. Subo la secuencia de video, los últimos fotogramas justo antes de la caída: 4 de la mañana, tres hombres con bufandas en la cara aparecen, algo brillante debajo, la cámara tiembla mucho, cae.
Una vez configuramos la cámara, que debe enfocar a las "liebres" trepando por encima de la valla. Mientras conducíamos, pensamos en cómo designaríamos el punto donde debería aparecer el intruso. No resultó útil: en los 15 minutos que estuvimos allí, 30 personas ingresaron al objeto solo en el punto que necesitábamos. Mesa recta.
Como ya di un ejemplo arriba, la historia sobre el edificio demolido no es una broma. Una vez que el enlace al equipo desapareció. En su lugar, no hay un pabellón donde pasó el cobre. El pabellón fue demolido, el cable no estaba. Vimos que el enrutador estaba muerto. Llegó el instalador, comenzó a mirar, y la distancia entre los nodos es de un par de kilómetros. Tiene un probador de Vipnet en su aparato, el estándar - sonaba de un conector, sonaba de otro - se puso a buscar. Por lo general, el problema es inmediatamente visible.

Seguimiento de cables: esta es una óptica corrugada, una continuación de la historia desde la parte superior de la publicación sobre el nudo. Aquí, al final, además de la instalación absolutamente increíble, el problema era que el cable se había alejado de los soportes. Aquí escalan todos y cada uno, y aflojan las estructuras metálicas. Aproximadamente cinco mil representante del proletariado rompió la óptica.
En una instalación, todos los nodos se apagaban una vez por semana. Y al mismo tiempo. Hemos estado buscando un patrón durante bastante tiempo. El instalador encontró lo siguiente:
- El problema se da siempre en el turno de la misma persona.
- Se diferencia de los demás en que lleva un abrigo muy pesado.
- Una máquina automática está montada detrás de una percha.
- Alguien tomó la cubierta de la máquina hace mucho tiempo, allá en tiempos prehistóricos.
- Cuando este compañero llega a las instalaciones, él cuelga su ropa y ella apaga las máquinas.
- Inmediatamente los vuelve a encender.
El equipo se apagó a la misma hora a la misma hora de la noche. Resultó que los artesanos locales se conectaron a nuestra fuente de alimentación, sacaron un cable de extensión y colocaron una tetera y una estufa eléctrica allí. Cuando estos dispositivos funcionan simultáneamente, todo el pabellón queda fuera de servicio.
En una de las tiendas de nuestro vasto país, toda la red se caía constantemente con el cierre del turno. El instalador vio que toda la energía se llevaba a la línea de iluminación. Tan pronto como se apaga la iluminación del techo de la sala (que consume mucha energía) en la tienda, todos los equipos de red se apagan.
Hubo un caso en que el conserje interrumpió el cable con una pala.
A menudo vemos solo cobre tirado con una ondulación desgarrada. Una vez, entre dos talleres, los artesanos locales simplemente enviaban un cable de par trenzado sin ninguna protección.
Lejos de la civilización, los empleados a menudo se quejan de que están expuestos a "nuestro" equipo. Los tableros de distribución en algunos sitios distantes pueden estar en la misma habitación que la persona de turno. En consecuencia, un par de veces nos encontramos con abuelas dañinas que, por las buenas o por las malas, los apagaron al comienzo del turno.
Otra ciudad lejana colgó un trapeador en la óptica. Rompieron la corrugación de la pared y comenzaron a usarla como sujetadores para equipos.

En este caso, claramente hay problemas con la nutrición.
Qué puede hacer el monitoreo "grande"
También hablaré brevemente sobre las capacidades de los sistemas más serios, usando el ejemplo de las instalaciones de Infosim. Hay 4 soluciones combinadas en una sola plataforma:- Gestión de fallas: control de fallas y correlación de eventos.
- Gestión del rendimiento.
- Inventario y descubrimiento automático de topología.
- Gestión de la configuración.
Por separado, sobre el inventario. El módulo no solo muestra la lista, sino que también construye la topología (al menos en el 95% de los casos lo intenta y lo hace bien). También permite tener a la mano una base de datos actualizada de equipos informáticos usados e inactivos (equipos de red, servidores, etc.), para reponer equipos obsoletos a tiempo (EOS/EOL). En general, es conveniente para las grandes empresas, pero en las pequeñas, gran parte de esto se hace a mano.
Ejemplos de informes:
- Informes por tipo de SO, firmware, modelos y fabricantes de equipos;
- Informe sobre la cantidad de puertos libres en cada conmutador de la red / por fabricante seleccionado / por modelo / por subred, etc.;
- Informe sobre dispositivos recién agregados durante un período específico;
- Advertencia de tóner bajo en la impresora;
- Evaluación de la idoneidad de un canal de comunicación para tráfico sensible a retrasos y pérdidas, métodos activos y pasivos;
- Seguimiento de la calidad y disponibilidad de los canales de comunicación (SLA) - generación de informes sobre la calidad de los canales de comunicación, desglosados por operadores de telecomunicaciones;
- La funcionalidad de control de fallas y correlación de eventos se implementa a través del mecanismo de análisis de causa raíz (sin necesidad de que los administradores escriban reglas) y el mecanismo de máquina de estados de alarma. El análisis de causa raíz es un análisis de la causa raíz de un accidente basado en los siguientes procedimientos: 1. detección y localización automáticas del lugar de la falla; 2. reducir el número de eventos de emergencia a una clave; 3. identificar las consecuencias de una falla: quién y qué se vio afectado por la falla.

Stablenet - Embedded Agent (SNEA) - una computadora un poco más grande que un paquete de cigarrillos.
La instalación se realiza en cajeros automáticos o segmentos de red dedicados donde se requieren pruebas de accesibilidad. Con su ayuda, se realizan pruebas de carga.
Monitoreo en la nube
Otro modelo de instalación es SaaS en la nube. Hecho para un cliente global (una empresa con un ciclo de producción continuo con una geografía de distribución desde Europa hasta Siberia).Decenas de instalaciones, incluidas fábricas y almacenes de productos terminados. Si sus canales cayeron y su apoyo se llevó a cabo desde oficinas extranjeras, comenzaron los retrasos en los envíos, lo que, a lo largo de la ola, provocó más pérdidas. Todo el trabajo se hizo a pedido y se dedicó mucho tiempo a investigar el incidente.
Configuramos el monitoreo específicamente para ellos, luego lo terminamos en varios sitios de acuerdo con las especificaciones de su enrutamiento y hardware. Todo esto se hizo en la nube CROC. Completaron y entregaron el proyecto muy rápidamente.
El resultado es:
- Debido a la transferencia parcial de la gestión de la infraestructura de red, se logró optimizar al menos un 50%. Inaccesibilidad del equipo, carga del canal, superación de los parámetros recomendados por el fabricante: todo esto se registra en 5-10 minutos, se diagnostica y se elimina en una hora.
- Al recibir un servicio de la nube, el cliente convierte los costos de capital de la implementación de su sistema de monitoreo de red en costos operativos por una tarifa de suscripción a nuestro servicio, que se puede cancelar en cualquier momento.
La ventaja de la nube es que en nuestra decisión estamos, por así decirlo, por encima de su red y podemos ver todo lo que sucede de manera más objetiva. En ese momento, si estuviéramos dentro de la red, veríamos la imagen solo hasta el nodo de falla, y lo que sucede detrás de él, ya no lo sabríamos.
Un par de ultimas fotos
Este es el "rompecabezas de la mañana":
Y este es el tesoro que encontramos:

Esto es lo que había en el cofre:

Y por último, sobre la salida más divertida. Una vez fui a una tienda minorista.
Allí pasó lo siguiente: primero empezó a gotear del techo al falso techo. Luego se formó un lago en el falso techo, que se erosionó y atravesó una de las tejas. Como resultado, todo esto brotó al electricista. Entonces no sé exactamente qué pasó, pero en algún lugar de la habitación contigua hubo un cortocircuito y se inició un incendio. Primero funcionaron los extintores de polvo, y luego llegaron los bomberos y llenaron todo de espuma. Llegué después de ellos para el desmontaje. Debo decir que el tsiska 2960 lo hizo bien después de todo esto: pude recoger la configuración y enviar el dispositivo para su reparación.
Una vez más, durante la activación del sistema de pólvora, el Tsiskovsky 3745 en una lata se llenó casi por completo con pólvora. Todas las interfaces estaban llenas: 2 x 48 puertos. Tenía que ser incluido en el acto. Recordamos el último caso, decidimos intentar eliminar las configuraciones "calientes", lo sacudimos, lo limpiamos lo mejor que pudimos. Lo encendimos: al principio, el dispositivo decía "pff" y nos estornudaba con una gran cantidad de polvo. Y luego retumbó y se levantó.
solicitud de eco
Una solicitud de eco (ping) es una herramienta de diagnóstico que se utiliza para averiguar si se puede acceder a un host en particular en una red IP. La solicitud de eco se realiza mediante el protocolo ICMP (Protocolo de mensajes de control de Internet). Este protocolo se utiliza para enviar una solicitud de eco al host que se está comprobando. El host debe estar configurado para aceptar paquetes ICMP.
Examen
por solicitud de eco
PRTG es una herramienta de monitoreo de red y ping para Windows. Es compatible con todos los principales sistemas de Windows, incluidos Windows Server 2012 R2 y Windows 10.
PRTG es una poderosa herramienta para toda la red. Para servidores, enrutadores, conmutadores, tiempo de actividad y conexiones en la nube, PRTG realiza un seguimiento de todo para que pueda eliminar las molestias de la administración. El sensor de ping, así como los sensores SNMP, NetFlow y de detección de paquetes se utilizan para recopilar información detallada sobre la disponibilidad de la red y la carga de trabajo.
PRTG tiene un sistema de alarma incorporado personalizable que le notifica rápidamente los problemas. El sensor de ping está configurado como el sensor principal para dispositivos de red. Si este sensor falla, todos los demás sensores del dispositivo se ponen en modo de suspensión. Esto significa que en lugar de un flujo de mensajes de alerta, recibirá solo una notificación.
En cualquier momento que desee, puede mostrar una descripción general rápida en el panel de control de PRTG. Inmediatamente verá si todo está en orden. El tablero se puede personalizar para adaptarse a sus necesidades específicas. Fuera del lugar de trabajo, como cuando se trabaja en una sala de servidores, es posible acceder a PRTG a través de una aplicación de teléfono inteligente y nunca se perderá un solo evento.
El monitoreo inicial se configura inmediatamente durante la instalación. Esto es posible gracias a la función de detección automática: PRTG hace ping a sus direcciones IP privadas y crea automáticamente sensores para los dispositivos disponibles. Cuando abre PRTG por primera vez, puede verificar inmediatamente la disponibilidad de su red.
El programa PRTG tiene un modelo de licencia transparente. Puede probar PRTG gratis. El sensor de ping y la función de alarma también están incluidos en la versión gratuita y tienen una duración de uso ilimitada. Si su empresa o red necesita más funciones, es fácil actualizar su licencia.
capturas de pantalla
Una breve introducción a PRTG: supervisión de ping



Tus sensores de ping a la vista
- incluso sobre la marcha
PRTG se instala en minutos y es compatible con la mayoría de los dispositivos móviles.
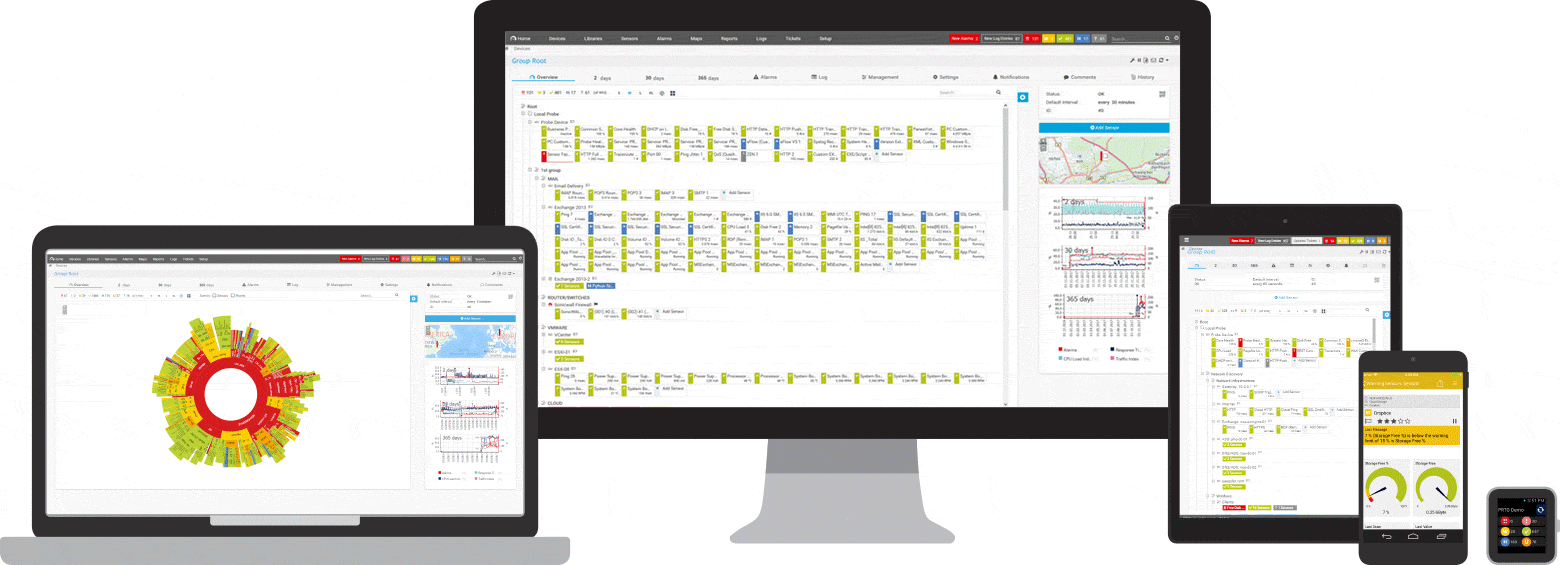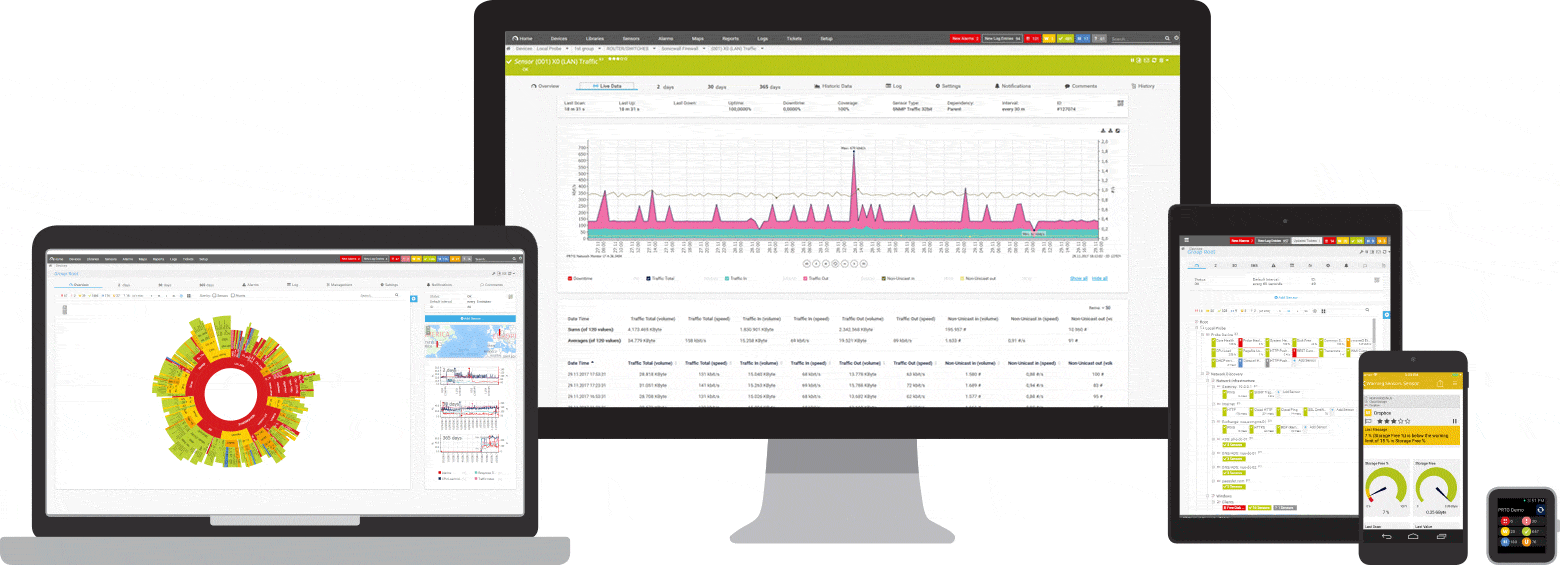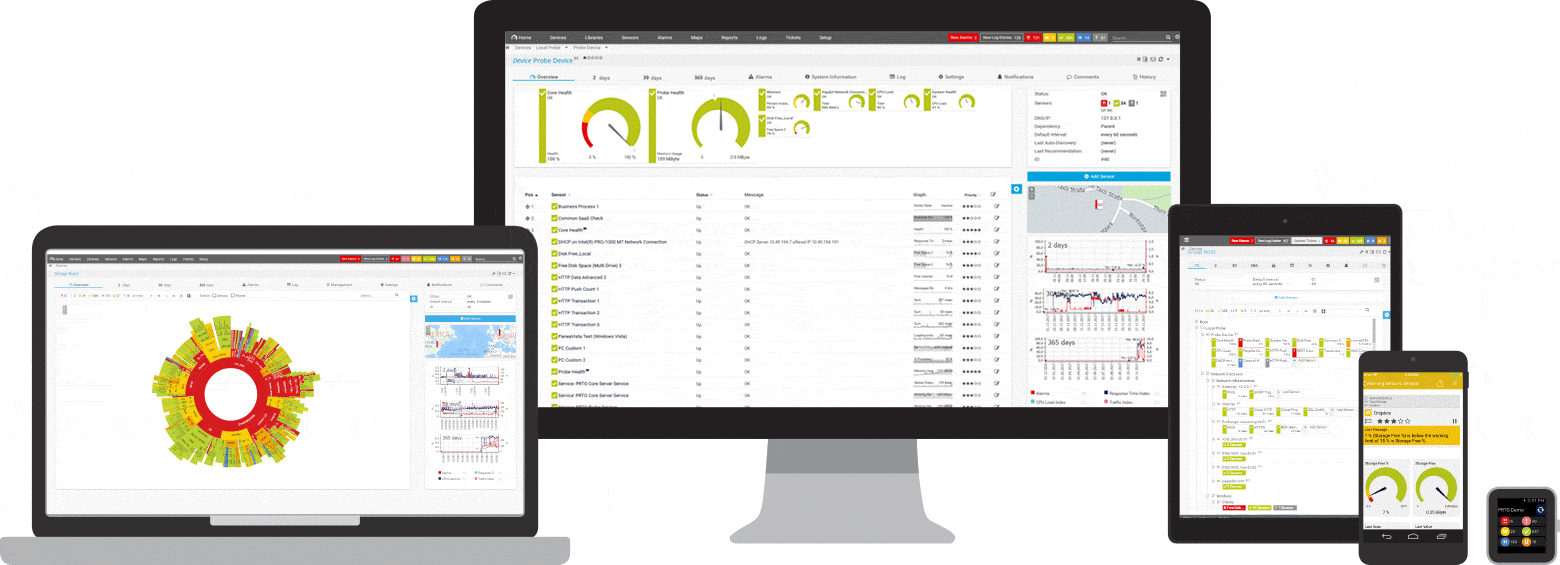
PRTG controla estos y muchos otros fabricantes y aplicaciones para usted
Tres sensores PRTG para monitoreo de ping
Sensor
solicitudes de eco
de la nube
El sensor de ping en la nube utiliza la nube de PRTG para medir el tiempo que lleva hacer ping a su red desde varios lugares del mundo. Este sensor te permite ver la disponibilidad de tu red en Asia, Europa y América. En particular, este indicador es muy importante para las empresas internacionales. .
Al comprar el software de PRTG, recibirá un completo soporte gratuito. ¡Nuestra tarea es resolver sus problemas lo más rápido posible! Especialmente para esto, junto con otros materiales, hemos preparado videos de capacitación y una guía completa. Nuestro objetivo es responder a todos los tickets de soporte dentro de las 24 horas (días laborables). Encontrará respuestas a muchas preguntas en nuestra base de conocimientos. Por ejemplo, la consulta de búsqueda "supervisión de ping" devuelve 700 resultados. Algunos ejemplos:
“Necesito un sensor de ping que recopile información solo sobre la disponibilidad del dispositivo, sin cambiar su estado. ¿Es posible?"
"¿Puedo construir un sensor de solicitud de eco inverso?"

“Con PRTG, nos sentimos mucho más cómodos sabiendo que nuestros sistemas están siendo monitoreados continuamente”.
Markus Puke, administrador de red, Clínica Schüchtermann (Alemania)
- Versión completa de PRTG durante 30 días
- Después de 30 días - versión gratuita
- Para versión extendida - licencia comercial

| Software de monitoreo de red - Versión 19.2.50.2842 (15 de mayo de 2019) | |
|
Alojamiento |
Versión en la nube también disponible (PRTG en la nube) |
Idiomas |
Inglés, alemán, ruso, español, francés, portugués, holandés, japonés y chino simplificado |
Precios |
Gratis hasta 100 sensores (precios) |
Monitoreo integral |
Dispositivos de red, ancho de banda, servidores, aplicaciones, entornos virtuales, sistemas remotos, IoT y más. |
Proveedores y aplicaciones compatibles |
Supervisión de red y ping con PRTG: tres casos prácticos
200.000 administradores de todo el mundo confían en el programa PRTG. Estos administradores pueden provenir de diferentes industrias, pero todos tienen una cosa en común: el deseo de garantizar y mejorar la disponibilidad y el rendimiento de sus redes. Tres casos de uso:

Aeropuerto de Zúrich
El aeropuerto de Zúrich es el aeropuerto más grande de Suiza, por lo que es especialmente importante que todos sus sistemas electrónicos funcionen sin problemas. Para que esto sea posible, el departamento de TI implementó el software PRTG Network Monitor de Paessler AG. Con más de 4500 sensores, esta herramienta garantiza que el equipo de TI detecte y resuelva inmediatamente los problemas. En el pasado, el departamento de TI usaba una variedad de programas de monitoreo. Pero finalmente, la gerencia concluyó que el software no era adecuado para el monitoreo especializado por parte del personal de operaciones y mantenimiento. ejemplo de uso

Universidad Bauhaus, Weimar
Los sistemas informáticos de la Universidad Bauhaus de Weimar son utilizados por 5.000 estudiantes y 400 empleados. En el pasado, se usaba una solución aislada basada en Nagios para monitorear la red universitaria. El sistema estaba técnicamente desactualizado y no podía satisfacer las necesidades de la infraestructura de TI de la institución educativa. Las actualizaciones de infraestructura serían extremadamente costosas. En cambio, la universidad recurrió a nuevas soluciones de monitoreo de red. Los ejecutivos de TI querían un producto de software integral que fuera fácil de usar, fácil de instalar y rentable. Por eso eligieron PRTG. ejemplo de uso

Servicios públicos de la ciudad de Frankenthal
Un poco más de 200 empleados de los servicios públicos de la ciudad de Frankenthal son responsables del suministro de electricidad, gas y agua a consumidores privados y organizaciones. La organización, con todos sus edificios, también depende de una infraestructura distribuida localmente, que consta de aproximadamente 80 servidores y 200 dispositivos conectados. Los ejecutivos de TI de Frankenthal buscaban un software asequible para satisfacer sus necesidades específicas. Primero, TI configuró una prueba gratuita de PRTG. Las empresas de servicios públicos de Frankenthal utilizan actualmente alrededor de 1.500 sensores para monitorear, entre otras cosas, las piscinas públicas. ejemplo de uso

Consejo practico. Dime, Greg, ¿tienes alguna recomendación para monitorear pings?
“Los sensores de pingback son probablemente los elementos más importantes del monitoreo de redes. Deben configurarse correctamente, especialmente teniendo en cuenta sus conexiones. Si, por ejemplo, está monitoreando una máquina virtual, es útil colocar un sensor de ping en la conexión a su host. Si un nodo falla, no recibirá una notificación por cada máquina virtual conectada a él. Además, los sensores de ping pueden ser buenos indicadores de que la ruta de la red a un host o Internet funciona correctamente, especialmente en escenarios de alta disponibilidad o conmutación por error”.
Greg Campion, administrador de sistemas, PAESSLER AG
Por la apariencia de esta óptica, atravesando el bosque hasta el colector, podemos concluir que el instalador no siguió un poco la tecnología. La montura de la foto también sugiere que probablemente sea un marinero, un nudo marino.
Estoy en el equipo de salud de la red física, es decir, el soporte técnico, que se encarga de que las luces de los routers parpadeen como deben. Tenemos bajo nuestro ala varias grandes empresas con infraestructura en todo el país. No nos metemos dentro de su negocio, nuestra tarea es asegurarnos de que la red funcione a nivel físico y el tráfico pase como debe.
El significado general del trabajo es el sondeo constante de los nodos, la eliminación de la telemetría, las ejecuciones de prueba (por ejemplo, verificar la configuración para encontrar vulnerabilidades), garantizar la salud, monitorear las aplicaciones, el tráfico. A veces inventarios y otras perversiones.
Te cuento como se organiza y un par de anécdotas de los viajes.
Como suele ser el caso
Nuestro equipo se sienta en una oficina en Moscú y toma telemetría de red. En realidad, estos son pings constantes de nodos, además de recibir datos de monitoreo si el hardware es inteligente. La situación más común es que el ping no pase varias veces seguidas. En el 80% de los casos para una cadena minorista, por ejemplo, esto resulta ser un corte de energía, por lo que, al ver esta imagen, hacemos lo siguiente:- Primero llamamos al proveedor sobre accidentes.
- Entonces - a la planta de energía sobre el cierre
- Luego tratamos de establecer una conexión con alguien en la instalación (esto no siempre es posible, por ejemplo, a las 2 am)
- Y, finalmente, si lo anterior no ayudó en 5-10 minutos, nos dejamos o enviamos un "avatar": un ingeniero contratado sentado en algún lugar de Izhevsk o Vladivostok, si el problema está ahí.
- Nos mantenemos en contacto constante con el "avatar" y lo "guiamos" a través de la infraestructura: tenemos sensores y manuales de servicio, él tiene alicates.
- Luego el ingeniero nos envía un informe con una foto de lo que fue.
El diálogo a veces es así:
- Entonces, la conexión se pierde entre los edificios número 4 y 5. Verifique el enrutador en el quinto.
- Pedido, incluido. No hay conexión.
- Ok, ve por el cable hasta el cuarto edificio, hay otro nodo.
-… ¡Opa!
- ¿Qué ha pasado?
- Aquí se demolió la cuarta casa.
- ¿¿Qué??
- Adjunto una foto al informe. No puedo restaurar la casa en SLA.
Pero más a menudo, todavía resulta encontrar un descanso y restaurar el canal.
Aproximadamente el 60% de los viajes están “en la leche”, porque o se interrumpe el suministro eléctrico (por una pala, capataz, intrusos), o el proveedor no sabe de su falla, o se elimina un problema coyuntural antes que el instalador. llega Sin embargo, hay ocasiones en las que nos enteramos del problema antes que los usuarios y antes que los servicios TI del cliente, y comunicamos la solución antes incluso de que se den cuenta de que algo ha pasado. En la mayoría de los casos, estas situaciones ocurren por la noche, cuando la actividad en las empresas de los clientes es baja.
Quién lo necesita y por qué
Como regla general, cualquier gran empresa tiene su propio departamento de TI, que comprende claramente los detalles y las tareas. En las empresas medianas y grandes, el trabajo de los "enikeevs" y los ingenieros de redes a menudo se subcontrata. Es simplemente beneficioso y conveniente. Por ejemplo, un minorista tiene su propia gente de TI muy interesante, pero están lejos de reemplazar los enrutadores y rastrear los cables.Que estamos haciendo
- Trabajamos en las solicitudes - entradas y llamadas de pánico.
- Hacemos prevención.
- Seguimos las recomendaciones de los proveedores de hardware, por ejemplo, en términos de mantenimiento.
- Nos conectamos al seguimiento del cliente y le quitamos datos para poder viajar en caso de incidencias.
La primera forma, comprobaciones simples, es simplemente una máquina que hace ping a todos los nodos de la red y se asegura de que respondan correctamente. Dicha implementación no requiere cambios en absoluto o cambios cosméticos mínimos en la red del cliente. Como regla general, en un caso muy simple, instalamos Zabbix directamente en uno de los centros de datos (afortunadamente, tenemos dos en la oficina de CROC en Volochaevskaya). En uno más complejo, por ejemplo, si usa su propia red segura, a una de las máquinas en el centro de datos del cliente:
Zabbix se puede usar de manera más complicada, por ejemplo, tiene agentes que se instalan en * nix y ganan nodos y muestran el monitoreo del sistema, así como el modo de verificación externa (con soporte para el protocolo SNMP). Sin embargo, si una empresa necesita algo similar, entonces ya tiene su propio monitoreo o se elige una solución funcionalmente más rica. Por supuesto, esto ya no es de código abierto y cuesta dinero, pero incluso un inventario preciso banal ya supera los costos en aproximadamente un tercio.
También hacemos esto, pero esta es la historia de los colegas. Aquí enviaron un par de capturas de pantalla de Infosim:
Soy operadora de avatares, así que les contaré más sobre mi trabajo.
¿Cómo es un incidente típico?
Ante nosotros hay pantallas con el siguiente estado general:
En este objeto, Zabbix recopila bastante información para nosotros: número de lote, número de serie, uso de CPU, descripción del dispositivo, disponibilidad de interfaces, etc. Toda la información necesaria está disponible desde esta interfaz.
Un incidente ordinario suele comenzar con el hecho de que uno de los canales que conducen, por ejemplo, a la tienda del cliente (de la que tiene 200-300 piezas en todo el país) se cae. El comercio minorista ahora está bien desarrollado, no como hace siete años, por lo que la taquilla seguirá funcionando: hay dos canales.
Cogemos los teléfonos y hacemos al menos tres llamadas: al proveedor, a la central y a la gente del lugar (“Sí, aquí cargamos herrajes, a alguien le tocaron el cable… Ah, ¿el tuyo? Bueno, qué bueno que lo encontramos").
Como regla general, sin monitoreo, pasarían horas o días antes de una escalada; no siempre se verifican los mismos canales de respaldo. Lo sabemos de inmediato y nos vamos de inmediato. Si hay información adicional además de los pings (por ejemplo, un modelo de una pieza de hierro del buggy), completamos de inmediato al ingeniero de campo con las piezas necesarias. Además ya en su lugar.
La segunda llamada habitual más frecuente es la avería de uno de los terminales de los usuarios, por ejemplo, un teléfono DECT o un router Wi-Fi que distribuía la red a la oficina. Aquí aprendemos sobre el problema del monitoreo y casi de inmediato recibimos una llamada con detalles. A veces la llamada no aporta nada nuevo ("Cojo el teléfono, algo no suena"), a veces es muy útil ("Se nos cae de la mesa"). Está claro que en el segundo caso esto claramente no es un salto de línea.
El equipo en Moscú se toma de nuestros almacenes de reserva caliente, tenemos varios tipos de ellos:
Los clientes suelen tener sus propias existencias de componentes que fallan con frecuencia: teléfonos de oficina, fuentes de alimentación, ventiladores, etc. Si necesita entregar algo que no está en su lugar, no a Moscú, generalmente vamos solos (porque la instalación). Por ejemplo, tuve un viaje nocturno a Nizhny Tagil.
Si el cliente tiene su propio seguimiento, puede subirnos datos. A veces implementamos Zabbix en modo de sondeo, solo para garantizar la transparencia y el control de SLA (esto también es gratuito para el cliente). No instalamos sensores adicionales (esto lo hacen colegas que aseguran la continuidad de los procesos de producción), pero podemos conectarnos a ellos si los protocolos no son exóticos.
En general, no tocamos la infraestructura del cliente, solo la apoyamos tal como está.
Por experiencia puedo decir que los últimos diez clientes cambiaron a soporte externo debido al hecho de que somos muy predecibles en términos de costos. Presupuesto claro, buen manejo de casos, reporte de cada solicitud, SLA, reportes de equipos, mantenimiento preventivo. Idealmente, por supuesto, somos para el CIO de un cliente como los limpiadores: venimos y lo hacemos, todo está limpio, no distraemos.
Otra cosa a destacar es que en algunas grandes empresas el inventario se convierte en un verdadero problema, y en ocasiones nos atrae puramente llevarlo a cabo. Además, hacemos el almacenamiento de configuraciones y su gestión, lo cual es conveniente para diferentes reubicaciones y reconexiones. Pero, nuevamente, en casos difíciles, este tampoco soy yo: tenemos uno especial que transporta centros de datos.
Y un punto más importante: nuestro departamento no se ocupa de la infraestructura crítica. Todo lo que se encuentra dentro de los centros de datos y todo lo relacionado con la banca, los seguros y el operador, además de los sistemas centrales minoristas: este es un equipo X. estos chicos.
Más práctica
Muchos dispositivos modernos pueden brindar mucha información de servicio. Por ejemplo, las impresoras de red son muy fáciles de controlar el nivel de tóner en el cartucho. Puede contar con el período de reemplazo por adelantado, además de recibir una notificación del 5-10% (si la oficina de repente comienza a escribir furiosamente fuera del horario estándar), e inmediatamente envíe un enikey antes de que el departamento de contabilidad comience a entrar en pánico.Muy a menudo, nos quitan las estadísticas anuales, lo que hace el mismo sistema de monitoreo más nosotros. En el caso de Zabbix, se trata de una simple planificación de costos y la comprensión de qué fue a dónde, y en el caso de Infosim, también es material para calcular la escala durante un año, cargar administradores y todo tipo de otras cosas. Hay consumo de energía en las estadísticas: en el último año, casi todos comenzaron a preguntarle, aparentemente para distribuir los costos internos entre los departamentos.
A veces se obtienen auténticos rescates heroicos. Tales situaciones son muy raras, pero por lo que recuerdo este año, vimos alrededor de las 3 am que la temperatura subió a 55 grados en el interruptor de Cisco. En la sala de servidores distante había acondicionadores de aire "estúpidos" sin monitoreo, y fallaron. Inmediatamente llamamos a un ingeniero de refrigeración (no el nuestro) y llamamos al administrador del cliente de turno. Apagó algunos servicios no críticos y evitó que la sala de servidores se apagara térmicamente hasta que llegó el tipo con un aire acondicionado móvil, y luego se arreglaron los regulares.
Polycom y otros equipos de videoconferencia costosos controlan muy bien el nivel de carga de la batería antes de las conferencias, lo que también es importante.
Todos necesitan monitoreo y diagnóstico. Como regla, es largo y difícil de implementar sin experiencia: los sistemas son extremadamente simples y preconfigurados, o del tamaño de un portaaviones y con un montón de informes estándar. Afilar con un archivo para la empresa, inventar la implementación de sus tareas para el departamento de TI interno y mostrar la información que más necesitan, además de mantener todo el historial actualizado es un rastrillo si no hay experiencia en implementación. Cuando trabajamos con sistemas de monitoreo, elegimos el medio dorado entre soluciones gratuitas y superiores; por regla general, no los proveedores más populares y "gruesos", pero claramente resuelven el problema.
Una vez hubo un tratamiento bastante atípico.. El cliente tuvo que entregar el enrutador a algunas de sus divisiones separadas, y exactamente de acuerdo con el inventario. El enrutador tenía un módulo con el número de serie especificado. Cuando el enrutador comenzó a prepararse para el camino, resultó que faltaba este módulo. Y nadie puede encontrarlo. El problema se agrava un poco por el hecho de que el ingeniero que trabajó en esta rama el año pasado ya está jubilado y se ha ido a vivir con sus nietos a otra ciudad. Nos contactaron y pidieron mirar. Afortunadamente, el hardware proporcionó informes sobre los números de serie e Infosim hizo un inventario, por lo que encontramos este módulo en la infraestructura en un par de minutos y describimos la topología. El fugitivo fue rastreado por cable: estaba en otra sala de servidores en un armario. La historia del movimiento mostró que llegó allí después del fracaso de un módulo similar.
Un fotograma de un largometraje sobre Hottabych, que describe con precisión la actitud de la población hacia las cámaras.
Muchos incidentes de cámara. Una vez 3 cámaras fallaron a la vez. Rotura de cable en uno de los tramos. El instalador sopló uno nuevo en la ondulación, dos de las tres cámaras se levantaron después de una serie de chamanismo. Y el tercero no lo es. Además, no está claro dónde está en absoluto. Subo la secuencia de video, los últimos fotogramas justo antes de la caída: 4 de la mañana, tres hombres con bufandas en la cara aparecen, algo brillante debajo, la cámara tiembla mucho, cae.
Una vez configuramos la cámara, que debe enfocar a las "liebres" trepando por encima de la valla. Mientras conducíamos, pensamos en cómo designaríamos el punto donde debería aparecer el intruso. No resultó útil: en los 15 minutos que estuvimos allí, 30 personas ingresaron al objeto solo en el punto que necesitábamos. Mesa recta.
Como ya di un ejemplo arriba, la historia sobre el edificio demolido no es una broma. Una vez que el enlace al equipo desapareció. En su lugar, no hay un pabellón donde pasó el cobre. El pabellón fue demolido, el cable no estaba. Vimos que el enrutador estaba muerto. Llegó el instalador, comenzó a mirar, y la distancia entre los nodos es de un par de kilómetros. Tiene un probador de Vipnet en su aparato, el estándar - sonaba de un conector, sonaba de otro - se puso a buscar. Por lo general, el problema es inmediatamente visible.
Seguimiento de cables: esta es una óptica corrugada, una continuación de la historia desde la parte superior de la publicación sobre el nudo. Aquí, al final, además de la instalación absolutamente increíble, el problema era que el cable se había alejado de los soportes. Aquí escalan todos y cada uno, y aflojan las estructuras metálicas. Aproximadamente cinco mil representante del proletariado rompió la óptica.
En una instalación, todos los nodos se apagaban una vez por semana. Y al mismo tiempo. Hemos estado buscando un patrón durante bastante tiempo. El instalador encontró lo siguiente:
- El problema se da siempre en el turno de la misma persona.
- Se diferencia de los demás en que lleva un abrigo muy pesado.
- Una máquina automática está montada detrás de una percha.
- Alguien tomó la cubierta de la máquina hace mucho tiempo, allá en tiempos prehistóricos.
- Cuando este compañero llega a las instalaciones, él cuelga su ropa y ella apaga las máquinas.
- Inmediatamente los vuelve a encender.
El equipo se apagó a la misma hora a la misma hora de la noche. Resultó que los artesanos locales se conectaron a nuestra fuente de alimentación, sacaron un cable de extensión y colocaron una tetera y una estufa eléctrica allí. Cuando estos dispositivos funcionan simultáneamente, todo el pabellón queda fuera de servicio.
En una de las tiendas de nuestro vasto país, toda la red se caía constantemente con el cierre del turno. El instalador vio que toda la energía se llevaba a la línea de iluminación. Tan pronto como se apaga la iluminación del techo de la sala (que consume mucha energía) en la tienda, todos los equipos de red se apagan.
Hubo un caso en que el conserje interrumpió el cable con una pala.
A menudo vemos solo cobre tirado con una ondulación desgarrada. Una vez, entre dos talleres, los artesanos locales simplemente enviaban un cable de par trenzado sin ninguna protección.
Lejos de la civilización, los empleados a menudo se quejan de que están expuestos a "nuestro" equipo. Los tableros de distribución en algunos sitios distantes pueden estar en la misma habitación que la persona de turno. En consecuencia, un par de veces nos encontramos con abuelas dañinas que, por las buenas o por las malas, los apagaron al comienzo del turno.
Otra ciudad lejana colgó un trapeador en la óptica. Rompieron la corrugación de la pared y comenzaron a usarla como sujetadores para equipos.
En este caso, claramente hay problemas con la nutrición.
Qué puede hacer el monitoreo "grande"
También hablaré brevemente sobre las capacidades de los sistemas más serios, usando el ejemplo de las instalaciones de Infosim. Hay 4 soluciones combinadas en una sola plataforma:- Gestión de fallas: control de fallas y correlación de eventos.
- Gestión del rendimiento.
- Inventario y descubrimiento automático de topología.
- Gestión de la configuración.
Por separado, sobre el inventario. El módulo no solo muestra la lista, sino que también construye la topología (al menos en el 95% de los casos lo intenta y lo hace bien). También permite tener a la mano una base de datos actualizada de equipos informáticos usados e inactivos (equipos de red, servidores, etc.), para reponer equipos obsoletos a tiempo (EOS/EOL). En general, es conveniente para las grandes empresas, pero en las pequeñas, gran parte de esto se hace a mano.
Ejemplos de informes:
- Informes por tipo de SO, firmware, modelos y fabricantes de equipos;
- Informe sobre la cantidad de puertos libres en cada conmutador de la red / por fabricante seleccionado / por modelo / por subred, etc.;
- Informe sobre dispositivos recién agregados durante un período específico;
- Advertencia de tóner bajo en la impresora;
- Evaluación de la idoneidad de un canal de comunicación para tráfico sensible a retrasos y pérdidas, métodos activos y pasivos;
- Seguimiento de la calidad y disponibilidad de los canales de comunicación (SLA) - generación de informes sobre la calidad de los canales de comunicación, desglosados por operadores de telecomunicaciones;
- La funcionalidad de control de fallas y correlación de eventos se implementa a través del mecanismo de análisis de causa raíz (sin necesidad de que los administradores escriban reglas) y el mecanismo de máquina de estados de alarma. El análisis de causa raíz es un análisis de la causa raíz de un accidente basado en los siguientes procedimientos: 1. detección y localización automáticas del lugar de la falla; 2. reducir el número de eventos de emergencia a una clave; 3. identificar las consecuencias de una falla: quién y qué se vio afectado por la falla.
Stablenet - Embedded Agent (SNEA) - una computadora un poco más grande que un paquete de cigarrillos.
La instalación se realiza en cajeros automáticos o segmentos de red dedicados donde se requieren pruebas de accesibilidad. Con su ayuda, se realizan pruebas de carga.
Monitoreo en la nube
Otro modelo de instalación es SaaS en la nube. Hecho para un cliente global (una empresa con un ciclo de producción continuo con una geografía de distribución desde Europa hasta Siberia).Decenas de instalaciones, incluidas fábricas y almacenes de productos terminados. Si sus canales cayeron y su apoyo se llevó a cabo desde oficinas extranjeras, comenzaron los retrasos en los envíos, lo que, a lo largo de la ola, provocó más pérdidas. Todo el trabajo se hizo a pedido y se dedicó mucho tiempo a investigar el incidente.
Configuramos el monitoreo específicamente para ellos, luego lo terminamos en varios sitios de acuerdo con las especificaciones de su enrutamiento y hardware. Todo esto se hizo en la nube CROC. Completaron y entregaron el proyecto muy rápidamente.
El resultado es:
- Debido a la transferencia parcial de la gestión de la infraestructura de red, se logró optimizar al menos un 50%. Inaccesibilidad del equipo, carga del canal, superación de los parámetros recomendados por el fabricante: todo esto se registra en 5-10 minutos, se diagnostica y se elimina en una hora.
- Al recibir un servicio de la nube, el cliente convierte los costos de capital de la implementación de su sistema de monitoreo de red en costos operativos por una tarifa de suscripción a nuestro servicio, que se puede cancelar en cualquier momento.
La ventaja de la nube es que en nuestra decisión estamos, por así decirlo, por encima de su red y podemos ver todo lo que sucede de manera más objetiva. En ese momento, si estuviéramos dentro de la red, veríamos la imagen solo hasta el nodo de falla, y lo que sucede detrás de él, ya no lo sabríamos.
Un par de ultimas fotos
Este es el "rompecabezas de la mañana":
Y este es el tesoro que encontramos:
Esto es lo que había en el cofre:
Y por último, sobre la salida más divertida. Una vez fui a una tienda minorista.
Allí pasó lo siguiente: primero empezó a gotear del techo al falso techo. Luego se formó un lago en el falso techo, que se erosionó y atravesó una de las tejas. Como resultado, todo esto brotó al electricista. Entonces no sé exactamente qué pasó, pero en algún lugar de la habitación contigua hubo un cortocircuito y se inició un incendio. Primero funcionaron los extintores de polvo, y luego llegaron los bomberos y llenaron todo de espuma. Llegué después de ellos para el desmontaje. Debo decir que el tsiska 2960 lo hizo bien después de todo esto: pude recoger la configuración y enviar el dispositivo para su reparación.
Una vez más, durante la activación del sistema de pólvora, el Tsiskovsky 3745 en una lata se llenó casi por completo con pólvora. Todas las interfaces estaban llenas: 2 x 48 puertos. Tenía que ser incluido en el acto. Recordamos el último caso, decidimos intentar eliminar las configuraciones "calientes", lo sacudimos, lo limpiamos lo mejor que pudimos. Lo encendimos: al principio, el dispositivo decía "pff" y nos estornudaba con una gran cantidad de polvo. Y luego retumbó y se levantó.
Monitor de ping de EMCO. Asistente de administración gratuito
Si su infraestructura tiene hasta 5 hosts de virtualización, puede usar la versión gratuita.
Ping Monitor: herramienta de monitoreo del estado de la conexión de red (gratis para 5 hosts)
Información:
Herramienta de monitoreo confiable para verificar automáticamente la conexión a la red de hosts ejecutando un comando silbido.
wiki:
Ping es una utilidad para probar conexiones en redes basadas en TCP/IP, así como el nombre común de la solicitud en sí.
La utilidad envía solicitudes (ICMP Echo-Request) del protocolo ICMP al host especificado y captura las respuestas entrantes (ICMP Echo-Reply). El tiempo entre el envío de una solicitud y la recepción de una respuesta (RTT, del inglés Round Trip Time) le permite determinar los retrasos de ida y vuelta (RTT) a lo largo de la ruta y la frecuencia de pérdida de paquetes, es decir, determinar indirectamente la carga en los canales de datos. y dispositivos intermedios.
El programa ping es una de las principales herramientas de diagnóstico en redes TCP/IP y está incluido en la entrega de todos los sistemas operativos de red modernos.
https://ru.wikipedia.org/wiki/Ping
El programa, mediante el envío de solicitudes ICMP regulares, monitorea las conexiones de red y le notifica sobre la restauración / caída de canales detectada. EMCO Ping Monitor proporciona datos de estadísticas de conexión, incluido el tiempo de actividad, las interrupciones del servicio, las fallas de ping, etc.


Una sólida herramienta de monitoreo de ping para la verificación automática de la conexión a los hosts de la red. Al hacer pings regulares, monitorea las conexiones de red y le notifica sobre los altibajos detectados. EMCO Ping Monitor también proporciona información de estadísticas de conexión, incluido el tiempo de actividad, interrupciones, pings fallidos, etc. Puede ampliar fácilmente la funcionalidad y configurar EMCO Ping Monitor para ejecutar comandos personalizados o iniciar aplicaciones cuando se pierden o restauran las conexiones.
¿Qué es el monitor de ping de EMCO?
EMCO Ping Monitor puede funcionar en modo 24/7 para rastrear los estados de la conexión de uno o varios hosts. La aplicación analiza las respuestas de ping para detectar cortes de conexión e informar estadísticas de conexión. Puede detectar automáticamente cortes de conexión y mostrar globos en la bandeja de Windows, reproducir sonidos y enviar notificaciones por correo electrónico. También puede generar informes y enviarlos por correo electrónico o guardarlos como archivos PDF o HTML.
El programa le permite obtener información sobre los estados de todos los hosts, consultar las estadísticas detalladas de un host seleccionado y comparar el rendimiento de diferentes hosts. El programa almacena los datos de ping recopilados en la base de datos, por lo que puede verificar las estadísticas para un período de tiempo seleccionado. La información disponible incluye tiempo de ping mínimo/máximo/promedio, desviación de ping, lista de cortes de conexión, etc. Esta información se puede representar como datos de cuadrícula y gráficos.
Monitor de ping de EMCO: ¿Cómo funciona?
El monitor de ping de EMCO se puede utilizar para realizar un seguimiento de ping de unos pocos hosts o de miles de hosts. Todos los hosts son monitoreados en tiempo real por subprocesos de trabajo dedicados, por lo que puede obtener estadísticas en tiempo real y notificaciones de cambios de estado de conexión para cada host. El programa no tiene requisitos especiales para el hardware: puede monitorear unos pocos miles de hosts en una PC moderna típica.
El programa utiliza pings para detectar cortes de conexión. Si fallan algunos pings sin procesar, informa una interrupción y le notifica sobre el problema. Cuando se establece la conexión y los pings comienzan a pasar, el programa detecta el final de la interrupción y le notifica al respecto. Puede personalizar las condiciones de detección de interrupción y restauración y también las notificaciones utilizadas por el programa.
Compare características y seleccione la edición
El programa está disponible en tres ediciones con diferentes conjuntos de funciones.
Comparar ediciones
La edición gratuita permite realizar un seguimiento de ping de hasta 5 hosts. No permite ninguna configuración específica para hosts. Se ejecuta como un programa de Windows, por lo que la supervisión se detiene si cierra la interfaz de usuario o cierra sesión en Windows.
gratis para uso personal y comercial
Edición profesional
La edición Profesional permite monitorear hasta 250 hosts simultáneamente. Cada host puede tener una configuración personalizada, como notificación de destinatarios de correo electrónico o acciones personalizadas que se ejecutarán en eventos de pérdida y restauración de conexión. Se ejecuta como un servicio de Windows, por lo que el monitoreo continúa incluso si cierra la interfaz de usuario o cierra sesión en Windows.
Edición de Empresa
La edición Enterprise no tiene limitaciones en la cantidad de hosts monitoreados. En una PC moderna, es posible monitorear más de 2500 hosts según la configuración del hardware.
Esta edición incluye todas las funciones disponibles y funciona como cliente/servidor. El servidor funciona como un servicio de Windows para garantizar el monitoreo de ping en modo 24/7. El cliente es un programa de Windows que puede conectarse a un servidor que se ejecuta en una PC local oa un servidor remoto a través de una LAN o Internet. Varios clientes pueden conectarse al mismo servidor y trabajar simultáneamente.
Esta edición también incluye informes web, que permiten revisar las estadísticas de monitoreo del host de forma remota en un navegador web.
Las características principales del monitor de ping de EMCO
Supervisión de ping de varios hosts
La aplicación puede monitorear varios hosts al mismo tiempo. La edición gratuita de la aplicación permite monitorear hasta cinco hosts; la edición profesional no tiene ninguna limitación para la cantidad de hosts monitoreados. El monitoreo de cada host funciona independientemente de otros hosts. Puede monitorear decenas de miles de hosts desde una PC moderna.
Detección de cortes de conexión
La aplicación envía solicitudes de eco de ping ICMP y analiza las respuestas de eco de ping para monitorear el estado de la conexión en el modo 24/7. Si el número predeterminado de pings falla en una fila, la aplicación detecta una interrupción de la conexión y le notifica el problema. La aplicación realiza un seguimiento de todas las interrupciones, para que pueda ver cuándo un host estuvo desconectado.
Análisis de calidad de conexión
Cuando la aplicación hace ping a un host monitoreado, guarda y agrega datos sobre cada ping, para que pueda obtener información sobre los tiempos de respuesta de ping mínimos, máximos y promedio y la desviación de respuesta de ping del promedio para cualquier período de informe. Eso le permite estimar la calidad de la conexión de red.
Notificaciones flexibles
Si desea recibir notificaciones sobre conexión perdida, conexión restaurada y otros eventos detectados por la aplicación, puede configurar la aplicación para enviar notificaciones por correo electrónico, reproducir sonidos y mostrar globos en la bandeja de Windows. La aplicación puede enviar una sola notificación de cualquier tipo o repetir notificaciones varias veces.
Gráficos e informes
Toda la información estadística recopilada por la aplicación se puede representar visualmente mediante gráficos. Puede ver las estadísticas de ping y tiempo de actividad de un solo host y comparar el rendimiento de varios hosts en los gráficos. La aplicación puede generar automáticamente informes en diferentes formatos de forma regular para representar las estadísticas del host.
Acciones personalizadas
Puede integrar la aplicación con software externo mediante la ejecución de scripts externos o archivos ejecutables cuando se pierden o restauran las conexiones o en caso de otros eventos. Por ejemplo, puede configurar la aplicación para ejecutar una herramienta de línea de comandos externa para enviar notificaciones por SMS sobre cualquier cambio en los estados del host.
 Amplificador Bluetooth compacto Lo que necesitas
Amplificador Bluetooth compacto Lo que necesitas Resumen Pantalla alta Zera S Power
Resumen Pantalla alta Zera S Power FAT32 o NTFS: qué sistema de archivos elegir para una unidad flash USB o un disco duro externo
FAT32 o NTFS: qué sistema de archivos elegir para una unidad flash USB o un disco duro externo ¿Falta sonido en Galaxy S9?
¿Falta sonido en Galaxy S9? Actualizar flash player a nueva versión
Actualizar flash player a nueva versión Actualizar flash player a nueva versión
Actualizar flash player a nueva versión Unidad virtual Daemon Tools Lite para imágenes de disco
Unidad virtual Daemon Tools Lite para imágenes de disco