Приклади select group by. Пропозиція GROUP BY. Що таке оператор GROUP BY
Пропозиція GROUP BY використовується для визначення груп вихідних рядків, до яких можуть застосовуватися агрегатні функції (COUNT, MIN, MAX, AVG і SUM). Якщо ця пропозиція відсутня, і використовуються агрегатні функції, то всі стовпці з іменами, згаданими в SELECT, повинні бути включені в агрегатні функції, і ці функції будуть застосовуватися до всього набору рядків, які задовольняють предикату запиту. В іншому випадку всі стовпці списку SELECT, що не увійшли в агрегатні функції, повинні бути вказані в пропозиції GROUP BY. В результаті чого всі вихідні рядки запиту розбиваються на групи, що характеризуються однаковими комбінаціями значень в цих стовпцях. Після чого до кожної групи будуть застосовані агрегатні функції. Слід мати на увазі, що для GROUP BY все значення NULL трактуються як рівні, тобто при угрупованню по полю, який містить NULL-значення, все такі рядки потраплять в одну групу.
Якщо при наявності пропозиції GROUP BY, в пропозиції SELECT відсутні агрегатні функції, то запит просто поверне по одному рядку з кожної групи. Цю можливість, поряд з ключовим словом DISTINCT, можна використовувати для виключення дублікатів рядків в результуючому наборі.
Розглянемо простий приклад:
виконатиSELECT model, COUNT (model) AS Qty_model,
AVG (price) AS Avg_price
FROM PC
GROUP BY model;
SELECT model, COUNT (model) AS Qty_model, AVG (price) AS Avg_price FROM PC GROUP BY model;
У цьому запиті для кожної моделі ПК визначається їх кількість і середня вартість. Всі рядки з однаковими значеннями model (номер моделі) утворюють групу, і на виході SELECT обчислюються кількість значень і середня ціна для кожної групи. Результатом виконання запиту буде наступна таблиця
|
Якби в SELECT присутній стовпець з датою, то можна було б обчислювати ці показники для кожної конкретної дати. Для цього потрібно додати дату як групують стовпчика, і тоді агрегатні функції обчислювалися б для кожної комбінації значень (модель, дата).
Існує кілька певних правил виконання агрегатних функцій.
- Якщо в результаті виконання запиту не отримано жодного рядка (або жодного рядка для даної групи), то вихідні дані для обчислення будь-якої з агрегатних функцій відсутні. У цьому випадку результатом виконання функцій COUNT буде нуль, а результатом всіх інших функцій - NULL.
Дана властивість може дати не завжди очевидний результат. Розглянемо, наприклад, такий запит:
виконатиEXISTS (SELECT MAX (price)
FROM PC
Підзапит в предикате EXISTS повертає один рядок з NULL в якості значення стовпця. Тому, незважаючи на те, що ПК з негативними цінами немає в базі даних, запит в прикладі поверне 1. - Аргумент агрегатної функції не може сам утримувати агрегатні функції (функція від функції). Тобто в простому запиті (без підзапитів) не можна, скажімо, отримати максимум середніх значень.
- Результат виконання функції COUNT є ціле число (INTEGER). Інші агрегатні функції успадковують типи даних оброблюваних значень.
- Якщо при виконанні функції SUM буде отримано результат, що перевищує максимально можливе значення для використовуваного типу даних, виникає помилка.
Отже, агрегатні функції, включені в пропозицію SELECT запиту, що не містить пропозиції GROUP BY, виконуються над усіма результуючими рядками цього запиту. Якщо ж запит містить пропозицію GROUP BY, кожен набір рядків, який має однакові значення стовпця або групи стовпців, заданих в реченні GROUP BY, складають групу, і агрегатні функції виконуються для кожної групи окремо.
По батькові |
Год_рожд. |
||||
Іванович |
|||||
Петрович |
|||||
Михайлович |
|||||
Борисович |
|||||
Миколаївна |
|||||
Сидорова |
Катерина |
Іванівна |
|||
Валентин |
Сергійович |
||||
Анатолій |
Михайлович |
||||
Мал. 4.20. Використання LIKE "^ [Д-М]%" |
|||||
Тепер Ви можете створювати предикати в термінах зв'язків спеціально визначених SQL. Ви можете шукати значення в певному діапазоні (BETWEEN) або в числовому наборі (IN), або Ви можете шукати символьні значення, які відповідають тексту всередині параметрів (LIKE).
4.4. GROUP BY і агрегатні функції SQL
Результатом запиту може бути узагальнене групове значення полів, точно так же, як і значення одного поля. Це робиться за допомогою стандартних агрегатних функцій SQL, список яких наведено нижче:
Крім спеціального випадку COUNT (*), кожна з цих функцій оперує сукупністю значень стовпця деякій таблиці і видає тільки одне значення.
Аргументу всіх функцій, крім COUNT (*), може передувати ключове слово DISTINCT (різний), яке вказує, що дублюючі значення колонки
повинні бути виключені перед тим, як буде застосовуватися функція. Спеціальна ж функція COUNT (*) служить для підрахунку всіх без винятку рядків в таблиці (включаючи дублікати).
Агрегатні функції використовуються подібно іменам полів в реченні запиту SELECT, але з одним винятком: вони беруть імена поля як аргументи. Тільки числові поля можуть використовуватися з SUM і AVG.
З COUNT, MAX, і MIN можуть використовуватися і числові або символьні поля. Коли вони використовуються з символьними полями, MAX і MIN транслюватимуть їх в еквівалент ASCII коду, який повинен повідомляти, що MIN означатиме перше, а MAX - останнє значення в алфавітному порядку.
Щоб знайти SUM всіх окладів в таблиці ОТДЕЛ_СОТРУДНІК (рис. 2.3) треба ввести наступний запит:
FROM Отдел_ Співробітники;
І на екрані побачимо результат: 46800 (в таблиці буде один стовпець з ім'ям СУМА).
Підрахунок середнього значення за окладами також простий:
SELECT AVG ((Оклад))
FROM Отдел_ Співробітники;
Функція COUNT дещо відрізняється від усіх. Вона вважає число значень в даному стовпці або число рядків в таблиці. Коли вона вважає значення стовпця, вона використовується з DISTINCT (різних) щоб виробляти рахунок чисел унікальних значень в даному полі.
У таблиці вісім рядків, в яких знаходяться різні значення окладів.
Відзначимо, що в останніх трьох прикладах враховується інформація і про звільнених співробітників.
Наступна пропозиція дозволяє визначити число підрозділів на
DISTINCT, супроводжуваний ім'ям поля, з яким він застосовується, поміщений в круглі дужки, з COUNT застосовується до індивідуальних стовпчиках.
SELECT COUNT (*)
FROM Отдел_ Співробітники;
Відповідь буде: |
COUNT (*) підраховує всі без винятку рядки таблиці.
DISTINCT не застосовують c COUNT (*).
Припустимо, що таблиця ВЕДОМОСТЬ_ОПЛАТИ (рис. 2.4) має ще один стовпець, який зберігає суму зроблених відрахувань (поле Відрахування) для кожного рядка відомості. Тоді якщо Вас цікавить вся сума, то вміст стовпця Сума і Відрахування треба скласти.
Якщо ж Вас цікавить максимальна сума з урахуванням відрахувань, що міститься у відомості, то це можна зробити за допомогою наступного речення:
SELECT MAX (Сума + Відрахування)
FROM Ведомость_ оплати;
Для кожного рядка таблиці цей запит буде складати значення поля Сума зі значенням поля Відрахування і вибирати найбільше значення, яке він знайде.
ПРОПОЗИЦІЯ GROUP BY (перекомпонування, порядок)
Пропозиція GROUP BY дозволяє визначати підмножину значень в особливому полі в термінах іншого поля і застосовувати функцію агрегату до підмножини. Це дає можливість об'єднувати поля і агрегатні функції в єдиній пропозиції SELECT.
Наприклад, припустимо, що Ви хочете визначити, скільки співробітників знаходяться в кожному відділі (відповідь наведено на рис. 4.21):
SELECT Ід_Отд, COUNT (DISTINCT Ід_Отд) AS К-во_сотрудніков
Отдел_ Співробітники |
|||
Дата звільнення |
|||
К-во_сотрудніков |
|||
В результаті виконання пропозиції GROUP BY залишаються тільки унікальні значення стовпців, за замовчуванням відсортовані по зростанню. В цьому аспекті пропозиція GROUP BY відрізняється від пропозиції ORDER BY тим, що останнім хоча і сортує записи по зростанню, але не видаляє повторювані значення. У наведеному прикладі запит групує рядки таблиці за значеннями стовпчика Ід_Отд (за номерами відділів). Рядки з однаковими номерами відділів спочатку об'єднуються в групи, але при цьому для кожної групи відображається тільки один рядок. У другому стовпці виводиться кількість рядків в кожній групі, тобто число співробітників в кожному відділі.
Значення поля, до якого застосовується GROUP BY, має, за визначенням, тільки одне значення на групу виводу так само, як це робить агрегатна функція. Результатом є сумісність, яка дозволяє агрегатам і полях об'єднуватися таким чином.
Нехай, наприклад, таблиця ВЕДОМОСТЬ_ОПЛАТИ має вигляд рис. 4.22 і ми хочемо визначити максимальну суму, виплачену за відомістю кожному співробітнику.
Вид оплати |
||||
В результаті отримаємо.
Мал. 4.23. Агрегатна функція з AS
Угруповання може бути здійснена і за кількома атрибутам:
FROM Ведомость1
GROUP BY Ід_сотр, Дата;
результат:
Мал. 4.24. Угруповання по декільком атрибутам
Якщо ж виникає необхідність обмежити число груп, отриманих після GROUP BY, то, використовуючи пропозицію HAVING, можна це реалізувати.
4.5. Використання фрази HAVING
Фраза HAVING грає таку ж роль для груп, що і фраза WHERE для рядків: вона використовується для виключення груп, точно так же, як WHERE використовується для виключення рядків. Ця фраза включається в пропозицію
лише при наявності фрази GROUP BY, а вираз в HAVING повинне приймати єдине значення для групи.
Наприклад, нехай треба видати кількісний склад усіх відділів (рис. 2.3), виключаючи відділ з номером 3.
SELECT Ід_Отд, COUNT (DISTINCT Ід_Отд) AS Кількість _сотрудніков
Отдел_ Співробітники |
||||
Дата звільнення |
||||
HAVING Ід_Отд< > 3; |
||||
Кол_во_сотрудніков |
||||
Останнім елементом при обчисленні табличного вираження використовується розділ HAVING (якщо він є). Синтаксис цього розділу наступний:
HAVING
Умова пошуку цього розділу задає умову на групу рядків згрупованої таблиці. Формально розділ HAVING може бути присутнім і в табличному вираженні, що не містить GROUP BY. У цьому випадку вважається, що результат обчислення попередніх розділів є сгруппированную таблицю, що складається з однієї групи без виділених стовпців групування.
Умова пошуку розділу HAVING будується за тими ж синтаксичними правилами, що і умова пошуку розділу WHERE, і може включати ті ж самі предикати.
Однак є спеціальні синтаксичні обмеження по частині використання в умови пошуку специфікацій стовпців таблиць з розділу FROM даного табличного вираження. Ці обмеження випливають з того, що умова пошуку розділу HAVING задає умову на цілу групу, а не на індивідуальні рядки.
Тому в арифметичних виразах предикатів, що входять в умову вибірки розділу HAVING, прямо можна використовувати тільки специфікації стовпців, зазначених в якості стовпців групування в розділі GROUP BY. Інші стовпці можна специфікувати тільки всередині специфікацій агрегатних функцій COUNT, SUM, AVG, MIN і MAX, що обчислюють в даному випадку деякий агрегатний значення для всієї групи рядків. Аналогічно іде справа з підзапитах, що входять в предикати умови вибірки розділу HAVING: якщо в підзапиті використовується характеристика поточної групи, то вона може здаватися тільки шляхом посилання на стовпці групування.
Нехай запит виду (в якості базової таблиці див. Рис. 4.22):
SELECT Ід_сотр, Дата, MAX ((Сума))
FROM Ведомость1
GROUP BY Ід_сотр, Дата;
необхідно уточнити тим, щоб були показані тільки виплати, що перевищує 1000.
Однак за стандартом агрегатную функцію в реченні WHERE використовувати заборонено (якщо ви не використовуєте підзапит, описаний пізніше), тому що предикати оцінюються в термінах одиночного рядка, а агрегатні функції оцінюються в термінах групи рядків.
Наступна пропозиція буде неправильним:
SELECT Ід_сотр, Дата, MAX (Сума)
FROM Ведомость1
WHERE MAX ((Сума))\u003e 1000 GROUP BY Ід_сотр, Дата;
Знову ж правильним пропозицією буде:
SELECT Ід_сотр, Дата, MAX ((Сума))
Угруповання даних дозволяє розділити всі дані на логічні набори, завдяки чому стає можливим виконання статистичних обчислень окремо в кожній групі.
1. Створення груп (GROUP BY)
Групи створюються за допомогою пропозиції GROUP BY оператора SELECT. Розглянемо на прикладі.
SELECT Product, SUM (Quantity) AS Product_num FROM Sumproduct GROUP BY Product
Даним запитом ми витягли інформацію про кількість реалізованої продукції в кожному місяці. оператор SELECT наказує вивести два стовпці Product - назва продукту і Product_num - розрахункове поле, яке ми створили для відображення кількості реалізованої продукції (формула поля SUM (Quantity)). Речення GROUP BY вказує СУБД згрупувати дані по стовпцю Product. Варто також відзначити, що GROUP BY повинен йти після пропозиції WHERE і перед ORDER BY.
2. Фільтруючі групи (HAVING)
Так само, як ми фільтрували рядки в таблиці, ми можемо здійснювати фільтрацію по згрупованих даних. Для цього в SQL існує оператор HAVING. Візьмемо попередній приклад і додамо фільтрацію по групах.
SELECT Product, SUM (Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM (Quantity)\u003e 4000

Бачимо, що після того, як була порахована кількість реалізованого товару в розрізі кожного продукту, СУБД "відсікла" ті продукти, яких було реалізовано менше 4000 шт.
Як бачимо, оператор HAVING дуже схожий на оператора WHERE, Проте між собою вони мають істотну відмінність: WHERE фільтрує дані до того, як вони будуть згруповані, а HAVING - здійснює фільтрацію після угруповання. Таким чином, рядки, які були вилучені пропозицією WHERE НЕ будуть включені в групу. Отже, оператори WHERE і HAVING можуть використовуватися в одному реченні. Розглянемо приклад:
SELECT Product, SUM (Quantity) AS Product_num FROM Sumproduct WHERE Product<>"Skis Long" GROUP BY Product HAVING SUM (Quantity)\u003e 4000
![]()
Ми до попереднього прикладу додали оператор WHERE, Де вказали товар Skis Long, Що в свою чергу вплинуло на групування оператором HAVING. Як результат бачимо, що товар Skis Long не потрапив до переліку груп з кількістю реалізованої продукції більше 4000 шт.
3. Угруповання і сортування
Як і при звичайній вибірці даних, ми можемо сортувати групи після угруповання оператором HAVING. Для цього ми можемо використовувати вже знайомий нам оператор ORDER BY. У даній ситуації його застосування аналогічне попереднім прикладам. Наприклад:
SELECT Product, SUM (Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM (Quantity)\u003e 3000 ORDER BY SUM (Quantity)
або просто вкажемо номер поля по порядку, за яким хочемо сортувати:
SELECT Product, SUM (Quantity) AS Product_num FROM Sumproduct GROUP BY Product HAVING SUM (Quantity)\u003e 3000 ORDER BY 2

Бачимо, що для сортування зведених результатів нам потрібно просто прописати пропозиції з ORDER BY після оператора HAVING. Однак є один нюанс. СУБД Access не підтримує сортування груп по псевдонімами колонок, тобто в нашому прикладі, щоб сортувати значення, ми не зможемо в кінці запиту прописати ORDER BY Product_num.
В рамках даної статті я розповім вам про те, як здійснюється угруповання даних, як правильно застосовувати group by і having всередині SQL-запитів на прикладі кількох запитів.
Більшість інформації в базах даних зберігаються в деталізованому вигляді. Однак, часто виникає необхідність отримати зведення. Наприклад, дізнатися загальне число коментарів користувачів або можливо кількість товару на складах. Подібних завдань маса. Тому в мові SQL спеціально для таких випадків передбачені конструкції group by і having, що дозволяють, відповідно, групувати і фільтрувати отримані групи даних.
Однак, їх застосування викликає чимало проблем у початківців авторів програмних творів. Вони не зовсім правильно трактують одержувані результати і сам механізм угруповання даних. Тому давайте розберемося на практиці що і як відбувається.
В рамках прикладу я буду розглядати лише одну таблицю. Причина проста, ці оператори застосовуються вже до отриманій вибірці даних (після об'єднання рядків таблиць і їх фільтрації). Так що від додавання операторів where і join суть не зміниться.
Уявімо собі абстрактний приклад. Припустимо у вас є зведена таблиця користувачів форуму. Назвемо її userstat і виглядає вона таким чином. Важливий момент, вважаємо, що учасник може належати тільки в одній групі.
user_name - ім'я користувача
forum_group - ім'я групи
mess_count - кількість повідомлень
is_have_social_profile - зазначений в профілі форумі посилання на сторінку в соціальній мережі
Як бачите, таблиця проста і багато речей можна самому порахувати на калькуляторі. Однак, це лише приклад і тут всього 10 записів. У реальних базах записи можуть вимірюватися тисячами. Тому приступимо до запитів.
Чистий угруповання за допомогою group by
Уявімо, що нам необхідно дізнатися цінність кожної групи, а саме середнє значення рейтингу користувачів в групі і загальне число повідомлень, залишених в форумі.
Спочатку, невелике словесний опис, щоб легше було розуміти SQL-запит. Отже, вам потрібно знайти обчислювані значення по групах форуму. Відповідно, вам потрібно поділити всі ці десять рядків на три різні групи: admin, moder, user. Щоб це зробити, потрібно в кінці запиту додати угруповання за значеннями поля forum_group. А так же додати в select обчислювані вирази з використанням так званих агрегатних функцій.
Вказуємо поля і обчислювані стовпці select forum_group, avg (raiting) as avg_raiting, sum (mess_count) as total_mess_count - вказуємо таблицю from userstat - вказуємо угруповання по полю group by forum_group
Зверніть увагу, що після того, як ви використовували конструкцію group by в запиті, можна без застосування агрегатних функцій використовувати тільки ті поля в select, які були вказані після group by. Решта поля повинні бути вказані всередині агрегатних функцій.
Так само я скористався двома агрегатними функціями. AVG - обчислює середнє значення. І SUM - обчислює суму.
| forum_group | avg_raiting | total_mess_count |
|---|---|---|
| admin | 4 | 50 |
| moder | 3 | 50 |
| user | 3 | 150 |
1. Спочатку все рядки вихідної таблиці були розбиті на три групи за значеннями поля forum_group. Наприклад, всередині групи admin було три користувача. Усередині moder так само 3 рядки. А всередині групи user було 4 рядки (чотири користувача).
2. Потім для кожної групи застосовувалися агрегатні функції. Наприклад, для групи admin середній рейтинг обчислювався так (2 + 5 + 5) / 3 \u003d 4. Кількість повідомлень обчислювалося так (10 + 15 + 25) \u003d 50.
Як бачите, нічого складного. Однак, ми застосували всього одна умова угруповання і не застосовували фільтрацію по групах. Тому перейдемо до наступного прикладу.
Групування за допомогою group by і фільтрацією груп з having
Тепер, розглянемо більш складний приклад угруповання даних. Припустимо нам потрібно оцінити ефективність дій по залученню користувачів до соціальної діяльності. Якщо по простому, то дізнатися скільки користувачів в групах залишило посилання на свої профілі, а скільки проігнорувало розсилки та інше. Однак, в реальному житті таких груп може бути багато, тому нам потрібно відфільтрувати ті групи, якими можна знехтувати (наприклад, занадто мало людей не залишило посилання; навіщо захаращувати повний звіт). У моєму прикладі це групи, де всього один користувач.
Спочатку, словесно опишемо що необхідно зробити в SQL-запиті. Нам потрібно все рядки вихідної таблиці userstat розділити за такими ознаками: ім'я групи і наявність соціального профілю. Відповідно, необхідно групувати дані таблиці по полях forum_group і is_have_social_profile. Однак, нас не цікавлять ті групи, де всього одна людина. Отже такі групи потрібно відфільтрувати.
Примітка: Варто знати, що це завдання можна було б вирішити і за допомогою угруповання тільки по одному полю. Якщо використовувати конструкцію case. Однак, в рамках даного прикладу показуються можливості саме угруповання.
Так само хотів би відразу уточнити один важливий момент. Фільтрувати за допомогою having можна тільки при застосуванні агрегатних функцій, а не по окремих полях. Іншими словами, це не конструкція where, це фільтр саме груп рядків, а не окремих записів. Хоча умови всередині задаються аналогічним чином за допомогою "or" та "and".
Ось як буде виглядати SQL-запит
Вказуємо поля і обчислювані стовпці select forum_group, is_have_social_profile, count (*) as total - вказуємо таблицю from userstat - вказуємо угруповання по полях group by forum_group, is_have_social_profile - вказуємо фільтр груп having count (*)\u003e 1
Зверніть увагу, що поля після конструкції group by вказуються через кому. Вказівка \u200b\u200bполів в select відбувається аналогічним чином, як і в попередньому прикладі. Так само я скористався агрегатної функцією count, яка обчислює кількість рядків в групах.
Ось який вийшов результат:
| forum_group | is_have_social_profile | total |
|---|---|---|
| admin | 1 | 2 |
| moder | 1 | 2 |
| user | 0 | 3 |
Давайте розберемо по кроках, як вийшов цей результат.
1. Спочатку було отримано 6 груп. Кожна з груп по forum_group була розбита на дві підгрупи за значеннями поля is_have_social_profile. Іншими словами групи:,,,,,.
Примітка: До речі, груп не обов'язково повинно було б вийде 6. Так, наприклад, якщо б всі адміністратори заповнили профіль, то груп було б 5, так як поле is_have_social_profile мало б тільки одне значення у користувачів групи admin.
2. Потім для кожної групи було застосовано умову фільтрації в having. Тому були виключені наступні групи:,,. Так як всередині кожної такої групи була присутня всього один рядок вихідної таблиці.
3. Після цього були обчислені необхідні дані і був отриманий результат.
Як бачите, нічого складно в використанні немає.
Варто знати, що в залежності від бази даних, можливості цих конструкцій можуть відрізнятися. Наприклад, агрегатних функцій може бути більше або ж можна вказувати в якості угруповання не окремі поля, а обчислювані стовпці. Цю інформацію вже необхідно дивитися в специфікації.
Тепер, ви знаєте як застосовувати угруповання даних з group by, а так само як фільтрувати групи за допомогою having.

Транслює запит SELECT у внутрішній план виконання ( «query plan»), який може відрізнятися навіть для синтаксично однакових запитів і від конкретної СУБД.
Оператор SELECT складається з декількох пропозицій (розділів):
- SELECT визначає список повертаються стовпців (як існуючих, так і обчислюваних), їх імена, обмеження на унікальність рядків в повернутому наборі, обмеження на кількість рядків у повернутому наборі;
- FROM задає табличное вираз, яке визначає базовий набір даних для застосування операцій, визначених в інших пропозиціях оператора;
- WHERE задає обмеження на рядки табличного вираження з пропозиції FROM;
- GROUP BY об'єднує ряди, що мають однакове властивість із застосуванням агрегатних функцій
- HAVING вибирає серед груп, певних параметром GROUP BY
- ORDER BY задає критерії сортування рядків; відсортовані рядки передаються в точку виклику.
структура оператора
Оператор SELECT має наступну структуру:
SELECT [DISTINCT | DISTINCTROW | ALL] select_expression, ... FROM table_references [WHERE where_definition] [GROUP BY (unsigned_integer | col_name | formula)] [HAVING where_definition] [ORDER BY (unsigned_integer | col_name | formula) [ASC | DESC], ...]
параметри оператора
ORDER BY
ORDER BY - необов'язковий (опціональний) параметр операторів SELECT і UNION, який означає що оператори SELECT , UNION повертають набір рядків, відсортованих за значеннями одного або більше стовпців. Його можна застосовувати як до числовим стовпцями, так і до строкових. В останньому випадку, сортування буде відбуватися за алфавітом.
Використання пропозиції ORDER BY є єдиним способом впорядкувати результуючий набір рядків. Без цієї пропозиції СУБД може повернути рядки в будь-якому порядку. Якщо впорядкування необхідно, ORDER BY повинен бути присутнім в SELECT, UNION.
Сортування може проводитися як по зростанню, так і по спадаючій значень.
- Параметр ASC (за замовчуванням) встановлює порядок сортування по зростанню, від менших значень до великих.
- Параметр DESC встановлює порядок сортування за спаданням, від великих значень до менших.
приклади
SELECT * FROM T;
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
SELECT C1 FROM T;
| C1 |
|---|
| 1 |
| 2 |
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
| C1 | C2 |
|---|---|
| 1 | a |
| C1 | C2 |
|---|---|
| 1 | a |
| 2 | b |
| C1 | C2 |
|---|---|
| 2 | b |
| 1 | a |
Для таблиці T запит
SELECT * FROM T;
поверне всі стовпці всіх рядків цієї таблиці. Для тієї ж таблиці запит
SELECT C1 FROM T;
поверне значення стовпця C1 всіх рядків табліци- в термінах реляційної алгебри проекція. Для тієї ж таблиці запит
поверне значення всіх стовпців всіх рядків таблиці, у яких значення поля C1 одно "1" - в термінах реляційної алгебри можна сказати, що була виконана вибірка, Так як присутня ключове слово WHERE. Останній запит
SELECT * FROM T ORDER BY C1 DESC;
поверне ті ж рядки, що і перший, проте результат буде відсортований у зворотному порядку (Z-A) через використання ключового слова ORDER BY з полем C1 в якості поля сортування. Цей запит не містить ключового слова WHERE, тому він поверне все, що є в таблиці. Кілька елементів ORDER BY можуть бути вказані розділені комами [напр. ORDER BY C1 ASC, C2 DESC] для більш точної сортування.
Відбирає всі рядки, де поле column_name одно одному з перерахованих значень value1, value2, ...
Повертає список ідентифікаторів відділів, продажі яких перевищили 1000 доларів за 1 січня 2000 року, разом з сумами продажів за цей день:
Обмеження повертаються рядків
Згідно ISO SQL: 2003 повертається набір даних може бути обмежений за допомогою:
- введенням віконних функцій в оператор SELECT
Віконна функція ROW_NUMBER ()
існують різні віконні функції. ROW_NUMBER () OVER може бути використана для простого обмеження числа повертаються рядків. Наприклад, для повернення не більше десяти рядків:
ROW_NUMBER може бути недетермінованим: якщо key не унікальний, кожен раз при виконанні запиту можливе присвоєння різних номерів рядків, у яких key збігається. коли key унікальний, кожен рядок буде завжди отримувати унікальний номер рядка.
Віконна функція RANK ()
Функція RANK () OVER працює майже так само, як ROW_NUMBER, але може повернути більш ніж n рядків при певних умовах. Наприклад, для отримання top-10 наймолодших людей:
Даний код може повернути більш ніж 10 рядків. Наприклад, якщо є дві людини з однаковим віком, він поверне 11 рядків.
нестандартний синтаксис
Не всі СУБД підтримують вищезгадані віконні функції. При цьому багато хто має нестандартний синтаксис для вирішення тих же завдань. Нижче представлені варіанти простого обмеження вибірки для різних СУБД:
| Виробник / СУБД | синтаксис обмеження |
|---|---|
| DB2 | (Підтримує стандарт, починаючи з DB2 Version 6) |
 Поява помилки під час запуску програм
Поява помилки під час запуску програм Плагін friGate для Firefox
Плагін friGate для Firefox Як показати приховані папки і файли в Windows
Як показати приховані папки і файли в Windows Способи, як зробити екран на ноутбуці яскравіше або темніше
Способи, як зробити екран на ноутбуці яскравіше або темніше Як форматувати флешку, диск захищений від запису
Як форматувати флешку, диск захищений від запису Якщо установка Windows на даний диск неможлива
Якщо установка Windows на даний диск неможлива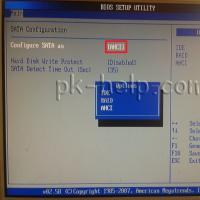 Під час установки Windows «Переконайтеся що контролер даного диска включений в меню bios комп'ютера
Під час установки Windows «Переконайтеся що контролер даного диска включений в меню bios комп'ютера