Suppression des enregistrements de la base de données SQL. Oracle - Supprimer - Supprimer le nom de la section de partition SQL Duplicate SQL
Suppression des enregistrements
Pour supprimer des enregistrements de la table, l'opérateur de suppression est appliqué:
Supprimer de Nametablitsa où condition;
Cet opérateur supprime l'enregistrement de la table spécifiée (et non des valeurs de colonne distinctes) qui répondent à la condition spécifiée. La condition est une expression logique, dont les différentes conceptions ont été prises en compte lors de classes de laboratoire précédentes.
La requête suivante supprime l'enregistrement de la table du client, dans lequel la valeur de la colonne LName est "Ivanov":
Supprimer du client.
Où lname \u003d "Ivanov"
Si le tableau contient des informations sur plusieurs clients avec le nom de famille d'Ivanov, ils seront tous supprimés.
Dans la déclaration où, il peut s'agir d'une sous-pièce à un échantillon de données (sélection de la déclaration). Les sous-requêtes dans l'opérateur de suppression fonctionnent de la même manière que dans la déclaration SELECT. La demande suivante supprime tous les clients de la ville de Moscou, tandis que l'identifiant de la ville unique est renvoyé à l'aide de la sous-requête.
Supprimer du client.
Où identité dans (sélectionnez l'identité de la ville où Name Name \u003d "Moscou")
Transact-SQL étend une SQL standard, vous permettant d'utiliser dans l'énoncé de suppression d'une autre. Cette extension dans laquelle la connexion est définie peut être utilisée à la place d'une requête investie dans la clause WHERE pour spécifier les lignes amovibles. Il vous permet de spécifier les données de la seconde à partir et de supprimer les lignes correspondantes de la table dans la première offre. En particulier, la demande précédente peut être réécrite comme suit.
Supprimer du client.
Du client k rejoindre interne
L'opération d'élimination des enregistrements de la table est dangereuse dans le sens, qui est associée au risque de perte de données irréversible dans le cas d'erreurs sémantiques (mais non syntaxiques) dans le libellé de l'expression SQL. Pour éviter les problèmes, il est recommandé d'exécuter d'abord la demande de sélection appropriée à afficher que les enregistrements seront supprimés. Par exemple, avant d'effectuer le précédent pris en compte, la demande de suppression n'empêchera pas la demande de sélection appropriée.
Sélectionnez *
Du client k rejoindre interne
City c sur k.idcity \u003d c.idcity et c.CityName \u003d "Moscou"
Pour supprimer tous les enregistrements de la table, il suffit d'utiliser l'instruction DELETE sans le mot clé où. Dans le même temps, la table avec toutes les colonnes définies est définie et est prête à insérer de nouveaux enregistrements. Par exemple, la requête suivante supprime des enregistrements de tous les biens.
Supprimer du produit.
Tâche pour un travail indépendant: Formuler dans la demande de langue SQL pour supprimer toutes les commandes qui n'ont pas de produit (c'est-à-dire toutes les commandes vides).
Suppression de lignes répétitives de la table dans Oracle (14)
Solution 1)
Supprimer de EMP Où Rowid pas dans (Sélectionnez Max (Rowid) du groupe EMP par EMPNO);Solution 2)
Supprimer de EMP où Rowid Rowid Rid, Row_Number par EMPNO) RN de EMP) Où RN\u003e 1);Solution 3)
Je teste quelque chose dans Oracle et remplir la table avec quelques exemples de données, mais dans le processus, j'ai accidentellement chargé les doublons des enregistrements, je ne peux donc pas créer une clé primaire en utilisant certaines des colonnes.
Comment supprimer toutes les lignes répétitives et laisser un seul d'entre eux?
Pour une meilleure performance, c'est ce que j'ai écrit:
(Voir Plan d'exécution)
Supprimer de votre_table où Rowid in (Sélectionnez T1.ROWID à partir de votre joint externe gauche de T1 (Sélectionnez Min (Rowid) comme Rowid, Colonne1, Columin2, Colonne3 de votre groupe de colonne1, Colonne2, Colonne3) CO1 On (T1.ROWID \u003d CO1. Rowid) où co1.rowid est null);
Vérifiez ci-dessous les scripts -
Créer un test de table (ID INT, Sal int);
Insérer dans les valeurs de test (1 100); Insérer dans les valeurs de test (1 100); Insérer dans les valeurs de test (2 200); Insérer dans les valeurs de test (2 200); Insérer dans les valeurs de test (3 300); Insérer dans les valeurs de test (3 300); S'ENGAGER;
Sélectionnez * à partir du test;
Vous verrez ici 6 enregistrements.
4.Run sous la requête -
Supprimer du test dans lequel Rowid In (Sélectionnez Rowid de (Sélectionnez Rowid Row_Number () sur (Partition par ordre d'identité par SAL) DUP de Test) Où DUP\u003e 1)
- sélectionnez * à partir du test;
Vous verrez que les doublons des enregistrements ont été supprimés.
J'espère que cela résout votre demande. Merci :)
Pour sélectionner des doublons, seul le format de la demande peut être:
Sélectionnez GroupFunction (colonne1), groupe de groupe (Colonne2), ..., Compte (colonne1), colonne1, colonne2 ... de notre groupe_Table par colonne1, colonne2, colonne3 ... ayant le nombre (colonne1)\u003e 1
Ainsi, la demande correcte sur une autre suggestion:
Supprimer de Tablename A Où A.Orowid\u003e Tout (Select B.Orowid de TableMame B Où A.FieldName \u003d B.FieldName et A.FieldName2 \u003d B.FieldName2 et .... Pour identifier les lignes en double .. ..)
Cette requête enregistre l'enregistrement le plus ancien de la base de données pour les critères sélectionnés dans la clause WHERE.
Oracle Certified Associé (2008)
Je n'ai pas vu les réponses qui utilisent des expressions générales de table et des fonctions de fenêtres. C'est ce qui facilite la tâche de travailler.
Supprimer de votre carte où Rowid in (avec des doublons comme (Sélectionnez Rowid Rid, Row_Number () sur (Partition par First_Name, Last_Name, Naissance de Naissance) comme RN Sum (1) sur (Partition par Name_Name, Last_Date Order Order_Date Order par Rowid Rows entre illencée précédente Et illimité suivant) comme cnt de votre carte où load_date est null) Sélectionnez RID des duplicats où RN\u003e 1);
Que doit être noté:
1) Nous ne vérifions que des champs en double dans la section.
2) Si vous avez une raison de choisir un duplicata sur d'autres personnes, vous pouvez utiliser la commande par offre afin que cette ligne puisse avoir Row_Number () \u003d 1
3) Vous pouvez modifier le duplicata du numéro enregistré en modifiant l'offre finale de l'endroit où "où rn\u003e n" avec n\u003e \u003d 1 (je pensais que n \u003d 0 supprimera toutes les lignes avec des doublons, mais supprimez simplement toutes les lignes. ),
4) Ajout de la section de champ de champ, la requête CTE, qui épousera chaque nombre de lignes de précision du groupe. Par conséquent, pour sélectionner des lignes avec des doublons, y compris le premier élément, utilisez "où CNT\u003e 1".
1. demande
Supprimer de EMP Où Rowid pas dans (Sélectionnez Max (Rowid) du groupe EMP par EMPNO);
2. Slution
Supprimer de EMP où Rowid Rowid Rid, Row_Number par EMPNO) RN de EMP) Où RN\u003e 1);
3.Solution
Supprimer de EMP E1 Où Rowid pas dans (Sélectionnez max (Rowid) à partir d'EMP E2 où E1.empno \u003d e2.empno);
4. demande
Supprimer de EMP Où Rowid Rowd Rid, Dense_Rank () Over (Partition par Empno Ordre par Rowid) RN de EMP) Où RN\u003e 1);
Créer ou remplacer la procédure Delete_Duplicate_enq en tant que curseur C1 est sélectionnée * de l'enquête; Commencez pour Z en boucle C1 Supprimer une enquête où Enquiry.Enquiryno \u003d Z.Nquiryno et Rowid\u003e Tout (sélectionnez Rowid de la demande où Enquiry.enquiryno \u003d Z.ENQUIRYNO); Boucle de fin; Fin delete_duplicate_enq;
Créer une table ABCD (numéro d'identification (10), nom Varchar2 (20)) Insertion dans les valeurs ABCD (1, "ABC") Insérer dans les valeurs ABCD (2, "PQR") Insérer dans les valeurs ABCD (3, "xyz") insert Dans les valeurs ABCD (1, "ABC") Insérer dans des valeurs ABCD (2, "PQR") Insérer dans des valeurs ABCD (3, "XYZ") Sélectionnez * Nom de l'identifiant ABCD 1 ABC 2 PQR 3 XYZ 1 ABC 2 PQR 3 XYZ Supprimer un enregistrement en double, mais gardez un enregistrement distinct dans le tableau Supprimer de ABCD A d'ABCD A Où Rowid\u003e (Sélectionnez Min (Rowid) de ABCD B Où B.Id \u003d A.Id); Exécutez la requête ci-dessus 3 lignes Supprimer Select * du nom d'identification ABCD 1 ABC 2 PQR 3 XYZ
retrait par Rowid Oracle (14)
Je teste quelque chose dans Oracle et remplir la table avec quelques exemples de données, mais dans le processus, j'ai accidentellement chargé les doublons des enregistrements, je ne peux donc pas créer une clé primaire en utilisant certaines des colonnes.
Comment supprimer toutes les lignes répétitives et laisser un seul d'entre eux?
Solution 1)
Supprimer de EMP Où Rowid pas dans (Sélectionnez Max (Rowid) du groupe EMP par EMPNO);Solution 2)
Supprimer de EMP où Rowid Rowid Rid, Row_Number par EMPNO) RN de EMP) Où RN\u003e 1);Solution 3)
Pour une meilleure performance, c'est ce que j'ai écrit:
(Voir Plan d'exécution)
Supprimer de votre_table où Rowid in (Sélectionnez T1.ROWID à partir de votre joint externe gauche de T1 (Sélectionnez Min (Rowid) comme Rowid, Colonne1, Columin2, Colonne3 de votre groupe de colonne1, Colonne2, Colonne3) CO1 On (T1.ROWID \u003d CO1. Rowid) où co1.rowid est null);
Vérifiez ci-dessous les scripts -
Créer un test de table (ID INT, Sal int);
Insérer dans les valeurs de test (1 100); Insérer dans les valeurs de test (1 100); Insérer dans les valeurs de test (2 200); Insérer dans les valeurs de test (2 200); Insérer dans les valeurs de test (3 300); Insérer dans les valeurs de test (3 300); S'ENGAGER;
Sélectionnez * à partir du test;
Vous verrez ici 6 enregistrements.
4.Run sous la requête -
Supprimer du test dans lequel Rowid In (Sélectionnez Rowid de (Sélectionnez Rowid Row_Number () sur (Partition par ordre d'identité par SAL) DUP de Test) Où DUP\u003e 1)
- sélectionnez * à partir du test;
Vous verrez que les doublons des enregistrements ont été supprimés.
J'espère que cela résout votre demande. Merci :)
Pour sélectionner des doublons, seul le format de la demande peut être:
Sélectionnez GroupFunction (colonne1), groupe de groupe (Colonne2), ..., Compte (colonne1), colonne1, colonne2 ... de notre groupe_Table par colonne1, colonne2, colonne3 ... ayant le nombre (colonne1)\u003e 1
Ainsi, la demande correcte sur une autre suggestion:
Supprimer de Tablename A Où A.Orowid\u003e Tout (Select B.Orowid de TableMame B Où A.FieldName \u003d B.FieldName et A.FieldName2 \u003d B.FieldName2 et .... Pour identifier les lignes en double .. ..)
Cette requête enregistre l'enregistrement le plus ancien de la base de données pour les critères sélectionnés dans la clause WHERE.
Oracle Certified Associé (2008)
Je n'ai pas vu les réponses qui utilisent des expressions générales de table et des fonctions de fenêtres. C'est ce qui facilite la tâche de travailler.
Supprimer de votre carte où Rowid in (avec des doublons comme (Sélectionnez Rowid Rid, Row_Number () sur (Partition par First_Name, Last_Name, Naissance de Naissance) comme RN Sum (1) sur (Partition par Name_Name, Last_Date Order Order_Date Order par Rowid Rows entre illencée précédente Et illimité suivant) comme cnt de votre carte où load_date est null) Sélectionnez RID des duplicats où RN\u003e 1);
Que doit être noté:
1) Nous ne vérifions que des champs en double dans la section.
2) Si vous avez une raison de choisir un duplicata sur d'autres personnes, vous pouvez utiliser la commande par offre afin que cette ligne puisse avoir Row_Number () \u003d 1
3) Vous pouvez modifier le duplicata du numéro enregistré en modifiant l'offre finale de l'endroit où "où rn\u003e n" avec n\u003e \u003d 1 (je pensais que n \u003d 0 supprimera toutes les lignes avec des doublons, mais supprimez simplement toutes les lignes. ),
4) Ajout de la section de champ de champ, la requête CTE, qui épousera chaque nombre de lignes de précision du groupe. Par conséquent, pour sélectionner des lignes avec des doublons, y compris le premier élément, utilisez "où CNT\u003e 1".
1. demande
Supprimer de EMP Où Rowid pas dans (Sélectionnez Max (Rowid) du groupe EMP par EMPNO);
2. Slution
Supprimer de EMP où Rowid Rowid Rid, Row_Number par EMPNO) RN de EMP) Où RN\u003e 1);
3.Solution
Supprimer de EMP E1 Où Rowid pas dans (Sélectionnez max (Rowid) à partir d'EMP E2 où E1.empno \u003d e2.empno);
4. demande
Supprimer de EMP Où Rowid Rowd Rid, Dense_Rank () Over (Partition par Empno Ordre par Rowid) RN de EMP) Où RN\u003e 1);
Créer ou remplacer la procédure Delete_Duplicate_enq en tant que curseur C1 est sélectionnée * de l'enquête; Commencez pour Z en boucle C1 Supprimer une enquête où Enquiry.Enquiryno \u003d Z.Nquiryno et Rowid\u003e Tout (sélectionnez Rowid de la demande où Enquiry.enquiryno \u003d Z.ENQUIRYNO); Boucle de fin; Fin delete_duplicate_enq;
Créer une table ABCD (numéro d'identification (10), nom Varchar2 (20)) Insertion dans les valeurs ABCD (1, "ABC") Insérer dans les valeurs ABCD (2, "PQR") Insérer dans les valeurs ABCD (3, "xyz") insert Dans les valeurs ABCD (1, "ABC") Insérer dans des valeurs ABCD (2, "PQR") Insérer dans des valeurs ABCD (3, "XYZ") Sélectionnez * Nom de l'identifiant ABCD 1 ABC 2 PQR 3 XYZ 1 ABC 2 PQR 3 XYZ Supprimer un enregistrement en double, mais gardez un enregistrement distinct dans le tableau Supprimer de ABCD A d'ABCD A Où Rowid\u003e (Sélectionnez Min (Rowid) de ABCD B Où B.Id \u003d A.Id); Exécutez la requête ci-dessus 3 lignes Supprimer Select * du nom d'identification ABCD 1 ABC 2 PQR 3 XYZ
Oracle vous permet de supprimer des lignes des tables, des vues, des représentations matérialisées, des sous-requêtes et des vues partitionnées et des tables comme suit.
(Nachetables | Seulement (nom_ttable)) [pseudonyme] [(partition) Souspartition
(nom)))] | (sous-requête)]) | Table (expression_lit_collection) [(+)])
Dans la variable [, ...]]
Les paramètres sont indiqués ci-dessous.
name_table [pseudonyme]
Spécifie la table, la représentation, la visualisation matérialisée ou la table ou la vue partitionnée, d'où les enregistrements seront supprimés. Si vous le souhaitez, vous pouvez envoyer le schéma Name_table spécifier le schéma ou spécifier après le nom de la connexion de la table à la base de données. Sinon, le système Oracle utilisera le diagramme actuel et le serveur de base de données local. Si vous le souhaitez, vous pouvez attribuer un nom de pseudonyme. Le pseudonyme est nécessaire si la table fait référence à la méthode d'attribut ou de type d'objet.
Section du nom de partition
L'opération DELETTION s'applique à la partition spécifiée et non à la table entière. Lorsque vous supprimez d'une table partitionnée, il n'est pas nécessaire de spécifier le nom de la partition, mais cela contribue dans de nombreux cas pour réduire la complexité de l'offre de l'endroit où.
Subpartition)
L'élimination s'applique à la sous-section spécifiée et non à la table entière.
(sous-requête)])
Il est indiqué que le but de l'opération d'élimination est une sous-requête imbriquée, et non une table, une représentation ou un autre objet de base de données. Les paramètres de cette proposition sont les suivants.
sous-requête
L'instruction SELECT est spécifiée, qui est une sous-requête. Vous pouvez créer une sous-requête standard, mais elle ne peut pas contenir d'ordre par des offres.
Avec lecture seule
Il est indiqué que la sous-requête ne peut pas être mise à jour.
Avec option de contrôle
Le système Oracle déviera les modifications apportées à la table distante qui ne sont pas visibles dans le jeu de données de sous-équipage résultant.
Contrainte Name_name
Le système Oracle limitera les modifications apportées à la base de la restriction avec le nom Name_Name.
Tableau (expression pour rouler) [(+)]
Le système Oracle traitera des expressions de la diversité comme une table, bien qu'elle puisse être une sous-requête, une fonction ou un autre constructeur de la collection. Dans tous les cas, la valeur renvoyée par l'expression pour le roulement doit être une table imbriquée ou Varray.
Expression de retour
Rangées affectées par la commande où la commande DELETE ne renvoie généralement que le nombre de chaînes distantes. La proposition de retour peut être utilisée si l'objectif de la commande est un tableau, une vue matérialisée ou une représentation d'une table de base. Si l'offre est utilisée lors de la suppression d'une seule ligne, les valeurs de la chaîne distante, définie par l'expression sont stockées dans des variables PL / SQL et des variables de liaison (variables de liaison). Si la proposition est utilisée lors de la suppression de nombreuses lignes, les valeurs des chaînes distantes qui sont déterminées par l'agriculture et m sont stockées dans des tableaux de liaison (réseaux de liaison).
En variable
Spécifiez les variables dans lesquelles les valeurs renvoyées à la suite de la proposition du retour.
Lors de l'exécution de l'instruction DELETE Oracle, renvoie la place à la table ou à l'index dans lequel les données ont été stockées dans la table (ou la table de base).
Si les données sont supprimées de la présentation, la vue ne peut pas contenir des opérations via les ensembles, le mot-clé distinct, les connexions, la fonction d'agrégat, la fonction analytique, les sous-requêtes Sélectionnez, propose un groupe par, propose une commande par, des offres de connexion par ou de commencer l'esprit.
Vous trouverez ci-dessous un exemple dans lequel nous supprimons les données d'un serveur distant.
Supprimer de Scott. [Email protégé];
Dans l'exemple suivant
nous supprimons les données du tableau spécifiées dans l'expression de la collection.
Supprimer la table (sélectionnez ContactName des clients
avec où c.customérid \u003d "bouteille") S où l'art. La région est NULL ou S.Country \u003d "Mexico";
Mais un exemple de suppression de la section.
Supprimer de la partition de vente (Sales_Q3_1997) où la Qté\u003e 10000;
Enfin, dans l'exemple suivant, nous utilisons la proposition de retour pour voir des valeurs distantes.
Supprimer de l'employé où Job_id \u003d 13
Et hire_date + to_yminterval ("01-06") \u003d.
Dans l'exemple précédent, les entrées de la table des employés sont supprimées et les valeurs de J obi VL sont renvoyées à une variable prédéterminée: Intol.
 Apparence d'erreur lors du lancement du programme
Apparence d'erreur lors du lancement du programme Plugin de frégate pour Firefox
Plugin de frégate pour Firefox Comment montrer des dossiers cachés et des fichiers sous Windows
Comment montrer des dossiers cachés et des fichiers sous Windows Façons comment faire un écran sur un ordinateur portable plus brillant ou plus sombre
Façons comment faire un écran sur un ordinateur portable plus brillant ou plus sombre Comment formater un lecteur flash, protection de disque
Comment formater un lecteur flash, protection de disque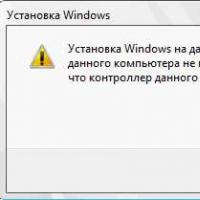 Si l'installation de Windows sur ce disque n'est pas possible
Si l'installation de Windows sur ce disque n'est pas possible Lors de l'installation de Windows "Assurez-vous que le contrôleur de ce disque est inclus dans le menu BIOS de l'ordinateur.
Lors de l'installation de Windows "Assurez-vous que le contrôleur de ce disque est inclus dans le menu BIOS de l'ordinateur.