Datos de cubos. Introducción a las bases de datos OLAP y multidimensionales.
Anotación: Esta conferencia discute la base del diseño de los Cachorros de Datos para los almacenes de datos OLAP. El ejemplo muestra el método para construir un cubo de datos utilizando una herramienta de caja.
El propósito de la conferencia.
Después de examinar el material de la conferencia actual, lo sabrá:
- ¿En qué se trata los datos del cubo? Almacén de datos OLAP ;
- cómo diseñar datos de cubo para Almacenes de datos OLAP ;
- ¿Cuál es la medición del cubo de datos?
- como un hecho se asocia con el cubo de datos;
- ¿Qué son los atributos de medición?
- ¿Qué es la jerarquía?
- ¿Qué es una métrica de datos de cubo?
y aprender:
- construir diagramas multidimensionales ;
- diseño ordinario diagramas multidimensionales.
Introducción
La tecnología OLAP no se toma por separado software, no lenguaje de programación. Si intenta cubrir OLAP en todas sus manifestaciones, este conjunto de conceptos, principios y requisitos que subyacen a los productos de software que facilitan el acceso a los datos.
Los analistas son los principales consumidores de información corporativa. Una tarea analítica es encontrar regularidades en grandes matrices de datos. Por lo tanto, el analista no prestará atención a un hecho separado de que, en un día determinado, el comprador de Ivanov fue vendido por una fiesta de bolas de globos, "necesita información sobre cientos y miles de eventos similares. Los hechos individuales en HD pueden interesar, por ejemplo, un contador o jefe del departamento de ventas, cuyas competencias están respaldadas por un determinado contrato. Analítica de una entrada no es suficiente: para él, por ejemplo, puede ser necesario para todos los contratos para el mes de venta por mes, trimestre u año. El análisis puede no estar interesado en el comprador positivo o su teléfono, funciona con datos numéricos específicos, que es la esencia de sus actividades profesionales.
La centralización y la estructuración conveniente no es todo lo que se necesita por análisis. Necesita una herramienta para ver, visualizar información. Los informes tradicionales, incluso construidos sobre la base de una sola HD, están privados, sin embargo, cierta flexibilidad. No pueden ser "Twist", "implementar" o "colapso" para obtener la presentación de datos necesaria. Cuantas más, las "secciones" y los "recortes" de estos analistas pueden investigar, mayores las ideas que, a su vez, requieren todos los "recortes" nuevos y nuevos para verificar. Como una herramienta para investigar datos, OLAP es el analista.
Aunque OLAP y no constituye el atributo necesario de HD, se usa cada vez más a menudo para analizar la información acumulada en esto.
Los datos operativos se recopilan de varias fuentes, limpian, se integran y se plegan en HD. Al mismo tiempo, ya están disponibles para su análisis utilizando diversos medios de creación de informes. Luego, los datos (en su totalidad o en parte) se preparan para el análisis OLAP. Se pueden cargar en una base de datos OLAP especial o a la izquierda en Relacional XD. El elemento más importante de usar OLAP son metadatos, es decir, información sobre la estructura, la colocación y transformación de datos. Gracias a ellos, se garantiza la interacción efectiva de varios componentes de almacenamiento.
De este modo, OLAP se puede definir como un conjunto de medios de análisis multidimensional de los datos acumulados en HD. Teóricamente, las herramientas OLAP se pueden aplicar directamente a los datos operativos o sus copias exactas. Sin embargo, existe el riesgo de analizar los datos que no son adecuados para este análisis.
OLAP en el cliente y en el servidor
OLAP se basa en el análisis de datos multidimensional. Se puede producir utilizando varios medios que se pueden dividir en los olps de cliente y servidores.
Los olps de clientes son aplicaciones que calculan datos agregados (sumas, valores promedio, valores máximos o mínimos) y su pantalla, mientras que los datos agregados en sí se encuentran en el caché dentro del espacio de direcciones de tal OLAP.
Si los datos iniciales están contenidos en los DBMS de escritorio, el Cálculo de los datos agregados se realiza mediante OLAP. Si la fuente de datos de origen es un DBMS del servidor, muchos de los OLAP del cliente se envían al servidor de grabadora SQL que contiene el grupo por instrucción, y como resultado, se obtienen datos agregados calculados en el servidor.
Como regla general, la función OLAP se implementa en los medios de procesamiento de datos estadísticos (los productos de Stat Soft y las compañías SPSS están muy extendidas en el mercado ruso) y en algunas hojas de cálculo. En particular, Microsoft Excel 2000 tiene buenos medios de análisis multidimensional. Con este producto, puede crear y guardar un pequeño OLAP multidimensional local en forma de un archivo y mostrarlo dos secciones o tridimensionales.
Muchos herramientas de desarrollo Contienen bibliotecas de clases o componentes que le permiten crear aplicaciones que implementan la funcionalidad OLAP más sencilla (como, por ejemplo, como componentes de Cubo de Decisión en Borland Delphi y Borland C ++ Builder). Además, muchas compañías ofrecen. elementos de control ActiveX y otras bibliotecas que implementan una funcionalidad similar.
Tenga en cuenta que los usos del cliente OLAP se utilizan, como regla general, con un pequeño número de mediciones (generalmente no más de seis) y una pequeña variedad de valores de estos parámetros, después de todo, los datos agregados obtenidos deben ser alimentados en el Dirección del espacio de este medio, y su número está creciendo exponencialmente con mediciones de números crecientes. Por lo tanto, incluso la OLAP del cliente más primitiva es la de la aservación, como regla general, le permite contar preliminarmente el volumen de la RAM requerida para crear un cubo multidimensional.
Muchos (pero no todos) La protección contra OLAP de (pero no todas) le permite guardar los contenidos del caché con datos agregados como un archivo, que, a su vez, no les permite volver a calcular. Cabe señalar que esta posibilidad se usa a menudo para alienar los datos agregados para transferirlos a otras organizaciones o para su publicación. Un ejemplo típico de tales datos agregados alienados son las estadísticas de incidencia en diferentes regiones y en varios grupos de edad, que es información abierta publicada por el Ministerio de Salud de varios países y la Organización Mundial de la Salud. Al mismo tiempo, los datos iniciales, que es información sobre casos específicos de enfermedades, son datos confidenciales de las instituciones médicas y, en ningún caso, no deben caer en manos de las compañías de seguros y, especialmente, convertirse en publicidad.
La idea de guardar un caché con datos agregados en el archivo ha recibido su desarrollo adicional en los Olaps de servidor, que ahorra y cambia los datos agregados, así como el soporte de almacenamiento que los contiene, se llevan a cabo una aplicación o un proceso separado llamado OLAP servidor. Las aplicaciones de clientes pueden solicitar un almacenamiento multidimensional similar y en respuesta a recibir ciertos datos. Algunas aplicaciones de clientes también pueden crear tiendas de tales o actualizarlas de acuerdo con los datos de origen modificados.
Las ventajas de la aplicación de los usos del servidor OLAP en comparación con los clientes de OLAP del cliente son similares a las ventajas de la aplicación de DBMS del servidor en comparación con los escritorios: Si se usan las herramientas del servidor, el cálculo y el almacenamiento de los datos agregados se producen en el servidor, y la aplicación cliente recibe solo Los resultados de las solicitudes a ellos, que permiten en general, reducen el tráfico de la red, tiempo de espera Solicitudes y requisitos para los recursos consumidos por la aplicación del cliente. Tenga en cuenta que el análisis y el procesamiento de los datos de la escala empresarial generalmente se basan en el servidor OLAP-Service, como Oracle Express Server, Servicios de análisis de Microsoft SQL Server 2000, Hyperion Essbase, productos de las decisiones de cristal, objetos comerciales, Cognos, Instituto SAS. Debido a que todos los fabricantes líderes de DBMS de servidor se producen (o con licencia de otras compañías) aquellos u otros usos del servidor OLAP, la elección de ellos es bastante amplia, y casi en todos los casos puede comprar un servidor OLAP del mismo fabricante que la base de datos servidor en sí.
Tenga en cuenta que muchos usos de OLAP del cliente (en particular, Microsoft Excel 2003, Seagate Analysis, etc.) le permiten acceder a las instalaciones de almacenamiento OLAP del servidor, que actúan en este caso como aplicaciones de clientes que realizan dichas solicitudes. Además, hay bastantes productos que son aplicaciones de clientes al uso de OLAP de varios fabricantes.
Aspectos técnicos del almacenamiento de datos multidimensionales.
El HD multidimensional contiene datos agregados de diversos grados de detalles, como los volúmenes de ventas de días, meses, años, por categorías de bienes, etc. El propósito de almacenar datos agregados es reducir tiempo de espera Las solicitudes, ya que en la mayoría de los casos no se detallan, y los datos totales son interesantes para el análisis y los pronósticos. Por lo tanto, al crear una base de datos multidimensional, algunos datos agregados siempre se calculan y guardan.
Tenga en cuenta que la preservación de todos los datos agregados no siempre está justificada. El hecho es que al agregar nuevas mediciones, la cantidad de componentes de datos del cubo está creciendo exponencialmente (a veces hablan sobre el "crecimiento explosivo" del volumen de datos). Si hablamos de manera más precisa, el grado de crecimiento de los datos agregados depende de la cantidad de mediciones de los miembros del cubo y la medición en varios niveles de las jerarquías de estas mediciones. Para resolver el problema del "crecimiento explosivo", se utilizan una variedad de esquemas para permitir, al calcular, no todos los datos agregados posibles logran una velocidad aceptable de consultas.
Los datos de origen y agregados se pueden almacenar en estructuras relacionales o multidimensionales. Por lo tanto, actualmente se aplican tres formas de almacenar datos.
- MOLAP. (OLAP multidimensional): la fuente y los datos agregados se almacenan en una base de datos multidimensional. El almacenamiento de datos en estructuras multidimensionales permite que los datos se manipulen como una matriz multidimensional, debido a que la tasa de cálculo de los valores agregados es la misma para cualquier medida. Sin embargo, en este caso, la base de datos multidimensional es redundante, ya que los datos multidimensionales contienen completamente los datos relacionales de origen.
- Rolap. (OLAP relacional): los datos iniciales permanecen en la misma base de datos relacional, donde fueron originalmente y fueron. Los datos agregados se colocan en las tablas de servicio creadas específicamente para su almacenamiento en la misma base de datos.
- Hollar (OLAP híbrido): los datos iniciales permanecen en la misma base de datos relacional, donde se mantuvieron originalmente, y los datos agregados se almacenan en una base de datos multidimensional.
Algunos OLAP utilizan el almacenamiento de datos de soporte solo en estructuras relacionales, algunas son solo en multidimensional. Sin embargo, la mayoría de los olps de servidor modernos son compatibles con los tres métodos de almacenamiento de datos. La selección del método de almacenamiento depende del volumen y la estructura de los datos de origen, los requisitos para la velocidad de ejecución de las solicitudes y la frecuencia de actualización de OLAP -CUS.
También observamos que la gran mayoría de los usos de OLAP modernos no almacenan valores "vacíos" (un ejemplo de valor "vacío" puede ser la falta de venta de productos estacionales fuera de la temporada).
Conceptos básicos OLAP
Prueba FAMSI.
La tecnología de análisis integral de datos multidimensionales se denominó OLAP (procesamiento analítico en línea). OLAP es el componente clave de la organización HD. El concepto OLAP se describió en 1993 por Edgar Coddo, un investigador de base de datos conocido y el autor del modelo de datos relacionales. En 1995, según los requisitos establecidos por el Código, fue formulado por el llamado prueba FASMI. Análisis rápido de la información multidimensional compartida: un análisis rápido de la información multidimensional compartida, que incluye los siguientes requisitos para aplicaciones de análisis multidimensionales:
- Rápido. (Rápido): proporcionar al usuario a los resultados del usuario para un tiempo aceptable (generalmente no más de 5 segundos), incluso si el precio es menor que el análisis detallado;
- Análisis. (Análisis): la capacidad de implementar cualquier característica de análisis lógico y estadístico de esta solicitud, y su ahorro en accesible al usuario final;
- Compartido. (Compartido): el acceso multijugador a los datos con el apoyo de los mecanismos relevantes de bloqueos y medios de acceso autorizado;
- Multidimensional (Multidimensional) - Presentación conceptual multidimensional de datos, incluido el apoyo total para jerarquías y múltiples jerarquías (este es el requisito clave OLAP);
- Información (Información): la solicitud debe poder acceder a cualquier información necesaria, independientemente de su ubicación de volumen y almacenamiento.
Cabe señalar que la funcionalidad OLAP se puede implementar de varias maneras, comenzando con los medios más simples para analizar los datos en aplicaciones de oficina y finalizar con sistemas analíticos distribuidos basados \u200b\u200ben productos del servidor.
Presentación multidimensional del informe.
Cuba
OLAP ofrece herramientas convenientes de acceso de alta velocidad, visualizando y analizando información comercial. El usuario se pone natural, intuitivamente comprensible. modelo de datos, organizándolos en forma de cubos multidimensionales (cubos).. Los ejes del sistema de coordenadas multidimensionales sirven como los principales atributos del proceso de negocio analizado. Por ejemplo, para las ventas, puede ser un producto, región, tipo de comprador. El tiempo se utiliza como una de las medidas. En las intersecciones de los ejes de medición (dimensiones), hay datos, caracterizando cuantitativamente el proceso: medidas (medidas). Estos pueden ser volúmenes de ventas en piezas o en términos monetarios, los restos en stock, costos, etc. La información que analiza el usuario puede "cortar" un cubo en diferentes direcciones, obtener consolidado (por ejemplo, por año) o, por el contrario, Información detallada (durante semanas) y ejerce otras manipulaciones que vendrán a la mente en el proceso de análisis.
Como medidas en una cuba tridimensional mostrada en la FIG. 26.1, usó cantidades de ventas, y como medición: tiempo, producto y tienda. Las mediciones se presentan en ciertos niveles de agrupación: los productos se agrupan por categorías, talleres, por país y datos en el momento de las operaciones, por meses. Un poco más tarde, veremos más los niveles de agrupación (jerarquía).
Higo. 26.1.
Cubo cubo
Incluso el cubo tridimensional es difícil de mostrar en la pantalla de la computadora para que los valores de las medidas de interés sean visibles. Qué hablar de cubos con el número de mediciones, los tres grandes. Para visualizar los datos almacenados en Cuba, generalmente habituales de dos dimensiones, es decir, vistas tabulares que tienen títulos complejos jerárquicos de filas y columnas.
La vista bidimensional del cubo se puede obtener al "reducir" a través de uno o más ejes (mediciones): fijamos los valores de todas las mediciones, excepto dos, y obtenemos una tabla de dos dimensiones convencionales. En el eje horizontal de la tabla (encabezados de columna), se presenta una medición, en la vertical (encabezados de cadena), la otra, y en las celdas de la tabla, los valores de las medidas. Al mismo tiempo, el conjunto de medidas se considera en realidad como una de las medidas: seleccionamos una medida (y luego podemos colocar dos mediciones en los encabezados y columnas), o mostrar varias medidas (y luego una de las ejes de la tabla Tomará los nombres de las medidas y el otro, los valores de la única medición "no adoptada").
(Niveles). Por ejemplo, las etiquetas presentadas no son compatibles con todas las OLAP. Por ejemplo, ambos tipos de jerarquías son compatibles con Microsoft Analysis Services 2000, y Microsoft Olap Services 7.0 solo está equilibrado. El número de niveles de jerarquía, y el número máximo permisible de miembros de un nivel, y el número máximo posible de mediciones en sí mismo puede ser diferente en diferentes herramientas OLAP.Arquitectura de aplicaciones OLAP
Todo lo que se mencionó anteriormente OLAP, de hecho, se relaciona con la presentación de datos multidimensionales. La forma en que se almacenan los datos, no se encargan de que no se preocupe si el usuario final ni los desarrolladores de herramientas al que usa el cliente.
La multidimensionalidad en las aplicaciones OLAP se puede dividir en tres niveles.
- Representación de datos multidimensionales: herramientas de usuario final que proporcionan visualización multidimensional y manipulación de datos; La capa de representación multidimensional se abstiene de la estructura de datos físicas y percibe los datos como multidimensional.
- Procesamiento multidimensional: medios (idioma) de formular consultas multidimensionales (el idioma relacional de SQL tradicional aquí no es adecuado) y el procesador que puede procesar y ejecutar dicha solicitud.
- Almacenamiento multidimensional: medios de una organización de datos físicos que garantizan la ejecución efectiva de las solicitudes multidimensionales.
Los dos primeros niveles están necesariamente presentes en todas las herramientas OLAP. El tercer nivel, aunque está generalizado, no se requiere, ya que los datos para la representación multidimensional pueden eliminarse de las estructuras relacionales ordinarias; El procesador de consulta multidimensional en este caso traduce las solicitudes multidimensionales a las consultas SQL que se ejecutan por DBMS relacional.
Los productos OLAP específicos, como regla general, son una herramienta de presentación de datos multidimensional (cliente OLAP, por ejemplo, tablas de pivotes en las firmas de Excel 2000 de Microsoft o Proclaridad de KNOSYS), o un DBMS de un servidor multidimensional (servidor OLAP, por ejemplo, Oracle Express Servidor o Microsoft OLAP Services).
La capa de procesamiento multidimensional generalmente está incrustada en el cliente OLAP y / o en el servidor OLAP, pero se puede resaltar en forma pura, como el componente de servicio de tabla de pivote de Microsoft.
En la tabla de resumen estándar, los datos de origen se almacenan en un disco duro local. Por lo tanto, siempre puede administrarlos y reorganizarlos, ni siquiera tener acceso a la red. Pero esto no concierne de ninguna manera las tablas resumidas OLAP. En las mesas OLAP consolidadas, el caché nunca se almacena en un disco duro local. Por lo tanto, inmediatamente después de la desconexión de la red local, su tabla consolidada perderá el rendimiento. No podrás mudarte, no es un solo campo.
Si aún necesita analizar los datos OLAP después de desconectarse de la red, cree un cubo de datos autónomos. El cubo de datos autónomos es un archivo separado que es un caché de tabla de pivote y almacena los datos OLAP que se ven luego después de la desconexión de la red local. Los datos OLAP copiados en la tabla consolidada se pueden imprimir en el sitio http://everest.ua descrito en detalle al respecto.
Para crear un cubo de datos autónomos, primero cree una tabla OLAP consolidada. Coloque el cursor dentro de la tabla consolidada y haga clic en el botón OLAP Herramientas (Herramientas OLAP) de la configuración de la pestaña Contexto (Herramientas), que se incluye en la pestaña Contexto de la pestaña Contexto, trabaje con tablas consolidadas (herramientas pivotables). Seleccione el modo OLAP sin conexión (OFLINE OLAP) (Fig. 9.8).
El cuadro de diálogo Configuración de cubo autónomo OLAP aparece en la pantalla. Haga clic en el botón Crear archivo de datos sin conexión. Lanzó un asistente de creación de archivos de cubo de datos. Haga clic en el botón Siguiente para continuar con el procedimiento.
Es necesario especificar la dimensión y los niveles que se incluirán en los datos del cubo. En el cuadro de diálogo, seleccione los datos que se importarán desde la base de datos OLAP. La idea es especificar solo aquellas dimensiones que se necesitarán después de desconectar la computadora de la red local. Las más dimensiones indican, cuanto más largo sea el tamaño tendrá un cubo autónomo de datos.
Haga clic en el botón Siguiente para ir al siguiente cuadro de diálogo Asistente. En él, obtiene la capacidad de especificar miembros o elementos de datos que no se incluirán en el cubo. En particular, no necesitará la medida de la cantidad extendida de ventas de Internet, por lo que la casilla de verificación se descargue en la lista. La casilla de verificación Freeze indica que el elemento especificado no se importará y tomará un exceso de lugar en el disco duro local.
En la última etapa, especifique la ubicación y el nombre de los datos de CUBE. En nuestro caso, el archivo CUBE se llamará myofflinecube.cub y se ubicará en la carpeta de trabajo.
Los archivos cúbicos de datos tienen una extensión. .cachorro
Después de algún tiempo, Excel guardará el cubo autónomo de los datos en la carpeta especificada. Para probarlo, haga doble clic en el archivo, que conducirá a la generación automática del libro de trabajo de Excel, que contiene una tabla consolidada asociada con el cubo de datos seleccionado. Después de crear, puede extender el cubo de datos autónomos entre todos los usuarios interesados \u200b\u200bque trabajan en el modo de red local deshabilitado.
Después de conectarse a la red local, puede abrir un archivo independiente del cubo de datos y actualizarlo, así como la tabla de datos correspondiente. El principio principal establece que el cubo de datos autónomos se aplica solo a trabajar cuando la red local está deshabilitada, pero es obligatoria actualizada después de que se restaure la conexión. El intento de actualizar el cubo autónomo después de romper la conexión causará un fallo.
Lo que hoy es OLAP, en general conoce a todos los expertos. Al menos, los conceptos de "OLAP" y "datos multidimensionales" están conectados constantemente en nuestra conciencia. Sin embargo, el hecho de que este tema se levante de nuevo, espero, seré aprobado por la mayoría de los lectores, ya que no está desactualizado por la idea de nada con el tiempo, debe comunicarse periódicamente con personas inteligentes o leer artículos en una buena edición. ...
Almacén de datos (Ubicación OLAP en la estructura de información de la empresa)
El término "OLAP" está inextricablemente vinculado con el término "Warehouse de datos" (almacén de datos).
Damos una definición formulada por los almacenes de datos de "Founder Fountder" Bill Inmona: "Data Warehouse es un tiempo orientado al sujeto y una recopilación de datos inmutables para respaldar el proceso de tomar decisiones de gestión".
Los datos en el repositorio caen de sistemas operativos (sistemas OLTP), que están diseñados para automatizar los procesos de negocios. Además, el almacenamiento se puede reponer debido a fuentes externas, como informes estadísticos.
¿Por qué construir almacenes de datos, después de todo, contienen información redundante a sabiendas, que vive "en vivo" en bases de datos o archivos del sistema operativo? Puede responder brevemente: analizar los datos de los sistemas operativos no es directamente imposible o muy difícil. Esto se explica por varias razones, incluido el escáner de datos, almacenando en los formatos de varios DBMS y en diferentes "rincones" de la red corporativa. Pero incluso si en la empresa, todos los datos se almacenan en el servidor de la base de datos central (que es extremadamente raro), el analista casi seguramente no se averigua en sus estructuras complejas, a veces intrincadas. El autor tiene una experiencia suficientemente triste de intentos de "alimentar a los analistas hambrientos", los datos crudos de los sistemas operativos, resultó ser "no en los dientes".
Por lo tanto, la tarea del repositorio es proporcionar "materias primas" para analizar en un solo lugar y en una estructura simple y comprensible. Ralph Kimball En el prefacio de su libro "El kit de herramientas del almacén de datos" escribe que si el lector entenderá solo una cosa en la lectura de todo el libro, a saber: la estructura de almacenamiento debe ser simple, el autor considerará su tarea.
Hay otra razón por la que justifica la apariencia de un repositorio separado: las solicitudes analíticas complejas para la información operativa inhiben el trabajo actual de la empresa, bloqueando las tablas durante mucho tiempo y la captura de recursos del servidor.
En mi opinión, bajo el almacenamiento, puede entender no necesariamente una acumulación de datos gigantes: lo principal es que es conveniente para el análisis. En términos generales, un término separado: los Martes de datos (quioscos de datos) están destinados a instalaciones de almacenamiento pequeñas, pero en nuestra práctica rusa, no lo escucha a menudo.
OLAP - Herramienta de análisis cómodo
La centralización y la estructuración conveniente no es todo lo que se necesita por análisis. Todavía requiere una herramienta para ver, visualizar información. Los informes tradicionales, incluso construidos sobre la base de un solo almacenamiento, están privados de una flexibilidad. No pueden ser "Twist", "implementar" o "colapso" para obtener la presentación de datos deseada. Por supuesto, puede llamar a un programador (si quiere venir), y él (si no está ocupado) hará un nuevo informe rápidamente, digamos, durante una hora (no creo y no creo, tan rápidamente en La vida no hay nadie; le damos tres horas). Resulta que el analista puede verificar por un día no más de dos ideas. Y él (si es un buen analista), tales ideas pueden llegar a la cabeza varias por hora. Y cuanto más se ve las "secciones" y "Cuts" de estos analistas, mayores las ideas que, a su vez, requieren todos los "recortes" nuevos y nuevos para verificar. ¡Esa sería su herramienta que permitiría implementar y convertir los datos de manera simple y cómoda! Como tal herramienta y realiza OLAP.
Aunque OLAP no es un atributo necesario del almacén de datos, se usa cada vez más a menudo para analizar la información acumulada en este almacenamiento.
Los componentes incluidos en el almacenamiento típico se presentan en la FIG. uno.
Higo. 1. Estructura de almacén de datos
Los datos operativos se recopilan de varias fuentes, se limpian, se integran y se plegan en el almacenamiento relacional. Al mismo tiempo, ya están disponibles para su análisis utilizando diversos medios de creación de informes. Luego se prepara datos (total o parcialmente) para el análisis OLAP. Se pueden cargar en una base de datos especial OLAP o se deja en un almacenamiento relacional. El elemento más importante es el metadato, es decir, la información sobre la estructura, la colocación y la transformación de los datos. Gracias a ellos, se garantiza la interacción efectiva de varios componentes de almacenamiento.
Summing Up, es posible determinar OLAP como un conjunto de medios de análisis multidimensional de los datos acumulados en el repositorio. Teóricamente, las herramientas OLAP se pueden aplicar directamente a los datos operativos o sus copias exactas (para no interferir con los usuarios operativos). Pero, por lo tanto, está arriesgando a pisar el rastrillo ya descrito anteriormente, es decir, comenzar a analizar los datos operativos que no son adecuados para su análisis.
Definición y conceptos básicos OLAP
Para empezar, descifrado: OLAP es un procesamiento analítico en línea, es decir, análisis de datos operativos. 12 Los principios definitorios de OLAP formulados en 1993. E. F. CODD - Base de datos relacional "Inventor". Más tarde, su definición se volvió a trabajar en la llamada prueba FASMI, que requiere la aplicación OLAP para proporcionar la capacidad de analizar rápidamente la información multidimensional compartida ().
Prueba FASMI.
Rápido. (Rápido): el análisis debe hacerse igualmente rápidamente en todos los aspectos de la información. Un tiempo de respuesta aceptable es 5 S o menos.
Análisis. (Análisis): debería ser posible llevar a cabo los tipos principales de análisis numérico y estadístico predeterminado por el desarrollador de aplicaciones o un usuario definido arbitrariamente.
Compartido. (Compartido): muchos usuarios deben tener acceso a los datos, es necesario monitorear el acceso a la información confidencial.
Multidimensional (Multidimensional) es la característica principal y más importante OLAP.
Información (Información): la solicitud debe poder acceder a cualquier información necesaria, independientemente de su ubicación de volumen y almacenamiento.
OLAP \u003d Vista multidimensional \u003d CUBO
OLAP ofrece herramientas convenientes de acceso de alta velocidad, visualizando y analizando información comercial. El usuario recibe un modelo de datos natural e intuitivo, organizándolos en forma de cubos multidimensionales (cubos). Los ejes del sistema de coordenadas multidimensionales sirven como los principales atributos del proceso de negocio analizado. Por ejemplo, para las ventas, puede ser un producto, región, tipo de comprador. El tiempo se utiliza como una de las mediciones. En las intersecciones de los ejes de medición (dimensiones), hay datos, caracterizando cuantitativamente el proceso: medidas (medidas). Estos pueden ser volúmenes de ventas en piezas o en términos monetarios, los restos en stock, costos, etc. La información que analiza el usuario puede "cortar" un cubo en diferentes direcciones, obtener consolidado (por ejemplo, por año) o, por el contrario, Información detallada (durante semanas) y ejerce otras manipulaciones que vendrán a la mente en el proceso de análisis.
Como medidas en una cuba tridimensional mostrada en la FIG. 2, se utilizan cantidades de ventas, y como medida: tiempo, producto y tienda. Las mediciones se presentan en ciertos niveles de agrupación: los productos se agrupan por categorías, talleres, por país y datos en el momento de las operaciones, por meses. Un poco más tarde, veremos más los niveles de agrupación (jerarquía).

Higo. 2. Ejemplo Cuba
Cubo cubo
Incluso el cubo tridimensional es difícil de mostrar en la pantalla de la computadora para que los valores de las medidas de interés sean visibles. ¿Qué podemos hablar de cubos con el número de mediciones, los tres grandes? Para visualizar los datos almacenados en Cuba, generalmente son habituales bidimensionales, es decir, representaciones tabulares, que tienen títulos complejos jerárquicos de filas y columnas.
La vista bidimensional del cubo se puede obtener al "cortar" a través de uno o más ejes (mediciones): fijamos los valores de todas las mediciones, excepto dos, y obtenemos una tabla de dos dimensiones convencional. En el eje horizontal de la tabla (encabezados de columna), se presenta una medición, en la vertical (encabezados de cadena), la otra, y en las celdas de la tabla, los valores de las medidas. En este caso, el conjunto de medidas se considera en realidad como una de las mediciones: seleccionamos una medida (y luego podemos colocar dos dimensiones en los encabezados y columnas), o mostrar varias medidas (y luego una de las tablas a Tome el nombre de las medidas, y el otro, los valores de la única medición "no adoptada").
Eche un vistazo a la Fig. 3 - Aquí hay un corte bidimensional Cuba para una medida: ventas de la unidad (unidades vendidas) y dos mediciones "indiscutibles": tienda (tienda) y tiempo (tiempo).

Higo. 3. Rebanada de cubo bidimensionales para una medida
En la Fig. 4 Muestra una sola tienda "no adoptada", pero los valores de varias medidas se muestran aquí, las ventas de la unidad (vendidas), las ventas de la tienda y el costo de la tienda (gastos de la tienda).

Higo. 4. Rebanada de cubos bidimensionales para varias medidas.
La vista bidimensional de la Cuba es posible y cuando se mantiene "continuados" y más de dos dimensiones. Al mismo tiempo, se colocarán dos o más mediciones del cubo "Corte" en los ejes de corte (líneas y columnas): vea la FIG. cinco.

Higo. 5. Rebanada de cubo bidimensionales con varias medidas en un eje
Etiquetas
Los valores, "pospuestos" a lo largo de las mediciones se denominan miembros o marcas (miembros). Las etiquetas se usan tanto para el "corte" del cubo, y para limitar (filtrado) de los datos seleccionados, cuando se encuentran en la medición restante "incomprensible", no somos todos los valores, sino su subconjunto, por ejemplo, tres ciudades de varios docena. Los valores de las etiquetas se muestran en una vista de cubos bidimensionales como encabezados de cadena y columnas.
Jerarquías y niveles.
Las etiquetas se pueden combinar en jerarquías que constan de uno o más niveles (niveles). Por ejemplo, las etiquetas de medición "Tienda" (tienda) se combinan naturalmente en una jerarquía con niveles:
País (país)
EXPRESAR
Ciudad (ciudad)
Tienda (tienda).
De acuerdo con los niveles de jerarquía, se calculan los valores agregados, como las ventas para los EE. UU. (Nivel de país) o California (nivel estatal). En una dimensión, puede implementar más de una jerarquía, digamos, por tiempo: (año, trimestre, mes, día) y (año, semana, día).
Arquitectura de aplicaciones OLAP
Todo lo que se mencionó anteriormente OLAP, de hecho, se relaciona con la presentación de datos multidimensionales. La forma en que se almacenan los datos, no se encargan de que no se preocupe si el usuario final ni los desarrolladores de herramientas al que usa el cliente.
La multidimensionalidad en las aplicaciones OLAP se puede dividir en tres niveles:
- Representación de datos multidimensionales: herramientas de usuario final que proporcionan visualización multidimensional y manipulación de datos; La capa de representación multidimensional se abstiene de la estructura de datos físicas y percibe los datos como multidimensional.
- Procesamiento multidimensional: medios (idioma) de formular consultas multidimensionales (el idioma relacional de SQL tradicional aquí no es adecuado) y el procesador que puede procesar y ejecutar dicha solicitud.
- Almacenamiento multidimensional: medios de una organización de datos físicos que garantizan la ejecución efectiva de las solicitudes multidimensionales.
Los dos primeros niveles están necesariamente presentes en todas las herramientas OLAP. El tercer nivel, aunque está generalizado, no se requiere, ya que los datos para la representación multidimensional pueden eliminarse de las estructuras relacionales ordinarias; El procesador de consulta multidimensional en este caso traduce las solicitudes multidimensionales a las consultas SQL que se ejecutan por DBMS relacional.
Los productos OLAP específicos, por regla general, son un medio de representación de datos multidimensionales, un cliente OLAP (por ejemplo, tablas de pivotes en las empresas de Excel 2000 de Microsoft o PROCLARITY de la compañía Knosys), o un servidor multidimensional DBMS, OLAP Server (para obtener Ejemplo, Servidor de Oracle Express o Microsoft OLAP Services).
La capa de procesamiento multidimensional generalmente está incrustada en el cliente OLAP y / o en el servidor OLAP, pero se puede resaltar en forma pura, como el componente de servicio de tabla de pivote de Microsoft.
Aspectos técnicos del almacenamiento de datos multidimensionales.
Como se mencionó anteriormente, las herramientas de análisis OLAP pueden extraer datos y directamente de los sistemas relacionales. Tal enfoque fue más atractivo en aquellos momentos en que los servidores OLAP estaban ausentes en las hojas de precios de los principales fabricantes de DBMS. Pero hoy y Oracle, e Informix, y Microsoft ofrecen servidores OLAP completos, e incluso aquellos gerentes de TI que no les gusta reproducirse en sus redes "zoológico" de diferentes fabricantes pueden comprar (más precisamente, para aplicarse a la administración de la compañía) Servidor OLAP de la misma marca que el servidor de base de datos principal.
Los servidores OLAP, o servidores de base de datos multidimensionales, pueden almacenar sus datos multidimensionales de diferentes maneras. Antes de considerar estas formas, debemos hablar sobre un aspecto tan importante como el almacenamiento de agregados. El hecho es que en cualquier almacén de datos, tanto de lo habitual, como en una multidimensional, junto con los datos detallados extraídos de los sistemas operativos, se almacenan los indicadores totales (indicadores agregados, agregados), como la cantidad de volúmenes de ventas por meses, Por las categorías Bienes, etc. Los agregados se almacenan explícitamente con el único propósito, para acelerar la ejecución de las solicitudes. Después de todo, por un lado, el almacenamiento se acumula, como regla general, una gran cantidad de datos, y, por otro lado, en la mayoría de los casos, no detallados, pero los indicadores generalizados están interesados. Y si cada vez que tuviera que resumir millones de ventas individuales para el año para calcular el monto de las ventas, la velocidad más probable es que haya sido inaceptable. Por lo tanto, al cargar datos en bases de datos multidimensionales, todos los indicadores totales o su parte se calculan y guardan.
Pero, como saben, tienes que pagar por todo. Y para la velocidad de procesamiento de solicitudes en los datos totales, es necesario pagar un aumento en las cantidades de datos y tiempo en su descarga. Además, un aumento en el volumen puede ser literalmente catastrófico, en una de las pruebas estándar publicadas, un conteo completo de unidades para 10 MB de datos de origen requeridos de 2.4 GB, es decir, los datos aumentaron 240 veces. El grado de "hinchazón" de los datos al calcular las unidades depende del número de mediciones de cubo y la estructura de estas mediciones, es decir, la relación de la cantidad de "padres" y "niños" en diferentes niveles de medición. Para resolver el problema del almacenamiento de agregados, a veces se aplican esquemas complejos, lo que permite no todos los agregados posibles al calcular, para lograr un aumento significativo en el desempeño de las consultas.
Ahora sobre varias opciones de almacenamiento. Ambos datos y agregados detallados se pueden almacenar en estructuras relacionales o multidimensionales. El almacenamiento multidimensional permite que los datos sean tratados como una matriz multidimensional, lo que garantiza los mismos cálculos rápidos de los indicadores totales y varias transformaciones multidimensionales de acuerdo con cualquier medida. Hace algún tiempo, los productos OLAP apoyaron el almacenamiento relacional o multidimensional. Hoy, como regla general, el mismo producto proporciona ambos tipos de almacenamiento, así como el tercer tipo: mixto. Se aplican los siguientes términos:
- MOLAP. (OLAP multidimensional), y los datos detallados, y los agregados se almacenan en una base de datos multidimensional. En este caso, se obtiene la mayor redundancia, ya que los datos multidimensionales contienen plenamente relacionados.
- Rolap. (Relacional OLAP): los datos detallados permanecen donde "vivieron" inicialmente en la base de datos relacional; Los agregados se almacenan en la misma base de datos en tablas de servicios especialmente creadas.
- Hollar (OLAP HYBRID): los datos detallados permanecen en su lugar (en la base de datos relacionales), y las unidades se almacenan en una base de datos multidimensional.
Cada uno de estos métodos tiene sus ventajas y desventajas y debe aplicarse dependiendo de las condiciones, la cantidad de datos, la potencia de los DBM relacional, etc.
Al almacenar datos en estructuras multidimensionales, se produce el problema potencial de "hinchazón" debido al almacenamiento de valores vacíos. Después de todo, si la matriz multidimensional está reservada en todas las combinaciones posibles de las marcas de medición, y solo una pequeña parte (por ejemplo, una serie de productos se venden solo en un pequeño número de regiones), entonces Bo / incluso parte del cubo volará Estar vacío, aunque el lugar será ocupado. Los productos OLAP modernos pueden hacer frente a este problema.
Continuará. En el futuro, hablaremos sobre productos OLAP específicos fabricados por los principales fabricantes.
Es posible que alguien utilice la tecnología OLAP (procesamiento analítico en línea) cuando los informes de construcción parezca algún tipo de exótico, por lo que la aplicación de OLAP Cube no es en absoluto uno de los requisitos más importantes para la automatización de la presupuestación y la contabilidad de la administración.De hecho, es muy conveniente utilizar un cubo multidimensional cuando se trabaja con los informes de gestión. Al desarrollar formatos de presupuesto, puede enfrentar el problema de las formas multivariadas (más sobre esto se puede leer en el libro 8 "Tecnología de presupuestación en la empresa" y en el libro "Puesta en escena y automatización de la contabilidad de administración").
Esto se debe al hecho de que la gestión efectiva de la Compañía requiere informes de gestión cada vez más detallados. Es decir, en el sistema, se utilizan más y más secciones analíticas diferentes (en los analistas de sistemas de información están determinados por un conjunto de libros de referencia).
Naturalmente, esto conduce al hecho de que los líderes quieren recibir declaraciones en todos sus recortes analíticos que les interesan. Y esto significa que los informes necesitan la fuerza de alguna manera "respiración". En otras palabras, se puede decir que, en este caso, estamos hablando del significado del mismo informe, debe proporcionar información en varios recortes analíticos. Por lo tanto, los informes estáticos ya no están satisfechos con muchos líderes modernos. Necesitan una dinámica que pueda dar un cubo multidimensional.
Por lo tanto, la tecnología OLAP ya se ha convertido en un elemento obligatorio en los sistemas de información modernos y prometedores. Por lo tanto, cuando se selecciona un producto de software, debe prestar atención a si es utilizada por la tecnología OLAP.
Y necesitas poder distinguir los cubos reales de la imitación. Una de estas simulaciones son tablas de resumen en MS Excel. Sí, esta herramienta es similar a un cubo, pero de hecho no lo es, ya que son tablas estáticas y no dinámicas. Además, son mucho peores que implementados la posibilidad de construir informes utilizando elementos de libros de referencia jerárquicos.
Para confirmar la relevancia del uso de Cuba al crear informes de gestión, puede traer el ejemplo más sencillo con el presupuesto de ventas. En este ejemplo, las secciones analíticas actuales de la compañía son relevantes: productos, sucursales y canales de venta. Si estos tres analistas son importantes para la empresa, las ventas presupuestarias (o informes) se pueden mostrar en varias opciones.
Cabe señalar que si crea una línea de presupuesto basada en tres secciones analíticas (como en el ejemplo en cuestión), le permite crear modelos presupuestarios suficientemente complejos y compilar informes detallados con Cuba.
Por ejemplo, el presupuesto de ventas se puede compilar utilizando solo un análisis (directorio). Un ejemplo de un presupuesto de ventas construido sobre la base de un análisis de productos presentado en figura 1..
Higo. 1. Un ejemplo de un presupuesto de venta construido sobre la base de un análisis de productos en Olap Cuba
El mismo presupuesto de ventas se puede compilar utilizando dos analistas (libros de referencia). Un ejemplo de un presupuesto de venta creado sobre la base de dos "productos" de analistas y "sucursales" se presenta en figura 2..
Higo. 2. Un ejemplo de un presupuesto de ventas construido sobre la base de dos "productos" de analistas y "sucursales" en el OLAP Cuba del complejo de software "Integral"
 .
.
Si es necesario crear informes más detallados, puede realizar el mismo presupuesto de ventas utilizando tres analistas (libros de referencia). Un ejemplo de un presupuesto de ventas construido sobre la base de tres "productos de analistas", "sucursales" y "canales de venta" se presenta en figura 3..
Higo. 3. Un ejemplo de un presupuesto de ventas construido sobre la base de tres productos "productos", "sucursales" y "canales de venta" en el complejo de software OLAP Cuba "Integral"

Es necesario recordar que el cubo utilizado para generar informes le permite generar datos en diferentes secuencias. Sobre el figura 3. El presupuesto de ventas primero "se desarrolla" por productos, luego por sucursales, y luego en los canales de venta.
Los mismos datos se pueden representar en otra secuencia. Sobre el figura 4. El mismo presupuesto de ventas "se despliega" primero por productos, luego en los canales de venta, y luego por sucursales.
Higo. 4. Un ejemplo de un presupuesto de ventas construido sobre la base de tres "productos" analista ", canales de venta" y "sucursales" en el complejo de software OLAP Cuba "Integral"

Sobre el figura 5. El mismo presupuesto de ventas "se despliega" primero en sucursales, luego por productos, y luego a través de los canales de venta.
Higo. 5. Un ejemplo de un presupuesto de ventas, basado en la base de tres "sucursales" de los analistas, "productos" y "canales de venta" en el complejo de programas OLAP-CHEP "Integral"

De hecho, esto no es todas las opciones posibles para generar el presupuesto de las ventas.
Además, debe prestar atención al hecho de que el cubo le permite trabajar con la estructura jerárquica de los libros de referencia. En los ejemplos presentados, los directorios jerárquicos son "productos" y "canales de venta".
Desde el punto de vista del usuario, recibe varios informes de gestión en este ejemplo (ver Higo. 1-5), y desde el punto de vista de la configuración en el producto de software es un informe. Solo usar un cubo puede verse de varias maneras.
Naturalmente, en la práctica, es posible una gran cantidad de opciones para la producción de varios informes gerenciales si se construyen sus artículos sobre uno o más analistas. Y el propio analista depende de las necesidades de los usuarios en detalle. Es cierto que no debe olvidarse que, por un lado, cuanto más analistas se puedan construir los informes más detallados. Pero, por otro lado, significa que el modelo financiero del presupuesto será más complejo. En cualquier caso, si hay una Cuba, la compañía tendrá la capacidad de ver los informes necesarios en varias versiones, de acuerdo con interesantes recortes analíticos.
Es necesario mencionar más sobre varias características de OLAP Cuba.
En una Cuba OLAP jerárquica multidimensional, hay varias medidas: un tipo de cadena, fecha, cuerdas, libro de referencia 1, manual 2 y manual 3 (ver Higo. 6.). Naturalmente, se muestran tantos botones con libros de referencia en el informe, cuánto está en la cadena presupuestaria que contiene el número máximo de libros de referencia. Si no hay un directorio en ninguna línea de presupuesto, no habrá botones con libros de referencia.

Inicialmente, el cubo OLAP se basa en todas las mediciones. De forma predeterminada, con la construcción inicial del Informe de medición, se encuentra en aquellas áreas como se muestra en figura 6.. Es decir, tal medición, como la "fecha", se encuentra en el área de las mediciones verticales (mediciones en el área de la columna), las mediciones "líneas", "directorio 1", "directorio 2" y "directorio 3" - En el campo de las mediciones horizontales (mediciones en las líneas de área), y la medición "Tipo de línea", en el área de mediciones "subestimadas" (mediciones en el área de la página). Si la medición está en el último área, los datos en el informe no se "revelan" en esta medición.
Cada una de estas mediciones se puede colocar en cualquiera de las tres regiones. Después de transferir mediciones, el informe se reconstruye instantáneamente de acuerdo con la nueva configuración de medición. Por ejemplo, puede intercambiar la fecha y las filas con los libros de referencia. O puede transferir una de las referencias al área de medición vertical (ver Higo. 7.). En otras palabras, el informe en OLAP Cuba puede ser "Twist" y elegir la salida del informe, que es más conveniente para el usuario.
Higo. 7. Un ejemplo de un informe del informe después de cambiar la configuración de la medición del complejo de software "Integral"

 La configuración de medición se puede cambiar ya sea en la forma principal del cubo, o en el Editor de tarjetas de cambio (ver Higo. ocho). En este editor, también puede arrastrar mediciones de un área a otra. Además, es posible cambiar los lugares de medición en un área.
La configuración de medición se puede cambiar ya sea en la forma principal del cubo, o en el Editor de tarjetas de cambio (ver Higo. ocho). En este editor, también puede arrastrar mediciones de un área a otra. Además, es posible cambiar los lugares de medición en un área.
Además, en la misma forma puede configurar algunos parámetros de medición. Para cada medición, puede configurar la ubicación de los resultados, el orden de clasificar los elementos y los nombres de los elementos (ver Higo. ocho). También puede especificar qué nombre de los elementos para mostrar: abreviado (nombre) o completo (nombre completo).
Higo. 8. Mapa de medición del mapa del editor del complejo de software integrado

Editar los parámetros de medición pueden ser directamente en cada uno de ellos (vea Higo. nueve). Para hacer esto, haga clic en el icono ubicado en el botón junto al nombre de la medición.
Higo. 9. Un ejemplo de los directorios de edición 1 productos y servicios en

Con este editor, puede seleccionar los elementos que deben mostrarse en el informe. De forma predeterminada, todos los elementos se muestran en el informe, pero si es necesario, no se pueden mostrar parte de los elementos o carpetas. Por ejemplo, si desea mostrar solo un grupo de productos al informe, todos los demás deben eliminar las casillas de verificación en el Editor de medición. Después de eso, solo un grupo de productos estará en el informe (ver Higo. 10).
También en este editor puede ordenar los artículos. Además, los elementos se pueden reorganizar de varias maneras. Después de una reagrupación de este tipo, el informe se reconstruye instantáneamente.
Higo. 10. Un ejemplo de salida en el informe de un solo grupo de productos (carpeta) en el paquete de software "integral"

En el Editor de Medición, puede crear de inmediato sus grupos, arrastrarlo de los elementos de referencia allí. De forma predeterminada, solo el grupo "Otro" se crea automáticamente, pero se pueden crear otros grupos. Por lo tanto, utilizando el Editor de medición, puede configurar qué elementos de los libros de referencia y en qué orden deben mostrarse en el informe.
|
|
Cabe señalar que todos estos reordenamientos no están registrados. Es decir, después de cerrar el informe o después de su recálculo, todos los directorios se mostrarán en el informe de acuerdo con la metodología configurada.
De hecho, todos estos cambios podrían hacerse inicialmente al configurar filas.
Por ejemplo, utilizando restricciones, también puede especificar qué elementos o grupos de libros de referencia deben mostrarse en el informe, y cuáles no.
Nota: Con más detalle el tema de este artículo se considera en talleres "Gestión presupuestaria de la empresa" y "Detención y automatización de la contabilidad de la administración" quien sostiene al autor de este artículo - Alexander Karpov.
Si el usuario prácticamente necesita retirar solo ciertos elementos o carpetas de referencia en el informe, dicha configuración es mejor para hacerlo con anticipación al crear líneas de informe. Si varias combinaciones de elementos de referencia en los informes son importantes para el usuario, al configurar la técnica, no se deben instalar restricciones. Todas estas restricciones se pueden configurar rápidamente utilizando el Editor de medición.
En el artículo anterior de este ciclo (consulte No. 2'2005), hablamos sobre las principales innovaciones de los servicios analíticos de SQL Server 2005. Hoy veremos los medios para crear soluciones OLAP que se incluyen en este producto.
Brevemente sobre los conceptos básicos de OLAP
a directamente para iniciar una conversación sobre la creación de soluciones OLAP, recordamos que OLAP (procesamiento analítico en línea) es una tecnología integral de análisis de datos multidimensional, cuyo concepto se describió en 1993 por EF Koddom, el famoso autor de la Relacional modelo de datos. Actualmente, el soporte OLAP se implementa en muchos DBMS y otros instrumentos.
OLAP-CUBA
¿Qué son los datos OLAP? Como respuesta a esta pregunta, considere el ejemplo más simple. Supongamos que, en la base de datos corporativa de alguna empresa, hay un conjunto de tablas que contienen información sobre las ventas de bienes o servicios, y según las facturas, el país (país), la ciudad (país), el nombre personalizado, el país, el vendedor (ventas del gerente), ordenado. (Fecha de colocación de pedidos), CategoríaNombre (categoría de producto), nombre de producto, Nombre de Shipper (Compañía Carrier), PRIPCIONES EXTENDIDOS (pago para productos), mientras que el último de los campos listados, en realidad, es un objeto de análisis.
La selección de datos de dicha vista se puede implementar utilizando la siguiente consulta:
Seleccionar país, ciudad, personal de personal, vendedor,
Pedido, Nombre de Categoría, Nombre de Producto, Nombre de Shipper, PRIPCION EXTENDIENTE
De las facturas.
Supongamos que estamos interesados \u200b\u200ben cuál es el costo total de los pedidos realizados por los clientes de diferentes países. Para obtener una respuesta a esta pregunta, debe hacer la siguiente consulta:
Seleccione País, Suma (ExtendedPrecio) de Facturas
Grupo por país.
El resultado de esta consulta será un conjunto unidimensional de datos agregados (en este caso: montos):
| País. | Suma (prontio extendido) |
| Argentina | 7327.3 |
| Austria. | 110788.4 |
| Bélgica. | 28491.65 |
| Brasil. | 97407.74 |
| Canadá. | 46190.1 |
| DINAMARCA. | 28392.32 |
| Finlandia. | 15296.35 |
| Francia. | 69185.48 |
| 209373.6 | |
| ... |
Si queremos saber cuál es el costo total de los pedidos realizados por los clientes de diferentes países y entregamos varios servicios de entrega, debemos ejecutar una solicitud que contenga dos parámetros en el grupo por cláusula:
Selecty, ShipperName, Sum (ExtendedPrecio) de Facturas
Grupo por país, ShipperName
Sobre la base de los resultados de esta consulta, puede crear una tabla de la siguiente forma:

Este conjunto de datos se denomina tabla consolidada (tabla PIVOT).
Selección, nombre de Shipper, Suma de vendedores (ExtendedPrecio) de Facturas
Grupo por país, Nombre de Shipper, Año
Sobre la base de los resultados de esta solicitud, puede construir un cubo tridimensional (Fig. 1).

Agregar parámetros adicionales para el análisis, puede crear un cubo con un teóricamente en cualquier número de mediciones, mientras que junto con las cantidades en las celdas del cubo OLAP pueden contener los resultados del cálculo de otras funciones agregadas (por ejemplo, el promedio, Valores máximos, mínimos, el número de entradas de representación inicial correspondientes a estos parámetros establecidos). Campos basados \u200b\u200ben qué resultados se calculan se denominan medidas de cubo.
Jerarquía en mediciones.
Supongamos que estamos interesados \u200b\u200bno solo por el costo total de los pedidos realizados por los clientes en diferentes países, sino también el valor total de los pedidos realizados por los clientes en diferentes ciudades de un país. En este caso, puede usar el hecho de que los valores aplicados en el eje tienen diferentes niveles de detalle, esto se describe como parte del concepto de la jerarquía de cambios. Diga, en el primer nivel de la jerarquía hay países, en las segundas ciudades. Cabe señalar que desde SQL Server 2000, los servicios analíticos soportan las llamadas jerarquías desequilibradas que contienen, por ejemplo, a dichos miembros cuyos niños no están contenidos en los niveles vecinos de jerarquía o ausentes para algunos miembros del cambio. Un ejemplo típico de una jerarquía de este tipo es la consideración del hecho de que en diferentes países puede haber unidades tan administrativas-territoriales, como el personal o un área ubicada en una jerarquía geográfica entre países y ciudades (Fig. 2).

Tenga en cuenta que recientemente, las jerarquías típicas se han asignado, por ejemplo, que contienen datos geográficos o temporales, así como mantener la existencia de varias jerarquías en una dimensión (en particular, para el año calendario y fiscal).
Creando cubos OLAP en SQL Server 2005
Los cubos de SQL Server 2005 se crean utilizando SQL Server Business Intelligence Development Studio. Esta herramienta es una versión especial de Visual Studio 2005, diseñada para resolver esta clase de tareas (y si ya hay un entorno de desarrollo fijo, la lista de plantillas del proyecto se actualiza con proyectos diseñados para crear soluciones basadas en SQL Sever y sus servicios analíticos) . En particular, la plantilla del proyecto de Analysis Services está diseñada para crear soluciones basadas en servicios analíticos (Fig. 3).

Para crear un cubo OLAP, en primer lugar, debe resolverse, en función de los datos para formarlo. La mayoría de las veces, los cubos OLAP se basan en la base de los almacenes de datos relacionales con los esquemas de "Star" o "Snowflake" (nos dijeron sobre la parte anterior del artículo). En el kit de entrega de SQL, hay un ejemplo de tal almacenamiento: la base de datos de AdventureWorksDW, para usar la cual se debe encontrar la carpeta de fuentes de datos como fuente, seleccione el nuevo elemento del menú Context Fuente de datos y responda sistemáticamente a las preguntas de la Asistente (Fig. 4).

Luego, se recomienda crear una vista de origen de datos, una vista basada en la que se creará un cubo. Para hacer esto, seleccione el elemento apropiado de la carpeta Vistas de la fuente de datos y responda constantemente al asistente. El resultado de las acciones especificadas será el diagrama de datos mediante el cual se construirán las fuentes de datos, y en el esquema resultante, en lugar del original, puede especificar nombres de tablas "amigables" (Fig. 5).




El cubo descrito de esta manera se puede transferir al servidor de servicio analítico seleccionando la opción Implementar en el menú contextual del proyecto y ver sus datos (Fig. 7).

Al crear cubos, actualmente se utilizan muchas características de la nueva versión de SQL Server, como la presentación de fuentes de datos. El contenido de los datos de origen para la construcción del cubo, así como la descripción de la estructura del cubo, ahora se produce utilizando un amigo para muchos desarrolladores de herramientas de estudio visual, que es una ventaja considerable de la nueva versión de este producto. - Se minimiza el estudio de los desarrolladores de soluciones analíticas del nuevo kit de herramientas en este caso.
Tenga en cuenta que en la Cuba creada, puede cambiar la composición de las medidas, eliminar y agregar atributos de medición y agregar atributos calculados de miembro de medición según los atributos disponibles (Fig. 8).

Higo. 8. Añadiendo un atributo calculado
Además, en los cubos de SQL Server 2005, puede realizar la agrupación automática o la clasificación de miembros de medición mediante el valor del atributo, para determinar los enlaces entre atributos, implementar los enlaces "muchos a muchos", identificar indicadores clave de negocios, así como resolver Muchas otras tareas (detalles sobre cómo se realizan todas estas acciones, puede encontrar en la sección Tutorial de Servicios de Análisis de SQL Server del sistema de referencia de este producto).
En las partes posteriores de esta publicación, continuaremos familiarizándonos con los servicios analíticos de SQL Server 2005 y descubriremos lo que ha aparecido en el área de soporte de la minería de datos.
 Aspecto de error durante el lanzamiento del programa
Aspecto de error durante el lanzamiento del programa Fragation Plugin para Firefox
Fragation Plugin para Firefox Cómo mostrar carpetas y archivos ocultos en Windows
Cómo mostrar carpetas y archivos ocultos en Windows Maneras Cómo hacer una pantalla en una computadora portátil más brillante o más oscura
Maneras Cómo hacer una pantalla en una computadora portátil más brillante o más oscura Cómo formatear una unidad flash, protección contra el disco
Cómo formatear una unidad flash, protección contra el disco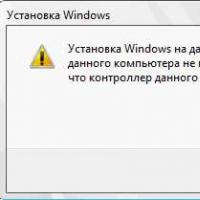 Si la instalación de Windows a este disco no es posible
Si la instalación de Windows a este disco no es posible Durante la instalación de Windows "Asegúrese de que el controlador de este disco esté incluido en el menú BIOS de la computadora.
Durante la instalación de Windows "Asegúrese de que el controlador de este disco esté incluido en el menú BIOS de la computadora.